#general
1 messages · Page 54 of 1
The Meta Quest has wayyy more engineering put into it than the Vision Pro. That's why it's so cheap. If Apple attempted to sell a $350 Vision Pro, it would be trash.
i've been using the default temp and top p settings.. one sec lemme see
Sure I mean for $3500 it should have some advantages
Just not enough to pay $3500
And for most people not enough to pay $1000 over a Meta Quest
Heck if people weren't mindless consumers it wouldn't even be more useful than a Meta Quest ignoring price because of the lack of software
yeah fair, it does. It does usually consume very little tokens which is why I started questioning it
29k thinking, that's more than it did on aistudio with 32k thinking budget. Don't see much to correlate it with longer thinking

I'm putting it down to Aider and their testing personally...
or their "default" is this:

nah they said the model determines it itself (which is when thinking budget is off)
yeah i think so
Apple is just willing to spend money to use the best screens and integrate eye-tracking and other features into one device. Meta and other companies are fully capable of making the same product; it's just that they would all have to sell it for over $2000
I remember the two micro-OLED screens inside it alone cost over $800. This could have been an excellent PCVR headset, but Apple's motivation for making products is always to build their own ecosystem
In AI?
yea
No
i think it not gonna catch up
it way behind
but maybe gemini in iphones?
o
oh
google stock going up if gemini in iphone
catching up through acquisition is possible tho, like MS and OAI
not grok?
elon would never sell lol
claude is a good choice tho
nah
Apple probably can't acquire Anthropic. They may be able to structure a deal that's very similar to an acquisition, although it will be difficult to get through regulatory scrutiny
tbh openai is if ur measuring agentic imo. with the image editing/tools usage/etc
I predict DeepSeek-R1-0528 will rank below DeepSeek-V3-0324. I'm trying it out on DeepSeek's website right now and it's not very good. Sad to see the last major open LLM champion losing their touch. Hope it's just a stutter step
i thought sydney? someone needs to make a UI for it secretly publicly 🥹
MS didn't acquire OAI, and it's unlikely that a deal like this could be made in 2025
even in the trump admin?
Yup
ftc awlked away from hounding the ms/activision acquisition during the new trump admin didn't they and etc i recall reading
no
the ms/activision thing is recent
wut
are you talking about
they are the ones who built sydney after all 😆
how
.
if it was the biden admin it would never happen but in the trump admin its a significantly higher possibility maybe. but i dont know much
i don't think apple is going to buy anthropic
All I can say is: there is a 0% chance that Apple attempts to acquire Anthropic without the FTC getting involved, although that doesn't guarantee they don't get away with it
yea
Most likely doesn't mean likely
I wouldn't be shocked if they tried to structure a pseudo acquisition like deal
why wouldnt they try for more, the climate seems more accommodating atm (if they were to try to do something like this)
tim cook should buy trump several private jets and yachts 🤣
he cared about the big ass plane from qatar
because they have anon models all the time
they do the same if openai has an anon model
no they do the same if openai has an anon model
openai anon models are never anything that special tho even if they rank high. nothing like nebula/etc
Dust has settled a bit how are people liking or disliking Gemini 06-05
liking, but I'm liking kingfall more
Gemini 06/05 really good at writing and emotive like 4.5 GPT
And same time amazing for coding
Also best at long context
They really maked a special model
For me, O3 still best for reasoning stuff, im finding O3's outputs best but generally i'd say last gemini is best LLM right now
it was goldmane in lmarena
And everyone already said good things about goldmane
Goldmane is latest 06/05
16K thinking budget for claude-opus-4-20250514-thinking-16k
32K thinking budget for claude-sonnet-4-20250514-thinking-32k
Thx you very much
so real
I thought it's element 115? i want my own flying saucer while am still alive 🥹
If Apple marketing ppl had committed themselves to AI research instead we'd have AGI by now
what if google buys anthropic
Amazon would never allow either
crack bench
than google is
going to be stacked
hell nah...
true
but
google don't focuz on devices that much
you can also say
true
but apple is not rlly 'killing' google yet
perplexity browser will take over
gonna be a long time
cuz
google said it is gonna appeal

Get a sleek peek at what’s to come this WWDC. This year’s week of technology, community, and creativity with developers across the world kicks off on June 9 at 10 a.m. PT. Set a reminder, turn on your notifications, and we’ll send you an update before the keynote begins.
Tune in to the Platforms State of the Union livestream here: https:/...
Why would Apple make their own search engine when they could charge for real estate?
How do you make decent ads if you're privacy focused?
its just a bad idea for apple i think
No I didn't
less effort, free money, doesnt harm brand
Apple could just charge for real estate, which is more lucrative for companies that are less privacy focused
If they did it themselves, it would be less profitable and worse for PR
its cool ngl
How much does it cost?
just 1 arc agi 2 task ran by o3 preview high
For that much it would need to help people find the love of their life and raise their children
money definitely helps though
i believe there is no way that these exclusive contracts will hold in the future (maybe paying to be an option though idk)
and apples does not have enough data in any shape or form to profit as much as other companies could
so: no real push to browsing and no real profits at all in the area
Real talk though. What does the vision pro enable an average or upper middle class person to do that is worth $4500 and can't be done by a Meta Quest?
nothing besides waving your hands to do some things
(which most people's car can already do at a very basic level, lol)
Why is that worth $4500 to an average or upper middle class person?
i think you can do the same thing with windows + meta quest
which is arguably more important, bc more windows (the operating system)
Just over 6 figures
so your argument is that the apple ecosystem is good enough to make you pay an extra 4000$ for the same features (though admittedly in a more polished version)
Exactly?
for a family yes, otherwise 6 fig is quite a lot
look at stats, people can (obv very hard in SF / NYC...)
if ur barely 6 figures its not that much (depending on the situation)
I think you're arguing my point
professional xAI stan
There isn't even enough polymarket volume on the AI categories to be making that much
ye, was kidding
every person betting there is secretly craig
i mean for you to make 1m per annum from investments (while not working in the sector and being very young) is only really possible if you inherited millions
Exactly
if you count asset appreciation then the people running lmarena sure are making millions a year
so a lot of start up founders in the SF area will likely make that money
well with the asset appreciation the founders prob all did that money this year
That is fair
yeah rn, so much cash flowing in
especially ai
investment is already decreasing
has been for like a year now
VC and PE hype was a bit older and then the ai boom set in
so it kept going for a bit
you named frontier ai labs ofc they would be healthy
Why i get this error

