#✨│ai-help
1 messages · Page 233 of 1
No phones just use cloud
I was just using the wrong copy pasta, don't worry about it lmao
Use the links I sent above
ok thanks
yw and lmk
can someone tell me why like this ?

its my first time use kaggle
andi cant see the notebook settings there

Help me pls I want to make voice model...😭
what's ur pc gpu
elaborate:
- what's ur pc gpu (check via task manager)
- what tutorial link are u using
- what u want to do
- what links are u using
i click the one wrote open the colab
i want to u se the voice changer but sorry the tutorial its confusing me
elaborate the things I asked you
@cobalt vine
@low shard wsg did you know how to fix my issue?
elaborate
Hi guys, I wanna have a suggestion born from your experience with AI training.
I have prepared in these days a good Italian dataset with 16 female speakers and 26 male speakers, good amount of hours (haven't calculated totally yet, but it could be > 20 hours).
I already know how to train a model with Applio, and how to prepare the dataset ecc. just wanna know if there are some solutions I can use since my actual workstation is resource-limitated for that task. I mean, is there any cloud platform where I can just upload my dataset and do the fine-tuning on the original RVC model?
are you going to train a pretrain?
Yes
I just want to understand the best practices to do it since my dataset is ready
free or paid cloud providers? because i'm not sure you will be able to do it for free
Both of them, I want to invest on that
If there's no free alternative then go for paid
Train (make) RVC Models on cloud:
- Prepare the Dataset
- Setup RVC:
Choose a cloud way to use RVC,
- Google Colabs (max 4 hours of daily gpu not granted for free, not much hours for training, but easy to use, there's a paid tier):
- Kaggles (a bit harder to use and needs phone number but gives 30 hours weekly of better gpus, only free):
- Lightning.ai (Kinda hard, needs login, no issue with web uis or anything, but only free 15 credits monthly, but there's a paid tier):
- Be sure to know about the tensorboard
Google Colab = Easier but risk of getting disconnected
Kaggle = Harder but way more gpu time
If you are looking for the easiest way and for free, is using https://weights.com/ which ofc uses RVC
RVC Inference (use models) on pre-recorded audio on Cloud
You can use either:
- Weights.com: Easiest Possible Ever Automatic
- Ilaria RVC Zero: Fastest free on cloud
- Applio UI Colab: RVC Fork with some extra features like TTS
- RVC AI Cover Maker UI: Automatically Separates the Vocals and Instrumentals, converts the voice and mixes them back
for training a pretrain, it would be better you may pay for colab or use another service (like runpod) with your own notebook (should be similar to the google colab code), there isn't much support for paid ones because usually they don't use cloud to train pretrains as people don't really want to pay
the max you could get for free is kaggle applio, but i really doubt it will be enough
30 hours... mh it depends on which GPU they are going to assign
How many epoch should I use for training a pretrain? Not from scratch, it's a fine-tune, I want that the RVC model is going to understand better the Italian accent
either T4x2 or P100
yeah that's the thing, we can't know, you have to use the tensorboard https://docs.aihub.gg/rvc/resources/training/#epochs--overtraining
Last update: Dec 24, 2024
https://docs.aihub.gg/rvc/resources/training/#how-do-i-make-pretrain this can also help you
Last update: Dec 24, 2024
I'm italian too btw, goodluck
Thank you man, hope I will succeed on that. If I will get a good result, I'll share it for sure
there's #1235952130855010365 for that
you need to be model maker first of all though
it works so much better now! only now if i play the game and use it it will freak out again, is this just a graphics card issue atp?
what game? did u set the graphics to the minimum?
overwatch, and yes everything lowest possiblee
show a screenshot of ur wokada while running it in game, and close everything else in background

this is while running the game?
yeahs
it doesn't seem lagging, the perf value is green
go in game in a match and see how's the perf value

So I think I have to post a model on Weights.gg
Calculated the dataset length, currently is 13:46:59
For 17 female, 28 male speakers
set extra to 0.2, uncheck sup1, set chunk to 1400
kk should i send another screenshot when i do?
you dont, you can post it to huggingface or weights
13.5h is not a particularly good size for a pretrain dataset
if you're doing it from scratch
I want to do a fine-tune of the original model, not from scratch, it's not my intention
okay, just don't expect to get 45 unique voices out of that
you were unsatisfied on finetuning a single speaker normally?
I read on the docs that for doing a pre-trained model I must have at least 10 hours of data with many speakers
It's not a question of not getting satisfied with single speakers
for some inspiration, you can take a look on this pretrain https://discord.com/channels/1159260121998827560/1339155300720054316
it was trained on a lot hours of dataset
imo, if you want to make a pretrain dedicated for a specific language, it tends to be better to use much more amount of dataset
Thank you for the advice, I will consider that
atp it might be a gpu issue

yeah seems like your gpu is too weak
i mean
it's pretty old
u can't expect so much
it is lol well thank you so much for the help
you can try https://docs.aihub.gg/w-okada/local/w-okada/#reduce-more-delay , setting the f0 to fcpe, setting extra to 0.1
Last update: April 5, 2025
this would be fully focusing on speed rather than quality
or if you want, there's cloud (remote good pc), the only working one at the moment is wokada deiteris fork kaggle https://docs.aihub.gg/w-okada/cloud/w-okada-kaggle/
Last update: Feb 19, 2025
which gives 30 hours weekly of good pc, but you need to login + do a phone verification + it's kinda harder to setup
i see, ill just stick to what i got now and later save up for a more modern and better gpu ;p
alright
Let me show u
number of times the model has seen its dataset
Yo bro, Do you know what's the open-source version of ElevenLabs? I noticed there's a lot of great TTS but it seems like none of it have the quality of ElevenLabs...
does anyone know the solution to this problem in applio google collab plz ?

