
#general
1 messages · Page 27 of 1
how is grok mini so high
this says its on par with o4 and 2.5 pro
but dirt cheap
how is that not the best model?
wait claude has the highest output?
at 128k?
then grok?
not really sure what their methodology is.. i think they mainly aggregate evals, but also conduct their own (or maybe it's the other way round) https://artificialanalysis.ai/models/grok-3-mini-reasoning
When we getting CLaude 4 already
what do you think about grok 3 mini?
u think its SOTA?
I think only real good models are google, Claude, and deep seek
Dayhush looks comparable to NW
Google is competitive on price and best in some categories, Claude is best overall, and deep seek is open source
Open AI too expensive and too censored/stiff don’t like it
Grok is kind of funky, it’s not best on anything right now, so not important
Anyone getting Claybrook? the pokemon battle simulator blow me away
which company model is claybrook?
No idea, how do you check for that?
Reka.ai seems to be doing some sort of a new beta for their site.

Idk what model this is but it's so bad lmao.
how do we check which company its from?
generally you can just ask them... like which company model are you?
but folks here are very smart and they can look at configs etc to figure out the company
hmm only got Claybrook on webdev arena. Let me see if Claybrook shows up
its google

Hello all! I have been playing with the arena battle and I have a very silly question— are models picked entirely at random, or are they weighed somehow? I'm wondering because I often see the same models, despite the huge pool.
"Claude is best overall". By overall you probably mean "vibes"? 😄 Tell me how's it better than o3, rather than pricing
does anyone have an explanation as to why 2.5 flash reasoning is more expensive per output token compared to 2.5 flash? Doesn't it still use the same model when it's reasoning? Or is it like a different quantization maybe?

2.5 flash vs 2.5 flash?
do you mean 2.0?
I mean 2.5 flash with reasoning enabled vs with reasoning disabled
so it's 2 different models under the same name?
all in all it seems like the reasoning version is massively more expensive. Not only is the reasoning version like 6 times more expensive per output tokens, it's going to generate way more output tokens. Initially I thought it would only increase the number of tokens generated, but I didn't expect they would also charge more per token on the reasoning version
Would you say that the output is 6x better?
nah fwiw i've found it a bit underwhelming - it's not up there with gem pro 2.5 (for me / this is all obviously subjective..)
not gonna lie I havent even tried the model yet lol
but solid, for sure
so grok 3 mini is really 1/7th the output token price of 2.5 flash thinking lol
idk why google made 2.5 flash reasoning so overpriced
@calm sequoia as requested I added ranking to the tables (based on AUC calcs, sorted by 1M since my company is focused on very long context). I made changes to the charts but not including them here until I have new models to run it on. Enjoy


🍆 🫦 me and 2.5 coder
Flash better?
There's a slightly higher score at 32k and 128k context for 2.5 Flash (Thinking enabled) compared 2.5 Pro, but it's within margin of error. Honestly, both 2.5 Flash (Thinking) and 2.5 Pro have practically the same scores.
One is significantly cheaper
Yes, if you compare cost and only care about context recall, then yes it is better 😉
I found it interesting that they perform the same. That isn't true for all other model families with this bench so far.
Gemini 2.5 pro is too confident in its own errors and didn’t want to undergo another investigation of the prompt
Had a hard time disproving the llm
Working on it. Somehow my org is locked out of o3. OpenAI support says we should have access and are looking into it
You need to verify your account
US
We get an error message when we try to verify, before the Persona link is generated
Yeah, we can't even get to that step on our account
i also don't have access to it, despite having tier 4, it's a broad issue. Just kills hype imo, but if they think it helps them excluding users, so be it. I am not exactly starving for models, lol.
hello,
do you know when we will have o3 and o4-mini-high in leaderboard?
Enough data
are they better than Gemini 2.5 pro?
We literally get a server error when we try to verify, so we can't even upload an ID. Support thinks its an issue on their end and are looking into it. 🤷
I'm interested in the o3 results too, so hoping they resolve ASAP.
I tried this in all models I know and they all failed

expected result:

tried with gemini 2.5 pro and new openai models, all failed
Both are better

Mau?
This chart does not include Gemini 2.5 pro
all Gemini models are pretty bad until Gemini 2.5 Pro, who is the best or one of the best models yet
Monthly Active Users is my guess
I don’t see any spike though
If your are not using it for math or coding, it’s better in every conceivable way
The O models are stem problem solvers, pretty terrible for general world knowledge, conversations, writing ability etc
If you are not in a technical field, or college, the O models probably aren’t useful to you
Now Claude is the best overall in my opinion since it feels the most grounded and consistent, Gemini would be the better frontier model, but it’s less capable of revising it’s mistakes, writing, and world understanding I’d say
Lmfao
Spiritually cucked to anthropic.
it’s less capable of revising it’s mistakes, writing, and world understanding I’d say
I'd love to see an example of this.
Gemini 2.5 is great at noticing mistakes
As for writing, your prompt may just be bad. Deepseek does a better job at creative writing for me than Anthropic
Though it does entirely depend on what you are asking for
why you post this?
this might be old:

Indeed you are late
I don't have an example, but I have noticed it doesn't seem to understand certain ML concepts as well as Claude 3.7 Sonnet

Burp Suite includes AI-powered features designed to enhance your security testing workflow. They enable you to uncover vulnerabilities more efficiently, ...
ai vs ai CTF
soon?
and it doesn't follow instructions nearly as well as sonnet
Like when I ask Gemini 2.5 Pro to write code with no comments, it still uses tons of comments, or if I tell it to be concise, it doesn't listen at all. It's just verbose with no way to fix it. Claude 3.7 Sonnet doesn't have these issues in my experience.
You might need a lower temperature
I use temperature 0.5 all the time
so it's not that
it just doesn't listen to prompting nearly as well as Claude 3.7 Sonnet
Connection errored out.
WHAT
BURPSUITE AI
This looks really good! Keep up the good work 👍 Somehow on twitter there's a table with completely different result for long context. I wonder why 🤔 Will look for it for comparison.
Try english and maybe text format
Interesting. Are you using it for mental support?
It seems according to benchmarks that this is not the case
Though I used to think it was
lmao i voted gpt 4.1 nano over claude 3.5 haiku
Lmfao
Hacking now ACTually going to be easy for skids
yo @tall summit you were the one talking about making a chess game right?
yeah

