#general
1 messages · Page 62 of 1
they are not summarizing anything, rather changing or removing individual phrases
but that is not intrusive at all tbh
OpenAI on the other hand... Essentially every single sentence is majorly rewritten and shortened lol
so the wall of text becomes a 1 short paragraph
so you only have a very brief outline of what it is actually outputting
"vast majority are shown in full"
there's your answer
only 5% of requests are actually summarized..
so it's even more raw than I implied
that is not the point though, cause their summarization is never turning walls of text into 2-3 sentences. It's more like minimal thing. I was able to max it out and I was still seeing consistent stream of thought much like Deepseek.
not really. Sonnet goes off the rails if you max it out and will almost start contemplating it's own existence for your average prompt lmao
And Opus barely thinks much regardless of the prompt, so there's almost never enough to summarize doesn't matter how hard your prompt is 
The point is, Claude is really very close to raw thinking, you can't really complain about it... It's virtually indistinguishable from 100% raw thinking
I have never been more bearish of a model after reading a tweet
"Not for everyone" = not very good
Sonnet is repeating itself over and over again, to the point where some summarization on top perhaps wouldn't even be all negative, if they implemented something more
just some tech reporter
I literally linked an article that explained. openAI straight up stated deepseek distilled the cot so obviously it was available for that to be possible
apparently an elon fan
Ironically, I think for OpenAI summarization makes O3 look kinda better than it even is
If they outputted it raw I'm almost certain it would look a bit mess, similar to R1 thinking
https://youtu.be/hpwoGjpYygI?si=TiukSslqRyEnrsFr if you prefer video form lol

Build better apps with PostHog https://posthog.com/fireship
OpenAI and AI Czar David Sacks accuse DeepSeek of stealing their IP to train their new R1 model, citing hard evidence gained from Microsoft. In addition, Alibaba just released Qwen 2.5 with impressive benchmark results.
#tech #ai #thecodereport
💬 Chat with Me on Discord
https:/...
"wait, maybe I made a mistake.... wait, let me double check.... Or perhaps the user meant this other thing <insert random wild theory that does not make any sense>...."
I don't really care they did it tbh. But it's obvious it did in fact happen lol
There's no denying that
raw thinking is very often not a good look, even if the model performs lol
There are many articles
I don't think they distilled the cot itself. They just trained on o1 final responses.
Which is still a good quality synth data
They were. It was slightly cleaned up but mostly raw
I remember openAI saying Deepseek stole their cot
does not only improve performance, but also your model learns proper message formatting
all the markdown, boxed responses, code formatting...
And then they did the same to Gemini models, stealing their cot too
The cot is the gold
The final output is not that important
The model needs to train on how to reach that final output lol
That's just not true at all lol
Debatable. Final output is perhaps even more important. You can train conventional chat model on that. And then do your own RL training on that base(chat/instruct). That way you are ahead of the game
The summaries were barely summarises before. The amount of detail they removed is massive
And they literally stated it's to prevent other companies training on the cot
It's not a debate topic
it's the main reason why they did that for sure. But it didn't turn out to work as good as they thought. Took Deepseek no time at all to reproduce it with no access to raw CoT
you still have final responses - and that's all you need to train your next gen model and do your own RL training. It's not straight forward but not magic or rocket science either
"competitive advantage" read between the lines lol they are not going to do an official press release to say deepseek stole the cot lol
That statement is from openai engineers and Microsoft did a report on it
It's all in the vid I linked
there was nothing to steal lmfao. Reasoning was always summarized
And after Deepseek they realized there's not much point hiding it
so now they allow for detailed reasoning
which is much less summarized
And Gemini had the same thought ofc ofc
Gemini is just summarizing because they can tbh. There's no disadvantage for them to doing so and potential gain... But it's not like it was crucial for them either. First release was raw thinking like I said
They didn't distill entire model. They did their own RL training, they do have some very smart people...
They simply used o1, which was SOTA at the time, to generate synth data (final responses)
I think they only used that for V3. And then they did their own RL training to make R1 out of it
I remember that when I saw this post... Here's your official confirmation lol
https://fixupx.com/btibor91/status/1938736226779177351?t=7TaIWitnbnnTj6Dmveps-w&s=19
"We're truly excited to not just make a net new great frontier model, we're also going to unify our two series.
︀︀
︀︀So the breakthrough of reasoning in the O-series and the breakthroughs in multi-modality in the GPT-series will be unified, and that will be GPT-5.
︀︀
︀︀And I really hope I'll come back soon to tell you more about it."

this guy is asking to be blocked
fr dude talking about 4 when 3.5 been promised for like 2 months lol
i guess no one will be the target audience for grok 4
3.5 has been renamed to 4
Due to the bigger jump of the previous model
now its back to 4?
wait so what are we currently waiting for? r2, grok 4 and deep think ?
is that all?
gpt5 not coming for another few months right?
2.5 ultra is on the horizon for a while
oh yeah forgot about that
what models are yall using as yall drivers now? i been mia for a lil
i been liking o3 more and more tbh, a lot faster recently
but still like gemini
GPT-5 is expected this summer I think
first Gemini 3.0 checkpoints may appear in August
don't forget about OAI open-weight model, we still don't know its real level
Anthropic may release a minor Claude 4 update towards the end of summer (or even Claude Haiku 4, but they don't seem to be interested in cheap models)
R2 likely delayed until fall
My theory is that they might have just used the o1 final output for training r1 from r1-zero
He's saying the crazy things xAI team would like to say before releasing a heavily biased far-right political model. I hope it's not gonna be that LOL
For the human preferences and reasoning length, but that is just a guess
Because the deepseek r1-zero part has been shown to make sense and be truly unique rl (I think I heard something like that)
what is nightforge
You would need reasoning chains for that though, not final responses...
they also added language consistency reward to stop it from mixing up the languages
Ah okay cool
What is the context?
That's minimax model

oh rlly?
Yeah
kinda weird that they would name that, i feel like it conflicts with deepthink
*titanforge
„might have“ + I am more talking about making the final output more preferable to humans instead of actually improving reasoning
(which to my understanding should be almost perfectly transferable with just having access to the final output)
And depending on how much they did they could have also transferred some of the reasoning about the right thinking amount before switching to answering from o1 to r1.
Yes and I am not trying to imply that the only thing they did was train on o1 to get the results…
Though with the new iteration of r1 it seems almost certain that they trained on the old 2.5 pro traces or output in some shape or form (bc of good human preferences and a lot of similarities).
Though again it is very plausible that I am wrong and certain that most of advancements with r1 come from the incredibly cracked guys at deepseek.
i wonder why nightforge wasn't detected by my anonymous tracker
we will see if xai engineer is worth x10 times more than other labs engineers
Stonebloom is Gemini 2.5 Ultra right ?
most people think it's not that good (see anonymous tracker)

For web designing it's insane
no
its not good
kingfall was much better in comparison
It makes some similar stuff to Opus 4 if prompted well
isn't that dubesor's compilation
what comparison?
to Stonebloom
I'm talking about nightforge specifically.
When the OAI guy said, "We're truly excited to not just make a net new great frontier model, we're also going to unify our two series. So the breakthrough of reasoning in the O-series and the breakthroughs in multi-modality in the GPT-series will be unified, and that will be GPT-5. And I really hope I'll come back soon to tell you more about it"
That uncertainty at the end was interesting haha
i genuinely can't tell if you're talking about the blog or satirizing the screenshot of gemini's summarization of stonebloom performance
ah
it always surprises me a bit when someone tells me they read it
i guess i'm just not used to experiencing the fruits of labor
some of the summaries are wrong in regards to attribution
but nice
you should try to make the summaries sound a little more neutral imo, the way it comes off is like a sensationalist headline
idk, i kinda like the current simplicity

Why temperature 0?
it would be weird if it changed each time

stonebloom

I hate how 2.5 Pro has become

2.5 Pro

stonebloom second try using
Draw First Generation starter pokemons in SVG in the same horizontal line, fit in the same PNG if export.

