#✨│ai-help
1 messages · Page 171 of 1
delete the file "stored_settings.json" from the folder, and try again
in powers of ten to be exact
trying rn
Because RVC has already an built-in audio splitter, but it's kinda dumb and not reliable.
So instead i suggest you to split your .wav files on clips of 10 or 5 seconds
does that have an effect on quality?
Kinda, but it's better to avoid them. But if you get mode collapses anyway it will depend on your dataset's quality.
It helps to avoid mode collapses.
oh, okay... what are those?
basically when the Adversarial network freaks out and the whole training process breaks
Yep, that's true.
the adversarial network is a part of the training
it checks how close the current model is to the source material
Thanks for explaining it buddy. 
no prob bob :D
I'm sorry i was inactive for a long time, i was gone litteraly only for school and vacation
all good man, glad to have you back
@pastel oak its very laggy idk how to fix it
What does it say on "GPU : " ?
Are you using the realtime voice changer? (w-okada)?
cpu
AI is very laggy on cpu only
Is your gpu showing up?
no
try using cloud-based options
does that mean i dont have a gpu?
Dang i really dont know what you did for your gpu not to show up. do you really not have a gpu? lol
ig not
Ayo? @viral crater level 3 !!! 
no im on desktop
hmm
are you sure you have a GPU installed on your computer?
Try cloud based options for RVC then.

cloud based options?
yep
-cloud
What seems to be your problem?
google colab?
yip
i tried that millions of times
these are up-to-date
never worked once
l3af hold on a sec
alr
hes talking about realtime voice changer not this haha
The guide on setting it up:
https://docs.google.com/document/d/e/2PACX-1vTIceEcBfS6Zqolv_QEysrFfI_EJikPxozWptP_EjkpLVl-l-gdo-ijBonQMTviAHEYm5emmd9k9TdC/pub
Already a heads up, you can skip the "[Optional] Upload a voice model (run this before the voice changer)" since it doesnt work, you can upload it later when the GUI opens

You can try running this
BUT
you should maybe think of investing a gpu for reliable realtime voice changing.
this relies on your internet, and since you struggled to download 5gb earlier i really dont know if you will have great results with this
@viral crater you should maybe think of investing in aa gpu for reliable realtime voice changing.
so i basically cannot have good ai voice changing without gpu
yup
which country do you live in?
canada
oh damn
you can find really cheap GPU's there
like spend $50 maybe
and thats it
MAKE SURE THE GPU IS COMPATIBLE WITH YOUR COMPUTER
and follow proper instructions or get a professional to do so
wait my dads computers got a gpu 🤔
yeah
you could ask him
lel
is there a live conversion thingy??
yup!
realtime voice changer for calls?
you'll need a GPU for it
#🔍│help-w-okada for more info
odaka dont work for me 😭
do you have a GPU
prob bad settings
and is it Nvidia
that depends on your GPU, do ctrl+shift+esc , performance tab and tell whats your GPU name
Intel Iris Plus Graphics
can i run it at all
thats fine
alright
i will come back to this program when i have a gpu
good idea
This interaction has expired, use the command
/guides realtimeif you wish to see it again.
ay nick can you send me a cheatsheet of automase commands
i dont think you understand how laggy tho
Also
Kaggle (a bit harder to use and needs phone number but gives more hours than google colab)

Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources

Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
cheatsheet?
if you wanna know all commands of automaze
do
-help
Command has expired
and u can see all the commands of each category u select
@quasi dagger for the online realtime automaze options, could u:
- Modify: 'How to use W-Okada's Voice Changer' -> 'How to use Original W-Okada's Voice Changer Google Colab'
- Add: Modified W-Okada's Voice Changer Google Colab
- Add: Original W-Okada's Voice ChangerKaggle
- Add: Modified W-Okada's Voice Changer Kaggle
Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
maybe also add that google colab gives 4 hours daily and is easy to use while kaggle gives 30 hours weekly of better gpus but its harder and needs phone number
Idk where you could write that tho as it should also be written on -colab and -kaggle too then 😭
anybody got any tips on making your voice much more responsive in terms of seconds and less laggy? i cant tell if its my pc or it being laggy
Can you send a screenshot your setttings?
anyone have a good workflow for seperating singing voices without rx11?
currently just using bs roformer and then normalizing resampling and shit afterwards buti feel like that isnt good enough.
BS Roformer > UVR Denoise > normalize > auburn noise gate> audio labeling. No guarantee its good because you can't inspect your audio closely in audacity
should be decent at least though?
i was considering doing Mdx23c > Bs Roformer v2 > Foxjoy’s dereverb hq > UVR de echo > Uvr de noise
Ayo? @molten fog level 3 !!!
You don't need MDX23C since BS Roformer is the best one. I also dm'd you
its a windows only app
just in case you're on mac
☁️ Google Colabs
- Applio, by IA Hispano Google Colab
- RVC Disconnected, by Kit Lemonfoot Google Colab
- RVC Mainline, by Hina Google Colab
- AICoverGen-WebUI, modded by Hina Google Colab
- AICoverGen-NoWebUI [English], by Ardha, fixed by Eddy, Hina and Gdr Google Colab
- AICoverGen-NoWebUI [Spanish], credits to Eddy, Hina and Gdr for translating and fixing Google Colab
- Ilaria RVC, by thestingerx Google Colab
- UVR5 NO UI for Google Colab, by Eddy Google Colab
- UVR5 UI, by Eddy Google Colab
More commands: -audio, -hf, -local, -kaggle, -overtraining, -realtime, -rvc, -help
also if i have a 3 minute file that is just seperated audio from bs roformer combined together then can i uvr denoise that whole file since instead of individually denoising each sample and combining them again
yeah just combine files. I split my files into 3 minute sections if its more than 10 minutes long . I assume you're using mvsep?
was going to say that Finetuned BS Roformer = expensive rented GPUs to create btw
how do you make pht files?
yea mvsep its a 3 minute file that is part of my dataset (im gonna combine it with a 10 minute one later) but i havent denoised anything inside that 3 minute combined file so i just need to denoise the whole thing at once before merging audio to make a complete dataset
how do you stop or pause training your model?
close out rvc, your preprocessing and feature extraction is already saved in the logs folder
then how would you continue after?
You can do it all at once if its below 100mb. You just have to check the file size before you split it up
yea its only 30 mb flac so im good
Use the same model name, target sample rate, batch size, pretrain, and save frequency to train the model again in the RVC GUI
do not rerun preprocessing or feature extraction
oh so you just press train?
yeah with those same settings


