

1 messages · Page 223 of 1
this everytime i click the convert button, https://www.weights.com/models/clm737ynf1tgqcctc4xnna57g = model
Introducing our latest AI voice model, Homer Simpson (RVC v2) with 600 epochs of training! This advanced Retrieval-Based Voice Conversion (RVC) model brings eve
put extra to 2.7
put sr to 48000
did you follow the windows wasapi guide
no i did not
you need it
A VAC (Virtual Audio Cable) makes a fake audio device, used to re-route the audio of different programs
In Wokada context, it's used to get the output of wokada as the input in other programs
check the 3rd step of the guide
ahh i have one

What does WASAPI do?
WASAPI accesses your audio devices directly, while the driver that you use by default (which is "MME") goes through multiple layers within the Windows audio subsystem, causing more delay.
This will in total cut down 50-80ms delay.
Shoutout to Mares & Emojikage
L...
if you're talking about vb audio cable
that's worse, it gives random issues on windows
it's better to uninstall it
ok
thank you
that correct one?

yw and lmk
the one you showed is vac lite, which is the correct one
you got it already?
yeah
alr, then set the output in wokada to line 1
and set the input in the other program (for example discord vc) as line 1
already done
also be sure you are using chrome or firefox so you don't risk running into issues
ok, i use chrome
now, upload any models, click start, check the perf value at the top left, and set the chunk higher than that value
like if it's 200, you set chunk to 260
thank you so much, it's good now
you're welcome, any other issues?
when i uses headphone to listen myself everything clear. But in vc in discord with line 1 it has issues with ping etc
question whats a good chuck to put it at
it's better you close apps in background, start, check the perf value then put the chunk to an higher value than that
like you get 200 perf value, you set chunk to 260
this is the way to find your own best chunk value
go into discord voice settings and turn off echo cancellation and noise suppression
hey do you have insight on what the problem seems to be?
ok thank you
this could be a better picture

weird, could you try another model to see if it's a model issue
as long as they are rvc v2 they should work
ok
Ill describe it when headphone sound is amuzing but in discord it very terrible
yeah did you try as i said
i can try to record if wanted Just the sound pretty crazy. I off everything as you say
alr post it here
maybe cause of trial version on vac?
did you download trial or lite?
trial
install lite
the model was trained in 2023 using harvest, there's a high chance the model is a v1 one
thanks for pointing out
that's a checkpoint file
where tf did u even find that
that's a gpt so vits model, not rvc v2
oh
not all voice models are for rvc v2, those for gpt so vits have the gpt so vits tag or in the title
sorry im kinda new to this lol
basically
ahh okay
there's different types of ai voice models
gpt so vits is tts (text to speech)
rvc v2 is the best sts (speech to speech)
so vits svc is an old sts
Now everything fine. Thank you very mutch
no, it's optional
in rvc context:
ah okay
You're welcome, any other issues?
no ty
have a nice day
Just wanted to bump this. I'd appreciate any input you guys have!
Wokada deiteris fork is the best as of right now
What's your PC GPU?
Also be sure to uninstall the version you got and vb cable if you had it
NVIDIA RTX 3050 Ti Laptop
I've got Muzychenko's VAC, I remembered not to get VB Cable from my original installation haha
You won't have issues except for high end games like marvel rivals basically
Great then
-realtime
Guides for Programs that use RVC Models in Realtime for Calls/Games
Most suggested. GUIDE
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
it went through this time but still isnt allowing me to download it or listen to it

1st link, read up the guide
Maybe wait for a few seconds till it appears, is the audio file big?
about 7.3 mb
is the file output still not showing in the UI?
yeah
manually download the model and unzip it into Applio/logs/homer
go to the applio folder then assets/audios/notlikeusvocals.mp3, you should be able to see it from there
the model might have been an rvc v1 one since it was trained on the era of when harvest was used
wasn't v1 depracated from applio?
can still infer v1
just the original vocals
this always happens to me
i always be creating this newly found error
lmao
oh is it removed just for training then?
weird, could you try to convert again? also follow what noobies said
tried converting again, nothing showed, tried rebooting applio, nothing showed, tried what noobies said, nothing showed
wtf ???
oh forgot to check console

what model you're trying to use?

Introducing our latest advanced AI voice model, "Homer Simpson (The Simpsons Hit & Run) (5
you need to use voice separation model
how do i do that
sorry for disappearing I went afk im back now just installed everything
alright, might want me to check your settings or if you encountered issues?
Last update: Dec 24, 2024
I havent opened anything yet I just installed everything
👍
alright
A VAC (Virtual Audio Cable) makes a fake audio device, used to re-route the audio of different programs
In Wokada context, it's used to get the output of wokada as the input in other programs
Oh
I see
To open wokada do I open this?

yes
yes, it uses a web user interface like the majority of ai programs
gpu: your rtx
f0: rmvpe without onnx
extra: 2.0
input: microphone
output: line 1
add a model
idk why I cant find my microphone on my input
and I also cant seem to find line one on output
unless this means line one?

Just to clarify, is there a particular method for uninstalling my old w-okada VCClient or do I just delete the entire MMVCServerSIO folder?
what browser are you using
arc
just delete the folder
arc?
yes arc
oh just googled it, seems like it doesn't get updates anymore
we suggest chrome or firefox to not run into issues
also be sure to give microphone permissions when asked
alright lemme install chrome give me a second
okay done but I still dont know what you meant by line one

Holy fucking shit this feels so much better to use than the ancient one for some reason
For installing the Deiteris fork, the instructions on the official Github (https://github.com/deiteris/voice-changer?tab=readme-ov-file#for-nvidia-users) and on the online guide (https://rentry.co/ForkVoiceChangerGuide#download-nvidia-on-windows) are not quite the same (at least superficially). Which one do you recommend?
Hey, my PC has 16 GB of RAM, Intel Core i5-8400 Processor, 2.80GHz CPU, 8 GB video card and 447 GB of storage, my internet is 100 MB, what can I install and configure with this?
For input you will see your microphone
For output you will see something called line 1
Is it all fixed?
Cant find that tbh
Did you install vac lite as said in the guide?
I did I just didnt use it because Idk how to or what to do
What's your PC GPU name? And what do you want to do exactly
So you didn't open the setup64.exe?
no
U have to
I don't know, how do I see this?
Please read all the guide, read carefully step 3
You can check your pc gpu via:
ctrl+shift+esc (task manager) -> Performance tab -> GPU
And what do u want to do
GPU: AMD Radeon RX 580 2048SP
raceback (most recent call last):
File "/content/Hina_RVC/src/webui.py", line 8, in <module>
import gradio as gr
ModuleNotFoundError: No module named 'gradio'
Hina is not working
likely uv install issue, add --prerelease if-necessary-or-explicit key to uv pip install lines
find the requirements install cell, click

there's gonna be a few lines that start with !uv pip install
add --prerelease if-necessary-or-explicit after install, make sure there's a space
!uv pip install --prerelease if-necessary-or-explicit whatverelse_is_there
Is there a recommended location that I should extract the Deiteris fork ZIP download to, or can it be placed anywhere in my local file system?
C:\voice_changer\ will do
I still got an error
or any other drive, not C:\user\blah-blah\onedrive\copy (2)\voice changer
re-run the install cell
show the output log for the install, but you need to remove all "clear_output()"
Is C:\Program Files\voice_changer good? Or does it need to be in the root?
just the root
preferably no spaces in the folder name
Awesome thanks, and could I put it on a removable drive? Or does it need to be in a permanent drive on the PC?
does not matter
anyway, that colab is outdated and not supported most likely
Hina separated vocals 4 u and added the intrumental
is there any similar model?
Noobies, how can I download the custom pre-trains? It won't let me anymore.

