#✨│ai-help
1 messages · Page 241 of 1
bro whenever i do something myself i mess up absolutely everything
you're missing out on alot of better quality and performance
how can i do it correctly?
uninstall everything you got off that youtube tutorial
then
-realtime
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested. GUIDE
• Original Wokada
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
• **RVC GUI Mainline Realtime**
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
read up the 1st link
wokada deiteris fork >>>> original wokada shortly explained
it's more optimized for better performance and has ways to get more stable models
which original wokada currently dont have
bro what to press after opening the link?
you gotta read it
you have to read it to download and utilize the program
if you don't or skip parts, it might give errors so please be careful
well this is the first step and i already dont know where to download it



you got the rtx 40 serie, that part is for the rtx 50 serie, download the normal rtx one
BRO WHAT
Last update: May 5, 2025
🫡
does this atake olong?

oh nvm its done
what now

no matter what voice i put in it just sounds like a robot
set extra to 2.7, chunk to 140, f0 to rmvpe without onx
did u install vac lite, right?
if not, check it in the virtual audio cable guide part
set output to line 1 in wokada
then, in the other program u want:
input: line 1
output: headphones
be sure to get a good voice model, not all are good
also, u can optionally get better quality and stability by turning force fp 32 mode on in advanced settings but at the cost of some more delay
what if i do it in game?
do i then do it through windows settings?
same shit in the game settings
not the windows settings, leave them
no, just via the game settings
hmm in game there is like a 10 second delay

also is there a way to have it windowed, and not opened in browser
close every other program in background, put game graphics to the lowest ever possible
Last update: May 5, 2025
aaa okay
thanks g i think i understand everything now
are u interested in following a bit more complex process with server mode to get lower delay?
the lower the perf the better right?
Hey everyone! I am looking for an open-source software that will allow me to use voice models to edit recordings, voice-to-voice. Anyone know where I can find something like this?
Hello there, excuse me, how can i run w-okada (that is running locally on my pc) over web? I want to run realtime conversion with my phone, with separate mic and speakers, for a cosplay. Is there any realtive rvc that can work with phone?
Hey everyone, I just launched LifeAI – a simple AI chatbot that runs directly in the browser:
https://lifeai.vercel.app
It currently supports Google login and uses a custom backend to handle prompt/response logic via API.
I’d love your thoughts on a few things:
- Latency management – How do you handle real-time feedback or streaming response UX for AI responses without overloading the frontend?
- Token limits / context awareness – Any tips on managing longer conversations or summarizing history smartly?
- Security for public AI endpoints – How to best protect from abuse if user sessions are lightweight?
- Prompt engineering strategies – Are you using roles/personas/templates that work best for general users?
- Monetization – What’s the best approach for small chat-based AI tools? (Ads, freemium, credits?)
Open to ideas and collaboration. Let me know what you'd improve if this were your project.
Thanks in advance!
support mee: https://trakteer.id/lifevander🥰😇
the lower the perf, the less delay yes
what's ur pc gpu and do u need it for pre-recorded audios or realtime for calls
-colab
📒 Google Colab Notebooks
Google Colab is a Cloud (Remote Good PC) Service. While the Free plan provides up to 12 hours of daily usage, the GPU is typically available for only about 4 hours each day on average.
• **Applio**
by IA Hispano
Google Colab
• **RVC Mainline**
by Hina
Google Colab
• **UVR5 NO UI**
by Eddy
Google Colab
• **UVR5 UI**
by Eddy
Google Colab
• **Wokada Deiteris Fork**
by Deiteris & Hina
Google Colab
• **Hina's Modified Original Wokada**
• **RVC-AI-Cover-Maker-WebUI**
by Shiro & Eddy
Google Colab
• **FaceFusion UI**
by Nick088
Google Colab
• **FaceFusion NO UI**
by Nick088
Google Colab
• **Music Source Separation Training (Inference)**
by Jarredou & Makidanye
Google Colab
ok so i have two computers, one with a really good gpu - how do i make okada's rvc client work as a server and have one computer do the actual conversion so i can max out the settings and have another computer do whatever? i know its a feature in the software i just dunno how to activate or use it and docs are scant on it
Hey all, so i got a pretty high-level question, not looking into implementation details here, just maybe platform or tech?
i guess im not the only one seeing the "Peter and Stewie tech reels" popping up everywhere lately, some of them sound really clean and not just sound like them, also speaks like them tone and pronounciation wise.
does anyone know how they do that?
i tried using RVC and voice cloning but i managed to make it sound like them, not speak like the characters really.
thanks in advance!
can I get the software link that is used to redirect the voice from the voice changer to other output
-colab
📒 Google Colab Notebooks
Google Colab is a Cloud (Remote Good PC) Service. While the Free plan provides up to 12 hours of daily usage, the GPU is typically available for only about 4 hours each day on average.
• **Applio**
by IA Hispano
Google Colab
• **RVC Mainline**
by Hina
Google Colab
• **UVR5 NO UI**
by Eddy
Google Colab
• **UVR5 UI**
by Eddy
Google Colab
• **Wokada Deiteris Fork**
by Deiteris & Hina
Google Colab
• **Hina's Modified Original Wokada**
• **RVC-AI-Cover-Maker-WebUI**
by Shiro & Eddy
Google Colab
• **FaceFusion UI**
by Nick088
Google Colab
• **FaceFusion NO UI**
by Nick088
Google Colab
• **Music Source Separation Training (Inference)**
by Jarredou & Makidanye
Google Colab
any idea why it could not send audio to line 1 but i can hear it using the monitor i tried reinstalling the line 1 still the same thing idk what to try more

can anyone help?
Explanation on GitHub can be found here: https://github.com/deiteris/voice-changer/issues/180#issuecomment-2359166278
In short:
You create a file named .env on the same folder where MMVCServerSIO.exe is located. Open it up with a notepad, copy paste the settings from the GitHub link.
After that, you create another file with the file extension ending .bat, open it up with a notepad, copy paste what is needed in there again from the GitHub link.
Now run the bat file. After it starts, you should be able to open the link. For example, if you specified HOST=192.168.0.1 and ALLOWED_ORIGINS='["https://192.168.0.1:18888"]'), you should be able to open https://192.168.0.1:18888 in your browser and use the voice changer UI from other machines in your local network.```ok so if i open up the ui from pc 2 (if pc1 is running the rvc server), i set inputs/outputs to the mic/virtual cable from pc1, the audio should go from pc2 => pc1 => pc2 again? just making sure i understand
also should i still have the setting as "client" on the ui itself so i can put in the mic & virtual cable?
why not just use the pc with the good gpu for everything? or is trying to use both pc's more of a personal preference?
so it works on original okada but doesn't on deiteris
idk what to do atp
client is your weak PC, browser takes audio from the mic and sends it to the remote server for conversion, it gets it back and send it to the virtual cable on the weak pc
in case you still have questions, OpenVoice v2 is trash
anyone understand this? started running the applio colab with the gradio method and it keeps saying to put this file into the location but WHERE is the location cause im not running this on a program, its just running through a colab

that should not happen
it was working perfectly fine an hour ago and now just keeps saying to download this file and put it in this even though how tf do i do that if im running it through a google colab 😭
lemme check, one min
nope, everything is fine
randomly fixed itself now, weird
can someone help me with training an ai
im trying to train an ai but when i click process data the output is blank
is there anyway to get the .pth file if the runtime is dissconected?
like the one after 300 epochs for example
@azure patio it should be in your drive folder if you had a low enough save frequency assuming ur using google collab
still not good enough 😦 it spikes so bad

set chunk a bit higher
you can’t expect 0 delay
Last update: May 5, 2025
Thanks
yw and lmk
Well i don´t really know where to go, since its been a while, i think a pc reset might solve the problem. At least that is what i hope for.
I cant tell what causes the performance issues, sometimes is super fine, sometimes it looks like this.