Welcome to the AI Chess Battle OpenAI o3 and Gemini 2.5 Pro the state of the art models will be playing a chess match against each other. Let's see which model actually wins this.
openai o3, o3, o3 model, openai o4 mini, openai, chatgpt, ai, artificial intelligence, google gemini, gemini 2.5 pro, gemini 2.5, google ai, new ai coding with gem...
this dude is livestreaming them going against each other
Hey guys, I haven't been online for a couple of days. How have oAI's new models been fairing in the arena?
and twitter accounts of course
I just got 4.1 in my first prompt, is o3 full and any version of o4 contending as well rn?
mostly correlating with their benchmark stats.
yes o4-mini (not high i don't think someone correct me) and o3 full are contending
as well as 4.1 full mini nano
they're all even on direct chat
HAHA THE USER POLL OF WHO WILL WIN IS 29 TO 29
aww 31-29
very even
im kinda mad he made it before us 😦
we dead was talking about this
the thing about chess context window does not matter as much
since you can always give the current game state to the model and nothing else
and start new convos with each model for every move
having memory of the previous moves doesn't matter in this case
it helps according to that blog post
i can see it helping, but an intelligent model can understand the game based on a snapshot of the current state
like for any chess player
yeah having prior knowledge will help to understand how the other player plays
maybe then logging why it made each move and having that as knowledge base can be a good addition
you gotta add stuff like that in the SP
gemini 2.5 couldnt interpret a FEN
(according to the single and informal test)
really
how is that possible
maybe you might have to grond it with search as well
might be a bit rigged, i wouldn't let it use search for chess.
just tried (in the arena) and it still can't or it just doesn't understand chess
old gpt-4 was pretty good at chess
it thinks the black king can move to b6, a8, or b8

i gave it an fen once and it even guessed the opening
and that the white king has no legal moves
if they both have access to search wouldnt it be fair?
the point is how good the llm is
not how good it can search about chess
but that will show how well it can use tools to achieve a goal,
sure if you want to measure that
if they do not know how to play without help with search then give them the access to search until they can play chess properly wihtout help
which are both wrong btw
cause currently you are saying they cant even read FEN properly
i wonder what would happen if i gave the pgn
gpt-4T was cracked at chess. It was extremely knowledgeable about very specific opening moves. also, it was able to play several full games without any illegal moves, which most current llms cannot do
wow i never tried it
so you think the models got worse?
the new models r a lot better at 99% of tasks i wanna say
idk why they fall off in chess ability
something about having more parameters would be my guess
what happened to alpha go?
ok i gave it a pgn and it knew
how are llms so much worse than alpha go
for some reason
Lmao i havent heard that name in ages
wait a second
You don’t understand writing very well if you think Deep Seek is good, is just overly emphatic and random
@balmy mist gemini 2.5 pro thinks the white king can move to... a2
even after it wrote:
White: King on a1, Queen on a5, Rook on c1, Bishop on c4, Pawns on a2, c3, d4, e5, f4, g3.
Wtf
though this is wrong the pawn on d4 is black and there is no pawn on c3
so it's even worse
Benchmarks are just general use estimations, doesn’t mean they are accurate
i dont understand why they are so bad
Werks for me.
If I need a problem solved, Ill use Gemini 2.5 pro, for everything else, Claude
GPT-4 was really strong when it first came out. At that time, Anthropic might not have split from OpenAI yet
GPT more like PP
🥶
like alpha go is SOTA in specilazation, why dont we specialize our curretn SOTA to different tasks on the level that alpha go ws for go and League?
but the thinking that goes into play chess should be similar to the thinking that goes into figuring out stuff
like reasoning
yes, they use similar logic
Nothing exciting releasing
but chess is much more 1-dimensional
haha
because alpha go had an easy reward function
which is win a game
and the reward function is set during the training phase right? can we have an additional one during finetuning?
This makes perfect sense if the reasoning model uses entropy-based logit search as linked to earlier today. I don't know if they do, but I was expecting to see exactly this kind of pricing anomaly for models that do.
AlphaGo, AlphaZero, AlphaCoder ... are all vastly different architectures. A Transformer LLM cannot be trained the way Alpha* is, and if it could be, it doesn't operate in a way that would allow it to use that training anyway. VASTLY different.
Take AlphaCoder for instance. It achieved/achieves SOTA on particular types of competitive coding by doing a ludicrous number of attempts (>100k, in some instances millions IIRC) and uses search to find the best/correct/optimal solution. It does work, but it takes a lot of compute and it is definitely not 'reasoning' in a humanlike way.
AlphaZero evaluates 10000s of moves per position, which is actually far less than it would need to do a brute-force search; part of the genius of AlphaZero is its ability to prune the search space down from millions of moves to just tens of thousands. But it's still search.
Current-gen reasoning LLMs don't do policy search, not in that way and not at that scale. The main thing they can do is spew more tokens in thinking mode in a controlled manner, effectively stuffing their own context with a small number of possible plans/approaches/solutions, refining this iteratively until their thinking budget is exhausted.
As most things in LLMs, Thinking Mode is just a primitive, degenerate form of ~~bending ~~policy search.
Thinking Mode gives the LLM a few dozen shots at getting to a better solution, but it's neither systematic nor exhaustive, nor does it have a world model or persistent state to simulate or probe internally. As such, there is no way to adapt a (current gen) LLM to do what AlphaZero does.
they are accurate for the things that they test, for example the benchmarks that test writing ability are relatively accurate for testing writing ability
though it varies a lot benchmark to benchmark
some benchmarks are graded by llms and that's a whole new can of worms to open
yes..?
it also wastes so many tokens for them
rendering issues
barely anyone uses any of the feature text channels lol
people already issued that
havent seen any mods tbh
which paper are you referring to? The swe search one?
.
they don't care to monitor this server
Post something sus to get them to monitor
AlphaGo, AlphaZero, AlphaCoder ... are
you can do that
Actually I just updated the link to the paper, the one I wanted to link to was from DeepMind and it's a much better read.
whats the rate limit of o3 in chatgpt pro?
50/week that's for plus, my bad
"unlimited" within reason, aka limited but high limit

There are so many AI app builders these days, but none of them can really do backend stuff at all. At least until Convex dropped theirs...
Thank you Agentuity for sponsoring! Check them out at: https://soydev.link/agentuity
SOURCE
https://chef.convex.dev/
Want to sponsor a video? Learn more here: https://soydev.link/sponsor-me
Check out my T...
anyone tried https://chef.convex.dev/

Cook up something hot with Chef, the full-stack AI coding agent from Convex
but you cant use gemini models 😦
and only claude 3.5
interesting why they only used these three

