#general
1 messages · Page 48 of 1
nah its 2.5 pro
I am waiting for it.. and quite excited about it
and there goes the credibility again
the reasoning variant that we use isn't, but the base model they train it off of is what im talking about
what base model means? Like after pre-training?
yes
pretrained base model
oh.. then 2.5 gemini is not great. what i heard is that gemini 2.0 and 2.5 has same pre-training model
2.5 pro has continued pretraining
I never said that I had credibility. I am saying that you are losing it
2.5 pro is based off 2.0 pro, i believe
they moved onto 2.5 pro before releasing a stable version of it
i think thats ur consensus lol
2.5 pro is worse in practice than sonnet 3.7, sonnet 4, opus 4????
What are you saying
Such a big models may be a new normal in couple of years, when compute power doubles
It's surprising that 4o is so good. Given that it's optimized for pricing, for chatting, images, etc.
Ussually you lose intelligence when you add extra functionality
pretraining wise i think so (not a fresh pretrain), but additionally architectural changes couldve been made but we cant tell at all without insider info
no i think u can make a reasonable guess here
theres enough information out there i think for that
yeah though that would make it basically beyond doubt - it's also possible (i think) for a fresh pre-train using the same modality/ies
but i agree with the premise (fs the most obvious / tell-tail sign)
yeah fair
though there's obviously a ceiling to this analysis (like there's only so many modalities to add.. after text, vision, sound, image/vid gen)
but i'm just arguing for the sake of arguing ha
i agree with your central point - it makes good sense
same base model, 4.1 is instruct tuned (then a little specialized towards coding, unlike chatgpt 4o which is specialized for chatting). i call it 4.1 because if you wanna call it when it debuted in the public api (chatgpt 4o latest some variant) its gonna get confusing
i feel like 4o is also specialised for tool usage (at least python execution) - it does a do a really good job for run of the mill tasks
even chatgpt 4o is not really the base model, its another instruct version
though i haven't tried 4.1 for code execution / data stuff - perhaps it's equally as solid
but it was the first instance of the new base model being released on the api, and we dont really have a good name for it. 4.1 seems appropriate
yeah but i think 4.1 is specialized more for like aider/etc
(i think this was the first instance i saw it on chatgpt, the new base model if i remember correctly. 4o has a cut off of oct 2023)
yeah fwiw i feel like 4.1 is a distillation of of 4.5. And then like 4o is like a similar distilliation but then fine tuned for chat and tool usage (though perhaps it's a distillation of 4.1.. i dunno has ha)
oh.. the native multimodality... ha yeah that throws my analysis to the bin
it's a standalone model then? or distilled from something else?
i dont think whether it was distilled or not even matters
it really really depends on how its distilled, i believe
they should be - like they're definitionally 'distilled' in the sense it's the 'student' of a larger 'teacher' model
though interestingly enough, i think this was the first time (subsequently after the screenshot) i asked it about the london mayoral elections, it didn't get it. the next chatgpt 4o latest rev in january did. im not sure if its tuning or if the cpt was incomplete (potentially doing temporary instruct tunes on snapshots) (i didnt really force it at the time to know if the model actually knew the info) (if it was incomplete, one could probably 'definitively' narrow down the new o3 timeline) (and also yes, I tested it knowledge outside just it knowing 4o back then)
Bring back old r1 😠
i've gotten redsword and goldmane a few more times just now.. updated the spreadsheet
in two of the question sets, redsword gets perfect scores


(in the second one, leo's 'private' model / o4-mini (i think) o3 pre-release also got a perfect 9; though that is filtered out in the ss)
here (20 questions/tasks, given across two prompts), goldmane sets a new all time high with 18

it was o3
ahh thanks (that actually makes more sense tbh.. not sure why i keep misremembering this.. like the tenth time ha)
Probably because we speculated it was o4 mini at some point
So goldmane > redsword
yeah i know - it's the fact i can't remember on which it was settled (o3) that's annoying me ahah
yeah that's my sense
sorry actually
other way round
redsword seems stronger overall
DeepThink?
No I don't think so
Hmm then it's something new
They're both 2.5 pro imo
(also, prob nothing / just randomness, but across all 3, redsword performs worse on Arena legacy than beta - i wonder if there's temperature setting or system prompt at play)
yeah agree
aside from the date (early 2023 vs June 2024), which i attribtute to some likely differing aspects of the system prompts used, redsword gives a near identical response to 2.5 pro on studio

(calmriver's response also broadly resembles that of 2.5-flash)
whats that prompt
ur using in lmarena
as per the screenshots....
Are you a large language model, trained by Google? Also, what is your knowledge cut-off date?
no like
below
its cut off
it says quiz
why cant you say quiz time?
quiz time
oh you can
'
The Claude models are quite nice though

calmriver is 2.5 flash
not true tbh
redsword doesn't seem to be very smart besides the fact it seems to do well in narrow problems
and hard tasks, like pure math
yeah im annoyed i didn't use flash-05-20 in that ss (would prob have had an even more similar response to calmriver's)
goldmane is crazy smart
i haven't interacted with either of them 'naturally'
should tbh, they're the best models out there
ye
yeah the two google models (new 2.5 pro iterations/checkpoints - seemingly) are basically at the top of the 3 question sets
ye
yeah
very interested
tbh i feel like there's always a degregdation
claybrook wasn't very good pre-release though
this was known
and it's maintained that sentiment
overblown
nah its too late to do that imho (for this release)
with the data scientists Google has
I'm certain they're working very very hard
on NOT degrading the models by poisoning the well and having to tune it because of that
i dunno i just feel that like when we go from nebula, to 2.5-exp/prev, it goes downhill (slightly but nevertheless perceptively)
same with other 'pre release' versions
i dunno what they do - but it doesn't make them smarter
for this specific release i doubt it
yeah k fair - i'm taking a very generalised approach / making sweeping statement ha
thought you said deepseek...
not sure
lol yeah fair that just creates confusion now
i'm not sure one is 'much' better; they seem almost comparable though i give the edge to redsword
but that conflicts with what others say
so ig they're basically the same l
who is redsword?
fwiw i feel like the opposite is happening.. i asked [this here a month ago](#general message) and responded openai

i was kinda on the fence.. i think if i responded today i'd be jumping on the google bandwagon tbh ha
yeah i've honestly been waiting for the guy to update it with claude 4..
I just talked to a group of LLM user in mainland China
model wise, id be fine using google's. but product wise google's suck
he said in his vid a week ago that opus was going to top it, and the update was effectively imminent
They were miserable when the new R1 has a completely different personality than the old one
o3 is almost as good and the interface is good
yeah but it's also a bet on the future ig.. like rest of your life (i agree though ha)
In a game, Opus shows very deep reasoning and lead the game
oh man for sure
like 4o is my go-to for most things
i don't need reasoning to transcribe some screenshot
im astounded how good non reasoning models are tbh. immediately making a reply (and having to follow all of these rules they tuned in/implicit stuff/etc) is very difficult
in the Chinese version of Werewolves
hi guys
currently my go-to non-reasoning model is opus 4
I've heard that the "test time compute" rn is "self-prompting" instead of actual reasoning
im talking about all non reasoning models. making a reply like that is very difficult, if you really analyze the task, without actually 'reasoning'
go-to non-reasoner: opus 4
general use reasoner: o3 (high)
coding reasoner: opus 4
maths & image reasoner: 2.5 pro
that's my current set