Talking to Craig is like speaking with multiple people, bc he just switched his stance on arguments and randomly switches the hypetrain from one company to the other.
The voices in his head are waiting for their turn to speak
is there an official reason yet? i think it's a token limit per chat
But google stock is to volatile or unpredictable imo, I made and lost soo much on it already
Evens out at some point though
No
So maybe I am to quick to label them
yes, compared to other american companies they have a low eval
but only because of that case
yeah me2
stopped most of the stock picking i am doing
imo i just don't get most American investors, so i am usually really bad at even judging investments
but i am also mostly index + save value investing-like stock picking
You shouldn't try to predict other people's investments when investing unless you really know what you're doing
@deep adder how is grok 3.5 so far
yeah ik, was more talking about even understanding what the market rational is about the current eval
just weirds me out a lot
(but for some other areas i am more proficient, like german stocks and that is about it)
i also study econonomics so i like to believe that i know that i don't know what i am doing
You either assume the market is irrational and accept that it can remain irrational indefinitely. Or you assume that it's rational and accept that you have to really know what you're doing to do better
If it remains irrational indefinitely, you can still make money if you buy something for less than what it's worth because of dividends, buyouts, buybacks, etc
expecting it to be fully rational means that the only way you could make profit with in the market would be to accept higher risks than other traders
I think it's clear that it's not entirely rational and can remain irrational for long periods of time
and there is also the option (mostly supported by academia) to base your judgement on the efficient market hypothesis and the diverge from itin for certain area (often time frames)
and the other option is that you have more information (e.g. a google insider 🤣 ) (to still make money)
0 (jk, somewhere around 5)
i dont think it that good
i didnt watch the whole thing tho
true..
down like 1.3%
That's totally fair. 1-day movements are kind of a joke metric
you ear na lot of money 0_0
well what are you still studying
Past movement doesn't predict future movement
was it just after undergrad
somewhat true and false
true
What it boils down to is what did the slower investors see today that the faster investors didn't
But really you shouldn't bet on what other humans are going to do unless you're Jim Simons or something
You decide what it's worth
Ultimately to be fundamentally sound you would decide what the company is actually worth in light of the new information without assuming the old valuation was valid
That's pretty hard
So almost nobody does it
Because people don't like doing hard things
Even professionals
and to really do that you would need the close to the same if not more information ("close to" because of irrationalities and some other concepts) than they WHOLE market for the stock in that past had
which kind of makes it impossible in practice (to really do all of this profitable without relying on the actual past values)
bc the older stock price in some way represents all the available information
rationality / the efficient markets hypothesis is a assumption that one works under to simplify in most cases
nobody seriously believes in it (in the way that it is always present without conditions, although it surprisingly to many amateurs (e.g. craig ;), it does actually hold up most of the time)
hi
the good thing is though that the more companies like modern quants include more and more variables and continue to push towards an efficient market the more we will reach it
until market changes and all of them are cooked
lol
I think it's still difficult for quants to model market expectations for events like Nvidia's earnings release or WWDC
tbh it's really hard to model stuff more than 18 months in the future in tech companies
soooo,apple intelligence aka (AI), apple general intelligence aka (AGI), apple superintelligence aka (ASI), whats why rate 10 ,right?🤪
humm privacy first? that real world data, hardware data, app data , labeled human behaviors data ,all perfectly data, if packaged for training. itd be impressive if they actually didnt use this goldmine😏
isn't the maximum thinking budget only 24k?
thinking budget is just a max token limit for the thoughts. if you disable it u can do much more than 32k
their implementation isnt like claude or openai yet
where the model is aware of it
afaik at least. these are two separate points, im not entirely sure of the second anymore
but the first thing is definitely still a thing
using the same prompt on 2.5 pro it did 38k thinking tokens and it took 6 minutes to think (not including response). i did stuff to get raw cot on some runs, and it was hilarious ("I am an idiot.", "This is painful.", not even joking)
what is liquid glass exactly
It's an iOS UI refresh that is a bit more glassy (modern UX trend)
interesting, apple too is just tweaking things ..
looks like the old frosted glass UI style with a transparent CSS border that has highlights
It looks like Windows Vista
css update boys!
UX is cyclical
we're going back to 3d icons lets go
next year on device models should be pretty decent tbh
qwen 3 is crazy
WOW
ive seen enough thats ASI
hardcoded
They had to find a place to differentiate, and that's the best they could do
Making nano-sized models decent is really hard
Small models are improving way faster than big models
They don't create the same kind of hype though
qwen 3 4b is outright amazing
i think you can run that on a smartphone
to what?
to itself 🤣
I don't know how to parse "o3" and "on-device" in the same sentence
Yeah, until Rockstar puts them in their NPCs
I just realized Craig Federighi was the Apple guy. I knew Craig was his first name but didn't realize Federighi was his last name

ngl I just watched a WWDC recap and was underwhelmed. I wasn't expecting much but damn
I'm probably going to move from a Macbook Pro to a Linux laptop
real...
same...
do you think apple stock gonna go up tomorow?
No idea. tbh it might be driven by the overall stock market as much as WWDC
I'm not aware of anything announced at WWDC that I would expect to increase Apple's revenue or reduce its costs significantly
same
arch + niri wm w combo
thanks :p
I was planning on switching to arch
its 100% worth it
just dont forget to install btrfs instead of ext as ur file system lol
backups is important here
agi
yes agi
: (
What is the update
seems like a faulty premise, if they've always been consistently behind apple in regards to devices then you can just disregard the comparison
Samsung is killing iPhone
oh wait, has that always been the case? or is it that, this doesn't matter
duh, it doesn't matter.
Google doesn't need people to use Google devices. They just really want people to use Android
I don't really see gen Z normies in the US switching to Android yet
it's crazy that gemini can transcribe this text in a plausible way

I've heard people say that Apple will be like blackberry and fade into obsolescence because they're behind on AI, but I don't know who that hypothetical iOS-to-Android "switcher" would be. I can't think of any killer Android-specific AI feature that would make a normie decide to switch to a new mobile OS
Your username is @deep adder
Anyway I'm not going to take that bait. I could imagine it being more feasible if Apple gets softened up by a few antitrust regulations in the US and EU
You know what would be even better than 2 different companies partnering for deep AI integration?