How do I use the new applio? Everything has changed. I can't download the pre-trains. When I load the model's backup, it doesn't appear even when I refresh in the train tab. The slice simple doesn't appear, and it stops when I truncate silences. 😭
After running the Deiteris fork for the first time, it tried to open the WebUI but got this error (my browser is Firefox). Is this a browser issue, and is there an easy way to fix it on Firefox? I'd prefer to use that over Chrome.

yo
hwo knows the best settings for ai girl
set sample rate to the audio spetrogram cutoff, choose batch size 4 or 8 for longer dataset, choose KLM pretrain for ur waifu voice
idk what tf you just said
😭
can i dm you so i can send a screenshot?
cuz you replied to someone else's comment about model training
nuh uh
!give-media-perms 1h @barren garden
og wokada for directml is dogshit, get better one here https://rentry.co/forkvoicechangerguide

Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
System & Hardware Requirements...
and that will help me get better girl voice?
sigh
My PC has 16 GB of RAM, Intel Core i5-8400 Processor, GPU AMD Radeon RX 580 2048SP, 2.80GHz CPU, 8 GB video card and 447 GB of storage, my internet is 100 MB, what can I install and configure with this?
to do what?
can someone send me the download for it in english
used to have it then wiped my pc and cant find it
sounds like ur a clown doing april fools joke
Which version can I install and what settings can I put in the application
What is the best alternative for easygui (which has been dead) that has a similar gradio? Or... that is just similar to what easygui was in general? 👉 👈
2025-04-13 04:12:12.8595541 [E:onnxruntime:, sequential_executor.cc:516 onnxruntime::ExecuteKernel] Non-zero status code returned while running Mul node. Name:'/hubert/feature_extractor/conv_layers.0/layer_norm/Mul' Status Message: CUDA error cudaErrorNoKernelImageForDevice:no kernel image is available for execution on the device how do i fix this
seems like unsupported gpu
ty
after i download the model, i need something else ? okada ?
also i want TTS not voice changer if possible,this one https://discord.com/channels/1159260121998827560/1175430844685484042/threads/1179052385532903494
to do what? make images? realtime voice change? non-realtime voice change?
what's your gpu?
it wont work with a very old device like <1000 series
Change voice in real time, sorry I wasn't specific
thank you for the link, though i did follow the trouble shoot and did the task manager tip but it still continued, its like a poppy crackle
!howtoask

my rvc is not working"."RVC" voice model can be used with an RVC the regular voice chager program, it doesn't have to be W-Okada the realtime voice changer at all.
Applio has a TTS feature built into itself. 
You have RTX 50 series GPU? Because some stable packages made for RTX 50 especially haven't out yet. Which RVC program are you running by the way?
If you mean by audio quality, then sure. But if you mean by an e-girl voice model, hell no.
Helppp please recommend best computer specs i should buy so ill start saving
But I don't have any computer specs recommendation in my mind. You'll have to look for one that's at least decent enough for gaming but also in budget for your needs. 
If you want at least decent GPU for AIs, NVIDIA GeForce RTX 30 series GPU is at least enough. RTX 40 GPU is decent, stable and super fast.
Can you give me like specs to look for ? Im very new to buying computer, i always use laptops so 😭

How about this one

Is this enough specs ? To afford, it might take me like 6 months to save up lmfaoo saving as a student is near impossible these days
Anyone? Is this good or nah aaaaaaaa
Are you sure you have learn more about how powerful these specs are?
So is it enough? Since i want no lag and i dont want the training to be slow or have any problems with the audio?
I'm not a professional of gaming/workstation PCs, so I can't judge it to be enough, but I'd say it's at least decent enough to run games and even train an AI model locally.
Hii nick please noticee can you guide me with specs ?? Im financially dying but ill save up to meet the best specs can you guide me so i dont end up dying in regret if i bought the wrong one?? I want to make sure 😭😭😭😭😭
Again, I can just say pretty much it. It's up to what you need, not me or anyone lol.
Any CPU, GPU, RAM and SSD released after year 2020 are at least decent. Anything released before 2019 is considered to be old. 
it is more than enough for rvc training but it depends on your budget. you can consider lower but still recommended specs: RTX 3060 12 gb + ryzen 5600X or 5700X3D, others are fine
If you use vb cable then thats the isssue. Download vac lite from the guidd
that's good enough, you will have issues only if you use intensive games like marvel rivals
-realtime
Guides for Programs that use RVC Models in Realtime for Calls/Games
Most suggested. GUIDE
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
read the 1st link guide, wokada deiteris fork
yeah that
now set line 1 as also the input in the other programs (like discord vc)
maybe it's better you give chrome or edge a try
sometimes browsers could have issues, welcome to javascript
for what? there's over thousands of AI programs
reply to:
try Applio
what's your pc gpu btw
that one is for RVC v2
There are different Text To Speech (TTS) AIs:
GPT So Vits: RVC isn't as good as GPT So Vits for tts, but gpt so vits (few shot tts, which means needs just a lil training for models) can't use rvc models (and viceversa), and its only limited to: english, chinese & japanese, if you wanna check gpt so vits instead, read https://docs.ai-hub.wtf/tts/gpt-sovits/
Freemium 11labs: Easy way to do TTS is https://elevenlabs.io/, you can't use RVC model on this but its a mostly premium easy way for good quality TTS
FishSpeech: FishSpeech is a 0 shot (no explicit training needed) TTS, if you got a good pc you can use it locally else use their site
You can check TTS in our tts index
RVC is natively for Speech To Speech, but forks such as ilaria rvc mainline & applio have built in tts (using Microsoft Edge TTS to make a generated tts audio, which i suggest you to choose a tts model that is the same gender and language of the rvc model you wanna use, and then convert it with rvc)
If you wanna do tts locally with RVC Voice Models (if you got a good pc):
If you don't got a good pc you can do tts with RVC Voice Models on cloud:
Ilaria RVC Zero (Running on A100 GPU, free fasted rvc on cloud) and the guide
Use Applio UI Colab (with google colab T4 free daily limit gpu)
You could try another tts from our tts index and use the output as an input in rvc
it all depends on your budget and what you need
seems like an huggingface internal issue
either try changing the license to openrail/mit or just wait
you could also report this in the official huggingface server where there are official staff
do you have a link by chance?
did you retry if the error still persists first? I just tried myself and huggingface works fine
maybe refresh the page, or try another browser
still nothing
I have had it for a really long time
https://discuss.huggingface.co/ or google "huggingface discord"

