#✨│ai-help
1 messages · Page 279 of 1

With Deiteris' W Okada Fork or Vonovox is there any way to slow down the voice?
@simple ore I have this error in the kaggle applio space, is there a new link or method to get it working

currently using the 3.4.0 branch
I remember someone saying to update applio but I don't remember who
I have, I've used the method you said to use

it's the third option right?
I've tried it twice now and it gives that error at the third cell

which is that
anyway, make a new cell
paste !sudo apt-get update && sudo apt-get install -y python3.11-dev portaudio19-dev then run it
that should fix the error with portaudio
should that cell be before the first second or third cell
or does the order not matter with that
What rvc should I use?
I really hope I don't have to do this every time
make sure the notebook clones 3.4.0
by not deleting that part of the code in the first cell right
yes
Link?
that's not for you
bro probably replied to the wrong message
thx it worked, if I need to do this again in the future is there a way to easily upload the version of the notebook onto github and just find it the same way I do the usual kaggle applio notebook for importing it
Yall got any good Vonovox settings..?
you only need to import the applio notebook once
(until we switch the version)
it stays unchanged in Kaggle in your account and you dont need to edit it
I delete the notebook after it's full, as idk how to remove those files

can't keep training once it's full
can probably nuke the model name in the logs
how?
only option is for downloading
unless it's something to do with code
I am looking for an AI program that can convert my 3D renderings into an icon style while still making them look like my 3D model. I tried Midjourney, but when it comes to icons, I can't get anything decent out of it. ChatGPT comes closer, but I have over 100 icons to generate, and at some point ChatGPT always deviates from the style, usually after 2-3 generations. Do you know of any software that can consistently generate the same style for me? Where I can specify a style with images and my 3D model, and then it is converted for me?
i need a rly good vc for a girl im jus gonna troll to my frnds (ive got a rly bad accent )
oh im sorry i didnt read the rules sorry
np
The number of these people grows each day
im sorry twin 😭 forgive me
uhh i need help
i got error when i launch voice changer
i wanted to send a photo
butt
okeey sir
my voicechanger cuts out while im talking how do i fix it
How much "faster" would a 5090 be vs a 4090 for rvc? Would it be a noticeable difference in ping/delay i can run it at
it's ok man, as long as you don't do it again 
using file manager URL?
using training UI at the bottom
I don't know what that means
For some reason I have all the input and output right but I still can’t hear the voice
hey how can i make the delay a bit shorter?
hello does anyone know how to make rvc work on 50 series ?
Do you know why it doesn't detect my voice or why I can't hear it? Yesterday the program was fine.
is there a video tut ?
Are these normal graphs while training or should I restart altogether?

you did not stop the training cleanly at the end a saved epoch, so the chart have a step back
look at avg 50 charts instead
oiii @simple ore
i'm training a 1hours 40 mins data set, it's been 345 epochs Y_Y
how much can I push more
i actually don't know how to check properly, is loss/g/total smoothed to 0.987 good to check?

click 'Scalars' at the top
then expand two avg_50 sections and collapse others
it's like this

what abouy loss_avg_50?
lemme see

other 3 charts?
lemme send

something happened after 30k steps
probably not worth looking at those
so take the model saved around that step and give it a test
fp16 is not quite stable and it exploded for you
you can probably use a much smaller dataset.. 30-40 minutes
 i trained it different times
i trained it different times
 using gdrive backup
using gdrive backup
something got messed up
 how bad
how bad
perhaps the precision got switched mid-way
is that a good thing or a bad thing
like you started training with applio 3.3.0, then the discriminator got fixed in 3.4.0 and default precision was set to fp16
in this case you need to restart
sorry about that, you better off using 3.4.0 anyway
💀 i've been trainin for 15 days
but give the model from ~30k steps a try
 each session gives me around 20 epochs
each session gives me around 20 epochs
can I know did the quality have gotten worse after 30k
cuz im not sure what you mean by that 30k, and what's before and after 30k
the model name has a number of steps
like

your model got messed up after ~35k steps

most likely you did train at fp32 at the start, then we had 3.4.0 released and you resumed with fp16
then you also resumed after 58k steps with a wrong batch size
please elaborate, this is a general AI server
what program are you talking about? please elaborate more
RVC does work on rtx 50 series, what program and tutorial link are you using?
hello, could you please elaborate more on what you're talking about?
!howtoask
❓ How to Ask for Help
✅ Before You Ask!
- Check Docs & Guides: Your answer may already be in the AI Hub Docs or the https://discord.com/channels/1159260121998827560/1159513888199540817 channel.
- Search the https://discord.com/channels/1159260121998827560/1192011222023950368 : Look for existing posts that solve your issue. Do not invade someone else's post.
📝 How to ask?
Tell your:
- Full GPU Name: (e.g.,
NVIDIA RTX 3060) - Operating System: (e.g.,
Windows 11) - Detailed Description: What were you trying to do and what went wrong?
- Tutorial Used: Link to the guide you were following.
- Screenshot: A picture of the full error message is very helpful.
🚫 Prohibited Topics (We Will NOT Help With These)
To maintain a lega, safe & ethical community, we will NOT provide help for:
- (E girl, as an example) catfishing/trolling, scamming, impersonation.
- NSFW/Porn.
- Any illegal activities.
Requests for these topics will be ignored and may result in moderation action.
<:matsuripray:1159685390156967936> Community Expectations
- Be Polite & Patient: Our helpers are volunteers. You may ping the
Helpersrole once. - English Only: Please keep all conversations in English.
As in the real to voice it has almost a 6-10 second delay and I was wondering if there’s anyway to shorten that delay
This is a General AI Server, please elaborate more your PC specs, the tutorial you're using and a screenshot of the settings, we unfortunately can't know which program and settings you're talking about (I'm guessing a realtime voice changer, but there are different programs and versions)
 AAHH YES I CHANGED BATCH SIZE
AAHH YES I CHANGED BATCH SIZE
can anyone solve it :--
cpt = torch.load(modelPath, map_location="cpu")
2025-09-08 11:17:20,560 ERROR [MMVC_Rest_Fileuploader] 'config'
Traceback (most recent call last):
File "restapi/MMVC_Rest_Fileuploader.py", line 67, in post_load_model
File "voice_changer/VoiceChangerManager.py", line 118, in load_model
slotInfo = RVCModelSlotGenerator.load_model(params)
File "voice_changer/RVC/RVCModelSlotGenerator.py", line 42, in load_model
slotInfo = cls._setInfoByPytorch(modelPath, slotInfo)
File "voice_changer/RVC/RVCModelSlotGenerator.py", line 58, in _setInfoByPytorch
config_len = len(cpt["config"])
KeyError: 'config'
you're trying to use a non RVC model
Please, can you share the correct link for the RVC model I can upload?
whatever you've downloaded is probably some old SVC model or something
how would I know that?
its like you went to a junk yard, ripped out a carburator from a 1960s car and now trying to plug it into a modern car with fuel injectors
I just want to use basic voice conversion, like any voice.
I just found out on Saturday that you can listen to your "microphone" or "Line 1 (Virtual Audio Cable)" on VLC. Can be useful if you wanna hear what "W-Okada with output set to Line 1" is outputting, although the VLC can add up the delay for the audio you selected to hear but not really affect its actual "input" signal overall. 



