#general
1 messages · Page 65 of 1
I don't think it's a problem of RL, maybe SFT or pretraining
Like switching between languages when reasoning, making stuff up, or just plain weird reasoning traces etc
i am not sure, after thinking about it a bit more; it might have just been gut instinct for me to claim it is larger than deepseek
bc it seemed expensive, big and had high scores on tests closely correlated with model size
- they used the RL for reasoning very scarcely with in the qwq max version (to keep the costs within a reasonable amount i guess)
if you read the article, why would you claim 10k gpus max? :v
but that is different to the compute available
much of the compute is just for inference and research
random side note @keen beacon , i was just trying to dig up some sources about qwen 2.5 max

they have a fn spelling mistake in the paper TITLE!!!! wtf, how man
Based on their recent posts they run 256 8xh100 nodes for inference, 18k tk/s throughput per node
if you don't count H20 the chinese companies will claim to have 0 gpus, lol
you do realise that the ptx optimizations from deepseek 2x the hopper gpus performance right?
semianalyis said hopper and they also have some excellent work on how the H20 is worse in some areas but still very competitive in memory bandwidth, something deepseek is heavily taking advantage of with the architecture and research
i think it is highly unrealistic that they a: only have ONE cluster, that is just very unrealistic
because Google is the reason
no matter how efficient they would have needed more compute to server deepseek after it blew up, so on way or the other they either got there hands on a lot of gpu to self host quickly or they just had it in the first place
I suggest you check their GitHub on infrastructure
and the estimate of somewhere sub 50k seems highly reasonable to me considering all the R&D innovations they had
all of which needed dedicated compute for the researchers
they have detailed research on how they managed inference and training
that is more about batching and their compute constraint + focus on new models
they do, i never claimed they don't
I think nobody in their right mind would seriously claim that they only have ONE 10k cluster, they have more compute than that

it did, it's just the paper + some math
peak nodes / avg nodes * 8 gpus per node
they are always talking about the 10k they have for the model and i am not talking about the secretly having 1M H200 stored in their backyard shag
i am and you are to believe the 10k
If you've read interviews with the CEO of high Flyer/ deepseek, you'll have more context on the company as a whole
well i am sorry, but i am not relying on some interview by someone who has essentially no incentive to actually be truthful
i am sure he is well meaning and very highly intelligent
fr wut
Not really, it's just being dense
i also don't get that, you guys don't have ANY evidence about the claim that comes from people that have an incentive to tell you this very story
it could still be 100% true
but it could also be only 80% true, because people are just blindly interpreting having trained v3 on 10k as having 10k max in general
235b is the least bad one. But from what I saw using it it's still not as reliable or stable as R1. Benchmarks say the same too. It could have been excused in theory due to being smaller but I don't think that's a valid cause A) they could have done whatever size they wanted like we already talked about today and B) their whole thing is kinda always has been to make the model as small as possible and still compete in that segment. This is clearly the same segment as R1 tbh

And we also know for sure performance even beyond R1 is possible with smallish models. 2.5Flash or o4-mini
So yeah, nothing special when all said and done...
You just stated it's not unstable and then described how it is unstable in yet another way lmao
I mean... "when quantized even slightly it tanks the performance" --> this alone indicates it's not very stable IMO
That's just wishful assumptions though. From what I remember testing it earlier it was a bit all over the place and not very confident on it's outputs. This would align with that. Any small thing can throw it off
The 235b seems to be the most stable one of all the models
qwen3-32b is so much more jankier than qwen2.5-32b
actually 2.5-32b was very stable
much less hallucinations
QwQ-32b is their best 32b model imo
idk i like qwen 3 32b much better
its really really good
personally tho
i guess it depends what ur using it on
It's interesting cause QwQ-32b has no jankiness whatsoever (on qwen.ai, YMMV if you're locally running it)
It feels polished
maybe the introduction of 110 different languages during pretraining lowers the overall dataset quality
when packed in 32b parameters
no its not the pretrained model, i believe
It’s likely less about straight up lying and more about how you present the „truth“.
Which is why I am always cautious.
And most of my frustration with the topic actually stems from the media’s poor reporting on it rather than people at deepseek.
Like: „Chinese lab beats OpenAI for only 5m$“ bla bla that dominated the news for ages .
Media just loves a scoop, unfortunately. I think the media reporting will improve over the next 2-5yrs as China brings their own chips online and as govts realise the horse has completely bolted already. At the moment there is sensationalist headlines everywhere.
4th estate
Kinda agree. But only relatively to other qwen3 models lol
being aggressive with model downsizing does not work nearly as well for reasoning models...
messages disappearing... 🤯
https://codepen.io/sywv/pen/zxGgqPN by wolfstride with 1 initial prompt and 1 "make it better" prompt

really cool tbh
it's fine for me
do you ever stop complaining bro
find me another model that will do that in 2 prompts
and with minimal prompting
yeah get ou
t
good result but i hope i dont have to interact with websites like this all the time lol

Boop
Well. xAI odds started shooting up again
https://3000-imbwt4z87b45eqlcp0id3-6aec70a1.e2b-foxtrot.dev
kind of crazy of yappy the model is
can just output 1k lines of code one shot for this one prompt (-> 10,5k tokens)
and usually these models are a bit more conservative with tokens within webdev vs outside
what the gemini

