#general
1 messages · Page 58 of 1
it's not like there a whole ass forum talking about it, but will do, are u female tho
@deep adder
huh sure
me neither
theres a trick, u have to remove token count or something like that
but i couldnt bother
huh
thats just the modal info
idk have u seen the link?
yea someone sent me that already
mhmm
the thing is, they're talking about models that require the thinking budget to be turned off in order to work
use flash as a template instead of pro so you can do that
the models suck anyway
the ones that remain
yea
google employees are probably reading that 🤣
Guys, have anyone here used Copilot 365?
I need an agentic tool liek Cursor but for documents.
When I hear "copilot" i get ick. But it seems to be only solution
I think they need to add smth like SimpleQA into their test suite. We need at least 1 benchmark where model size does make a difference
otherwise people looking at this may just as well conclude that there's no point paying for larger models lol
2.5 Flash 26% vs 54% for 2.5 Pro
kinda same story for other labs as well
whatd they send
udes
real
I'm pretty sure there are better ones out there
yo!!

eeeeeh
Fake
100% fake... why do you folks do that?
That's what I thought, but there doesn't seem to be anything.
Reddit
Explore this post and more from the singularity community
New open source large reasoning model, from minimax
https://huggingface.co/MiniMaxAI/MiniMax-M1-80k


2.5 pro beat it in literally every benchmark in that image lol
These kinds of charts must be made by Apple UI developers
again,"there was an error" to everything
I’m getting “there was an error” to everything too
as George Martin said, "outage is coming"
Great

team gets my thanks
"There was an error." is the new "As a AI language model..." at this point.
500
there error is happening on mobile and pc both
why no ultra model from gemini yet? They not have like 200$ per month subscription. they should have one, even if it's only 10-20% better
my apologies for the inconvenience everyone! we are looking into getting a fix out asap
but why, if i can ask, arena doesn't allow the use of o3-pro as well as it didn't do for the previous o1-pro? because it costs too much?
I won't be able to share details sorry to say 😦 but note this has been passed along to the team to consider
oh ok, no problem. thank you for the answer, appreciated
Hi, is there an error on the site?? I'm receiving there was an error message everytime xD or is just me??
Ye me too
they re working on it i think
Right thanks 🙏🏼
we are aware of these issues and working hard to get it sorted soon, our apologies!!
Thank youu 😄 I'll just be patient then 😄
pineapple is really patient xD, great person
you're too kind!
 okay should be working again!!!
okay should be working again!!!
get back to battling!
no, thank you all for flagging! truly helps us so much. we couldn't be more thankful for an active community ❤️
It's because nobody gonna pay 200 for +5 ELO points 😄
They use it as a defense somehow. Like o3 pro would top the simple bench if only they benchmarked it 😂 like barely anyone can afford to bench it lol
new deepseek r1 got #2 on webdev arena

Blacktooth feels noticeably worse than Kingfall
I saw some others saying they like it
Qwen no thinking better than thinking

GPT-4o and FLUX.1 Kontext are the leading image editing models after more than 20,000 votes in the Artificial Analysis Image Editing Arena!
Here are the key takeaways:
➤ OpenAI's GPT-4o and @bfl_ml FLUX.1 Kontext (both Pro and Max) sit close together at the top of the

Wow we may be entering the Chinese century
Speak for yourself. FOMO is a helluva drug lol
What checkpoint is dropping in 3 days? Is it kingfall?
surprising overperformance by DeepSeek and Alibaba!
Is black tooth Gemini ultra I saw ppl say that
if u mean ga 2.5 pro, it will be the same as the 0605 preview just renamed to ga
Kingfall is ultra?
also, when the leaderboards were fully transferred over to the new LMArena site, did they just standardize them around 2.5 Pro 05-06 being 1446 Elo in every category?
it’s exceptionally smart so I wouldn’t be surprised, not sure what this “kingfall” model is that ppl are talking about
blacktooth made me this plane svg which is pretty cool


It even did some really nice details like the hint of the far wing
Here is another (https://pastebin.com/TM5CuvKm)


v-jepa 2 having only 1.2b parameters but being near o3 is crazy
This is gemini-2.5-pro-preview-05-06 😂 no way blacktooth is just another checkpoint of 2.5 pro

blacktooth does better than 0605 on SVG, but still not as good as kingfall
why comparing with Flash version? And not imagen 3 or imagen 4? 🤔
i dont really see much difference with the robot face ngl
Wow! Deepseek is doing great
the plane one is so much more obvious
ohk
what is this?
Looks like a new model.. do we know which company Blacktooth is from?
Can you share the prompt you used?
"Generate an SVG of a plane. Make it as detailed as possible" This is it
oh..looks like blacktooth is gemini
reminds me of:

Is there some way to use images as reference to generate?
is knightfall still showing in battle?
i dont seem to get it yet
Did you try Claude?
It was generally the best model at drawing in TikZ.
claude-sonnet-4-20250514-thinking-32k

yup! there is the capability to do image edit, you can learn more here: - https://x.com/lmarena_ai/status/1929953954554884211
Image Editing just got real on LMArena 🖼️✨
Introducing Image Edit Arena: where AI editing models go head-to-head on your images. Upload, edit, vote. It's that simple.
Who edits it best? You decide🫵
Learn how it works in thread 🧵