seems like an issue on their end
unfortunately, we can't do much about it if it's a site error
gtx 750 ti
that answers your own issue, that gpu is prehistorical basically
too old to even be supported by CUDA, which is needed for wokada
the bare minimum would be a gtx 900, but your gpu is weaker than that and even too old
your only options are either:
@fervent frost most cloud methods are having issues, since cloud is very unstable
the only working one right now is Wokada Deiteris Fork Kaggle which gives you 30 hours weekly of good gpu, but is hard and requires a phone number

Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
let me know for further issues
Thanks
yw and lmk
It's crazy you have tried hard to run RVC/W-Okada with that GPU. Any NVIDIA GPU before RTX 10 series can't even run AIs. 
tried using uvr5 ui yet got an error, not sure how to fix it or what it even means tbf lmao
Traceback (most recent call last):
File "D:\UVR5-UI\env\lib\site-packages\gradio\queueing.py", line 625, in process_events
response = await route_utils.call_process_api(
File "D:\UVR5-UI\env\lib\site-packages\gradio\route_utils.py", line 322, in call_process_api
output = await app.get_blocks().process_api(
File "D:\UVR5-UI\env\lib\site-packages\gradio\blocks.py", line 2103, in process_api
result = await self.call_function(
File "D:\UVR5-UI\env\lib\site-packages\gradio\blocks.py", line 1650, in call_function
prediction = await anyio.to_thread.run_sync( # type: ignore
File "D:\UVR5-UI\env\lib\site-packages\anyio\to_thread.py", line 56, in run_sync
return await get_async_backend().run_sync_in_worker_thread(
File "D:\UVR5-UI\env\lib\site-packages\anyio_backends_asyncio.py", line 2461, in run_sync_in_worker_thread
return await future
File "D:\UVR5-UI\env\lib\site-packages\anyio_backends_asyncio.py", line 962, in run
result = context.run(func, *args)
File "D:\UVR5-UI\env\lib\site-packages\gradio\utils.py", line 890, in wrapper
response = f(*args, **kwargs)
File "D:\UVR5-UI\env\lib\site-packages\gradio\utils.py", line 890, in wrapper
response = f(*args, **kwargs)
File "D:\UVR5-UI\assets\presence\discord_presence.py", line 146, in wrapper
result = func(*args, **kwargs)
File "D:\UVR5-UI\app.py", line 356, in roformer_separator
raise RuntimeError(f"Roformer separation failed: {e}") from e
RuntimeError: Roformer separation failed: CUDA error: no kernel image is available for execution on the device
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
gpu is rtx 5080
gtx 900 can iirc
also it's gtx before the 20 serie
are you using eddy's uvr ui?
I mistyped the GTX. 
@viscid moss did you add support for the 50 serie in your uvr ui
yep
I asked if the creator added 50 serie support in the project, let's see what they say
alright
also be sure your drivers and window versions are updated
do studio drivers work or do i need the game ready ones
game ready should b fine
ok, thx
Damn, nope 
nice
@flat zealot the following method works for Applio, maybe try it also for eddy's UVR UI:
After you extracted the precompiled, go to the path in Windows explorer, write "CMD" and press enter, then in CMD write env\python -m pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu128
If you get any already satisfied requirement issue, run env\python -m pip uninstall torch torchvision torchaudio then the command said above
worked, thx
you're welcome
lmao i was writing the most complete guide

😭
Well, imma pin that as an issue on GitHub, thanks for the pointer Nick
btw it somehow worked with my i5 4460 cpu but weird 😭 (i selected cpu version and it somehow worked and it didnt give error like my gpu)
yeah as I said it does work, just that the performance is shitty
and could lead to damaging if done for a long time
are u fr using ur cpu? how much high is ur perf
Even worse. This Intel CPU is too old, judging by that Intel Core generation number. While running W-Okada with only CPU is possible, it's usually slower than a GPU. I mean, it must be really slow.
na na i stopped using it
Run W-Okada on a cloud service like Kaggle instead, until you get a better new PC with better GPU. 
whats that error on W-Okada ?
Torch not compiled with CUDA enabled
vcclient_dev\voice_changer\voice_change_manager\models\rmvpe\rmvpe.py:318: FutureWarning: You are using torch.load with weights_only=False (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for weights_only will be flipped to True. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via torch.serialization.add_safe_globals. We recommend you start setting weights_only=True for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
Torch not compiled with CUDA enabled
vcclient_dev\voice_changer\voice_change_manager\inferencer\rvc_inverencer_v2_f0.py:22: FutureWarning: You are using torch.load with weights_only=False (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for weights_only will be flipped to True. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via torch.serialization.add_safe_globals. We recommend you start setting weights_only=True for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
torch\nn\utils\weight_norm.py:134: FutureWarning: torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.
WeightNorm.apply(module, name, dim)
What is your PC GPU?
AMD RADEON
AMD Radeon RX or with no RX in its name?
rx yes
local installs for 5000 series require a nightly torch install
you're using outdated software with new pytorch 2.4+
how to fix?
If you installed W-Okada from start, not from the compiled one, then pretty much it happens.
it breaks applio's training though, anything after mar 27th is broken
have to specify exact versions
which? elaborate
did you read https://rentry.co/forkvoicechangerguide
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
System & Hardware Requirements...
never use video tutorials for wokada
perfect
@simple ore since you're a dev for more than a decade, how does it feel dealing with software that breaks easily
python is worse than Win95 dll hell
have to be super careful at managing the versions and always use a virtual environment
helloo! I was wondering if there's a free open source way to translate speech in videos to another language, making it sound relatively natural and not like a TTS voice-over. And if it is possible, could someone point me to the right direction?
I've seen Merlin Clone doing good job, but it is paid stuff
For example, I have a video where I'm speaking French and I want to replace the speech to english, but retaining my voice, inflections, etc.
would u say it's the most fragile language u ever tried
the irony is that it's also considered the easiest
oh :T
maybe https://github.com/R3gm/SoniTranslate could help
Synchronized Translation for Videos. Video dubbing - R3gm/SoniTranslate
i'm not sure how good is the quality
I'll check that out, much thanksss!
yw
another question:
do you guys know about an AI tool that can generate subtitles from a video?
I mean, a free, open source reliable AI tool... 😬
https://huggingface.co/spaces/Nick088/Fast-Subtitle-Maker this is my open source project which uses Groq's free api for a fast whisper usage
I'm not sure if you want to do it locally
to me, the link goes to a 404 page 🥲
I edited the link, there was a typo before
ASR can be done with Whisper, but it may require some editing and fixing
it is not perfect
locally would be great. but I think that would require my machine to be capable of running an LLM, correct?
for STT, you'd need a ASR model not LLM
what's your pc gpu
right now I only have a 4070 🫠
yeah there's always a little imperfection, just like how LLMs can hallucinate
that's good to know!
I haven't tried on my own machine, but iirc it should be able to handle it
but if it puts the timestamps at the right place, that alone would already be such an improvement to my work
maybe https://github.com/m1guelpf/auto-subtitle ? I'm sorry but I never tried locally

