#✨│ai-help
1 messages · Page 234 of 1
how do you take a screen shot lol
- press stamp/print depending on your keyboard
or - windows+shift+s
skibidi
here it is

did i already show u the screenshot that the upload failed lmao
how do you manage to f this up


I created a new folder in my C drive and then extracted that folder their
put it in a path without spaces
just remove the spaces where the program is
what do you mean remove the spaces
rename the folder
to not have spaces
after renaming the folder,yes
is this apparently hard?
for ipad generation it seems so
says this nowwwwwww

holy shit, finally
did it open ur browser automatically
yuh
then boom ur in it
it runs locally, just uses a web browser interface

where do i add my voice
click the resize button again

are you training without a pretrain?
me?
yes
why
Last update: Apr 01, 2024
i didnt know what model to use ngl
use default then
i have to download them to get them on the list

on the training tab
truly ipad generation
you're training a model, why you're looking at inference tab?

mb
down to training in advanced options

do not uncheck

was it ticked when you started the training?
yh
how can you add just the file that I downloaded
oh
put the model files into /logs/ folder
wdym
it's explained in the guide how to add models
it says link where am i gonna get the link
i went into my game files and got the audio like that and got like 400 voice clips totalling up to 28 mins and then i combined the audios it cuz uploading it through the batch file link thing was being stupid
you dont need to create a dataset or upload files if you run it locally
only if you're using UI Colab
yeah im using it on ui not local
Whats the best settings for it?
Convenient file sharing. Registration is not required. Large files are supported.
you usually just need to play around with the search feature ratio and pitch that's all
it all depends on how good is the trained model
Anyone on linux can help me set up the a virtual audio cable so I can use okada on other programs? 🙂
this is my first time using this. how can i stop my wokada from stuttering?
Hey so if were using a virtual cable how do we hear the audio of a video for example?
you dont need on at all times
what if were streaming for example?
elaborate:
- your pc gpu
- what u want to do
- what tutorial link did u use
- a screenshot of ur wokada
wdym? the output in twitch settings will still be ur headphones, the input will be line 1
the vac is only used on okada
for example I have right now Line 1 virtual cable audio on and if i go to youtube I cant hear the audio their
change ur audio in settings
do ctrl+windows+b and show a screenshot
my laptop uses a rtx 3050. i want to change my voice in real time. i used a youtube tutorial from ai search.
Nothing pops up when I do it
i cant send screenshots
rip, video tutorials are very outdated, that's the issue
a year old video tutorial is prehistorical in ai field
all youtube tuts use an old version of original wokada
and vb audio cable which causes issues
uninstall all you got off youtube
-realtime
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested. GUIDE
• Original Wokada
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
• **RVC GUI Mainline Realtime**
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
read the 1st link, wokada deiteris fork
alright thanks man
try ctrl+windows+v
Can I have the output on RealTime Voice Changer Client on Line 1 Virtual Audio Cable and the output of my pc for my headphones??
yw lmk
yes, that's what im trying to help you get, try that combo so i can see the output device you're using
I just tried it
did it show something on the right bottom of ur pc?
no
is it windows 10 or 11?
10
oh
go to settings > search "audio" > click the 1st option > then select ur speakers as the output device
that should fix it
is this done?

you can do it with default PulseAudio
not even close
I changed my audio from virtual cable, to my headset on my PC and when I open the app it goes to my headset on my PC if I change it on Realtime Voice Changer Client back into Line 1 virtual cable for the output on the website and for my actual audio I change it to my headset for my monitor itself would it operate the same?
it should work
okay prec8 it, just a question how did you know my file name?
ugh i may need to leave it overnight or sum shit
training takes hours
Remember when you showed the screen shot and it said my file name when I had no spaces?
How? I've tried a few tutorials but nothing is really working 😛 The deiteris guide just says to google it which also doesn't help a ton
because it shows the path of the file in cmd (the black window u saw)
it was literally showed in ur screenshot since there was an error lol
i actually did a screenshot of ur own screenshot that time to show u the error lol
I thought bro was a hacker lol
Yeah I can tell lol I’m on my 2 hrs mark
u just needed to check ur own screenshot 😭
u can go back and read it if u want
I trust you bro lmaoo
goodluck 🔥
yep i defo need it, when its done what do i do?
stop training on applio?
then export?
well u would actually need to check the tensorboard to check how's the training going
yhh ik but lets say i checked tensor and its done what do i do/
u stop training and get the best epoch based on the lowest point step
how
epoch is the y axis?
how do i get the best epoch?

