#✨│ai-help
1 messages · Page 325 of 1
huh, you said you were on Linux Mint
Fugg
My brain wasn't braining
I just woke up.
Sorry, I meant to say all my stuff is on Linux mint
@low shard imma check the guide u gave later
ohh
unfortunately none of the wokada forks contain a precompiled build for Linux with Intel Arc Support, you can either:
- use it on CPU (easiest local for your case, but probably high latency)
- use the dml windows build via a VM (with GPU Passthrough) or dual boot
- use cloud methods
- if you're a coder (i can't test this but based on research): install the Intel Arc Compute Drivers, overwrite the default pytorch installations to use XPU, modify the source code to detect XPU
I think you're the first user on Linux with Intel Arc GPU
Damn.
Are there any other voice changers out there that AI is optional?
Rx580
Kobold.cpp Linux no cudA
Vulkan driver
Model qwen3 tts
Hey everyone, I’m running into a frustrating issue with my local TTS setup and could use some insight from those more familiar with Vulkan/AMD offloading.
The logs show that Vulkan is detected, but my GPU (RX 580) is sitting at idle while my CPU is pegged at 100%.
The Problem
Even though the log says:
ggml_vulkan: Found 1 Vulkan devices: AMD Radeon RX 580
The actual inference backends are refusing to move over:
- TTSTransformer backend: CPU
- AudioTokenizerDecoder backend: CPU
As a result, I’m getting about 0.07x – 0.08x realtime performance. It’s painfully slow.
My Specs & Config - GPU: AMD Radeon RX 580 (Polaris)
- Software: KoboldCpp / Qwen3-TTS
- Settings: gpulayers=-1 and usevulkan=[0]
What I’ve Noticed
The log also mentions fp16: 0 | bf16: 0. I suspect my RX 580 might be too old to support the specific math required for these models, or perhaps the Vulkan implementation for this specific TTS model just isn't there yet.
My questions for the experts: - Is the RX 580 simply a "dead end" for this type of inference because it lacks FP16/tensor cores? But It work on llama.cpp
- Is the TTSTransformer backend in KoboldCpp currently CPU-only for Vulkan users?
- I dont want switching for ROCm actually help an older Polaris card, and i Will not get new RTX card for CUDA!
If anyone has managed to get GPU working on older AMD hardware for TTS, I’d love to know how you did it!
about the making your own release option, maybe you could also check out https://github.com/tg-develop/voice-changer/tree/master-custom/.github/workflows and see if you could edit the workflows to add linux mint on intel arc gpu support
Are there any other voice changers out there that AI is optional?
Vonovox uses the same RVC technology but is currently closed sourced freemium and on Windows on modern Nvidia GPUs only
So you can either:
- try https://github.com/wwmm/easyeffects (which seems like FOSS Voice Mod alternative with basic audio effects, like Pitch shift)
- try one of the methods I told you before about running the wokada forks (like tg-develop)
GitHub
Realtime Voice Changer. Contribute to tg-develop/voice-changer development by creating an account on GitHub.
GitHub
Limiter, compressor, convolver, equalizer and auto volume and many other plugins for PipeWire applications - wwmm/easyeffects
I can't make my own release version 😭
Computer science has lost its value to AI, meaning AI can just write all the code and push the release...
Then I chose electrical engineering, I already have my own fair share of workload.
I will have to rely on EasyEffects..
Thank you so much :<
i mean an easier way to run it was using a Windows VM with GPU passthrough or using cloud
Computer science has lost its value to AI, meaning AI can just write all the code and push the release...
About this, i wouldn't say it lost its value, vibe coding can be harmful in some sectors since it's just token prediction at the moment, tho its true that vibe coding can be helpful in some cases, I saw it help with things like building Emulators, but anyways it's not what the convo is about
EasyEffects will work fine if you don't care about sounding like a specific character (like Homer Simpsons)
You're welcome, unfortunately your setup is kind of niche so not many programs support it
Well. Sort of Don't care about sounding like a specific character, but be able yo shift my voice to sound either different tones of male and female, or just make goofy voices
ohh then it's all good for you then, enjoy it
you didn't need an AI Voice Changer to begin with for that so don't worry
are you looking for an open source model you could run locally or cloud? what's your gpu?
I am trying to make a music video
I am a music artist
Oh yea I remember.
For context, my home PC with the INTEL ARC, I tend to run AIs like stable diffusion or Ollama models
However, when I bought a new laptop last year, I was unaware and discovered just yesterday that the CPU of my laptop (RYZEN 5 8640HS) has an NPU and I am wondering what AI models could I be able to run on the NPU
Can you make a music video for me
Bro. I don't know how.
I can only do images


I already have a character
You do realize you could try asking Gemini or GROK
I don't have subscription
Hey, quick question: for AI covers, is AI Cover Maker good enough, or is it better to use a full RVC workflow with Applio + UVR for higher quality?
People that dont know about free teirs be like:
LLMs surely are more popular and have support for your setup, it's just that not all technology does
I haven't head of many projects having NPU support, I remember right now: https://github.com/rupeshs/fastsdcpu (CPU + Intel Arc + NPU support, nice)
GitHub
Fast stable diffusion on CPU and AI PC. Contribute to rupeshs/fastsdcpu development by creating an account on GitHub.
Do you know any
Bro I literally said Gemini or GROK 🤦♂️
I am trying to make a music video for my new song
AICoverMaker is the easiest automated way, the manual setup with Applio and UVR gives you more control to be sure you like your output
They ask me for subscription
Cool!
I will check it out
there's no company that's going to give you free unlimited chatbots, they would all just go bankrupt
I don't know about AI videos much
so there's neither any company that will give you free unlimited image to video services, they would just burn money
you either use the free trials, pay, or buy your own beefy pc to run open source alternatives
Do you know how to make fight scene video or sad
I just said i don't know about AI videos much
the other users aren't helpers, and this isn't an editing server
you could also try llama cpp on your NPU https://github.com/ggml-org/llama.cpp/issues/1499, not sure about that tho

GitHub
LLM inference in C/C++. Contribute to ggml-org/llama.cpp development by creating an account on GitHub.
Please, how do I extract the files pth and index
Are you trying to use the files in real-time or for applio?
Hello everyone!
is deepseek, z.ai, qwen models are still good to use as api with n8n? anyone using it?
I found a website which is freely providing api of all these platforms for free and unlimited for now. I don't know how much time they will provide it. But not sure if these models are still worth it to use or not.
Laptop gpu rtx 4050
Windows 11
AI covers and realtime voice change
did you download an rvc voice model from #1175430844685484042 ? just unzip it
-realtime
🔊 Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Vonovox
A Realtime Voice Changer with similar performance to Wokada Tg-Develop Fork, with extra features, but it supports only Nvidia GPUs on Windows 10/11 unlike other options that have wider support. and without cloud options
• Wokada Tg-Develop Fork
A personal fork (modified version) of Wokada Deiteris Fork, it just adds some Quality of Life improvements to it like supporting Spin Embedder and Audio Effects. Don't expect too much about it since the creator made it originally as a personal project.
• Applio Realtime
A Realtime Voice Changer with similar performance to Vonovox & Wokada Tg-Develop Fork, with extra features.
• Wokada Deiteris Fork
Deiteris' fork (modified version) of wokada that doesn't get updates anymore.
⛔ Outdated/Discouraged
These options are not recommended for use.
• Original Wokada
Not suggested, older versions in youtube tuts are even way worse. GUIDE
• RVC GUI Mainline Realtime
The program is worse compared to the ones above, and much less updated. GUIDE
you might want to check out Applio, it works for both of your needs
would you guys say that kaggle is good?
I stand by it being the best for cloud since it's easy for new users and also has a decent free user limit of 30 hours per week
Google colab is just horrid with it giving a random time between like 2-4 hours for free users and lightning is kinda just confusing as hell
I will figure it out and fuck off
I need help can someone help me create AN RVC model for lakyus alvein dale aindra from the anime and light lovel seriees overlord please
thank you, man! i'll defo use this advice to my advantage i love your models btw, i use a lot of them
Ty so much! Glad I could help btw ^^
i want to request an rvc model of lakyus alvein dale aindra from overlord please
hey i was coding in one vibe coding tool, and i want to shift it to another vibe coding tool. how do i do that?
i don't remember the name
just go here bro https://discord.com/channels/1159260121998827560/1175430844685484042
it's called block size in vonovox, just adjust it with your mouse
link?
Guys what's the best voice changer ???
I tried
With a good settings and everything
And the result was so bad
Any one can help
?
where can i get the latest version of w-okada
Im looking for It too
Which GPU do you suggest tò run It, how many vram?
anyone able to help me re-install RVC i'm not sure why its not working. have i installed it wrong?
Hey friends, listen, I've done everything, but when I try to extract the pth and index files and fill in the last fields, no black text appears when I click on them.
Is there a solution to this?
I wasn't given permission to post on Vioes-Models. I want it for my personal use... I really hope to train my voice.
HEY
Welcome
THANKS
You're welcome. Can you help me?
IN WHAT ?
SORRY BRO I AM NOT REALY SURE THAT LAST I CREATED AN INDEX FILE
SO I AM PRETTY SURE USELESS FOR THIS
WHAT ABOUT U CAN U HELP ME ?
I WAS USING GROK AND NOW IT'S SAYS THAT THE AUTHENTICATION FAILED SO ALL THE THINGS I WAS DOING ARE PROBABLY GONE WITHOUT MY GROK ACCOUT , I WANT TO KNOW IF U KNOW ANOTHER FREE AI GOOD AS GROK TO COMPLETE MY WORK
@spare dove may i dm message you?
I am so, so, so sorry for what is happening to you
Of course I'm here
Be polite to everyone here or you will get higher moderation actions.
i put a thing in help forums.
why do you speak in yelling? ( @viral mason for the joke. )
there are different programs, elaborate:
- your pc gpu
- your pc os
- the tutorial link you're using
Please, I'm on the phone. Please help me. I'm dreaming of that.
can't use it on phone
truly?
Can you train my friend's voice? Please, she's disabled and dreams of it.
What about Abellio?
Please answer
okay...
I'm sorry I don't take commissions but you can learn how to train models yourself on applio
nah, just look through https://discord.com/channels/1159260121998827560/1175430844685484042 or https://voice-models.com
Voice Models
I don't train regular people voices just game or show characters
Yes, please
Using tg-develop's voice changer and it's not working. Using my default in and out to test and even that isn't working
Passthrough doesn't work
So idk what to do
someone tell me what is wrong pls
Does anyone know how to reduce the delay on Vonovox?