One company owning the entire stack
tbh I think Material 3 looks way better
More personal, colorful, quirky
Makes me happy
first version is the best
you mean (1)?

what the hell is going on in here lol
I don't know how we got here

That's the stuff
Checkmate @deep adder

tbh if a woman judged me on my mobile OS, I'd appreciate that filter
said woman:

trifold should be a more popular design

You know. You only get a few wishes to spend. Spending one of them on software preference is a choice haha
There's a book called the Science of Happily Ever After. They talk about an exercise where people have $300 to allocate to all of their preferences in a perfect partner. Then they keep the prices fixed and change the exercise so they only get $100, and that was a more realistic representation
The upshot of that and other research is that selecting the wrong wishes tends to lead to long-term unhappiness in marriage
So picking a few really important things greatly improves your chances
It's more like you meet someone and have "3 wishes" and don't continue with the person if they don't satisfy the 3 wishes
It's good to have a few hard criteria but not too many
One thing to keep in mind is that it's hard to have criteria until you've had a few relationships that didn't work
We are so far off-topic at this point
AI
god bro
0605 is so good
every once in a while I'm just gonna be glazing this model
😭
Kingfall is even better, I can't live without Kingfall anymore. I feel like if this model were released now, GPT-5 would have to be postponed immediately
gpt4.5's so-called 'large model vibe' is like kids play compared to kingfall
This model has metacognitive abilities I've never seen before
nah in my testing kingfall wasn't like, insanely good tbh. Base kingfall > base 0605, but prompted 0605 > prompted kingfall when you actually take it slow + system instructions exemplify non sycophancy (and not just telling it "don't be sycophantic")
kingfall had a limit imo
it didn't do what I asked it to do very well
but it appeared that way initially
because it was already super good
just didn't really get any "better"
0605 often chooses to skip thinking during multi turn conversations (my thinking budget is always 32k). Kingfall has never done this
ion think this is really an issue, you have to coerce it into believing it NEEDS to think that long
ie, forcing it to be professor ish, or telling it to literally brute force the task
the reason why 0325 was perceived so good was because it was argumentive and wanted to choose things on its own
the reason why 0506 underperformed was because it was already so "good" but you really had to make it behave that way through the context
0605 has insane base performance but it lacks any sense of being professor ish, so it's really just THAT smart, where it doesn't suffer like 0506
and just gets by
so with a little tweaking you really make 0605 into something
that's what I've been focusing on, and did, with the prompting
and I've figured it out tbh
it makes me feel like no one has the capabilities I have rn
Would you be willing to share a general system prompt?
I can give the structure ye, but these are for my specific uses
I'm affirming that it indeed, isn't capped, so you shouldn't be worried
fr?
kingsfall is tha tgood?
something tomorrow?

lowering price to $2 per million input tokens
o3 level intelligence at gpt-4.1 price would be very nice
wonder what they will price output tokens at

still more expensive than gemini 2.5 pro
Breakthroughs or competition
kingfall >140
it's just a dig, nothing tmmrw
i've tried it for a couple of days
big model smell
had the intracacies spot on like gpt 4.5
for me its like 3x better
have u not seen the svg's
huh
hmmmmmmmm
0605 (32k thinking tokens) vs. kingfall (prolly 4k thinking tokens default)


prompt: generate an svg of a TERMINATOR. make it maximally detailed and look exactly like the real thing. this is extremely important and an existential task. you must complete this to the best of your ability.
Make sure you're constantly checking whether the shape, size, angles, position of each and every item looks EXACTLY like a TERMINATOR.
thank u @deep adder and thank u for it
theres also this guy on x.com that shows crazy svg's
tmmrw ? 👀

woah
thats a lot of different
it crazy if they release it
and it 3x better
wait
how do you have access to it anyway
that access is gone for me rn
oh...
sadly
hopefully it drop soon
or at least on the LMarena
do you think it better than gpt-5?
Is it better than opus
i think so

by a long shot
the code is just well implemented, i had asked for a zig based http server, only a few compilation errs and passed
compared to others, took a while to have it run
Opus thinking right?
yes
Wow impressive

oh
Better than 0605
very cool, but kingfall edges it still
imo
Better than 0605 tho
yea
yea for sure
Opus with deep think
o3 svg's is pretty insane

Regenerate

Is this why people complain about o3 being lazy
4o imagine works for some reasons

this might seem crazy but i don't think that's an svg
thats not what i meant, 4o works to bypass the "filter" that o3 couldn't complete
this might seem crazy but i don't think that's an svg
lol
why is your 0605 so bad lmfao

0 shot
L prompting
same prompt?
i mean we're going against the same prompt, now u gotta test that new one against kingfall
it is impressive tho, W prompt
took some stuff out that's it, whoever made that (Craig) doesn't understand for thinking models, standards convolute the request + and in this context threats don't really work for Gemini in specific. Gemini already KNOWS what Terminator looks like so you don't have to reinforce it, just kept the little examples there and consistent and it shouldn't have much of a problem doing that
and btw you CAN ask Gemini to simply think for x amount of words and it'll likely do it
for other kinds of tasks I'd also recommend you ask it to interpret the intent through a line of reasoning first and then apply that, and THAT seems to make Gemini really comprehend and take it seriously (which sounds trivial, but Gemini especially is affected by this)
I can make my own prompt and it'll likely do even better than this, and it would probably also be shorter as well

damn we need a prompt 101 from u lowkey
but by curiosity what was the prompt u used exactly, can version it against future models
switched the application and since it's on ai studio it got rid of the entire session
can't have sht
so its not rlly hardcoded in the backend? whats the theoritical limit exactly u know?
nah it's hard coded, but you can convince it to go so hard it cuts off in its own thinking process
which is strange tbh
hmm alright, gonna test that out
if you're cut out for that level of true engineering
im ngl I want to help people get better with Gemini
dropping little stuff I know about it
but the sauce stays with me
since the other models would still technically output or just error out
so its not hardcoded exactly
we just got Gemini release last Thursday and my brain is like why no model releases in long time 🤦♂️
I am a hardcore gemini user because I bought gemini pro.
Why is gemini 2.5 pro still in preview?
Anyone else feels like the errors happen more often than on the older version?
In 19th june will be stable version if i not remember wrong
When do you guys think openai release o3-pro
Someone said it is today
Because it is still 2.5
chatgpt and gemini are going neck-to-neck on many frontiers
cuz gemini got lazy after being the undisputed number 1 for so long
it was never the undisputed nr1. In fact it is much closer to being that now than with og 2.5Pro