!howtoask
❓ How to Ask for Help
✅ Before You Ask!
- Check Docs & Guides: Your answer may already be in the AI Hub Docs or the https://discord.com/channels/1159260121998827560/1159513888199540817 channel.
- Search the https://discord.com/channels/1159260121998827560/1192011222023950368 : Look for existing posts that solve your issue. Do not invade someone else's post.
📝 How to ask?
Tell your:
- Full GPU Name: (e.g.,
NVIDIA RTX 3060) - Operating System: (e.g.,
Windows 11) - Detailed Description: What were you trying to do and what went wrong?
- Tutorial Used: Link to the guide you were following.
- Screenshot: A picture of the full error message is very helpful.
🚫 Prohibited Topics (We Will NOT Help With These)
To maintain a lega, safe & ethical community, we will NOT provide help for:
- (E girl, as an example) catfishing/trolling, scamming, impersonation.
- NSFW/Porn.
- Any illegal activities.
Requests for these topics will be ignored and may result in moderation action.
<:matsuripray:1159685390156967936> Community Expectations
- Be Polite & Patient: Our helpers are volunteers. You may ping the
Helpersrole once. - English Only: Please keep all conversations in English.
That one from other guy was being sarcastic for sure. SVC and RVC are two whole different voice model architectures. SVC (so-vits-svc) is the old one from 2023, while RVC (Retrieval-based Voice Conversion) is the newer one and currently widely used. Also, SVC voice model cannot be used in an RVC program.
apologies..
I'm using the link below and following every step in it in kaggle,
When I finished uploading the model i got some errors related to config in kaggle...
https://docs.aihub.gg/realtime-voice-changer/cloud/deiteris-w-okada-fork-kaggle/
I am using RVC b2332 Nvidia-Cuda, how do you slow the voice down? When I speak i can hear it in the monitor speaking faster then what I speak
In this context, RVC voice model can only be used in Deiteris fork W-Okada, even as locally and online, because any voice model other than RVC was removed from that W-Okada.
Why slow? Do you mean like to make the audio delay more or something?
check your i/o sample rates
Not delay from when I start to speak but slow down the speaking between words
can you share any links from where i can download and use models for W-okada (kaggle)
!howtoask
❓ How to Ask for Help
✅ Before You Ask!
- Check Docs & Guides: Your answer may already be in the AI Hub Docs or the https://discord.com/channels/1159260121998827560/1159513888199540817 channel.
- Search the https://discord.com/channels/1159260121998827560/1192011222023950368 : Look for existing posts that solve your issue. Do not invade someone else's post.
📝 How to ask?
Tell your:
- Full GPU Name: (e.g.,
NVIDIA RTX 3060) - Operating System: (e.g.,
Windows 11) - Detailed Description: What were you trying to do and what went wrong?
- Tutorial Used: Link to the guide you were following.
- Screenshot: A picture of the full error message is very helpful.
🚫 Prohibited Topics (We Will NOT Help With These)
To maintain a lega, safe & ethical community, we will NOT provide help for:
- (E girl, as an example) catfishing/trolling, scamming, impersonation.
- NSFW/Porn.
- Any illegal activities.
Requests for these topics will be ignored and may result in moderation action.
<:matsuripray:1159685390156967936> Community Expectations
- Be Polite & Patient: Our helpers are volunteers. You may ping the
Helpersrole once. - English Only: Please keep all conversations in English.
What do you use W-Okada for? Funny or trolling or catfishing? And what is your PC GPU?
Huh? Can you explain that again?
If I say a sentence in my normal speaking speed I can hear it in the monitor speaking faster then I speak which leads it to sound weird
my goal is to use it on call centers... I've tried elevnlabs but there's no real time voice conversation option....
and its for one of my projects and not for catfishing or other spammy thing
I find myself have to purposely speak slower
my end goal is that multiple people can use it so I'm only thinking about production grade solutions, so basically runpod or other hosting things
Why would you use it for "call center"?
okay, mind if i dm and explain my needs?
Does anyone know the best set of resources or guides for hosting a huge model on a Google Cloud Compute Engine VM with a T4 GPU
If nothing is personal, no need to direct message me.
try runpod maybe
okay so it's a project for one of my clients.
Nah, you can't make W-Okada to slow itself down. Instead, there can be issues with your W-Okada settings, the program lagging or your PC lagging.
What is your client's PC GPU?
As I’ve said, I’m using a cloud-based GPU, so that’s not a problem. Currently, I’m on the Kaggle free tier (T4) and at least I’ve got an interface for real-time, which I wasn’t getting with direct RunPod GPUs. But with Deiteris’ W Okada Fork on Kaggle it worked — the problem I’m facing now is a KeyError: ‘config’
I've never used Runpod service for myself. I only use Google Colab and Kaggle for most parts. But how did you integrate the whole "Deiteris fork W-Okada" into Runpod by yourself? And yes, there are download links for fork W-Okada.
if im using kaggle for w-okada do i have to rerun the cells every time i want to use the voice changer?
Not the fork version — I was using the old RVC repo which is discontinued. With that, I could only do basic voice conversion (uploading audio and getting output), not real-time.
Yesterday I found out about this server and tried the W-Okada fork, which surprisingly looks like it supports real-time.
But now I’m stuck on one error… someone mentioned I’m using RVC-based models, but I’m not sure what other types of models I should actually be using?
Yes, you'd have to run each cell after you start up the notebook, but just to ensure that the notebook should work as intended.
Deiteris' fork W-Okada, as what I said, only supports RVC voice models.
select run all every time you refresh the page
These are RVC voice models. Their file extension is .pth, and its file size should always around 55MB. Most of RVC voice models often come with an index file, which is where it stores accent of that voice model.

can i use models from the link below ?
https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main
You can't use "pretrained voice models" that come from any RVC repository. These pth files are too large to be used as normal RVC voice model, and they all supposed to be used in training another voice model.

Instead, you might wanna find "voice models" in #1175430844685484042. The thing is there is no known "generic" voice model there; most of which are of characters and famous people.
Typical pth file size for a normal RVC voice model is around 55MB; any size that greater (> 60MB) or less (< 40MB) than this doesn't sound right.
well well well that's some help I was expecting.
thank you very much WBN 🙏
one more question will i also get an index file from here and do i need to upload that too in the interface for real-time convo ?
Most RVC voice models typically come with an index file. You can use both files in an RVC program. But in W-Okada, the index file is usually rarely used anyways, so only pth file needed.
great 👍🏻 appreciate your response.
Thank you, and have a good day.
i used the one that you sent in the dev channel but it is a web version and it only works on server and not client for me and even after i make it work it has many problems like not beign realstic or glitching a lot while breathing or luaghing i also sent u a dm
I'm not sure what you're talking about, please elaborate more on what you mean, remember that RVC means Retrieval-based-Voice-Conversion, not realtime voice changer
i used this one for nvidia
i have a 5070
it opens in browser and my mic sound only work in it when i pick the server option with windows direct
client doesn't work
oh that's not rvc, that's a modified version of the wokada deiteris fork, it's meant to work in realtime for roleplay
and even after it work it has too many glitchs
then what is the best version i could use ?
it's normal that it opens in ur browser, try different browsers and be sure to give microphone perms, then show a screenshot of ur settings
This is a General AI Server, the program you need depends on what you want to do
RVC = Retrieval-based-Voice-Conversion, the best Few Shots Speech To Speech AI Models (on v2), Inferences (use models) pre-recorded audio (ai covers) and train (make) models. Technically, Mainline RVC does have a go-realtime.bat (aka RVC-GUI), but it's pretty messy and outdated so it's extremely not suggested for realtime. There also updated forks with extra features like Applio.
Wokada = uses RVC for realtime inference.
Vonovox = Another Realtime Voice Changer based on RVC, with similar quality and performance to wokada deiteris fork but other perks
Wokada isn't RVC
and RVC isnt realtime voice changing
i sent you the pictures in dms
i need it for vc in games , streaming etc
Oh I didn't check you dmed me, that's because it was in a request lol, i will reply there
oki
please check settings for the client mode
you can first tell me if you need to show the screenshot
Wokada or Vonovox which one is best for real-time according to you ?
there isn't really a "best" one, there are different Wokada Versions/Forks (Original, Deiteris, Tg-Develop's one), and each has it's own pros&cons, it also depends on your specs since vonovox works only nvidia users on windows (as of now)
sure look dms i am just trying to figure out models and stuff
It was about RVC, but I was able to solve it, it only took me 3 hours
rvc is many different things lol
anyone know why wokada gives me over 11000ms ?
if you're playing a game, play on lowest graphics 1080p 60fps cap
show a screenshot of your settings, elaborate more since there are different versions
sure can i get pic perms?

capped myself on 60 fps roblox and still 17000 ms
from the interface, that looks like a 2 year old outdated original wokada, did you use a youtube video tutorial?
yep
could u provide me a link to a newer version?
yep, don't use video tutorials for realtime voice changers, they are pretty old
delete the folder
also, if you have vb audio cable
ok
i do
uninstall it from windows app settings
kk
sure, could you tell me your pc gpu? because there are different versions depending on that
amd
I'm guessing you're on windows 10/11
11
could you tell the full gpu name please?
to check if it's also good enough
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested WebUI with the best general support for many platforms. GUIDE
• Vonovox
A Realtime Voice Changer with similar performance to Wokada Deiteris Fork, with extra features, but supported only for Nvidia GPUs on Windows. and without cloud options GUIDE
⚔️ Wokada Deiteris Fork vs Vonovox
For Windows Nvidia, Both Wokada Deiteris fork and Vonovox have similar performance & quality. Users should read the pros and cons for both and choose based on their differences, such as UI and Vonovox's paid effects.
Read Wokada Deiteris Fork Pros&Cons & Vonovox Pros&Cons
⛔ Outdated/Discouraged
These options are not recommended for use.
• Original Wokada
Not suggested, older versions in youtube tuts are even way worse. GUIDE
• RVC GUI Mainline Realtime
The program is worse compared to the ones above, and much less updated. GUIDE
you can use either wokada deiteris fork, or tg-develop's fork (which is just a deiteris fork but with some Qaulity Of Life additions, don't expect too much from it ofc)
You can check each pros&cons in the docs :D
Just wondering, im testing some models and even though i have the monitor set to none, i can still hear myself play back. How do you turn that off?
Could you please show a screenshot of your settings? I?m guessing you're talking about realtime voice changer, this is a general ai server, so we don't know which program you might be using
!give-media-perms 1h @craggy dune

okay so im on https://github.com/deiteris/voice-changer and im confused where and which file do i download ?

