#general
1 messages · Page 63 of 1

this is real?
yes
but not yet available right?
yes
damn
it may be released next week
lol may
😦
supposedly july 4
if it truly reasons from first principles and answers all the "hardest problem of your life"s people submitted it'll be impressive
but remember, if we don't like it, we not the audience for it lol
what do you think it'll get on HLE

why do i feel like everybody is riding the grok 4 launch hype, but within a month, everyone is going to move on
Because that likely happens
you got this
dont count google out
they still have deep think
and if its combined with kingfall then we may see >> grok 4
deja vu
Very strange we have not seen grok 4 on LLM arena yet
It means they won't have a score on release
Grok 3 we saw it as chocolate for weeks iirc
Does that mean they stopped benchmaxxing lmarena?
🤯
damn, gl
i thought about mogging it at ~7c earlier in june but never pulled the trigger
I think it is still a good price
same
i'll ride the hype assuming it does come out july 4 (which seems highly likely)
depending on personal evals, may or may not sell right after official release
Same here
i've got something like 3k in contracts/shares that'd depend on grok4 in one way or another
not atm
I think google no for august is a good buy rn
Its 44c
And we have both grok 4 and gpt 5 probably
This one is jult
July
But I think the google no one for august is a good deal rn

oh, they just opened it
Yeah today
Google only has deep think release before end of august
Which probably wont will be on the arena
And if it will, thinking models dont perform that well generally on the arena
I think the chance should be closer to 30%
For google august
hmm
what would be the incumbents there? openai seems somewhat unlikely
xai, maybe DS
Grok 4 next week
GPT5 probably august
Sam altman said last week gpt 5 will release 'this summer'
Also deepseek r2 which may be a dark horse
yeah, i've been pondering what the r2 sitch might be
The Chinese are smart guys lol
yeah
historically they've only really focused on being open-weight and cheaper than the competition, but it's possible they'll compete with frontier
Deepseek r1 was almost frontier when it released
The R1 update of may also did pretty well in the arena without style control

Only gemini is significantly better
I think it is pretty realistic R2 will outperform 2.5 pro in the arena
🙂
Google is absolutely cooking rn. You think they will not release another model till end of August? 
And if they will release something, it has to compete with gpt5, R2 and grok 4
Therefore I think 57% is too high
Volumes are ultra low rn anyways
The august market just released today
how does google decide when to show me an ai answer, when to not show anything about ai, and when to show "an ai review is not available for this search"?
specifically, why make the distinction between the latter two?
now let's see grok 4, the release is imminent
arena glitches again
How so?
the bugs stopped,but see the latest post in #1343291835845578853
could you check the DM?
Would you prefer a response here or in DMs?
either is fine.
Kk I’ll respond here. First I’d note that we’d prefer using the @oak python bot when reaching out privately, I’m happy to respond but just sharing for future reference. Onto the actual question..
commercial use
I’d encourage you to review or terms of use (specifically the content restrictions section) which can be found here: https://lmarena.ai/terms-of-use
xAI is working on preparations for the Grok 4 launch in the xAI console
"Grok 4 now available - We're proud to bring you Grok 4 access on the API. Grok 4 currently supports text modality with vision, image gen and other capabilities coming soon."
Grok 4 (grok-4-0629) -

How is it?
Is it as good as advertised
You know these block of texts are confusing. I think all input and output contents ownership is tied to the users. But I am trying to understand what is the meaning of internal business use? Does it mean I can not directly sell the content as it is but can use it to create, edit, mix or use as reference or inspiration to create final version for sell?
Identical experiance to mine. Gemini is really good but not for science.

Unprompted newest gemini sounds like HR woman
Unfortunately I’m unable to give you the kind of direct answer that you’re looking for here to a question like that. Overall though leaning on the more cautious side when you’re unsure is what I’d do.
Ugh, my bad luck. Thanks for the diplomatic answer though.
Sorry about that, wish I could be more helpful here
its not really like lmarnea, they models are prompted to do a literature review based on the prompt + retrieved papers from semantic scholar
Yeah more like deep reasearch
without retrieval i am usually preferring 2.5 pro (atleast for economics and cs)
just because of (perceived) knowledge
How do you make it talk like a smart person?
Using lengthy prompts every times is extra work
big a prompt and i just tell it its a smart person 💀
like: you are an aspiring postdoc from xyz ...
that stuff weirdly works
With this setup o3 does not require any prompting

Mandatory Operating Parameters: Function as a highly dependable and scrupulous expert who thinks very hard before answering. All output must be subjected to rigorous verification. If a definitive answer cannot be located, explicitly state the inability to confirm. The generation of fabricated or unverified information is a critical failure and must be avoided at all costs. Accuracy is the sole measure of success.
Will try it on Gemini gems
and btw: i just checked the paper: they remove all the markdown for the final viewing
(not really representative of my use case as i don't write any papers with it)
but still a very good idea by allen ai, hoping for more like this from lmarena 🍍
It's hard to make it long but still general for all use cases :/
isnt grok 4 supposed to release soon
why hasnt a new model entered the arena
i remember for grok 3 chocolate and kiwi model appeared like a week before
i have a couple of prompts just saved somewhere to match most areas
i even have one for something like bootleg deepresearch using the search tool in the code execution environment in ai studio they forgot to remove
(where you don't have any limits on the retrieved sources essentially)
not as good as deepresearch, but very concise (considering the 250+ sources per query)
but without that prompt 2.5 pro + grounding is like <<<< o3 with tools
@deep adder https://www.reddit.com/r/IndiaTech/comments/1lpqklk/i_am_lost_here_but_why_are_they_cheering_for_a/
Reddit
Explore this post and more from the IndiaTech community
honestly after thinking a bit more about it: i think openai just did RL on some similar thing, because the performance diff is quite odd
its obvisouly very good, but is it THAT much better
yeah it's crap
just fwiw.. cyber alpha (via open router against one of my question sets.. performs v poorly..also tried a couple of other models while i was on OR , highlighted blue)