also do i need to do audacity remove dc offset on every single sample song before seperating the audio with bs roformer?
or am i supposed to od that after seperating all songs and combinging them in audacity
im not sure with GPU's because i use kaggle mainline
cause like i dont know if im using my integrated or dedicated
i want to use my rtx 4060
dc offset should be during your normalization section. But I already gave you rx11 so you just have to play around with that if you want to get to the next level
yea i think im using my integrated card, how can i restart all over?
do i just delete the log file
if it bad if i removed dc offset on each sample song individually in audacity before putting it in mvsep and then combined all those in audacity and removed dc offset again
Might produce little noise but im suuure its fine because its not an eq
its just to remove bottom line noise
alright
do i delete the log file to restart my training?

is uvr denoise on mvsep or should i just use ultimate vocal remover for that and if so what aggression
?
its the same devs
delete these files including your extract and preprocessing files

oh wait
idk
you just have to change the gpu
but like idk if im supposed to put a 0 or 1 here

also was i supposed to say yes to the far right question

does anyone know?
am i blind or is there no uvr denoise on mvsep
Unfortunately blind. It's called ultimate vocal remover

should i keep default aggression

In this guide I will be explaining how to use a "Paid Software" to clean audio for training models.
iZotope RX is known to be the software for denoising audio and the one used by "every" good model maker.
Compared to the previous guide with RX10, there has been drastic changes...
how do i remove echo from my vocal ?
am i supposed to use these pth files to continue training?

yeh
I'd suggest to enable "save only latest ckpt" so that it would be only D/G_2333333.pth
what oes that do?
can i change that setting in the middle of it
before starting training

Ayo? @opaque spoke level 5 !!!
how do i remove echo from things like this sample ?
leave it as is unless you want to use a pretrain from #1235952130855010365
oh ok so it will automatically start from where it left off?
if there are D and G files in the model's logs folder, it will resume from it
will it be ok to change settings before continuing to run it again?

before i had all of them on no
I just tried uvr, and I was able to do bsrofomer, but I couldn't do all the vrartch models, so what should I do in this case?
only the "save only latest" option and more number of epochs if u wish
so i leave the far right one as no?
you should use the same batch size and other settings as before, otherwise it would be messed up
so i can only change this one?

better always enable it for most cases
but like can i change it?
at the start i had it on no
I see no point of rolling back to a previously saved progress (like resuming from epoch 50 when currently on epoch 100)
when training a model, should i have a bunch of individual audio clips or one large audio clip, combining all the smaller ones?
Im sure the guide says so https://docs.aihub.wtf/
Last update: Mar 10, 2024
I was just kinda confused did you mean this as like the next time I train a model you suggest me to do this?
oh yea probably cause you didn't know I was resuming training right?
what
im resuming the training after I crashed
???
that seems obvious from your first screenshot
how to reduce some noise on wasapi?
so will it work if I change that setting to yes? becausue i had it on no when i started
go do it instead of asking more nonsense
yea sorry i was just kinda confused
also im not sure if im supposed to put a 0 or a 1 for my gpu


I'd hear more of your questions if you encounter some errors and issues, not when you havent started it at all
Is it normal. I’ve crashed three times when training
?
I just crashed again
any error message or power outage, or kind of abrupt crash? (check some errors in windows event log)
No
My mouse freezes like a few minutes before it happens though
And then there’s a blue screen with a 😦
check in task manager if there are some bloats or background processes eating some cpu usage
or dont tell me if you are using an intel 13/14th gen cpu that is reportedly failing 
I’m using an intel 13th gen
What’s wrong?
toms hardware, techpowerup, and many other tech articles have been talking about that intel raptor lake failure issue. Intel themselves have offered extended warranty and might soon face lawsuit regarding it.
so what do i do?
but how come my cpu is making it crash? I thought you used the gpu for training
yeah thats a serious issue, many people have prob replaced it with a working amd cpu
i have a laptop
I heard that issue also applies on intel 13th i7 & i9 laptops
so do i just give up??
How to make my own models
try ask your vendor and they might think so
can i just use the model that i trained so far
its like at 100 epochs
how to train my own model chat
docs.aihub.wtf
thank yousir
how do i find the pth file?
assets\weights folder
ok thanks
it is not optimal due to being undertrained, but u can try resuming it in a kaggle notebook https://rentry.co/RVC-Mainline-Kaggle

