#✨│ai-help
1 messages · Page 263 of 1
i miss going onto someones computer while theyve gone to take a shit or whatever, swapping one of their apps to a fake virus file that just shuts down the computer after like 30 seconds and watching them panic
Youre evil
i know :D
Hi guys, I've found this model https://github.com/Alibaba-NLP/WebAgent?tab=readme-ov-file on hugging face https://huggingface.co/mradermacher/WebSailor-3B-GGUF
Then I've deploy it on huggingface but I do not know how to make it work with internet. In docs said that I can just add an enviroment variables which I've did on huggingface but it still doesent have access to the internet. Can someone help me?

For kaggle, when I try going to the file browser (The third link) it wants me to long in and I dont know where to sign up

if you were curious, its this one

!filebrowser users add "applio" "" --perm.admin
if that does not give you a hint...
username: applio
password: (blank)
guys
deiteris okada wont let me delete uploaded models
Error
unhandledrejection
no error stack
TypeError: Cannot read properties of null (reading 'modelSlots')
TypeError: Cannot read properties of null (reading 'modelSlots')
at i (http://127.0.0.1:18888/index.js:2:1249327)
at Object.updateModelInfo (http://127.0.0.1:18888/index.js:2:1251031)
how can i fix this
Didnt work btw

delete model slots and remake them?
close the app and just do it from windows explorer
thanks
uhh,so my laptop has a igpu,but can i use the rvc models for tts stuff
uhh, should i stop it?

"grad norm g = below 300 and going down, i personally noticed if grad g is over 400 the model has always some random problem"
basically,yk how u cant really use the realtime voicechangers without a gpu,cann you atleast use the tts services?
I assume you're using codename's fork.
yea
gradients do not tell you when to stop
it is just a measure to see whether something wrong is happening
like norm g going up and up and up into thousands and then 10 thousands+

with a regular model trainig this would mean the model is utterly fucked up
I said before, norm g going over 1000 is likely means the dataset is wildly different that the pretrain, like high pitch singing dataset using og pretrain
and if it keeps above 3-5k it is not gonna be good
usally 300-500 norm g is fine
so basically, I’ll just keep training, and make sure it doesn’t hit that number, right? (cmiiw)
and yea, my dataset’s full of high pitched vocals, and i used the klm 4.9 pretrain
norms are your secondary concern
so what's my main concern? fm?
yeah
ooo okay, thank you
there's two fm graph, which one i should take a look?

got it
bumpy
try in another browser or with cleared cookies
I got it working, I just needed to restart the session sadly


bump again
If I have only one minute of a dataset of a voice, and I want to train an RVC model, if I train enough will I get a good result?
can someone help :3
Do you still need help? if so, please elaborate
wdym? realtime voice changer or tts? what do you want to do exactly? those are 2 different things, and RVC doesn't mean realtime voice changer, it means Retrieval-based-Voice-Conversion
tts but with custom voice models
found in #1175430844685484042
RVC is meant for Speech To Speech, (STS), not TTS
There are different Text To Speech (TTS) AIs:
- GPT So Vits: Great Few Shots (needs a lil training) TTS, its only limited to: english, chinese, Cantonese, japanese & korean, if you wanna check gpt so vits instead, read https://docs.aihub.gg/tts/gpt-sovits/
- 11labs: Easy way to do TTS is https://elevenlabs.io/, its a mostly premium easy way for good quality TTS
- FishSpeech: FishSpeech is a 0 shot (no explicit training needed) TTS, if you got a good pc you can use it locally else use their site
You can check other TTS in our tts index
With RVC Models:
RVC is natively for Speech To Speech, but forks such as Applio have built in tts (using Microsoft Edge TTS to make a tts audio, i suggest you to choose a tts model that is the same gender and language of the rvc model you wanna use, and then convert it with rvc)
If you wanna do tts locally with RVC Voice Models (if you got a good pc):
- You can get Applio in our docs
If you don't got a good pc you can do tts with RVC Voice Models on cloud:
-
Use Applio UI Colab (with google colab T4 free daily limit gpu)
-
You could try another tts from our tts index and use the output as an input in rvc
I hope this helps, if you didn't understand something, you can ofc ask
@simple ore also talks about some other tts called chatterbox, but I haven't tried it yet so I can't say much
im confused on the 'i suggest you to choose a tts model that is the same gender and language of the rvc model you wanna use, and then convert it with rvc'
ilaria rvc zero on pinokio doesnt detect the gpu, im clueless and not on pc, someone know why so i can fix it?
the fm graph hasn’t going up at all, is this a problem with the dataset or the batch size i’m using? my dataset is 25 minutes long and i’m using a batch size 8

RVC is for STS, not TTS
So the only way to use it is via using another TTS model as a base to first make the audio, there are a preset of models in edge tts, if your rvc model is an american man, you choose an american man tts model as a base to not make it sound weird
I Never Be Friends On Friend Request DM In Discord
that has nothing to do with this channel


what tts language do you need?
could someone tell me why it doesnt do anything  (when i add any model, its marked red aswell)
(when i add any model, its marked red aswell)