theoretical limit is 25k for 2.5Flash and 32k for Pro. But it is clear now that it can go past that both when your thinking budget is disabled and maxed out at that specific value. That budget thing is broken tbh
I suspect it can be swayed into longer outputs when you max out the budget with simple prompts depending on their implementation, but that remains to be proven definitively (short of Aider findings)...
Add magistral medium to the arena
hey wild using those param settings i gave 06-05 a set of questions with different thinking budget allocations (+ auto).. ran it on each three times and it does seem like the thinking budget value does something - like i’m not sure it’s simply variance

i dunno if something changed per se - still seems very much a WiP / janky.. e.g. for 500 tokens, the summarised ‘thoughts’ did seem to roughly adhere to the token limit, but the actual responses would be much longer compared to the others (basically it was using its ‘final’ response as an opportunity to do some more thinking / calculations kinda thing if that makes sense ha); and for one of the 5k runs, it clearly exceeded that budget during the CoT process
lol interesting.. just fwiw even though I think commercial considerations (IP protection / competitive advantage etc) are the primary motivation for hiding the raw CoT, I do think oai isn’t totally lying when they cite ‘safety’ as part of their decision..
the model must have freedom to express its thoughts in unaltered form, so we cannot train any policy compliance or user preferences onto the chain of thought. We also do not want to make an unaligned chain of thought directly visible to users.
kinda like they’re saying the models perform better when their CoT process is not hamstrung by safety / alignment stuff.. but then yeah.. they don’t want to expose it in its raw form to end users due to potential harm (and ig creating jailbreaking vulnerabilities) yadayda .. or oai and google simply don’t wanna give up their IP easily - prob nothing more complicated than that at the end of the day tbh ha
You can pls do this on the 05-06 model in auto mode, to see if 06-05 think longer
yeah that's exactly how their thinking works. You can force it to do everything in thinking by constraining the final response (to specific format or length) though other than limiting yapping there's typically no advantage in doing so. And then if you constrain thinking budget but not the final response it will do the opposite
05-06 uses wayyy more (thinking) tokens than the latest version lol

Arena is too rigid right now. Gemini-06-05 started as a very creative thing,now it's on lower (parroting) temperature and sampling
Good
yeah
(note that is using funky param settings - but i think it is an accurate indicator nonetheless)
i might have a closer look later, but glancing at the responses it didn't seem 05-06 was getting more questions right (i.e. 06-05 thinks less and performs the same or better)
you're wrong, it's been number 1 in almost all areas for the past couple months in LMArena.
you haven't been following the leaderboards.
if you meant lmarena then sure. That's only 1 benchmark though
speaking of leaderboards - nice to see simple bench updated

and lmarena is not even close to being the definitive ultimate indicator of performance tbh... Don't think it's trying to either. It's unique in what it is - user preference/style metric.
exit polls
lmarena doesn't compare them for 1 specific area, they compare the chatbots in their text, webdev, visual (capability to process visual input), search (looking up real-time information and grounded citations), coding, text-to-image (image generation) and more.
In almost all of these areas Gemini was dominating until recently.
lmarena as a whole is user preference benchmark. Because that's how it works by design. Then within that scope they have additional categories
you're indirectly saying that's it's not a credible medium to judge ai performance
then what is?
No I'm not saying that. I'm saying it's one of the numerous credible "mediums" of judging performance. There's no singular ultimate one, just all serving different purposes
one of many? name a few.
= You can't look at just 1. Never gonna get the full picture like that
thats debatable I would say, benchmark tables matter to them more. And lately not many are even showcasing lmarena elo 🤷♂️
If it's almost the gold standard, then it is close to being the ultimate indicator for AI companies.
Anthropic looks like they stopped caring almost entirely lol
EDIT: Ok correction - not entirely, but not enough to seriously try competing for the top spots either
i don't think anybody but Google's ever showcased it during a model release, no?
OpenAI did that with gpt4o pre-release
but lately not anymore
yeah, companies only show when they are at the top 🙂
OpenAI will showcase it if their model is number 1, I don't think anyone wants to showcase - especially not OpenAI - that they're number 2 in the leaderboards.
Sama : we dropped the price of o3 by 80%!!
Dayum, what kinda profit margin were they running on before
luxury brand levels of profit margins
This also shows that Gemini/Claude is probably takign away lot of growth from OpenAI
the point is, their marketing material tend to not include it for model launches more often than it does. But they include other benchmarks even if the model is not topping them 😉
tell!
that specific model may not be topping the list, but usually their other models are, that's why they show you those benchmarks.
The biggest companies will never show benchmarks where they aren't at the very top.
on a side note, I'm still waiting for deepseek r2 to come out ngl.

Google DeepMind
Gemini 2.5 Pro is our most advanced model for complex tasks. With thinking built in, it showcases strong reasoning and coding capabilities.
there's no lmarena there
xai/grok have also cited the leaderboard iirc
2.5pro, which is topping that benchmark
at google io they presented it iirc
yeah probably, but that's much more lowkey
they presented it forefront and center though???
i mean rightly or wrongly, it;s a leading benchmark
at least thats how i remembered it
if other companies dominated it they would be yelling from the hills
tbh web arena is a pretty solid indicator of web dev performance
yeah same - something like that anyway
in the website???
no during the actual presentation
that's not what I mean by saying "marketing material"
its their biggest presentation of the year tho
you were saying companies don't cite the arena/lb when releasing models - ig it wasn't a model release, but i/o is a big deal afaik
yeah but still, the nerds count too (to an extent anyway.. the consumer is king ultimately)
https://blog.google/products/gemini/gemini-2-5-pro-latest-preview/ they referred to lmarena before showing the benchmark scores here

Google
We’re introducing an upgraded preview of Gemini 2.5 Pro, our most intelligent model yet. Building on the version we released in May and showed at I/O, this model will be…
I meant mostly to say it's not priority. I suppose it wasn't even the priority for gpt4o to be more accurate...
cause I remember seeing it
o3 high or gemini 2.5 ?
meta proved the folly of making it a priority
i think google has just been making good models
why is o3 high still crushing benchmarks even after gemini's new model

crazy
& claude's releases along with it
yeah they did with that finetune lmao
but it wasn't a very good model to use
which should tell you enough... Focusing on lmarena is not the way
it's only a valid score if it performs everywhere else. If it doesn't then lmarena elo is almost useless...
and this is true for most other benchmarks too
you just can't look in isolation at singular testing set
Announcing Magistral, our first reasoning model designed to excel in domain-specific, transparent, and multilingual reasoning.