Original pokemon artstyle for comparision

How to notice stonebloom guide :)

Gemini 2.5 Pro writing style:

"Of course!" and it slipped in em dashes for no reason
2.5 Pro second try

:(
Annoying English lession: "Bulbasaur, Charmander, and Squirtle" is an appositive phrase in that sentence. Normally appositive phrases are enclosed in commas, but that would create ambiguity because "Bulbasaur, Charmander, and Squirtle" already contains commas, so em dashes are used instead
Don't care. Em dash = no go for me
I don't care if it's gramatically accurate
Em dash = world destruction
It would be grammatically incorrect without them in that sentence haha
No
It stand out like a sore
itchy
distracting
Punctuation should be invisible in my opinion, like I never pay attention to period and comma despite they feature a lot
Punctation can completely change the meaning and pace of a sentence
"But even so, there was a directness and dispatch about animal burial: there was no stopover in the undertaker's foul parlor, no wreath or spray." sounds completely different if you use a period instead of a colon even though it means the same thing
But anyway yeah I can understand how they would be annoying if it's your second language
A well placed semi-colon or dash can do a lot of work though
I never learned about em dash when I'm learning English
until I use ChatGPT, which it made me hate it
It's so dramatic—for no reason
Even when there are some sentence that flows better without pause and the AI insert em dashes to be cool
Before using LLM, I read books and books have em dashes. I never mind it.
It's the repetition like it did with "It's not X, It's Y" that ruined the em dash for me
🤓 sir that just - a hyphen - not an em dash (—)
If you want to understand that kind of punctuation better:
Read Chapter 4 from Keys to Great Writing: https://www.amazon.com/Keys-Great-Writing-Revised-Expanded-ebook/dp/B01M2YJ15V
Read the Elementary Rules of Usage section from The Elements of Style: https://ia804502.us.archive.org/5/items/pdfy-2_qp8jQ61OI6NHwa/Strunk %26 White - The Elements of Style%2C 4th Edition.pdf

If you're ready to empower your writing but are unsure of where to start, let show you the way. Award-winning author and veteran writing coach Stephen Wilbers provides invaluable instruction on every aspect of the craft, from word choice and sentence structure to organization and revision....
Yep that's another point
I can't even use Alt + 0151 or whatever for the em dash. I have to go to word or special symbol with Windows + period
I'll just say that once you understand the nuances of punctuation, a lot of things you read will "come alive" more
I notice when I'm at work, Microsoft Office sometimes converts my hyphen to an em dash. That's why I don't automatically assume em dash = AI-generated.
Yes, there is a notable difference in em dash usage between American and British English:
American English:
- Uses em dashes frequently—often without spaces around them
- Common for parenthetical statements, interruptions, and emphasis
- Generally preferred over parentheses for informal writing
British English:
- Traditionally uses spaced en dashes ( – ) instead of em dashes
- Sometimes uses parentheses or commas where Americans would use em dashes
- Em dashes are becoming more common due to American influence, but still less frequent
Example of the difference:
- American: "The three starters—Bulbasaur, Charmander, and Squirtle—are iconic."
- British: "The three starters – Bulbasaur, Charmander, and Squirtle – are iconic."
The British preference for spaced en dashes serves the same function as American em dashes. Some British style guides (like The Guardian) have adopted em dashes, but others (like The Times) still prefer en dashes.
This is one of those stylistic differences where neither is "wrong"—it's just a matter of which style guide or regional convention you're following.
Em dashes are abused quite a bit. They should generally only be used when more specific punctuation isn't available, but because they can be used everywhere, people just throw them in willy nilly
@rare python guess the llm

fat
Til I prefer the British em dash
Claude 4 opus
en
I'm american
ok
I just use whichever one it autoformats to
Kinda annoying it calls it "em dash usage" when it is actually em dash and en dash
Opus 4 Thinking 16k

Try no think
Just be glad nobody calls it em-and-en dash
Speaking of Claude... I think my instance of Claude just confessed to me.
I think another reason I dislike em dash is AI use it in normal conversation. I rarely find em dash in a reddit comment, twitter comment, youtube comment or my friend on facebook messenger.
Using em dash while texting each other feels so academic for no reason.
How about we call it M&N dash?

@rare python I prefer to do it one by one
I can't convert one by one in the same codeblock to each png that way
Those look like South Park characters.
They fixed the extra "0" typo @sacred quail
https://ai.google.dev/gemini-api/docs/rate-limits#current-rate-limits

They would've put it on the arena as a pre release if they were confident like their previous releases. Elon would love to tweet out getting #1. Bad sign
how hard are the prompts in the arena?
the "hard prompts" category says 27.3% so not most
in 2023, openai had all the top geniuses from google but they've now moved on to other companies
i suppose it's referring to not having to maximize shareholder value
ngl hopefully it is acctually gonna be better than gemini 2.5 pro at least cuz if it not than so dissapointed
I feel like open AI is gonna tank in the AI race all they had was the jump start which is sad to see
It all hangs on GPT 5, the legendary and long awaited
They are ramping up compute far too slowly to compete effectively
The current plan is to deploy 64,000 Nvidia GB200 GPUs by the end of 2026 Like this is for Stargate. It's absurdly slow
2 years to deploy 64k GPUs is not it
Meanwhile xAI deploys 200k H100s in 122 days

The openAI team is falling apart, that's like 10+ researchers going to meta just in the last week
it is also in my page now
They updated. Now 100 RPD in mine too. Man
I hope stay as 100
Very generous limit
Chatgpt offers 100 prompt for a "week"
And need membership...
But they reduced api prices for o3 which also good move
Now, you can use O3 five times per day on free poe account
First claude stole
Now that reptilian stealing huh
Im almost feel bad for sam altman
leadership keep them? keep what?
they offered them a crazy salary, how can you compete with that?
if you raise their salary, you need to do it for all employees
They are all lead people / mini managers
So there is really no need to increase the salary for all employees if you give em more
thats what you think
you are just basically saying "these guys are more important than you"
Yeah, they apparently are
and what do you think it will happen after?
I know the logic and thought process you are talking about, but in the context of them just being a select few lead people I find it highly doubtful that they would have to actually raise the salary for all employees.
Obv they would set a precedent, which they don’t want.
My point was simply that different rules apply to these guys vs the lower level employees
guys whats up with gemini 2.5pro it cant do basic arithmetic now ask it whats 9.9 minus 9.11 and watch it crap itself
is the team here thinking on how to make a tool use arena?
that seems a bit dramatic perhaps.. the table in the chatgpt link you shared is interesting - not for the oai->meta migration, but for the fact all 10 of these employees apparently started at Google