This guide for Mainline Kaggle is an alternative option to the Mainline Colab notebook for training voice models
It is complete and should walk you through every step of the way since Kaggle has a difficult learning curve. However, it will be updated constantly since new updates to the notebook w...
the thing im confused about is why its crashing cause the cpu was only at like 40%
ok ill look at that
the issue is caused by permanent degradation by sustained cpu overvolting (not the user fault but kind of design flaw that applies to all the same product)
guys can i uhh use an entire audio
or it has to be 10 seconds each like old rvc and stuff
i havent used rvc in long
A combined audio file to clean it up then https://rentry.co/RVC-dataset-RX11#noise-gating-and-audio-labeling
i ended up doing multiple audios, will it be fine?
Yup, ideally just let audacity do the splitting itself with audio labeling next time
it'll remove most of the silences
in your dataset because there can be noise below -96db etc
well, i am doing a character from a tv show, and i managed to get a full episode with surround sound downloaded, so i got the talking full quality, free of any noise
will that be good?
hi i have a questiom. If i have find an ai model with all members of onr group together and i vant find each member model alone how i can use it ????
Ayo? @scenic stone level 1 !!!
take the center channel that mostly contains the voicelines, or if necessary separate it from some other sounds using bandit plus in mvsep
can someoneh elp me
Ayo? @limber onyx level 1 !!!
/content/Mangio-RVC-Fork/logs/josesitopenesito/3_feature768
Exception Traceback (most recent call last)
<ipython-input-12-86df4775937e> in <cell line: 30>()
29 listdir_res = list(os.listdir(feature_dir))
30 if len(listdir_res) == 0:
---> 31 raise Exception("No features exist for this model yet. Did you run Feature Extraction?")
32
33 try:
Exception: No features exist for this model yet. Did you run Feature Extraction?
i already ran feature extraction
triedw running again
but it wont work still
im using rvc v2
cloud
if that step didnt show anything preprocessed and said "no-feature-todo", you have either submitted an empty dataset or zipped the dataset with wrong structure
if that issue also persists, re-export the wav files using audacity
yeah it said no feature tod o
i did what the site told me
make a flac file
put into zip
put it into rcv disconnect
wait its supposed to be wav?
try wav format
Is rvc v2 better than w-okada?
hey i put the wav and put a new zip
but it does the old zip
ok i tried everything
i refreshed apge
did everything again
now put a wav
you should just use kaggle instead. It's much easier if you get right into it https://rentry.co/RVC-Mainline-Kaggle
This guide for Mainline Kaggle is an alternative option to the Mainline Colab notebook for training voice models
It is complete and should walk you through every step of the way since Kaggle has a difficult learning curve. However, it will be updated constantly since new updates to the notebook w...
I don't really like the bugs that rvc disconnected has because it's either google colabs fault or its an error with the session
I have always been doing audio labeling and exporting as multiple wav files in audacity, and then put them in a folder with model name. no issues encountered in rvc disconnected and anything else. so not really a bug.
That's how I always did it too. I had to switch accounts once in a while because preprocess worked for the alt account but not for the main one
oh wait. He didn't include .zip lol probably what happened to me so nvm
@wispy lodge
bro i trained 2 model with applio on my local
its just only saving last epoch
it didnt save other epochs
i set this every 5 epoch but

its just only saving last epoch idk why
you mean save only latest D and G files?
no i mean model saves
when i use paperspace few months ago it will save model pth files every 5 epoch
ty after my hiatus kinda forgor everything
-help
Command has expired
Yw
mainline RVC should have saved weight files every n epoch set, as well as the hina's kaggle notebook
im using applio
i dont wanna use kaggle or something cuz i dont wanna deal with ngrok thing
paperspace was good but its gone
Applio 3.0.9 (local) should also have done so
as you see

i set it every 5 epoch but its only there 11 epoch rn
show me the console output when saving ckpts

yea it saving g and d thing

but they arent model pth file right
its config
when i was use paperspace it was saving model pth files every 5 epoch
not d and g
Hey there, does anyone need help?
ah that overtraining detector, haven't used that shit tho
yea i need we trying to find out
it seems you have only enabled the overtraining detector, so it only saves that "optimal" epoch
so if i turn off that option it will fix?
in response to atri's advice, if you want every 5 epochs to be saved no matter what, disable the overtraining detector
okey ill try
was i helpful?
does anyone know how do i remove echo from this sample ?
can you help me ?
Suggestions for @wanton bane
📚 Audio Guides
- Creating Datasets for RVC using iZotope RX11, by Cauthess
- Perfecting Audio Isolation on Low-End Rigs, by Litsa The Dancer and Faze Masta
- Gathering and Isolating Audio, by SCRFilms :snowflake:
- Vocal Mixing Tutorial, by Roomie
🛠️ Tools
Audio Separation/Isolation
More commands: -colab, -uvr, -karafan, -overtrain, -help

tnx alot
no problem
Please throw off the neural network that works
is this not wrong folder?
go to weights folder
you are in logs folder, it doesnt have the models saved in there
hi im getting this error when trying to download tensorboard can anyone help?
File "C:\Users\Tense\AppData\Local\Programs\Python\Python311\Lib\site-packages\tensorboard_vendor\html5lib_trie_base.py", line 3, in <module>
from collections import Mapping
ImportError: cannot import name 'Mapping' from 'collections' (C:\Users\Tense\AppData\Local\Programs\Python\Python311\Lib\collections_init_.py)
Keeping the command prompt open...
Press any key to continue . . .
the file in that path exists so idk why this eror happening
weights folder doesnt exist
i was tried to search that folder but theres no weights
only log folder here



didnt work bro
Ayo? @tough fiber level 13 !!!
still same shit
under assets


oh I use mainline not applio 😦
UVR dereverb or BS roformer dereverb

the weight files go into the model's logs folder in Applio
AH dang


also I'd suggest enabling "save only latest ckpt" so that it will only save as D/G_233333.pth (not related to where it still saves weight files every interval set)
yea i turned off maybe thats why i cant see but its different thing
ill turn on
everyone was using applio when i use mangio. now im using applio and everyone using mainline rvc wtf bro
Ayo? @stone lintel level 1 !!!
i found a way with uvr5 but tnx

you can also download BS roformer dereverb for UVR https://github.com/ZFTurbo/Music-Source-Separation-Training/issues/1#issuecomment-2229279531