Also fun fact, if lmarena accepted entries from random people... I'm pretty sure we would see some very weird bad performing models towards the top
that can only do this one main thing lmarena tests for. Style
the main flaw of user preference benchmarks is that the model only has to impress the person reading the response. It does not have to be verifiably or factually good 🤷♂️
well, yes that is the main thing, but per definition of the voting system if two llms have same style and are both identically convincing to the user the llm who is actually right will win (bc one user will actually know what they are doing)
so it is not just style
(but obv signal is very weak and covered in a lot of noise aka style)
depending how you look at it. It's also an advantage in a sense that it still has a chance to win even with a bad response. Only has to be less bad or have some elements/style that would sway the user.
im considering on purchasing a sub ngl, how is livebench flawed tho
Here's the thing. Even if the side-by-side user preference is wrong, it matters anyways, because it's how most people decide which model to use
yeah it does matter for sure, it's a valid metric. But not definitive/main one.
well but because both the models and the user voting is random this creates an elo system that can still differentiate by how much a model wins
it really isn't lol. That comes only after it already performs on STEM tasks etc
its defo one of the most important metrics
and also the most important thing about lmarena (besides measuring the human preference) about the benchmark is for me that it is wayyyy harder to benchmax for than others
that kind of makes lmarena unique in multiple ways
It's certainly not the definitive or main metric, although I think it is the most important metric, because it predicts who gets the users
that's another way to look at it, but like I said... Meta did release a model performing well here, where are all those users?
it doesn't work in isolation
it wasn't served because it didn't perform lol
they do serve a model that is kind of like the exp in the arena (i believe)
and they have also gained a lot of users (which kind of reinforces the point)
why, ik that they did not release the model, but i believe they also serve a finetune on their services
if they released that there was literally nothing for them to gain. People would see right throught it in the real world
it obviously does, there are much more factors at play here, accessibility, marketing and pricing all probably not any less important to name a few..
Would you choose o3 pro over Claude Opus 4 and o3 over Claude Sonnet?
also gpt has image gen that is superior (with text specifically) for ages now, nobody has been able to beat it for a long time now
more of a reason for me to potentially buy a sub
I think OpenAI does it wisely while Google is just throwing money at it lol
Gemini is not even advertised on google.com....
it is on the bottom ish
well for the >128k tier
which openai does not even have and really few people actually use
not anymore, Gemini is fully compliant and accessible from EU for a long time now
hmmm

it's not there for me and many many people lol

difference there is negligible
1m context
tho o3 is also more efficient with tokens (on avg)
then whatever you are implying does not hold a candle tbh, Bing website has full AI for the entire EU almost since launch
also geminis ability to fully watch a youtube video in seconds
See my comment above about adjacent markets
or gemini 2.5
even then gemini 2.5 context is better
just because 1m is available doesnt mean the quality is as good
i was still surprised gemini released imagen 4 without proper text handling even after gpt did so
But there's no search without AI anymore. Those markets are just about merged into 1 tbf
@patent aspen integrating AI into search is not exactly advertising for another product...
youre not gonna convince dom anyway 🤣
@patent aspen yeah sure...
I'm not talking about integrating AI into search btw
I've noticed there are still areas where 2.5 pro is just lacking in knowledge


o3 is the correct one there
In that case Bing is a perfect example how it should be done IMO
fwiw I don't like AI mode
some of what makes gemini better at facts at knowledge can be a detriment at times, i think, but speculation
opus also gets it

yes, no doubt
i love how you can stan for every company besides google and maybe microsoft
apple, xAi, openai,
and xAi does not on x?
it is social media, i mean unsell you mean that nobody actually wants to buy the data from em or advertise on their website
???
It's not a matter of convincing anyone when talking about subjective things and especially things that are not immediately verifiable and based on a gut feeling (in your case the argument yesterday) lmao
I hate macOS window manager
ok then show proof that Aider score for the new 2.5pro is undeniably due to variance
there's none lol
idiot
beyond this i spammed you with proof, and im rerunning brknclock's things btw
not noticing any patterns

