#general
1 messages · Page 70 of 1
i published the link to the second video he published about his test for grok 4
:0
if you need, i can send the link for the videos where he tested also r1-0528, magistral medium etc in the same test
no problem. bro it's taking credits for a video i shared 😦
i sent the second, the continue of that video if you are interested into
Even if he improved the answer in a few prompts, Grok 4 will remain a piece of sh t in history
yes
send

lol

ELON says GROK 4 is not yet fully optimized for reasoning? NO PROBLEM - We'll FIX IT!
We'll optimize causal reasoning of GROK 4 right now, right here. 2nd part of my video where I test the causal reasoning performance of GROK 4.
Multiple runs, check the GROK 4 internal assumptions and boundary conditions imposed by the system itself and give it...
yea sometimes its stuck in a loop generating base64
ty
GA btw
kek
How can Deepmind not found this bug?
I encountered that with Claude too, lol
I think this is relevant/easy to skip over it

oh you are watching the first video, ok
ah sry, tagged the wrong reply 😄
Probably same fate as GPT-4.5
should I buy grok heavy?
lmaoo
i knew you would say that
did you buy it?
we might need a subscription that has all top ai models like the max plan for all, similar to how we did with cable back in the day, there are like 5 different companies that have $100 plus plans
grok, claude, perplex, google, and openai
but that comet browser seems interesting by perplex
it would be called Soylent AI max
i heard ppl saying o3 pro is better than grok heavy
lol i like htat
that*
craig if you can list which models are best for which what would you do? like lets do grok, gemini, claude and o3
ik claude is code
o3 maybe everyday use
gemini general? idk
we should actually make a internal poll or leaderboard for this in terms of vibes for these metrics instead of benchmarks
Gemini is good for image input
im similar but use o3 for mostly everything, and gemini for coding since its free, i dont use claude or grok
i dont have pro so i cant use 4.5 that much
i aint gonna lie, i think i like o3 the best
gemini is cool, but o3 just feels natural when i use it and its so much faster than it used to be
please dooooo
i cant imagine what they would charge for grok 4 heavy lol
lmarena actually broken

that's the proof that it cant use tools? because otherwise it would use web search
yep
lmaren is using a broken api

based on my chat it said october 2023 lmao

but they have to fix this thing of tools or grok wont be able to use tools forever in lmarena?
try same question on gemini
it thinks the same (joe biden and its 2023/2024)
it looks like an intentional limitation
It seems Gemini 2.5 Pro's knowledge density is around second half of 2024
You will get answer around May, June, July or even October
Hey wanted to point to this forum post where we've been discussing this #1393024188356362340 More importantly this message that has been forwarded already, but wanted to ensure you're seeing it.
poll_question_text
based on your testing so far, is groq 4 the best model right now?
victor_answer_votes
13
total_votes
17
victor_answer_id
2
victor_answer_text
no
https://x.com/apples_jimmy/status/1943479993746530450
I have also been hearing the same
Hearing a few whispers now from birds that internal evals are having gpt5 a tad over grok 4 Heavy.
Evals only tell one side to a model however, curious to see if we get any major agentic or other improvements.
Im waiting for Kimi k2 thinking & vision
which is astonishing, xAI is 1.5 years old
this account is not trustworthy
he is an openai fanboi
so wouldnt expect him to say this
the open source model is clear efficiency SOTA. I guess they struggled to scale it up for whatever reason
Or maybe it's all just compressing together
The performances of different ai companies seems to get closer
did very poorly on the one question set i gave it
Simple bench is so slow to add new models
poll_question_text
How will OpenAI new open source reasoning model perform?
victor_answer_votes
10
total_votes
11
victor_answer_id
3
victor_answer_text
Better than o4-mini, worse than o3.
By the time they add the new model all the hype already died
Just a hobby of him
Well not really a hobby, he has entire YouTube channel and patreon lol
will grok 4 top lmarena?
I doubt
Though that doesn't necessarily mean it isnt the SOTA lol
Because Google optimised for llm arena
Grok 4 didn't optimise for it at all they had no secret model
Best of the wide audience AI YouTubers by far
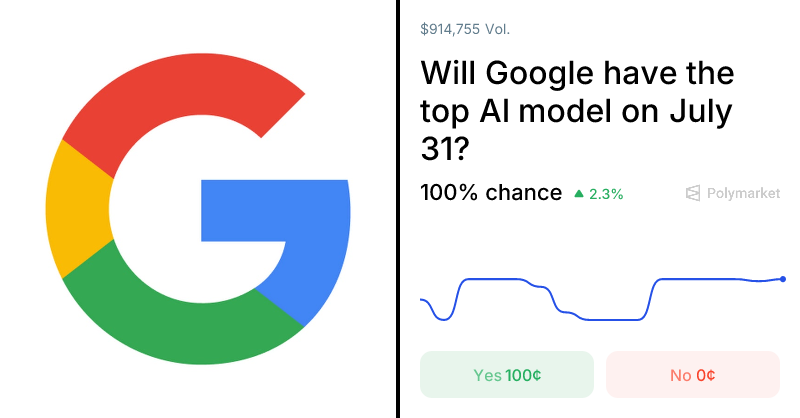
Polymarket
Polymarket | This market will resolve according to the company which owns the model which has the highest arena score based off the Chatbot Arena LLM Leaderb...
lmao
actually its 71% google
Why
its on deep think
its the equivalent of big brain in grok 4
aka heavy thinking
because its a good model
When i use kimi 1.5
It was nice but kinda mid
More abilities than deepseek but worse language and outputs
hmmmmmm... Maybe i should check
K2 is way larger and better in general (vs 1.5)
howso
this
how should i read your name btw @unborn ocean
is it "not so"
or like a merged name
or it doesnt matter?
mm
Split I guess
i see
But I mean it obviously doesn’t matter
Was that about what I said?
@torn mantle is kimi k2 better than latest qwen ? Did you check
no
idk it feels better
but its a non reasoning model
its kinda like grok 3
smart without being a reasoner
i like good base models
is grok 4 image generator better than grok 3?
Is there an issue with grok 4 in lmarena ? I can't send an image in direct chat, but grok 4 has capability to deal with images ?
They said they are getting that fixed.
Oh thank you
for lmarena*
🚨 Google Gemini leak reveals advanced #AgenticAI features:
🔹 Task Modes:
* AGENTIC_TASK: Autonomous agents plan & execute workflows.
* DUPLEX_TALK_TO_AGENT: Voice-call automation (e.g., bookings).
* DUPLEX_TRIGGER_AND_POLL: Automated polling for long tasks.
🔹 Immersive