This is Grok? Pretty good
Hmmm not great, lol. How does Opus compare?
i had one with opus but it was just as bad so it lost
It's not available anymore, but I really hope @echo aurora and google can bring it back to the arena😭
On Claude Web, you can feed back the image and ask it to iterate on the design.
Seemed to work on a unicorn example.
I’m still getting the error message when I try to send something or something went wrong with this response try again
Claude 3.5 I think. Someone made a timelapse from feeding the outputs of each iteration back to the model. In TikZ (very difficult to draw in, but used to prevent data contamination).
Is anyone else getting the error message or something went wrong with this response try again
you are? is it for all models? in all modes?
I don’t know, it’s for Claude opus 4 in direct chat mode
I keep getting at least 1 blank output for 95+% of WebDev Arena battles. Idk how the results would even be useful.
In 20+ battles, I think I only got a response from both models once. All the other times, one of the models would think for a long time but output nothing.
👍 we have a thread spun up for this so will tag you there with followup questions.
Ok
The only loser here is Musk 🙂

Musk: 200k SOTA GPUs, DeepSeek: 0 SOTA GPUS (smuggling)
These are literally my last 12 rounds on WebDev Arena:
- R1 0528 blank
- R1 0528 & prowlridge blank
- R1 0528 & prowlridge blank
- R1 0528 blank
- blacktooth blank
- blacktooth & gpt-4.1-mini-2025-04-14 blank
- R1 0528 & blacktooth blank
- R1 0528 blank
- R1 0528 blank
- R1 0528 & blacktooth blank
- R1 0528 & blacktooth blank
- R1 0528 & prowlridge blank
These are in consecutive order too, I'm not cherry picking.
Not a fan of blackbooth
imo that's just nonsensical, blacktooth is really good
it gaps all the other models
personally i like kingfall better
yeah but they're likely just different models and as far as I can tell, blacktooth is much more refined
no syntax problems in its output, respects the thinking process unlike kingfall, doesn't jump to conclusions, still understands everything
I can't trust that you guys experienced the same thing I did with kingfall, but it's not the insane model you guys are making it out to be
it has insane spatial abilities imo and excells in some tasks, but it performed worse usually in plain context tasks where it has to track maybe an argument, or conclude something within that box of context without just "I feel like overall x is better", stuff that necessitates an inherent grasp before even thinking about it
o3 imo WAS the best at this, kingfall couldn't fill that, but 0605 accomplishes these "if you know, you know" tasks
and that's the same thing I'm getting with blacktooth, which kingfall ultimately failed
blacktooth is a lmarena proc, not at all functional compared to kingfall when u look at coding, hence why the svg's were also not as high-fidelity
cool but I don't get how that's relevant
I don't get the glaze tbh, I abused that model a ton, it was so good I can't tell if it just had a different thinking summary, or that thinking summary just really liked what it was seeing
kingfall felt like it had less work done on it. it had a lot of magical moments/etc where it wasn't diluted by the post training and was unintentional. (being amazing at svgs which isn't a usual post training thing you usually do, i think, and a case where it consistently started solving two 6x6 zebra puzzles when it consistently failed when given one, by spontaneously making a system when faced with increased complexity) blacktooth feels like an overcorrection/overdone post training cooking the model on stuff outside of distribution whereas your task might be in distribution for this revision. (i believe kingfall/blacktooth use the same base model, they're just different post training revisions)
were your prompts mostly riddles/simplebench q's?
this could be the case ye
who does that lmfao
id already moved on from kingfall with riddles or tests
after like a couple hours of release
anyone feel this way too
did nobody see how different the summary was
or nah
it was way different
i heard someone talk about that
i dont pay attention to the summary that much though
i leak cot if i want to read it
ye I'd expect that, I just ignore it
but it caught my eye when it started naturally capitalizing and emphasizing things
and placing things where like, damn you can really understand it
and not the roboticness that the current summary has in aistudio
iirc it will remain on chatgpt tho
I got blacktooth in general arena, not dev
we'll see with grok 3.5, google had so much more computanional power than OAI but since they joined the LLM party late, they were behind for like 2 years. Same should apply for XAI and it's evenworse since xAI started from scratch while it wasn't the case for google, you need some nuance in your thinking.
But yeah I see OpenAI and google on top of xAI in the long run.
why AI companies doesn't know how versioning works ? could'nt they call call it deepseek r1.1 or r1.5 ?
it's annoying as hell
Gemini with their 0506 and 0605 confusion
why are they trying to mess with us so badly ? a simple versioning would have done the trick
but NO they want to f***k with us it seems
Not even mentioning OAI who are the jerks king when it comes to bad versioning and confuse the hell out of the user
BREAKING 🚨: Google is preparing Gemini 2.5 Pro Deep Think for a release!
It will appear as a new option in the toolbar and will take several minutes to finalise.
Kingfall? 👀

o3 pro counter attack
its so sad that LLMs are focusing codes more and focusing writing less
i can understand why but still
its so good that they removed it, holy moly
i'd say gemini 06/05 best(even better than opus 4) but im a gemini fan soo i could be biased
why aren't 01 pro and 03 pro on lm arena ?
expensive, too much time for answer
after months of shtting on gemini
this MIGHT actually be real now
the great flippening
well but then they can use any marketing BS to say its the best model in the world ever. I don't understand why OAI don't give free acess for 03 pro to lm arena for Batlle (and not direct access), it's not like they don't have the computational power to treat 500 request per day for 03 pro. I call this BS. OAI could if they wanted to
huh i get temporarily limited on o3 pro occasionally, they are still compute constrained
I remember anthropic did diss against lmarena because they think human feedbacks turns models lame
I mean, peoples likes emojis and charts and theyre listen us about that but
still useful to see people's feedback
yeah but its because i'm sure they're like hundred of thousands of prompt per day for 03pro alone
They are tied each one has its own skills
At writing
Gemini is more Descriptive Opus feels more natural
openai scammed you
best benchmark i saw so far is lm arena but yeah the problem is people often ask AI on something they're not well versed on. it's like 2 ai giving you 2 different answer on the best move on chess is but since you know nothing or not enough on chess, you can't know whose right
you pay for my subscription then ?
well you have gpt 4.5 unlimited at least
they took that away too
what is the limit?
😂 for real ?
better off holding it for deepthink
how do u know though
where is o3 pro usamo 2025
all I want to know is how this happened

hmm

is that open source too?
bing chilling wants to see ur id
there's going to be a decent amount of people literally worshipping ASI once it's created, there's already a religion for people who think current AI's are gods