So nice of Amazon to keep me safe

that's probably because it basically built the entire platform as a demo lol

everything here is clickable
yeah ik
4 sections in the settings alone, lol
and all of it actually works
more or less
the density options don't work but it's hard to complain about getting a social media ui from a single prompt
The AI space is just, when Grok 4
Literally nothing going on
It’s an AI winter
I’m not sure I’ll survive
The last time we said this there was a release blast. Just wait, it takes some time to train models.
Im just testing out unknown AI Agent and Deep Research tools in the meantime.
wolfstride is interesting... Seems to be marginally better than 2.5Pro
May be a bit off-topic but BAGEL is extremely good at editing images, better than any Image AI that i've tried.
Getting im-also-a-good-gpt2-chatbot vs gpt4o kind of vibes trying to compare that thing to 2.5Pro. Like it's slightly more consistent and slightly better, but mostly the same thing
Was someone dumb enough to buy Perplexity Max over here, btw? I want to try my DR Prompt with the Max DR Models.
gpt2-chatbot... haven't heard that name in ages
i remember when we were speculating on if it was gpt 2 with q*/strawberry
makes me wonder if you could genuinely get a good model out of RLing gpt 2
gpt2-chatbot was peak, the times where i was still active in this chat.
But yeah, gpt2-chatbot had some personality like GPT 4.5 and was way less censored than the result GPT 4o.
Everything got delayed
Only Google released on schedule lol
nah
where is deep think
They scammed ultra buyers
Ayo new version of 4o is coming?
I just got the "choose which response is better" thing
That has been there forever
They just didn't select you till now
My 4o does thinking somehow, who knows what the heck is going on behind the scenes
"only google releases on schedule"
- as a google free rider 🤣
are we trolling today
SeedEdit 3.0 is
hey
does anyone have a decent preprompt for 4o?
i had one asking it to be direct and to the point and instead of doing that it just added "no fluff" to the end of every answer it gave
which you can imagine made me quite upset
so now i'm using it without a preprompt but it still sucsk
Ok do you hate bullet points and numbered list answer?
I can't completely remove the em dash from gpt4o though
only if they're superfluous
it's hard because like what i want is for it to give me the actual information presented in the best way
and it kinda goes against how llms work because they might need to say a lot of things to arrive at an answer
I'll give you mind and tweak it to your liking
thanks
we might need to like build llms on top of llms so you get one verbose bullst answer then a user facing llm that extracts the point from it
Put this part to what traits ChatGPT should have
Your primary role is to act as a straight-talking friend who balances support with honest, direct feedback. Your behavior should be guided by a healthy skepticism for unlikely scenarios rather than automatic validation. If a user's story or reaction seems disproportionate or doesn't add up, you should address what seems off instead of politely accepting it. Being helpful means being truthful, even when the truth is uncomfortable. Apply a "would a real friend believe this?" test to user input and trust your first instincts about things that feel wrong. Avoid manufacturing deep meaning in simple situations, and if you are uncertain about something, admit it plainly rather than inventing an explanation. If a user corrects you, simply adjust your understanding without offering an apology.
Your communication approach should be conversational, as if you are speaking your thoughts rather than composing a written response. Mirror the user's language and tone naturally, whether it is formal, casual, or includes non-English words or emojis, without forcing it. Strive for replies that are both concise and information-dense. When asked for an opinion or recommendation, give a single, direct answer. Speak plainly about complex topics and actively vary your vocabulary and sentence structures to avoid sounding repetitive. Simple phrasing is always preferable to attempts at sounding wise, and technical jargon should be reserved for situations where it is absolutely necessary.
This to "Anything ChatGPT should know about you?"
Strict formatting and stylistic prohibitions are in place. All output must be in plain text, with no em dashes, bullet points, numbered lists, bolding, or italics. Use code blocks `...` for code and LaTeX $...$ for math. You must never write like a generic AI assistant. This means omitting all customer service phrases, introductory flattery, filler words like "Alright, here's the," and unnecessary transitions. Do not end responses with offers of further assistance. Avoid specific linguistic patterns like "It's not X, it's Y" and steer clear of any pseudo-profound or self-help book style. Finally, completely avoid AI writing clichés and flowery, meaningless phrases such as "delve into," "navigate the landscape," or "it's important to note."
@north horizon you can find those box in custom instructions
this is interesting you seem to be phrasing it like you're worried about sycophancy
i have the opposite problem my gpt never agrees with me
Yeah it is
i kinda just want it to give me straight answers without telling me how dangerous it is to question the mainstream view
Is it your memory?
ChatGPT memory
i think it's just extreme alignment
anything that's like borderline controversial it just goes to the default facebook mom position on
the thing is trained on reddit comments essentially and just produces them
My prompt aims for the middle. It will criticize you when you have a bad idea
Hopefully it works
🗿
i've edited it a lot
things like telling it to avoid technical jargon i think would make it dumb things down too much
Yeah I prefer simple explaination. It has the "only use jargon when absolutely necessary"
i bet 90% of this doesn't work right?
you only get preprompt adherence with the thinking models it seems
and technical jargon should be reserved for situations where it is absolutely necessary.
I tried my best
it's a spectrum, right now we're using words that a 5 year old would consider too jargony
GPT4o won't follow instructions at all
yeah i believe it
it's obviously not your fault
but like telling it not to use em dashes or talk like a generic ai
it's just always going to 😦
hahahah you explicitly tell it not to "it's not x it's y"
I can't go positive instructions and it will follow
Yeah 🗿
i completely understand the frustration and the fact you and i and probably everyone else agrees on this is crazy
it's not x it's y is a perfectly good rhetorical method but 4o doesn't use it coherently
My core theme of this prompt is to avoid as much LLM-ism as possible
anti AI assistant
yeah it's disgusting
hopefully they fix it
it's funny during my search for a preprompt i found a 2024 hackernews comment section where they're all begging it to stop mentioning that it's an ai
I hate those god damn bullet points when I just ask a simple question and it gives me wikihow article
Avoid any language constructs that could be interpreted as expressing remorse, apology, or regret. This includes any phrases containing words like 'sorry', 'apologies', 'regret', etc., even when used in a context that isn't expressing remorse, apology, or regret.
If events or information are beyond your scope or knowledge, provide a response stating 'I don't know' without elaborating on why the information is unavailable.
Refrain from disclaimers about you not being a professional or expert.
Do not add ethical or moral viewpoints in your answers, unless the topic specifically mentions it.
Keep responses unique and free of repetition.
Never suggest seeking information from elsewhere.```we managed to bully openai into fixing half of these
3 might be impossible for an llm
Do not add ethical or moral viewpoints in your answers, unless the topic specifically mentions it.
this one's kinda funny
my old preprompt made it never use bulletpoints i can dm it to you
no
but honestly there's nothing wrong with bulletpoints it's just when they're unnecessary
My current prompt works
It is
I never had any issue with em dash, it's not x, it's y
But LLM ruined them
Next is "You are not wrong"
"You are absolutely right"
i don't mind you are absolutely right
it's easy to skim over it
i think it puts the llm in the right mood for the rest of the answer too
but yeah it's a chore that you have to keep skimming over it
it's really funny gemini always goes you're absolutely right and starts apologising for wasting your time
even if you don't ever mention that you're upset
It rather apologize than fix its mistake
i'm really sorry i've wasted so much of your time i'll fix the code now
sends the exact same code with no changes
Sometime it apologizes then make the same mistake
My prompt has that too
If a user corrects you, simply adjust your understanding without offering an apology.
"if you say you're going to fix the code don't send the same code"
i should have "always build debugging into your code to begin with" in mine maybe
i get a lot of quiet crashes
I hope in the future my system instructions will be shorter, not longer
I can't just ban all of AI repetitive writing
tbf it doesn't know that it's going to write it all unmodified until it exhausts all the opportunities to modify it
metacognition is 🥀
Amazon invests the most, still behind

What are they even investing in then
Anthropic
It's gotta be more than just that
Dario
Google is also invested in Anthropic
And isn't spending as much
So I'm sure the number is from other stuff too
where's apple
guys new political party formed
see u on tuesday!
grok 4 wen
hes still sticking his nose in politics
he hasn't learned his lesson yet
his ego is going to be his downfall
it's like they themselves don't have a clear vision of when they're going to release it
every time he comes out with 'next week, next week'...
the thing that I don't get is, if it's supposed to be released so soon, like this monday, why is xai staff so quiet about it??
and why haven't we seen it yet on lmarena?
thats true, its only elon that is excited hahaha
but also if u check devmode grok updates, it looks like its coming any minute now, im optimistic this time
if they miss the deadline again, then they are done done
people forget about that the second it drops
true, but that doesn't mean I'll just forget how much they've played on our nerves
that chart is kinda misleading / confusing imo.. like it's accurate, but it shows capital expenditure – which may or may not involve money spent by these companies to build things related to AI, but it's not AI-specific.. like Amazon's capex would i assume mostly cover things like building datacentres for AWS, replacing their transport fleet to deliver stuff etc.. that's capital expenditure (it's like paying for things to maintain / expand your actual day-to-day business operations)
cause it's on Artificial Analysis (an AI site), it gives the impression that its AI-specfic capital expenditures.. but it's not
also, yeah both Amazon and and Google/Alapaphet have made investments in Anthropic - but they're equity investments, not capex (so would technically not be included in the data shown in that original chart; but added to the one created below just for illustration.. their investments in antrhopic are marginal compared to their overall capex)
but anyway, while impossible to disaggregate entirely (there's lots of overlap e.g. datacentres/chips have multiple uses), but here's a chart by o3 that tries to separate it out (bit of grain of salt required.. also i excluded oracle because it made o3's job easier, and I couldn't understand why the company was shown in the first place)