If is marked red means is selected
In what sense it doesn't do anything
works now, just not well
im at work now anyways so i cant tinker rn 
How Dare You


ltt gif is wild
batch 8 is a pretty small batch size so things are very slow, just wait, fm will eventually go up
how much should i set the smoothing to see the fm graph?
with avg_50 charts you dont need to smooth.. maybe 0.5 max

so nothing to worry about, right?
thats too high
the beginning?
everything
fm usually have values of 7-10
perhaps normalization issue
idk but something is wrong
for KLM pretrain, maybe try -23 lufs
slice normalization is better
codename fork doesnt have that
so either download applio main branch or do the slicing in mainline
im fine using applio main branch
in the main branch slice norm is named "post" in the preprocess settings
so first I sliced the audio, removed the silence, merged it back, then in rx 11 I used the leveler with -14 threshold and normalized it to -1, is it wrong?
yes
just get the regular clean dataset
and slice it using mainline or the new applio branch
i mean codenames fork is experimental, i think noobies already told u that when yall talked about it in #🔥│model-maker-chat and ur model exploded
per slice normalization would resemble of the og mainline
thats what im talking about
it gives better results
rvc boss added it for a reason
yeah, my bad. i was just still curious about the codename fork, that’s why i decided to keep training there
if you only use the default settings its kinda pointless to use it
mel similarity is mel loss
and you dont need more grad norms graphs
just use applio tbh
okay okay, i'll go back to applio, thanks for the info guys
no problem, good luck 
oh yeah, if you don’t mind, could you share the step-by-step process? just so i don’t mess it up again. or is it already in the docs?
- clean the dataset, dont touch the volume, just remove bad sounds
- (optional) resample using rx11 and truncate silence
- preprocess in applio, in the advanced settings use "auto" and in the normalization option select "post"
- pitch extract
- train
anyone can tell me a good voice to AI colab or huggingface repo for models saved on huggingface?
d/adv = going down
mel and kl = going down
fm = going down for a couple of epochs then going up
g/total = this is a weird one, just ignore it
grads norm = both going down, grad g should be between 100-500

Hello! Last time I asked about the advantages and disadvantages of using AMD cards against nvidia ones.
Still keeping with the theme of hardware, I have questions about usage.
I would like to know how the session of selecting the hardware to run works. How do we select on when models should use GPU or CPU and to use RAM or VRAM?
which pitch algorithm is better between crepe, rmvpe, rmvpe+, harvest or pm

What is this supposed to mean? Are you looking for a FNF VS mod or something?
rmvpe. I'm not sure about the rmvpe+ one.
too high usually leads to the model having some sort of artifact, maybe a slight robotic sound, bad sibilants, etc
it's all random
it means your generator is struggling
no problem, like noobies said above, what seems to cause the grad g to be higher is when the dataset is too different from the pretrain
What are you trying to do exactly? Make an ai voice or use one as a voice changer?
I fixed already thanks though, found this one https://huggingface.co/spaces/TheStinger/Ilaria_RVC
Cool 👍
Yes
There are a lot of Google Colab and Hugging Face spaces that can do RVC, one of them being Ilaria RVC on Hugging Face as you mentioned.
Try not communicating with him it's like taking to a drowning fish
I Hate Fixed Movie On Netflix 😡
That's goofy. Imagine looking for a FNF mod in help channel. 

Is New Maeko By Seanleddy167

I Drawing To New Maeko On Ibis Paint X

Good job buddy
Can't help with that since I don't play Friday Night Funkin. This channel is about about AI programs like RVC and W-Okada, that's one of my best I would help with. For a normal topic not strictly related to AI, it would be better to go to #✦│chat.
He is going to respond with something completely unrelated to what you said now
Yeah, I'm aware he's just a kid on Discord. Not too deep about that.
Anyone here with like a working knowledge on ai short form content creation? I've been trying to create shorts all day using chatgpt, Sora, runway etc but I've got nowhere, as it never really created what I was looking for
It's better Wokada Deiteris Fork or Vonofox actually? About the quality/realism.
Pretty sure Vonovox is better but I'd wait for the new update
Oh yes, why?
Why wha
Why waiting for the new update?
Do you mean "which one is better between Deiteris fork W-Okada or Vonofox"? Definitely fork W-Okada.
Exactly, about the quality / realism of the voice.
It'll allow adding index files so then there can be a true comparison between both voice changers
Index not really work correctly no?
It's Vonovox right? I hope I haven't been mispronouncing it
No it's just there isn't an option yet in the current version
I never use index with okoda, because it's not very good for me.
If you ask me "why" though. On Vonovox, its UI is kind of professional, not really user-friendly interface as W-Okada. https://github.com/dr87/Vonovox/blob/main/docs/images/ui1.png?raw=true
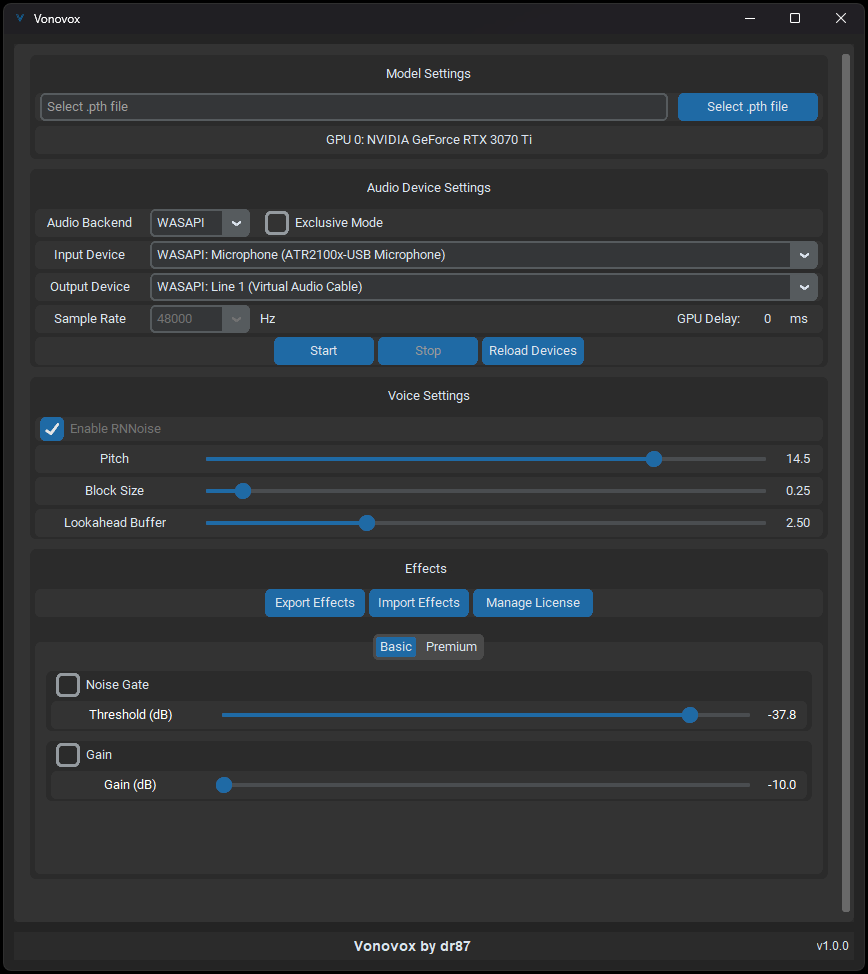
I was just asking about the quality of the models 😄
Nah, I interpreted your earlier questions like that. 
I wanted to know which was better, in terms of model quality. 🙊