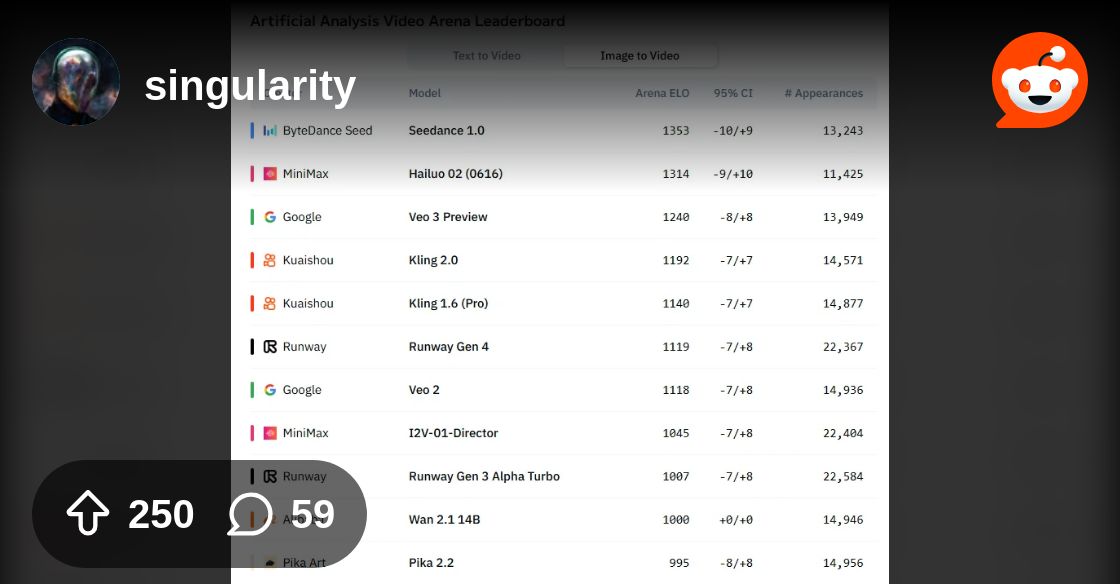
the video generators that are apparently "better" on all these leaderboards are pretty fake imo
I've tried them, none of them are nearly as good as veo 3
and it's not even close, most of them aren't as good as veo 2
it's really strange how high rated they are though
I do notice that they excel off of an image prompt or a flow-esque setup, and do pretty well for fantasy (because they're fine-tuned for that) but it shouldn't be this close
ye but I can't imagine that's anything but a flaw of the benchmark
rather than how good the model is in reality
I haven't used seedance
I'm just going off of all the other AI like Kling etc
Naaaah that’s just as symbolic as saying money is your god, ai is just silicon or bismuth if we get there
yes marginally better
also I think claudes are dense models, whereas gemini is MoE, so it can use all those parameters for creativity
no, but they have higher quality human feedback and also a higher quantity of it
that is the main part
it is also why the models are really good in these short human preference evaluators
that said, bytedance still build a very impressive model, mainly because they can achieve lower prices than competitors (the models we get is already greatly distilled and technically 480p with a 1080p upscale)
true
yall
do you think kingsfall is gonna be better than claude 4 opus (at those specific coding)
100%
mhmmm, not rlly
dang
they are not as strong in the llm space
it's not much more creative but it tends to play into fun and cohesive tropes more than 2.5 pro so it can appear that way, it's more natural, to a point
but i was (and i assumed you aswell) refering to their video models
isn't a secret that 0325 was extremely creative
deepseek is a very respected newcomer, but there are other companies that capture more of the consumer market there
it should also be noted that bytedance operates a ranking platform almost identical to the one used by aritificial analysis but for the chinese market (also including competitors, very similar to artificial analysis)
and that is probably also a reason why they are so good at the specific format
One thing I haven't seen many people point out: if the video leaderboards included native audio generation, there would only be one model
"Google facing the worst stock crash in its history, because its new veo 3 only reaches a 50% win rate!!!"
- the market is in shambles
reporting live
Anyone know what model this is: prowlridge
Just realized flash lite could be a pun on flashlight
allegedly
I'm just curious, has anyone opted out of the arbitration section of the ToS?
2.5 flash lite
v3?
deep think
2.5 flash lite - prowlridge
2.5 ultra - blacktooth
so dt is still coming early? did that get revised alrdy?
that would be a dream come true tbh
it seems like it's going to be blacktooth aint it
hmm damn
I know right


what the horse ?

