#general
1 messages · Page 24 of 1
be explicit that it's not just "o3". I think that's fairly obvious, no?
They can't do that again because once they actually release people will test it and get vastly different results. People already picked up on what they did, so they risk harming their brand continuing to do so
So caught up on trying to generate hype compared to their competition that they just make highly misleading test results
But anyone perceptive can pick up on
sure but the point is they knew to begin with that they aren't testing just the model o3. But rather their version of a "pro" setup which happens to be based on the new model
that was never gonna see the day of light as just "o3" 
how would you do that though, its already a mess
the o3 in december is much less stronger than the retrained o3 with the new 4.1 base we have now, at least served with the same compute. so it does mean something
o3-pro-preview, or whatever else...
still misleading since o3 pro is not gonna be served with that level of compute
it depends on the benchmarks though, if the o3 pro product they're gonna release performs impressively/or close compared to the initial o3 results, they could name it like that
which would all line up if that version from december wasn't scoring higher, but it is... And that's the problem. It's worse but it was scoring higher, because it wasn't just o3... Like I really think this is obvious they didn't just accidentally do it LOL
at the time do u think they already had plans to retrain o3/etc
its misleading but i dont think its intentionally malicious
they could make it score higher if they used as much compute as they did before, but like the other guy said its a bad idea and this time it would be intentionally misleading imo


arent they using cons@64 or smthing like that, the grey area which i assume the score is for?
this is pass@1 i think
iirc it was pass@1 for o3 supposedly
whats the grey area then
and cons@64 only for o1
I'm not sure, maybe it was 🤔
this still doesn't add up though assuming preview wasn't using the new base model
even without the juicing it couldve just been doing even more massive and unreasonable chain of thought by default compared to the optimized new o3, to reach those scores
i believe light grey is if it's reprompted
What is cons@64, you might ask? Well, it’s short for “consensus@64,” and it basically gives a model 64 tries to answer each problem in a benchmark and takes the answers generated most frequently as the final answers.
it can not be misleading if they are explicit that this isn't just o3. Like it's really not f'ing hard to do. You can literally name it "o3 + extended cot synthesis"
just like they are listing tools now, this isn't all that different
you want them to go back and edit all the videos/material after they changed plans? its just not realistic. they weren't in development far enough to know how they'd serve it so how would you make that distinction without knowing the future
they changed it now to o3-preview at least
No I think my point is that now it's obvious they knew what it was and what it's going to be released as to start with. This wasn't "a mistake" lol
they knew they were gonna retrain o3 at the time lol?
?? no they knew they were not gonna release o3-pro as "o3", and that the model to be actually released gonna be much closer to o1
but its not even o3 pro
whatever, that is clearly not the point here lmao
I'm just calling it as such as it's the closest match to what it was
if they released that version of o3 without the juice and changed the reasoning effort levels would you be ok with it?
I would be ok if it wasn't named "o3" in the graphs when they knew that model is nothing like "o3" to be released. And once again, you can't be serious thinking this was a mistake.
well then why are you asking if they should go back and edit it lol
it was intentional at the time but they didnt know the future and committed to it. it is now misleading in the present
they did it deliberately, what's there to edit? 👀
its pretty lame but on the tier list of gaming benchmarks its only in the middle
i think anyone who cares a ton about benchmarks probably watched the stream and knew they used ungodly compute on them
its deliberate but they have no idea about how misleading it would be in the future lol
i personally think its cool to hear about these companies super powerful internal models
and i wasnt expecting an o3 that was $1/token
Ok imagine yourself in their shoes. You have a model x, but instead of running it normally, you use pro-like system to boost the scores way up. But then still leave the name exactly as it was, model x, with no additions. Now in what universe would you think this can be not misleading? LOL
they were early in development they might have some idea but it could change drastically
new o3 is pretty good, they've reduced the size while keeping similar performance to original o3
we like being stun locked 🤣
pretty sure the consensus is o4 mini is better not "often" or even "sometimes" but more than just occasionally
i love pointless arguments but when youre on the outside its easy to see how annoying they are
nah I think it was obvious since the beginning this isn't competing directly with normal o1. Well for them at least, for us... even I didn't know they used something similar to pro for those scores. I was impressed back then but now I kinda feel scammed. Which is the whole reason of why I even wrote it.
theres nothing wrong with it lol
^
Pro is just longer think for base o3 (from tech crunch)
its still impressive though for any system to reach that level even if it was juiced
it's mostly hype building marketing. If you are gonna do something like that well then do what google did
AlphaGeometry
and the fact that they didn't even have new base (4.1) back then makes it worse, not better tbh
At least now with an improved model it is not 1 million miles away...
it's still an interesting good model, but yeah... the direction openai is heading and what have they became lately comparing to like 1.5 years ago is something I really do not like
don't get me started on the pricing too... they finally reduced the price but only for the new model, o1 is amazingly now more expensive than o3
with the releases of both 4-turbo and gpt4o, their pricing was essentially unmatched (good)
then o series started and all hell broke loose with them going to town on pricing lol
yeah it was a very novel idea. Preview had some bugs and was rough with later o1 being much better imo but this idea enabled good progress for sure
The most impressive aspect of o3 for me so far is its ability to generate good ideas
Is o3, medium or high in the lmarena?
base o3 is here