What do I do here?
icl my w-okada keeps delaying for some reason even though i have an 4060ti and it can run pretty fast mostly but now for some reason it delays a lot more.
to like 220ms
Im trying to make it record so I can make a video
even though it can handle 120ms
why did you select the entire assets/audio for batch infer?
what am i supposed to do to fix that beacuse its annoying asf
how do you put a model into it and actually use the damn thing
wokada deiteris fork btw.
ts pmo bro why is this suddenly so ass
go to download
scroll all the way down once ur on the download tab,then go into download pretrain model

no way yall r still here
as I said, put the model into /logs/, click refresh, pick it from the drop-down
i think this might just be a genuine glitch
from wokada
he needs to download pretrained models first from the download tab
Could yall do a tutorial
Like genuinely if someone downloads the app what should they do and etc
have u figured it out?
Nope
ohj
Whattt
updating my gpu bc maybe thats the issuetbh

I have a problem, I had a crash on my pc and the okada launched in “security” mode but deleted all my voices. How can I get it back to the way it was before?
For example I download a model RVC here and then I copy paste that file into Logs and then refresh it and then put it into Appoil?
all .pth transform on .safetensors
u talking to me or wha
if u can help me yes
wdym
i just got it fixed with you and it reponsded faster finally, like it SHOULD.
now its back to the delaying thing.
for some reason
i dont know if its even using my GPU correctly.
but i never had this problem and it just randomly came
and ive tried so many things.
updated my gpu. deleted the old driver, bc i replaced the driver thing like u said.
What is Wokada?
the realtime voice changer program
does it like go idle and cut at the start of your phrases?
it must be like an glitch or something by the program itself because this is crazy
it’s different then the two you recommended me?
yes that ifmy phrases even COME.
as of right now no phrases are workin
no, it's literally the first program i recommended u for realtime lol
like i genuinely feel like a dumbass
ohh shiii😭🤣🤣
@low shard imma leave my pc on overnight now is there anything i should do?
share a screenshot of ur wokada and tell what program ur using it with
on kaggle?
like if ur using it on discord or a game
just discord
not even discord tbh
discord is running in the background
just it it self.
you should be fine, just be aware that you could risk being disconnected for inactivity but it's rare that happens on kaggle
are you using wokada for using models on pre-recorded audios or smt? wokada is meant for realtime like discord vc
ah okay wish me luck ig for tmrw and thanks for urs and @simple ore help
yw
im using
wokada models
not prerecorded
like realtime
this is not my first time it being ass
this is my first time it being ass.
I was just asking if you were gonna use wokada for realtime usage or for pre-reocrded audios
like right now, its speaking live again. but after a while, it will die out again, and suddenly delay. if i open it again in abit, do you know why these issues could happen?
ohh yeah i use realtime mostly.
i mess around with friends a lot with it and its fun

rn its running as it should
but if i closed it and tried again im sure it wont
mmm, close the program, run the force gpu clocks then restart the program and show a screenshot of ur entire wokada

see now i restarted it and it has the delay again
even though i know it can run fast
it always has
ts pmo
nice image model, set chunk to 192
does it go like 'idle' everytime u put it on background?
Lmaooo
ive tried that didn’t work
it’s not that the chunk is the issue it’s the fact that it just gives up on loading like it always does for some reason
It’s just literally sometimes it wants to work like it used to but mostly it’s just this shit
it delays like crazy ior just freezes up
I deleted it at first thinking it got outdated.
@reef flax could u answer this precisely
my bad man
what do you mean with idle exactly?
like it just stops or doesn’t perform as well?
yes
not every time I put it on background
Every time I start it in general, unless. I’m lucky
You said if I needed to record something like a yt video I should use Applio, so how do you operate it and add the voice and get the system running?
maybe after a while?
maybe.
did u run the force gpu clocks?
Either way it does fall under that category I’m assuming
I did
are ur nvidia drivers up to date?
what about windows version?
Also.
you mean that's updated too?
Yes
does your gpu have hiccups/issues at any other program like 3d rendering or games?
No I replayed resident evil 4 remake and village
It went great
GPU is pretty recently put in too
just try to re downlload it
and delete all the other files
that's pretty weird since i have your same gpu lmao
right?
i can run alot of games
just fine
Restart your PC
i already did multiple times gng.
Bro tried everything lmao
@crude flame do you may have an idea?
it seems like his gpu goes idle after a bit the program stays in background, even if he has no other program than discord opened and already tried force gpu clocks
i used to run the w-okada voice changer i think this is deiteris fork with no issues. same gpu, same settings. now suddenly its super delayed or i hear nothing at all. gpu is active (30–40% load), so the model runs, but no voice comes out. and if it does? it delays like crazy.
short explanation so your buddy doesnt have to scroll up and go crazy.
how do you put a model voice youve downloaded from the server?@low shard

