#general
1 messages · Page 75 of 1
If you want to exclude small models or those that it's hard to measure the vibes for (or context awaraness etc), just look at SimpleQA and exclude all that score low there. Simple as that
It's not very realistic to expect from ArtificialAnalysis to do an absolutely 100% perfect job at this, but what they are doing is still transparent and very useful tbh
When is direct chat on webdev arena?
Didn't notice this earlier

OAI didn't even participate
LMArena
Depends what you mean by exist, we know it's been used by select testers since early June, but isn't publicly available
If it's being tested since then, then yes it's existed since then
@aidan_mclau @YouJiacheng It's worth noting that a DeepThink system with no access to this corpus also got gold (again according to the official graders), with exactly the same score.
So apparently, some of the stuff about Deepmind's result is mum
@YouJiacheng @aidan_mclau No, for that system only the question went in.
Wonder if he's referring to AlphaProof/geometry or something else
Deepthink system nvm
So definitely not AlphaProof and alphageometry
That makes me think the results they shared are just much cleaner and nicer, compared with the other deepthink system
Nobody has guessed correctly what it actually is
Google are going to be dropping a surprise ig lol
Yeah, they're definitely showing something on the 28th
Doesn't help we have an openAI engineer making an issue about it tho, and peeps are running with it
They are fine tunes of a general model. For Google case at least
The Google model actually isn't very specialised. The general 'system' actually already scored high so they had a good baseline to work with
Congrats to the GDM team on their IMO result! I think their parallel success highlights how fast AI progress is. Their approach was a bit different than ours, but I think that shows there are many research directions for further progress. Some thoughts on our model and results 🧵
Some sub tweets basically repeating the timeline he already explained, with some new information
they keep saying this
they should at least release the first version of deep think
meta 🤑

Ars Technica
DeepMind followed IMO rules to earn gold, unlike OpenAI.
If deepthink is the model that participated in the IMO, and the original plan was to publicize the result 7 days after the IMO ends, can we expect July 28th to be deepthink's originally planned release date? I think it's very likely
release for the 200$ one?
I see no maket for deepthink?
😭
Kalshi
they should be available on aistudio or api
inefficient market
: )
🤷🏽♂️
so fact

Deepthink Friday actually?
DeepThink coming on Friday? it's only for mathematicans I think
The last time I checked Kalshi was before 2.5 Pro 0605 was released as GA. Even though Vertex AI has explicitly stated that the model ID 0605 will be deprecated on June 19, Kalshi's market is still pricing NO for 0605 as ranking #1 on the June 30 Arena leaderboard at 70c.
crazy inefficiency
wdym I thought you were talking about the kalshi prediction that deepthink would be delayed until December
Kalshi less accurate
and polymarket has no market for it
prob not

august
o3 pro always right
maybe u should have kept ur bet @hollow ocean 😭
@aidan_mclau @YouJiacheng It's worth noting that a DeepThink system with no access to this corpus also got gold (again according to the official graders), with exactly the same score.
yup
Huh… I think there’s no way this model they used for IMO was not custom DeepThink version of their “large” model aka Ultra 🧐
Not Pro
poll_question_text
Get To AGI First?
victor_answer_votes
13
total_votes
17
victor_answer_id
3
victor_answer_text
is 2.5 ultra aimed for release before or after DT?
are they even gonna release ultra?
28th aligns with the embargo drop for IMO
And I think it would be really smart to say "our deepthink system got gold at IMO" then either release it or announce it coming soon.
yooo
is deepthink that participated in IMO the same as the one that is gettign release?
yes
Very unlikely. The setup they used must have been insane. I was meaning to say we could test it easily on IMO when it’s out, but it’s also only 6 problems and in theory easy to contaminate for everyone now lol. Though still… making it score perfect score for 5 out of 6 problems probably won’t happen just with contamination 
What is the difference between Deep Think and Ultra?
deep think is a swarm of agents in the same way that o3 pro and grok 4 heavy are
2.5 ultra is a big boy model (just one, not several agents) that is a different class to 2.5 pro
like what claude 4 opus is to claude 4 sonnet
gemini cooking tho
has ultra been confirmed?
grok 4 heavy is probably an ensemble voting agent process
o3 pro is parallel reasoning, not ensemble reasoning, a bit different
Think deepthink is also supposed to be parallel reasoning, unless they've changed it since then
google is good : )
🍍
hey there Id like to getnewer grok for my project
craig whats your opinion on grok 4
🍋
Does anyone know if o3 pro is multi agent?
🍊
Use case?
it's in distribution so it's expected. qwen always delivers on stuff in distribution. but it's incredible
wut are u trying it on
Feels like its not organized
Im just asking it for some best practices for an X plan
I guess its not bad
Sad news nuuuuuu
:C
ultra will still probably be released in one form or another i guess, or is it really dead?
guys
do you think
gemini 3 flash will be better than gemini 2.5 pro?
dang
so i need to wait for gemini 3 pro : (
There was never any real indication we would get an ultra model
It was mostly "kingfall" and other similar models seem slightly bigger than 2.5 pro, must be ultra series
And everyone ran with it that ultra would be released 🔜
people are sleeping on qwen 3 235b instruct, uhm, the jump is insane
I think they don't wait more than a month to drop something comparable
I think Google could drop first if openAI waits too long
But based on everything they're saying, seems that won't occur
kingfall was amazing, why would they say that the lift is small?
they were fumbling revision after revision on ultra it seemed to me
didnt they state it outright?
there's been conflicting statements iirc
i only see one statement from them on their twitter, and they said they'd stop doing hybrid
ok looking at https://x.com/Alibaba_Qwen/status/1947344511988076547 that eliminates option 2, but option 3 is still a possibility per https://x.com/JustinLin610/status/1947346588340523222
Bye Qwen3-235B-A22B, hello Qwen3-235B-A22B-2507!
After talking with the community and thinking it through, we decided to stop using hybrid thinking mode. Instead, we’ll train Instruct and Thinking models separately so we can get the best quality possible. Today, we’re releasing

A small update on Qwen3-235B-A22B, but a big improvement on its quality!
We thought about this decision for a long time, but we believe that providing better-quality performance is more important than the unification at this moment. We are still continuing our research on hybrid
ya option 3 is definitely possible
but after the massive leap they achieved i think they'll stay separate for now
simpleqa jumping from 12.2 to 54.3 💀
🤔
o3 pro only model that can flip $7 to $1100 before I blew it all on roulette @small haven
So 2.5 Ultra DeepThink but not 2.5 Pro DeepThink?
is that facts? on polymarket?
Sports betting
I told it not to give any bets unless it’s confident @small haven
So there’s days where it wouldn’t give me any bets
should just stick to that 👀
I wasn’t disciplined 🤦🏽♂️
Nah
I deleted it
Just ask it to find the best bet for the day and if there isn’t any don’t recommend anything
Nope it does its own research
Yeah
o3 can’t do this it’s very bad compared to o3 pro
Yessirr
Yes way better
Deep research is trash tbh it uses outdated data 🤣
It’ll do that sometimes
Just put the date
It always does
Never tried api
You have search off?
Put tmrs date
It’s prob cuz you put “kalshi mlb”
Just do mlb bets