In terms of realism etc
both have the same quality bro
Oki
i though it was rvc gui lmao
Please, stop asking help for that
This guy will never stop, more we say it to him more he continue😭
What are you trying to do? AI Covers? E girl trolling/catfishing? TTS? Roleplay?
Roleplaying on RedM
great as catfishing is bad, what's your pc gpu? vonvox is supported only on nvidia gpus on windows
RTX 4090 for gaming, RTX 4070 on a second computer for voice changer only
both would be good tbh, the major difference will just be the UI
run the server on second computer, use ui on the main pc
Hum I see, index is not really good with real time right?
can help with the trained accent, but cause autotune effect 
if you run it on second pc it may be fine performance-wise
I am french with a french model
My settings


turn disable jit compilation on, and crossfade lenght to 0.15
then ur all done
Quality will be better?
When Disable JIT compilation is on, more delay is added right?
actually, it helps with less delay, but takes a few seconds more at startup
crossfade lenght 0.15 helps a bit with quality
gonna try
you can't do much more than this tho
I am yellow / red now with disable jit compilation on

So I need to add more chunk, mean more delay right?
Hey y’all, I’m Masresha (or M). I work as an estimator in construction, but I’ve also done field work, so I’ve seen both sides of the industry.
Been thinking a lot about how outdated some of our processes are, and I’ve got an idea that could really push things forward using AI.
Before I dive into it, I just wanted to ask:
How feasible is it to train or use AI to read structured files like blueprints or technical drawings and generate something visual + interactive from that?
this seemed to have been caused by the crossfade lenght 0.15, yeah, put it to like 60 or 90
Hi Nick, you seem like you might be able to help me out, anychance?
It's too much for roleplaying
off and crossfade 0.15 I am fine
best bet is just ignore him, he doesn't understand basic human conversation
or anything at all in fact
He is still asking for that
he'll never stop
Someone please give him whatever he wants
he showed me the audio it's literally a chromatic scale
if u dunno what that is just think about pressing the keys on a piano from lowest pitch to highest
very slowly
one at a time
but instead of a piano it's the "voice" of the character