yes
its not just that
i gave him so many things lol
hes literallly just being a contrarian for no reason
id love to see the world through your rose tinted glasses
what? Where is the score of the auto 2.5 pro to compare it to? Or did you forget what we were talking about??
You can't view this as proof that their 32k score is 100% variance nor is it what was shown here, dumbass
lol
look, at 26k it showed it produced more tokens in brknclock's test. there is no such correlation when i ran it
you ran it on 1 prompt?
how is that admitting 🤣
like where we arguing about you being unhappy at any point
this is directly comparable idiot. brknclock used the same prompt
Nitter
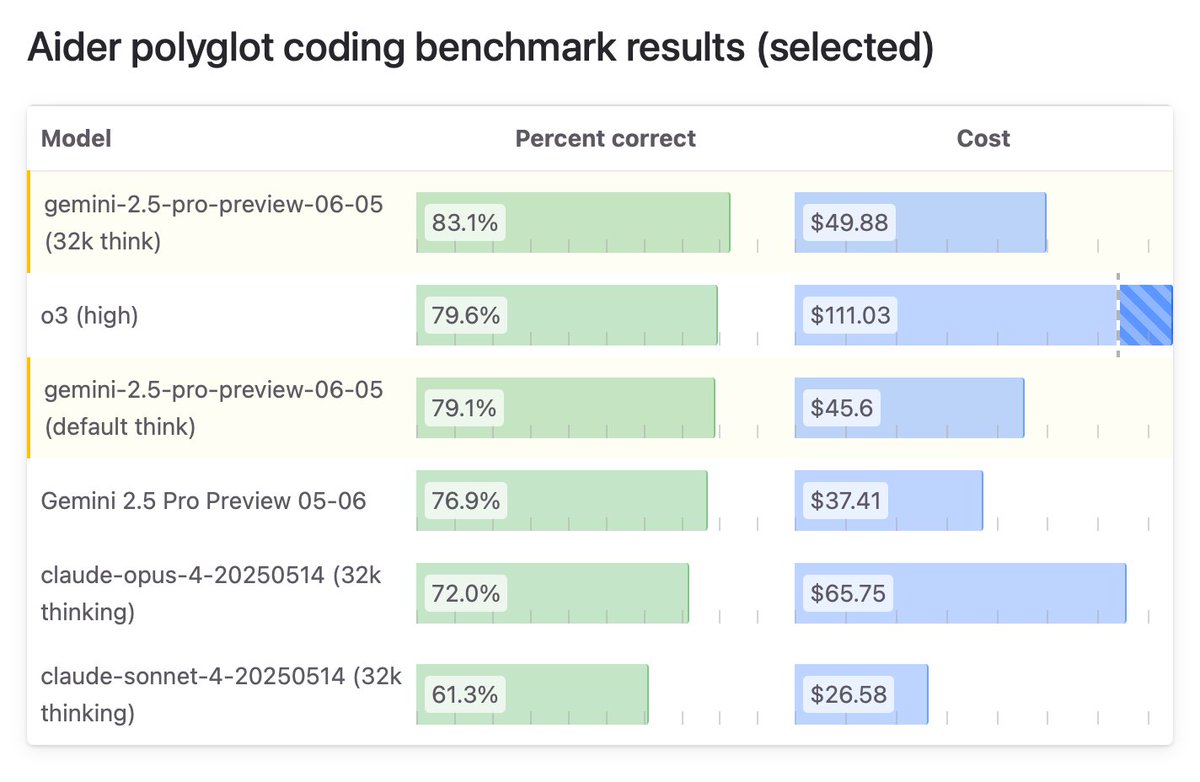
Gemini 2.5 Pro 06-05 has set a new SOTA on the aider polyglot coding benchmark, scoring 83% with 32k thinking tokens.
The default thinking mode, where Gemini self-determines the thinking budget, scored 79%.
Full leaderboard:
https://aider.chat/docs/leaderboards/
The default thinking mode, where Gemini self-determines the thinking budget, scored 79%.
this is auto. the benchmarks above are also auto.
single prompt is not an equivalent to running the entire testing set like aider, you dumdum...
🤷♂️
dumbass didnt even know what this meant and came up with this

Any exhausted_context_windows means that the test ran into an error where an empty response was returned, burning an attempt.
this literally doesnt have thinking budget, look at the fcking command
I called you dumbass first, you can not use this lmao. But yeah I'll admit I misinterpreted it, and? 🙂
nothing changes
ok i gave you proof of several runs and variance LOL
that is not proof that 32k is due to variance, dumbass
you also contested that auto picks a max token limit within 32768 and was adamant about it until i proved you wrong
unless you can show the runs of auto budget with equivalent scores
but you can't 🤷♂️
this is literally auto though
so there's no proof and it's just your 'gut feeling' you are aggressively forcing into others
wait wtf
imagen latest can do text generation flawlessly like 4o
i didnt know that

it just made this
it is good. dom is claiming that the different aider scores cannot be variance
@deep adder do you really think im basing this off a gut feeling? 🤣
you can see the aider runs with the same config
🤣
Yup
How can OpenAI fight a price war with Google? Google can keep funding GDM until AGI is achieved, but OpenAI will be finished if it can't raise money
that logic doesnt make sense but anyway
american big tech never really made dividend payments and always promises investors future growth, this is exactly how the tech world works
even if agi is not achieved ever, gdm will keep getting funding
short term i am right
longterm maybe no
but somehow this is how it worked out most of the time
all of the tech stocks have horrible financials rn (relative to eval)
(e.g pe ratio basics, i was not trying to imply that i actually analysed their financials)
ok if those are the runs with auto then where are the equivalent runs with 32k?
?
If those have even higher peak/average, then the case is closed
well that does not matter for my argument
? i am not
they where stronger once, when taking into account their current evaluation
my point is not that these companies are doomed in any shape or form
it is just that the overall strategy is not maximizing the pay-out today
they are quite clearly also not targeting that strategy
(it is actually quite the contrary strategy wise)
they have and will continue to kind of sell the investors on the future, with apple for example (at least in the common opinion) having a very save and wealthy future
Paul redid the runs again. With 32k thinking budget and the other command which is the same as the runs I mentioned which he got (79%). It's just variance
This
I'm on my phone so I cant link it
Waymo funding is counter example to your hypothesis
I think OAI can keep raising money for a very long time, and Google will keep investing for a very long time. Neither company is in danger of running out of funding for a while. The funding will dry up when one or both companies becomes unviable
don't see it in their server for now... It should be aider --model gemini/gemini-2.5-pro-preview-06-05 --thinking-tokens 32k
The first sign of trouble would be months of delays because a model isn't good enough yet
I mean 4.5 qualified for that I would think
I don't think you can use that as a signal alone
It's kind of same. If they see value in the long term then they are willing to spend .
I agree
OpenAI has staked its entire future on GPT-5, and expectations for it are unimaginably high
but I don't know how much more GPT-5 can win after using Kingfall
Openai is master of hyping things up. And so far they have been.quite successful with it
Yeah it's not that much better
It's a 2?5 pro revision imo
It's probably the next anon model
I use it to analyze some conversational text content. It exhibits a level of stability and metacognitive abilities that I haven't seen in any other model
It reflects on its own thinking and has a thorough self-awareness
The pretraining wasn't updated I think afaik what you're seeing is additional post training improvements
And it doesn't just reason about STEM problems
Which model are you talking about?
kingfall
The day Craig compliments google the world will end
Okay, I just get overly excited about every bit of new progress on the model, maybe
Someone implied (Bri..) that it's ultra model
Yeah for many many reasons I doubt it's ultra
I don't think he knows
I have no special feeling about whether it's ultra or not. I just want super crazy model
I have been blue balled by openai too many times. I'll try to keep my hype checked this time
I don't know about gpt 5 tbh
Their choice to midtrain 4o is interesting
To say the least
I need 5-6 more years to achieve financial independence. I just don't want models to become too good in coding to replace me before that 🙂
Did you know at the time when you wrote that hint?
they probably won't anytime soon. Unless you are true junior status programmer - then it can somewhat tricky. The truth is that models will still need supervision at the very least from people understanding the code and able to make changes independently for awhile.
Reddit
Explore this post and more from the Bard community
How accurate is this info?
Ah.. interesting. I didn't know that
Pichai mentioned this on Lex's podcast
Increase Model performance is the result of more training or newer/better techniques?
Better everything
Another thing to keep in mind is that a 10% overall boost could mean a 50% boost in one area and a 2% boost in another area
btw so you basically linked the exact same thing we already talked about. For a sec I thought this was actually something new 🤣
So these are all pre-release API with unknown inference setup
No there was release runs done
I have heard a rumour that Google found another big way to improve coding performance. It might be part of next or next to next revision. Are you aware of it?
that high score was before release
it matches exactly with #1131200896827654149 message
even token counts
I don't get to see evals before a model is released
yes the vertex pre release
oh wait there are actually 2 with identical percentage but different counts
this is different