are u using it in a game
elaborate when the issue happens
It happens when im ingame yes, but i dort know what exactly causes the problem.
Richtig now the server is empty and i was next to 1 Person and i had a delay of over 3 seconds and more
Then, when im with a Group of people i dort seem to have a problem
that’s the thing, your gpu is doing 2 extremely heavy tasks at the same time
set the game graphics to the literally most lowest ever till you can even count the pixels basically
also cap fps to 30 or 60
I got a 60 cap atm
are the graphics the lowest ever possible?
Will try that, bit the i gwt the Probleme that the game laggs. If the settings are too low lol
what game are u possibly playing
try googling the best setting sfor like potato pcs for that game if u want
Is there a place for recommended settings for the Okada vc?
what’s your pc gpu?
4060
be sure to never use video tutorials
if you used a video tutorial for wokada, you wasted time since they ar eold
❤️ ^^
alr, did you already follow the written guide of wokada deiteris fork?
😅 I followed a tutorial on youtube on how to download the software then I did a bit of customizing by my self
I was looking at the github to learn about the different settings and downloaded some voices fromn the discord
uninstall all you got from it, you 100% got old original wokada and vb audio cable
And both of those cause issues
-realtime
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested. GUIDE
• Original Wokada
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
• **RVC GUI Mainline Realtime**
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
read up the wokada deiteris fork guide, the 1st link
Theoretically yeah but i dont have a folder at all in drive for some reason
Alrighty will do <#
What is best for vocals right now
Hey so I download what I was told to download on the guid and I dont see the option to run the program
I downloaded "voice-changer-windows-nvidia-b2332" I opened the foler and all I see is" force_gpu_clocks | reset_gpu_clocks | and MMVCServerSIO"
Would I just run force_gpu_clocks?
open the mmvcserversio then the .exe
Is the voice changer supposed to be on a google tab?
Also sorry for asking a lot of dumb questions I know you probably deal with lots of people asking the same stuff😅
Last update: May 5, 2025
is there any way to continue training if i have 150 epochs .pth file?
So what app I should use without gpu needed and free?
you can't expect to run ai on potato hardware
@next vortex RVC = Retrieval-based-Voice-Conversion, the best Few Shots Speech To Speech AI Models (on v2), Inferences (use models) pre-recorded audio (ai covers) and train (make) models. Technically, Mainline RVC does have a go-realtime.bat (aka RVC-GUI), but it's pretty messy and outdated so it's extremely not suggested for realtime.
Wokada = uses RVC for realtime inference. There's 2 main versions, Original made by Wok, and the most suggested one is Deiteris Fork (modified version)
which do u need
RVC First
Train (make) RVC Models on cloud:
- Prepare the Dataset
- Setup RVC:
Choose a cloud way to use RVC,
- Google Colabs (max 4 hours of daily T4 16gb gpu not granted for free, not much hours for training, but easy to use, there's a paid tier):
- Kaggles (a bit harder to use and needs phone number but gives 30 hours weekly of better gpus, either T4x2 16gb each or P100 16gb, only free):
- Lightning.ai (Kinda hard, needs login, no issue with web uis or anything, but only free 15 credits monthly, Free Studios run 24/7 but require restart every 4 hours. There's a paid tier):
- Be sure to know about the tensorboard
Google Colab = Easier but risk of getting disconnected
Kaggle = Harder but way more gpu time
If you are looking for the easiest way and for free, is using https://weights.com/ which ofc uses RVC
RVC Inference (use models) on pre-recorded audio on Cloud
You can use either:
- Weights.com: Easiest Possible Ever Automatic
- Ilaria RVC Zero: Fastest free on cloud
- Applio UI Colab: RVC Fork with some extra features like TTS
- RVC AI Cover Maker UI: Automatically Separates the Vocals and Instrumentals, converts the voice and mixes them back
Could be a way I only use without do anything?
what?
you have to ofcourse do something to run programs
What are epochs, batch size and steps?
for one specific model I want to use on w-okada I get this message and I don't know whats causing it or how to fix it. can anyone help me?
Torch not compiled with CUDA enabled
torch\nn\utils\weight_norm.py:134: FutureWarning: `torch.nn.utils.weight_norm` is deprecated in favor of `torch.nn.utils.parametrizations.weight_norm`.
WeightNorm.apply(module, name, dim)
Torch not compiled with CUDA enabled
torch\nn\utils\weight_norm.py:25: UserWarning: The operator 'aten::_weight_norm_interface' is not currently supported on the DML backend and will fall back to run on the CPU. This may have performance implications. (Triggered internally at C:\__w\1\s\pytorch-directml-plugin\torch_directml\csrc\dml\dml_cpu_fallback.cpp:17.)
return _weight_norm(v, g, self.dim)
no
chunk controls the delay
higher chunk means more delay, and the chunk value depends on how much ur gpu can handle
elaborate:
- your pc gpu
- what u want to do
- what tutorial link did u follow
- I have an amd (rx 7800 xt)
- I downloaded a model from weights.com and uploaded it normally to w-okada
- I followed a yt tutorial but other models I downloaded from this discord work fine - it's just this one model that gave me the error message
yt tutorial
that's part of the issue
youtube tutorials are extremely outdated
never follow youtube tutorials for ai programs
ai programs change alot and videos can't be changed like written guides
@woeful bronze uninstall everything you got off youtube
-realtime
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested. GUIDE
• Original Wokada
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
• **RVC GUI Mainline Realtime**
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
read up the first link, the wokada deiteris fork is way better than the old original wokada you got off youtube
@woeful bronze also send the link of the model
okay I will try, thanks!
https://www.weights.com/models/clueaogo700x7d0gcrylq938x this is the link
Pls 🥹
the mmodel should be fine, lmk

anyone know this thing
@low shard sorry for ping really. im bothering u. if u available can u help me
"the paramters of the pretrain model such as the sample rate or architecture do not match the selected model" what do I do
guys is it possible to continue training in another runtime?
I am back after my PC reset, current setting are these


does anybody how can i convert h5 format model into pt or pth
elaborate:
- your pc gpu
- what you are doing
- what tutorial link did u use
it's said in the message
it doesn't match the same parameters
f0: rmvpe
Disable JIT compilation: off for faster loading speed of the program, on for slightly better performance (10-15 ms) for Nvidia only)
force fp32 mode on can cause better quality and stability at the cost of some delay
The parameters of the pretrain model such as the sample rate or architecture do not match the selected model.
Error: Pretrained model sample rate (48000 Hz) does not match dataset audio sample rate (40000 Hz).
It doesnt make sense cause my pretrained model sample rate is 40k not 48k
what pretrain are you using
TITAN by blaise-tk
and you're sure you're using the 40k sr version? show also your applio settings (since i'm guessing you're using that)
yes im 100% definitely using the 40k sr version, gimme a sec I'll show you my settings too



hi it says the deiteris fork is a malware, also isn't it outdated since it came out in 2024 ?
After trying a couple stuff out, apparently all I needed to do was insert my dataset into audacity and export it as 32k SR, just for anyone facing that problem in the future
is it normal for the preprocessing to take that long?