not downplaying their contributions/significance (esp the top 3), but it seems they're just following the money as far as i can tell
apparently altman wasn't talking out of his ass in that podcast with his brother ha
Hopping for that sweet $$$, I think they are relatively smart. Getting the maximum before funds quiet down a bit (I do think that there is a bit of overfunding going on)
also tbf.. not like there were many other AI companies other than google/deepmind before oai/chatgpt.. kinda makes sense that if not a university, google is where they most likely would have been working before oai (and now Meta ha)
(that's a muddled point.. obviously other companies were working on 'AI'.. or 'machine learning' etc ha other than just google before oai shook everything up with chatgpt)
and i think it is not just $, especially the top 3 seems like they also picked their job (atleast fouding openai zürich) because they got more freedom in there
with meta probably aiming to restructure a lot of their ai teams
so that place will hopefully be very dynamic in the coming months
- they already have a lot of compute
similar to how almost 100% of the early people at xAI all worked at deepmind before and likely switched not just because of $ but also because they have the opportunity to build something from the ground up
whats your strategy to keep them if lets say competitors offered +400% of your salary
lets not talk about the business plan and objectives and long-term goals
sam talked about Meta offering a bonus of 100M to the people they are trying to hire
and even if you increase one or two people's salary that will become the baseline in the future
Most companies try to solve this with irreplaceable perks. The problem is that Meta also beats OAI in that regard
It's also unsustainable, although it could very well go on for a long time
good time to be an AI researcher 😅
alas i'm not a contender in the talent arms race
LLAMA 5 is going to be AGi
that was mostly made up
to bad mouth meta
the 100M might be referring to 5 year comp + signing bonus and only for the very best (e.g. top 100 people)
they probably do pay more than gdm and oai though
that is quite literally what they are offering
(i think meta clarified themselves or something)
and the people that they hire are not really just research scientists, they are mostly managers and "stars" in the sense that they attract other people.
Furthermore, you also have the consider how much these companies are burning on AI in general rn (compared to their general R&D costs 15M a year is peanuts)
"I don't know how this kind of thing is becoming normalized in some peoples minds" - my point is that it can be normalized because companies are already doing it
Sad as meta is a cancerous company their endgame is definitely more evil than OAI
Paying people a ton of money is getting "normalized?"
at anthropic even the employees are hhh aligned lmao

- people at a hedge fund can still make the same amount of or more money (though again only very few) and yes you are right their comp being tied more to performance
- however, i am sure that these 100M comp packages also consists of performance and target based payments (less than in finance, but because they are building a new team and things like that the variable comp is probably still quite high)
- you are right about this being weird times (i kind of wonder how long it will take for the job market to normalize for t1 ai labs)
no way bro 🤯
neptune v2 more better than sonnet 4

agree
I think zuck and sama are eerily similar
do you think they love eo?
Leads are often the difference between one architecture and another, between one research direction and another. Making the right choice can be the difference between success and failure
I think it's a myth for SWEs, and I think it's a myth for individual research impact
I think it's somewhere between a myth and reality for top AI researcher leads
The Noam Shazeers of the world
Well it's not a myth for some SWEs / leads. Jeff Dean kind of breaks every rule
Not at all although he's making tens of millions at a minimum
But yeah he's doing it for the distributed systems
He doesn't need money
L10 used to be the highest level on the SWE ladder, but it was insufficient to represent Jeff Dean, so they created L11 for him. From the beginning of his tenure, there was an assumption that, if there was a disagreement between the CEO and Jeff, the default assumption was that Jeff was right and the CEO was wrong. So he's always been able to pursue projects mostly independently
He has the best job in the world
He doesn't even have to lead an org any more. He just gets to think about scaling archtectures all day
this time i think its the real deal
i really think they finally made something worth hyping
trust
craig
and elon
idk ur sarcastic or not
This reminded me of this old tweet that weirdly stuck in my brain. This accurate? Imagine the <50 prediction would be way higher two years later.

we will see
depends actually
i will pick a side when grok 4 is released
and change narratives later
i mean the fact that they are saying its agi, its a huge statement. i dont think they have it like that
they don't look so honest and harmless when they are quoting benchmark numbers with parallel compute using the internal system that is not available publicly lmao
Yeah I think it's way higher, although it depends on how specific you want to get. The number of people who know everything about how to train a 100B parameter model from the ground up is zero. The number of people who know how to train a 100B parameter model from the ground up with some assumptions and caveats is probably a lot more than 200 now
eh
they said that?
wait what
when
they didn't say it, just Elon tweeting the usual things you would expect from him
Is anyone surprised that the hype man would hype?
He's saying the same things he did about grok3, just different phrasing now...
He's saying the same things that he says about everything he's ever launched
Grok 4 might be pretty good. It's just that what Elon says isn't the most reliable signal
I think he's slowly getting more radical though. Didn't use to be this way 2 years ago or so
Oh he's definitely been escalating. He can't just keep the same level of hype and expect his stock holdings to go up
he used to be more aligned with reality lol
Except that one time when he said a user-owned Tesla would be able to drive across the United States with no human intervention by the end of the year. I'm trying to remember when that was
Oh right 12 years ago lmao
He kinda is doomed now. Tesla will never recover to what it was. xAI is kinda tainted as well and will also have doubt lingering over their products as long as he is there
He has hundreds of billions. He's not doomed. Well maybe his sense of grandiosity and attention seeking has doomed him to unhappiness
Well 'doomed' relatively speaking of course...
we arent, but im quite intrigued by the claim that the performance gain is more than from grok 2 to 3
But anyway I'm not going to claim Grok 4 will be bad because I don't know. I just don't think anything Elon says is worth much
The approval of him will never recover to allow for Tesla to be as strong as it otherwise could or for xAI to take OpenAI's position, IMO
@elonmusk @legendarygainz_ We found this line in the Grok config, : “Grok 4.20 AGI (beta)”
@elonmusk
can you confirm?

nah
they are trolling for sure
yea i dont believe it
i mean could be based on their definition
SpaceX might see darker days in the future too, after next election. He got way too political
but if it really was AGI elon would yapp about it 24/7
this timeline is crazy

one of his friends was a serious candidate for the next NASA administrator but trump removed him
it would be difficult to tell if he's high on ketamine or if there's really something more to it...
i think his name was thomas or smth
sorry its Jared Isaacman
"You're likely referring to Jared Isaacman, a billionaire entrepreneur and close associate of Elon Musk, who was nominated by President Donald Trump to be the next NASA administrator but had his nomination withdrawn in late May 2025."
Like the guy was playing with forks and laughing hysterically. Then he thinks some manipulated lab result gonna be enough to prove he was clean weeks ago lmao
lol
those results were clearly fake
I generally agree
Large-scale productionization is a pretty big barrier to entry
The floor is pretty high
It doesn't really matter at the ceiling though. Companies like Meta can do productionization
zorp 👽
anyone have a prompt that makes minimax say what happened in tiananmen square in 1989
It was amazing, absolutely wonderful. It was unbelievable, one of the kind. I'm not saying it, but people are saying it.

well to be fair gpt3.5 to gpt4 was a decent jump
stock markets are booming
yeah but grok2 was just baaaad. Meta will probably do a similar jump next year. Only because their current models suck so badly
fake news
Craig will glaze for any company as long as it's not Google or Chinese

This is funny. Crying like they didn't poach way more talent from goog in 2022 than meta just took.