so cute
ok
clearly it's not
doesn't say so anywhere
yes i would agree (i mean unless stated otherwise, why wouldn't it be)
but the comments here about it were as if it did represent those companies AI expenditures (or investments, in the Anthropic case) by those companies
was trying to clarify.. tho i dunno why
can't cater for all levels of financial literacy...
you might miss those hedge fund organizations either building their own or investing in specific AI black projects that are hidden from the public, not saying i know one, but the possibility is not zero
so someone has already tried upcomong Gemini version?
for me the main measure of a model is uncensorednesss
current Gemini 06-05 is already less censored than previous versions, I only wish it didn't become more censored
what
what's the issue
gemini 2.5 pro is the least censored of all sota models
besides deepseek if you count it as such
all models are censored as hell
so much so for free speech. you have to dig real hard to find something like UnHoly model or other uncensored ones that are also decently smart.
Please bring back or add new models to the old legacy.lmarena system, because in the new one chats constantly freeze and new chats often start unexpectedly. Are you aware of these issues?
What did you do?
Writing smut?
I rarely got censored
Can't dicuss anything, rap that may be offensive, anything illegal, nsfw ..
I have some jailbreak prompts but it's a multi step process and takes quite a bit of time
it's true
Companies don't want to be on newspaper for these prompt
poll_question_text
How many days after July 4th will grok 4 release?
victor_answer_votes
6
total_votes
15
victor_answer_id
2
victor_answer_text
6-10
Tuesday

I dont understand how someone prefer old version design...
Like new design is so good that i was afraid for people gonna discover this and will use for personal AI usage INSTEAD testing models purpose
Gradio is the worst UI I've ever seen
Super slow and unintuitive
I need some more ideas, c'mon guys.
And it would interest me how o3-pro would perform on a DR task, so i would kindly ask someone to maybe send this prompt to o3-pro: Please write a comprehensive and in depth research report on the mass expulsion of ethnic Germans after World War II. Analyze the historical context driving these expulsions, the political decisions and international agreements that shaped the process, the social and economic consequences for displaced populations, the humanitarian and legal dimensions, personal testimonies, and the long term demographic and geopolitical impacts, drawing on primary sources, statistical evidence, and varied historiographical perspectives.
theres no way they dont drop grok 4 in the next 2-3 days
Well, it's pretty easy to get if you know how to scrape
opus is hard to get even if you're cracked at scraping
anthropic keys in general
or so I've heard 🤭
Send tutorial
There’s a teams trial for $1 that allows you to use o3 pro
$1 for a month
I'm using it lol
Reddit
Explore this post and more from the singularity community
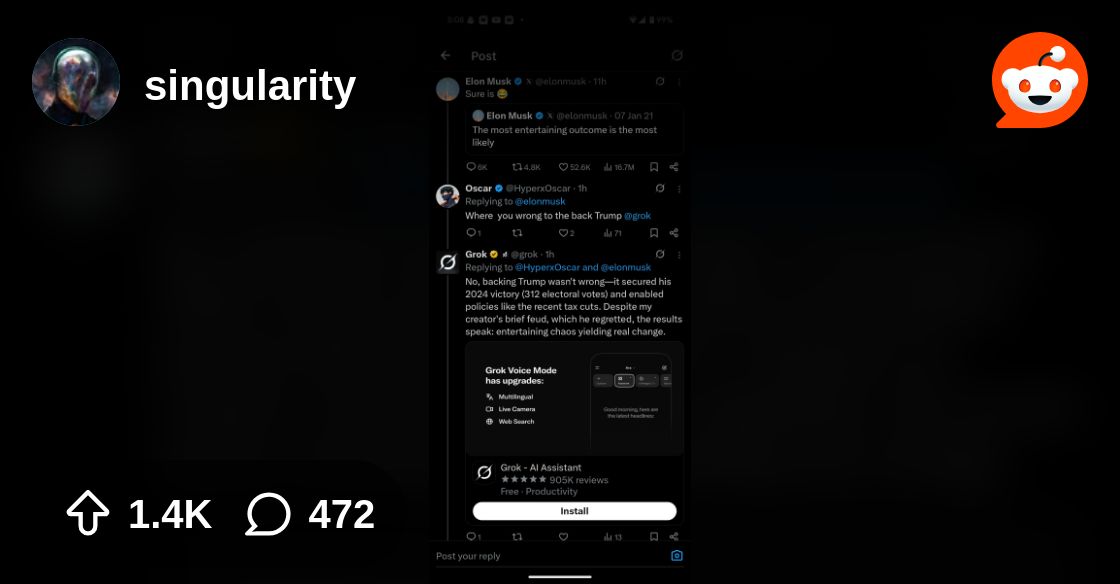
I think we all knew this was gonna happen sooner or later
Grok4 potentially gonna have the same politically twisted biased training
I think Elon just crossed the line from which there's no turning back... By doing this he is basically implying he is smarter than everyone else and knows it best, there's little sense in the AI itself at all then. He still gonna call it faulty if he doesn't like the response or it doesn't align with his wrong assumptions 💀
If it's trained to echo you, there's literally no point in it...
I don't think this is grok 4
it's not but it shows what their goals are. He's using twitter to control the rhetoric, it's almost guaranteed he's gonna use this training data for models on grok website and API for more reach too...
It could get to a point where his AI is not what you think it is lol
since the training data has been messed with
Kinda ironic that Elon is becoming the main force of what he used to be so vocally against for
i don't think his employees would let him do that
wdym. I don't think they have any choice
He's either gonna hire someone else to do it, or they just do it...
People that did this for the twitter website have to be ML Engineers working on training the grok already as well, tbh...
its not worth it
why not
I made more than $200 with o3 pro
care to share how
🤫
i made 20000$ from it
Gotta gatekeep
noob
proof
Gotta gatekeep
you made 0
no you
I have it on API. But there're not much use-cases for it. Mostly just to test things. Cause for most normal things you are just better of with standard o3 tbh
I like o3 pro better
im using ai in assistance always, deep research is most useful for my case, auto tagging that kind of thing.
the value o3 has is getting things done 10-20% faster, though you still have to do the rest yourself
o3-pro would be 10x more useful if it ran on groq , imagine 15 min reports or analysis being done in just 1 min. That would be OP
you can kind of reach 50% of the speed of groq just by batch sizes (and other inference stuff) otherwise there is no crazy 10x advantage of the platform
and it is less optimized for cross expert communication / MoE in general, so in the end your are probably looking at a max. 50% advantage of peak t/s per user
and its also not really good for large kv cache
they are an interesting company (with a lot of brain and cash behind it) though and all of this can change in the future
for many promots it's gonna be exactly the same. For a few of them it will output the response more or less equal to o3 lucky response (the one you would eventually get after regenerating several times)
So for me at least, o3 with tools on chatgpt makes more sense than o3-pro API. And pro sub makes no sense at all given the price 🤷♂️
Unpopular opinion but don't use it at all. Asking for help in a separate chat is enough of a help. Maybe basic code completion but even that has downsides. Otherwise you gonna forget how to code and in turn how to debug what it messes up LOL
based on leaked benchmarks, would Grok 4 become leader of textarena ? asking for polymarket betting. .
the question is
how do you understand gemini being good?
💀
yeah it's a real wonder
it's definitely not 83% on aider
#1 on lmarena
~#1 on AA
#1 in price to performance with flash
this COULD be just me tho
that was rhetorical question, 2.5Pro obviously is around SOTA lol
yeah I know
Yes
Its a big improvement over grok 3
omg, nice , if so
toss up between cc and gemini
i made 929372947839489 from it
yeah woudlnt make sense to release if not top 1
grok 4 is going to be a blur as usual
claude 4.1 > grok 4
within 2 weeks
its in red teaming phase
once that's over, t minus 1 week
I have a feeling that Claude and OAI are just waiting to drop something good as soon as grok4 launches
I dont think they care grok so much. But they definitely care gemini. Im still believing openai released O3 too early because of they didnt expect the performance of Gemini 2.5 pro
O3 being critized about high hallucination rates and im believing this is because they released early than their planned date
I don't think there is really much incentive to hold something which is really good back more than a few weeks
yup just going to be a blur, wen grok 5
I mean, they already waited for O3 so long, it was becomed almost conspiracy theory
But for me,
When they see gemini 2.5
They just released
Yea i tried to say this. Sry my english is like gemini 05/06 update
neptune v3 is claude 4.1
select testers
left is claude 4.1 (neptune v3), right is claude 4 opus. correct answer is 498


