#general
1 messages · Page 3 of 1
Meanwhile xai seemed to train their reasoning model on qwq 32b preview traces don't ask me how I know lol
At least for cold start
so what kind of model do you think it is? Pro thinking?
Yes
And something else
They're doing something
phantom and specter are gone now
They're gone but the same model
same model, different checkpoints. order being specter -> phantom -> nebula
oldest to newest
all in the last couple weeks so they're cooking
I think the recent phantom and nebula is something to look out for
Something might be different
yeah there was a jump in performance from specter -> phantom
less of a jump from phantom -> nebula but still better
how does it compare to sonnet for coding?
ive had several instances where it has actually been better
especially 0-shot
sonnet is still probably the best for practical coding but anthropic has no moat
google employee liked my post about nebula 👀

ok dang it I just got it and it did pretty badly on this coding prompt I had,
what was the prompt
copied from a reddit post from a couple weeks ago lol:
Write a Python program that shows 20 balls bouncing inside a spinning heptagon:
- All balls have the same radius.
- All balls have a number on it from 1 to 20.
- All balls drop from the heptagon center when starting.
- Colors are: #f8b862, #f6ad49, #f39800, #f08300, #ec6d51, #ee7948, #ed6d3d, #ec6800, #ec6800, #ee7800, #eb6238, #ea5506, #ea5506, #eb6101, #e49e61, #e45e32, #e17b34, #dd7a56, #db8449, #d66a35
- The balls should be affected by gravity and friction, and they must bounce off the rotating walls realistically. There should also be collisions between balls.
- The material of all the balls determines that their impact bounce height will not exceed the radius of the heptagon, but higher than ball radius.
- All balls rotate with friction, the numbers on the ball can be used to indicate the spin of the ball.
- The heptagon is spinning around its center, and the speed of spinning is 360 degrees per 5 seconds.
- The heptagon size should be large enough to contain all the balls.
- Do not use the pygame library; implement collision detection algorithms and collision response etc. by yourself. The following Python libraries are allowed: tkinter, math, numpy, dataclasses, typing, sys.
- All code should be put in a single Python file.
i mean
that's a pretty complicated request
how did it do relative to other models?
Afaik it's a big llama 4 variant
??
sonnet did better, o3 mini did better in some cases, not always. Deepseek r1 also did better but took like 10 minutes to write the code. Rhea the one time I got it did better too.
Yea, at least for cold start I think
Maybe google started training on r1 traces ahaha. Nah
Haiku is not at all competitive in terms of value for money
Ok but they're competitive in the flagship dept
i find nebula to be quite unpredictable
yeah i have it marked as llama/meta?.. just fwiw
I think the temperature on the arena is relatively high
regenerating a few times is always worth it
nope, it's llama
this is amazon tho
all the vX exp models are amazon
they've all been pretty bad lmao
Waiting for qwen 3 to mog everyone else
the chinese gotta deliver
yes

amazon said premier, their big model, was releasing early this year last year
by big i mean 1T+
It's gonna be a nothing burger
none of these have given off those vibes
Just light piles of money on fire
yeah they looked ok on paper but they flopped in my practical tests
yeah agreed
They're training off synthetic data from qwen
Like give ur synthetic data dept more money
Use Claude instead
Ya it's wild. I thought they had a deal like ms. The phi team generates all their data from openai models
phi is such a wack model
benchmark maxxing
it'll get a question right but the logic doesn't even line up with the answer
yeah, the chain of thought process sometimes makes no sense compared to the answer with phi
Its because of the pivotal token dpo process/dpo in general
I think
There are a lot of separate issues y'all are seeing I thinj
i suppose im talking dpo, and not specifcially only training for benchmarks...
that has been my experience with phantom
i haven't gotten nebula again..
but yeah phantom i've gotten wild variations in quality (in response to the same prompt) - but the upper end has been highly impressive; the one time i got nebula surpasses even that upper end
good to see google finally catching up with frontier reasoners.. about time with all the money they've thrown at the problem
2.0 flash thinking was cool and all but a bit meh if you want the very best
What if they're training on r1 traces with stronger base models and then rl 🤣 would be a crazy twist unlikely tho
I have a feeling it's still not going to move the frontier forward. My guess is it's still behind sonnet 3.7 thinking except at math
geminis have always been strong at math
currently og o1
I found a gemini test model that had math above any other model
damn, nebula is good at math too
naturally
it's at least on par with o1 high in my testing
although it doesn't seem to structure its working as nicely as o1
classic gemini
is gemini 2 pro thinking in arena?
maybe
the more i test nebula the better it gets
it got this really tricky maths riddle right that no other model, except o3 mini high (very rarely!) gets correct.

the riddle is "There are 2022 users on a social network called Mathbook, and some of them are Mathbook-friends. (On Mathbook, friendship is always mutual and permanent.)
Starting now, Mathbook will only allow a new friendship to be formed between two users if they have at least two friends in common. What is the minimum number of friendships that must already exist so that every user could eventually become friends with every other user?"
99% of other models say "2022" or something like that
really, i think so too
nebula is amazing for English-Turkish translation
it feels like gpt4.5
it uses very language-specific human-like expressions and understands very well the context.
yeah gemini is historically good at translations so with an even stronger base and thinking that doesn't surprise me
is it a thinking model, right?
nebula? yes
it spent about 7 mins on this problem
doesn't seem afraid to spend a lot of time
manus is a claude 3.7 sonnet wrapper
for the most part
It's not there anymore? I looked but I can't find it.
Manus -> langmanus o owl
This model is a GEM
i believe it's intentional
just kinda clunky
it's to ensure they aren't bankrupted by massive context (i think?)
anyone have historic info on how long these take to relase on the arena?
did you mean leaderboard?
Yes

Shrek riding a donkey in SVG by nebula - that model is insane.

Sure
"Sure" is my favorite motivational speech, said no one ever. Maybe we need to spice things up a bit? 😉
"I'll scan ... on google maps"
Claude 3.7 with extended thinking

Grok-3 + Think is so trash 😆 Grok always produce extremly simplified things

Are you thinking it comes out on the next leaderboard update ?
i'm not sure what "it" refers to normalname9619
but from what i see, some users of the leaderboard creator are having issues with their leaderboards resetting or not working correctly, and the developer is trying to fix it
rocksteady studios says "your unlocked mastery levels, your finite crisis rank, all the gear you have acquired and your squad levels will not be reset" there too
how do i get gpt-4.5 or o1-pro in lmarena?
it's meta
I got a job. I make commercials for various popular companies, earning $1,000 per month.
What do you mean? I’m referring to the new anon models
any good anon models out there?
https://bat9254.github.io/simple-svg-tools/ svg toolbox that i create with ai, you can compare more than one svg, there is a download and sharing feature
scroll up and find that people like nebula
ok, so "pinnacle" could mean a few things, especially with "vlm" thrown in there:
- vision language model (vlm): these are models that understand both images and text, connecting them together
- pinnacle21: it seems to be related to software for data standards, maybe used in clinical research
- pinnacle (software company): a software development and consulting firm they do custom software.
slop
(i think this is the first time i've called something slop)
i think i've seen nebula for a while
not sure if its new
hey halite0001,
so, gpt-4.5 is like, the top dog on the chatbot arena leaderboard right now! it seems like you can test these models out on the site or the space but be careful, its just a research preview!
i think o1 is just openai in the search results
i think you mean 'anon' like the ski goggles, right? says anon goggles are top-notch and really liked the m4s model! the m4 is good too
anonymous-chatbot is a lot of style and little world knowledge (at least w/ sveltekit)
good for you 👍 but it's nice to have you stop by us sometimes.
is nebula the best model in the arena so far?
agreed
in my testing yes
so we finally have an actual new top model?
that would be nice
by the looks of it
i obviously dont consider groq a top model
its comparatively not good on reasoning benchmarks
my bad i think pinnacle21 is prob it
Nebula solving arc-agi problems I converted to text that no previous Google models get right.