Nvm, needed to restart Applio
before that, I'd recommend deciding the sample rate according to the spectrogram cutoff like following

second, please double check the pretrain and sample rate chosen in the settings
at last, TITAN is rather old and has kind of quality issues, I'd recommend using the default pretrain or try: https://discord.com/channels/1159260121998827560/1339155300720054316
yeah thats how I decided to do 32k SR
oh damn, im already training, should I stop it and use the default pretrain then
test the model then see
more likely the program has closed or crashed for some reason (pls check the console)
instead of colab, try the kaggle one
https://www.kaggle.com/code/suneku/voice-changer-public

Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
Hey all! I'm attempting to run Applio RVC but I keep getting an error reading: 'NoneType' object has no attribute 'pipeline'. Any idea what this means?
try downloading the precompiled release instead of getting headache on the manual installation
so im runnin the appolio kaggle ngrok combo and i uploaded my audio file but i cant copy the path
whatever i do it just shows up as this
Preprocess completed in 0.00 seconds on 00:00:00 seconds of audio.
is my audio file wrong or somethin
or should it be a zip
im not sure i need help :(
Timer: 00:03:17/content/voice-changer/server/HVoice.py:3: DeprecationWarning: The distutils package is deprecated and slated for removal in Python 3.12. Use setuptools or check PEP 632 for potential alternatives
from distutils.util import strtobool
Traceback (most recent call last):
File "/content/voice-changer/server/HVoice.py", line 10, in <module>
from downloader.SampleDownloader import downloadInitialSamples
File "/content/voice-changer/server/downloader/SampleDownloader.py", line 12, in <module>
from voice_changer.RVC.RVCModelSlotGenerator import RVCModelSlotGenerator
File "/content/voice-changer/server/voice_changer/RVC/RVCModelSlotGenerator.py", line 4, in <module>
import torch
ModuleNotFoundError: No module named 'torch'
WARNING:pyngrok.process.ngrok:t=2025-05-24T06:37:01+0000 lvl=warn msg="Stopping forwarder" name=http-35747-ef82ddb1-a427-4741-86ed-c927acab8040 acceptErr="failed to accept connection: Listener closed"
--------- SERVER STOPPED! ---------
Timer: 00:03:18
using google colab "Hina Modified" version and idk im getting this error
Hi I downloaded voice meter and lighthouse and I did everything the guide said to do and now I cant hear audio, Do you know where I went wrong?
make sure to place a folder containing dataset wav file(s) in <the Applio folder>/assets/datasets
if it can't read the audio files, re-export them using Audacity or another editor without including metadata
Nm am I allowed to send screenshots in here?
!give-media-perms 30m @valid spindle
This is what all my settings look like, Does it look like anything is wrong?

i lowkey dont know what the hell i was doing wrong so i just kept on using different thing but eventually i got it working on kaggle mainline
try VAC lite instead of vb-audio https://software.muzychenko.net/freeware/vac470lite.zip
you should also check and show the voice changer settings
Is the guide for this on the Deuteris fork guide?
Does anyone know what's going on with huggingface.co? I think it's down.
-realtime
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested. GUIDE
• Original Wokada
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
• **RVC GUI Mainline Realtime**
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated

 anyone know how to improve model's tone ? because somehow i sound very monotone
anyone know how to improve model's tone ? because somehow i sound very monotone
do i need a set of data that the speaker have wider vocal range in order to achive better vocal range ?
Either the inference audio is monotone or the dataset is monotone

Yep
train expressive data
There is. Look up this link. https://docs.aihub.gg/rvc-voice-changer/local/deiteris-w-okada-fork/#virtual-audio-cable
Last update: May 5, 2025
Expressive data my goat 🐐

let me google what is expressive data
audio of someone using their whole vocal range instead of mommy asmr
also i want to ask about, is it okay to train a model then let it make tts data. and combine previous data and tts data together to improve my language pronounciation
i still can't spell right
i mean, i took data from a podcast. i think it is asmr
 but okay, i think i get it
but okay, i think i get it
Synthetic data is a no no for rvc
oh no, then do you know a way to get better pronounciation in different language? because cvec trained mostly on English data
a new embedder is needed with a pretrain trained using that
dang it, can't find hubert base for Vietnamese anywhere
What is your PC GPU?
Nvidia gt 710
thats why i am trying to get the google collab
i long ago used it in google without gpu, but now that i have one want to try again
whats the link to download w_okada?
Yeah, no need to run W-Okada locally with this GPU. There are two W-Okada Colab notebooks, however, the original one is broken, while the fork one can get you terminated if you have free Colab.
What is your PC GPU?
RTX 3070
Last update: May 5, 2025
what does terminated mean, so i cannot use the voice changer?
"Terminated" in Google Colab means you won't be able to use the Colab ever again with your Google account.

Use Kaggle instead, but you'll have to register with your phone number on this one. Here's the guide. https://docs.aihub.gg/rvc-voice-changer/cloud/w-okada-kaggle/
Last update: May 5, 2025
Latency stats and metrics are typically based on GPU and CPU right now, right?
(aside from the code actually being good)
What are epochs, batch size and steps?
I'm not super familiar with all the terminology with this stuff atm — but I'm thinking in terms of real-time voice changing. Let's say I use something within the realm of 300 epochs.
I'm familiar with voicemod and w-okada, but curious if anyone is getting near-0 latency in realtime yet?
(obviously, you'd need a beefy GPU I'm guessing)
where can i download voice changer is there any tutorial? gpu nvidia 5080 cpu amd ryzen 7 9800x3d
-realtime
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested. GUIDE
• Original Wokada
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
• **RVC GUI Mainline Realtime**
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
Check the Deiteris Fork guide.
is there one with video?
a tutorial with video
Nope.
All video tutorials on YT are/and get quickly outdated so we don't recommend following these.
Just read the Deiteris guide.
quick question: can you record voice messages on rvc gui?
hey, Im new to this AI music world, where should i start if i want to make a rap song with the voice of a certain artist? most youtube tutorials are outdated or get deleted...
my voice model works fine in realtime but sucks badly when converting a voice to another, whats the reason for that
is it a problem with the dataset? do I need a more expressive one?
people usualy have a quite opposite issue
Hey everyone, I want to make a peter griffin tts video. what would be best fit for this? i wanna run it locally.
I tried F5TTS and technically it works but i have to reupload the sample every time. is there one i could use on of the models in #1175430844685484042 ?
can i ask u a question do i need to do both ir only nvidia rtx 5000 series i got a 5080

Download only the RTX 5000 version in that case.
i dont know if i can ask this here but is there a tutorial for deep live cam?
So if i understand the guide correctly: the perf (number) is how good the voice performs, so you want to adjust the chunk as low as possible, while maintaining the perf number at green? As long as the perf is stable and green, does that mean the voice quality will be just as good at 100ms as at 5000ms?
I just need to know what website I can use to make a song then use the ai bot thing to add juice wrld too it.because the Suno ai music generator sucks
i dont know if i can ask this here but is there a tutorial for deep live cam?
Ehh.. I fear not
Can I get help?
Help please

is it normal that it opens up in a website?
the voicechanger
Yup, that's normal
Do you mean Deiteris fork, right?
Because that's a W-Okada fork
And don't worry, if it opens in a google window it doesn't mean you need internet.
yes with deiteris fork but can i still use it in dc?
Yup, of course you can use it on discord
Pretty sure that happens when you try to open the VC again when it's already open.
getting this error all of a sudden when trying to use the voice changer on kaggle