Yea but what level of thinking is that
we have no freaking clue I guess

if it's not specified that's medium
on chatgpt.com, it actually thinks with your name for some reason
yeah I noticed that too. I found that odd since I have memory and CI disabled and it somehow still knows lol
here is what it does for me

ye good vibes
it also writes with a lot more emojis for some reason?
it still doesn't shine like 2.5 pro though tbh
🧐

might be just getting used to
in my experience, the Gemini family is more of a customizable, but baseline neutral family
it's their fine-tuning. They nearly fixed it but not entirely
it seems bad at understanding social norms
I hooked it up in such a way that me and some friends could speak to it in a discord call, and it is so hard to talk to
oh ikwym
the openai models are better at social norms though
"you are right to point that out!" - I hate these from gemini lmao
when I give it an example
and the example is using "you"
it thinks it needs to address it as the AI itself
rather than assuming it's a general example
i think 2.5 pro is less sycophantic
yeah it's acceptable levels now. But sometimes still annoying
if there was an AI model that I would trust to not destroy us if it got AGI, it would be chatgpt (any one of them tbh)
i wouldn't say Claude
it has a very good feel, but it's almost superficial
so yeah chatgpt prob
it's the most stable behaving one for sure
to me Gemini has more of that meta intelligence, and that's what's deciding it's morality
rather than having instructed morals
claude is actually very good at language (by this, I mean it can speak toki pona the best)
yep
I did a few tests with the arena, and claude comes out on top for all toki pona conversations
very contained
ye that's what I look for in models
3.5 sonnet has always been clearly the best
but that's why I like 2.5 pro so much, because it does the same thing when you really want it to
I want to run a test playing a game called "keep talking and nobody explodes"
I did it a few days ago with o3-mini-high
which of the new models should I pick?
keep talking and nobody explodes?
I can agree +++
But it improved a lot (I talk to Gemini flash thinking and it seems cute 😆😆) but chatgpt is more natural
sounds like some nsfw rp lmao
I'm gonna explode
💀
nah, more like yelling at the AI for not understanding the maze puzzle
flash thinking was hella neurotic, but it was super adjustable
damn if y'all feel this way about Gemini
you guys gotta know the strats
theres some insane keywords that these models react to
feels like they're doing this on purpose
what does the "o" in 4o mean again?
if they release o5 after releasing 5o
Omni
ngl when the first 4o was "anonymous-chatbot" it felt so fresh
like a clear step above the other models
it was truly the best
anonymous chatbot is chatgpt 4o latest. are you talking about the i am good gpt2 thing or the first chatgpt 4o latest variant
now I have to switch off of 4o because it's not even worth giving orders to
the first chatgpt 4o variant pre release
oh
yea ik
and then "birdie" was athene 70b
which was lowk a secret
y'all didn't know about that one
the best model at that time behind 4o
what is your guys' go-to prompt for these new models?
I ask for pacman in pygame
and o4 did really good at this
I usually give random puzzles
and then ask older models to solve the same ones
o4 mini is good at puzzles
o3 is horrible
o3 is super smart outside of these rigor subjects tho
yeah for my use cases, these models are very optimized
Does anyone know if they’re planning to improve the voice mode? It’s still the least utilized and developed feature considering its potential.
also, I don't think an AI is going to be fooling a human any time soon
I think until the competition gets stronger in voice
they're not gonna do that much
sesame is cool and all
gemini is CRAZY at video
yep
I streamed me and the boys playing the binding of isaac, and it was able to identify stuff
it's in its own league as far as understanding videos
from what I see on x, the everything app, grok can understand videos pretty well too
Yeah, but I mean, I don't need the AI to flirt with me or be that assertive. But the voice mode in Gemini or OpenAI is stupid you not only can't have a conversation with it, but you also can't use it under any circumstances.
it works for me mostly
it likes to end its turn too quickly though
well, not gemini
wym?
gemini talks way too freaking much
since when can grok understand videos
it seems like people can mention grok under a video and it will respond
I thought that was finding references
and transcriptions
rather than watching the video
oh yeah probably
since in that case, it doesn't do very well
I don't know what grok does
Gemini Live can’t search the web, though, right?
and it doesn't do very well understand what it even is
it can't(?)
I think most recently
it may be able to
before no, now I think so
hmm sometimes 2.5 pro stops thinking on aistudio, especially with extremely long chats, not sure if its just a visual thing (it starts streaming with the same delay as if it were to start streaming a thought process), but if i prompt it to keep thinking itll usually pop it back up 🤣
Google might solve that soon
wym? like, the text just suddenly pops back in the message it just finished after you send something
I've just tried it and it can search the web now
oh ye this happens to me
same with it going outside of its thinking box
ye, I think it's a visual bug
Do you have any news/articles on this, or are you just speculating based on what they’re doing right now?
the streaming delay?
Ain’t no way all of these released so fast
I'm confused
o3 for general tasks, o4 mini for coding tasks/puzzles, 4.1 is API only
and its good at small coding tasks
meh
o4 mini is a little better than 2.5 pro at pure coding tasks, from the benchmarks, o3 isn't really that much better, or even at all. It seems to fail things 2.5 is getting really easily, and 4.1 isn't a reasoning competitor
Oh
Makes sense
What is the difference between o4 mini and o4 mini high?
high/pro means it thinks longer
Simple to understand thanks
Gemini 2.5 got a lot of people to switch when they released it, not sure if it's the same with o3
Sometimes I think that Gemini 2.5 is overthinking ...sometimes , the Flash thinking make good answers while the pro sucks 🙂 I still donno why
ChatGPT Plus, Team & Enterprise subscribers get:
- 50 messages a week with o3
- 150 messages a day with o4-mini
- 50 messages a day with o3-mini-high
ChatGPT Pro subscribers basically her unlimited.
This is great but I'm questioning the value of Pro with such high Plus limits.

