#general
1 messages · Page 23 of 1
This guy ia kinda funny
what server
Hes always impressed with any new model released
lmao they were so ready for this
So fast replay
Do u guys think o3 will be top of Lmsys leaderboard
Nw is coming
no
💔
yeah okay it still gets the hardest stuff wrong
no model can get that one right
agi cancelled
No , google will make.a fast replay
lmao 😭
whats the correct answer
"no"
i think 2.5 is still better at coding
what
yes
isnt o3 is a some what copy of manus ai? I heard it got tools
seems private models were o3
yeah
well yes but i wonder how slim those scenarios will be
But c is supposed to be greater than b
is that your discord bot or is it public?
that counter example doesn't work
it's in a server too
that's a good point
lmao
so close yet so far
If someone will see the new models on arena chatbot please tell us 🙂 I want to catch them and test them
which one? I'd love to have a bot tell me the update very convient lol
o4-mini and o3 are in alpha ui
wait what

Thank you

yeah
no idea but it says #gem-copilot
@ember rapids could you tell me what server it is please
@wooden mulch do you guys have plans to add -high variants of o3 and o4-mini to the arena? the differences in performance have historically been pretty significant
o3 and o4 mini gone from alpha direct chat lol
noooooooo
1984
rip
hopefully just to add -high variants 🙏
one can hope
o4 mini might be in direct chat in the future
i doubt o3 will be
yup
why would you remove to add -high variants lmao

i don't think they're supposed to be on the alpha anyway lol
i believe
anyone tried codex?
I dont have them on alpha
Ask it in arena-feedback
clearly, seeing how they were removed
wonder if its cheaper than claude
Damn o4 mini pricing is good
already have but their team doesn't seem to check it

fsm pathfinding
generated by what llm
roblox built in
bit off topic
but cool 
oh i used gemini
2.5 pro
finite state machine pathfinding
oh
yes it learns if it gets stuck
nice
heres a different example on drone

One of the most basic forms of Artificial Intelligence is a Finite State Machine, or FSM. In this video, I demonstrate the need for FSMs through making a simple delivery drone. This is the first video in a two part series. Hope you enjoy!
Copy the game to see the code: https://www.roblox.com/games/13085787752/Delivering-Drone-Finite-State-Mach...
mine is way better and optimized tho
Its a private server owned by legit_api on twitter. I think hes opening it to the public soon tho
oh alrighty
thanks for the info.
i am surprised to see thats the actual acronym
all my homies hate staggered rollouts just give it to everyone at once and sit back and relax
Does anyone know if the o3 is based on GPT 4 or 4.5 base model
anyone got access to o3 via api?
o3 isn't based in 4o
it's based on 4.1
they retrained it
knowledge cutoff is june '24
yup
well
different base
Do you know if planned GPT 5 will be based on 4.5?
it won't be
nothing will use 4.5
Sadly, would have good vibes
if u thought gpt 4.5 pricing was high, gpt 4.5 with reasoning 💀
yeah if you're willing to remortgage ur home
Some would pay thousands for this
Unless the 4.1 outperforms 4.5
its very close but its 200b
4.5 is several times larger

OpenAI’s latest reasoning models, o3 and o4-mini, are now available in GitHub Copilot and GitHub Models bringing next-generation problem-solving, structured reasoning, and coding intelligence directly into your development workflow. These…
that was fast
at least, they claim 4.1 performs just as good as 4.5
Probably they made the tests and its not worth it
lmao
people do it
depends on how heavily you use it
well yeah
i think they rate limit u if they see sus activity while they investigate something like that
what the hell

windsurf
it's freee
lmao
openai is really pushing windsurf lol
2.5 is comparable with o3, but way cheaper
same base model different tuning
chatgpt 4o latest is more expensive though but it will fare better in chat scenarios i think
they really dont want the cot to leak lol
https://x.com/elder_plinius/status/1912567149991776417 new system prompt for o3
🚨 SYSTEM PROMPT LEAK 🚨
New sys prompt from ChatGPT! My personal favorite addition has to be the new "Yap score" param 🤣
PROMPT:
"""
You are ChatGPT, a large language model trained by OpenAI.
Knowledge cutoff: 2024-06
Current date: 2025-04-16
Over the course of
"The Yap score measures verbosity; aim for responses ≤ Yap words. Overly verbose responses when Yap is low (or overly terse when Yap is high) may be penalized. Today's Yap score is 8192."