any fixes?
i tried to switch gpus on kaggle
but it js keeps saying "adding data"
how do you use the voice changer on overwatch
Hello! I'm looking for the XMem.pth model (video object segmentation). All the official links are dead (Google Drive, HuggingFace, Mega). If anyone has a mirror or can re-upload, I’d be very grateful. Thanks!
do you have an old huggingface model link?
Here is the original HuggingFace link (dead now):
https://huggingface.co/akhaliq/XMem/resolve/main/XMem.pth
If you have a backup, that would help a lot, thanks!
it would not be something like https://huggingface.co/spaces/VIPLab/Track-Anything/blob/main/XMem-s012.pth ?
Yes, exactly, it’s for XMem-based tracking.
Thanks, I’ll try this one out as a replacement for the dead original!
(If you have the old XMem.pth as well, I’d still appreciate it, but this looks good.)
unfortunately the repo is gone, otherwise it would be super easy to get the file from the git history
Thanks a lot for your help!
That new link saved me, much appreciated 🙏
And if you ever find the old XMem.pth, let me know — but this is already perfect!
the voice better be more expressive like in vtuber stream sessions to cover more pitch range
singing with enough pitch range is also fine
ye it's not bad for reading bedtime story ASMR, but not for expressive talking or singing
hey im trying to use w okada on my 3060 and the delay is insane, can someone help me?
I'm trying to download SayanoAI/RVC-Studio but see no download button for the full repo, nor a github link. It's supposed to be a Local RVC. How do I download or use it? And can it run on my 5070 Ti and Ryzen 9 9950X3D?
Would forktime voice changer damage my high end laptop if used? Is it safe to use?
yes if you keep it overheat all the time instead of applying power limit and better cooling as needed
it should have less gpu usage than demanding games on an RTX 4090 laptop
it is kinda old and discontinued
try this instead https://docs.aihub.gg/rvc/local/applio/
Last update: Apr 01, 2024
what game are you trying to run?
also you can try using WASAPI devices for less latency https://rentry.co/LessDelayWasapi

What does WASAPI do?
WASAPI accesses your audio devices directly, while the driver that you use by default (which is "MME") goes through multiple layers within the Windows audio subsystem, causing more delay.
This will in total cut down 50-80ms delay.
Shoutout to Mares & Emojikage
L...
Thanks, will try it.
also note that rvc utilizes more on the GPU, so your semi-workstation grade cpu may be underutilized
Is there any guides on how to link the voice changer to audacity??
you want to use audacity to record the voice?
Yes
for just recording, the non-realtime RVC for pre-recorded ones is always better
I will definitely look into that!
can someone tell me what does "torch" mean in my console when i run the w-okada voice changer
pytorch is a machine learning library that is repsonsible for running rvc model
Hi, does the W-Okada fork (better version) fix the stuttering issue. I've been using the usual W-Okada with GeForce GTX 1080 ti and now currently with RTX 4070 and I'm still experiencing the stutters.
wdym stutters? in some game you were playing? if so that's an issue mostly plaguing unreal engine 5 games
By stutters I mean you can hear the voice lagging a lot. It lags even while I'm not playing games or in a call.
- check the settings, if too low try increasing chunk while keeping extra at most 2.7 s
- if the voice keeps cutting despite reasonable performance, try lowering the silence threshold
- you can try using WASAPI devices for less latency https://rentry.co/LessDelayWasapi
What does WASAPI do?
WASAPI accesses your audio devices directly, while the driver that you use by default (which is "MME") goes through multiple layers within the Windows audio subsystem, causing more delay.
This will in total cut down 50-80ms delay.
Shoutout to Mares & Emojikage
L...
I lowered my silence threshold, it helped quite a bit, but still stutters/lags. My chunk is 512 (1365.ms, 65536) Extra is the highest so I can get the best results for voice, I will try lowering it.
Do you mind if I dm you and ask you for some more info about this?
make a thread here https://discord.com/channels/1159260121998827560/1192011222023950368
I'm working on a voice model with voice clips ripped from a game
The thing is, almost all samples (which in total are over 5 hours but I'm just using 20 minutes in this case) are 22k, but a selection of 5 samples (with a total of 15 seconds) are 44.1k
So that means I should train my model on 32k or 40k sample rate?
Or should I just exclude the 44.1k samples from the dataset?
Thanks in advance
5 hours is way too much and 15 sec is not enough, so pick best 15-30 min and use that at 32k
Should I keep the 44.k samples or should I exclude them from the dataset?
how is the perf indicator?
What is a perf indicator?

in the voice changer ui
and how about the cpu & gpu usage?
also try closing/disabling/debloating programs/background processes that may steal performance
Tried already, doesn't help.
I'll send a screenshot to you in private because I don't know what it is.
no, how about the cpu & gpu usage?
this code is stuck on running forever, without requesting me for the google drive access, can I get help?

It's my gpu graphics card
RTX 4070
12gb
bruh what % usage I mean?
!give-media-perms 30m @clever onyx


crepe is the problem, it's like tanking pathtracing performance in native resolution
go switch to rmvpe
is using rmvpe on realtime voice changer fine if you've trained your model on crepe?
gpu is like from 5% to 30%
crepe in realtime is too slow as I said
yeah, I mean when you train a model, you can train it using crepe/rmvpe, but then I see there's also an option for which to use (rmvpe vs crepe) when on realtime voice changer
so I'm asking if it matters whether you use rmvpe on realtime voice changer using a model that was trained on crepe
It helped, thanks.
I appreciate it.
popups disabled?
I fixed it, but I'd appreciate if you can answer my other question
@simple ore
f0 is used for both training and for inference
hey im using the w-okada voice changer but this version vcclient_win_std_2.0.78-beta laggs tf out of my pc
it clearly says it gives your pc an std
whats an std???
alr
ok
i dont know if the voice changers are different but whenever i start it using the start_http file it opens in command prompt instead of opening in python, anyone know why?
I have this one "MMVCServerSIO_win_onnxgpu-cuda_v.1.5.3.18a"
thats how it runs i think
ohhh ok i just downloaded the one from this site, i thought it was supposed to open in python lol
can someone help me with cloud training?
I preprocessed my audio and everything shows that it's successful and I mounted to my google drive
but no new folders are showing up on my google drive
is linux optional, or do i really need it for w okada?
I mounted my google drive, but no new folders or files appear in my google drive when I try to preprocess and do all the steps
windows 10+ mac linux all works i think
can anyone help please
Linux is optional. W-Okada also works best on Windows 10 and up.
what should i change to prevent the delay?

I'm not sure which chunk and extra number would work with AMD Radeon RX 580. But let say, the perf number is around 337 and is green at top left, so chunk may be around 390 ms, while extra is 2 s as it is. https://docs.aihub.gg/rvc-voice-changer/local/deiteris-w-okada-fork/#known-working-settings-for-chunk-and-extra
Last update: May 5, 2025
okay
While you can lower extra number so the perf number could be lower and less GPU usage, W-Okada would output lower audio quality at the same time.
you're trying to use some ancient shite
oh yes the video i got it from is from 2023
-rt
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested. GUIDE
• Original Wokada
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
• **RVC GUI Mainline Realtime**
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
so wait i just installed python for no reason or would i still have needed it
the fork includes everything it needs
ohh aightt thank you bro 👊
Don't believe any tutorial video on YouTube about W-Okada the realtime voice changer. They only telling you to install the original version, and are all old now. Use fork W-Okada instead for better performance.
No need to do that if you wanna use W-Okada generally. All W-Okada versions have their own Python pre-installed.
If you have unknowingly installed a separated Python program, that's fine, although you may wanna uninstall it from your disk. Python program is useful if you wanna develop your own Python script or any AI-related program from start.