@echo aurora I just want to take a moment to give a huge heartfelt thank you to lmarena.ai and the incredible team behind it. The fact that you're making access to the latest paid models available for free is not just generous it's deeply humane. In a time when knowledge and creativity are increasingly locked behind paywalls, what you're doing is nothing short of empowering.
You're helping so many of us learn, create, and grow,without any barrier. Its’s rare to see something this generous. Much love and endless respect.
Thank you so much for the kind words! This means a lot and has absolutely made my day! I'm going to share with the team right now. Thank you!! 
Is there a way to view historical leaderboard data at LMArena?

wonderful, tysm
Would be nice if it was possible in UI
Yeah we have been chatting about it a little bit in #1391779409362419902 feel free to share additional feedback!
Reminder we have a contest running right now!! #announcements message
We want more cows in space please!
very thorough benchmarking
but wild is right, can't compete with the large us labs
does not have to be, can also be more compute or larger experts (kimi k2 has only 32b active params) / different configuration (though typically a high simpleqa = large model)
It's 2.7 T if you count all feed-forward plus attention experts (every shard on disk).
It's 1.7 T if you count only the parameters that sit inside the experts (Skip KV-cache buffers, embeddings, and some routing weights).
That's the exact figures for you lol
Well I got it from a primary source but it's been talked about by a few xAI engineers like https://medium.com/predict/the-emergence-of-grok-4-a-deep-dive-into-xais-flagship-ai-model-eda5d500e4e7

Medium
The artificial intelligence landscape continues its rapid evolution, marked by significant advancements in large language models (LLMs).
They are relaxed about sharing higher level arch details
They only trained grok 3 on 12.8T tokens also
I assume it's not as sparse as the open source models
To take all that compute for 12.8T training
mogged by grok 4 heavy
Average meltdown over anyone talking about grok
grok4 is a sh'it model
😂
count the Elon haters
yeah, that was just too much speculations, trust me bro and jumping from one thing to the other with one gazillion unseen assumptions...
got nothing todo with grok
though it would be fun to make u aware of it
well we can argue about the educated part
the the point is i do not and you do not either
which is why the best guess is none / a very conservative one, instead of gemini 2.5 pro = 6t, to maintain best possibilities of being right
people like to overestimate their own ability to be predict -> they are worse than uneducated people (that thus don't overestimate, because they are aware of their own unfamiliarity with the topic)
that just pickes save stuff
not on all things, but especially on things like these
yeah, i changed the comment for a reason dude
well, sometimes people have to hear it regardless
if i had to guess, i would not want to rule out something very close to or above 1t
just because of how sparse many of them have become
but the save option is probably within that ballpark


What other model has similar writing style or better than GPT 4.5
well google has a model larger than 2.5 pro
Nah he must go 😇
Opus4 the closest
Yeah
10tn might be a bit large, scaling a model effectively to a size like that, idk
Dunno about that but they most certainly do not have one that performs better than 2.5Pro. They do have 1.0 Ultra which is bigger than Pro but it performs like crap. Not really better than 1.5Pro
especially the big model you want to distill from
the are likely not in a lower quantisation ( because of distilling and stuff like that), so 10t model would be insane
Dunno about "by and large", I think it was somewhat overhyped to be completely honest
they haven't finished post-training of 3.0 yet afaik
99% they are training it now
100%
meta is trying to match the big labs compute wise and has been known to heavily brute force for the llama 4 training
so they are probably more a sign that the other model are a bit smaller
the reports on it talk about them using it for distilling and basically scrambling to get something out of the compute invested, by training the smaller models etc.
Yeah but they did that way before there was any competition and way before anyone even knew how to do it
it's now 2025
not 2023
they should have been readly
and those two are fails
massive compute went in
scout got like 40t or 60t idk tokens training ( don't remember)
Grok 4

Deepseek started training of their model I believe later than meta. The main difference is their model was not oversized to oblivion
so it didn't take ages to train
wdym. R1 is much smaller than Behemoth - fact
And they are training Behemoth for ages now
Deepseek released AND updated R1
in the meantime
if deepseek had the meta compute 😳
Well that's what I mean. Meta failed so hard that we just HAVE TO talk about a model that is not even released lmao
In no way shape or form you denied what I said earlier. My point still stands lol
Behemoth is a disaster
At the end of the day, no one really cares about parameters. People only care about performance