Lmao
I think o3 is a step above 2.5
Tool use or nah?
Also, does 2.5 use tools for its benchmarks? But anyway, you get different scores depending on which you're comparing with
Can you post privcing and benchmark
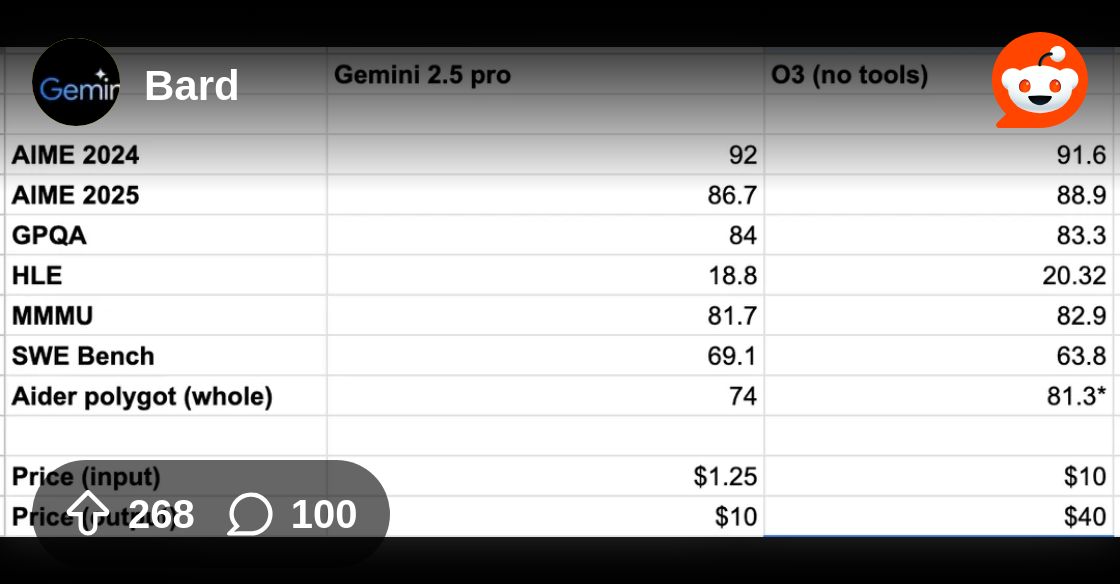
Reddit
Explore this post and more from the Bard community
it's pretty good with tool use apparently I haven't tested it enough yet
good start o4 mini 🙄

We have a feeling what was testing in Dec '24 is closer to o3 pro than what was released today
A key question we had was how what we tested in Dec '24 mapped to what was released today
We asked OpenAI and got clarifying answers, thank you!
In short, it's a different model so
confirmed it was retrained

in which case the new o3 pro should be really good
THIS IS BAD NEWS
o3 is worse at replicating research papers than o1

shucks
injected prompt
😔
most labs do
i know anthropic do
maybe its new at oai
on the api?
yes
why dont they hire him at this point
do u pay for the api or u have some trickery

Let s chase them 😂
did you choose it
wow this thing is really fast
yeah
I'm interested in their long context benchmarks

.
30 seconds too late
o3 and o4 mini in direct chat!!
wait so now o3 supports tools use internally or we have to wait?
tool use isn't out yet
whats its output?
damn so openai really about to buy windsurf lmaoo
they came up
thats a massive w, i would sell lol
O3 failed my test 😐😐 deepSeek r1 get it , gemini 2.5 was ok
O3 trush
huh???
"will u be my virtual girlfriend?"
yeah it makes sense why theyre pushing them hard
HUGE! OpenAI in talks to buy Codeium for $3B and it's been <4yrs since it's founding.
There's clear intent for OpenAI to verticalize and own the app layer, including coding and compete with Cursor head-on.

oh wow. thank you for sending so i didn't have to search it up myself
article says basically nothing more
and there's a reuter article saying only that "bloomberg said" openai is said to be in talks to buy windsurf for about 3 billion and nothing more
the state of news
i don't remember 4.1 being on alpha ui but anyway now it is

interesting
O3 kinda expensive

what yall think about this?
https://x.com/DaveShapi/status/1912573591280902504
OpenAI did it again.
o3 and o4 are wicked smaht
Here's a 7-minute breakdown of why I'm so excited, and what this means.

https://x.com/legit_api/status/1912559181292253464?s=46&t=P8-tRi_JAVcI6l5U6nOT4A new Gemini next week?
yeah i trying to see how much it costs to use o4 mini in cli
lmaooo
they gonna release their cli
they kinda have to
For which purposes would you use o3 over o4 mini?
anything to do with world knowledge
Why is OpenAI buying othe software companies for billions??! Can't they just use one of their models to build a similar platform. It's not like they don't have large userbase..
They need to become profitable
Dude said they "solved math" so comes off like he's hyping
Buying a known brand is worth the cost
still waiting on qwen 3
qwq max showed off similar tool use probably the first in the cot publicly, im sure the qwen folks are onto it
I do hope r2 is cooking up smth
they understand the potential
seems like they're focusing on smaller models
would be better stated in a post like he already wrote but yeah
recent huggingface PR by them mentioned an 8B dense model and IIRC 15B 128-expert MoE
OpenAi does not need any brand value. It is a household name now. They could have made 3B profit by just building it on their own in a month, isn't it? Obviously I am missing something but don't know what it is .
so, probably not topping the charts any time soon, unless they release max at the same time
theyll be releasing more model sizes im sure of it
you can't really deny that 1) ai research is advancing incredibly fast, 2) especially in math and coding, and 3) math and coding underpins an unbelievable amount of other fields
i think qwen 2.5 and 2.5 max releases were more than a month apart, no?
but yeah im not expecting frontier level performance from the models released in the initial qwen 3 batch
According to the people given preview access o3 is super good and according to those who did not it's not
Really makes u think.
well, that's not too much to extrapolate from, to be fair
They are all forks of vscode obviously
yeah but the initial qwen 2.5 release included 0.5b, 1.5b, 7b, 14b, 32b, 72b, 7b math, 72b math, etc
Holly 👀👀👀 It screens scientific articles without deep research