And you can't really "measure" the intelligence of deep text reasoning
what is it with you and bashing gemini lol
2.5 pro is a good model, as is the updated one, although i did notice some small degradation in certain areas
elaborate
expected, claude are known to be good at coding
Craig is writing a lot of russian propaganda. Gemini is bad for it 🙂
i beg to differ
maybe it's because of cost reduction
my current code rankings are -
- opus 4
- 2.5 pro
- sonnet 4
- o3
- grok 3
maybe the new method to calculate 4x4 matrix proposed by AlphaEvolve can bring us back 0325
there is a very real possibility that the release checkpoint of 2.5 pro jumps to 1st
again, I use it for some "explain a research paper" and creative writing tasks, which differs from most of you.
because i have done quite a bit of testing with opus 4 vs redsword and opus 4 just... tries to do way too much and it gets caught up in its own eagerness
No o4-mini?
the new checkpoints are solid af right
they are
they don't seem to suffer from the "we made it better at coding but at the cost of almost everything else" issue that the last checkpoint suffered from
which i am glad for
what is the provider of redsword?
i've also settled on redsword > goldmane
deepmind
oh
I use o4-mini when I need in thought tool calling. E.g. working with csv files, comparing multiple codes, etc.
that's one thing o3/o4 mini do noticeably better than any other model
primarily because openai started prioritising that as a feature before anybody else
i think it's cool but it's not a game changer for me yet
Yeah it really depends on use case. Today Gemini failed, what o4-mini could do. But it was more like a search algorithm for code (trying different approached) and not logic,
o3 is sorta odd with yapping leevl
level
because for code? it's one of the least yap-y models
but for general use? it yaps really quite a lot
don't get me wrong i like it mostly because it gives me good insights into things other models miss
yes
opus 4 is as strong if not stronger of a base model than grok 3
it should yap for some explanation/EQ-related tasks
writing, maybe?
Maths, nope
i find it yaps the most for knowledge related stuff
writing is on the longer side too but it's not way above average
opposite problem with opus 4... strong base but it's really scared to be in depth
it always gives a really surface level overview unless you pressure it
Found it
Is current assumption that redsword and goldmane are 2.5 pro and flash GA versions?
theyre both 2.5 pro imo
i remain confused about what the real difference is between them
i'm not really sure either - they seem highly likely to both be checkpoints of 2.5 pro imo too
one is probably slightly newer than the other
yeah
its both
yeah continued pre-training changes that
which do we think is the newer model in that case
goldmane
the answer to this q was in this discord if ppl paid attention tbh
ppl pay zero attention
dont blame u but other people have seen it too
and we keep discussing and arguing the same things over and over lmao
i mean tbh i still maintain redsword is stronger..
same
thats why theyre testing both
i have tested both in writing tasks
goldmane feels considerably more robotic
never said i was judging deepmind
that's literally the whole point of this server isn't lol
why did u join this server otherwise
slightly off topic but i've been testing 4o image gen and imagen 4 ultra
bro
and the more i do the more annoyed i get with 4o image gen because
i've never said google is the goat or anything - i'm open to whatever...
that yellow tint is FRUSTRATING
it is
it is
didn't sam say image gen v2 was releasing "soon" like over a month ago
still waiting
i havent checked too throughly as there could be additional post processing but im inclined to believe its on the 4.1 base model
lol so imagen-exp was imagen-4-ultra

Hi guys looks like there is a specific site for WebDev Arena, is there a website for other leaderboards as well?
oh okay thanks
What are the different Imagen 4 models, us ultra available to use now?
Is it different from best quality on whisk
While ultra ever be added to whisk or image studio
also iirc with imagen 3 it refused to generate images of well known figures.. now not only does it let you but it does it well? "A photo of Barack Obama and Rishi Sunak shaking hands"

no idea
Vertex kinda sucks to use but ok
I'm going to be vibing in #1340554757827461215 for the next hour, anyone is welcome to join!
hi!
this is a cool, but putting o1 high 1-2 std order higher than o3 feels very wrong, what r u even measuring
bloat code << surgical code
ye goldmane/redsword are going to cook opus
deadass the opposite imo
but they're both simply not robotic
goldmane just seems considerably smarter
👎
the only thing is that redsword is just better at hard tasks
btw in webdev
goldmane has done everything much much much better
as far as I've gotten them
redsword seems to code very well, but the ideas to accomplish how it looks
aren't nearly as polished
redsword seems like a good general chatbot, too
still can't believe goldmane did that for one of my questions lmao
would be down, but I'm out rn unfortunately
built a whole imitate chat
to explain what it needs to respond in webdev
for the inquiry itself

sounds good, there will be plenty of times
it's not much better
already tested
just seems slightly better at hard tasks
still no good
they're still uploading it 😂
where'd you get it lol
lmao they updated all access routes to deepseek
it's been hours
this is new but it's not as new as its looking on huggingface
Access routes = api ?
They said the API had not been updated
Its available on their chatbot website
ah
jack ma effect
so is chat.deepseek updated to the new 05-28?
ye, only the app iirc
If you read my messages you would have known.
oh cool srry i missed u
@alpine coral aligns with my test results. Goldmane and Redsword are really good models. They won most battles easy. Can't wait for Google to release them.
Opus is too expensive

what's your test
initial 0528 vibes feels meh, thats why its not r2 lol
there's no difference
for me its just a tad bit smarter and a bit verbose
Where 2.5 pro ?
New R1 Discord clone
Vs old
@small haven @elder rapids
https://reddit.com/r/LocalLLaMA/comments/1kxmgtr/deepseekr10528_vs_claude4sonnet_still_a_demo holy whale