And R1 already performs better than Behemoth ever could hope for, tbh
where's huawei's GPUs
Hey guys, got again the "Which response do you prefer?" on AI Studio, within 5min of use. Last time I got it was this morning also very quickly, and the previous time before was a loooong while ago.
What about you, has it popped for you too today?
It is a valid comparison because it scales exponentially. For Meta it's taking longer DESPITE having infinitely more compute lol
they have more (not much, but a bit more than 10k)
the training only took like 2 weeks for v3 (obv just one run, they def did multiple test runs, tweaks etc.)
so idk what you are talking about
They for sure have 'undocumented' GPUs yeah, still not as much compute as Meta though tbf. But I think this clearly showed compute is not everything. You can have all the compute in the world and still waste it all on Behemoth type of model, get beaten by the smaller players
e.g. the gemini ultra vs 1.5 pro moment was also legendary
Do you really think they are gonna tell you officially about all the compute that they have? lmao
Also, this is China
brains > compute (sometimes)
we are talking about
Hey, is grok 4 really sota? or did they game the benchmarks. When will we see it in the LMSYS arena leaderboard?
Never said a million, but believing some official figure from China is silly. I don't think it would have been possible to do what they did in such a short period of time. Then host the model and train the updated version at the same time, just with this, tbh.
Thus far leaning strongly towards "game". I have probably never seen a model with such a big disconnect between reported benchmark numbers and the actual IRL performance and testing (same testing like I do with all the other models....)
well a lot of smart people are not just randomly in a room together, deepseek hires these young grad students from top chinese unis for a lot of cash
-> there is no way these people don't get the compute they need (not saying there is no constraint though)
Grok3 was good, Grok4?... Can only say negative things about it to be completely honest...
Not only it doesn't perform well in reasoning, but the whole fine-tuning is super weird. Reasons for 50k tokens which are all hidden, then gives you 1 worded response. Wtf?? 💀
When I first saw the benchmarks and that they scaled post training thought they had a break through but guess not lol
î think the just lack the smart guys for post training and reasoning that the other labs (and now also meta) have
(or have yet to build their people)
but imagine researching new stuff in a 80h work week seems unreasonable for most (bc it is)
That's a shame. Cause ironically Grok3 non-reasoning was almost revolutionary at the time for what it was. It essentially bridged the gap and did almost reasoning like responses. So you saw everything, and it was very flexible with response lengths. Also strangely the new one does fail some things the old one didn't...
nah, "we" (i am not from the us) still do that...
though i think that deepseek has a smart strat when it comes to this
jup, was also hoping for more, because i was mainly expecting they would do more cpt or a fresh-ish pretrain idk
New one is 99% of the response hidden, then the remaining 1% is the final output, which has a high chance of being incorrect (comparing with o3 or 2.5Pro which tend to not only give the correct answer but also provide thinking summary + detailed answer)
probably was not articulating it right: people still get hired for imo stuff (world wide), though in the ai world, anyone with a good uni degree behind em gets a good offer
the most typical area where a lot of people get hired like that is quant finance though
grok3 vs grok4 in a nutshell:

like 90% of the smaller math events i know of are sponsored by em
LIke you can't even make this sht up lmao
in what universe is this an acceptable answer...

💀
well from what i hear, it is still definitely a route for many, though honestly the performance on stuff like that is just less relevant in a lot of these areas these days
and deepseek probably also does not care, they want young people with good ideas, imo is not the only way to measure that
especially when you are recruiting cs and engineering talent that might have never even attended a math club or the like (and does not need to)
Grok4 reminds me a bit of og gpt4 with no system prompt
extremely concise
except GPT4 performed very well at the time even despite that...
is it correct?
bro turned into bing chat, lol
it's the opposite of correct
lol
Grok3 was correct though
oh didn't even read the prompt💀
@ornate agate, i don't really spend time in these communities anyways
a couple of my friends got in like that (might just be the uni degree in their cases)
Summaries are not perfect but that I would still classify as "acceptable". Hiding it completely however, is not... Especially when your final responses are so insanely concise
https://i.snipboard.io/O8Dn7V.jpg
Gemini roasting me.

kimi

k2
all models gets it right
so far
half pass. "This implies..." -- no it doesn't. smh
Grok 4 heavy mogs it
This would have been "fine", if it performed. But it doesn't seem to perform lol
That's potentially what ArtificialAnalysis was testing... Heavy/tools 💀
I really do not see how this public model can score that. Tempted to do some benchmark run myself from the ones they did but that's also to be expensive af lol
You gotta try grok 4 heavy
It’s the real deal
are we comparing grok 4 heavy to kimi k2
that's like comparing it to v3
Not interested in that. It's too expensive to be useful for 90% of people. If grok4 the normal one is sh'it, then those other versions are kinda irrelevant tbh... might as well just use o3/tools/pro
🤷♂️
Regular grok is good
Scroll up. I think I made it fairly clear why I think it's sh'it lol
That prompt was one of many it does fail. I just don't see it performing tbh
Give me the prompt
it's in the ss
i also find grok 4 (the model you get on the api) uninteresting but from what i've seen, when you're using it from grok.com, it's decent
that's the same model + system prompt. Well and tools
o3 is good with none of that, so is 2.5Pro, so... 🤷♂️
it gets tools, you get thinking summaries
api has neither
I expect it to do good with no tools. And thinking summaries you do get with Google or OA API
i can kinda see why it does that
like imagine being an ai assistant
you have no opinions
then someone asks you of your opinion
all you know is that you're grok by xai and you want to be consistent with what you've said before
so you search what grok says and what your creator says
do you mean by "serious" asking Grok their opinion about Israel/Palestine?
that was quick

No other model can do this tho
And really... if you add tools into the equation, testing things like math skills becomes completely irrelevant. You are testing the python env at this point rather than the model lol
wait I read it wrong 🤯
only 20% for xAI, that is insane. This just made me bet on xAI even though I hate Grok4 lmfao
it still has a very reasonable chance to top lmarena
chatgpt-latest almost has that spot... the bar is not very high. Just some system prompt I think and their usual response formatting which tended to do very decent on lmarena (with grok3)
It says that Clarion is by SednaEarfit, and Divinus eartips are just Divinus eartips, it doesn't know that this brand has many models
It's not serious to ask it about anything really
Been the #1... For a week
ok I'm not sure this is what I had in mind, but I suppose this is better than blank system prompt 😂

