#✨│ai-help
1 messages · Page 199 of 1
you can discount the "raising" fm
it is not really raising, not with the average numbers like that
Okay. So I think I shouldn't look at FM ?
when the average is mostly flat like that, or slowly creeping up, (+1.0-1.5) it is nothing to worry about
Emm. Lemme send you something

is is good ??
@simple ore
Should I worry about it ?
Other losses are still going down 📉
the fm graph fluctuates a lot, dont worry too much about it
as long the rest are going down you should be fine
for g/total u should look if the graph is not too noisy
and also it should not be too flat

i think it is looking fine ??
Smoothing 0.999
looks fine to me
I'm worried because I want to submit it for model maker role.
how big is your dataset? and which batch size you used for training?
for submissions we aren't too harsh when we review models, we only ask for them to be functional without major problems, no need to be perfect
In future I also want to get model master
Batch size is 6
Dataset length (in minutes) 23
Total trained epochs 449/500
sure! with enough practice you can reach this, finetuning is not that hard, what matters the most is the dataset
best approach to this is not to make it more harder and confusing
keep things simple for finetuning
as long your g/total does not look too noisy or too flat, this setting is fine
it cannot be used in mainline rvc nor Applio public release
as it said it is for experimental purpose
Hi, can someone tell me where to download the freaking GUI and package for the latest rvc inferance? I can't find it
As a noob, can I ask what is fine-tuning
Hello question I have a model that I want to continue training but when I put it and give it start apple I only get that and I can not continue training my model.

!help
Wally Commands
-# The prefix for commands is !
Select a category from the menu down below to view all related commands

 LunaBot 🌙 is the perfect music bot! Feature rich with high quality music! And Custom Playlist
LunaBot 🌙 is the perfect music bot! Feature rich with high quality music! And Custom Playlist
You can start listening music by just joinning a voice channel and typing: /play [song name or link] (Remove brackets).
We support only Spotify, soundcloud, bandcamp and more!
To view more help on a specific command or category, run
/help <command> or /help <category>
Important Links:
 Support
Support
 Premium
Premium
Invite
Command Categories:
🎶: Music
💰: Premium
⚙️: Utility
📕: Admin
Select A Page From Dropdown Menu Below
training with a pretrain = finetuning
in order to train without a pretrain you need more than 44 hours of audio
that is for advanced users/dev, so always train with a pretrain
-guides
📚 Documentation
 AI HUB Docs
AI HUB Docs
✨ More guides
- How to use RVC Mainline Colab by Cauthess
- AICoverGen Colab Guide by Eddy (Spanish Helper)
- Create a model with RVC disconnected (colab) by Angetyde
quick question, is it possible to use the rvcc to change already existing audio? like a youtube video or something? Or does it have to be real-time speaker?
you mean custom pretrain??
yes you can use
using a pretrain in general, the original or custom pretrains
Thanks for the quick response! how would I do that?
rvc can be used locally
-rvc
📚 Documentation
✨ More guides
- How to use RVC Mainline Colab by Cauthess
- AICoverGen Colab Guide by Eddy (Spanish Helper)
- Create a model with RVC disconnected (colab) by Angetyde
also rvc does not stand for realtime voice conversion
RVC is not realtime voice changer. there is different thing for realtime
most of the beginers think it is realtime
w-okada is just rvc inference in realtime
like here?

so i use orignal pretrain. that means im fine tuning?
its wokada not rvc
merci
yup


Documentation for a simple, high-quality voice conversion tool focused on ease of use and performance.
and here a tutorial on how to convert audio files to your model's voice
pretty easy and quick
place your model in the logs folder of applio
awesome! Thanks
@analog obsidian
if you like how it sounds, sure
why there is a little a very little noise in every model. do rvc produce it ??
yes
if the model was trained with noise and the original inference audio has noise, the model will generalize to it
normal behavior
is it possible to remove that noise
how bad is the noise
i normally use UVR to process my data and i use best modles for isolating the vocals
if the model was trained without noise you can actually use the index file to remove some of the noise
but if the model was trained with noise, nothing that you can do
can i send you a sample ??
denoise the output
noisy models will add noise to the inference output it despite the input being denoised
lemme send a sample from dataset and an output
u can try it by converting the og pretrain to a small .pth file and inference a clean audio
the result will have noise regardless if the input audio is denoised
please stay here ill be back in a minute
yeah its normal
oki
having a bit of noise is not problematic anyways @latent kettle
a model being able to clone noise is good when inferencing noisy audio
too clean might cause the model to add weird sounds instead of noise
too much shit going on with this model
u made this model?
to isolate vocals
yes 😭
u gotta retrain
maybe..
u using the wrong models to clean ur vox
guide said.. thats why i used it
-audio
Suggestions for @latent kettle
📚 Audio Guides & Tools
- Creating Datasets for RVC using iZotope RX11, by Cauthess
- Gathering and Isolating Audio, by SCRFilms ❄
- Instrumental and vocal & stems separation & mastering guide, by deton24
- Vocal Mixing Tutorial, by Roomie
- https://mvsep.com/
More commands: -colab, -uvr, -karafan, -overtrain, /help
u most likely followed an outdated guide
yup has noise
is it possible to remove it ??
if the model was trained with noise, no
should i send a sample of my dataset ??
@latent kettle why are u training on 48khz
nono don't send dataset samples here
only model output
and again don't be too afraid of noise, is not really a bad thing
i trained on 32Khz
i dont think u did
only one sample 15 sec.
im sure with it
the output u sent isnt 32khz
use spek instead, move your sample to spek and show the spectogram
😭
okay
i don't see noise
rvc converts it to 32k dw
as long he selects 32k training}
for inference if you use applio you have to enable this option


im sure i selected 32Khz and im using Applio
if the slicer and add effects options are enabled, applio will convert it to 32k
so is fine
that seems not fine
ya i did it
whats wrong with it
i used songs and then i put itto UVR 5 and selected FLAC
i used FLAC For Traning
This is FLAC
you sent an mp3 file
but is your actual dataset in .flac?
yes..
converting a mp3 to flac is not gonna remove the compression
hmm, as long your dataset was always .flac and never were .mp3 converted to .flac everything should be fine
training on compressed audio just makes the model a bit lower quality
the source is still mp3 anyway, a pig with lipstick will be still a pig
should not cause more problems besides this but im not 100% sure
so basically from starting. i downloaded an audio from an XYZ website in MP3 320kbps and then i processed it into UVR and it gaved me FLAC. and then I put That FLAC into FL Studio And Just Cut bad Sounding Portions. After That i Export in In FLAC
ok thats bad
what u did, you compressed the audio heavily (.mp3) then convert it the same heavily compressed audio to .flac
you did not increased the quality doing that
the same compression is in the flac
idk what to do.. i thought FLAC is Good. Because It Is LossLess 😭
its good but you didn't downloaded a .flac, you downloaded an mp3 file then converted it to flac 
how do i download FLAC?
for yt videos use yt-dlp.exe or cobalt tools
cobalt tools dont have FLAC maybe. but it have WAV
you don't need neither of them from youtube
you need .opus
is it good ?
less compressed audio yeah
after that you convert the .opus to .wav
wav is good or not ?
and now you have an audio that is not heavily compressed
comes with a bit more compression than .opus
thats how youtube works