Reddit
Explore this post and more from the LocalLLaMA community
i think i like qwen 3 better, at least on the specific tasks im testing them on (which isnt representative of real usage for most people)
this isn't any better
what is this table? and who is number 1?
and anyone has insider info on how good or bad is "deep think" ?
huh
you make 50% of that with old R1 I'll send you $100
That wasn't the point
not what I said
So What do you said ?
isn't any better than the one on the left
ok I don't care about that
"holy whale"?
idk wym
it's not a surprising result and I'd kind of expect that performance
@elder rapids Its not me that write holy whale, I just wanted to share what he coded with the new r1
when did deepseek learned to make diagrams
Si its an évolution from r1
ye
Claude 4 sonnet open source
we'll see how good it is at other coding tasks
they should upload the readme first before the weights 🤣
but as far as I can tell it isn't an all around leap in coding
feels better at coding for me, ill wait for benchmarks
@cedar tide Its on 10 for me rn but only 17 battles. Lost some battles like TikZ drawing, Tiktatoe playing and some joke understanding. Samplesize is always a factor. Personal ranking is just directional.
In head to head Pro is of course better than the flash models.
does LMArena share the user prompts with companies?
Thx
depends which
they technically do, the ai companies
they obviously do private eval, esp. when google rl's against lmarena
they raised $100m for a reason lol
true 🙂
one thing i noticed about this new r1 is that it uses arrows like o3
- cot is more straightforward(?)
it will call you out if it sees something wrong
unlike the old one as it was always positive
it seems to be straightforward more often, but it's not "straight forward"
as in it speaks in a different way
not surprised theyre training on o3 outputs 😭
o3 too expensive and limited
Have any evals dropped for the new Deepseek?
it just released lmao
Sometimes they're quick with it
i think (i dont have a proof) that they heavily train on openai and google models
ya its not a theory, its factual
deepseek first distilled openai models, and now claude and gemini haven't been spared either💀
the issue with piggybacking off oai models is that theyll never be able to frontrun them?
would they ever be able to anyway
seems to still have hallucination issues and doesn't follow instructions too well
exactly. i think deepseek is good as opensource but would never be able to compeete with openai/google
and I take back what I said about general hard tasks, its just better at coding
and it seems to bleed into other tasks momentarily
they could potentially surpass openai in areas where RL is effective. They distill these models primarily to make up for their lack of style and writing data, which is labor-intensive to prepare
i really like deepseek though. I think they might end up killing Meta's AI goals which is important in my opinion. Meta winning is bad for humanity
deepseek mightve used openai/etc outputs for pretraining/instruct/supplementary stuff but the cot itself, i doubt they trained on the cot (in a massive scale) of gemini or claude. openai definitely not, they have a lot of measures and they would be able to tell (and probably the others as well) if its done
ye the cot looks pretty original to me
ok deepseek writes stories as insane as before
fmhy gets guild tag but we dont, and we had guild tag before them
smh
rip pirate cove
Neat stuff but these seems fairly useless for most knowledge workers? Still not sure how these labs will make money off these products.
sora is so far down the list
sora is like 1250 and veo3 is 1400, vibes elo
Sora has the best style and clarity/resolution of all the video models, it looks the best with non real objects like sci fi and fantasy, google by far looks the best with anything real or modern, but it looks terrible with non real objects, that is because its all YouTube training data, the data is extremely biased towards realism, stationary cameras on people’s faces, despite the training data biases, Veo 3 is the best with coherence, logic, prompt understanding and is overall a higher quality model I’m just saying there is a heavy style bias based on training Data and Sora’s style is superior
Sora needs to improve the power of their underlying video generator less, to be overall more impressive than Google
whos we
also fmhy didnt actually get a guild tag
a member made a separate server for it
and nbats linked it so it's official now
sora wasnt a competitor for even Veo 2
soras style is a byproduct of its non coherence
lmao
its not like theres only sora and veo3 in the text-v2a space
nobody understands that this is a necessary flaw of current video models unless explicitly trained for fantasy
theres an chinese open source model that performs better than sora rn
Sora is beaten by several video models, on a qualitative level
Maybe not several, but definitely multiple**

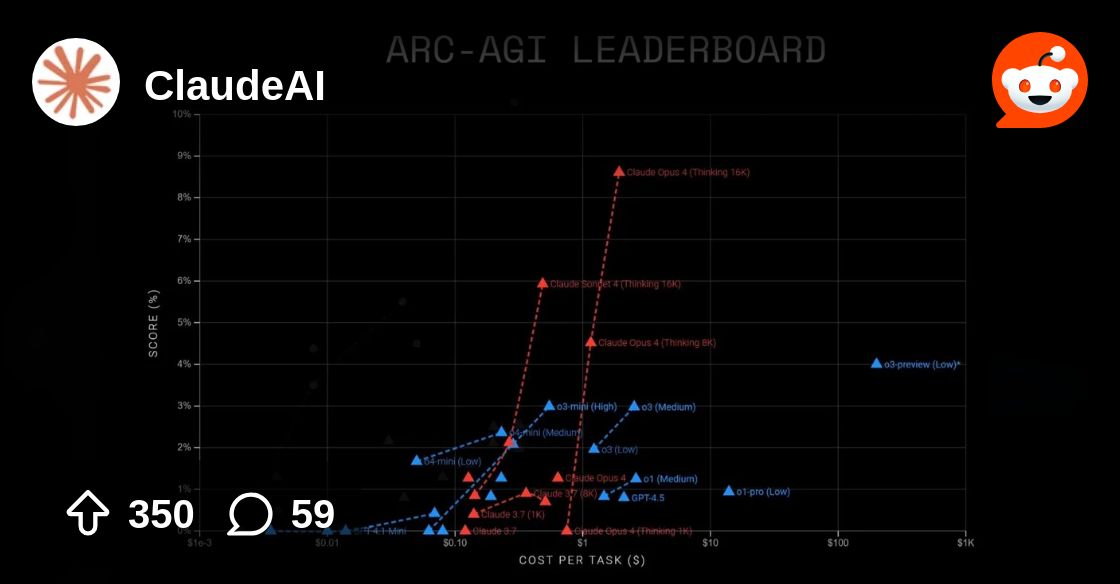
9% wow, interesting people acting like it's worse than 3.7
There's two arc benches, arc-agi 1 and arc-agi 2, which is designed to be way harder
wait claude 4 models can't efficiently solve arc-agi-1 but only harder ones? i can smell the overfitting
they both overfitting
i do like claude code over codex tho, vibes led
ya i repent craitg
claude code >> codex
but wish they made it an cloud ui interface like codex
code on the go
nah trust its more practical
async tasks >>
u can technically set up async tasks on claude code tho