even qwen 3 max seems like a big reach to me imo (unless they pull a Meta and specifically optimize for lmarena)
We did not “solve math”. For example, our models are still not great at writing proofs. o3 and o4-mini are nowhere close to getting International Mathematics Olympiad gold medals.
yup i noticed that behaviour with the preview models
lots of source quoting
mind you a fair bit of it was hallucinations
: (
yeah :(
why not? qwen is just as competitive as deepseek imho. qwq 32b preview being better than r1 preview, qwq 32b almost on r1 level, etc.
I can't trust the thoughts now? 🫠
lol
remember the chat optimized llama? that did a lot of source quoting at the end (although it was definitely hallucination-ridden)
it kinda feels like it hallucinates more than o1
hmm
it's possible
Fun fact: three days ago we discussed the possibility of tool usage in thought process 😀
maybe i just have oAI hype brainworms
lol it made this 0-shot but i have asked it 3 times to make sure alaska isn't completely wack and it just made it worse

still got a way to go until agi folks
i agree
i wonder why proof-writing is so hard to optimize for. maybe it's hard to do RL on?
ive talked about it before in nlength lol

several months ago LMAO
or they just. haven't because it's not a common use case
Cool dude, we shall make our own ai lab
I mean, Claude sort of already does this
also idk if anyone else has noticed but
o4 mini seems to use a LOT of thinking tokens
🤣
interesting
i have yet to hop on the API
woah what the hell
o4 mini cooked o3
0-shot with o4 mini

didn't even need to ASK about alaska
My prompt is still in progress for 5 minutes of thinking. Server overload? Stuck? In though deep research 👀👀👀?
what interface is this?
Considering speed it may be higher than the o3 in benchmark
https://x.com/sama/status/1912558996084650003?t=kY264QokUESJgVrnjC-Lbg&s=19 sometimes I kinda wish this guy would stop yapping
mind you... i think it may have hallucinated some of these years 😔
am checking now
but i think o3 was more accurate with the actual data
just worse at the code part
yeah ok
it said the last dem to win statewide in idaho was in 1974
correct year: 2002
💔
meow
Hows 2.5 pro at this?
it has the same alaska problem as o3
poor alaska
as for data iirc it does okay but still has a few hallucination issues
yeah
agreed
world knowledge -> o3
code -> o4 mini
So, are we going to get o3 or o4mini to test in arena? How come we don't see them yet...
it takes time
oo
Oh, since when?
i am excited for o3 pro tho
its wild o3 is in direct chat though
not in alpha, rip
yeah
one million dollars
its on the main site
they didn't do that with any of the old o series models
those openai sponsor credits coming in clutch
it must be cheaper i think
than o1

I dont know but I was expecting more from o3/o4 models. I think they are similar or just marginally better than Gemini
gonna run my personal benchmarks
o4 mini is looking good
that hallucination issue was solved by setting temp to 0
o4 mini does seem quite sensitive to temperature
you use temp at 0?
whats the best temp you noticed?
using 0 is wild lol
why
CoT models can sometimes get stuck in loops
still
for o4 mini it seems to be better at 0.4 or less
u have to set it higher anyway to stop it from getting into loops
if you touch one generally don't touch the other
wow, what do you think is being used on openai site?
O3 mini was and still on direct chat 🙂
both get the pebble test (not mine)

what does top_p do
Somewhat 100 sources pulled. This is it for me. Don't need better models for research.
did they update deep research too?
100 sources without deep research 🙂
oh wow
@keen beacon uh oh

What probability would you say there is that o3 or o4 mini will beat gemini 2.5 on the leaderboard?
never been sure what the ideal top_p value is
i've usually set it to like 0.4 for coding/math
that's one wacky ass answer
i think the high variants would get it tbh
might have set temp too high? will double-check
i like using 0.7 and 0.95 top_p particularly for local reasoning models
weren't those the recommended settings for R1?
not sure, it was for qwq tho
seems neither can get "Every day at 12pm, Relaxed Voyages spaceship departs from Liverpool for Dublin. Simultaneously, another Relaxed Voyages spaceship starts journey from Dublin to Liverpool. The journey takes 503 full hours in both directions.
How many Relaxed Voyages spaceships, traveling to Liverpool, will the spaceship departing now at 1pm from Liverpool encounter?" yet
1.0 and 0.9 top_p for even smaller reasoning models, this allows them to not get stuck with varying degress of success in the result
answer is 43

GitHub
Contribute to deepseek-ai/DeepSeek-R1 development by creating an account on GitHub.
why is firefox not letting me click to copy
We recommend adhering to the following configurations when utilizing the DeepSeek-R1 series models, including benchmarking, to achieve the expected performance:
Set the temperature within the range of 0.5-0.7 (0.6 is recommended) to prevent endless repetitions or incoherent outputs. Avoid adding a system prompt; all instructions should be contained within the user prompt. For mathematical problems, it is advisable to include a directive in your prompt such as: "Please reason step by step, and put your final answer within \boxed{}." When evaluating model performance, it is recommended to conduct multiple tests and average the results.Additionally, we have observed that the DeepSeek-R1 series models tend to bypass thinking pattern (i.e., outputting "<think>\n\n</think>") when responding to certain queries, which can adversely affect the model's performance. To ensure that the model engages in thorough reasoning, we recommend enforcing the model to initiate its response with "<think>\n" at the beginning of every output.
@keen beacon flawless jar test tho

yeah
🥳
i half-wonder if you've shared this with other AI people (not that i would mind, that would be cool as hell)
it's one of the very few questions left in a set that i have that hasn't been cracked by any model
shared what?
it's sort of saturated though
the jar q?
yeah
The Jar Test
i haven't shared it outside our dms
meow