GitHub
リアルタイムボイスチェンジャー Realtime Voice Changer. Contribute to deiteris/voice-changer development by creating an account on GitHub.
its realtime voice changer by okada

always check the Triangle, it's very important for non nvidia gpus
turn on echo, lower your headphones volume and keep your microphone far
Note that those 3 links are just for reference to the Source Code Github Repositories of both projects, you should instead follow the guide below.
Please read the guide below
okay, well i've done that but as i understand, having monitor selected give you audio feedback
but i have nothing selected for monitor and i can hear myself through my headphones
monitor is to hear yourself, since you don't want that and it's not used to your headphones, you seem to have issues with echo,
have you tried what I said?
i enabled echo, swich back from cpu to gpu
still having echo issues?
you aren't using monitor, this isn't related to it, this is related to an issue with echo,
have you tried also lowering ur headphones volume? and are you sure you setup correctly vac lite?
also, be aware that extra over 2.7 could cause cutoff issues in some cases
What does that mean, echo
I just dont want to hear myself
and what i was lead to believe monitor lets you hear your audio playback
which is what im hearing
Does anyobody have a up to date tutorial how to install comfyui-zluda on My rx 6750xt
echo means the repetition of a sound, this isn't a setting, it's an issue caused by your setup
What is vac light
The sound isn't repeating like a loop.
When i say hi, i hear hi back with the voice changer once
vac lite, it's the one you're using right now as Line 1, used to get the output of the voice changer as input in other programs
you sure you did this?

can you show a screenshot of the recording and playback tab?
Okay i fixed it. I clicked on the clear settings button and now i cant hear myself
perfect
That's pretty weird? Might have been some settings stuck you messed with, since that shouldn't have happened
But glad to hear it's fixed now
Hello! Is there anythig I can do about weird pronounciation issues? For example, when i try to say words like "going" it pronounces as "gohee" as if it cant produce the "ing" sound
Why shouldn't i do 5 second extra?
why my voice lagging and cutting out
5 seconds extra could maybe sound better, but in some cases, any value over 2.7 could cause a bug in some models to cutoff
Hello, could you please elaborate more? This is a general ai server, and there are many different programs, showing a screenshot would deffo help us 😁
why when I turn on the downloaded voice, the res parameter increases to 8000, resulting in a huge delay
Hello, could you elaborate more please? Such as your GPU and a screenshot
All u do is download it, download vac lite, extract both, install vac lite on your PC then restart it (if needed), run the setup file in vonovox, then once that's done run the start file in vonovox
There's no RVC deiteris' fork, rvc doesn't mean realtime voice changer
RVC = Retrieval-based-Voice-Conversion, the best Few Shots Speech To Speech AI Models (on v2), Inferences (use models) pre-recorded audio (ai covers) and train (make) models. Technically, Mainline RVC does have a go-realtime.bat (aka RVC-GUI), but it's pretty messy and outdated so it's extremely not suggested for realtime. There also updated forks with extra features like Applio.
Wokada = uses RVC for realtime inference. There's 2 main versions, Original made by Wok, and the most suggested one is Deiteris Fork (modified version)
Vonovox = Another Realtime Voice Changer based on RVC, with similar quality and performance to wokada deiteris fork but other perks
Maybe you meant wokada deiteris' fork?
What's your PC GPU and OS?
-# downloads it on Intel Mac 
Some people are bad at reading (lazy) so I explained how to do it without a guide
more ppl falling to the random tuts in youtube
Yeah, I wish those yt tutorials that are several years old would get taken down
Tbh all of them should be taken down especially since a lottttt use them specifically for the one thing (egrill shit) that 85% of the people that join here for want
RTX 4060 Windows 11
I heard something about python, do I need that?
It feels odd that a voice changer is only 6.6 mb
I wouldve used W-Okada but vonovox seems a bit better
I believe so, I can't fully remember if you do but it's most likely needed just to be easier when it is downloaded and used
great, you will be able to use vonovox then
@viral mason @wanton rapids You don't need to install python externally/globally, it comes bundled with Vonovox

Ah alright
Thanks
Btw uh theres 3 different setup files in vac lite
Which one do i run
Setup, setup 64 or setup64a
setup64
It's written in the guide, and the next step will be crucial, be sure to follow it :)
Which is?

Ah i see, theres line 1 in both input and output
I switch back to normal?
your recording tab default should be ur usual input device
your playback tab default should be ur usual output device
So yes
Oki
Done
In vonovox do i run setup? The windows batch file
after you extracted it, yup
alr it opened cmd idk when to expect the finish
it will tell you when it finished
Splendid
holy
3.5 gb
yea now it feels real
the models usually sound normal only in english/japanese?
i mean i see that most of them are english/japanese
Hi guys I’d like to create an AI that plays perfectly any time of SHOOT EM UP game but idk where to start and know nothing about programming.
Is there any tools that can help me achieve it with no programming skills ?
Thx in advance 🙂
Guys, what is the recommended specs for streaming realtime with Deiteris' W Okada Fork?
If I were to shop for a GPU now, which would you recommend?
Do you need any other help?
im confused on how to actually use the voice changer
i just download a model and thats it?
i think i gotta set the virtual cable as the input device actually
upload a model in a slot, use f0 as rmvpe, extra as 3.0, output as line 1, input as microphone and you can start it
thanks alot
you're welcome, let me know if it's solved :)
and uh, if im in call do i have to change output device?
To use the voice changer in other programs, be sure to use those audio routing settings
- vonovox:
- input: microphone
- output: Line 1
- other programs:
- input: line 1
- output: headphones
ah yea makes sense
vonovox output is set to line 1 just so i can hear the voice changer myself right?
nope, it's used so that the converted voice can be used as input in the other programs
you can't hear yourself in vonovox unless you do a workaround https://docs.aihub.gg/realtime-voice-changer/local/vonovox/#how-can-i-hear-myself
Last update: September 6, 2025
oooooooh
Is there something you need to understand still? I'm here to help ofc
all good, thanks
Is contentvec or spin better for non-English RVC models? I'm looking for a Chinese and Japanese pretrained model, please give me recommendations
there are chinese and japanese embedders, but there are no chinese or japanese rvc pretrains done using them
Shucks
spin-v2 is what we got now
hello, do we still need to install this "python 3.12.7" to our windows, i use fork okada
I'm guessing you're talkin about either deiteris or tg-develop forks, since "fork" just means modified version in tech,
You don't need to install any global python, the program comes bundled with it
@low shard sorry if im bothering, do you know any good female voice models? the one i downloaded sounds kind of weird when i use it
What are you using those for hmmmmmmmmm? 🙂
sshhh
no one has to know
but basically, even the ones meant for english sound like they were made for japanese or smth
idk if im using it wrong
Do you have an accent by chance?
eehhh a little bit maybe
The voice could be trying to copy that too
how to fix lag and cutting out
a bit of a slavic accent but its not anything crazy
You could try searching the Russian tag in the voice model section
it is over 5 sec
Might help
im not russian lol, bosnian
like i said, the accent is there but u can barely hear it
i dont think it should present a problem
Fix your settings

maybe its the pitch?
My bad lol
If you're a dude try turning the pitch to 3, 6, if it really needs it out up to maybe 8 or 10
Usually 3 is good
its at 12 rn
Oop
Hmm
Just mess with the pitch until it sounds like the model, btw it really helps to actually put effort in maybe making your actual voice a bit higher pitched when talking
i would do that..if i was home alone
I change my voice a little in how I talk with some models like if I use the battle droid compared to just a normal person
yea i need a better voice
you got any good ones?
Uhhh probably not regular female models but u could check my weights page if u wanna browse through everything
just pick a random one lol
ill try it
I mean u could look, I kinda have to use the bathroom rn 🙏
okay thanks
Can someone tell me the setup for wokada with my 3060 ti and AMD Ryzen 5 3600 6 core? thanks
Just look on weights, and search my name
Sure, are you having any issues or want a guide to install? I'm guessing you're on windows 10 or 11
can i ask for help?
is it just me or did wokada recently start bugging where your not able to hear yourself nor hear anything coming out of your mic to others
How can I get the voice of a character?
!howtoask
❓ How to Ask for Help
✅ Before You Ask!
- Check Docs & Guides: Your answer may already be in the AI Hub Docs or the https://discord.com/channels/1159260121998827560/1159513888199540817 channel.
- Search the https://discord.com/channels/1159260121998827560/1192011222023950368 : Look for existing posts that solve your issue. Do not invade someone else's post.
📝 How to ask?
Tell your:
- Full GPU Name: (e.g.,
NVIDIA RTX 3060) - Operating System: (e.g.,
Windows 11) - Detailed Description: What were you trying to do and what went wrong?
- Tutorial Used: Link to the guide you were following.
- Screenshot: A picture of the full error message is very helpful.
🚫 Prohibited Topics (We Will NOT Help With These)
To maintain a lega, safe & ethical community, we will NOT provide help for:
- (E girl, as an example) catfishing/trolling, scamming, impersonation.
- NSFW/Porn.
- Any illegal activities.
Requests for these topics will be ignored and may result in moderation action.
<:matsuripray:1159685390156967936> Community Expectations
- Be Polite & Patient: Our helpers are volunteers. You may ping the
Helpersrole once. - English Only: Please keep all conversations in English.
You can ask anything, it doesn't have to be "can I ask a question?". Also, make sure to read help guidelines before start asking.