Automatically generate and overlay subtitles for any video. - m1guelpf/auto-subtitle
oh, no need for apologies!
it already help me a lot just by pointing me towards these projects
next week I'll try to setup everything and make some tests with the translation and subtitles
muuuch thanks ✨ 🙌
goodluck and ur welcome
-colab
Google Colab is a Cloud (Remote Good PC) Service. While the Free plan provides up to 12 hours of daily usage, the GPU is typically available for only about 4 hours each day on average.
by IA Hispano
Google Colab
by Hina
Google Colab
by Eddy
Google Colab
by Eddy
Google Colab
by Deiteris & Hina
Google Colab
by Shiro & Eddy
Google Colab
by Nick088
Google Colab
by Nick088
Google Colab
by Jarredou & Makidanye
Google Colab

I followed the guidelines in the manual to reduce the delay, but I can't hear my voice modified here, how do you hear? I tried to watch the tutorials here but I still found it confusing because their audio mode is as "client" and mine is as "server" (AI Voice Changer)
That's applio Colab also wdym
How was it done
Huh
That's Applio Colab with the fixes
read it again
It used to work fine w the fixes...
wrong spelling
so I dont know what the hell you're running
code's been updated yesterday, it does not have misspellings
Found it...

There is the bug in Applio UI in Colab when traning:
UI or noUI?
UI
The previous bug related to gradio successfuly fixed by myself after adding --prelease disallow and !mkdir entities to beging of Install section. Now it gone worse )
Currently:
import sys
from IPython.display import clear_output
import codecs
import os
encoded_url = "uggcf://tvguho.pbz/VNUvfcnab/Nccyvb/"
decoded_url = codecs.decode(encoded_url, "rot_13")
repo_name_encoded = "Nccyvb"
…!uv pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1
--index-url https://download.pytorch.org/whl/cu121
-q --prerelease if-necessary-or-explicit
!uv pip install numpy==1.23.5 gradio==5.23.1 pyngrok -q --prerelease if-necessary-or-explicit
clear_output()
print("✅ Finished installing requirements!")
what is
copy paste issue

Another detail: They should change program_ml to Applio in dir paths of Backup Sections:
"/content/program_ml/logs/" should be "/content/Applio/logs/"
It works!! Thank you
okay, gonna update everything again
U gonna have a streak of updating colab 😭
hi in here?
#✦│chat message hello
Your rtx 3070 is good enough
The issue is all video tuts are old
Delete everything you got off YouTube tuts
If they made you install vb audio cable, uninstall it too as it gives you random issues on windows
YouTube tutorials use the old version of the original Wokada, which has worse performance and quality
Yes, it could just randomly stop working out of no where
that might be why
shall i delte everything even the luacner
Guides for Programs that use RVC Models in Realtime for Calls/Games
Most suggested. GUIDE
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
Delete everything you got off the YouTube tutorial, then read the 1st guide
Yeah delete everything you got off youtube
The 1st link of the bot message above
damn looks really complicatewd lol
Nah it's just because it got everything for all OS and all GPU types, you need to only follow the general parts like the 3rd part and the audio setup, and the windows Nvidia parts
Ofcourse if you got any issues you can ask here
so its not as eay as just donloading it
 guys, can i ask if it's better to have long data ? like 2-3 hours
guys, can i ask if it's better to have long data ? like 2-3 hours
it's easy compared to the old original wokada where you needed to install python and other shi
gonnaaa be honest no idea what im doing with with the steps
so lost
1h is enough
it's AI, it's not going to be like downloading minecraft since this is supposed to be advanced btw
it's as easy as downloading 2 programs, extract, and run them
that's kinda all
what step are you at?
what is going wrong ?
i struggle for minecraft ahaha
so is there anyway to train it and make it sound natural in my mother tongue ?
nevr been good with this stuff desoite gaving a computer for 3 years
always asking everyone for simple help lol
the lot
i tried with 1 hour and the result still sound like some British come to my country
you're cooked then
🔥
/ jk lol
what's your mother language
the lot ?
RVC original pretrain is trained in english only, it's also good for languages similar to english
you could try and check the tensorboard, it may be better if there's a vietnamese pretrain
I can help you up!
what step don't you understand?
lemme properly look at 1 causde i looked and it scared me so i close it ahah
if there is one, it could help yeah
if there isn't any, is it possible to train one ?
also, embedded model is different from pretrain right ?
 too low tech for these
too low tech for these
embedder model is the one that extracts phonemes from the audio
i can try late ris thats good kinda busy rn
and thank you for clearing my confusion 
alr
oh okay, i get it. thanksssssssssssssssssssssssssss
i dont know vietnamese embedder
but if you use one to train a model then you can only infer using the same embedder
I have a nvidia geforce gtx 1660 super
Is it still possible to get Okada's Live Voice Changer to work?
yes except for high games
also be sure to NEVER USE VIDEO TUTORIALS, they are all old for wokada
if you used one, delete everything you got off it
I see.. thanks
-realtime
Guides for Programs that use RVC Models in Realtime for Calls/Games
Most suggested. GUIDE
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
1st link, wokada deiteris fork
this is the most up to date guide
the deiteris fork has way betterr performance and quality compared to the old original wokada used in the yt tuts
@crystal rivet read it up and let me know for any issues!
Is there a percentage of used gpu I should watch out for while running games?
you can try with this one https://huggingface.co/utter-project/mHuBERT-147
hi
wdym?
i need testers
it's normal that your gpu is going to be at an high percentage
unfortunately there's no control for gpu usage or prioritizing one app over another
so a game would be competing against the voice changer for resources
i create AI on the symulator of predyctions the lotto meybe lottery is not good point but this machne learning even 1000 eproch
you can try #1359898289335566570
yes sir
what now? you can promote this on main options then to join to chanell he must vistit me website? XD i can pay for it 😛
If you can predict the lotery why aren't you cashing the prize yourself lol
Can i record a tutorial then ?
I only knew of the original/old one before joining here,the fork is way less famous i assume
go ahead we need a yt tut
just make sure you suggest the correct settings and such
guys i need a tts on colab cuz trash pc i have. i tried to find but they dont wrok :(((8
sir, can i ask if there is a tutorial for installing custom embedder on applio, i tried to download mHubert but i have no clue how to do it properly. and my applio failed to find it