I wanna start making models but dont know understand anything about Datasets or how to do it, any guides out there?
yes I saw this message but I am used to using Applio and I am sure I didn't forget anything, I followed each step
I have the impression that the problem is at the extract features step. Because it almost skips the step by telling me "extracted successfully"
show a screenshot of preprocess log and extractr features log
epochs are a unit of measuring the training cycles of the AI model
basically the amount of times the model went over its dataset and learned from it
they don't mean how good is the model, it's just an info provided on how they trained the model by the model maker
More ≠ better
Less ≠ better
There's no way to determinate how good the RVC model is until you try it out or listen to the audio samples if there are
?
there's no open source better than 11labs
is training voice models locally better or worse?
but you can check https://docs.aihub.gg/tts/tts-tools/
Last update: Dec 12, 2024
what's your pc gpu?
i got a 3060 with 12GB Vram
it all depends on how powerful is ur pc
i heard Vram is what matters
great
also i got a APU but im not sure if that matters


is applio better and easier to use than the regular RVC? because its my first time making a model
applio has performance improvements + easier
okay, so 3 min, 68 slices.. how big is the batch size?
I set batch size at 15 on the ui
for 3 min? make it 4
umm i went to Applio's huggingface site and i cant find the download button. I'm i blind?
ok I will try
Do i download the one called "ApplioV3.2.9.zip"?
yes
It doesn't seem to work to change the batch size, but am I the only one who have this problem ? because in this case I will try with another dataset
i have a voice model but i wanna add a few things to it, is there a way with Applio?
-colab
📒 Google Colab Notebooks
Google Colab is a Cloud (Remote Good PC) Service. While the Free plan provides up to 12 hours of daily usage, the GPU is typically available for only about 4 hours each day on average.
• **Applio**
by IA Hispano
Google Colab
• **RVC Mainline**
by Hina
Google Colab
• **UVR5 NO UI**
by Eddy
Google Colab
• **UVR5 UI**
by Eddy
Google Colab
• **Wokada Deiteris Fork**
by Deiteris & Hina
Google Colab
• **Hina's Modified Original Wokada**
• **RVC-AI-Cover-Maker-WebUI**
by Shiro & Eddy
Google Colab
• **FaceFusion UI**
by Nick088
Google Colab
• **FaceFusion NO UI**
by Nick088
Google Colab
• **Music Source Separation Training (Inference)**
by Jarredou & Makidanye
Google Colab
I'm not good in terms of PC things, but for what I read, the colab use part of your PC for run? I'm using RVC and I can only ran on 2 VRAM, because if I put 4 (my max VRAM) it will stop the process.
And what is the difference between 50 epochs to even bigger ones? I have only done some models with 50 Epochs, they do work well, but I don't know what it will be the difference with 100 or more (and not the laptop for train one of 100+)
Actually no, colab doesn't use your PC's hardware to run because it's cloud based to work
In few words, it works using a remote PC from a server.
.
And actually i would suggest you to train your model till it reaches it's lowest point on the tensorboard graph. and bigger epochs doesn't mean better results because overtraining exists.
Add a few things like?
You only can by expanding the original dataset you used to train it on first place.
And then retraining it of course.
But keep in mind RVC and realtime/w-okada struggle to reproduce laughing properly without breaking even if you add laughing to the dataset. (but it can at least reproduce some light laughing types but not all)
Thanks god.
I did also read that you need keep attention while training for some errors? I read this I believe a year ago so I never have try out.
Welp, you need to keep attention on tensorboard to avoid overtraining.
it can do a couple of laughing types but not all
factos.
Tensor... what? the image generation page? Sorry, I got a little confused there.
Nope, it's unrelated to image generation.
In few words it's a graph that allows you to see when to stop training a model.
It's included within Applio colab. (but you won't be able to see anything on TB until you actually start training a model)
There you have more info regarding training/tensorboard:
Last update: Dec 24, 2024
I was just reading it. Still it doesn't clarify if stopping the model generation will cause it to finish it or fix the low bar
Do you mean stopping model's training?
But in case of any confusion, there you have a guide.
Yes, because it says it is used for see when it reach the overtraining, so I kinda though it will give you a "stop it there" warning for one to see? Sorry, I never used this method
Nope, it won't give you any sort of warning about when to stop training.
You must figure when to stop training (for example: whenever the g/total graph goes up again after a while)
Wait, so it wouldn't give "it will take this xxxxx amount of time" or stop on itself when is done?
Nope.
That's not how tensorboard/training works
Good to know. So in resume I have to put to train, see the bar how gets low and when it reach once again the top tier I have to stop the training, no?
have you read the doc? there's no bar
there are different charts for losses, the supposed to go down and converge/stabilize at some level
once that is done the model is ready, if you keep training some charts may go up (or may not) so the model may end up screwed up as it forget the pretrain information
weights its saying i have trains avaliable but its saying no files found
its still doing it
hi where can i get the voice model
Mb I was supposed
To show u but I was on my way back from the gym 😂😂
You can search rvc ai voice models at:
- #1175430844685484042
- In #🔍│find-models , Do /find with @earnest musk
- https://weights.com/ (login required)
- https://huggingface.co/models (but watch out cus in hugging face there arent only rvc ai voice models)
- https://voice-models.com/
- https://thevoicemodels.com/ (for Turkish Models, login required with discord and level 2 on their server)
if there isnt one, you can:
- #1159289738314919936
- #1191429836321849435
- make it yourself with our docs guides https://docs.aihub.gg/essentials/how-to-make-voice-models/
:wave: @low shard, How can I help?
Available Commands:
• @weights find <query> or /find <query> - Search for RVC Voice Models
• /create - Create an AI Cover
• /image - Generate an Image
I’m sorry
-colab
📒 Google Colab Notebooks
Google Colab is a Cloud (Remote Good PC) Service. While the Free plan provides up to 12 hours of daily usage, the GPU is typically available for only about 4 hours each day on average.
• **Applio**
by IA Hispano
Google Colab
• **RVC Mainline**
by Hina
Google Colab
• **UVR5 NO UI**
by Eddy
Google Colab
• **UVR5 UI**
by Eddy
Google Colab
• **Wokada Deiteris Fork**
by Deiteris & Hina
Google Colab
• **Hina's Modified Original Wokada**
• **RVC-AI-Cover-Maker-WebUI**
by Shiro & Eddy
Google Colab
• **FaceFusion UI**
by Nick088
Google Colab
• **FaceFusion NO UI**
by Nick088
Google Colab
• **Music Source Separation Training (Inference)**
by Jarredou & Makidanye
Google Colab
Any easy way to lower the audio quality output when using okada? It's almost too clear and I want it to sound a bit worse if that makes sense. I'm currently on linux
@low shard so i got my audio all ready
it just doesnt let me select a voice model
I need help with Image generation
How does Voyages compare to Midjourney
Hello, what gpu is good recommend atm for voice changer ai? i have rtx 2060 but it feels rly bad for stream
it is still better than GTX gpus, but you might want a 4060 for streaming+vtubing
ty
what can u say bout 5060-5070?
idk what should i choose and what settings are best for this
if 5060 Ti 16 GB is not more expensive than 4060 Ti or far above MSRP, sure
if u want to stream with this buy a cpu with a gpu
note that we can't guarantee the voice changer for 50-series is stable enough
for example?
though we've got another person getting it work #1367649960685862952 message
i have a i7 13700k
so i can stream in high quality without stressing my main gpu