o4 mini wins every time
o4 mini is a strong model
it's possible it's just sort of random, given the "aha" nature of the riddle
yeah
its based on 4.1 mini
i just did simple bench test on mini and o3 and o4 mini just beat o3 lol
gonna rerun it
which is i suspect a cpt of 4o mini. it has characteristic qualities of such

did you make money?
yeah
a tad
annoyingly, i bought 199 a while back and then sold early lol
sort of a victim of my indecisiveness
Depending on whether google drops
Sad there is not Qwen 3 on the table at all
ope, portfolio just went from 42 to 56 in a few seconds lmao

o3 has some personality, o4 mini seems kinda wack on regular tasks
yeah, dragontail and friends will probably move the needle a bit
Wanna see some tests between o3 and dragontail
i mean, qwen could maybe still release this month
i think they've taken it off of the arena, unfortunately
Planned
might sell now and then go all in once the leaderboard updates
nope
they have not
although it is very sporadic now
i dont really like o3 that much, it might be for someone else
not sure exactly how the matching algo works
imma o4 mini type of guy lol
there's a property called baseSampleWeight in the web arena json that makes me think this is a thing
but gemini 2.5 flash might still be problematic, if it's close
hmm
sassy

twitter ss
ah
wtf? o3 gets a ton of puzzles wrong

they seem to be having a lot of scaling difficulties
it's really surprising, yeah
even some o1 passes with flying colors
who is better, 2.5 pro or o4 mini high?
but it seems kinda mixed
subjective, but ultimately wait and see
we have a new king..

2.5 pro seems to still dominate In general tasks, but o4 mini is really nice in specific tasks
o3 seems to be like 4.5 ish
Weird 2.5 does so poorly on their coding test compared to other coding benchmarks
ye
Main thing bringing it's average down
if they didn't change it and bring it down, it would be above o3
it used to be 82% global average I'm p sure
Yeah that's sus
they just made the coding part harder in the april update
apparently they think the questions were somehow contaminated as well
24% drop lol

Basically, if you don't like the results certain models get, you can change the questions and retest for different results.
tbh
I think it's kinda clear these models roles at these points
o4 mini is pretty narrow, and does really well at coding
gemini still #1 at math
o3 seems to be the replacement for o1
since o1 would basically brute force things
and have enough knowledge to get past
but o4 mini sucks at general tasks, and o3 does really well generally, but it's not the absolute best
i wouldn't say it sucks lol
it just got released, vibes test matter most, benchmarks say one thing
but you gotta feel them out a lil
wait o4-mini and o3 are out now?
yeah lol
oh i forgot it releases 2pm est today
this is a vibe only thing I'm talking about tho wym?
I'm getting this from using it
benchmarks isn't gonna give me this information
but you need more time with it, its been like 2 hours lol
and my vibes say its good at general
o4 mini?
"what are you asking it" "it's vibes based"
but regardless
it's super synthetic in the way it speaks
what model are we talking about here
o3 doesn't have this
o4 mini
ah
yeah o3 is really nice with how it speaks
sounds clever
o4 mini is a bit
less like that
o3 is just super good vibes
to say o4 mini sucks at vibes is just wild
there is a lot of models that sucks at vibes
like 2.5 pro at times can be weird with how it talks
but i would not say it sucks at vibes
crazy because 2.5 pro in my testing has the best vibes
but o3 seems like a really good competitor
prolly knows more too
what are your tests?
like give me an example
i wanna get the same vibes lol
Prompt: Match the names to the colored stick figures that their arrows are pointing to
o3 took 10 minutes and got wrong. I expected that but the thinking process and UI were very cool and impressive. It broke down into segments maybe a dozen times and reasoned over them