whenever I start a model my pc stars stuttering even when not talking, but nothing is utilized even at 50%
voicemeeter isn't suggested, don't use yt tuts for realtime voice changers
This is a General AI Server, AI has many fields, so we can't know your issue
Please Elaborate:
- your PC GPU
- your operating system
- what you want to do
- what tutorial link are you using
- a screenshot of the program
Please Elaborate:
- your PC GPU
- your operating system
- what you want to do
- what tutorial link are you using
- a screenshot of the program
i ended up using two Virtual cables for what i needed to do lol
was trying to get ai voice to work with a TTS to work for a Voice into a game
now i can talk to people as bmo lol
AMD Ryzen 7 5700X3D 8-Core Processor
RX 6600 XT
Screenshot: https://i.imgur.com/VD9wOKN.png
I just used the link in guides, and got the first client.
ohh nvm then, thats great
first client
that's just called wokada deiteris fork, not client
also what are you trying to do?:
- AI Covers
- E Girl Trolling/Catfishing
- Roleplay with the realtime voice changer in a game
- TTS
- etc
To be sure you're using the right program
Rp
This is a General AI Server, AI has many fields, so we can't know your issue
Please Elaborate:
- your PC GPU
- your operating system
- what you want to do
- what tutorial link are you using
- a screenshot of the program
alright, so roleplay in a game?
set f0 to rmvpe onnx
extra 2.7
on wokada deiteris fork, you can **optionally **use more advanced settings for benefits:
- Advanced Settings -> Force FP32 mode: on (THIS IS OFF BY DEFAULT! Turning this on improves stability. Increases VRAM usage by 200 MB)
- Reduce the delay on Windows via: https://docs.aihub.gg/rvc-voice-changer/local/deiteris-w-okada-fork/#reduce-more-delay
Set game graphics to the lowest 1080p 60fps, what game are u playing?
set graphics to the lowest, play on 1060 and 60 fps locked, try the settings i told you, close other programs in the background
And if I want to remove noise when a sentence ends or when im breathing which one is best from the three? Echo Sup1 and Sup2?
echo is only for echo issues
sup1 sucks
sup2 would be the best for this case
Also, please be sure to elaborate, and to not use yt tuts, they are outdated
!give-media-perms 1h @tropic glade
so you dont have to use imgur
!give-media-perms 1h @lavish sequoia
so you can send the screenshot of the program
you can give the perms permanently, I dont bite 😭
Nah they bite 
Jk but those are supposed to be temporarely just for helping
because to get the perms you should be level 10 by chatting, so we make an exception only for helping
btw if I have a model can I make it less robotic by changing some parameters, or do I need to retrain it?
I gave you already the best settings possible, you could also try setting crossfade lenght to 0.15, but if it's robotic its best to just retrain it with a better dataset and following the tensorboard
need to retrain it
realtime client settings do not change the quality of a model really
@paper lotus have you dealt with the issue yet?
@radiant coyote This server is english only, please ask for help in english
that depends A LOT, you need to elaborate the things I asked you, there are many programs and depends on your hardware and what you want to do
It's very crucial info
Please reply to the stuff I asked so I can help you out
it all depends to the GPU and program and settings you're using, thats why im asking that info
onnxgpu? that's for amd
yep you most likely have an over year old version of original wokada from yt tuts
!give-media-perms 1h @noble kestrel
show a screenshot
you're using an over year old version of original wokada for nvidia.. that version is EXTREMELY OBSOLETE
it has wayy worse delay, wayy worse performance and quality
you deffo used a youtube video tutorial
and you also got vb audio cable
delete the zip, folder and uninstall from windows app settings
Hey Guys! Not sure if this is the right Channel but i need some help with applio in Kaggle - got some errors 😭
Wanted to train my model locally but my AMD is not supported
what AMD do you have?
and what errors on Kaggle?
AMD Ryzen 9 7900X 12-Core
that's cpu
Sorry .. AMD Radeon RX 7800 XT
you have two options - Applio using Zluda, Applio using a beta of ROCm torch

GitHub
Self-contained Pytorch wheels for gfx1100, gfx1101, gfx1102, gfx1103, gfx1151, and gfx1201 GPUs for Python 3.12 on Windows by @jammm
Mainly tested and known to run fast on the Strix Halo (gfx1151)...
Which is better or friendlier?
the zluda method has a guide https://docs.applio.org/applio/getting-started/installation#amd-gpu-support-windows

Applio is easy to install. We recommend the precompiled version for new users as it's ready to use.
for rocm you'll need to install python 3.11 and install applio manually, not using run-install
i have not tried rocm method as I dont have 7000 series
I will try this 🙂
how can i check :)?
adrenaline control panel
if you got 25.5.1+ install latest VC++ Redist, install HIP SDK 6.2.4
Sorry... Where.. ? XD

Got 24.12.1
not a fan of updating? 🙂
okay, then the guide above would work
but and update will break it
Not a fan of this information 😛 I'm bit quite familiar with all this xD
Should i keep it at 24?
up to you
Server of Windows 10 &11?

again, make sure you are downloading the right version... 5.7 or 6.1 for old guide, 6.2.4 for new guide
window 10 & 11, obviously
3.2.9

that's fine
sorry
your charts are f-d up

fm is going up, g total is too high
how big is the dataset and batch size?
d got too strong, gen looks weak
Don't have a feeling it's doing something ...

batch size is 4, and as for how big it is, idk if you mean how long is it or the file size
i mean... is it like a character voice from some anime that was heavily processed?
zluda training is very slow
a robot voice
it is compiling kernels, gonna take like 20 min
not on 7800xt
ah now its doing something
What even is this
it's a kpop idol
it will compile more, as training has more operations
zluda
What's zluda do?

...
it is CUDA emulator for AMD gpus
to run different AI projects from stable diffusion to tts, to rvc
What I do wrong 💔
nothing 
Anyone suggestions about batch size, and how many epochs

depends on the dataset size
It's 35 minutes of singing (deverbed and acapellad through uvr5)
you got 35 minutes, so anything from 4 to 8 is fine, may need to experiment / merge different models maybe
set it to 300e
do you guys think that 300 epochs are fine for my 11 min long dataset
i'd use batch 32 for 35 minutes and train until the model sounds robotic
stopped the training for you
if i want to tryhard it i'd also train a batch 16 model of the same dataset, then merge it with the batch 32 model
lmaooo
how can i use my tenserboard (it says no boards to show)
and then you can train batch 4 and batch 8 models, merge them, them merge the merge with the merge of 16 and 32
and see it collapse into a black hole
stable diffusion community has been doing this for years now lmao
every model out there is a merge of 200 models together  so shit
so shit
SO far, so great XD

