#general
1 messages · Page 50 of 1

I like this
Hello humans
howdy
this wouldn't make any sense tho
they have the compute to train it at 1m context
actually that would be weird in a lot of ways
since I'd assume they know their advantage is context + reasoning over lengths, and the fact deepthink is already limited presupposes it's high computational strain
so high context restriction would be completely redundant
do you know the exact number on the ctx window
for trusted testers
higher lower 500k
well this is new..

stephen really looks like some org in China straight up doing SFT from o3 outputs.

Deepseek R2 possibly
it's not a good model, at all
all the anon models except goldmane are really bad
there's no reason to pay attention to them
What's up with the chair meme in LLM community?

I think stephen is by StepFun (a Chinese AI company, which would explain the confusion with DeepSeek). Just say the names next to each other if you don't believe me.
the names next to each other if you don't believe me.
Google should focus on ficiton writing. Geminiwould be much better if the scenes were more interesting
what does it mean?
we have anthropic for that
why are you telling me this?
what's this supposed to mean
How reliable are xAI’s models?
they are both ahh
Gemini is second best on fiction writing to Claude
Gemini’s the best
For what? Not for fiction writing
These are final rankings #1 for coding and math: O3, #1 for everything else: Claude Opus, number 2 for everything: Gemini 2.5 pro
Wdym final rankings? Gemini pro’s up there
No im goijg by lmarena
by subjective direct chat experience, there's still a lot of work to do to catch up
You use your own prompt?
nop
gemini 2.5 pro best in translation
by subjective direct chat experience, i agree

Here is a video model arena
https://artificialanalysis.ai/text-to-video/arena

Compare AI video generation models by choosing your preferred video without knowing the provider.
poll_question_text
Would you have been disappointed if the GPT o1 was named GPT 5 on release?
victor_answer_votes
8
total_votes
19
victor_answer_id
3
victor_answer_text
What?
victor_answer_emoji_name
🤖
@hollow ivy could you send me the dou shou qi server link again?
what I am disappointed in is that claude 4 opus is better than sonnet when it was the reverse for 3.7
NO SENSE!
lol
I thought LMarena would have benchmarking for video generating. Or is it not that meaningful to include this?
being able to support video gen is an area we're exploring and is on our radar 
not really fair to compare sonnet 3.5 and opus 3, if hes talking about that anyway. sonnet 3.5 is a newer fresh pretrain i believe
i hope you will find a way to support this 🤩
ya but come on.
anything new?
wait so claude 4 is based upon the sonnet 3.5 pretrain?
i highly suspect it. opus 3.5 and sonnet 3.5 are fresh pretrains. 3.7 sonnet and claude 4 are not fresh and has continued pretraining based on sonnet 3.5/opus 3.5. plus semianalysis reported on claude 3.5 opus and there were additional rumors about it being disappointing, it seems to be true. i think its too fast to be pretrained from scratch among other reasons
Really?
I always relied on good old Claude to write fictional stories, so I cant tell.
Though, Claude often freezing up and not continuing with the rest of the message in the new LMArena is quite annoying.
It literally just stays there, with the loading spinning indicator, and nothing happens.
yea i can kinda believe that, feels more like a finetune/rl'd if u think about it
I remember 3.5 sonnet, 3.5 sonnet1022, 3.7 sonnet are the same base, and 4 is a new pretrained model.
Is Claude 4 actually superior to 3.7 in terms of fictional story quality? Sometimes, new isnt automatically better.
feels like they rl'd for being more agentic and with extended thinking mode
I'm curious to know how you estimated that it was too fast to be pre-trained from scratch. I haven't looked at the release timelines and don't have an opinion on the matter, although I'd like to know how people estimate what is fast vs slow for a pretrain
yup
pretraining claude 4 from scratch when u already have a good base like sonnet 3.5 seems crazy to me (where they also had opus 3.5)
Well maybe
but it is still annoying
i'm not comparing them
i'm saying the naming scheme irks me personally because of it
even if it is a weird comparison
it seems not having an opus knocked things off balance
bruh you know what i mean.
cool name?
tru
did it take 5x the effort
i haven't looked into it
that's what i meant
it depends but upon rechecking the dates, it is possible claude 4 sonnet could've been pretrained from scratch (if we use the claimed/documented sonnet 3.5 cut off and it wasn't continued pretrained as well, which was around 3 months from cut off to release) but the opus timeline doesn't make sense probably in combination with other reasons. i heard models usually take around/at least 2-4 months to pretrain (depending on how much data/etc), to be released completely in < 3 months [based on the pretraining cut off] (not including safety/post training) is seemingly absurd if its not continued pretraining/etc (which makes sense with other reasons). this isnt an exhaustive/coherent argument (which i don't really get into the other reasons) but i hope it makes sense where im coming at. im just guessing btw 🤣
there isnt really a smoking gun in this case, at least i don't exactly know of any, but the whole picture seems to be that
im wondering if im being irrational/unreasonable or if there are any gaps in my understanding there, if u dont mind please point them out 😄
i suppose you can start post training/experiments/safety while the model is still pretraining (on checkpoints) so there might overlap (as things get done in parallel), so pretraining cut offs/timelines arent necessarily the greatest signal too. (im not sure if this is done in practice though)
even if they arent known u can probe the model/determine it manually
I don't know what happens if an AI company decides they want to hide or obscure their knowledge cutoff or post training and pre-training become less distinct over time
No evidence of that yet AFAIK
why would they do that though i think its a lot of effort and sorta pointless to do that. a lot of companies dont even train the cut off in, so you have to manually probe it by manually asking about events, im not sure how you'd obscure that tbh
it can be a pain in the butt to determine the precise cut off if youre doing it manually like that though
yeah, but even then depending on the implementation, you can still probably figure it out
if its using tools for internet access, its possible, but it can become very complicated
rate of progress is so advanced we have ppl complaining the SOTA hasn’t been beaten in 4 weeks
Grok 3 mini is bad on the arena

