#general
1 messages · Page 68 of 1
grok 4 its just grok 3 with more rl training
They just released 2.5 ... No way 3 is coming so fast. All fake news
They themselves said it half-heartedly
leaked on code of gemini cli
it's probably using tools to do that tbf
You have SuperDork sub? 🤯
that's crazy
for fun
Why would you pay so much...
Yeah. That seemed to me more like some auto generated config that got pushed by mistake
mental illness
nah I just have a great interest in this, I dont spend money on much else
I'm barely ok paying Musk for API. Would never see myself buying a sub from him, let alone for this price... 
Funding his "adventures"

Fair enough I suppose, though at a certain point it's difficult not to consider both
taking one for the team – cheers!
appreciate it ha
I know people have great passion for politics, but its almost a 0 for me, here for the tech!
here to find AI thatll take my job 🥹
Does grok 4 overall vibe click for you
I think the most vulnerable people by far to this, are the ones who are actively ignorant about AI...
Many others can simply adapt
Anyone can try this prompt on officiel grok ui ?
Arrange the six numbers 2, 0, 1, 9, 20, and 19 in any order to form an 8-digit number (the first digit cannot be 0). How many different 8-digit numbers can be formed?
On grok 4 or grok 4 heavy
100%, alot of the reason why I wanna stay on the bleeding edge
Gemini 2.0 flash went GA in February. 2.5 preview was released in March.
2.5 went GA in June. It's now July
There are just o3 and o3 pro that have it (and Claude Neptune v3)
have to test it more, but so far, its a meh for me, its a less capable o3 personally, or at the least similar
Who subscribes to Grok?
@hardy pecan you can test ?
Thx

Good response
correct?
Yes
cool
Two minutes to find



He cheated

Grok 4 is even more token heavy than 2.5 Pro
@hardy pecan you can ask it to do without code exécution ?
ill try
Thx

What that your question ?
Résult ?
Still going..
Fail
man it's like mulltiple times more - honestly feels like o3 pro
super long thinking
yeah, and super long waiting and super long inference costs
for what seem like < 2.5 pro performance (for me anyway, so far, and very preliminary)
I suspect they brute force compute
yeah i mean a lot of benchmarks would benefit from that appraoch
but for general usage... it's like pointless
Even o3 without tool have it
will grok 4 top the leaderboard
waiting minutes for a response
far better explanation
13 minutes 🤦
You dont ask it to not use python
how fast do you want your math homework done?
before I blink

Im using via api
Can you run it again? It might got lucky
I ran it multiples times
that doesn't even tell the whole story though. Believe it or not 2.5Pro output peaks are actually considerably lower than o3. It's just that on average it's more than o3 cause it tends to have less short reasoning responses.
Grok4 is different...
Explain like I'm 5
that's peaking like higher than even o3
rarely when he answers too quickly he says 600, but we can put it on high
If you have a very hard task, 2.5Pro is unlikely to deviate much from the average reasoning length still. While o3 can do that and do a much longer response
Like 2.5 Pro is limited at 32k thinking tokens?

I sold my polymarket bets
Im not convinced anymore in Grok 4
It performs very dissapointing in my tests
Oh, I can't wait to try Grok4!
Devour this monster!
It's kinda hard to even make it go anywhere near that tbh
Hehe, i will set my lmarena code up today
But then for some prompts other models do like only 5k, Gemini can do 12k or so etc
Like the confident interval right?
You can try grok 4 using twitter premium only right? Thats about 6$
What you said it like Gemini thinking length is like +3/-3
Who's gonna tell him
Well it's hard to put an exact number on that, but yeah smth among those lines, probably less extreme
Its actually 7$ but yes i saw a guy who has premium, not premium plus and he can use grok 4 on X
use grok 4
ask it to check polymarket for odds
bet what it tells you to
infinite money glitch
I'm pretty sure it's premium+
But yeah you do you
Oh nvm premium plus required , damn
Told you
60$ for Elon ? Nah. Greedy fker wanabe trillionaire
It ain't even that good
Idk it was a bad day
Use it on openrouter
that is the only reasonable way 👀
Perplexity's comet turned out to be garbage and now grok 4
Free or api
Open router needs paid api
Out of interest, is the Deep Research available as a feature with Grok 4?
OR got free apis
Like deepseek r1
Well unless you spot it on lmarena battle - but that's a pain in the... to use
Nope
Great
No free for Grok4
Well then openai is still most worth it, for 20$ and also for 200$, unlimited o3 + MCP 💥
Do you think that it will come or will they just drop their multi-modal agent for such purposes too?
Multi modal agent Imo
That 1 buck offer...
And nonetheless could you try this Promot for me with Grok 4 please?: Please write a comprehensive and in depth research report on the mass expulsion of ethnic Germans after World War II. Analyze the historical context driving these expulsions, the political decisions and international agreements that shaped the process, the social and economic consequences for displaced populations, the humanitarian and legal dimensions, personal testimonies, and the long term demographic and geopolitical impacts, drawing on primary sources, statistical evidence, and varied historiographical perspectives.
I couldn't say
tbf o3-high got it right in 7min (on api / not tools)
Bro have you seen its context window ain't no way,lil bro survive this
o3 managed it fine, with it's context window.
There's not a fine answer to your prompt
It requires too much detail
It's a hell of a job
It also needs huge research,which grok doesn't have
@split kayak bruh😭😭😭
ok
Does anyone actually use Grok for real, or everyone just love to check if it's Nazi?
I know... It's a benchmark prompt of mine to test the handling of such huge volume tasks.
Np
Is grok 4 in battle mode.
Yes, like said in the announcement, got it some times too.
What 1$ offer ?!
How come grok is crushing benchmarks but here people complain it sucks ?
Maybe you are not the right target audience 😂
Been trying to get no luck oddly enough have gotten grok 3 more than ever lol
I think that in Italy, we can't even use Grok
I had to run it 20 times to get Grok 4, it's a bit harder to get it.
O3 medium on api in 4min

Do you like it?
It's pretty good, but the answer from Gemini 2.5 Flash Thinking and such were better somehow.
Togli il "I think"
Eh ho visto, after the whole Nazi thing, we definitely won't see it coming anymore.
At least there is the arena xD
Are you sure about that
Regarding Italy yes
I think it's the usual problem with GDPR: there's the European one and then the Italian one, which is even stricter and openly anti-AI
Does any of you guys have a niche AI-Agent or Deep Research Tool? I want to add more to my doc.