idk for sure
but i think voice model
. it literally says select the voic emodel to use for the conversion..
💔
go to the download tab
I tried it but doesnt work I think theres another way for Applio
It says google drive link in the Guide
What does it mean by that
the type of model download link
else if u already downloaded it on ur pc, just extract it and upload the pth then .index
yeah the delay is still crazy
do yk the immense ragebaiting
w-okada is doing to me rn
I click on upload Audio??

this bro
im the tiger
w-okada the monkey (wise and ragebaiting)
in the download tab, there should be an upload model part
Dont work tryna join the VC and check it out
my suspects are that ur gpu goes idle after the program goes in background for a bit, but usually force gpu clocks totally fixes that
!give-media-perms 1h @delicate whale
u can just send screenshots
i might force bro with my fists
no but im force gpu'ing a million time srn

click the Download tab
Just did
i added it to NVIDIA Control Panel
specifically in 3D settings > program settings, ykyk.
hoping maybe this might work?
Bro got unlimited Ideas lol
bro was a alone child thats why.
still dont work fr
I fking told you twice
- put the models into logs, 2) click Refresh on inference, 3) select the model from the dropdown

Whats your guys's go to for ai tts? Applio still?
icl i think its still idling ive tried almost everything doesnt work

I put the models there and it wasnt appearing, this shiiii is soooo fking harddddddd

Can we please join a VC call and actually help me out
😭😭😭😭😭😭😭😭😭😭
I SWEAR THIS SHI HARD ASL
i'm fking done... i'm gonna open a bottle of vodka and just drink it all
im sorry man
im actually sorry for you
PLEASEEEEEEEEEEEEEE HELP MEEEEE
Buddy quit yapping and figure out the shi w ur GPU
already did everything anormal person could do , even the dev didnt know im just waiting maybe theyll come back with something
u on the other hand are just making their lives a living hell
use common sense before you ask for help
did you unzip the downloaded model or you're expecting applio to load .zip for some reasonm?
yes
yes yes or yes no?
YES YES YES
how i upload
my private model
in this huggingface website, so the aicovergen can download the model
icl w-okada ragebaiting me like crazy ive tried everything and this dumbass shit still delaying for no fucking reason bro praying on the application's downfall, have a good day
HOW DOES APPLIO WORK TO PUT IN YOUR MODELLLLLLLLLLL
on huggingface make a new model

I putted the model link then clicked on Download Model
then from the model card

I've explained 3 times
I can not explain any more
Whats Next Come on Dont be like that
I can not help you if you can not do a basic computer stuff
Just one more time thats it
I been trying to figure it out for the past 2 hours its frustrating please
and I finally did it
explain in your own words

anyone know how i can remove some light backround talking in a clean acapella
Once I download the model I put it in logs
right
elaborate
then Refresh it?
Put pth and index models into /models
Refreshing does not make them appear, have tried a restart on applio. Ideas?

anyone know of a model that can remove backround talking on a acapella of some rapping
just no
just no?
logs, not rvc/models
that's how it is
lol your a noob thats how it is in rvc
rvc/models is for internal stuff
you got spoild on aplio
Sounds like some developer made a dumb choice and it's never been changed
just stop
Oh well ill modify it