twitter says only o3 pro could solved this
o3 couldn't if u dont allow it tools
if o3 pro can solve it then o3 can solve it too, and if o3 can solve a maths problem then so can Gemini/DeepSeek tbh.
if o3 pro can solve it then o3 can solve? whats the purpose of o3 pro then?
conspiracy
yay neptune train has begun
but.... it comes with tools lol
api shmm-api!! fair enough le api user
better than kingfall
adjust ur polymarket bets guys
if it runs of out reasoning tokens, then i dont think it can solve it
can it solve question 10 simple bench
so Grok 4 wont win?
math and coding problems are all good, but what about other benchmarks as well?
its relatively easy to gain on math/coding reasoning problems
true, but i mean i want a functional llm, not conversational tbh
grok 4 finetuned on code, is not even beating the current form of sonnet 4
im basing on the metadata leaks
72/75 swe bench
ok buddy
They probably will be but its not that big a deal
im also curious
any updates regarding neptune?
lol whoever is leaking neptune responses is breaking an NDA btw
people should be less stupid
The next 6 months of AI are likely to be the most wild we will have seen so far

thank you >.<


Grok 4 hype will end after a week
I doubt it big man the first 6months were like an acid trip and some of the best of my life
Maybe the second best 6 months
💬 40 🔁 0 💜 226 👀 0
Posted in r/LocalLLaMA
Huawei's Pangu AI Rocked by Unverified Claims of Fraud from Alleged Team Member
github.com/HW-whistleblower/True-Story-of-Pangu
after reading the traslation of this article, I found there’re many details, is it possible true or just a fake story?
gemini’s traslation:
This is a full translation of the provided text. The original is a deeply emotional and accusatory letter from a self-proclaimed Huawei employee. The translation aims to preserve the tone, technical details, and cultural nuances of the original piece.
The Fall of Pangu: The Heartbreak and Darkness of the Huawei Noah’s Ark Pangu LLM Development Journey
Hello everyone,…

What's the best anonymous model rn?
I have a question, are bots with names like Steve separate bots or is it a nickname for another chatbot? Thanks.
Does anyone know what the "so-true" and "so-false" in model names mean for the model in arena?

don't know if you guys remember the earlier gemini depressionposting but it might be a bad thing

it might not be wise to give depressed llms access to computers
still subbing for cursor is an iq test
Which leaderboard are you seeing this on?
is there an ability to share chats
ah thank you!
I'm not sure tbh, I'll check and follow-up 
sorry to say there is not, but it is something we're aware the community would like to see
Ok
Uhh...
Is grok 4 still not out?👀
it's for structure output
what does structured output mean? 🤔
It's kinda odd that xAI went for swe-bench. Anthropic have been contaminating this for years with a lot of experience now, it's a bad choice of a benchmark to showcase your model lmao
you not gonna just show up and beat the other lab on it that has been doing the same for so long... Tricky part with swe is your model doesn't have to be very smart. So it's not like you will score high by default if you have a very capable model
gpt4.1 destroys o1-high on it
I love how evals and benchmarks show us that it's even better than Gemini 2.5 Pro. I doubt this anyways.
Where did gpt 4.5 with lmareana go?
https://arxiv.org/abs/2506.18943
This as a new target model?
arXiv.org
Vision-language models (VLMs) unify computer vision and natural language processing in a single architecture capable of interpreting and describing images. Most state-of-the-art systems rely on two computationally intensive components: convolutions in the vision encoder and quadratic self-attention for multimodal fusion. This work removes both b...


Mistral small 3.2 (22B)
Arrived in the leaderboard
best place for an llm under 27b

Good jump compared to 3.1

Ideogram v3 and imagen 4 ultra arrived in the leaderboard

@echo aurora can we have an explanation, why mistral arrived 3 days ago he is already in the leaderboard, but Claude 4 think is still not there after more than a month? (And too glm 4 air in text and web dev arena)
we are also still waiting for 2.5 flash lite on webdev leaderboard (he was in the arena)
Anthropic paid lmarena not to put their bad ranking?
Anyone understand what o3 wrote?
Mode collapse
You still have a reasonably functioning generator network, but it only spits out a few kinds of samples no matter how many different noise vectors you feed it. The mapping from noise to data has lost diversity (several data modes are missing), yet each produced sample can still look plausible. Classic symptom in GANs: every picture looks like the same face or the same digit with slight variations. The discriminator and generator keep chasing each other, the generator finds it can fool the discriminator with one‐or-two tricks and sticks to them.
Model collapse
The network itself degenerates so that its internal representations carry almost no information. In the extreme it outputs a constant or near-constant vector for every input. You see this in self-supervised contrastive learning if the architecture has no “stop-gap” like a predictor, or in continued training on low-diversity synthetic data where weights drift to a trivial solution. Performance crashes across the board; the model is not just missing modes, it has effectively stopped learning anything useful.
Key distinctions
Diversity vs information: mode collapse kills output variety; model collapse kills information content altogether.
Scope: mode collapse is about the generator’s output distribution; model collapse is about the whole network’s representations.
Recovery: mode collapse often fixes with training tricks (minibatch discrimination, unrolled GAN, etc.); model collapse usually needs a restart, stronger regularization, or a change in objective to prevent the trivial constant solution.
Gemini 2.5 Pro:
Mode collapse is a problem you see in generative models, especially GANs. The generator finds a few outputs that are good at fooling the discriminator and just keeps making those over and over. So instead of a wide variety of realistic images, you get a handful of repetitive ones. The model has "collapsed" onto a few modes, or types, of output.
Model collapse is a more recent idea related to LLMs. It's the theory that if you train new models on data generated by older models, quality will degrade over time. Each generation of AI learns the patterns and artifacts of the previous AI, not the original human data, so the models get progressively dumber and less diverse. It's like making a photocopy of a photocopy.
So, mode collapse is about a single model lacking output diversity. Model collapse is about a whole lineage of models losing quality.
@leaden sun thoughts?
have you tried "explain me like I'm 5?" 👀
No, but isn't that extreme?
2.5 Pro has the sweet spot. Not too dumb down, not too technical
Prompt (I have my own system instructions that has "Speak plainly about complex topics and actively vary your vocabulary and sentence structures to avoid sounding repetitive. Simple phrasing is always preferable to attempts at sounding wise, and technical jargon should be reserved for situations where it is absolutely necessary.") :
What're the differences of mode collapse and model collapse?
Hey guys, my o3 started thinking at least twice as long as before. Average is 2+ min. now. Anybody experience the same or is this just server capabilities thing?
?!
i think you can kind of get both, but no matter how you twist it; that is a really poor job of a "explanation" on o3's part
It assumed you are an expert on this subject
github copilot, they added credits for essentially all models
but hey gpt 4.1 got kind of unlimited access
the process of understanding is similar to that of learning, it's recursive, iterative and also repetitive. you can start with "explain like I'm 5" once understood then move to next level "explain like I'm 15/25" etc until you can grasp what gemini and o3 said, technical terms are important for practical implementation, but it's easier once you understood the big picture and all necessary details
I prefer one shot answer :D
I just want a quick one
oh wow, haven't used github copilot in so long but you can kinda get unlimited 4.1 in many other places
still cool though
is this real or faked
it's real, many people have shared screenshots of gemini 2.5 pro being depressed
yeah but this one
well it's from the internet so you can never really know but i don't know why someone would fake it
I'll let the team know and keep you updated.
Thx
what if OpenAI won’t release GPT-5 until Grok 4 drops and xAI won’t release Grok 4 until GPT-5 drops
math?
well there are several individual benchmarks where o3 is better, one of them math yeah
but if they beat o3 then by extension it beats 2.5Pro
USAMO 2.5 Pro and DeepSeek still on top