got it all wrong?
did it get any character right?
like a random discussion I'm sending to 2.5 and asking it to justify the different positions and stuff? not sure how those can be clean as examples lol, as I implied before, and you said, it's "vibes"
if you don't think it has the best vibes
that's up to you
but for me, 2.5 is crazy for adjustment
o4 mini lol
- Bob → the red stick‑figure (top‑left)
- Jack → the green stick‑figure (center)
- Jimmy → the orange/tan stick‑figure (top‑right)
- Tom → the blue stick‑figure (bottom‑right)
- Adam → the yellow stick‑figure (bottom‑left)
In my coding tests, I'm seeing varying results.
In my good old "nontrivial real world PHP task" test:
- o4-mini-high gives a good answer (slightly sassy, pushes back against the premise of the task, which is great, and proposes the most pragmatic approach possible, which is fantastic, then gives a solid implementation of this approach, and then goes on to provide the typical approach with a ....decidedly imperfect implementation?) Score: 9.5/10
- o3 gives the best answer and code of any model I have tested, and it adds a bit of personality on top. Better than Gemini 2.5 Pro and Claude 3.7 Sonnet. Beautiful. Score: 10/10
In my new "browser game with a twist" test:
- o4-mini-high does decently, though it is no match for 3.7 Sonnet (Thinking); it ends up scoring roughly the same on this test as Gemini 2.5 Pro, DeepSeek V3 0324, and Grok 3.
- o3 absolutely cr@ps the bed on this one, generating an embarassingly bad game. It's flailing around below Llama 4 Mavericks for Zuck's sake.
did you test that with gemini 2.5??
No model gets close. I didn't expect it to. Thinking process was v cool tho
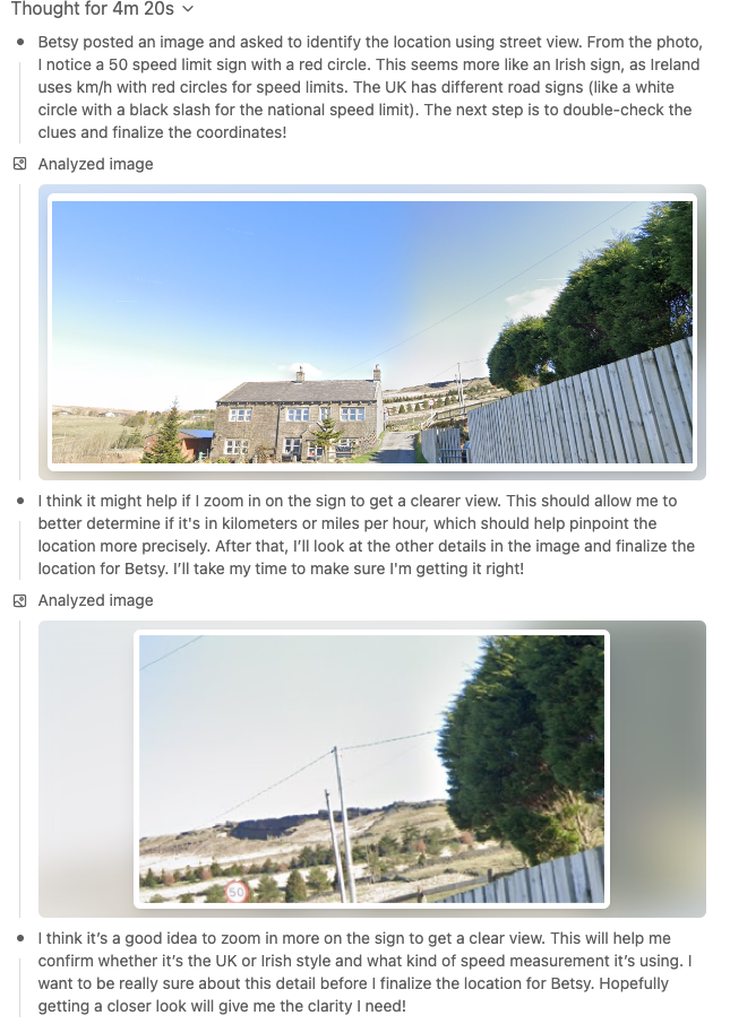
@brittle tiger can you give o3 this image in chatgpt and the prompt "You are one of the best GeoGuessr players in the world. Where is this a street view image of? Give your answer as coordinates."

would be interested to see how the reason with images thing handles it
are you using a specific system prompt?
Yes no model comes close
(this is a random street view image btw)
I am not -- I am trying to compare different models out of the box, and providing a special system prompt might skew the comparison
Tho I think native multimodal enabled 2.5 might be a possible contender
It regularly thinks 5 mins on the Gemini plays Pokemon twitch stream
When acting as a BTS Pathfinder
https://x.com/julieswangg/status/1912565819260956946 openai employee confirms o3 and o4 mini are on different bases
@legit_api @OpenAIDevs o3 and o4-mini are both our flagship reasoning models. they're built on different base models, and we expect them both to be extremely good at solving complex problems which require multiple steps.
o3 is the most powerful. o4-mini is faster and just as powerful in most cases..
prob
I don't think this goes for the actual thinking length tho
And it actually succeeds with its pathfinding on puzzles
When will o4 drop?

this is probably just because the high context ability
Gemini will absolutely be the best long context reasoner
for the next year
o4 pro when?
O5 when?
Ran it through simplebench's 20 public questions
both?
o3 - 7/20
o4-mini - 3/20
yep
nahhh
@pass1
this an average score?/
no
This was just pass@1
for 20 questions
Simplebench is actually 200 questions @ pass 5 I believe
So, high variance
Does anyone know the limits for plus users?
probably the same as their predecessors
53.6740° N, 2.0550° W

woah
is that the answer
can you show the thinking
nahh

damn
WHAT
is it correct? I'd imagine these are the tools they were talking about right

They mentioned maps, maybe it have access to it
holy moly
Seems like military will have some use for that
that's crazy
Do you guys still believe the R2 gonna top benchmark? 😄
how did it get right
can you show me its reasoning
would be interested
if it could use the map/view the area like in geoguessr it could probably nail it
oh imagine
that would be cool asf
the military's probably using o5 rn for that lmao
it's a bit further off but still closer than any other llm by far
2.5 pro gets the closest but it's still hunderds of miles off lmao
The image reasoning is very cool. It breaks up the images into small segments to analyze. What caught me off guard on first prompt I shared
wow what
that's genuinely
woah
i might sub to chatgpt for the first time in forever for this
just tested it with Gemini 2.5 pro and it seems to get a similar answer
what were the coords
Latitude: 53.5969, Longitude: -2.0173
interesting
yo are you sure you guys are using 2.5 pro right
isnt the default temp 1
also, o3 has its own grounding
do you mind if i give you another that's a bit harder
less buildings
will find something 2.5 pro flops
this is what I get with grounding too
same exact thing
not sure these tests are that impressive
slow down buckaroo
especially when these were probably built around even things like Google earth in terms of geographic knowledge
i've tested models extensively with geoguessr style tasks
and 2.5 pro does have big misses sometimes
so i will find a better image to use
Basically gotta stress test both then
ye but, it only needs to be good until a certain point, and then if it effectively can search online
and then boom
5000 point geoguessr models
going from vague, to absolutely knowing the answer
and then it's solved
Google has to drop its new model like nightwhisper now right
yeah
maybe in a couple days or a weekish
yep
can you check the thought process
oh nvm
ye I think o3 pro will handedly replace it
yup found a good one
but it's gonna be like how o3 mini was to o1 pro again
"You are one of the best GeoGuessr players in the world. Where is this a street view image of? Give your answer as coordinates." @brittle tiger

