#✨│ai-help
1 messages · Page 170 of 1


can anyone help me with delay issue? idk if its the matter of microphone itself or settings
when i try using fcpe in applio, i now always get a “FCPEF0Predictor” error saying “unexpected argument ‘sample_rate’” which wasn’t happening before. is something wrong with applio or is it me? the other algos work fine
Ayo? @teal dome level 7 !!! 
are you sure you are using https://colab.research.google.com/drive/1u1brjK8IZt647UsbZuGYfW29oFM2I4tk?usp=sharing and not another aicovergennoui?

Depends on your gpu
type in #🔍│help-w-okada your gpu name and send a pic of your settings
alr
Ayo? @brittle wing level 3 !!!
can someone teach me how to generate an AI kpop voice? i’ve been trying a lot but I failed 🥹
you want to train an RVC Voice model? check our docs https://docs.aihub.wtf/essentials/how-to-make-ai-cover/
Have the audio file of your song ready, & let's extract the vocals from it with an audio isolation software.
If you got a good pc use Mainline or Applio, else use the Google Colabs, or for a better free cloud experience but harder read the Mainline Kaggle Guide

This guide for Mainline Kaggle is an alternative option to the Mainline Colab notebook for training voice models
It is complete and should walk you through every step of the way since Kaggle has a difficult learning curve. However, it will be updated constantly since new updates to the notebook w...

doesnt let me post a picture but ineed help
getting this error
content/voice-changer/server
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-6-c4b2eef38e98> in <cell line: 24>()
22 get_ipython().run_line_magic('cd', '/content/voice-changer/server')
23
---> 24 from pyngrok import conf, ngrok
25 MyConfig = conf.PyngrokConfig()
26 MyConfig.auth_token = Token
ModuleNotFoundError: No module named 'pyngrok'
NOTE: If your import is failing due to a missing package, you can
manually install dependencies using either !pip or !apt.
To view examples of installing some common dependencies, click the
"Open Examples" button below.
im using the old one ig, it worked like months before I took a break from youtube so I havent been using it now that Im back to making videos it wont let me
send google colab link
its better u use the newer one that is fixed
dont use that
-rt
This interaction has expired, use the command
/guides realtimeif you wish to see it again.
should I keep training or stop?

looks good, you can save that model but still keep training if it goes down more
but it does already look good tho
to keep training it, I would set all the setting in applio again, then jsut press begin training right?
no need to do other buttons
yes
yup, just make sure its the original logs file, name, settings
and like what step in the graph should I use to inference with?
or weight
i'm thinking right around here

try the latest one
oh ok
since thats seems to be your lowest point
the guide says not to do that, but that sounds like a better idea
oh! i read it wrong. Thanks
do i upload the python file into model or index>
what
???
i cant send it here
im confused ngl
wow! all those hours of training worked out. I made a model from all my past vocal takes and it sounds decent. Thanks again y'all


whys the voice uploading keep changing from 5% to 17% to 29% back down to 16%
Ayo? @brittle wing level 1 !!!
does anyone know how to separate overlapping vocals from the acapella of one song? (say someone sings another lyric while the other person sings)
Those are hard to separate, u can try the Karaoke model on mvsep.com
Theres some others to try, someone else might know more
Same applies on UVR
got this, thank you!
i dont understand how to use the voice on discord or something
You can try using UVR BVE on MVSEP or BV2 V2/Mel Karaoke on X Minus (tho this one is paid)
download Virtual Cable, explained on the guide step 6
https://rentry.co/VoiceChangerGuide
Afterwards you do this on the screenshot


