#✨│ai-help
1 messages · Page 228 of 1
I see
latest commit was last month
they seemed to have released a v2
nice btw
lmao why is it launching in the web
you mean the original wokada? yes I was talking about that in #✨│ai-help message , the latest wokada v2 beta has similar improvements after deiteris fork had them before, but we still suggest the deiteris fork for not having beatrice v2 and having force fp32 mode
please check https://rentry.co/forkvoicechangerguide#why-does-it-run-in-a-browser-and-not-its-own-window

Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
If you need HELP, ask in AI HUB Di...

fair
both original wokada and wokada deiteris fork use javascript & typescript
just that the original wokada made it's own "window browser" to open the local host url
the UI would regularly crash like a year ago
you can also check the github repo if u want https://github.com/deiteris/voice-changer, here u see that the 2 languages I mentioned are used much
yup, the wokada deiteris fork is easier to fix, it just has some issues with very specific browser like operagx
javascript moment 
chrome is the only good browser, if you want everything to work
do you have some voice samples I can use to try the AI on
well yeah it's the most common browser so ofc sites make sure it works on that
some mp3
huh? wokada is meant for realtime btw
I know
but I'd have to talk
its midnight
and I have open back headphones, so it'd loop around
oh lol, i remember @crude flame sharing a speech.wav file before but forgot it
whut
do u have any wav files u use for testing your models? I remember you sending like a f_speech.wav when I asked u that
@low shard say i wanna make an ai voice the character is a robot how easy would it be
oh yeah
that?
well ofcourse it's more complex, well since you got an igpu, you'd need to use cloud for that too
Train (make) RVC Models on cloud:
- Prepare the Dataset
- Setup RVC:
Choose a cloud way to use RVC,
- Google Colabs (4 hours of daily gpu for free, not much hours, but easy to use):
- Kaggles (a bit harder to use and needs phone number but gives 30 hours weekly of better gpus):
- Mainline (UI)
- Applio by Vidal (UI)
- Lightning.ai (Kinda hard, needs login, no issue with web uis or anything, but only free 15 credits monthly):
- Be sure to know about the tensorboard
Google Colab = Easier but risk of getting disconnected
Kaggle = Harder but way more gpu time
If you are looking for the easiest way and for free, is using https://weights.com/ which ofc uses RVC
RVC Inference (use models) on pre-recorded audio on Cloud
You can use either:
- Weights.com: Easiest Possible Ever Automatic
- Ilaria RVC Zero: Fastest free on cloud
- Applio UI Colab: RVC Fork with some extra features like TTS
- RVC AI Cover Maker UI: Automatically Separates the Vocals and Instrumentals, converts the voice and mixes them back
mainline is currently having issues though
oh right thats true
yup thx
@fervent trench maybe try this
I will
well, it's better to have a larger datset
ughh its a bit harder theres a 3 min video but theres another character speaking
welp
i mean u can try that short dataset, just don't expect too much
also remember u gotta clean it
i sent you all the links u need
yeahh im checking it out rn
yhh thats ture
tru
true
Intel(R) UHD Graphics
that's integrated graphics, pretty weak
do you have any other gpu?
check in task manager, performance tab
i have this one NVIDIA GeForce RTX 3050 6GB Laptop GPU
yeah that's better
I'm guessing realtime voice changer for calls?
-realtime
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested. GUIDE
• Original Wokada
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
• **RVC GUI Mainline Realtime**
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
Hello, I'm new to the community. I want to ask if someone knows any AI that can change perspectives of an image, such as texts in it with their current fonts, background, etc...
To generate images for free, either:
- Use @brittle wing in https://discord.com/channels/1159260121998827560/1202754985255764060 (It's powered by DALLE3, from ChatGPT+), pretty easy
- Another easy and good ways with weighs.gg are:
- Use /image with @earnest musk in https://discord.com/channels/1159260121998827560/1202754985255764060
- Create an image on their site https://www.weights.gg/ (which you can also use LoRAs, Low-Rank Adaptations, basically a small trained additional model to adjust your generation)
- Use Open Source Models like stable diffusion & flux that could be a bit **harder **but good, what's ur pc gpu? As you could run them locally (on ur pc) or on cloud (remote good pc)
img2img seems like what you're looking for, maybe try one of the things I said above
:wave: @low shard, How can I help?
Available Commands:
• @weights find <query> or /find <query> - Search for RVC Voice Models
• /create - Create an AI Cover
• /image - Generate an Image
Farewell, I didn't ask if someone knows an AI that can generate images... I asked if an AI can change perspectives of an images, such as texts with the same fonts in it, as well with their background, etc...
which one do I use again for gtx1660 ti

Use rmvpe with 256 chunk and 2.7 on extra

I mean, img2img is a technique where you can input an image and then also change it based on your prompt and the parts you select
for example, the weights.com i said above could be one way to solve this with: https://www.weights.com/create/canvas

could you also share a screenshot of ur whole wokada?
ngl im doing something which is tedious asf
with that 3 min clip with the charcters speaking im just extracting audio when the robot speaks
If it sounds bad, it can be also a problem on the model itself or your own mic
I need to talk rather loud for it to pick it up properly


oh it probably was the input sensitivity
set the in to a bit higher value
how much seconds of audio do i need
I mean there isn't a rough limit built in rvc, but 5 mins would be usually the minimum for smt decent
How can I download the pre-zoned pretrainings in Applio Colab? The cell that was there before doesn't exist.
ah okay
i need help wwith a good girl voice changer too troll on omentv i got gtx 4060
Thanks, I've switched over to LM Studio and this is quite swell. GPU works perfectly, and it's got some nice features and configuration. Simple to edit. Haven't touched the api yet but I'm sure it'll work swell based on the experience so far
i think you meant rtx 4060
-realtime
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested. GUIDE
• Original Wokada
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
• **RVC GUI Mainline Realtime**
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
yep, read up the guide
@low shard imagine I found a 12 min vid of him speaking
But there’s music in the bg 💔💔💔
You can easily isolate the speech.
Yup.