be greatful the developer created this
ok and ill be greatful that im going to change it because why the hell would you put premade models in a folder where logs should lie
its not that deep
tbh it also felt weird to me applio stores models in the logs folder, mainline has its own dedicated folder for that
lol it is when your learning rvc. do your own research if you don't like it.
 again some developer made a stupid decision and no one decided to change it
again some developer made a stupid decision and no one decided to change it
no big deal
ill change it myself
logs is for saving all the trained data such as index. the wav. ect
okay just leave and quit talking about it if you can't understand my simple point
i dont care what the standard is, the naming makes no sense.
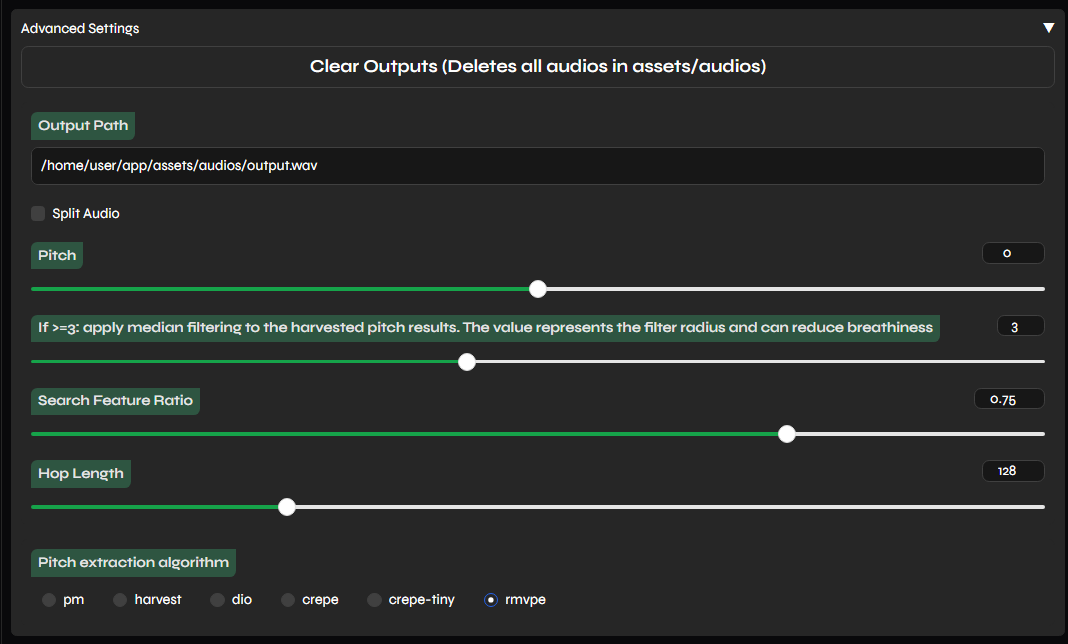
I dont have hop length and the if......... one on their @low shard

this is the picture of the guide and it has it
bro
i literally tried every signle thing
my w-okada is still annoying
can someone lockin and help please
💔
sorry your wokanda is broke
where is that
your welcome
you know with how tech is its easy to figure out stuff without peopole
yeah well
ive tried 20 times
without people
ive tried multiple things
went on here and he didnt even know what to do
gang
such as?
did you try googling it?
i updated my gpu
wdym which one
i have chatgpt plus
the newest model
and the smartest
wdym with grok gang
grok by x
grok ai?
yep
yea okay
I FINALLY DID ITTTTTTTTTTTTTT
deep research helps
OMGGGGGGG
i used grok to help me fix why sovits svc wasn't installed properly and it help me fix it so..
ONCE YOU GET THE AUDIO FROM APOLLEI YOU PUT IT IN REALTIME VOICE CHANGER CLIENT?
???
its for cloning and infer voice
ur idea
ur AI
came iwth everything IVE ALREADY TRIED.
im just gonna post on github
last resort.
do you think it makes a bigger difference if your only using Voice Changer Demo AI?
Heyo again; quick question!
I'm experimenting with the experimental KLM6 Spin pretrain. I know for a fact I've 1. placed the embedder in the proper folder and selected it when training, and 2. opened up filelist.txt to replace /mute/ with /mute_spin/, but so far the early model sounds like... well, it sounds like whispers and noise. Is this normal, or is something not working properly?
noooooooooooooo
Using MelKaraoke
Last update: Dec 24, 2024
available on UVR5, UVR5 UI, MVSEP and MSST Colab
do u have UVR5 beta?
if not it will no work
idk
could be
so i need full release
of this ubr5
it isolated automatically and everything
pls check this
it depends if u want that locally or cloud
locally i think lol
nice

let me try again
ok, just download, extract and run
yup
Traceback (most recent call last):
File "E:\RVC-AI-Cover-Maker-UI-main\RVC-AI-Cover-Maker-UI-main\programs\applio_code\rvc\lib\tools\prerequisites_download.py", line 3, in <module>
from tqdm import tqdm
ModuleNotFoundError: No module named 'tqdm'
Traceback (most recent call last):
File "E:\RVC-AI-Cover-Maker-UI-main\RVC-AI-Cover-Maker-UI-main\main.py", line 1, in <module>
import gradio as gr
ModuleNotFoundError: No module named 'gradio'
An error occurred. Exiting...
Drücken Sie eine beliebige Taste . . .
xd