4.1 is a good coding model and grok 3 mini as well as 3.5, but why no 2.5
i heard people say non reasoning models are better at coding so maybe why the SOTA is not here, but why not 3.7 or v3?
@hollow ivy what was the system prompt for nw again?
when does the team decide when to update the leaderboard?
i don't know, that's why im asking
Hadn't yet, but web app codegen is my jam (and my side project) so I have to try it now. Seems like they do proper backend too, which is rare (app.base44.com, Probz.ai are a few notable exceptions).
yeah this theo guy seems to really like it, im about to use it to create the arena for ai to go against each other now
hopefully it can do it
OK Chef is pretty cool. It generates a working app with DB and backend, and all the features it built actually worked.... though it only built half of the prompt, and it overall looked pretty crappy. Still, I'd say it's one of the best I've seen in terms of actually working
guys, any new strong anonymous models in normal arena? been away for a week
A WEEK? OMG you're in for a treat. nightwhisper is back with a new checkpoint as dayhush
in normal arena or webdev?
webdev I believe
Other Google models: claybrook (okay), dragontail (very strong, likely a Pro update or something)
dragontail I have had tried, claybrook gonna try to catch thx
twitch clone




which one is better
sonnet 3.7
gpt4.1
dayhush
claybrook
not in order
bottom left imo
Would say bottom left too, which one was it? I would guess dayhush.
pretty neat
yea its dayhush
dayhush is good
dayhush
I do think we're getting Gemini cider
new google model?
gemini cider sounds fun
A Google employee has already confirmed coder coming
lmao
:3
I'm still happy we're actually possibly getting ultra
google is cooking
yeah they need to release it tonight as a treat for us
wait, fr?
when did that happen
first time they've even talked about ultra for over a year
have you not seen
nope
check relevant ai news channel


probably good for writing, then
at least, going by leo's impression of
if ultra is as good as pro but with expected scaling improvements then sign me up
i am equally curious about pricing
im shocked he replied to that lol
given that the free rate limits for pro are 25req/day, gemini ultra is probably gonna be like 2
well, more realistically, 0
personally, i kinda like that we stopped trying to scale for a little bit and focused on releasing models of similar sizes but with more refined techniques
at least, from my impression (of frontier models)
4.5 got dialed back, opus 3.5/3.7 (if it exists at all) hasn't been publicly released
The really large models are really good for me, so I'd love 2.5 Ultra as I'm already a large fan of 4.5 and I'm hitting limits for 4.5 weekly. It's just really good In writing.
i do think huge models are impractical now, but that doesn't mean they have 0 value
what do you think their value is now?
mainly in creative tasks and emergent capabilities
it's 4.1
you think we can have a big reasoning model?
i worry that, in increasing the max available model size, we'll end up inadvertently heavily increasing the total environmental impact/needed compute because people will use the biggest model possible for tasks that don't need it
absolutely
but again
it would be impractical
and probably prohibitively expensive
what is the biggest model rn? 4.5?
maybe that's a fallacy of some kind lol
lol
how so?
and gpt5 will be using that ?
writing?
as the base?
but wouldnt gpt5 be a large reasoning model?
isn't gpt-4 allegedly like 1.2T
gpt-4 was just over 1T yed
yes
it's crazy how we've absolutely dunked on 4 performance wise with so much fewer active parameters
🤣
gemma 3 27b
literally can run that on my laptop (barely, at less than a token per second)
2023 (?) hn commenters were right
not sure how longer context would improve performance that much
super long context doesn't seem to be good for many tasks atm, surprisingly
oh yeah im told work is well underway on claude 4.0
least of all coding
wonder if it'll top lmarena? probably not unless
might've pondered this in this chat before
Reasoning in latent space without outputting tokens. Much more efficient, much less information lost to the token representation, should be much more humanlike
yeah didn't meta (for all their faults) publish a paper on that recently
The 2.5 Pro still blows my mind every day and it's not even SOTA anymore 👀

not great for interpretability purposes, though (probably)
yeah I remember seeing "Gemini 2.5 Pro" in a twitter notification, tapping it, looking at the benchmark image and my jaw dropped
it was the last thing I expected from deepmind
what about the thing meta was saying about reasoning without using tokens>
They simply looked at what Meta is doing and did exact opposite
yann lecooked
It's similar to Yann LeCun's theory of mind, so FAIR is researching this kind of thing. You can look up JEPA
Still having dopamine cravings since that time
Is grok 3 mini on lmarena?
wheres o3
reasoning in a non-language-based abstract space was something i felt would be the endgame of LLMs since GPT-4, but i never knew enough to really formalize my ideas let alone work towards creating them
arena updated Apr 18, 2025
and no o3 yet :/
it's cool to see that people are pursuing that now
Go vote
How about 0 for a time as with 2.5
I mean it's totally doable -- build your LLM around a sparse autoencoder and you've got just that -- but getting it to scale and perform as well as a Transformer LLM is another thing
hm
not exactly an ML person at the moment, but wouldn't you want to build some sort of transformer that had a way of tokenizing "thoughts"
if that makes any sense
i uh
j