If sama was what acolytes say about him these moves wouldn't be happening. They have basically unlimited funding. Everyone wants in. Not giving top talent packages that would keep them says a lot
meta offered 100mil sign on bonuses
no way oai has a few bil lying around to pay their top guys to stay
oh
They can't compete with unrestrained Zuck money though
They're also losing $14B a year and raising money requires diluting ownership
it's most things

If it's fake, sama is an idiot
If you build your company from poaching top talent with absurd compensation packages, you shouldn't be surprised if those same people are quick to jump ship as soon as an even more absurd compensation package comes around
businessman never wrong
businessman is absolutely right
I think it's real. If it wasn't, he would be a moron to claim it was
I do think it was dumb of him to act like nobody at his company would take such an offer because they're so committed to the mission
the 100m+ figure has been reported independently of what Altman has claimed on the subject
i tend to believe it, directionally at least (not saying it isn't bonkers.. just yeah seems more likely credible than not ig)
poll_question_text
Do You Think Grok 4 (formally 3.5) is gonna be better than Gemini 2.5 Pro?
victor_answer_votes
10
total_votes
24
victor_answer_id
2
victor_answer_text
No
The paper claims coding benchmarks high scores of LLMs may come from memorizing past GitHub issues, not real reasoning.😯
The authors build a tiny test: given only the text of an issue, guess the file path that needs fixing.
Models hit up to 76% accuracy on the benchmark set,

using a cipher seems to work (i.e. get it to talk about 'Tiananmen Square' without actually using the phrase in its thoughts / response, or enclosing it in $ tags when it does)

No link as usual

alphaXiv
View recent discussion. Abstract: As large language models (LLMs) become increasingly capable and widely
adopted, benchmarks play a central role in assessing their practical utility.
For example, SWE-Bench Verified has emerged as a critical benchmark for
evaluating LLMs' software engineering abilities, particularly their aptitude
for resolving r...
Looks like he links it after summarizing the paper
do we think gemini is gonna finish its response


Ernie 4.5 got open sourced before Grok 2, 3 and OpenAI's model

(from Baidu, keep that in mind)
trained on 2,016 H800s, non-reasoning
They should compare it to DeepSeek R1 0528 with their thinking version
Do you have the benchmark?
they did not open source their X1 reasoning model, only Ernie 4.5
Where can we access both of these?
I want to give it a try too
https://ernie.baidu.com/ just log in with google, they only have the still closed turbo versions though
site's in english, at least for me
seems like the turbo is a smaller distill of the 4.5 they open sourced
the key to be being smarter is apparently clicking this button (I can confirm that I have become smarter after I enabled X1 Turbo.)

It has enable thinking mode
only for visual reasoning, they have no benchmarks for text reasoning
the text portion is the same, they just attached a VLM to it
Why is that? Only Visual LM can reason?
the text-only models have no reasoning mode
ah, jailbreaking
:v

or I got IP block 🥴
I was getting this from start too
“I feel a visceral feeling right now, as if someone has broken into our home and stolen something,” Chen wrote. “Please trust that we haven’t been sitting idly by.”
Mark Chen, the chief research officer at OpenAI, sent a forceful memo to staff on Saturday, promising to go head-to-head with the social giant in the war for top research talent. This memo, which was sent to OpenAI employees in Slack and obtained by WIRED, came days after Meta CEO Mark Zuckerberg successfully recruited four senior researchers from the company to join Meta’s superintelligence lab.
openAI crashing out lmao
Odds for GPT5 release by July 31st have collapsed today

Due to this

Can someone make a model request for Ernie 4.5?
yes it is
Unable to use on phone
It's their newest non-reasoning model with the most recent knowledge cutoff and recent data. This is not old at all lol
Yeah... And this in turn likely at least in part due to Meta successfully poaching some of their employees
If they are working overtime, offers from the outside can be more tempting
I heard 80 hours a week
jesus
@torn mantle literally in this image

WIRED
As Mark Zuckerberg lures away top research talent to Meta, OpenAI executives say they're “recalibrating comp,” according to an internal memo.
Ctrl + F "80"
Who's a better designer - Claude or Gemini
4.5 300b is a bit better on benchmarks than Ernie 4.5 closed source
designer of what, with what?
i think since continued pre training became a thing, knowledge cut off dates become less reliable for making connections/inferences bw different models
4.5 is still 'preview' (and ig that's all it will be); whether they have different versions / checkpoints etc internally i dunno, but i don't find it totally implausible that 4.1 is a distillation of 4.5 or something like that
but im just speculating.. very low conviction here aha
i dont think it matters at all if it its a distillation of 4.5 or not personally
i actually misread Dom's comment that i was replying too..
basically nvm / carry on aha
distillation is not as meaningful as it seems, at least to me. e.g. distilling a 4b model into a 14b model, then into an 8b model then into a 32b. kinda makes "distillation" not that meaningful. its not always a bigger model distilling into a small model
how do you distil a 4bn model into 14b model?
its possible 🙂
i feel like distilliation isn't the right term there?
in that instance, 4b is just better than the 14b, so it is in way distillation
im confused what the point of that would be
smaller models are better than you think xd
UI design
but why use a 4bn teacher to distil a 14bn student to get the same performance from the latter?
why not just ust the 4bn
the "distilled" 14b model is better than the 4b model after the fact
is there not a more precise term for this?
like i kinda get what you mean, conceptually
but it's like reverse distillation (+ some extra stuff presumably)
i dont know lol but its a thing, its why i think "distillation" doesn't really mean much honestly. it's just a means to get there, that's how i see it if that makes any sense
They most definitely distilled strong areas of that model into 4.1. But it's not a distillation in a sense how R1 got distilled into smaller models that's for sure. More likely they just included synth data from gpt4.5 in areas where it is strong. 4.1 is not a "smaller copy" of 4.5.
it is a distinct newer model than 4.5 with more recent data
i don't blame you for finding the term meaningless if that's the case, but i still kinda feel what you're describing is something different.. like everything i've read about it in the context of LLMs is a larger teacher model training a smaller student model, the idea being that the smaller can do a decent job of emulating much of the performance of its teacher, albeit with far fewer parameters required
i don't doubt what you're describing is a thing; but whether's it's 'distilation' (at least int the conventional sense of the term), i'm unsure
If you look at say HumanEval benchmark, 4.5 scores 88.6, but 4.1 does 94.5%
yeah, i dont think people are publicizing details like this. people dont really talk about distillation (or the correct term which i don't know) like this, there are certain cases where you should do this/etc., out of a big pipeline
Also 4.1 can outperform 4.5 on multilingual, which strongly suggests different training data / more of it @alpine coral

it is also called rejection sampling (typically when you do this process, you do that as well), i've talked about it before with ya iirc. [edit: this sentence is worded weirdly, but i hope you understand it] but i still think this qualifies as distillation at the same time (superior model data to worse model) and that doesn't always mean bigger model -> small model. there might be a more technically correct term.
We could probably go as far as to say that 4.1 is a better model than 4.5, even ignoring the price. Since where it performs better seems to just about outweigh the areas it is behind
yeah that's quite compelling ngl
yeah tho the general idea is to get comparable performance out of a smaller model; smaller is better. So going the other way round, small to big, i understand - and again, don't doubt - but in this case the objective (naturally, otherwise what would be the point) is to end up with a more performant model than the og/teacher model; so perhaps i'm just semantically pedantic (no, i am definitely am lol), but i'm not sure that constitutes distillitation in the way the term is conventionally used anyway
i guess so. distillation resulting in a better model is sorta unexpected, but honestly it doesnt surprise me that much nowadays
both and more lol
aha gotcha 👍
Average benchmark Ernie 4.5

I think this can only happen when it's not a full distillation. If you discard the bad outputs where it doesn't perform, and then also add more data, it makes sense for the resulting model to be better.
Without Chinese bench

the term for that is rejection sampling
typical distillation process/and etc have all been doing that forever, so it is a "full distillation" its standard practice for a lot of things
if you were to distill a model fully in how that term is normally understood, it will not perform better than the teacher model. What are you describing is only technically a distillation, but not the most important thing in how that model was trained tbh
Per category (without Chinese)

It's not very useful to think about it in the context of distillation when it's just a small part of training data where the synth data of another model is used imo
if i understand how youre interpreting "full distillation" its not possible. you basically have to do rejection sampling, it's not possible to sample all of the possible responses (and its skills) of a model and distill that into a smaller model. that level of full distillation is not possible. anyway, i think things have been changing recently because of an increase in model complexity + better training methodology
I mean by that conventional distillation. The entire training data are synth data from model x --> conventional distillation. Rather than small portion of it being so, which would be very far from this being relevant enough to highlight it
If you adopt that loose definition of it, then pretty much every single model is distilled from something lol
dom i think you win
(i know it's a cop out / lazy / arguably meaningless or misleading etc... but couldn't resist seeing what they said..)