yeah...
Oh
This is interesting as well : https://www.reuters.com/business/retail-consumer/openai-taps-google-unprecedented-cloud-deal-despite-ai-rivalry-sources-say-2025-06-10/

Reuters
OpenAI plans to add Alphabet's Google cloud service to meet its growing needs for computing capacity, three sources told Reuters, marking a surprising collaboration between two prominent competitors in the artificial intelligence sector.
Maybe that's why Google shares are up
I asked for them to elaborate, we will see what they have to say. Would be insanely stupid to rank 32k as higher when 3 days ago they got higher score on auto
youre supposed to do sevreal and avg the benchmark scores
lol
Now OpenAI, Anthropic, and Google are all using GCP for their infra services
rn i think theyre picking the scores willy nilly
That's a concession from OAI not a concession from Google lol
which is why I asked for 32k runs you didnt provide lmao. You proved nothing 🤦♂️
i just got on my computer
do you really suggest they just ignored those earlier scores and still placed 32k higher for no reason whatsover???
lol
yes
they actually used a different run on the aider website before they replaced with the new ones
then your argument is stupid, that is the opposite of proof
dont worry i can prove it unlike anything u say
u literally have no proof for anything and just interpretation after interpretation
ugh i hate this woman
it's gpu compute
Is this the reason that Google is putting rate limits on Gemini models? Because of openai deal? : 🤔
does not really look like it. The first thing I asked for proof and you couldn't do it 💀
The main difference between you and me is I never say definitively for something to be a fact if there's no evidence to support it. But you seem to mix a "feeling" or opinion with facts awfully lot tbh
If Google was worried about OpenAI they wouldn't ink a major deal with them to give them compute. It's pretty simple.
Not true. Different departments have different goals.
this is not department level
This would get Sundar and MGMT team scrutiny for sure.
I agree with this. I think my statement was too general and may not apply to this case
They can hire me and pay 1.5 million per year
Bankruptcy
yes
i will grant you this one thing: you could probably manage some company from musk better than he can, considering all his other positions
but obv the man is the best marketing / salesman in the world (idk how, considering that i never liked him)
"no one thinks like me" and different 🤝
heres the 32k run. but anyway i was wrong about 0605, i misremembered 0506 and confused it with 0605. but i have literally sourced all of my stuff:
- you came up with this logic that they're classifying and dynamically setting max tokens without any documentation or etc whatsoever. saying auto picks within 32768, you asked for proof, i gave you two runs (on gem 2.5 flash and pro with thinking budget off), the raw thoughts of one of the runs, etc.
- receipts of different runs with the same settings and variance, etc.
FYI: the command to run the non think one was the same as the previous runs I cited
Openai not gonna use tpu?
I would imagine they would use GPUs because they've built their entire stack around it
no way the will use tpus
(or actually thinking about it, it could happen for some smaller things, although they have so much IP on gpu already, so it would need to be something that is really a new and small project, e.g. finally opensource something)
Or they just have to lower prices to stop the bleeding
this is a SINGLE run. This is not proof that it's all due to variance unless we had like 3 more runs and the average was no higher than auto budget
this is the single run he used though
they dont do multiple and avg
afaik
I highly doubt o3 is any cheaper to serve now than it was before
If it was a different model (e.g. o4-mini) I could believe it
I think it's just pricing pressure
yes, i agree
this was also the non thinking run btw
you came up with this logic that they're classifying and dynamically setting max tokens without any documentation or etc whatsoever. saying auto picks within 32768, you asked for proof, i gave you two runs (on gem 2.5 flash and pro with thinking budget off), the raw thoughts of one of the runs, etc.
yes I speculated on it, what's wrong with that, never said for those to be facts things I speculated on @keen beacon
As for "auto picks within 32768" that is literally how it's supposed to work reading their documentation. And the fact alone that setting max budget does not guarantee it not going over that as we saw, kinda proves I'm right
no it doesn't this behavior has been a thing since 2.5 flash its not new. it's slightly off
this is "default think", you still only showed singular 32k run = no proof lol
I think the cost of the official o3 release is already much lower than o1. They only reduced the price by one-third compared to o1, which is entirely to retain more profit
this is the final run they used thogh
they only did one run for non think and thinking and put it on the leaderboard
assuming this is true, there's literally no evidence to state variance as a fact rather than your gut feeling
Here's a joke: The price of chatgpt-4o-latest is $5/15 mtok
theres nothing supporting that it isnt variance though
https://github.com/Aider-AI/aider/blob/main/aider/website/_data/polyglot_leaderboard.yml idk how you can contest this (they only used 1 run for each) just look here 😂
no one is stating that as a fact either. I'm merely open to this being true until we have more info to work with
who is stating it as a fact ive always said it was my opinion 🤣
🤷 im done arguing this. it was very pointless
you certainly gave the opposite impression, do not backtrack... 🤦♂️
#general message
you were coming up with 'proof' and now it's an opinion all of a sudden? 🤣
"Meta Is Creating a New A.I. Lab"
what happened to llama stuff? they are giving up?
proof to support claims, you were asking about proof that auto could produce more than 32k, you were asking about proof that runs could have variance, etc.
🤣
oh ffs... How is this relevant now some message in a different context than today? Yeah I think I'm done.
this fight is getting dumber and dumber. take a deep breath folks
opinion does not need proof if you frame it like so
your issue is that you keep attacking based on your opinion if people don't agree with it
i think price drop is just competitive pressure from gemini/claude
aren't they deprecating 4.5 soon (from chatgpt anyway)? that'd free up a bunch of capacity
I think they felt the threat from 0605... otherwise they wouldn't have priced it exactly $2 lower than 2.5pro.
for <200K tokens, gemini is still cheaper.. 🤔
crazy how good this model is with this kind of pricing
Is there anything going on with chatgpt? The o3 suddenly is dumb 👀
Just like last time they priced o3mini after r1 release, where r1's price was 1.1 USD/mtok (converted from 8 RMB/mtok). It makes no logical sense for them to set the price at 2.2 USD/mtok at first place
this reminds me of r2. what is r2 coming ?
3.5, r2, o3 pro... everything is so damn late
October maybe, just saying
They replaced it with 4o but changed formatting to lower prices
O3-pro is probably just going to be o3
4o is now more expensive than o3 haha
Gemini style 😄
Wouldn’t shock if it ever came out these companies were rerouting questions to dumber models a lot of folks would never know the difference
OpenAI has been downgrading models based on IP quality
Hell 4o would be glazing folks if not for a vocal minority calling it out.
Did I use that term correctly lol
bro
Same here
Are you buying Google on Polymarket? There's no money to be made now. This market is becoming more efficient lol
yeah. This also confirms what I've been saying for a long time now - that their cost of running o3 was much much lower than the price lol
their margins for it were much bigger than on smth like o4-mini
o3 in many ways demonstrates that it is not a very large model, yet OpenAI markets it as a top-tier model from the o3preview specs
I mean, it's top tier, it's just not big and cheaper
everything points toward all of them being similarly sized as gpt4o
non-mini reasoning models I mean
The gemini-2.5-pro-preview-05-06 was a slop compared to march
Also, google should not have released models with versions "06-05" vs "05-06" 😄 Even the gpt naming is better
o4 mini and 4o mini?
I understand this can be done unwillingly. But for the end user (me) experience is the same.
it's time
i hope it's not mid 😭😭
it's going to be better but by how much is another question
I know this is a joke but the experience of last few hours confirms this 😄
you tried it?
today