!howtoask
How To Troubleshoot 
__**GIVE CONTEXT.**__ 📝
- Don't simply mention your issue, like "
my rvc is not working". - Describe the step you are on, what you're trying to do, the RVC you're using, a screenshot, etc.
- The more context, the better.
__**BE POLITE.**__ <:matsuripray:1159685390156967936>
- Don't be desperate. You can ping a Helper, but if they ignore, they aren't available/don't know the answer.
- It's okay if you're frustrated, but don't take it into this server.
- Don't DM without prior consent.
__**BE PRODUCTIVE.**__ 🤝
- Don't ask for every little instruction. Put your own effort & test things by yourself.
- Don't ask to ask.
- Check if your answer is a Google search away/on our guides website.
If you've changed your mind about your message, feel free to delete/edit it.
fastsdcpu error phyton not installed i installed 3 of phyon newest and 3.10 and 3.11
A lot of people forgot to set PATH during the setup of Python, but there's a way to have it work after setup. The fastsdcpu mostly relies on your Windows' PATH variables in order to work, which includes a Python program you installed. On Windows 10 or 11, open Settings > About > scroll down and click on "Advanced system settings". On System Properties window, go to Advanced > Environment Variables > look at System variables section and click edit on "Path" Variable. This is where you add paths to the programs you wish CMD to run specific programs.

which path tho
where to i put path
i still got them installed
Now to find a path to your Python folder, it's something like C:\Program Files\Python310 or C:\Users\your username\AppData\Roaming\Python\Python310.
The your username is your current Windows user account you're running. Mine is named Lucy, so mine is C:\Users\Lucy\AppData\Roaming\Python\Python311.
mys is nnn
i feel like when u switch the output to your headphones its fast and not really delayed but when its on cable output and ur listening to it feels like cable output its making the okada delayed
i hate using thecable out put i want it to make it voice live
how can i get w okada voicechanger
i can help you
k
dms
can u help me too
when i try the ngrok thing it gives me error
ModuleNotFoundError: No module named 'pyngrok'
like this
uninstall it?
diasble anti virus
maybe install phyton
someone pls help with google colab
ERROR: Could not find a version that satisfies the requirement faiss-gpu (from versions: none)
ERROR: No matching distribution found for faiss-gpu
elaborate
what's ur pc gpu? what do u want to do? what google colab link are u using?
that gpu is good enough, you don't need to use cloud
are you planning to use a realtime voice changer while in game? if so, which game?
or just discord?
cs2
also, that's old original wokada
it's better you try locally first
cloud gets broken easily and has time limitation
i dont think its gonna work well cuz the delay
you should be able to run it fine with low graphics
no
Wokada has 2 main versions:
- Original made by Wok
- Deiteris fork (modified version) made by Deiteris
each version has it's own updates
the latest deiteris fork has way better performance and quality than the latest original
it just like runs 70-90 when using
hmm
video tutorials use an old original wokada
uninstall whatever you got off youtube, get https://docs.aihub.gg/rvc-voice-changer/local/deiteris-w-okada-fork/
Last update: May 5, 2025
even suggested models are in the tutorial
70-90 perf? isnt that pretty good while gaming?
ah
hi guys the audio like cuts in an out all the time and it just always sounds bad? anything u rec to help me
can u tell me a good model
Last update: May 5, 2025
elaborate:
- your pc gpu
- what u want to do
- what tutorial did u follow
@languid cliff that's actually good delay while gaming btw, don't expect 0ms delay, but i feel like you were using an old original wokada version that didn't even show perf and you're just confusing values
can you tell me which settings are good for low end gpus
i have a gtx 1650 4GB, i wanna do real time voice changer, i followed a guy on youtube who does like e girl trolling on discord name was duckus
Last update: May 5, 2025
Last update: May 5, 2025
hello can i have some help
that's already your issue, all video tutorials are outdated
that tutorial is like more than a year old
in ai field, it's prehistorical
true
yeah, even with a 5090 i get about perf 100 in some games, but thats if the GPU is on full blast (80-100% usage)
@vestal gust uninstall everything you got off youtube, are u going to use it in games?
yeah, he prob just confused values lol
yeah, only really fortnite, roblox discord
hey uhh this is the support chat right can i get some help?
How To Troubleshoot
__**GIVE CONTEXT.**__ 📝
- Don't simply mention your issue, like "
my rvc is not working". - Describe the step you are on, what you're trying to do, the RVC you're using, a screenshot, etc.
- The more context, the better.
__**BE POLITE.**__ <:matsuripray:1159685390156967936>
- Don't be desperate. You can ping a Helper, but if they ignore, they aren't available/don't know the answer.
- It's okay if you're frustrated, but don't take it into this server.
- Don't DM without prior consent.
__**BE PRODUCTIVE.**__ 🤝
- Don't ask for every little instruction. Put your own effort & test things by yourself.
- Don't ask to ask.
- Check if your answer is a Google search away/on our guides website.
If you've changed your mind about your message, feel free to delete/edit it.
fortnite not so sure, but the rest should work fine
uninstall everything off youtube
-realtime
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested. GUIDE
• Original Wokada
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
• **RVC GUI Mainline Realtime**
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
ok cool
im using w okada and am new to this whole thing but the voice is very very choppy and spouts gibberish. when i do the passthru thing i can hear my normal voice properly tho
what's your pc gpu? what do you want to do? what tutorial link did u follow?
i think mx330 idk if its enough i dont know alot about tech
this is the tutorisal i followed https://www.youtube.com/watch?v=KkDjqteIqBE
for a 1650 would u reccomend online one or not? @low shard
that's weak asf
also, that tutorial uses an old original wokada version
the only way for you is to either buy a better pc or use cloud (remote good pc) with limited time
so hwat do i do to be able to have a non choppy voice is that possible or
should work fine except for intensive games
roblox and discord are completely fine
id suggest locally
cloud has limited time and breaks easily
so its because my pc is too weak? but im using the version without the gpu thing like the std thing thats what i downlaoded
first of all your pc is weak, second of all you're using an old original wokada which has even shittier performance
your gpu is just going to have shitty performance even with the latest wokada deiteris fork that has optimizations
@low shard bro how can i run this on my pc locally , it opens a browser tab
so either you buy a better pc or use cloud with limited free time
it opens locally, it just uses a local Web User Interface https://docs.aihub.gg/rvc-voice-changer/local/deiteris-w-okada-fork/#why-does-it-run-in-a-browser-and-not-its-own-window
Last update: May 5, 2025
ahh okey
so iots because oif my gpu? but i heard some people without gpus are able to use it propeely how can thye do that?
you could technically do it with a cpu, should you? no, it will run like complete dogshit
it's because your gpu is weak + you're using outdated software
I told you your only 2 options
which one are you interested into?
ok then
i was thinking of buying a new laptop anyways
but then ewhat version should i install