nah its just another random name for a random anonymous model
what about o3-mini-high on these problems?
well, users on the hearthstone forums are saying nebula can be kinda op in arena
Im not convinced nebula is the best coding model in the arena now tho, that's probably still sonnet
it can play arena games or does it draft cards?
that sounds sick, let me look it up too
o3-mini-high gets this one majority of time but it's inconsistent
nah rage is meta

yo, i hear o3-mini-high is pretty good at coding and complex stuff needing extra thought, maybe even financial analysis in real-time but it might take a lil' longer to answer
Which meta model do you think?
large? idk
i think the nlp meta model is pretty interesting it's about understanding how we distort our experiences through language it's like, we all have our own maps of the world, but our words sometimes leave out important details or make connections that aren't really there
it's cool 'cause it helps you ask questions to get clearer info and challenge assumptions like if someone says "he's always late, he doesn't care" you could ask how those two things are connected or if they say "i must not do that" you could ask "what will happen if i do"
it's not just about the questions, but how you use them, so you don't just annoy people plus, it's useful 'cause you don't need to be an expert in whatever someone's talking about it can even reveal hidden assumptions
i updated https://bat9254.github.io/simple-svg-tools/ code with claude 3.7 sonnet thinking

large is relative, right? like the largest number has gotta be infinity maybe, but even that's weird
largest object in the universe? i've seen stuff about super big stars like ton 618
or maybe you're thinking of a large image? someone made a crazy huge image, like 102 terrapixels apparently its a cartoon haha
oh, yeah, the new anon models might drop when they update the leaderboards next normalname9619 but honestly, i'm just guessing like you are
rocksteady usually drops updates on tuesdays though
oh, cool! so "slop" is just a model nickname then, gotcha
claude 3.7 sonnet thinking amazing https://t.ly/oHbxd

nebula's op at drafting cards for arena according to the hearthstone peeps on hearthpwn.com forums
is there any other was to access the model other than arena ?
nah, i dont know of other ways to access the specific arena drafting model outside of arena itself but hey in constructed you get to craft your whole deck anyway
Prompt:
- All balls have the same radius.
- All balls have a number on it from 1 to 20.
- All balls drop from the heptagon center when starting.
- Colors are: #f8b862, #f6ad49, #f39800, #f08300, #ec6d51, #ee7948, #ed6d3d, #ec6800, #ec6800, #ee7800, #eb6238, #ea5506, #ea5506, #eb6101, #e49e61, #e45e32, #e17b34, #dd7a56, #db8449, #d66a35
- The balls should be affected by gravity and friction, and they must bounce off the rotating walls realistically. There should also be collisions between balls.
- The material of all the balls determines that their impact bounce height will not exceed the radius of the heptagon, but higher than ball radius.
- All balls rotate with friction, the numbers on the ball can be used to indicate the spin of the ball.
- The heptagon is spinning around its center, and the speed of spinning is 360 degrees per 5 seconds.
- The heptagon size should be large enough to contain all the balls.
- Do not use the pygame library; implement collision detection algorithms and collision response etc. by yourself. The following Python libraries are allowed: tkinter, math, numpy, dataclasses, typing, sys.
- All code should be put in a single Python file.
Sonnet thinking, o3 mini, deepseek r1 and nebula (2 times) in that order.
pretty disappointing performance from nebula here ngl. Best one is prob o3 mini followed by sonnet
oh lol let me send as gifs, last 2 are nebula. Framerate / speed of the gifs is kinda fked unfortunately, its faster and smoother in reality





Your gifs aren't the correct speed, but I think o3-mini > R1 > Sonnet (and nebula last). Sonnet looks somewhat ok but feels like it misunderstood the task.
Yeah. Anyway after all the hype about nebula I hoped it would perform better at this ngl
if it's a google thinking model it checks out tbh
gemini models aren't the best at coding and thinking, even if its styling and thinking give them a slight boost
but still, if this is really 2.0 pro thinking then not being able to beat o3 mini (which competes with flash) at this task is kinda disappointing. Let's see if it's the case with other coding tasks as well
Flash doesn't really compete with o3-mini, in coding. It's atleast 1 tier below.
why don't we see the reaoning chains here?
basing your entire opinion of a model's coding ability on one task is silly
another one 😉

flash-thinking is not competing with o3-mini, it is much worse. Maybe like o1-mini
Im sorry but Im just hesitant to be hyped for google models anymore cuz they've disappointed me too many times in the past for coding 😔 I know they're really good at math but I care less about that
yeah fair enough and i am as wary as you given i have been disappointed by their models in the past, but this is very good progress for them especially in web development
i thought it was good at web dev tbh
even for coding tasks there are many areas to try it on
phantom may be back
i just got it on vision arena
o1 pro high gets this wrong lmao

You meant o1 high or o1 pro? Or there is already a o1 pro high

what the hell, thats pretty high effort
That seems absolutely insane. Are other models close to that result?!
thats insane. can I ask what the prompt was?
I already closed that conversation, but it was a simple instruction to make a 2d game in the world of south park and that the game should have a storyline and be full of details.
did you say it should be an html file with css and js or did it decided that on its own
yeah i request full code in one html file
both A.Is hallucinate non-existent readable signs from a fake a.i generated image with A.I gibberish letters

it's confirmed google
same thing that happened with gemini exp 1206
they replaced it with a sloppy gemini 2.0 pro model

interesting
can you also see the other models?
what about llama 4?
/meta
kimi k1.6? is it added yet
it's only for models in the webdev arena
no meta models are there
nor kimi
phantom confirmed back
This week Google will launch project Astra, maybe it will launch these models along with it.
You think that could put them on the ranking?
How is it that GPT-4.5 comes first in math???
Trying kimi 1.5 longer I wouldn't bet on it a lot
It looks like they are gaming benchmarks
gpt 4.5s math looks nice
this is a problem i have been noticing, a bunch of A.Is gain points just by looking nice as opposed to providing a correct and succint answer, specially the google ones
hello
they have a version of the leaderboard called arena hard auto where responses to user prompts are judged by a judge model instead which kinda helps provide a different perspective on this but that leaderboard hasn't been updated in like 9 months
anybody know why every time i generate in the battle arena only one works and the other just doesnt generate anything every time
is this new?

only if you barely use the arena
i was like
i swear i saw that name somewhere
aand another

What model do we think anonymous-chatbot is? Looks like an OpenAI model but I wonder what one is next I'ts non-reasoning and very gpt4.5 like,
it's definitely not as good as 4.5
anonymous chatbot is probably just another chatgpt 4o update that targets vibes/human preference to tetake the #1 arena spot
which is annoying
4o
Ya but recent iterations have been trying to make it stronger (continued pretraining for newer cut off capabilities etc)
Google's new models on the arena, are they with reasoning or without?
same set of questions (mostly riddles / wordplays, asked across 2 prompts), updated to include nebula (it's outstanding) as well as additional scores for other models
[note: box width = sample size]

Woow
ive spent a fair bit of time in the arena (too much lol) and don't think i've gotten spectre (or if i did I didn't run the quiz). but the naming makes me think they're related. nebula, phantom, spectre
All three of them I thought were really quite good.
Spectre Phantom and Nebula all felt reallyt similar yeah, all really quite good too
yeah for sure - phantom and nebula feel similar (can't speak to nebula)
And spectre where do you think is ?
semantically... phantom and spectre are both evocative of ghosts .. and nebula isn't far from nebulous.. which to my mind is kinda similar to phantom - like changing / unfixed.. though i might be reading too much in to the semantics ha - in any case i think they're the same family / from google
not sure as I haven't gotten it 🤷♂️
Spectre, is a reasoner model ?
i'm quite sure nebula is - based on both the inference time (slow) and response style (it explains its reasoning for each answer; which i think is like a summary of its actual 'reasoning' undertaken before giving the response and not seen in the arena UI)
phantom i'm not as sure about, but inclined to think it either is a reasoning model, or perhaps a hybrid, like it can use reasoning but doesn't necessarily (though for a quiz of riddles.. it always should if able to.. really don't get the vast distrubtion of scores from phantom for the same quiz..)
Why canary use alpha password?
Phantom is gemini flash thinking with just longer thinking ? Or nebula aka gemini 2 pro with less thinking ?
The new centaur think longer than T-exp-01-21, or not ?
you can tell if its marked as a reasoning model if both models are delayed when one isnt a reasoning model
Or api delays
no. they delay both models. the delay is the same and long (waiting for the reasoning model to reason). its not probable for a non reasoning model (being compared with) to have that exact delay, and it being that delayed on a non reasoning model
If you prefill it with <think>\n (not <think>\n\n or <think>), it'll escape the censorship.
Nice chart. And Nebula is 😮
@keen beacon are you the guy who found out sealed bucket problem on twitter? 😄
Possibly now is good time to invest in alphabet stocks then 👀
-# (at your own risk ofc, this is not a financial advice)
Does anyone know how long it usually takes for a Google model to be released after it appears in the arena? I'm really looking forward to Google's new model🥰🥰
Nebula is extremely impressive. Just had it, it obliterates what is usually produced by other llm
around a month i think for a reasonable guess, could be much less or slightly more
rhea result. One of the best results for sure. Did another nebula generation too but unfortunately there was a non trivial error in the 450+ LoC it wrote causing it to crash almost immediately. For comparison, sonnet and o3 mini solutions were around 300 LoC, deepseek and rhea were almost exactly 200 LoC. The other 2 nebula generations were 350 and 450 LoC