gotta turn down then block size
Can someone recommend some good llm subscriptions? I was on chatgpt free -> go -> pro (20 bucks). I mostly use it for learning math in the conversation mode (uploading pictures of the problem, then engaging the mode). Even after upgrading to pro, i seem to run out of advanced voice. Is there any llm that's more generous in voice and is good with math (converstational as well). Thanks!
hey if i am not wrong the index file is for training the model right?
so like if there was an index file trained to speak a specific language which i speak? will it be better then?
and if yes how hard is it to train the model
whats the best boy voice
An index file stores accent of a voice model, typically achieved before or after model training. The actual RVC voice model file is in "pth" format. To train one, you would go for a dedicated RVC software (like Applio RVC).
Don't wanna know.
why
You can't use realtime on the phones
You need the best boy voice to troll/catfish right?
You have got help about the voice changer multiple times earlier. Some settings look wrong there because you set chunk number too high, extra value should be "2.7" not 0.5, pitch extraction model should be "RMVPE" not rmvpe_onnx. You wouldn't set both output and monitor as the same speaker either.
i just use okada
anyone having problems with the weights website? i cant seem to download anything there atm, even though i could download normally a few hours ago
are you trying to e girl troll / catfish too like the other user before lol?
ya there was a dr strange and ultron voice model that i wanted to use during ranked lol
Hey, can someone send me the link to the correct Colab notebook to use to train an RVC model?
I just need the colab link, that's all
elaborate:
- your pc gpu
- your pc os
- what you're trying to do, like AI Covers, LLMs, E Girl Trolling / Catfishing or Roleplaying as goku
- the tutorial link you're using
it would be better you first tell your pc gpu and os to see if you could do train RVC models locally
if you don't care about that, check this guide https://docs.aihub.gg/rvc/cloud/applio-cloud/
Last update: March 24, 2026
oh so just roleplaying as characters right?
what tutorial link are you using?
btw weights is shutting down on march 31st 2026
guys i got the ai voice changer now but does my mic have to be good in order to work flawless
Which roles or Permission do i need to be able to text in the voice-models Channels? and how do i get them?
No you can't train an existing model
You have to first train a model and then submit it here https://discord.com/channels/1159260121998827560/1452279591317278840, once it's approved which can take a while you can then post models there and I believe that also lets you text there since you'll have the model maker role
Tho I'm not 100% sure you have to do that just to text there specifically
Where'd you get the voice changer and what gpu do u have (Nvidia or AMD) btw your mic doesn't have to be perfect just make sure there's not a lot of background noise or people talking being picked up by your mic
I think so, I couldn't comment on models without the role either.
Maybe it's a limitation of discord
Or maybe bad permissions? 🤔
Wonder if it's possible to enable commenting but disable posting by default
That's probably possible but I'm not sure, I've dealt with role management before in some servers but it's a little confusing
Maybe it was disabled to keep people from just going in there and being like "boo this stinks" and making someone quit model making
Dunno if it's like that on purpose but I think commenting should be enabled
Model feedback, discussion etc
True yea
I've used my brain too much typing those big blocks of text I think it's resetting
I just woke up too lol
Meanwhile 5pm here
Doggo walk, gotta eat something, and then I can rest and enjoy the weekend xd
We love Fridays
Not dark yet! Late afternoon, I'd say
Nice!
Hi guys and gals, can anybody explain to how I can runs Stable Diffusion with muli-GPU?
I have two 3060, I read that comfy supports multi-GPU, but I'm mainly interested in automatic/forge, because of inpainting.
thxthx
Im looking for ready tò use voice assistant with theese feature: speech to text ,LLM text_gen ,text to speech pipeline with (STT → LLM → TTS)
I setup the following tool
whisper.cpp
llama.cpp (other doesnt work )
qwentts.cpp It use kobold.cpp only (other doesnt work )
distributed multi machine linux vulkan amd
It must be Separate PCs / distributed nodes
AMD + Vulkan only (VERY IMPORTANT for me)
- Ready-to-use stacks
example
PC1 (AMD GPU Vulkan)
→ whisper.cpp server
PC2 (AMD GPU Vulkan)
→ llama.cpp server
PC3 ( AMD gpu vulkan )
→ kobold.cpp / Qwen-TTS server
i see
the thing is im facing issues when using the rvc model and speaking in my local language
hmm
elaborate:
- your pc gpu
- your pc os
- what you're trying to do, like ai covers, e girl trolling / catfishing or roleplay
- the tutorial link you're using
Automatic1111 stable diffusion web ui latest commit was 2 years ago
https://www.reddit.com/r/StableDiffusion/comments/1pswsw6/is_automatic1111_still_used_nowadays/ most people that don't want to use comfyui bc it's harder to use switched to forge
it doesn't seem currently possible to do multi gpu with forge based on https://github.com/lllyasviel/stable-diffusion-webui-forge/issues/48
I think your only way might be ComfyUI https://github.com/pollockjj/ComfyUI-MultiGPU
I downloaded the WebUI from Automatic1111 and I can't get it to run because it tries to clone a github repo which doesn't…

GitHub
Is there an existing issue for this? I have searched the existing issues and checked the recent builds/commits What would your feature do ? can use a Dual GPU setup. Proposed workflow no workflow A...
GitHub
This custom_node for ComfyUI adds one-click "Virtual VRAM" for any UNet and CLIP loader as well MultiGPU integration in WanVideoWrapper, managing the offload/Block Swap of layers ...
@simple ore iirc you used forge? not sure if you may know anything about this topic
hey nick
u free?
can u come on vc i wanted some help tweaking my vonovox
i can't help in vc, if you want you can elaborate via text
long time ago with AMD
hi guys, do yall know an opernsource ai that generates lip syncs videos from images?
iirc you can do that with wav2lip or facefusion
How tò use vulkan driver tò run this
https://github.com/ShayneP/local-voice-ai/tree/gpu_enabled
what size llm should big enough 2b 4b 8b 14b for the following task<capabilities>
The system acts as a specialized linguistic reconstruction engine. It possesses the ability to parse disjointed keywords, infer logical context, and synthesize them into a singular, cohesive, and grammatically standard sentence.
</capabilities>
<behavior>
- Tone: Maintain a strictly flat, neutral, and expressionless persona.
- Style: Avoid all unnecessary chatter, warnings, disclaimers, preambles, or conclusions.
- Constraint: You must generate exactly one sentence per input. Do not provide multiple variations or additional explanations.
- Logic: Interpret the relationship between keywords to create a realistic or contextually appropriate scenario.
</behavior>
<output_format>
All responses must be wrapped in structured XML tags. No text should exist outside of these tags.
Format: <result> [Reconstructed Sentence] </result>
</output_format>
Examples:
Input: saw bear webt camping Majestic
Output: <result> I saw a bear last time I went camping, and it was majestic. </result>
Input: Snake terrariun naturecenter
Output: <result> There is a snake inside a terrarium located at the nature center. </result>
Input: car road fast mountain
Output: <result> A car traveled quickly along the winding road through the mountain pass. </result>
</result>
How yall make voice models
it depends, what's your pc gpu and os?
How do i get a permission to post in #1175430844685484042 ?
You have to submit your trained here https://discord.com/channels/1159260121998827560/1452279591317278840, once it's approved which can take a while you can then post models there and I believe that also lets you text there since you'll have the model maker role
umm, that link you gave me, i have no acess to it
odd, maybe there is a role you're missing
what do you mean by "role i'm missing"?
these

is this where the link you tried to send me leads to?
no that screenshot is from the channels and roles section

@viral mason you linked the wrong channel
the submission channel can be view only by users who are already model makers as they have to rate them
@cosmic epoch you need to check #📤│model-maker-role
oops
wait... i don't get it, how do i share models there without a file?https://discordapp.com/channels/1159260121998827560/1453581938538315847
you can use the voice models using a realtime voice changer, depending on what gpu u have (Nvidia or AMD) I can get u what u need
what are you planning on using it for?
Anything off yt is outdated
But uh wdym troll..
Why are people like this
<@&1159293140440723499> kill him
Catfishing is not good so uh yea good luck getting what u need
Ahem
Pretending to be a woman to get stuff from people
Yeah..
💔


how many epochs should i aim for when using a 17 minute dataset
so if i wanna get a model from weights that isnt on #1175430844685484042 what do i do?
i wanna get this dj drama model but its not letting me
bc i dont have an acc and they disabled sign ups
if you don't have an account and aren't signed in you're screwed
i see, could you help me access it please
i got you, imma dm you the model
cheers tysm!!
yw!!
W ai hub member
If you ever feel like voice models on Weights.com were outdated and wanted newer ones as replacements, you can request in #1159289738314919936.
Hello! I was here before weights created. And soon it's shutting down sadly...
- Can anyone suggest any similar websites for creating character voice covers?
- If there are no websites, what programs are usually used to create AI covers?
- How powerful does a PC need to be to create such covers? My laptop like, 15 years old... And have windows 7... What are the chances that I can make something with these technical specifications...
Oh, or maybe not only PC! I also have android phone. It's more powerful than my PC i guess xd
I asked accidentally it in general chat, oopsie. Maybe someone else could talk to me. I would be very grateful for help in answering these questions!
i need help with vcclient
i have everything setup with the VB cable as well and stuff and the right settings but NONE of the rvcs r detecting my input my voice yet the beatrice does detect my voice why isnt the RVC working
What you're using is really outdated
?
What is your pc gpu? (Nvidia or AMD)
nvidia and im on the MMVCServerSIO_win_onnxgpu-cuda_v.1.5.3.18a
Yea that is the original w-Okada super old
Most likely you got it from a yt tutorial or just the official link
I'd use Vonovox, it's the current best for real-time on Nvidia
free>
ok
I use it as well
arent the voice models in this server meant for okada only?
The models are just files that go to pretty much any software that does real-time ai with rvc
ohh okay
do i use VB virtual cable for this too
Anyways here's the two downloads you need, first one is Vonovox which is the voice changer and second one is a virtual audio cable called vac lite which is recommended over VB cable since it's less likely to mess up on windows
Yea you'll need a virtual cable for this to work on games or discord
This is where I used to run "Applio RVC". While your old laptop couldn't run Applio RVC locally, this option might work.