hey so i found this while trying to run it
can someone tell me what this means, and if it has something to do with my problems >/ if i can fix it/how.
use ur C drive
right now im assuming its because my CUDA is maybe TOO up to date then w-okada can do right now gpu wise?
so im going to CUDA 12.2. someone tell me if im on the right track here or completely off track
maybe even flying off a bridge right now.
damn, i think that's the problem. Earlier a guy had the same problem
What about cloud then?
Colab
you're trying to install ancient requirements
or just did not install requirements properly
like did you just clone the stuff and trying to run it?
Haven't updated the code tbh 
did not do pip install -r requirements.txt?
it's using the precompiled version made by nick
that look confuing
confusing
whats nko
did @echo meadow download the precompiled?
ngrok*
yep
why would it then break at missing requirements?
a tunnel to access the interface, u can use gradio instead. For ngrok u need a ngrok token
i've no clue 😭
Do you guys think using VCD and then recording it in OBS is better than using Aplio?
well, no he did not
precompiled works fine
source needs install
@echo meadow download precompiled RVC-AI-Cover-Maker-UI-main for local use
a

a
1 question
i used collab
where i find background vocals in this
like only this
file where its done
its like
this got all added in 1 song, but cant see them seperate
like i dont see instrumental
lead vocals
like the old one that you made
oh, but need to disable an option "Delete the audios after the conversion."
hmmm
where is that
advanced settings
yea
disable it
ok ill try again
ok
show me
now u can

karaoke
thanks
ur welcome
hello! Im new to AI stuff and I just wanted to know some stuff about it. I have a laptop and I want to build my AI bot for Telegram, but I'm unable to do so, since it takes all my CPU and not loading a response. I suspect it to be due to my hardware being shit, but I just wanted to ask if thats the case
My AI right now has a model of Tiny Llama 1.1v - this is like a last resort and it still doesn't work properly. My whole project is on venv (like when you do cmd stuff, it shows (venv) at the very left), everything is parsed and should be working as expected, but my AI just doesn't want to respond
hi! does anyone know an ai that seperates the leading and backing vocals?
You can use the MelBand Roformer Karaoke model (particularly, Becruily's model). That model can separate the leading and backing vocals.
Thank you!
Figured out the problem, the embedder wasn't being regognized properly. I had placed the embedder folder in embedders_custom thinking it'd automatically select the proper files, but it wasn't actually doing anything 😅
maunally placing the files worked 👍
when you have more epocs for training ai does that mean that the quality of the ai will be better
Not necessarily. In simple terms it's possible to overtrain a model if you train it for too long (too many epochs)
Is there a free version of Voice Mod with unlimited free voices and soundboards
It's kind of like baking a cake!
You want enough time in the oven so the model sounds like your voice (dataset)
However, you don't want to overbake it, because if you leave it cooking for too long it can't generate new sounds easily, and can start to sound robotic
how many epochs would you suggest i use for 12 minutes worth of the certain voice
So, each voice dataset is different. Two 12 minute datasets can potentially need different epochs
What most people use to figure out just how many epochs is through something called Tensorboard
Last update: Feb 10, 2024
does the folder that i put the tensorboard bat into need to have a specific name
Not that I know of, no
because when i run the bat it says "system cannot find the path specified"
because it doesnt have any spaces or special characters
the folder name is just "rvcs"
And you've made sure the whole filepath also has no spaces or special characters?
yeah
Hmm
like after the folder is open its just that
Is the RVC folder also located on a filepath in your C drive?
The rvc folder is in the download file path
are you using applio?
if so you dont need to download that file in the docs
Does applio have a feature that does something similar to tensorboard?
There we go that's probably the issue
When looking for specific files, RVC defaults to your C drive, so it's recommended to place your folders there (like on your desktop or something)
Applio is an offbranch of RVC that users here are regularly improving
yes
its called the tensorboard
just run
when i run that it says "no module named 'rvc' "
does anybody know why my w okada voice crackles and bugs in discord but not in like other games
step 1 - disable hardware acceleration in discord so it does not offload work to GPU that is busy handing the voice changer
and browser too
Can i ask? How to train a voice model for RVC?
the complete guide is there https://docs.aihub.gg/
Last update: Oct 21, 2024
wait where is that
i wonder if theres a realtime rvc client that able to apply vst plugin into the converted voice
Does anyone know an ai that can increase the quality and clarity of audio?
Now that I think so, is there a way for test already made models with index in a tensorboard way? I have some old models made on RVC that are actually good and have used in years, but I never test them with tensorboard when I was making them years ago. So it bring my curiosity now.
think its called audioSR
I wonder how to make models 😔
tf is this