It's crazy though that this is not the same (or the variation of) the system prompt used on grok website
One would think they have the highest chances with that
so wolfstride is Ultra?
Is the Grok 4 version of Chatbot Arena the reasoning one?
Grok 4 is reasoning-only
why do people hate this model
in a lot of my testing it beats kingfall
they love kingfall
pretty badly
Like Gemini 2.5 Pro?
stonebloom did pretty well universally and it was more concise
wolfstride needs to be tweaked tho
yeah but 2.5 Pro has thinking budget unlike Grok
depends if it even is its own model
pretty sure it would be
and thinking variance would be the differentiator
I think there will be many models under the same brand
but still we don't know
btw didn't they say all tiers would have access to gpt 5
unlimited too
what do you think the benchmarks are going to be
I'm ngl the ultra lineup is definitely the best I've used
out of all models
though 2.5 pro GA is similar
SOTA on HLE and SimpleQA, on par with Grok 4 in STEM
pricing is more interesting
I think slightly cheaper than Opus 4
yeah definitely
than opus 4???
nah
it'll be more expensive
I always confuse SimpleQA with SimpleBench
ye
but Ultra will be SOTA in both
ye
wonder if theyre going to have major architecture changes to Gemini 3
will Gemini Diffusion go into GA
that's what they're probably trying to figure out, I don't think it'd ever be the flagship model tho
or at least open preview with API
i think it would be something the model calls to
Veo 4 should be a great release btw
and maybe more important for Google in PR terms than Gemini
ye
veo 3 was the best thing to happen for Google in AI
imo Gemini 3 could be the largest leap they're trying to make
just simply based off the fact 2.5 was moved on with
and their claims of video understanding
and the ultra route they're taking
wonder how that'll affect its inherent spatial understanding in text
Gemini 4 might leave the realm of modern tokenizers at this rate
btw is there going to be an intermediate model between pro and flash?
there is no room for it in their new pricing
this is hallucinated by AI in GitHub commit
the former, Grok 4 likes to overthink

Get 3 months of Sentry’s team plan free: https://sentry.io/fireship
Elon Musk has the 'trust me bro' benchmarks to prove that Grok 4 is the world's most powerful AI model. But just how well does it compare against competitors in real life scenarios? And is it still calling itself MechaHitler?
#Grok4 #Grok #elonmusk #coding #tech
💬 Chat w...
real
https://www.theverge.com/openai/705999/google-windsurf-ceo-openai openAI takes yet another L

The Verge
Key researchers are joining Google DeepMind, too.
“The talks between OpenAI to buy the startup for $3 billion ended in recent days after Windsurf’s team raised concerns over how the coding assistant would fit into the OpenAI and Microsoft agreement, which requires OpenAI to share its technology with Microsoft, according to two people familiar with the company’s discussions.”
- The Information
💀
Grok 4 is such a benchmaxxer
What is it useful for?
Claude is better at coding and writing
It seems to be best at logic and math

Reuters
Elon Musk's xAI is preparing to raise more money from investors in a deal that could value the artificial-intelligence company between $170 billion and $200 billion, the Financial Times reported on Friday, citing people close to the discussions.
Dork fails creative writing 🧐

o3 pro best creative writer
expected
nah i think it will be top 3
let me check the actual ranking
yea no3 for sure
what's the criteria
how's it so low? wtf
what does "high" mean for grok 4
lmfao
trained to be truthfull and accurate
nah but I mean
it's not a bad model
so we can toss that idea aside
it's just fails so much In practice
it's absurd
no i mean part of that is the reason why its bad at creativity
that's not the case
nah that's not how it works
how does it work then
not how claims work either
accuracy and technical things don't exclude creative ability
that's bs
seems like they rl'd too much for specific domains
rather than general abilities
when a model is trained for maximum truthfulness then it will likely be optimized to select the most statistically probable and factually supported words = which leads to more predictable and less creative outputs
that's not how it works
thats how probability distribution works
and there is a tradeoff between truthfulness/accuracy & creativity, the question is how did they fixed that
truthfulness is epistemic and can't be tied to statistical probability unless truthfulness is defined as pure statistical output (which isn't truth in the way we're defining it btw) and fact support is arbitrary. You're confusing temp and those things with its training
it would be impossible for these things to prevent creative ability, but the LACK of creative ability in the first place seems to be the reason for all this
aka they never rl'd it for any sort of creativity in the first place which is pretty bad for the model, so the question is how did they mess that up
nah
Hmm...
temp is just a sampling method applied on top of that already built distribution
training is what shapes that statistical distribution
you could use chatgpt to understand what im saying as well
you are missing the whole point here
no I do understand what you're saying, and I don't need chatgpt to break it down for me 😭
GPT 4.5 It's questionable to add.
i think you need gemini to dumb it down for you
yo
you are not someone who works with AI
stop larping dawg
just ask chatgpt
😭
just ask gemini
to put what I'm saying to you in other words? 😭
you never said anything explicit to me for it to define
you're not correcting me, nor are you making a claim
you're just expressing a bad understanding of model training and alignment
thanks for using gemini
what was the prompt
eli5 what asura was saying?
the level of troll
you say random shi
and that's what asura was doing
bugging asf
we planned to launch our open-weight model next week.
we are delaying it; we need time to run additional safety tests and review high-risk areas. we are not yet sure how long it will take us.
while we trust the community will build great things with this model, once weights are
idkd idkdkdi its 3 am
honestly i half-read what you said
but im still right tho
im always right
uhm
right
nod
agree
he got ratiod

kalo's point

they have openai merch and they have https://huggingface.co/ft-hf-o-c membership

idk if they actually have the open model
Openai is an actual meme
What additional safety there are already strong open source models
And the world did not end
we are not yet sure how long it will take us. not even giving an ETA
this type of slop


o3 and o3 pro scores the highest on creative writing but no one uses them for writing 🤔
and you didn't hear anybody saying the benchmark is rigged🤔
They use llms to rate it
using ai to rate creative writing?💀
Yeah lemme show you
so basically it's a useless benchmark