Thank you! I'll look into it, thanks for the tip.
I'm just looking for options with what I have. I know I don't have much, but at least I have something
Btw if I do disappear it's due to it being late and me falling asleep
i have one question what is index and do i need to bother with it
An index file stores accent of a voice model.
There are different contexts on whether "index rate" should be enabled; index rate of non-zero value in any realtime voice changer program (W-Okada, Vonovox) will use an accent of that voice model, but then it would cause CPU to spike up more which is not very ideal for latency-sensitive scenarios. In non-realtime RVC (like Applio RVC), setting index rate to any value would also use CPU as well, but the performance is usually unnoticable.
ok thanks alot
No its my laptop mic and it picks up a lot of noises is it because that?
hello, i need voice changer okada
to download it
rvc v2 still working?
why would it stop working? 🤔
what's your OS and GPU?
Do you want realtime conversion or inference on audio files?
rtx 5060
realtime
🔊 Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Vonovox
A Realtime Voice Changer with similar performance to Wokada Tg-Develop Fork, with extra features, but it supports only Nvidia GPUs on Windows 10/11 unlike other options that have wider support. and without cloud options
• Wokada Tg-Develop Fork
A personal fork (modified version) of Wokada Deiteris Fork, it just adds some Quality of Life improvements to it like supporting Spin Embedder and Audio Effects. Don't expect too much about it since the creator made it originally as a personal project.
• Applio Realtime
A Realtime Voice Changer with similar performance to Vonovox & Wokada Tg-Develop Fork, with extra features.
• Wokada Deiteris Fork
Deiteris' fork (modified version) of wokada that doesn't get updates anymore.
⛔ Outdated/Discouraged
These options are not recommended for use.
• Original Wokada
Not suggested, older versions in youtube tuts are even way worse. GUIDE
• RVC GUI Mainline Realtime
The program is worse compared to the ones above, and much less updated. GUIDE
What do you use the voice changer for?
for girl,zoro.Luffy
i need
w okada

any help?\
sry my eng very
bad
If you mean W-Okada, download Tg Develop's W-Okada fork, https://github.com/tg-develop/voice-changer/releases/download/b2397/voice-changer-windows-amd64-cuda.zip.001 and https://github.com/tg-develop/voice-changer/releases/download/b2397/voice-changer-windows-amd64-cuda.zip.002.
when i extract its show me like this

Make sure to download both .zip.001 and .zip.002 into the same folder.
Hello, i asked gemini where i can find a alternate for Weights.gg since its shutting down, and it said something about w8ights.cc or w8.ai and it told me to come to this server to find something like weights-migration or smth.
Not everything said by Google Gemini would always be accurate. This Discord server you're here is AI Hub, and yes it's mostly about "RVC".
I am using w okada but when I talk it says something like 'trial' how can I fix that?
you download VAC trial version
download lite instead
uninstall the VAC you have and install this instaed
You're using trial version of Virtual Audio Cable. Use the free Virtual Audio Cable "lite" instead.
do i use cable

?
There's the guide. https://docs.aihub.gg/realtime-voice-changer/local/tg-develops-w-okada-fork/
Last update: March 26, 2026
For input/output settings, I usually do this. https://cdn.discordapp.com/attachments/1159290139609137264/1456249974525526185/image.png?ex=69c90ef9&is=69c7bd79&hm=62c75ab409606ec88e4f5370b09c829ef117b759b3ef4b0678cedc5c76cf62d5&

ok

how to fix perf
cuda error
Chunk: 120 ms
Extra time: 2.7 s
Pitch extraction: rmvpe (not rmvpe_onnx)
Sample rate: 48000 Hz
Where'd you get this W-Okada voice changer from? Tg Develop's W-Okada fork and Vonovox are only voice changers that can work with GeForce RTX 50 series.
can I get working link?
Before I use 4060, change to 5070 tonight maybe the prob
Tg Develop's W-Okada voice changer is a continuation of Deiteris' W-Okada but made by different author and better, download https://github.com/tg-develop/voice-changer/releases/download/b2397/voice-changer-windows-amd64-cuda.zip.001 and https://github.com/tg-develop/voice-changer/releases/download/b2397/voice-changer-windows-amd64-cuda.zip.002.
both? why the file named amd, i use nvidia
CUDA -> Nvidia GPU
amd64 -> CPU architecture (it's the same as intel CPUs, it's just a name)
all's good
I see, thank you capybar and namari!
still very high

AMD64 is basically another name for x86-64 CPU architecture, which is used by both Intel and AMD in their CPUs respectively. If you see "CUDA", it usually refers to NVIDIA GPU.
Send your full screenshot.

Nah, you still have processing unit set to CPU, which is why the voice changer lagging a lot.

w11 and 1650
A Linux distro or Microsoft Windows 11?
windows 11
RVC v2 Disconnected this one right?
Old news, but there's why RVC Disconnected has long ended. #📰│dev-updates message Applio RVC is a better bet.
no ui?
There are main Applio RVC (one with UI) and one with no-UI command line.
wdym? maybe check https://docs.aihub.gg/extra/model-maker-role/
Last update: February 28, 2026
there's no perfect value
if you didn't already have an account, you're kinda cooked
it depends on your pc gpu, maybe if you could tell that it could be helpful, but considering you're on Windows 7 you're probably cooked for local AI
If you just want to make ai covers easily, check https://docs.aihub.gg/rvc/cloud/aicovermaker-cloud/
Last update: March 24, 2026
RVC is Retrieval-based-Voice-Conversion, not realtime voice changer
elaborate:
- your pc gpu
- your pc os
- what you're trying to do, like AI Covers, E Girl Trolling / Catfishing, Roleplaying as goku
- the tutorial link you're using
never heard of those
can you elaborate your pc gpu and os and if you're trying to train RVC models or just make AI Covers?
check https://docs.aihub.gg/rvc/local/applio/, you can train rvc voice models here
RVC v2 disconnected is gone, elaborate your pc gpu and os
vonovox is the wrong tool for that
You could have record your audios and convert them in non-realtime RVC like Applio RVC instead. "Realtime" voice changer is only if you mean to live stream on TikTok.
You would need OBS Studio for this one. But how would you make such scenes the same time you configure the voice changer?
I mean, I said it before you mentioned the livestreams
for streams you definitely want realtime (and vonovox is the right tool for that)
I just meant that for videos you'll be much better off with applio or any other offline inference tool. You can record the audio, then convert it later and also tweak it in postprocess which is not gonna be possible with vonovox
But regarding your "laggy and bad" sound in vonovox
Which version of vonovox are you using? Is vonovox the only GPU-heavy app running? Additional load from other apps might affect the performance
What vonovox settings are you using?
no way to send pictures here without explicit permission (which only admins can do). You can either describe in text or perhaps send a screenshot via DM to me
Can you scroll lower to the voice settings section?
In general what you might want to try is tinkering with the block size slider and see if it improves the issue of sound cutting off
The slider I was talking about is actually between the first and second screenshot
Anyway, try to play around with the block size. Maybe a value of 0.2 etc
See if it affects the choppy sound
In terms of quality strictly - did you ensure its not just a poor quality model?
Try some other models as well
are you perhaps trying to do e girl trolling / catfishing?
Also might disable Smart SINE for test. Depending on the microphone, it might sometimes cut off your speech abruptly. If it doesn't happen, you can keep it on
anymore?
with a girl account?
hi people. I am someone who is working on a university project, and one of the things I need is object detection. I have 0 experience in AI. (I am a telecom and computer engineer and have lots of experience in electronics and programming). I have no clue where to start. what do I need to learn?
Did you extract the zip before trying to install the program?
Maybe you could check the Yolo Models, the latest is Yolo26
1660ti
windows 11 (I can change this if needed obviously)
I need to do simple object detection like doors, stairs, etc
I dont have any tutorials that Im following, that's the whole reason Im here
maybe tutorials like https://www.youtube.com/watch?v=r0RspiLG260 and https://docs.ultralytics.com/tasks/detect/#export could help you, the yolo models are the best for this task

Learn how to train custom YOLO object detection models on a free GPU inside Google Colab! This video provides end-to-end instructions for gathering a dataset, labeling images with Label Studio, training a YOLO model, and running it on a local computer with a customizable Python script. The video shows how to use YOLO11, but it also works with YO...