rtc? could you please elaborate more on what you mean / program you're talking about? Since this is a general AI Server, there are multiple programs with different versions based on OS & GPU
I hope you understand :)
oh uhh lemme see wat the name is
i use deiteris wokada fork
I'm guessing wokada deiteris' fork (modified version) b2332, could u please show a screenshot of ur settings?
!give-media-perms 1h @short oracle
its loading D:
btw, are u using it in games?
Play on lowest graphics 1080/720p 60/30fps
the gpu prioritizes the game since it's rendering something on the screen, so you have to give more resources to the voice changer
i have...
5080


lowest graphics 1080p 60fps cap is usually suggested for everyone, because this way it can give more resources to the voice changer to have less delay
The GPU is doing 2 very intensive tasks at the same time, if you get what I mean
I mean you're free to experiment to see, but playing on like 4k max graphics is going to take more resources which can higher up the delay, ofc this can depend by the game too
on wokada deiteris fork, you can **optionally **use more advanced settings for benefits:
- Advanced Settings -> Force FP32 mode: on (THIS IS OFF BY DEFAULT! Turning this on improves stability. Increases VRAM usage by 200 MB)
- Advanced Settings -> Disable JIT compilation: off for faster loading speed of the program, on for slightly better performance (10-15 ms) for Nvidia only)
- Advanced Settings -> Crossfade Lenght: Controls how smoothly the AI stitches different processed parts "chunks" of your voice back together. 0.1 for fastest voice, 0.15 for improved quality but increases delay by ~50 ms
- Reduce the delay on Windows via the Wasapi / Asio Guide
You could also give Vonovox a try, it still gets performance updates, you can cehck its pros&cons if it fits your needs btw
i mainly wanna use it when hanging out with friends and streaming them game

i would never doo that, (totaly not streaming metal gear delta on 4k)
Yeah those are optional settings, each is explained to help with delay, like wasapi
They are in the Advanced settings section, and in the docs
okayy thank youu
Btw vonovox can do that too, it's another realtime voice changer that uses RVC models, but it still gets updates especially about performance, it's in the docs if u wanna check it, your choice
is it better ?

You can give it a test, there's no official benchmark test that I can give you
is there a one that i could run on like phone, and just stream the audio to pc?

It will never work on your phone because of lack of power + no VAC
ahh i see
I'm having a problem installing it
okay I fixed it myself
hi new here - I'm looking for a voice changer to do agent voiceline soundboard ingame - can anyone tell me which one can I use?
Basically, the "realtime voice changer" program converts your voice in realtime with a given voice model.
Similar to RVC that converts an audio with an AI voice model, but this one converts and processes audio in realtime.
@hallow thistle I'm having trouble getting the cable output VBCABLE to get the voice changer to sound in it and have it working.
Is there any guide link or information available to get this fixed?
I'd appreciate even a copy paste link from a previous question of this type as well
Use Virtual Audio Cable lite instead of VB-Cable. Also, did you follow any tutorial before this?
I was using some youtuber's tutorial who told to use VB-Cable and the comments on the video really said it was working, I'll try the one you suggested, do I uninstall vb cable?
W-Okada can't work on phone (Android and iOS) like in desktop PCs, as there's no virtual cable for this and the audio system is far different from desktop one.
I annalyzed in virustotal the (vac) and is this a false positive?
- Win32.Troj.Undef.a
Virtual Audio Cable exe program
Yes, you can uninstall VB-Cable to save up your PC disk space.
Why would you use an antivirus program for this? Some antivirus programs, aside from Microsoft Defender, can give false positives against certain programs.
Try download the program from this link. https://software.muzychenko.net/freeware/vac470lite.zip
And what is your PC GPU?
I was about to ask if zip or exe, thanks
To check your PC GPU, open Task Manager, go to Performance tab and locate GPU 0 or GPU 1.
System Information
Current Date/Time: Wednesday, September 10, 2025, 3:07:51 PM
Computer Name: DESKTOP-9BIQ8BE
Operating System: Windows 10 Pro 64-bit (10.0, Build 19045)
Language: English (Regional Setting: English)
System Manufacturer: LENOVO
System Model: 82H8
BIOS: GGCN29WW
Processor: 11th Gen Intel(R) Core(TM) i3-1115G4 @ 3.00GHz (4 CPUs), ~3.0GHz
Memory: 8192MB RAM
Page file: 11621MB used, 8657MB available
DirectX Version: DirectX 12
Name: Intel(R) UHD Graphics
Manufacturer: Intel Corporation
Chip Type: Intel(R) UHD Graphics Family
DAC Type: Internal
Device Type: Full Display Device
Approx. Total Memory: 4123 MB
Display Memory (VRAM): 128 MB
Shared Memory: 3995 MB
DirectX Features
DirectDraw Acceleration: Enabled
Direct3D Acceleration: Enabled
AGP Texture Acceleration: Enabled
Can it run in cpu (since no dedicated gpu bc laptop)
Intel(R) UHD Graphics is an integrated GPU; not really recommended to be used with any AI program such as W-Okada.
Yes, you can run W-Okada with only CPU but it will be really slow as hell; also not recommended.
the cpu is kinda good I'd say for being a budget laptop

400$ laptop, scam?
you don't seem to have Nvidia/AMD gpu
it's a laptop.
it will run on the cpu just fine don't worry
my cpu never failed me
But it's not recommended, you know. There's an online option for this one.


tell me more
do I run setup64 or setup exe for vac
setup64.exe
"I am an advanced user" ?
yeah 20+ sec delay seems fine for you
doesn't it?
It was running 500ms delay with through mode it will be fine
in 192
Also, don't expect to run the program with another game at the same time. You know right?
it will, trust
also when I installed the mmvcserver it wouldnt work and I had to manually create some folders and empty jsons that were missing idk if this has to do with anything
What the hell?
my laptop is the best
I don't trust you for this, seriously.
I got the cable installed Imma try to figure the rest
I think I should reset my pc
restart
If you really really wanna try W-Okada with CPU-only that bad huh, there's a better W-Okada version, which is in this link. https://docs.aihub.gg/realtime-voice-changer/local/deiteris-w-okada-fork/#download-amd-intel-and-cpu-on-windows I just better hope this is for experiment and not anything else.
Last update: September 6, 2025
nah I'll be fine, you'll see
No.
It will run very bad, this is more intensive than a game, I can say it since I had previously a laptop with a similar CPU and same RAM
AI is intensive, it's not easy to run locally nor a site like chatgpt
Any W-Okada variant, like NVIDIA and AMD/Intel (DirectML), that made for Windows can work with only CPU; the AMD/Intel one is somehow known to work with an integrated GPU like Intel UHD Graphics while NVIDIA one doesn't.
the console keeps saying
Pipeline is not initialized.
Waiting generate pipeline...
You can't be overconfident on this one. 
I still dont get volume in the virtual audio cable
Deiteris' fork W-Okada should look like this. If you still use the version that has many files in the same folder, you'd better stop use that version.