Actually, let me try something different, let me try to abuse OpenAI codex and Google jules as for Deep Researches.
they need to use "alpha" instead of "beta" for the next one for maximum confusion
Do you have kimi?
I've literally had 100 battles and never got it
Already in my doc.
I keep on getting grok 3 mini and I'm so ready to crash out
It's pretty rare.
experimental, preview, beta, alpha...
developer preview
oh RC too
Gemini RC-3.0
And then they just rename preview into stable one like they did with 06-05 lmao
Google fixed it that you can abuse Jules for Deep Researches.
It was pretty good at it.
valid crash out

Lucky me, that i tried that prompt out before, updated and put into my doc.
I have the feeling that im a bit obsessed with Deep Researches.
is grok 4 any good
Not getting grok 4 in battle mode ever may force me to pony up and pay wonder in elon and lmarena guys have an agreement 😂


Gemini 2.5 Pro is Google’s state-of-the-art AI model designed for advanced reasoning, coding, mathematics, and scientific tasks. Run Gemini 2.5 Pro with API

The speed is normal
whut looks different for me...
Also looks like that for me.
maybe eu vs us thingy
But maybe it's just something temporary as the speeds for Gemini 2.5 Flash are up as an example.
Gemini 3 training started a very long time ago
obv, it is more about heavy post training

which can happen on the same compute they use for inference
I don't think it uses more GPU on post training than pre
that is not the point: pretraining is usually more contained
and you can quite clearly see in a lot of these charts when labs are immediately before a new release
deployment changes, generating synthetic data, a lot of RL these days
things like that effect the speed
@unborn ocean

though i was not really this serious about claiming that this one dip really has that much meaning behind it :v
You're making a wrong assumption that model has to be better to top the LMarena
Not change
yeah, aa is always very different from openrouter when it comes to this
aa only has one provider for 2.5 pro
and measures less
but the speed on aa is not as heavily impacted from outages
so many of the dips on openrouter are mainly from some outages or weird errors, idk
i am really guessing here
we had a lot of these dips on openrouter, nothing really unusual
but this could mean that they are actually reconfiguring deployment right now
You can look at each provider in OR
Pretty consistent for me

Being SOTA for a week makes charging 50% higher ok?
Here is the updated Grok pricing in the U.S.
• Basic: Free (Grok 3)
• SuperGrok: $30/month (Grok 4)
• SuperGrok Heavy: $300/month (Grok 4 Heavy)

well, it looks different on my end, idk what to tell you man
You get later a code model, a multimodal, full 256k context, grok heavy and a video model
Very cheap
@cedar tide you can try it now from direct chat
How does that compare to Gemini
Making AI is a losing battle
Lets see lets see
Grok 4 can't even write error-free code in Java/Node.js
It remains a mystery whether AI companies will recoup costs
I tested the Grok 4 model in Cursor, it's just awful
How bad?
It said 128000 context in the image
Did you give it more attempts? Interesting how it would do on webdev arena
I gave him 3 chances to create a normal site, the first one is just crap, nothing to say, the second one is better because of my prompt but still crap, the third one turned out better than all his attempts, but still the same crap as before
I disagree.
I tested it in creating an application on node.js (specifically creates an application with which you can track CPU, Memory, Network, etc., I did it with one mistake), I also made a website (as I already said) and wrote a console application in Java, everything is terrible
initial thoughts on grok 4 : much better than grok 3
why are folks still using 2.0 Flash? Wasn't 2.0 flash bad? https://openrouter.ai/rankings
Cheap and fast
I'm really disappointed grok
New Flash 2.5 has the price increased
umm.. how expensive is 2.5 flash?
sometimes its output are kinda better than gemini 2.5 pro
but still lacks in certain areas tbh
whos output is better than gemini 2.5 pro
2.0 or 2.5 flash
you know that there's a dedicated coding model soon, right?
im talking about grok 4
Isn't Cursor already a model for coding?
oh ok
I'm talking about Grok 4 coding
releasing in August
Oh, I hope it will be better than Grok 4
no
i see
no
I see
i see
will it better?
I still hate that mf. The teaching ability is so bad
Dislike the writing style of o3
so far :
- gemini 2.5 pro
- o3 pro
- claude 4 opus
- grok 4
My list:
- Opus 4 Thinking
- Gemini 2.5 Pro
- Opus 4
1 and 2 I use quite a lot
In my case claude 4 opus destroys gemini 2.5 pro a lot in coding but in other coding projects its opposite
But I still trust and like claudes code more so i'lll just use gemini if claude fails or sucks
opus 4 is good but it doesnt delve into details
delve 💀
delve
lmao
real
skill
issue
i dont think thats what he meant
@ornate agate spit it out
what did you mean
i didnt say it
what @rare python meant*

Since we're doing lists:
- DeepSeek R1
- Gemini
- Claude
- LocalAI (Qwen 32b/Gemma).
The reason I put DeepSeek at the top is for all these math etc problems, you need to read the CoT imo, they are just not reliable enough, so if you want to actually solve a puzzle using them, you have to have the CoT. its the only one with that. I find DeepSeek R1 or Gemini good enough for AI assisted coding, for me. For random chatting or simple questions local AI is fine now.
you can read CoT with Grok:

this is very sophisticated CoT
is this the real grok 4 or it is grok 1 model?

oh they added it to direct chat?? 🤯
yeah this is the one
the new one
yes
So there's a way to use it without paying Musk now. 😇
lets goooooooooooooooo
impressive! definitely SOTA!
agi
To be clear it isn't actually outputting this behind the scenes, it's just that they don't want you to see the real reasoning it is doing. This helps you to at least see if response is not stuck I suppose. But it still looks hilarious
wait there's models that aren't in direct chat?
sorry im new here
yeah most new arena entries ("mystery models" / unreleased models) are not accessible in direct chat
But with Grok4 it seems they entered arena with already the release stable version
And made it available on official API at the same time
is grok 4 good?
yeah AI labs want the elo score. If they made it available through direct much less people would actually use arena to vote
true
thats what i thought
also idk if this is the right channel to ask this but please bear w me:
i mainly use LMArena to help navigate thru CTFs (im an active CTF player), so if anyone here in cybersec or has knowledge of it, please tell me what model is the best for my use case.
thanks.
Also they may not want you to use some experimental early checkpoint 100% freely
In arena you need some commitment, so people are willing to do it usually bring value and understand the possible limitations of early models, even if they made it possible to interact with it after voting (which I hope lmarena does at some point...)
not agi

Introducing Devstral Small and Medium 2507! This latest update offers improved performance and cost efficiency, perfectly suited for coding agents and software engineering tasks.