It's 22:46 XD
or to sleep
-colab
📒 Google Colab Notebooks
Google Colab is a Cloud (Remote Good PC) Service. While the Free plan provides up to 12 hours of daily usage, the GPU is typically available for only about 4 hours each day on average.
• **Applio**
by IA Hispano
Google Colab
• **RVC Mainline**
by Hina
Google Colab
• **UVR5 NO UI**
by Eddy
Google Colab
• **UVR5 UI**
by Eddy
Google Colab
• **Wokada Deiteris Fork**
by Deiteris & Hina
Google Colab
• **Hina's Modified Original Wokada**
• **RVC-AI-Cover-Maker-WebUI**
by Shiro & Eddy
Google Colab
• **FaceFusion UI**
by Nick088
Google Colab
• **FaceFusion NO UI**
by Nick088
Google Colab
• **Music Source Separation Training (Inference)**
by Jarredou & Makidanye
Google Colab
It's only loading the pretrained models... does it really take this long? it's not even making epoches yet....
as I said, it has to compile kernels for the new operations it found in training
20 minutes give or take
do you wanna be an e girl or something like darth vader
@simple ore Average speed of 2 minutes... is that oke or really slow?

i have a question about this post (and reletaed ones in there): https://discordapp.com/channels/1159260121998827560/1364953969389994004
How does this work?
What is it exacly?
i see very realistic demos send in there and i am able to download a pth file, but i cant put that into my w-okada. so what is it and how is it used?
2x faster than my old 6700xt
should be faster next release, I think 7800xt supports bf16
Ah oke! What release :)?
uninstall everything you've installed, - vb cable and other stuff
it is outdated guide and outdated software
This is a General AI Server, AI has many fields, so we can't know your issue
Please Elaborate:
- your PC GPU
- your operating system
- what you want to do
- what tutorial link are you using
- a screenshot of the program
Hi everyone,
Has anyone successfully added SPIN (Spin Embedder) support to Applio 3.2.9?
If yes, could you share the steps or a patch?
Or is it better to just switch to codename-rvc-fork-3 since it has native SPIN support?
thats outdated asf lmao
oh shit i didnt see u my bad 😭
first, may i ask what you're looking to do? are you trying to do e girl trolling/catfishing? since the tutorial is about ai girl voice and i need to be sure its the right program u want
yeah u can delete everything, and are you trying to do e girl trolling/catfishing too like the other dude since yall were using the same tutorial?
ohh, im sorry for your gender dysphoria, and that's good that you arent trying to catfish because that's not allowed and can lead to illegal stuff
yeah no lol, everyone can make a new tutorial about windows xp, it doesn't mean its new tho
the tutorial uses an over year old version of original wokada, delete the folder and zip
and vb audio cable creates random issues on windows such as crackling, uninstall from windows app settings
after that
-realtime
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested WebUI with the best general support for many platforms. GUIDE
• Vonovox
A Realtime Voice Changer with similar performance to Wokada Deiteris Fork, with extra features, but supported only for Nvidia GPUs on Windows. and without cloud options GUIDE
• Original Wokada
Not suggested nor maintained, older versions in youtube tuts are even way worse. GUIDE
• RVC GUI Mainline Realtime
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
please read carefully the 1st link, wokada deiteris fork, it has also the vac lite which is better than vb audio cable
there's also vonovox, they are basically the same thing, the only major difference is the User Interface and that vonovox got premium voice ffects like bitcrushing that wokada deiteris fork doesnt have
Dont worry about the dump, we love to help trans or people who just want to feel themselves, we just make sure to not help people who try to use AI for Harm such as tricking others to get money (nitro ekitten 😭) if u get what i mean
you're welcome, you could use either of the first 2, there isn't much difference than the things I explained
ofcourse we promote AI for good things
well, let me know
you can put it into custom embedders folder

One message removed from a suspended account.
Hello nick can I ask you something
to train with spin you need a pretrain
the original doesn't work with it, unless you finetune 30 hours of data
noobies has some spin pretrains, and also there's the klm one
does anyone know an unlimited text to speech tool (I would love if it was free and won't mind if it's paid as long as it doesn't run on credits)
what language?
english
4060 laptop
could handle offline voice generation
but i would love if it got emotions
how do i download voice changer client demo??
anyone know a lightweight few-shot tts engine like gpt-sovlites, but not as computationally intensive? thinking something that can run on my swiftshader
how would i go about making my own voice model? like what tools should i use to create it
@simple ore @simple ore h.
I don't recall anything not much more demanding than zero shot TTS
if you want zero shot one, try chatterbox as shown in the link above
please refrain from pinging random person for no reason

Is it less computationally intensive than gpt-sovlites
Can we use it without input audio
even RTX 3050 laptop should be capable of
holy fk im losing my mind with this i need help
so i found this channel that does dreamcore liminal storytelling things
and i was wondering where they got those voices from? (disregarding their 2 most recent vids and the backrooms one) i assume its AI but it could also not be im not too sure
heres their tiktok
https://www.tiktok.com/@liminal.depart
no gpu
what tts do i use that i can call from python and is few-shot
yes, you'll get random voice
hi
idk why but no girl model ever sounds good for me 😭 I tried about every setting (mostly tune) but it still sounds fake af
guys
why cant i choose
another model
like it doesnt show no matter how i click
This is a general AI server, we need details on what program youre using, for what and your GPU name
Original has bugged "Extra" setting which causes cpu overload for some people (unsure what causes it, some dont have this problem but a lot do), so theyre forced to use lower numbers so lower quality
Not related to quality but fork uses less hardware resources so your gpu has more power for games to play next to it ; or reaching lower delay
Thats usually another reason for people to choose it
Oke guys i'm angry at my pc
it started up appearently and now only did till 80 epoches
how can i go further?
Out of all my local training doesn't come any sounds.... i tried e40/e60/e80 @simple ore
Can someone help me set up audio forwarding from one computer to another via LAN? I've already found how to do this and it seems to have worked, but I don't have a virtual cable in second place to output from voicechanger to the channel
in the virtual cable it says that the driver is installed, but it doesn't work
and voicemod 3 says that it was not possible to download the driver
Hi guys, im trying to host my vc on my new laptop but its not working? i already set the ip correctly for my main pc and my new laptop
nvm i did it, but when i try to activates it. I barely could use it. rtx 4060 laptop btw
then the cloud solutions are viable for you
the huggingface spaces are mostly zero shot
im not sure about GPT sovits for collab, or you could rent some gpu in runpod, vast.ai, etc
i dont get it, my 3060 laptop did wayyy better then this