Its like using 2.0
bientot
Flash lite
Ok

Huh?
I have no idea what you're talking about
must be about "speed"
Wasn't there a code name for the Mystery Gemini models on the arena related to a horse?
?
?
@patent aspenYou deleted your "prediction", did you think people were stupid?
?
Are you doing okay? I hope the rest of your day goes well!
no
none
should tweet a 👑
Du coup tu parles francais
Your eyes played tricks on you
Es tu une femelle
Femelle pfffft
lol
just seems like flash lite, pro, and flash lmao
the horse could be work horse, or horse for speed but can probably be inferred speed due to the strength emoji
so it could go like
flash lite - super speed, pro - powerful model, flash - fast model
deepthink seems to be on the way but I don't think it's guaranteed GA like with the other models, that was never set in stone
nor alluded to
Yeah now that you mentioned it, I think the horse emoji is regular Flash because it's the "work horse" model
just simply "comes later"
f's
ye but it could also be that it's previewed first tmr
and the info you're getting is different because while that's technically true
unless they don't want a preview
and it's just simply that dangerous
I think they were waiting for o3pro, but o3pro turned out to be garbage and completely not worth competing with😂
well at least it falls far short of the expected o1 to o1pro leap
Does an ultra exist
ye
Is that what this blacktooth is lmao
There's no way it can be deep think, it responds way too fast
nah I don't think so
if they never planned to release it, they would've likely never put it in the arena
I think it's coming ngl
Sundar said before they were considering releasing the ultra models
Est tu une chocolatine ?
and an ultra would be, by the CEO's mouth, inefficient and overall not something they'd want to serve
non ca c'est asura
via "next generation performance would already close that gap"
sure but if that's not the reality, then there's no point in speculating
true, pro could just be getting an upgrade and therefore that's blacktooth
but not quite ultra size
ye and also it's not far fetched to say that, they could be coming up with some really good efficiency innovation
hope they don't want profit over retention
benefits me more that they make things cheap
off topic, but will google ever create a claude code equivalent (gemini code assistant/jules don't compare), but with gemini models? that's where they would rlly win against anthropic imo
guess so but they could see AI as something that has nothing to do with profit or retention, and or just restrict chat AI access and go fully into subtle AI
where it's still beneficial for them, but removes the hope people have so when prior they could say "no profit over retention please"
ye but that just sidesteps the question I was asking lmao
"early"? if this is a distinction then it concedes user retention
especially when its cli/terminal bound
what the best for coding rn
there is no "early" or "for a time"
opus 4 unfortunately
if it's not perpetually free then it isn't user retention in AI, simple
but i already spend all my uses ; (
2nd best?
fr?
yooo w
i can use 4.5 than
best for coding imo is 2.5 pro but by virtue of his assertion, then 2.5 pro still
no
hm
Craig just says stuff
for coding? nope
don't look at what he says
nah don't, 4.5 isn't a coder at all
oh
you'd be wasting your time trying to find a middle ground
he's just saying random shi
u could have at least said o3/o3 pro
deadass
but
i haev a question
when every i use o3
it doesn't even put code in the canva
don't worry about it
it's simple, don't use o3, gpt 4.5, 4o
for coding
cool 90% of people would agree
there's a sentiment behind asking them not to monetize or concern themselves with major profit
that's why the initial question was asked at all
yo, id rather use 4o mini
😭
^
retention includes a lot of things implicitly, I don't really care about how they view it
or their philosophy, or their definition of retention
100m users organically with/without forced google integrations? 😂
this is already the case
with forced Google integration it would prob be close to a billion
lol
define natural acquisition
yo what does that even mean
yo
you know that's contradictive
😭
bro not even trying
i dont think 4.5 worked
ok that was funny
help
cool an outlier on the biggest stage where by your definition would be unnatural
ive been using less of oai models fwiw
do you not think this possibly alludes to other things
like maybe the ability to generate other ads
you can simply not count them yourself
the numbers are there brochacho
great time to use AI
ngl
whats ur risk appetite
no reason for that to be valid if we have no idea where openAI stands currently since it's visible growth was around a year or two ago, and Google might start going uphill given their innovations
like with that alphadolphin bs
what that
i mean obv oai then
use gpt 4.5 for prompt?
no
google as a company is alrdy mature
wut does it mean
different now
oh fr?
then DeepMind
easy
lmao
dude just trapped himself
😭
😭
in the ai scope, deepmind is considered infant
^ pls help
yep, very infant
a lot younger than openAI
ignore Craig completely
It would be crashing rn
I'd guess 80% but slowly going down
At it's peak maybe
private equity
These days the landscape is far different
so prolly even $1b at ipo, i wouldnt be surpirsed
what does that have to do with what I said lol
deepmind is older than oai, but not as infant in that regard
Bro has to resort to mind share now 💀
its obviously >80%
holy retardo, if that's what you meant then you're wrong lmao, you mentioned maturity then narrowed it down to DeepMind in specific, and then narrowed it down more to AI, which can ONLY mean productization and that's why I agreed
all centered on the fact we were talking about implicit growth
it's getting old Craig
so what are u trying to accomplish/prove here? deepmind age in aggregate, as a research comp, push to market? i'm talking about in aggregate, deepmind is founded earlier than oai, and thats what i meant about not as young as oai.
sonnet 4
why ; (
than deepmind very happy (:
:0
i want google win (:
Me too orange me too
then google buys it out, *its staff
I don't get what you mean lol, that's completely removed from context, DeepMind is way older than openAI so that's obviously not what I mean myself by age. The ONLY way it could possibly be an infant compared to openAI is productization, which is also the only thing relevant in context as well given the dichotomy presented by Craig lmao
yes obviously, gemini is younger, im agreeing to that..
dawg you know that's not retrospective framing on my part either, if what I meant was nothing else but that, and that was what you meant too, are you wrong or am I wrong
for asking for clarity
deepseek server busy..
yea my bad for not being clear about it, my point is if deepmind is isolated from google, then its an obvious pick to invest "$10m" on deepmind vs. oai...
@deep adder I think you tend to decide what you want to be true and then ignore everything that doesn't conform to that
ye
we agreed
Craig is always right
it doesn't have to be a stop sign if he can't read
get with the program brochacho
guys..
Gemini didn't work
chatGPT didn't work
I ran out of claude
DeepSeek server busy
I don't think grok is gonna work
what should i try next (for coding, pygame for exact)
craig is funny imma give him that
I personally think, as soon as Google starts tackling personalization, OpenAI is cooked
At least, that's what I want to see happen.
I would add one caveat that it's hard for DeepMind to exist in a vacuum. The computing power, supporting teams, data from products, etc all play a role. If we assume they retain those advantages, I would definitely bet on DeepMind
Granted OAI can't exist in a vacuum either. They need Microsoft to bankroll them to remain competitive
I doubt they want to bite the hand that feeds them
but does msft own 49 or 51% of oai?
I think OAI would probably issue new shares when raising money to avoid losing voting control
Did OAI actually sue Microsoft?