If you change your mind and thinking to use the program with a game or Discord, I'd suggest to consider for an online option like Kaggle instead. https://docs.aihub.gg/realtime-voice-changer/cloud/deiteris-w-okada-fork-kaggle/
tell me which voice changer version you're currently using?
(first ask me for image perms to show the screenshot)
I was using the latest nvidia 18a something
I'm using this rn
"Waiting for the operation to complete..."
it loaded
if you seem to feel fine on it, then you wouldn't need our help anyway 😔
I dont understand

well the ping says over 11000ms and it keeps raising
so you've got the problem, eh
I can change the settings
do you know what we were recommending you?
@agile relic
v.1.5.3.18a and b2332 are not the same one.
15k ping on the version we gave you, but normally on your current .18a?
I am trying this web version that has so much ping
"Download AMD, INTEL and CPU on Windows
The latest version as of December 7th 2024 is: dml-b2332 (click here to download)"
should I just stream
Struggling huh, that's unfortunate, but here's the settings you can try:
Chunk: 300 ms
Extra: 2.7 s
GPU: CPU
F0: rmvpe_onnx

Now expect it where its audio being delayed more with higher audio quality at the same time.
Is Line 1 supposed to never register anything it's just my microphone's volume bars that increase, but the Line 1 Virtual Audio Cable is not getting any signal
Input: your microphone
Output: Line 1 (Virtual Audio Cable)
Monitor: your speakers/headphones
Yeah and it doesn't work
"
Input: Microphone (TRM-10 Audio Device)
Output: Line 1 (Virtual Audio Cable)
Monitor: Headphones (Realtek(R) Audio)
"
just forget it, ig my pc is just dumb
I'll just stick to voiceweave or some shi
that one did work for me and it was just 200ms delay
You should've give up expecting your laptop to be great the first time I told you to go for an online option lol.
oh you meant this when you said online
p2w
that means you don't need help from us, thinking "if it ain't broken don't fix it"
seems more like a cloud service tho
well whatever you'd experience is your own responsibility 
Never heard of voicewave, def worse than any rvc program if it doesn't use rvc
it has the option to use dedicated gpu for quality or simply your cpu but some sound dogshit others are passable for the most part
"some" almost every single one
sorry, I called it the input name, the program is EaseUS VoiceWave
@viral mason gang you know anything about realtime voice changing apps?
I know absolutely nothing about the code but I know how to use them, only Vonovox and wokada
which one is good to use gang, imma try it
If u got Nvidia I'd say use Vonovox as it's just better but only issue is it has only 8 model slots
That is the only flaw
as in I can only put 8 epochs?
No, you can only put 8 models in the voice changer at a time
Dr87 is working on that tho
Eventually
I used ai to make me look like a chad in my selfie 🗿
ohhhh it still works with the epochs I trained in rvc right
Good for you 🧍
Wdym epochs 😭
idk how to use it
It has nothing to do with training man it's you just put models in it that were already finished
 gang finished in where
gang finished in where
im confused
I also used AI to create a relistic guy pooping in a bucket
like the models im trainin in applio rvc?
And then he ate it
Why 😭
will this work?

Like, any models, the ones in the voice models section, the one's on weights, any of them
That'll work yes
okie lemme tryyy
Epochs aren't important on the voice changer because it's just using the model you have live
Instead of putting like a silly song in it to make it sing
im confused lemme try and tell
so shmelly and wet
I wish I had time to show u how to use it but I got work soon
Btw u have to have vac lite downloaded
It should be in the guide
it's alright I'll try a bit on my own and I'll ask you for doubts later on too
OHHHH lemme download
oh it's just virtual audio cable
i already have it
diareaa
Ye
Because your statements made no sense, and this channel is not your typical general chat. Hope you understand. 
Shh don't interact with it
Yes, I know about realtime voice changer.
I'm aware he's just a kid who joking around. 
I just got vonovox but haven't downloaded files yet how many gbs will it be
Vonovox won't gonna look like a typical W-Okada. Would you still go for this one? https://raw.githubusercontent.com/dr87/Vonovox/main/docs/images/ui1.png
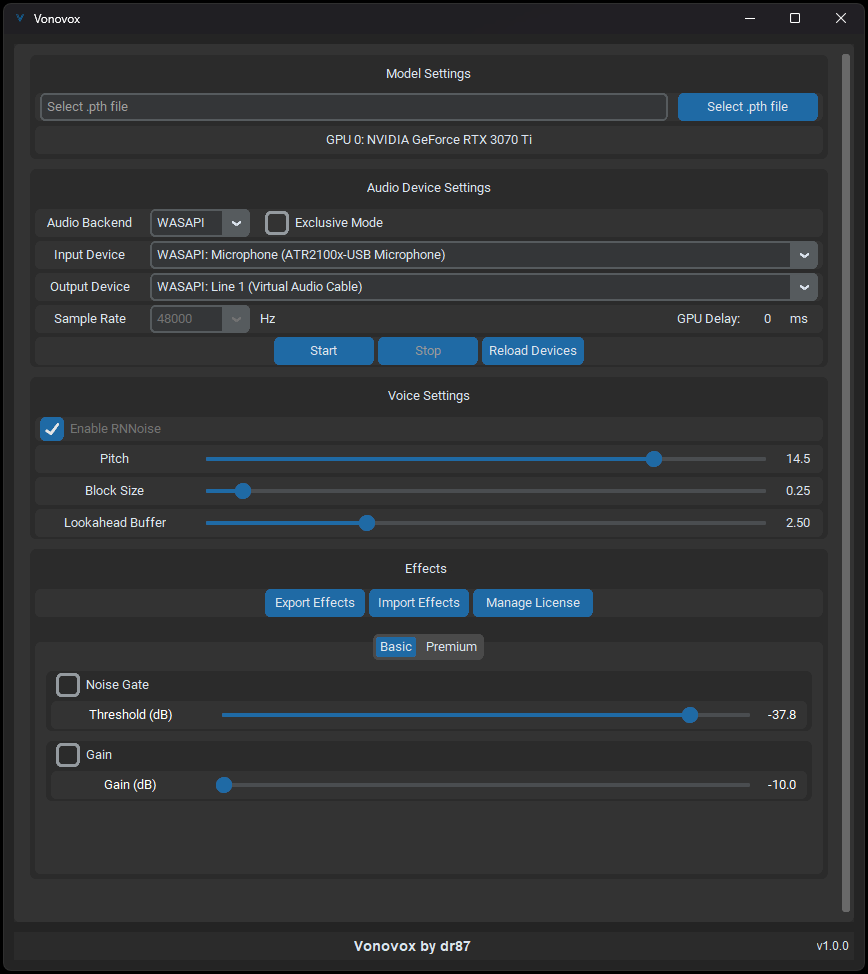
Deiteris fork W-Okada has more friendly GUI, while Vonovox is more of professional.
im confused i have nvidia gpu
the terms block size and lookahead buffer is confusin
but whatever gives me best quality im ready to learn
Has anyone ever used vibe voice?
will Kraggle ever be fixed? Does it have any relation to this server? its on aihub
I did
Do u need to input/type in speaker in order for the ai to work for one person?
1.5B is bad. 7B (large) is good. For English. You can add multiple speakers and create podcasts
Do you mean by Audio output?
Yes
Im basically trying to create or clone a character voice and trying to get realistic emotions
Idk if vibevoice is best for that
It's better than others but you can try chatterbox Too.
what are you
Yes you can clone
I see
Im using it for my manga and stuff
Maybe chatterbox performance is better. Wait I'll send you demos
chatterbox_demopage
thx
I'm guessing it's a typo of Kaggle,
Kaggle is just a Cloud (remote good pc) service, we can't know which notebook you're talking about since anyone can code one and this is a general ai server
Please elaborate more :)
it's the one on aihub that links to it. should i link it?
What do you think? How it is
If you're talking about https://docs.aihub.gg, this is our documentation, it contains various guides and programs, we can't know which specific kaggle notebook you're talking about, since we help with all programs
It would be better if you elaborate more your PC Specs, the error and the link to the kaggle notebook
Give me a sec Im gonna try to install it
Well you will get an error if the visual studio is not installed. Building wheel error
Also hit a try to huggingface space here https://huggingface.co/spaces/ResembleAI/Chatterbox