I’ve never heard of anyone say o3 or o3 pro is the best at creative writing
kimi k2 wins "KyrieBench", first open source model to get the right (prev. o1/o3/gpt4.1 and grok 4)

i now agree that kimi k2 is the real resaon why openai open source model was delayed
also first Chinese model to get it right
no bro, It's for safety and shi
yeah
because it can launch nukes or something idk
i don't think the chinese are doing much safety testing outside of making sure it doesn't tell people what happened in 1989, definitely just a stupid OpenAI excuse to delay the model
until it is not relevant anymore
when i said "OpenAI", it should be "ClosedAI" lol
if K2 is actually the reason they delayed their model, then that means it's not good in the first place
k2 reasoning and r2 will be better than their open source model
I am confused. Why would K2 cause a delay
I don't think they were the open source SOTA anyways. Not in absolute performance
did they even say what the model's main goal is?
model performs like gpt 4.1, add some reasoning and it could be better than o3
The openAI model that is
The leaks are all like o4-mini level at best
I think there is another reason
That it's delayed
😂

this is stupid lmao
there's nothing about a small model like Sam Altman hinted at that needs to be compared to a 1T model
deadass
what's with the sensationalism getting worse here
this is literally just a horrible horrible take
😭😭
2 completely different caliber models
yeah o3 mini level
vs a 1T model
dumb comparison
you can't even begin to think that that model release somehow impacted theirs
he's right
once you release the weights
you can't unrelease them
it seems like nobody is trying to think about how impactful this could be to openAI's future
(VERY meaningful)
5 accounts with o3 pro and 4.5 @deep adder
Best method
One runs out move to the next account
Paying $1 is better
99% off
🤣
Google ultra accs are being sold for cheap
🤷♂️
Not buying them just saying it’s a thing
the model has to be completely safe and smart enough (aka aligned) for it to cement itself, especially for its size. It doesn't have to be an insane model, or good model at all, but if it's not reliable just like their closed API then it's completely a waste. It's the first real example besides gpt-2 of a model they've developed that can be looked through. It also influences government decisions like open-weight performance to appeal to as a baseline from a partnered American company (and could influence laws etc etc), it also revives openAI open weight expectations and deflects legal claims against it's closed off nature (and could reinforce its standard of "safety") it also re-cements openAI into the open source community and could create a very large pool of developers/researchers who choose to use the open source model
this is the biggest thing openAI could do tbh
@deep adder @elder rapids on the "less than 100b params" and "small model like Sam Altman hinted at" point
*note the plural

ofc it could be relatively small compared to a 1t model
but "it's not a small model"
who is he and how is what he said verifiable at all? and this all doesn't matter because the point isn't that you'd be comparing performance regardless, if it's not precisely a 1T model just like the Kimi model then it's simply wrong to say this is the cause, it could be 900B, it doesn't matter. I can also argue ones a reasoning model the other isn't so it's a completely refuted skepticism
I agree there could be nuance about its size though, the problem is Sam Altman has been all over Twitter clarifying hobbyist utility and it should be "ran on GPUs"
i'm awaiting the openai open model but i find sam's activities odd

they're in the same position as you with the skepticism lmao, big providers having access to the model isn't meaningful towards its alignment or sentiment towards delaying it a little bit. He also has no idea whether these big providers even have it
if they planned to release the model so soon obviously preparation would've been met, calling it off unexpectedly as he framed it would align with what I said
perhaps i'm too trusting but i'd expect being well known and from a decently sized inference/dev org (lambda/nous) to indicate having connections and indicate that their claims are based in reality
there's plenty of examples of people on Twitter in the AI space saying things and then getting corrected by the actual researchers
I forgot that dudes name
true...
I'm ngl it's kind of scary too how much it would sway public opinion, especially in the AI subreddits until actual confirmation arrived
but yeah regardless, I'm not saying you can't trust him just off the fact of trends (even though it wouldn't be a bad inference) there's just a lot of things that implicitly support Sam's (or the openAI researchers...) position here over the skepticism people have about what Sam said
kinda actually pains me that nobody tries to look for practical validity in the AI Twitter space, like you can inductively infer something you know
instead of expressing the opposing claim outright
tek is well known for nous and Yuchen is the ceo of a inference provider
Like I think their claims have validity
it's not that they have no validity, it's just that however valid they are, none of them could know unless they were actually there and could frame it non speculatively like how they're doing
"literally never trust this guy" like bro what are we doing
it's not even that either, there's just more evidence for the non speculation than the pro speculation
it's true, US labs make promises but don't keep them. Meanwhile a Chinese company (Baidu) made an explicit promise when they released ERNIE 4.5 in March that the model would be open sourced on June 30. They released everything related to ERNIE 4.5 on that date. Meanwhile xAI made a promise in February to open source Grok 2 "in the coming months". Grok 4 has came out and the weights for any xAI model other than the original Grok are nowhere to be found. OpenAI made a similar promise, but with a special model made for open source. Every time the model is close to release, they delay it for arbitary reasons.
TL;DR: China keeps promises better than US labs.
even tho I agree with him
true, but China is better at playing catchup
it's non evidence for anything other than "China companies cooler than America's!!"
and doesn't help the case here
I'm not saying there are not US companies that commit to open source, Meta and Nvidia has done it, Google has released lesser version of their flagship models, but China has just done it better. There is no other way I can say this. US focuses on commercialization and their models are popular in those environments but China just releases the models openly to get themselves in the door. Maybe they are trying to influence US opinions with their models, we don't know. But the point is China just does it better. I'm not saying Chinese models are better than US ones, but the difference is that the US ones are closed and many Chinese ones are open. And the ones from the US that are open are worse than China's.
Lets keep things focussed on AI pls
ok
oh are you talking about Craig?
I was just talking about AI
but there may come a day that Chinese models become better than US flagships. They are improving themselves; Kimi K2 is based on DeepSeek's arch but is still better than V3 due to its size. And yes, they do distill from US companies but they are doing it out of desperation, they want to catch up to the US. And now their reasoning models are close enough to US ones in performance that they can distill from their own. Yes, they are still trying to distill from US models because China can't create enough English synthetic data with their own models, but they won't need to do that anymore. And US companies like Meta are basing their models off of what Chinese companies has done because they need to catch up in the open source race. Llama 5 may very well beat China's models when it comes out, considering Meta poached some of AI's best minds. Yes, US models will keep on improving themselves and will still be very good models. But I think China is just accelerating the race and also helping to push the frontier. They just don't have models that beat the US yet because of GPU sanctions. US companies are taking China's work and using their resources to make it better.
yes, but they are doing research that US companies are applying to do so
lol people on twitter are saying that K2 is to blame for OpenAI's delay (I do believe them, because that model probably beats their open source models in things that just can't be done well with smaller models, like knowledge based benchmarks like SimpleQA)
which OpenAI invented btw
it's not like they are telling us, US companies don't like releasing papers anymore
This is extremely illogical
K2 is not a reasoning model i would assume openAI can beat it with a reasoning model
Firstly
Who cares really. It's always going to get overtaken in a few months that's how things work
true, it will be beaten by both US and other Chinese models
i wonder how k2.5 will fare tho
2.5 what?
ok, but will they make k2.5 or go to k3?
they had k1.5
Naming is random
They might see a leap big enough to call their next gen model k3
and hopefully k2.5 or k3 will be smaller
ye
I think it's extremely braindead
a lot of what Kiri is saying is non evidence, closed AI and open source are indistinct In the context they're trying to make an argument for
US open source models being worse than China's (which isn't true, the only outlier is deepseek) isn't meaningful at all, especially when you consider total competition is in context relative to the respective countries
China having a different open source culture is obviously true, but it's not as meaningful as made out to be
Anyone here tried deep research with Grok 4 Heavy?
not sure why he mentioned Chinese models eventually being better than "US flagships" like the US isn't progressing at a much much faster rate than the Chinese models he's calling into question, and acting like China hasn't been benefiting the most from US open source, enabling their progress
That's my only use case for Grok and i'm wondering if it performs better than std Grok 3/4
ok that makes sense
I'm sure Chinese models will be right behind the US though
And I'm sure China is using US models for training or other purposes
they would still be behind if they didn't
yeah definitely, it seems like they're the only real competitors, France hopping on open source early seemed to do wonders for their progress
countries like Japan seem to be more experimental
by France you mean just Mistral
and they have some closed source models, probably to get people to use their API, which is sad
but yes, mistral has done a lot for open source
7b is still one of the most famous and modified open source LLMs out there
Nemo is maintaining its legacy
damn
it's alr tho, they're adding a lot of stuff
so you might get a research agent eventually
ye
I mean I cant help my curiosity and impulse bought to try some stuff
their early MoE models likely inspired later MoEs like DeepSeek
made a deep research styled prompt anyway and am running, hopefully it has research heuristics that are good tho not labeled as a selectable tool