OpenAI is reportedly considering accusing Microsoft, its largest backer, of anticompetitive behavior throughout their partnership.
Right I knew about that, but I think it's more like OAI is doing the bare minimum where Microsoft will still let them use their cloud at a discount
mainly started when oai asked to allocate some gcp servers
I guess OAI will start paying GCP to have some negotiation leverage
The rift definitely started earlier than that
oh yea, but this is literally nail in the coffin
i wonder if they will get relatively the same discount considering theyre a big volume client
Maybe. I think if Microsoft stops providing any servers for a discount, that would truly be the nail in the coffin
google is seeping into oai ecosystem, what u gonna do about it craig
Then their losses for 2025 would likely be closer to $18B
holy
I think OAI lost around $8B in 2024 and was on pace to lose $14B in 2025 before all of this Microsoft stuff
just another funding round, no biggie
@patent aspen have u tried o3 pro, how does it compare to dt
What’s coming tmr
hmm damn
Will pro GA be good
isnt it literally 0605
What if @deep adder was actually Craig Federighi?
can i have an autograph
ngl I think the real Craig Federighi has the most punchable smirk
Like I'm not an angry person at all
do u have the same agility like him when he goes down the stairs at apple hq
wow
lemme know when, so i can short
Sometimes I think Apple is like a mustache twirling villain
Like when they designed their own protocol for air pods that didn't allow third party buds. Then they made the excuse that they couldn't allow 3rd party buds because it wouldn't be secure - with the protocol that they designed
And they will never have an opportunity to try until the EU gets tired of their anti-competitive practices
Like with lightning cables

oh naw @deep adder how do u respond to this
had to check why i blocked that dude
looks like it was justified


guess they should focus less on design and more on hardware
lol
back to the block list
wait what
craig is also getting hate from other servers 😭
that must be some sort of achievement
mods should ban him
tbh i enjoy his company
why
funny is an interesting way to describe it
Hey folks
howdy 
LMArena is my only way of stress relief these days
after yet anothe rmssile in my city this morning, my mind wants to rest
☹️

This is AGI
Seriously I laugh when i see people saying AI will replace 20% of jobs in the near future
Will I be able to use deep think Gemini without the ultra subscription??
Will i be able to get a decent job if i don't study?
too trained on the classical riddle or simply decided to forgive the possible mistake the riddle gave lol, models are like that and the thinking process would probably point that out, but since it likes brevity it'll just spit out the total corrected answer
which Includes the model forgiveness factor
Go to people on the street and ask them this question. Report back what % gets it right
Human intelligence is so overestimated
I tried asking some basic times tables to some people and they messed them all up
Meanwhile LLMs can multiple two 8 digit numbers with no tools easily lol
Sometimes I get the feeling AGI is already here. And it's just not that world changing is all
Maybe when simple bench falls. That will be the marker
Need a WeChat account
Google cooking like crazy ATM
Like bruh I thought every 3 months was fast now they releasing a new batch of models and it's not even been 2 weeks since the last
Thanks to the integration of AI departments of Google
Meanwhile over 2 years between chatGPT 4 (march 2023) and upcoming chatGPT 5 in July
This cadence won't work now
With Google on the scene
Deepmind is a very strong team
And I guess the next step for Google is combining V-JEPA 2, Veo, Imagen and LLM to create the base of AGI
Google says they don't think the LLM arch can reach AGI
Probably they have something else developing for that
Imagine Google drops Gemini 3 same time as gpt5
That would be so brutal kek
no llm can reach AGI alone
and at the same time deepseek r2 lmao
Imagine if human reasoning really isn't special and a LLM is enough to reach it
Dunno whether that would be good or bad lol
It seems increasingly likely as the days pass
am afraid if human reasoning isnt special, we wont be able to survive til today as a species 😅
V-JEPA 2 is a world model
And it can predicts the future event well, much better than current video-generating AIs
I just asked Skywork to do a deep research on this topic.
pretty sure 100% of people are getting it right, and if they're somehow not, it's not an intelligence problem they just don't have the information in their face, they heard it once and now have to answer so "the surgeon who's the boys father" could've just never registered
this is not by any means a simple bench esque problem either
so many problems that aren't "solved" by these AI is because there's a level of forgiveness because it has the necessary "truth" in their training data
whether this is a flaw is random
was it done statistically using huge random sample groups (>=1000 people, this is the sample size that is common in clinical trials for testing new medication for example, the smallest being 100, you need at least 10 to test new cosmetics products sigh)
or you just went on street somewhere randomly and asked random people passing by? here in my place, if i do that, everyone will solve correctly, but i need to admit my town is famous for academics 😆
lmao. Yeah this is a classic example of changing the riddle it was trained for just marginally to change the whole meaning but the model stays with the same answer. Used to be a bigger problem in the past, kinda surprised o3-pro fell for it. 4.5 and Opus would probably answer this correct
yeah Opus does get it right. Seems that I overestimated 4.5 though since that doesn't...