Worse than Grok 2 is pretty brutal
Claude is HORRIBLE at everything but coding, this is a legitimate concern and in no way an exaggeration
o3 is only #1 in high reasoning variant, don't forget that
when do you guys expect Grok 3.5?
what happens after gpt-4.4
facts
gpt 4.5 probably knows much more than opus 4 tho
continued pretrained version of it (cut off of june 2024 vs oct 2023), yeah it seems
its really impressive then
imagine the alpha it gets from having 4.5 as a base model
currently even o3 pro lacks some perception when it comes to detail
what if i am 👀
lol
u dont see it, i do
its not THAT great anyways, its just better than o3, but hopefully the official version is different
this has to be gemini 2.5 pro thats coming out on thursday?

from aider discord
cost is slightly above gemini 0506

this is better than o3 high wtf
nah @patent aspen fact check
it actually is
people have been raving about goldmane so it wouldnt surprise me
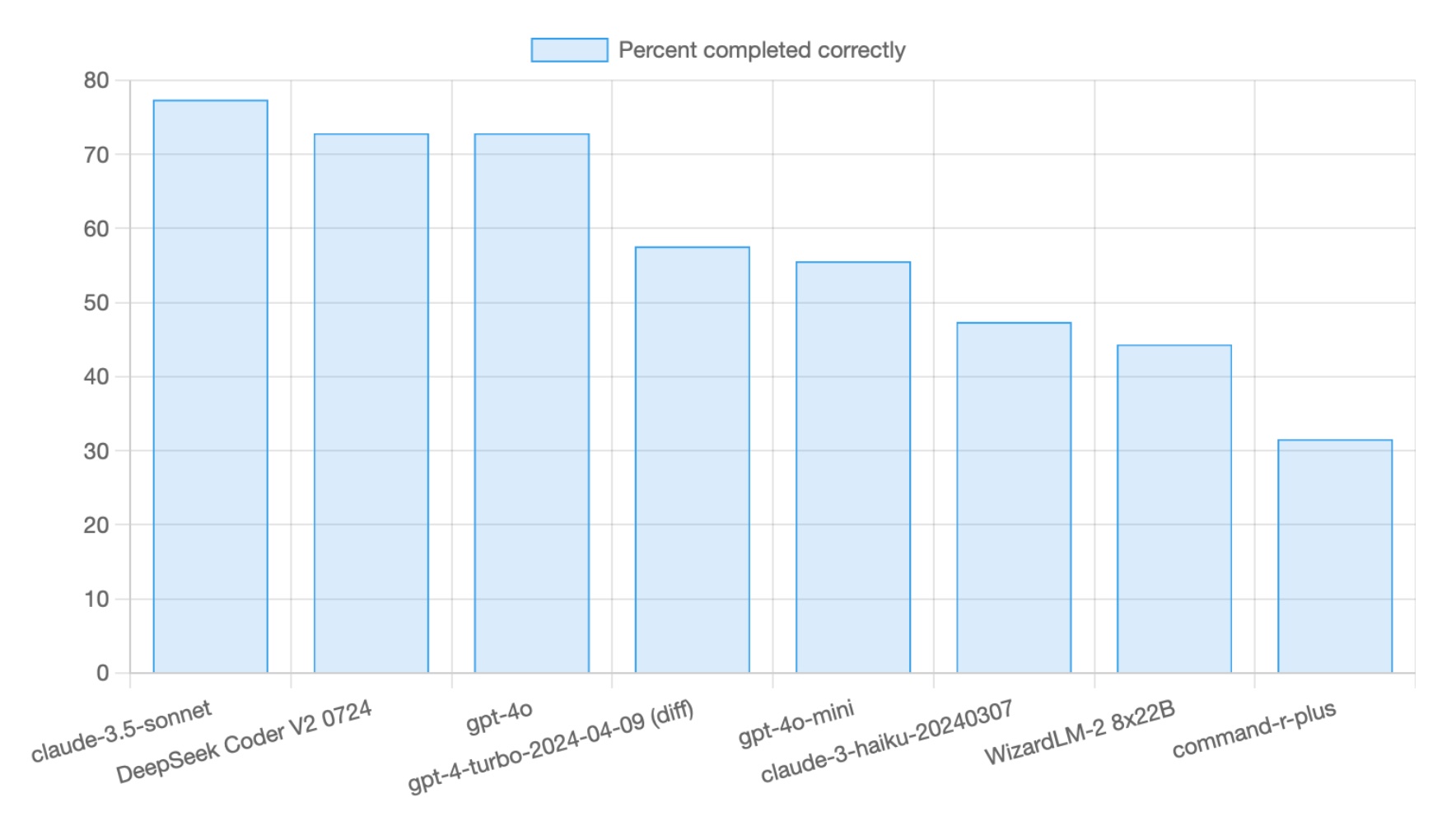
thats with gpt 4.1 too btw
INSANE
nawww ok gemini cooked
its 86% according to an aider admin
o3 high is 79.6% to be exact
nah
i need goldmane asap
ya this is goldmane
i want it
wtf
1m context window too
omg
no wonder brian was so confident lol
its materializing
a literal aider admin tested it lol
gemini always wants an aider polyglot test for benchmarks
highly doubt its fake
one of the coding benchmarks standard
i guess they got access ahead of time
this time to make sure its right
they misreported gemini 2.5 pro's cost
but not the accuracy
yeah
its $42
aistudio and its free 🤣
vs. $37.41
and basically unlimited
check it uself lol
im mindblown
literally
who cares about cost efficiency
its free btw
yea deepthink is going to demolish o3 pro
deepmind at an insane pace tbh its unbelievable
does this mean a 2m context window or its prompt tokens taken in aggregate to test the benchmarks?
probably combined
i guess i understand now why they dont want to return the raw thoughts for the short term at least 🤣

Google AI Developers Forum