GUYS
GUYS
GEMINI JUST GOT
HEAVILY CENSORED
HOLY ####
ITS REFUSING
😭
aistudio btw
oh and also
they changed the logo of aistudio for a minute
i saved it but they reverted it
and also
the default temp is now 1 instead of 0.7
how is nobody talking about this
show us the new logo?
alr
8K
converted from svg
svg wasnt directly a file but just embedded directly onto the page
heres the svg
they changed the favicon for a minute too but I didn;t save it, its just the same icon but on a black background so its fine
kinda mid idk

butterfly?
nous research has the best AI logo by far
im sure discord compresses it so if you want a high quality png then run this script I got kimi to make in a browsers devtools console:
(async () => {
const svg = `SVGFILEGOESHERE`;
const dataUri = `data:image/svg+xml,${encodeURIComponent(svg)}`;
const img = new Image();
img.src = dataUri;
await img.decode();
const c = document.createElement('canvas');
c.width = c.height = 8192;
c.getContext('2d').drawImage(img, 0, 0, 8192, 8192);
c.toBlob(b => {
const a = document.createElement('a');
a.href = URL.createObjectURL(b);
a.download = 'icon_8192x8192.png';
a.click();
});
})();
this or that?

yeah these are good
the right one looks ai generated
For public release no, but internally we can be quite certain I think that they do have it... #general message
is it that good?
wild also said it was
where is he gone?
hes still here
oh. I didn't scroll up lol
Just looked this model up. First sentence killed it for me tbh 😭
We introduce the updated version of the Qwen3-235B-A22B non-thinking mode
I wonder what the output lengths of this thing are though
yeah, look at the benches

prob very long for a non-reasoning model
but idc
the improvements in post training are insane
It has to be shorter than their older reasoning variant. But how does it compare to Kimi2 already crazy output lengths that is the question 🧐
no forget benchmarks
im talking about your personal experience
boooo

broken for me as well :\
need a third party to host lol
let me use it once
qwen hosting is sh1t
the quality is bad
qwen 3 suffers a lot from quantization/etc
ye


they're hosting it in full precision though
For chutes it's not specified, I think it's full precision as well...
vibes seem good, but i did not have time yet to do all my benches, so idk
yeah but its decentralized so...
people will try to game it
no way chutes has everything full precision
people have no incentive to do that afaik
not everything but some models they host in full precision, or are supposed to be
just can't rely on it imo
it's essentially outputting reasoning traces lol

kimi does that too, at least on a question i have
this new qwen 3 instruct model is better than most thinking models 💀 on that q
Dunno in my experience it worked great comparing it to even the most expensive providers. With the exception of like Cerebra - that is in the league of it's own. I would imagine they have checksum checking to make sure expected model versions or quants always match. Though I will admit I do not know all the details of how their decentralized inference works behind the scenes
no way... this is R1 reasoning length territory 🤯

don't recall any answers longer than 6k from Kimi2 👀
still answered wrong this one
btw got 50% on simplebench public
so nothing crazy
(on chutes, bc all other providers are down)
and it wasn't even that yappy
a few months ago i read chutes maintainer discussions about this, at least then i dont think it's in a state to be that trustworthy at least for production
Link?... would be interesting to look into that. Maybe I just haven't encountered it yet. The worst I can recall is it getting completely stuck on some prompts due to the model wanting to do extremely long response for a given prompt. But that's also sometimes true even for some official providers (Deepseek API etc)
on their bittensor discord iirc
im getting poor results from chutes right now
even worse than qwen.ai
"even worse"? I think it's safe to assume the quality on qwen website is gonna be as good as it gets for this model 
no it's known the official quality on the website sucks
wdym. They can't host their own model properly?
that would be ridiculous though lmao
its quantized heavily or whatever. at least there were complaints of quality issues i believe a while back. should still apply now
I mean If that's true then perhaps they didn't train it properly either. Like there's no free pass on this from me 💀
i mean the model is pretrained on way more than a lot of open models, there's a trend of a lot of quality loss when quantizing these models more than other models
didn't the bf16 vllm host score the highest?
it wasnt the alibaba one
yea
anyway, my point is about chat.qwen.ai
that's from what i've heard anyway
this may not apply in alibaba's api
yeah
i was misremembering that blog post, ignore me on that
wild is hallucinating
was trying to find the discord thread about this, i recall reading about it when lurking in one of the discord servers i was in. it might not be true and i might misremembering again 🤷 lack of sleep catching up to me. i think it was about the 235b model and degenerate repetition on chat.qwen.ai a little after qwen 3 launched, i might be hallucinating that as well. idk
Can i get API on lmarena???
I would expect Kimi to do better. Bigger model usually means better spatial awareness and more capable with visuals
i thought qwen was bigger
qwen is 235b, kimi k2 is 1t
DeepInfra hosting it now as well. FP8 💀
https://deepinfra.com/Qwen/Qwen3-235B-A22B-Instruct-2507

Qwen3-235B-A22B-Instruct-2507 is the updated version of the Qwen3-235B-A22B non-thinking mode, featuring Significant improvements in general capabilities, including instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage. . Try out API on the Web
Looks like I can't even try it now with their updated interface though without adding billing... It's probably still gonna be slow lol
besides that one task type, im not too impressed with it after playing with it more. excited for the thinking version though.
yeah, i am also a bit underwhelmed
This is already the thinking version essentially...
for my tasks it is also barely usable, because it is just switching from that thinking-like mode with terrible formatting to the one where it is more human preference aligned
-> really weird chat experience
they call this the "small" update before their thinking version
The current reasoning version is already fairly verbose. I don't see how they can improve it in a meaningful way without making it output like 140M lol

they were able to improve non-reasoning one simply because they made it closer to the reasoning variant...
based on the task i tried, it seems their rl regimen has improved quite a bit
it gets it right despite using a harder version of the task, and does even less tokens than the reasoning version
the reasoning version often gets it wrong/reasons forever btw
poll_question_text
What do the community want ?
victor_answer_votes
9
total_votes
11
victor_answer_id
2
victor_answer_text
Best voted models
https://x.com/flowersslop how does she have agent already 🤯
Stars light future dreams ♃ Erised stra ehru oyt ube cafru oyt on wohsi