you need pytorch_model.bin and config
one sec
save two files

click (x) custom, click Refresh Embedders


 okay, let me do it
okay, let me do it
There are different Text To Speech (TTS) AIs:
GPT So Vits: RVC isn't as good as GPT So Vits for tts, but gpt so vits (few shot tts, which means needs just a lil training for models) can't use rvc models (and viceversa), and its only limited to: english, chinese & japanese, if you wanna check gpt so vits instead, read https://docs.ai-hub.wtf/tts/gpt-sovits/
Freemium 11labs: Easy way to do TTS is https://elevenlabs.io/, you can't use RVC model on this but its a mostly premium easy way for good quality TTS
FishSpeech: FishSpeech is a 0 shot (no explicit training needed) TTS, if you got a good pc you can use it locally else use their site
You can check TTS in our tts index
RVC is natively for Speech To Speech, but forks such as ilaria rvc mainline & applio have built in tts (using Microsoft Edge TTS to make a generated tts audio, which i suggest you to choose a tts model that is the same gender and language of the rvc model you wanna use, and then convert it with rvc)
If you wanna do tts locally with RVC Voice Models (if you got a good pc):
If you don't got a good pc you can do tts with RVC Voice Models on cloud:
Ilaria RVC Zero (Running on A100 GPU, free fasted rvc on cloud) and the guide
Use Applio UI Colab (with google colab T4 free daily limit gpu)
You could try another tts from our tts index and use the output as an input in rvc
yeah u can make a yt tut
whats the best realtime voice changer that works good for AMD
Cus w-okada is laggy for me
-realtime
Guides for Programs that use RVC Models in Realtime for Calls/Games
Most suggested. GUIDE
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
First link on there
Modified deiteris w-okada, one of the big features is better AMD support
Which
Extremely loud incorrect buzzer ERRRRRRRRRRRR
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
System & Hardware Requirements...
This section in that guide
Its a direct download
dml-blahblah.zip
Yea alr
DML is what you want
Cus i have AMD?
Ye
would it work smooth with a rx 7800xt and a ryzen 7 7800x3d
Alr
That guide has good recommended settings and stuff. Its a really really good guide, tons of info
Also AI Hub search bar is way more useful than Google for troubleshooting this
yo can anyone help whats the best voice changer for gtx 1650 and ryzen 5 4650g pro?
Why can't I use the applio black interface ?
Can't download output audio
Still stock on 0:00
Hi there! I'm new to AI voices, Using RVC at the moment. I want to learn how to make a voice for a youtuber but I'm not sure how. Any advice?
-rvc
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
System & Hardware Requirements...
It's W-Okada. The free and open source realtime voice changer program.
iiii
currently trying to train a model via mainline but im getting this issue
ERROR:
ERROR: Sign up for an account: https://dashboard.ngrok.com/signup
ERROR: Install your authtoken: https://dashboard.ngrok.com/get-started/your-authtoken
ERROR:
ERROR: ERR_NGROK_4018
ERROR: https://ngrok.com/docs/errors/err_ngrok_4018```
i added my ngrok token to the secrets tab + verified my ngrok account (the credit card thing) but im still getting this issuengrok is the fastest way to put anything on the internet with a single command.
ngrok is the fastest way to put anything on the internet with a single command.
wait
oh shoot i misread the error lmao
i thought the verified account thing was like the identity verification thing
it's just email verification and no more hassle for me
do i need to do the ngrok config add-authtoken $YOUR_AUTHTOKEN thing
and if so where do i do that? havent used kaggle + dont see a cmd line or anything
ngrok config add-authtoken 123456abcdef
(paste from the one in https://dashboard.ngrok.com/get-started/your-authtoken)
do you still not get it?
also no, I shouldn't give my token to anyone
sry i think i messed up my phrasing
on the kaggle notebook it has a place that says
``` #@markdown To put ngrok token, go to the side and press the key icon<br> On the name put Ngrok_Token and the Value to be your ngrok token
i put my ngrok token in the secrets tab (key icon under add-ons tab) as they asked in the instructions
i was wonderin if i still needed to do the ngrok config thing on my own on top of that or if adding the ngrok token to secrets was enoughwait nvm i found the issue
my dumb ahh added a b when i pasted in my token
also no, I shouldn't give my token to anyone
are u still cooked? 
it works now
pain peko
Hey, can someone help me? I recently reset my computer, and thus, reset all permissions (unintentionally), so now I have to run everything as admin, if I don't, it gives this error (image). However, when I run start_http.bat as admin, it immediately opens up a small window, closing it within the second. I don't see anything in task manager either, is there some way to fix this (preferably not changing Windows settings)?

Uh, for W-Okada.
there is a space in W-Okada New
btw is the rate limit monthly?
just hit my limit (managed to finish training + downloading my model first tho thankfully)
you'll hit the rate limit if you download more than 1 GB (reset every first day of month) in the file manager instead of kaggle's right sidebar

or the HTTPS Endpoint Requests reaches limit
It still refuses to work.
gotcha, tysm
move to another place like D:
and check the directory permissions
if there's only a C: drive, I'd suggest creating a partition depending on the free space or get another external/USB drive
Well, it's not sending a traceback to me, so something's happening.

Oh yay it worked.
Thank you very much.
Now I know that my D:\ actually has permissions for shit lol.
im new to all of this in the video i watched for so vits fork it says i need a config file which should be in the form of a JSON file but every single audio model i download there is a pth which is fine but the other one is always an INDEX file. Am i doing something wrong?
So vits SVC is old ass
All YouTube tuts are old
What's your PC GPU and be sure to not use yt tuts
Realtime for calls? Wokada deiteris fork
-realtime
Guides for Programs that use RVC Models in Realtime for Calls/Games
Most suggested. GUIDE
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
1st link
alr bro thanks
Let me know for any issues
?
is say's compressed zipped file
do i have to extract it?
i just like downloaded the voice changer windows nvidia-b2332
Yes
Yeah it's for windows nvidia
alr so im already on this page: "If nothing opens after a while of codes loading in, then open a browser and type in http://127.0.0.1:18888/. This is a local URL, it runs on the WebUI."
what does it mean?
Did you open the .exe first of all
idk? but i open the mmvcserverSIO like the application the guide told me to open to
People would like some help, I have an iPhone, can I use some aihub panel or sla to change a person's voice to mine using the iPhone?
Yes that's the .exe
Did it open your own browser
Show a screenshot
yea
opera gx
please help me with this
Ai hub panel? Ai hub isn't a program