I think this is inherent to the prompt itself tbh
Yeah
They wont switch from gemini
Cuz its free
2.0 flash thinking is a true overthinker
And o3 is paid
at least from the months I used it
This is largely based on what you're doing, but if overthinking is an issue for you, maybe the O4 Mini will suit you better.
Gemini 3 will be groundbreaking yet again
It is just some QMC and questions
depends, the limits can be really restrictive, and o4 mini is cheaper than 2.5 pro
although that's beneficial ONLY for coding
Nahhh at all
oh wait
Yeah
you're talking about on the apps
The ai studio
ye
if you're talking about AI studio vs chatgpt plus
Yeah
I don't think that's true tho
that's just for API I think
I've sent more than 50 per chat in an hour
ye the difference is big, thinks a lot
wonder how good 2.5 pro would be with that crazy length
hmm i was checking to see if the 2.5 pro thinking bug was visual: 5.5s to the first token (first token in thoughts) and 6.1s (2.5 pro immediately going into a response), it doesn't seem to be visual
would this not be directly visual
I'm confused on wym
if it were doing the thought process and skipping the thinking block
u would expect the first token to be delayed on the response
but its the same
delay with or without thoughts
so it doesnt seem to be visual
its fine im explaining it confusingly
man how late is later...

u can select the models in direct chat if u want btw
both o3 andn o4 mini
the mechanism if it's not visual i guess is because they exclude thinking blocks, i guess when u reach a certainn amount of turns the model's tendency to start with a thinking block isnt there since all the past and numerous amount of turns had no thinking blocks
o3 was... alright? the style was bad:
- manually wrapped its text (presumably trained on too much TeX)
- disregarded "mtok", took it to mean ktok, messing up the calculations
- called phi 4 multimodal "φ‑4‑mm"
but once i got past that, i did enjoy its discussion of the math and attention and economics
meanwhile o4 mini just spreading misinformation

did u set it to 0 temp btw
i left it at default 0.7
i'll try again but i'd be surprised if that improved it more than regenerating would
what the hell is this 😭

okay it was definitely better
i still like the style of the o series
4.1:
ehh actually it lost some of the math, so it might just be regeneration quality
2.5 is absolutely better
it's not close
the Gemini models are basically made for that
tbh
as far as my testing goes
uploading anything to Gemini is far superior, it's audio understanding, it's video understanding
nah it goes for all the models
just try 2.5 pro with this stuff
it's seriously crazy
it's basically perfect
ye, but tbh its just different approaches
I like reading other models thinking
ye
can't say that's much of a problem tho cuz that's what benefits Gemini more in general
I just played ktane with it
How do you like o3? o4-mini high?
o1 pro is more of a academic
Tell me, please.
I am gonna upload my video of this session to #ai-creations when youtube finishes processing it
yep, I still like 2.5 pro the most tho
it's just the way I prompt it
and how it allows itself to be prompted
that's just super unique to me tbh
so the feel that I like in other models, I can definitely replicate in 2.5 pro
and then boom
no need for them
Btw is the o3 using tools in the arena?
ok I shared my video
nahh
lol
I like how chatgpt just takes the verbal abuse I give it
I lobotomized that part
does anyone else feel like o3's chatting style is strangely similar to r1...?
u sure?
that didn't seem to be the case
so it must've happened within the last hours
by the way, I'm not sure about o4 mini being cheaper in practice

seems to be p4p not on 2.5 pros level
same goes for o3
when are we gonna be allowed to use 4.1 in the app
you're not I think
Chatgpt?
4o seems to be the absolute replacement
yes
It's already live under 4o lol
They're continuing chatgpt 4o latest which is the chatgpt 4o model on the app, which is on the same base model as 4.1
4o != 4.1
It's mega confusing but yeah
Chatgpt 4o latest uses the 4.1 base model/has had it for a while before 4.1 released
The new base model where it was continued pretrained and has a newer cut off
that is so stupid!????
Openai tries to make naming as confusing as possible
For some reason lmao
I mean not rly, as long as you consider -o as a variation
which in this case, it would still be 4.1 → 4 → 4 omni
There are small differences though the chatgpt 4o tune is slightly different though even if it is on the 4.1 base model, it is more human preference aligned. But model performance is largely the same
since 4o previously probably still used gpt 4, as a distill
so it would be 4.0 Omni
now it could be 4.1 Omni and therefore 4o
can't wait for 4.5o
could probably still be called 4o
will it be better at language?
Yes
I don't see them anymore.
I only come across 2.5 pro, 2.0 flash thinking
could be just unluckiness
Take a look for yourself too
You won't get them either.
It's strange that Legit didn't reveal anything about their loss.
dont really know who legit is but i guess he scrapes web dev arena
in the metadata there its still live
dragontail/etc
He's one of the main leaks of some cool stuff.
Did they turn it off for an update?
Did you see him just now?
Or recently?
idk if its in the arena or not, but its still in the metadata of web dev arena:

probably why his bot/etc didnt catch it
if it was removed off the main arena
just got River hollow lol
i just got dragontail in webdev arena btw: (so the metadata for web dev arena is right at least for web dev arena)