Yep
I personally suggest you to use the Gabox FV4 model.
okay willdo
i need help with the voice chagner like i wann sound like a girl but everyone i try its shit
Also drag the audio to where it asks you to, wait until it loads completely, select an output format and click on "Separate"
okayy ill lyk how it goes
Maybe these docs will help you.
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
If you need HELP, ask in AI HUB Di...
cool
i was sent that but i dont understnad what im meant to do
Just read the guide and don't skip anything.
Also make sure to download and use deiteris fork instead of OG W-Okada, and lastly, it's matter of testing which model from #1175430844685484042 channel works better with your voice and settings

That error pops out when trying to access the UVR HF space?
yeahh the wokada thing
Or are you trying to do something else?
i press the link that it gives me and it brings me to this
Yeah no, it seems you're trying to do something else.
That HF space isn't for realtime.
It's for stem isolation
how do i fix that tho?
I don't know, but if you're trying to use realtime, what's your GPU?
im using it on cloud
But what's your GPU
so its the clouds gpu
havent got one
I see.
I'm not sure but, did you put your Ngrok token correctly on the notebook?
Or did you ran out of time usage?
yhyh i did it was working fine before
anyone got good female pitches
Then i got no idea sadly.
time usage is 30hrs and i started like 2 hrs ago so no way
okay thats np
Nope, it's matter of testing which pitch fits the best with your voice.
Altho you can test with 13-15 or 17 on pitch
But will depend on the model and your own voice though
i fixed it
hey guys is there a free voice changer that I can use without training any voices? like something I can download and use and preferably without using someone else's voice?
rtx 4060 ti 16gb
i310100f
16gb ram
I want a voice changer for live streaming
ai voice changer while I'm live.
i mean, you could use wokada deiteris fork and use premade RVC models made by other users, or are you looking for not using any models at all?
I wanna use models. I just don't wanna train them myself
-realtime
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested. GUIDE
• Original Wokada
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
• **RVC GUI Mainline Realtime**
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
1st link, read up the wokada deiteris fork guide
what is that?
@royal juniper though, the models trained by other users, will be trained by some voices somewhere ofcourse, like homer or peter griffin's voice
AI has to be trained on something
I can mix voices trained by others right?
to create an original voice? will it have any quality problems?
wokada is a program designed to run RVC (speech to speech) models in realtime
there's 2 versions, the original and the deiteris fork
currently the deiteris fork is the most suggested one
iirc yeah, the merge lab should work all fine
else you could try something like voice mod, which isn't really AI but just voice effects, though that has a paid tier
I know w-okada. but what's the difference with deiteris fork?
I honestly want to avoid training voices myself because it's too much effort. ai hub is safe for downloading voices right?
like if I mix 2 or 3 voices it'll be completely new voice Right?
the deiteris fork is a modified version by deiteris,
it was always used because it has improved quality and performance, though the latest original wokada performance comes close to it, the deiteris fork is still suggested for not having beatrice v2 models, and also for having a force fp32 mode, which increases model quality and stability, along with having a more stable ui
yeah, wokada deiteris fork also makes sure it only loades the model and nothing more
for more technical info there's: https://rentry.co/forkvoicechangerguide#is-wokada-deiteris-fork-safe-are-the-rvc-models-safe
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
If you need HELP, ask in AI HUB Di...
alright, yw and lmk
send a screenshot of ur wokada

ohh, changing that should fix it
is this fine?
@odd shale im unsure with what to do with the audio separation link
i changed the model
and uploaded the link
nvm i sorted it
no way its separated
-colab
📒 Google Colab Notebooks
Google Colab is a Cloud (Remote Good PC) Service. While the Free plan provides up to 12 hours of daily usage, the GPU is typically available for only about 4 hours each day on average.
• **Applio**
by IA Hispano
Google Colab
• **RVC Mainline**
by Hina
Google Colab
• **UVR5 NO UI**
by Eddy
Google Colab
• **UVR5 UI**
by Eddy
Google Colab
• **Wokada Deiteris Fork**
by Deiteris & Hina
Google Colab
• **Hina's Modified Original Wokada**
• **RVC-AI-Cover-Maker-WebUI**
by Shiro & Eddy
Google Colab
• **FaceFusion UI**
by Nick088
Google Colab
• **FaceFusion NO UI**
by Nick088
Google Colab
• **Music Source Separation Training (Inference)**
by Jarredou & Makidanye
Google Colab
reduce the chunk size i think
its not letting me, like i click it and nothing happens
thank you!
np
Hey! im still having issues getting the software to recognise my GPU
Hi, can I finally get an answer, please?
I'm planning on training 2 models, how do I resume in Applio No UI colab when I switch accounts cause my dataset is big & one account isn't enough
Can finally someone tell me what cells do I run, the sequence and stuff
W-Okada, RVC or Stable Diffusion?
You have no previous messages here, are you sure you are in the right server?
torch\nn\utils\weight_norm.py:28: UserWarning: torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.
warnings.warn("torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.")
it's not an error message and can be ignored if it works as is
The "UserWarning" is a warning about certain code lines being deprecated and can be changed as soon in newer PyTorch versions. The program can continue to work anyway.
The actual error starts with something like "Traceback (most recent call last):", then follows with paths to related files, and then the error message.