qsv = intel gpu
nvenc uses ur main gpu so it may stress the gpu too much if you are running the voice changer
the gpu should be capable to do AV1 streaming
^
saves you resources and allows for smaller chunks
and saving you from cracking sounds
sounds good, thx a lot
adding more cpu usage could bottleneck the performance
its dumb but it can be a real issue in cpu heavy games lols
at least i can say my i7 is enough for this, never had such problem

So I was right all along... thx for confirming bro👍
Minecraft 
How do i fill the epoch with my weights voice model

does this app can be used using AMD?
RVC? voice changer? stable diffusion?
voice changer
get the AMD version here https://rentry.co/forkvoicechangerguide#download-for-amd-intel-and-cpu-on-windows

Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
If you need HELP, ask in AI HUB Di...
thanks!!
so my friends have the dml files for the correct ai voice changer but for some reason the program isnt letting them run on their gpu it keeps it on the cpu even after all the changes
make sure the GPU is supported
if it's an Nvidia gpu, should use the cuda version instead
they're using a amd and so i at first thought that they had a nividia like me but they didnt so i had them redownload the other package and its all set up but they are still not getting any slear feed back, shits all choppy as if they're still running on the cpu. they clicked on all of the gpu options 0-3 and none of them are the gpu. i also had them check in task manager which one their gpu was on and it says 0 but nothing works on 0 either so im at a loss
the fork version is strongly recommended for AMD gpus, which has GPU dropdown instead of the dml button crap
it should detect the GPU, as long it's RX 580/5000-series or newer
They have the 6600
Do you have the package name for the fork version? Im not to fluent with how everything is labeled yet
when monitoring myself on wokada im noticing my mic getting quieter?
is that normal
recording myself 3rd party seems to be fine but I can't figure out why it suddenly gets so quiet
through monitoring
you should find it there #✨│ai-help message
i mean that i record an audio with headset, the voice is clear, but after using the voice clone, it have some effects like an echo.
it is perhaps a post processing effect in the process, check the settings
Hi yall, I use a voice from this server and it works pretty good except for in vr chat it’s horrible. If anyone knows what I’m talking about or has any solutions in mind lmk
Thank you!
explain how horrible is it
Hard for me to since I haven’t heard it but my partner says as soon as step into vr chat it goes so wonky
I’ve tried adjusting my mic input setting multiple ways and it’s weird and tricky
could you record it and see if so?
maybe you need to give it a bigger window to process audio?
idk what kinda application you're using
how about in discord or another game?
Discord is good and I didn’t get and I don’t use game chat so I haven’t tried
It was a free one
VRChat uses your PC GPU. That's where it makes W-Okada to lag.
if the output voice cut out, it was lagging due to not enough gpu performance or that you need to adjust chunk & extra
note that the VR mode may be demanding
Do u think the model is too demanding and if I find a smaller one it make work better
I don't think the voice changer performance vary on different models
unless perhaps 32k vs 48k models
slightly in the memory usage
I see
tqdm and gradio is installed but anyways i getting this shit

elaborate:
- your pc gpu
- what you want to make
- what tut link are u using
2060
for now start rvc
https://github.com/Eddycrack864/RVC-AI-Cover-Maker-UI u mean this?
GitHub
Performs the entire AI cover generation process with UI - Eddycrack864/RVC-AI-Cover-Maker-UI
2060
for now start rvc
btw, the project you mentioned is made specifically for automating the project of making ai covers, you're looking for that?
if so, tell what you did step by step
yep but i also would like to train my own
pip install -r requirements.txt
run bat and got error
installed other modules manually
again run and error again
speak English or use a translator
the project you said isn't meant for that, it's meant only for automating the ai covers making process
else you could use Applio, an RVC fork, modified version, that can do both inference (use models) and training, but it won't automate the process of making ai covers, you will have to manually separate the vocals and instrumentals
or do you need both tools?
@granite dew
this server is english only, be respectful to everyone here
applio is local?
if you don't be respectful, we will take an action
yes, it's open source
soo, do you rather use applio? or both projects?
i can separate vocals so i can use this too
i just want generate covers and make my models
GitHub
Enhanced RVC Variant: Optimized Performance Through Modifications, Built upon Mangio-RVC-Fork. - Render-AI/Applio-RVC-Fork
no
Last update: Apr 01, 2024
that unofficial fork seems sus, if it ends up having some issues
it's 2 year old
alr, if i install this what needed to make model? just audio sample of clear voice?
Anyone use okada on linux? I'm struggling to set up a virtual mic to output the changed audio
Could someone help me with some img2vid? Trying to make something for fun but im not really getting what i want
there are many img2vid, which one you're trying to use?
Tried to use googles gemini, read a couple times its the best free one
there are plenty of options for local as long as your PC has enough memory and a decent GPU
I think it does, what are some options?
newest one if FramePack, based on Hunyuan, can generate basically unlimited length videos
ideally you want 48GB RAM and 12GB VRAM
but with lower resolution it can be used with 32/8GB
Tysm, appreciate you
In the context of RVC, the dataset is an audio file containing the voice the model will replicate. It can be either speaking or singing.
thx\
Last update: April 5, 2025
yw and lmk
That doesn't say anything, I have it installed already
can you elaborate exactly what's the issue then
I'm not able to output from the program into other programs without a virtual audio cable, The deiteris guide doesn't elaborate on how to outside of google it, which I haven't been able to find anything on how to set it up
Please run 'run-install.bat' first to set up the environment.