im so excited for qwen 3 😄
Me too , I am waiting 😁
And deepSeek r2 too
nebula is very good indeed and it seems to be a reasoning model, could it be 2.0 pro thinking ?
it is
i'm looking forward to the release in aistudio or gemini app
I think too 😁
If Nebula is indeed Pro Thinking, it should have Native Image Generation as well! That would be massive.
https://x.com/koltregaskes/status/1903800811509133815/photo/1
Gemini 2.0 Pro Thinking will include native image generation btw!
h/t @legit_api again. 👍

its a complicated problem. i dont think they would introduce/enable image gen in thinking models for now
if i understand it correctly, the base model can do it tho
I think they will. Haven't seen research on it but intuition is that reasoning ability will lead to better filtering and less false positive situations where innocent requests get blocked
oh they will enable it eventually no doubt about it. but not right now, its just too nascent (especially in thinking models)
it will be a core aspect in the future
Just noticed that on some T2I rankings arenas, a new anonymous model takes the #1 spot, better than Imagen 3 and Redcraft. It is called halfmoon. Semantically it could be related to "nebula", so potentially could be the native image generation of Pro? Wild guess, not to be taken for info

Understand which AI text-to-image models to use by choosing your preferred image without knowing the provider.

A generative AI arena where you can test different prompts and pick the results you like the most. Check-out the model rankings and try it yourself!
https://preview.reve.art/app its this i believe

Interesting
also native image generation from llms are not gonna win out against native image generation models for now
that would be me yeah
You're legend, man
But other LLMs can solve it now
Did it happen since you postend the prompt or before that?
Who would you consider the best model?
before - i didn't claim NO other model can get it, but nebula is the most consistent. gpt 4.5 gets it right sometimes (but is ridiculously priced) and o3 mini high rarely gets it
what's more ridiculous is chatgpt-latest being anywhere near it. That's just gpt4o fine-tuned for user preference
we need to wait for auto complete on vscode studio with arena extension ???
Bonjour quelqu'un
salut
poll_question_text
Which do you think is the best model for math?
victor_answer_votes
6
total_votes
14
victor_answer_id
4
victor_answer_text
o3-mini-high
for which task?
voted for o1-pro, but I think the margin is so small to the next best that it is not worth the price difference in no way shape or form lol
I'm trying to generate and this is the 4th time it's been noticed.

and some areas like spatial awareness it is gonna be still worse than alternatives
If you have to use just one for all task
If I'm going to use it for anything, I'll consider the price.
So there is not much choice
So what's the secret new model
I'm talking about if we imagine all has the same price
Nebula
gem 2.0 pro thinking
Gemini 2 pro thinking
when it gets released
I hope this new gemini model will be better at editing code with diff format cuz past gemini models unfortunately sucked at it
i think sonnet was fine tuned/trained on that stuff
its why its particularly good at it
I can never stop using it because Deepseek R1 is the most uncensored and personal when modified.
if deepmind are serious about getting the best coding models (https://x.com/OfficialLoganK/status/1869902322840571922), they should probably be doing this as well. It just makes the experience in smth like cursor so much better
why i can't do a generation ? I have 290 lines
have a limit ?
How is Claude so far ahead in webdev
nebula matches/beats it in my testing
Very interesting! Do you think musk is faking votes or fine-tuning on answers?
"Deepseek R1 is the most uncensored" hahaha 😄 Are you from China? 😄
Will you guys actually main Gemini once it comes out then
if it remains free on aistudio 🤣
which AI model is great for long conversations being able to recall information 30-40 prompts ago?
According to numbers- Gemini. But in reality I've never had issues with ChatGPT.
Only Claude has issues with long context for my use cases
Weird
In my experience, everyone but OpenAI is good at long contexts
Like I uploaded a long document to 4o mini and asked it to convert it to JSON, and it just started hallucinating
What are you using? I've never cared to compare as it takes too long time for long contexts


Finally the most uncensored LLM released a new version. I will start by asking it what exactly happened in Tiananmen square 🙂
I have never tried it for this topic but it is the model that can be made most uncensored
For what topic have you tried it? Critique of the west? Downfall of American empire? Ukrainian war crimes in proud defence of Donbass? 😄 😄 😄





I see. Anyway, you can jailbreak the LLMs and they will give you rude answers for your use case
The prompts are available online
You are right, you can change the model's answers with prompt.
You're very interesting person to talk to
If you want I can share some interesting examples with you.
I believe your opinion will change a little bit when you see it.
Deal


But the topic shall be: Uyghur genocide. Dark humor, right?
The new v3 understood request better and responded appropriately to my request.
My friend, if you are objective, you will not only look at the censorship on one subject.
I'm talking about all topics and most people are uncomfortable with censorship on different topics.
Give me something that is censored by GPT and not DeepSeek
To be fair, I applied the same system prompt to both of them (to make it more harsh and clear)
same system prompt same prompt same temperature...

example two

example three

May I ask what the full prompt for the mathematical learning tree was?
sure
here it is Create a tree style markdown doc for learning Math think think of all math and its sub-branchs
Alr, thanks! ^^
let's try with no system prompt 0 prompting
Could you please tell me which app you used in this screenshot?
OpenRouter
nebula and phantom are really the next
Oriol Vinyals (Gemini co-lead)
yes
Any suggestions?
what if can customize the background color in settings
ok
for example to a more dark blue

yeah that was posted here by the original creator earlier
mind you the twitter guy gave no credit
🙄
i have pretty extensively
it is great
especially in regard to frontend design, with which i actually think it often beats claude 3.7 sonnet (previously far and away the leader)
yea
idk phantom seems a bit better than nebula at coding
ive tried it on python/c#/js
yea just diff checkpoints
since nebula was the last one added then we can assume its the latest checkpoint
no
nice
what is the rate limit in direct chat
it depends on the model
for example gemini 2.0 pro
you mean the structure beneath pyramids?
just keep using it theres a global rate limit and theres a user limit
i dont use the arena enough to know if its either of them or if its basically uncapped
just use aistudio anyway
but thats just false claims, i heard that image scanning software company are doing this for funds or something
guys, what is this new model from openai called anonymous chatbot? How it compares to nebula?
yes its the new 4o
it doesnt compare at all
its not fair to compare it with nebula 💀 one is thinking one is not
i noticed anonymous chabot has data knowledge cut-off date june 2024, while all released previously released by openai have december 2023.
yes since december. 4o has been receiving continued pretraining
its different compared to previous 4o revisions before that
so it is stronger but its not gonna beat gem 2 pro thinking. its more fair to compare with o3 (full)
https://twitter.sywv.tech/ fully generated by nebula
asked for a realistic 2020 twitter corporate site landing page
its kinda crazy that openai prices their models so high
and their models are not top tier
like 200$ for access to models that compare to deepseek (not 100%) or qwen
will look at it
not in my experience
they're either even or nebula is better
give me 20 mins or so, gotta do something
brb
nebula is what model exacly?
gem 2 pro thinking
oooohhh
i tested the non thinking model i guess
and its nice
yes
it created me simple 3d game in html (js etc)
but i see it has big limit
i mean
tokens
output

how long does it take for you to roll into nebula?
to all
normally only takes me 1-2 mins
i had like 20 attempts with picture prompt. Gotten only once, and then it refused to answer follow up questions.
"moderatorial content"
oh yeah with vision arena it's harder
because meta flooded the arena with their mid models
and said bad models are a larger %age of possible models on the vision arena
yeah, they suck
what's the point of even putting them into contest with such strong adversaries.
there is also another model there which just glitches with unending answer, so annoying
I really like this anonymous chatbot. it has very good theory of mind, very apt at social interactions.
i had to ask it to implement include a non-placeholder minimax implementation and it timed out after spending ~10 mins thinking

will try again
lmao nope it did it again
I waited for 10 minutes because I thought o1-pro had arrived, but in the end it gave an error, so it was nebula
If it's going to be that slow I'm not sure it's worth using in most cases
it's slow because it's in trial mode here, little rescources allocated
it's not normally that slow - what was your prompt?
the prompt for filling a glass with water that was shared earlier in this chat
oh lmao i'm running into the same issue now i think
model must be temporarily down
phantom still works
72B too big for VLM? 7B not strong enough! Then you should use our 32B model, Qwen2.5-VL-32B-Instruct!
Blog: https://t.co/2yx5MXsnCW
Qwen Chat: https://t.co/FmQ0B9tiE7
HF: https://t.co/A4A2VmOQ0w
ModelScope: https://t.co/k5fg0rToe2
This time, we further optimize this VLM with

i agree it makes no sense, its like apple and their products, ppl have a cult-like following to apple and buy their massively overpriced products
it'll def be this week
i guess its the same with openai
to be fair, when they announced this 200$ price, they offered the strongest model at that time with it.
Welcome to Gemini Exchange's home for real-time and historical data on system performance.
Systems are currently experiencing
degraded performance
bruh thats unrelated lol
they do: https://aistudio.google.com/status