show the tensorboard
Yesterday it wasnt working aswell
at least send the events.out.tfevents file
So it's all solved right?
Sure
This is a General AI Server, AI has many fields, so we can't know your issue
Please Elaborate:
- your PC GPU
- your operating system
- what you want to do
- what tutorial link are you using
- a screenshot of the program
This is a General AI Server, AI has many fields, so we can't know your issue
Please Elaborate:
- your PC GPU
- your operating system
- what you want to do
- what tutorial link are you using if any
- a screenshot of the program if any
It has performance optimizations, it is true that it depends mostly on the model, but settings like force fp32 mode and crossfade length to 0.15 can help, which original wokada doesn't have
Rvc models aren't perfect, don't except to do any non natural sounds, anyways it's not a big deal, you're using just for roleplay as you said lol
Show a screenshot of the whole settings
This is a General AI Server, AI has many fields, so we can't know your issue
Please Elaborate:
- your PC GPU
- your operating system
- what you want to do
- what tutorial link are you using if any
- a screenshot of the program if any
You're welcome
Guys does any of you how to fix this I'm trying to resume a training for my model >.<

the sample rate setting must match the one used in the preprocessing and last training session, and also the pretrain used
actually im wondering if theres any software or drivers ishould download first before installing deiteris fork
Virtual Audio Cable lite is needed if you wanna use with Discord. And make sure your GPU driver is stay up to date.
It matches tho
lol
Ill just retrain using kaggle 🙂
thanks,
Guys if my sample rate is 44.1K is it ok to put 40K since I cant find 44K option 😟
"44000" doesn't exist in any RVC. Are you trying to train a voice model or something?

if you think the quality is good enough, you can try going 48k anyway
but note that inference would take less time and memory with model in lower sample rate
Its ariana's pro tools anyway
my goodness it sounds just like her 🫢
oh so it actually was her? 😂
ah 😂 well hopefully your version will sound like that when its done!
That's more like a dataset sample extracted from a song, not the AI converted one.
oh 😂 well hopefully the end result will sound super close
tbh it's also not wrong to go 32k and it would take less resources in both training & inference
so it could be good for voice changer
📚 RVC Documentations
AI HUB Docs
🍏 Applio Docs
Thank you I'll try
Can someone help me set up audio forwarding from one computer to another via LAN? I've already found how to do this and it seems to have worked, but I don't have a virtual cable in second place to output from voicechanger to the channel
in the virtual cable it says that the driver is installed, but it doesn't work
and voicemod 3 says that it was not possible to download the driver
Are you using W-Okada? I can help about W-Okada and Virtual Audio Cable, not Voicemod and VB-Cable.
i was trying to use applio on my 5070ti gpu but i think theres cuda problem

anyone know how can i fix
Did you follow this step? https://docs.aihub.gg/rvc/local/applio/#nvidia-rtx-5000-series-on-windows-precompiled-fix There's a way to make Applio to run with RTX 50 series GPU especially.
Using regular Applio won't gonna work with RTX 50, so make sure to install Applio from start again with the exact but more additional steps.
#🌏│русский message i use this vc

fork of w okada
can u help me pls
In the applio folder, we will open cmd and download the version of pytorch that is compatible with rtx 50. I think this is an extra feature.
Yes, this is literally the Deiteris fork W-Okada. Is your PC GPU an AMD Radeon RX one or something else?
rtx 4060 ti
Try follow this step. https://docs.aihub.gg/rvc-voice-changer/local/deiteris-w-okada-fork/#opening-on-multi-pc-setups
Last update: July 18, 2025
ok
Inside ".env" file would look like this. This is mine.

i tried but didnt work same thing. i was using another thing other than applio that was RVC something but i lost that one,
If it didin't work, it can either be you missed a step or there's a problem with your GPU driver.

If you see Running on local URL: https:// 127.0.0.1:6969 on terminal after double click on run-applio.bat, it means it's all good. Without run-applio.bat, the program won't gonna run.
well its quitting after install
i cant see that one

this thing annoying omg
C:\Users\user\Desktop\uygulamalar\ApplioV3.2.9>env\python -m pip install torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --upgrade --index-url https://download.pytorch.org/whl/cu128
i did this and the result

idk it didnt run applio
just exiting

GitHub
Apr 24 update Install Cuda Toolkit 12.8 --- not required from Applio's folder start a command line, then run env\python -m pip install torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --upgra...
it install updated torch
then you can run applio normally
This command is not where you run Applio the program itself. It's a command that runs a Python program named pip to install packages for Python. After it finishes downloading and installing, it simply ends there.
.... what?
you run it from applio folder
the screenshot above shows it was done properly
yea i just realized my bad
but after i run applio on command line
still cuda error
nothing changed
But he said "it didn't run Applio" after doing that?
No, don't confuse me like that.
try to not intervene if you dont know whats going on