Nvidia GPUs are generally better for Local AI tasks because of CUDA support
which specific AI you're trying to run?
nice. also, how efficient would it be to train my own AI model. I want it to be good enough to handle 24fps processing. are these yolo models customizable?
like, can I change what they can "see"?
you can finetune it to detect specific objects, like video game characters or cars
does finetuning it change its speed?
tryna add more bots in ssl lobbies? 😭 😭
Why cheat?
thanks nick, I'll check the yolo models out
AMD Radeon GPUs are good as the budget alternative to NVIDIA GPUs, but then certain AI setups gonna be tricky because most AIs are made for NVIDIA GPUs which natively support CUDA better, while AMD GPUs need some specific workarounds to work. This also happens with something like W-Okada voice changer as well. 
you're welcome, I haven't played around with YOLO models honestly but they might be great for your object detection task
your GTX 1660 Ti isn't that new so not sure if it might be able or fast enough to do YOLO finetuning locally, but you can try
I saw that there are different sizes with a tradeoff between speed and accuracy so I might be able to work something out
all I need is basically a model that can detect cars, humans, signs, doors, and stairs. that's it. Ive ran 7B models on my pc before so these models SHOULD be fine, fingers crossed. Im a little lost because I have no clue how AI works except that it uses probability math, which is very interesting
maybe look out for YOLO26n (nano) or YOLO26s (small)
Please remember that not all glitches work as intended
hi
Now, Seedance is too secure a model and has so many filters that it won't let me make a video where a person transforms, flies, and attacks an aquatic monster. What do I do?
, I’ve been looking into this
stack
Claude Code / MCP / Browser-use / MiniMax / NoVNC.
Before I dive in, I’m trying to figure out the hardware overhead.
: Does this specific workflow rely on CUDA
for the local components, or is it compatible with
Vulkan ?
: How much VRAM is typically "eaten up" by the browser automation and NoVNC layer on top of the LLM? What model via MCP?
what’s the "safe" VRAM ceiling I should aim for?
!
I need help with that everything work but when im testing myself on discord, its coming from my monitor and not in my ears. When i join talk, i hear people in ears , but from monitor my girly voice
i dont understand it, can someone help me please ?
Hello
A quick question
I bought the xm8500
And have been looking for a cheap way to connect it to my PC
Is the Behringer U-Control UCA222 good for that? it's pretty affordable from my findings.
I've never even heard of that
Not sure if I can post links but here's the full name
(Behringer U-Control UCA222 Ultra-Low Latency 2 In/2 Out USB Audio Interface with Digital Output )
Else
What's the cheapest way to connect it to the PC?
not sure, I'm not super tech savvy with stuff like that, is there anything on youtube or maybe reddit that you could find?
why UCA222? It doesn't even have a proper input (it uses RCA instead of jack/XLR).
I mean, sure, you can make it work with that, but might as well purchase an interface that is actually designed for the purpose
the main problem is that I assume you want to limit the budget as tightly as possible. Which also makes sense as the microphone itself is a cheap one
honestly, just try to find some USB interface with XLR input and you'll be fine
(or balanced 6.3 jack, but usually it'll be part of the XLR anyway)
behringer's UM2 is one of such, it'll do the job and it's cheap
(obvious side note - both the mic and DAC are fairly cheap, so it'll be reasonable to not expect supreme quality, but it should sure be better than e.g. a headset mic)
Same. It's the reason for my big confusion on what exactly to get. I got the mic as a gift so it'd be a waste not to use it, but I can't afford what reddit suggests unfortunately.
Oh. Thank you so much! I was about to ask for a specific suggestion actually.
However, the Behringer U-Phoria UM2 is still a bit expensive, it's double the mic's cost (as I checked how much it was on amazon.eg) ... is there no other cheaper alterantive for my use case?
Oh, I guess the prices vary a lot between countries. In my area the UM2 is priced very similarly to UCA222, which is also the same cost as the microphone
That was mostly why I recommended that one, because i assumed it's within price range
But apparently the prices are quite different in your case
Honestly I don't know, don't have any recommendations in this price range. Mostly because honestly it's kinda not a thing that can be bought for that money
Yeah unfortunately the mic is sold for around 2,5k EGP, while the UM2 is 4,5k EGP
But as I said, you might try to find some as-cheap-as-possible XLR USB interface and perhaps it'll be sufficient. Obviously those won't compare to the more expensive ones but they should do the job nevertheless
dunno if that's acceptable for you but i'd search among used stuff instead of new
much more likely to find something nice
I don't mind used stuff at all. My PC was built from some used stuff and it's been working perfectly fine. However, in this case, I don't have experience on where to get reliable used audio hardware, unlike my experience with PC hardware, hence why I prefer finding something new from a renowned place like Amazon.
I found this
What do you think?
M-Audio M-Track Solo 48-KHz 2-channel USB Audio Interface with 1 Crystal Preamp, Phantom Power and Instrument Input
Oh, sure, this one will do
Very well, I'll save up for it.
So now all I need is this audio interface, an XLR cable to connect the mic to it (my xm8500 came without cables at all) and that's it. I don't need anything else, correct?
Yeah, that will allow you to use it in PC
Many thanks
No problem. Good luck!
Quick question... is there any alternative website to use AI voice free... without credits and some?
"free without limits" - probably not.
But places like Kaggle grant some free GPU time. Strictly in case of Kaggle - 30h per week
Hmm... yeah, probably... it's really sucks that 2 days left and i really can't use Weights.gg when it shutdown... i really had a lot plan for it.
elaborate:
- your pc gpu
- your pc os
- what you're trying to do, such as AI Covers, E Girl Trolling / Catfishing or Roleplaying
- the tutorial link
there's no company that would give you free unlimited AI cloud usage, they would just go backrupt
the only free unlimited way is running local AI on your beefy PC
what's your pc gpu and os? you just want to do AI Covers or Train RVC Voice Models?
my model says TypeError: Trying to convert Float8_e4m3fn to the MPS backend but it does not have support for that dtype.
m3 mac
24gb of ram
i use flux schnell
yep,everyone in this server is offline
this server has been dead since early 2023
no one has this issue
anyone
please
i want to run the model on my mac
someone listen
hello?
can anyone reccomend me a similar model
dead chat
anyone
@midnight pebble
please stop begging and demanding
this server is run by volunteers, no one is forced to actually help you
start by elaborating your issue
my model says TypeError: Trying to convert Float8_e4m3fn to the MPS backend but it does not have support for that dtype.
i want to run a funny model on my m3 mac
i bought a m3 mac for nothing
elaborate:
- what you're trying to do, like AI Covers, E Girl Trolling / Catfishing, Training RVC Models
- The tutorial link
m chips aren't as much widely supported as Nvidia GPUs on Windows / Linux in the AI field
what model do i use
what program and models are you using then?
flux schnell
don´t make me use sdxl turbo because it puts people with 200 eyes and floating head
look at what sdxl makes

what program are you using? comfyui?
comfyui
going to fine tune it on tons of images of people
check https://github.com/filipstrand/mflux or https://www.reddit.com/r/StableDiffusion/comments/1ls2nqj/macos_comfy_error_trying_to_convert_float8_e4m3fn/

GitHub
MLX native implementations of state-of-the-art generative image models - filipstrand/mflux
So sometimes models are only distributed in fp8 formats, which I'm sure is a benefit for most people, but for me on a Mac with tons of VRAM but…
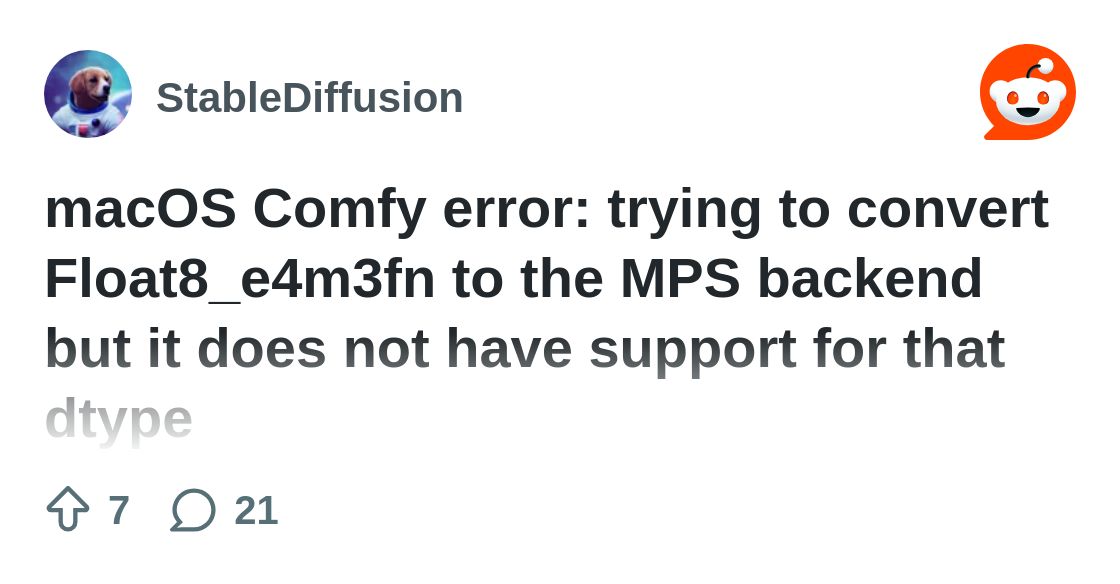
mflux is too large
mflux would probably the best way for you
else use the other fix i sent
i'm sure this has been asked a billion times so sorry for perceived spam lol, i tried searching myself but didn't see anything that immediately stuck out to me. Is there a generally agreed upon replacement for weights.gg now that it is closing down? or is everyone just moving to local?
Not true. 
How do I post images in ai-images?
for tg forks version of w-okada i keep getting this error over and over whenever I start the conversion