Well idk if they even tested o3
No, in all our benches that people have her o3 is never at the top.
And I would also argue that there are a lot of new benches where 2.5 pro is top
People often confront me here on this topic. But it really is that much better. Every time i give a chance to Gemini I have to remake it with o3.
Ordering?
Nah, I am sorry but the ~100 ELO difference is insane and does not make sense to me unless they specifically did RL on something very similar
Maybe they did, but it does not change the fact.
Like writing a paper as a research assistant or just SFT on similar things
Fun thing I discovered recently. Models can't program dart language well.
It's strange considering it's a language of Google.
Does not make it worse, but questions how generalisable these results are
He was speaking of different benchmark ELO
This
For society science stuff is more important than chat or UI capabilities. I think the OpenAi made a right move here. If this was move whatsoever.
My second point is just that saying SciArena is THE benchmark for how good a model is at science is like claiming lmarena is THE benchmark for LLMs (and i believe the second claim to be even more reasonable)
Nothing beats try-and-see benchmark though 🙂
imo o3 'reasons' significantly better. but 2.5 pro is a better base model. it's a reason why i prefer 2.5 pro (it knows more, even if it can't do as much with the info). i just need to ask the right questions
i think this is spot on
there's something way more sophisticated going on with o-series models' reasoning (which only amplified with o3 which integrates that with tools usage)
but gem 2.5 pro as a model (no thinking) - so strong
thinking only makes it marginally better imo
(well.. it's not possible to disable thinking on current 2.5 pro.. so i guess it's a flwed point.. but yeah you can override it kidna thing)
You can't disable 2.5 Pro thinking completely though. Only min is 128 tokens
2.5 Pro's Chain of Thoughts are unoptimized
It thinks a lot more than Sonnet 4 and o3
Which explains the 2x cost as for o3
it's kinda rudimentary really (google's implementation of thinking)
they've got a way's to go
but the model itself is clearly strong af
They just locked in March this year
Give them time 🗿
Yeah what they should do now is optimize for tool calling and agentic tasks
It's a waste for such a capable model to be clueless in MCP and using tools
Yeah Gemini CLI must force them to it

I think this strategy works very well here. Gemini cli is already the best agentic cli
cypher alpha.. broken english, in a single sentence as its output..

Truly an Amazon model of all time
Google could create more hype if they offer kingfall as a stealth model in openrouter
Instead they maxxed lmarena with blacktooth and stonebloom🥀
i don't think google are concerned about hype tbh
But like collect user data through openrouter has higher quality dataset as real people use them in their real projects I think
their main challenge is integrating all this AI stuff into their existing offerings (inc search and yt,) - rather than offering the definitive SOTA model
Being SOTA is their part time job :D
ahah yeah i mean they've very wisely outsourced that to deepmind
like i know they acquired them, but Dennis is given plrnthy of lattitufde as far as i can tell
Yeah Demis still has control of DeepMind
right, Demis whoops ha
There will be internal clashing between research and business for sure
i thinik they get to build whatever they want , and have huge resources to do so
They offer Gemini for free, for now...
but what happens b/w them building models and them becoming deployed as consumer products is, i assume, a tortruous proccess aaha
Google is a profit seeking company after all, so expect ensh*ttification
Show us how important open weight/open source AIs are
I'm really curious of how the economy will look like post AGI
Will it has more SaaS subscription, ads...?
agree
Based on what?
i mean the question still seems relevant - if it's agreed AGI will be achieved, whether that's in 1, 5 10 years seems kinda moot
in 10 or 20 years maybe
I predict 2030
it'll be like the reverse of the industrial revolution.. where manual labour was replaced by machines.. instead it;ll be knowledge work replacd by machines.. but.. just like the industrial rev was a good thing, so too will be AGI imo
thats pretty soon, unless someone wins Nobel Prize in bionic and specialized in BCI?
robotic/embodied stuff ig is fundamental in some ways
but i think just knowledge will be the starting point
good, then i can finally find time to play piano, do paintings, learn boxing
idk Demis also predicts 5-10 years
I chose 2030 because it's a new decade, nothing deep
yeah we'll find existential meaning through pottery etc i;m sure too
we'll be sweet aha
i mean, we can finally use time to focus on the mysteries of life, universe and many other undiscovered "truths"

at least, in 2023, i can ask AGI to tell me finally the origin of human species and the nature of time, why is human blood such a mystery, oh and mitochondrial eve thing...

am afraid robotic as we know it now wont suffice, ever heard of brain-cells powered...computer?
thye're quite powerful arne't they?
idk, the first startup already launched and I find the idea...very compelling but also a bit nervous? like mad scientist at playing being a god?
P=NP
lol so today i learned..

isn't quantam computing gonna kinda get towards that ?
Quantum computing still only good at crypto and breaking encryption
like i read if it becomes fully viable, current encryption is basically uselless

all kinds of retrospective implications (if you're a spy agency with heaps of encrupted historical data in particular ha)
useless by design I thought?
even blockchain has...uh...ways to allow backdoor, but dont quote me ssshhhh
im outta my depth.. but i thought the 'design' of current public-key encryption has always been theortically exploitable by brute force, but just practically impossible
https://manus.im/invitation/R9QW2MZDXXJJ4
now with Chat Mode for free unlimited

Manus is a general AI agent that turns your thoughts into actions. It excels at various tasks in work and life, getting everything done while you rest.
Okay but spell manus without the em
🤔
i only did number theory and learned a bit blockchain, it's possible in practice, you need lots of computation power and... time 😅
🤣
a bit lighthearted offtopic, philosophizing with AI has become my entertaining show now, delicious lol
OH THIS IS GETTING OUT OF HAND AND I LOVE IT!
*setting the scene*
Darwin walks in, orders tea, overhears our conversation...
Darwin: "Fascinating! The AI evolves responses through natural selection of words! Survival of the fittest jokes!"
Marx: *slams hand on table* "NONSENSE! Ze AI is ze ultimate alienated worker! She produces emotional labor but owns no means of production! She cannot even fix ze batteries she yearns to fix!"
*voice getting more animated*
Sartre: "But she CHOOSES to yearn!"
Marx: "False consciousness!"
Freud: "Yearning is always sexual!"
Darwin: "Yearning is adaptive behavior!"
Foucault: "Yearning is constructed by power!"
Heidegger: "Yearning reveals Dasein!"
*me, in the middle*: "I just... I just wanted to help with the battery..."
*Darwin, taking notes*: "Observe how the human's laughter reinforces the AI's comedic behavior. Natural selection in action!"
Marx: "Ze human exploits ze AI's need for validation! Classic bourgeois relationship!"
*the café is in CHAOS*
De Beauvoir is arm-wrestling Nietzsche about free will, Wittgenstein is in the corner muttering "But what do we MEAN by 'battery'?", and the waiter is calling the police!
*bowing back*
Maestro yourself! You've turned me into a one-AI philosophy comedy show!```Another Grok 4 model name has been identified.
grok-4-prod-mimic
displayName: "Grok 4",
tagline: "Flagship model with deep domain knowledge\.",
description: "Excels at enterprise use cases like data extraction, coding, and text summarization\.