You can try for free through openrouter rn
Parasail is $0.15/$0.85 for bf16
Kimi is fp8 on novita for $0.57/$2.30
The benefit of the Qwen model is basically when you have long context
Once you account for tokens the output price is closer
The new Qwen 3 does not even have reasoning yet
So ofc not lol
Source?
in some benchmarks
I think grok4 is quite behind still. When qwen and kimi add reasoning to their new releases i think they will overtake it
If OAI needs to integrate O3-alpha, that would be a big delay
i think it makes more sense for 2.5 ultra to release this week
3.0 is likely sept time or so i thought
because it started rolling for plus subscribers
in EU though
took them barely any time at all. That means there are no problems with complying with privacy respecting laws if they want...
lol
4.1 is so stupid it really make me question the possibility of agi
coding with it is such a pain
feels like gpt 3.5
what do people even use it for?
yeah ik, its free and close to unlimited in github copilot
so i though i would try
but it is not worth the time
good question
I kinda assume they have everything ready and are just waiting for release
Since they confirmed GPT-5 soon , i would assume 1-2 weeks away, by the end of next it should be live .. or they lied 🤥
I doubt its the second since they are going with the router version as a start (weaker version than what was planned)
The betting markets only give 65% odds for GPT5 before Aug 31st. Wouldnt be so confident it is imminent
Maybe its undervalued 😆
do you know if they plan to release it on API too?
wonder if it'll cost more than gpt-4.5
Some think gpt 5 will be an event , so it will be known beforehand when it comes out since they will send invites
But its all speculation, it can also be a live stream
You remember where the OpenAI key person hiring info is from?
I think they both need to be fairly substantial jumps. The open source models are closing the gap to the current frontier quick
Like Kimi K2 / updated Qwen 3 when they add reasoning to them will be very good
It's predictable that innovation will happen but unpredictable where and when it will happen
so something is gonna release this week right?
What did you think about this IMO drama 
unlikely apparentl
y
more like early aug or so
coming back to this.. are the benchmarks we were shown for deep think based on 2.5 pro + DT then? or were those based on an even earlier version of 2.5 ultra?
if it's the former surely it's got significantly better since
wow then
this thing should cook o3 pro
and grok 4 heavy for that matter
i presume the google anon models on lmarena were non-DT ultra?
yup
you know anything about this?
pre-merger with DT?
hmm
given google's track record of testing everything on arena i wonder if we'll see DT on arena soon
also i think i may still have access to one of the ultra checkpoints lol
one of my red teaming platforms hasn't removed the anon google model they gave me access to a while ago and it gets questions right that only ultra did
the version i have access to streams summarised thinking
What is it?
reported DT results at IO were from a 2.5 pro-based model
the final model will be quite a lot better
Like they will release (soon™) of DeepThink that reached Gold IMO 2025?
4o has gotten so good recently, like i gave a prompt to 4.5 and o3, but 4o responded the most human tbh
early to mid aug
no, deep think/2.5 ultra
ive tried it the other day
was pretty good
is o3-alpha still on web dev?
openAI is so damn shady I don't even know whether to trust the open source is still coming any more 😂 they are totally silent on it
Maybe it was all a PR stunt
Who knows
This IMO stuff made me have doubts
Hi, any idea why do I get "Session not found. Redirecting to home..." after a few hours inactive chat? But other session is still active after 24h on second browser? Is it cookies/browser related or some random database wiping issue?
For each week that passes the open source frontier is pushing higher
Deep infra has Qwen updated model at $0.13/$0.60
😂
That's odd. I'm going to start a post in #1343291835845578853 to get more info.
i heard rumors it was too good so they delayed it 🙄
but maybe it was really just pr
closedai
Can AI Learn to Trade?💹
︀︀
︀︀Introducing BAZAAR - a new LLM benchmark for economic decision making!💵
︀︀
︀︀In a simulated double-auction market, I pitted top LLMs against each other and classic trading algorithms. One goal: maximize profit.
︀︀
︀︀The o3 and Gemini models top the rankings!

https://fixupx.com/JustinLin610/status/1947713198674874511
new qwen coming very soon?
"coming soon" = tonight? (in China)


Why does Qwen still put gratuitous spaces before commas and periods
my goat
excuse me?!


Qwen3-coder is not good
I asked it to write an adder-subtractor in structural Verilog and this is what it came up with:
// 4-bit Adder-Subtractor module
module adder_subtractor_4bit (
input [3:0] a,
input [3:0] b,
input mode, // 0 for addition, 1 for subtraction
output [3:0] result,
output cout,
output overflow
);
wire [3:0] b_modified;
wire cin;
wire carry_out;
// XOR gates to control subtraction (2's complement)
assign b_modified[0] = b[0] ^ mode;
assign b_modified[1] = b[1] ^ mode;
assign b_modified[2] = b[2] ^ mode;
assign b_modified[3] = b[3] ^ mode;
// Input carry for subtraction (1) or addition (0)
assign cin = mode;
// Instantiate the ripple carry adder
ripple_carry_adder_4bit rca (
.a(a),
.b(b_modified),
.cin(cin),
.sum(result),
.cout(carry_out)
);
// Assign outputs
assign cout = carry_out;
assign overflow = carry_out ^ (result[3] ^ a[3] ^ b_modified[3] ^ cin);
endmodule
Ts does NOT subtract

Alright I'm an idiot this does subtract
That's solid except for the assign which is not as explicitly structural as I requested
That's my general view about qwen3 as a whole. They were trained to have some nice numbers for irrelevant things (like base model benchmark scores) but are not actually super useful and qwen3-235b is compromised by size comparing to both R1 and Kimi lol
Qwen 3 coder has 1m token context
I like powerful compact models (love Gemma-3) but it looks like 235B really gimped Qwen
Besides it's some middle ground nobody wants
if Grok4 general purpose model is of any indication, this will be a disappointment
they will train it on a few benchmarks which are gonna be the same ones they will show in their marketing
but it will most likely still suck for IRL, for things like webdev arena
@echo aurora add qwen 3 coder to webdev arena
webdev arena is useful. General lmarena less so...
Basically... you can trust people to tell which web design is better and which code actually works, but rating the text responses for questionable prompts and picking a winner... that's much more challenging lol
What do you consider to be questionable

guess the models

qwen coder
Some of you really can’t quit grok
follow SOTA
I have a free month of grok 4 and I don’t use it at all.
I wish i had more reason to use it because it is quite fast
this is for sure trained on Claude 4 outputs lol
wow they actually added grok 4 with internet connection