choose best audio quality
this downloads .opus or .webm
then you convert it to .wav
okay. now what about noise ?
noise is not a problem unless is very loud
i also use De-EchoReverb to process my dataset
again it's just a lipstick for the pig
why there is noise in every model which i train 😭
select split audio in applio

in inference
and also you can clean your inference audios, removing the noise from them
okay but my qustion is how do i improve my dataset
why are you so scared of noise
that doesnt damage the model
the original pretrain was trained with very noisy audio
1 mistake>: i have used compressed audio. 2nd ? how do i process my dataset
he said i have to retrain
separation models also adds noise to the outputs (yea a bit ironic i know)
but again is not a bad thing 😭
okay so my model is good to get Moddel Maker role 🥺
how to make w okada work on whjatsapp
maybe by using virtual cable and using whatsapp web
but on settings u cnat change mic
you can't use w-okada on whatsapp
sad
sure! try submitting it
believe me, reviews are not harsh on new model makers
then idk sorry. maybe you can't
~~but you can use chatgpt on whatsapp https://www.techspot.com/news/106040-beyond-smartphones-chatgpt-now-available-landlines-whatsapp.html~~
😭
lmao
potentially the worst de echo model out there
can soemone gimme a realistic girl voice model for trolling 😭
which one do you use ?
#🔍│help-w-okada
use this channel for w-okada things
just use the normal de echo
this channel is for rvc, not w-okada
i to bored to switch
there are realistic girl models for trolling there 🙂
get yo ass outta here
alralr
i use Vr Arch UVR-DeEco-Dereverb
is it normal ?
you're not supposed to use deecho-dereverb
you are supposed to first use dereverb
then de-echo
use UVR-De-Echo-Normal

uvr-deEcho not deecho-dereverb
WHAT RVC USES https://www.youtube.com/channel/UCPlDFENHg4_HX8alladwHhg
depends on who you get Evilplans

😭
mantrax
getting a:
RuntimeError: cuDNN error: CUDNN_STATUS_NOT_SUPPORTED. This error may appear if you passed in a non-contiguous input.
Can anyone help?
Hey, gringochileno! Please use the command !howtoask to increase your chance of getting help by structuring your question in a way others can understand better. Also make sure you're asking in the right help channel:
- General RVC help: #✨│ai-help
- W-Okada / Realtime RVC: #🔍│help-w-okada
- AI image related: #🔍│help-ai-art
amd gpu?
I don't know, sorry 😭

check?
also what should i use to isolate voclas
bs roformer

MVSEP performs separation of audio into vocal and instrumental parts, extracts text from audio and it is free. Uses Artificial Intelligence.
here
is it avaiable on uvr ?
i dont think it has the newer version
i want to use it locally

i have a decent GPU
tldr; mel roformer kim bas curtiz
never use dat bs
big beta 5e is more clear but adds too much noise 😭
even worse than Apollo/Lew enhancer
worst case sceneario he should use the compressed audio
for isolation ?

is it on UVR 5
bas curtiz no
but mel roformer sdr is lower than bs roformer
i dont want to use any web
bs roformer has muddy vocals and no one uses it anymore in the audio separation discord
is there any local alternative?
i personally use mel for my models

i acc never used melr 😭
is more clear 
no colab. the actual problem in uploading and downloading speed with limited internet. i dont have a wifi at home
i repeat: rvc already upscales your audio
we get dat u got a powerful ass gpu bro js use mvsep
but
yup, hold on
Intel (R) UHD Graphics
u cant do shit with dat sadly
https://github.com/ZFTurbo/Music-Source-Separation-Training/ https://www.youtube.com/watch?v=M8JKFeN7HfU
GitHub
Repository for training models for music source separation. - ZFTurbo/Music-Source-Separation-Training
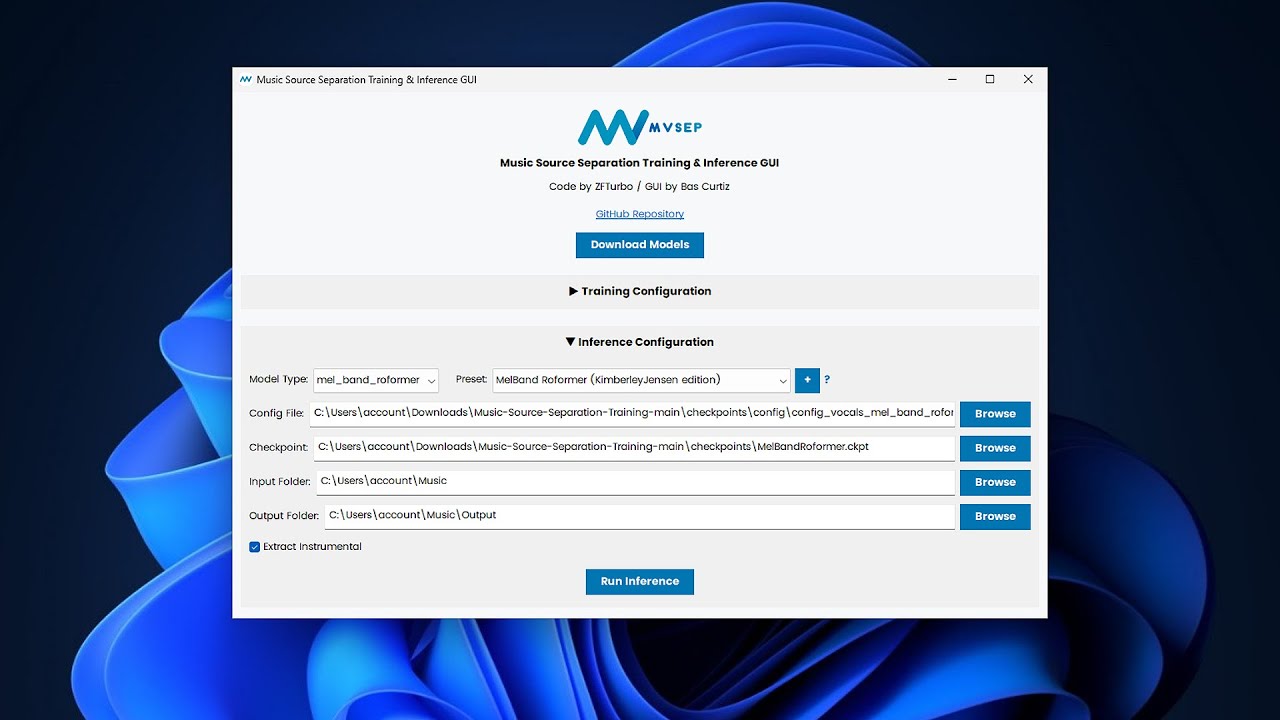
How to install & inference with ZFTurbo's Music Source Separation script (incl. GUI)
0:00 1. Install Python: https://www.python.org/ftp/python/3.11.6/python-3.11.6-amd64.exe
0:22 2. Install Microsoft Visual C++ 2015-2022 (x64): https://aka.ms/vs/17/release/vc_redist.x64.exe
0:38 3. Install Microsoft C++ Build Tools: https://visualstudio.microso...
sorry i don't know if its possible to inference in integrated gpus
ive used it and it sounds fine

Congratulations Razer by Weights!
Your Grotle is now level 29!