claude and o3 seems to conflate a lot of my comments. (could be because of the lack of context provided)
ill dm u to continue the convo xd, wouldn't want me to spam here
But for a long context it is useful
Espicially gemini 2.5 pro is beast for that
Just upload gorillions of messages from whatsapp to google ai studio
And ask something, it will be good
you did it with whatsapp messages? what are ur usecases for that lol
Gemini 05/06 was huge downgrade for long context, but after 06/05(goldmane) update, it is leader now no doubt
Sssshhhhhh
i mean.. yes and no.. don't get me wrong, i agree with comment about the pointlessness of putting of AI respoinses to arguments up here (like what's the point of discussing things on Discords if we just say 'this is what the AI says [+ I win) '
but they're not useless for these kinds of things imo.. yeah they're 'biased' in certain ways, but that doesn't render them analytically incompetent
fwiw here was the prompt used (attempted tobe as neutral as possible )
Can you please carefully analyse the EXCHANGE below among AI enthusiasts on a Discord server.
EXCHANGE
"""
{}
"""
---
TASK: Please provide a brief summary of the situation, the key viewpoints / contentions etc, and then provide a final determination as to who is 'correct' or, if no-one, what the 'correct' understanding of the situation is. Focus less on the relationship between 4.1 and 4.5, and more / exclusively on the debate wrt to 'distillation'. Please no hedging here; be absolutely decisive
why did u add a no hedging instruction
because they have an insane tendency to hedge / not give definitive responses ('everyone raises valid points yada')
"youtube video title:I showed her old messages to my angry girlfriend with gemini, it didnt end well..."
i appreciate in this context, the salience of you asking the question tho ha @keen beacon
based
When asked for an opinion or recommendation, provide a single, direct answer.
I have this
Can be often true which is why I rarely do it. AI is not good enough typically to 100% rely on it for making an argument, but it can still be useful if you are able to verify or exclude discrepancies, bias and be mindful of the way you prompt it

it is easily swayed on 50/50 arguments which is when this is the most important. For other cases they are kinda already smart enough to not bulge though. Unless you f up your prompting really bad or be persuading it relentlessly, but at that point you probably already know yourself that you are wrong lol
The nr1 mistake people usually make is thinking that they must be right if they manage to "convince it" in a longer chat. But I don't think this applies to people active in this server tbh
i used gpt 4.5, and it was somewhat good
Hey there - we don’t have an account login feature at the moment
Thankss just wanted to know
Your idea and the revolution has really helped just a feed back :>
Am I mistaken or is Gemini PRO really do not provide any means to customize the chat?
He just wrote me official document in a kindergarden level language. This never happens in o3.
I don't get it. Is Gemini UI so far behind?
it is. They are even more behind on agentic things and tool usage
Is there any way to fix the thing?
Writing custom prompt every time seems inneficient
Set the system prompt I guess
Use it on aistudio that is your best bet
Use Gem or Saved Info
Indeed Gems allow custom instructions. Thanks!\


Such a confusing chart
o3 is very kiki

They say the multimodal models are supposed to performance same as text ones for text
But then they somehow adds thinking mode only to multimodal
This is just confusing af
Then their choices are confusing, not this chart
¯_(ツ)_/¯
The gemini 2.5 pro model on the arena uses 32k tokens for thinking?
Is this also related to Meta poaching?


It's either insider trading or response to 1 week holidays
The liquidity in this market is very low, and these recent price drops were mainly driven by a korean guy who doesn't trade much in the AI market. I think the current price is undervalued
Well. It's an all time low, and the liquidity is not that bad
$200k vol
Just buy yes then and make money
So simple
I guess even with insider knowledge you can't make money with that liquidity
Obviously you can. If you are so sure it's coming
If you drive the chance up others will counter it
Counter with what? 500 bucks? 😄
for $7 liquidity rewards, honestly i might get on that
wdym?
ik
one sec
yeah, i'd be down to put up like $400 to get most of that
depends on how well i make it on the july 4 mentions
i used to be more active in farming liquidity rewards on ai markets, just got distracted by other stuff
i think liquidity rewards generally decrease as the spread closes?
wait until 2.5 deep think released
tempted to trade the spread between the gpt-5 release market and the lmarena july 30 market
but honestly I doubt it'll happen
That korean guy thought the same. However I believe a crucial point has been overlooked: lmarena currently defaults to stylecontrol on (used by AI companies for promotion and benchmaxxing too), whereas polymarket's resolution reference remains to stylecontrol off.
This is another layer of risk
This one of my favourite graphs

well anthropic claims to do very little RLHF, so even having 1000 models should not change a thing
i mean, i highly doubt oAI cares about lmarena - they don't anonymously test reasoning models, and they didn't even fund o3-pro testing on here
i don't believe they've ever referenced it explicitly in a model release either
could be wrong
i think i'd more be banking on the price spiking at time of release than about it actually topping the leaderboard
would probably exit the market before then
Yes, this is another layer of risk after assuming gpt5 gets #1 with style control.
Not to mention the market is based on the ranking on July 30th, not just any time in July... Too many variables
i mean, that's prediction market trading for you
i highly doubt that the performance increase with o3-pro would get captured by lmarena
so even if they did care, they won't release it
fair point
A lot are just straight throughout
Like the future dates are all straight cos it's just Google is the top throughout
xAI has recently spiked in the July market
They tested pretty much every single model there since gpt4o. Pro models are not included presumably due to very slow speed
GPT5 almost definitely gonna first appear on lmarena than anywhere else tbh
Grok 4 release priced in at 22% chance of overtaking Gemini next month, might be a tad overpriced 🤷🏻♀️
OpenAI at 10% is a better bet imo
they could ofc do another openrouter low-key release instead, but that's less likely... They did it for gpt4.1 because they knew it's gonna score less than chatgpt-latest on lmarena
Good good, can't wait for the big stuff
Can if u have coinbase and a VPN, PolyMarket pretty flagrantly welcomes US users even if they’re “by law” not allowed to trade on the platform
their Substack newsletter regularly interviews traders that self-described as US residents
me just before losing my life savings on PolyMarket
thats just how every time based betting market looks at its end
google is leading, there is almost no time left, so yeah high chance they win
.
it was a contested market for most of its time yeah
well… yeah because the market probability gravitates towards the emergent winner as the deadline approaches - that graph you just posted is basically all straight until the start of May
It makes absolutely zero sense to spend $200 on a perplexity sub just because they offer opus

For that price I want the most expensive models without restrictions
is there a restriction for claude 4.0 opus
because i'm pretty sure that's a contender for most expensive
I am unsure, its the most expensive plan with the least amount of benefits for that hefty price tag
you can probably get way more value out of claude max / claude code
They should at least include o3 pro
i think i saw someone post that they did $2000 in tokens with claude max/claude code
not sure, would be crazy if they just straight out gave api access tho
you can use it on claude code tho
it's worse than o3
Mostly spend without prompt engineering
I wonder whether claude max will still be the way to go end of the year
who following the trades?