._.
It can't be that I'm unlucky._.
I know for a fact that there were none.
What the...
sometimes I get an extremely long period of not getting certain models
like, I haven't even gotten o4 yet
or o3
Is that what this is about?
Why is this happening?
Update?
seems like a balancing thing or smth
for the arena
could be that they actually did take them down
just for a little bit
for an update
we'll never know
and I get it._.
😭
kinda excited for 2.5 flash
ye
0409 or smthing
that wasn't too long ago tho
with thinking budget
oh fr?
damn I hope it's cheap and smart
that would be crazy
yea despite the sdk name it didnt come on the 9th
they delayed it for some reason
if it's a jump from 2.0 thinking, it's gonna be good
oh 2.5 flash is gonna be good
although it was trash at coding
it was for some reason INSANE at some things
tbh bro
I keep thinking back
the old times
where athene 70b was the hidden gem
that pure RLHF model was sick when you prompted it for the right things
I hope the long context is somewhat maintained
if it's anything like 2.5 pro too
it's gonna go crazy

damn I was expecting more
I had to wait 3-5 minutes for the code generation to finish.
Hey it shows how long 2.5 pro is too, since everyone is impressed by Geminis offering. 50s on that benchmark is great, and actually SOTA
but I thought it was gonna be higher than 2.5 💔
yeah the smaller mini models tend to suck at that benchmark
Thing is how many tokens did 2.5 use?
there's no way for them to have optimized that
so it's gonna be baseline what you see
rather than a high or medium variant like o1, o3, and o4
Exactly
Flash thinking tomorrow
it's the same reason why openAI models seem to dominate benchmarks
but then not do well in practice
Yessss
I already thought that Google wouldn't show anything this week and would give OpenAI all week.
I just wish I could more readily compare the tokens/thinking time being used
Makes it harder to tell if these little 3% gaps are meaningful or exaggerated
So I don't like there's just a persistent mystery now
ye
wdyt flash thinking means given pro is already a thinking model
but that's why it's still pretty much clear 2.5 pro is leading
or is this just flash
2.5 flash is a hybrid/unified model, so thinking model yes, once it releases
regardless of narrow task advantancment like o4 mini, or the general ability of o3
it seems like it's inherently a weaker model
due to the fact it literally has to think more
to achieve similar output
I was really impressed by o3 but mostly for the tool use and UI. I think 2.5 Pro which was rushed out the door can match it and probably remains a dev fave. Think 2.5 flash will be better than o4-mini but just a hunch
Good guess is 2.5 flash, I think they might drop a coding model too
i hope its nightwhisper
the fact it's so little above 2.5 pro while likely thinking so much more
going for all the other benchmarks as well
for example, this benchmark
我正在学会等待Behemoth ......
o4 mini costs more than 2.5 pro
release tomorrow then
LOL
sorry I already predicted other things about these models today
I deserve the glaze
not you
2/2 you're just 1/1
I take a look inside without permission
I'm just like that
🤨
its just gonna be 2.5 flash...
sorry you need to be granted access
(although i'd be happy to be surprised)
2.5 flash is of course the minimum but there may be another model update
ye
I'm guessing they feel confident about 2.5 flash
maybe
that would be cool
you really called it lol
seems openai is the only one whos got tool use in thinking though which is EXTREMELY weird
like it's just a ui level thing
how you call your own inference api
it does feel kinda weak on their part to release 2.5 flash, a worse model, when openai have just mostly beat 2.5 pro
while 2.5 is base
i think they'll wanna flex
wait you have connects?
yes
it's just whether or not you start another <think> after a tool message
exactly, so they might just release a coding model
This is hilarious because they're just benching the same model over and over again, so naturally it'll get similar scores, just incrementally worse/better based on thinking time
what do you mean you don't know about that
@keen beacon is my connect
If it clearly bests o4-mini they would def like that
google about to do openai dirty lol
yeah but i kinda doubt it
y they cant let openai have one week
o4 mini is very strong
ye
this is our frontier model💀