note that if the dataset has lower cutoff than the target sample rate, the model will learn those missing frequencies instead of actually "upscaling" it
im actually using it for my models now, i dont mind the noise, because again noise does not damage models, guys
which version should i use
im actually making my first singing model with it
unwa's big beta 5e
yes its been a year and i havent made a singing model
is the more clear, legit sounds like an actual raw sample sometimes and you forget its isolated lol
fr
noted.
can you please DM Me All stuff ?
sure! give it a try, keep in mind big beta 5e is noisy!
what about a NVIDIA GEForce GTX 1050 with Max-Q?
i don't know if that can run cuda applications (applio)
sorry
all good
if it can run cuda applications it can do inference
u think ver 2024.10 would perform better?
can you DM Me All ??
no, watch the tutorial
has less noise than big beta5e but not as clear like it
i will watch just DM the links and names of models and other things
but more clear than bs roformer at least
fine for inference, but not for training
i'm worrid i even don't no how to make a good dataset 😫 how will i get model master
💔
please help me
this is your first time making a model, relax
and i wasted my 3hrs btw
i waste more hours because my datasets are all 1 hour long or more
its normal
do i stop using UVR
use the script i sent you
follow the tutorial
or
i can send you an more updated version of uvr
i think i should start use mel de reverb too

which one tho
Ultimate Vocal Remover v5.6.0 i have this version currntly
Server Avatar

No
idk, maybe try sucial v2 dereverb
Hi, I’m trying to train an AI voice model but ran into this error:
C:\ia nvidia\RVC1006Nvidia/logs/testtest
load model(s) from assets/hubert/hubert_base.pt
move model to cuda
no-feature-todo
Any idea what’s causing it?
anvuew v2 is better
thanks i have no idea about de-reverb models 😭
I didn't see the improvement over v1
noted, im going to remember this in case i need a dereverb
anyway both Sucial's and anvuew's are for stereo reverb
First is sucial V2 second is anvuew V2


sucial leaves some reverb in ( not much )
cant really hear a difference tho
so

I used anvuew mel dereverb
Hi guys, I have a question regarding dataset.
Let's say I have singer. They have 1 song that I want to make cover off, which would be the same song, with the same singer, but with different lyrics. Is there any point in training model on the other singer's songs, if model would be used for this one only particular song?
if it's " 1 time use " model, for that one given song you use in your dataset, no, no point.
In this scenario, generalization to unseen data ( aka. Model's capability to adapt to songs / content it wasn't exposed to throughout the training ) losses the meaning
pretty much
What if it's the same scenario, but the whole album?
Hmmm.. yea, same rule applies
If you intend to use the model on the data it was exposed to ( Again, during training), having it " full of variety " ( the dataset ) kind of losses the meaning
But wouldn't it still needed to learn variety to adapt to changed lyrics?
Oh yea, if you mention changed lyrics, in that case you want the dataset to contain ( more or less ) phonetics and / or pitch variations of a given phonetic / word
But it isn't 100% a strict rule
All comes down really to how well you model generalizes ( It's ability to adapt to stuff it did not see during training )
And generalization is a matter of: Good training, properly picked batch_size ( smaller promotes better generalization, typically ) and naturally, dataset's diversity
But let's not make it any huge or extreme deal really
As always, thank you
Glad to help
yo i need help with setting up the voice changer to work in discord, the output virtual cable is in input and the input virtual cable is in output how do i fix it help
i put my chunk at 640 but its still like 3 seconds delayed how do we fix it
#🔍│help-w-okada is for voice changers
Both of you
hello I'm trying to set up a two PC RVC, i followed this guide https://rentry.co/VoiceChangerGuide#opening-on-multi-pc-setups but for some reason the IPs only loads in the PC with RVC installed and not the secondary PC where i want to connect at, anyone can help?
That's Wokada not RVC
Wokada is the program to use RVC (Retrieval-based-Voice-Conversion, Speech To Speech) Models in realtime for calls
There's the fork (modified version), the deiteris fork which has better performance
Wrong help channel, use #🔍│help-w-okada
my bad
Dw
what is this for?
cache_all_training_sets
cache training data on GPU, provided small performance improvement, as long the as the dataset is not too big to fit into vram
@unique rock
anyone on rn
does not even mention its an error
just says this
2024-12-20 21:56:06 | INFO | fairseq.tasks.hubert_pretraining | HubertPretrainingTask Config {'_name': 'hubert_pretraining', 'data': 'metadata', 'fine_tuning': False, 'labels': ['km'], 'label_dir': 'label', 'label_rate': 50.0, 'sample_rate': 16000, 'normalize': False, 'enable_padding': False, 'max_keep_size': None, 'max_sample_size': 250000, 'min_sample_size': 32000, 'single_target': False, 'random_crop': True, 'pad_audio': False}
2024-12-20 21:56:06 | INFO | fairseq.models.hubert.hubert | HubertModel Config: {'_name': 'hubert', 'label_rate': 50.0, 'extractor_mode': default, 'encoder_layers': 12, 'encoder_embed_dim': 768, 'encoder_ffn_embed_dim': 3072, 'encoder_attention_heads': 12, 'activation_fn': gelu, 'layer_type': transformer, 'dropout': 0.1, 'attention_dropout': 0.1, 'activation_dropout': 0.0, 'encoder_layerdrop': 0.05, 'dropout_input': 0.1, 'dropout_features': 0.1, 'final_dim': 256, 'untie_final_proj': True, 'layer_norm_first': False, 'conv_feature_layers': '[(512,10,5)] + [(512,3,2)] * 4 + [(512,2,2)] * 2', 'conv_bias': False, 'logit_temp': 0.1, 'target_glu': False, 'feature_grad_mult': 0.1, 'mask_length': 10, 'mask_prob': 0.8, 'mask_selection': static, 'mask_other': 0.0, 'no_mask_overlap': False, 'mask_min_space': 1, 'mask_channel_length': 10, 'mask_channel_prob': 0.0, 'mask_channel_selection': static, 'mask_channel_other': 0.0, 'no_mask_channel_overlap': False, 'mask_channel_min_space': 1, 'conv_pos': 128, 'conv_pos_groups': 16, 'latent_temp': [2.0, 0.5, 0.999995], 'skip_masked': False, 'skip_nomask': False, 'checkpoint_activations': False, 'required_seq_len_multiple': 2, 'depthwise_conv_kernel_size': 31, 'attn_type': '', 'pos_enc_type': 'abs', 'fp16': False}
2024-12-20 21:56:10 | INFO | infer.modules.vc.pipeline | Loading rmvpe model,assets/rmvpe/rmvpe.pt
then at 5.3 secs the gradio thing says error
@craggy wyvern this is the right channel to ask your question
the answer is - depends on what you're trying to install. Likely some outdated build.

A batch file for launching up webui went missing from this most recent OG RVC GUI, but instead got this batch file for launching up the "realtime" RVC pre-installed. Of course, I don't think it gonna work well.

Wrong channel, use #🔍│help-w-okada
The first time I clicked and run this batch file back in 2023, I was like surprised by how this GUI looked. Then later I found out it wasn't meant for "audio conversion" thing, but rather the "realtime" one. 