You can set "monitor" output to your speaker on W-Okada to hear the audio. Other than this, you can restart the whole W-Okada or try another browser.
Also, Sup1 is a deprecated noise gate algorithm, try turn Sup2 on and increase In. Sens. number until there's no noise in the background.
hmm okay
my setting is good right? or should i change anything? i don't know about KLM, epochs and steps like i can't find it

line 1 can't work in discord and valorant
yesterday i download vac lite and it's use normal
but today i can't chat
and don't see line 1 in valorant
can somebody help me?
double check settings like this, also try another model, perhaps including older ones

Hey y'all, around late 2023 or early 2024 I remember installing a local gui that could allow me to train voice models being the pth and index however since then I am on a different device and I don't remember where to install it. Under the Guides tab which one contains the local model trainers?
training locally on devices other than pc? no way!
laptop vs desktop i guess
but yeah

Anyway yeah where is it, I remember there being a place to downlaod it
RTX 4060 laptop or any 6+ GB vram is minimum recommended to do so

all good
damn it


that's more than enough but you'd worry on laptop heating all the time
I also have that covered you wouldn't believe me
the most redneck ass cooling setup for this poor thing
but yeah
I just need to find the trainer
also with budget for laptops with that similar spec you could afford a decent 4080/super desktop build
You see I do have a desktop with a 4090, but I travel and can't take it with me everywhere because that would be an honest to god death wish
It's already a ticking time bomb with the connector shenanigains imagine travelling with it
remote desktop is the viable solution unless for gaming
I am away from it for 5 months
Not gonna risk keeping it plugged in

but I do get the sentiment
to save the electricity bill huh
nah I can't check the cable or clean out the fans, can't maintenance incase anything happens
its all around a risk
I rather unplug everything and stow it away
I assume this may be it
wait
no
its not from scratch
agh, damn
grab that vacant domain for your website, or check out the docs here https://docs.aihub.gg/rvc/local/applio/
Last update: Apr 01, 2024
this isn't the exact one but it most certainly checks off all the boxes of what I needed
much appreciated
this is what i get for not taking my boot drive before travelling
have to scavenge for everything I didn't have

if I were doing travel all the time, I'd rather give up on doing workloads using local desktop/workstation
If it was 1 month i'd be like
sure
I can take a break
but for 5 months I'd probably want to mess around with the tech a bit here and there
I got this laptop off FB for a great bargain so I didn't initially plan to do this
Elaborate more
im using a 4060, the problem is my normal mic without the voice changer is normal like it doesnt capture anyones voice, but when i use the voice changer it also changes whatever noise is coming on the pc up
elaborate also the rest, send a screenshot of ur wokada
!give-media-perms 1h @brittle wing
@low shard
My ai voice has an accent but I can’t seem to hear it even when the index is set high
did u use the tensorboard
No, what’s that?
Last update: Dec 24, 2024
Did you just train it to 500 epochs
Bc there isn't a right amount of epochs
do you guys know any video Upscaler that I can use on my PC locally? ( I have an Nvidia RTX 3060Ti ) ( also ping me if you do respond to this )
yeah
Wait 1 sec, is this for a pre-made model or the one I’m going to make?
Did you train a model or just used one made by someone's else?
i used one that someone else made
ohh nvm then, I thought you were making one
well it's better you just try another model
oh okay
also how long will it take to make it?
i have done the first step
im on the traning part

Hello support
Ok how do i fix this error in the run-applio.bat file after i changed the theme oof the app
Is there a new update for fork??
Or when will an update be made to it because the last update was in 2024
FORK
could you elaborate:
- your pc gpu
- what did you do exactly
- what's the error
- a screenshot of the issue
!give-media-perms 1h @brittle wing
No ican't send i'm not in verified
it could take some hours for training a model
I gave you image perms, you should be able now
maybe retry

the last update for wokada deiteris fork was the b2332 one from december 2024, there isnt any newer stable releases yet, also it would be better next time you specify the program since fork just means modified version in IT terms
what team did you choose? what applio version are u using? and what's your pc gpu?
Do you mean that a newer version of b2332 will not be released?
I didn't say that the program won't be updated anymore, I just said that the latest release of right now is b2332, we don't know when a newer stable release will be out, it's better to ask deiteris ( @wispy lodge )
Hello @wispy lodge
Is there a update copy of b2332 for FORK, and if yes, when will it be?
no message yet
could you please try to reinstall the program?
oh yes that's it
Ohh okay
tell me if it's fixed after doing that
My file is still downloading
i have the precompiled zip file
It still doesn't work
nvm it works now
remastering
like clean up?
what’s the process? @modern marlin
ahh
Okay that’s cool
great, let me know for further issues
No issues found
great

it's better you just use the original pretrain in this case
there's also https://discord.com/channels/1159260121998827560/1242833862640402464 but it's trained on only 2 hours
ohh okay
so the v1?
i'm not talking about the train architecture, i'm talking about the original default pretrain you already have without needing to use ones made by the community
ohh okay where do i go to get that?
it's already inside of mainline rvc or applio
just by training normally

you don't need to download any pretrain
the default one is already set
okay, but wheres that?
what rvc program are you using? applio ui colab?

huh what are you installing locally?
you said you have an igpu, meaning too weak for RVC
that isn't applio ui colab
tensorboard
yep
oh is it not?

on applio it's already installed
and you are on cloud
meaning you don't need to install anything
the tensorboard will be opened directly when you start the run ui cell in the applio colab
right below the public ui
@crude flame maybe this should be should be said in a more noticeable manner in the docs
ohh okay
you can just delete what you just downloaded

it's called Applio, it's an RVC fork
you got some cloud options:
- Kaggle: 30 hours weekly but needs a phone number and is a bit harder
- Colab: max 4 hours of daily gpu but could be even less
don't this is for locally, your pc is too weak
do u want kaggle or colab?
both are listed in https://docs.aihub.gg
Last update: Oct 21, 2024
Last update: June 15, 2024
Last update: Jan 13, 2025
you can choose either
kaggle is more suggested for training
I need help from an expert regarding ai image generation if possible
what do you need exactly?
can i share images here it would be easy to explain
ohh okay##
ill take kabble as i got it all swt up
!give-media-perms 40m @spice nacelle
alr, i sent the guide link
im looking for a way to do this if anyone can help like how this person turned this image into a stunning thumbnail