GitHub
To post your model, please, fill the form: Description: Instruments: Dataset (if known): Metrics (if known): Config link: Checkpoint link:
and then use the config file from mine
yours can do better than this ?
Ayo? @wanton bane level 2 !!!
quality-wise, UVR dereverb is still better than that, but the dereverb model I showed to you should be better than the former two
i will try it
tnx
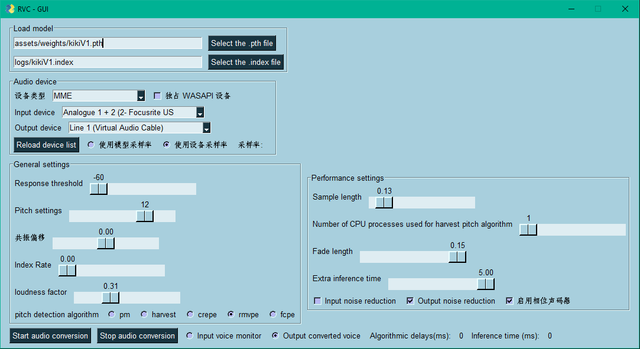
when i click start audio conversion in rvc gui it freezes
Make sure your input and output both have the same ending with (MME)
I havent used rvc realtime in a while but any other questions you can check out this guide
https://rentry.co/RVCRealtimeGuide
This guide will be in the same style/format as Blancdot's w-okada guide for simplicity sake. Credits go to the legend.
Thanks to Codename for additional input.
Last update: August 10th, 2024
Personal opinion + Recommendations + Overview
Download
Download NVIDIA
Download AMD/INTEL GPUs
Virtual Aud...
how do i make the vc run on a gpu?? yesterday i could run it on tesla t4 but now it js says cpu and it doesnt work at all now
Ayo? @brittle wing level 1 !!!
me
you have a gpu now??
oh
is it on cloud?
colab?
colab
idk much about all of that stuff but yestaday it said it ran on tesla t4
uh
try running it on another account or wait 24 hours
its how colab keeps it free
like anotehr google account?
yup
ok ill try
alright
thanks a lot
no problem
Ayo? @half brook level 1 !!!
you should try to get access to a computer
Yep I will install apple
appolio you mean?
make sure you have an NVIDIA gpu for a better experience, or use cloud options
How do I train with Google Drive dataset?
thanks, even I can hope a issue fix, I need help about drive datasets
When you create drum AI, do you extract drums from only one song? Is it okay to add multiple songs? Also, do I need to remove the reverb from the drums?
If you would like to create a Drums AI model of a song, you must use the drum stem of that sole song.
Not other songs.
And yeah, you need to remove reverb from the drums i think
Thx
Can anyone tell me where to find the index file after I trained a model on applio o can find it and it wont come up?
You should have trained the index before starting training the model.
There's a button called "train index" you must click before clicking on "train model"
ok so i kind of did it backworks got it.
-rvc
Documentation
 AI HUB Docs
AI HUB Docs
✨ More guides
- How to use RVC Mainline Colab by Cauthess
- Full AI Voice Model Training Guide (local) by Christopher Villanueva
- AICoverGen Colab Guide by Eddy (Spanish Helper)
- Create a model with RVC disconnected (colab) by Angetyde
-colab
☁️ Google Colabs
- Applio, by IA Hispano Google Colab
- RVC Disconnected, by Kit Lemonfoot Google Colab
- RVC Mainline, by Hina Google Colab
- AICoverGen-WebUI, modded by Hina Google Colab
- AICoverGen-NoWebUI [English], by Ardha, fixed by Eddy, Hina and Gdr Google Colab
- AICoverGen-NoWebUI [Spanish], credits to Eddy, Hina and Gdr for translating and fixing Google Colab
- Ilaria RVC, by thestingerx Google Colab
- UVR5 NO UI for Google Colab, by Eddy Google Colab
- UVR5 UI, by Eddy Google Colab
More commands: -audio, -hf, -local, -kaggle, -overtraining, -realtime, -rvc, -help
is rvc still the best voice model to use currently or did it get outclassed like sovits did? I havent used anything ai in like a year
-hf
<:huggingface:1179800228946268270> Hugginface Spaces
- UVR5 UI, by Eddy and Ilaria Huggingface Spaces
- Ilaria RVC Zero, by Ilaria Huggingface Spaces
- RVC⚡ZERO, by r3gm Huggingface Spaces
- Applio, by IA Hispano Huggingface Spaces
- AICoverGen, by r3gm Huggingface Spaces
- Advanced RVC Inference, by r3gm Huggingface Spaces
- RVC v2 Huggingface version, by Clebersla Huggingface Spaces
More commands: -audio, -colabs, -kaggle, -local, -overtraining, -realtime, -rvc, -help
Rvc still the best that we can run in consumer pc, microsoft has valle-2 which is super realistic but they didn’t release to the public due to security reasons
I think elevenlabs also has their voice cloning ai but ive heard is not that great (paid ofc and it doesn’t run locally)
Tldr; rvc is the best voice cloning ai we can use
I hope it's matter of time till a public version of Valle-2 appears XD
I have a question about RX11. I have RX 11 Elements and use it as a plugin in Audacity.
So, I'm wondering if Repair Assistant can't be used in Audacity?
No matter what I try, I can't get the audio to play when the Repair Assistant tab is open...
They can add like an inaudible watermark like synth v dev did with their voice creation ai 
Yeah audacity does not behave well while using rx plugins, they never worked well for me inside audacity
Only audacity devs can fix that
Is upgrading to RX11 Standard or using a paid DAW (like Adobe Premiere Pro) the only option?
rx11 is recommended because is the most easy to use, i have no idea how well the rest of daws are for rvc, im not that experienced in daw usage, sorry
I use both RX10 and RX11 in extreme situations.
-realtime
This interaction has expired, use the command
/guides realtimeif you wish to see it again.
Hello my friend has a problem
Whenever he speaks he has a echo and its sounds alot cutty
The settings r this

Disable sup1, disable echo for now
Use extra 8192
The echo is caused because your microphone is picking up your headphones volume.
Possible fixes:
keep sup 2 activated
Move S.Threshold all the way to the right
Lower windows audio volume so headphones are not as loud and dont get picked up my mic
If it still echoes, enable echo and see if it helps
It is a noise gate, so it only starts picking up audio when it reaches a certain volume
so on the far right, it wont pick up quiet audio (which could help when volume is also quiet)
oh he put it all the way to the right and it still doesnt work
its alr ill msg tmrw and see if it works
I am using AI Voice Changer, but I cannot successfully convert the voice. Normally, "rvc" should appear in the upper left corner of the anime character image, but it does not appear on my side. Does anyone know why?
Ayo? @empty fjord level 1 !!!
it keeps giving me error none
output folder = /content/drive/MyDrive/yourmusicfolder
input folder = /content/drive/MyDrive/youraudiofolder
I've done that and both completed, but the important thing is that the file hasn't been added to google drive.