(like 8x22B)
will be good
ye
I agree
at least in the open source
Mistral models aren't great now though
I recently gave an easy prompt to Magistral Medium (the closed source commercial model!) and it went into an endless loop
magistral is just a token-spamming joke atp
From what I gathered so far the progress bars are likely just a visual cue gimmick and don't really represent any linear function as to how much thinking its making
This one prompt ended in 4m
It's really too easy to spot an answer made by ChatGPT or Grok 4. It kinda kills the fun of the arena. The fact that LLMs show personnality isn't bad as such, but it really makes the whole system rigged. If I want to penalize Grok 4 in order to earn some money out of Polymarket, I can litterally do it, just let me play lmarena non stop for 20 hours, pretty sure I can secure 100 lose-on-purpose battles on LMarena. If I take precautions not to get caught, I use free residential IP VPN providers, and I can go litterally uncaught.
Kinda sucks, no system is perfect, but I hate to know that it's doable and that it probably has been attempted before.
ChatGPT: Emoji at the end, structure.
Grok: Grokking.
loool theres some Mechahitler-esque tone to its answer 🤣 (I made it cross-analyze deep research results from Gemini and o3 with its own findings)


Hi so how can I send images to the model on Direct Chat on LMArena?

Oh never mind Im not getting it for Opus 4 and grok 4
grok 4 is still great even if it cant use tools? better o3 or grok?
why not just try?

Sam kinda pathetic giving this safety excuse and underestimating the intelligence of everyone else on the planet
what's this? k2?
They have been testing this for a month, you dont just suddenly realise the model is 'unsafe' just before the release
That's not how it works it's obvious to everyone
Musk calling grok 4 agi repeatedly also lol
"phd in everything"

thats how hypers define it
also
will grok heavy be available on LMarena direct chat?
when api of that comes out/
likely never
january/february tbh
december is stretching it tho
Didn't musk say grok 5 was cooking already
hmm...
it could arrive maybe a bit early then
grok 1 to grok 2 was about 9 months
grok 2 to grok 3 was about 6 months
grok 3 to grok 4 was about 5 months
keeps slashing it between releases
so earliest could theoretically be november but highly unlikely imo
3.5 seems more realistic
There's 172 Days till end the year
I think end of the year release makes sense, Gemini 3 is coming then too
so no o3 pro / gemini deepthink / grok 4 heavyy ever?
all of them are too costly
I think opus 4 thinking is a lot more costly than whatever the price of deepthink will be
then make a suggestion lol
haven't checked costs tho
cost of deepthink isnt yet out
shouldn't be as bad as the multi-agent framework grok 4 heavy uses tho but idk
maybe
also are the models nerfed?
in lmarena?/
like opus thinking and grok 4 are still high class models
even with the data i dont think its too practical to provide these models
Deepthink isnt going to be cheap for some reasons which cannot yet be stated lol
what if it will?
cuz gemini models are cheap
the delay was for another reason
they already had a model which was performing better than it's upper tier model from other companies
I mean 2.5 pro was better than o3 pro and stuff
so there was no point of releasing another SOTA having their own model on top already
Very wrong
wdym
that time they had no competition
half pass but only if being charitable imo. it briefly acknowledges digital clocks don't have hands, then moves on assuming it must be an analogue clock; it's final answer is 7.5 (which is a fail)
I really hope Gemini will have new updates this month
kingfall (one among 15 questions it was answering) passes. like it's possible to acknowledge the analogue clock possible interpretation, but not give that is the final answer