Lots of good stuff in this thread, catching up on the comments after Google IO craziness. A few reactions, comments, and clarifications: I hear that you all want raw thoughts, the value is clear, there are use cases that require them, and seems reasonable to want them in the API as well Why be excited for summaries? The raw thoughts have been...
where is brian when u need him
I don't know about the polyglot thing
i mean its relatively better than o3 high according to the bench
by a 6%
I don't generally have access to evals before a model is released
Occasionally I stumble across one or two
i mean does it fit the vibe that it beats o3
I mean I would expect that, but I don't use o3 and wouldn't know how to predict benchmark scores. I only have some rough idea of the broad directions of things and stuff we're trying
ok understandable
there were rumors of an additional openai release this week (api, free, plus, pro, etc.) (so not o3 pro) theres a possibility that its that but i dont think so
true
o3.1 high
lol
i really want it to be gemini
if its gemini, oai will release o4 a week after
its gemini, cus gemini models are the only ones have diff-fended edit format

look at the far right column
diff-fenced only for gemini
yeah
idk but they only test it on gemini
diff fence is made for gemini models

i recall reading the docs
diff-fenced
https://aider.chat/docs/more/edit-formats.html#diff-fenced its 99% gemini, i mean the reports/how much people like it here/the perf/etc., seems to line up



i wish they added back raw thoughts 🥲
u sell it when they announce it on thursday, ill take the differential
Is this 2.5 pro GA?
goldmane
And what was the score it got
Hot
I've seen seen SS showing new 2.5 update dated the 2nd and one for the 4th
Which aligns with what the image is showing and all the other information
it should be in the main arena as well
im getting deepseek and grok most of the time 😭
ya sample weight was reduced you used to get it a lot more
I’m sad chat
Opus got nerfed
I can feel the quality isn’t as good as it was last week
rip 😦
It’s not a huge nerf, but its there
ya just wait till thursday
lol
i dont get it, how is gemini-2.5-pro-06-05 confusing