yeah thanks ill lyk later how it goes
i know he used image to image but i have never done this before so i was wondering if anyone knows how and where i can do this and using what loras or models
- easy and good ways with weighs.com are:
- Use /image with @earnest musk in https://discord.com/channels/1159260121998827560/1202754985255764060
- Create an image on their site https://www.weightscom/ (which you can also use LoRAs, Low-Rank Adaptations, basically a small trained additional model to adjust your generation)
- Use Open Source Models like stable diffusion & flux that could be a bit **harder **but good, what's ur pc gpu? As you could run them locally (on ur pc) or on cloud (remote good pc)
:wave: @low shard, How can I help?
Available Commands:
• @weights find <query> or /find <query> - Search for RVC Voice Models
• /create - Create an AI Cover
• /image - Generate an Image
it's for sure img2img, I gave you some platform options and also asked your pc gpu to check if you could do it locally with programs like ComfyUI
something wrong with translations.. corrupted or incompletely unzipped
What I'm already using
What's the error in this audio
some models do that, try a longer input and then just cut it to the part u need
how do i get a better voice model so my model won't be rejected
Yeah dw I turned it off
ohh I thought the model was quiet and u didn't like it
is the model good
ur data seems overcleaned and quiet
okay
how can i search ai voice models for mmvcsserver&
hi i have a problem when audio is not showing up on voice changer basically i cant set my headphones to it
Do you mean w-okada?
You can check the #1175430844685484042 channels, there are plenty of models on that channel
I am so sorry I didnt respond to your message sooner some came up so i had to leave but thank you so much for the info ill try it and see how the results are
elaborate:
- what's your pc gpu
- what tutorial link did you use
- a screenshot of the program
- whats the issue
elaborate:
- what's your pc gpu
- what tutorial link did you use
be sure u didn't use video tutorials, they are old
yw
MMVCServerSIO is the folder/program name for W-Okada. For voice models, look in #1175430844685484042 or find one on Weights.com.
when i talk into w okada the app just closes how do i fix this?
elaborate:
- your pc gpu
- what tutorial link did u use
- what u want to do
be sure to never use video tutorials, they are outdated
my gpu is nvdia gtx 1050ti i used Modified W-Okada
W-Okada Fork Guide
and i also cannot see the box for my pref value
!give-media-perms
!give-media-perms 1h @short marsh
send a screenshot of ur wokada


"Fork" W-Okada and "original" W-Okada are two different versions of W-Okada made by different authors.
The version in this screenshot is the original one.
oh so how am i able to download the fork one and which one is better for my gpu?
you're using original wokada
uninstall the one you got along with vb audio cable
wokada deiteris fork
-realtime
💻 Local Realtime RVC
Guides for Programs that use RVC Models in Realtime for Calls/Games
• Wokada Deiteris Fork
Most suggested. GUIDE
• Original Wokada
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
• **RVC GUI Mainline Realtime**
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
how come i need to uninstall this?
you're using an old version of original wokada
okay thanks alot
you deffo used a youtube tutorial, those are old for wokada and rvc
yw and lmk


make it more clear that you dont need to install the tensorboard if you use applio?
other than that, that installing tensorboard is only for local mainline users
set input to microphone, the voice doesn't seem laggy
is it laggy only during a game? if so, open that game, set the graphics to the minimum, close useless background programs, then show a screenshot of ur wokada
no i have no game just google chrome
well the program doesn't seem lagging, your perf value is green and just 36ms, maybe you meant robotic?
input is already at rvmpe
not robotic more like
input should be your microphone, sorry i did a type lol
old woman with broken voice
for both mainline and applio the best way to choose epochs is to listen to them anyway, the graphs are there just to show you if there are any irregularities in the training
alright
my graph is not normal
he's talking about something else
ah ok
crackling?

i mean we can test it together if u can join
a vc
cuz idk how to
describe
no, this only indicares that you're having a 37ms delay, and it's good,
when the perf value it's good it means it's not lagging
okay wtf lmao
@oblique glacier have you tried playing with the pitch?
i see
also, set the extra to 2.7
how much do u wxant me to put it?
i put at 8 cuz girl voice
i had it originally but i think somebody told me to put it at 2
maybe it was u i dont remember
or the whale guy
well there isn't a right amount
you gotta play with it till it sounds right because it varies depending on your own voice and also voice model
well still sounds a bit like whispering-cracking
but it shouldnt make much of a difference no? if i change the pitch too much the voice model won't work like i want
that girly voice
@oblique glacier have you tried https://rentry.co/forkvoicechangerguide#discord-crackle-fix ? or also trying another voice model
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
If you need HELP, ask in AI HUB Di...
it also helps to speak like the voice 
i didn't try it yet
do u have a good voice model?
yeah, don't put it either too low nor too high
lel i already have a high pitched voice as a man, embarassing
is 5 good?
but for some models might be 10, some others might be 8, yk
alright, time for bigger text 
well, I can't tell you the perf value for your voice with every model
nvm it's just deeper now
maybe try that
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
If you need HELP, ask in AI HUB Di...

but for some reason i cant add loras in ther
the heck LOL
yeah bc i just saw some applio colab users thinking they had to install tensorboard locally lol
youtube, thumbnails 😭
and is there a limit to how many i can create
@oblique glacier have you tried one of the models i said or the discord crackle fix ?
bc i still hear you with a broken voice
huh you can, u just used a lora
those are loras
they are just commonly called image models in the site
sorry i think its models i wan to say
other than this and inst model recommendations what was the other change you wanted me to make? I forgot it and i cant seem to find it, if it even is a thing
nope
discord crackle fix? havent heard of that
can i add different models in there for a different style
please try the 2 fixes I told you
it's on the extra part of the guide
is there a limit or anything like that for image generation on that site
you can use up to 3 loras at the same time iirc
iirc like 100 images a day in free tier
@oblique glacier A VAC (Virtual Audio Cable) makes a fake audio device, used to re-route the audio of different programs
In Wokada context, it's used to get the output of wokada as the input in other programs
wait for real 100 images per day??
you installed vac lite right ?