where do you see that phrase?

delete the folder, re-download the Windows 3.2.9 precompiled (which is the latest version right now), then, be sure to use Winrar/Peazip/7-zip to extract the .zip file, and run the run-applio.bat

its exatly same as i installed
are you sure that you extracted the same version with another tool rather than window's default extraction method?
¯_(ツ)_/¯ i try again with winrar
also, where are you exactly extracting it?
?
what is the full absolute path you're extracting the .zip at?
E:\ApplioV3.2.9
i got the same thing
could you try extracting to the C drive?
so it works only on the C drive? or was it related to smt else?
@low shard so i got my audio all ready
and its not letting me select a model on the interface page of applio
maybe it because of start as administrator
i have a problem on my pc that most of things wont work good if not launched as admin
Applio is auto or i need separate first?
weird? so it worked only after running it as admin?
no
@simple ore have u heard others running in the same issue?
Edit: nvm
as normal
oh lmao
as admin not working
yeah it's said to not run it as admin in the docs lol
show a screenshot
elaborate more
im lazy ass xd
it's not auto
so i need to put vocals only?
yes

@low shard lowest_value, lower = better?


Why don't just drop files?
thats what im about to do
hello guys
i'm having issues with w-okada real-time voice changer
it has robotic glitches, is there a way to make it sound like real voice?
@low shard what should these vlaues be

Are there any tools like RVC available on Linux? I wanna make AI covers without shelling out money or using Michaelshaft Winblows.
just type 50k lines of code and you might get it working
Hardy har har.
Seriously. Is there anything out there?
Don't know. I'm on Win10
elaborate:
- what's ur pc gpu
- what tutorial link did u use
- what u want to do
- a screenshot of the program
https://docs.aihub.gg/rvc/resources/training/#batch-size, https://docs.aihub.gg/rvc/resources/training/#epochs--overtraining
Last update: Dec 24, 2024
what's your pc gpu?
damn never heard of this parody

ty
@low shard wait when do i need to use tensor?
tensorboard? you have to always use it when training
oh okay, but i havent started the training bit yet
you can just set the training to an epoch like 500, then monitor the training process in the tensorboard to see if u need to stop earlier
yes i just done that thx
how do i set up tensorboard?

you're on cloud right?
yh
wait for it to train a bit, open the cloud url link, select scalars, then click the gear icon and select Reload data
https://huggingface.co/Shadicti/deiteris-Fork/blob/main/voice-changer-windows-nvidia-b2332.zip I had this version of W-okada and it ran well until it suddenly just delayed a lot, i got like 2 normal versions of W-okada and it sounds a lot worse than the voice used to be. and its glitching, what can i do?
okay ill let u know how it goes
elaborate:
- what's ur pc gpu
- what program are u using wokada with
- show a screenshot of ur wokada
4060 ti
nice, reply to the rest of the questions too
program ? there was no program running other than discord.
and i only have on escreenshot of the w-okada
the link is the w-okada iw as using
i already deleted it
because it suddenyld idtn work anymore
i just need reccomendations
or a good program to get for w-okada
because i feel like im doing something wrong.
tf it was done in like a minute....

yes, like discord, I thought you were running a game with wokada
that's the best wokada version as of right now, there was 100% something wrong with the settings, please reinstall the latest version of wokada deiteris fork (b2332, the one you sent), and show me the settinga along with the discord one
be sure you're using https://docs.aihub.gg/w-okada/local/w-okada/
Last update: April 5, 2025
and aren't using vb audio cable
lemme guess, you firstly used a youtube tutorial that suggested you that, then went here, directly got the new wokada download link?
im downloading it again right now, it's weird how it started delaying like crazy
no, i bought a model,.
the person who i bought it from reccomended it to me
vb audio cable has been reported by very many users here to cause issues of it not working for windows
who told you that?
vb audio cable i was using that yeah
is it ass?
😭
vb audio cable is a common VAC (Virtual Audio Cable) known for having issues on windows, so yeah as many others said it will give you issues out of no where lol
cause now im using the virtual audio cable
that is in the site.
im downloading it rn
the link you sent.
oh yeah okay makes sense man.
i didnt know that.
this right?

ohh, I thought the dude you bought the model off told you to use vb audio cable lol
at first when original wokada and RVC AI Covers were trendy alot of people used it, it's been months that it's not suggested anymore (prob like half a year)
alright
i see
its weird how that ver got laggy somehow
outof nowhere.
which is the reason I thought you used a youtube tutorial, they suggest an old version of wokada with vb audio cable because that was trendy like 2 years ago
makes sense yeah and ive seen those tutorials are like 2 years old etc.
dw, I will also help you with the settings, prob some wrong settings + vb audio cable fucked it up

save every epoch should have been a bit lower for accuracy like 10
also, check the output in the colab/kaggle
ohhh shi let me just fix thst

apparently not enough data was present
Whats the best settings to put in voice changer native client?
elaborate
right so i downloaded everything
- what's your pc gpu
- what tutorial link did u use
- what are you going to use the program with
- show a screenshot of the program settings
you forgot to slice audio files in the preprocess part
alright, want me to check your settings ?
wait let me do the uh new audio thing.
oh the audio cutting part? i wasnt too sure if it should be on simple or auto
i might sound dumb, is this wrong or right?