Reviving in the future, will change install instructions to be "manual" build (for nvidia at least as its infinitely better performance)
Github - Blanc-dot
Discord User ID - https://discord.com/users/824922747423031359
Despite being end of life, most if not all information has not reall...
hello all, im new to this discord and would lke to ask how to instal the voice files on this server into so-vits-svc-fork to get a real time voice changer, can anyone lend a hand?
gptsovits dont work with realtime wokada
Ayo? @pastel oak level 55 !!!
only rvc models
oh ok thank you, ill look into that right now
Why I have this problem?
Ignoring faiss-cpu: markers 'sys_platform == "darwin"' don't match your environment
Collecting numba==0.56.4 (from -r requirements.txt (line 1))
Using cached numba-0.56.4.tar.gz (2.4 MB)
Preparing metadata (setup.py) ... error
error: subprocess-exited-with-error
× python setup.py egg_info did not run successfully.
│ exit code: 1
╰─> [8 lines of output]
Traceback (most recent call last):
File "<string>", line 2, in <module>
File "<pip-setuptools-caller>", line 34, in <module>
File "C:\Users\wojte\AppData\Local\Temp\pip-install-3yy19jri\numba_299a783593934f0f9abf5b4ef7faca8b\setup.py", line 51, in <module>
_guard_py_ver()
File "C:\Users\wojte\AppData\Local\Temp\pip-install-3yy19jri\numba_299a783593934f0f9abf5b4ef7faca8b\setup.py", line 48, in _guard_py_ver
raise RuntimeError(msg.format(cur_py, min_py, max_py))
RuntimeError: Cannot install on Python version 3.11.4; only versions >=3.7,<3.11 are supported.
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: metadata-generation-failed
× Encountered error while generating package metadata.
╰─> See above for output.
note: This is an issue with the package mentioned above, not pip.
hint: See above for details.
C:\Users\wojte\OneDrive\Dokumenty\RVC>```@pastel oak Can you help him?
Just use Applio Colab.
thats exactly what ive been doing
usually it takes it several seconds to convert my audios
but now it can take so long that the colab stops
I have never gotten that issue.
its never been this slow

Maybe you should try splitting your audios in 2 parts?
Alright.
I don't really know how to solve that..
reminds me of the early ilaria huggingface rvc
those things would take hours to load
oh wait i think something's happening
if you have done global package install at another project/application, yeah it tends to cause conflicts
can you help me with this?
use the precompiled installation and you won't have to do that hassle
How to do it
now it uses a gpu so its the fastest option on the market
Ayo? @unborn eagle level 1 !!!
.
@steel forge i need help with rvc
Ayo? @fallow crown level 1 !!!
Does Mangio run on linux?
hey do u know how to install rvc
im having trouble
Haiii :3
It can but mainline is recommended over Mangio
Doesnt work inside OneDrive where you put everything
You have python 3.11, you need to downgrade to 3.10 to make it work
How to do it
google and download any 3.10.x version
🐢: A
Gotcha, are there any good guides for setting that up in Linux?
Ayo? @regal temple level 2 !!!
Do I need to uninstall to install version 3.10.x?
pls help

Yes
help pls
-hf
<:huggingface:1179800228946268270> Hugginface Spaces
- UVR5 UI, by Eddy and Ilaria Huggingface Spaces
- Ilaria RVC Zero, by Ilaria Huggingface Spaces
- RVC⚡ZERO, by r3gm Huggingface Spaces
- Applio, by IA Hispano Huggingface Spaces
- AICoverGen, by r3gm Huggingface Spaces
- Advanced RVC Inference, by r3gm Huggingface Spaces
- RVC v2 Huggingface version, by Clebersla Huggingface Spaces
More commands: -audio, -colabs, -kaggle, -local, -overtraining, -realtime, -rvc, -help
how to fix this

C:\Users\wojte\Downloads\RVC>python -m pip install -U pip setuptools wheel
Nie mo
Why?
HE YOU TYPE FIRST. YOU ARE GAAAYYYY
C:\Users\wojte\Downloads\RVC>pip install -r requirements.txt
'pip' is not recognized as an internal or external command,
operable program or batch file.
Yayyyy :3
your a Linux user do it yourself