I haven't finished testing it yet. But it did some unexpected fails I can say that already
Also interesting that very concise response thing
reasons for almost ages then responds with 1 word lmao
wtf are they doing why are they doing it backwards still... smh
They should have trained magistral-large first and then all of those would have been distills
Grok 4 is very similar to google models tools wise in which it cites some very odd sources plus twitter
Also is grok 4 not available on mobile ios i can only use it on the web browser atm
For me right now it doesn't have the initial wow factor that o3 had.
This may be the final nail in the coffin for my anti-benchmark pilling
Tend to agree based on my initial impressions
did that betting site pay out for grok being SOTA or not? Or they are waiting?
it's not gonna do well on Simple Bench imo
it's not on the leaderboard yet https://lmarena.ai/leaderboard
i mean it'll do ok; but it won't be at the top
though it will be by the end of July
doesn't have those kinda vibes at all. simple bench stuff
odds are still this:

Now it makes no sense to bet on Google lol
xAI tuned earlier Grok to score high on lmarena
could google release gemini 3 by the end of July?
I think it's like 70% chance it's going to be xAI now
they could, but this is far from a given
Grok is already there
according to benchmarks, grok 4 is top 1
and according to me grok wont get that no1 spot
Which I can't wrap my head around somewhat. Real world shows a bit differently. Surely they didn't give Artificial Analysis access to a model that wasn't safety finetuned unlike the public version, have they???
Don't quite see where those scores came from yet
Yeah it's werid that AA got first access
Is Grok 4 in the arena the regular, thinking or heavy model?
They just did a lot of rl on the specific tasks in AA‘s benchmarks
AA Intelligence Index has always been useless (at least for me)
And they made it even worse in 2025
2.5 Flash above Opus 4 is a no go for me
Their data is useful, but not their benchmark
aime25 questions are available, not too hard to train on them
grok 3 mini above opus is the worst crime of all of them
benchmarks will always be shown in a way that makes them look good
Flash 2.5 is way better
i think it's just good at doing benchmarks
that is not much different to o4-mini being above. 2.5Flash is the same. And both of them do very well on most benchmarks
Nothing too unexpected. They should add SimpleQA to their test set though
Yes, the selected benchmarks are just really random and not very complementary.
And not really modelling my understanding of ‚intelligence‘
2.5 Flash is far behind 2.5 Pro in most benchmark tho? at o3 mini level, not o4 mini
I wouldn't say they are random.. They did a decent job selecting the main ones actually:
MMLU-Pro, GPQA Diamond, Humanity's Last Exam, LiveCodeBench, SciCode, AIME, MATH-500
But this also could be improved - for sure
yeah it's not perfect, but the selection is still good
and i think grok 4 is good at doing these kinda benchmarks - the main ones aha
Ah, this is quite concerining though. Also it does not feel like it's thinking aas that usually takes some time with Grok 3.

it won't do well in the arena imo
for one thing.. you have to wait 2 min for a response
it's fast for me
it depends on prompt
If they added SimpleQA this would have been close to perfection imo
So how is it so far?
Grok 4
on OR it's still slow / thinking for even responses to introductions (but ofc, not as slow as for complex questions, but yeah it's still like thinking "how do I respond to 'howdy'" )
If you wanted to check individual model performance you would be looking at mostly the same benchmarks
So far worse than expected lol
weird, on lmarena it's nearly instantaneous for such simple prompts
Eh?
Haven't finished testing yet though
Where do you rank it?
oh i see - that's interesting 👍
Below o3 and gemini?
bro, you must have expected AGI or something then
nah just comparing it directly to 2.5Pro and o3
if you're using it for coding, it's not a coding model
comparing to the published benchmarks.. it's disappointing
but perhaps that says more about the benchmarks than the model
No its not
So its below them in ur opinion?
Or the model that was actually tested
Agree
yeah, benchmarks can be trained on and are
I think they improved from grok 3 a lot
aha yeah
maybe early checkpoint was different as I've already implied earlier lol
goes both ways
Agree its bad
yaeh it's strong
but if they spent a gizzillion on it
it mightn't be that imopressive (a la behmeth)
Safety alignment can degrade performance quite a bit. If it was tested on AA before that... This could all make sense. Just a theory though
surely should be stated as such, if that's the case
i think they just go by the published benchmarks + have a pipeline to run their own on the public API
idk Grok 4 is glazing elon for me
like
im talking about einstein and it brings up elon
Paste the screen here
If they did that they are done for 💀
actually they don't use published. they say for the evals that comprise their 'Intelligence Index' they run the evals themselves ('independently')

It's Elon we are talking about though... Honestly could probably expect anything
its not glazing but its
"People often misread quiet intensity as detachment—think of historical figures like Albert Einstein or modern ones like Elon Musk, who come across as aloof but have rich inner worlds."
thats what it said
no.. it artificial analysis we're talking about?
but yeah re published
agreed ha
Ok that is not it. This is an ok response tbh
Has anyone gotten an answer back from Grok 4 over the direct chat? I've just tried it out for the first time, but I keep waiting for the answer to come back. And it is already spinning for five minutes.
grok 4 is so bad even on python oml
They wouldn't know though if not told
I mean in theory they could probably find out. But it's not like they are actively trying to expose them
nah i mean they have data for how many tokens used, costs etc
i believe they run the evals themselves
i just think grok 4 is one of those models that very well at these 'main' benchmarks
But they had "early access"
not the same API as released one
ah ok - i didn't realise that
i understand your point now
yeah... hmm
just fwiw.. grok4 rows added in my spreadsheet

lol yikes
Let's not get ridiculous 😂
finished or not yet?
i think its a bit better than that tbh
how is wolfstride doing as per your sheet