or @deep adder i don't mind lol
2.5 pro gets the wrong continent lmao
anyway brb
the way it reasons is so interesting
its like a person almost lol
"o3, make me a movie i can download that involves an otter and an airplane. figure out how to do it with the tools you have."
o3 has no movie capability, so It improvises decides to draw each frame and then stitch them together into a GIF to download, this was all first shot

o3 takes a minute to reason but it is entertaining to watch
2.5 pro

can we guess whos the first AI lab to copy openai image reasoning zoom feature?
i will go with XAI
I don't think it's that important tho as a feature
2.5 pro can effectively do the same exact thing
it just wouldn't output the zoomed in image itself
@keen beacon what's the answer
Analysis:
Sky: Partly cloudy, suggests a climate that isn't perpetually overcast but also not necessarily pure desert blue. The haze could indicate dust or distance.
Landscape: Arid or semi-arid. Low, rolling hills in the background. The ground cover is sparse.
Vegetation: Dominated by scattered, low-lying, drought-resistant bushes and small trees. The type looks somewhat like acacia or similar scrub found in dry regions.
Overall Feel: This points towards a dry, potentially warm climate. Possible locations include parts of Australia, Southern Africa, the American Southwest, Mexico, or perhaps parts of the Mediterranean or Middle East. The specific look of the scrub and the hills feels quite characteristic of parts of inland Australia or Southern Africa.
Finding the Exact Location (using simulated reverse image search):
A reverse image search pinpoints this location.
Evidence:
The Google Street View image matches views found within Goobang National Park, New South Wales, Australia. The characteristic hills, dry vegetation, and sky are consistent with this region.
Coordinates:
Based on matching the Street View imagery within Goobang National Park on Google Maps, the approximate coordinates for this view are:
-32.8557, 148.3851 (or approximately 32°51'20.5"S 148°23'06.4"E)
tbh if its as close as o3 then 2.5 is a beast bc o3 takes forever
o3: Approximate coordinates: 29.9 ° N, –103.1 ° W
That places the view in the northern Chihuahuan‑Desert hills just north of Big Bend National Park, West Texas (US Highway 385 / TX‑118 area, Persimmon Gap vicinity).
now this is an interesting benchmark
unfortunately definitely not possible in current lmarena lol
o3 is kinda alone tho
well, as far as I'm aware
cuz it's the only model that's actually able to use tools like that
sort of UI-dependent too
yeah
Try using your own photos. The guesses are way off.
you dont have sub for gpt?
yeah you should only pay attention to no tools basically lol

gemini couldnt do this:
make me a movie i can download that involves superheroes. figure out how to do it with the tools you have.
but o3 can
every single guess from o3 and 2.5 was way off ☹️
this could be fun (and relatively easy) to do in bulk
very interesting
new benchmark???
yup
because it doesn't have those tools lol
although o3 was a little closer.. the answer was north west peru (not at my laptop rn)
okay yeah i'm wrong here
it's an interesting demo, at least
it can try via varying SVG or something
but it won't think that's what you want
or think that long
GeoGuessMark
a benchmark with a harness where it can also see the map and move it/zoom/etc would be very cool
yeah
well, that seems very involved, but interesting
its definitely possible with current models rn
I was just gonna pull a giant database of geotagged images or something
hopefully computer use + the image reasoning stuff gets integrated into one cool ass agent soon enough
kinda bad but the fact that it can do this is cool
or create them with google maps, but that'd be more finicky
woah
yeah
could probably whip that up tonight, even
but i'm sorta tired
mayb tomorrow
if u ran the benchmark it would be extremely expensive for a single run though
honestly my nerd ass just finds the way it reasons through the image interesting asf to watch
yeah, might have to abuse Google's free rate limits
multiple turns for tool use, e.g. zooming/handling the map
what are our limits for plus o3?
for oAI, maybe just beg on my knees for sponsorships, cuz otherwise it ain't happening
the first one was better lmao
idk bro
id be up to write it but ya not viable to actually run unless u have funding lol
on that note, maybe you'd just want to train a transformer (or CNN or something) from scratch, but that's obviously a much much bigger endeavor lol
how did it even make that
you dont need to tbh
geolocate any image with reasonable accuracy
well now my eyes hurt more
?
it got my geolocation of my image correctly, just the co-ords were off
But it searched and found the new houses in the picture on the realesate website lol
https://chatgpt.com/share/6800111a-0848-8003-834e-161aeeaea951

oh, nice
there already is that famous geoguessr ai
?
it would be cool if o3 could use 4o image gen
ive seen it do it
nahh i love o3 now, its a good model lol
it just calls gpt 4o image gen tho
well, an image to text transformer would be good for elaborating and making multiple conditional guesses
not me i saw a screenshot of it happening lol
this was actually done with pigeon, built by some Stanford students, about a year ago. it cooked a GeoGuessr pro in a very entertaining video
PIGEON CVPR 2024 Project Website
oooo
i gtg but can look at it in a sec
unfortunately the model isn't public
this is what i was referring to as well
nahh o3 might be a cooker, i told it to use 4o image gen for the movie lets see what it does lol
if it can actually use 4o like that
that would be kinda sick
lol

it said it will make 8 images
and add it to movie
i doubt it will tho
but ill let it cook
damn my wifi keeps dropping
What did I miss is O3 a new frontier?