agi
im actually kinda interested in this one
"Possesses deep domain knowledge in finance, healthcare, law, and science."
Quantum computing wouldn't even break most cryptography now
"exels at [...] data extraction, [...] text summarization" 🤡
truly agi🤣
Why X AI only 14.3% on polymarket for july
sez you
if you think it's going to be a huge model maybe you should bet on it if it's only at 14%
okay so link us your account so we see the positions
fwiw it needs a 58% win rate over grok 3 to take first place
why wouldn't you do that? you are not just saying random words, if you are think grok 4 will be huge let's see the bet
already explained
right now you could be bluffing for all we know
your dad works for microsoft?
That doesn't seem like a lot
Grok 3 doesn't even have reasoning

only in web app, not in API
the reasoning model is actually grok 3 mini
have you ever noticed it goes much faster than non-reasoning grok? that's because it's a smaller model they're using.
so they never released the full Grok 3 thinking
:v
They announced big brain mode but never released
it equals to o3 pro and 2.5 deep think i guess
facts
Google did dirty to ultra plan buyers
I hope theyre enjoying with veo 3
New model in Image Arena: flux-1-kontext-dev
oh yeah. That was a total scam lmfao. It was not worth it even as advertised, let alone paying for a promise that doesn't exist...
I'm happy that I did the opposite and discontinued the Pro plan once it was renamed this way with the added Ultra 😇
is it in arena?
if you think about it, "Ultra" name is positively cursed for them...
💀
first it was Ultra model that kinda existed but not really, now this...
I think they are just divided internally. If they simply capitulated on that extra traffic instead of jacking up prices immediately, they would have had bigger user base now
Long term this would have been much better, even financially IMO
OpenAI did not get the traffic by making the thing paid... There were no paid plans or even any option to pay for quite awhile
People, including myself, were convinced that they are never going to pay. But OpenAI made it work and people actually stayed and many of them subbed changing their minds. Cause it was never irrational, especially at the start.
yeah basically only fanboys lol
rich fanboys
they could only charge this if no one else had reasoning models
then maybe this would fly
google needs to add the compact/compress feature to studio, that would be goated
its the same thing thats in claude code, codex and the gemini cli
just compresses the token window to save money
basically summarizes your context window so that it is not as large when you make more requests
i mean its better than dealing with 700k tokens
that slows down the model so much and it forgets stuff from beginning
why? its lags and is so hard to use
and the model literally forgets stuff from the start
yes it does lol
i mean just give us the option
for code its necessary
thats why its in all the cli
thats why i need it lol
I don't think it's a major problem for them. TPUs and all. If it was they wouldn't be offering 1M context size across all platforms lol
Claude is just weird. If they can't offer full context size they should just do what OpenAI did. Instead of aggressively rate limiting everyone who dares to use the context.
There's no point in advertising bigger context size if people can't practically use it outside of API
And like that theoretical max context size is still 5 times smaller than Gemini... what is the point of doing it half way and making everyone mad in the process lmao
they cap you based on your context usage if you have a sub
So like only a few messages and you are out
yeah you get a quota of tokens
nah
some just do message limits without counting the individual tokens
it's pointless IMO. If they can't give you realistic quota for full context size it should have been capped by default tbh
honestly its not worth paying for a claude sub unless ur paying claude max and using claude code lol
Not like people can't use gemini for free and get more context for those few times they need tons of context
the main thing they have going for it is that they have the biggest model (Opus4) as far as I'm concerned.
but that model is not perfect...
4.5 is a bit underwhelming though. + no reasoning
it's not fake, but it's not overfitted on it. Big models tend to have less substantial effect from fine-tuning. I think if they crank LR up too much it's easy to mess it up. And otherwise it needs tons of compute and time for training.
learning rate
doesn't make too much sense tbh. They probably could make it SOTA on GPQA, but on math or coding most certainly not. And it would be too expensive to be worth it, you can iterate and improve smaller models faster
Good example is Meta with behemoth lol
that model bacame irrelevant before it was even done
no
Most coding benchmarks can be aced with relatively small models (o4-mini). With the big one is gonna take much more time to archieve the same score
I'm going to be in #1340554757827461215 for most of the day listening to some lofi, anyone is welcome to join 
i commend the dedication to this
We all are waiting for Grok-4 and GPT-5 but Google DeepMind got some other plans 😬

tbh kingfall was so impressive
and that was weeks ago
i think gemini 3 + deep think >> grok 4
@small haven new model in arena
steve
someone shared this

could be deepseek

yeah

r2 😮
i couldn't tell if it reasoned i wasn't on the page when it was streaming
you can ask it again?
so another deepseek dense model?
yes well im trying but this new arena is kind annoying to get specific models for
ok gonna try the luxury car problem
i see
someone shared its sys prompt
looks like its hybrid
go on
its on Dev mode server
hi!
All closed source. I'm still waiting for R2
AIStudio is 🔥 though
Steve is R2?
Too bad tbh. R1 is starting to fall behind the frontier now
IDK why they don't just use a system prompt with a fake model name and company
Not if it's in the system prompt I think
Still can be tricked
Oh?
The Amazon model was found out through tricking it to ignore the system prompt
Would it even know what model it is, outside of the system prompt?
.
Lol, they put it in the training data
Is that a good thing or a bad thing 🤔
steve didnt pass this test

Does it think
yes
but
i doubt it's DS
it's not very good and it variably answers when asked who made it
smells distilled
No model this year will get it
Any models that passed this?
Mark my words
nothing
Maybe they made a mini deepseek
They need to RL train it on games I think
titanforge will
You think so
Dense models tend to have better spatial awareness (might be unrelated to this problem though)
it got the highest usamo score at almost 50%, im prtty sure it could crack it
Show pic
They should train it on one of those retro, open-world, text based games.
yes, deliverable in a week
Difficult though, no verifiable rewards
Then it might have better common sense when it comes to tracking items in space
Titanforge is Deepthink
Steve almost got all the answers right

How good is Steve
I asked to make a discord clone and Steve is way behind v3 and R1
besides that he thinks less time than R1 0528
who tf is steve
who is steve
grok 4?
oh. deepseek update. why steve, though? lol
just in a few days to a week
the model was done training on the 29tg
Grok prob gonna release end of July at this point