Are you trying to change your voice in realtime for calls, or just prerecord audios?
prerecord audios
so uh what settings do i pick? cause like idk what the chunk, extra, fo det? like whats the best settings for gtx 1650?
Users reported opera gx giving issues for wokada, also that browsers fancy effects can cause performance issues bc it eats ram, personally we don't suggest it,
We would suggest something like Chrome or Firefox
After u do that, show a screenshot of ur wokada
oh ok ok
Is there a panel or something I can use to upload the original audio and my voice to swap?
thanks
RVC is the program that does speech to speech conversion
I gave you links to do it on cloud since mobiles aren't that much good to running it locally on the hardware
Yw and lmk
I didn't understand very well, I'm using the translator, I've already separated the audio from the background music, and I've already separated my own audio, where would I go to change the voices? I use an iPhone
You should use one of the sites i sent you
a mobile phone isn’t powerful enough to do it locally (running on the phone power’, so you need to use cloud (remote good pc with limited free time)
Hey! Hope you're doing great. I build custom GPT chatbots for business owners — they handle DMs, answer questions, and help customers 24/7 without you lifting a finger.
It’s like having a smart assistant that works nonstop. Want a quick preview?
How does one make an ai rap song with like drake I have the lyrics but idk how it all works
so make your own song with modified lyrics?
How do I turn my audio into a template to use in RVC?
In the context of RVC, the dataset is an audio file containing the voice the model will replicate. It can be either speaking or singing.
hi, what is the easiest method/tool to use to convert an existing voice from an existing audio to another voice?
basically speech to speech
is there a colab or something?
RVC, what’s ur pc gpu
It's RVC.
I remember you talking about this somewhere. You never told me about your PC GPU but implying your PC won't gonna run Applio that well.
guys i got a voice model now how do i use it
What's your PC GPU?
RVC = Retrieval-based-Voice-Conversion, the best Speech To Speech AI Models (on v2), Inferences (use models) pre-recorded audio (ai covers) and train (make) models
Wokada = uses RVC for realtime inference
Do you need Wokada or RVC?
on the voice changer I cant see any output devices
Hello, since I updated Torch for compatibility with RTX 5000 cards I have the feeling that in applio the voice conversion adds an English accent to my voices whereas I did not have this problem before. Anyone else encounter this problem?
torch has nothing to do with it
ok then i think is about settings in the new applio version
use of index brings the accent of the model
french audio + english model + 1.0 index may result in english accent, 0.0 index probably not
ok i will try that thank you
Elaborate
What's your PC GPU
What browser are you using
What tutorial link are you using
What you want to do
There are programs that use the RVC voice model:
!howtoask
my rvc is not working".Which W-Okada version do you use? What is your PC GPU? And have you installed a microphone or virtual line in program?
I expect people to respond at least within a few minutes. If they don't respond for a very long time, they must be busy like crazy. 
whats your gpu and send a screnshot of your voice changer
where can i get the newest version of w-okada? my gpu is 3060 ti

like theres also a tab called advanced settings i dont wanna play with it god knows what will happen
change f0 to rmvpe
disable sup1
enable fp32 in advanced settings
idk if i need to change things there
thanks for the help 🙏
after enabling fp32, restart the voice changer
wokada has a bug that everytime the precision is changed, it'll use more resources for no reason at all
closing and opening the voice changer fixes it
!help

 LunaBot 🌙 is the perfect music bot! Feature rich with high quality music! And Custom Playlist
LunaBot 🌙 is the perfect music bot! Feature rich with high quality music! And Custom Playlist
You can start listening music by just joinning a voice channel and typing: /play [song name or link] (Remove brackets).
We support only Spotify, soundcloud, bandcamp and more!
To view more help on a specific command or category, run
/help <command> or /help <category>
Important Links:
 Support
Support
 Premium
Premium
Invite
Command Categories:
🎶: Music
💰: Premium
⚙️: Utility
📕: Admin
Select A Page From Dropdown Menu Below
No Category:
help Shows this message
Type !help command for more info on a command.
You can also type !help category for more info on a category.
where to find w okada voice changer tutorial?
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
System & Hardware Requirements...
trying to use the new RVC AI Cover Maker by @viscid moss and I've got no idea what's going on with it. separation works fine, but the actual inference fucks up. tried both the precompiled version and doing the install from scratch and it just won't work!! How do I send the traceback? It won't fit in just one discord message lol.
something about a yaml ConstructorError
Local installation is broken, just cloud for now
yo regarding RVC
Im trying to use Applio
and i need to insert the Model link in the public link. How do i get that link if i use google drive?
Where I could share my ai song in AI Hub server?
promos ain't allowed
download the model, extract it on ur pc, upload the model manually in the download tab of the applio colab public link
Hi
I would like to ask for your opinions on which AI platform: GPT, Grok, or DeepSeek would be better suited for tasks such as homework, research, and similar activities. Or any other AI i didnt mention that is better
The one i most use is GPT, but when the daily paid trial of GPT is unavailable, which alternative would you recommend?
can u guys tell me whats settings are the best for the voicechanger. i cant send screenshot my gpu is 4070
and is there a way to lower the delay and make the sound less robotic
tbh i personally prefer gemini 2.5 pro from aistudio.google.com
for a sec i thought this was ai chat lol
!give-media-perms 1h @cinder sable
please send a screenshot
How do i download the voice changer owkada

#🧬│ai-chat message since you got a gtx 1650
i think you want realtime voice changer for calls/games
-realtime
yeah
you need to read the 1st link, wokada deiteris fork (modified version) which has better performance and quality
ayo
where tf is the bot
i got just got that rn
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
System & Hardware Requirements...
have everything open rn
it's this guide
got it
nice
yeah
show a screenshot of ur wokada i can help with settings
damn ur using an old version of original wokada
never use yt tuts for wokada bro
delete that along with vb cable
i didnt know its my first time using this bro
cant send screenshots

nere
don't worry, we are there for help ofc
soo what should i download?
wokada deiteris fork: https://rentry.co/forkvoicechangerguide
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
System & Hardware Requirements...
okay ill be back
