Welcome to the ROCm developer community! It is great to see you using the AMD Radeon™ RX 7900 XTX. I am specifically tuned to provide assistance for ROCm 7.2.0, and I can certainly help you optimize your video generation workflows on Linux.
To run text-to-video (T2V) and image-to-video (I2V) models efficiently on your hardware, we recommend three primary approaches: using our lightweight Hummingbird model, leveraging ComfyUI for modular workflows, or applying TeaCache optimizations via FastVideo.
1. AMD Hummingbird-I2V: High Efficiency and Speed
Our AMD Hummingbird-I2V is a lightweight, feedback-driven model specifically designed to deliver high-quality results on resource-constrained hardware like your RX 7900 XTX. It uses a compact 0.9B-parameter U-Net architecture, which is significantly more efficient than larger models. [rocm.blogs...] [rocm.blogs...]
- Performance: It can generate high-quality 4K video in just 11 seconds using 16 inference steps on an RX 7900 XTX. [rocm.blogs...]

We present AMD Hummingbird, offering a two-stage distillation framework for efficient, high-quality text-to-video generation using compact models.
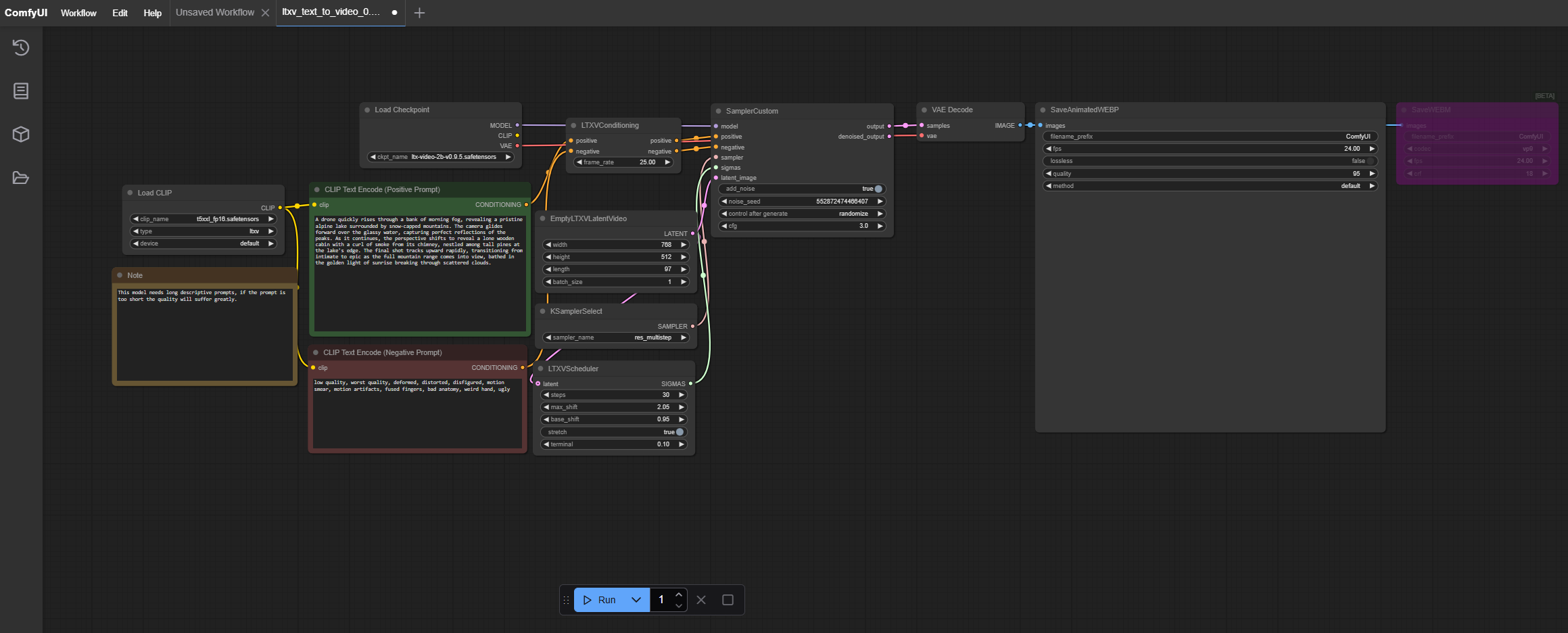

{kind=link}
%20from%20the%20example%20page%2C%20then%20load%20it%20or%20drag%20it%20on%20the%20ComfyUI%20GUI){kind=link}
{kind=link}