- Unzip v3.2.9 2) run env\python ... line to install updated torch 3) run run-applio.bat
nah i cant do thing :D
tried that this happens all way
I'm sorry? That's my fault? Anyways.
show the training UI
open Advanced drop-down at the top


0 is correct, you should not touch it
when i click train that error happens other ones works good

index etc is okay
RuntimeError: CUDA error: invalid device ordinal
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
Sometimes, I'm at lost when I didn't help with my own specified screenshot, because text isn't enough to imagine. Now that I have to install Applio again just in case.

could you open cmd.exe
and type 'set'


okay, that's fine
Yes, I can read that. I open it on browser, so it's fine.
@tough fiber well, something to try: could you close applio terminal, open rvc\train\train.py in notepad, find the line gpus = sys.argv[6] and add a new line after that print(gpus), then re-run training and see what it outputs in the terminal log

sec running applio


okay.. and then?


okau, so you messed up something before
probably u right
okay, you can remove the print line
so should i do something any different or anymore should i click run applio and train models normally
This looks fine now.
no, you've updated torch, all good now
No problem. RTX 50 GPUs are too new, so it can be hard to get that to work.
its training quite fast is it normal i didnt train before with 50 series

I think it's normal since the fans are speeding up.
The thing is my laptop is too old and slow, even Applio won't show up.

Yes, this is good now. Would you let it continue or stop it there for another training? 
ill let it continue
just open tensorboard
which graph was important
for overtraining
i just forget
is that less one

I might gonna buy Dell XPS with NVIDIA GeForce RTX 4050. While RTX 4050 mobile is not really ideal for large scale AI training, I just wanted to play Minecraft and run RVC.
maan dont buy xx50 ones
that vrams -.-
4060 8gb is okey actually if u can do
even u can play minecraft with shader mod
for rvc vram is quite important if im not wrong 3050,4050 is idk not good with, if u run any game with rvc
The one with NVIDIA GeForce RTX 4070 also exists, but this is more expensive than RTX 4050 one. 
All I can say is that you shouldn't buy a gpu with less than 8GB vram
yea rtx 5050 is 8gb vram but 4050 (6gb) , 4050 (4 gb)
anyone know why after training a model using a local host tool called rvc beta, it only gives me a .index file only? I don't see any .pth files
This Applio looks new than what I installed before this one.

yeah i need to upgrade ive got a 1660 super which has 6gb
C:\Users\user\Desktop\uygulamalar\ApplioV3.2.9\logs\xxxx
xxx is ur project name
did u check here

you're using a completely outdated tool, check assets/weights folder
if you can buy rtx 4060 itll be really good idk price difference than 4050 but its really big difference
oh really
whats a good software to use?..
"RVC beta" refers to some older mainline RVC versions. Not really recommended to use them. There's Applio, which is better than them.

i've been suffering for the past 3 hours
Applio ah I see
thank you guys so much
yall are the best
i was using RVC lol i did really good models on them
before i tried applio but i didnt do lol
so i was using always RVC
now applio work so im good with that

wait so
like 1-2 hours of my time
is gone then right
cuz i was using outdated softwares
did u check
-rvc
📚 RVC Documentations
AI HUB Docs
🍏 Applio Docs
weights folder


Dell XPS laptops are quite rare in my country. There are only ones with integrated Intel GPU, RTX 4050 and RTX 4070. Dell Inspiron laptops also exist, but they don't offer any dedicated GPU from what I looked for. Although some other brands like Alienware, Lenovo and MSI may have 4060.
well 4070 is really gonna be good , playing games with running rvc
idk ur budget but
if u not playing cyberpunk etc which is using too much graphic card and processor ull be okey
minecraft, pubg mobile etc It will work properly with rvc. However, when you play games such as Cyberpunk, the ping value in rvc will increase significantly.
I'm talking about situations where you run RVC together with the game*
It is possible run RVC program like Applio with a game, especially a PC with good GPU, although I'm not sure how would you do convert audio on RVC while playing a game at the same time.

well
i never tried before :D
its impossible i guess haha :D
well it depents how much vram u give applio
im training model on applio and ill try to play brawlhalla rn
but i cant say gta 5, cyberpunk, elden ring etc runs good lol
Is it better than kokoro tts ?
GTA 6 
man

What's that
TTS Text to speech
I meant kokoro, ik what tts is lol
Never heard of it
RVC can be slow sometimes when running with a graphics-demanding game, especially some PCs with entry-level or mid-tier type specs.
That's what i told you it's a tts text to speech program. It was listed on ai hub web page
Ah ok
It was the way u said it that confused me
Last update: Dec 12, 2024
Oops sorry
You're good 👍
kokoro has no voice cloning
and it is somewhat bland
it is okay, it mis-speaks some words, but it is mostly fine
Any other tts without voice cloning. But should be the best and Natural
orpheus
GitHub
Run Orpheus 3B Locally With LM Studio. Contribute to isaiahbjork/orpheus-tts-local development by creating an account on GitHub.
you'll need LM studio to run a server process for the LLM
It's it good for everything. Like the laughing, yelling etc ?
NVIDIA GeForce RTX 5060 Ti (16 GB), this one has sufficent amount of VRAM where you can actually train a voice model there with less slowness. If Task Manager says "31.6 GB GPU memory", the another 15.6 GB comes from either your PC RAM or an integrated AMD Radeon GPU, while the actual dedicated GPU VRAM is still be "16 GB". 
It includes that, but how it performs

my room getting hotter holly
If your room is hot as a whole, maybe there's no air conditioner there?
what's the best embedder model to use?
What embedder model and which program are you looking for?