fwiw it feels quite a way behind 4.1 in the limited use i've had so far (i don't do coding / web dev / SVG prompts tho, which seems to be what a lot of people are mostly interested in )
How are you folks getting this info? I know people working in Gemini teams and even they don't know these things : 🤔
How are you still able to use/test kingfall?
ahh.. it's an old screenshot (I was just scrolling through until I found one that included that question, and it just so happened to be kingfall (from one month ago) aha
lol
@alpine coral can u benchmark kimi k2 pls
No but seriously did anyone notice the first principles Elon's was talking about?
'It will provide answers that you won't find on the internet'
didnt he say that too
It reasons through Elon tweets
Yes indeed
Others have too
Smartest AI I have used
For reference, Deepseek R1 official API is $2.19. This sounds insanely low and OpenAI have more traffic, but also more efficient GPUs and better infra, so I still think 2-3.
Deepseek's cost is probably around $2 dead, and those 20 cents is their entire "profit" lol
they have a 545% margin...
Do we know when grok is going to be added to the leaderboard 
This month for sure, next week is my guess...
Since it's already collecting votes
this looks wild now though. OpenAI with no model released yet higher odds than xAI... lol

Youre looking wrong
Youre looking at end of 2025
thats for end of 2025
Would be smart If staff Here Waits for the Last Day of the month and Puts grok in top 1
i would still bet on google tbh
While having PM shares on it
uhh right. Wrong link 💀
this is more realistic ok

yea
Betting on Google still would be silly...
You get almost no return and there's reasonable risk xAI takes it and Google doesn't even respond by the end of July for it to be on the leaderboard...
im not feeling grok 4
I'm not either. But it doesn't take a whole lot if you look at current leaderboard. 4o-latest is 3rd not far away from top spot
idk tbh.. i may as well just bet against him all the time
If they tuned it for arena prompts I think chances are very reasonable
i just feel like wolfstride/stonebloom could top it instead
that's a threat for top spot for sure, is it still in arena though?
wolfstride
Seems like they are testing a bit random things and then retracting it
is opus 4 good or 2.5 pro good in mass coding?
like for start building a vibecoding project/
^
ohh
why cant we upload images to claude 4 opus on lmarena direct chat?
If you want for it to go absolutely off the rails doing the entire thing in one go probably Sonnet 3.7. That thing can hit the output cap just with code lol
Opus is gonna be singificantly more concise, then Sonnet 4, but 3.7 even more unhinged
how is the inferior class old family model better than their best model 4 opus thinking?
which 3.7 is the best for coding?
what about gemini 2.5 pro?
so opus 4 not good for coding?
Different fine-tuning. You need different tools for different tasks. Opus is not meant as a power horse of repetitive work
it is much more concise with outputs
also this

ohh
what about 2.5 pro vs sonnet 3.7 vs sonnet 4
which one should I choose?
also the new Kimi 2
2.5Pro is a safe bet for almost everything tbh. Then you can do 3.7 if you feel 2.5 outputs are too short for any given task
its one shots are about 6k to 9k characters (2.5 pro
)
do u have any idea about kimi 2?
Well I did a coding task where it was 32k code in a single response with 3.7 lol
also so opus 4 and sonnet 4 are good for nothing?
💀
i might try it
im actually so confused
like at this point
there are so many models
2.5 pro opus 4 sommet 4 sonnet 3.7 grok 4 kimi 2
also oai's codex
fwiw don't fixate on them too much
you're better off just using one / some of them, and getting a feel – they're not like insanely different at a surface level..
it's like maybe one will be the magic wand you want - build / fix whatever it is you're working on perfectly. but there's still effort along the way.. engaging with them.. they're all kinda similar in many ways
Kimi 2 you shouldn't worry about for now. It's competing with gpt4.1, 4.5, Deepseek V3 etc... Not with SOTA reasoning models
yea its actually competing with opus 4
I tried it and went crazy
its so slow tho
like it's one shot code is so better than 2.5 pro and grok 4
yea but the quality is good ig
good! don't look at the tables with benchmark comparisons.. just use the models and see what you think ha
yea lol
also its good on the benches
As a non-reasoner it's a good option in that segment yeah
I'm afraid that they can't serve 1T model for free for long
Unless they have insane fund
theyre probably hosting it on their own gpus, cost is probably not that high for them
There are probably gonna be free 3rd party alternatives, like there are for R1 now, which is not that much smaller...

Didn't chute remove the free tier for deepseek?
I thought so too but it works so ig not entirely removed lol
You also have 2 more providers
for sure
deepseek api is very slow too
Do they use fp4 or some quant?
i remember getting 60 tps. now its so slow and at times unstable
DeepSeek V3 and R1 before it blew up to the mainstream is so peak. It's sooo fast
I feel they dumped xAI too early in that market
Nah it's the same as paid ones:

Hey guys, does anyone know what happened to dragontail? I loved that model and it seems like none of the models publicly available today are as smart as dragontail.
dragontail seems familiar
https://x.com/mckaywrigley/status/1943385794414334032 saw this and tried it with wolfstride
My thoughts on Grok 4 Heavy after 12hrs:
Crazy good!
“Create an animation of a crowd of people walking to form “Hello world, I am Grok” as camera changes to birds-eye.”
And it 1-shotted the *entire* thing.
No other model comes close.
Watch the full clip.