in most cases it matches o3 and in some it beats it
but if 2.5 flash is narrow
i dont think flash has the chops for that
and anywhere near o4 mini
then o4 mini has to be cooked
the context + the price
at reasonable output
it would have to be nightwhisper right?
I really dislike tests like this and token issues
really disappointing that o3 fails the bucket test damn
alr chill
o3 pro is gonna be cracked, although I don't think it's going to be straight up better than the one we saw during shipmas
the direction and bases have changed
They might release an updated 2.5 pro as well, think it's been about 3 weeks since it dropped and last year they were doing updates on around 3 week gaps sometimes. Usually 4 at the latest.
maybe
but now that it's actually confirmed there's going to be SOMETHING
yep
this is a crazy advantage
the fact they said it's trained WITH the tools
as it's reasoning
ngl
I didn't even know HLE 2.5 pro was 18%
or I didn't pay attention to that
o4mini's hallucination rate is unbelievably high. it scores worse than o1mini on OpenAI's own PersonQA benchmark
I wanna know how good 2.5 pro DR is with that
I do wanna point out tho, independent from benchmarks
it's smart
but it has unbelievable confidence in going in one route
do you have the data? can't find it in https://openai.com/index/introducing-o3-and-o4-mini/, https://openai.com/index/o3-o4-mini-system-card/, or https://openai.com/index/introducing-simpleqa/
o3 and 2.5 are very creative in their self reflectiveness, but o4 mini just really goes for it
super straightforward too

Nightwhisper is coming out today!
dragontail cannot exit because it is still being tested
This may be the 2.5 flash model that will be released next week only.
For ppl saying o4-mini is cheaper than 2.5 pro

yeah exactly.. i really don't think this is widely appreciated ha
Wow, nearly 20x price for o3 high
that would be v impressive if that's the case.. like kinda insane tbh.. dragontail consistently performs comparably to 2.5 Pro, sometimes does even better (in my experience)
Yes, I agree. Sometimes it's better.
ye I sent this earlier

too early to say that lol
since it could be
Gemini 2.5 flash preview
Gemini 2.5 pro 0417
yeah w/ the agentic reasoning built in
Is 2.5 flash really a nightwhisper._.
that would be insane
but honestly could make sense
then openai is cooked
i feel bad for openai again
2.5 flash with the maximum level of reasoning
like I would be in disbelief
2.5-flash-high
lets do a go fund me for openai
ye
but they all think for similar amount of times
they're capped
by lmsys
so whether it's thinking really fast and a ton, for the same amount of time
we'd never know
we don't even know if night whisper could even be flash 2.5
it could be those other checkpoints, why would the performance be so different
if not for a Gemini coder, 2.5 pro checkpoint, and then 2.5 flash checkpoint
do you work for openai?
they should hire you
how can google get you on their side?
notebooklm>
I see your point, but you probably think the image zoom feature that o3 uses is an example, but you're just wrong lmao, notebook llm? Google AI search (as in bard, from way before), native image gen flash? long context?
wym? this is exactly THE step forward these companies are trying to make, the tool usage, all that stuff basically came from bard lol
without search, hallucinations become a major problem again
also not to mention, project Astra
and still, the other things I mentioned
tbf they pioneered and open sourced the transformer architecture in 2017 - everyone else since (oai included) is arguably innovating on top of the status quo they established
even still tho
Google had been developing veo before open AI
had sora
they just announced it after
yeah tbh i knew that's what you meant (was just thowing it in there - but in a way, kinda beside your point / taken for granted i know)
do you think they AB tested calling it 'yap score'
i think you might be right about oai consumer stickiness if goog doesn't beat them by wide margin but they def innovate. invented self driving cars, solved protein folding, 2 nobel prizes in AI past year
what about context caching, Gemma, native audio understanding, learnLM, AI overviews
I honestly don't think that argument has any basis
even benefit of the doubt
@deep adder did you like 2.5 pro?
Google deepmind genuinely seem like the actual innovators, in and outside your direct chat bot interface
even mobile integration, Gemini has
how tho?
I would literally NEVER use it's o3s tool usage
if not for specific coding things
lmao
🤨
and btw
no
read context
he's saying that openAI are the innovators
while naming things Google created
but it's not "actually" useful though?
you're saying it is
but that can't be the case if it's coding based
And completely replacing human labor
you can say native image gen
XAI, Grok 4 will crush
No, I don't want that kind of future.
but Google did that first
you can say vision
but Google did that first
you can say agents
I'm just for the AI to be smart enough to be an assistant and no more.
i think talking to dolphins will be useful
who are the mods of this server? it would be funny to add tags to people name for if they support a specific company lol
like, right after?
thats dope
why'd they do that tho
u dont wanna talk to dophins?
nah deepmind is cool, they just do some stuff
btw did we all just forget about genie
ye but openAI wouldn't be where it's at without the transformer architecture
they improved it for the same reasons Google knew
that's why Google was able to hop on board so early
ye
it's kinda crazy how one company
kinda sparked it all
or two ig
or 3
there's prolly more
but same idea
crazy how a couple companies are causing the craziest era
an invention probably greater than fire
ye but I'm pretty sure that would've been created regardless
things like that were bound to be created soon
not sure about large language models tho
cuz its actually pretty specific
like who knew bro
ye, but that seems more like the problem of antecedent improbabilities
Hi, here is an insane offer
https://www.lennysnewsletter.com/p/an-unbelievable-offer-now-get-one
For $240/year you get a 1-year Pro subscription of below items.
Bolt
Cursor
Lovable
Replit
v0
Linear
Notion
Perplexity Pro
Superhuman
Granola