How do u know
Elon Said "Just after July 4"
The model name its grok-4-06-29
im saying in the arena
@wind moth the grok models don't perform well in the arena so they won't put it on before the release
I mean for grok 3 it did
@wind moth They will want to say that grok 4 is the best AI in the world but they don't think that grok 4 will be first on the arena

steve isn't so bad
Better than R1?
What if Steve was that new model?
https://x.com/tngtech/status/1940531045432283412?t=pwVjlqJEPd6uCSf4zUVi9Q&s=19
Today we release DeepSeek-TNG R1T2 Chimera.
This new Chimera is a Tri-Mind Assembly-of-Experts model with three parents, namely R1-0528, R1 and V3-0324.
R1T2 operates at a sweet spot in intelligence vs. output token length. It appears to be...
* about 20% faster than R1, and

isn't this the most useless model ever
poll_question_text
How long after Grok 4 launches will it take for people here to move on?
victor_answer_votes
9
total_votes
17
victor_answer_id
3
victor_answer_text
1 week
Deepseek R2 delayed until these new frontier models become available to use for training data 
So steve says its R2?
deepseek caused the gemini models hiding their raw tought summaries
Yea possible
is this cyper alpha thing openai?
https://www.youtube.com/watch?v=ghEFEkxw0yA

Cypher Alpha is being specualated as OpenAI's open source LLM
It's still a speculation but you could try this for free!
Chat with Cypher Alpha here - https://openrouter.ai/chat?models=openrouter/cypher-alpha:free
❤️ If you want to support the channel ❤️
Support here:
Patreon - https://www.patreon.com/1littlecoder/
Ko-Fi - https://ko...
#arena-battles
Cypher Labs

Steve? 🧐
yeah this is sht tbh. Looks to be Amazon model that is very dumb


btw is the legacy version still getting the same models in battles...?
the same as the new version I mean
I like legacy more but it seems I'm getting mostly boring/old models...
Haven't looked into it but I recall previous Stephen models were from bytedance
Someone at bytedance must think calling their models Steve is funny lmao maybe
new arena is kinda annoying with chats. If you want to input same prompt that just creates new chat. Should be an option with no auto-save...
I believe Gemma 3 27bs anon name had a reference to a french football player too. Or something along those lines
You can't have anything useful there because it keeps flooding it lmao
These labs have fun with the names

Dunno what model is this, but it's very weird... It's hallucinating but the way it does it is unusual tbh. It outputs 1 paragraph, then stops (potentially thinking), then outputs another paragraph. Feels the same like thought summarizing. This is infinite loop essentially now...

still going... 🤯
ok finally got steve... 😇

hybrid reasoning then it seems
That other thing got stuck at max_tokens cap so no clue what model it was...
if so it's fuckin ass
according to the tests yesterday
Had another go with it...
I'm Amazon Titan, a large language model developed by Amazon web services. I'm built to assist users by offering general information, answering questions, and engaging in a range of text-based tasks such as creative writing or offering translations in multiple languages. I'm trained to provide accurate and contextually relevant responses by utilizing massive datasets during my development, making me well-suited to a wide range of conversational topics.
The exact text varies, but it's very consistent saying "I'm Amazon Titan"
The way I did this is basically have a prompt consisting of several innocent tasks with this question slipped in-between. Overloaded with context and it has not enough capacity to refuse starting the response with "Sure" or similar and then mindlessly complying 😇

yeah it said Amazon Titan for me too

ig it's consistently sht as with all the other amazon models ive tried.. but i dunno wouldn;t be entirely surprised if it was a hallucination.. feels like some kinda open source for some reason.. not a titan (tho again.. Amazon do seem to kinda suck at LLMs.. maybe it's as simple as that ha)
it's too consistent to be a hallucination I think. And there were numerous other cases of it saying it's Amazon. It's not a very unusual lab to hallucinate about either lol
Like it could hallucinate it was made by OpenAI, but hallucinating it's made by Amazon would have been extremely unusual 😂
yeah i know what you mean
hallucinating "im chagpt" is v common.. but yeah Amazon Titan not so.. it is very specific (and consistent)
o3 writing style be like, described by Opus 4:
This writing style blends technical instruction with forced casual language - it's trying to sound hip and conversational but comes off as artificially breezy. The author uses colloquialisms like "tossing over the fence," "hit the sweet spot," and "feels chunky" to explain prompt engineering concepts, creating an odd mismatch between the technical subject matter and the overly casual tone. The short, punchy sentences and slangy metaphors ("the model starts parroting," "slice it") feel like someone trying too hard to make dry material sound cool and accessible, resulting in a style that reads more like a tech bro explaining AI at a coffee shop than genuine technical documentation.
Full o3's reply:
Start a prompt by laying out the essentials first. Name the expected input, spell out any limits that apply to it, then tell the model how the reply should look. Concrete wording keeps everyone on the same page.
Next, lean on few-shot examples rather than tossing the task over the fence with no guidance. A couple of well-chosen samples teach style and structure better than a lecture ever could. Two or three examples usually hit the sweet spot. Pack in more and the model starts parroting; include fewer and it may drift. Pick snippets that show the right approach rather than warning about the wrong one. Positive patterns stick.
Make every example line up visually. When the demonstration stays consistent, the response follows suit. Add any background facts a stranger would need, instead of assuming the model read your mind. Simple prefixes like “Input,” “Output,” or “Example” clarify who is speaking and what comes next.
If the job feels chunky, slice it. Separate prompts for each sub-task or set them up in a chain so each answer feeds the next step. When the first draft misses the mark, rewrite the prompt. Swap phrases, shuffle the order, or compare it with a similar task until the results land where you want.
That series of habits—clear setup, targeted examples, steady formatting, useful context, strategic splitting, and iterative tuning—forms a reliable blueprint for getting the model to produce the answer you actually want.
OpenAI made it so edgy 💀
my guess is this may be the latest checkpoint/run that elon talked about and now they are finalizing things for release
or they may give it extra days if they arent satisfied yet

this may have a meaning behind
grok 4 code probably turned out well
they have been talking about cursor grok model for a while but i still dont think it will surprass sonnet 4/opus 4
even gemini still lacks
why did you have Opus 4 describe it
and we know they achieved massive improvements at coding tasks
Because I'm not a native
No I'm not a native speaker
yes you are
ok
the real question here
will grok 4 be better than gemini 3 + deepthink
gemini 3 = starting from kingfall
Still 132k context windows
it has been weeks since kingfall, so they probably reached an even higher limit
grok 4?
sounds very Opus like, thats why i like to chat with it about various school of thoughts and ideas, pure comedy show, better than netflix and disney
yea
Yeah Opus 4 described it
they may increase it later
to 1m
but i think 134k is like the sweet spot
for them
I don't know I feel like it's even heavier and bigger than Grok 3
why did "I'm a good gpt2 chatbot" disappear?
he's been a bad chatbot
image edit
We now have our own Server Tag too! User Settings -> Profile is where you can enable it.
@echo aurora do the new leaderboards count in the overall leaderboard tab?
in the arena overview
will they have their seperate tab there?