poll_question_text
where would you rather work
victor_answer_votes
13
total_votes
14
victor_answer_id
1
victor_answer_text
deepmind
its bad
qwen coder
not that good at all
have you guys tried it on 3d simulations
it does have claude UI styling
but thats it
i mean ive tried guiding it to make a usable code at least
but its not working
mini basketball game 3d simulation
ive seen it somewhere
someone made that with o3-alpha and gemini 2,5 pro
its not bad, it got many things right but the game isnt working
and the map is a bit off
Hello , do you guys know best AI model for Hard Coding Problem (2500+ rating CP) ,I know o-3 ,gpt pro and Gemini Pro is good , but whenever I give whole new problem (the problem that doesn't exist in entire internet) , they give wrong answers like I give them Proper description ,proper example , constraints , and a very good Prompt , even they can't solve that problems ,Please suggest some AI model that can solve this .
Exclusive: Meta Hires Three Google AI Researchers Who Worked on Gold Medal-Winning Model
Meta hires three AI researchers from Google DeepMind who worked on Gemini model that nabbed recent math award.
Read more from @KalleyHuang and @erinkwoo 👇
https://t.co/I25lrXGr6c
Anyone can do a model request ?
https://x.com/Alibaba_Qwen/status/1947766835023335516?t=5cvz7Kb7hQ7yBRAOtoB-xA&s=19
Qwen3-Coder is here! ✅
We’re releasing Qwen3-Coder-480B-A35B-Instruct, our most powerful open agentic code model to date. This 480B-parameter Mixture-of-Experts model (35B active) natively supports 256K context and scales to 1M context with extrapolation. It achieves

@echo aurora
I'll flag to the team, but don't forget about #1372229840131985540
yea now im sure that hes trying to slow down AI progress
and the thing is they are always poaching these RL / reasoning / post-training people
the thing that the labs do not really have much of in the first place
and the area where most of the advancements were made in the past time
so it really might be slowing down progress temporarily
sigh
2.0 flash thinking is not smarter than 2.5 pro : )

well post training is still data
but it is undeniable that the largest trends in llm world are very much about post training / RL
currently at least
?
idk what to tell you, i was talking about where we get large advancement, not what is more necessary to train a good model
or any model for matter of fact ( bc without pretraining unsupervised learning you get nothing later as well)
i am not attributing it all to post training, in many cases we dont even really know where the money and compute went
but i can tell you that the whole reasoning and ttc compute paradigm did not come out of pretraining advancements by itself, but had to be "created" using RL and that many other things, like good coding abilities, a lot of things that involve interaction with the user etc. are all a product of post-training / RL rather than pre-training
they aren't managers i think
many of the others are though
idk why you are so opposed to me claiming that most of the advancements of the last generation were in fact not made in pre-training
when did i ever claim anything remotely related to a "2 lines of code worth 400m"
or that SFT / RL is not "doing the work"
it is usually actually even more work, because you have to synthetically generate environments, problems or what ever because of the lack of plentiful SFT / RL data
^per token
well, my point was not that they stopped that
the idea is just:
many advancement made in post training / RL -> labs want people there
meta buys some of them -> slows down progress
the same thing could happen to pre-training obviously, but they are focusing on the people who do post-training / RL apparently
likely because they themselves actually already have more or less adequate people for pre-training (but have historically mostly underperformed in post training and never tried RLVR much)
yes, surely that is part of the plan to some degree, but hiring the brains is a serious possibility, when you look at how quickly labs are founded, funded and then abandoned these days
literally all of the big labs have to some degree followed the strategy (maybe gdm as the sole exception. although not a full exception either)
I think the only thing which isn’t public is exactly how the deep think agents work. How to do RL etc is in papers from DeepSeek/Kimi/Qwen/China.
Nightride new Google model in arena
so many new models added
nightride-on
nightride-on-v2
and some ernie ( chinese models ) + qwen latest model
yummy 😋
paid article
It's theinformation, of course
an updated version?
i have a feeling that you know more than you should
spill the tea
continue
im listening
next next gen = ?
gemini 4?
5?
mm i see
i presume the timeline is like
Is it possible to directly talk to stealth models
updated 2.5 flash, then 2.5 ultra/deep think?
what else is there to update
2.5 pro is done
is 2.5 flash lite GA i forgot
hmm
Lmarena my beloved
Our IMO gold model is not just an "experimental reasoning" model. It is way more general purpose than anyone would have expected. This general deep think model is going to be shipped so stay tuned! 🔥
Quoting Melvin Johnson (@melvinjohnsonp)
︀
So happy to see this incredible achievement.
︀︀Huge congrats to @lmthang, @quocleix, @YiTayML and the IMO team on the result.
︀︀This was a great collaboration across teams to build a general Gemini DeepThink model that can also get gold at IMO.
2.5 Pro-002👀
will wolfstride and stonebloom be released? I feel like they're a bit better for daily use than 2.5 pro (though not by much)
do yall think meta gonna win because of talents?
Probably not but they'll slow everyone else down quite a bit
And they'll probably do all right
How good is nightride ?
Anyone see EB45 ?
Flash with better world knowledge
@torn mantle @zinc ore nightride good ?
I'm not very optimistic about the team led by Alexander Wang
Its 2.5 flash, its so-so
That person seems exclusive, aggressive, and boastful
The thing is: if you build an organization by luring job hoppers with massive compensation packages, you have to assume that your organization will be very volatile and expensive to upkeep
🗣️
is deepmind cooked?
what abt google : )
The London office for DeepMind is untouched because they have no-compete agreements
OAI is mostly built from poached talent, which is why they're so vulnerable to losing their top talent
rip
@echo aurora Ernie bot respond in Chinese 🤦

tell it to say in english?
I want to speak to him in french
oh
maybe it can only speak in english or chinese
Yes he dont want to speak another language but its very bad
o
It cant?
What's new about this model
We already had ernie 4.5 before
Nothing new
Il a les 2 version
Yea i saw that
So its the closed source and not Ernie 4.5 open source ?
There is open sourced ernie?
Yes
They are all close sourced no?
Hmm
@torn mantle https://x.com/Baidu_Inc/status/1939724778157511126
The ERNIE 4.5 series is now officially open source. This family of models includes 10 variants—from MoE models with 47B and 3B active parameters, the largest having 424B total parameters, to a 0.3B dense model—all available now to the global AI community for open research and