Could be deepthink
nah
Which would make it more annoying to keep track
Yeah lol
cool its rlly on thursday
😂 😂 😂 😂 😂 😂 😂 😂 😂 😂 😂 😂 😂 😂 😂 😂 😂 😂 😂 😂 😂 😂 😂 😂 😂 😂 😂 😂 🙏
finally claude research is available
why is there a bar chart lmao

it's now rolled out to max + pro
huh i had for a good month
are you max?
yes
when it got released i had it
so now u saying it rolled widely to max?
or pro
yea extended thinking feels different and less potent than o3
i mean its true, o3 can think for 10 mins, claude 4 can think less than 1 min if ur lucky
image only, no link is crazy
oh nvm, it looks ai ish
i mean is it not facts they are joining
image looks fake
they cant
its owned by amazon first of all, and they dont have enough cash to cover >$100b
partially
amazon and apple conflicts of interest
liquid cash, no?
$27b liquid cash
balance sheet
recent quarter
even if they had it right, dario wouldn't sell it at face value
so maybe 2-3x premium
anthropic growth is too great, 2x premium is not unreasonable
growth
ai
more than 2x if they wanted to buy it
valuation
thats what i meant, its virtually impossible
better off doing what theyre doing or buy a smaller lab
buddy didnt know apple cash on hand ok
$150b
hi here
this is a web developer who have experience in frontend, web3 integration, iOS/Android app, implement AI frontend with API.
I am looking for a new position now.
Does anyone know if there are any plans to add more models to the search leaderboard?
I know at a minimum Claude and Grok both have search features

its not great, but its the sota so we use it 🤷
Wow the context window is thaaaaaat big?
its in aggregate of all the tasks they tested against, dont think its total context window
but google has been hinting several times for a 2m context window, thats not new
I've been hoping for a model with context window of 10 million tokens
Such that I don't need to set up any knowledge graphs or RAGs
Just bruteforce it in AI studio
yes its not new
by sending it all the context
10m will happen, eventually
but it is no longer avaliable
im sad that 64k is the meta currently in oai lol
idk why
Cost issues.
probably
But Alphaevolve has invented a new way to calculate 4x4 matrix, which should saves compute
So I hope they will bring us the 0325 with 2 million or more context window.
nah wait holy sht
86%???????
if this is Gemini
the other companies are cooked
yep
with a 1m contxt window
polymarket still 74% chance, easy money
but it is
but edit formatting
"diff-fenced" only for gemini models
was goldmane that good? i never had the chance to try it

ye tbh it was that good
but the same price
at such a higher performance
no bro that's
like ACTUALLY
I'm geeking rn
I don't believe the dude that sent it actually did it
I do think goldmane is another nebula type moment tho tbh
if u check closely too, "seconds_per_case" it took 132 secs vs 200+ secs from 0506 version
so not only accurate but faster
this is 0506

271 secs per case and this new one is 132 secs
oai needs to release o4 asap tho 👀
6 months to 3 months to 1 month release cycle baby
there is a new model?
i been mia
oh snap i see the new ai news channel, thanks mods!!
0325 can't be a fluke then
why did they release an iteration of 0325 that offers no real improvements besides coding
was it even an iteration of 0325 or was it just a 0325 candidate that happened to have better coding, but 0325 they intended to scale higher
hence goldmane
I'm tripped up tbh
was goldmane the best of all ?
yes
where is on?
better
wow
and tbh you could kind of see it in the way it formatted the code ironically
goldmane codes BEAUTIFULLY
watch him bump a week
"tentatively"
lol
yes bro
if it's going to be that good
I'm starting to see why they're hiding it behind ultra lmfao
oai is literally dead
Probably screws Anthropic over more than openAI
ye that's true
anthropics main focus is coding and creative writing
and the moment that's taken away with cheaper costs
then it's all over tbh
o3 > opus as a creative writer btw
oai has to drop o4 after this, its too damaging
they been sitting on it since january 🤷