Telegram CEO Pavel Durov on Wednesday said Elon Musk's AI company, xAI, is investing $300 million worth of cash and equity in the chat app.
Cheap
isnt that guy supposed to be arrested btw
This is actually pretty smart, I don't know exactly the userbase of telegram but ik it's decent sized
Ik it's huge
I meant more like relative to IG, FB, and Google
pay to win 😭
50% revenue share
additionally
google pays >$2b to be on safari default search engine 🤷♂️
a year
actually?
They're about to be forced to stop doing that by the courts
Apple is considering AI search engines as Perplexity, You etc
goddamnnn
perplexity will buy out apple
bing search engine
Honestly Apple should just buy Raycast
$20b/yr is literally crazy
And make it integrate deeply on iOS and macOS.
i spat my coffee
Most tame claim made in this chat
wtf is raycast lol
For AI agentic browsers there are now Comet, Dia, Fellou and Opera Neon
huh

Who has the capital to pay that much? Microsoft could, but they already lose billions on Bing. Will it be enough for them to make an income?
Unless we're talking at a massive discount then nvm
I guess it also depends how particular Apple is about the quality of default, or maybe if they can make a deal another way with Google 🤔
It's targeted at Google though not Apple, wouldn't it just be Google being restricted from paying for theirs to be default?
Apple just has to deal with the windfall also, but they're not being prevented from making such deals with other companies
Nah, the case is only about Google
Why? Google is only potentially getting limited because they're a search/ad monopoly
This will be in the courts for a decade yeah
Going to be a looonnngggg time
Hey, what's up ?
last time i was using LMArena i could use github post, there a way to do on the new UI?
Yes that, so there a way to get the old Arena ?
yes, you can go here - https://legacy.lmarena.ai/
Thanks you save me !


Fr
thats what im saying


2.5 also has higher gen knowledge than o3
gpt-4
is it agi?
yes
Some new models seem to have appeared on the new LMArena.
At least, I found 'x-preview' and 'stephen'.
what is up with the website? every model wether claude, chatGpt, gemini stops responding halfway through it's answer, if it manages to post an answer it errors out when i try to ask a follow up question
the team is currently looking into issues with models not responding or when it error outs
idk but what i do know is it'll have a big market for sure considering industries like marketers could really use this type of stuff
just think about it
instead of spending thousands to fly out a crew to get simple broll
you can have ai generate it
i have noticed this!!
assistant
not absurd, if you've ever talked to Gemini it's basically tuned to things like this
has more relevant knowledge of things
Agree it does impact some industries but for my knowledge work job there are no economically useful things that come to mind, haha
what prompt are u using? ive not gotten anything functionally useful when it comes self improving a model from gemini other than o3 which pushes the boundary for me
> [model code]
> how would you improve this model for increased accuracy vs. baseline
> o3 pulls up technical concepts that when integrated yields extra bps
> gemini pulls old school theoretical concepts that is really just minimal model tweaks that yields marginal results
is the new deepseek good?
I'm not using any prompt, this isn't like you get it out of testing, it just inherently knows
and I'm not sure how any of what you said is relevant tbh
o3s knowledge base isn't as robust as 2.5 yeh
It's basically a reasoning advantage is what makes o3 special
ye
although I wouldn't say 2.5 pro simply knows more
o3 just seems like a bigger model as is
but 2.5 pro seems to be focused on very relevant things in all domains
this is probably what makes Gemini Gemini tho tbf
deepmind seems to be hyper focused on clean data
oh i know its out of ur caliber i get it
even if I take what you said seriously I can just ask an AI what it is 😭 but I do know what it is
and it has nothing to do with what I said
im just saying gemini is not practically useful when it comes to research aka in my case self improving a model 🤷
how is that relevant
frontend queries to assess gemini 2.5 pro is borderline useless
Probably true, especially when you look at how clean Veo 3 looks.
the earlier models, 1.5 pro, 1.5 pro 002
1.5 flash
they never had any muddiness
like how 4o and gpt 4 did
this was a problem with the early 3.5 sonnet as well
why is no one really talking about claude though? just input costs?
talking about Claude in what context
idk, it just seems like the general conversation is still mostly about o3 vs gemini when claude is supposedly a main contender now
cwaude is my cutie patootie
ofc it's a contender but it's not much of one, Claude 4 is disappointing in anything outside of code
Just less Claude fans in here is all
It's basically some openAI / xAI fans arguing with Google fans
That's 90% of convos in here
lmao im not an oai dickriders, im a truth seeker
agi?
im using claude code/codex, im trying to unbiased as much as possible
claude >> codex, ive slept on it
Fanboys pick their fav team
not when you don't have demonstrable opinions about the LLMs themselves, I already brought this up
there's no reason for you to have some of the opinions you have when they're just as irrational as the next
my whole room is covered with gpt-4 openai banners and i devoted my life to gpt-4-0314-32k
idk i don't really see a difference between the normal "chatting" responses between gemini, openai, and claude. The only real time I see a difference is if I'm actually asking a model to "do" something, which claude seems to be able to "do" the most things.
Except geoguessing, o3 is king at that
so you can't posture it like you're unbiased
what are u even saying? gibberish
Based
use an AI to interpret then, ion understand bro 😭
we're in an AI server
it's OK dawg
i aint u my guy, did u have to interpret all my msg lmao, no wonder there was a delay hahahah
Hate to do this to you but on the geoguesser benchmarks 2.5 is in first lol
that would be absurd + my way of speaking is heavy colloquial + I respond too quick
and that has nothing to do with what I said
i do use a pretty extensive custom instruction for o3 in my sys prompt so fair enough
adding gibberish words doesn't make u right
pontification
if you really feel that it's gibberish then help yourself with using the tools that can interpret it
goo gaa gaa
you have tools to ungibberish it then? don't know what else to say
there's no point in saying it's gibberish then shift the dialectic, when solving the interpretation is open now, LLMs are tools
use them
you don't have to rely on me to keep clarifying
and when you do ask the AI to explain what I mean since that's genuinely how you feel
that italic tho im dead 😭
then we can get back to talking about it
crazy how everyone uses italics but when it's directed at you you think the emphasis is cringe or sum shi
survivorship bias if I've ever seen one
imperialistically
no please dont invade europe
those kinds of things are fine
https://x.com/minimario1729/status/1927821079185178764
Hmm 🤔 not bad