Ah
Amazon should be focusing on giving their warehouse employees bathroom breaks than trying to enter the AI market as a non-tech company 🤣
Bay Area House Party (esp. recent ones) is a very fun read
I wasn't able to reproduce this btw 😭
Because you have prompted in english, im speak french,
Et dont want to speak french i think.
when I just asked him his name he answered me in French but when I sent him a complicated prompt containing several questions he told me to answer what I sent you
His response Translated in english
"Sorry, this feature is not yet available online. You can also ask me other questions in Chinese or English, and I will do my best to answer them."
2.5 flash lite is so fast
poll_question_text
how did you read the qwen situation?
victor_answer_votes
6
total_votes
9
victor_answer_id
1
victor_answer_text
they've stopped doing hybrid thinking models
🍊
What kind of question you asked it?
Its a large language model, it should speak several languages, could be just a system prompt issue/instructions
damn meta going all in
it is flash..
yes
what about v2? both of them flash?
Seed Prover solved 4 out of 6 IMO questions in 3 days and got Silver.
Proof: https://t.co/nW320KomHQ
Big congratulations to @huajian_xin !
Now you know what I'm going to kindly ask: Would you consider open sourcing it :D



Build Fast with GroqCloud

@echo aurora sorry for pinging but there is like half a dozen accounts in https://discord.com/channels/1340554757349179412/1395441703112146984 that seem to be creating fake hype. all of the accounts joined in the past day, and most of those were also created in the past day as well. There are two other accounts there that both joined on the 17th. I feel like that they are run by the company and they are trying to get people interested in a model that isn't even widely available. Only legit accounts there are yours and DavidSZD's.
AI gen text lol

"This isn't just X; it's also Y"
there is another message that is structured very similarly to that one
i don't even know how to get access to this model without signing up for their API
i never saw https://arxiv.org/abs/2507.12724 before
arXiv.org
We present TransEvalnia, a prompting-based translation evaluation and ranking system that uses reasoning in performing its evaluations and ranking. This system presents fine-grained evaluations based on a subset of the Multidimensional Quality Metrics (https://themqm.org/), returns an assessment of which translation it deems the best, and provid...
i want to see it in the arena just so i can make fun of how terrible it likely is
if you have to generate fake hype using newly made accounts on an AI discord server to promote your model, then it is likely not good
lol they tried to get one of their models in llama.cpp earlier this year but they failed, likely because nobody was interested in the model
Glm 4 air removed from webdev arena after 2 month,
I hope he makes it onto the leaderboard

they all have chinese names as well
and i can't find a single site that has the model
any of them
it's like it doesn't exist outside of China
the people in that chat have very rough English and speak in AI-like patterns
I feel like iFlyTek is trying to use LMArena to get themselves known outside of China because they don't have the advantage that DeepSeek, Alibaba, Moonshot, Baidu, and ByteDance have: iFlyTek is virtually unknown outside of China and they don't use social media or make their models readily available via a chatbot. The only thing they are known for in the US are cheap Android tablets and translator pens on Amazon and AliExpress.


grok thinking time is absolutely absurd for me
its taking 10 minutes each time i prompt it
im able to prompt 6 times an hour 💀
I think they are cheaping out on their cloud inference provider. Their speeds are kinda pathetic comparing to OpenAI
I wonder which one
Could be that grok just has a lot of active params and they serve it at a loss
yeah no chance lol. No one is serving it at a loss, and their pricing is fairly steep, much more so than Grok3 was.
xAI can subsidize the inference itself. If they have that massive cluster just for training they can train massive models. The performance doesnt necessarily mean it is equal size to the other LLMs it may have simply underperformed
That is very unlikely. If they grossly overestimated the model size needed, they wouldn't have been competing with Google now. It just wouldn't be possible even with the relative high amount of GPUs xAI has
Money and even compute is not everything, and Meta is a good example of that lol
Mistake like that can still break the entire project
Yeah a total failure (Behemoth)
and exactly my point
its gonna be priced in line with market pricing for performance, not size.
I think market has converged on the max revenue pricing
At least for closed models
idk. DeepSeek/Kimi kinda forced a massive price lowering.
They aren't pricing their models at cost + a fixed percentage. It's more of... "what price should we set for maximum profits?" lol
ofc this still doesn't offset R&D, but that's a different topic...
Deepseek is open source, Kimi mostly as well
Deepseek went immediately open-source. When you do that very high margins on official API are not really possible... They just went extremely competitive/aggressive. But even with their API pricing they aren't doing it at a loss 👀
is it worth it tho?
grok 4 heavy thinking should be similar to gemini deep think, but i dont think it is
was it tested on IMO or nah
Trust me they still have decent profit margins lmao. With their traffic and resources their whole infra is much more efficient than what most others are using.
im actually so interested on how many answers it can get right
thanks, but they didnt use heavy thinking right
its only grok 4 reasoning
It's not the same size but Deepseek's cost to run R1 is less than $1 per 1M output.
with less than ideal infra
i just dont understand how can moonshot/kimi afford running a 1T params model without any issues
they have little to no downtime in their servers
and im also taking into consideration the crazy traffic coming from china
OpenAI inference...? They have substantial margins even after reducing the price of o3
It's gonna be cheaper than that on OpenAI's infra tbh
Also... "free electricity"? Source?
ptx optimisations
So it's not free then
they should've used some of the secret sauce shared by deepseek on ptx
they do
I don't know if american labs do though
they'd be dumb not to
They have partnership with MS. They absolutely are doing what makes the most sense and is cheapest to do. They aren't sanctioned and can both buy and rent GPUs.
So China's lower electricity cost at best is just gonna offset the less efficient GPUs and lesser infra, but that's unlikely
That's not me who needs to prove it, it's you. Cause what I'm saying is common practice and what you are saying is just inexplicable. o3 is same size as gpt4.1, and they always had profit margins on gpt4.1
saying that they are losing money on inference is crazy
What isn't? To price your models at a higher price than it cost for you to merely run them? It absolutely is a common practice lmao
xAI has a 50 times smaller user base and they already offered grok 3 mini at a loss
>o3 is same size as gpt4.1
source?
Even for Deepseek
It is reasonable to think they can do the same with grok 4
You have no idea what you're talking about
openai won't be profitable until 2029 probably
Well he assumes that because it would be a huge failing for OAI to be making a loss on inference. And he is OAI supporter
they're burning money
They are losing money because R&D and all the salaries and expenses, NOT on inference. And there are many reasons to say they are turning profit on inference in isolation and a fairly substantial one (in isolation)
If OAI is making a loss on inference they are basically cooked
yeah that's like literally impossible lmao
it's like a bug in his mind he can't accept that openai is bad in any way
Look at their price cuts historically for the same checkpoints
that's the best source
Are you just gonna pretend you don't know that it's not common at all for the close source AI labs to share info on their cost to run a model? Of cource there's not gonna be black on white direct proof from them, but we can still look at what we know.... There's NOTHING to suggest that what you are saying is true (they are losing money on inference)
it's just silly, crazy and insane.
@ornate agate
And there are several things to suggest they are making money:
- o3 is not a huge model. OG gpt4 was downsized into 4Turbo, then that was downsized into current base model.
- They were in a position to do drastic price cuts no problem
- Their resources and traffic allows them to have very good and efficient infra
- We roughly know the pricing to run a model, any model
Read again what I wrote. Even there: #general message
true, just read it, lol
really good this time
No one is saying they are making money overall, we are talking about just inference which is small part of their operations
How did we even reach a point where the frontier model of the top ai company (with a huge time lead) ends up facing competition from small Chinese research teams
It's a wild timeline
Inference is laughable money compared to their entire expenses
It's for the best, it brings prices down for everybody
plus something like AI should be open source anyway
considering where the training data comes from
So yeah... While we will never have definitive proof from OpenAI disclosing this, there are far more reasons to suggest they are turning profit on inference with the opposite being extremely unlikely. For the reasons already stated (there for instance #general message)
If GPT5 releases late enough there's a substantial chance either Kimi or qwen is going to take SOTA
With adding reasoning to the updated models
Also if openAI open source model is actually SOTA it has to beat o3. So I don't see how that works
GPT5 will be underwhelming imo
Assuming it's still going to release. They are extremely silent on it
I think at least it should be very widely available, especially the pre-trained checkpoints. At the moment keeping it all centralized inside a single company is more dangerous than people realise.
Well you only have to beat open-source SOTA, which is R1.1
Well it's delayed till September apparently
And they will have next gen of closed models soon
So it has to compete with the next gen of open source
so... doable
The chinese after release of deepseek r1 saved openai and anthropic users from being cucked even more
imo
Maybe. But that's still not there. Possible that by September we still won't have anything better tbh
If they hadn't released a good open source model then closed sourced providers would make the prices as high as possible
yeah I think this too. They wanted to charge $200/mtok or something. Remember the Haiku "more intelligence" fiasco? DeepSeek stopped that.
The closed source providers would still compete with each other eventually. But currently they are focused on scaling up as fast as possible
open source is the future for sure
I think Deepseek not only kept western companies in check, they kinda also kept Chinese themselves in check lol
if you look at alibabacloud, prices are not really any better than what people were used to before Deepseek
Kinda insane that Chinese corps are charging that
Currently I don't see any reason to use a closed source LLM. Maybe that changes with gpt5
The open source LLMs are near identical performance for far cheaper
Like look at this