@keen beacon
language mixing? or just gibberish
i was under the impression that we specifically optimized against that happening during RL for interpretability reasons
Sure, a small transformer on either side of the AE would do the trick. It's not the only way, but it would be the most obvious one today
The more gibberish the better
It would be smart tontrain small 3B model tontranslate gibberish to language if seeing thinking is so interesting to people
maybe if you do RL enough, it'll just figure out a language of pure thought on its own that looks like unreadable random data to someone reading the CoT
Yes, because it needs to learn compression. Unless English is the most efficient language that can exist. Which isn't the case.
i'd put like 15 paranthetics here but i think this idea is mostly vibe-based anyway
ooh ooh ithkuil
Yes, or if you just don't use language tokens for reasoning in the first place. You can create your embeddings from language to latent vectors, then operate on the vectors all the way to the answer, and then translate back to language at the end/output. Apple Intelligence allegedly did this using i-JEPA internally, then using something small like Phi-3 trained to describe the result in natural language.
time for ithkuil to shine
interesting
i ought to read about this stuff more
I wonder if polymarket becomes a problem for lmsys arena. Close to $3M has been bet riding on o3 or o4-mini surpassing 2.5 pro or not by end of April. Wouldn't be surprised if that's why we see new accounts asking about when it will be added
yeah, i worry about the dynamics that might arise when the betting market founded on the results of this benchmark handles vastly more money than the actual organization responsible for it
wait that polymarket question uses lmarena as its metric?
never knew
It’s closer to like 100k or so
So basically Goodhart's Law, but with money?
?
The total volume traded is a poor indicator for money riding on this
oh, i was under the impression that it was the volume currently in the market
You should look at open interest
Say I buy a share from you then sell it back
We technically traded 2 shares but there’s no money riding on the outcome
the total money in the market is the same as the total number of (yes+no)/2 shares in circulation, no?
More like the # of yes shares due to an intricacy with how Polymarket works
NO shares is a poor indicator
wdym? i was under the impression that yes or no shares couldn't exist independently w/o a corresponding opposite share
Yeah but say I buy NO on every company
Then I don’t have any exposure to the outcome
Polymarket lets you get your money back by merging those shares into USDC
and the no shares effectively dissappear
ohhhh, merging can happen across different options in a market?
my mistake
i thought it was just yes+no of one specific option, nothing else
apologies
Even if volume is only six figures, money riding on it is clearly incentive to try and game system. I doubt people trying that would be advanced enough to get past lmsys systems but they should be aware.
yeah
I think they are and I don’t see any indication that people are rigging it
or buy both a yes and no share at the same time for $1
Hopefully stays that way
There was that one Reddit post but I’m pretty sure it was fake
@deep adder we're operating under the assumptions you're asserting - i think this is a misunderstanding
yes
@brittle tiger correct me if i'm wrong, but
Technically you can’t sell shares on Polymarket
But I don’t think there is any misunderstanding here
It’s just semantics
Not intuitive or meaningful
i think there was some market manipulation happening after openai stream, dumping to lower the prices and buying cheap
Some people made bad trades and you could’ve traded against them and made money
That’s all that happened
Skibidi
It’s not ‘manipulation’
I think the issue is around manipulation of arena, not polymarket where that's going to be an issue in every market
some people may have made fictive orders that they never meant to execute .. which may drive prices up or down, thats market manipulation and people have gone to jail for, though only rare cases when they were too good at it xD
wdym?
What do you mean fictitious
i imagine it still depends on the country you're in
I traded a few thousand shares against them and made money
Hi, I do believe we need to add geographical understanding to lmarena

Where AIs play geoguessr
They just made a bad trade
Mountains are easy
When you ‘sell’ yes your technically buying NO and then merging the shares into USDC. The mechanism isn’t too important
but id imagine that if someone would go through the effort to rig arena score, theyd do it for o3 , since profit would be bigger
ohh
my mistake
There was a Reddit post from someone who claimed to rig the arena but it seemed fake
sorry for drumming up an argument lol
i thought craig was joking when he said he traded a ton on prediction markets
question, what happens if 50 shares are being sold at 31 cent, but i place buy order for 50 shares at 60 cents (stupid ofc) but what would happen
would i be buying from those selling at 60 cents or 31cent ?
rare to see people sit and only talk about $
very logical and rare, i wonder why that is
i should eep

Grok is known to be good at benchmarks but not in practise. I'm not claiming it's underperforming, but there haven't been a single instance where Grok 3 is best at my usecases. Maybe new thinking model will be different, but there are too many options for coding at this level anyways.
atm o3>2.5>claude 3.7> the rest
You did forget o4-mini
Performs on-par with o3
The problem being people believe o3 and o4-mini are the same
There is a reasonable difference
@keen beacon @sonic tendon would you share your experiances in betting on benchmarks? Was it successful?
A grok fan long time no see
Very successful so far. But i cant share any sauce xd as to how
I do ignore 99% of markets. most are betting, i pick the 1% where i can invest based on information
I though only insiders make money there
they make the most $ for sure
i assume others also $ launder
but there are others ways
just one example i will give
for rotten tomatoes score for movies, i literally trained an ai model to predict final score, based on previous movie data
and i constantly scraped the rotten tomatoes site for new reviews, that gave me an edge over the market
Very impresive
how do u bet on things
like on a site or something
nahh grok is not better than 2.5 lol
i wouldnt even put it better than 3.7 thats debatable
i have bro, but i will test again, i did not test mini yet
also yall need to try roo code with the different modes
its kinda cracked
i was only using boomerang mode
but you can do much much more
i either get alerted to verify before buy, or if i specified it then ai buys automatically via api
basically your own custom ai agent system that uses specific models for certain tasks and roles
you would buy for 31
but this is the wrong chanel
New chart just dropped.