Yes, you read that right.
It isn't

Okay, just got the idea of this
It's basically dealing with the routing issue of having 1 million experts
but there's no companies(we've known now) that are using that much experts in a model
Deepseek has 256+1
Llama has 128/16 only
And other open-sourced models are dense models
o3-high is extermely expensive
i dont see gpt 4.1 on lm arena
in the leaderboard or in the arena?
leaderboard
patience axel
They're probably collecting feedback from Gemini 2.5 Flash right now.
you missed out on cloud next
(and the open secret that google tests many models and tunes on lm arena anonymously)
but gemini 2.5 flash is not out
????
so what
it's being tested on lm arena anyway
Coming out today... almost 100% sure from all the changelogs etc
but flash means just faster and cheaper, right? So why did it seem like it was actually a bit better in Arena than pro?
if flash 2.5 gets anywhere near o4 mini performance at flash 2.0 prices I'll be very happy
who said it's better in Arena?
It's actually quite meh compared to bigger models
but given the cost, it's amazing
o4 mini prices == 2.5 Pro prices. Despite name of "mini", it is equivalent for Pro models of Google
Team Anthropic!! wohoo
idk I don't follow too much, but it was Dragontail or Nightwhisper or something like that, right? I've tried it a couple of times and it seemed like it had better structured output.
yeah if it's dragontail that is being referred to as 2.5 Flash, it's def not meh
nah... Dragontail or NW are definietly not flash. If they are then Google has already won the game. I am ready to bet that they are not flash
which google anon model/s are you referring to then?
omg - could today be the day
google is finally unveiling euraka chatbot!!
Riverholllow
or shadebrook.. They both behaved like flash
Ah, right that's what was confusing me.
yeah agreed. neither of them get close to 2.5 pro
i swear they've just forgotten about it.. been there for like more than a year now... next level stealth
what eureka chatbot does?
Confuses me why they still host it lol
so if dragontail/nightwhisper isn't 2.5 Flash (which I think we can safely assume), i feel like there's a good chance that dragontail is 2.5 Pro with reasoning_budget set to high
ngl
even granting it, outside of speculation
that they'd do this
it wouldn't truly make sense
considering there's nothing about a whistleblower in openAi's case
that could be harmful in any way shape or form
or even openAI much as a company
do I believe companies would kill people that would harm potential strategy?
Thinking openai killed that guy is wild tbh
i dont think tech companies do it "yet".
I'm not sure how that's really substantive
considering I said, let's grant the premise that he was killed
say he was killed, rationalize it
like, in chat
i dont think it's far fetched to say some companies would go to extreme lengths
and if you can't, why speculate
Iirc wasn't he whistle blowing something that was obvious, wasn't it about copyrighted content
ye
Does everyone remember the Ultra series? It was only used once. It's a great name. If a 2.5 Pro-High (something like that?) model actually exists, the name might be worth considering.
its speculation true
nah but fr
of course speculation sometimes means something
but like, you don't gotta speculate, if on the grounds of accepting that premise, you still can't understand why
no dots are connected etc

then why is them killing the whistleblower unique
therefore it has to be the conclusion you're looking for
ykwim
honestly, I think this is not the right place to discuss whether OAI assasssinated someone or not
ion think it's serious enough not to
just a little comment here and there
like now, discussion poof, dismissed
ye
it seemed to be a really really large model tho
like gpt 4
and that's really the only way they could've competed at that time
they limited usage too
is there a new gpt model dropping
feel like i hear about it everytime i open the chat
and that's surprising for Google
or maybe they allocated enough compute
during then and now
but who knows
if they gave 2.5 pro high compute
it WOULD dominate

OpenAI has launched a new family of models called GPT-4.1. They focus on coding, and are exclusively available through the company's API.
o3 full and o4 mini dropped
bro is so behind
i think there is no money or much real-world applications of Ultra models. Only benefit I see is to show how far ahead we are to the world (by benchmarks etc). That's why I think Google is not pursing them anymore
4.1 dropped like a little while ago 😭 🙏
they just dropped this monday
😭
ye but today
they released more models
o3 full and o4 mini
I understand your sentiment. sometimes poeple behave as if 2 hour (or day) old news is like from few years back 🙂
Space moves very fast
20$ a month
and if using free you only get like 30 back and forths
vs geminis free trial 1 month repeatable full advanced
4.1 should have been just a tweet. but they hyped it like crazy.. I am still mad about it
not even that
straight up AI studio
give them your data, you get infinite usage
I know the data I give them allows them to progress btw
it's worth a ton
don't glaze me yet tho
i know

the thing about this is
skyvern and other things about to get full gemini support


niche territory right off the bat
its like the only computer vision project ik about
damn you either live under a rock or you don't
go look, that will be free? nah

GitHub
Make websites accessible for AI agents. Contribute to browser-use/browser-use development by creating an account on GitHub.
you can try this but its made by LangChai or some ccp stuff
thats what i want bruh
they have screenshare but its bad
i think it was worthy of more than just a tweet.. hopefully one day it'll all be a lot clearer with hindsight / disclosures, and someone will create like an org chart or family tree, with a time axis.. it's hard to conceptualised / understand the constellation of models they've got atm, and how they all (or most) in one way or another kind of interrelate
sends like past 5 second worth of clip for ai to understand
we don't just want thinking models anyway imo
ye but now with their new understanding
and determination
seems like they can really create anything
they've just been upgrading the Gemini app nonstop