Im planning on using it in ComfyUI
Okay
Hmm, is it natively supposed in comfyui ?
looks like it, ill update u on what happends
No it requires custom nodes. I guess
i js tried training my first model on rvc but i didnt get the pth, how do i get it?
/Logs
Check logs folder 📂
theres only an index in the logs folder of my model
Are you using mainline or applio
i usually use applio but im using this one now https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI?tab=readme-ov-file
theres no pth with the name of my model
Have you checked "save every weight " In GUI ?
How to use voice model?
yes
if u mean the save small model
does anybody know why your not able to hear yourself or anything come out from wokada
or is it just me
I don't even think if rvc comfyui is well maintained as the standalone Applio
For the Kaggle Applio notebook, what's the format for the dataset file path?
im new to this ai stuff i made a song but i want it to sound real as possible like ynw melly voice can i send it to someone to help
Ah man, now I feel like a fool; I had leftover datasets from a year ago, I just forgot about how to do that part lol.
Thanks man.
you're good, some things never get explained in guides or are easy to skip over
Yes, a guide would be great, I am on windows 11.
!howtoask
❓ How to Ask for Help
✅ Before You Ask!
- Check Docs & Guides: Your answer may already be in the AI Hub Docs or the https://discord.com/channels/1159260121998827560/1159513888199540817 channel.
- Search the https://discord.com/channels/1159260121998827560/1192011222023950368 : Look for existing posts that solve your issue. Do not invade someone else's post.
📝 How to ask?
Tell your:
- Full GPU Name: (e.g.,
NVIDIA RTX 3060) - Operating System: (e.g.,
Windows 11) - Detailed Description: What were you trying to do and what went wrong?
- Tutorial Used: Link to the guide you were following.
- Screenshot: A picture of the full error message is very helpful.
🚫 Prohibited Topics (We Will NOT Help With These)
To maintain a lega, safe & ethical community, we will NOT provide help for:
- (E girl, as an example) catfishing/trolling, scamming, impersonation.
- NSFW/Porn.
- Any illegal activities.
Requests for these topics will be ignored and may result in moderation action.
<:matsuripray:1159685390156967936> Community Expectations
- Be Polite & Patient: Our helpers are volunteers. You may ping the
Helpersrole once. - English Only: Please keep all conversations in English.
RVC or W-Okada realtime voice changer?
-realtime
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested WebUI with the best general support for many platforms. GUIDE
• Vonovox
A Realtime Voice Changer with similar performance to Wokada Deiteris Fork, with extra features, but supported only for Nvidia GPUs on Windows. and without cloud options GUIDE
⚔️ Wokada Deiteris Fork vs Vonovox
For Windows Nvidia, Both Wokada Deiteris fork and Vonovox have similar performance & quality. Users should read the pros and cons for both and choose based on their differences, such as UI and Vonovox's paid effects.
Read Wokada Deiteris Fork Pros&Cons & Vonovox Pros&Cons
⛔ Outdated/Discouraged
These options are not recommended for use.
• Original Wokada
Not suggested, older versions in youtube tuts are even way worse. GUIDE
• RVC GUI Mainline Realtime
The program is worse compared to the ones above, and much less updated. GUIDE
RVC
or you can use dataset creator from UI
Did you installed it ?
Just realize that now, oops.
Thanks for that as well.
So I already trained my voice model to have a neutral voice, but how do you give it a wide range of voices that emulate emotion?
its with ai helping stuff
not the ai heliping
the people is gonna help you not I
ai*
can we give homeless guy the award for most useless help message in this chat
Hey! I'd like to upscale and interpolate a video from compressed and grained 1080p 30fps to clean 8K 60/120fps. The video is a gas giant in space, so with a lot of black and a lot of big compression blocks.
I tried multiple models (OpenProteus, Real-ESRGAN and another I can't find in my mind) but every models has an issue.
Open Proteus has a blurred result for great colors, the keyframes of the video are pretty visible (even more when slowing it down) and the compression was not perfectly concealed.
The other model I can't remember has good details but a bit too much contrast, the real-looking video almost became like an anime, and the keyframes was no longer so much visible, but the compression was looking blocky and weirdly colored.
And Real-ESRGAN is very slow (It's not a problem for me if the result is good, I can keep my computer running for a few days if needed) and has wayy to much contrast, it's anime-looking (But I feel like it's typical Real-ESRGAN, almost every photos I upscale with it has too much contrast)
Can you recommend me a good model for upscaling compressed videos?
(I don't need interpolation in first time, I can do it after upscaling and most interpolation models are pretty good)
how to train models/voices?
Sorry work got in the way, I’ll update u on what happens
I’ve made sentences where I say gibberish, and Speech To Text translates it to what it thinks I’m saying. What channel should I share it on?
hey guys so i installed a voice and when i talk it just like freezes mid talks
Does anyone have a working link for okadas voice changer? Bc my pc isn’t too good for the program
what gpu do you use, Nvidia, Intel, AMD?
hey i was wondering
what's the difference between one big dataset file for RVC voice training
like one big one with 90 minutes
or the same one but its just split in 50+ different audio files
what's the difference?
does it produce better or worse results or
I'm not entirely sure, I use just one thing of audio but I think if you select the post option in normalization it auto cuts the dataset into smaller files
Im on a shitty mac even the kaggle link had delay for me
Is there any links?
If the one on kaggle didn't work I think you're out of luck unless you can afford to upgrade 🙁
so it doesn't matter much right
even if the audio isn't split
how to i change epochs on rvc
Again I'm not entirely sure, I'd ask other ppl who train models to get more opinions on it
Hi, i am searching for an AI to sort my mail, for example Gmail.
no
guys when i downloaded the main voice changer and i try open “http_start.bat” it doesn’t work for me what do i do?
how to change my birth date
it doesn't matter if you make sure to use preprocess settings like this

Anyone know what app would be suitable for a voicechanger in mac i5? Ive been trying so hard but no results. It would be great if someone also gave me a tutor
Okay not a problem
https://github.com/resemble-ai/chatterbox Im trying to install it using cmd but I get an error
What error?

Send the full error
If it says unable to build whell, install visual studio 14+
Than you have to download Microsoft visual studio and install some frameworks
ok
Which python version are you using
25.1.1 im upgrading it right now

and please show the error message, I bet it must be different
Im trying to get that done right now and set it as path, give me some time sorry
YESYESYESYSEYESYYESYES
ITS WORKING
ITS INSTALLING
I set it to path
Okay I have it installed I just need to open it
@knotty moth are you able to help figure out VAC its not being detected even in discord
are those the default settings?
Hey I got error on building wheel
Update: after 10 trillion times on fixing it, it was dependencies that did not come with the package
So I used chat gpt to help me 💀
And it worked eventually
Also for some reason it’s using my cpu now which is weird so I gotta change it to use my gpu
chatterbox can run with 3.11 or 3.12, you need to modify pyproject.toml to fix numpy dependency to 1.26.4 and remove pkuseg
and for gpu use you need to run torch install with cuda
Anyone know what app would be suitable for a voicechanger in mac i5? Ive been trying so hard but no results. It would be great if someone also gave me a tutor
I set deteris w-okada fork for cuda and everything and the voice changer seems to work fine in all of the tests but whenever I talk over discord it shows that there's no sound? I have a GTX 1070 Ti I know it's not the best but when I test my mic within discord settings it sounds perfectly fine and everything runs smoothly, it's only when I try talking in a voice call or within a game where there's zero sound being heard or indicated
There were a few threads about this issue but none had an answer so I was wondering if anyone experienced knows why this is happening?
anyone knows if the training script from applio is different from the original rvcwebui?
question lol 1-Does anyone here use voice.ai and 2- have people been getting the "No network connection, voice initialization failed. Please try again #3769" error? I can't find any way to see if their servers are down :/
I wonder if using applio instead could improve my model
Also I wonder what happens if I train directly using multiple voice sources, in contrast to using model blender(average the weights) of multiple models
one one voice per voice model
If u use an Nvidia GPU u should try out both but if u have some other one like AMD or Intel you could use the first link/guide
-rt
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested WebUI with the best general support for many platforms. GUIDE
• Vonovox
A Realtime Voice Changer with similar performance to Wokada Deiteris Fork, with extra features, but supported only for Nvidia GPUs on Windows. and without cloud options GUIDE
⚔️ Wokada Deiteris Fork vs Vonovox
For Windows Nvidia, Both Wokada Deiteris fork and Vonovox have similar performance & quality. Users should read the pros and cons for both and choose based on their differences, such as UI and Vonovox's paid effects.
Read Wokada Deiteris Fork Pros&Cons & Vonovox Pros&Cons
⛔ Outdated/Discouraged
These options are not recommended for use.
• Original Wokada
Not suggested, older versions in youtube tuts are even way worse. GUIDE
• RVC GUI Mainline Realtime
The program is worse compared to the ones above, and much less updated. GUIDE
I’ve had success with it so far haha I have like 200k credits for some reason lol I just wanna be a cringe ass eboy online so people stop going “mommy? Sorry. Mommy? Sorry” 😫
Hey I got error with pkuseg. How to fix it. There is no wheel file already built for it. And I don't want to install that visual studio thing

remove it from pyproject.toml
And what to add instead ?
nothing, if you dont need chinese it should be fine
I see. Thank you. Is there anything I have to do with numpy ?
with python 3.11
you can install as is, you just need to clone the repo, update pip setuptools wheel packages
then install numpy standalone, then you can use pip install .
for python 3.12 you need to modify pyproject.toml and change numpy version to ==1.26.4 instead of the existing stupid requirement
then it installs just fine
I see, thank you again 
Dunno if anybody has experience with this, but is there a reason why in the tg-dev fork I cannot select GPU under Processing Unit? My only option is CPU
What is your GPU? screenshot task manager/performance screen with the gpu selected

In deiteris I can and did select my 4090 no problem
but here I seem unable to do so
It's just not an option in the select field
you got the right fork?