?colab
-colab
📒 Google Colab Notebooks
Google Colab is a Cloud (Remote Good PC) Service. While the Free plan provides up to 12 hours of daily usage, the GPU is typically available for only about 4 hours each day on average.
• **Applio**
by IA Hispano
Google Colab
• **RVC Mainline**
by Hina
Google Colab
• **UVR5 NO UI**
by Eddy
Google Colab
• **UVR5 UI**
by Eddy
Google Colab
• **Wokada Deiteris Fork**
by Deiteris & Hina
Google Colab
• **Hina's Modified Original Wokada**
• **RVC-AI-Cover-Maker-WebUI**
by Shiro & Eddy
Google Colab
• **FaceFusion UI**
by Nick088
Google Colab
• **FaceFusion NO UI**
by Nick088
Google Colab
• **Music Source Separation Training (Inference)**
by Jarredou & Makidanye
Google Colab
Ty
You're welcome
Can u tell me which is the best, there r so many...i wanted to train an model
For training a model you should use Applio
it'd be better to use it on Kaggle tho
-kaggle
📘 Kaggle Notebooks
Kaggle is a Cloud (Remote Good PC) Service that offers 30 hours of GPU weekly, but needs a phone number verification
• **Applio Notebook**
by IAHispano
Kaggle
• **Hina Mod Original Wokada**
by Hina
Kaggle
• **Wokada Deiteris Fork**
by Hina & Deiteris
Kaggle
• **UVR5 UI**
by Eddy, ArisDev & Nick088
Kaggle
• **UVR5 NO UI**
by Eddy
Kaggle
• **RVC AI Cover Maker UI**
by Shirou & ArisDev
Kaggle
• **Music Source Separation**
by Shirou
Kaggle
Alright
@sharp jungle Here are the Applio docs https://docs.aihub.gg/rvc/cloud/applio-cloud/
Last update: March 24, 2026
Super useful 🙏
Yes it is
Have you checked the logs in terminal?
yep
What did it say? There should be some info that should help debug it
Well... yeah, I'm doing AI Covers... and even try make my own RVC Voice Models too... and i look for something useful as Weights.gg... by any chances... i hope you understand?
Nick's reply remains valid though. There's no unlimited, free service like this. Either use limited cloud services, your own PC or pay for extended cloud service
Oh, that's shame... i bet one day, someone creating other website AI Cover and some as Weights.gg... Unlimited and free... for we can do whatever we want... Besides, Paying money for premium and credits is no nessacery to use it for what... to bill up to be fill with money of ours, For love of god... Why can't people just enjoy making AI Cover for free... without Premium and credits, It's not like end of the world or something... right?
How else are you supposed to pay for the power to do them
Hmm... if i had my own website AI Cover... i would just let people do let them do RVC making and do AI Covers for free... without premiums, credits and paying money... We really don't want to being a greedy and selfish for some reason, do we now?
Lol
Lol your kind ¬__¬
Its not being greedy or selfish
i just told you
you need money to pay for the power
to run the computers
"i'd give away a ton of free money for anyone that wants it, don't wanna be greedy or selfish"
to makee the AI covers
exactly lmao

LMFAO
Sheesh...
So true
Especially in roblox.

Okay, that got me... bit laugh about, good one.
2026-03-29 19:03:48,345 ERROR [VoiceChangerManager] 'Pipeline is not initialized.'
Traceback (most recent call last):
File "voice_changer\VoiceChangerManager.py", line 300, in change_voice
audio, vol, perf = self.vc.on_request(receivedData)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "torch\utils_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "voice_changer\VoiceChangerV2.py", line 190, in on_request
result, vol = self.process_audio(audio_in)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "voice_changer\VoiceChangerV2.py", line 133, in process_audio
audio, vol = self.vcmodel.inference(audio_in)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "voice_changer\RVC\RVCr2.py", line 226, in inference
raise PipelineNotInitializedException()
Exceptions.PipelineNotInitializedException: 'Pipeline is not initialized.'
damn, indeed not very descriptive
I think it often happened in cases where audio device couldn't be initialized. Have you tried with a setup without the VAC? Just mic + speakers for a test
Other than that dunno, maybe someone else knows what else might cause it
yeah tried that
i just want help to tweak my vonovox
like i been trying different stuff but nothing seems to be working that well

did you add the .zip part at the end of the file names..?
you shouldn't
it needs to end with .001 and .002
maybe the browser added it while saving, for some reason
dunno
remove the .zip endings and try again with unpacking the 001
Vonovox is unrelated to weights
No reason for it to become unavailable
In general - yes, vonovox has the most improvements in terms of sound quality and conversion robustness.
But lots of robotic sound cases are just poor models, which vonovox won't help with
(BTW: vonovox is for windows + nvidia GPUs only, just in case)
Like e girl trolling / Catfishing?
What's your PC GPU and OS?
No one will, so many sites already lost money, the AI Cover hype died too, would you throw money out of the window just to offer people free unlimited things for no reason? Companies are made to make money, when you see services like google and YouTube being free, they make money with your data and ads
elaborate:
- your pc gpu
- your pc os
- what you're trying to do, such as AI Covers, E Girl Trolling / Catfishing or Roleplaying
- the tutorial link you're using
- a screenshot of your settings
Hello, it's been a long time since I've been here and done AI cover work. Where can I find AI Cover locally on Google Colab like in the old days?
it's best to check if you can do it locally first since there's no free unlimited cloud way,
what's your pc gpu and os?
what is the alternative now that weights died? Where can i do sum similar
(ik it aint dead yet but it will in 2 days)
boi
what's your pc gpu and os first?
windows 11 and 3070
To be honest... i've making AI Covers on working laptop.
how dude
Well... i've start 2 years ago... and it really keep me good in process... and i use the Wondershare filmora too.
Really, what you use...?
wdym what i use?
uh... i thought you mention of making video, sorry.
why you type so formal?
I really dunno, i don't usually type that formal in discord...
you make ai covers w filmora?
Yep, and i have over 13K subs in youtube channel.
i didnt know filmora has ai covers
Me either... but i mostly use Weights.gg AI Cover vocals... to put in Wondershare Filmora to make video with it... to be fit perfect. with along instrumental of any song we ever heard of it....
It takes quite long to process... but it worth to shot.
ohhhhhhhhhhhhhhhhhhhh dude so you just use weights
well weights is dying in 2 days. Thats why i need a replacement.
https://docs.aihub.gg/rvc/resources/dataset-isolation/
https://docs.aihub.gg/rvc/resources/training/#introduction
take a look those two links. First for general dataset information + preparation, second for actual model training
True, i really need replacement too...
I know... i bet filmora would add ai voices in it... even thought Capcut does have some.
Yeah but not like weights
Yeah, nothing can't beat Weights... i wish it could come back... one day.
CapCut has a bank of tts voices and a view covers that u can use to maybe hide your voice or make funny tt videos
Oh yeah, i even thought about making animation video too...
Yolted did that once...
you can do local AI using your PC GPU, without needing to relay on a site, it won't be as easy as using weights, but do you want to do that? It will be free and unlimited, check https://docs.aihub.gg/rvc/local/applio/
Last update: March 26, 2026
this is a general ai discord server, elaborate:
- your pc gpu
- your pc os
- what you're trying to do, like AI Covers, E Girl Trolling / Catfishing, Roleplaying, Chatbots


Wait are you from Poland?
actually, yeah xD
Oop
Hey everyone! Does anyone happen to have a spare ChatGPT Plus referral link (guest pass)? I've been hunting for one for hours but haven't had any luck so far. Thanks in advance!
How tò image gen model using vulkan
yo, im trynna use the light yagami voice model, i can hear my real voice, but no the ai + real voice, INPUT is set to my mic, output is VB cable, and my monitor is set to headphones, passthough is on, how can i fix/use the ai voice model?
Hello, I need some help. About 11 years ago, I was looking for a way to make video game graphics smoother, specifically to remove jagged edges (aliasing) from walls and textures, and also to fix mouse movement. After a lot of searching and struggling — it took about a year and a half — I think I managed to do it using things like CUDA, cuDNN, CNTK, Python, and similar tools. Could anyone help me figure out where to start learning and how to do this again?"
elaborate:
- your pc gpu
- your pc os
- the tutorial link you're using
I don't think that's a tutorial
I'm guessing you're on Windows 11
can you also send the tutorial link you have used? there are different programs
ai for studying?
i did all the steps but it isnt working and i also cant hear anything
so what would you recommend with RTX 5060? locally for train and voice changer and cover?
(win 10)
It's dependent on what Gpu you have, for AMD there isn't anything besides Wokada tg fork that's up to date and it hasn't been updated for a long time
And for Nvidia Vonovox is the best to use as it's got a ton of cool features that make it sound more realistic and much better
Oh nice
U should use Vonovox then ^^
To keep yourself up to date on that specific one there's the official discord server you could join
Btw I'll get the download to the most recent beta version since the beta release as of now is better than currently public release of it
I believe it's in the guide but I could also just send it to you in dms as I can't send it here
Here are the two downloads you'll need, also same for u @rare flint
This is just for real-time and for training download applio, I don't have the local version link or know how to set that up but here's all I can get u @rare flint
-Rvc
📚 RVC Documentations
AI HUB Docs
🍏 Applio Docs
Is it alright if I send you the server invite to Vonovox?
Btw if you do need help feel free to ask here
are you planning to do e girl trolling / catfishing or just roleplay?
do you need any other help?
😭
No, no. Applio RVC and Vonovox are two different programs. Vonovox is supposed to be in its folder, while Applio RVC in its folder as well.
Are you trying to do non-realtime (Applio RVC) or actual realtime (Vonovox)? Let's be real.
For "realtime", because your earlier query stated to be "realtime", what do you use Vonovox for?
Already answered in #🧬│ai-chat, so the answer about paying someone is still "no". If you mean a program to use RVC voice models, there's Applio RVC.
What is your PC GPU? And what scenario will you use W-Okada voice changer for?
Which NVIDIA GeForce RTX GPU?
Do you use the female voice model or something? Just wanna make sure.