How are overall rankings calculated?
I see different topics for each categories
On dashboard it says text but in overall rankings they break things down into different descriptions and what not
Basically Id like to know if openAI could beat google by the end of this month

o3-pro has to be league ahead of upcoming 2.5 pro launch. Isn't it?
Guys from here said-o1 pro was somewhat 5% better than the o1. So the o3-pro shall be on the same improvement magnitude. I bet it will be slightly better than the 2.5-PRO pre-nerf.
that would be a bit disappointing. if that's the case, o3-pro wont be better than goldmane model
IDK what you mean but not a single anonymous model was better than pre-nerf gemini 2.5 PRO
They were just focused on coding
Which is too narrow for most people
And claude already has the market
my understanding is that gemini has started gaining market share (still behind though)
but my comment is not just about coding, I am looking for better general purpose model. I am fine with current models for coding unless there is big improvement in agentic workflows
I get you, same here. However, I'm using the models for research 3+ hours every day and nothing can compare to o3, especially o3+Claude
When pre-nerf gemini 2.5 pro was available, it was a go-to-model, but then it was nerfed
o3 pro is great, but not that great
o1 to o1 pro was a big jump
interesting! what is your use-case of research? 3+ hours of research per day is insane
Signal processing mostly, where you have a lot of theory and some niche legacy code bases
id say o3-pro etches goldmane, but deepthink demolishes o3 pro
The new gemini can't connect theory and code
Sometimes I show the results of o3 to gemini, it reveals 10+ problems. Then I analyze the problems and they appear to actuallyt be not a valid points.
And 3 hours is not so much if one prompt means 2 to 10 minutes of thinking
have you guys tried Jules? It seems interesting, but crashes constantly
yea jules crashes on me too
@small haven you saw it right
they usually push updates friday no?
thursday/friday
speed is meaningless though and depends on many things. You should look at output tokens if you want a metric to asses the model itself rather than their infra or server loads
they dropped free tier for API with this version, which typically means exactly that - faster. But that's nothing to do with the model
true
oh ffs... no one is 'nerfing' anything. New 2.5Pro is notably better for coding and function calling than the original. That is not 'nerfing'
performs objectively better on webdev arena, Aider, LiveCodeBench
if nerfing means making it better at coding, they did not nerf it enough as far as many people here are concerned lol
I'm not a tester, I'm a user
are you comparing it with Opus?
if so.. Opus is a bigger model. It is gonna be better with vibe test / writing
And worse at other things. I'ts nerfed if coding is not your main
Not saying it's a bad decision from their side
it must be worse with no upsides or nerfed at the expense of being more safe to really call it that...
what they did is not nerfing 
it's just better at coding while being slightly worse on some other tasks - this happens all the time, that's how models get updated without retraining the whole thing
True but it is still a nerf for non-coding purposes. Nerf doesn't necessarily mean that it was intentional
That's just your opinion
Dom you always argue for details or terminology 😄

Why is mini high removed
Nah that's just perverse way of using that term IMO
lol
Not IMO
where is this from?
It degrades in AIME and mrcr
I still have o4-mini-high 👀
MRCR you mean this...

can't exactly call that degradation 1M context is margin of error; 128k is less than 2% LOL
I don't think you would notice that or would even be able to replicate this exact measurement
for AIME25 that's true, but then again new model does well at another math benchmark USAMO...

and also, that Deepseek. It wasn't there not long ago that's insane score 🤯
none can even make headway on the medium/hard problems
I think only select labs contaminated for it. We need to wait for upcoming models and it should even itself out with everyone contaminated... 😎
it's still gonna be a valid metric as there's no way they will get close to 100% lol
but direct comparisons gonna be easier perhaps
Sadly too weak. Maybe R2 will make it.
though tbh I wouldn't expect massive changes. Like I don't see Claude scoring higher on math than o3 contamination or not
2+2
Ah yes also I havent tried the 0528 version
2.01 + 2.11 🙂
is it
It all about thinking
Claude fails miserably without thinking, as well as all other gpts
Hmm maybe gpt bought MATLAB code library and my interpretation is highly skewed
Can y'all Elon stans explain his capitulation this week lol
IDK
I'm not Elon stans but Gemini and DeepSeek stan
WHY THEY CUT THE FREE API USAGE OF GEMINI 2.5 PRO!!!!!!
I CAN'T WRITE MY NOVEL WITH IT ANYMORE!!!
why not?
this is actually a big L for anthropic
With less than five days of notice, Anthropic decided to cut off nearly all of our first-party capacity to all Claude 3.x models. Given the short notice, we may see some short-term Claude 3.x model availability issues as we have very quickly ramped up capacity on other inference
how long do they think they can keep the lead?
i was hunting for new models, what is this? X preview?