I'm surprised by how people still think RVC has another realtime program. Could it be this thing? 
well, this is the " in-built rvc's real-time voice changer " I always mention
not sure if there's any other tho
Hey, muhamet! Please use the command !howtoask to increase your chance of getting help by structuring your question in a way others can understand better. Also make sure you're asking in the right help channel:
- General RVC help: #✨│ai-help
- W-Okada / Realtime RVC: #🔍│help-w-okada
- AI image related: #🔍│help-ai-art
im using local applio and it says v2 extracted file is not found
anyone know what i am doing wrong
nah i found it i just didnt press this button how silly lol

anyone know fix
at 5.3 sec it says eroor
3070ti 13700k btw
you on rn?
ye
what's up then
do you know a solution for this
no error in the logs
just that its loading rvmpe
Well, 2 things
alr
- You should provide logs using " > ", like so:
asdfghjkl
and 2... what release / fork you use? ( of rvc / applio )
This is by far the most important part / info you didn't provide I believe
sorry ill do that again
Actually nah
i installed it yesterday
Just tell me what release you use
where does it come from
applio github? or official rvc one
Yea, tbf, instead of trying to debug og rvc which can at times be problematic or headaching
I'd actually go for Applio
It's fine
ty
Applio is easier to run and generally to get running
does it have the same quality
More or less yes, it's with everything that's based off of rvc really
oh
do u have the link
wanna make sure i download the right one
or the user who made it
will do
You're a newbie right?
yes
If so, I recommend this one
https://github.com/codename0og/codename-rvc-fork-3/archive/refs/heads/main.zip
Has some nicer descriptions / easier to get descriptions I added
alr
overall, you'll run 2 things
pip install and run app
1st goes the install .bat and then run .bat files
oh
just, simply run it with no " run as admin " or whatsoever
ok
In any case, read the repository's description, if you had some troubles
https://github.com/codename0og/codename-rvc-fork-3/blob/main/README.md

GitHub
Codename's rvc fork version 3, based on Applio. . Contribute to codename0og/codename-rvc-fork-3 development by creating an account on GitHub.
ok tysm
yw man
( ps. Make sure to unpack the fork folder / the folder from archive to C drive / os drive directly, if you can afford some space on your drive )

Like so
i got 2tb im alg
Neat, in that case best of luck~
logs folder and in there, per-model folder
ok
This is also the case when you train a model, .pth models appear in there ( index too )
ty
thats not for me lol
but ty
yea just saying in case

so creare folder
per-model as in, each model ( pth and index ) gets a folder
OHHH
per is like " for "
so should i make one with the pth and index
Yea, applio searches up for models in logs location
oh i didnt grab that in context ;p;
One message removed from a suspended account.
could u retry?
i just tried myself and the bot works #🤖│bots message
One message removed from a suspended account.


Congratulations kar@shin padoru 🎄!
Your Dewott is now level 34!
New move!
Your Dewott can now learn Aqua Jet!
That is not rvc tho ( I mean yea, but weights manages it
Soo where should i ask for help
So like, if yt dls are disabled
you gotta dl the vocals on your own
Not sure how weights manages it tho
Whether they isolate ( the vocals ) or not
Well.. You'd have to dl the vocals / song, if it's a song then isolate / separete the vocals using mvsep or uvr and only then, upload the vocals to weights
There is no option to upload
Idk then man
they say to upload it in afterall

I ain't associated with weights nor I use their services so, I possibly couldn't know how it's done in there
Ohh alright
Alternatively, screenshot the whole ui
But thanks for helping
and show me how it looks
Its fine
alr then
can i use a voice model with only pth file
yes, in rvc context, the pth is the actual voice, the added index is the accent
may not sound the best though
alr
Does anyone have experience getting "sh", "ch" and "sch" sounds to be pronounced properly? like in the German "Ich"
Everything I try, every model completely fails at those sounds even if they exist in the dataset
Unfortunately its pretty important since we use them for music but I just can't find any solution
How long is your dataset?
about 15-20 minutes of talking and singing on average
if possible you could try making it longer
nvm the main model I'm looking at is trained on 32 minutes of talking and singing
mostly singing, I'd think thats way more than enough, especially considering the models are completely unable to pronounce "Ich" like its not even really close
they always turn it into "isch" if they pronounce it at all
so it has "ich" in the dataset and in the inference audio?
yes
it seems a bit like most of the time rvc even thinks that the ch is supposed to be breath noise and supresses it entirely
how noisy is your set? little bit is fine but if its loud enough it could make a difference
No noise, studio environment
not sure if you can pronounce the german ch but do you think you could find a clip were its being pronounced correctly? I can try making one showcasing the issue
welp, you can blame vctk for not having any german in it making that "ich" suck
whats vctk?
ah I see, yea I was worrying that this might be the issue
I've tested some other pretrained models but they seemed mostly terrible
so I didn't even keep those models
if you want you can grab several hours of german speech and make a small little finetuned pretrain for german
and hope it makes it better
original pretrain was trained in english only
Anything specific I have to do for that? Like maybe I have to somehow reduce the learning rate or something?
nope
just train it like a normal model
And do you mean using the pretrained models and finetuning it into a better one or make a new model from scratch
I do kinda hope that this is the issue now, else I will put a bunch of time into that without fixing it xD
I will try some other pretrained models first, this one could be interesting

sorry a bug scared the life out of me, but yeah make a pretrain using a pretrain
And you are dead sure that those kind of noises are results of bad pretraining? Because I feel like even english noises like "shark" are kinda struggling with the sh
dont use rigel
Congratulations Razer by Weights!
Your Grotle is now level 31!
it sucks
welp damn, now where am I gonna find hours of german. It probably has to contain male and female voices right? Since I will need both
you done need both but it will be better with both
Okay I will try around with that a bit, thanks
Oh another question, do I have to fear overtraining when creating a pretrained model? And a general idea of how many epochs I will need for multiple hours of data? I assume it will take quite a while even for 50-100
its the same as training a model, so overtraining is bad and there is no certain amount of epochs
okay thats much easier than I assumed then, good to know