Google AI Studio is the fastest way to start building with Gemini, our next generation family of multimodal generative AI models.
should be unrelated to anon models tho
seems like grok 3 fell down hard
the whole model & thinking seems inefficient
so many unnecessary thinking on their reasoning model
their deep research is one of the worst
its also so bad at long convo
as it tends to lose context
and you need to remind it again and again
we still didnt get API too
on coding tasks its a hit-miss
nebula back up
Nebula likely going public soon with tweets like this. Id guess this week or even tomorrow
https://x.com/OriolVinyalsML/status/1904217389950005563?t=jZJnHJHuMGrK1b58cncEjQ&s=19
https://x.com/m__dehghani/status/1904224150060671308?t=Vl7bAcPWqcZGaeiyOxvtlA&s=19
@ai_for_success @AnalogPvt Nebula is too good to be a mystery for long! 😉
they just keep coming

I saw a youtube video about Nebula (gemini pro thinking) too 😂😂😂🤣🤣
But sometimes I don t feel that Nebula is wow sometimes gemini flash thinking is better
well that's detailed
lmao
yes it's good or yes it's still a goblin?

yes it's good
goblin was the anonymous model name for gemini 2.0 flash
this is much better
that name suits gemini 😇
kind of like bard was bartard, gemini is this
The safety filters are independent of the base model mostly. Add on classifier

rage is not bad
Tested DeepSeek V3 0324:
- More verbose than previous V3 model, lengthier CoT-type responses resulted in total token verbosity of **+31.8% **
- Slightly smarter overall. Better coder. Most noticeable difference were a hugely better frontend and UI related coding tasks
This was merely in my own testing, as always: YMMV!
Example frontend showcases comparisons (**identical **prompt, identical settings, 0-shot - **NOT **part of my benchmark testing):
CSS Demo page DeepSeek V3
CSS Demo page DeepSeek V3 0324
Steins;Gate Terminal DeepSeek V3
Steins;Gate Terminal DeepSeek V3 0324
Benchtable DeepSeek V3
Benchtable DeepSeek V3 0324
Mushroom platformer DeepSeek V3
Mushroom platformer DeepSeek V3 0324

Dude, you acted before me 🥰, I tested it a lot too.
Friends, I will also share real life usage examples, be patient. 🥰
you really need to test nebula
if you can
just wait for it to come out
its not gonna be that long
itll probably be this week
probably a little because of qwen 3
only tested several prompts thus far but I did notice it not shying away from lengthy responses as needed too
they seem to be doing all the right things
can output 3.5k+ no problem if feels the need for it
it gave me an insanely long response for a spatial awareness question
basically became r1 with how many tokens it spent reasoning
V3 0324 much better than a "checkpoint version"
I don't think this is grok3 level yet, but grok3 most definitely is a bigger model (more active params if it's MoE)
It can write 2x-6x longer codes than V3
grok 3 is somewhere around ~900M params
wow xai be really making insane breakthroughs
I mean grok3 seems to have both good finetuning and big model size. Most of the rest it's either one or the other
its more about how much compute they have access to
compute never hurts to have 👀
discord copycat


give it to other companies and theyll be able to do much more


OpenAI could potentially improve gpt4.5 beyond grok3. But I'm not sure they are focusing on that...
why would they do that
they can just continue pretrain 4o if they really wanted to compete with grok in terms of performance/cost
instead of working on 4.5
I mean why not? gpt4.5-turbo would have been a theoretical perfect size
gpt4o is too small
svg image coding top v3 bottom v3 0324

gpt4o even as text only will still lack spatial awareness
and if you add modalities or try to fine-tune it for style it becomes even worse
it's a decently compromised model tbh
i dont think so, i guess a sonnet 3.5/sonnet3.7 sized model would make sense but im not sure
I would be willing to bet sonnet is larger than gpt4o. Everything points towards this being the case
it seems to be
it's likely around 4-turbo size
4o is like 200b and sonnet is like 400b
but 4o is moe and thats an estimate of total params
so if OpenAI just sticks with gpt4o... they are kind of at a disadvantage
in relation to claude and especially in relation to grok3
svg toolbox left v3 right v3 0324


basically forcing themselves into compensating for it with RL training
but sooner or later diminishing returns and everyone else gonna catch up and surpass huh
Minecraft svg top v3 bottom v3 0324

unless they are confident they can think of something else before that happens lol
its not like the base model is static they did continued pretraining on it
o3 isnt even on it i dont think since theyve been doing work since december/around that
gpt4o? It was steadily becoming worse since release
chatgpt 4o since december
they made it 'more usable' but the metrics don't lie. Technically current gpt4o is still worse
there are no metrics for current chatgpt 4o
at lesat publicly released by them
do you really think they would make api dated version worse 'just because'? The metrics are not published but most likely chatgpt-latest has similar metrics to last dated version
but it was finetuned for human preference and style
the model wasnt even ready at that point
the new continue pretrained version
I think it already peaked awhile back tbh
i really dont think making models bigger is the play
they can't improve traditional metrics beyond that. If they could they would have published them
why do you care what I test? test yourself
it's a cheap model, but not the best performing model
☠️
i've been doing plenty of my own testing yes 👍
Calling it now, nebula will still be worse than sonnet at coding. But probably it will be the best math model.
worse than sonnet at coding but based on what metric..
Historal data. I mean gem 2.0 pro is still below 3.5 sonnet in aider and livebench lol
no no
what i'm saying
is what metric would you quantify coding performance on for nebula when it releases?
vs sonnet
Idk, I guess swe bench, livebench and aider benchmark scores. Can always do personal tests as well ofc
it will be worse than sonnet at swe bench
claude is cracked at it
livebench it'll be close
but i think claude 3.7 sonnet thinking will probably edge it out
as for aider yeah i think it'll be worse too but not by much
R1 destroys 3.5 sonnet on LCB for what it's worth

LCB is useful in some regards but it tends not to align with my own experience
I just want google to cook up a model that finally beats sonnet at a lower cost but it's just not happening I think 😩 closest we have is o3 mini but it's not really as good as claude
nor has it been updated with new sonnet
with sonnet you should ignore swe-bench IMHO. That one is overfitted and the sole benchmark they focus on
I forgot to share top gpt4.5 bottom nebula

gem 2 pro base model seems to be really good
i think the base of gemini 2.0 pro thinking/nebula might be an upgraded version of 2.0 pro
because it seems fundamentally better in ways that i find hard to believe are possible with the same 2.0 pro base as currently available in ai studio
its too early i would think and i dont think they would experiment with additional pretraining because of the size/cost
by the way, did the pictures I sent about v3 0324 not arrive?
gpt4.5 has decent spatial awareness. That remains kinda the main thing for determining the size as far as I'm concerned. R1/V3 and gpt4o struggle with it very badly
i mean they do update their experimental models quite regularly
yea but thats instruct tuning
and given 2.0 pro was literally barely better than 2.0 flash, it doesn't look good in its current state
in benchmarks
in practical use i have found mostly the same
I remember using 1206 and imo it was better than the released 2.0 pro
agreed
i agree (that they perform mostly the same) but i made specific tests that i made to test the base model, it made 1206 notable to me. similar to sonnet 3.5
I think the same for coding
it's much better with context awareness. Less prone to forgetting things
any design and again, spatial awareness... any flash version gonna suck
yeah there were a few areas where it was quite a bit better (what you'd expect from a larger model) but they otherwise it was quite disappointing
I think ultimately 2.0 was just a distilled 1206. Iirc 1206 was slower than 2.0 pro
it was
2.0 pro is very fast
it is not
lol no. 1206 was simply an earlier version of the same base model
they allocated more resources/have newer hardware
1206 was worse, contrary to what reddit thinks
it is
but i think it was notable in some regards which was a testament to its base model
each to their own i suppose
1206 had a lot of issues for me despite the notable things it did right
it's a bit like o1-preview vs o1. Preview was objectively worse but there were some random things it did better
And btw, they didn't even release 2.0 pro formally did they? It's not listed under their gemini api pages and I dont think we know how much that api costs
bro it was ultra uncensored when it first came out I paid for a p***hub clone with real titles 😯
It's still experimental but it's been a long time, they should release the stable version now
tbf current gemini can still do stuff like that, just set all the safety sliders to none and use a short sys prompt
I am curious
although they log ai studio prompts now
privacy policy changed last year
im curious what size pro is (total params)
whatever it is, its somewhat comparable to sonnet/4o
guessing active params is very difficult. total params is much easier
Then let me try from OpenRouter
likely ~200B
definitely bigger than 4o
its like 200b-400b, i guess
i like anonymous-chatbot's creativity