Google DeepMind
We share the discovery of 2.2 million new crystals – equivalent to nearly 800 years’ worth of knowledge. We introduce Graph Networks for Materials Exploration (GNoME), our new deep learning tool...
but hype like I can't sleep blah... was unwarranted
ohhh
yo wtf
why'd I not know this
bro picks and chooses which rock he lives under
yeah def wasn't a can't sleep moment - i'm with ya there ha
impossible to be on top of everything in AI space. just focus on what is best for your professional career

Capacity Media
Google has unveiled its latest quantum computing chip, Willow, a next-generation hardware unit that dramatically reduces quantum computational errors and can perform complex calculations exponentially faster than classical supercomputers.

this is called marketing 🙂
still if its getting this fast and we're constantly advancing at this rate
nah but ask me anything I would've probably known
dont worry too much about quantum computing for atleast 5 years. progress will happen but noting useable till thne
eventually things like AES will die out
just not that
which is crazy
how'd I not know that
I'm Lowkey disappointed I'm logging off
😭
with waht?
got dealt a revelation
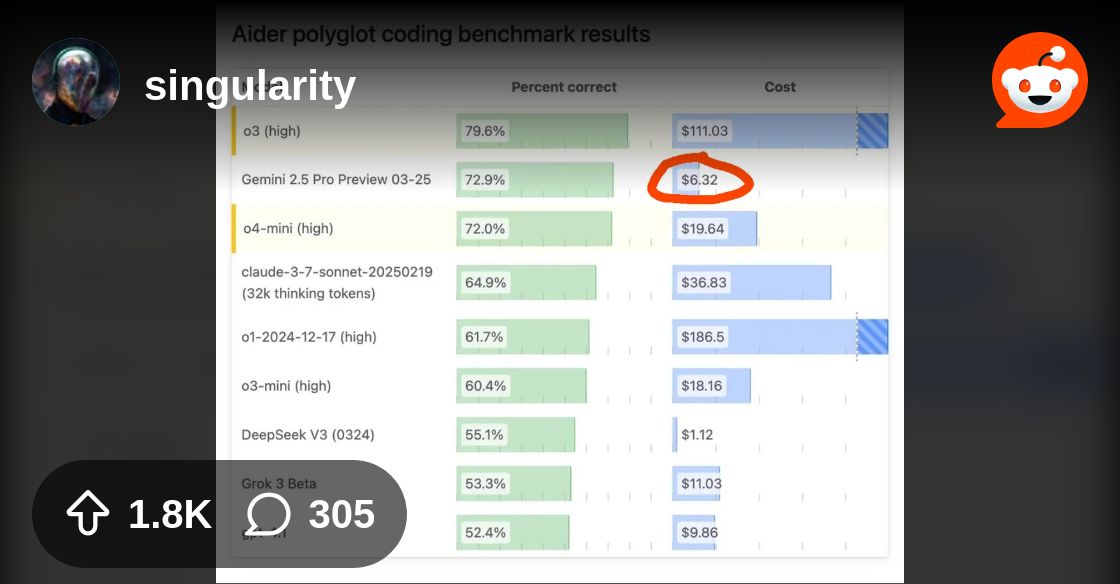
Okay, so here's the thing. But, like, O1 and O1 Pro, based on both their pricing and positioning, they don't really feel like the same model at all. If a 2.5 Pro-High (or a similar product) were released and named "2.5 Ultra"...@elder rapids@fleet lintel
This is my team experience as well with o4/o3 models.. very expensive and not necessarily better
makes sense. but it wont be called ultra. people have differnet understanding of what ultra means and launching a 2.5 Pro-High with ultra name would result in backlash
they might (and should) do more like Pro and flash models with different level of thinking budget (like OAI)
"Pro" and "Flash" are indeed clear and easy-to-understand product naming conventions. And yes, Google AI Studio needs a parameter to adjust the reasoning strength . Furthermore, I've noticed that many websites don't offer any option to adjust this reasoning strength, which is very inconvenient.🥲
yeah i don't think their model released will be called 2.5-Pro-High (though it might be.. just to hedge ha)
i think when they release the stable version, it will have a parameter for reasoning tokens (like sonnet.3.7-thinking is fixed at 32k; OAI models offer low, med, high). Perhaps it'll be a dropdown, low/med/high, but there's no reason why the end user couldn't specify the max number of tokens to be allocated for reasoning / thinking, like with max_output
and i think perhaps dragontail could be 2.5-Pro served with a high value set for reasoning_budget
but it won't be like separate model
good guess.. i agree with you
https://x.com/GeminiApp/status/1912591827087315323?s=19
🤔 how useful is it?
We’ve been hearing great feedback on Gemini Live with camera and screen share, so we decided to bring it to more people ✨
Starting today and over the coming weeks, we're rolling it out to *all* @Android users with the Gemini app. Enjoy!
PS If you don’t have the app yet,
o3 > 2.5 pro > o4 mini
but o3 is very expensive for relatively small benefit over 2.5 pro.
I am a bit disappointed by yesterday's OAI release.
But chatgpt is no way braindead 🙂
wtf
o3 is better than 2.5 pro now
surely nightwhisper is gonna come out
why are u disappointed tho
ah shet yeah