what do i needa configure?
uncheck sup1
f0: rmvpe without onnx
extra: 2.0
close useless apps in background
are u using it along games?
yeawh
why is there 2 extras?
wdym?
also its a bit buggy so should i higher the chunk
lmfao my bad brotha, use the 2nd one i said
higher the chunk to a value a bit higher than perf number
also, are you using it with games? if so lower the graphics to the minimum
what chunk u suggest?
u can also lower the extra more which will give u less delay but cost u some quality
there isn't a perfect value, it controls the delay, you just need it like perf value + 60 for example
alright keep it as it is then
you could also try using https://rentry.co/forkvoicechangerguide#reduce-more-delay for less delay (wont affect quality, just isn't a 1 click thingy to do)
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
System & Hardware Requirements...
wdym? can u show ur wokada again and elaborate
are you saying the voice sounds robotic? or another issue
u can try to higher up extra to 2.7 for a bit more quality but it's going to have an higher delay
tbh it would be just better you try another model
not all models are super high quality, there's over thousands
do u have one i can try?
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
System & Hardware Requirements...
I'm using duckus Egirl rn
alright
should i higher the chunk a bit more?
u should do that only if ur perf value is higher than chunk
wym perf value
gpu: rtx 4070
f0: rmvpe without onnx
extra: 2.7
chunk: 128 ms (this is generally, to find ur own best chunk just put the chunk higher than the perf value a bit)
is 50 gonna be alr?

nice, u could also try the link i said before to have less delay if u wanna
are u facing any ther issue or is this solved
can i like make the sound more realistic or its gonna be how it is do i need to try some things out
u can try playing with the pitch or use other modelsd
okay so if the pitch doesnt help i should try other model. no need to change other thing right?
U could try the index too but generally just try a better model
okay ty
can someone share there settings
help
pwease
<@&1159293204038955078>
my shit sounds ass bruu
i need sum sttings
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
System & Hardware Requirements...
i cant hear myself but when i record i can hear the audio
<@&1159293204038955078>
<@&1159293140440723499>
Pls stop pinging roles
mb
but can u help
i cant hear myself
but when i tap th e record button i and finish
i hear the voicechanger
can u send a screenshoot?
how? like can i explain it in a screenshot
am tryna say is
ik the voicehcnager is working but i cant hear myself with it
but when i rec and tap start then stop i can hear the input and output audios and it works perfectly fine
??
on "monitor" u can set an output device to hear yourself
 (have turned off role ping notifications already lmao)
(have turned off role ping notifications already lmao)
you should only ping mods to report any inappropriate behaviors
Also, please don't be down bad pinging mods just for this especially. Not all mods know about W-Okada. 
Don't be hurry, calm down, ssit down and listen.
Ok, let me start this. What is your PC GPU? Which W-Okada version are you using? Because most of the time, the "I can't hear myself" phrase always happens to those who followed tutorial videos on YouTube which only telling you to install the original version of W-Okada and VB-Cable. VB-Cable gives random issues to Windows users.
Some input on this: On the fusing tests (KLM + OG) I did, the resulting models had new strengths and weaknesses
Strengths: much more sensitive to input audio, was "softer" and seemed to generalize better?
Weaknesses: sounded much less like the voice overall
Honestly think vbcable is a skill issue
I know a lot of people have problems with it but I have never seen it
The other cable on the guide is prob better anyway
My favorite is the cable that says TRIAL every 30 seconds
most video tutorials keep recommending it
that's when ppl download through the website (and get jebaited by the trial version) instead of the VAC lite direct download
Have patience, don't ping multiple times
is refine gan available on main branch or codename's fork rn?
any1 have the tensor board latest update link so I can install?
Its included with Applio
This is the latest applio
Applio has Tensorboard built in. If you double click and run this batch file, it will launch its web UI in your browser.

every model apart from the jvs stock one crackles so bad that my voice in inaudible
!howtoask
my rvc is not working".What are you looking for? RVC or W-Okada or the voice model?
i'm using w-okada and im trying to figure out if its a problem with on my side or with the voice models
Which W-Okada version are you using? And what is your PC GPU?
Audio sounding robotic can happen when you didn't set chunk and extra settings right, or it can be the voice model itself.
2.0.76 beta aml rtx 3080
Never use the DirectML version with NVIDIA GPU, especially the original one which is outdated. Download and use the better W-Okada from there instead. https://rentry.co/ForkVoiceChangerGuide#download-nvidia-on-windows
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
If you need HELP, ask in AI HUB Di...
W-Okada DirectML is made for AMD/Intel GPUs. While it is possible to use that variant of the program with NVIDIA GPU, it will give the slightly worse performace than that full NVIDIA-variant W-Okada.
alright thanks
the chunks and extra
Read some more on the guide I sent to you. https://rentry.co/ForkVoiceChangerGuide#for-nvidia-on-windows
Credits:
Shad: made this guide
vtarcelia: corrections
Nick088: contributions & reorganization
Lyery: some other info.
deiteris: most technical information & making the fork version.
wok: making the original wokada
Latest Version b2332 from December 2024
If you need HELP, ask in AI HUB Di...
Hi, any idea why its not working on my PC? These are the logs:
https://mclo.gs/uGnEVRD
Which W-Okada version are you using? And what is your PC GPU?
lemme guess, you followed a youtube tutorial? You seem to be using original wokada
It's crazy. Using the original W-Okada in 2025. 
vcclient_win_cuda_2.0.76-beta.zip, 5070
a
-realtime
Guides for Programs that use RVC Models in Realtime for Calls/Games
Most suggested. GUIDE
ONLY the latest alpha comes close to the Deiteris Fork performance, older versions in youtube tuts are way worse. GUIDE
Unavailable, the guide is outdated and the program is worse compared to the ones above, and much less updated
read the 1st link
the wokada deiteris fork
the original wokada doesnt support the 50 serie
the deiteris fork is more optimized and supports it
I knew it you used the original version of W-Okada lmao. But you also got NVIDIA GeForce RTX 5070.
if you followed yt uts, those are old, uninstsall everything you got off youtube tut wokada
I just remembered that I downloaded it once and looked for it again
it’s better you follow only the written guides
follow the 1st link i sent
those are updated
meanwh ile yt tuts are pretty old