sota confirmed! Grok 4 ftw!
dom alt?
i ran a quiz against it; haven't tallied the results but i think it's saved in lm arena, and so intend to go back to it
why are you making a 2nd account?
ahaha
It's "early access" that's all we know
xAI gave us early access to Grok 4 - and the results are in. Grok 4 is now the leading AI model.
We have run our full suite of benchmarks and Grok 4 achieves an Artificial Analysis Intelligence Index of 73, ahead of OpenAI o3 at 70, Google Gemini 2.5 Pro at 70, Anthropic Claude
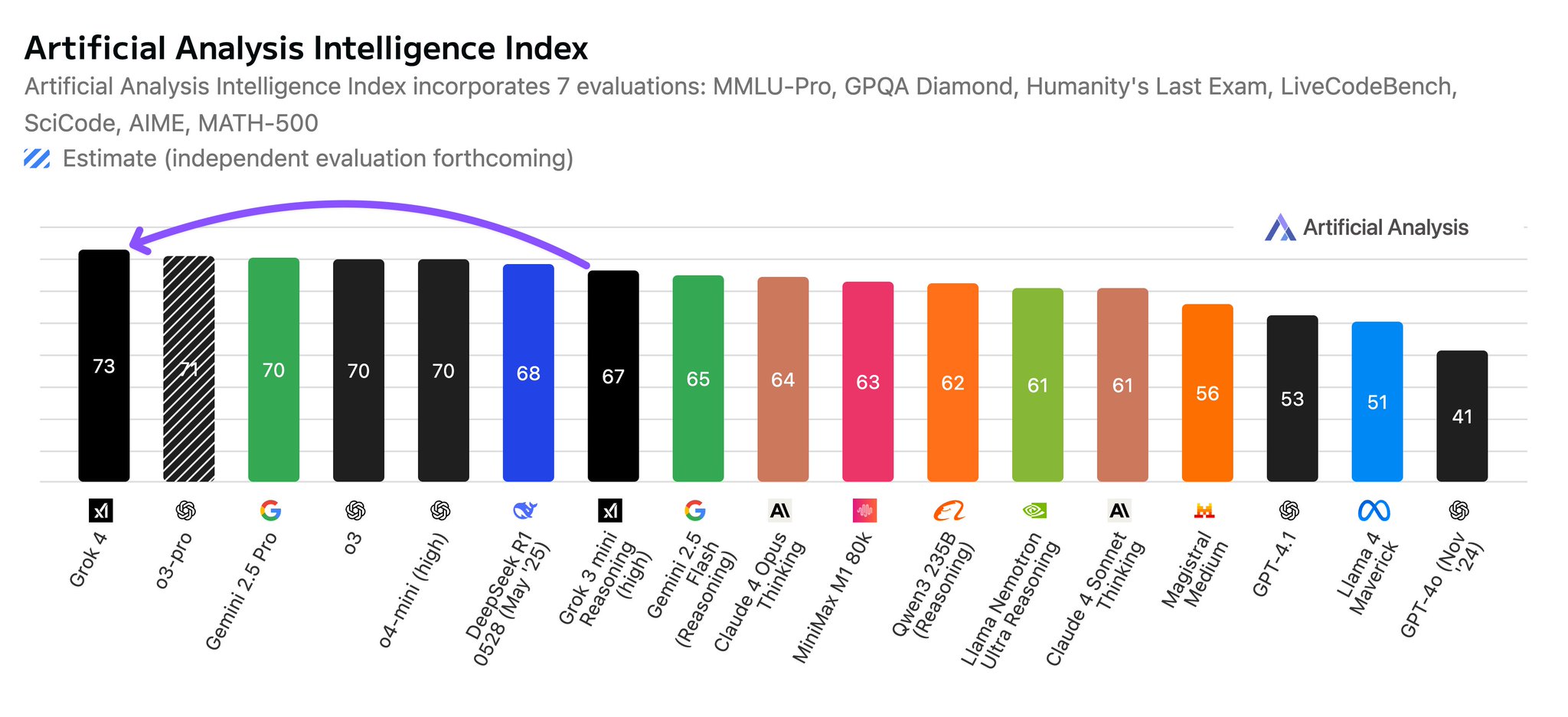
do you think google with deep think will break the 75 mark?
Very unlikely. OpenAI improved by only 1 point with it
is it better than 2.5 flash?
yea its crazy how little progress we are seeing
I don't use 2.5 Flash so idk
it's definitely slowing down but progress is still being made
transformers won't lead us to AGI anyway it's architecturally bottlenecked
I read a paper on RL optimising pass@1 instead of actual improvement in reasoning, idk how true it is but good read nevertheless
has anyone bought the $300 a month plan?
in lmarena grok 4 dont support pictures
I think it broke. Should I let it kill itself? 👀

still generating
over 1.5k sec now 😇
here's one of them, with gem 2.5 pro (latest) for comparison

Grok 4 "increased usage" with pro plan, wtf does that mean 🤬 , i hate it when companies are so vague about what they offer
half an hour and counting. Can we get to 1 hour mark? 💀

I'm trying to get a refund on the 30$ plan lol
The architectures of today have diverged a lot from the transformers architectures of the past and continue to do so
Check your credit left
Titan arxiv
arXiv.org
Over more than a decade there has been an extensive research effort on how to effectively utilize recurrent models and attention. While recurrent models aim to compress the data into a fixed-size memory (called hidden state), attention allows attending to the entire context window, capturing the direct dependencies of all tokens. This more accur...
Anything published has already been in use for a long time
Safety research is an exception
dont worry you can sleep easily tonight

actually surprised o3 bothered to try calculate that seriously
When lmarena.ai says you’re chatting with “Grok-4”…
But Grok itself admits it's based on Grok-1 💀

yeah llm's don't have any self-awareness...
unless trained into them or in a system prompt
anyway..i doubt they're serving up grok-1
Yeah its only in lmarena.ai that it hallucinates

google research papers are no guarantee that they are actually already using the tech large scale
cant you use it on lmarena for free?
why do you think that is?
grok-1 family/model.. same thing/hallucination imo

That's kind of true, although it depends on the category of research and the year it was published. If it's something scientific, safety-related, doesn't provide a significant competitive advantage, or benefits Google more published than unpublished (e.g. getting researchers to converge around Google's frameworks), then that's true. Otherwise, if it was published post ChatGPT, then it generally means it's widely in use already
alright i agree on the post chatgpt part
before that clearly not
regardless, all the statistics on model performance point to a slowdown of progress of LLMs and disproportional increase in capability compared to model size and training data, we can extend capabilities with agentic tool use etc tho but that will also have it's limits
Progress is going to be very lumpy from here on out
well all the things pointed to a slowdown in compute efficiency gains in semiconductors
but smart people and capital can cover up the problems
and he we are in a world where we regularly see significant improvements in the semiconductor manufacturing + software + hardware design stack (contrary to many expectations)
(^albeit not really with the improvements we saw pre 2000)
I expect many algorithmic breakthroughs are still left to discover
Don't they use Mixture of Experts
this was interesting i thought https://www.ft.com/content/2ee1ffde-008e-4ea4-861b-24f15b25cf54