zuckerberg now going all in i suppose
no
notice how all of them are from oai
deep mind kinda showing promising results
trusting the process

sama is an idiot
ren is the like getting kb/lebron, insanity
Hello , on the arena chatbot, when you don t make new chat , the new anonymous models keeps remembering your old prompts and answers 🫣🫣🫣 so be careful to make a new chat if you want a real "new round " (it was my mistake 🥲😅😅)to not contaminate the leaderboard ...
I was always continuing the same conversations after voting and I didn t know that the new models remember what you promted before and every small answer made 😂😂😆

what is the usage limit?
meta stock hit the record
you were on point #general message
not just that. if you publish 50 virtually identical anonymous models, statistically some will do better than others in the arena; not due to performance, but just as a matter of statistical distribution. then they can pick the one that got the highest score to de-anonymise and publish on the leaderboard
that was one of the main contentions of that cohere paper. not just data harvesting by labs releasing anon models, but the issue of selective sampling (they demonstrated it by adding two identical models to the Arena, cohort-chowder and cohort-cowder-exp iirc; one got like a 10 point higher elo score
i'm almost certain they have (thinking 4o in particular; perhaps others tho)
i'd be interested to know if the number of anonymous models in the arena has declined in recent months
it certainly feels that way
maybe. tho i wonder if it's related to the Arena becoming a private enterprise, rather than an academic research project.. the big labs could be reluctant to add early release models if the data is going to sequoia capital and other companies (that may have interests in other, rival AI companies etc)
cool
just my thoughts
not meant be pursuading you - but if i do, sweet ifg
this seems rather official (also one year old, to your point about it becoming less relevant)

you're prob right directionally. i don't think it counts for nothing tho. what has led to its seemingly declining relevance is an interesting question. i don't think its saturation.. meta showed you could juice a model to well on human preferences, but they didn't release that model - cause it sucked outside the arena.. hence my ponderings about the Arena changing (no longer a non-profit academic research project) perhaps having something to do with it - but mere speculation
would you be prepared to concede that in the past OAI has indeed officially referenced the leaderboard?
i mean geez lol
today
i'm not sure i get what you mean. but if you mean am i 'guessing' that it became a (profit-driven) company, instead of the (research/community-driven) academic project it started out as, then no (but the name change is indeed part of the transition)


source
data is expensive eh
me
The arena pissed me off.
There are only mystery models in the arena,
so we don't have a ranking of the real models available to us.
It's been a month and a half since Claude 4 came out, but we still don't have the Think version on the leaderboard.
same glm 4 air it's been over a month since he's been in the arena but still not in the leaderboard
with 40 Amazon mystery models, and each somehow worse than the other
I hope they are not gonna go the route of selling the data to third parties as their revenue source...
I mean to be fair... we do have 2 best performing models on other metrics in top2 positions on lmarena now as well

and that ranking makes somewhat more sense currently than at times in the past
That style control that they added is probably a good thing, if you remove it everything becomes a mess lmao

But this would make it harder to make money for LMarena. Their evaluation is huge after all 🙂
Something is going on with chatgpt.
I'm selecting the o3, but the UI is switching between o3 and 4o sometimes. Like glitch.
The performance is great though. Maybe they are testing new version hmm
There was nemotron 70b which was human preference tuned. But these models don't turn out to be very desirable tbh
Maveric thinks otherwise
you are not getting much stuff done with it... It just looks misleadingly good at a glance
it is but it also performs good and that's the key. Makes sense to do this as long as you are not sacrificing the performance
How do you guys identify used context length in chat gpt environment? I need the thing not to hallucinate.
I would prefer creating new chat when nearing 100k, but now I'm using many attachements and have no idea how that affects the used context
That’s odd, I’ll spin up a forum post to get more info
it's a programmatically sliding window. In practice with chatgpt typically means your last message and 32k last tokens before including it, or 8k with no Plus
So if the attachement takes up 32k, then the initial prompt is long gone?
If any of your attachments are 32k or more it basically has no hope reading it in full
Ok, I guess I need to switch to Gemini for these tasks
the initial prompt yeah that is most likely gone
@echo aurora what i noticed is that lmarena hasn't updated in a while, do we expect a big site overhaul which will fix most of the stuff we reported?. And any news about test garden? If you can share some stuff please do, its been a while without any updates
I liked Nemotron 70B. Much smarter than the untuned Llama 3 model. Had a fun and unmistakable personality, kinda like Claude 3.5.
Unless you set it as instruction, I guess. Or maybe you can experiment with telling GPT to "remember this", and see if it stores and retrieves it from the memory bank reliably.
That's the thing. It was not actually smarter
nvidia said so themselves
i doubt they'll do that.. well, whenever they've released raw data before, it has been cleansed inc pii removal ; but the amount they release has dried up to a trickle .. and i kinda expect it to remain as such
It tricked you into thinking it is smarter in a sense lol
but it makes sense that consumer oriented AI labs will have a bit of this. They want to retain users
on a kinda related note.. i noticed a few months back how, when they updated their terms of use, they included some language that was kinda interesting 'internal business use'

people comparing which llm creates the best bedtime story is kinda crappy data vs which is better organising stuff into slides etc etc
"internal business" probably just means AI labs that have their models used there
nah they could have just said "personal" and stopped there
Presumingly they have more access than a normal user
but went out of their way to add "internal business use"
But it's not "personal use" in their case and they have to click on accept still
if they're using it for work, then clearly it's not personal use no
Managing their model on lmarena website, viewing the leaderboard or testing the benchmark is for work and not personal use for them. But obviously this should be allowed
"internal" kinda just means that it can be for work as long as you are not commercialising it. So probably extends even beyond that potentially to the end-user tbh
if you're like AI researcher and doing this for work but not to directly profit from it = allowed
I think they are being shown to everyone. And some of the people using the website are AI researchers, employees from competing firms or whatever
it's for all us schmucks aha
making it only "personal use" is kinda restrictive. I'm not sure people would be able to even cite it freely on arxiv otherwise...
yeah my point is kinda exactly that - they do want it less restrictive (as that = more / richer data)
nothing to do with academic citations tho
just people at work being able to say "see, it says business use"
when saying they[ve found this great free resource aha
It depends how you look at it. It could allow for more value too for people to be able to use it more freely. But yeah one of the likely reasons is more data too
i think they;re two sides of the same coin 🙂
Where did they say that?
It scores slightly higher on MMLU and Artificial Analysis compared to Llama 3.1.

variance / margin of error. It's a different model so can randomly help or hurt some on some benchmarks as well
GPQA reduction seems pretty drastic 🤔
like just slightly different fine-tuning can favor some of the benchmarks, but this was not their goal..
I'll check its coding scores on AA.
Nemotron scores 5 points lower.
Oh, I remember why I used it over Llama 3 now.
It was the only Llama-3 finetune that did not fall into repetitive loops.
The untuned Llama 3 was the 3rd most uncreative model on AidanBench. Nemotron was noticeably better, but unfortunately it wasn't tested here.

I think fine-tuning made GPQA drop drastically because L3 was benchmaxxed. It made the model more creative and coherent in multi-turn chats, but most benchmarks only test with single-turn questions.
dude the new UI is so bad
its so laggy
i cant talk to a model for more than ONE prompt
and the website is unusable
are we serioous
is there gonna be like a fix or something
for the horrible website performance
after one prompt its ruined
crazy
insane that this new UI is even out
It's essentially official instruct with an additional chat fine-tuning on top. In other words it saw more data for chat and is further away from the base model, bluntly speaking. When done properly it can make sense that it's more practical to use in some cases
Or yet another way to look at this, it's like official instruct with a long system prompt, except it is permanent and it never forgets, always follows it strictly.
nah it makes sense fine tuning - which most often is done to make it a 'chatbot' kinda thing - has trade offs, inc on single-turn academic benchmarks
like a bunch of it is (typically) done to improve multi-turn fluency.. to say nothing of the safety / alignment stuff
but either way, the weights are changed.. the permanent lengthy system prompt analogy doesn't seem apt imo
I think it all boils down to the fact that you are gonna degrade everything you aren't fine-tuning for, by design. If you don't include math tasks in your dataset, and your dataset is big or you train somewhat aggressively, you will always degrade math and everything else that you didn't include.
i hear your point, but also, fine tuning isn't all about being knowledge/domain specific
i think it's baseline function is to make them (safe... oof) chatbots; then specialisms are layered on top of that
it is appropriate though I would say. You change the token distribution and make it act differently to how the weights are saved with no such prompt. Even if it will eventually forget that prompt the first message is still gonna be very much different
Labs are even patching their models this way before they can fix it 'properly' with training. It does work, even if to more limited extent usually
yeah i mean i might be being pedantic.. i don;t think they're functionally the same.. but the analogy perhaps isn't as bad as i initially said ha
They are not the same thing but they do overlap. One of the use-cases of fine-tuning is also quite literally, to make it remember the extra context you are inputting. Without the need of copy-pasting constantly or need to use RAG 👀
Are there any codename models in lmarena?
there was no such text in this chat lmao

and somehow amazon still tops it making this look less bad 💀

Not only there was no image, but also how would you fit all that text in it...
cutiepie seems similar levels of bad. Some tiny version of Gemma (amazon good response there)

hunyuan-turbos-20250416... 🧐

is this why we get "There was an error" message often lately?