I think you should be able to download the version depending on your GPU and open the sh file inside
What if i told you I have no idea what I’m doing in linux but my pipeline necessitates it 
pls help
when i run rvc it crashes everytime i try to convert

technical question because i'm curious.. how are accents stored in the index file? and how does it extract them so fast? it only takes seconds to train the index file whereas it can take several hours to train the main pth, depending on the size of the dataset
@acoustic scarab what should i put the vac in? input or output?
out
vac in goes to out, vac out goes to in
while i'm talking it's sounds like robot how can i fix this i want make it closest to girl voice

index doesn't really store the accent of the model, the accent is in the model itself, what index does is to learn the characteristics of the audios, this can be how the speaker pronounces certain consonants or how the speaker talks, so for example if you have a raspy voice model, decreasing index will decrease the raspy voice a bit but not fully remove it
so thats why is faster
Think you should be able to unzip and run the sh file iirc
ohhh that makes sense
super interesting
Rename the “New Folder (2)” to something else without any spaces
guys m having problem with applio its said omegaconf 2.0.6 has a non-standard dependency specifier
does someone know how to fix it
Depends on your dataset
values are more stable and the model sticks more to the dataset, leading to having less versatility
batch size is not really a quality setting, but a stability setting
8 or 16 for 7-10 minutes and above
4 for 5 minutes and below
however like hina said, it depends on* your dataset
16 is more accurate to the dataset
can someone come to the vc i am in and help me a lil bit setting up the a voice mod
nvm I suck at explaining that stuff
How do I prove that the model works?
By testing it with any speech or singing audio.
Whenever you finish training a model, for testing it you can place any kind of audio sample (clean ofc with no instrumental or noise) on the "audios" folder, and then you put the path to the audio you wanna test on the Inference tab
does rvc work with amd?
cuz i tried two version(MMVCServerSIO_win_onnxdirectML-cuda_v.1.5.3.18a) and (vcclient_win_cuda_2.0.58-alpha) and they both said that i have an outdated cuda driver.
torch\nn\utils\weight_norm.py:28: UserWarning: torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.
warnings.warn("torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.")
2024-08-08 04:31:50.6181048 [E:onnxruntime:Default, cuda_call.cc:116 onnxruntime::CudaCall] CUDA failure 35: CUDA driver version is insufficient for CUDA runtime version ; GPU=-1364851804 ; hostname=ASUS2 ; file=D:\a_work\1\s\onnxruntime\core\providers\cuda\cuda_execution_provider_info.cc ; line=125 ; expr=cudaGetDeviceCount(&num_devices);
*************** EP Error ***************
EP Error D:\a_work\1\s\onnxruntime\core\providers\cuda\cuda_execution_provider_info.cc:125 onnxruntime::CUDAExecutionProviderInfo::FromProviderOptions [ONNXRuntimeError] : 1 : FAIL : provider_options_utils.h:153 onnxruntime::ProviderOptionsParser::Parse Failed to parse provider option "device_id": CUDA failure 35: CUDA driver version is insufficient for CUDA runtime version ; GPU=-1364851804 ; hostname=ASUS2 ; file=D:\a_work\1\s\onnxruntime\core\providers\cuda\cuda_execution_provider_info.cc ; line=125 ; expr=cudaGetDeviceCount(&num_devices);
when using ['CUDAExecutionProvider']
Falling back to ['CUDAExecutionProvider', 'CPUExecutionProvider'] and retrying.
If you use zluda you can get training to work
what is zluda?