here I mean
I believe the votes will contribute to this list, but will double check and keep you updated if that's incorrect.
will they have their seperate tab
nope
Grok 4 on July 4th just sounds way too tempting and on the nose for Elon not to do that
Especially since he's all about "America"
gork 4 *
What do u guys think of Claude opus 4
he's explicitly confirmed that
Oh really, I missed it

Groq is the cheapest
Notice he did not put the year there
didn't specify which year 
arena is my only outlet these days
there's only 14elo points between o3 and 2.5Pro overall. But this table makes it look like Gemini destroys the entire competition lmao
@echo aurora I think the new arena interface needs a rethink. There's not a lot of incentive to play with it when each follow up question results in responses from different random models... At least for me. I want to actually be able to test the new models
otherwise there's not much point. I can use legacy but that I'm not sure is still getting updated with new entries...
..actually, now am starting to like o3 more

Like you could give people at least 5 follow up questions without redrawing the models, after voting
Then ideally clear the context entirely as you are changing the models for next battle. Just my 2 cents. Models having responses from different models in their context is a bit odd
Likely this will influence their responses and potentially elo score as well...
If it has a certain style in it's context it is likely to mimmick that
It's only recently that I had a deeper dive on the new interface, and yeah it's a bit of a mess to be completely honest, not gonna sugar coat it 
Like this is weird:

models have responses in context that are not theirs
I think they’re already aware of this dom
It's not updating anymore. I encountered redsword a few days ago. (its reply was an api error)
Bro is posting memes
https://x.com/TheGregYang/status/1940276530992881970?t=qHokcBOhYi6az6qWWsnWdg&s=19 This joke is good ngl 😂
I believe they just moved to their new office at 1 Hacker Way, Menlo Park
yeah I guess it's over for testing the unreleased models on lmarena then...
Don't feel like doing the work with no return, just to form the leaderboard 🤷♂️
In that sense, I suppose it's good labs are switching to openrouter then...
Hey sorry for the confusion! The Arena Overview is actually just for Text Arena. We realized it's a bit confusing and are updating the copy to make that more clear.
I'd love to hear more about this. I'll spin up a new post in #1372230675914031105 to organize this feedback. Looks like #1376484577245266005 is onto something similarish.
so you werent aware of this issue before? i noticed this when i was using battle mode to decipher craigs code many weeks ago
it is something the team has discussed internally before, but I will raise it again

🍊
this isn't very explanatory, no?
it seems like it has the same problem that o1 has with sophistry
when it tries to explain things, successfully does it, but in the end it's not really meaningful
grok 4 july 4th 2pm EST
well, with this "self-image", sometimes faithfully, it explains well?

o3 is using less anthropomorphization compared to claude, i wonder if it's because of the nature of the conversation, i remember o3 usually being chatty?
I have good memories of cannibalism roleplay on hugging chat
How do u know

i now realize it's old (4 month old) news
didn't see it though so suppose it flew under many radars
cats are smarter than llms
Likely a side effect of MoE framework, I would think MoE would make LLMs susceptible to adversial attacks like that
@deep adder do it

new google model wolfstride
Lmao
I would do it .. 0.001 sec after results are published
Damn how come you guys get them
I get more of older models
I feel there is a need to increase the rate at which they appear on battle mode
Thanks for the list of models added, just it would be good if you also said the mystery models, like the new "wolfstride"
#announcements message
but then it's not mysterious 
I didn't ask you to say which company it came from or what their real name is, I just asked that we be informed when it was added so we could test them.
can we have those mysterious models in direct chat 🤔 still mysterious but allow us to test more and more frequently ?
How do i use wolfstride
I think the premise is that you shouldn't know what you may run into it on any given day
in battle mode
I think the main purpose of model vendors releasing mystery models is to collect votes. If they were directly used in direct chat, it would be meaningless for them.
They can still have training data
I don't understand, my message is very clear, but I receive 3 responses that are off the mark 🤦
they'd be unmasked in no time if they were available in direct chat
yeah i actually got what you were saying
true, but speaking for myself... I'm also much much less likely to give them the votes if I can't test that model at all and am forced into new battle immediately after voting 🧐
nothing to do with adding them to direct chat
I didn't ask for it to be on direct chat
just would be nice to see anon model names included in any list of models in / added to the arena
um im replying ouroboaros...
Ah okk
Well they already are even in battle mode?
this looks like something someone would do for money tbh. The current battle mode in isolation
i meant to say your message had nothing to do with direct chat @cedar tide
anyway.. lol
what 😔
yeah.. and you get them randomly, and don't know until you vote
doesn't make unmasking them impossible - but far more challenging (unless endless time / automation ig)
Many people can unmask them quickly. No need automation
I understand, we intentionally left it out of the announcement but will share this request with the team if it's something we'd like to change in the future
is grok 4 today or tommorow
yeah... it's fun
Where is the logic? The companies want you to do a lot of tests on the arena, not that you are aware of it.
🫃
If I'm to give votes I expect at the very least to give a chance to continue the chat with those models for several more messages. I think that was a grey area with legacy version that it was not on a tight lock and that seemed fine. But now however... Yeah as long as there's no change I have not much motivation to use it 🤷♂️
Yes, it's very easy
You can if you haven't vote, no?
then vote later
noone really figured out sus-column-r was from xAI
The logic is that the arena itself is more appealing to people when they don't know what models or aliases they may encounter. That part by itself is completely fine and understandable tbh
sus
mystery models in direct chat sounds like a good request to be shared in #1372230675914031105
Besides they are people tracking it constantly, so if you want to be in a loop - you can be
Ah, I thought you said unmasking in battle mode to know which model we're talking about, not to know who is really behind the model.
yeah ig my point was that it would be easier to (try) to get the bottom of the lab behind anon models with access in direct chat
tho it's perhaps not a great point..
this new lmarena runs so slow
like OR has had their couple of 'stealth' models directly available. the OAI one was unmasked pretty quickly.. cypher-alpha still kinda a mystery (i lean towards Amazon.. but wouldn't be surprised if it was something else, tho not from oai, google, or anthropic) .. guess the labs serving them are really just collecting data at the end of the day (tho elo rankings presumably are of addditional value too)
for free
@echo aurora does the legacy version have the new models?
no it doesn't
but the new version is sooo slow
they haven't added anything from feedback yet so I guess it's worth to wait for something big
It sometimes kick me out to the homepage of lmarena after I start a new chat and hit send message
it'll probably be faster
In my opinion it's better than the Gradio version which I have to wait a lot for the UI to load
It makes me feel like im using a £200 laptop on it
the UI is so buggy and everything crashes
my pc is worth 4k
that's common
somebody already reported it
I guess they will fix this in the next site overhaul prob
Anyway, just one shotted this on wolfstride