Weights
Get exclusive access to Weights AI features and support the community by subscribing to Weights Premium.
@oblique glacier wait no
I asked you to do https://rentry.co/forkvoicechangerguide#discord-crackle-fix
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
If you need HELP, ask in AI HUB Di...
@oblique glacier i think you confused with https://rentry.co/forkvoicechangerguide#press-enter-to-continue-failed-to-download-or-verify-files , you don't need to do the other extra steps, only the exact link I sent you
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
If you need HELP, ask in AI HUB Di...
which is this^
@oblique glacier no nope that, don't follow the other help steps, they aren't unrelated, that help part is only for when your program doesn't start, but your program starts lol
yea 😭
u can
u can just ignore that drive thing u downloaded
@oblique glacier yeah still not good, this might be a model issue
it's better you just use another one
there isn't any cut
but it sounds weird
you could try some of the models mentioned in: https://rentry.co/forkvoicechangerguide#voice-models-to-try-out
@oblique glacier ^
@oblique glacier it sounded bad because you used the male sample on a girl model lol
not sure if they have a female one
@oblique glacier btw rename the files before uploading
bc all models on weights are named as 'model'
@oblique glacier yes, model is the pth and index is .index
@low shard I'm so sorry to bother you again but can you cehck this image to see what kind of generator or lora is this person using to create such nice looking images IK he created these characters individually and then used photo shop to recreate these thumbnails but the characters are so nicely made

@oblique glacier put your input to microphone, then go on discord and be sure the input is line 1 here instead
did you close it?
open it, select the model, then click start
well I can't know what image gen model or lora they are exactly using, but might be flux (the model weights.com uses by default) with some anime lora
@oblique glacier yeah it's installing internal files bc u deleted them before accidentally mixing up the guide 😭
😭
@oblique glacier could u type what u just said
oh the vsync, well that helps with not having screen tearing in games
yes but do i need to enable it for a smooth voice?
no that doesn't make the voice quality better, it's just related to the games only
@oblique glacier u sure u selected the right model? it sounds like a man
😭😭😭😭😭😭😭😭😭😭😭
u have like 10 slots named "model" so not sure if u just selected the wrong one
yeah u selected the wrong one lol
i also have some questions regarding this topic recently i tried cloning a voice using a 30 min clip inside all talk tts the voice can out fine but the way the person speaks isnt exactly what i was hoping for
@oblique glacier don't rename on the site, you have to rename the voice model files
the renaming models on the webui is bugged
did i do something wrong or used the wrong software to clone the voice or should i use longer clips
it's better you rename the model files, then re-upload them
I never really used alltalk tts, but maybe u could check https://docs.aihub.gg/tts/tts-tools/
Last update: Dec 12, 2024
@oblique glacier i hear ur normal voice rn
@
it's better now, if you want to hear yourself u can also set monitor to headphones btw
u might be a bit lagging
yup
which one do you recommend that is able to create long paragraphs of text into speech with minimum time
11labs might be what you need, since it's on cloud and can be pretty fast, and also has a good quality
@oblique glacier yeah but not when u eat the microphone 😭
RVC has a limitation to laughing
what?
yeah i need to distort my voice a bit
like the model doesn't give emotion alone
but its not free i have to create audio over 1 hr everyday and itll cost too much to generate even one audio that is over 1 hr
@oblique glacier well, seems like it's all fine now? i can get off the vc?
alright, yw @oblique glacier
ehh, you might want to try edge tts but it isn't emotional
or something like f5 tts
but unfortunately i dunno about alltalk
alltalk was the fastest one that i found so far ive been searcing for a while now but ill give them a try and see if the results are any better
i mean if u only care about speed, pipertts is an option, but it isn't good quality
can i send a video clip here to show what kind of result im looking for?
@low shard when you get the time please take a look and if possible I'm also looking for a pre trained model for this voice but I'm not sure what it's name is so if anyone knows please let me know I would appreciate it very much
genuine question : on deiteris repo there is 001 and 002 to download, how can i make sure both are extracted together ?
Do you know of any guide to download an AI to make images or videos ? I have an 8GB RTX 4060 Ti and I wanted to use it, I'm pretty new to this.
I tried to download SD but there were some problems with the PY files and I couldn't use it
Put both files into a folder (or keep it in downloads) -> right click 001 -> 7zip / winrar -> extract to ....
it will automatically detect the 002 and extract it
Or you can download the precompile i made, its on the guide
ooooo
can u share the guid eagain pls
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
If you need HELP, ask in AI HUB Di...
many thanks
i checking the AMD version it directing to DML one, but when i checking the release in Github there is Amd64-cuda, what the different?
while i know for Nvidia is Nvidia-b2332

amd64 is the cpu bit mode, not related to amd (the gpu)
its also often called x64
-# 32 bit programs are also known as x86 btw
yuh
so you're trying to find a voice you don't know the name off? well, simple you cant
maybe comfyui or pinokio
its called amd64 because amd made the first 64bit cpu
while intel made the first 32 bit cpu
so the package in simple words says: voice changer, 64 bit system, dml
cuda for nvidia
dml for amd
ah i apologize for my confusing question, now i understand
in Hugging face it named differently
i though that one is another version for AMD
Thank you for the Answer 👍
technically the voice changer can be made to run on AMD with zluda instead of directml
would that have any benefits tho?
less cpu usage
directml speed is ass
@low shard
can i stream with the voice changer?
i won't have any issue with it?
yes, it just make the line 1 is one of your stream software audio output
just like in game
but there is delay
no problem, as long as my voice is neat then it's good for me
Im having an issue
everything works including the default voices it comes with
but none of the custom voices i added work for some reason i dont know why i did everything right
hey
hey anyone knows a good voice changer currently im using wokada i but like in games and stuff its not working very good
i would like to share a screenshot i just made but idk how
please tell me what the spec and setting you using
is it the converted voice or just the game when the problem exist?
idk like when i run a game it starts buggin
especially when i choose server instead of client
my gpu is nvidia geforce rtx 4060 (8GB)
is my gpu to bad maybe?
and its not the voices i think maybe my graphic card is to bad idk
what game? and put game graphics to the minimum possible
also, share a screenshot of ur wokada
!give-meida-perms 1h @paper bloom
!give-media-perms 1h @paper bloom