In the context of RVC, the dataset is an audio file containing the voice the model will replicate. It can be either speaking or singing.
Thank you 🫣 so much
If you face any problems ping me
can u help me bro
!howtoask
How To Troubleshoot 
__**GIVE CONTEXT.**__ 📝
- Don't simply mention your issue, like "
my rvc is not working". - Describe the step you are on, what you're trying to do, the RVC you're using, a screenshot, etc.
- The more context, the better.
__**BE POLITE.**__ <:matsuripray:1159685390156967936>
- Don't be desperate. You can ping a Helper, but if they ignore, they aren't available/don't know the answer.
- It's okay if you're frustrated, but don't take it into this server.
- Don't DM without prior consent.
__**BE PRODUCTIVE.**__ 🤝
- Don't ask for every little instruction. Put your own effort & test things by yourself.
- Don't ask to ask.
- Check if your answer is a Google search away/on our guides website.
If you've changed your mind about your message, feel free to delete/edit it.
What is the problem?
im on pretraining i was uploading the dataset
and randomly during that i faced this

and it stopped uploading
Well most of the collab notebooks are broken
damn so it's a problem on the notebook?
like its not something that i did wrong? can it be fixed?
thank you
if i have any other issues can i ping u?
📘 Kaggle Notebooks
Kaggle is a Cloud (Remote Good PC) Service that offers 30 hours of GPU weekly, but needs a phone number verification
• **Applio Notebook**
by IAHispano
Kaggle
• **Hina Mod Original Wokada**
by Hina
Kaggle
• **Wokada Deiteris Fork**
by Hina & Deiteris
Kaggle
• **UVR5 UI**
by Eddy, ArisDev & Nick088
Kaggle
• **UVR5 NO UI**
by Eddy
Kaggle
• **RVC AI Cover Maker UI**
by Shirou & ArisDev
Kaggle
• **Music Source Separation**
by Shirou
Kaggle
damn thank u bro
is there like a tutorial or something for kaggle?
@latent kettle
Last update: Jan 13, 2025
im running the last cell rn but i have a question will this disconnect like google colab when im inactive?
alr thanks
if i got any more issues ima lyk cause i deadass dont know shit about training ai
Be aware about ngrok bandwidth
tf is that
Its a limit of 1gb to upload or download data from connected agents
whats a connected agent bro
If you cross the limits you can't access your training session anymore
Here it is Your applio notebook
shit thats bad
You can monitor it on ngrok web page
oh so for example if my data set is above 1 gig its pretty much over?
Yep
damn my dataset is 521 MB
it's a big wav file i used to do it like chopped up into like 70 different files but i was told it was better with a big wav with all of them on it
and where exactly can i monitor this
You can use FLAC format it's lossless and also saves memory.
Dm me a screenshot of your dashboard.
hmm that's interesting i didnt know that
bet give me a second
the ngrok dashboard?
Yes
You must read "how to create dataset "
i didn't read it honestly but i saw on a yt video that they used .wav format
also im a lil bit slow where can i find the dashboard
Most of the yt tutorials are outdated don't follow them
yeah i noticed just by the google colab thing
i appreciate u for helping me bro fr if it wasnt cause of u i'd still be stuck tryna figure out wtf the problem was
also bro one thing
Last update: Dec 24, 2024
i'm on the actual training now
im training a future model from around 40 mins worth of studio sessions how much epochs do u think i should set it to
is it normal that i have this many path files after training?