it's right, you can also optionally set monitor to ur headphones to hear urself
i wanna hear like the voicechanger.
do i have to change it to my headphones then?
I know how to create vocal models. I just wanted to know if anyone has a finished vocal model from Turkish star Derin Talu.
i just set it to my headphones and it worked.
yup
You can search rvc ai voice models at:
- #1175430844685484042
- In #🔍│find-models , Do /find with @earnest musk
- https://weights.com/ (login required)
- https://huggingface.co/models (but watch out cus in hugging face there arent only rvc ai voice models)
- https://voice-models.com/
- https://thevoicemodels.com/ (for Turkish Models, login required with discord and level 2 on their server)
if there isnt one, you can:
- #1159289738314919936
- #1191429836321849435
- make it yourself with our docs guides https://docs.aihub.gg/essentials/how-to-make-voice-models/
:wave: @low shard, How can I help?
Available Commands:
• @weights find <query> or /find <query> - Search for RVC Voice Models
• /create - Create an AI Cover
• /image - Generate an Image
yes
you fixed the delay issue for me, thank you! , as of right now these are my settings, and its well. im not complaining, but do you see any issue further just to be sure?


So basically when I talk It doesnt sound crispy its pretty choppy sound
elaborate the questions I asked you: #✨│ai-help message
should it be simple or auto?
f0: rmvpe without onnx
extra: 2.7
chunk: 192ms
you can optionally set force fp32 mode on for better quality and stability, but more delay
you can also optionally use https://docs.aihub.gg/w-okada/local/w-okada/#reduce-more-delay
Last update: April 5, 2025

did you already manually slice your audios? if not, set it to simple if u deleted atleast the silence, or if it still has silence set it to automatic
@delicate whale i saw u deleted the message, if you do shift+enter you can make a new line on discord btw
like
this
telling ya since i thought that's what you wanted to do
naa i havent sliced it i put the audio into audacity thats it
did u remove the silence too?
then set audio cutting to simple
okay
What is the best tool to make high quality voice conversion (not in relatime). Like upload, wait for processing and have quality output. Would be there any difference between real time conversion in w-okada and not real time
it seems like its working

RVC, more specifically Applio since it's a fork that gets maintained and has performance improvements
what's your pc gpu?
local rvc
I mean, they can also use cloud if they don't have a good pc gpu
- PC GPU= Geforce RTX 2060 2. Tutorial https://youtu.be/dZ_2HELnWJU?si=4xXWwmYt_gqgS-Zj 3. Im going to use it for discord talking 4. I Will give the screen shot right now

the program (and code) is the same
rtx 4060
youtube tutorials are outdated, that's the issue
@delicate whale i just checked the tutorial shortly, and it uses an old version of original wokada
please, just forget everything you got off that tutorial, 1 year old is prehistorical in ai field
uninstall everything out of it
-realtime
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested. GUIDE
• Original Wokada
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
• **RVC GUI Mainline Realtime**
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
use the 1st link
rvc = retrieval based voice conversion 
wokada deiteris fork is the best rn
So you would like me to delete the voice changer app itself right now?
thank you!
yes, all video tutorials are outdated, that video is using a year old version, AI progresses at sonic speed
what is there most quality TTS nowadays? With emotion control and etc. All i hear is F5 TTS and FISH
https://docs.aihub.gg/tts/tts-tools might help
Last update: Dec 12, 2024
thank you!
I just deleted it what do you recommend me to do now?
@low shard apparently its done?

i wonder how are you not lazy to answer all the reapetitive questions from stupid(like me) users
to read the 1st written guide link the bot just sent after I wrote "-realtime", the wokada deiteris fork
there's no updated video tutorials
can we have a pinned message that explains rvc doesn't mean realtime voice changer
gtx 1660ti (laptop)
https://www.youtube.com/watch?v=_JXbvSTGPoo (don't mind title)
i want it to sound like real audio with good enough quality (it's scratchy even in the video introduction in the link)
edit:
it seems like some voices work better than others

Could you send me the link I dont see it
is this W okada?
I second this
yes
damn u carried, thanks man.
Technically I did
https://huggingface.co/Shadicti/deiteris-Fork/blob/main/voice-changer-windows-nvidia-b2332.zip
is this the right W okada link

How long does it take once the MMVServerSIO finishes downloading?
Every time I extract it I get a checksum error saying "corrupted archive"
depends in how fast is your internet
for me it takes like 50 seconds
uh try reinstalling 7-zip/winrar
Are you sure? cause its with one specific file (torch_cuda)
and it doesnt happen when extracting anything else
I have a nvidia
I only see AMD options on there
unless its fine to get one of those???


read the file name
cuda = nvidia
@low shard how comes my graph isnt showing

Oh
amd64 = x64 bit cpu
this is not common knowlege nerd boy /j
🤓 ☝️

read the github readme
GitHub
リアルタイムボイスチェンジャー Realtime Voice Changer. Contribute to deiteris/voice-changer development by creating an account on GitHub.
thanks
🔥
weird the docs give a bad link
i havent never tried that link idk
Last update: April 5, 2025
its the same program but they merged both zip files
this was the link given by the bot
interesting

do not follow video tutorials for AI lol
you got the latest version of original wokada, but it has worse performance than the latest wokada deiteris fork, also you prob got vb audio cable that gives issues
now why is there no graph
@dry jewel uninsstall everything you got off youtube
get wokada deiteris fork https://docs.aihub.gg/w-okada/local/w-okada/
Last update: April 5, 2025
why tf is there 4 graphs

you're welcome
forsome reason i generated index before training my model tf
Is it okay if i follow this tutorial? https://www.youtube.com/watch?v=VAtnHB9Y9UA&ab_channel=Mourn
It says to download the 3.24GB one and I think it might be new i dont know

no, i just told you, video tutorials are outdated
that video tutorial uses original wokada too
read the written guide
there's not even a single thing correct in that tutorial
Once I click the link which link is for windowas?
read the tutorial
it explains you
the only way to get the correct program is by reading the guide
@low shard does this look correct?
There isnt a Guide when I click the link
https://docs.aihub.gg/w-okada/local/w-okada/ is a guide
Last update: April 5, 2025
you have to read it

the training just started, also you have to look at g/total
BRO

WHYY
😭
reinstall 7zip or winrar bro
lol
something crazy going on in your system
Could you please send the download link of it here, I dont see anywhere where it says Windows download I only see Mac Download
Do you think its cause im extracting it in the E drive?
try drive c
not a onedrive folder
https://docs.aihub.gg/w-okada/local/w-okada/ it shows a Table Of Contents at the Right Part