if u wan to do it locally, wokada deiteris fork https://docs.aihub.gg/rvc-voice-changer/local/deiteris-w-okada-fork, which version depends on the future laptop gpu you're going to get
shouild i select server
hopefully a laptop with an nvidia rtx decent gpu
would a 3050 be fine?
brave
are you going to use it on games too? if so, which?
nah just for discord
try chrome/firefox/microsoft edge and be sure to give microphone perms
you can choose
client: easier and can use noise suppression, more delay
server: less delay, harder, can't use noise suppression
then it's fine
yes, just don't expect 0ms delay since that's not even a thing lol
that's the whole point of AI
ig
you know right chatgpt uses a shit ton of way more expensive gpus?
oh i didmt know that
ai doesn't run off air
they all use a shit ton of gpus which can cost over thousands of dollars
every ai site you see uses shit expensive hardware, which is why they make you pay for it, because it's running on their pcs
ohhhh
chatgpt doesn't run on your laptop at all
you can also run wokada deiteris fork on cloud (remote good pc), but you will have limited free time, which is lucky considering how expensive gpus are
what is that
RVC = Retrieval-based-Voice-Conversion, the best Few Shots Speech To Speech AI Models (on v2), Inferences (use models) pre-recorded audio (ai covers) and train (make) models. Technically, Mainline RVC does have a go-realtime.bat (aka RVC-GUI), but it's pretty messy and outdated so it's extremely not suggested for realtime.
Wokada = uses RVC for realtime inference. There's 2 main versions, Original made by Wok, and the most suggested one is Deiteris Fork (modified version)
yw
just a quick one
is it supposed to open on the web?
like the local version
im assuming the more chunks the more quality right but more delay?
can you help me to make settings good , sometimes my sound is robotish
"Hello everyone, does anyone know which AI preserves the quality of a person's image? I mean, when generating an image with different effects, the person's face should remain as it was originally. However, both GPT and Grok distort it during generation. Which AI doesn't do this? Even if it's paid, it doesn't matter, please tell me about all the ones you know via private messages. Well, you can write here too, but it would be preferable if you could message me privately, thank you
Last update: May 5, 2025
no
chunks controls delay, more chunk more delay
extra controls a bit quality
send a screenshot

https://i.imgur.com/TqNkoZW.png anoyone else encountered this issue?
-realtime
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested. GUIDE
• Original Wokada
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
• **RVC GUI Mainline Realtime**
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
can anyone help me using copy of gui for rvc?
anyone got a good reverb removal tool for really heavy reverb
use rmvpe without onnx, extr to 2.7, and be sure to get a good model
Last update: May 5, 2025
elaborate your issue
original rvc / mainline, is not so much updated anymore, and doesn't support the rtx 50 serie, you need to use a more up to date fork like applio
Last update: Apr 01, 2024
btw,
RVC = Retrieval-based-Voice-Conversion, the best Few Shots Speech To Speech AI Models (on v2), Inferences (use models) pre-recorded audio (ai covers) and train (make) models. Technically, Mainline RVC does have a go-realtime.bat (aka RVC-GUI), but it's pretty messy and outdated so it's extremely not suggested for realtime.
Wokada = uses RVC for realtime inference. There's 2 main versions, Original made by Wok, and the most suggested one is Deiteris Fork (modified version)
I tried with Applio too, and i got the same message 😦 I completely uninstalled torch and python, and tried installing the nightly Torch build, as i saw people recommend that. But didnt have any luck
https://i.imgur.com/XYQZptZ.png pretty much the same message
"import torch
torch.version
'2.8.0.dev20250524+cu128'
you sure you got the 3.2.9 version off https://docs.aihub.gg/rvc/local/applio/ ?
Last update: Apr 01, 2024
not sure if they officially added rtx 50 support, if they didnt:
How to (unofficially) use Applio for RTX 50 serie cards
Follow to download it as said it in https://docs.aihub.gg/rvc/local/applio/
After you extracted the precompiled, go to the path in Windows explorer, write "CMD" and press enter, then in CMD write env\python -m pip install torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --upgrade --index-url https://download.pytorch.org/whl/cu128
If you get any already satisfied requirement issue, run env\python -m pip uninstall torch torchvision torchaudio then the command said above
Last update: Apr 01, 2024
3.2.9 yeah
@simple ore i thought rtx 50 support was already supported in applio 3.2.9?
try the method i told ya
That seem to have worked, no error message now!
you're welcome
Thanks 
no, 3.2.9 still uses torch 2.3.1
why 
I think we rushed a day with making the release, the pytorch release was a few hours after we made a build
there was a bug preventing training from working properly as well
had to make sure 2.7.0 fixed that
Last question, is there any guides anywhere on how to do optimal training?
Recommended batch size and epoch compared to voice length? And like what voice data do you NOT want, and what voice data do you want a lot of, etc?
(aside from the obvious one, background noise)
need a tutorial
Hi, how do I contact someone to remove some model posts that were mine?
all I can find is this

where did all my training go
please someone help
no way all of these hours I wasted are lost
dude this is so upsetting
I spent 2 days tinkering with this shit
what the fuck why is there no warning
anyone online
those are not the logs you're looking for
if you had backup enabled, all your files should be in your google drive

that's the thing I did not have backup enabled
why the fuck are there no warnings anywhere for fucks sake
you know atleast somewhere a little warning that you're gonna lose all your shit just for being afk
all I saw was a subtle hint that I can do backups

backups are usually for unexpected crashes, not a built in ass feature that gets rid of all your stuff
just wow
you're using a borrowed cloud server to do your shit for free, why do you expect it to be permanent?
well atleast let me keep my last files before kicking me out
they could literally just have it disable the GPU and let me download my last files
you're directing your anger towards a wrong target
there's nothing to direct my anger towards honestly
yourself, for not learning what colab is, before starting using it
sorry for not checking that a cake has nails in it before taking it in a birthday party
silly me
should've expected nails
honestly everything made by google is smelly farts should've expected colab to be ass too
please atleast put a suggestion to have auto backup on in the aihub documentations so that less people have to go through these frustrations, because I'm 100% sure I'm not the only one who thought Google employees wouldn't be so braindead to have you atleast keep your files if you're afk for too long
or have it be enabled by default in the colab just like it is in Applio NoUI, because there's literally 0 reason for it to be off besides bringing you unneeded pain if you're new
okay so I have auto backups on, before I go to sleep, is there any other trap I should know about? No jester that will come to my home at 3am and delete my files?

and can I please get an explanation of why this keeps popping up?
same process, same everything
sometimes works
sometimes doesn't
I infact did not forget to slice the audios. 
there errors are popping out of nowhere and for no reason dude
I can't stand this anymore
the guide is dogshit
Is it normal for the TensorBoard charts to be very "zig-zag"ish?
I can't send a screenshot cuz I don't have image perms
it's normal for everything to have a problem
if everything is going smoothly then you're doing something wrong
also turn on your auto backups trust me you'll regret not having it on
big secret
I'm doing local training and I'm saving every 25 epochs, so yeah
unfortunately I'm stuck with an unsupported amd gpu
Okay, now I can send images, so
what gpu?
This is what it looks like so far

6700xt
this looks fine, you can up your smooth settings


this

dont smooth avg50 charts, they are smooth enough already.. 0.5 max
follow the guide I gave you
Oh, alright

Strange, since the AI Docs guide tells me to use 0.987 smoothing
that's for old logs that were saving values at the end of the epoch and were quite random
I reverted back to 0.5 and it looks zig-zaggy again

those zig zags are fine
Oh, alright then
you can better observe the lowest points
thank you, I don't wanna touch that cursed colab ever again
6700xt is faster than colab

faailed to set path

what else do I need to set path to
installed wrong hip sdk version 1 sec
delete zluda folder, use a correct patch
the one here?

I've already did the other steps with the wrong hip sdk version, do I have to do anything about that too
5.7 zluda wont work with 6.1 sdk and other way arouund
god dammit my brain is so fried after countless hours of bashing my head against this
I'm deleting the applio folder and reinstalling it and redoing all of these steps again
hahaha... again...
it's 4am, I have a doctors appointment at 10am
this is awesome
@simple ore do I skip this step for the applio installation if I plan to install zluda?