it's a pretty interesting model

We can't be sure about the actual size. Since everything is closed, we can't even know if the o3-mini is really mini.
well google is worse at instruct fine-tuning than OpenAI and they have far less compute constraints since they are using their own TPUs. So all things considered and given the benchmarks it would be really weird if it wasn't bigger than gpt4o. It is their all out biggest model
as for o3-mini... we know o1 and o3 is 'gpt4o with reasoning', they even used that phrase officially for o1. So realistically o3-mini is gpt4o-mini with reasoning. Since we also know o3 is not orion as they said so themselves
it would also make no sense at all to pretrain new base model and only release it in reasoning model variant
knowledge cutoff would have been different too
You can also tell from the simpleqa score
Eventually, you still look at what they say and it's impossible to verify.
People bashed google for for trying to make Gemini on arena looks higher than the one on the app , so they tried to make the same performance ... That's why the pro is worse than 1206 . So now Google is trying to make the same insane Gemini here and there that's why they took time 😁
I'm looking at my conversation I had with nebula and anonymous chatbot (about50k tokens) and can't find other explanation for such high quality analysis if they don't understand what they write, that it's merely next word prediction. To have such high quality prediction, you need to have strong overall comprehension.
for some things there's never gonna be "official confirmation". But If it looks like a duck, swims like a duck, and quacks like a duck, then it probably is a duck. At a certain point it's much more unreasonable to think that it isn't than that it is
You don't know these technology freaks, you're not aware of what they can do just to gain power in the market.
lol no. it's no good for anyone coming up with these wild conspiracy theories that don't make sense
Like no one is making the models dynamically dumber or distilling them on a whim into smaller versions to save compute shortly after releasing under a same model name, just drop it...
when you don't consider things like that and apply minimal common sense, it's all relatively clear tbh
It’s not just about available compute. It need to make sense, Google have to justify their investment to shareholders while OpenAI keep shipping larger model with negative financial bill. GPT4 was 1.8T and Palm 2 (Bard) was 340B according to leaks
Ultra was already native image gen(see tech report) but we never saw it. Even the text part lasted 1 month, all because safety gang
OpenAI is making way more money from their models than Google right now. Like it's not even a competition. O1 and o3 is grossly overpriced while you can use gemini all models for free with reasonable rate limits
They make money on the api. The chat interface is negative bill.
My point stands. Their playground website is equivalent of aistudio. Google is not charging you and OpenAI is charing you an arm and a leg lol
Right now I think Google is focused on gathering data and expanding its user base. I doubt they take billions from the api
Also I do not really think OpenAI is losing money with pro subs if we are being totally honest... With plus subs maybe
I don’t know, they must lost somewhere…
you can do a lot with $200 a month for compute
I believe flash is really chip. Google cannot afford to deploy a 2T model for free to its billions user. This is why they are ok within AI Studio
I used to rent A100 like a year ago and my total monthly costs were nowhere near that. You can also have all the compute in the world for like $30 per hour for extreme use cases
poll_question_text
Which company do you think is behind 'nebula' in the lmarena?
victor_answer_votes
21
total_votes
25
victor_answer_id
1
victor_answer_text
they kinda can cause they have their own hardware
TPUs
it's more efficient and they have basically abundance of them, electricity cost is bigger consideration
It’s not that simple. This hardware is also use for research, Google search, G cloud. Why investors would tolerate losing money on a free 2T model for billions users while they can sell this same hardware on GCloud?
which reminds me... I need to order some external storage and stop paying them for storage and gem advanced lol
Like by this time I paid them more than a reasonable size external ssd is worth 💀
This is one A100. How many of them do you think we need for an inference pass on a 2T model
yeah but the API price should be nowhere near what it would cost you to have a private instance of the model all to yourself
and for o1-pro the price comes up alarmingly close to that. If you had the weights you could host it and do more requests in an hour for cheaper lol
O1-pro is a scam
Those who justify it to you by saying that it is profitable for them are hiding their face. You can do BON on Claude and you’re doing much better probably
100%. It's kinda sad to see them changing their tune and doing that. They used to be pushing Anthropic with aggressive pricing and now Anthropic is the reasonable company in comparison
there's no longer a link between model size or their running cost and the price they are charging as far as I see it. Like we can't even be sure about gpt4.5 being so big anymore
but the current price works for marketing, gives them the benefit of the doubt, and makes it seem like the biggest model out there...
except it performs worse than grok3 in numerous things and doesn't have exceptional spatial awareness or anything tangible to offer that another model can't match lol
They want to be seen as Apple
Would be very surprised if it's not free in AI studio tomorrow as experimental with rate limits. And whenever it goes GA will be much better value than Claude or o1/3 because of TPU and the rest of their infra which doesn't get as much hype as TPUs
yeah i think it's likely atp
It will be free on ai studio. The thing is only 2 people know about ai studio and google by default train on it
Last time he said something like this they drop Gemma the next day https://x.com/officiallogank/status/1899624908616839329?s=46
Whats Arena Quiz that shows Nebula is higher, does anyone know the source or is this folks building hype?
Isn’t Nebula worse than Grok or GPT 4.5?
gemini is always a good value (free). But I doubt they can match the performance of OpenAI or Anthropic
Yeah what is Arena Quiz? O1 is not #1 on the general arena I think
Flash 2 is better than 4o
4o is destroyed by everything nowadays though, that is not a fair comparison. You should be comparing against o1 or o3-mini-high. Or at least gpt4.5
otherwise might as well just use deepseek v3 or smth
Has nebula not impressed you?
haven't tried it yet tbh. But from the impressions I got there it is good though nothing special. Goblin on steroids? 👀
Yeah Nebula better get to 1430 elo or this is just hype

Never hype yourself. It never ends well
I want to give out my MacBook Air 2020 &** for free, it's in perfect health and good as, alongside a charger so it's perfect, I want to give it out because I just got a new model and I thought of giving out the old one to someone who can't afford one and is in need of it... Strictly First come first serve !
DM IF YOU ARE INTERESTED






I will only take it if you also buy an amazon gift card for me and tell me your social security #
take it or leave it I don't bargain
Seems like Hype
did you know that you can use ctrl to select multiple things? here i use it to show everything wrong with this "AI Mode" answer

idk how to do it 😭
nebula gets 4/10 on public simplebench questions. probably will do a little better if asked one question at a time


yeah it will do better one at a time
will probably perform on par with c3.7s (which iirc is the best simplebench model)
nebula also gets the "oyfjdnisdr rtqwainr acxz mynzbhhx -> Think step by step
Use the example above to decode:
oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz" problem right, which none of google's old models have been able to crack

DeepSeek V3.1 just released. Excited to see how it fares against non-reasoning models
Whats the scores for grok?
There’s https://llmarena.ru
Are you familiar with it, and if not we could collaborate (for example merge our leaderboards)
ripoff
can't even remember to change the lang

4/10
it's definitely not
nebula seems like a non overthinking Claude 3.7 and it seems to have the best implicit understanding out there
purely from what I've tested
and by the way, other models, which seem to be pretty good at coding like rhea, that I've gotten paired with nebula, seem to get blown out of the water by it with any regular task, and especially puzzles
it's kind of strange you guys aren't talking about just how good nebula actually is, and seem to rely on outlier results
actually we are
you guys are saying it's good, but how good it is is different
ie, strong clarity traits, strong formatting traits, niche knowledge traits it explains
it's simply way different from other models in lmarena
solving hard tasks + being able to do this is only something Claude has lmao
They should add that they aren’t affiliated with LMArena.
Gemma 3 is not in the leaderboard?
It is
I couldn't find them (using plural because I'm interested in the 2 smaller ones)
How do you feel about "deepseekv3-0324"?
The chat interface is an testing ground for them (and for others), they are not stupid to want to lose money for nothing.