Last update: April 5, 2025
aight
you have to get the Vac Lite at the Virtual Audio Cable step, then downlaod the nvidia version for windows
users > name here > voice-changer
all of your questions are probably already answered in the written guide
oh okay why do i need to look there for>?
oh just straight in the root eh?
alright
can be anywhere tbh
as long it doesn't say onedrive
I think i removed one drive
hate that shit
Last update: Dec 24, 2024
Do I download this one
Download AMD, INTEL and CPU on Windows
The lastest version as of December 7th 2024 is: dml-b2332 (click here to download)
Intel UHD Graphics do NOT work at this point in time. Use Online Alternative.
i forgot to remove onedrive when i installed ts 😭 😭 😭
I just told you get the nvidia windows version
you got an RTX 2060, which is made by Nvidia
it's an nvidia gpu
For anyone on Win11 who's using Edge as their browser to have the voice changer interface open:
Microsoft did some kind of update and it completely fucked the voice changer for some reason. I don't know why. It introduced a huge amount of delay and I was going crazy trying to figure it out.
Using Chrome works just fine. I have no idea what they did and why it would do that.
The update happened some time today.
GRAAAAH
im reinstalling midrar
hold on
don't make a folder with spaces
just name it voicechanger
lol
alright

There doesnt say anything about Nvidia Windows Version, It only says
Download NVIDIA RTX 5000-series on Windows
NVIDIA RTX-5000 series, the newest release of GPU's, require a separate download. You do not need it if you have an older GPU, follow the normal Nvidia link in that case. nvidia-5000-Series (click here to download)
that's for the rtx 50 serie, you got an rtx 2060.
https://docs.aihub.gg/w-okada/local/w-okada/#download-nvidia-on-windows it's this one for you
Last update: April 5, 2025
ty
oms
omd
my shit just crashed
@delicate whale don't skip steps on the guide, be sure you download vac lite too
wtf why is my tensor still running
please have a careful reading of the whole guide, skipping steps (except in cases of the step being related to another OS or GPU) can cause issues
wdym
Is there anyway I could get you on the VC call very fast
I can't VC
what's the matter?
You dont have to talk Im going to share my screen
join support one
my browser crashed rn and my applio just shut down however my tensorboard is still running
@delicate whale you have to download only the normal NVIDIA on windows version
so the first one
how did ur browser crash 😭
im gonna reinstall midrar.
yes, the 2nd one is only for RTX 50 serie users
so yes the 1st for you
try 7zip
winrar goated
now it shows that
download
do I click download
yes
i have like 70+ tabs open xddd what should i do now lmao, should i restart?
the training isn't affected because it runs on a remote good pc
Once Im finished downloading whats gonna happen and then?
also don't torture your browser with over 70+ tabs pls
ohhh okay
let me show u
then you have to extract it with winrar or 7-zip or pea-zip
i've been a d1 7zip hater since day one. If it works im finna be mad
whatever tool you use
lmaoo
I have Winrar
pea zip 😭
what should i do abt the applio part?
oh god. and I thought i had many tabs
BRO

im a student lmao half of them are for revision n shit xddd
you should be able to just reopen the colab/kaggle and continue from where you where, firstly close some tabs
okay we need a better nerd than me to know how to fix this
AUAAUAUAUU
then use that to extract
and then thats it?
yeah ngl some of these tabs have been here since deceber
how do i chat to the ai
why are u using the github one?
because the doc one gave the same error

can i install like
did you extract it? i didn't see you do that
I got 1 minute till its done downloading
even with 7-zip?
can you try makin your own zip for a sec and extract it
for the voice software or
any
just any to test if ur extracter is actually extracting
im extracting
alright, meanwhile, did you also download vac lite?
could you also extract it yourself?
let me go onto collab
also yeah why did u send it lol
no
could you send me the download link
A VAC (Virtual Audio Cable) makes a fake audio device, used to re-route the audio of different programs
In Wokada context, it's used to get the output of wokada as the input in other programs
Vac Lite is the suggested one for windows: https://docs.aihub.gg/w-okada/local/w-okada/#virtual-audio-cable
Last update: April 5, 2025
ive read that if ur getting those weird checksum errors in both 7zip and winrar it could mean your ram is dying

@low shard uhm i see nothing?