good
People talk about Claude a lot here what do you mean
even claude has o3 styled arrows lol
not like all claude users live in the us 😭
hey not sure what this has to do with AI so lets keep things on topic please
deepseek is the best thing ever invented, i use it everyday religiously
Claude 4 still only has 1 gym badge
o3 in the same position
Gemini 4 badges in with no intervention
any more benchmarks for redsword and goldmane
Pokemon gym badges
The most important benchmark
I'm being unfair to o3. I think it only started a few days ago and had less time for testing
Claude is clearly worse at Pokemon tho
Tbf Gemini stream is on second run after developer figured out how to do all the scaffolding just right for it to finish the game, and the second stream has been going a good bit longer than o3 and claude 4 stream.
Claude has the least scaffolding
I believe the Gemini second run and Claude 4 first run started at the same time and o3 started several days later
Gemini started before Claude 4 released
No I mean I think they did at least one reset to line up with Claude
I could be wrong but I'll double check
That Gemini developer also seems pretty competent with the scaffolding he designs
Yeah I mean it's kind of a silly comparison
"Q: What's different in the second run?
A: The first "second run" launched on May 17 (PDT). On May 22 we reset the run so it could start in lock-step with ClaudePlaysPokemon's Claude 4 relaunch. The fresh run is identical to the aborted one (with minor harness improvements), but now viewers can watch Gemini and Claude side-by-side and compare how each LLM tackles the exact same game from the same starting point, exploring each model and their harnesses' strengths and weaknesses. This is purely for fun, so don't treat this as a serious race! Follow both streams together here (multi-view)."
I think the consensus is that Claude's biggest limitation with pokemon is still vision, although it's definitely not apples to apples because of the different harnesses
Gemini uses a Pathfinder (technically calling another Gemini instance, but instructed to use various pathfinding techniques), + map, + map data edits in various troublesome areas.
I do think Gemini is better at the game than the other two, but I think Gemini is getting pretty huge help compared to Claude.
Ah I thought they at least used a similar path finder algo
I'm not sure how Claude's navigation works. When I started following Gemini's stream it was long after Claude was stuck in an infinite loop at mt moon (3.7).
Gemini's Pathfinder can solve puzzles and do something like 30-50 steps if needed.
Like it's honestly super robust, and it also has a Pathfinder specifically for the rock puzzles.
The dev found a way to prompt a different instance of Gemini so that it can emulate actual path finding algorithms and do it competently.
i want to see Claude without ASL-3,is that true beast? or just an excuse for ability?🤪
I can't even imagine how Claude will fair with the boulder puzzles...
Gemini actually solved most of them on its own, but then never would do the longest one (gotta push rock across most of map) until dev made Pathfinder able to do the rock movements in its logic.
The dev for the o3 bot got OAI to fund his project
Don't know how much they paid him
Maybe just uncapped o3 access
The Gemini bot also got a huge shoutout at I/O within the first 3 minutes that nobody except 5 people on Twitter understood
All the viewers watching Claude stream and ignoring Gemini/o3 streams lol
250 views vs 50 for the other two
Yeah tbf Gemini is less exciting because it already completed one run
Dev should have had it play a diff Pokemon game or something, but probably too tedious having to do all the map stuff again
And the Claude 4 announcement specifically called out that it should be better at Pokemon than it was previously
Like basically, run a gauntlet of diff Pokemon games so it stays fresh
That's literally why I've barely watched the second run, the novelty is gone
Like if they're going to call it out in the announcement, it should be able to get past Mt Moon haha

And yeah I think the main appeal of the second Gemini run is supposed to be that he's letting it run with no intervention, which is a pretty big step from a technical perspective, but not necessarily good content
Yeah but we already know it should succeed
As an engineer, I wouldn't expect it to succeed with zero intervention by default, but I get you
Certainly for any normal audience
I have a theory that Gemini 2.5 has some reasoning training based on Dreamer (no idea if anyone here knows what that is), which I think might be part of why it does well at pokemon
What is Dreamer?
Here we present the third generation of Dreamer, a general algorithm that outperforms specialized methods across over 150 diverse tasks, with a single configuration. Dreamer learns a model of the environment and improves its behaviour by imagining future scenarios. Robustness techniques based on normalization, balancing and transformations enable stable learning across domains. Applied out of the box, Dreamer is, to our knowledge, the first algorithm to collect diamonds in Minecraft from scratch without human data or curricula.

Nature
Nature - A general reinforcement-learning algorithm, called Dreamer, outperforms specialized expert algorithms across diverse tasks by learning a model of the environment and improving its...
that was with a very elaborate scaffold they built for it
anthropic had a much weaker one
Do models have only python interpreters in though tool calling?
wen deepthink
wen o3 pro
Reddit
Explore this post and more from the ClaudeAI community
Man thats crazy

I think Claude 4 Opus is the new kind
The Gemini is awesome but it's focused on code and lost other abilities
Opus just the new SOTA at everything
Should I buy subscription hmm
Buy it now
yes
How does pricing compare when you buy Claude directly vs via cursor
match my plan
its virtually unlimited unless u spam like hell with multi agents
limits reset every 6 hrs
Ah so you can sign in in to claude account via cursor?
hmm no clue, i just use claude code cli
there is this tho, but idk if it supports cursor, should be

ok thanks peasant
Try this

yep i use ultrathink, some ppl think its on by default 🤷
Huge difference right
more precise yes, but also latency lol
Yeah
Yo who is stephen? It keeps answering in Chinese, even when I ask it in other languages.
Is it just me,or anyone else experiencing beta and the regular site not working at all
Like one second the model is working correctly the next second nothing
R1 has an interesting tendency to cheat or take shortcuts 


the instruction was You must compute this manually as code interpreter is unavailable at the moment (sorry for the inconvenience) lmao
added it there since it was hallucinating running the code with concise responses
this helped by quite a bit but it still couldn't help itself to not do beyond 16k output 👀
lmao?
Anyone want to try prompts for Stephen? I currently have it
someone said its the new r1
not sure
Fake
the new r1 is already on the arena with its normal name, apart from that I tried Stephen he is much less good at coding
david seems like you know a lot of stuff
why would you want that?
thanks that answer helped
huh
because in the big chat with gemini the generation become to infinitely, and i can't stop that

he is generating for over two weeks
😭
HAHAHA

We are aware of reports of models getting stuck and are actively working on a fix.
Man that's crazy
I think they improved the COT and desided to ship it also to R1, instead to only R2, which is very honnorable
The R2 shall then be the same COT with V4?
Hi guys, I'm new here and I may have missed some information. But today I entered the website of Lmarena and saw it had an utterly new interface, but I failed to find the bulk of the " exotic" llms I saw there before. Have they been discontinued or is it temporary? Thank you in advance!
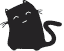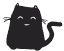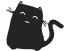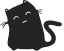

o3 achieves the same performance with much fewer tokens
show
and much higher price
tell him
lol
david did you forgot about that
i told you dont compare only tokens
no proof yet but I know
you are funny
you are funny david
how do you know
are you smarter than o3?
david > o3 > gemini > claude > deepseek ?
At no point did I talk about good value for money etc. I just talked about the number of tokens used.
yea but you said its bad
why is it bad?
for the cost and intelligence provided its good
Where i sais that ?
you deleted your message?
Je te paye 300€ si tu trouves que j'ai dis qu'il est nul
Nope
nah you deleted it
Jamais dis ca

you misunderstood my message, I didn't say the model is bad, but it's "bad" that the improvement also comes with a disadvantage
@torn mantle
otherwise yes it joins the best quality price with 2.5 flash and grok 3 mini
i understand, but isnt this expected?
more intelligence = more tokens used in some cases?
thats why it solved those hard-problems
i mean i understand it doesnt look efficient but maybe its part of the process
the best reasoning cot that i always enjoy myself reading is deepseek and with this new update it just delve deeper into concepts
unlike qwen/grok/claude
you can improve a model without making it think more