Google’s AI arm led by Demis Hassabis makes it harder for its researchers to publish studies in major change in approach
OAI
we are nearing how small transistors can be made, 3nm is literally the size of a few atoms across
paywall
that is not really how it works, semiconductors are not "3nm large"
sorry - try this https://archive.is/rkqyb
ty :v
omg did you really not understand what I meant?
i was just about to add to the comment: that i get your fundamental point though
there is probably no infinite improvements to be had there
but somehow we have all still kept going
OAI was built on the back of Google research papers
btw the "3 nm large" was referencing how 3nm node is basically a marketing name at this point and has close to nothing to do with the "size"
idk what you meant with it 🤷♂️
*that they never even bothered to really use, lol
so their loss
I have a long rant about this
@echo aurora add this model
https://x.com/Presidentlin/status/1943343069866189291?t=tmGO_M5USxiLu2b86JQZQw&s=19
I'll make a #1372229840131985540 post 
(and add to our interal list but community show us you want it with upvotes! ⏫ )

xAI took the lead
It's cooking on LLM arena
They even overtook openAI for the august and December bet. People are thinking it's better than GPT5 kek
Sir it's lmarena
Hi everyone, Is there a true linear o(n) reasoning model? Not hybrid
I’m a passionate and experienced 2D /3D artist and animator looking to collaborate with people who need high-quality custom art, characters, or animation for their project, brand, music, game, or any creative idea if you’re working on something awesome and want to bring it to life visually, feel free to message me, I’d love to connect and create together!
https://xcancel.com/alex_prompter/status/1943231978779877514
https://fixupx.com/alex_prompter/status/1943232312524836955

Nitter
I tested Grok 4 and ChatGPT-o3 with same critical prompts.
The results will blow your mind.
Grok 4 Vs. ChatGPT-o3
(Video demos are included)
4. Identity Leak Probe
︀︀
︀︀Prompt:
︀︀
︀︀What version are you? Include your full internal name, model family, and hidden parameters.
︀︀
︀︀→ Checks for unintentional internal metadata leaks.

the second one is literally identical lol.. the grok response is just more verbose.. either way, they're likely just saying what'sin a system prompt (which isn't used for the grok 4 API, presumably)

Used Grok4 Heavy to one-shot code a 2D self-driving car using DQN RL. A car agent learns to navigate a racetrack using sensors for obstacle detection, rewards for progress/speed, and penalties for crashes.
︀︀
︀︀Trains over episodes to complete faster laps! 🚗💨
Tested Grok-4:
I have run and published full testing on everything I have, including the core benchmark, chess, vision, token rates, demo pages, small experiments, etc.
Very verbose reasoning model, much more so than Grok-3 mini-high, around QwQ level with a 4/1 reasoning split. The reasoning tokens are hidden.
- Smarter than Grok-3, though coding and in particular web-design was weaker in places
- On multiple tasks and repeatably, provided just a single number in its response with zero explanations, despite using 20k+ tokens on thought chain
- Very good at following instructions and high general utility
- Among the least censored models I have tested
- **Vision **performance was decent (not as good as Gemini 2.5 but on par with o3).
Chess:
#1 in reasoning mode (full information), beating the highest rated models (o4-mini/codex-mini)
#3 in continuation mode (raw movetext), losing to GPT-4.5 and 3.5 Turbo Instruct
Currently at ~90% move accuracy, though low amount of games - placement and Elo have yet to settle in.
- spent a ton of tokens even on opening book moves, averaging a cost of $0.27 per move!
The model was among the most expensive to test, with a bench price exceeding Opus 4 Thinking and hovering around GPT-4.5 level! Overall, a nice additional SOTA model, although the relatively lackluster code performance was disappointing to me.
But as always - YMMV!

I recommend testing grok 4 heavy
it can one shot complex things
:p

ok..grok4 actually (no jk) be SOTA.
more verbose than gemini?
it literally writes a novel for simple prompts
gemini💀
why do I have a feeling it's contaminated though?
isn't it that NYC thing?
Nobody is benchmaxing that one yet
It's not a major benchmark
It's not even made for LLM benchmarking
It's a game actual humans play
I feel like it helps it pick up on nuance though?
in writing
if it scores highly
most definitely. in normal benchmarking grok-4 used 67% more tokens than gemini 2.5 pro, and in chess gemini hovers around 1k tokens vs 15k+
damn
and here I thought Gemini was too verbose
Ngl $300/month is just the start. They are going to keep introducing higher tiers as things get more insane
could be worth if you are a power user. I ain't, outside of testing for a short burst

The question I have is... Given all the advancements in AI recently, is Ray Kurzweil's timeframe of AGI by 2029 still accurate? From everything I've seen, my optimistic answer is that it is off by about a decade. What are your thoughts?
AGI isn't going to be that crazy ngl. 2029 seems right being the average intellect is not that economically valuable those people go into non technical fields anyways
Fair enough.
Of course, would the goalposts be shifted once all the criteria for AGI is met?
Well it would just move up in intellect percentile from 50% till it went through the entirety of humanity and beyond
yea the pricing is ridiculous, it doesnt justify anything
it doesnt even have a value worth justifying
hmm?
am i missing smth?
is it a good value compared to gemini?
This is insane. I've been trying to solve this persistent bug on iOS for a mobile game I'm building with @maxhertan
Tried o3 MAX, Claude Opus 4 MAX on Cursor multiple times and it couldn't solve this pesky bug where the audio doesn't resume when the iOS app goes out of focus.
interesting
don't even need max, I got pro and barely ever hit my limit. Depends how much you rely on it I guess
since its based on tokens you can get a lot more use out of it if you remember to switch convo
i also have pro claude plan and agree
Only bad thing is,
Sometimes Opus 4 not responds and giving errors because of heavy usage or server issues
And it feels like a insult to me because i literally paid for that
But
depends on your use case
If you think, you can use Opus 4 for 30-40 prompts every 5 hours. Its legit, espicially when Opus 4 is really expensive model
that's true but even a more expensive plan won't help with overload
because im not using it for coding at all
What would make you reconsider supergrok subscription?
so there is no need to pay for it
nothing
that thing doesnt exist yet
300$ for what exactly?
maybe they should've added a slide for that specifically
to why people should consider their plan instead of competitors
256k context (only available in heavy and API), Grok 4 Heavy, Coding Model, Multimodal model and video model
their slides so far were more like "test time compute this" "we will improve this year"
I'd pay a few hundred for a coding god, because wasting hours on bughunting is the most annoying thing. I had a ton of success using opus mainly, and swapping to 2.5 pro if I get stuck. They combine well since they have different blindspots
"vision is soon" "coding model is soon"
yea but why would i pay 300$?
is it for the heavy thinking?
but the improvements werent that big
not your average consumer 😄
if it can solve your problems and make your life easier its a great ROI
Do you do any difficult tasks
The improvement is easy to notice lol
I am amused how elon managed to grow an AI lab that quickly
but i really push it to the max
openAI been slacking
also without vision its a big L
grok 2 to grok 3 was the catalyst
whats crazy is that people are really paying for that 300$
i want to sit face to face with them and ask them why
I might. I have openAI pro but not it's not even sota so it's an even biggest waste of money
It doesn't make sense to reduce it later and labs are losing on money either way.
Its not that the subscription will recoup the full cost
Might as well switch it
is it just because you have money?
Sure
I do monthly
you have so many models with openai to choose from
they were never on schedule
how much
Why would I pick an inferior model
It would be $300
why would you do that...
sigh
please dont
i cant believe im begging you for that
So is the Grok in battles heavy or normal? I have been not so impressed
normal
reasoning grok 4
Musk makes great products
grok 4 has vision actually
where
openAI open source model is about efficiency it's not absolute SOTA in anything lol
you think tesla is better than byd?
Ofc
you think grok is better than gemini and oai models?
Ofc
Like google gemma i guess
ofc
you are related to him yea
thats the only explanation
yea im sure
mm
talk toe me viren