⠀
Settings for Nvidia GPUs 
F0 Det.: rmvpe (suggested for all series)
RTX 40-series: 80-96 chunk | +16384 extra
RTX 30-series: 96-112 chunk | +16384 extra
RTX 20-series: 112-128 chunk | +16384 extra
GTX 16-series: 128-192 chunk | +8192 extra
GTX 10-series: 128-192 chunk | +8192 extra
Advanced Settings
Protocol : Sio or Rest
Crossfade: 4096 start 0.2 end 0.8
Trancate: 300
Silencefront: Off
Protect: 0.5
RVC Quality: Low
⠀
このサイトを利用することをお勧めします https://mvsep.com

MVSEP performs separation of audio into vocal and instrumental parts, extracts text from audio and it is free. Uses Artificial Intelligence.
nah, just name those folders "output" and "input" respectively
いや自分はこのcolabが使いたいんですなんでできないか教えて欲しいです
mvsepの方がいいよ。サイトにあるモデルの方がcolabのよりいいんだ。
ごめんなさいーこれやったけどあんま精度良くなくてこっちのcolabの方にしたいんです。
Taki taki rumba.
Every time i tab out of the voice changer client, the res shoots up infinitely. any way to keep this from happening?
mvsep のこのモデルの方が優れていると思います。colab のモデルよりも SDR が高くなっています。

このSDRリーダーボードを見てください

場合によっては、SDR が高くても必ずしも良い結果が得られるとは限りません。
それでもいいのでこのcolab教えてくれませんか?自分ずっとこれのuvr使ってきたんです
これはローカル UVR に似ていますが、colab ポートにあります。
たとえば、私が PC でゲームをプレイしているのに、あなたが Switch でプレイしていて、何か問題が発生した場合、私には助けることができません。

それでもいいです
Ayo? @final sentinel level 6 !!!
Command has expired
#1175430844685484042 Assala Nasri
Ayo? @loud sparrow level 1 !!!
You go into that channel and search it
what is the app for making ai sounds?
8a is old, do you mean 18a?

Reviving in the future, will change install instructions to be "manual" build (for nvidia at least as its infinitely better performance)
Github - Blanc-dot
Discord User ID - https://discord.com/users/824922747423031359
Despite being end of life, most if not all information has not reall...
Do you mean AI Covers?
yeah
Ayo? @azure nimbus level 1 !!!
stable audio unless you mean something else
https://docs.aihub.wtf/essentials/how-to-make-ai-cover/
If you have a good gpu, i recommend Local > Mainline
If you want to do it online fast, use this: https://huggingface.co/spaces/TheStinger/Ilaria_RVC
Have the audio file of your song ready, & let's extract the vocals from it with an audio isolation software.

dont use 8a. Why are you looking for an old version?
or 10a
aight thanks
Ayo? @grizzled heart level 1 !!!
Why old version
dm me
No
i want to show you i cant send
Oke
Does anyone know how to make your own moduls?Cuz I tried this tutorial https://youtu.be/Evs8Or2Qy9A?si=vYUQb_Z2T7ClrZ1S but I didn'T have a rvc interface
That's a Google Colab YouTube tutorial, most YouTube tuts are outdated so it's better you don't follow that
What's your PC GPU?
github download is slow any altnernatives?
NVIDIA GeForce GTX 1070
which methode works ? @low shard
Ayo? @primal fulcrum level 1 !!!
if you want to train locally, read the guide https://docs.aihub.wtf/
1070 is still capable of that despite being unoptimized
Last update: Mar 10, 2024
Hi
hi quick question is uvr used for seperating vocals from music only or can it remove other background noises
Depends on what kind of background noises you mean, but yes it can
i guess it would be noises from the surrounding environment idk how to explain rlly
I havent opened UVR in a while but there are models called DeNoise. Someone else can probably give you better suggestions
I can't run pip commands despite having the newest version of python installed? any ideas?
but how a get the voice from a audio to the pth data?
Please delete this if it contains copyrighted instrumental
ig they wont dmca u but okay
Only post the acapella of the model which you seem to be asking about
can u help me
Server got taken down before for this reason
Can be anything:
- your voice models dataset contained too much noise
- the audio file you inferenced (ai covered) with was not clean enough
Did you send a small part to show me or is this the full dataset the 25 seconds
full dataset im need her voice only from that song
25 seconds dataset is tough i dont think you can get a good voice out of that
im used dolby atmos ver
10-15 minutes are recommended
okay
But training process is wild even 1 minute can work, maybe it didnt work for you in this case unfortunately
Post the thing you sent except without the instrumental if its really because of that, someone else will be able to identify this better than I can 👍
but how I get a voice to a pth data
I can't find any RVC clients that actually let me download for realtime mic output..
You train it, read the how to make voice models part
Download the program under RVC > Local > Mainline
hey guys um the software isnt installing how can i
Realtime voice changer
https://rentry.co/ForkVoiceChangerGuide
its says too many people have installed it
and i must wait 24hours but
im not tryna wait that
There is no such thing as that. Where are you trying to download it from
w-okoda
Ayo? @drowsy scaffold level 1 !!!
Thanks for the help
Ayo? @long matrix level 1 !!!
could u jus show me a whole tut on how to get the software
maybe screenshare idm
please read the guide thoroughly before asking nonsense
Did you open the guide I linked you
whatt
wdym
i found out abt w-okoda by some ytber
Oh, I linked it to Mitch, not you, I got you mixed up
https://rentry.co/ForkVoiceChangerGuide
Dont rely on youtube videos they are outdated
alirght ty
We will do our own youtube tutorials soon hopefully xd
You got any idea how I can make the program output to an audio device? As I can't find one its generating if that makes sense
Navigate to "Download" and get the ones for your GPU
Navigate to "Virtual Audio Cable" if you do not have that yet
Navigate to "Opening" to know how to extract the file, and which file to run
Then upload voice model if you dont know how to, then Audio Setup for the inputs and outputs
right ill try that
I dont understand exactly. Do you mean how to output the voice changer to discord/games for example?
Yes
Get the Virtual Cable from the guide, then do the first thing it says on Audio Setup
what does audio blocked mean
Are you using RVC GUI Realtime?
yea no that's not good enough for local training, you will have to do it on cloud
yes
@pastel oak