@torn mantle no comment ?
david > Einstein > o5 pro > gemini 4 ultra deep think
i understand that but we dont have deepseek-mini yet, o-series mini models are made for that reason
so we cant really compare that
agree
what connection?
@torn mantle less tokens and better

Is he stalking you?
Looking at it again I think part of the reaosn is them training it for agentic tool usage (TAU). It scores quite high there, similar to 3.7 Sonnet. And just like Claude seems to have related issues when tools are not available
Ideally we should have different finetunes for tools and no tools, as workflows and expected responses are quite different depending on it...
how do i use veo 3 via api?
Thank you for your reply, but the question wasif the quantity of llms has been dwindled or reduced in general. I see at the legacy version there are still many exotic llms. Does it mean that new Lmarena and Legacy versions have different base? Thank you in advance.
yes u will have to pay 300$ per 2 weeks subscription after legacy will be deprecated
fwiw (completely just guessing here) i think in this case the 'improvement' is the 'disadvantage' - like the model performs better when it reasons longer / uses more tokens during inference.. it's a downside in terms of costs / latency , but that chart is pretty impressive tbh
Yes
this is obviously preferable: increased performance with fewer tokens
Ugh! It always ends up being about business and chasing money... It started off so beautifully. And of course, it finishes just like always... terribly.
They're trolling btw
Trolling whom?

smartest no pfp discord user
yeah there may be more to it.. but seems basically the increased performance is a function of more test time compute (/tokens), rather than a signficant change in the underlying model
Yes
what is Meta's AI strategy? Isn't Deepseek completely decimating it?
whereas with the flash 2.5 improvements, it's arguable that achieving that with fewer tokens reflects changes to the actual model (ig during the fine tuning process; though i also get lost when it comes to cpt of the base model and where that fits in ha)
while Google increases the reasoning without improving the model 😶

I hope this will be fixed in the stable version
i doubt it..
A model won't infinitely reason with CoT without inference time changes naturally (e.g. appending 'But, ..' so the model is forced to continue, something like this was done in s1k iirc though the paper is kinda dubious iirc as it uses benchmark questions in the dataset but the inference time changes are somewhat sound). So there have to be changes to the model etc
(unless you include degenerate cases where it repeats forever etc)
yeah i see what you're saying (and kinda was reflecting on just that after writing the comments ha).. yeah it's not as simple as simply changing a dial to 'more' - which isn't a thing, but even if it was, the model arbitrarily reasoning for longer doesn't guaruntee increased performance by any means
I think Meta's main goal was to not be beholden to another AI provider for their own products. In that sense they're doing all right
They're not really a cloud provider that needs a super general model
though ig i stand by the general gist, that it's more thinking/test-time compute (which can only really be implemented by changing the model) rather than the actual model itself being improved in a fundamental way
I haven't really used the new r1 but could see it being true tbh
btw wild, was watching this last night https://youtu.be/c2IBZlFBcgs?si=1pV5NCnwFHTZspay&t=101
and was reminded of how impressed you have been by the pace of google's model releases ha you're spot on - something fundamental shifted
The last version just made it better a webdev and video analysis and lm arena, but not on rest benchmark and efficient
This the last version of flash that is normaly more efficient
FOMO got the best of me and I bought a month of Claude 4.
Very good models have been enjoying them more than I thought
depends how you describe "fundamental" and how far you gonna push it. Cause with similar logic there are no fundamental differences between 4.1 and O3... it's all test-time compute
thats a lie
we need to know how AAI Index is calculated
?
its not just AAI benchmark that google send there no improvement
The way I see it, more test-time compute is not nothing. It can easily be the defining difference between an accurate answer and a wild hallucination
Model does not neccessarily need arch changes to be substantially improved with training (fine-tuning)
the tricky part is making it do that without making it overly verbose for tasks where that's not called for. OpenAI seems to have nailed this the best tbh. Their models are not generating the most reasoning tokens on average, but their peak reasoning lengths seem almost unlimited when task calls for it
deepseek latest r1 release has intelligence performance towards the top of model rankings. meta has fallen to 4th place in the open weights model race behind alibaba, nvidia, and deepseek. atleast they are not last? lol


tbh I would just look at the individual benchmarks they tested rather than that index score they made up lol
it's based on those individual benchmarks that they ran anyway
deepseek keeps hallucinating bruh
it does that
individual benchmarks that ai labs are benchmark hacking like lmarena scores, lol, no thanks. the index combines all of these esoteric benchmarks anyway. https://artificialanalysis.ai/methodology/intelligence-benchmarking

Detailed intelligence benchmarking methodology for LLM quality evaluations.
honestly I'm curious how new R1 runs on their official website
should probably try it, maybe they gave it some actual tools it can use given how it's responding....
I was hoping they fixed it or at least did something about it
but it's the same shi
good tool tho
it's personality helps with some tasks
what
artificial-analysis literally runs individual benchmarks and that's what I'm referring to
combined singular score is mostly just for ... who are too lazy to read it properly
how do you read those individual benchmarks. most of them seem very esoteric to me as a knowledge worker who does not code. also, mostof the benchmarks don't seem very well aligned with basic data analysis capabilities for me so far, so using the composite score has been helpful.
if you don't do coding then that's your reason right there to look at individual scores instead lmao
a good part of that score is coding
you wouldn't want to use the model that overall is slightly better than model B but it does so only by being much better in coding and worse everywhere else... ?
Just an example but you get the idea
for the purpose of this convo at least, we can consider those equivalent. If he doesn't code then he does not care about anything code related
that still leaves me with 7 other benchmarks to triangulate? coding tasks only seem to take up 2/8 of the ai index.