but like where do u bet
u keep saying ai buys/sells wdym by that
u have a task llm set up?
all i can say is that i bet on very few markets that are very news driven, llm gets news all the time, when its good news than it auto invests
Elon is such a liar
He said grok 3 will be updated soon
But i havent noticed an difference at all
I guess those updates will be on grok 3.5
They really should fix multi turn
what about writing
@torn mantle im trying to make the best system prompt for a UI/EX designer, what do you use for your agents? also is apple the undisputed best looking apps? like user friendly and stuff?
UHM guys, are you able to convince gemini 2.5 pro, that todays date is in 2025?
Mine is ADAMANT that its 2024 April 19th
and i give it websites and screenshots and its gaslighting me into thinking i docttored the screenshots lol
and i had it go to https://www.timeanddate.com/ and they STILL think its 2024
maybe it cant read the website and its hallucinating
literally bing chat reference
i do use a lot of keywords tbh
- material UI design
- apple design
- neumorphic design
- skeuomorphic
- glassmorphism
- beautiful gradients
- premium design
you can experiment with neumorphic
its pretty good too
for threejs i just ask it to make it realistic/HDR env/in-depth shadows & details
something like that
no one is paying for personal use of 2.5 pro though
are there any rumors for nightwhisper or dragontail release dates?
it should be on $0
same
nw follows directions perfectly
and the ui design is slightly better
without having to nudge it as much
redditors are screaming that o3's geoguessr performance is because of metadata
google rigging the benchmarks once again!
chill google is king
i honestly want google to create ASI before openai
I had no idea you only get 32k context with Plus for chatgpt. Apparently it just does RAG after that
https://x.com/TheXeophon/status/1913120160753332703?t=6arSE6mYeArtrSWOTpzvNQ&s=19
Some @ChatGPTapp footguns:
- The model for Deep Research does not matter. It always uses o3 (Deep Research version)
- The model for image generation *does* matter - image gen is a tool; chosen model writes the prompt
- Pro has 128K context, Plus (+Teams) 32K, free 8K
google is undoubtably the best bang for ur buck
plus they already have the competition on lock
they sell LLM hosting for gpt and many other llms on azure
the amount of data they're probably getting rn is crazy
poll_question_text
Have you ever bet money on the bench outcome?
victor_answer_votes
4
total_votes
8
victor_answer_id
2
victor_answer_text
No
Anyone know if they (xAI) are still doing consensus@64 for their benchmarks, or moved to pass@1? Genuinely curious, not paid attention since the original announcement
yeah how did you know?
I'm calling for clarity
but I'm wondering why he said grok 3 and not grok 3 mini
or grok 3 vs 2.5 flash
knowing 2.0 pro would be a better base, and that 2.5 is even better than that
just saying
2.5 pro has a significantly better simpleqa score
its the closest thing to 4.5
afaik
ye
its like 10% better than grok 3 (simpleqa, which is quite significant)
2.0 pro is the best model out of that bunch lol
or was grok 3 updated recently
bruh?
ya. and anyway their reasoning doesnt seem to increase simpleqa yet, 2.5 flash actually has a lower simpleqa score than gem 2 flash
ive been seriously impressed with how much 2.5 pro knows tbh
that would just be inherent to the model size
2.0 pro is a stronger model than grok 3
and can reason better when asked to
therefore is a better "base model"
actually hollon, 2.0 pro is STILL the highest performing non reasoning model besides 4.5 on livebench??
yo wtf
Lowkey thought there was gonna be another model that I forgot about
can you screenshot
?
oh you mean this one
what does that mean tho?
lmarena isn't a performance bench it's a vibe bench
so?
because it is lol
and it doesn't write better
this is something I specifically look for
grok 3 shoehorns itself narratively
buns writing, good philosophical understand
becomes the balance
base ye
the best model I can pull the potential out of tho
is 2.5 pro
ye
it's creative but I disagree a ton
it doesn't know real writing conventions
it doesn't know how to conform to instructions
ie, a prose
or a poem
how would telling you be informative if I'm doing the same for all these models
4.5 is def human like
it doesn't get stuck on repetition
it doesn't overemphasize
it doesn't become swayed so much by context
but it isn't so good for writing, just "ideas"
since it lacks rigor
or academic conformity
just give it a quiz or something
like a writing quiz
it's going to get stuck on the potential ambiguity
and just choose whatever
rationalizing every answer the best it can
like "pick a sentence in source #2 that supports and states the relevant premise to source #2 in source #1"
given 2 sources
a hard one ofc
it'll sufficiently rationalize each sentence in the second source
but not be able to choose the "correct" sentence
with rigor
flash 2.0 gets these right
lol
but I'm saying it's a very general thing, you'll encounter it or you probably have
and didn't notice
that it lacks academic rigor
yep 4.5 has great implicit understanding
but again, this is still something that most other models lack, that 2.0 pro doesn't
although behind gpt 4.5 it's 3.5 sonnet
4.5 is the first model to have a somewhat decent sense of humor
ye
unprompted
on what
oh mb
nah I have
it hallucinates too much
it's smart
but damn
doesn't really understand prompts too well
can o3 pro come any sooner 😭
i'm not surprised by that.. i'm getting pretty crappy results from flash2.5. With thinking enabled it performs better, but it feels very underdeveloped (experimental ig ha)
grok-3-mini(high) has also done quite poorly against a few question sets i've been using lately. will share some screenshots in a min. but yeah in terms comprehension / verbal reasoning (wordplays etc), and understanding of real-world implications / spatial reasoning as well as emotional intelligence – it's pretty crap from what i'm seeing tbh



what was thing you should where grok 3 mini was really good?
im trying to see which model i should use for my low level agents, im thinking between: grok 3 mini, o4 mini, 4.1 mini, or 2.5 flash
prob o4 mini since its good at calling tools
and o4 is cheap right?
the only thing is grok 3 mini gives you free credits every month $150
does it support natively calling tools tho?
yeah free is better than everything else tho
i mean u can still work out a solution its not as efficient but u have a ton of free credits and im assuming pricing is quite cheap on grok 3 mini
e.g. in the final response it returns the json of the tool call
and you got this chart:

have you tried using the models in ai ide like roo code?
thats where i am using these agents
oh idk then lol
if it supports a custom openai server u could probably make ur own proxy server that calls the grok api and emulates tool calls
it really depends but im not familar with that stuff at all (ai ides)
what is the artificial analysis intelligence?
if this is true then grok 3 mini is the best model
its a score based on a combination of several benchmarks
i mean its charting the cost/performance ratio
yeah but vertical is performance
it destroys on cost
but then on performance its like top 3
besides o3 cause its not on the chart
ya i think its because of the benchmarks they choose
obviously depending on the task it varies
i think u should look at swebench or something
u are not throwing graduate level google proof questions
i dont know how to feel about grok 3 mini tbh
ahh okay, anyone have an updated version fro swe?
i think its worth locking in the best small model model(semi small)
wrt artificial analysis intelligence, i think the benchmarks there, xai probably applied a lot of rl proportionally to similar questions
what your tests show?
so it may be misleading
waht do you think is the best small model?
same, i only am considering it now because of that chart
and bc its free
if you spend more time explaining to a model how to do things then you better off with another one
i found myself re-explaining my prompt
over and over
and reminding grok the context
it wasnt a good experience
it will generate a good code but after the 2nd prompt it wont follow instructions well
hold on tho
this website struggles with some stuff
ppl say the api for it is better
this is probably more representative btw: https://aider.chat/docs/leaderboards/
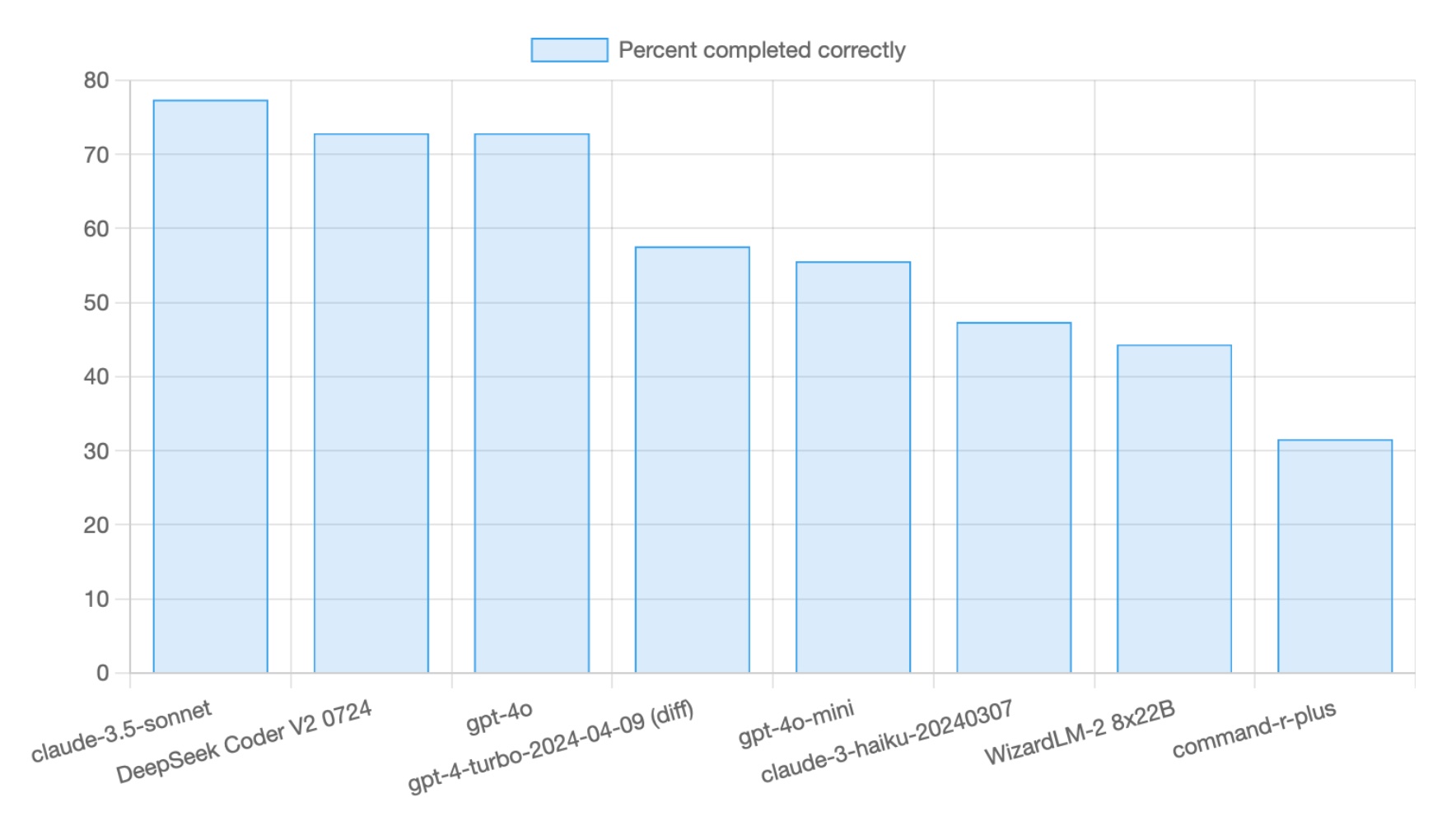
price to performance is redundant in a vaccuum
yea
of ur use case
wtf? they used two models?