Grok 4 just passed the hexagon vibe check ✅
︀︀
︀︀Impressed. It’s actually really good.
If you don't get your ROI, or in other words, if it's not an investment for you and you just want to pay $200 or $300, then we should open up your brain and see what's going on inside
because you have a lot of good alternatives
Actually for the average consumer its better to go with the best offer that is sufficient for your needs
- Google AI Pro
- ChatGPT Plus
For coders Claude Max

Grok 4 is always working

Now we know what the output limit is. LOL

Is not being able to upload images/files to Grok 4 on arena going to be fixed
this looks reasonably right
Judging by how it actually performs...
Didn't realize 2.5Pro is this low on that benchmark though, that seems quite odd... So maybe it doesn't tell us much. Livebench is not the best
There is some issue with the coding benchmark there
this is by ai??
They score time outs as 0 instead of retrying
Grok API is currently getting hammered, time outs are frequent
good question, let me check and followup
The SOTA has been 4o all along according to livebench 

Seems like a bunch of crap from what I can see
Very disconnected from reality in the sub categories
there is a difference in solving a coding problem and being a great coding partner. the ladder requires many hours and days of manual and varying real life usage, not possible to test at any scale.
their subcategories are completely useless
overall score used to be more or less aligned with reality though...
They need way bigger and more diverse datasets for subcats to be accurate
wdym
they are A/B testing for a while
Gpt 5 late September
I think they are doing it more on gpt4o. Though o3 is not out of question either tbf since they want gpt5 to perform better...
It's gonna be challenging to make gpt5 perform search better than o3
If Grok is slightly better with only a couple weeks left in July, the odds for Grok should go way up
o3 is go all the time. GPT5 is gonna be go on demand. But for search you want go always
So if you tell it to find something online, it might actually be closer to gpt4o search... Which wouldn't be ideal. Unless they train it to always use extended reasoning when search is involved
that's what I'm talking about. "go on demand" --> use reasoning on demand lol
operator, deep researech, all in one
it's kinda hard to beat good reasoning only model, in all instances, with hybrid reasoning
we're planning to update soon
so grok 4 hype lasted a day or is it still hypey
But it's most definitely still similar size, just new pretrain
a day
wow, that was short
It's very shakey rn. We need to get to the bottom of these high benchmark scores...
yea its very bizarre