what did you download?
Lemme check, perhaps I picked the wrong one from the release page?
Oh damn that's it, sorry for being such a noob
Download NVIDIA on Windows
Download all of the voice-changer-windows-amd64-cuda files. This will include multiple files, likely ending in .zip.001, .zip.002, etc.
your name nickname would be more appropriate for me in this case damn
sorry for wasting your time!
Agentic AI Framework (agenticaiframework) is a next-generation Python SDK for building agentic applications with advanced orchestration, monitoring, multimodal capabilities, and enterprise-grade scalability.
It offers a modular, extensible architecture for creating intelligent agents that can interact, reason, and execute tasks across multiple domains — from simple automation to complex multi-agent ecosystems.
anyone?
everything is up to date & i'm using the right virt cable
may want to use push to talk in discord
i'll try it
so have you got the correct installation?
So I have 3 voice source for 3 different languages, and I want to make one model out of it. I don't think blending would be a good idea
you not gonna get what you expect to get
Is there some out of the box mixture of export for this purpose?
you can train 3 separate models then merge/blend them with each other
I didn't. I downloaded the right one and the issue got fixed
Hey is there a ticket system? I have a mod question
few questions im quite new to whole real time voice changer thingy... so how much quality is lost if you speak in language model wasn't trained on, what is good few voices i could get to play around with them, and what are the best settings for mmcv ?
what gpu do u have, also what voice changer are u using, there's two Vonovox and Deiteris Okada
if u got the voice changer from a yt video it's probably over a year old btw, and for ur question pretty sure if using a different language on a model trained on something specific doesn't change quality
Dm AI HUB Modmail :)
I do have 3060 mobile 6 gig of vram and I think I got this one ?https://huggingface.co/wok000/vcclient000/blob/main/MMVCServerSIO_win_onnxgpu-cuda_v.1.5.3.18a.zip
3060 mobile? is that Nvidia, AMD, or Intel
It's Nvidia just laptop version
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested WebUI with the best general support for many platforms. GUIDE
• Vonovox
A Realtime Voice Changer with similar performance to Wokada Deiteris Fork, with extra features, but supported only for Nvidia GPUs on Windows. and without cloud options GUIDE
⚔️ Wokada Deiteris Fork vs Vonovox
For Windows Nvidia, Both Wokada Deiteris fork and Vonovox have similar performance & quality. Users should read the pros and cons for both and choose based on their differences, such as UI and Vonovox's paid effects.
Read Wokada Deiteris Fork Pros&Cons & Vonovox Pros&Cons
⛔ Outdated/Discouraged
These options are not recommended for use.
• Original Wokada
Not suggested, older versions in youtube tuts are even way worse. GUIDE
• RVC GUI Mainline Realtime
The program is worse compared to the ones above, and much less updated. GUIDE
it's the best realtime voice changer out there (rvc doesn't stand for that) but if that doesn't work just download deiteris
When I hop on laptop imma test it out any voices/settings you recommend ?
for vonovox I'd use these
0.3 block size, 2.0 second extra, 0.15 crossfade
and if u need to switch to deiteris use these

for voices, depends on what u want but u could test my Venom model out, just made ithttps://discord.com/channels/1159260121998827560/1416114563845324930
how much index file influence voice ? and if i can ask what will change if you swap audio backend, f0 method, RNN noise and upscaler (im guessing that last one make it slower but better)

it's best to not touch the index, just import it in but don't use it as vonovox has had issues with index causing exreme gpu/cpu usage in the past
also dumb question how do you eject file?

keep smart sine on, not sure what you mean by this tho "what will change if you swap audio backend" and keep f0 at rmvpe
does anyone know good ai voice cloning stuff that I could use for voice modding that is low gpu usage
oh I don't use that feature so I got no idea
I am bored
in audio device setting you have "audio backend" and im curious if it changes much or its just backup system
wdym voice modding, are yu looking for a voice changer or to make ai voices of existing characters/people

wasapi is recommended
voice changer
I want to use it for horror games
since I can't afford a voice actor
make sure your voice settings are
input: regular mic (headset, headphones ect)
output: vac lite
@hidden hinge
what gpu do u have, Nvidia, amd, intel
and what is F0 method or i shouldn't really bother ?
I got a 3050

that should work fine with either of these, there's a guide for both but f u want good quality go with Vonovox, there's a guide here, it's what the other person is using too
-rt
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested WebUI with the best general support for many platforms. GUIDE
• Vonovox
A Realtime Voice Changer with similar performance to Wokada Deiteris Fork, with extra features, but supported only for Nvidia GPUs on Windows. and without cloud options GUIDE
⚔️ Wokada Deiteris Fork vs Vonovox
For Windows Nvidia, Both Wokada Deiteris fork and Vonovox have similar performance & quality. Users should read the pros and cons for both and choose based on their differences, such as UI and Vonovox's paid effects.
Read Wokada Deiteris Fork Pros&Cons & Vonovox Pros&Cons
⛔ Outdated/Discouraged
These options are not recommended for use.
• Original Wokada
Not suggested, older versions in youtube tuts are even way worse. GUIDE
• RVC GUI Mainline Realtime
The program is worse compared to the ones above, and much less updated. GUIDE
yee it doesn't use much of my vram so you should be able to run it on 3050
what is the one that has the least amount of artifacting
guys im lost what rvc is the best to use on web?
idk what it really does but use rmvpe, the creator of this vc said that swift is good but it's still kinda new
what are u looking for, a voice changer or to make model
rvc doesn't mean realtime voice changer btw lol
i have my models so voice changer
yep ik
which tutorial do you guys use for comfyui zluda windows 10
hi, can you guys help me? I try to find good RVC for voice change
Depends on what gpu I have, Nvidia, AMD, intel
also since I am on the topic of game development and I can't hire a 2d artist/don't wanna dox people, what should I use to make realistic images (the game I am making is like welcome to the game)
What gpu do u have
Nvidia, amd, intel
I don't personally know but if you are making a game I'd avoid using AI art in it as could get a lot of hate, u could use a drawing software and teach yourself on a free app like medibang pro
only reason why I am asking is to not use real humans and not hurt people, welcome to the game is based on the dark web
I like the game so I wanted to make my own version of it on unreal
not drawing anyone
That's interesting
I have reasons to do stuff I wanna do
since I am a gamedev
and I believe that fiction is fiction
and shouldn't go into the real world
Y'know you could put in the lore that an ai is making the art so you have an excuse for ai art
I mean real life looking human beings
Just a suggestion of course
and I want to have the same type of person so I don't want it to have overlap and look like a completely different person
-colab
📒 Google Colab Notebooks
Google Colab is a Cloud (Remote Good PC) Service. While the Free plan provides up to 12 hours of daily usage, the GPU is typically available for only about 4 hours each day on average.
• **Applio**
by IA Hispano
Google Colab
• **RVC Mainline**
by Hina
Google Colab
• **UVR5 NO UI**
by Eddy
Google Colab
• **UVR5 UI**
by Eddy
Google Colab
• **Wokada Deiteris Fork**
by Deiteris & Hina
Google Colab
• **Hina's Modified Original Wokada**
• **RVC-AI-Cover-Maker-WebUI**
by Shiro & Eddy
Google Colab
• **FaceFusion UI**
by Nick088
Google Colab
• **FaceFusion NO UI**
by Nick088
Google Colab
• **Music Source Separation Training (Inference)**
by Jarredou & Makidanye
Google Colab
ty
I just don't like using real humans in works of fiction so that is my reasoning
espesically of this topic
I don't really understand it but no judgement from me 🤷♀️
Ill send you a vid of the game
so you can understand why I DON'T want to include real humans in this
also the creator themselves use pictures of real women and a lot of people didn't like that
and I agree with them
well it really depend on what gpu do you have and how many really similar photos of a character you need
my gpu is 3050 if there is a cloud company that I could use I could pay for it and enough to make fake dark web social media (basically how you talk to other hackers with stolen info)
hmm then you have few options you can install stable diffusion model that is good at realistic or flux model (second probably better for realistic) or use some websites that give you free daily use of img generation and use something like flux kontext or qwen image edit to modify already generated by you photos to get new variants
Anyone got this working on NixOS?
Even with FHS I couldn't get Deiteris' fork working:
ImportError: /home/xnefas/Documents/AI/MMVCServerSIO/_internal/libstdc++.so.6: version `GLIBCXX_3.4.29' not found (required by /home/xnefas/Documents/AI/MMVCServerSIO/_internal/onnxruntime/capi/onnxruntime_pybind11_state.so)

sudo apt-get update
sudo apt-get install gcc-4.9
sudo apt-get upgrade libstdc++6
sudo apt-get dist-upgrade
Hello, everyone. Where can I try seedream v4 edit? I couldn't find it on Hugging Face.
bruh how yall doin this
I got following message after running the training script: "Not enough data present in the training set. Perhaps you forgot to slice the audio files in preprocess?" I do have sliced the audio, and roughly 400 audio files in the sliced directory. what could I miss?
If you left before a helper came in, it's your loss. 
oh, my f0 directory is empty...
I thought the extract.py would do the feature extraction
Why did you pay for this?
where's my RMVPE