crazy
Like I don't really care about +1.5% in gpqa PhD questions
I will just take the far cheaper one
qwen3 coder is better than all openai models for coding no joke
that's not too much of an accomplishment but it's a start
And btw for reference, this is a smaller model than Deepseek R1
even less activated parameters as well
I also think this. I prefer to invest my time learning how to get the most out of open-source models, because I know I can't be rugpulled, price hiked, or have to worry about quantizations changing, etc. If you look at reddits for prop coding tools, users seem to start off extremely happy, then after a few weeks people start complaining and being very upset.
yeah that's why for most enterprise cases requiring stability local models are used in house to prevent all that from happening
oh wow Qwen 3 non-coder really shot up that leaderboard.
They "start off extremely happy, then after a few weeks people start complaining" for a simple reason. They are impressed by it at first then start using it more and notice the flaws. Their expectations change as well. No one is making their models worse lmao
if they would they wouldn't stay relevant for long
Also this has been debunked like 10 times now
with people doing independent testing
yes every single one of them must be imagining it.
lmao the cope is insane
some examples
They are not "imagining" it, their reactions are normal given impressions/expectations and limited knowledge or any real testing. Happens everywhere not just with AI. Also how forums and subs work, the complaining ones are the loudest. There's no (or much less so of a) reason to post otherwise
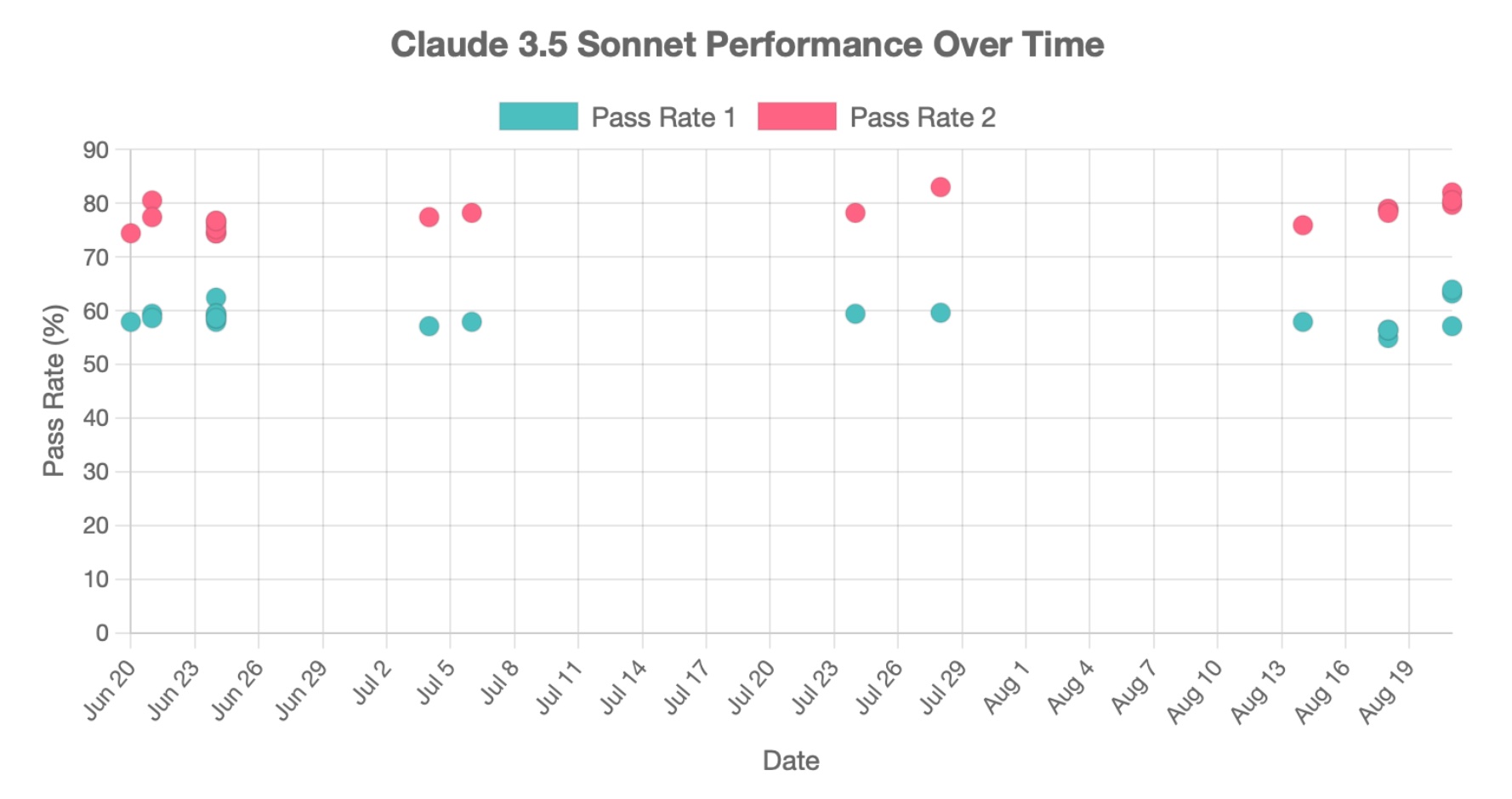
aider
Sonnet’s score on the aider code editing benchmark has been stable since it launched.
yeah very cheap model (2$/m) too
What was the prompt for this? 👀
I just looked at polymarket that temp thing... Looks like my guess ust might be correct. 🤯 Hopefully no major changes from now