Yes. But it's eating kaggle storage which is also limited
yeah i can tell so which one is the file i need?
and how do i clear my storage?
i think the one with the highest epochs if u set it to the prevent overtraining mode
normally it would save the best epoch i think
is the epoch the number before pth?
@latent kettle how much total epochs u recommend me to get for this model
notice how it says 240e, 250e etc thats the amount of epochs
With modelname_e
What's the dataset length and batch size
seems like my highest epoch is 430
dataset length is 50 minutes and batch size is set to 15 by default idk if i should change it
yeah i see it so my highest is 430 is that the one i should download?
i'd say try that one since it's probably the best if there's no overtraining
the reason why u have so many of them is because u set it to save every 10 epochs im pretty sure
yeah i might do that, how do i download it?
yh i did and i left for 7 hrs
hmmm tbh i dont really remember how to get the index file 😭
its in the same file as pth
Broh... you should look at tensor board
i jus downloaded it
dude i dont know any of that graph shit LMFAO
tensor board is the graph where u check overtraining and such right
?
You can check tensor board and download the best. 7 hours must be over fitted
Yes
alr so i set the save every epoch to 50, batch size at 15 rn is that good
i wanna have a decent amount of max epochs but idk if 600 total epochs is too overkill
that'd mean 30 pth files
that could be risky what do u think
Last update: Dec 24, 2024
Epochs are not equal to quality
ik the dataset gotta be clean too
it is
i mean its studio sessions i cleaned them up a lil bit as well
Oh okay how would Ik which one is the best?
it's raw vocals of future
Last update: Dec 24, 2024
wait what if i enable overtraining detector @latent kettle
That's also good but I never used it
what does it do? i assume it automatically stops it
Make sure to read advance guide too
@latent kettle are these the correct settings?

😭
i just dont wanna fuck it up my previous models were bad like weird typa bad they didnt even sound like the person i trained them off of
Remove save only latest and save every weights. Reduce batch size to 8 or 10
Set max epochs to 300 for now
okay thank you
Enable fresh training
Okay
anything else?
Only for now (don't do that when you are going to resume training)
Not sure
Show me all settings


so are these ready?
Read the guides to observe tensor board
Everything is inside the guide good luck
okay thank you
can i ping u if i need anything else?
You can but there will a chance for late reply
okay
thank you
dude @latent kettle i dont think theres any info about tensorboard on kagglio on the guides
how do i get it to work i dont see it anywhere normally on colab it will open automatically not here tho
select scalars, then click the gear icon and select Reload data
Nd select ur model near the left
on kagglio or ngrok?
ohh
nahh i get what u mean but i dont see that thing on my kagglio
Wait press the tensorboard link
ohhh
It’s given in kaggle
Nwrs and just do the bit I told you
yup just did it
btw if i let it run nothing wrong gonna happen right?
im asking since u let it run for 7 hrs
😭
its 4:11 am bruh
i wanna sleep
Hopefully not it didn’t happen to me it just stopped ngl
Ahaha
ight ima gts now
bro im meant to be at the gym at 11 am
Have a good one
😭
aye u too man
7hrs of sleep is not
Enough 😭😭
nahh, did Razer reply?
Sorry but I thought you got you answer
batch 15 is ridiculously high, change it to 8 for 50 min set
I recommend 10
it can be experimented, 4, 6, 8, maybe 10, it is something to experiment and compare the result
no.
maybe @pastel oak or @analog obsidian could help too, or you could retry the force gpu clocks
i tried 2.0.77.beta and it works but its not as good as the previous one, and i just want the previous one to work again.

this is what im getting by the way
try the fork version

Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
If you need HELP, ask in AI HUB Di...
okay
i think this is just the same i already have

it works just not as well as its supposed to
its delaying, and lagging.
which is not supposed to happen because it used to work fine and fast.
now its giving this lil warning
how about another model? or perhaps the chunk settings? or perhaps some GPU issue?
icl i tried everything
another model i already tried
chunk settings ive played arouind it
an dmy gpu is new..
like recently bought
not RTX 50-series for sure?
4060ti
have you tried different driver version? perhaps Dec 2024?
does it lag on certain games?
if ur talking about my gpu
no ive said thsi before i played re4 remake and most of the other games smoothly
ye it runs smoothly alone but it is rather demanding
try lowering graphics settings and cap fps to 60
do you mean my hertz or something
i dont mean im using it while playing a game.
im using it while playing absolutely nothing other than having disord run
ive had it run perfectly before, while no teven playing games.
now its just delaying

and it gives me this warning,
im not playing anything.
it makes sense if for running discord
uhhh
dont make sense to me because it used to work perfectly fine
im confused
what might be the issue
or are you lost too
lol
I mean also the performance
previous versions, and the most recent one like 2.0.77 beta
does work well
and how its supposed to
but the fork one, which runs models more smoothly for me
suddenly doesnt work anymore.
so you'd want to roll back to the 18a?