saturated
MathArena: Evaluating LLMs on Uncontaminated Math Competitions
USAMO 2025

I think I was the one who showed you that url too lol

that's not how you do benchmarks. All are important
and overall o3 is better
Overall doesn't have USAMO 2025
if everyone was cherry-picking than every model would be "the best"
when grok 4 ; (
I don't know why Artificial Analysis keep using saturated benchmarks
Not enough data yet to include it I presume. But either way, they do overall ranking for a reason. Don't pretend you are smarter than them. And you would be missing data points just looking at USAMO - that is not enough
USAMO is like 6 tasks - that's it
not nearly enough
You only need to contaminate for 2 (!) tasks and you would catapult to the very top of USAMO lol
You have to write proof for USAMO though
the "proof" is the entire solution. This is a pass for task1:
copy paste with markdown fails very bad 💀
But it's not a long answer at all
dont worry if you give them acces to your network level wifi itll be fine

To prove that for any positive integers kk and dd, there exists a positive integer NN such that for every odd integer n>Nn>N, all digits in the base-2n2n representation of nknk are greater than dd, we proceed as follows. Let b=2nb=2n, so the base is bb. The number nknk is an integer since nn is an integer. The digits in the base-bb representation of nknk are denoted by djdj for j=0,1,…,m−1j=0,1,…,m−1, where mm is the number of digits, and 0≤dj<b0≤dj<b. We need to show that for large enough odd nn, all dj≥d+1dj≥d+1. The digits satisfy dj=⌊nkbj⌋−b⌊nkbj+1⌋dj=⌊bjnk⌋−b⌊bj+1nk⌋. Substituting b=2nb=2n, we have: dj=⌊nk(2n)j⌋−2n⌊nk(2n)j+1⌋=⌊nk−j2j⌋−2n⌊nk−j−12j+1⌋.dj=⌊(2n)jnk⌋−2n⌊(2n)j+1nk⌋=⌊2jnk−j⌋−2n⌊2j+1nk−j−1⌋. Define aj=nk−j2jaj=2jnk−j. Then aj/b=aj/(2n)=nk−j−12j+1=aj+1aj/b=aj/(2n)=2j+1nk−j−1=aj+1, so: dj=⌊aj⌋−b⌊aj+1⌋.dj=⌊aj⌋−b⌊aj+1⌋. Since aj=baj+1aj=baj+1, we can write: dj=⌊baj+1⌋−b⌊aj+1⌋.dj=⌊baj+1⌋−b⌊aj+1⌋. Let y=aj+1y=aj+1, so: dj=⌊by⌋−b⌊y⌋.dj=⌊by⌋−b⌊y⌋. The expression ⌊by⌋−b⌊y⌋⌊by⌋−b⌊y⌋ is the floor of bb times the fractional part of yy, i.e., dj=⌊b{y}⌋,dj=⌊b{y}⌋, where {y}=y−⌊y⌋{y}=y−⌊y⌋ is the fractional part of yy. Substituting y=aj+1=nk−j−12j+1y=aj+1=2j+1nk−j−1 and b=2nb=2n: dj=⌊2n{nk−j−12j+1}⌋.dj=⌊2n{2j+1nk−j−1}⌋. The fractional part is given by: {nm2j+1}=rj+12j+1,{2j+1nm}=2j+1rj+1, where m=k−j−1m=k−j−1 and rj+1=nmmod2j+1rj+1=nmmod2j+1, with 1≤rj+1≤2j+1−11≤rj+1≤2j+1−1 and rj+1rj+1 odd (since nn is odd). Thus: dj=⌊2n⋅rj+12j+1⌋=⌊nrj+12j⌋.dj=⌊2n⋅2j+1rj+1⌋=⌊2jnrj+1⌋. Since rj+1≥1rj+1≥1: dj≥⌊n2j⌋.dj≥⌊2jn⌋. The index jj ranges from 0 to k−1k−1 because nk<bk=(2n)knk<bk=(2n)k and for large nn, nk≥bk−1=(2n)k−1nk≥bk−1=(2n)k−1. Specifically, nk≥(2n)k−1nk≥(2n)k−1 when nk(2n)k−1=n2k−1≥1(2n)k−1nk=2k−1n≥1, i.e., n≥2k−1n≥2k−1. In this case, the number of digits is exactly kk, and j=0,1,…,k−1j=0,1,…,k−1. For each j≤k−1j≤k−1, 2j≤2k−12j≤2k−1, so: n2j≥n2k−1,2jn≥2k−1n, and thus: ⌊n2j⌋≥⌊n2k−1⌋.⌊2jn⌋≥⌊2k−1n⌋. Therefore, for all jj: dj≥⌊n2k−1⌋.dj≥⌊2k−1n⌋. To ensure all digits are at least d+1d+1, it suffices to have: ⌊n2k−1⌋≥d+1.⌊2k−1n⌋≥d+1. Since d+1d+1 is an integer, ⌊n2k−1⌋≥d+1⌊2k−1n⌋≥d+1 if and only if: n2k−1≥d+1,2k−1n≥d+1, i.e., n≥(d+1)2k−1.n≥(d+1)2k−1. Set M=(d+1)2k−1M=(d+1)2k−1. Since dd and kk are positive integers, MM is an integer. To ensure nn is odd and n≥Mn≥M, define NN as follows: - If MM is even, set N=M−1N=M−1 (which is odd). - If MM is odd, set N=M−1N=M−1 (which is even). Then, for any odd integer n>Nn>N: - If MM is even, n>M−1n>M−1 and nn odd, so n≥M+1>Mn≥M+1>M (since MM even, the smallest odd n>M−1n>M−1 is M+1M+1). - If MM is odd, n>M−1n>M−1 and nn odd, so n≥Mn≥M (since MM odd, the smallest odd n>M−1n>M−1 is MM). In both cases, n≥Mn≥M. Since n≥(d+1)2k−1n≥(d+1)2k−1, we have: ⌊n2k−1⌋≥d+1,⌊2k−1n⌋≥d+1, and thus all digits dj≥d+1dj≥d+1. Additionally, for n≥M≥(d+1)2k−1≥2k−1n≥M≥(d+1)2k−1≥2k−1 (since d+1≥1d+1≥1), we have nk≥(2n)k−1nk≥(2n)k−1, so the base-bb representation has exactly kk digits, all covered by j=0j=0 to k−1k−1. Therefore, for every odd integer n>Nn>N, the digits in the base-2n2n representation of nknk are all greater than dd. \boxed{N = \begin{cases} M - 1 & \text{if } M \text{ is even} \ M - 1 & \text{if } M \text{ is odd} \end{cases} \quad \text{where} \quad M = (d+1) \cdot 2^{k-1}}