i dont think totally random - the more well known the 'truth' (or in this case, the riddle) is, the more likely it is to result in an overfitted, wrong answer to a slight variation of the question asked related to it (and designed to get an alternative response as the solution)
with yeah assumed typos etc on the part of the user as the rationale
the son mother doctor setup is as 'classic' as they come imo
o3 gets it wrong, unless instructed to interpret the question literally (funnily, it's reasoning summaries indicate that the CoT was entirely wrong.. but ig the model corrected for the actual answer)

o3-pro, when told to interpret it literally (i.e. not assume typos on the part of the user or that it is a failed attempt at asking the 'classic' version of the question) also gets it 'right' (but not really ofc, as Dom points out)

oh that's o1-pro..whoops
this is pretty good from opus (it hedges and gives both answers, but not unreasonably)
you can't tell it to take literally or not, that's a huge hint
I tried this on 2.5Pro, no go, it failed as well 
it's either model capacity problem (not big enough to not fallback to more common interpretation), or it was overfitted on the original riddle. Neither causes are very desirable tbh
fundamentally it means the model is less flexible
yeah obviously (i'm not saying they get it 'right') - demonstrating the point that they don't interpret it literally, unless told to, and instead assume it's meant to be 'classic' formulation, and the user made a typo or something, and then go onto to spit out the classic but wrong answer
I think that is hard to say definitively though. Models will often arrive at the answer one way and then "justify it" another. Like if it was overfitted it could still output reasoning making assumptions that the user made a mistake or whatever
yeah tho look at o3's response reasoning summary above; it doesn't say typo, but it says "the user's phrasing is a bit off", which to my mind is basically the same thing no?
the issue is that it still settles on the wrong answer with no disclaimers or caveats of any kind. You can not do that. Something swayed it from disregarding that initial reasoning path to the point of ignoring it completely lol
could still be just the lack of capacity tbh. You can see reasoning helps it, but still not enough and it goes with the easy answer the path of least resistance eventually
the fact that o3-pro gets the original wording wrong, would suggest that virtually no attempts of o3 get it right. They probably only contemplate it in reasoning but I'm not sure reasoning traces are even considered with parallel compute for response ranking - would make it much more expensive
I think the bottom line is, if the model is to assume the user made a typo or intended to say something else, at the very least that should be in the final response when giving an answer for alternative interpretation
If it assumes things wrong (not how it was written) and then just provides you with a concise simple answer - that's automatically incorrect, in my book.
well i mean this is why i like riddles ahah
regardless of the reasoning even
or twists on riddles.. they trip LLMs up
(as was mentioned before tho, in a way that might trip up many humans too, like pretty easy to gloss over the phrasing of the quwstion and assume it's the 'classic' and the answer is the mother.. but kinda beside the point to the discussion.. nvm / carry on aha)
but yeah, opus' response was good because it did provide those caveats etc - i do hear your point, and agree
yeah.. the reason I even tested it is because from my experience bigger models are considerably better at things like this. They are somewhat less likely to assume things that sound similar and already exist in training data but lead to different outcome 👀
I am excited about deep think models. Is there any insider or trusted tester info out on Gemini Deep think models? .. @patent aspen
I am not paying 3000$ per year yet but might be able to get share access from time to rime
its worth it
3000 $ is not a small amount. I can afford but I rather not unless it's necessary.
Honestly, my company should provide me an ultra subscription.
i really like simple bench. when it becomes impossible to create new, more challenging 'simple' (for human, hard for AI) tests, i feel like that might be some kind of marker
was reading through this from ARC the other day, thought this was on the money:
You'll know AGI is here when the exercise of creating tasks that are easy for regular humans but hard for AI becomes simply impossible.
lol yeah prob tbf ha
but i do think for 'general' intelligence, some expectation that you can give it a basic af question or riddle, that the overwhleming majority of literate humans would get right, and it too gets them right, is reasonable
anyway.. not a can of worms i wanted to open.. let's move on ha
AGI is perhaps my most disliked term.. it means [so many different things to different people that it basically means] nothing
i would like to open that can of worms
go on 😉
olonly real wo/men ur claude max/code
Deep think seem like it is just a graph of thoughts prompting technique so you can get it now lol via manual request into Gemini models
The Claude code running for 7 hours was a bit odd. What the hell was it doing for 7 hours??? Was it just stuck accessing a database for that long haha
I am sure they will be doing RL / SFT on top of that
I simply added a ":" in that version of the riddle and most llms got it right suddenly, sadly chatgpt still got it wrong 😔
Or I hope, bc otherwise it might be a bit boring
oh nice! that's interesting - did you literally just prepend or append a colon to it?
The surgeon, who is the boy's father, says*:*"I cannot operate on this boy, he's my son." Who is the surgeon to the boy?
the colon somehow has helped to make clear that sentence in quotation mark is what the surgeon has literally said, hence explicitly stating, he's the father. but:

wdym
i meant chatgpt
ahh gotcha gotcha
the punctuation does matter, i knew it right away
i dont get the way it starts with "Ah, I see now!" - it's like a follow-up or from reasoning?
i used the version from above first, most got it wrong, then I added the colon, suddenly, it's clear for most but not all
i cant reproduce with 4o after adding the colon

https://x.com/OfficialLoganK/status/1934767666239004994?t=2iIud5gAUdwJebqpQRAZMw&s=19
Flash lite preview, deep think, 2.5 Pro GA
This what we think?
strange...
i agree.. his tweets are worth something.. and that interpretration of the emojis makes sense ig
i use the battle mode, so the previous rounds might have influenced it
lightning bolt = flash; arm = pro; horse = fast = flashlite
i take back this statement, the previous round might indeed have influenced it, so I started with new chat every time, most still got it wrong despite the colon 😅
while u cope and hope of free lmarena models...
olonly real wo/men us e claude max/code for swe.
🙂
how boring. if u stop dreaming and wanna be actual productive u do cc/cm
/s

The horse is regular Flash. They've said dozens of times that it's the "workhorse model".
that does ring true
so still no affordable deving with gemini 2.5 so sad
go claude max/code
logan didn't say that?
Maybe interpreting the emojis or 3 x gemini
hi
on vertex