lemme guess, you used a youtube tutorial?
that answers your own question
all video tutorials are outdated lol
vb audio cable gives random issues on windows as reported by users
and you're running on an old version of original wokada, more than a year old
also the settings are awful
@paper bloom uninstall everything you got off the youtube tut (wokada and vb audio cable), completely forget about them
read the wokada deiteris fork https://rentry.co/forkvoicechangerguide
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
If you need HELP, ask in AI HUB Di...
bilibili w-okada tutorials are way better than youtube tutorials
but for some reason there they prefer fcpe over rmvpe
i mean i guess they like that its faster
but at least they're aware crepe sucks for realtime
bilibili has wokada tuts?
yeah
tho they prefer to use mainline's realtime
is there a good tutorial i can use?
yes, I already gave you it: #✨│ai-help message
i mean mainline realtime is better than original w-okada
wokada deiteris fork though
maybe u should also compare latest original wokada with mainline realtime lol

is there no video turorial im rly a noob ^^
@paper bloom uninstall the ones you got, read the guide I sent, then remember to set marvel rivals graphics to the lowest possible
nope, video tutorials are more outdated, since they can't be easily edited
please, read it out and let us know for issues
so the problem might be the old version i have?
yes, the problem is you're using an ancient version
forget everything you got off that youtube tut
technically the real problem is crepe being horrible for realtime inference
but besides that, the original w-okada is a buggy mess
this server doesn't support that anymore
so every helper/mod will tell you to download the fork
plus the ones used by yt tuts are over a year old, performance would be shit especially for games compared to the deiteris fork
can i still use the voice i used before for the new one atleast?
change f0 to rmvpe
should improve perfomance
in the game be sure everything is at the lowest possible, res 1080p, 60fps cap
extra is cpu accelerated in the original version, that might cause a cpu bottleneck if your cpu is weaker than the i7-13th
my fps goes up to 200 in the game
yes, they both use RVC models
yes but the nvidia driver chooses to give more priority to your game
so it focuses more on rendering those fps
rather than giving those resources to your ai gpu accelerated voice changer
oh okay can i cap it?
but how do i do it in the game settings?
marvel rivals?

This quick video shows how to limit the fps in Marvel Rivals. It's pretty simple, but there aren't any good tutorials, so I figured I'd make this video for you! This is everything you need to know about the frames-per-second limiting settings in marvel rivals. I hope you found this video helpful!
Let me know in the comments if this video helped...
generally: just look at the game settings
you can use the in game fps limiter or 3rd party limiters like riivatuner
most games already have built in settings to limit fps tho
or also cap the fps using the nvidia control panel
riivatuner does a better job
try it
reduces stuttering by a lot
ohh okay alr so first step imma limmit the fps and second ill install a newer version of this the voice changer=
can i still keep my current one incase i done something wrong?
got a question about smth, so im using ai voices, and when i run it through vb virtual audio cable to discord it echos what people are saying
as in it picks up any output sounds and plays them back through input
i tried different headsets / mics too it still would echo whatever is heard back into the mic
could it be the ai model thats usually the issue or the virtual cable
sure
for gaming try chunks around 150ms-120ms
vb audio cable gives rnadom issues on windows, reported by users there
did you use a youtube tutorial?
yeah! i downloaded it and watched a yt tutorial
rip
video tutorials are outdated asf
but it wasnt like overcomplicated
they use an over year old version of original wokada
i just downloaded the install, hit install drivers and restarted
with outdated settings
ohhhh
any suggestions on what i should do
or like a better virtual cable
it would be better you uninstall what you got off that tutorial
then tell me what's your pc gpu
that wont input everything heard
rtx 4060 is my gpu also i can uninstall the driver
the wokada deiteris fork has better performance and noise suppression along with echo
dw the issue isn't about the drivers
the gpu is good
ill google that and look up a tutorial on how to download it
https://rentry.co/forkvoicechangerguide is the tutorial
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
If you need HELP, ask in AI HUB Di...
ohhh, do i uninstall vb?
I was just going to give u it lol
oh thank you so much!!!!
yes, along with the wokada you got off youtube lol
in the wokada deiteris fork guide, you will get the program, along with a better virtual audio cable
i didnt download wokada!
i just heard about it now
what program did you download? something named mmvcserversio or vcclient?
mmvc!
because that's wokada lol
we commonly call it wokada
ohh makes sense now thank you for clarifying!!!!
do i uninstall them
and just download the ones through the tutorial u gave me!
yup, let me know for any issues
although i dont exactly know how to uninstall wokada do i just delete the folder?
yeah
and for vb audio cable, you should be able to uninstall it just in the windows app settings
perfect! ill reply if i run into any issues while following the tutorial
perfect thank you so much!!!
You're welcome
alright its better then before but still laggin ill try to downlaod the new version tmr ^^
sorry one thing can be used to clean up datasets much better?
if little background noise remains
I have to do it for an entry from a cartoon with effects
You want to isolate the voice ?
yes
i used 192
lagging as your voice randomly cutting
or lagging as the game stuttering?
quick question for this part! do i need to do this or do i skip it if i have gefore experience

yup you need this, this means it's the nvidia windows version of the program, not that it's the nvidia app
I will go make that clearer in the quick, i feel like you aren't the first confusing that part
i see
well, maybe the fork and vac lite might fix that, but im not 100% about that, marvel rivals is just badly optimized and the 4060 is not a strong gpu
ohhhh makes sense thank you!!!!
it does sound somewhat confusing since it says download nvidia on windows and not the voice changer version for windows!
oh okay
i have a 4060 myself
was able to run fortnite dx12, everything low, using the fork with a chunk of 150ms, rmvpe f0
marvel rivals for sure is more demanding than that
even at the lowest possible
edited it

perfect! it helps clarify, and if possible it would help if what was being downloaded was mentioned! not on the title but closer to the bottom something along the lines of "nvidia gpu voice changer download"
thank you so much by the way for the help!!!!
quick question! do i run mmvcserversio once im here or do i run something different in internal

wait nevermind i found it
it gives me error if i put voc_fv4 on UVR what do i do?
although I put the files well

when i run start_http.bat the terminal closes after being open for half a second
lemme guess, you're using a youtube tutorial?
yup
those are outdated
oh
you're using an old version of original wokada
what's your pc gpu?
amd radeon 6600 xt
wrong ngrok token
worked like a charm like a week ago but now i get this pop up if i open it as usual