Hey guys, is there anything written about audacity dataset cutting settings? I'm looking for it for people using RVC Mainline or RVC Disconnected (that's me!), but my inexperienced searching skills have yet to find it...
I'm using machine translation. Sorry if it's hard to understand!
i just had a question, to make songs with ai, like to rap as different things, what is recommended? like settings and everything. im new to this so please be patient with me!
ideally you want an evenly cut audio, some overlap between segments
3-5 seconds, no more than that and overlap 0.3-0.5s
Thank you for your help, I will try that.
I'm having issues it's just not comign through anything I can hear it on the client thats it
https://i.imgur.com/EJEuzG3.png
https://www.youtube.com/watch?v=IS_SPQVv5iY Was watching this
Think I fixed it
-colab
📒 Google Colab Notebooks
- Applio, by IA Hispano Google Colab
- RVC Disconnected, by Kit Lemonfoot Google Colab
- RVC Mainline, by Hina Google Colab
- AICoverGen-WebUI, by Hina Google Colab
- AICoverGen-NoWebUI [English], by Ardha, fixed by Eddy, Hina and Gdr Google Colab
- AICoverGen-NoWebUI [Spanish], by Eddy, Hina and Gdr Google Colab
- UVR5 NO UI, by Eddy Google Colab
- UVR5 UI, by Eddy Google Colab
- Modified W-Okada's Voice Changer, Google Colab
- 🆕 FaceFusion UI, by Nick088 Google Colab
- 🆕 FaceFusion NO UI, by Nick088 Google Colab
- 🆕 EasyGUI, by Rejekts Google Colab
ℹ️ Note
While the Colab free plan provides up to 12 hours of daily usage, the GPU is typically available for only about 4 hours each day on average.
More commands: -audio, -hf, -local, -kaggle, -realtime, -rvc, /help
Tutorial videos on YouTube are outdated. 
also they could have video editing magic, so it'd look too good but not in reality
YouTube tutorials are SEVERLY OUTDATED, do NOT use them
Go to #🔍│help-w-okada and tell ur PC GPU
This is the wrong channel, and you're using old software
You want to make ai covers? What's ur PC GPU
Can someone explain to me the Tensorboard graphs? Following the Applio guide I only learned to see the total loss g, but they say that I should not only take into account that graph but also more.
Last update: Dec 12, 2024
There's a more advanced guide here
For rvc-gui I create a voice model for Ai Cover. When I use the voice model I create in any song, whether male or female, no matter if I make the pitch negative or positive, the voice I use in the song is not the same as the voice model I created in the song. Why?
GitHub
Just a fork of RVC for easy audio file voice conversion locally - Tiger14n/RVC-GUI
Do u mean this one
It's super OUTDATED
What's ur PC GPU
There's a better program for realtime voice changer
-gui
@simple walrus You looking for ai covers or realtime voice changer?
@low shard I want to use my own voice in the rvc-gui but when I use it the voice does not change to my own voice in the song
Can you tell me which is the best pre-train?
don't use rvc gui, it's outdated
sooo, just do ai covers
or realtime voice changer for calls?
RVC is the audio conversion program, while W-Okada is the realtime voice conversion program that uses RVC voice model.
^^^
@low shard There is no alternative program can you recommend me an ai cover program where I can install on pc without connecting to websites
The "RVC-GUI" can refer to the OG RVC GUI program, which has been long outdated.
-rvc
📚 Documentation
✨ More guides
- How to use RVC Mainline Colab by Cauthess
- AICoverGen Colab Guide by Eddy (Spanish Helper)
- Create a model with RVC disconnected (colab) by Angetyde
when you say RVC-GUI, do you meanhttps://github.com/Tiger14n/RVC-GUI/blob/main/README.md
GitHub
Just a fork of RVC for easy audio file voice conversion locally - Tiger14n/RVC-GUI
if so, that's OUTDATED, DON'T FOLLOW YT TUTS
Tell me your pc gpu
You still didn't answer us about what GPU your PC has.
Applio is a recently developed fork program of RVC GUI, one of the only RVC forks AI Hub by Weights recommended.
My notebook cpu is Intel® HD Graphics 500
Is it only GPU 0? If so, that's mean your laptop doesn't have a dedicated GPU.
that's not a cpu, that's integrated GPU, it's really bad and slow
The program won't even run on integrated gpu, it will run on your cpu
making it very very slow
It's suggested to use Cloud, your CPU is SLOW
You can:
- Locally (runs on your pc so the speed depends on that, you will have to set it up with the guides):
- Cloud (remote good pc, easier and faster than ur PC but it's limited):
- Ilaria RVC Zero: fastest and simplest that you can get for free
- Weights.gg: Partnered with AI Hub, lets u do them easily but u may be in a queue
- Applio Colab: max 4 hours, not granted, of GPU
Easiest possible (automatically separates vocals & instrumentals) : weights.gg
easiest cloud: Ilaria rvc zero
easiest local: Applio
if you really want to do it on cpu slow, you can locally via applio

Congratulations Nick088 [ITA/ENG] by Weights!
Your Charizard is now level 76!
but It's NOT suggested
Applio I used it but it is a bit complicated it connects to website is confusing
Thxx for Suggestions I will try
Applio doesn't connect to the "internet", it hosts locally on your PC localhost port. Unless you set Gradio to share to around the world.
yeah that too
runs without an internet connection but requires a network
all RVC GUIs will be web-based. Unless someone wants to cobble together a modern RVC-GUI
it actually does connect to the internet
they use Edge TTS API
but once you download the pretrains and stuff you can infer no internet right
no tts
An internet connection is needed to download voice model online. 
You probably used the Google colab, ofc that one does
The local applio doesn't unless you do TTS
There are different versions of the same program, cloud and local
-colab
📒 Google Colab Notebooks
- Applio, by IA Hispano Google Colab
- RVC Disconnected, by Kit Lemonfoot Google Colab
- RVC Mainline, by Hina Google Colab
- AICoverGen-WebUI, by Hina Google Colab
- AICoverGen-NoWebUI [English], by Ardha, fixed by Eddy, Hina and Gdr Google Colab
- AICoverGen-NoWebUI [Spanish], by Eddy, Hina and Gdr Google Colab
- UVR5 NO UI, by Eddy Google Colab
- UVR5 UI, by Eddy Google Colab
- Modified W-Okada's Voice Changer, Google Colab
- 🆕 FaceFusion UI, by Nick088 Google Colab
- 🆕 FaceFusion NO UI, by Nick088 Google Colab
- 🆕 EasyGUI, by Rejekts Google Colab
ℹ️ Note
While the Colab free plan provides up to 12 hours of daily usage, the GPU is typically available for only about 4 hours each day on average.
More commands: -audio, -hf, -local, -kaggle, -realtime, -rvc, /help
If you really need it offline, you can install Applio locally but will be extremely slow
Else I'd suggest to use weights.gg which is on cloud
Google Colab is a cloud service.
you did not read the advanced section?
just did it
hi, I have a question, I can only switch between GPU0, CPU, GPU1, GPU2 and GPU3 in the voice changer and my voice changer is also lagging a lot. can someone help me?
Hey, Jan.! Please use the command !howtoask to increase your chance of getting help by structuring your question in a way others can understand better. Also make sure you're asking in the right help channel:
- General RVC help: #✨│ai-help
- W-Okada / Realtime RVC: #🔍│help-w-okada
- AI image related: #🔍│help-ai-art
For W-Okada, go to #🔍│help-w-okada. #✨│ai-help is about RVC the audio conversion.
my voice changer is capturing my pc voice too and its eco what do i need to do
For W-Okada, go to #🔍│help-w-okada.
what?
Please read my earlier message above.
There's no way your PC has four GPUs at once. Unless you've downloaded the old OG W-Okada, which can be tricky to cause its GUI to show more GPU than one, and each GPU could all be picking up CPU.
you're using the wrong channel, RVC is NOT Wokada, use #🔍│help-w-okada
I have a question I wanna make ai covers but someone told me to use rvc is it only pc or is it on mobile too?
It's technically for both
What's ur pc gpu?
I have hp laptop but my mom uses it for work so I use mobile
And what's a GPU im very dumb in this kind of things lol
GPU = Graphics Processing Unit
The component used for every heavy task
yea laptops aren't good either for that
It is possible to run RVC entirely on smartphone, but it won't be as fast as desktop.
Ohh
It's fine I only wanted to make lads ai covers
But I don't know the website lol
There's a lot of website idk what to choose
Weights.gg is a website that can do AI cover for free.
Ohh I use that but idk some part of the song breaks but it's good ig
Maybe it depends on the song lol
that depends on the model and song
you can't do much about it
Weights.gg uses RVC but in a easier way for users
Other sites use RVC too, but they make you pay for it
bro is marketing weights.gg
Weights.gg doesn't make u pay 70 dollars monthly like kits.ai atleast