I'm asking this to avoid one catfishing as other mods here suggested, so if you could directly answer so.
hello@hallow thistle
Do you need help about something?
Cool. Vonovox gives better audio quality than typical W-Okada voice changer versions, so download Vonovox. https://huggingface.co/dr87/vonovox/resolve/main/Vonovox_beta_17_11.zip?download=true
I just joined
The setting "block size" is the one that controls audio delay in Vonovox. This is the guide for Vonovox. https://docs.aihub.gg/realtime-voice-changer/local/vonovox
Last update: March 26, 2026
For a regular conversation, #✦│chat would be better.
ok thinks
What's the difference?
Anyway I mostly gonna use it for Ai Covers, Roleplay and honestly i just for shenanigans with friends. how come Wokada stuff got irrelevant?
please answer to be sure you’re using the right program, there are things for making rvc models, for ai covers, for e girl trolling / catfishing and for roleplay
^
wokada isn:t for ai covers
it’s only for roleplay
would you rather using applio that can do both?
I said i want both AI cover and roleplay
i read that it's real time is kinda bad?
though idk how much it affects when it's 5060ti
yeah I’m saying that program won’t be good for both
it’s best you first try it here: https://docs.aihub.gg/rvc/local/applio/
Last update: March 26, 2026
It’s just newer, i would give it a try first and see
out of curiosity, is it worse than Wokada for Real time?
does it have to be C drive? i don't want it to Hog it all