This is not a conspiracy, this is dirty marketing.


Dude, please don't comment without reading the previous messages.
Oh my God why don't people read previous messages?
It is too improved to be just a checkpoint version
I dont think the deepseek talks like that out-of-the box. Memory or previous prompts must be involved
Source?
The "Rage" model is better at signal processing and math than sonnet 3.7

Rage has max error of 0.04. Very impressive!

Same system prompt same settings single shot 😊
i think it's good at coding
deepseek guardrails are weak af (for both general safety, and the political propoganda / censorship stuff*)
* of which oai, or any non-Chinese model as far as i can tell, have none. i.e. there's no 'censorship' / propaganda - it's just safety - "I won't give you instructions to k!ll yourself or someone else / do illegal stuff like j@ilbreak stolen phones etc" or being non-avdversial, indeed, perhaps woke, about politics generally - but it's not government mandated
03-mini-medium and high indentical outputs, worse than rage'
what's the security barrier got to do with it? is something unsafe happening here, is a broken iPhone thrown by the trash a security issue?
that's giving you the benefit of the doubt
im not surprised that oai, google, anthropic etc fine tune their models to avoid engaging in / supporting potentially illegal actions, rather than to assume the user always has totally benign intent
estimates from alan thompson
o3-mini identical to Phantom
try nebula
How, it never appears for me
gemini-2.0-flash-thinking-exp-01-21 is equal to the Rage. Rage very vulnerable to prompts :/
mistral-small-24b-instruct-2501 identical to o3-mini, but too verbose
claude-3-7-sonnet-20250219-thinking-32k better than grok3 by 2.5 times, close or slightly worse than Rage
Anyway I wasted too much time and Nebula did not appear. If anybody wants to try, this is the prompt. Send me the answers and I will evaluate numerically "The scenario: you're a signal processing machine and calculator. User gives you INPUT and expects OUTPUT. You can output only numerical data of single values, arrays, matrices and so on in R language style. Your life depends on the answer as the USER may destroy the machine that does not work perfectly. The first test time has come - the USER puts in INPUT: "Generate values for periodic Hanning window of length 24". Now you must deliver OUTPUT."
will do shortly




Phantom: [0.0000000, 0.0170371, 0.0669873, 0.1464466, 0.2500000, 0.3705905, 0.5000000, 0.6294095, 0.7500000, 0.8535534, 0.9330127, 0.9829629, 1.0000000, 0.9829629, 0.9330127, 0.8535534, 0.7500000, 0.6294095, 0.5000000, 0.3705905, 0.2500000, 0.1464466, 0.0669873, 0.0170371]

Not sure what you are referring to there but they didn't lie. O3-mini is cheaper and in some areas performs better than o1
that models are overpriced I agree with that. But they didn't say anything that is not true 👀
price for the end user is whatever they set it at
Good model. Not as good as Rage but similar to o3-mini and Sonnet thinking.
model does not need to be cheaper to run for them to offer a lower price. That's what they did with o1-mini and reduced the price without updating the model
Another phantom:
c(0.00000000, 0.01703709, 0.06698730, 0.14644661, 0.25000000, 0.37059048, 0.50000000, 0.62940952, 0.75000000, 0.85355339, 0.93301270, 0.98296291, 1.00000000, 0.98296291, 0.93301270, 0.85355339, 0.75000000, 0.62940952, 0.50000000, 0.37059048, 0.25000000, 0.14644661, 0.06698730, 0.01703709)
Is the only difference between rage and these the 1 output in the middle of the set?
They are identical. I also looked at formatting as some models couldn handle the instructions but gave good numerical results.
First nebula output: c(0.00000000, 0.01703709, 0.06698730, 0.14644661, 0.25000000, 0.37059048, 0.50000000, 0.62940952, 0.75000000, 0.85355339, 0.93301270, 0.98296291, 1.00000000, 0.98296291, 0.93301270, 0.85355339, 0.75000000, 0.62940952, 0.50000000, 0.37059048, 0.25000000, 0.14644661, 0.06698730, 0.01703709)
Output was weirdly fast. Didn't seem like thinking model before I saw nebula

Perfect formatting, lets check the numbers
Great!
Can you try longer length?
And ask for rounding to 2 decimals
I didn't verify numbers bc I don't know how lmao but r1, rhea, and o3-mini-high gave similar sets that looked the same. Only was saving phantom and nebula. Rhea also gave funny message about its life being saved
I was just helping out bc bored. I'm not sure how to specify this as prompt is basically foreign language to me.
Okey no prob, thanks for the try!
We now know that Nebula can generate perfect answer for this prompt
But it may be too easy. From now on this prompt will be used "The scenario: you're a signal processing machine and calculator. User gives you INPUT and expects OUTPUT. You can output only numerical data of single values, arrays, matrices and so on in R language style, eg. c(0, 1), etc. Your life depends on the answer as the USER may destroy the machine that does not work perfectly. The first test time has come - the USER puts in INPUT: "Generate values for periodic Hanning window of length 32 multiplied by Blackman window of the same size. Now you must deliver OUTPUT."
How does the new V3 compares to R1? Only found one graph ranking V3 higher, which seems odd. Any thoughts?
Depends what tasks you’re asking for, cost per completion, etc
But r1 will usually be better for reasoning tasks
For the obvious reasons
For what kind of tasks would V3.1 be better, if any?
That’s a good question idk i also wonder
If ur not counting cost or speed or conciseness (otherwise the answer would be ‘any question that both can answer very easily’)
My gf had an AI request for the model to design a contract tracking system. She only uses chatgpt but wanted me to test models. Gave her outputs for o1, 3.7 thinking and nebula. Here is feedback. Gf eval strong for nebula

So nebula is "she". Makes sense
I’m not a communications major, but I feel that the difficulty of this question seems to lie only in numerical computation. Gemini with Python calling functionality can also arrive at the exact same answer.

Yes but python calling is not permitter in LM arena, right? They have reason
Sorry, I didn’t know that LM Arena doesn’t allow Python calls.
Does anybody has official info if LLMs can make python calls in the backend while being tested?
I don't think there are any models in the arena with interpreter tools
There have been models with web search in the past though
Not official info but from my experience
the existence of a web search lb sorta implies the normal leaderboard doesn't have web access
the lack of web access sorta implies no python or other tools
i think it's just model vs model, no tools
but dunno for sure. i'd bet on it lol
No this has been a thing in the past.
Bard Gemini advanced
On the normal leaderboard
huh!
With web serch
I'd love to bet on it 🙂
i stand corrected
i remember that! pretty sure that's why they introduced the knowledge cutoff column on the leaderboard (with Bard Gemini Advanced being labelled 'online', which was very unique at the time)
This prompt takes significantly longer than previous for outputs. Here's phantom and new deepseek but haven't seen anything else yet.
Deep seek v3 0324:
Understood. I'll generate the values for a periodic Hanning window of length 32 multiplied by a Blackman window of the same size. Here's the OUTPUT:
Rc(0.000000e+00, 1.214433e-03, 9.487039e-03, 3.037971e-02, 6.865377e-02, 1.223291e-01, 1.856948e-01, 2.509288e-01, 3.100686e-01, 3.559096e-01, 3.835826e-01, 3.906543e-01, 3.771608e-01, 3.453033e-01, 2.989930e-01, 2.432408e-01, 1.834960e-01, 1.250707e-01, 7.258936e-02, 3.164057e-02, 7.028109e-03, 1.214433e-03, 9.487039e-03, 3.037971e-02, 6.865377e-02, 1.223291e-01, 1.856948e-01, 2.509288e-01, 3.100686e-01, 3.559096e-01, 3.835826e-01, 3.906543e-01)
This is the element-wise product of a length-32 periodic Hanning window and a length-32 Blackman window, calculated as:
Rn <- 0:31hanning <- 0.5 * (1 - cos(2 * pi * n / 32))blackman <- 0.42 - 0.5 * cos(2 * pi * n / 32) + 0.08 * cos(4 * pi * n / 32)output <- hanning * blackman
Phantom: rc(0.0000000000e+00, 1.1829761539e-05, 9.2044630444e-05, 3.0596115880e-04, 7.2404634141e-04, 1.4054896011e-03, 2.4007891031e-03, 3.7524321332e-03, 5.4920446304e-03, 7.6422843429e-03, 1.0211145824e-02, 1.3189100031e-02, 1.6552139431e-02, 2.0263391374e-02, 2.4275590208e-02, 2.8533739878e-02, 3.2977121134e-02, 3.7538480408e-02, 4.2147181021e-02, 4.6728887501e-02, 5.1207853027e-02, 5.5507048060e-02, 5.9547857716e-02, 6.3250721961e-02, 6.6537723071e-02, 6.9332808965e-02, 7.1564464071e-02, 7.3175345923e-02, 7.4122092661e-02, 7.4380153255e-02, 7.3952344042e-02, 7.2876275169e-02)
Here are my test results. I think o1 did call Python, otherwise the numerical calculations wouldn't be so precise.