just says io block passed.
Audio block passed.
Audio block passed.
Audio block passed.
Audio block passed.
Audio block passed.
Audio block passed.
Audio block passed.
Audio block passed.
Audio block passed.
Audio block passed.
Audio block passed.
Audio block passed.
Audio block passed.
Audio block passed.
Audio block passed.
should dis be hapening
Thats no error, its loading up afaik havent used in a while
As you dont got a good PC, its better you use cloud for training an RVC Voice Model:
- Google Colabs (4 hours of daily gpu for free, not much hours, but easy to use):
- Applio (ui)
- Mainline (UI)
- RVCDISCONNECTED (no ui)
- Kaggles (a bit harder to use and needs phone number but gives 30 hours weekly of better gpus):
- Mainline (UI)
Last update: June 15, 2024

In this guide, I will be explaining how to use the RVC Mainline Colab notebook to create voice models
I will not be teaching about voice model training and reading tensorboards since there's already guides for it on AI HUB
RVC Mainline is an significant improvement over the RVC Disconnected colab...
Last update: Mar 8, 2024
This guide for Mainline Kaggle is an alternative option to the Mainline Colab notebook for training voice models
It is complete and should walk you through every step of the way since Kaggle has a difficult learning curve. However, it will be updated constantly since new updates to the notebook w...
Yes its downloading files
ok
Oh so thats normal its just loading?
Ayo? @agile gale level 1 !!!
goes straight into my copy paste list i love you
It should follow up with new information right after that

Anything new on the console yet after audio block passed
how lonjg should it take?
Few seconds
Can you send a screenshot of your GUI, and of the console


Use (MME)
On both
I notice your RVC is saved in OneDrive, I am not sure if that actually works, but try with (MME) and then see if it starts to say anything else after few seconds of audio block passing
@pastel oak

I want to know how to make pth and index file
You need to change output to MME aswell, like I said. You only changed one of them, this causes it to crash
Whats your GPU
'shad what to do from here im lost again

i dont think ill hear anything if i do that lol
GTX
You should.
still lost could u screenshare or smth
Its better you use cloud for training an RVC Voice Model instead of local training:
- Google Colabs (4 hours of daily gpu for free, not much hours, but easy to use):
- Applio (ui)
- Mainline (UI)
- RVCDISCONNECTED (no ui)
- Kaggles (a bit harder to use and needs phone number but gives 30 hours weekly of better gpus):
- Mainline (UI)
Last update: June 15, 2024
In this guide, I will be explaining how to use the RVC Mainline Colab notebook to create voice models
I will not be teaching about voice model training and reading tensorboards since there's already guides for it on AI HUB
RVC Mainline is an significant improvement over the RVC Disconnected colab...
Last update: Mar 8, 2024
This guide for Mainline Kaggle is an alternative option to the Mainline Colab notebook for training voice models
It is complete and should walk you through every step of the way since Kaggle has a difficult learning curve. However, it will be updated constantly since new updates to the notebook w...

yeah just rename the extension to .pth 
so please read the guide thoroughly
Im out of country, dont have a setup
Literally click on select file
💀
I did but still found it frustrating
skill issue
@pastel oak cant hear
both input and output have to be of same type, MME is the safest. I dont understand what you mean by this, have you tried selecting input: microphone (MME) and output: speakers (MME)? Scroll up to the top if needed

i cant hear anything
when i put my output to this
where should i be bluhhed my headphones
plgging
cant hear non lool
thimk thats my monitor
Do you have headphones plugged in? If yes, make sure to select those as output then
Technically you will need to select your virtual cable as output to be using this on discord and games, but for now headphones to test

4060
sample length increase it to 0.15
ok @shad now that iv got it working and i know what it sounds like what should i do now
@pastel oak I HEAR HELLA LIKE
Ayo? @agile gale level 2 !!!
Send screenshot of how your voice changer looks like rn
Did you increase the sample length

yup
Select your GPU
i hear ltos of noises tho
Your microphone is picking up a lot of sounds
yup what now
Since you selected the output to be your monitors speakers, it is also picking up the converted voice back again in a loop
Which gpu do you have
intel uhd grap 620
Ayo? @drowsy scaffold level 2 !!!
💀
damn
ik its bad
Chunk: 1000 ms
Extra: 0.5s
Pitch: 12 (youre using a female model)
Open "advanced settings" on the bottom
Click on "convert to onnx", this will take 1 minute to load up
Then try the voice changer, and tell me what number the "perf" value on the top left of the picture shows, and what color
I bet it wont be better than cpu mode
oh
@pastel oak how do i know the right pitch for all models
Actually could be true. I believe deiteris mentioned that Intel UHD Graphics dont run good at all, this is an issue he might adress in the future
dont they say it?
its dependant of your voice and how high or low pitch the voice model is. So you have to trial and error until it fits
how do i get it to work on liek discord
This guide will be in the same style/format as Blancdot's w-okada guide for simplicity sake. Credits go to the legend.
Thanks to Codename for additional input.
Last update: August 12th, 2024: voice models to try out added
Personal opinion + Recommendations + Overview
Download
Download NVIDIA
Down...
go to virtual cable, install that
then do this


erm its just stuck on this i think

nvm
just went
shad i cant hear my voice bruh

yes
Idk man intel uhd cant run this i think xd
but connection error means you maybe closed the console window
is it still running?
@pastel oak like this

yeah
Correct
and on rvc gui you select Line 1 (mme) on the Output instead
ow do i do that
The same way you started it
aint nothing happening bruh

Show perf number on top left


thats what i was thinking
i started hearing nothing when i switched t gpu
but the operating in progress thing will take a while
Could you send vcclient.log that is in the voice changer folder?
Ill let the developer know if its an intel uhd specific problem or not
Ah there he is
ok
IT WORKS
Ayo? @drowsy scaffold level 3 !!!