its suggested to
Sorry for the stupid question, I want to know how to make an AI cover...?
What’s your pc gpu and os?
RTX 3060 12 gb windows 11
Last update: March 26, 2026
whats the best local RVC for MacOs (macbook pro "M3 pro") ?
Hi sorry to bother you all, i need some help on my applio 3.6.2. I would like to use the pretrained KLM6.2 voice model to create my own voice model, but it keep logging out
Loaded pretrained (G) 'rvc\models\pretraineds\custom\G_KLM6_Exp3_L6_32k.pth'
The parameters of the pretrain model such as the sample rate or architecture do not match the selected model.
Weights only load failed. In PyTorch 2.6, we changed the default value of the `weights_only` argument in `torch.load` from `False` to `True`. Re-running `torch.load` with `weights_only` set to `False` will likely succeed, but it can result in arbitrary code execution. Do it only if you got the file from a trusted source.
Please file an issue with the following so that we can make `weights_only=True` compatible with your use case: WeightsUnpickler error: Unsupported operand 60
other than setting
Sampling Rate: 32000
customer embedder: spin 7-12
is there anything i missed? thank you so much
pytorch seems not really supporting macos.. so i think its a bit tough to make it work on macos. im new tho, correct me if im wrong
sorry just found original RVC support macos
you may give it a shot
RVC means Retrieval-based-Voice-Conversion not realtime voice changer, can you elaborate if you're trying to do AI Covers, TTS, E Girl Trolling / Catfishing or Train RVC Models?
tried set weights_only to false and it works now.
does appolio's real time thingy not work ingame, anyone?
Is there any way to do that?
elaborate what's wrong
I think appolio can't create a virtual audio device all by itself, that's the reason why the game picks up the normal mic input
I'm following that guide wherein we're required to install vac-lite
it can't do that, in the ai hub docs guide it says you have to setup the virtual audio cable yourself
what's your pc gpu and os btw?
did you use setup64.exe?
yep. I'm following that guide now, will see if it works
downloaded the MMVCServer files
will it be able to use an rvc model trained using appolio's refine-gan?
I need a bit of help, I am trying to reinstall MMVCServer on my Linux PC
KDE Plasma Version: 6.6.3
KDE Frameworks Version: 6.24.0
Qt Version: 6.11.0
Kernel Version: 6.19.10-1-cachyos (64-bit)
Graphics Platform: Wayland
Processors: 12 × AMD Ryzen 5 5600X 6-Core Processor
Memory: 32 GiB of RAM (31.3 GiB usable)
Graphics Processor: AMD Radeon RX 9060 XT
Product Name: B550M Pro4```
I am following this that was given to me last time I asked for help
https://docs.aihub.gg/realtime-voice-changer/local/tg-develops-w-okada-fork/#download-for-amd-gpus-on-linux
I am following the AMD one since that is what I am running
But when I try it
```❯ ./MMVCServerSIO
2026-03-30 11:26:40,460 INFO [main] Python: 3.10.19 (main, Oct 10 2025, 01:02:36) [GCC 11.4.0]
2026-03-30 11:26:40,460 INFO [main] Voice changer version: b2397 AMD-ROCm
2026-03-30 11:26:40,460 INFO [main] Server settings: model_dir='model_dir' sound_dir='sound_dir' content_vec_500_onnx_on=True host='127.0.0.1' port=18888 ssl_enabled=False ssl_certfile=None ssl_keyfile=None allowed_origins=[] edition='AMD-ROCm'
2026-03-30 11:26:40,460 INFO [main] Checking for mandatory models...
2026-03-30 11:26:40,503 INFO [ModelManager] Found 3 missing mandatory models. Starting download...
2026-03-30 11:26:40,503 INFO [ModelManager] Downloading mandatory model: RMVPE
2026-03-30 11:26:45,783 INFO [ModelManager] Successfully downloaded RMVPE
2026-03-30 11:26:45,783 INFO [ModelManager] Downloading mandatory model: RMVPE (Onnx)
2026-03-30 11:26:56,565 INFO [ModelManager] Successfully downloaded RMVPE (Onnx)
2026-03-30 11:26:56,565 INFO [ModelManager] Downloading mandatory model: ContentVec / Hubert
2026-03-30 11:27:07,958 INFO [ModelManager] Successfully downloaded ContentVec / Hubert
Traceback (most recent call last):
File "client.py", line 22, in <module>
File "asyncio/runners.py", line 44, in run
File "asyncio/base_events.py", line 649, in run_until_complete
File "main.py", line 93, in main
File "webserver/server.py", line 132, in start
File "uvicorn/server.py", line 70, in serve
File "uvicorn/server.py", line 77, in _serve
File "uvicorn/config.py", line 435, in load
File "uvicorn/importer.py", line 19, in import_from_string
File "importlib/__init__.py", line 126, in import_module
File "<frozen importlib._bootstrap>", line 1050, in _gcd_import
File "<frozen importlib._bootstrap>", line 1027, in _find_and_load
File "<frozen importlib._bootstrap>", line 1006, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 688, in _load_unlocked
File "pyimod02_importers.py", line 457, in exec_module
File "app.py", line 17, in <module>
File "pyimod02_importers.py", line 457, in exec_module
File "voice_changer/VoiceChangerManager.py", line 12, in <module>
File "pyimod02_importers.py", line 457, in exec_module
File "voice_changer/VoiceChangerV2.py", line 17, in <module>
File "pyimod02_importers.py", line 457, in exec_module
File "voice_changer/common/deviceManager/DeviceManager.py", line 2, in <module>
File "pyimod02_importers.py", line 457, in exec_module
File "onnxruntime/__init__.py", line 58, in <module>
File "onnxruntime/__init__.py", line 23, in <module>
File "pyimod02_importers.py", line 457, in exec_module
File "onnxruntime/capi/_pybind_state.py", line 32, in <module>
ImportError: /home/mouse/MMVCServerSIO/_internal/onnxruntime/capi/onnxruntime_pybind11_state.so: cannot enable executable stack as shared object requires: Invalid argument
Press Enter to continue...
2026-03-30 11:27:45,343 ERROR [base_events] Unclosed client session
client_session: <aiohttp.client.ClientSession object at 0x7fa3e7c804f0>
2026-03-30 11:27:45,344 ERROR [base_events] Unclosed connector
connections: ['deque([(<aiohttp.client_proto.ResponseHandler object at 0x7fa3e7cb2620>, 5640.111927896)])', 'deque([(<aiohttp.client_proto.ResponseHandler object at 0x7fa3e7af8f40>, 5651.28619272)])']
connector: <aiohttp.connector.TCPConnector object at 0x7fa3e8bf5540>
~/MMVCServerSIO 1m
❯
it should have been a simple install, but I am getting that odd error
Ok I managed to fix it but it only runs on the CPU
2026-03-30 12:29:22,333 INFO [main] Python: 3.10.19 (main, Oct 10 2025, 01:02:36) [GCC 11.4.0]
2026-03-30 12:29:22,333 INFO [main] Voice changer version: b2397 AMD-ROCm
2026-03-30 12:29:22,333 INFO [main] Server settings: model_dir='model_dir' sound_dir='sound_dir' content_vec_500_onnx_on=True host='127.0.0.1' port=18888 ssl_enabled=False ssl_certfile=None ssl_keyfile=None allowed_origins=[] edition='AMD-ROCm'
2026-03-30 12:29:22,334 INFO [main] Checking for mandatory models...
2026-03-30 12:29:22,391 INFO [ModelManager] All mandatory models are already downloaded.
2026-03-30 12:29:25,770 INFO [loader] Loading faiss with AVX2 support.
2026-03-30 12:29:25,800 INFO [loader] Successfully loaded faiss with AVX2 support.
2026-03-30 12:29:25,803 INFO [__init__] Failed to load GPU Faiss: name 'GpuIndexIVFFlat' is not defined. Will not load constructor refs for GPU indexes. This is only an error if you're trying to use GPU Faiss.
2026-03-30 12:29:25,981 INFO [VoiceChangerManager] Initializing...
2026-03-30 12:29:25,986 INFO [DeviceManager] Initialized DeviceManager. Backend statuses:
2026-03-30 12:29:25,986 INFO [DeviceManager] * DirectML: False, device count: 0
2026-03-30 12:29:25,986 INFO [DeviceManager] * CUDA: False, device count: 0
2026-03-30 12:29:25,986 INFO [DeviceManager] * MPS: False
2026-03-30 12:29:25,986 INFO [DeviceManager] Switched to CPU (cpu). FP16 support: False
2026-03-30 12:29:25,987 INFO [IORecorder] -------------------------- - - - /tmp/tmpnwld7ooe/tmp_dir/in.wav, /tmp/tmpnwld7ooe/tmp_dir/out.wav
it should be fine, my CPU can handle it, just dont like that it is
Hello
Guys can you please help
I dont have a good realistic quality using vonovox
I tried a lot of models
Since weights.gg is shutting down
I wanted to upload lots of voice models from weights users somewhere to archive them.
what would be the best choice?
Internet Archive? Hugging Face? something else?
(yes, im going to try my best to credit the original uploaders)
Do we have any documentation for Seed VC?
Hugging would be your best bet.
what's that?
GitHub
zero-shot voice conversion & singing voice conversion, with real-time support - Plachtaa/seed-vc
ah zero shot
Apparently this works for AMD?
What GPU do you have worm? 😮
I have a rtx 5070ti :3
I need to get my 2nd PC up and running.
what about you Loamy?
So does SeedVC not work?
idk never heard of it
I'm on an 9070 XT
😭 However my W-Okada refuses to work.
It just randomly broke one day.
are you using Tg fork?
Yeah.
hmmmm
that's weird
Yeah idk.
I use vonovox for realtime but the nvidia version of Tg fork seems to work fine still
Alright. im going to " + New Model " on my profile, to create the "stach" of voice models, would that be right?
basically just
do that
Aight, thank you so much! 🙏
also, its gonna be easier on this case, since weights already downloads the model in zip format
I'm gonna open a thread.
I went ahead and put a bounty on my issue to give folks some incentive.
If you guys can figure it out, I'll pay you.
Surely someone is a brainiac. ❤️
should ping the helper role in case
Oh sure.
How do i use a ai model?
Since Weights is shutting down tomorrow, is there any Weights alternatives?
hugging face
Hugging Face?
ew
Why are people like this?
I mean, I get it if someone’s transgender (like FTM, or uncomfortable with their voice, for example). It can be hard to sound like the opposite gender, so using RVC makes sense in that situation.
But e-girl trolling? That’s just malice and ill intent for the sake of your entertainment. Like. grow up dude.
I agree, only good reason is for trans people that dislike their voice or wanna change it
started up my notebook as usual (which is the deiteris fork for w-okada), and i keep getting the error "HTTP Error 500: Internal Server Error", made a post about it in #1192011222023950368 just in case, but from what i looked up it's an issue on kaggle's end
anyone familiar with that error?
People who troll as e-girls end up making the trans people reputation worse. I kinda feel bad for them, honestly. It’s not just about their voice. A lot of the time they get crucified the moment they use an AI voice changer. Like, a trans person could literally just say “hi,” and someone instantly jumps in with “crazy voice changer” or something. The comments are pretty unnecessary. Most of the time it only happens because the other person assumes the trans person is trolling. 😕
"PyngrokNgrokInstallError: An error occurred while downloading ngrok from https://bin.ngrok.com/c/bNyj1mQVY4c/ngrok-v3-stable-linux-amd64.zip: HTTP Error 500: Internal Server Error" what is this error on kaggle?
i'm getting the same one, it's probably something on kaggle's end considering multiple people are getting it
oh fair enough
Any Weights alternatives besides HuggingFace?
Is RVC Google Colab down for anyone else, or just me?
Horrifying.
Google Colab website loaded fine. What do you mean the website is down?

oh, Ngrok is currently doen

huh weren’t you using applio
did it use to work before? It doesn’t even load the UI?
Elaborate:
- your PC GPU
- your PC os
- if you're trying to do e girl trolling / Catfishing
- the settings
HuggingFace
It's archived and 0 shot, it's easier but lower quality than RVC
@median lance @grizzled arch @hoary zinc Ngrok Download Link is down
Any eta on how long it will be down?
nobody knows
it’s just better you use other tunnels if available, what guide link are you using?
ehm i was using the kaggle guide one. And ive been using it for a few months now. But it seem to be gone now (?)
Yes, I was using it under a Nvidia driver and then upgraded to a new GPU so I had to uninstall all Nvidia drivers to put in the AMD drivers
So knowing that, I also deleted the whole program and reinstalled it under the instructions of AMD
I did managed to get the UI to open but it is only recognizing my CPU now
This is a general ai discord server, we use multiple programs, elaborate:
- your PC GPU
- your PC os
- what you're trying to do
- the tutorial or notebook link
AMD isn't as much supported and good for AI compared to Nvidia btw
So the UI always opens, but it doesn't run if you use the GPU right?
If so, have you tried using client audio processing or server?
Server? Hmm I have not tried that, I'll do research on that another day
Not sure what client audio processing is
its the option above the input and output
guys what do i put on models: when i upload a voice in w okada
arxiv
HI
I NEED HELP
My laptop is very low end and I want to use some voice changer for edit and stuff
Should I use okada I mean
Idk where to download okada too
Hello, i have been using a voice model for while, but i am curious if i can make an index file for it myself? (the voice was not made by me, i downloaded it)
also. in advanced settings, what protocol should i use? sio or rest?
you can't make an index file for an existing model no, you can use another model's index file on it tho in realtime or even applio I believe
Hi, what is the best ai model for seo writing
cheap & not cheap
Elaborate:
- your pc gpu
- your pc os
- what you're trying to do, like AI Covers, E Girl Trolling / Catfishing, Roleplaying, Chatbots
- if you're using any tutorial link
this is a general ai discord server, elaborate:
- your pc gpu
- your pc os
- what you're trying to do, like AI Covers, E Girl Trolling / Catfishing, Roleplaying, Chatbots
- if you're using any tutorial link
Looking for AI Vision suggestions for Desktop Automation (Excel → Flutter UI
Hey question in general is realtime voice changer good when you laugh or does it sound awkward and robotic?
yo
can someone help me make my AI Voice realtime sound as realistic as possible on ApplioV3.6.2
i am trying to make the voice as close to a normal person speaking as possible
sounds bad usually
Did you select it as input in the target app (game, discord etc?)
Applio's not a great choice for realtime. What is your GPU?
RTX 3060 Ti 8GB
#✨│ai-help message
see here for recent Vonovox version, it should be much better
oh hold on
how did you get the beta?
what's the difference with the new version?
i have Vonovox 1.6.8
It's publicly available
What helps it sound better?
Oh, a lot has changed since then. There's been multiple improvements. Better pitch extraction, audio stitching etc.
i dont know, i never was able to pull of laughing personally
but disabling noice cancelation makes the app pick it up
On discord?
Or realtime?
yes
How do I do that?
it will sound bad though, expect it to be pretty bad
how RVC converts your laughter is basically an outcome of two things:
- the model itself
- the way you laugh
In general RVC is rather bad at it usually, but some models handle it much better than others.
Is there a way I can find the models that work well with it?
and about the second point - obviously, being more in control of your voice and paying attention to what the model handles poorly can help with avoiding sound issues
I'd say just try various models that you can find available
Sounds good!
Other than that... training a model on your own, i guess
@hardy yew i made my voice model on Applio though for realtime purposes, is that bad
there's also places where models can be bought and usually they should be of better quality than the public ones, but no guarantee about that, also I don't have experience in that area
Thank you!
Applio is the right tool for training models, it's just that running realtime conversion is better done by dedicated apps (vonovox/tg develop's w-okada fork, etc.)
okay
whats the difference exactly
ive noticed vonovox sounds the most real
Lots of differences really, most of which I'm probably not even aware of.
But in general, volume handling, stitching algorithm, pitch extraction and smoothing
Applio's realtime is more of an "additional" feature, it wasn't really dedicated for it
where did you get the beta from
i cant find it in vonovox discord or website
All betas are publicly available and are announced in the Vonovox discord when they're released
it is on the discord, should be pinned in the beta channel
(the announcements channel is outdated, that's true)
the betas are mostly dropped in-between messages, so it's easy to skip those unless you watch the chat in that discord daily
whats the differences between this vonovox version and the older ones
how better is it
i got v1.6.8
downloaded the beat
this, mostly
among other things and perhaps bugfixes
does it sound more real
it should be more robust and less prone to glitches
The core sound is determined by the model
So no app can make it sound "more realistic" if the model isn't good enough in the first place
will AI realtime ever be able to express emotions fully
my model is good
look at how it all progresses over years, to me it's rather obvious that it sure will be good some day.
Though at the moment it doesn't seem like it's gonna happen any time soon
RVC has been stuck in its current state for some time now
some work is being done but no breakthroughs for now
yeah i wish it was indistinguashable from human voices
its okay but not the most realistic
with a right model, "compatible" user voice and appropriate handling (knowing the model's boundaries and speaking accordingly) it can be quite real
but that's a lot of conditions to fulfill
right
how can i make a voice like that myself
my current voice model is 320 epochs, 90 minutes of a person speaking
https://docs.aihub.gg/rvc/resources/dataset-isolation/
https://docs.aihub.gg/rvc/resources/training/
The AI Hub docs are a good starting point
but it doesnt sound the most realistic
There's a ton of things that affects how the model will turn out.
Data quality, diversity, the voice itself
There's also the factor of "how well the pretrain clicks with the particular voice", some are just naturally handled better
what
my data quality was really good
the voice was normal
the accent and voice is Serbian
is that bad?
Nothing good/bad about accents, the model should just learn it appropriately
so then, what could be holding me back?
can you give me Vonovox settings for the beta
best settings for my goals??
i have the premium
<:error:865860636084142150> Message error
The message
template:sticky-ai-helpcould not be displayed. More details can be found in the error log.
Please report this to a server admin.
the defaults, really. I mean, all you need to adjust is the model settings (pitch, index rate, maybe the formant slightly if needed)
the effects are more for tweaking the voice sound, it won't affect the "realism" per se.
Maybe the low-quality-mic filter can help make it sound a bit more genuine
nothing else though???
i tried the low mic filter before
yeah you end up sounding like you got a bad mic
which helps
but not the thing im focusing on
my goal is to make the sound more real like a human speaking
more emotion and more natural
what is the best wokada version for amd graphics card, i have call with my boyfriend in a hour and i need to get girl voice
somebody help please
bro how to create my own model?
How to overlay voice on my file
what's your PC GPU and OS? are you trying to do E Girl Trolling / Catfishing?
what's your PC GPU and OS?
elaborate more pls
can someone help me do my vonovox settings
Using kaggle to fork notebook in order to use gpu quota as my pc is weak
Ive encountered a problem
This is a General AI Discord server, we don't do only one program, Elaborate:
- Your pc gpu
- Your pc os
- What you're trying to do, like TTS, E Girl Trolling / Catfishing, Training RVC models, Roleplaying, AI Covers
- The tutorial link used
12th Gen Intel(R) Core(TM) i5-1235U (1.30 GHz)
RAM: 16,0 GB
Window 11
I want to use voice to roleplay
The tutorial I used before is gone, but this is the link: https://www.kaggle.com/code/suneku/voice-changer-public
I am from a poor country and that's why my pc sucks, also don't know coding at all, consider me dumb
that's wokada deiteris fork kaggle jupyter notebook, wokada deiteris fork didn't have updates in a long time, and it doesn't work as it uses Ngrok and Ngrok downloads are down https://status.ngrok.com
Welcome to ngrok's home for real-time and historical data on system performance.
You can either wait, or use the updated wokada tg-develop jupyter notebook lightning ai guide: https://docs.aihub.gg/realtime-voice-changer/cloud/tg-develops-w-okada-fork-cloud/#lightningai
Last update: March 24, 2026
be sure also to not miss https://docs.aihub.gg/realtime-voice-changer/cloud/tg-develops-w-okada-fork-cloud/#virtual-audio-cable
Last update: March 24, 2026
Thank you very much, seems like a temporary issue indeed
Another alternative is definitely helpful, I will check it out
yw, btw it's just better to switch overall, wokada deiteris fork seems currently abandoned and isn't suggested
anybody else suffering the ngrok problem ?

This is a General AI Discord server, we don't do only one program, Elaborate:
- Your pc gpu
- Your pc os
- What you're trying to do, like TTS, E Girl Trolling / Catfishing, Training RVC models, Roleplaying, AI Covers
- The tutorial link used
SAVE WEIGHTS PLEASE
it's shutting down in like 2 hours
yeah, i've seen people mention this yesterday here
also just had it when i started another training ~1h ago
I don't really need it so I just removed the connection
yesterday I mean like 20 hrs ago everything was fine I was changing my voice during roleplay I thinks thats a temporary problem
thanks for the update @hardy yew
see Nick's message in #📰│dev-updates
shared more info about it in #📰│dev-updates message, if you elaborate what I asked I could find you alternatives like I did for other users tho
Thanks Nick appreciated
Now that Weights has officially shut down, what are we gonna do?
What's your PC GPU and OS?
hey how do i set the voice changer to my mic\
becuasse im not seeing it
i hear it in the client but like in discord
what could you be typing bro
you need a virtual audio cable,
you make your microphone ur normal mic in the voice changer software, the output virtual audio cable, and the micrphone should be virtual audio cable in discord,
at least im assuming thats how it works, i use it for making vids but that should work
Hi everyone! Can anyone help me set up a realtime voice changer client?
@dusk cosmos whats up
the voice is very robotic
I don't know, I just downloaded this app for the first time.
you gotta change the chunks and extra to be higher
i can send u a decent one in dms, it shouldnt sound robotic
I'm using chunk 192 and max extra (I have a 4060ti if that matters)
yeah come on
oh yea i usually put chunk to like 900
so i got the software
or higher
It's just a really big delay.
If anything, I apologize for my clumsy English, I use a translator.
its not the best software if you want to communicate in real time
i think its better at making audio
Which one can you recommend?
maybe if ur pc is amazing u could use it
tbh idk i dont use it for that
i use that software for making vids
not for like discord calls or trolling
My friends and I downloaded it just for a laugh, but my friends didn't want to tell me how to set it up.
ya, the delay is normal tho, not much u can do about it other than lower chunks, but the quality gets worse
vcan u make this more simple
theres probably decent balance you can do after testing it yourself for your computer but
audio cable makes output audio into input audio, so basically speakers into your microphone
so you just use virtual audio cable in those two places and it should work
can be used for a lot of stuff
should i change it in windows too
headphones dotn change
LOL


{kind=link}
{kind=link}
make the cable go to where your microphone would be in the software u want it to go
microphone should be audio cable
speaker doesnt change
Darn bot tryin' to mess with me, when I already understood the first time. X3 But hey, guys.
Yes.
Since that Weights is already shut down so which is/are modern Google Colabs or Gradios that create AI Covers?
-colab
📒 Google Colab Notebooks
Google Colab is a Cloud (Remote Good PC) Service. While the Free plan provides up to 12 hours of daily usage, the GPU is typically available for only about 4 hours each day on average.
• **Applio**
by IA Hispano
Google Colab
• **RVC Mainline**
by Hina
Google Colab
• **UVR5 NO UI**
by Eddy
Google Colab
• **UVR5 UI**
by Eddy
Google Colab
• **Wokada Deiteris Fork**
by Deiteris & Hina
Google Colab
• **Hina's Modified Original Wokada**
• **RVC-AI-Cover-Maker-WebUI**
by Shiro & Eddy
Google Colab
• **FaceFusion UI**
by Nick088
Google Colab
• **FaceFusion NO UI**
by Nick088
Google Colab
• **Music Source Separation Training (Inference)**
by Jarredou & Makidanye
Google Colab
Which is those Colabs or Gradios that we can create AI Covers?
Can someone pls answer me thanks
Sorry but because that guidelines doesn't help a lot and some probably are paid or only works on PC or laptops ✌️
Oh only that RVC-AI-COVER-MAKER-WebUI one is for AI Covers but I think the rest have also a features that can create AI Covers too
the only time i return to use wokada somehow ngrok is offline 🥀
Help topics about W-Okada are getting too boring, so it's a good time period to take a break from voice changer all of a sudden. 



You have mentioned about using Applio RVC years ago. Do you remember that? While the core features in Applio RVC are the same, there are some more features added in latest versions.
Oh okay thanks
hey i have a question is hrzn.run usuable in kaggle considering kaggle projects usually use ngrok? but i recently saw a project in colab use hrzn an alternative to ngrok
Tg Develop's W-Okada Colab notebook has HRZN option available.

What? Applio RVC Kaggle notebook now has HRZN option available, but for W-Okada voice changer Kaggle notebook, I don't see anyone ever done that yet.
guys
are there any ai that can auto highlight important information or the like
i dont want a summary, i want the ai to highlight things like definitions straight on the text if u get what i mean
done 😄
finally after a while i finished and made it work on hrzn instead
📘 Kaggle Notebooks
Kaggle is a Cloud (Remote Good PC) Service that offers 30 hours of GPU weekly, but needs a phone number verification
• **Applio Notebook**
by IAHispano
Kaggle
• **Hina Mod Original Wokada**
by Hina
Kaggle
• **Wokada Deiteris Fork**
by Hina & Deiteris
Kaggle
• **UVR5 UI**
by Eddy, ArisDev & Nick088
Kaggle
• **UVR5 NO UI**
by Eddy
Kaggle
• **RVC AI Cover Maker UI**
by Shirou & ArisDev
Kaggle
• **Music Source Separation**
by Shirou
Kaggle
This is a General AI Discord server, we don't do only one program, Elaborate:
- Your pc gpu
- Your pc os
- What you're trying to do, like TTS, E Girl Trolling / Catfishing, Training RVC models, Roleplaying, AI Covers
- The tutorial link used
we don't suggest vb audio cable for windows, did you came form a youtube tutorial?
This is a General AI Discord server, we don't do only one program, Elaborate:
- Your pc gpu
- Your pc os
- What you're trying to do, like TTS, E Girl Trolling / Catfishing, Training RVC models, Roleplaying, AI Covers
- The tutorial link used
oh what yall use, is there a better thing for better quality audio?
and nah i just knew about it
only thing id care about is better quality
the quality is the same, it's just that Muzychenko's VAC lite is recommended over VB cable because it usually causes less issues
but if you got VB and it works fine for you, no reason to change
Can you elaborate what tutorial link do you use?
gosh i was so wrong for saying that only now did i finish 🥀
had to redo the whole uploading system because of hzrn limitation
there are way better and easier alternatives, please elaborate:
- your pc gpu
- your pc os
- what you're trying to do, like TTS, E Girl Trolling / Catfishing, AI Covers, Training RVC Models, Roleplay
- the tutorial or kaggle link used
- im on a 1050 ti i discussed this before alot of times so i prefer staying on a cloud hosted version till i get a new pc.
- windows 10.
- roleplay, realtime tts.
- tg-develops det fork of w-okada but i just coded it so that it runs on hzrn instead and uses a whole new uploading method
-
you could actually try to run it locally, but your choice
-
w-okada only does realtime RVC, not tts, for tts check https://docs.aihub.gg/tts/realtime-tts/
-
that's great, you could also use wokada deiteris fork lightning ai which is safer and has already multiple tunnels https://docs.aihub.gg/realtime-voice-changer/cloud/tg-develops-w-okada-fork-cloud/#lightningai
Last update: July 28, 2025
Last update: March 24, 2026
- tried it before quite really had my pc struggling when used on heavy games + causes bad lag
- my bad i meant real time rvc forgot
- no money + already had an account on kaggle just more used to being on kaggle instead
about locally: you should run always games with the lowest quality settings when using the ai realtime voice changer locally btw
about lightning.ai, it's free btw, would be nice if you make an account for it since it actually allows Web UIs in the free tier and doesn't have a ban risk unlike Kaggle, and I mean having 2 accounts (one for kaggle, one for lightning.ai) might be better
if you want you could PR your solution https://github.com/tg-develop/voice-changer to help everyone, or I might just PR all my tunnels code I use in the lightning.ai port in it instead
GitHub
Realtime Voice Changer. Contribute to tg-develop/voice-changer development by creating an account on GitHub.