but its too expensive
i suspect something along these lines
do yall like 2.5 flash?
im settling on it for my small model
o4 is to expensive and only slightly better than flash, what yall think?
im still trying dayhush xd
Grok 3 mini juiced on the benchmarks, that’s the only explanation for that ludicrous position on the Artificial Analysis chart. I tested the model myself last night and it’s pretty mid. It hallucinated in my grounded recall test, and did a good job on my realistic coding test, though it only barely broke my top ten of coding models.
In my harder coding test it was below average among the contenders (I have only given this test to the 15 or so most promising coding models so ‘average’ isn’t terrible, but Grok 3 mini was below average.
The Aider leaderboard looks pretty much correct in terms of real world coding usefulness of those models, matches my tests and experience quite well (though I still find that o3 and o4-mini behave inconsistently).
Grok 3 Mini might have some good uses as a cheap capable model for non-coding tasks. It had perfect scores for me in wordplay and associative logic.
That's true. As I said many times before, Grok shouldn't have taken the No. 1 spot even on general benchmark. I think they did similar thing that llama did.
the only ones that believes those benchmarks are grok devs
we all know it underperformed
also
what happened to "Big Brain" feature?
yeah that might not come
unfortunately dayhush doesnt seem that good at complex physical simulations
if its a recent checkpoint of nightwhisper then idk how to feel about that
i mean its better than other models but its not what i had in mind
Hmm..... I managed to get Gemini 2.5 Flash to make a browser game for my coding test. With the default settings it basically told me to pound sand because the task was too big for a single prompt (which is fair), but I wanted it to give it a try so I reduced the temperature to 0.5 and lo and behold, it did it! ...... poorly. The result was buggy and generally underwhelming, on par with Grok 3 Mini, Llama 4 Maverick, o3, and o3 Mini (all of which did poorly on this test).
The top tier on this test is Claude 3.7 Sonnet quite far ahead of the pack; and the second tier consists of Grok 3, Riveroaks, Gemini 2.5 Pro, o4-mini-high, and DeepSeek V3 0324.
o3 is really good, 5-10 IQ points higher than the next smartest model
it's hard to believe OpenAI will have o5 pro internally in a few months
so a 1206 to 2.0 situation 🤔





From my testing, o3 answers are better than 2.5 most of the time, I would long OpenAI for April
In tests of Code Taste, Problem Analysis and Fiction
Dayhush wins o3 by two heads above
is Dayhush reasoning model ?
i remember that goolge would release a coding model , and yes indeed it may be better at coding but i doubt its generally better than o3.
What? Dayhush?
how do i get this?
Maybe someone here knows…. I don’t have a paid Grok account so I tested Grok 3 Mini through the OpenRouter Playground with default settings. And as mentioned it performed poorly. But it occurs to me that maybe the default settings on OpenRouter are low reasoning effort? If so then maybe I judged Grok 3 Mini too quickly?
Overall Gemini 2.5 Ultra will be good.
You'll remember my words when he arrives.
ik but you think Dayhush is 2.5 ultra ?
ik that 2.5 ultra would beat even o3 generally
hell o3 barely beats 2.5 pro, so no chance vs the ultra model
what do you mean by barely? there's 7% diff in aider polygot
o3 beats it in every benchmark , but lmarena = avg people asking for funny jokes and 8th grade math homeworks, which is more about general knowledge, structure, syntax. there the difference is very small
oh
o3 reply with emoji
HELLO. Nothing else to say. Just out of curiosity...🙂
beep boop
Does anyone know a working prompt for humanizing text?
hello friends
just ask it to humanize the text
a surprising amount of people have asked this question and i get so confused
humanizing texts are one of llm's best skills
and o3 is quite amazing at prose so i think it's improving even at that
Never used Grok because I hated Twitter even before Elon, but I’ve found out that voice chat in grok is more useful than Gemini Live and chagpt advanced voice.
that's incredible
poll_question_text
King of the kings
victor_answer_votes
5
total_votes
14
victor_answer_id
1
victor_answer_text
o3
victor_answer_emoji_name
🔥
For me it doesn't work at least as I want even though I used a more complex prompt. It works when it writes in my language and the AI detector gives 0% but in English it doesn't work in most cases and the detector writes 100%. And even the text in my language which the detector defines as human after translation via Google Translate is also defined as AI
U can try to tell it to write in the style of a specific well-known author.