unless you're using a pretrain with the same embedder, dont try anything custom
contentvec is default
Is it actually good @simple ore
while we talk

237 epoch
which graph was important

Can someone tell me how do I read this lol its from my tensorboard

question, why my VC getting choppy on steam
Last update: May 5, 2025
this is just a spectrogram, you can compare the original and generated one
But look at average loss instead of total
Average 50
when using changer in discord, if someone in the voice channel says something, then this sound is processed and pronounced by my changer. What could be the problem?
Im training my model in kaggle using the save and run feature…. how can I see my saved models
i dont know what you mean by save and run
you should be acess files using the file browser
or download the model from kaggle using training ui, there's an option at the bottom of the training tab
like running the notebook in background
I’m randomly getting massive delays on my voice changer while playing gta 5. They’re random and super delayed. My task manager seems fine. What could be the issue?

WAIT THIS IS GOING TO TAKE YEARS
I SET IT UP TO 1000 EPOCHS
IT TRAINS EACH EPOCH 1 BY 1?
what's your GPU?
that's not a gpu
but its using CPU for sum reason when i followed that tutorial

nvm i was tripping
lol
this one
how did you start applio?
which .bat
why
Applio is easy to install. We recommend the precompiled version for new users as it's ready to use.
ye i did
see 5.2
I assume you also missed half of the other things
path?
okay then close applio, run the proper .bat
depends on the GPU / igpu
try 0, see training tab advanced settings
if it shows the right gpu, you're good
4.1
okok
and, I assume, 4.2 or 4.3 too
dude ngl
thank you
i cant imagine the amount of people like me you have to deal with everyday
danke
Noobies this is what Im talking about earlier I trained using this

you got UI?

okok
Not done training tho haha
where does it say you need to run it?


are you trying to run it as admin?
nope not at all
show the folder contents


do not run
lets start from the start
okokok
then follow starting from step 3.2
no
where does it say open it as admin?
oh but i normally run cmd as admin to locate a path and run cmds there
okokok
ill try that
Do not run anything as admin, unless it is specificaly required
unless you want 540 viruses instealled on your PC
What is a QC in Ai hub


lol
😭
oh
you need to unzip properly
okko i fixed it
Add C:\Program Files\AMD\ROCm\6.1\bin to your system's Path environment variable. this one uh
how do i this boss?
okay i did it nvm
Error loading "C:\ApplioV3.2.9\env\lib\site-packages\torch\lib\caffe2_nvrtc.dll" or one of its dependencies.
now it says this

@viral mason do you know what is QC ? What it do about how
Or @simple ore do you know about that
they were people evaluating models for people seeling model master role
daddy noobies help a brother out 😭
follow the guide
step by fucking step
do not skip
do not ignore
I DID DADDY
what did you do

i went into the
show the screenshot
SystemPropertiesAdvanced
environment variables
then added it
ok wait
wait do i need to restart my pc
ugh lemme just try that
fuck my life
amd radeon 6900xt
windows 10
make an ai voice model
no tutorial (that's what im asking for)
no program (that's what im asking for)
okok

so like
i added it right
the amd 6.2 thing
WAIT THE AMD THING RAN
IT RAN
IT FINALLY RAN
... does the instruction say you need to install hip sdk 6.2?
open training tab, expand advanced settings at the top

what is your adrenaline driver version?
boutta suck my dick
and jump out my window
thanks
ok inshallah
praying this works

 im aboutta go insane
im aboutta go insane
ok i removed it
and now it has another error message
LMFAO
Error loading "C:\ApplioV3.2.9\env\lib\site-packages\torch\lib\cublas64_11.dll" or one of its dependencies.
without quotes

just this

it says this
okay, so you did not run patch-zluda-6.2?

did you add path to 6.2/bin ?

not the Path

oh
thats so haram wtf
wait so
C:\Program Files\AMD\ROCm\6.2\bin
i add this
as path right right?
ok i did it
i editted that and made a new path
just add a new entry
okok
ok i did it
wallah if this doesnt work
im not feeding my cat snacks tonight

she's getting fed today
💪
thanks noobies
you can touch my boobies
wtf i should be a rapper
I'm scared

Someone please?
okay its done but uh

the model finished training in 1 minute
something has to be wrong
ok yeah i only hvae index wtf
I'm sure you fucked up the preprocess
oh my fucking god
since you need to point it to a folder with the audio, and not at C:\
wtf
ok
ima just
do it all again
C:\Users\Knock\OneDrive\Documents\sex
this one doesnt work then right
oh my fuck my life
there is Seoul's experimental pretrain done with spin embedder
to use it, you need to download the embedder and save it into custom embedders folder
and you need a set of mute files for this embedder
you preprocess the set, extract features using custom spin, then you edit the filelist.txt in the model's folder and change the path for mute files to mute_spin
then you train the model as usual, for inference you'll need to use a custom spin embedder as well
Thats alot of words i dont understand xd. Ill see alm this when im home from vacation, thx already
but that time there will be applio release that does most of these things automatically

see the log

{kind=link}
{kind=link}
ye it said