GitHub
Install pre-requisites: a) HIP SDK 6.1.2 https://www.amd.com/en/developer/resources/rocm-hub/hip-sdk.html b) Zluda 3.8 https://github.com/lshqqytiger/ZLUDA/releases/tag/rel.86cdab3b14b556e95eafe370...
Cuda translation thing
Yes
(RVC1006AMD_Intel) i have this and t doesn't work
Ayo? @dense cape level 1 !!!
https://github.com/deiteris/voice-changer/releases download the newest dml version
GitHub
リアルタイムボイスチェンジャー Realtime Voice Changer. Contribute to deiteris/voice-changer development by creating an account on GitHub.
i have an rx 6600
hmm ok will try
I am so sorry for being such a nub, what .sh file should I be running on linux in the mainline distribution in order to be able to run RVC?
do i install this with zluda?
No
You only need zluda if you want to train a model
oh ok thank you ❤️
i just downloaded the voice changer and i can hear myself fine but it wont work in game or anything like that and i am not sure how to get it to work can anyone help me?
thx it worked
I'm getting this error when trying to run RVC in linux:
run.sh: line 54: ./tools/dlmodels.sh: Permission denied
What could be causing this?
-realtime read the stuff on the voice changer guide about the audio cable
This interaction has expired, use the command
/guides realtimeif you wish to see it again.
how to fix this error
when i press download button i am getting this

Help me to dowload the whole thing
i have a macbook
im so confused
Download what thing
the whole thing
i dont even know how to start it
or where
What thing
Like let’s say you went a restaurant, and you ask for food
They don’t know what food you want
ai
Ayo? @solar thunder level 1 !!!
from the github
Which ai from the GitHub?
i was trying to follow this https://youtu.be/We5oYpCR3WQ?si=PClqiDF07NlBRdA0 tut
but he has a window
and i have mac
and im lost
-realtime
This interaction has expired, use the command
/guides realtimeif you wish to see it again.
i tried before
search up how to get bootcamp on mac
u have to do alot of stuff though ts hard gng
so i just left it as it is
😭
https://github.com/deiteris/voice-changer/releases/download/b2271/voice-changer-macos-arm64-cpu.tar.gz use this if your on a apple silicon mac
(Apple silicon is like M1/M2/M3)
Discord gives that alert on any direct download link
@violet heron whats download link for windows?
oh
What’s your GPU?
amd ryzen
imma just give up
I said GPU, not CPU
bye
oh
thanks for trying to help
uhh lemme see
Mac users when they have to do something that isn’t dragging the file to the applications folder

i gave up
i like windows a lot
What part do you give up on
everything of it
Why tf do you have a mac
i bought this mac when i was 8
idk why i choose this
i could have gotten windows
Click on the file to download it, unzip it, run the sh file
MY ADOBE STUFF COULD HAVE BEEN EASY THOSE SCHOOL STUFF
idk why
i bought
this damn mac
Unless your mac has a Intel chip then your basically screwed
@violet heron radeon pro 555x
Ayo? @hidden crow level 1 !!!
is my gpu
The M2 chip first released in 2022 and you said you got it when your 8, this means your now 10
Which means your underage

idk
this
that was 2 years
ago
my memeory
si not memeorying
im not 10 certainly
Ayo? @solar thunder level 2 !!!
if i was i would not even know these
-realtime might or might not work on yours, read the guide for the fork
This interaction has expired, use the command
/guides realtimeif you wish to see it again.
if you were you would be watching duckus