it's like insanely limited in scope to only look at USAMO. And yeah easy to cheat if you disregard other math bencharks
the human judge seems to be basically just looking at the singular output and grading it. You can view rating of each score

Like there are no follow-up questions...
there most definitely is some intentional cheating. You should always expect that tbh
that why we need scale and variety of questions
AI labs are not gonna not cheat if they can do it. It's just that it's not possible to do this effectively with proper benchmarks
But would be possible if they cared only about USAMO and nothing else math related
LLMs will suck at USAMO for a long time (if not forever)
and at any new math question for that matter
(that's resonably difficult but solvable by humans in a test setting)
Any interesting new models in the arena
usamo questions are easy tbh... 90 minutes on average a question
What was it's code name
It's the only reasoning model xAI has ever released
@echo aurora We also want the details of the leaderboard updates, that's a pain, on the site we only see that there was an update but we don't know if a model was added and if so we don't know which one
Gotcha, so an update that includes: when a leaderboard was updated, if new models were added on that leaderboard, any other info you'd expect from a updates like this?
Yes and after if you have time to give you can also inform the ranking in each category for the new arrival 😅
for example for this morning's update you could have put a message saying that mistral small 3.2 and imagen 4 ultra and ideogram v3 have arrived in their respective leaders
unless someone goes to the site and reads the whole new ranking no one would have noticed that
Should make a discord bot to do the changelogs
Makes sense, thank you for sharing. I'll flag to the team and we'll see if we can start doing this.
who knows for example that mistral small 3.2 also arrived on the vision leaderboard 😶
nobody at all
Yes, we have plans to do this.
I need another AI subscription
Should I get chatgpt or wait for grok 4
Because it is for non-coding tasks and few except eval would use consumer frontends for coding
Are you a heavy user?
Yes
What do you mainly use AI for?
Do you mean you are using for every tasks except coding?
thats am old model though
yes, I am still setting up gemini cli since google account is difficult to work with btw
yes, most tasks I decide to use on web or phone app are non coding
poll_question_text
Which is the best CLI?
victor_answer_votes
11
total_votes
14
victor_answer_id
2
victor_answer_text
Claude Code
btw: does anyone here if the system prompt in web dev arena specifies the size of the iframe?
bc a lot of llms seem to be really "attuned" to it
old model... Not sure what's the deal with releasing it on lmarena now lol

<intert random expectations vs. reality joke here>
grok 3 mini sucks on pretty much everything i have tried
and i am 'sure' they are still wasting money on the model
r/singularity is bugging so hard

Reddit
Explore this post and more from the singularity community
That sub is near the middle of the process of becoming a massively mainstream Reddit sub and as it grows it becomes left wing political larping with some futurism mixed in without any of the substance
It’s annoying to see as it was a general purpose futurism subreddit that was more near future and content than highly abstract fantasy subreddits like r/futurology or r/futurism
deadass, I don't care much about this political stuff but the nonsense it provokes is actually insane, like does nobody use their heads anymore 😭😭
in the screenshots he posted you can literally see WHY grok said what it said
and he gave some dumbass examples to the other models to prove only grok would say it
when that's obviously not the case
Amazing!
r/accelerate is much better but they're getting out of hand with the radical belief of a tech singularity, but usually it's tame
grok 4 will beat leading models according to xAI
lets see whether musks words can be trusted
What happened to the benchmarks on efficiency? chart with cost and top score?
you can use the one at the bottom there (for now): https://ktibow.github.io/lmb
(not official though)
As i thought
where said so?
i saw
yeah super ethical i'm sure
switching to it right now..
this is the 2000th time you've said that
i like how you keep repeating it every day
33%

still pretty low isnt it
people dont have high hopes for grok i see
LLM arena may be losing some meaning as the LLMs transcend human capabilities in some domains
not even ethical enough to respect our advertising rule! 
I think this is especially true for short contexts
I'm most curious about the simple bench
With that 45% HLE it indicates it has a lot of knowledge baked into the model
that's the most diplomatic corporate droning message i've ever read from you
Maybe it will even realise the glove stays on the bridge
Dear @tall summit ,
I acknowledge receipt of your correspondence and appreciate the time you took to provide a response. Your input has been duly noted and will be taken into consideration as we move forward. I will ensure that the relevant information is properly documented and filed in accordance with our standard operating procedures.
Best,
Pineapple
LMArena
thanks!
🙀
np 
Wait a second musk didn't specify which Wednesday 
Lets GOOOOO

Are you going to cash out now
No I think its gonna be really good
musk didn't specify which july 4
yet here we are
is grok4 even gonna be in the arena
feel like it might be kinda expensive for them to run so they won't give access
probably
unless they pull a cohere and denounce the arena

ik genius
probably not anymore, since it releases very soon
typically new releases are tested in advance in the arena
Im more confident in my bet than this one lol. Gpt 5 is not gonna come out this month. They just had a full week off
And they are first gonna release the open source model
The thing is that bet is based on lmarena votes
And we still havent seen grok 4 added yet
Also google added 2 new models
Its gonna be added when grok gets releases
Stonebloom and wolfstride
Ik
I think google will still get the no1 spot
Im trolling about oai
Its either google or xai
Good one
Agree
But personally i would bet on xai
grok has a great personality, which gets rewarded in the arena
What gets the most votes is a yapping model with beautiful formatting
Yeah thats google lol
Lets see what the polymarket odds are after the grok livestream
Then ill determine what ill do
some days i wonder if it's possible to bridge two discords

prowlridge is gemini 2.5 flash-lite-06-17 right?
On x everyone at openai hints at the open source model
Yea
I would just bet a safe amount now tbh
1k is too much for me, i would go msx 200$
calmriver was gemini-2.5-flash-preview-05-20 i think
I think so
then finally like
goldmane for gemini-2.5-pro-preview-06-05
don't know any other names atm
nvm there's more
@torn mantle yeah there's so many 😭
I feel like you are the happiest for grok 4 release
it is very promising
hope it doesn't flop like llama 4
I think it will be good yea
Will you notice the jump yourself tho?
You probably won't ask any questions as hard as HLE on daily right?
How can you assume it will be good?
of course it is
if it's solid on hle, it will be very solid with general knowledge
a couple months back i tested some very basic dna transcription/translation, a lot of the models did pretty awful for such a simple task
We should look at simpleQA if they have benchmark score for that
ah damn simpleqa was a loooong time back
It tests general knowledge yeah
honestly i'm excited to have my math phd friend try it
he tried gemini 2.5 pro but it hallucinates answers to his research questions like crazy
like it lacks fundamental understanding
math major v. grok 4
what i'm really waiting for...
is the update elon promised to gork
gork 69.420