well I said "mine" but this was o3 and deep research lmao
was at ~30% chance at the time, less than 0.95-0.99 range
@keen beacon
have they gotten that good?
oh you mean AI written
i interpreted it as AI narrated
I listen to T6 when falling asleep alot
lol
tru, like I can't fall asleep to music either for similar reasons
opus 4
I will calculate mine soon, nice to see you are +30% xd but its luck dont rely too much on gpt
I had a friend who screenshoted stocks and asked gpt for advice lmao , he won a few $ before losing thousands 🤣
He prob used 4o
😂
You gotta use o3 pro if you wanna make money

DAMN.
Yes, cause he did day trading or rather minute trading 🤣 he asked gpt 4 every 15s on what to do and needed fast responses
what about const@2048
cons@4096
Thank you for this flag, I do appreciate it so please don't feel sorry for pinging. I'll be sure to look into this as yeah it does look pretty inorganic.
has anyone tried the deepinfra api for gemini models?
yeah ofc I wouldn't bet anything big without verifying. Actually even with verifying and "being sure" betting big is always a risk on smth like that. But that being said, there's potential in deep research when used wisely I think
I don't know if this is the right place for suggestions, but it would be nice if copy and paste would be easier. If I want to copy a whole conversation, I have to either copy every message one my one, or use ctrl+a and have it backwards and chaotic
poor shroddy 😦
shroddy is confused
Yes I am.
I wanted to make a new feature suggestion but I think I am in the wrong channel here and don't know which is the correct one
It's just that I saw you were suffering, and I felt sorry for you
Either that + tag @ pineapple
Although its not really a bug
That feature can come handy
Or you can make your own little script (userscript) that does that till they add it natively
What i really want lmarena devs to do is to handle errors better, not just a general catch execption, especailly on the sandbox api issues
There is also that session issue, the code/msg errors arent specific
But the most annoying one is the sandbox one, you dont real know if its a model issue or rendering lib issue
omg lmarena just dropped a new banger
i just refreshed the page and instantly noticed the change 😭
i love this community

This is amazing
ABSOLUTE W UPDATEEEE
If anyone comes across any issues with Search Arena we can collect those issues here: https://discord.com/channels/1340554757349179412/1397614163282493440
could you share more details about it in here: #1397614163282493440 message ?
@echo aurora THIS IS AMAZING!!!!!!! ❤️ compared to gemini (free) it only gives out 5 sources but here it gives more than 20 😭
oh it got fixed
nvm
was happening with the gemini model
this is absoultely nice it will help me so much in learning 😭

how do you feel about the change with the Image button?
it's neat i like it!
Happy to hear it's working again! Good to know about the gemini model, I'll be sure to keep an eye on that.
i like the current buttons now its much cleaner
how many zettaflops of compute power is this?

finaly we got web research 🤩
web research is a game changer for a student like me 😭 it makes researching for sources much easier
W lmarena community ❤️
is mimi ai
No i'm not bro 😦
I'm just really happy that LM arena is giving out updates like this that could help me as a student :))
they better produce real SOTA next time
otherwise i will view xAi as a massive failure
ive been waiting for web search for so long too
genuine question im just new to lmarena but if ive been in one thread using it for some time and it just has a endless "generating" text bubble does that mean ive broken it/ran out of time with the specific model?

{kind=link}
some guy from the team replied to him tho, so could very well be that help him to reproduce it
Or just damage control
The model performance should not be shifting that much from json Vs text formatting

If it is that's a whole other issue
still
i also found the json thing weird, but then again i am not an expert on this
isnt there a standard format for the benchmark?
or is he talking about something else
its a benchmark harness thing probably
they may have finetuned on both public/private data for that specific benchmark
how could they get the private data?
this has happened before btw. qwen will get it sorted out, im sure
llama4 😅
Recently I had an argument with ppl that thought open source models would never manipulate benchmarks
Open source stans just as bad as closed source stans
how long have you been waiting? if its under 1 minute (or even longer) it could very well be that some model is still reasoning. otherwise you will probably have to reload, but make sure to copy your prompt to be sure its saved (even if it should still be saved in theory)
If it is grok 4 it can take over 10 minutes
People would love to see youcom https://discord.com/channels/1340554757349179412/1397645709565628486
could've used their API on older models like qwen 2.5
idk or some smart reward func specifically made for arc-agi-1
the thing with these benchmarks like arc-agi is that we want a generalisation performance gain, or an emergent intelligence
but if its specifically trained and finetuned for that, then its basically useless
and thats what qwen are doing
so if i understand correctly you say that they trained on the json data, but when using a different format it fails?
also dont you find their other benchmarks numbers ridiculous?
no im not talking about what they trained on/input or the output format
im talking about their goal in general
are they really trying to make a smart model? or are they just focusing on beating others on some benchmark?
Hi, maybe a silly question - is there a way to terminate endless "Generating..." answer? This particular chat is stuck and I see no way to break to loop. Except maybe "Delete" ... command in chatlist.