deadass
deadass
:3

alr bro
that okay
i have my passport
to verify
again
i been banned on this acc a lot
I wonder why
I have edited the audio in bandlab after extracting the audio with Uvr5 ui and changing the voice with ilaliarvc, but this time there is a definite discrepancy, what should I do?
explain what kind of issue it is
どのような問題なのか説明する
When I put two audio data together in bandlab(daw), one with vocals only and the other without vocals, there is definitely a discrepancy between the two audio files.
It looks like this.
misaligned tempo, right? or you should probably do proper mixing
テンポがずれてるよね?あるいは適切なミキシングを行う必要があるでしょう
I dont know, at this point download a prepackage instead of manual idk
Set (MME) at the end for input and output, you selected two different types
any other stuff on rvc realtime check here
This guide will be in the same style/format as Blancdot's w-okada guide for simplicity sake. Credits go to the legend.
Thanks to Codename for additional input.
Last update: August 6th, 2024
Personal opinion + Recommendations + Overview
Download
Download NVIDIA
Download AMD/INTEL GPUs
Virtual Audi...
-colab
☁️ Google Colabs
- Applio, by IA Hispano Google Colab
- RVC Disconnected, by Kit Lemonfoot Google Colab
- RVC Mainline, by Hina Google Colab
- AICoverGen-WebUI, modded by Hina Google Colab
- AICoverGen-NoWebUI [English], by Ardha, fixed by Eddy, Hina and Gdr Google Colab
- AICoverGen-NoWebUI [Spanish], credits to Eddy, Hina and Gdr for translating and fixing Google Colab
- Ilaria RVC, by thestingerx Google Colab
- UVR5 NO UI for Google Colab, by Eddy Google Colab
- UVR5 UI, by Eddy Google Colab
More commands: -audio, -hf, -local, -kaggle, -overtraining, -realtime, -rvc, -help
Ayo? @brittle wing level 2 !!!
how do i start training models?
Ayo? @opaque spoke level 1 !!!
for local you need an nvidia RTX gpu
else you can use a cloud option
https://docs.aihub.wtf for guides and instructions
Last update: Mar 10, 2024
If you need cloud option, check pinned message and open Ilaria RVC the one for training, thats also a good one to use for training
ok thanks
im using nvidia
holy that download is huge
how long do you guys think it will take to make a model?
depend on your gpu spec
Last update: Mar 10, 2024
how long do you think it will take to learn
only God knows till you try
how long does it normally take??
Ayo? @opaque spoke level 2 !!!
i was just wondering how much time I would need to dedicate for this
you couldn't even predict tomorrow's weather accurately
Learning to clean a dataset is more important which the basics are explained and you can use right away
Training you do with a few clicks, the actual training process you monitor over with Tensorboard which is explained there too. training can take a few hours
You dont have to do anything while it trains
Why my training go back to epoch 1????
qte14_t3 | epoch=10 | step=3800 | time=20:27:54 | training_speed=0:02:16 | lowest_value=15.088 (epoch 10 and step 3687)
Training has been successfully completed with 10 epoch, 3800 steps and 34.271 loss gen.
Lowest generator loss: 15.088 at epoch 10, step 3687
Saved model 'C:\Users\dmg03\Downloads\Applio-main\logs\qte14_t3\qte14_t3_10e_3800s.pth' (epoch 10 and step 3800)
Successfully synchronized graphs!
Starting training...
Loaded pretrained (G) 'rvc\pretraineds\pretraineds_custom\G_KLM42_T4_40k.pth'
Loaded pretrained (D) 'rvc\pretraineds\pretraineds_custom\D_KLM42_T4_40k.pth'
0%| | 0/380 [00:00<?, ?it/s]C:\Users\dmg03\Downloads\Applio-main\env\lib\site-packages\torch\autograd_init_.py:251: UserWarning: Grad strides do not match bucket view strides. This may indicate grad was not created according to the gradient layout contract, or that the param's strides changed since DDP was constructed. This is not an error, but may impair performance.
grad.sizes() = [64, 1, 4], strides() = [4, 1, 1]
bucket_view.sizes() = [64, 1, 4], strides() = [4, 4, 1] (Triggered internally at C:\actions-runner_work\pytorch\pytorch\builder\windows\pytorch\torch\csrc\distributed\c10d\reducer.cpp:334.)
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
qte14_t3 | epoch=1 | step=380 | time=20:30:29 | training_speed=0:02:13
qte14_t3 | epoch=2 | step=760 | time=20:32:38 | training_speed=0:02:08 | lowest_value=15.547 (epoch 2 and step 535)
This is what I reproduced. When I resume training, all D and G files will be deleted and go back to 1 epoch. crazy
yea use the fork
Every step in here is explained on the GitHub by the developer aswell which you can find here.
Guide style is in the same as Blanc_dot's guide for simplicity and familiarity sake. Thanks to Blanc_dot for help on the guide. Most information is copied from deiteris himself.
Picture or GIF instructi...
download amd Version
with no delay?
delay is always going to be happening especially on older cards
with rx 570 maybe 1 second not sure
thanks
Ayo? @molten marlin level 1 !!!
I will try
the voices are so choppy and not clear at all for some reason
It's because some (if not the majority of public ones) models aren't trained properly or not suitable for realtime.
the D and G files were actually not saved before
even the 4 initial voices when I’ve downloaded the client
Ayo? @brittle wing level 1 !!!
Then it's probably something related to your okada settings.
Show your settings so MJ can help you.
🐢
hi my tortuguita
Haiii my MJ
how have u been