yes
could you try maybe some big files?
Its weird though since this is the only thing I've ever gotte nthat on
whatever biggest file you got
I jsut downloaded it
extract that too
ok
now just open the extracted vac lite, run setup64.exe, and select yes when asked
Its still packing but, have you ever extracted W Okada before and it worked?
yo@low shard, wassup. just wanted to remind you that your amazing <33
@delicate whale you should have selected extract in it's own folder, don't extract everything into a big folder
thank you
yeah lol, a user literally extracted wokada infront of me in vc rn
WHAT THE FU
oh my lord
i have a feeling there's something wrong extracting any big files for you
wdym
first i read "a user extracted infront of me in vc"
😭
anyway nick check this

fumiama realtime gpu usage

I only see setup64 check my screen and im on the VAC folder
smh the unstable realtime program
chatgpt goated for fixing every dependency for me
yes that's what i mean, .exe is just the file extension, every file has an extension like .mp4 or .mp3
you just didn't enable to show extensions in file explorer, anyways you don't have to, just click setup64
@I used it to help me find my data folder
for you not even changing system locale could have helped me
@low shard still nothing in applio 😦
are u using same account? you should check the colab output and tensorboard
not the applio ui
@delicate whale click yes
@delicate whale now, just select your usual devices for playback and recording as default ones
find playback usual device
set default
and do the same for recording tab
did you do the above that i said?
which one
I just selected ok and thats it
ywah i should be however its been stuck on 56% for a while

oh, that's bad
click windows+r, type "mmsys.cpl", Enter
then select your usual devices as default one
it's a must for it to work
it says draft session stopping.. seems like you stayed without checking it for too long and it went afk and stopped ig, unless you stopped it manually
well shortly, rip your training
@delicate whale i can't know which speaker is your default one, you need to check the name, and if it's your usual device, click set default
i extracted a 5.71 GB file with no problems
I use a microphone and headset
ah great time to resart it seems, how do i like check it? when im doibg iy
by speaker you mean the output audio right?
wtf? i'm gonna try to the extact exactly the windows amd one just to check again
yes
playback is output
recording is input
check what? the training stopped
you have to restart
you've never had problems unzipping files before?
I have selected my output audio
GitHub
リアルタイムボイスチェンジャー Realtime Voice Changer. Contribute to deiteris/voice-changer development by creating an account on GitHub.
though you probably already know
I just extracted the huggingface one, works all fine

I mean I guess but like its literally only this weird ass file
Okay, how do i stop tensorboard?
other big files extract perfectly fine
everything stopped, the whole session stopped
I picked the output
oh right
did u do also the same for the recording tab?
u had to pick your input here too
the default one?
yeah
like your usual device?
alr
now just go to the MMVCServerSIO folder
then open the MMVCServerSIO file
just did it how long would this take
depends on ur internet
it's downloading internal files
your internet is downloading in kilobytes 
thats slow?
pls tell me its near 1k kb not 100 kb

holy shii, its cause im upstairs and thats why
300 kBs
let me open the door so its faster
it means that your internet was so extremely slow that it was slower than the program timeout error time for downloading 😭
basically it took so much time that it went pass the timeout time
either redo it, or just follow https://docs.aihub.gg/w-okada/local/w-okada/#help
Last update: April 5, 2025
you will basically download the internal files from google drive, so it won't have a timeout
I opened the door it should be faster
@delicate whale btw when i said redo it, i meant redo it hoping that it won't be so slow that it will timeout again
slightly but yes
thank god
maybe it's just better to follow that guide part if you still get time out lol
what if i try to share u my extracted wokada amd
okay if I get it one more time Im doing it
that would be appreciated
I wonder if that would work
gimmie 2 mins

😭
💀
lemme redo the job for the nvidia one
I love you
@delicate whale did u place the downloaded internal files from google drive to the internal folder in the program?
no need to retry
your wifi is way too slow, you will always get a timeout
Do i extract the file there and then
nowdays having kBs is too slow
copy paste all files in the pretrain folder in the program
I think I have to download those files first because it wont paste it their
i meant the pretrain folder
I deleted all the files that were orignally in the pretrain folder

download the files, extract them into the pretrain folder
okie

I click extract here and then on the pretrain folder right
You still uploading the files?
you gotta extract them into the pretrain folder
ok
the nvidia version is bigger than amd's one
so it's still downloading
i really hope it will work
Sorta unrelated but I tried download the AMD version out of curiosity and it extracted
why does nvidia hate me
because you didn't buy 99 pairs of the rtx 9090 ti super 💔
jokes aside
btw is ur windows updated and drivers too?
I updated my drivers about 2 weeks ago and windows is updated
I updated my drivers about 2 weeks ago
then they need to be updated
latest driver was 30th april
nvidia releasing drivers weekly bc mostly are rtx 50 serie fixes, but there are also other fixes that might help for all other series
@delicate whale so?
@low shard ah crap how do i fix this