-colab
📒 Google Colab Notebooks
- Applio, by IA Hispano Google Colab
- RVC Disconnected, by Kit Lemonfoot Google Colab
- RVC Mainline, by Hina Google Colab
- AICoverGen-WebUI, by Hina Google Colab
- AICoverGen-NoWebUI [English], by Ardha, fixed by Eddy, Hina and Gdr Google Colab
- AICoverGen-NoWebUI [Spanish], by Eddy, Hina and Gdr Google Colab
- UVR5 NO UI, by Eddy Google Colab
- UVR5 UI, by Eddy Google Colab
- Modified W-Okada's Voice Changer, Google Colab
- 🆕 FaceFusion UI, by Nick088 Google Colab
- 🆕 FaceFusion NO UI, by Nick088 Google Colab
- 🆕 EasyGUI, by Rejekts Google Colab
ℹ️ Note
While the Colab free plan provides up to 12 hours of daily usage, the GPU is typically available for only about 4 hours each day on average.
More commands: -audio, -hf, -local, -kaggle, -realtime, -rvc, /help
hi, i downloaded the ngrok file, but cannot open it, can u help me?
cannot find or open /Users/batokaraevzafarbek/Downloads/ngrok-v3-stable-darwin-arm64.zip, /Users/batokaraevzafarbek/Downloads/ngrok-v3-stable-darwin-arm64.zip.zip or /Users/batokaraevzafarbek/Downloads/ngrok-v3-stable-darwin-arm64.zip.ZIP.
i tried through collab, but there is a 403
по русски можно
-rules
rules
@acoustic scarab

speak english here, or use the channel that @acoustic scarab said
what are you trying to do?
so i was trying to set up through the collab
and firstly i was getting 403 errors so i tried using ngrok
and getting erroro there too
yes, please show screenshot and elaborate more on #🔍│help-w-okada , also tell me what colab & tutorial you're using (send the link)
you shouldn't download ngrok,that gets downloaded on google colab not ur pc
Hello there, I have a question, I would like to try and make an RVC model based on sherry birkin from RE 2 remake, but I have only maybe 2-3 minutes of dialogue from her that is usable, is that enough to work with or is it just not going to work ?
Hewwo! I was wondering if anyone can help me to get my voice onto discord and games?
just struggling a lil, got the virtual audio cable installed etc, just dunno how to do it
Wrong channel, use #🔍│help-w-okada
RVC ≠ Wokada
!help
Wally Commands
-# The prefix for commands is !
Select a category from the menu down below to view all related commands
Available Commands
!ping - Check bot latency
!help - Show all commands
!status - Show bot status
Where is the link for actual rvc?
!help
Wally Commands
-# The prefix for commands is !
Select a category from the menu down below to view all related commands
I'm tryna find the link for this version of rvc

This is the realtime .py for RVC, which can be found inside the folder of the most recent original RVC GUI. However, the OG RVC GUI has been long outdated, and the realtime RVC won't be working as well as the fork W-Okada.

I'm not sure why you're looking for this specific RVC version when there's a recently developed real-time voice conversion program available, which it works better than that.
If you're looking for the best real-time program out there, let me know at #🔍│help-w-okada.
- colab
📒 Google Colab Notebooks
- Applio, by IA Hispano Google Colab
- RVC Disconnected, by Kit Lemonfoot Google Colab
- RVC Mainline, by Hina Google Colab
- AICoverGen-WebUI, by Hina Google Colab
- AICoverGen-NoWebUI [English], by Ardha, fixed by Eddy, Hina and Gdr Google Colab
- AICoverGen-NoWebUI [Spanish], by Eddy, Hina and Gdr Google Colab
- UVR5 NO UI, by Eddy Google Colab
- UVR5 UI, by Eddy Google Colab
- Modified W-Okada's Voice Changer, Google Colab
- 🆕 FaceFusion UI, by Nick088 Google Colab
- 🆕 FaceFusion NO UI, by Nick088 Google Colab
- 🆕 EasyGUI, by Rejekts Google Colab
ℹ️ Note
While the Colab free plan provides up to 12 hours of daily usage, the GPU is typically available for only about 4 hours each day on average.
More commands: -audio, -hf, -local, -kaggle, -realtime, -rvc, /help
!howtoask
How To Troubleshoot 
__**GIVE CONTEXT.**__ 📝
- Don't simply mention your issue, like "
my rvc is not working". - Describe the step you are on, what you're trying to do, the RVC you're using, a screenshot, etc.
- The more context, the better.
__**BE POLITE.**__ <:matsuripray:1159685390156967936>
- Don't be desperate. You can ping a Helper, but if they ignore, they aren't available/don't know the answer.
- It's okay if you're frustrated, but don't take it into this server.
- Don't DM without prior consent.
__**BE PRODUCTIVE.**__ 🤝
- Don't ask for every little instruction. Put your own effort & test things by yourself.
- Don't ask to ask.
- Check if your answer is a Google search away/on our guides website.
If you've changed your mind about your message, feel free to delete/edit it.
what is the best download for amd :(
this one is very old and sucks, check the fork i was saying in #🔍│help-w-okada
for what
to be honest I don't know, because i thought okada was rvc but i think rvc is okada
😭
what do u want to do
wdym u don't know
yea u can just say that dw
let's go to -> #🔍│help-w-okada
ok ty
my audio is around 3 minutes long and its separated into like 10 shorter audios, is THIS normal?

Also my epochs are 250 and save time 30
rmvpe_gpu, no other settings touched
rtx 2060 S
its been around 20 minutes, no changes/updates in the console as well
Are you training a model? Show me the console screen
Nvm its solved, I just had to uninstall Python

btw if u tryna download a model for wokada, u can just continue in #🔍│help-w-okada
link me the discord post where u got that model
Dunno how
Also I thought it was related since rvc thingy
yea but u using it for wokada, so maybe let's go to #🔍│help-w-okada


Is the applio-rvc colab ver. working for anyone? I seem tobe getting an error related to circular imports upon training the model (index seems to be training without any problem)
how to use rvc v3 in applio colab or other colab?
depends on if you cleaned your data well or not
Rvc v3 doesn't exist
Officially
Since like 2 years
There's some unofficial forks that are experimental like @glacial pollen 's fork but idk if there's a colab
Show a screenshot
i had that error
i had that error and idk what i did spicifically but i kept switchiung google accounts and it eventually worked
I said Codename fork

wtf never seen that before
looks like smt isn't installed properly
you told noobies about it?
yeah i did it seems like a new issue that hasnt happened before and a lot of ppl are getting it
noobies dosent even know why its happening
i said you may need an update to colab
Vidal did fix some torch imports
you can just manually re-install torch
!pip uninstall torch torchvision torchaudio -y
!pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --upgrade --index-url https://download.pytorch.org/whl/cu121
okay thanks
u should tell that to vidal or push the update if u can
coloab moment 