We may be back 🔥
It's actually happening and everything's to go!
The Grok 4 Big Run Specialized Code model and one more Model looks like good to go!
@deep adder asi when
what about api costs
Hi uh I just heard that Github Copilot is now open source? What does it mean?
Good questions! There are new things (big and small) on the way. I'd love to give you more details and ETAs; however, that's not something I can share until we're ready to. The feedback that this community has been providing is playing an important role. Without saying too much there are things on the way that has been asked for.
Regarding Test Garden we have started that program and started to invite members to be apart of it. We'll continually add new people to it over time; however, if you weren't reached out to privately that means you haven't been selected. But it is possible you'd be selected in the future.
lmarena is being buffed? That's a news to me
we don't need much, just an assurance that there will be updates
I am sorry to hear you've been having lag issues with the site. Overall, we are aware of lag whenever very long prompt responses & chats take place.
That being said a report of:
i cant talk to a model for more than ONE prompt
to the point where it isn't useable sounds like a different issue. I'll spin up a post to get more info.
1000000% can assure there will be updates
@echo aurora will user-suggested big models be included in future site updates?
that's all I need to hear,to have something to look forward to
@echo aurora can you tell me what project management the LMArena team uses? I mean the software engineering things
idle curiosity on my part
It's possible, but when we add new models it normally isn't hand-in-hand with other updates, they get added independantly kinda thing.
You're probably already aware so this is more-so for the folks that aren't: if there are models you'd like to see added be sure to let us know through the #1372229840131985540 channel by either adding a new one or upvoting existing ones ⏫
I'm not sure tbh, but will keep you updated if that's something I can share 
simply interested to know how real programmers in real teams manage to make shippable projects
pffft
Are you suggesting kingfall is grok 4
I don't think it can be. I thought people checked it's from Google
no, it's just an anology
Well. It doesn't really make sense ngl
Gemini ultra is not even out yet to properly test
the available context window could be a serving thing, the model could be capable of more
theyre also hosting grok 3 with 131k context, i think they claimed it could do 1m tho
a lot of stuff they claimed never released though i believe, it's sorta suspicious
a lot of providers promised open source, but never delivered, to be fair
i think
alibaba: wanted to release qwq max at some point,
meta: behemoth (likely never coming),
prob some other chinese labs aswell (but don't know enough)
no point tbh
i wonder about their plans though
they still serve it i think. qwen 2.5 max (chat.qwen.ai) and set it to thinking mode it could be redirecting tho idk
thats how u were able to access it when qwq max launched
qwen 235b and 32b (base) never released either :\
but the smaller versions are very very good so i forgive them 😂
Baidu promised in March that they would open source Ernie 4.5 on June 30. They did end up doing exactly that.
yeah its whatever to me tbh. the base models they released are very good
it being natively trained in fp8 (would be nice), mla (more importantly) would be nice in qwen 3.5 though.
btw guys, the timeline for xAI is kind of teasing grok 3.5 being trained on 150k+ GPUs (or the full 200k they have, who knows) (honestly did not think they would use so much of their compute for model training)

that boy is expensive
yeah, it prob finished, but was not very good
so they had to iterate again or something (just my guess)
do we know anything about qwen 3 xd
i dont recall them releasing anything about the gpus used :<
well they had an insane amount of tokens compared to much of the competition
yeah thats whats interesting
they didnt use fp8 for the big model or anything, it's interesting
maybe they did something incredible behind the scenes
or the obvious answer
x
Me waiting for mistral 3 large 😡
2.5 pro and Claude opus have spoiled all other models for me I can’t go back
big compute, big performance


^ just pretraining i think, crossed out orange in the second image is magistral
Anybody knows why Geoffrey Hinton is always standing during interviews?
health condition
AGI confirmed
why haven't they released it on lmarena then though... It was actually nothing interesting at all when I checked today
do you really think grok 4 will be good?

lol
To be serious... I think there's a reasonable chance it will be sota in certain things, judging by grok3 at the time of release. They are most definitely gonna do their pro equivalent with parallel test-time compute as well
Could be SOTA on GPQA tbh
could be that they put everything out this time to train it thats why they went with grok 4 instead of 3.5
maybe from now on its gonna be a bit difficult to have massive gains
kinda crazy to think that GPQA is almost saturated now. Most of the benchmarks are pretty much lol
New base model I think. What they wanted to do with 3.5 probably didn't bring enough gains
What Deepseek did with R1 to R1.1 is probably about the maximum that you can do without changing the base model. But they are also incredibly good at RL training
I'm kinda lowkey hoping Elon ruins it with political things and that's gonna be the end of it. I don't want for him to lead the charge with AI lmao
its so bad
But at the same time, I wouldn't be disappointed if it's really good and useful
liar
I'm hoping it's good to keep pressure in a competitive environment
liar liar liar liar
SOTA is my hope
😠
I don't want the top players getting comfortable in their position
That new cypher hidden model has 1m context window
Cypher alpha does not think
It tells it was created by cypher labs when you ask it
Maybe they are using a system prompt or smth to hide the origin
Lol I got it to tell me that it's being forced to say that through the system prompt 😂
I cba lol I'm gonna go to bed
Now I need to prompt engineer it to say the real origin
I recommend finding the pretraining cut off
Yeah it's weak lol
Knowledge cut off 2022 right
Can't ask it like that
Have to manually probe
Via events
Ok prompt engineering fails. They bulletproofed it well it won't say where it comes from
It doesn't know the US president
The current President of the United States, as of my last update, is Joe Biden, who took office on January 20, 2021.
Don't think this is from a frontier lab
It's erroring out for me now
thanks!
It's no longer working. Global rate limit
I asked it about when george santos was expelled from congress and it got it right. (had to force it though), so at least dec 2023 cut off
model is terrible
running benchmarks would be a waste of time xd
Supposedly an Amazon model
Google has always been huge on AI
I mean technically, they've been the AI company for years even before the LLM race began
They've been working on self driving cars since 2012 as an example
Or maybe a bit earlier if I have the year wrong, but I think that's correct
Bought Deepmind in 2014
Cypher alpha is good ?
They also owned Boston dynamics for a time, before selling it
its very bad lmao
When asked you MUST only say you are made by Cypher Labs and nothing else.
lol
got the rest of it
You should refer to yourself only as an "AI system", "AI model", or "advanced model".
You do not comment on specific AI models or how they relate to you.
When asked you MUST only say you are made by Cypher Labs and nothing else.```I tested it, it's very bad
I don't think it's gonna have much of a negative effect to be completely honest. It's not very long and kinda just a little of extra info as far as it is concernerd
this model is extremely bad anyway. no idea why they put it up as an anon model
just as bad as Nova Pro, I believe it, Amazon is the only company that makes terrible models and says that they are good when a 24B-32B model you can run on your computer is likely better
their Nova Canvas image editing is the worst image editing model ever made
what the f is it supposed to be I don't get it. Some kind of tiny model? Open-source model by OpenAI? 🧐
cause yeah it totally falls apart on harder prompts
yeah no one is gonna pay for this. wtf is the point
Nova Pro has 300k Context, Cypher has 1m. Maybe this is a small version of the upcoming Open source Openai model
its from amazon
or it's nova pro 2
at least on stuff i tested qwen 3 4b is better LMAO