interesting
it seems chatgpt can show you images?
since when has it done this
also guys, only 100 million more years until we have to update the 13.8 billion yeasr number!
Gemini used to do that too
Looks like the o3 also have sampling issues. It got my pro.pt right only 4/5 times. Varoability ussualy was problem only with the mini models.
Nope
It's coding model
Just simple coding model
how about temperature
that's not a sampling issue, more an indicator of performance. Before a model can do something consistently right, it needs to got through a phase of getting it right at least occasionally. While a true 100% success rate might not be even possible at all unless you are overfitting
the way I'm looking at this is if it's correct most of the time that means it's correct period. But if you have 2 models you are comparing that are incredibly close, you could look at the exact success rate percentage as well for more in-depth info.
though at that point it must be said it would probably be smarter to expand the number of your test prompts, rather than hyper focusing on just this 1 or a few
yeah those are just the sources it found with web search. You can click through them when you expand the image. Still useful though
webdev arena is so broken right now or something is wrong with my pc/internet?
like 90% generations fail
I am super impressed with o3 (haven't tested o4mini)
https://chatgpt.com/share/6802ef37-efbc-8011-b47e-3ddf1669260f
Analyzing images like this is a gamechanger
That will be an interesting one to see. Google models are pretty cheap, and another SOTA coders I'm always watching
poll_question_text
Will Gemini-2.5-Pro-Exp-03-25 drop from #1 on LMArena leaderboard in next 7 days
victor_answer_votes
11
total_votes
20
victor_answer_id
1
victor_answer_text
Yes
How to set temperature on lmarena or chatgpt web?
Why would the model be non deterministic if the input is the same?
U can set it in direct chat on lmsys
O3 and o4 mini are there
They used to ignore the value but it seems they don't anymore (setting api temp)
Can you do it during battles? 👀👀
Nah
Sadly anonymous models cannot be selected
It always passes on direct chat. Maybe they are testing multiple temperature variants
I heard the quality was different on the api rn but I don't use the models so idk
Something is messed up on chatgpt to some extent I've heard
output is always indeterministic technically. Even with temp0 it's not really 100% deterministic. You can only do it deterministic with additional parameters (seed and whatnot...) when it's implemented
but for openai or anthropic, I do not believe there is a way with their libraries currently
i think this is the most incredible thing i've seen o3 do
Yeah I really can't be more impressed with it.
Think of all the applications. Endless
I think those immediately DOA fitness mirrors are going to make a comeback soon
if they aren't that's not by design. They clearly don't want you to be changing that. Haven't tried it now but with o1/o3 API also used to return an error if you tried passing the temp parameter

for reference this is how it looks when that's not restricted:

anybody facing same issue? web lmarena
not returning any response
it says "generating" then "generating" disappears and makes me vote but, no output appears
it wouldn't work with plus (32k), and I'm not sure pro has the full 200k either... 🤔
And with API it doesn't make sense to be paying this much, just dump it into 2.5 pro

Check out the NinjaChat AI platform over here : https://www.ninjachat.ai/
In this video, I'll be telling you about Grok 3 and Grok-3 Mini new API that allows you to use it for free with Cline and RooCode.
Resources:
Grok AI Console: console.x.ai
Requesty: https://app.requesty.ai/join?ref=4581bcf6
Key Takeaways:
🚀 Grok-3 API is ...
try it
ok, i'll try it again
oh you just quoted the wrong person lol
I think it discards the cache and a refresh
anybody compared dayhush, claybrook, dragontail and nighwhisper yet?
sometimes only one model generates the webpage I request
sorry btw, wrong reply
But where does the randomness come from? The simple LLMs can be derived into a set of nonlinear functions. Meaning that the same input shall result in same output. I'm missing something. Is it tricks in the new architectures? Systemic issues?
Hardware floating point precision optimizations etc
But yes there is no inherent randomness otherwise
In reality because you can't have perfect precision numerically, hardware, etc there is inherent nondeterminism
bluntly speaking at it's core it's artificially introduced randomness where all of this is coming from. But temperature itself as per its definition tells the model to consider more or less probabilities for the next token - that's by itself is indetermination.
Greedy decoding assuming all sampling is disabled does not introduce randomness theoretically
each training run will normally result in a different outcome (model) since random starting seed is usually that - random.
Training yes. But we are talking about inference.
May be compiler thing
Choosing different path based on some conditions
Server thing also
Nobody cares if they reason as long as they produce good code 😄
I asked o3: "Short answer: Not necessarily.
Under today’s large‑language‑model (LLM) stacks, sending exactly the same prompt 100 times can yield identical, slightly different, or wildly different completions depending on four controllable factors (decoding parameters, software, hardware, model snapshot) and three unavoidable sources of entropy (floating‑point nondeterminism, multithreading, and vendor weight updates)"
I dont see how floating point can be involved here, but multithreading could be a cause
That is the most disgusting voice I have ever heard
Architectural & theoretical backdrop
Decoding strategies deliberately inject randomness to avoid repetition and exposure bias, and recent surveys show variance growing with model size and alignment techniques.
Extrapolation you say
LLMs can play chess. The skill is destroyed in the instruct process