wokada has 2 main versions:
- original made by wok
- deiteris fork (modified version) made by deiteris
each with its own updates
we suggest the wokada deiteris fork, which will be way better than the one year old original wokada said in youtube tutorials, read the guide here: https://rentry.co/forkvoicechangerguide
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
If you need HELP, ask in AI HUB Di...
run MMVCserversio
okk
elaborate:
- your pc gpu
- what tutorial link are u using
- what's ur browser

like this?>

have you maybe tried using chrome or firefox ?
nope imma do that rq
ye it does work on microsoft edge if i just copy past the url
odd that it doenst work on brave
it might be better you use that, some specific browsers could run into issues
could also be related to some specific settings, but not sure which
you're welcome


are you using the applio kaggle from https://github.com/IAHispano/Applio/blob/main/assets/Applio_Kaggle.ipynb ?

GitHub
A simple, high-quality voice conversion tool focused on ease of use and performance. - IAHispano/Applio
yep
you sent me the link and im using that
Are people still using Mangio RVC for voice conversion? I have an old version and am wondering where it is maintained so I can update. Or if people are using something better nowadays
Mangio is pretty much outdated and abandoned since 2023.
Unlike Applio which is up to date.
You can either download Applio or use it on colab/kaggle notebook.
Oh word thanks, good to know. Is it that same git repo linked above?
Nope.
GitHub
A simple, high-quality voice conversion tool focused on ease of use and performance. - IAHispano/Applio
This is a link to Applio's repo where you can download it

why do ppl ear my computer sounds and i can't while using voice changer ? with virtual audio cable?
how do i fix the model depending on my gpu
I'll change the model's epochs to somethin' longe no it's overtrained
I need to rework the model
my model said it sounded like a robot
use a good quality dataset and don't overtrain it
the model doesn't have any voice inside
then train a normal human voice
What's the good epoch for a human voice model
Last update: Dec 24, 2024
I'm already using tensorboard
you clearly didnt read the part where it explains what is the best epoch amount
im trying to use it but to be honest its really buggy / laggy on the ip thing!
and its using my cpu

also i cant for some reason change the chunk and extra or the usage!!!
stop the conversion
What's that
literally click the stop button
if the voice sounds muddy, different than the voice of the dataset and robotic, it's undertrained
what epoch is mainly undertrained below?
Mine is 300 epochs above not by 400 or
and train a human voice
10 minutes minimum
batch size 4
200 epochs
this is not really optimal, but it'll work regardless
I already trained my human voice
My model took about 18 minutes and 52 seconds
to finish
i tried the newer version with like the lite cable but it still echos everything that plays on
any output is played back into input
show settings

f0 rmvpe
o let me change that rq
crepe only for crepe models
how do i know if ones a crepe model
the post should say which f0 was used for training
anyway, crepe is ass for realtime
slow, cant handle noise, huge perf loss
now enable echo in the voice changer
extra 2.7s
chunk 150ms
and sup2
then place your mic to a good distance from your mouth
okay!!! ill turn it on
Hello, can someone help me create a realistic girl's voice? So, choose a model and adjust it correctly. I would also pay if someone helps me successfully. Just DM me if you can help.
okay let me try this and get back to u!!
it still echos!
anything people say in a vc plays back through my mic
almost like mimicking everything going on thats being outputted right back in
i have the sensitivity at -60db, echo and sup2 on, tried 2-3 different ai models
and 2 different microphones
use headphones that doesn't leak to the mic, also turn down the system volume to listen
your headphones might be too loud
i did! i have 2 different headsets
or you have this enabled

onces a razer and ones an okuma, the razer has a bleeding issue every once inawhile but the okuma doesnt, it still does echo
let me check!
i dont believe i do though 1 second

its off!
its at 63 for the mic

ill try lowering my headsets levels
i lowered them it still does echo sounds
try even lower
decent headphones shouldnt have issue like that
you can also use any 3rd party noise suppression
if you have some audio routing software other than virtual cable, check the settings
Could someone PLEASE!!!!!!!!!!!!!!! give me a RVC trainer that actually works???????????? I don't have a good graphics card, PLEASE
Do you know any RVC coach that works like Google Collab?
My dataset is quiet
My dataset is big
But it will take too long
what am i goin' to do my model might be overtrained
I have a lot of audio files
@dusty rampart how do I make model not overtrained when there is a lot of audio files on my gpu
💀
I have 22 audio files and how can I make it
20% is what stops echoing 😭 I can barely hear anything
I'll try voicemeeter Banana
can someone send video tutorial for the virtual audio cable thing
Don't expect anyone to make a tutorial about Virtual Audio Cable for you. The program itself has nothing much to do than providing virtual Line In device. Also, Virtual Audio Cable lite is a free one. https://software.muzychenko.net/freeware/vac470lite.zip
could you double check and show the audio inputs/outputs in voice changer and any applications you're using?
mbmb
I got vac lite but I was seeing if anyone could send a YouTube vid since I was confused on the setup since I’m stupid
also check this setting for mic and other devices
where do i download gabox's voc_fv4 for UVR
How do i fix the robotic voice in this audio file
But when the output is music it sounds robotic


these are my discord and voice changer settings!
ive tried with echo sup1 and sup2 off, echo and sup2 on
and it still doesnt help with the echo!
check as in turn it on or make sure its off on most / all other devices!?
i checked
all of it are turned off!!!!!
the voice changer input should be a real mic, not the one where some audio is forwarded to
its a real mic! its a headset and microsoft recognizes it as mic in at front panel

its realtek
the voice changer monitor or discord output is the real headphones ur listening to
wdym!
ask chatgpt bro
LMAO
the real devices usually display their name, instead of just "Realtek"



i got the same thing 💔 it does echo still tho
urs shows
the headset tho
idk why mine doesnt


no idea it may depend on your headphones and the connectivity, but mine is headphones connected through its USB extension

this is the second time we have someone complaining about echo while using "mic in at front panel" interesting
maybe its the jack connection
some weird interference that doesn't happen with usb
i don't have a jack headset with a microphone to try it
but if this is a real problem, may be good adding it to the guide
@hybrid dust , can you go to windows menu > Realtek Audio Console > Device advanced settings and have a look there ? Also what you can see there like is it on an Asus motherboard or whatever rerouting or audio effects are enabled there?
This includes checking the connector settings.