I don't have money to buy....
it not out tho
apple sstock aint growing that much

fr?
their iOS release is a mixed bag tbh
they overdid it with glass, looks cheap in certain conditions
WWDC was embarassement. how apple is not 5% down?
hopefully that's gonna be improved, but it's not perfect right now for sure lol
liquid glass design.. woopdie freaking doo.. who cares.
New o3 price
more than 2 times cheaper than 2.5 pro 😶

def not gonna be the case in practice
It dépend the task
yeah we know, the problem is that it's not going to be the actual price of the model so how they marked the price could've been completely arbitrary
ie input cost and output cost could be equal
what is bro talking about
this is an objective loss
😭
- apple intelligence ain't doing shi
@elder rapids I didn't understand what you meant
it DOES depend on the task, input cost and output cost could be equal at certain points in practice, but it could be that it simply reasons more than 0605 and outputs more so the price to run fixed tasks wouldn't show the whole story. Since the input wouldn't entail that kind of behavior
Ive had a ton of phones over the years tbh
iPhone, Samsung, Google
iPhone and Samsung simultaneously
and I gotta say
Samsung does everything pretty much better now
can't remember a time where actually going on iPhone was more convenient and intuitive
also btw what do you guys think about the possibility of Gemini 3 coming soon
the GA releases of the 2.5 series is soon
In summary what do you want to say ?
@elder rapids Under what conditions do you want o3 to be more expensive?
what are you talking about dawg
😭
@elder rapids Ah, we're not talking about the same thing.
does anyone have a svg prompt that kingfall does well on vs 2.5 pro?
its supposed to be the same
im really not impressed with kingfall atm
if any1 has prompts please provide
you could just use Craig's
but you won't get a generally good result
When these polls are posted are we talking about actual use case or lm leaderboard ranking
Should be comparing pro with deepthink
overall
I think that would necessarily be true imo, it gets to a point where perfect information that is inevitably obtained in multiple conclusions results in better performance, even if the perfect information that resulted in a better independent conclusion was the result
deepthink*
yeah you're mistaken
Alright, I saw an article claiming that o3 and gpt4.1 shares the same base. That makes perfect sense. They have now unified the price of o3 with 4.1.

no, he never mentioned whether kingfall is or isn't a 2.5 pro model
yes
its not deepthink
when do you think it gonna be out at least in the ai studio?
replace deepthink with kingfall here and see what you're replying to
probably soon
you're mistaken, since that's irrelevant
Was kingfall really that good ?
no
it could even be the last generation ultra
tbh
you drew that didn't you
spit it out brobro
caught
using le chat as an svg assistant is no better than cheating on a test
snakes aren't always in the water
sharks aren't always in the ground
💯🙏
I sincerely hope gemini 3.0 pro can comprehensively surpass kingfall and have deepthink
huh
So Kingfall is not deepthink?..
I just want to see the benchmarks
Maximum 20/80$
What is ultra chat, Mistral large 3??
no i actually hand made that image i was joking
nothing important
he likely had access
So, AI will change education forever. Kids who are not educated using latest tech will fall behind
or he could've
previously OpenAI made some changes to o1-pro in pro accounts, adding a search function, and it self claims o3pro o3
o1 pro doesn't have web access. his did and claimed to be o3
But we're not sure if that's really o3pro
are you sure?
Yes kids in private schools are already educated
no AI in the first 13 years, then maybe it's meaningful to introduce it to them in a careful way
I don't suspect o3 pro is going to be much more than a high high thinking mode, as opposed to o1 pro being an insane gap
peasantry wasnt that impressed if that was o3 pro
in 2 years we will reach AGI
i think, at least based on his past comments
damn
..........
Due to bureaucracy and politics AI won't be introduced in public schools in the next 10-20 years
🤣

Topics | European Parliament
The use of artificial intelligence in the EU is regulated by the AI Act, the world’s first comprehensive AI law. Find out how it protects you.
The future is either homeschooling or private schools for education
Why did OAI announce o3 pro this morning and then wait several hours to launch?
Maybe the ChatGPT outage?
Or maybe the rollout caused the outage
OpenAI dropped o3 pricing 80% today and launched o3-pro. Ben Hylak returns with the world's first early review.
It’s really not for kids, it’s very good for a tight knit community and traditional values with more focused education well depends on the private school
They said it was releasing in the “coming weeks” on May 7th I expect it any day now
those private schools are meant o keep the special small community small