I think it depends on what is being predicted tbh
Can you give an example of one and what odds look like?
hot lmao
@echo aurora any news about lmarena test garden you allowed to disclose?
I'll have to take a look at it later
There for me too

crow collage videos https://photos.app.goo.gl/kd7TeRDdHE7YV6aq8

that isnt aistudio or
if u would need berberine u would know the answer
woah
no idea what that is
so 2.5 pro is officially on vertex studio?
ew no. i dont do drugs
i prefer safe streets, superb public transport system.
money if u get sick, so many holiday weeks as employee.
money if u loose job.
money if you cant work.
money if. if if if
SOURCE, old man?
oh ok
oh ok
the user?
vs qwen 1.5 0.5B

on the ga version its possoble to put off the thinking from 2.5 pro? ?
@kind cloud
interested in that too, havent gotten the chance to play with it yet
I don't see that but you can set thinking budget to as low as 128 tokens.


its the same as 0605 then
thx
so no price reduction when you are without reasoning like on 2.5 flash 🥴
@brittle tigeryou have the price of 2.5 flash lite ?
screen ?

same
06 05 and 05 20 gone
what did you do
?
you removed those models 🥲
"Gemma 3n E4B" was this model there already?
yes
Whats the logic behind the name?
dang

Chill the new ones are getting added very soon lol
Yes
W
blacktooth right
hopefully better than opus 4 at coding
because i ran out of credit soooo fast 😭
Pricing page it takes you too hasnt been updated to include flash lite yet

They are in Google ai studio now
yup
LMArena updated its leaderboard just now but 06-05 still top....where is stable 2.5pro?
Well. They just need to change the name lol
there is a new 2.5 pro?
Ppl not understanding blacktooth/kingfall is part of a different model line
Gemini 2.5 pro is done
no there might be more revisions of gemini 2.5 pro still
but blacktooth and kingfall are different
i agree
There won't be more revisions
there will be
That's the point of the ga. Logan already said it's final release
No there will be
Is Gemini 3 pro not cooking kek
Hm

Non-thinking update still not here tho.
So I think there will be revision soon ig
yeah tats a future revision i think
one of the side by side ab tests had it
not sure if it iwll be that though
IMO, a revision should go under a 2.6 name or smth
It's confusing to keep updating 2.5 pro
thats kinda surprising for 2.5 pro kinda i guess
yo
i would think they would keep incremental updates
it's using new formatting
whats the difference?

I thought it was just 0605
like which one is GA? which one is better
??
0506 is older. 0605 is gemini 2.5 pro
logan said it would be the same im kinda confused
ga and 0605
it's different
are people tripping balls?
which is deep think?
Iirc GA is about the user experience. The model intelligence is the same
why are the numbers so similar lol
fwiw it's possible there may be updates other than the model itself that result in differences in performance
brian explain
it's not just 0605
and it's not 2m context
Introducing the Gemini 2.5 model family:
- Gemini 2.5 Pro (Stable, no changes from 06-05)
- Gemini 2.5 Flash (Stable, updated pricing from 05-20)
- Gemini 2.5 Flash-Lite (Preview, small reasoning model)
More info in 🧵
what's flash lites pricing
Updated pricing 👀
ye because efficiency is part of the preview
Lmao so 2.5 Pro is 06-05, no changes
btw it is different its using line breaks more often, like how 4o spams it
Updated system prompt. It has been doing that ealier today already
that new lite model is fast af
yeah I'm averaging like 400 t/s with it
I don't know what to say. It is 0605. There could be differences in tools use, cascading strategies, etc
yeah i dont see why blacktooth would be a new model on arena if it wasn't a new model
Oh latency? Yeah that could definitely change without a model update
Yep
Flash had a pricing change
Ic so probably inference engine changes/related changes
New stuff doesn't drop on Tuesdays :p
no new news that I can share, but know the program is moving along
when new stuff drop ; (
Right there's a bunch of other teams that spend all day optimizing inference that don't work on the model itself
$0.30/$2.50 for 2.5 flash
pricing

Gemini 2.5 is production ready! We just launched 3 new Gemini models with 2.5 Pro and Flash being now generally available and a new Gemini 2.5 Flash Lite preview! 🧠⚡️🔦
Here is all you need to know:
🔦 New Gemini 2.5 Flash Lite (Preview) with Thinking, 1M context, only

flash lite evals

lol I love that they used the flashlight emoji. I just realized that was a pun yesterday
Woah

Hello Gemini 2.5 Flash-Lite! So fast, it codes *each screen* on the fly (Neural OS concept 👇).
The frontier isn't always about large models and beating benchmarks. In this case, a super fast & good model can unlock drastic use cases.
Read more: https://t.co/kbkC8CtVYb

My guess no
sadly
alr cool

it was iirc
"Sure, if your bar for AGI is 'unqualified human,' then yeah, I guess it's 'here' – and it's mostly garbage.
But for me and as the real definition goes, real AGI means an AI that's as good as the median human professional in that field (like coding in a particular language) doing actual work, not just acing some random benchmark. And it’s AGI for that field only, not AGI as a whole. Language models are not AGI in any field yet. Translation is probably the closest they get, but even there, your average professional human translator still does a better job.
Then there's ASI: that’s when no human in that specific field can beat the AI. We've got ASI already in super narrow areas – games like Chess, Go, and StarCraft 2. But those are specialized game-playing AIs, not language models, and they don't really have a 'productive' purpose beyond those games."
iirc ?
if i remember correctly
maybe it doesnt have enough data yet