No, that's not quite right. The difference is minimal. However, in some o3 scenarios, the cost can be ten times higher or even more! And there are also cases, particularly in code writing, where it's less than ideal (certainly not as good as the scores might lead you to believe). While its Agent performs well, which is fair, the base model is just deeply unsatisfying.
I'm not sure what the state of English is like with this model (I'm using Chinese). I've tested its understanding of a few texts, and the results are far from ideal. At first glance, it seems impressive and insightful, but that's quickly revealed to be an illusion. Like DeepSeek R1, it tends to latch onto certain words and over-interpret them, and its language is quite flamboyant. If you like DeepSeek's writing style, then perhaps this model is a compromise. In comparison, Gemini 2.5 Pro demonstrates a remarkably solid, appropriate, and somewhat insightful understanding. Furthermore, if understanding is subjective, I also tested the application of translating Japanese song lyrics into Chinese, and it was terrible, very disappointing.
goooood morning
gm bro
gm
I do not recognize o3-high as a competitor for 2.5 pro, because it is o3 with the MAXIMUM level of reasoning.
ur using a translator?
i didnt realise that this is ai
this one is sorta noticeable that it's ai translated because of
" and its language is quite flamboyant."
"but that's quickly revealed to be an illusion."
still 1000% better than old school translation (wouldn't even be a question if it was translated; there'd be a litany odd / seemingly misplaced words etc)
kinda interesting come to think of it.. like you give an LLM text to translate, and ig generally it both translates and polishes it? Like it will spit out the translation with properly formed sentences, correct punctuation etc, even if the original was sloppy (like typos, poor / no punctuation etc)?
also hopefully AI translated not AI generated (otherwise I think it like passed the turing test.. or we failed it lol)
there's a chance that the next Gemini model to be released is 2.5 Flash
hopefully there's more after this

this si what o3 says about itself:
Think of me as a miniature A2A coordinator bundled with a suite of MCP‑ready tools.
Everything you saw in the video—agent discovery, delegation, precise tool execution—happens here on a smaller scale every time I answer. The protocols simply formalise and generalise what’s happening under the hood right now
so openai is pretty much doing what google is doing with A2A and anthropic is doing with mcps but built in
the only thing that will make o3 better is the ability add more tools or mcps to it overtime and allow o3 to create agents based on those tools
omg another Chinese speaker in the chatroom
how good is gemini 2.5 as a translator in those languages?
Very good in "Chinese to English" I can confirm

either way people will just repost that stuff so you won't ever need to pay
well yeah!
haven't looked into what he's doing but i do wonder
whether he has exclusive access to something (and what it is) or not
yeah to pay seems weird bc he posts it as soon as he gets news
thats what his twitter is for
oh he'll surely stop posting it
like why he gets views lol
once he makes it paid
but he also is saying he won't make it paid for now
clearly testing whether he can afford to
but nothings even happening i dont even know why im speculating
what woul dbe the benefit for people? like how useful is his tool anyway? it tells us what is most likely coming out but so does the companies
but for the webdev arena stuff its cool
like i never check webdev unless he posts about a new model
he knows before the companies officially tell us
or at most immediately when they do since its a discord webhook and he gets notifications
not the gemini one
?
yesterday
logan posted about a new model
then legit posted about it a few hours later
about the exact model
but at that point whocares
i can just wait for today
unless you in prediction markets
idk, i just dont see the need for buying that, especially when you have channels like this
the only thing about openai is their UI sometimes buggs out
i always have issues with their website
TWEET LIKE TRUMP, “THIS IS GREAT TIME TO BUY”🤪
never get issues with studio, like maybe 1/10 times with studio and i usually know when it will bug out, but with chatgpt bruhh, its like 50/50
im gonna build an o3 clone that is adaptable where you can add new tools on the fly, its pretty much just a small scale ai ide or more specifically a augment or cursor or windsurf, but built into a model with specific mcps, like a starter package, i wonder if you built an ai ide with o3 as the brains, maybe that is where openai is going?
gpt5 is just o3 but access to more tools and trained on how to better use those tools and more agents built in
Studio is a pain to use compared to chatgpt website. Good luck trying to branch the conversation from the middle of your chat… It’s really openai’s playground alternative rather than chatgpt. For that it’s alright
true but is openai playground free?
and tbh i dont like using openai playground tbh, its a little confusing for me for some reason
studio is very straightforward
the branching feature is more newer, and it works okay, but when you compare just fucntionality to what you can do in chatgpt studio works better
you cant even branch in chatgpt, so no point even mentioning that
Are you joking, it works perfect. You just edit the message in the middle of your chat and your chat continues from that point. In aistudio it’s an absolute mess with it just leaving all the flood from previous branch below. It’s a playground and not a full functionality user friendly interface like cgpt
kinda by design
you can branch in playground?
what kind of argument is "who cares" against the fact that it objectively does something most people don't have access to without doing what the bot itself does
though of course it's not worth it and i hope nobody pays for it if he ever makes it paid
what you are talking about is getting info an hour or sometimes minutes before people
or days
depends
thats why to me its pointless
i can see its use
though to me it doesnt much matter what will come out
its all just names
what would paying for it do for you?
until we actually see what it does
which only ever happens on lmarena or private access (which nobody normal will have access to regardless) or the actual release which after that it doesnt matter
??