"rmvpe" is only available in NVIDIA variant of W-Okada, and it doesn't exist in DirectML of it. Judging by your screenshot, it seems like you're using the "original" version of W-Okada DirectML.
I would recommend getting better version here (depending on your gpu)
Last update: September 6, 2025
it worked nvm
yeah
i went through a few forums
and the reason why its outputting mumbling is because i was using a spin model which deiteris's fork of wokada doesnt support
neither does the base version
but apparently i can implement a SPIN embedder
but idk how to do that
I can implement a SPIN embedder
but I don't know how to do that
Really?
yeah like 70% sure
did u check the pull req
is it a fork of deiteris's fork?
For another fork W-Okada, you might wanna look at this one. https://docs.aihub.gg/realtime-voice-changer/local/tg-develops-w-okada-fork/
nvm i dont think it is
there's spin-v2 now
its just a fork of wokada
"Wokada Tg-Develop's fork since it's a fork of the Deiteris' Fork, containing the performance improvements, has an improved Web User Interface, supports Spin Embedder Models, and has Audio Effects."
wheres that
You can't judge it like that.
read the link above
You didn't see my link?
That's an issue.
its whateverrr
Still.
Almost every AI program is as big as that in GB. This specific fork W-Okada, as you'd imagine, would pack with many features in there. Deiteris fork, however, certain packages and features were removed or missing when those didn't need for most users.
If your current internet is slow, it's gonna hard to get it done lol.
is 10bytes per second good
😼
Seriously? This internet speed could download smaller text files or certain files in the past, but not other heavier file of today.
oh btw is it worth it to get a second gpu for just wokada
and if so whats the best one to use for primarily for it
in terms of value
My internet is around 120Mbps, while not the fastest, it can download files in gigabytes in not hours but rather minutes.
RTX 2060, 3060, or 4060 depending on your budget
4060 would benefit AV1 streaming
how long is latency for 2060
wdym
ask google/chatgpt
😭
wait so its just better for transmitting audio packets over the internet??
NVIDIA GeForce RTX 2060 is the minimum for most tasks, RTX 3060 is in between, and RTX 4060 is faster, depending on your budget. RTX 50 is the newest, but requires a specific fork W-Okada in order to work, which the Tg Develops one is not yet known to have the version for this GPU.
uhh? i tried downloading the new one

AV1 is a video codec. You might not need to know now, but only needed if you want to encode a video with higher quality possible some day.

Did you download a correct fork W-Okada?
yes, i think it's because forgot to download all 3
Your GPU is NVIDIA GeForce RTX 50xx?
get either of these for RTX 50-series:
Last update: September 6, 2025
Last update: September 6, 2025
yeah, it's a 5080
hold on i think it's working
and you used the og directml version that would perform like RX 580 or just throw some error messages
it's working now, troubleshooting for myfriend (and yes it was the DirectML issue)
Good day!
I need help about the changer it does not apply to discord...
!howtoask
❓ How to Ask for Help
✅ Before You Ask!
- Check Docs & Guides: Your answer may already be in the AI Hub Docs or the https://discord.com/channels/1159260121998827560/1159513888199540817 channel.
- Search the https://discord.com/channels/1159260121998827560/1192011222023950368 : Look for existing posts that solve your issue. Do not invade someone else's post.
📝 How to ask?
Tell your:
- Full GPU Name: (e.g.,
NVIDIA RTX 3060) - Operating System: (e.g.,
Windows 11) - Detailed Description: What were you trying to do and what went wrong?
- Tutorial Used: Link to the guide you were following.
- Screenshot: A picture of the full error message is very helpful.
🚫 Prohibited Topics (We Will NOT Help With These)
To maintain a lega, safe & ethical community, we will NOT provide help for:
- (E girl, as an example) catfishing/trolling, scamming, impersonation.
- NSFW/Porn.
- Any illegal activities.
Requests for these topics will be ignored and may result in moderation action.
<:matsuripray:1159685390156967936> Community Expectations
- Be Polite & Patient: Our helpers are volunteers. You may ping the
Helpersrole once. - English Only: Please keep all conversations in English.
I see thank you.🙂↕️
What is your PC GPU? Did you follow any tutorial before this?
Sorry but it's not Ubuntu, NixOS is one of these weird exotic distros that does everything differently
never used nixos but wouldn't you have to add all dependencies to nix os config and regenerate system so it will grab all packages ?
Unsupported post request. Object with ID 'xxxx' does not exist, cannot be loaded due to missing permissions, or does not support this operation. Please read the Graph API documentation at
GUYS HOW CAN I FİX THİS, WHATSAPP CHATBOT VİA FACEBOOK DEVELOPERS
-colab
📒 Google Colab Notebooks
Google Colab is a Cloud (Remote Good PC) Service. While the Free plan provides up to 12 hours of daily usage, the GPU is typically available for only about 4 hours each day on average.
• **Applio**
by IA Hispano
Google Colab
• **RVC Mainline**
by Hina
Google Colab
• **UVR5 NO UI**
by Eddy
Google Colab
• **UVR5 UI**
by Eddy
Google Colab
• **Wokada Deiteris Fork**
by Deiteris & Hina
Google Colab
• **Hina's Modified Original Wokada**
• **RVC-AI-Cover-Maker-WebUI**
by Shiro & Eddy
Google Colab
• **FaceFusion UI**
by Nick088
Google Colab
• **FaceFusion NO UI**
by Nick088
Google Colab
• **Music Source Separation Training (Inference)**
by Jarredou & Makidanye
Google Colab
hi! how would i go on about training a voice model?
i wanna use it for narration
literally have no time to read
RVC is STS (Speech-To-Speech), not TTS (Text-To-Speech) natively, unless you use another TTS to make an audio output to use as an input in rvc (which is what for example the Applio RVC fork does automatically with Edge TTS, which is multilingual and good but emotionless)
hmm so i'd need a tts to narrate and put the narration into the rvc?
yooo can someone help me out with formant shifting? (about how it works and how to use) for context i have male voice and trying to apply that voice for female portion of the song

So I got an AMD Radeon 860M gpu, should I run a voice model on cloud?
yeah, your gpu isn't the best for local AI
i'm guessing you want a realtime voice changer for calls/games (not pre-recorded audios) and are atleast on windows 10/11
-realtime
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested WebUI with the best general support for many platforms. GUIDE
• Vonovox
A Realtime Voice Changer with similar performance to Wokada Deiteris Fork, with extra features, but supported only for Nvidia GPUs on Windows. and without cloud options GUIDE
⚔️ Wokada Deiteris Fork vs Vonovox
For Windows Nvidia, Both Wokada Deiteris fork and Vonovox have similar performance & quality. Users should read the pros and cons for both and choose based on their differences, such as UI and Vonovox's paid effects.
Read Wokada Deiteris Fork Pros&Cons & Vonovox Pros&Cons
⛔ Outdated/Discouraged
These options are not recommended for use.
• Original Wokada
Not suggested, older versions in youtube tuts are even way worse. GUIDE
• RVC GUI Mainline Realtime
The program is worse compared to the ones above, and much less updated. GUIDE
you can use wokada deiteris fork or tg develop modified version
i mean, do you need specific voices or do u just want a general TTS?
u could just use a TTS alone
those sound awful
Hi, I need help with RVC.
I believe my RVC is not functioning as intended. It does not change my voice at all. the delay is also extremely inaccurate. It's my own voice no matter what I change. It also does not let me hear myself unless I use pass through option.
The GUI of it is also very different with what I've seen from others.
v 1.5.3.16a onnxdirectML-cuda
I also have an AMD GPU, so if I should download a newer/different version of it or do anything to get it to work please tell me.
-rt
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested WebUI with the best general support for many platforms. GUIDE
• Vonovox
A Realtime Voice Changer with similar performance to Wokada Deiteris Fork, with extra features, but supported only for Nvidia GPUs on Windows. and without cloud options GUIDE
⚔️ Wokada Deiteris Fork vs Vonovox
For Windows Nvidia, Both Wokada Deiteris fork and Vonovox have similar performance & quality. Users should read the pros and cons for both and choose based on their differences, such as UI and Vonovox's paid effects.
Read Wokada Deiteris Fork Pros&Cons & Vonovox Pros&Cons
⛔ Outdated/Discouraged
These options are not recommended for use.
• Original Wokada
Not suggested, older versions in youtube tuts are even way worse. GUIDE
• RVC GUI Mainline Realtime
The program is worse compared to the ones above, and much less updated. GUIDE
What about actual voice models? Like voices. What are some of the best/most popular and most importantly trusted models here? I want something standard, grounded and realistic above all. Not female since I don’t wanna accidentally catfish anyone.
There are thousands of models that you can search in #1175430844685484042 and https://weights.com/models, but there isn't like a "common guy voice", the models are trained off a voice
Hi, is the Spin pretrain supposed to sound like garbled mumbling, even when I'm using the new LegacyCore spin pretrain and have selected the Spin feature extraction?
you need to prepare your dataset with spin embedder and infer with spin embedder
i'd not use that pretrain because it got trained when the discriminators were broken
also there are two of them now (spin and spin-v2)

{kind=link}