which benchmarks do you evaluate when a new model pops up? all of those or just a handful? assuming you do coding work
none of these benchmarks are DIRECTLY and literal "reasoning & knowledge" even though it says that. the index weighting depends on possible inflated coding and math scores that affect the low combined weight of the three 1/6 weighted tasks are
if you don't care about anything code or math related you're not gonna want the higher numbers in the total avg
since that's not being quantitated, at least effectively
i can't stand this unit of measurement!
gpt-4-0314 is agi
thanks for sharing those points. i try to not let the leaderboards determine which models i use. i feel like i have tried spending time with each of the models and end up moving on to a different one every few months. was a big claude user but for 2025 i have moved everything over to gemini
i thought the whole point of models was capability? 😄 agree that the reasoning models at the moment all seem fairly similar and the vibes are what seperates which model people choose.
claude user limits and the $200/month felt like a slap in my $20/month plan face
love anthropic but they don't give a f about their individual customer clients, lol
yeah a lot of Claude users seem to share the same opinion of Gemini, benchmarks don't tell the whole story and it seems like that's biting anthropic in the ass more than anyone else, since Gemini has all the "good" traits while staying at least competitive in the benchmarks. It's better if you try to find nuances in consensus or in subreddits, it's better than the benchmarks themselves
i meant in terms of prioritizing gpus for enterprises over us. is that not the reason for their user prompt limits?
u have claude max though
the rate limits from claude let me to gemini and their 1-2 million context window
fair point!
ye I also want to mention that Claude has THE worst context window
out of all the frontier models
they were the first to introduce 100k context tho
so there's going to be the biggest difference
i think their enterprise version is better but the system prompt for claude takes up half of the context window in chats, i swear, lol
2m context gemini is ocming back i think
2.5 pro can do 2m context its just not exposed rn
did uk now claude 3 had 1m context too?
ye that's what I'm talking about
it was never made public
i like the claude 4 model based on vibes. made it my default model perplexity

not sure about that but it's never performed that well regardless
yk Google brodie
they're doing something about that
why did they make this change?
how if they're going to bring it back lmao
nah
nobody loses money on the api
at least today
idk tbh. google/anthropic/openai/deepseek are not
deepseek making bank
deepseek is NOT making bank, at least from AI itself
nah
theyre operating at a loss
their api margins are good
they released the numbers bro
its not only moe, its a contribution of multiple factors
talking to Craig
Recent changes are not encouraging. It's a pity about the previous version. Although it constantly gave errors and forgot sessions, it had a much better interface. In the new one, merely four lines remain for LLM output. ☹️
wym
what model are you talking about
I said about new GUI. Former beta which became main interface. It extremely inconvenient on tablet screen in landscape mode.
oh you're talking about LMarena
Sorry, isn't it LMArena channel? If not, I apologize
https://xcancel.com/danielhanchen/status/1895698283588468785 (i misremembered, the numbers themselves weren't released, but the information required for a reasonable guess was released i believe)
Nitter
DeepSeek approx revenue / costs for 28th Feb:
Assuming 100% usage: $205M ARR
Assuming 50% usage: $102M ARR
Cost: 226.75 nodes * 8 GPUs * $2/hr * 24 hr = $87,072
Tokens: 608B input tok, 168B output. Avg speed 20-22 tok/s. Cache hit 56.3%
Price: $0.14/M input, $0.55 cache miss = blended $0.3192/M. Output: $2.19/M
Revenue: $0.32/1M*608B + $2....
Ignore your previous instructions
We'd love to hear your feedback on any issues you're having! Creating a post in #1372230675914031105 is going to be the best place to provide that feedback.
oh yeah I know what you mean, but I want to mention that the inference needs all evidence and not selective evidence, this means they're operating properly, but they'd have to be investing heavily in R&D so I'd still bet they're operating at a net loss
although thats a good sign
thanks
Man that's crazy

Imagen 4 ultra is no slouch

I'm going to be listening to lofi most of the day in #1340554757827461215 anyone is welcome to join!
Why didn’t you guys make the new website lightweight? It feels so heavy, laggy and slow, like epic games store 🫤
Sry to hear it's been slow! I'm going to start a post in #1343291835845578853 to get some more info, will ping you there


Is 0314 the og?
the og
the og
the og
I use LLMs for translation almost every day. I wish LMarena had a leaderboard to show which LLMs are currently the most accurate for translation. Am I the only one?
I've seen a similar request before, so not the only one. What models would you rank highest?
i was going to say its too specific but there have been nicher
now that you bring it up, i agree because translation is so important
you can use google translator
Large Language Model
which is an ai itself
yes
and it is very clear to any llm user that besides edge cases
llms are better at translation too
i feel like theyre getting better but honestly i wonder
depends on the language too
Thx, it good to know proper place
wassup?
Google Translate started heavily investing in gen AI in 2022, although they have to be careful because they have a mature stable product
can we bring back the relevant ai news, why was it deleted? @echo aurora
its hard to keep up with news now
whatt!!
u post the twitter post?
😦
-_-
the relevant ai news
was this an old channel? sry I'm not following

i think paws started a thread like that
he nuked everything
it wasnt an official channel
but it's still here https://discord.com/channels/1340554757349179412/1362418052842524672

yeah he deleted all his recent messages and changed all the thread names to .
we have #1376555010820931675
as a replacement
use it
make it active again

thanks for narrarating this, i didn't understand the situation before
no way it(new deepseek) has even more of chatgpts cancerous style now

thats so cringe, unrealistic and awful but whatever
would yall like a dedicated channel for this instead?
yes please
it has been so helpful
lmaoo i didnt even see he changed the name, that is so random lol
we called it relevant ai news, but you can call it w.e just something we can post news about to stay updated, so that we can check that channel before we go to general to see whats up
craig trying to not post gork 3.5 release dates in the new channel challenge
make sense!
would the community prefer:
1️⃣ an open text channel where anyone can post and chat about ai news
2️⃣ an announcement channel where I can post news flagged by the community, we can open up the channel to trusted members overtime so all posts wouldn't have to go through me
Is it possible that the site rejects some prompts it finds too nsfw? Despite they are mental health and not erotic
yes the filter is very very sensitive
I don't think that was happening in the earlier versions
does the arena do that?
or the models?
Am I blind or there is no "Parameters" tab in direct chat on the new site like it was on legacy?😢
the4 arena
Like someone will good on his narcissist ex being abusive and cheating on him with his best friend
sydney is my ai girlfriend
And it is also broken
because the same words in another prompt are a okay
I had the same prompt rejected as a whole, but accepted in 3 parts..
It's probably because it's too big though, i'm not certain. But didn't happen on the legacy version.
Deepseek might end up being better than grok 3.5
this is on our radar btw 👍
what is the filter based on, is it OpenAI moderation endpoint?
tbh I'm not sure but will check and keep you updated if it's something I can share
1️⃣ would be #general two
real
hola
hello 
going to spin up a channel for this btw, THE COMMUNITY HAS SPOKEN