SimpleQA
2.0 flash lite 16.5
2.5 flash lite 10.7
to be fair flash lite is probably tiny
How is it going?
all of the 2.5 models except pro get lower simpleqa scores
than their 2.0 equivalents
oh yikes lol
SimpleQA
2.0 flash 29.9
2.5 flash 26.9
all my expectations have now transferred to grok 3.5 🥀
what about ultra?
Grok 3.5 gonna suck
They were supposed to release like a month ago or more
yeah elon and deadlines have almost never gone together
i don't even know why he bothers
i suppose im willing to wait if its better than the current model selection
which it probably will be, dk by how much though
yea
why is gemini 2.5 pro first in webdev but 4 opus is better?

lol the tease it works two ways
Ultra + DeepThink = AGI 
2.5 its officialy moe
What's that
AI's current prowess shines brightest in intensely text-based applications like translation, writing, and coding. In these areas, the path to AGI seems primarily constrained by the AI's capacity to handle and recall information across vast contexts or databases. Once this limitation is overcome – once they can process massive amounts of text without losing coherence or "forgetting" details – we will effectively have AGI for these domains, though perhaps not ASI.
IMO top-tier AIs today already operate at a near-AGI level within the very small contexts they can manage for translation, writing, and coding. However, for less text-centric or entirely non-textual fields, even at small context they can struggle very much. a different set of breakthroughs will be required.
Consider the potential: Imagine handing an AI your entire Git library and asking it to develop a new screen; it would immediately pinpoint what to modify and where. Or, provide it with all seven Harry Potter books and task it with crafting an eighth volume, and it would weave a new story while flawlessly remembering and integrating every key element. I think with LLM it's achievable with just tweaking on how it can handle huge informations
o3 pro is mid

Reddit
Explore this post and more from the singularity community
lol whenever something doesn't confirm your existing opinions you disregard it as some kind of cheating
You think so
how's translation been for ya?
nobody ever talks about it
i'm surprised how it's so good and yet nobody talks about it
insane
well very good but loose context in big chunk
still not as good as average pro translator
idk how DeepL is still alive
get it, because grok 3.5, there's 3 + .5
😐
what's the issue besides context
we know what he meant
we get it
but its getting on my nerves
they hyped it up for like 3 months
if they have something ready and its good then they should at least tease it properly
Also, Logan only does that to tell us release is next day
So his tweets are actually meaningful
it translate it badly with the wrong meaning sometimes but overall it's very good
same thing
Google just f'ing renamed it and called it a day lmao
with or without search grounding?
search grounding is cheating
exactly...wtf. i was expecting more
we are testing models here, not tools 😇
flash lite seems great though
They said goldmane would be GA
For weeks now
Yeah
I'm js, they clearly communicated this as their intent weeks back
all small models score low on SimpleQA, even o4-mini-high
without. that's what's reported in the main benchmark chart i believe. with search grounding its measuring more of the system rather than the model itself
bigger ones score higher, do not need tools
aren't they the same size 2.0 flash/flash lite with 2.5 flash/flash lite too btw?
People pretend that small models like o4-mini-high are just as good as the bigger ones. SimpleQA is a good benchmark to prove them wrong tbh
others and i find simpleqa to be representative of a model's world knowledge, so if the scores drops, means the model tends to have less. it affects other tasks as well
it wasn't exactly scoring high before, the drop is significant
MMLU Pro is decent as well, but at this point it's too saturated to say much...
its not just google anyway, apparently claude 4 dropped a lot too
it's not about that. It's about giving measurable reasons for bigger models to exist. Otherwise everyone would dumb them down because many other metrics are good even with small models... Which is just stupid. SimpleQA is great and we need more benchmarks like that
some of that for sure. but i think its important for these models to have a decent amount of world knowledge built in too
it seemed google made huge progress with 2.5 pro (nearly 10% boost from 2.0 pro) in this front, but the other 2.5 models don't reflect that
but 2.5 pro probably has other stuff that they didn't apply to the others
What about FACTs grounding
Isn't that bench about world knowledge
Which Gemini models score highest among all models
Like +20% over openAI models as an example
its different
i believe that one is just for the response to be grounded in the context provided
this is a little bit of a incoherent tangent but some, i believe, argue that for these models to "reason" at all or at least partly, it requires (at least partly) unrelated information that you wouldn't expect to be important. it might perform worse on scenarios you wouldn't expect or generalize worse if it has less 'world knowledge' which i feel correlates well with the simpleqa score and my experiences with it. grounded small models with large context windows are important, but i think the holistic performance of the model is affected in non obvious ways by the lack of world knowledge.
Feels like Google are the only ones that can do this ngl lol
yeah that is possible, but that would require a lot of changes to the architecture & pre-training probably. there are so many ways to do that, i don't really know what that'll look like. it really depends though. depending on the implementation, i still think it could miss out of some of the implicit connections if it had naturally more world knowledge. it's not really about the world knowledge exactly, but the world knowledge we see measures the breadth of data and unrelated data it understands and that correlates with "reasoning" and the connections its formed i think, if that makes any sense lol
I think relatively big models are here to stay
graph ai....i think the first time I've heard of such graph was an announcement by neo4j...a long time ago? such graph ai has evolved to design agentic workflow now too
im not even arguing for bigger models, just saying that world knowledge is important. i think models will trend smaller and smaller, and that there'll be much better ways of unlocking/training in a lot more world knowledge. probably in the near future
i hope i made sense lol
oh crows
🐦⬛
the grass is a little overgrown, u should consider mowing it
the city does this regularly
oh i thought it was ur yard
oh wait the last link, that is not graveyard
its crops
no my yard isnt a graveyard lol
the first video link is graveyard
the last one is public land
mhmm interesting
wait what why
just a filler, sorry idk what to say
yes.... the very close graveyard has crow nestings
i agree, my point was about how world knowledge is important. you can achieve that naively via a larger model but i think future smaller models will be much improved in that regard with better methodologies etc. it's irrelevant to the point i was primarily making anyway
yea i expect a lot of improvements in the near future