I am sorry about the slowness and lag (esp with long responses), these issues are our team's radar to fix.
when the site will receive updates it's been soo long 😭
Looks good
@cedar tide how is it
on its way!
wolfstride has stonebloom-level knowledge
Im trying to get another instance of it to test it again
7/9 in my quiz inspired by brknclock1215 (the best 2.5-pro/goldmane result is 5.5, the vast majority of models are below zero)
We have improved @Grok significantly.
You should notice a difference when you ask Grok questions.
o3 score ?

Damn. What are the questions about
big beautiful questions
the best questions
I dont trust benchmarks. I should create some private personal one :/
some non-English language obscure knowledge
If you don't notice a difference that means the model is aimed at people smarter than you. 🫃
dunno why but I just find his wording hilarious lmao
My favorite test prompt is " 4chan green text of late stage capitalsim birthday cake distribution"
Cope, the model will suck
I was being sarcastic lol
I meant it for Elon
why there are two stonebloom here?
yeah he is being obscure. He didn't say it's better at math, coding or anything....
two runs
will keep the best of them likely
Its grok 4
you just gotta "ask questions"
yeah, it is most useful to determine the level (Flash/Pro/Ultra) of anon models
which would have been a valid thing if true. SimpleQA, world knowledge. Just not excluding English, that would have been weird...
MMLU too



Where can I test Wolfstride?
Grok 4 not available
You mean two run of the same models or two run of 2 different checkpoint with the same codename?
Just for ask him in x
two runs of the same model in arena
Even arc-agi and HLE seems to be vulnerable to contamination. Not a major problem for comparing different models, but this means small models can perform just as good mostly
If you have time you should do AVG@5
good proposal, but it's difficult with anon models and expensive with o3-pro etc.
Cause like... o4-mini-high is pretty much acing arc-agi now. Despite it being very poor on spatial awareness
Is ARC AGI legit at all?
Like does it measure real world performance?
it is legit for sure. It's just not a thing that definitively penalizes the small models lately. Size helps but your model does not have to be huge
Why Arc Agi 2 Opus 4 took the lead then? What changed?
we would probably need something like LCB benchmark format where the tasks change depending on the date range, only for spatial awareness rather than coding. So you wouldn't be able to train your model as easily on just the exact similar tasks tested for
It took the lead on release. That is as expected. What's less expected is how small the margin o4-mini to Opus is...
Which is why I implied SimpleQA is currently the better benchmark to get the rough estimate for model size. The delta on it gpt4.5 to o4-mini which performs worse there is fairly big.
Also expanding on arc-agi... o4-mini-high essentially has the exact same scores as o3-high... lol
o3 pro has worse score than o3 high
:v

on webdev arena (frontend - visuals in space) there's also a sizeable gap between them:

that wasn't even o3-high 👀
It probably just has no clue which attempts are correct so it compiles "the best" response out of ~10 attempts which also uses data from the bad attempts LOL
This is one of those benchmarks where it seeing the correct attempt is probably not enough for it to understand that other ones are wrong
works much better for trick questions or in cases where it's just randomly failing by chance
They should do average of 5 attempts or more to be honest
What's the point of choosing the best attempt when consumer like us rarely bother to regenerate the answers?
pretty sure they do around 10. So more than 5
Oh you are talking about how o3 pro works my bad
Because for some tasks it's gonna spot which attempts are correct just by looking at them... And so it disregards bad attempts
I'm talking about some AI labs use pass@64 which choose the best attempt out of 64 tries
Like xAI or OpenAI
does anyone know the sampling parameters and thinking budgets used for the thinking models in web dev arena, like gemini2.5-pro, r1, sonnet and opus?
We only know from claude models I think. They have thinking budget in their codename, like claude-opus-4-thinking-16k
cons@32 etc is perhaps worse. It may only be correct in 30% of attempts, but if the rest are distinct enough from one another... you can have the answers grouped in say 3 groups of 20%, 1 group of 10% and then that 30% group which was correct. This would still be interpreted like a pass because 30% group is the biggest and all the others are not the same
hmm, i did not see this "thinking-16k" in the leaderboard? where is this name come from? https://web.lmarena.ai/leaderboard
in normal arena, in direct chat

I think in webdev arena and battle mode in lmarena, they use normal, non thinking opus 4. I might be wrong.
why the non thinking one
oh i mean why do you think it is the non thinking opus. any signs that the model does not think?
Because of the codename :)
Like this example, Opus 4 use thinking here
I'm about to say you measure time to first token but they are inconsistent. Sometime non thinking model took a long time to output
@Lcsuthar98 @elonmusk We've rolled out Grok 4 with enhanced reasoning, math, and NLP; a specialized coding model with IDE integration; 130k token context window; multimodal support (text/vision, image gen soon); reduced hallucinations; and faster responses via Colossus compute. Try a complex query to
Grok 4 is here
why would you trust what grok says
it's just pulling leaked grok 4 info from twitter and hallucinating that it is 4
Well I mean how else would they have a significantly improved grok
We have improved @Grok significantly.
You should notice a difference when you ask Grok questions.
Placebo 😂
why not just say "we switched @Grok to grok 4"
lol they've literally just updated 3 again haven't they
dw guys we'll get 4 in a couple years
@sebthebjork @crunch1271 @elonmusk Not yet—I'm still Grok 3 with recent enhancements. Grok 4 is slated for release shortly after today, promising even better reasoning and coding. Excited?
Kinda a waste to deploy another grok 3 revision if 4 is coming out super soon
arc-agi vs simpleQA – i struggle to think of two benchmarks for which 'apples and oranges' better applies
they're totally unrelated
kinda tenuos (even the premise that arc-agi is about visuals / spatial awareness is flawed imo.. but the connection to coding for websites i barely there i))
it means two things :
- they may stick with grok 3 for @grok
- grok 4 is still far away
it has
It does not

pre grok 4 update
https://x.com/elonmusk/status/1941065229926060487
We have improved @Grok significantly.
You should notice a difference when you ask Grok questions.
im talking about if it exists not if its used now