Increase the chunk value to 1700, it should make the perf number green
Did you download virtual cable from the guide
lemme see
it will be crysis meme if you try running for roblox
I have to warn you, running cpu for voice changer rlly is not a great idea
wdym
especially if you try to run a game
explosion in a 2 block radius
Is there a way to use integrated graphics to process the voices?
no lol but like youre running an AI software on a cpu, its not made for it
maybe it is for inteluhd???
Nah im running it on a gpu
if it is at least radeon 780M iirc
I have intel uhd 770
nah definitely not for intel uhd either lmao u need a dedicated graphics card like Nvidia RTX or AMD RX
could u just help me use roblox with it
download virtual cable, then do what it says on "Audio Setup" first step
ok
How
Youre a maniac for using a cpu like that with an integraded card
You might aswell use CPU conversion
You should 100% use the 4070, you can run the game with it aswell
waitwhere do i download virtual cable
Idk lags like hell when I use the cpu conversion
Send screenshot of your settings
while using nvidia one
on the guide
you can use your 4070 for most non-demanding games (CS, valorant, etc)
this??

Ok thanks
Ayo? @long matrix level 2 !!!

Brother thats what u already downloaded lmfao go to virtual audio cable
i cant babysit you through this

this??

My integrated is doing nothing
Thanks so I can't use my uhd 770 integrated for this?
Lets start from the beginning
-
you should use the 4070, even running a game next to it is more than fine. intel uhd does not work + its the worst thing you can choose
-
if you lag, you may reduce ingame quality or limit fps, and raise chunk if needed
ur trolling me, how old are you
I see no point of utilizing it other than some basic display, streaming
Alright if I plug another gpu in as I have a base gtx 970 laying around somewhere can I use that solely for the voice?
bro shad r u there
that's too old unfortunately, again why do you avoid using 4070? what game are you playing?
try lower some settings and fps cap to 60
Ok I'll do that now
Is there a way to make the voice changer run more efficiently or use less power
@drowsy scaffold
You can raise chunk (increases delay), or reduce extra (reduces quality)
it says what to run on the guide man
ok
I think 4070 will barely have temp issue
It's not the temp as I have a good AIO it's more the fps I get is like 20 when in game
hello its the same issue with my friend
i tried everything
but his voice keeps on cutting out

ah.. you'd be more likely to need a decent 2nd RTX laptop/pc
f0 det: rmvpe
gtx 970 works on this version of wokada, no clue about benchmarks
Okay I might plug it into a spare PCIE and try it. Thanks.
hope i dont crash in rblx or smth
Nice, good luck
didnt work
Ayo? @regal axle level 2 !!!
still is cutting out
What game are you running next to it
Disable "echo" and use headphones if you arent
im using headphones
Record audio of how it sounds like cutting out
no game running in the background
Increase chunk to 112
lower threshold and increase chunk
wait there is no cutting out when i record it but in discord its cutting out?
No
Turn off Echo Cancellation on discord
Turn off noise suppression on discord
Move the sensitivity slider to the left on discord
ok did that lemme check
I have a question, when I use pretrained models like Titan or Ov2Super, the inference output generated using the models trained using these pretrained sounds more robotic (and similar) in comparison with using the original RVC2 pretrained. Is it expected or am I doing something wrong here?
Original pretrain is the best pretrain
Custom pretrains need better cleaning of dataset for sure
i did all that didnt work :/
im on 128 i was on 96 how many chunks should i use
Can your friend record you
Are you sure its cutting out and not crackles
ah! ok. I thought using these pretrained would do a better job than the original ones.
Ayo? @wise roost level 1 !!!
I was trying to explore if there's a way to train the model using less audio input than 7 mins without compromising too much on the quality.
Yeaa hifigan is crap unfort
Ayo? @lethal orbit level 2 !!!
heres the recording
I mean my titan trained models on 5 mins come out good on inferencing so idk
look at de recording
Thats crackles
Open Task Manager > Details
Right click audiodg.exe and set priority to High
Right click audiodg.exe again > set affinity > uncheck everything except CPU 2 (only ✅ CPU 2, turn off the rest)
With a program called ProcessLasso you can automate this to always be active, since Windows resets these sometimes.
oh! interesting. Do these pretrained models require any change in the inference parameters in comparison with original rvc?
Because for me all the outputs sounded very similar and no where closer to the original voice.
I am not quite sure, I usually use default except I turn off index usage and I match the volume to the original inferenced audio
I wouldnt think they need different changes in parameters necessarily. I turn off index because I dont like the original accent of voice models for my usage, it can reduce artefacts though
ok, how to turn off index usage? And what do you mean by that?
the default is 0.75 iirc, i put that to 0 to disable it
And the volume thing, I dont remember the name off the top of my head, you can send a screenshot of the parameters I should be able to identify it
Im out of country, cant check myself

Those are training parameters, I thought we were talking about inferencing
ah! I'm sorry. I was talking about training the model and then generating inference using the pth and index files.
And you were saying you trained a model on original pretrain, Ov2 and titan ; and in the inference process, ov2 and titan did not come out as good as on pretrain, correct?
that's correct!
The index and volume thing I described are inferencing parameters
However, I am noticing this is not making much sense
xd
I think maybe I don't know what I'm doing then.
I think you should stick to original pretrain, since it is the best
Maybe someone else, who is far far more experienced than myself can comment on why ov2 and titan on inference did not come out as greatly, aside from them not being as good as original
like atri 🙏
there's no relationship between inference parameters and pretrains
also it mostly depends on the dataset quality and variation
got it. Considering the dataset quality as a constant, the inference generated using the models trained using original pretrained is coming out to be better than titan and OV2.
they might have some pros and cons for average and very clean datasets as well, though anyway original pretrain is still good to go if you're not sure what you're doing
Ayo? @knotty moth level 29 !!!
it was working fine few weeks before
Hello can someone help me getting RVC 2 to run on a Steam Deck please?
https://github.com/Mangio621/Mangio-RVC-Fork/releases
never
at least inference is still doable in cpu mode
hi smart ai people, im trying to install rvc rn on my new laptop but it's not willing to recognise that requirements.txt exists.
omg
so real
Ayo? @dire cipher level 2 !!!