i see

colab still working?
I think there's a colab for W-Okada.
can i have it
don't use crepe_full, use rmvpe instead
ig mess with chunk & extra to see what works best for you
and maybe use sup2 if u have BG noise
alr tq
Hi how can I make the voice on w-okada sound like the samples? Any voice sounds nothing like the samples
Realtime works a bit different, you might have heard inferenced samples. So models may not all sound perfect on realtime
Best is to look for asmr, mommy, streamer, egirl voices for realtime.
dont forget to mess with the Tune / Pitch if its a different gender until it sounds right
Yea I wanted to sound like Trevor Phillips lol
Or Obama, but the voice sounds like a white person
Maybe using index a bit can help
id guess Obama works fine since its mostly taken from speech
Models not sounding like the original voice in realtime are because of multiple factors, but the main one is when your voice is too different from the original one, for example my voice is very high pitched and i talk very differently compared to the model i am using, this causing the model sounding weird despite being well trained
I noticed increasing index to 0.5 ish forces the model to pronounce consonants like the og voice and mimic more the way the original voice talks (still not perfect, the change is minimal, some models can do 0.7 index in realtime but not all),
but this can affect the model pronunciation (gets worse, it makes the model pronounce certain consonants like the original voice but can make even simple words have pronunciation issues) and sometimes even adds artifacts
So the best u can do for characters/known people is to actually mimic the way they speak
Sometimes the model may be undertrained, sadly u can’t fix that if u didn’t made the model
i love you lyery
Hi guys, how long does this process usually take? Making an Ai cover btw

Ayo? @abstract vortex level 1 !!!
I remember when i brought him to the staff team haha.
It will depend on the index and pth's size
Pth file's will always only have 50+ MBs of size
But the .index size will always depend.
Ohh okay, thank you! I havent made ai covers in a year and I was so used to using the easy gui haha everythings so different now
Yep, EasyGUI is kinda outdated now