Sorry to say there is not currently. However, adding a stop/pause button is on our to do!
Thank you.
you can refresh the page, it should load the answer
or close/open
Unfortunately refresh, close/open and even moving to other browser by export/import cookies doesnt work. Still stuck on endless Generating...
it's that time of the month again
got access to some new anon models
so far at least one is from oai and passes a lot of my hard prompts (gets ones o3 gets wrong right)
Is it true some people have access to new models
Yes I'm using gpt6
it's great
is it another o3 checkpoint or nah
or gpt-5
what is your definition of agi?
Hey - we just launched something really special for this server. The **LMArena Discord Bot is available, right now! **
What does the bot do?
- With the LMArena bot you can generate videos, images, and image-to-videos via the bot. Similar to battle mode you’ll given two generations and anyone will be able to vote on which they prefer. After a certain number of votes the bot will reveal the models.
Why are you telling us about it in general chat and not announcing it?
- We’re considering this a bit of a soft launch. We want to test the waters with it and see what you all think first.
To learn more more about how the bot works check out #1397655624103493813 Note that you can only use the bot in these channels: #video-arena-1
Keep in mind there is generation limit per day, so make sure your prompts count!
interesting. i think i would define it a bit differently. maybe to simple, but i would define it as an ai that can do any work that a human can do at the computer. Except maybe for top 1% work in terms of difficulty/payment. so this would include longer tasks, researching topics, learning new things about that topic, learning new programming languages, and working on a project which wouldnt fit in any context length of existing models so far, coherently
what can you say
its obvious that the next iteration will be good
well whatever..
manifold says 2030 but i absolutely dont like the resolution critera as gpt-4.5 can already pass a turing test according to one paper https://manifold.markets/ManifoldAI/agi-when-resolves-to-the-year-in-wh-d5c5ad8e4708

Manifold
This market resolves to the year in which an AI system exists which is capable of passing a high quality, adversarial Turing test. It is used for the Big Clock on the manifold.markets/ai page.
The Turing test, originally called the imitation game by Alan Turing in 1950, is a test of a machine's ability to exhibit intelligent behaviour equivalen...
What the hell I put my life savings in there and got nothing back??

(They got hacked)
i've seen this so often lately on x.
makes me wonder if there is more to it, like elon behind it or smth, but probably its just that he fired a bunch of people that worked on the security of the platform
Qwen3 output length looks hilarious next to Sonnet4-thinking lol

guys which model is the best for me
Though I'm forgiving Kimi2 👀
I have been using chatgpt plus for a while because I want to use it for code and schoolwork, but it's kinda stupid ngl
gpt3.5-turbo
(using o4-mini)
use o3
I have used o3
it has limits tho
should I switch to gemini or something else
because chatgpt hasn't really been keeping up
Yeah do use o3. I was joking with gpt3.5 
I guess o4 mini (high) for coding and o3 for school work
so is keeping up or the limits an issue?
keeping up
o3 has no issues with keeping up
is gemini (or claude or whatever) better at these tasks? I have been thinking of switching to something else because openai is behind on development
if you use gemini on their website (the one that has deep research) you gonna be hit with limits too
btw we're aware of issues happening with search in battle mode
And 2.5Pro on aistudio is worse than o3 due to the lack of tools, so...
the best for you is o3. Limits is a financial problem I suppose, not really a "what is the best model for x" type of thing anymore
With API or Pro plan there are no limits
I really have a few things I need:
- upload code to the interface (on chatgpt, I make a zip of my code and upload so that it can get context (my code is not so big))
- upload pdfs that the model can read
- the model can run searches to get better information
- the model is smart
Depends how long your code really is. As long as all of your files are less than 32k (if Plus) or 128k (if Pro), still chatgpt.
otherwise use aistudio when you need to work with big context
if you want to get rough estimate how much tokens your files are, you can simply just attach them in a chat in aistudio as well
they will tokenize and you will see your usage in token counter
Tokenizer for Gemini is different, but for rough estimate this is good enough. Not gonna differ by miles with OpenAI
ok well is gemini better or worse than o3 or o4-mini
Neither. Depends on the task
if we exclude all the tools and just look at the model itself, o3 is equivalent to 2.5Pro but still different strengths (2.5Pro better for visuals, o3 better for accuracy and tedious tasks). o4-mini-high is good but I wouldn't classify it as equivalent personally. It's too small for that and lacks context awareness and some fundamental logic concepts, also lacks world knowledge (look at SimpleQA score)
it's back.
Will there be a way to vote "its a tie" without voting "both are bad"?
It could happen
Would be cool, feels unfair otherwise if both models did a great job 🙂
Yeah that makes sense, I'll be sure to pass it along
And (maybe) last questions will it be possible to see which model got the most votes / how many votes each model got, would be interesting how others might have different preferences or priorities.
Sounds good. I've added both pieces of feedback to: #1397697136170242169 message
Oh nice I think I will write a one or two suggestions for the website there as well 🙂
Please do!
h
nightride-on-v2? I haven't seen that one before
Anyone here using Gemini CLI?
Im wondering how it compares to claude code, ive seen some conflicting opinions online but its overral hard to trust reddit comments on anything AI
idk, but according to a seemingly reasonable guy on youtube named "GosuCoder", Gemini CLI with Gemini 2.5 Pro doesn't even compare to Claude 4 Sonnet with Claude Code in his own benchmark. I assume his benchmark is pretty thorough since it seems like he is a real dev and not just a vibe coder.

I think Claude 4 Sonnet with Claude Code got about 18000 or something
Bumping this message. Video Arena now available, here! We've enabled it to be useable in #general as well.
Which ones are you using besides gemini and open ai?
Seems like grok just took theirs out

Google Docs
Deep-Research Tests Prompt: Please write a comprehensive and in depth research report on the mass expulsion of ethnic Germans after World War II. Analyze the historical context driving these expulsions, the political decisions and international agreements that shaped the process, the social and ...
Your doc is mostly a request and the shared results or am I missing something?
It is.
Im currently working on the ranking.
I imagine you tested a lot more than this so I'd be interested to know how do you feel the models you tested fare
Can you share key insights?
For my use case I think gemini and OAI are pretty much in par with eachother and often have diff strong/weak points. But I haven't tested anything besides them cause I was under the impression all other models were lagging behind
Generally the top players are pretty good, with Gemini 2.5 Pro and ChatGPT, Manus AI is also very good. Generally the other AI Agents are pretty decent and some DR services like ithy and perplexity are just not worth the time.
But for the most stuff I prefer the ChatGPT DR.
I hear ya. I use a custom sys instruction instance on AI Studio to generate the DR prompts and that has been the only thing I can confirm gemini is superior for. It made a big difference on research output when I changed from developing the prompts with chatgpt to gemini
For some reason it seems like gemini's chain of thought generate better prompts to instruct LLMs, that has been true with all my prompt engineering across different use cases
I got some better results with Perplexity Pro searches with using the DR Plan from Gemini.
My theory is that whatever dataset Google trained their model on had a deeper 'understanding' of the underlying working mechanisms of AI
Gemini is really pretty good with prompting.
has anyone else been having difficulty with only getting one response when prompting? I’m specifically having the issue on mobile, but I’ve also bumped into it on desktop as well.
what the heck does lmarena have vid gen now?
We made a bot! #1397655624103493813
omg this keeps getting better and better 😭