could you tell me what you mean by that
it wasn't referred to u
im asking u how things are going
what's ur dataset lenght and batch size
its going good files are almost downloaded
24 mins and 547 mb the audio size
it wasnt do this before but now its doing this
im done extracting the files
show
what's the batch size
oh 15
@delicate whale now click the mmvcserversio file
too high?
and also makes it use more vram which they don't have access to
keep it at 8
ohhh
where
okay ty
should i redo the index file or na>
it's better you retrain
yeah thats what im gonna do
would u know roughly how long it will take to train?
it was reaching its 30 min mark last time
I started it and it opened it on a browser
@delicate whale set gpu to ur rtx 2060
set extra to 2.7
set chunk to 192
set f0 to rmvpe without onnx
set input to microphone
set output to line 1
set headphones optionally to hear urself
yeah that's completely normal
it runs on ur hardware
it just uses a web user interface locally hosted
So when ever in the future I wanna use it I open MMVCServerSIO folder
yes
use the settings i told u
ok
@delicate whale u gotta upload a model first
updated drivers, still doesn't work
I have a model downloaded where do I put the model file in my files at?
Did the guy who extracted it in vc do the AMD or NVIDIA one?
extract the model anywhere u want, click edit in the program, and upload it at any slot
im cooked
i also got an nvidia gpu and extracted it on nvidia
i also was able to extract it on my integrated graphics laptop lmao
oh my lord
winrar so goated
I got a model which file do I put for which
.pth for the model part
.index for index
it depends on the file extension
I guess its my ram then??
@delicate whale if u can't see that, then just check https://www.youtube.com/watch?v=CvJn_8ZUdpk
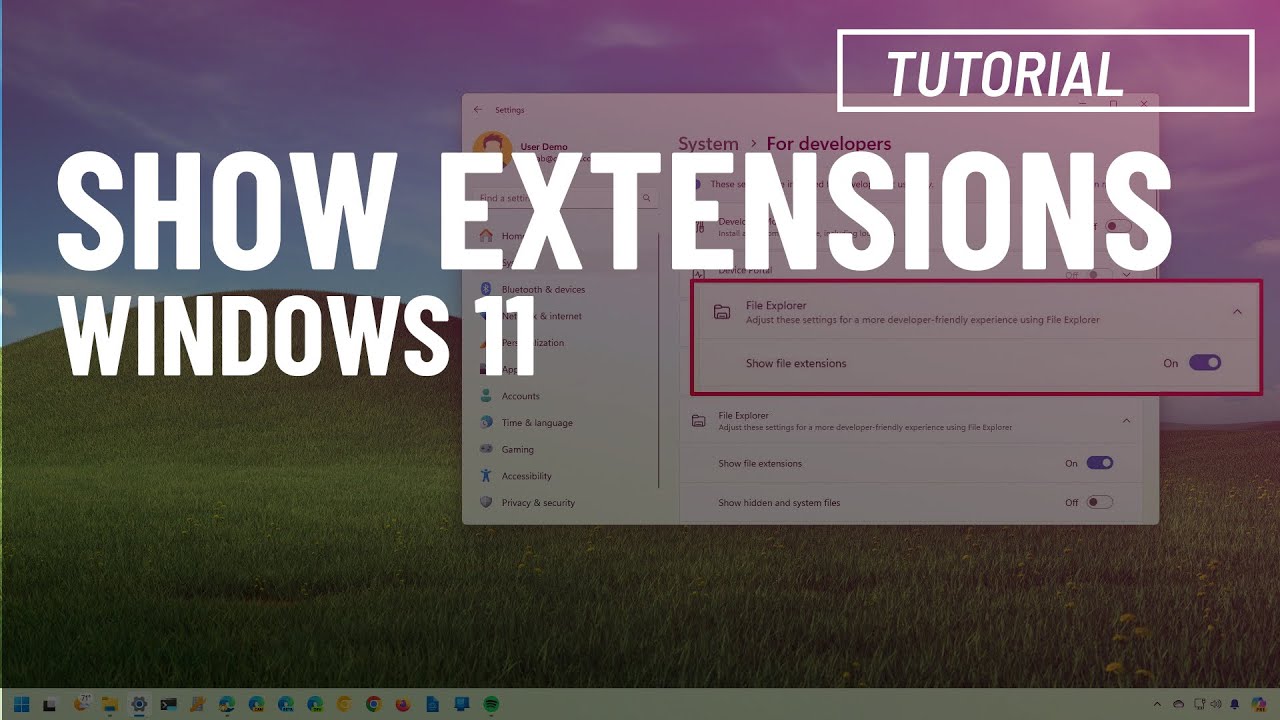
Windows 11 tutorial to show file extensions for known formats. Follow ➡️ link for guide ✅ https://pureinfotech.com/show-file-extensions-windows-11
This video demonstrates how to show file extensions through File Explorer, Settings app, and Command Prompt.
Table of contents
00:00 Intro
00:21 Show extensions via File Explorer
01:10 Show ex...
i'm not sure, i'm still reuploading the file
i compressed it in a .rar
thank you
I'd recommend 7-zip instead, but winrar is fine too
CAN IT
where do you set headphone to hear yourself?
even 7-zip doesn't work for Shy
in monitor option

skill issue?
7ZIP has no soul
btw the speed and shi should be pretty similar between the 2, just 7 zip is open source while winrar is 'free'
why do u hate 7 zip btw
no soul
this could be a hardware issue but we don't know


So IF i were to click start and record a video for example my voice would attomatically be in the video?
did u argue on reddit with someone about 7zip 😭
no?
yes
okay thank you very much bro
i wonder what type of argument u had with 7zip users bc i never had one
not much of an arguement just me shitting on it for no reason since i use winrar
btw are u going to use it only for pre-recorded audios?
nvidia is green

we are on discord, we do NOT know what is the sky and grass 💔
fair point
better than kBs tho
wasnt there a guy earlier with that 😭
yes, 300kBs
@low shard how do i know that im done training?

probably yeah
wait then you got the wrong program
are you going to use it ONLY for pre-recorded videos?
RVC = Retrieval-based-Voice-Conversion, the best Speech To Speech AI Models (on v2), Inferences (use models) pre-recorded audio (ai covers) and train (make) models
Wokada = uses RVC for realtime inference
Wokada is meant for realtime like discord vc
or like youtube lives or whatever is meant for realtime, since it prioritizes speed over quality compared to rvc
then yes wokada
And for PreRecording what would that be
i mean, if you're going to record youtube videos, you could set obs input to line 1 for example but this isn't really suggested, the best is you get applio (rvc fork for better performance) https://docs.aihub.gg/rvc/local/applio/
Last update: Apr 01, 2024
Can I have both of them installed or I have to delete one?
u can have both of them installed
read the guide and you will be fine
how do ik when its done
This bout to take a long time LMAO
not the charts you need to look at
these ones?

no
oh

collapse the 'grad' line, expand the loss_avg_50 line

dont type 'loss' in search
okay
just click the rows

ywahh i figured
I clicked the link and then the part where it says download here and it sqays Linux, Windows and a File that says Gitignore

you need to click the windows one
change smoothing to like 0.5 or less
I clicked it and it now says Gitignore, AppolioV3.2.8-bugfix.zip. and another AppolioV3.2.9.zip
AppolioV3.2.9.zip
Done
So what does the bug fix mean?
previous version, dont bother with it
How would the graph look when it’s done?
Ohh okayyy
normally, fm loss should be going down or at least not up, kl usually goes down and flattens quickly, nek abd total loss take some time to converge to some value and flatten
ahh okay its at its 30 mins mark
@simple ore like this?


omg bruh
how do you execute a folder?
bro I downloaded it
what do I do now I ran the file but I guess my internet was slow again for Apollio
u extract it and run the run-applio.bat