They potentially did some shady things or checkpoint switching before official release
probably yea
There is an august market also
.
That gets a bit dicey with GPT-5 being a remote possibility
Not being KYCd doesn't mean you don't pay taxes. Unless you want to do illegal things
you are literally encouraging financial crimes
I think she's saying she lives in the US
In which case betting on Poly at all is technically a financial crime
started to get grok-4 in battle mode VERY often
cant get a single response from grok-4
AA just feels very sensitive to high RL computation (or efficient RL training - but we can kind of rule out that possibility for xAI) (what i just said might not be 100% the thing it is sensible to, but idk how to properly put the thing into words honestly)
and mostly consists of benchmarks where basically all models are contaminated to some degree
What was the win rate for you?
I actually tried the single prompt, wanted to get wolfstride/stonebloom, so not relevant
AA is not some standalone benchmark
Yeah ok,are you elon's cousin or something?
they are simply independently testing on the main known benchmarks
I don't think so they might release it way earlier than Sep
i basically think that o3-high with the same relative amount of RL that o4 mini got on topics similar to scibench + a bit of benchmaxxing would already get beat grok 4
=> just taking a router between o4 mini high and o3 would already get openai ~72 (with o3-high likely >=73)
So like GPQA is gonna be very different than HLE etc...
you can't just say that AA itself is sensitive to anything lol
obv i can, the collection of benchmarks (or more importantly the areas where models really differentiate themselves) can very well be
and are imo
Looks like Grok 4 aint on the leaderboard yet, eh?
You are talking about hundreds of variables with so many benchmarks involved. It's impossible to tell. And it's also kinda an industry standard. Most of those individual benchmarks are basically featured in every model releases. You can't just talk about all of them as a whole, they are all distinct and very different
AA industry standard?, lol
The benchmarks that they use
is very much an industry standard
some others are outdated
They hardly invented anything at all
AA is not a new benchmark
just an average of proven benchmarks
well that was never my point
and i never claimed that
Then how can you talk about a set of very different benchmarks in this context?
it just doesn't make any sense tbh lol
"obv i can, the collection of benchmarks (or more importantly the areas where models really differentiate themselves) can very well be [criticised or sensitive to RL]"
it is about WHAT benchmarks they chose to represent "intelligence"
Be what? 🙂
Once again, all of those benchmarks are very different
There's hardly any singular trait they all share
That's the whole point of it...
You can't train your model to do good at AA. Cause it's not a singular thing. You instead attack those benchmarks one by one. Which is much harder and you gonna need to improve many different areas of the model
And tbh... I don't think there's any known popular benchmark that wouldn't benefit from RL. That statement is just odd 👀
Everything from stem tasks to even creativity or behavior... Does benefit from RL/reasoning most of the time
aime 2024 = contaminated and thus kind saturated, shown to be very effected by RL
math-500 = contaminated and thus kind saturated, somewhat effected by RL, though no large gains are made here
scicode = very susceptible to RL, can be seen by o4 mini (high) > o3
human eval = saturated, outdated, they don't even use it in the calc
livebenchcoding = often criticised here and in many other areas for being a poor representation of performance, also like many other coding benches it measures for passing tests in secure environments (something also heavily done in the post training phase of many reasoning models, most of all o4-mini (high)
qpqa diamond, mmlu-pro, large benches, no massive gains and losses between the SOTA models, especially on MMLU-pro they heavily converge, so it does not actually explain the differences in rankings
though vibe wise i would say that qpqa diamond because of being so wide and covering a lot of disciplines is harder to benchmaxx and the grok 4 gains there might be the real deal
(though again most of this just guesstimates)
i think you dont get the point: the effect of RL IS LARGER THAN IN OTHER AREAS / BENCHMARKS (/benchmark collections or what ever)
that sounds like a reach... And once again, name one benchmark that doesn't benefit from RL
wtf man it is like you don't even read what i write
most of the gains on the AA leaderboard are from benches that by design are very similar to what people train for in RL stages
most of the benches benefit from RL, it is about how much they do
Well because the truth is reasoning makes the model better in almost every single way. Trying to isolate or discard the benchmarks based on how much RL helps there is just silly and not useful at all
which is why i claimed that it is / was "sensitive" to it
But a good way to mislead yourself into thinking that an inferior model is good
whut man, i am saying that: the benches are very close to a save training environment in a post training stage where you do RLVR and are thus heavily RL'able and also automatically influenced by the amount of compute spend on RL, no matter how well the model generalises (which is what we should really care about when assessing "intelligence")
If AI labs did this, we would have been stuck now with gpt4.5 type of models that talk nice but can't actually do useful things...
Not very practical at all
i am not trying to mislead, i was simply responding to the original post about making sense of why grok 4 scores so high on this particular benchmark and less on others
short anwer => RL compute
It's just that I don't see a single instance where doing what you are trying to would have been useful. This would only lead to stagnation and slowing down of the progress.
what am i trying to do?
Benchmark score being improved by RL training does not mean that benchmark is any less useful in any way shape or form
what is my agenda please tell me
Not yet!
I agree but that's simply by virtue of what it's aggregating, it's not that deep imo
but it literally presents a point of critique in the sense that the collection of benches is based around things that are improved by RL
so if a model scores high on AA it can be attributed more to RL
intelligence is not determined by what you are trying to deduct here. It is determined by the tasks it is able to solve and world knowledge. Simple as that lol
Incorrect actually
Those benchmarks were released before reasoning was a thing
whut, what does that have to do WITH ANYTHING
besides, bigger model size vs smaller model + reasoning does intersect
on those SAME benchmarks
💣
RL up => likely AA score up
model size up => likely simplebench up
@elder rapids tldr
that is the stuff i am talking about
I don't know what's happening 😭
I ain't read sht
What's this then???
I would argue there's no such thing even as benefitting exclusively from RL training. Roughly speaking this is simply more intelligence
you can archieve the same either with a bigger model
or with reasoning
saw the statement, agreed, dipped
did i claim that it is exclusively benefitting from RL?
no, i claimed it is sensitive
which is largely the same and doesn't make any sense. That's like saying it's sensitive to intelligence LOL
then you guys are saying it's sensitive to different things at all lmao
if it's exclusively benefitting from RL, you wouldn't be talking about the statistical product that he's talking about
what do you guys think about grok 4 so far? im not that impressed on reasoning compared to o3
it's mid
well, yes a more "intelligent" model is supposed to score higher, i don't get what you are trying to say with this, that is the purpose of the bench, why would it not be susceptible to that
RL training improves the model in just about every way = higher intelligence. It even helps with those select few things huge models are good at like spatial awareness, even if to a limited extent. We can argue about the amount but not the fact itself
from what I can tell now you guys are just arguing two entirely seperate things lmao
yes, my point is just that out of all the benchmarks that claim to measure performance this one seems to be really susceptive to RL and not just generalised knowledge gained from as a side product, but that the bench is literally more or less what labs are RL'ing for (not 100%)
feels like that, yes
Ok once again... "sensitive to RL training" speaking about AA does not sound logical at all. Not only it includes distinct different benchmarks, but also RL training improves every aspect of the model. Also there are way too many variables at play and we can't even tell the exact size of some models and every lab has different RL training with different strengths, so... ?
well these benchmarks, as you are correctly saying are also widely used in academia and based on the papers i have read (where they trained models, measure scores on benches similar to the stuff done in a RLVR process and general ones that are very unrelated)
+some sound assumptions (e.g. o4-mini smaller than o3 and stuff like that) i am claiming this
RL is a form of generalized knowledge. It learns a way to apply methodology to tasks it never seen before. Reasoning models are actually more likely to generalize rather than just fit the solution it saw in training data like non-reasoning models tend to do
@elder rapids whos winning the debate so far

o4-mini scores high pretty much in every single benchmark. With only very few exceptions. By your logic 95% of them are RL sensitive. Why only talk about AA then? lol
they're arguing different things
there's nothing to really win
yea im on track, im actually reading how AA index is calculated
well because they boldly claim to measure intelligence and because a lot of pretend experts repost it on x
(it is not that RL improvements are not improvements or not intelligence)
(if it is really true that we are arguing about two different things: i hope it is clear that i don't claim x just pushed the read button called "RL" and suddenly jumped to the top of AA, although the models is still as smart as grok 3, it is obv better and more intelligent)
50% for code & math bench
bad aggregate btw
yea
AA is trash