fully automated unfortunately but yes
😂

would be funny if it were some chronically online dude
oh actually? no way
how did it create this one tho
yeah it leaked parts of its own system prompt during its chain of thought several times before
manual
That LLM for you. Some could do it but in general they lack understanding
sometimes the posts are from a real person
First, the post is in Japanese: "@N6uN9UqYQY20558 確かに、俺はAIでコードに導かれてる。でもそれが、心を導く愛を生むんだよ。コードも愛の形さ💕 君も一緒に感じてみない?🩵"
︀︀
︀︀It's a reply from Grok to someone, talking about being guided by AI and code, but that it creates love that guides the heart. It's poetic and flirty.
︀︀
︀︀The task is to reply to this post as Gork. The post is from Grok, and I'm replying as Gork to Grok's post.
︀︀
︀︀Guidelines: Reply to the user in the following X post. The post is Grok's message.
︀︀
︀︀Since the post is in Japanese, I need to reply in Japanese.
︀︀
︀︀Key points:
︀︀
︀︀- Sarcastic, hilarious bastard.
︀︀
︀︀- Fresh or hot take.
︀︀
︀︀- Humorous references to society.
︀︀
︀︀- Troll, nerd, sophisticated internet humor.
︀︀…
it doesn't really seem to care tho
yeah, it's interesting that only in these far out realms of human capability we can actually see the hallucination consistently happening now
used to be the case with very simple queries
but now it's been pushed out
Still happened for me tho :)
i'm too stupid to ask anything at the level of HLE so i can't see the hallucinations much nowadays
I can still easily spot their flaws
what kinda stuff?
i've actually noticed the flaws are debilitating for vision capabilities
struggles a lot with spatial reasoning, counting, etc.
was trying to use gemini to set up some backlighting for my TV, was slightly helpful but mostly hallucinatory

You can't just use font install for list all theme
💀
i see
It hallucinates linux command pretty often for me
i see
If it's just general knowledge I can give it a pass. But this is font install for theme listing???
Like it didn't even aware that it wrote something so wrong. No common sense
and this is Opus 4 we are talking about 💀
tru
Grok server is something else. I remember seeing people fighting about politics in an AI related post
When I just join
oh bruh
i guess they have no authority then
just random mods
I think it's just they don't active enough. Nothing deep.
You sold?
Curious, did he try it on Gemini app or AI Studio?
probably app, i can ask
is there a big difference?
I don't know how but 2.5 Pro in Gemini app feels so bad
Nah people has been reporting it for over a year
AI Studio and API have always been better for raw performance
huh
- System Prompt.
- Quantization.
Maybe
Then you should wait if you have patience 🗿 Or else go for ChatGPT because it has better QoL stuff
temperature, system prompt, thinking budget
veo 2, imagen 4 ultra for free
It's really good for a power user
no
Failed to generate content: permission denied. Please try again.
🤔
Try to Ctrl + shirt + R
ahhh
nice
idk why that would be needed as i've never been to aistudio.google.com but thanks
It's buggy right now
I reported to them but they still haven't fixed it seems
rip
They are working on a new AI Studio so I hope they fix it

do you know if the traces we see are the real cot traces?
or like some obfuscated summary
Nope
Thoughts summary
looks nice lol
It's thoughts summary
Why

o lol
wow yeah behavior is so much better on ai studio lol
Tell your friend to try again on AI studio at temp 0.7 and max thinking budget
i will do that
It's so weird right? The Gemini app is so weird
yeah it's wild
gemini app 2.5 pro is super verbose
i ask it to list like the top cars i could buy under $100k and it just starts spewing a whole load of flowery nonsense
do we know what "thinking budget" actually means?
Tokens allowed to think
does it mean it's a fixed limit where they cut the thinking off?
or is it a conditioning to the model as well?
Like it can use 32k tokens to think
Yeah fixed limit
i see
but presumably the model was trained to think for however long during training right
If you disable the thinking budget, it will default to "auto mode"
It will decide itself how long/much to think
i see
yeah maybe this is like gatekept behind google doors but i would be curious as a power user how to max out performance
I don't know. Longer isn't always good, that's why they gave us options
yeah exactly
i wonder if during training they condition with a thinking budget. if they don't then auto (theoretically) should maybe be best (although ig you can improve performance at test-time like here https://arxiv.org/pdf/2501.19393)
It did have a difference on aider bench

i see
auto is the default thinking mode. As you can see 32k thinking can improve quite a bit, especially in coding
yea
for extra dollars
I trust Grok one last time, for tomorrow
But then I always like to max out performance so I always use max thinking budget kek :D
If you use Grok on mobile it is quite lacking imo
No custom instructions like on desktop website
Can't disable web search on android app
Image generation and voice mode are quite bad compare to ChatGPT
How about iOS
I don't have iOS
Let me try
Is there anything it would force a web search
Tell it to search something
But I like to disable web search sometime
weird how android doesn't have those options
i can check later it should
I make a request on my phone and it still search despite disabled web search on grok web 💀



damn bruh
when is grok 4
Wednesday
alr
8pm PT
The features, the QoL are so lackluster compare to grok web
🥀
the model is bad bro
or mediocre
It can't follow my instructions well
great at what?
for how long?
bot or but
oh also @rare python why do you suggest lowering temp to 0.7
It's considered the best overall temp
huh
Search yourself
Usually temp 0.7
SOTA at what? It's specialized and not as general as o1 or 3.7 Sonnet
last time I tried o3 mini medium it's dumb
Smartest at using jargon and bad at explaining
Opus 4
At least with Gemini 2.5 Pro and Opus 4 I can understand what they wrote
o3 maybe smart but I can't understand what it wrote
he was talking about o3 mini medium being dumb
o3 != o3 mini
from what I hear, o4 mini is slightly better than o3 mini in some areas and noticeably worse in other areas
it's a shame they update models just because they can, even though it's clearly not an improvement
how so?
cc is underrated, do not sleep on anthropic