i just want my fork to work well ...
again.
like it used to
i dont know if theres an misunderstanding here
this is on the most recent one from w-okada
icl ill just show youi
its this one
which is not the one i want fixed tbh because that one just works, i want hte fork one or at least understand whts going wrong because it used to work well.
this one doesnt run through chrome and is just an application by itself, it just doesnt run models as smooth as it should
the one i had the w-okada deiteris fork one
runs it smooth and i like it more, but now its suddenly delaying.
we here don't support and guarantee it work
im trying to get the delay to be fixed..
the warning i get is from fork
https://discord.com/channels/1159260121998827560/1297207135469305866 the guide here does cover on the fork version
not the 2.x beta
paus elet me explain, the fork version ive already ran it before on the same settings and it worked just fine. the guide there probably tells me what settings to do best.
it just sudednly doesnt work anymore, doesnt matter what my settings are
but okay sure.
if ts seems puzzled, the last resort may be to clean install windows and Nvidia driver & cuda toolkit stuffs
icl ts pmio
lol
any other way than just cleaning my windows completely and having to download everything i needed all over again..

w-okada ragebaiting me
since yesterday
Lmao what does this mean the only word I understood is the pmo
@low shard it looks like its working it seems to be off a bit but its still good ngl
its a male voice what should the tune value be?
What do you mean by tune value
mb i meant pitch
If you are converting female to male you should go with -ve pitch values example-3 ,-5 or vice versa
okay ty
ngl my thing sounds good im surpised it works
Which model do you used
No, i mean you let it train for 7hrs
yes
And it created multiple pth
yes
So which one are you using
You can check tensor board for lowest Loss values.
how do i do that?
Do you used over fitting monitor?
whats that?
That thing automatically detect over fitting
ngl im not too sure is there a way to check?
There will be a sweet spot where your model will perform its best. There could be chance that your model is over trained
What batch size do you used and what was your dataset length @eternal aurora
ohhhh
gimme a sec
i guess bruh
my shit is bugging
@latent kettle my batch size is 10
and my length is 28 mins

what do i look for?

{kind=link}
Applio
Can you please read the guide?
whats the difference between that one and deiteris' optimized W-Okada?
i have
i genuinely cant tell if i have low points or not
Applio is the regular RVC program, a program that can do AI cover and train voice model. W-Okada is realtime voice changer program that mainly use RVC voice model to change your voice in real time.
!howtoask
How To Troubleshoot
__**GIVE CONTEXT.**__ 📝
- Don't simply mention your issue, like "
my rvc is not working". - Describe the step you are on, what you're trying to do, the RVC you're using, a screenshot, etc.
- The more context, the better.
__**BE POLITE.**__ <:matsuripray:1159685390156967936>
- Don't be desperate. You can ping a Helper, but if they ignore, they aren't available/don't know the answer.
- It's okay if you're frustrated, but don't take it into this server.
- Don't DM without prior consent.
__**BE PRODUCTIVE.**__ 🤝
- Don't ask for every little instruction. Put your own effort & test things by yourself.
- Don't ask to ask.
- Check if your answer is a Google search away/on our guides website.
If you've changed your mind about your message, feel free to delete/edit it.
Is possible to use 2 gpus to decrease the delay? 3060 12gb and 5060ti 16gb
In w okada
One W-Okada program can only use one GPU at a time.
there isn't multi gpu support unfortunately
@wispy lodge that might not be a bad idea (if possible) btw
so for realtime should i do deiteris' optimized W-Okada or the original one, i have a 4070 ti?
also, ofcourse the 50 serie would give less delay
you should use the wokada deiteris fork
don't use video tutorials
-realtime
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested. GUIDE
• Original Wokada
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
• **RVC GUI Mainline Realtime**
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
That's a confusing question I've ever seen. Yes, you should use Detris' fork W-Okada for realtime.
I'm not sure how one would attempt to run W-Okada with two different GPUs at a time. Plus, only Detris' fork W-Okada that made for RTX 50 could only work with RTX 50.
Okeyy thanks
Have you increased smoothing
okay and if I wanted a ai voice to say typed out text like TTS I would use applio
Also, it's unlikely for these two different NVIDIA GPUs of different generations to combine themselves and work together. Each one would work independently from other. But you can set W-Okada to use RTX 3060 and one of your games to use RTX 5060 Ti.
Applio has a built-in TTS feature. 