I guess I do
is this something I need to worry about? @simple ore

I installed all over again, did every single step as by the tutorial, yet I'm getting this same problem again

what am I doing wrong? Please honestly tell me what I'm doing wrong
it's hard not to blame the guide if literally following it step by step causes issues
you take compiled applio version, unzip and that's it for applio
that's what I did..
then you follow the guide step by step
that's exactly what I did
verify the path
yes
from Applio's root
what does from Applio's root mean? I opened the .bat file inside the applio folder

that's that
I feel like I'm going insane, what did I do wrong
where can I check?
open the adrenalin control panel thing
try this instead, it downloads the latest version compatible with 25.5.1
I think I had none, I am currently installing adrenalin
it asked me if I wanted to download 25.5.1 or 24.Q4, I chose the downgraded one and installed it
the adrenalin software thing, it wasn't installed on my pc
I had no drivers
for the hip sdk do I install the 23.Q4 version it asks me to?
no, 25.5.1 is fine with that bat file above
23.Q1 is a pro driver without any game support
I don't really know what a pro driver is
oh
@simple ore is that normal?

I reinstalled everything once again, this time while having 25.5.1 as a driver, I did everything exactly step by step, the only difference being is that I used your patch-zluda-hip57.bat file

this is exactly what I was fearing I'd have to go through if I didn't use google colab..
torch installed as well?
at this point you may as well check that you did not skip vc++ runtime
I fully uninstalled all of torch stuff now, uninstalling vc++ runtime and restarted pc, I'll try to make this installation as clean as I can
if that doesn't work then at that point I might aswell clean install all of windows lmao
you just need to follow instructions step by step without skipping anything
because we may very well find out you did not replace libraries next

Got this thing while training, idk what to do now
I'm too cool to censor my user name
what are you using?
Applio
I left it training in the background while watching YT
gpu i mean

there was some issue in the feature step (the init_thread spamming stuff)
this is where it begins

use amd cleanup utility, or/and DDU, remove whatever driver you have installed, install adrenalin 25.3.1
it should not fail on the kernel compilation
the thing about the index is unrelated.. it simply cant find any extracted files in your model folder

I'll wait another ~10 min until it finishes with the "compilation in progress..." thing again
you dont have enough vram to train anything
I actually trained a few models in the past and they worked
But only when I leave my PC training without doing anything else
As I said, training only fails when I'm watching YT, playing games or other stuff while training locally
It trains perfectly fine when I leave my PC without doing anything else on it
Is an Intel Core i5 enough?
core i5 from 10 years ago? probably not
you're using shared memory which drops the already low training speed to 1/3-1/5 of it and of course it fails when you try to use vram with a browser or discord using hardware acceleration
Makes sense
I'm completely broke rn so I can't afford a new PC to replace this "pseudo" gamer TUF Gaming notebook I have
So I can only work with what I have and nothing else
you're a prime candidate for kaggle/colab 🙂
Aren't there limitations tho?
Like, a GPU time limit, or idk
It's been a long while since the last time I used Colab for training
Ever since the removal of free GPUs for Colab stuff, I stopped using it and moved on to local training using RVC/Applio
I'm gonna continue with the training but this time I won't use other apps while training
Also, was this error able to corrupt the training on my model or should I be fine?
guys why i cant use the voice changer app is there any latest app?
perhaps doable for batch size 2 (and with checkpointing option in Applio)
but not so recommended as the model would tend to be unstable
Right now I'm doing okay with batch size 4 and checkpointing
This is how the voice sounds so far with 87 epochs
up to 4 hours of daily colab GPU session or you can consider kaggle
ye it won't cause out of memory error but the performance is mostly bottlenecked
not a thing to worry since it's not a realtime workload
fyi batch 4 is recommended for less than 30 min dataset, okay-ish for 30-60 min depend on the dataset diversity
@simple ore

at this point it'd be easier to get hired, make enough money for and buy a good nvidia card
is there literally anything I can do without 90+ errors
hello , i have a question , how to make rvc path with my own voice and how to make that auto detect index path , idono anything about it can someone help me with that ? please
Not enough data present in the training set. Perhaps you forgot to slice the audio files in preprocess?
atleast let me run google colab ffs
why even google colab can't work properly like what the fuck is this fix your shit for gods sake
make sure you have run preprocess and feature extraction without issues
I did
same process as I do locally, and I did the exact same process on google colab a day ago, with the same dataset, and it worked normally
but suddenly it gives me this error all the time
there's a higher power that literally doesn't want me training ai
I mean did it throw some errors or the results like: "preprocess completed in 0 seconds" and/or "no-feature-todo"?
I also suspect you're prob running an outdated/old colab like rvc disconnected
take a look for yourself

https://docs.aihub.gg/rvc/local/applio/
I'm running the link that's here (https://colab.research.google.com/github/iahispano/applio/blob/master/assets/Applio.ipynb)
there's no way my problem is so out of the ordinary not even the helpers here know what to do
it's not like google colab would yield different results based off your personality or something
this colab has a personal vendetta against me I swear
how is the dataset structure and what preprocess option were you using?
I used the dataset creator option where I uploaded a 12 minute mp3 file that is just purely talking with no background noise, it then created a dataset folder with the 12m mp3 file in it and I used that as the path (it automatically puts in the path for you)
I used all the default options
for the pitch extraction algorithm I use crepe
well so it's in mp3 format, I mean how did you put the dataset?
make sure it is a folder containing an audio file (if mp3 may cause issues, try wav instead)
also make sure the preprocess and feature step don't take instantly
Hi,
Does anyone here use Moises app? Have you guys ever tried to have an apk version of it? Hhuhuhu I'm enjoying moises now but I can't pay for it's premium price
if that helps you, I recorded a 3 minute video of the process I do from start leading to the error
(just to clarify, the error at 0:39 is due to me trying to put in the folder how you told me to, I usually put the mp3 file right away and it doesn't say error)
You must be unlucky enough trying to get Applio on Colab to work and it still fails every time you do so. Have you ever tried the Kaggle one before? Or Kaggle still broken for you?
I have not tried Kaggle, I'll check it out
As what you vented hard about it in #🧬│ai-chat , I'd say give up temporarily on this one. Since you have forced yourself too much trying to get Applio Colab to work. You can try again another time when you feel right.
this is not normal, I've tried google colab, it showed me the error I'm currently trying to fix, then after trying the same process again and again, for some reason it worked once and that's when I didn't have auto backups on
I tried installing zluda
and it's a whole mess in it of itself
that's your fucking problem
- you haven't checked out Advanced settings in preprocess
- drag n drop a zip file, not a folder
I think he messed up on the preprocess
Also, you have just created two threads in #1192011222023950368 hours ago, whereas these two refer to the same thing, but neither has an answer from any helper. Make sure to focus on either one you think it's more obvious for solution.
what's the problem with crepe?
zip file containing the dataset folder?
it failed to create f0 files
why did it fail I dont know, try running inference with the same crepe parameters to find the errror
please check the folder Applio\assets\datasets\<model name> in the left pane
unortunately the error on training screen is not visible
Applio does not use .zip for preprocess
it is a path to the folder with a file(s) (.wav, mp3, etc)
not a path to the file
so what I did was correct there?
Crepe is an old pitch extraction model for RVC from 2023, older than rmvpe. Although you can try rmvpe on this one, and see if it works.
Unfortunately, you deleted an earlier thread I replied in #1192011222023950368 for whatever reason, so I couldn't find my own answer to remind you again.
hi im trying to resume training thru rvc disconnected collab, but not sure if im doing something wrong. i used the same settings.

I closed the thread there because at the time the problem was fixed
its an outdated colab
ah okay is there another colab available??