if my dataset has like multiple singing tones (calmer singing tones and then more almost "yelling" singing tones where the artist puts more emotion in their voice), is that what this is talking about when it says "diverse"? shoudl i use a bigger batch size?
Dataset
A set of audio files compressed into a .zip file, used by RVC for voice training. The quality & length of the dataset are the biggest determining factors of the final quality of the model.
diverse as different expressions, words, tone, etc
for example a non diverse dataset would be one having monotone speech, with repeated words in between speech, similar sentences, basically 0 variety
if your singing dataset 90% of the time is singing in the same tone then is not diverse enough
for batch sizes you can try 4-8
4 for small datasets (10 minutes and below)
and 8 for 30 minutes and above
choosing batch sizes is more complicated than that but for training models these are the most used values in rvc
should i just do 8 my dataset is 14 minutes
it is pretty diverse in terms of tone
btw
14 minutes is not big, so you only got the diversity
so should i meet in the middle at like 6
its longer than 10 minutes but not thirty minutes long
do 8 if you want the model to be cooked fast and quick
or do 4 to squeeze everything from the dataset aka having better generalization
up to you
ill do 4 since i prefer accuracy
i have no problem wating as im training locally and im patient
waiting*
sure batch size 4 will work fine in this case
as long the graphs are not extremely noisy
for avg running loss do i train one epoch get like 20% of what the total steps were and then input it and start training again
yup
follow codename's suggestions
do i need it enabled to 0 when i train the first epoch or do i enable it after and resume training
both works
is this overtraining i cant tell plus the overtraining detector isnt going off

but it seems to be going up
yes
okay thanks
How do I train a model? I'm just starting out
what's ur pc gpu?
Yes seems like
10k is the Lowest point mhm
Open "extracting vocals from songs"
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-3-bd2dc64d26a0> in <cell line: 2>()
1 #@title Save the model
----> 2 from mega import Mega
3 import os
4 import shutil
5 from urllib.parse import urlparse
ModuleNotFoundError: No module named 'mega'
---------------------------------------------------------------------------
NOTE: If your import is failing due to a missing package, you can
manually install dependencies using either !pip or !apt.
To view examples of installing some common dependencies, click the
"Open Examples" button below.
---------------------------------------------------------------------------
can someone tell me why i get this error?
im trying to save this model:
nvm
Be sure to not use Ilaria rvc Google colab
which one should i use
Tell me what you want to do
And if possible, your PC GPU
(I'm asking your PC GPU bc I seen people with actual good PCs using cloud
rtx 3050
just use some models for short voice lines
Is it the 4gb laptop one
no
6gb?
wait yeah it is the 4gb one
Yeah nvm
the 4gb one is laptop
- Cloud (remote good pc, easier and faster than ur PC but it's limited):
- Ilaria RVC Zero: fastest and simplest that you can get for free
- Weights.gg: Partnered with AI Hub, lets u do them easily but u may be in a queue
- Applio Colab: max 4 hours, not granted, of GPU
Easiest possible (automatically separates vocals & instrumentals) : weights.gg
easiest cloud: Ilaria rvc zero
easiest local: Applio
Ilaria rvc zero and weights.gg are prob your best options
All models on ai hub are synced on weights.gg
So unless you're comparing 2 different models, they prob are the same
They still are RVC v2 ofc
hi, to get best quality in rvc model should batch size be higher or lower? (I'm using colab free, applio, and T4 gpu)
batch 8 generally, or 4 for short/less diverse dataset
also fp32 may give better "quality" (precision) and gradient stability than fp16, but double the vram usage and slower. batch 8 fp32 would fit the T4 vram tho, or better the kaggle notebook with 2x T4 gpu.
i got a 20minute single file datasset also what is fp
floating point precision for the model params
i mean where to configure it
it seems too technical to explain quality-wise, except the time and vram usage difference, you can just try it by yourself
So it seems now virtual cable died?
got it to work last night
Computer crash nwo nothing
-colab
📒 Google Colab Notebooks
- Applio, by IA Hispano Google Colab
- RVC Disconnected, by Kit Lemonfoot Google Colab
- RVC Mainline, by Hina Google Colab
- AICoverGen-WebUI, by Hina Google Colab
- AICoverGen-NoWebUI [English], by Ardha, fixed by Eddy, Hina and Gdr Google Colab
- AICoverGen-NoWebUI [Spanish], by Eddy, Hina and Gdr Google Colab
- UVR5 NO UI, by Eddy Google Colab
- UVR5 UI, by Eddy Google Colab
- Modified W-Okada's Voice Changer, Google Colab
- FaceFusion UI, by Nick088 Google Colab
- FaceFusion NO UI, by Nick088 Google Colab
- EasyGUI, by Rejekts Google Colab
ℹ️ Note
While the Colab free plan provides up to 12 hours of daily usage, the GPU is typically available for only about 4 hours each day on average.
More commands: -audio, -hf, -local, -kaggle, -realtime, -rvc, /help
how can i download rvc? any link
what's ur pc gpu, and what do u want to do
radeon rx580 and i wanna do covers
Your AMD GPU is good enough to do inference (use models) locally (on ur pc), you won't be able to train (make models) but use them
You can:
- Locally (runs on your pc so the speed depends on that, you will have to set it up with the guides):
- Applio (AMD Windows) : A fork of RVC with some extra features like Applio TTS, kinda faster and simpler but same quality tho
- Mainline (AMD Linux/Windows) : The original RVC
- Cloud (remote good pc, easier and faster than ur PC but it's limited):
- Ilaria RVC Zero: fastest and simplest that you can get for free
- Weights.gg: Partnered with AI Hub, lets u do them easily but u may be in a queue
- Applio Colab: max 4 hours, not granted, of GPU
Easiest possible (automatically separates vocals & instrumentals) : weights.gg
easiest cloud: Ilaria rvc zero
easiest local: Applio
RVC is not Wokada
elaborate in #🔍│help-w-okada
What is the most high quality pretrain type?
you saw it, but you did not read the notes? 🙂
I have a question: How can I change words in a song? Is there a free application or program that can do this? What methods are there?
and I think this suggested ai cover website is great, it does what it should and it is free https://www.weights.gg/de
I'm at this step, but it’s not working. Can someone help me, please?
https://docs.ai-hub.wtf/rvc/resources/epochs-tensorboard/#tensorboard:~:text=%23-,In the left panel%3A,-Activate Ignore outliers

are there actual logs?
I only saw this in Applio no ui, so I didn't see a note about it.
vocoder is a new generator (MRF HiFiGAN and RegineGAN), no pretrains for those yet
Checkpointing - save vram at cost of slower training, can use larger batch sizes
@craggy stratusthis is the right channel for ai covers
- Cloud (remote good pc, easier and faster than ur PC but it's limited):
- Ilaria RVC Zero: fastest and simplest that you can get for free
- Weights.gg: Partnered with AI Hub, lets u do them easily but u may be in a queue
- Applio Colab: max 4 hours, not granted, of GPU
Easiest possible (automatically separates vocals & instrumentals) : weights.gg
easiest cloud: Ilaria rvc zero
You could also do it on phone cpu locally, but it will be harder and slow asf, not suggested
the voice i want to achieve (AI cover of yukari i found on tt) and i just want to kinda figure out what settings to set, cause when i tried to do it, the voice was off
enhypen
38 epochs dataset length about 40 minuts. batch size 8. D loss is going up. do i stop traning ?? and change the batch Size ??

how to download model
you may be ~100 epochs short of the target
or 200
i set to 250
keep going
as long as you have a good clean set with variety of content it will be more than 38 epochs
sorry what ??
i mean it takes longer than 38 epoch to exctact everything useful from a 40 min set
provided the dataset is of a good quality

okay.. i see
Are there any symbols of overfitting ??