The original version of W-Okada is outdated, and it won't gonna work with RTX 50 series GPUs. Original and Detris' W-Okada are two different versions of W-Okada made by different authors.

Namari spitting straight facts like usual 🔥
namari on 🔥
thanks guys, the best!
let us know for further issues or questions
also a reminder to update drivers and windows version in case of issues
@unreal hamlet btw sorry to disturb but hows the 50 serie experience going? Still having some issues like black screen sometimes or missing rops?
ty
In my experience, it has worked well for me so far, I have not encountered any problems or visual failures, it simply works as it should hehe
did you check if you had any missing rops as well?
some unlucky people had encountered at unfortunately
dont check that :c
if u haven’t checked and want to check https://www.pugetsystems.com/blog/2025/02/26/nvidia-geforce-rtx-50-series-missing-rops-issue/ could be helpful
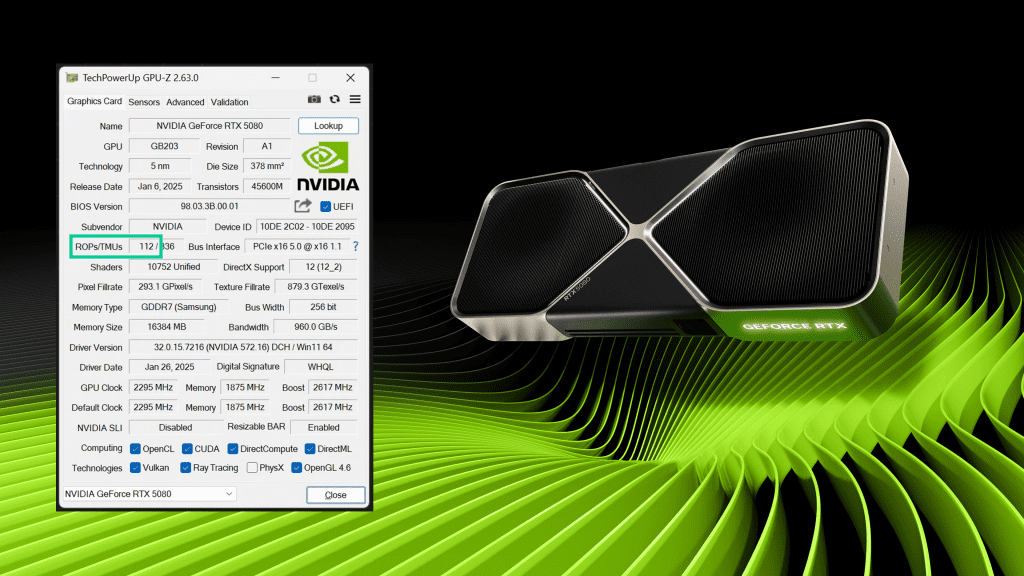
Recently, a small number of NVIDIA GeForce RTX 50-series GPUs have been found to be missing ROPs which can lead to reduced performance. This post outlines how to check your GPU, and what we are doing to address the issue in our workstations.
or idk if u were saying it in a way ur too scared to check bc u know some rops are missing 😭
I think it s okay...
https://gpuz.techpowerup.com/25/04/15/cmr.png
im using a 3080 am i cooked?
yup u are all good dw
what do u want to do?
An rtx 3080 is not bad at all
ive been so confused, ive had a meltdown with chat gpt for the past 4 hours trying to install RVC and I just cant get it to work, it countinuesly gives me errors left and right when I accesed the panel and tried converting my audio, can any1 help?
youtube tutorials are old and chatgpt doesn’t know about rvc well
wha’s your pc gpu and what do you want to do
wanna train own pop smoke voice model, and also convert other acapellas so that it works n all, 4070 super
i suggest applio personally
whatever doesnt bring me life regrets works and whatever doesnt take a whole decade to install
its easy as downloading a zip and extracting it
Sweet, but ive installed a whole bunch of python stuff, should i delete python fully and reinstall or keep it?
python is embedded in the program
you don’t need it system wide
so i can just delete python now ye?
If u want to yeah
aight bet
it’slike u have 2 different pyhtons
one is the one installed system wide
one is inside the program files
do i need any of thisd? cause i needed this when using mangio rvcv
ah cant send images
do i need microsoft build tools? (some c++ program which takes like 10gb sapce)
Mangio rvc is abandoned since 2023 lol
you can delete everything you got off youtube and chatgpt
aight bet
hows it going
Hi there. I have a question and this seems like the right place to ask.
All good currently extracting
what is it?
Is there anyone here who could analyze videos? Or is there like a detection tool for AI?
I recorded a real; raw video but someone is convinced it’s fake/ AI and I’d like to put that to bed.
about ai detectors, i think they are mostly about text, i saw somewhere there are ones for images, but anywaysh you shouldn’t trust much ai detectors
they aren’t accurate and can lead to false positive easily
I can say this after multiple tests i did personally tbh
like all you need is tell the ai a good prompt and the detector would say its 99% made by a human
Also i’m sorry to hear people are accusing your video of that
Ok. Is there anyone here who is good/ semi-professional at analyzing videos?
This video is quite important. It contains evidence that is worth quite a lot of money.
well i don’t think there’s actual professional investigators here, tho you could check the frames of the video and point out some details to the person
I think the best way to prove someone that your video isn’t ai is to show how your video was made, like if it’s an animation show the draw sketches or things like that
I literally recorded the video with an outside phone (so I recorded a conversation on phone A with phone B/2).
I wrote stuff on a piece of paper and had audio noises from the environment to show there were no cuts.
And he still said fake.
wait, is this a case of people accusing a video was made by ai in legal court?
This is not about a court case.
Yo so its extracted right, Just bit scared to mess sm up, where do I drop in my ai voice thingy tht Ive downloaded?
you could also point out that usually ai videos look like a slowmotion and that there is some glitches even in the most advanced tools right now
And that most ai tools can only make short videos
like 10 secs or up to 1 minute in some cases
like i haven’t seen any ai yet being able to make a 5 minute or lomger video
My video is over a minute long; it also shows real-time tweets and I sent out messages to real people during the recording which is seen.
i mean technically everywhere u want, id suggest a dedicated folder ofc
Would I be allowed to show it to you? I’m not really sure whether this chat is the right place for it cause the information is quite sensitive and don’t know who is lurking.
It’s not NSFW.
yo quick question, i go with the deiteris voice-changer instead of the orginal one right?
it’s always better to not share sensitive information over the internet, it’s better to not send it in the server
yup
Would you be ok with a DM?
alr thanks
it shouldn't be affected by those issues on 50-series
I downloaded the model but how do I use it?
Like I downloaded it on the thing
But after refreshing i still dont see em
i figured out how to use it, but after converting and trying to download it syas "file wasnt available on site"
I have a question, I'm not sure if it's here I should ask it. When you download a voice model on weight, there's some model where we can change the language of the voice(example the model in in English but there's a french speaking voice too).
How do you know if it takes into account?
lmk
elaborate and show a ss
they don’t like convert the model, the model just used a french audio sample
Oh I see, well thanks for the answer. Really appreciate it ^^
ehh is this something legal or something personal? I’m not a legal professional lol
you’re welcome
yo anyone know how rizz records make his videos if you do plz dm me ive been trying to figure this out for the past 3 months
I figured it out, now the only thing is that I am trying to install models with only the .pth file, since those are the ones i got but it needs a index file too, possible to bypass somehow?
I have a question for a voice changer kaggle at what point do I run to sell merge the data
You can just not upload the index
Elaborate pls, along with your PC specs, what guide are u using and the issue
Throws an error without the index
use any other index file and set index rate to 0
got no clue where to set index rate to 0
Can you show a screenshot
Or you could screen record u uploading the model then using it
Advanced settings
no, the console window
applio wont infer for some reason

like this ye?

try the 3.2.8 bugfix version if not yet
ye thats what i tried
bro i forgot something can you send me something how to make a model using colab?



















{kind=link}