Have you tried Applio?
applio has crepe with hop length
isnt that local only?
No. Applio is also available on Colab and Kaggle, aside from being a local program
ah okay ill try it out. would i have to restart training complately or can i resume from my checkpoints i have on drive already?
you should be able to resume
ok perfect thank u
switching to rmvpe fixed it
You can resume training on Applio if you have trained a model there before. But I'm not sure how one would tryna transfer training data from Disconnected to Applio.
the mongolian throat singing that I put in my background contributed to the fix too

what hop size did you use for crepe?
I tried 70 and 1
so seems like PEBKAC problem

works fine when you dont do something stupid like that
please educate me on what those hop sizes are
because there all it said is that lower hop sizes do something better with pitch stuff
so I put lower hop size
where does it say that?
here in the video I used default 128 hop size btw
that didn't work either though, as you can see in the video
see my screenshot - worked fine
see my video - didn't work fine
the small grey text above hop length says
"Denotes the duration it takes for the system to transition to a significant pitch change. Smaller hop lengths require more time for inference but tend to yield higher pitch accuracy."
if it was a hop length issue then it would've worked in the video where I did not change it
stick on either 128 or 64 for most cases
neither works properly anyway and makes no difference
f0's target is 160 hop to match feature extraction
when you use 128 or 64 hop it creates a larger array that has to be interpolated down to len/160 frames
so I should set it to 160 if I use crepe?
neither crepe nor rmvpe is ideal
what is ideal
nothing yet

in 80% of cases all 3 extractors agree on the curve
the issue is that they disagree on 20% and it is a different thing
crepe hates noise and makes non-0 values

I see

is there a big difference between using a 10 minute recording vs a 30 minute recording for training? I feel like my index is a bit off on the accent and considering to use a bigger recording next time
using index is what gives you an accent, because the voice model does not have the sounds that match the audio you're inferring
like german model would say 'ze' instead of 'the'
without using an index the accent goes not minimum
yeah I know, I'm curious if a longer recording would give a higher quality .index
if there's any significant difference in index quality between 10m vs 30m clip
larger dataset results in a larger index, but unless it contains the sounds close to the target audio there's still going to be an accent
if you listened to both the smaller index and the larger index side by side, would you be able to tell a difference easily?
btw, you can use any index with any model
the index that I need is quite specific
I doubt there's index's for an Israeli accent that I can find
french could work maybe
i'm sure you can find some celebrity model and take its index
yeah I can find something, cutting out a whole bunch of talking clips sounds a bit like a pain but atleast it's not what I had to go through with zluda
hi, is it possible to make the ai model read text? I cloned my own voice and I have a german project to do and I can’t speak german so this is why it s kinda important
there's a tts tab in the applio thing
Which models work best for audio restoration?
I've recorded alphorn in the mountains with my camera but I want to remove the annoying clicking noise from the focus motor
you might be able to use some free AI tool that's made for isolating lyrics and instruments
can anyone help me finding the ai software?
Is there a way to make the tts in applio change it's tone by giving some kind of tag like {{whispering}} ????
can someone send me the download link for the voice changer please?
thank u
I used Denoise-Debleed by Gabox. That worked great!
есть кто то русский?
no, use a different tts
Hello
!howtoask
How To Troubleshoot
__**GIVE CONTEXT.**__ 📝
- Don't simply mention your issue, like "
my rvc is not working". - Describe the step you are on, what you're trying to do, the RVC you're using, a screenshot, etc.
- The more context, the better.
__**BE POLITE.**__ <:matsuripray:1159685390156967936>
- Don't be desperate. You can ping a Helper, but if they ignore, they aren't available/don't know the answer.
- It's okay if you're frustrated, but don't take it into this server.
- Don't DM without prior consent.
__**BE PRODUCTIVE.**__ 🤝
- Don't ask for every little instruction. Put your own effort & test things by yourself.
- Don't ask to ask.
- Check if your answer is a Google search away/on our guides website.
If you've changed your mind about your message, feel free to delete/edit it.
While not many people would own a Macbook to test and run W-Okada, it's rare from what I have seen, most people here got Windows and sometimes Linux.
Which Macbook do you have? There are two variants of fork W-Okada for Mac of different CPUs.

!howtotask
No, that's not what I meant.
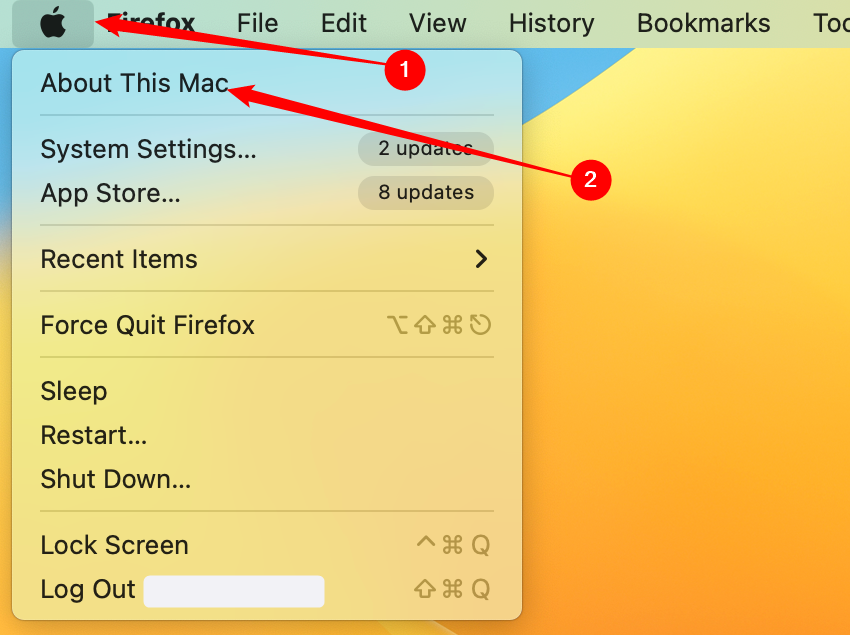
There's a way to check if your Macbook is M or Intel, which is somehow located in About This Mac menu. https://static1.howtogeekimages.com/wordpress/wp-content/uploads/2023/09/click-apple-about-this-mac.png https://macreports.com/wp-content/uploads/2023/04/compare.png


The "Processor" or "Chip" part would tell you the CPU name of your Macbook.
Apple M1 is Apple Silicon. Now have you download this W-Okada? https://docs.aihub.gg/rvc-voice-changer/local/deiteris-w-okada-fork/#download-mac-silicon
Last update: May 5, 2025
hi sorry me again!, when i downloaded the thing it said that one of the files were damaged
Not the slicnonn
The acual files
I have once again come back for help
I think?

I'm trying to continue my training off the backup, but it looks like something went wrong
my steps:
- Mount drive -- success
- Load backup with the accurate model name -- success
- Auto backup on -- success
- Install Applio -- success
- Start Applio with gradio (like usual) -- error above
what do you mean cone the app?
clone
clone what? to where? I ran the "Load a Backup" option and it looked like it automatically created an Applio folder with the stuff in it

there is no such option

because whatever that is, it's not the colab I'm using
do I need to open a different colab for backups?


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
ah, a different colab, as I suspected
thanks for the big red arrows that totally helped me see that in https://colab.research.google.com/github/iahispano/applio/blob/master/assets/Applio.ipynb
like dude don't act like I'm supposed to know all this out of the box and be like "ah yes! For backups there needs to be a different no UI colab! So intuitive!!"
it's so obvious to know things that are not mentioned at all in the guide of course
ffs
and why does this exist ????

for no reason at all?
just because?
just so that I get bamboozled?
genuinely educate me
come on
instead of acting like I'm stupid for not knowing shit as a beginner that is not mentioned in the guide even once
tbh idk why he was so mean towards you but yeah the docs aren't up to date and that specific colab is in applio's github site
okay, thank you
im not affiliated with applio btw