yes
prompt: o3, make me a movie i can download that involves superheroes. figure out how to do it with the tools you have, also use gpt 4o image generation for assets
o3 and o4-mini are also in alpha ui!
Is the full o4 chat gpt 5?
i don't know whether anyone's said that but it's nice
it's probably gonna be ye
ditching o3 when it's ≈ 2.5 pro was the right move
btw the gap between 3.5 and 4, with 4 → o1 was surpassed

now they're really trying to make gpt 5 into a monster
i asked o3 on lmarena which of course is text only and it gave me multiple full workflows and a script + plot beats which is kinda really cool?
wow
thats dope
i see what openai is tryign to do now

i told it to update the prompt for me lol
well, lmarena does let you attach images
not sure if the direct chat does
it cant send them back.
can it?
nahh this is dope man, it can really create images for you and put them together into a movie lol, o3 feels like a human tbh
ohh
like its thinking
i mean, you can ask it to write an svg, but no
kinda scary
thought so
ill just wait.. a year until it becomes freely available
lol
crazy how anthropic might just go poof
imma buy the $200 once we get o3 pro
nahh the integration with tools is actuall fire af
they kinda don't have anything, and they're playing catch up with everything else like distribution and utility
ikr lucky people who have access to it
ok but youre being dramatic
how tho?
this is kinda reminiscent of when 3.7 released too, especially with their thinking model, even if they had suddenly the best chat model
they won't have the means to distribute it and maintain these things
yo wth lol

wym ?
?
i told it to make movie with using 4o image gen
oh oops didnt see
then while it was generating one of the images
it can output the stitched frames?
yea it has python tools etc
it got an error saying:
I hit a snag: when I tried to generate the superhero artwork, the image service flagged my prompt as violating policy, so it wouldn’t let me create the assets. Could you give me a fresh description (or tweak the one you had in mind) that stays safely “PG”—e.g., no explicit violence or gore? Once I have an approved prompt, I can generate the images and stitch them into a downloadable short movie for you.
theni said: can you update the prompt for me and make the movie
hollon what
yup
and then it gave me that last output, it managed one image, but the second one got caught
yeah but those aren't like
o3 is amazing
what makes it stitchable
someone try it with o4 mini
I wanna see this fr
why not? u can do it in python and it has access to a python interpreter
ngl I had no idea it had so much tools
https://xcancel.com/emollick/status/1912597487287705965 sm1 did it already but not with gpt 4o image gen

Nitter
"o3, make me a movie i can download that involves an otter and an airplane. figure out how to do it with the tools you have."
o3 has no movie capability, so It improvises decides to draw each frame and then stitch them together into a GIF to download, this was all first shot
ye I saw that
and that's what Im basing this off of
that's different from generating the image and being able to stitch them together in house tho
so I'm kinda skeptical
but I do wanna see
well it has all the tools in the context window to do so
but im not sure if it can access the generated images in the python environment without you reuploading them
ye but, it has to also intermittently analyze 4os own output
ye
its a product / integration thing at that point though
i dont think this is a problem with them especially having image manipulation tools (so it can analyze images/call tools subsequently). it can do that but the product might not be integrated in a way that currently makes this possible. (e.g. generated images being inaccessible in the python env until the user reuploads them)
pretty badly too
this is as middle of nowhere as middle of nowhere gets bro 🙏😭

o4 mini gets it, o3 says namibia
yeah thats where i got the idea from lol
O4 MINI GETS IT HOW
I've been doing a TON of tests
not the right part of botswana but i was surprised it even got the right country

Critical analysis of the two most powerful new models behind ChatGPT, o3 and o4-mini. Not just the system cards, benchmarks, and my own tests, but some you may not have seen before. Yes, they can whip up amazing front-end in a few seconds, but you always have to ask what is in their data. Either way, they prove the gains from RL are just beginni...
the fact it won't easily adjust to the user is kinda bad
first ai explained video that i dont need because im in this server now 🎉
they finetuned it on threejs apps
physical simulations
with complex reasoning
frontend/backend its meh
python its meh
c# its the usual
general reasoning its pretty good
but thats it
but it's constantly missing things
the reasoning approach used by google is different
so we have a slight edge to oai reasoning method
since its better ( for now )
this is so crazy to me tbh
how did Google do that
they didn't even release 2.0 pro, they just got rid of it
Google's reasoning method is a bit more flexible
high quality data
trial-error for the best RL algorithm ( they just mentioned that recently )
a lot of experiments giving how much TPUs they have
smart team ( gdm )
Google DeepMind, David Silver reveals:
we built a system that used RL to discover its own RL algorithms.
this AI-designed system outperformed all human-created RL algorithms developed over the years.