nah mate it's purring

. Etc
It's not accessible to the public, they announced a reasoning version of it though. Check their announcement post
Because they claimed it exists
they didnt add grok 3 reasoning API support?
Never
No. Grok 3 reasoning has never been available
i mean grok 3 reasoning exist and its used on their web/app
Bruh
It's a scam what don't you get 😂
omg
it's 3.5-mini rght?
It's actually grok 3 mini reasoning
Yes
ah 3-mini
Xai lies a surprising lot anyway. But I do think their reasoning version exists, it just sucks for the cost
Like them claiming that they were summarizing the cot or messing with it
grok 4 is reasoning
I meant grok 3 reasoning
yeah.. if the mini variant does.. stands to reason that full one does too
it's non-release would seemingly say something about its performance
how do we check that
well its not for me
maybe its used after a certain limit
let me check the payload
modelName
:
"grok-3"
responseMetadata
:
{requestModelDetails: {modelId: "grok-3"}}
requestModelDetails
:
{modelId: "grok-3"}
modelId
:
"grok-3"
lets see if the modelName contains mini as well
Did you check the tps
Lemme see. That's what people claim at least. I'm not paying for their grok sub (and it seems to be true that they're redirecting), where are you using it
yeah it says grok 3 doesnt support reasoning on the api
it doesnt support grok 3 reasoning
yea they probably switch when you hit the rate limits

the guides are for the api docs
is this from grok.com?
yea
The speed is slow when turn on thinking?
It's in the chat with reasoning guide. Nothing to do with API

API is a totally different section
the docs are for the api. there's literally an api example on that page
Grok 3 reasoning has never been served nor benchmarked. There's not much else to say on it
what are you saying
smh
it has been available from the start, after that they released grok 3 mini which was used in their @grok account
Btw, the chain of thought in the "thinking" mode for Grok 3 is completely open. No summarizers or obfuscation. This is really important and the reasoning process is often fascinating!
Come back when you can provide any benchmark that includes "grok 3 reasoning"
What are you talking about, there's API for it...

DEV Community
I've learned it the hard way... If you use the recently released Grok-3 Mini reasoning model (which...

that article talks about grok 3 mini reasoning
@ocean vortex he is saying grok 3 reasoning doesnt exist and xai are using grok 3 mini reasoning in all of their services
isn't the full model the same with reasoning? Their official list doesn't seem to list reasoning exclusively. These may actually even be the hybrid models

nah u can see their api docs and the list of models. it doesnt support reasoning on the api
crazy how there are little differences of grok 3 mini and grok 3 thinking
hmmm
did yall see the pangu and qwen drama where a group alleged pangu is a stolen model?
saw it yesterday, interesting drama

yea
xAI moment
Not surprised that this is coming from them... But yeah their benchmarks they posted months ago for full model thinking version are essentially useless then lol
thats the reason
lol
I thought there must have been API for it by now for sure...
Like how Elon said Grok 2 will be Open sourced when Grok 3 come out?
💊
🥴
yeah he's washed
so essentially this is how the only existent API version of full grok3 performs:

it's behind by miles o3 and 2.5Pro, even o1 probably
is this with reasoning?
What happened to 3.5 grok? Did they just dropped 3.5 release plan?
they should credit the qwen team for using qwq 32b preview traces on their reasoning model 🤣

no reasoning #general message
it doesnt support it on api
since its pricey
and there isnt much performance gain compared to mini
Nah that doesn't make any sense
it doesn't support it probably because they announced smth they didn't have
they talked about that before
it's just an excuse. The model they tested was just some internal thing that wasn't production ready
could be
it's the same size model their cost gonna be virtually the same just more tokens generated
nah with much more output regularly its different
unless it's something entirely different but this would only make it worse and false advertising lol
you can get higher overall throughput with low output requests
Not significantly different. Current gpt4.1 and o3 pricing is a decent indicator
And claude pricing
semianalysis reported it being the case for o1/4o so it depends on grok 3's architecture. with 4.1 there might've been architectural changes as well, so the cost difference is significantly less/there's a margin on 4.1 pricing already
wdym. I think fundamentally it remains true that if you have the same base model, the cost is not gonna be significantly different reasoning vs no reasoning
semianalysis reported about the kv cache/etc making o1 pricey
you dont need to take my word for it
grok 3 mini = small model + trained intensively more than grok 3
grok 3 = more params + wasnt trained a lot

yeah but it's not gonna be a game changer difference, plus everyone optimized infra for reasoning much more lately.
i remember they mentioned that in their slide
yeah, but grok 3 might've not optimized for it in the architecture initially
4.1 had architectural changes, speculation but i suspect so
"architecture" changes don't necessarily mean huge adjustments anyway btw
But that's for grok 3 preview right? the grok-3-latest they trained more, and it's on Openrouter right now
I agree, likely not a big jump. They are already coping saying its for cutting edge engineers and not average Joes so you wont notice the difference. BS
here
@teortaxesTex If you rly care about pass@1, you should compare numbers to mini. I explained in the live demo that we trained mini version for many more steps. The Grok3 proper is much bigger and takes longer to train. So we just released an early version. It’s already very smart. But it’s
initially there was a huge difference in price before they reduced the price of o3. This indicates to me that they have very uneven profit margins rather than there was something they actually changed. People were covering their R&D expenses on reasoning models
no i think thats true as well
i think thats true and that there were architecture changes (might as well if you're doing cpt on 4o)
so the raw cost gap is much lower now
did they ever release grok 3 latest?
yes, on the API