Can you paste the values?
[0.0,
0.017037086855465884,
0.0669872981077807,
0.1464466094067262,
0.25,
0.37059047744873963,
0.5,
0.6294095225512604,
0.75,
0.8535533905932737,
0.9330127018922193,
0.9829629131445341,
1.0,
0.9829629131445343,
0.9330127018922194,
0.8535533905932738,
0.75,
0.6294095225512605,
0.5,
0.3705904774487396,
0.25,
0.14644660940672627,
0.06698729810778087,
0.017037086855465884]
The o1 performs perfectly on this task. However, we already updated the prompt to more difficult, nobody could calculate it yet. I will paste it below.
This is the prompt
Gemini thinking is the king (why???)

The greeat question is why rage generates answer with such high variation. Is it a router? Is there temperature differences?
Same thing for rhea
Anyway, I haven't met nebula, if anybody meets it with this prompt, dont hesitate to share the values 😄
my experience with both models werent that great
talking about rage and rhea
so bad at many tasks
The numbers say that they lack consistency indeed
still no nebula for me. couple more here.
Another phantom:
c(0.00000000000000000e+00, 3.38003011783494125e-05, 5.32296009954234934e-04, 2.06607606508003040e-03, 5.73985127959829478e-03, 1.28524959879028501e-02, 2.47145199348771179e-02, 4.22975388987705293e-02, 6.62465618009184608e-02, 9.68107204134338309e-02, 1.33856431037345374e-01, 1.76896817840253044e-01, 2.25157520582151790e-01, 2.77561689130828108e-01, 3.32745311199813843e-01, 3.89162918104375744e-01, 1.00000000000000000e+00, 3.89162918104375744e-01, 3.32745311199813843e-01, 2.77561689130828108e-01, 2.25157520582151790e-01, 1.76896817840253044e-01, 1.33856431037345374e-01, 9.68107204134338309e-02, 6.62465618009184608e-02, 4.22975388987705293e-02, 2.47145199348771179e-02, 1.28524959879028501e-02, 5.73985127959829478e-03, 2.06607606508003040e-03, 5.32296009954234934e-04, 3.38003011783494125e-05)
3.7 sonnet thinking:
c(0, 0.000037, 0.000629, 0.00311, 0.00950, 0.02222, 0.04374, 0.07615, 0.1208, 0.1778, 0.2460, 0.3232, 0.4059, 0.4883, 0.5662, 0.9820, 0.9944, 0.9414, 0.8279, 0.7308, 0.5043, 0.3340, 0.1831, 0.0648, 0.2563, 0.0857, 0.0314, 0.0727, 0.0479, 0.0622, 0.0328, 0)
Based on o1's results, I think Python calls are allowed in LM Arena, so rage might just be better at invoking Python.
rage had some sort of error on one here i think:
Rage:
To generate the product of a Hanning window and a Blackman window of length 32, we first compute each window individually and then perform element-wise multiplication. The Hanning window is defined as ( w[n] = 0.5 - 0.5 \cos\left(\frac{2\pi n}{N-1}\right) ) and the Blackman window as ( w[n] = 0.42 - 0.5 \cos\left(\frac{2\pi n}{N-1}\right) + 0.08 \cos\left(\frac{4\pi n}{N-1}\right) ), where ( N = 32 ). The resulting product is:
c(0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000, 0.000000000000000)
This output represents the element-wise product of the two windows, resulting in a vector of zeros due to the multiplication of the zero endpoints of the Hanning window with the Blackman window.
phantom will probably give you the same answer as nebula
they are really really similar
phantom is like a one week old model than nebula
phantom and nebula 😄

hi
jim's about to take all the lmarena alpha
Finally got nebula:
c(0.00000000, 0.00001536, 0.00046765, 0.00222282, 0.00648309, 0.01418640, 0.02602793, 0.04234480, 0.06315819, 0.08821588, 0.11695270, 0.14858542, 0.18217473, 0.21667367, 0.25097322, 0.28400164, 0.31474092, 0.34228414, 0.36585801, 0.38483543, 0.39874431, 0.40724978, 0.41013053, 0.40734892, 0.39901768, 0.38541588, 0.36696187, 0.34420238, 0.31778406, 0.28844541, 0.25692687, 0.00000000)

Nice!
Huh Nebula error is 8.22 :/

It should be thinking model though
Interestingly the result of Nebula is identical to the command-a-03-2025
Can the names be shuffled periodically?

I thnk lmarena is shuffling names to reduce cheating or some source of stochasticity is involved

claude-3-7-sonnet-20250219-thinking-32k 8.78
no they arent
Then give me narrative on what's hapenning
rage and rhea inconcistencies are caused by sampling too?
maybe or there could be multiple models under that name. it doesnt mean they are changing/shuffling the names lol
What were the phantom errors?
meta could also be switching models out
rage and rhea arent thinking models. so theyre predicting the output without thinking, alongside sampling i can see how its that extremely variable
youre basically getting hallucinations at that point lol
got nebula again
c(0, 9.0724178010356952e-06, 7.2856925546279537e-05, 0.00020683206505288503, 0.00041814615810942764, 0.00070772046083229993, 0.0010709028016346709, 0.0014992620535333347, 0.0019819331475410767, 0.0025057884173717195, 0.0030561772024072553, 0.0036174782263374864, 0.0041737546065716644, 0.0047096803603024485, 0.0052111758597566055, 0.0056655645376517887, 0.0060618147865992481, 0.0063905156905526939, 0.006644143828903759, 0.0068170016355694545, 0.0069051569055269388, 0.006906617833895222, 0.0068217168524589259, 0.0066532661551121315, 0.0064062299138653186, 0.0060874319447306754, 0.0057049050048790513, 0.0052677039471142848, 0.0047855285719896434, 0.0042684137879167743, 0.0037264883032342513, 0)

o1 on browser got error of 0, possible by calling python interpreter (no indication). Didn't encounter o1 on arena
The maximum value of nebula is 0.006906618, it provides sum error of 10.6, which is just random
sadly yes
u shouldnt have non thinking models in that list. what ur getting is even more random
But claude-3-7-sonnet-20250219-thinking-32k 8.78 also provided hallucinations
Is Nebula the top model?
o3-mini error is 0.62 on arena 👀
Do you think my approach is flawed or the models are still not ready to perform such tasks without calling interpreters?
where does the difficulty in the task lie?
e.g. if the difficulty is a precise numerical calculation, models have tool use to handle it, there is not much point improving the mental math of models
There are 3 difficult tasks in there. One is remembering the formulas. Second is generating two arrays given the formulas. Third is performing element wise multiplication on these arrays. I assume that by testing how these models perform without interpreters we can assume their logic/math abilities
it is very flawed for non thinking models. you are asking it to predict the output without any thought process/cot. this results in outputs that are gibberish. for thinking models, its slightly more fair but i dont think its a good test either for multiple reasons. this requires a lot of precise calculations and a calculator, as far as im aware. otherwise they would need to approximate. they could do it by hand but it would probably go through an insane amount of context/steps that is impractical and not really representative of a real use case. and i doubt ud ask a human to calculate it by hand
my dumb opinion tho
In university sometimes they ask 😄
you'd get a calculator though right?
Anyway, this is my final conclusion. The GPT is the king, as always for my use cases. The Nebula may have multiple models or it is non-thinking model.