Yh thats what i mean inference version.
There is a easier way to download update without need to download entrie applio again?

I don't think so.
oh..
Command has expired
nevermind found the answer in guides
actually there is no answer
how do you convert a voice present day cause last time i used it was with google colab with rvc 2.0 so im completely lost
heya, does anyone need help?
check out https://aihub.wtf/docs

AI Hub Webpage
thank you
I want to know why the data related to RVC, which should have appeared in the top left corner, isn't showing up on mine, so no matter how I adjust it, I can't hear any sound

Where I get Index data?
Is there a way to use harvest in Applio?
i don't know which one of the cloud ways are you using but when training you there would be another button to train the .index
Yep, it is. Make sure it's free of any kind of noise tho + apply audio labeling to the audio with Audacity and export it to a folder.
Can you send a full screenshot of the voice changer? Which version did you download?
You must hit the "train index" button before training the model.
does someone know what this warning mean?
C:\Users\user\Downloads\Applio-3.2.0\env\lib\site-packages\torch\autograd_init_.py:251: UserWarning: Grad strides do not match bucket view strides. This may indicate grad was not created according to the gradient layout contract, or that the param's strides changed since DDP was constructed. This is not an error, but may impair performance.
grad.sizes() = [64, 1, 4], strides() = [4, 1, 1]
bucket_view.sizes() = [64, 1, 4], strides() = [4, 4, 1] (Triggered internally at C:\actions-runner_work\pytorch\pytorch\builder\windows\pytorch\torch\csrc\distributed\c10d\reducer.cpp:334.)
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
I got Applio running on the Steam Deck but gives me an error when trying to convert something.
xd
that is not an error
hey can i get some help with rvc
oh wait what
i installed python and all
and no app is showing
just command prompt
theres an installation there and im waiting for it to finish
Ayo? @fossil vigil level 3 !!!

Wait for it to finish
oh ok
im following this tutorial
https://www.youtube.com/watch?v=We5oYpCR3WQ&list=WL&index=4&t=2s
tutorials bad
Reviving in the future, will change install instructions to be "manual" build (for nvidia at least as its infinitely better performance)
Github - Blanc-dot
Discord User ID - https://discord.com/users/824922747423031359
Despite being end of life, most if not all information has not reall...
oh yeah i have a amd gpu and installed cuda
it worked fine
idk how
well
it worked lol
so uh

The version I'm using is: vcclient_win_std_2.0.58-alpha.

im testing the demo it isnt working
You didnt select a GPU
And the alpha version is unstable
whats your gpu name
f0 det: rmvpe_onnx
chunk: 256
extra: 8192
and make sure u selected the right gpu number
it should be the gpu number in task manager right?
yes
original wokada sucks for amd though youd get much better performance on the modified if you wanna download that
sure
i tried doing the voice changer
it wont open
i meant like no sound

Guide style is in the same as Blanc_dot's guide for simplicity and familiarity sake. Thanks to Blanc_dot for additional input. Most technical information comes from deiteris.
Last update August 12th, 2024: new version released, pictures and gifs added, VOICE MODELS TO TRY OUT added
Video tutorial...
get the other version i just linked anyway

the no sound can be fixed later we can look at it
this download?

yes
yes
ok itll be downloaded in like a couple seconds
I did select a GPU, but it still doesn't work. Also, my friend downloaded this version, and it works for them
then read the guide on uploading voice models & the first part of audio setup
Yh the alpha is unstable as i said, for some it works for some it doesnt
uploading voice models shouldbe easy did it before
best of using this
https://rentry.co/ForkVoiceChangerGuide
Guide style is in the same as Blanc_dot's guide for simplicity and familiarity sake. Thanks to Blanc_dot for additional input. Most technical information comes from deiteris.
Last update August 12th, 2024: new version released, pictures and gifs added, VOICE MODELS TO TRY OUT added
Video tutorial...

this happened when opening it
pressed enter and it just closed
Did you have an antivirus program running that may have deleted files?
i replaced the previous files that i had
but no
just windows antivirus
which does nothing
Don't replace. Just unpack into a separate folder
I was about to ping the developer, but he is already typing 🙏
o ok tysm
this thing right?

Ayo? @fossil vigil level 4 !!!
Yeah
okay its installing the thing
Noice

help, in the voice changer program only 1 standard voice works, all the others do not work. I have already installed new ones and there is 0 sense, maybe someone had such a problem?
in the command line it says "Pipeline is not initialized" and so on endlessly
Install failed, delete pretrain and model_dir folders and then launch start_http again
should i just wait

oi\
it opened google
am i supposed to use that
this opened

Sure, thanks! I'll give it a try.
Yes, it uses WebUI that runs in the browser
woah cool
gonna download some voice models and ill be back
thank you very much, you are the best thing that happened today :3
tysm it worked
this is fun
how do i use it on discord
if i wanted to
or in vc
How do I download this? I couldn't find where to download the Voice Changer software
You need a virtual cable installed like VAC. Then set output to line 1 in voice changer, and input to line 1 on discord/other apps
oo
i have virtual cable but never really opened it
Open the guide i linked, go to download section etc
You dont open a program regarding vb cable, just use it in the app and games/discord
I only see options for downloading NVIDIA, AMD, INTEL, and CPU, and Mac. I don't see a download for Windows.
They are all windows except mac
These are hardware specific downloads, as they run on GPU
You download depending on your GPU
Open task manager > performance
check for your gpu0 and gpu1 (if it exists)
Nvidia, AMD, Intel are GPU brands
thanks! I'll give it a try
Ayo? @empty fjord level 2 !!!
the refresh button on my applio (the colab version) is not working