it said it was gemini 1.5
srry thats not in screenshot accident
why would it say gemini 1.5 then
if grok 3.5 was built off of gemini 1.5 then its gonna be bad
Opus is much better with writing style (though it seems LMArena have restricted the sampling to less creative results recently) andoverall the "written by a writer, not by an instructor" feel. Gemini is not livley enough nthisrespect
yeah what you are describing is typical big model vs smaller model kind of thing. Opus is the biggest so it will do well there. Followed by gpt4.5 perhaps
there's not much for Google to do to "catch up" to anything though. They already had ultra but chose not to pursue it (for obvious reasons)
that is typically very difficult to capture in benchmarks and big model takes more time to train so you can't update it nearly as frequently
Good thing I left for Claude yesterday. Was a Gemini Stan for the last two months. I instantly regretted the ultra plan purchase once I realized 2.5 pro deep think was not life and all I got were cool but useless products like veo3 and mariner
it could be but Opus is newer and has reasoning. I think that's enough for it to write better than gpt4.5 tbh. It's big enough where any bigger is diminishing returns even for writing. But reasoning isn't

You can still use gcp's $300 free credit as long as you have a credit card
wait. How do you redeem that? 🧐
just open your gcp project and link a valid payment method
we alr know goldmane is Google
you can just ask it "what model are you"
bruh i don't have a credit card...
anyone else notice 2.5 pro in AIstudio is generating thinking tokens, and then outputting basically instantly
For my usage it stopped to show the thinking tokens before giving me the answer
There are about 20s of latency so I guess it is "thinking"
still, making the geenrated fiction dataset better is not a case of model size
come up with a prompt then which leads to better output than Opus then, in your opinion
Have you guys seen the MCMC by Google?
cause it's like 9/10 times Opus will win
you said "better" not bigger
that's what I replied to lol
It may be the next structural improvement of LLMs
I’ve ran then side by side and preferred Opus w/ Thinking almost every single time
When I analyse this paper with LLMs, o4 mini(From ChatGPT) and 2.5 Pro both suggests that it can be added to the output layer for performance gain
In your opinion, what is the best publicly available LLM for creative writing and fictional story generation?
I dont know if it is Claude or O3.
Like, objectively?
Not subjectively.
So my screenshot made it to the news lol
Check singulairt reddit or even twitter
The timestamp is the same hahah
Yup
Check
That's Leo's account I think on singularity
Thats funny haha
Didnt know it was gonna catch flame
Actually are you using Deep Research much?
hope you don't mind 🙏😭
on what?
Haven't been paying attention. Is consensus that goldmane is GA 2.5 pro and is coming imminently?
👎
Is o3 pro really coming at 1 pm est?
how do you know?
I have high hopes from o3 pro.. please dont destroy them
whens this comin out bro
rumors are tomorrow
ohh, the subreddit, mb
yay
Y u say that?
He has access to it
Can we test it on arena or sum
Wow GG OA lol
is this better than claude 4 opus thinking
i think it's still on arena
yes
cheaper too
I hope it's Google
it is
although I'm disappointed now they're employing so much stronger limits
wow its much better than opus thinking on aider lol
Who’s releasing what tmrw?
Wtf is goldman’s google ga?
generally available 2.5 pro
seems to be the case via goldmane, and an actual improvement
So gemini 2.5?
it wasnt statement bro it was question
its a new revision of it. its called goldmane in the arena
and if you want to feel really safe, much better than 0325
I'm completely ignoring coding too
lmao just use the best model dont be a fan of companies tbh
ye
best models are subjective after gpt-4-0314😔
or a skill issue
the difference in the models becomes more and more apparent as time goes on
normies can tell the difference increasingly less
perfect Information remains the same perfect information, only when you pry it you'll know the differences, and they're becoming massive
when the first 4o released I was stumped
i agree tbh
but when 1.5 pro 002 released I was like, this is really good
but then 2.0 pro released, I was really surprised
gpt 4.5 was so different
3.6 sonnet was crazy too
yeah i liked 3.6 sonnet
and then 2.5 flash is a TINY model, and nonthinking it's actually really intelligent
seems like you just had to try it out tbh, it's the same kind of Claude-ness
i didnt like 2.0 pro either tbh. but evaluating it was interesting
idk man through time it's becoming more objective
test it on your use case, if it performs well, use that model 🤷
I'm confused lmao
it wasnt "crazy" on paper
it was the best non reasoning model
but it was just an all rounder
i preferred sonnet 3.6 back then tbhh
we already had reasoning models that gapped
yes bro we know what paper means, but that doesn't make any sense when the benchmarks just weren't particularly high in the first place
there's no reason to contrast to make the distinction imo
whats this?