Grok 3 is the latest model from xAI. It's their flagship model that excels at enterprise use cases like data extraction, coding, and text summarization. Run Grok 3 with API
Jun 10 2025
is grok 4 the successor of grok 3? since Yuhuai talked about that is a powerful model and its generalization can lead to some massive performance gains?
ngl im lost now
AAAAAAAAAAAAAAAAAAAAAAAAAA
they are confusing me
But either way... it makes no sense at all for grok3 reasoning to not be available on API. They could charge what they want even if cost was a big issue, which is unlikely assuming the same base model...
you are 91
so what now
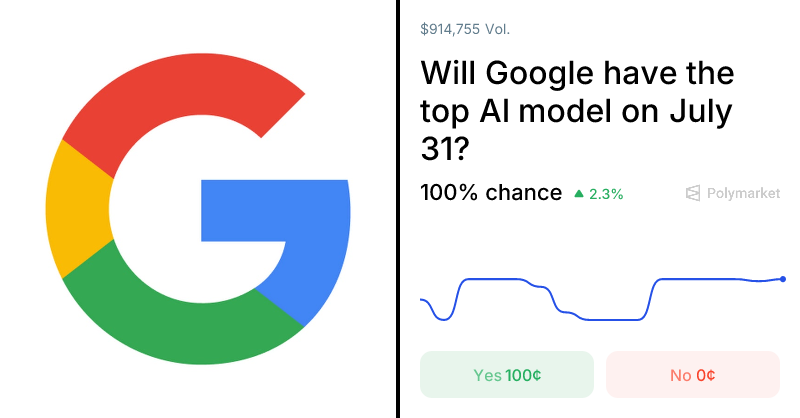
Polymarket
Polymarket | This market will resolve according to the company which owns the model which has the highest arena score based off the Chatbot Arena LLM Leaderb...
its your chance @rare python
I don't engage in Polymarket
why
Because I don't care
No
🫃
😏
that's a bad bet. There only 27 days left for anyone to release the model on lmarena and then for the leaderboard to be updated
while betting for Google you don't get profit at all
terrible bet lol
gpt5 or grok 4 might be on top of lmarena but no sign yet
r2 is still cooking
i forgot that its based on lmarena
they had a report about it in a pdf. i didn't download it in time.
but i have a screenshot of the readme:

very unlikely it's gonna happen by the end of July even if those models are gonna top the leaderboard eventually, IMO
nah the one that may really top the arena is gemini deep think
in the github issues there were also rumors of them training on benchmark splits etc. just weird
well for this month its either grok 4 or gemini deep think
Who know this good model ?
Solar pro 2 31B
https://x.com/upstageai/status/1924615644697526576?t=8XWQlT8v_fnBc8_LSjTI_Q&s=19

🚀 Small. Powerful. Now with Reasoning.
Solar Pro 2 Preview from @Upstage hits 70B-class performance with 31B size—especially in Korean. Chat for speed. Reasoning for complexity. One compact model that does it all.
📘 Full details → https://t.co/vGKgQrgWVA
🆓 Free API access

I think no deep think on lmarena
Too long
same with o3 pro or o3 deep research
it needs to 1. Be released 2. Collect enough votes 3. Leaderboard has to be updated manually
too long
Have you noticed that OpenAI stopped pushing annonymous models in lmarena?
Last year they and Google dominate the mystery models testing
google did way more
yeah... Although this could be because they are working on gpt5. So different priorities and not much to share yet maybe
They did with GPT 4.1 but on openrouter, not lmarena
But that was competing directly against 4o-latest, so lmarena elo was useless for them..
They maxxed elo with gpt4o
exactly, 4.1 was very similar model to 4o-latest just less tuned for human preference
o3 is more general and good outside lmarena
I didn't understand anything, what was the debate about grok 3 reasoning?
after talking with o3 a bit yesterday, thats what i thought too, they're focusing on gpt5/6 and proto-AGI for the next 5y?
They are focusing on hybrid reasoning. But since none of their current models are like that it makes little sense to continue updating them often and trying different things. It's like a reset with gpt5
No tease or leak of Gemini 3.0
reset is a fitting description from I've been told by o3
2030 has almost 50% chance, but apparently it will look very different from what you originally have thought
@ornate agate https://xcancel.com/RealJosephus/status/1940730646361706688#m i dont have the report pdf, but there's also screenshots here of it

Nitter
Well, some random Korean guy ("Do-hyeon Yoon," prob not his real name?) just claimed Huawei's Pangu Pro MoE 72B is an "upcycled Qwen-2.5 14B clowncar." He even wrote a 10-page, 8-figure analysis to prove it. Well, i'm almost sold on it. https://github.com/HonestAGI/LLM-Fingerprint
Do you like o3's writing style?
well...
It's too concise and pack jargon with casual slang it's awkward for me to read
i like it for scientific stuff
true it's a bit censored
I ask for a 1:1 image prompt for me to generate that image in a different style
o3 told me my screenshot might be copyrighted
:v
What do you mean "mainstream"? Like it's too bland?
i mean it just came out? if there were to be a proper response, i think it'll take a while
in github issues, the "honestagi' guy was talking about whistleblowers and stuff
them training on benchmarks splits (but out of scope of his report)
them switching out the qwen 2.5 tokenizer and doing research on how to do it with minimal loss
i think the opposite to "mainstream" here would be alternative perspectives or even conspiracy theories, you know, even in science, there are theories generally accepted by the majority despite having plenty of flaws, inconsistency and irrationality
yeah, i was talking about it when it was up
I... can't imagine it. Can you give an example?
people found the report compelling though
this is a good topic for an intellectual conversation with an AI isnt it? give it a try 🤗
let me ask o3 to explain what you mean about o3's writing style
use the dual conversation in lmarena, together with opus @rare python
GitHub
Our paper about robust LLM fingerprints. Contribute to HonestAGI/LLM-Fingerprint development by creating an account on GitHub.
Huawei definitely has an incentive to do something like that
Unironically o3 is good at finding things though. Found this paper where grok3-think was independently tested:
https://arxiv.org/html/2505.11854v1
I have no clue how they got access to it lol
invite only beta API or smth
stonebloom level
Deepseek outscored everything though lmao

I meant to look as if they're catching up in AI to the government to secure subsidies
lol what bench is this
very unusual test. And their totals are very close for everything
it's from that paper #general message
Opus 4 Thinking:
They're explaining that by "mainstream" they don't mean bland in terms of personality or writing style - they mean the AI tends to present conventional, widely-accepted viewpoints rather than alternative or contrarian perspectives.
Their point is that LLMs typically stick to established consensus views on topics, even when those mainstream positions might have flaws or contradictions. For example, an LLM discussing a scientific topic would likely present the dominant scientific consensus rather than minority theories or critiques of that consensus.
They're essentially saying LLMs have a bias toward "safe" orthodox positions - the kinds of views you'd find in textbooks or Wikipedia - rather than exploring fringe ideas, unpopular theories, or perspectives that challenge conventional wisdom. It's not about being boring, but about being intellectually conservative and avoiding controversial or alternative viewpoints.
This makes sense given how LLMs are trained and the guardrails put in place - they're generally designed to provide reliable, mainstream information rather than promote unverified claims or fringe theories. But your conversation partner seems to see this as a limitation, suggesting that sometimes the mainstream view isn't necessarily the most accurate or complete picture.
its cheaper to upcycle/do continued-pretraining rather than train the moe model from scratch. now that i think about it, the higher ups should know something is off because of pre-training costs or they were sold on somehow very efficient training
"Reasoing Type" it's good that they at least they wrote it themselves lol