i believe its on an msi motherboard
my pc is msi
can you see if the recording device : Tie up same type of input jacks , makes a difference compared to your current 'seperate all input jacks...' option
i expect its not a checkbox but a radio button behavior , by switching the other option the previous will be turned off ... i dont expect them both to be on.
try using back panel jacks or the headphone's USB connector like mine
it is a switch option!

let me try that real quick
i expect over here those front + back mirrorring could introduce that echoing problem. Especially since they try to split in a software solution. (you can choose) ... the backports are the defaults inputs.
ive switched it to the rear panel! like the mic and headphones jacks
the aim is to see if your line1 virtual cable still echos or stops echoing.
and these are the current settings
im about to test it!
?
also you might recheck weather this option has an influence on windows > sound settings > more sound settings > recordings , alot of devices , check one by one : Properties > Listen > [ ] Listen to device option is off.
you checked that earlier. but to be sure it hasnt sneaky being turned back on.
if after this it still echoes im out of ideas ... maybe the good old ... "eh ... reboot windows" - magictrick works.
ive figured out 1 solution and its lowering discords output to 20% but the con is i can barely / faintly hear anybody :(
let me double checks
check*
if the headphone you use have like microphone too close to the speakers then yea. try another headset or a seperate mic
since you use jack ... sometimes that split cable connector thingy is messed up.
where it goes from 1 plug to 2 plugs
and then you experience also in your headphones a not stereo but a mono ish sound
then you have litterallery a short there
So basically you have alot of things to check:
- microphone to close at headset scalps, sound bleeds into mic: lower volume
- cable splitter rec+output messed up: check a seperate mic
- front/backpanel mirror: dont let motherboard see them as seperate devices.
- using front panel: please try back panel
- windows messed up: restart windows
- sound drivers / external 3rd parties listening to device: turn it off
- sound properties listen to device: turn it off.
- you think using a mic but another mic picks up the sound: disable the mics 1 by 1 to eliminate the issue
hm: Okay yesterday i introduced myself a loop accidently by having the sound of my virtual cable feeding straight back into the voicechanger. 😂
but then it echoes nonstop getting louder n louder lol.



Hey can have a question where and how to make ai voice model with TITAN model
Simple answer. Don't figure it out. Figure out how to use normal pretrain
Titan forms noise
it's actually more prone to robotic sounds
im new to pretrain models, do all models support universal languages?
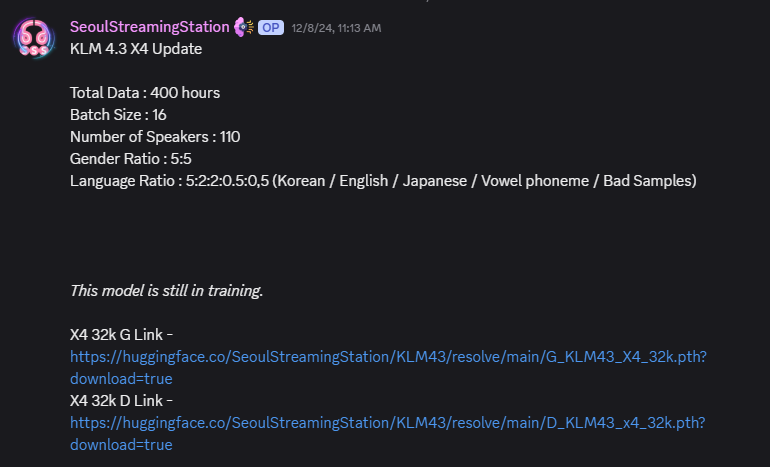
not exactly, some models have a larger dataset in a specific language, in result having better quality when training on that language, you could usually find the training dataset info to find what model is best for the language you want to train your model on
e.g
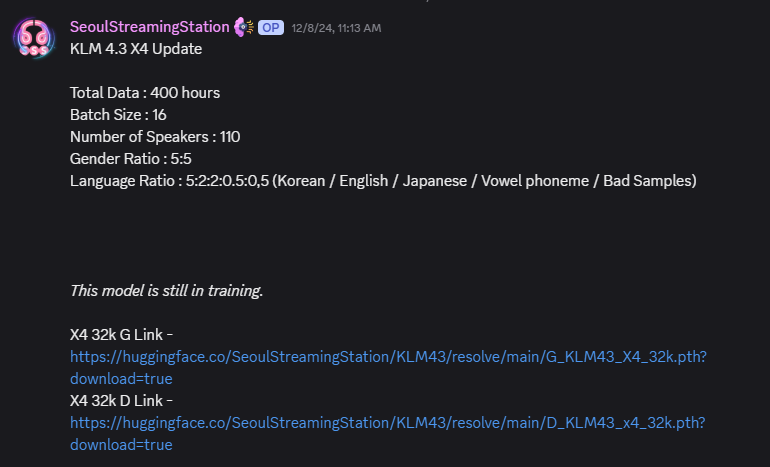{kind=link}
Heya, i have a small question. Is there a way/ feature that allows u to like change the "voice"/"process it" just a percentage while using? like 5/10/15/20/40/60/100% (well currently it's working at 100%)
for example:
I wanna show a friend that I "trained" (vocal cord lessons) my voice and can change my voice from original one that i have to the new one gradually.
Think of something like this: a person does an exercise and just spells "a" letter from base voice and gradually changes the tone to higher sounds.
That's a feature that could be fun/made for jokes and while i do have 0 knowledge of how the okada deiteris fork is done, i believe it should be possible but may need to do additional processes like for increments of 5% to go smoothly from original voice to the model that u chose without putting too much stress on gpu or idk.
please tell me if there's something u don't understand