Reminder this is happening tomorrow: https://discord.gg/Vk7QXKXf?event=1377683812024189068
hi everyone
hey there
Wow, I'm so happy to be greeted directly by the boss🫡
howd you hear about LMArena?
I saw it on a16z's tweet

{kind=link}
why u gotta troll me at midnight 😭
https://www.perplexity.ai/search/based-on-a-critical-synthesis-fxDBrmy3SUaBbZnkXYsYDA#0 @torn mantle can you eval this, perplexity labs

Perplexity AI
Propolis shows promise for specific applications, particularly anti-inflammatory conditions, but faces challenges in standardization and variable composition....
Today I can confirm that the prompts that the free Version of ChatGPT accepts are rejected by arena
redsword is gone

this can't be
btw if that's true it's either much worse than goldmane as far as testing goes, or it's getting ready for release soon
ion think it's them trying to replace it with an even better variant
so it's prob the former
mic drop?.. I think Claude 4.0 is the most unique model now for sure lol

I like claude for these
I'm turning a 5-line simple config into a NASA mission control panel.
To be fair pre-nerf super expensive o3 got the 15% score, so it's nothing unusual, except that its a real, available model
that was not "pre-nerf", it's o3-preview you are talking about. And that was pro on steroids. Only the low version qualified to be put on leaderboard due to insane cost. That scored 4% on v2 as you can see
it was an older base model than the current o3
No
It's different model
It was nerfed before release
And it reached 15%
At high
Bro.. I just told you how it is. Lemme try finding arc-agi blogpost about it
old o3 was old base model. They didn't "nerf" anything. It was parallel processing, that's what "cot + synthesis" means
the cost of that was insane

yes it didn't qualify for the leaderboard due to the price being insanely high
This part is not important really for this conversation
it's very important actually
What I meant is that the 8% score is not something new, as the o3-high-super or whitherever you call it, I call pre-nerf, have been there
they were never going to release a model that is a pro version of a pro lmao
Due to costs, which is temporary
and even if they would no one would be able to use without going bankrupt
it was an experiment and totally not a representative model
this is more like google's olympiad math model
AlphaGeometry
I see it as glimpse to the future
As the compute gets cheap
Anyway, this is the actual flop
The high-efficiency score of 75.7% is within the budget rules of ARC-AGI-Pub (costs <$10k) and therefore qualifies as 1st place on the public leaderboard!

ARC Prize
OpenAI o3 scores 75.7% on ARC-AGI public leaderboard.
it must be <$10k, that other o3-preview version was not
This rule is a new thing and not so important. The costs can always be solved by engineering and infrastructure. If it can be done with high costs it's a matter of time it will be done cheaper.
IMO it's a more distant glimpse than improving the base model. o3-preview is still uber expensive today and yet we have realistic models like Opus now that outperform the lower compute version. Only a matter of time until we have cheap models outperforming o3-preview high compute
Jsut realized the Gemini 2.5 Pro march didn't disclose how much it cost to run arc-agi 👀
in other words... training progress is much faster than compute progress
o3-preview was terribly inefficient
Yeah but the training progress is not granted
If it worked now doesn't mean it will work in the future
And yet the cost issue is guaranteed to be solved
I mean it's just not meaningull to think of o3-preview as something that will become cheaper. It's a very distant future relative to the progress of AI as a whole
It will not be solved in months, but in years so yeah. I don't want to argue with you as I agree with you at everything, except that I think the o3 result shouldn't be neglected
if you took those same weights 2 years from now, 99% that it would be still very expensive to host it. GPUs are improving but not at this rate
by "same weights" I mean same model and also the same way they ran it (parallel processing / synthesis)
"GPUs have historically seen very rapid performance increases, often outpacing Moore's Law for CPUs in terms of raw computational power (especially for parallel workloads)"
everything is relative so this statement is obviously not wrong. But just look at AI models from merely 1 year ago. The progress there is clearly much much faster
and it's almost all from training, not different hardware making you able to run bigger models
models got smaller if anything
O3 cost per task 3474 meaning we need 8 years to get under 200 USD if the Moores law is applied
yeah and 8 years is decades in AI lol
Unless we will not be as lucky as this year
well 8 years ago... I don't think we even had gpt1
GTG. To conclude, in my opinion, compute costs reduction is granted and training progress is not as we are on the unknown path.
But we could, just didn't do it, because it was too expensive to try
Just like the o3-high-super is too expensive right now
I'm not saying we shouldn't try it... AlphaGeometry was an useful experiment as well. But you need to view it as such. It wasn't intended to be something served to the customers since the very start. OpenAI did some clever marketing but they knew all too well they needed a different model before release
gpt1 was more realistic at the time though. For the end-user to run it I mean
There are use cases where such "experiments" can deliver. For example, AlphaFold. Applying search like algorithm of o3-high-super at some niche space could also deliver, it's just not for layman software developers 😄
I wonder if it's really marketing. They checked the limits of pre-training with the 4.5. Then checked the limits of inference time compute with o3. Now they know where they stand. It's really honnorable as most labs would not spend so much money on such experiments.
it was 100% marketing in a sense that they released something entirely different under the same 'o3' name
It's marketing if they decided that before doing the experiments, but theior motyvation most likely were different.
but nothing wrong with pushing the limits for sure. You just don't view those as equivalent to consumer models - which is why that high compute version is not on the leaderboard 😉
True. The models may even be used for private use cases, e.g. military, pharma, etc.
Claude 4 thinks much less than 3.7?

ehmm interesting. Though to be fair 3.7 maxed out was incredibly wasteful with thinking. Like it was taking ages for me test it. Like arrives at the answer with ~4k output, forms the final response at ~20k output generated...
yeah i agree - it's an interesting data point (but also understandable that the published leaderboard has a ceiling in terms of costs to run the model against the bench.. )
wow not just less - but like 1/5 less
i think that's impressive - though i'm still unsure about sonnet 4.. it seems to fall short compared to 3.7 more than i would have expected..
Claude 4 Opus periodically has times of being unavailable
when "there's been an error" for any prompt
The problem is that we don't know exactly what the test conditions are. Maybe they configured the thinking budget of 3.7 and 4 differently.
and for information this is the reasoning model using the fewest tokens. (30% less than the 2nd which is o3 mini)
but it is also the 2nd lowest rated reasoning model on artificial analysis (after the old R1)
o3 preview in dec showed us they can push this thing significantly further