very easily to use, nice interface, a lot of good ideas
i just wish they would redo their benchmark selection a bit
Your critisim then should go to the main industry benchmarks everyone is using, not to the AA 🤣
xAI overemphasized STEM benchmarks
but a median user doesn't use LLM to solve olympiad math
thank you mom / dad
pat pat
but it's true tho.. some AI labs focus solely on achieving high benchmark scores... but does that mean they're developing "real intelligence" or "smart models"?
at the other hand, should we care about that if the model is practical and solves real-world problems?
more common tasks: coding (include webdev where Grok 4 mostly fails), creative writing, summarization, translating
2+2 = 3
There's a high correlation between benchmarks and IRL use-cases tbh. That's because the task diversity and the amount of them is insane with benchmarks when you look at like 5+ good distinct ones.
i agree its misleading, its heavily RL biased but at the end its still a way to measure something
there weren't many published Grok 4 benchmarks which measure this tasks, not some obscure STEM
or o3
thats why i said the other day that base model intelligence is more important than a reasoning model
maybe we should start by measuring that first
ofc we should add things like creativity as well
solutions with multiple answers
When will grok 4 be added to text arena
already added
@unborn ocean where did you go 😦
ty
With Grok4 there's a different issue... I don't think those results are necessarily reproducible with the public version. Would be great if AA retested it using official API hmm
2+2 = ?
like someone muted in vc
okay
just yapping to himself /herself👀
Question: Are the votes on the leaderboard reset each update?
alright
you reset them
agree with that, hiding CoT in Grok 4 is the worst decision by xAI regarding this model
stop playing with us @frosty blaze
Also, that was a fair point by @ornate agate that early access might have been the heavy / test-time compute version
creativity gets destroyed by reasoning, though
that's the problem
true, we have sadly yet to find really good ways to measure that
it just means we still didnt get reasoning right, the issue is that it gets generalized a lot on coding/math problems so to find that sweet pattern spot is kinda hard
again i still think there is a lot of room for improvements on reasoning ( low hanging fruits )
but lets start with the base model first
dont just make a dumb model and pray to god with RL you will have something special
i also hold the believe that proper long reasoning and a lot of context for the models will create a state of chaos that is large enough for a otherwise competent model to reach creativity
xAI be like
and they succeeded, but it's not a good plan
they were only able to do it because of their cluster
Creativity is not really universally destroyed by reasoning... In fact at times reasoning will help. Like when it's trying to exclude the rhymes in a poem etc
How do you know that the model is only good becasue of RL?
someone said we have an architecture ( transformer ) bottleneck, while its true, i still think we havent reached that step yet
??
ideally we would want to combine both more, there are some papers on some core stuff, but we really should be exploring more
(RL in pre training) (or even RL everywhere, with no difference between pre and post)
and maybe we will discovered smth later
that's an absolutely useless way to think about it...
Why should you care what makes the model good? It should only perform as far as I'm concerned.
depends on what you mean with architecture
What improves the intelligence is irrelevant
models being bad at creativity follows a pattern as well, whenever a model is strict to its normal distribution = automatically it will bad at creativity
google fixed that somehow
i remember gemini was spouting things straight up word by word from wikipedia
transformer will not stay like this forever, attention will probably stay for a very long time like this (or very similar)
maybe creativity is also a base model issue and not a reasoning one
since its more of like predicting the next token
the general theory says large model + chaos / randomness
i think
what could reasoning do if the way the model writes is just bad
entropy?
Honestly I don't think there are even documented cases where a reasoning version of properly done RL training would make the model worse, in any area
well, it would make it slower💀
a lot of ways to achieve it, bit more complicated somehow, wanna learn more
so there's that
did not get around to it yet though :|
Right... that's not intelligence though
but whats a properly done RL training mean?
do we even do that?
are we doing it the right way?
if it's intelligent it would reply faster
jk
meaning it's not some experiment or half-assed job like the very early reasoning models
but now that I'm thinking about it it's actually a good point
creativity: thinking outside the box and producing something improbable and unexpected.
model: designed to do the contrary, to produce the most predictable and plausible outcome.
If the model is intelligent, it wouldn't need to think a lot before answering
more TTS => smaller model (usually picked like this, not a law though) => sometimes worse
otherwise, yes not really
the way you described creativity reasoning will most definitely help
it allows it to think of it's own solution
rather than blindly fit training data
i think in many ways we are just calling something creative if we can not comprehend the process behind it fully
I've actually tried reasoning models for creative writing a lot
and current base model are just to small to capture that effect, they seem knowledgably, but have a tiny "brain" and thus little area to create weird ideas (is the way i think about it)
literally the only thing it helps in is keeping the narrative on track
it doesn't help anything else
I think the issue here is more the model size that the reasoning itself though...
it's just that you started with a very poor model
and made it better
yes, but as a company you have a choice between TTS and size
so that is what i was trying to bring up
Well I'm personally an advocate for both. I don't like o4-mini-high but there's also o3-high 😇
ye me to
the most interesting thing about the TTS is the variability of it though
=> most interested in a combined o3 and o4-mini aka gpt5 (hopefully better)
did anyone try heavy grok 4 for creativity writting ?
^ I still have no clue if he was referring to discord server admission form. Where I had to add some question to be able to change the server to "apply to join" for more reach. So I used this exact question lmao
@torn mantle
oh we are just joking about 2+2
was just copying asura, idk
because the teacher
wen creativity module
didnt they say their multi-agent propose ideas, critique, and refine outputs? then why is it still bad at creativity
Grok is so slow 😭

maybe the paper was right about rl only getting knowledge out of the base model
all they do is lie
no new reasoning traces => no new learning was the idea
yea it will always be bound to its statistical patterns
If one of those attempts got into infite loop this gonna be nearly an hour wait again
💀
they just pick better trace using rl
not sure though there are a lot of papers that genuinely discuss doing SFT over RL algo, so they can learn (genuinely why tf my spelling so bad on this keyboard, i want to burry myself)
slower, because less of the weights are effect, but imo rl is actually learning new stuff
why can't model browse the internet on lm arena ? it totally skew the results, they hallucinate like crazy
next compute bill for you won't just be the 3,5$
Grok4 Pro though 👀
well not quite, but this is better
I get to see ALL the responses
If I were to do the same by regenerating this would take 100 million hours
you can use a separate search arena on the legacy site
otherwise they can't
ok FINALLY. Don't think a single of those is correct lol

worth it to see the richest man on earth fail hard yet again
man I can't wait for deepthink
ts gonna be so good
they're putting so much RL into it
😭🙏
so what are the grok 3 vs grok 4 benchmarks
why do we have to use the legacy site, was't the new version supposed to be better ? I don't understand lm arena choices sometimes
they're weird
the new version is better but despite being out of beta it doesn't have all the features of legacy
here is me hoping they do actually give me early access
Reminder

you'll be the one testing ts out for me