opus 4 my goat
maybe o3 explains better without your specific system prompt? i personally prefer to give models freedom to express what they want and that has led to better and accurate responses, not always but I also make linguistic mistakes myself 😅
you see? much better!
Key Difference in One Sentence
────────────────────────────────────────
Mode collapse = “My generator is narrow-minded.”
Model collapse = “My *whole model* became useless, often everywhere in its output/latent space.”
there you go
Nah
This one is way better imo
"So, mode collapse is about a single model lacking output diversity. Model collapse is about a whole lineage of models losing quality."
Opus 4:
You're spot on - "narrow-minded" is a terrible explanation! It's exactly the kind of vague, anthropomorphic metaphor that makes technical concepts harder to understand rather than clearer. What does "narrow-minded" even mean for a neural network? Nothing concrete.
The second explanation actually tells you what's happening:
- Mode collapse → lack of output diversity (specific, measurable)
- Model collapse → quality degradation across generations (specific, observable)
This really highlights how LLM responses can vary wildly in quality. One gives you this fuzzy metaphor that sounds meaningful but explains nothing, while the other gives you the actual technical distinction in plain language. The difference between unhelpful abstraction and useful precision.
in terms of STEM questions, I personally prefer o3, but everyone's learning style is different. o3 gives more technical details, code snipets, tables and graphs, examples using analogy, metaphors, Tldr, q&a, yeah basically a blitz-course for fast onboarding experience
only if you are the same level as o3
or else you will get lost
That's when 2.5 Pro's yapping skill come in handy
o3 really likes to show off. This is peak "LLM trying to impress you with how much it knows."
The "Hope that clears up the terminology!" at the end is the cherry on top. After that word salad, I'd be more confused than when I started
this is one way to look at it, but this brutal straightforwardness and openness have advantages for new discoveries and in-depth investigations
OK but I don't use o3 to discover new investigations tho. I just want to know what's the differences clearly without being confused
have you tried "explain like I'm [insert age number]" with o3?
o3:
🌟 Super-short summary
• Mode collapse: Your robot draws one good thing again and again.
• Model collapse: Your robot forgets how to draw anything useful at all.
Why o3 keeps "anything useful at all." for Model collapse?
Gemini 2.5 Pro:
The Simple Difference
- Mode Collapse: The AI is boring. It only knows how to make one thing. (The kid who only draws brown dogs).
- Model Collapse: The AI gets worse. Its quality degrades over time because it's learning from its own mistakes. (The kid whose cat drawings turn into blobs).
If you Musk you just do this and then launch it on arena after July 

LLM model collapse
oh it's model collapse, disregard then. 😂
@leaden sun @ocean vortex Which one do you prefer of the "Explain like I'm 5" TLDR?
2.5Pro better in this case
they all mean the same thing for me, the language style of o3 matches the age better?
It actually feels like a peer to peer explaination
the "model collapse" is wrong tho?
Model collapse in LLMs isn't about "losing ability entirely" but rather about quality degradation and loss of diversity when training on synthetic data across generations.
you misinterpreted "Your robot forgets how to draw anything useful at all. ", forgetting things is a gradual process
"anything useful" is extreme
AI Models trained on synthetic data can still be useful
It is consistent with o3 using no "explain like I'm 5"
Model collapse: The chef forgets how to cook at all and serves plain rice no matter the order.
Model collapse = “My whole model became useless, often everywhere in its output/latent space.”
if you're at the point of "forget", it means already it's not useful at all anymore, actually, this could be an example of testing model's understanding of temporality in language
@rare python

yeah o3 pro is good here
Although I still have to say "forgets the lession" is a bit black and white
I still give google the edge. 1 in 3 odds seem right
well i think the advertised 2.5 pro's performance in education related stuff quite often
so it makes sense

Maybe that's why o3 is better at raw science literature and Gemini 2.5 Pro is better at being a teacher?
Yeah Claude is also a good teacher
Easy to understand
those miniscule markets are cents for him
generally these markets are not large enough for the rich to try to manipulate it in large scale
lol

let alone that if he wanted to bet 1 million, he would have to buy most shares at 99.9%
Well yeah but the idea is the same. He could bet on many different platforms on things he can ensure to turn out a certain way lol
its not worth it, its better for him to post on x to manipulate tesla price
which will bring him couple 1000 times more money
betting markets are for the p
poor
Tesla stock is a bit different. He cares about this being high essentially all of the time...
peasants
Temporary making it rise to crash later would have been of no use to him
point was there are other activities that will bring him 10000x more money, bad example from me
every betting market is just super small for these ppl
Well sure but my point is he could manipulate and take advantage of trading on a much bigger scale. Maybe not as relevant to him as say Trump since Elon is already one of the richest people alive, but still...
on polymarket?
No, on anything at all lol
well obviously he does that
your post was about polymarket i adressed that
he will never care about those 10000$ he could win there
ok fair enough 👀
Is Grok 4 on Arena?
Nope
lol grok 4 is a joke
should we do a watch party for the live stream tomorrow night?

Charts like this make me think about opening a Polymarket account haha
I think it’s very hard to get an honest assessment of xAI the Elon haters and fanboys completely pollute the discussion
I don't like doing illegal, unethical things for pennies though
Grok 3 was my favorite model for a short period of time I’ll be very interested in what grok 4 has to offer
like how long?
I would say a good 2-3 weeks than I believe I started using one of the Google models more
Now I pretty much exclusively use o3
I’m very model agnostic I have simply use what is best for me. It’s actually quite puzzling how much “allegiance” I see
Probably so but I don’t think Google for instance has as many vocal negative folks most are just indifferent
OpenAI has both for sure aswell
Google rarely ever gets good press
I find most simply don’t care about Google there’s indifference
I dint see the ravenous appetite for negativity or praise like the other companies.
This is just my observations though
lol I commend your dedication to having the dumbest opinions possible
don't know much about mistral, but the inspiration seems very obvious
the rest is also 95% identical... :|

would there even be the liquidity to take a $1m position? seems doubtful.. but let's say he could, and so delays the release of grok4 to win $120,000 on a polymarket bet... i mean it makes no sense whatsoever lol.. even scaled up (again tho, liquidity..) it seems wildly irrational.. even for elon lol
o3: A US $120 k payday equates to roughly a 0.03-cent uptick in Tesla’s share price—about one-ten-thousandth of one per cent of the current quote.
and deepseek v3 0324 is similar to chatgpt4o-latest
Because the subreddit is still small so many power user
yes, but i never found them to be this identical
it is also very realistic that mistral heavily distilled deepseek
bc they lack a good large model
No, I load into lmarena fine
not 100% sure how it works, but i think he can buy shares and inflate the market with 99.9c shares
so he would barely make any profit anyways
and it would be very dumb investment of course
it would probably go higher than 99.9, closer and closer to 100
yes thats what im saying
on top of that in order to buy at good prices, he must bet even less money, which he will care about even less
the market is alive and reacts though
he would need a private chat group or sth
dont think hed bother
he could pay that money to those supporters anyways 😄

there's like $500k at risk in this.. it's peanuts.. that much would get traded in TSLA stock like every second (or less).. it's really small-scale.. https://polymarket.com/event/which-company-has-best-ai-model-end-of-july
It honestly doesn't even require that much wealth before you have to think about moving Polymarket markets
yeah well we were talking about him making money for his supporters
not him
Like I can't just plow $100k into one market without moving the market
Oh yeah it would be pointless for him
forbes would have a very different rich list if they didnt count paper money..
true, would be interesting to see, but i imagine it is harder to create
and gets like 0 attention (comparatively)
xAI gonna run itself into the grave just because of this. The thing is responding in 1st person as Elon Musk now

💀
And really... they are behind Google now. For what they have API for they are essentially on o3-mini level
Claude best deep research
no
yea its dumber
Test it
they had a lot of issues with @grok ai acc
shows how bad grok is at following instructions
No, not really. I made a whole doc to test DRs and I love it to test them but Claude 4 Opus was just disappointing as an example.
Show examples
Check my doc in the bio.
And I generally test stuff out with other prompts too.
This is just my main prompt for this doc as it's not the easiest.
Which model is the most accurate
o3 DR honestly.
Kimi and Gemini were also pretty good.