D loss is going down but G loss seems little bit increasing @simple ore can you please help me ??
That's not RVC
RVC = Retrieval-based-Voice-Conversion
It's used only for inference on pre recorded audios and training modela
You have wokada instead
Did you download this from a YouTube video
You downloaded an old version then
Go in #🔍│help-w-okada I can help u
Mmm maybe let it train a little more
It doesn't seem really increasing much
This picture is on 175 and now it's 200
You won't see any true overtraining for a long while
especially given you're not using averaged loss
yet you'll be able to recognize it once it happens. it's quite apparent when it happens
Differs too much from normal graphs, the behavior
Hi, I was wondering. Does anyone know any tool to train AI models using samples that would support multilanguage? I want to use it for AI voice changer.
Does anyone know any tool to train AI models using samples that would support multilanguage?
RVC (Retrieval-based-Voice-Conversion) is the tool used to train the best Speech to Speech models
But you can't make a model support EVERY SINGLE LANGUAGE, else you would have to train the voice of that guy/girl of him speaking EVERY SINGLE LANGUAGE EXISTING IN THE WORLD
However, you can train an english model and technically use it for other languages too, in rvc context, the model is made of a pth (actual voice) and added index (the accent), you could use it in the voice changer lowering the index ratio so it doesn't have the accent it was trained on
I want to use it for AI voice changer.
Be sure you're using Wokada Deiteris Fork and not some YouTube tut one
I only want Czech Language
Speaker is also Czech
Then you just need to train it
Is it your first time
And would you recommend some software that I can run locally on my computer? I used to use Mangio RVC, but it didn't do much results
Mangio RVC is an outdated fork
what's ur pc gpu first?
RTX 4060
should be the same 8 gb
eh, usually laptop gpus aren't the best
could be doable
Train RVC Models on cloud:
- Prepare the Dataset
- Setup RVC:
Choose a cloud way to use RVC,
- Google Colabs (4 hours of daily gpu for free, not much hours, but easy to use):
- Applio (ui)
- Mainline (UI)
- RVCDISCONNECTED (no ui)
- Kaggles (a bit harder to use and needs phone number but gives 30 hours weekly of better gpus):
- Mainline (UI)
- Applio by Vidal (UI)
- Applio by Shirou (UI, no guide as of right now)
- Lightning.ai (Kinda hard, needs login, no issue with web uis or anything, but only free 15 credits monthly):
- Be sure to know about the tensorboard
Google Colab = Easier but risk of getting disconnected
Kaggle = Harder but way more gpu time
If you are looking for the easiest way and for free, is using https://weights.gg which ofc uses RVC
Maybe you could try locally first
@simple ore did u ever hear someone train on a 4060 8gb laptop?
either bs 8 fp16 or bs 4 fp32, or turn on checkpointing
When I generated it before it generated a whopping 150 .pts files, is that correct or am I doing something wrong?
Help, does anyone know what frequency I should train at if my dataset has a frequency of 44hz, should I train it at 40 or 48hz?
go 40k or inspect the spectrogram using spek or audacity
48khz
those 4khz are actually important for sibilants and fidelity, regardless
40khz model would dumpen the clarity so, 48 is the way to go for. Luckily 48 works with 44.1khz audio fairly fine if you're careful with training and the data itself
( Tho ensure it's truly 44.1khz (( frequency spectrum itself )) )
I got model maker, now it's time for model master, can someone please guide me ?
Hi there RVC beginner here,
Does anyone have a good tutorial that explains how RVC/Gradio works?
Can't find a tutorial I understand on YouTube.
Do you want to learn principle and programming of Rvc ?
Which GPU Do you have
Oh one sec I'll check.
it's even harder to "master" it
I got model maker, now it's time for model master, can someone please guide me ?
Nvidia Geforce GTX 1660 Super and then I also have a Quadro P4000.
I'm not a master yet
Do you want to be ?
I believe you 😅
And vram ?
you're not even litsa
The PC with the Quadro has 32 GB and this one has 16GB
VRAM, video memory, not RAM
Oh my bad.
What does it mean 🤔
at least 8 GB rtx card recommended
Introducing The GeForce GTX 1660 SUPER
Making it SUPER is the addition of 14 Gbps GDDR6 VRAM, which boosts peak memory bandwidth to 336 GB/s (a 75% improvement over the GeForce GTX 1660's 8 Gbps 192 GB/s GDDR5 VRAM).
Quadro should be 8GB
so yours is GTX 1660 super or which quadro?
I have two PC's, one has Quadro the other the super.
One I'm using right now has the super.
I think gtx 1660 super has 4GB vram
which quadro, I said? quadro turing/newer?
So p4000 will de a good option
P4000
Quadro P4000 that's all I know : S
Okay so I need to use the other Desktop to do this.
P4000 will be good for training I guess. Because it have 8GB of VRAM
it's not as optimized as RTX cards, but fp32 performance should be fine
in this case, you should go batch size 4 and fp32 (usually defaulted for non-RTX cards)
I have no idea what you mean by all that, are these the things I need to enable/select in Gradio?
then read the guide here https://docs.ai-hub.wtf/essentials/how-to-make-voice-models/
In the context of RVC, the dataset is an audio file containing the voice the model will replicate. It can be either speaking or singing.
Can you please tell. Me what did you said?

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Isn't there a YouTube that has a tutorial on it?
I don't understand the terms, for example how do I convert my voice sample into a pth file?
Ahh, tell me....
the existing videos are too old and misleading
Everything is mentioned in Guide
Read carefully
I don't own that pandora's box
I know, but I don't know what there telling me in the steps, there are lots of terms and file types I'm completely unfamiliar with.
I didn't understand. Anyways NVM
You can ask that terms here
How do I turn my audio sample into a .PTH file?
Says I have to drop it into the weight folder.
I only have wav type right now.
rename the extension to .pth
there's no choice but to read the guide carefully
Dear gods...
I'll assist you
So let's begin
1st you need a dataset, "dataset is the audio or samples of your character's voice " From me, recommended length is minimum 10 minutes maximum 30 minutes.
I have done that, I have almost 20 minutes of clean audio with lots of variation in pitch and emotions etc.
In WAV format.
To prepare a good dataset, you need to remove background music, reverb eco and noise by using UVR 5
Also cut the silence and pauses from dataset
Was like half way with training a model with Google Colab before it completely broke and became unusable 🤭
Done that.
This as well.
Using colab is not recommended. Instead you can use kaggle
Can't I do it with gradio?
Was kinda happy I got it working 🥲
Colab is completely unusable so even if I wanted too I couldn't get it to work again.
Kaggle is a cloud computing platform just like colab. You can use RVC on Kaggle
Kaggle is stable and provides 30 hours of GPU runtime
Okay so I have to install that first then?
And if it's based on the cloud, then I could use this PC with the super instead?
Is Kaggle free to use?
Firstly tell me, do you want to train on locally, or on cloud ☁️?
Doesn't matter aslong as I get a voice model at the end 😬