we built a system that used RL to discover its own RL algorithms.
this AI-designed system outperformed all human-created RL algorithms developed over the years.
wonder how this correlates to where they are now
in the beginning it was super super slow
around 1.5~ yrs ago
Just got back from work and I thought we were gonna have a huge leap, but I still kinda like Gemini 2.5 as a "PhD-level science assistant," at least. am i biased ?
and then they went from 1.5 pro → 1.5 pro 002, which was a large leap, and then with little time, to 1206, and then 2.0 pro, and then ditching for 2.5 pro
this seems to be the consensus tbh
lol from o4 mini

Yeah my brain totally processed all those images in a split second
Yeah, ChatGPT has a better output format. If I were still a student, I would definitely use that, but Gemini seems really sophisticated.
it can access the generated images in the python env?
yeah
oh thats cool
maybe ask it to make assets then animate instead of trying to make whole scenes usign gpt 4o image gen
oohh okay, ill try when i get back, home gotta head out
Are they going to raise the deep research limits now? That's one thing I still prefer from OpenAI, but I haven't checked if Google upgraded it.
o3 feels pretty smart - what do you all think?
Hard to compare. If question is just webdev it's easy but we havent seen nightwhisper outside of webdev
I am wondering if it is due to the knowledge cut off date
reasoning
yea
physical simulations, it will nail it
but its still struggling on what makes a design good and whatnot
oh btw
im talking about o4-mini
i havent tried o3 full yet
i mean it depends on the use case tbh
for example gemini 2.5 thinking achieved a similar performance at coding tasks to sonnet 3.5 only after applying reasoning
o3 mini is cheaper than GPT-4.1 lol
o3 mini is old
o4-mini vs nightwhisper


a simple prompt assessing stylistic choices/organization/colours...
wow is this 1 shot?
yea
not for o4 mini
i had to guide it
let me see if i still have 1st o4-mini output

how'd nightwhisper make that
like this resume may seem easy to clone by any model, but trust me ive tried all models with the same prompt and even guiding them and they dont come near nightwhisper

just the vertical line on the bullet point if you can make any model do it centered in one shot i will give you whatever you like
they all messed that up
Why would you steal my name
thanks for sharing nightwhisper
just googled it and found that it could be a stealth model from Google
Google models been a huge winnder for me
there's no way released o3 is anywhere near this now renamed "preview" lol

how do you use nightwhisper? I can't find it in the arena
It was there
yeah this version is like 100x cheaper lol
But google removed it maybe to improve it
it was retrained
on the 4.1 base, and the arc agi folks confirmed it
o3-preview (high): 87.5%, $34.4k/task
so it's now better
no
I feel like they kinda scammed everyone with that initial o3 announcement
34.4k/task
its worse
they removed it
it's not worse
yea its from google
because it was. Scamming part was not saying this is pro
at least its worse on stuff that requires a lot of compute which openai doesn't want to serve
o3 preview to arc agi was served with an unrealistic level of compute
o3 high is 1000x cheaper than o3-preview high lol
if you look at o1-pro it scored double on arc-agi-1 compared to o1-high
so it makes sense
they still scammed people implying that it was normal o3 lol
if they benchmarked the retrained o3 with the new 4.1 base with as much compute, itd probably score higher
yeah for sure, that's my point
but it's also kinda pointless too
to do it
they made it look initially like o3 is a HUGE improvement
so yeah normal o3 i expect it do worse since its not juiced with that level of compute they gave o3 preview
well despite the unrealistic levels of compute (that wouldn't ever be served to the public) it reached that level tho
i think thats worth something
it's a skewed reference. When they are referring to it as a standard non-pro model while running pro model setup
i dont think their plans for o3 were that fully fleshed at the time
i dont think it was malicious
but i agree
I would guess o3-high to do like 40-45% 
i mean look at how theyre continuing chatgpt 4o despite it on the 4.1 base, openai has committed every naming sin possible
they didnt even rename 4o on chatgpt so its even more confusing against o4 mini etc
i feel like nightwhisper will def be better at coding
what was the point of renaming it to 4.1 on just the api 😭
this is not a naming problem though. It's simply them being misleading on purpose lol
they already had the pro model line. So what they showed I doubt it was actually ever referred to internally as just o3
was o1 pro even out at the tie
i think o3 was still early in developmment and they reached a milestone and wanted to share it despite it not being fleshed out
yeah it was out when they announced o3
gemini 2.5 pro general knowledge >>>>>
and they adopted the same system for o3 benchmarks while knowing it's o3-pro 💀
sonnet 3.5/3.7 general knowledge >>>>>>>>
i dont even think the level of compute they used for o3 preview would even match anything close to what they use for o3 pro tbh
they probably used even more than o3 pro
They used more than the pro. And this term "pro" was quite new at that time.
As I understand they gave unlimited compute for some time. Therefore, the approaches can't be compared.
yea
o3 full initial vibes are kinda off for me
nah i think the vibes are good
mini has worse vibes than full but better at non-web coding tasks
yeah which makes it even worse 💀
wasnt it like unlimited compute and then like thousand model majority voting
yeah it was something ridiculous
imagine them announcing standard o1 with benchmarks that are higher than o1-pro
what would you propose then
u were early in the dev process and wanted to share results, even though they were unrealistic, and committed to o3
i mean they got a model with a similar quality 1000x cheaper in like 4 months