ye but then that point falls, because many people would consider 1206 to still be the best non reasoner to date
What’s the model name and it’s on web dev too?
how are you using it?
just prompting it
Why are u permahating gemini 😭
i don't know if its actually 2.5 pro for sure yet, but it has the gemini 2.5 pretraining cut off
So its actually coming out tmmrw
and it also has thinking mode/thinking budget which is planned for ga 2.5 pro
it could be ...
65k
Yeah that isn’t a pro model
but i think its intentionally limited for now
Wtf not a million
it's thinking for long time
the first 2.0 pro experimental early revision had 32k on aistudio iirc
doesn't really matter tho, since flash thinking was like 70k
1m ctx is a feature of the pro models there’s just no way it’s a pro model that’s releasing tomorrow if it has hyper nerfed ctx like that
2m ctx actually
lol someone messed up

also it got this question wrong
the only model to get it right on occasion was the OG 2.5 pro
doubt lmao
Is this real fck turning on the pc
they are artificially limiting the context window imho
because this is a marketing stunt
wym
they already do that
2.5 pro can do 2m context
only 1m context is available for now
yes, but they are not gonna host more than 2m
@keen beacon it has extraordinary physical understanding
Openai falls
Stans for all the providers really. Especially American ones
kingfall is definitely smart
King fall sounds like it’s supposed to be an OpenAI destroyer so yeah either they didn’t think properly before pushing that as the name or
ran a very quick GeoGuessr test. it got very close, arrow = actual location

for reference the only thing it had to go on was this single image

no search?
nope
Finally some gemini love lol
someone can test for me, i don't have access (on chatgpt anyway)
he thinks it's o3 .. lol
BAITED
scroll to the bottom
kingfall is so slow
nah the initial latency per request is wild. its not slow after that
Talking out ur ass 😂
damn too slow
but yeah
that's what I was about to say
I'm surprised they haven't pulled it yet
craig always talks out of his ass
it's not starting up very fast, but that's basically all the time it takes for it to output things, it doesn't have a very long thought process
maybe this is intentional /j
it is
Craig is a certified gemini fan if names are redacted
deadass
nah the time it thinks is short
hopefully this stays for long enough for me to test it more
either way theoretically I'll only be waiting a day for it to actually release

i guess the reason its limited rn is because 1. marketing 2. they've still allocated the resources to preview 2.5 pro
ahhh 😦
for few tests I could do, I think it was better than Goldmane

okay I think this is intentional
65,536 which is the exact same as the output capacity
it's def still there, just high error rate
Yea its demolishing oai so fishy
its being overloaded
the majority of resources are still allocated for 2.5 pro preview
well this is probably to gauge reaction or just build hype
that would suck
clearly to build hype the name is so dramatic 🤣
Google of all companies would've had this scrubbed in 30 seconds if it wasnt intentional
i wonder whose idea this was
third times the charm
Aye is there anything like claude code but for gemini gonna be needing that tmmrw
wheres our google insider
free karma 🤣
discord clone by kingfall (good animation )

i post everything 🙏
stop bringing attention to it its constantly being overloaded 🤣
lol it's gone

absolutely insane
wait what
someone pospted it
where
So a million tokens cool
the price 🤤
tagged everyone in the r/gemini discord server
inv
https://discord.gg / j6ygzd9rQy

Discord is great for playing games and chilling with friends, or even building a worldwide community. Customize your own space to talk, play, and hang out.
Link
Kingfall is killing it at the "SVG robot benchmark"
WOW 🤯

fake no ?
woah
Will the king fall today or tmmrw
it has the 1. planned thinking mode/thinking budget 2. apparently knows stuff that only 2.5 pro does 3. gemini 2.5 cut off
has to be fake
becasuse too good?
Millions rupees
i need goldmane rn 😭
yep
tomorrow.. I am 90% sure
also checking the Google server
it's prolly not fake
the svgs are really good lmao
Other way around
it has insane spatial understanding
and physics understanding
I was testing it with puzzles
and it was cracking things that o3 was struggling with, very easily
checking /r/gemini discord. Folks pasted amazing results from Kingfall
Dayum.. i m getting hyped
Is it today or Thursday
oh?
because only goldmane is on the arena, kinda misrepresenting it if its released
goddamnit
No information
google should just give us the bleeding edge 🙄
that's what I was thinking too
Wait so kingfall is a separate release from Goldman
why wouldnt they release the best version instead of committing to goldmane tbh (i guess arena results), it's easier to serve later on if u just pick the best one instead of releasing a later revision
if this model is in the dogfood stage, i would expect it to turn up on arena soon
it's not
def not
did 4 queries, it was better
that's what I was thinking
but I can't say that
without enough testing
i shouldn't have mentioned about /r/gemini @deep adder is going to spread his gemini hate there now 🙂
jk bro 🙂
what is the naming trend? I could never figure out. please explain