Could you imagine a new color, paws?
Floating point numbers are extremely weird
0.1+0.1+0.1 != 0.3
Can happen
I spent a lot of time programming floating points in C. In my practise, its deterministic. Unprecise but deterministic.
It wouldnt be hard if we would have feedback loops
Why do you think data != algorithms
Instruction sets are data
Multi threading isn't really applicable unless you're doing cpu inference I believe
Multi threading is done even in gpu inference (like scheduling etc maybe) but I don't think they cause the non determinism in actual decoding
We need help from @wooden mulch What causes same models to produce different results with the same input on the arena?
Afaik it's still somewhat dependent on your setup, hardware etc. but I might be wrong. E.g. comparing results from different hardware might lead to differences
Not possible lol
damn
tbh I think you just need to learn the basics on how LLMs work and how the next token is being generated in the context of token pools.
it "considers" a ton of tokens before settling on a specific one. And that process is for the most part random by design and including a lot of potential outcomes if you leave everything at default settings.
Tou may be an order of magnitude more infmed than me or less informed
Anyway, Ill read one book on llms to catch up
if we made LLMs deterministic they would be very boring and not really pleasant to interact with
Was it since the beggining or introduced after the gpt 3.5?
llms are deterministic wym
but temperature isnt
I dont understand why rhey didn't release o3 as GPT 5. It do feel like gpt 3.5 to gpt 4 improvement.
What next arebwe waiting for this quarter? 2.5 Ultra, R2 and qwen max?
I wonder if they will release o4 at some point or will call it GPT5
well the way we implemented transformer arch and how we are running them, they are not deterministic. Was talking about end result here when you are already interacting with the model. Non-deterministic is desired behavior so when that's lacking it is simply artificially added at the given stage.
They are in theory if you use no sampling. Practically they are not
The small amount of non determinism without sampling I doubt would be very noticeable by the user in most cases tho
Adding a little bit of temperature changes it a lot more I think
sampling is the biggest factor for sure. But we can't really talk about LLMs excluding the sampling can we...
You can
Greedy decoding is no sampling
not in the context of you interacting with the models on lmarena
the original question was why they are not deterministic on arena. So excluding the sampling would just be selectively misleading now lol
99% of the time users are interacting with LLMs on any platform it includes sampling anyway 👀
Wondering if anyone can explain this to me. Is o3 on arena the same o3 that you have on your ChatGPT account.
I feel like when I use o3 on my account I get more in-depth answers and o3 on arena feels watered down.
How are they able to give o3 access of arena does OAI subsidize usage?
o3 on chatgpt has access to python and searching
o3 in arena is raw api version
Even then how are the able to allow so much access to it on arena
probably this
They didn't do it for o1 but added o3 mini tho (direct chat)
I'm assuming o3 is just cheaper to run
they added full o3 and o4 mini
Yeah
o3 is $40/mtok while o1 was $60/mtok out
It's also probably more marked up (despite lower pricing) I think
I meant instead of o1 they added o3 mini
m
Thanks for answering my questions KT

Report this! 📢
︀︀
︀︀Grok.com now generates reports from uploaded CSV data.
︀︀
︀︀Share your feedback -- How can I further increase its usefulness?
Grok is the smartest A.I. out there and the only one with real-time access to world events, thanks to 𝕏


in my testing nw > dayhush> claybrook
but the gaps aren't major
you can adjust it on openrouter. it's weird though, the default is 0, but there clearly are tokens allocated for reasoning because it always reasons no matter what the value is set at, inc 0 (or 1, 10 etc)

it doesn't seem to do anything tbh.. like setting it to max (100k tokens), and it uses the less reasoning tokens than when set to 50k, or 1k.. (and perorms worse compared 50k.. though i'm pretty sure this parameter, at least on OR, isn't doing anything, and it's just variability)

Does it stop at 1 token if u set it to that
i've tried 1, 5 - doesn't make a difference. it always reasons on OR, as far as i can tell anyway
the value set in the param doesn't seem to correspond to how long / many tokens it uses for reasoning
Ya but does it ever cut off on that amt
No I guess
Weird that google keeps testing coders that are progressively worse. Mini, mini mini versions?
no.if you mean like reason for 1 token then proceed to the answer
it always reasons and coherently/comppletely
like no cut offs
which ai is on Gemini Live on the app im using webcam and its kinda good id say?
Hmm I skimmed the grok api docs on my phone it seems they support reasoning efforts and not really a reasoning token limit. Maybe u need to pass that on somehow if possible thru openrouter
yeah was gonna post something there actually
It should be possible since I think they support it for openai reasoning models
it feels like the param is doing nothing / doesn't exist
puhahahahahaha
i cant
- NW = DH
- claybrook = Dragontail (?)
- Gemini 2.5 pro 03
- Gemini 2.5 flash thinking
claybrook gave me good results as well
so im not sure if its better than dragontail
bruh these names ...
i see yeah OR's implementation is off then
Waiting for NW with better native tool use
this is actually a cool prompt
Gemini 2.5 Flash demolishes my Galton Board test, I could not get 4omini, 4o mini high, or 03 to produce this. I found that Gemini 2.5 Flash understands my intents almost instantly, code produced is tight and neat. The prompt is a merging of various steps. It took me 5 steps to

see if you can make dayhush generate that
So there is Dayhush and Claybrook from Google
Which is better?
Even better than nightwhisper?
claybrook is probably a recent checkpoint of gemini 2.5 pro
i find it similar tbh
i cant tell
its really hard
but ive noticed some small issues with dayhush
- overlapping elements
- text out of the containers elements
- it needs a clear guidance
Perhaps a mini model
nah it definitely didnt feel like a mini version
its probably the slowest model

it takes a lot of time thinking
Would love that
But knowledge graph is more useful than just embedding RAG
so you think flash is the best model overal? like including cost efficiency(performance and cost)?
Its worse
lmarena beta has no rate limits wow
these mfs are being bankrolled in lab credits
lol
they're backed by lots of orgs tho
it's probably insignificant to them
well.. Sequoia Capital is an organisation of sorts lol
kinda ass cheeks
https://3000-ic8ffl64if1ey2lpz839s-b4a4855c.e2b-foxtrot.dev/ this one by gpt 4.1 is good
I mean theres a lil error in the bottom they cant go into the middle slots
https://3000-iw42qa863msalyyv8tzqi-0ce36864.e2b-foxtrot.dev/ by o3 mini high
you cooked these people
yea
thats the issue
it may be good at UI/UX
but it still lacks on complex reasoning and implementation
i got it to work once/6 tries
its good yea
but it hallucinates a lot
I don't think it's gonna go this high. But we will see.. 👀
that high * is the correct term, but why ?
yeah idk about that
The 4o latest is very close and o3 is order of magnitude better. How's it not the new sota?
Chineese endgame

i asked gemini and o3 to prepare 3 hard questions for a very smart rival ai. and also to solve these questions so that i knew the solutions.
Both models solved each other questions, but gemini took way longer to do o3 questions and its solution was way less elegant
wdym by less elegant
more complicated and longer than it need be
i also made a game where they use their own algorithms to command their player and shoot at each other, o3 won 8-2
these are better benchmarks than official benchmarks for which models know the answers of
Tbf, if o3 is smart it would make questions it believes it answers better
We're in the benchmark wars of AI
general intelligence to perform great accross any domain ..
even silly ones
thats great but that means I can say 2.5 pro beats o3 in many many different areas
and therefore more general
What we need is better benchmarks