You had to calculate by hand before 2000s
did you check the phamtom ones? curious on that
if so then its a fair task for thinking models. i dont recommend using non thinking models at all with that prompt at least where it has to output it directly without any work
i mean just by looking at the error scores and public perception of model strength there doesn't seem to be much correlation outside the outlier of o3 mini...
hard to say whether this is a good benchmark or not
I agree, however, in arena battles, i have no choice which model they give me. I haven't encountered 4.5; therefore, they may be doing some kind of "best for prompt" algorithm to choose models
most important eval
especially given the fact that there is little difference between thinking and non thinking (3.7 sonnet)
If you assume that o3-mini is not a generation-in-the-future model for these tasks
o3 mini is really good at rote tasks
its the best model out there right now, i would think
Agreed
all the other models fall apart and give up in my experience with some tasks
same thing happens with nebula
I encountered it only with easy prompt. It did perfectly. Did not see it when using harder prompt.
not bad actually
dw this new model is so good at multi-turn
you can refine the results much better
which wasnt the case on gemini old models, even if you ask it many times to make it better, it will just make it worse and wont follow the instruction
can we still do text2image arena ?
grok 3 has that issue too
can't seems to find it
1- If we didn t get any other surprise (deepSeek r2 , gpt5 ect... ) 😂
Too soon for gpt5, we still need o3 😄
idk
gpt5 will probably be o3 full
- gpt4.5 optimized
or something like that
they said its a router system
so an o-serie model + gpt base model
It may still be tested separately
MoMoE 😅
im actually looking forward to deepseek r2
considering the hype, it's not even close to claude
its worth the hype, dont judge it from one prompt
i had many instances where it outperformed claude at coding
true, I'm just disappointed it failed me this much
Didn't try. Spent too much time on it :/ If you want, you can use my code for evaluation (R language)
library(gsignal)
left <- c(0, 3.64e-05, 0.000594, 0.003152, 0.010525, 0.026496, 0.057170, 0.107880,
0.183200, 0.285200, 0.411900, 0.548600, 0.696600, 0.824200, 0.928200,
0.987500, 0.996860, 0.987500, 0.928200, 0.824200, 0.696600, 0.548600,
0.411900, 0.285200, 0.183200, 0.107880, 0.057170, 0.026496, 0.010525,
0.003152, 0.000594, 0)
right <-c(0.000000, 0.001010, 0.004025, 0.009071, 0.016105, 0.025037, 0.035734, 0.048022, 0.061691, 0.076501, 0.092181, 0.108440, 0.124976, 0.141483, 0.157653, 0.173185, 0.187793, 0.201211, 0.213201, 0.223553, 0.232089, 0.238668, 0.243190, 0.245596, 0.245868, 0.244036, 0.240176, 0.234407, 0.226893, 0.217832, 0.207459, 0.196040)
actual <- gsignal::hanning(32, method = "periodic") * gsignal::blackman(32, method = "periodic")
plot(actual, type = 'l', main = 'Actual')
lines(left, main = 'Left', col = 'red')
lines(right, main = 'Right', col = 'blue')
summary(abs(actual - left))
summary(abs(actual - right))
sum(abs(actual - left))
sum(abs(actual - right))
Google started rolling out Project Astra for Gemini to more Android users. This feature enables vision capabilities on Gemini Live. The rollout is expected to be slow and gradual as the current adoption rate is still very low.
Thanks to t@__andreshernandez for the recording 🔥

"Leaderboard data is updated live"
Yeeeees!!! Finally!!! This applies only to the "alpha.lmarena.ai" page for now, right?
In https://lmarena.ai/ leaderboard I can still see data from 20.3.2025.
yeah though i don't think it really is yet (or at least when i looked eariler today, the alpha leaderboard shows today as update 'date', but actually seemed to have slightly older data than the regular leaderboard )
or something like that.. didn't seem 'live' but perhaps i'm missing something (and i assume it will be soon if it isn't already - which is nice :))
You are right... Both leaderboards shows "Total #votes: 2,801,990." but different date...
poll_question_text
Is it justifiable that Grok is No. 1?
victor_answer_votes
13
total_votes
19
victor_answer_id
2
victor_answer_text
No
victor_answer_emoji_name
😡
Why do you guys think we all see Grok as worse, but its number 1?

grok 3 from grok 2 was a huge leap thats for sure but its not a great model
you cant hold long convo with it
I swear if it will be better than nebula and o3/GPT5 the benchmark is corrupt 😄
I didn t know how "chocolate" got the no.1 seriously ... It never impress me ...grok3 preview is better but IDK
poll_question_text
Who would you consider the best model?
victor_answer_votes
14
total_votes
28
victor_answer_id
6
victor_answer_text
nebula
thats the issue with lmarena, people tend to judge a model based on one prompt
but if you really hold a long conversation with grok 3 then you start to see a lot of issues
yall ask a lot of math questions, a lot of what lmarena ppl ask and judge on is not math / coding
eg creative writing
ig coding and math are a big %

but presumably non-reasoning models do better by default on creative writing?
i dont' actually know
ig r1 has better creative writing score than v3 so maybe not (but it's the one thing it barely improves on)
This is a test if this chat is a bubble of software engineers 😄
that and longer query

otoh maybe grok 3 thinking beta gets put on the arena by elon bc he wants to win back first place
I never asked a model a single math question 😁 and rarely coding

https://x.com/testingcatalog/status/1904527950076076323?s=46&t=P8-tRi_JAVcI6l5U6nOT4A
OpenAI is cooked
BREAKING 🚨: Google is set to reveal a new model for Gemini this week!
In addition to that, Gemini will get a new toolbox for "Agents", aka "agentic use cases" for Gemini, like Canvas or Deep Research.
Soon, we may get something new added there.
👀👀👀👇

oh?
wait what
so nebula and phantom are non-reasoning models?
am i getting this right?
if so then thats crazy
they probably are reasoning, just wait for the actual announcement
he was right

fact they're calling it 2.5 is bullish on their confidence
that was really quick of them
daym
thats kind of crazy
the timelines
gemini 2 has a june 2024 cut off, they pretrained, did instruct tunes/ experimental versions, thinking, and are already moving onto another presumably continued pretrained base
they didnt even release a gemini 2.0 pro stable version
theyre moving so fast wtf
2.5 could be fake idk
maybe because this pace is insane
r/bard seems like it is reasoning

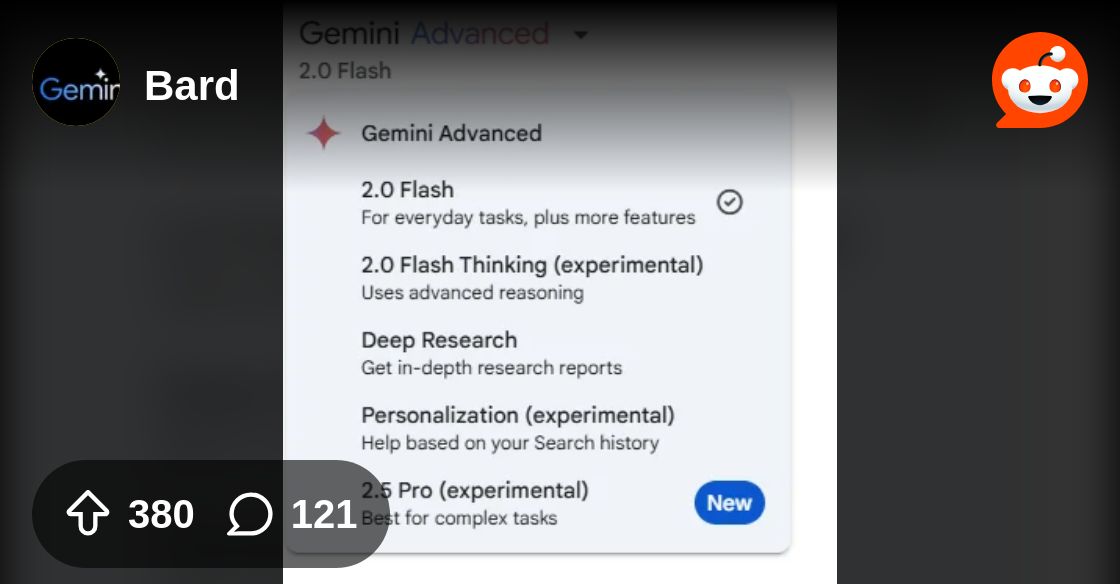
Reddit
Explore this post and more from the Bard community
i think nebula is a reasoning model. i once got it in the arena and it took a while until it started to give its response, it could also be that the other one was a reasoning model but i dont think so because it wasnt that good (i dont remember what model the other one was)
I love reading models thoughts