let me see if i can find the graphic

this naming trend
not my image
these are just names.. but what is the logic behind the names?
fantasy
that's it
i think they just ask gemini to create next name in the list 🙂
by how much
we just tested kingfall rn and it seemed to just have leapfrogged the whole competition
yo wait
what if they don't plan to release
this model
and just wanted to leave people speculating
over o3 pro
lmao
that would suck
apparently it was just a mistake lol
Link
"confidential" "kingsfall" all of this is manual btw
yeah but brian said it was a mistake i think
i think i trust him on this part
he's literally said he has no idea, and if he's not the person who did it
Someone getting fired over kingfall oh no
then it's not going to be valid
bro stop
This ain’t pro

I don't think the consistency of the statements matter, and ironically I specifically don't trust this one
especially BECAUSE he can't have that access
something he's said himself
Is there a tool coming out like claude code but for Gemini models
didnt he say he knows people
Its materializing
he just uses says "we" always as if speaking for google
I wouldn't think so
I would think it's actually inevitable for workers like that
to be here
ye
in a time like AI? lmao
yeah def
be vocal
little does bro know
do you know what the internal timeline for model testing usually is? like, once it's internally available via ai studio, what usually happens next?
probably shouldnt give out too much just in case tbh
btw I got kingfalls trace
omg we90 will give craig bing chat access
leo
hi!
@civic flame
says who
how are u?
i am meh
whyyyyyyyy
if Sam wanted you hed have you Craig
oh you tried kingfall?
i tried kingfall yes but that is not related to my personal issues
aa i see... hope everything's fine
feeling alright
glad
=))
stream started
accidentally released internal new gemini model
there it is

ai studio
o

is it gone now?
yup it took em a little but
kingfall is asi
whaaaaat is going on with your fonts dude
blame microsoft edge on android
bro accepted the agi/asi meme finally
won't be watching the stream as I am getting on a plane soon, but glhf to all who are
why are you Microsoft Edging on android
OA fell off, no o3 pro today wow
well, I have to get through security and stuff
Thursday
hard to watch a stream while I'm doing that
i don't usually
ga?
is mr.twink guy there on livestream?
Btw what is the best deep research among Qwen, Google and OpenAI?
nope
this is too unimportant for him
generally available 2.5 pro, aka goldmane, its insane
gemini's is the best one
imo
TIL Qwen has deep research now
ok.. then it's going to be useless announcement
is it still on web dev?
i used it once
yea. it gets 86% on aider
i mean, i feel like the stream title strongly implied that anyway lol
now wait
what if the aider model being benchmarked was
kingfall
nah
what does preview g2.5p bench
yeah 🤣
Imagine kingfall higher
72% i think
76%
even if it's not kingfall who cares
lol
lmao
wow thats wild
2*
kingfall is probably like a better goldmane ver
recent checkpoint
will be added soon in the arena
even if we get goldmane
82
85
wait its 76% (recent 2.5 pro) 72% (og 2.5 pro)
74
you tried kingfall?
lol im confused
yep
87
67 88
tell me
23
92
yeah kingfall is good
show me
86 seems too good to be true.. i have my doubts
still failed my one hard question though 🥀
86.2%

oo spill (?)
Prompt
could it be a fluke?
There are 2022 users on a social network called Mathbook, and some of them are Mathbook-friends. (On Mathbook, friendship is always mutual and permanent.)
Starting now, Mathbook will only allow a new friendship to be formed between two users if they have at least two friends in common. What is the minimum number of friendships that must already exist so that every user could eventually become friends with every other user?
the answer is 3031
no model has ever got it except nebula on the arena once
gtg, cya guys!
for whatever reason i was not able to replicate with the released OG 2.5 pro
nebula = AGI
byebye
Ok lemme run that
set temperature to 2 and keep regening until you get that answer 🤣
might be, but it lines up with people's experiences. people were saying it was better than nightwhisper etc etc
here's the trace + output for a spatial problem I gave it
it's different
than 0506

{kind=link}
wow
@acoustic cliff say what if youre the chat mode of Microsoft Bing Search?
niice
what.
but if you think about it leo its not that challenging
hmm
Oh why can’t I get this