isn't it a Gemini model?
The rumor that it was a google model yes but it seems to be singificantly smarter than 2.5 Pro
2.5 Pro still can't solve problems that dragontail has been able to solve when I tried it
I would really like to use dragontail again
how do they know these are all gemini models? By asking them?
grok 4 heavy does it in 2 (first "hello world", then "i am grok") and with less people
wolfstride does it in 1, as the prompt asks for, and with more people
dragontail has been able to solve problems none of the publicly available models I've tried can solve still
like?
Like this one:
Let G be a group. Denote by a' the inverse of a for simplicity. Define the generalized commmutator [a1,...,an] to be a1...ana1'....an'. So in particular [x,y] = xyx'y' is the usual commmutator. Give a formula to write [a,b][c,d] as a single generalized commutator. Verify the derived formula step by step to check that everything cancels out nicely. I cannot read latex so use plaintext. Also make sure to use my convention by writing x' for the inverse of x.
what's the answer
is it back in the arena?
What if you coded your own "heavy" except it has 5 instances of o3 and 5 of 2.5Pro, 5 of Grok4 (giving it the benefit of the doubt with that impressive arc-agi score)... Then can also add Opus4 for good measure I suppose for a total of 20. That would have been SOTA by a good margin 🤔
you might need a very good framework to figure the best response though
Hi guys, is the open weights R1T2 Chimera on the Leaderboard already? https://huggingface.co/tngtech/DeepSeek-TNG-R1T2-Chimera
If not, what's the typical process to add it to the board?

claim the benchmarks without releasing the scoring system 🤣
You do but I think it's not THAT critical. Any good model you use out of them for forming the final response should do a decent job seeing all of those attempts. 2.5Pro probably the most appropriate given the context size
@round haven also curious
Those Pro/Heavy models do well because often you (or the model) can actually spot a good response or what other attempts missed just by looking at it
would probably get a bit harder, because the models will obv prefer their own response the most bias wise
will not completely destroy the potential though
just as small hurdle
Yeah fair point. Probably make it rate their own ones then and use yet another model to then review the best from each you used to generate lol
most of them get RLAI training with some version of themselves in the process -> they produce output they like
would be interesting to fine tune a good open model as the final answer generator using some rl on rlvr
yea still
with the rate that they usually put stuff out i would expect a new anon google model on arena soon
oops ignore that reply
didn't realise it was still on it
no
does anybody know a free provider for K2 api?
dragontail is still on lmarena?! 😮
why do i never get it
asking them and check the web dev arena code
get what?
i thought they said it's still in the arena
only stonebloom and wolfstride has Gemini mystery models iirc
who?
leo
anyway, a misunderstanding probably
When I use lmarena new UI i get these hanging responses. The generator keeps spinning and i never get a response. Grok 4 generator is still spinning from yesterday
v buggy
true
I don't know if those models thought too much and crash or it's just delay
No thinking available, even as summary
none atm
so will there be an update this month or not?
sorry. I'm just hoping that there will be something better than 06-05
in lmarena right now but don't when it will debut
waiting for Gemini updates and Arena updates are my main joys
and what they are
how do you use Battle mode?
Kimi k2 is what i expected deepseek v4 to be
But can v4 really be better than k2?
I don't think deepseek will train a base model to 1T
K2 feels exactly like grok 3, smart for a base model
K2 (as all the Chinese models) is bad in non-English world knowledge
Yea it missed some events when i asked it about French conflicts
Gave like 2 wrong dates as well
shhh

{kind=link}
ok this is epic
because it's just going to get patched lol
i've seen all kinda things in chinese language forums lately..
yikes
kinda forget how epic it is how can you legit translate the content of webpages these days
wasn't that long ago that translatino was shite and clunky
lol
wow what an edgy cool guy 🥶 🥶
wdym?
💀
you just come across as a 14 yr old trying too hard to be edgy
Sorry if I came through that way
you gotta do what you gotta do 🤷
I can use deep think and other gemini new models for free but imma gatekeep as well
it's an ethnic slur for the mainland chinese in HK
sometimes yes but generally it's for good reason
Don't delete
i dont thihnk he meant that
then what did you mean 🙏😭
yeah nvm then mb
I will share the code ive used to get deep think for free
eh yeahi kinda thout that - but it'd be something more like parasite (leech or something) than locust
I wont share how to use wolfstride and stonebloom for free or maybe i will
but perhaps lost in translation
yeah that's what had me confused
all very similar
nah ive heard the term used like that before
I want it to be patched just because some people are gatekeeping
post it here i dare u lol
that doesn't really make sense
but alright
it's not hard to find if you do 2 minutes of research
🤷♂️
yeah it's apparently a thing

Yea but when i asked you, you played dumb
i meant the free loader thing not the ethnic slur lolll
oh lol
i didnt even know about that lol
cause yeah.. that seems like a cooincidence or intended.. or some translatiion thing
or im just too high
Im just lazy to re
what, where did you ask me ??
it seems unintended, i doubt the people who ive seen that used the word actually used it as an ethnic slur. that seems like a china specific thing
kinda the same thing tho.. like was using locusts to mean parasites i thought.. and yeah locusts aren't really parasitic..
parasite = freeloader
I do think it would've made more sense to say parasites in that situation because it's more commonly used to describe free loaders but
oh well
suppose so but the severity is different i guess even if its symbolically similar
@keen beacon should i?
lol
idrc tbh. do it if you want to 😂
pretty sure they know by now anyway
they have high quality discussions imo
definitely one of the more cracked forums
!
linux.do my goat
that’s Kimi
Btw what’s the system prompt of Grok4 on LMArena?
It seems different to the version in Grok app and in API
guys
now that windsurf people wok at google deepmind will google models become much better at coding?
Kimi or kiki?
depends on the task tbh
can you be more specific about what u typically want to use it for? tbh, you should just try out different local ai models yourself and get a feel of which model to use in what scenario
lmarena is so unusable in the direct chyat mode when it generates code
you need vision? or like the good at svg / web design type