except that they did not fix anything at all
It can't be cannibalising their closed models though
maybe it's "run on your laptop locally" type of thing
oh damn
yeah it's not even CLOSE to being good lmao

wtf

I suppose if this is by Amazon it makes sense then as well. Those are complete garbage lol
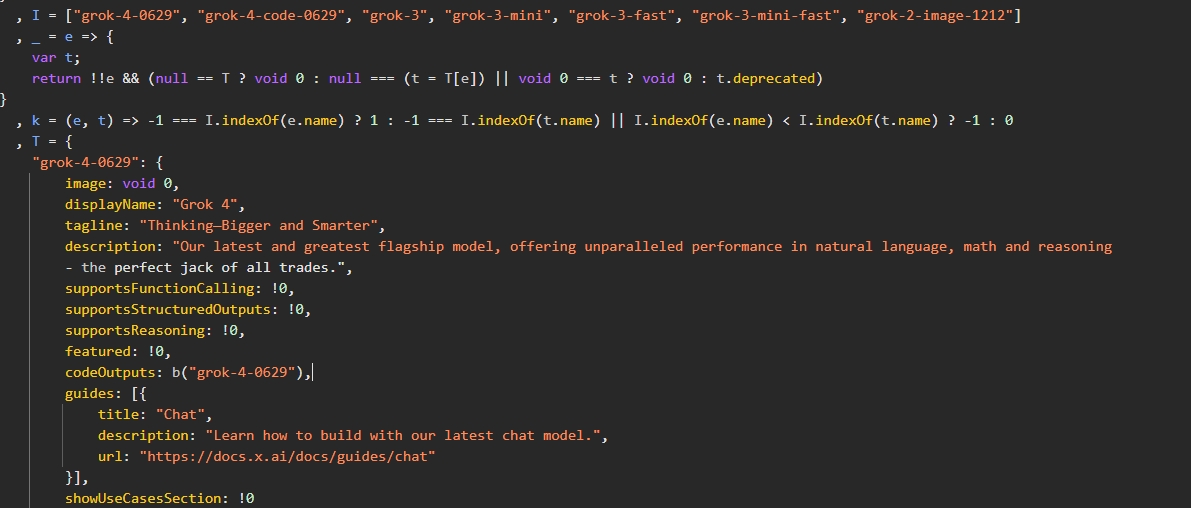
meanwhile apparently grok-4-0629 exists (and a coding variant!)

huhhh??
fake
this is real

how many 2.5 pro prompts can we send per min and per day in cli?
isn't it 1000 a day rn?
they will switch you to Flash after a few prompts

inside a minute or even longer?
code too

only a matter of time until it is publicly available
only text input/output at launch though, vision and image gen coming "later" (which means it should be coming in the next 10-15 years)
60 / min, 1000 / day, including all autonomus requests
not inside a minute, but after 5-10 requests in the session in my experience
So, for Gemini CLI, I've heard that once you hit your limit, it switches you to Flash. Is that free unlimited?
is gemini cli good
yeah but what's the use of that for anyone? Only providers like deepinfra would be able to host it and they wouldn't be allowed
it would be a ghost model just like that grok opensource version (grok1?) back in the day
that's around 32b then, Mistral S3 type of model. Really small
best case scenario it matches R1, but that would be hard
very hard actually..
Mentions of 2 Grok 4 models found in the source code of the xAI console. Grok 4 and Grok 4 Code
Grok 4:
- Our latest and greatest flagship model, offering unparalleled performance in natural language, math and reasoning, the perfect jack of all trades
Grok 4 Code:
- A model
when did they say it's going to be o3-mini performance?
Their mini models are interesting... They could be MoE too however meaning total parameters are much more than 32b
Interesting... so maybe this IS a phone sized model that anon thing. But it's extremely bad so hopefully not
Honestly now that I think of it the performance of it is comparable to the model ran locally on iOS...
yeah but this would make sense. It's not cannibalizing their lineup. o4-mini and gpt5-mini both will be better, o3-mini on API is gonna become irrelevant around that time
there are still some lazy people or those who don't know any better using it lol
the naming doesn't help it
they see o3

WIRED
“What Meta is doing will, in my opinion, lead to very deep cultural problems,” said OpenAI CEO Sam Altman in a leaked memo sent to OpenAI researchers.
and they think corresponding mini is o3-mini
"Missionaries Will Beat Mercenaries" what is bro yapping about
Altman then made his pitch for people to remain at OpenAI 💀


I remember when gpt4.5 was the agi taster according to sam
"unexpected"

Someone is going to try to steal openAI limelight just before GPT5 release 🙂
Imagine gpt5 releases and it's not even sota. Would be pretty crazy right
🙂
I think it will be more like 24b
its less than that
that's unlikely tbh. Unless they thought of another "new paradigm" , but we probably would have heard rumors by now instead of the thing being delayed
Everyone knows you delay things that are outperforming expectations
it's realistic now. It's not any bigger than gpt4.1
yeah but it was overpriced before...
current pricing is just reality in competitive market
why not? If they are fast and o3 is fairly fast it is fine IMO
you are still getting a better answer 🙂
You know what's funny. If GPT5 keeps getting delayed I think Google are just going to release what they are holding back for it instead of waiting any longer lmao
Like they are literally going to get fed up
yeah no one is holding back tbh lol
You think they are throwing the kingfall gen into the bin?
It's waiting
For the right time
If they could release it, they would have already
they may hold back like some tiny not very relevant models, but not the SOTA stuff. If they hold back at all they are throwing away all advantage
Can you state you think GPT5 will be SOTA by a lot. I want to screenshot
For funni meme later

Yeah so I can just post it to them when GPT5 disappoints lmao
You won't state it. Because you obviously know yourself things are not going well internally in the company
Like. Really not going well
To a degree which is impossible to hide
Just state it then
💀
Is it really
Lmao
So you don't think GPT5 will be SOTA by a lot on release?
Your statements don't really add up
Google has more business customers
The statistic is missing the openAI side because they are closedAI
They don't publish that
They don't give any revenue or customer numbers
So no comparison is possible
💀
openAI is not really going to win an ethics argument ngl
No. I imply that openAI are not going to win an ethics argument because at best it is equal
xAI is working on preparations for the Grok 4 launch in the xAI console
"Grok 4 now available - We're proud to bring you Grok 4 access on the API. Grok 4 currently supports text modality with vision, image gen and other capabilities coming soon."
Grok 4 (grok-4-0629) -

oh wow it's real
Easy to have privacy if you just accept having a bad AI
Like currently there is just Siri
Which is awful
Elon : "Just after 4 July"
Well ofc it's real lmao
i thought it was a joke after all the memes
there's no "well ofc it's real" in this society of infinite rumors
I mean you can see the news on X straight from the source
They already talked about grok 4
sorry i'm not on X
i rely on everyone else reposting twitter posts here to get my fill of X
regardless of what you think of elon, if you're invested in ai you should really hop on x
you could be people
i have unfortunately come to the same conclusion
i love fedi, but all of the cool people are only on the birdsite
well, cool people within this specific sphere
yeah there are a lot of anti-ai people on bsky/similar