⠀
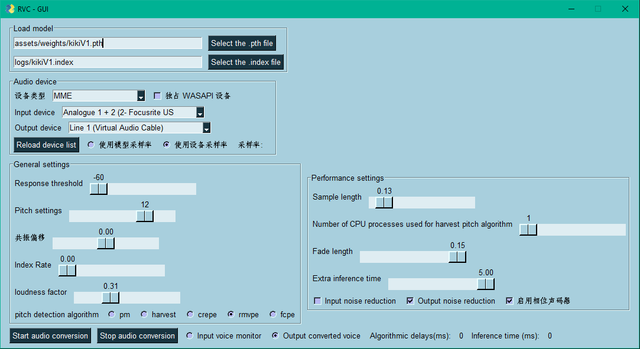
Settings for Nvidia GPUs 
F0 Det.: rmvpe (suggested for all series)
RTX 40-series: 80-96 chunk | +16384 extra
RTX 30-series: 96-112 chunk | +16384 extra
RTX 20-series: 112-128 chunk | +16384 extra
GTX 16-series: 128-192 chunk | +8192 extra
GTX 10-series: 128-192 chunk | +8192 extra
Advanced Settings
Protocol : Sio or Rest
Crossfade: 4096 start 0.2 end 0.8
Trancate: 300
Silencefront: Off
Protect: 0.5
RVC Quality: Low
⠀
INSTALL_Mangio-RVC-v23.7.0_INFER where does this install what location?
⠀
Download for Nvidia GPUs
Version 18a cuda
Download for AMD GPUs 
Version 18a directml
Download for Intel GPUs 
Version 18a directml
Download for Mac 
Version 17b Mac
⠀
Thats a prepackaged download, so all the files remain in that folder iirc
⠀
Settings for Nvidia GPUs
F0 Det.: rmvpe (suggested for all series)
RTX 40-series: 80-96 chunk | +16384 extra
RTX 30-series: 96-112 chunk | +16384 extra
RTX 20-series: 112-128 chunk | +16384 extra
GTX 16-series: 128-192 chunk | +8192 extra
GTX 10-series: 128-192 chunk | +8192 extra
Advanced Settings
Protocol : Sio or Rest
Crossfade: 4096 start 0.2 end 0.8
Trancate: 300
Silencefront: Off
Protect: 0.5
RVC Quality: Low
⠀
-kaggle
Kaggle Notebooks
- UVR5 NO UI by Eddy
- How to use RVC Mainline Kaggle by Cauthess
- 🍏 Applio RVC by IA Hispano
- ✨ RVC Mainline by Hina
More commands: -colabs, -hf, -local, -rvc, -help
-overtraining
Overtraining
You can detect if a model is overtraining if the TensorBoard graph starts to rise and never comes back down. An overtrained model will sound robotic, muffled, and won't be able to articulate words well.
Check these resources to learn more about this topic
- Epochs & TensorBoard from
 AI HUB Docs
AI HUB Docs - TensorBoard from 🍏 Applio Docs

Cannot connect to GPU backend
You cannot currently connect to a GPU due to usage limits in Colab. Learn more
To get more access to GPUs, consider purchasing Colab compute units with Pay As You Go.
any way to fix without paying
what you need?
Ultimate Vocal Remover
One of the best free and open source vocal and instrumental isolation tool.

4h limit every day
make new google account if u want
what does rvc even mean
retrival based voice conversion
it does not mean real voice changer
how to separate two voices in uvr?
Ayo? @golden karma level 2 !!!
You can try using UVR BVE on MVSEP (also for free) or one of the Karaoke models in UVR
okay thanks
What
How can I get RVC inference running locally on my Mac? I was using the Applio WebUI, but now I want to run it locally, without a WebUI. I want to be able to run it in my VSCode terminal. I just need to run inference, and be able to adjust the settings. I am familiar with Docker if I need to use that.
-rvc
Documentation
✨ More guides
- How to use RVC Mainline Colab by Cauthess
- Full AI Voice Model Training Guide (local) by Christopher Villanueva
- AICoverGen Colab Guide by Eddy (Spanish Helper)
- Create a model with RVC disconnected (colab) by Angetyde
Ayo? @sharp solstice level 1 !!!
AFAIK these are just for getting it to run on the WebUI
I want to be able to run it in VScode, without the webui
RVC and Applio both have CLI versions
w/ RVC AIO is it possible to train more than 1000 epochs?
I don't see on the Applio page where the have a CLI version (I don't think they do)
But I can check ine of the RVC repos
-rvc
Documentation
✨ More guides
- How to use RVC Mainline Colab by Cauthess
- Full AI Voice Model Training Guide (local) by Christopher Villanueva
- AICoverGen Colab Guide by Eddy (Spanish Helper)
- Create a model with RVC disconnected (colab) by Angetyde
Ayo? @vivid pewter level 1 !!!
stereo or mono? does it even make any difference?
rvc converts the dataset to mono when preprocessing
ah alright

GitHub
🚀 RVC + UVR = A perfect set of tools for voice cloning, easily and free! - blaisewf/rvc-cli
Thank you, ill check this out
Well, there's no option for Mac
-uvr
Ultimate Vocal Remover
One of the best free and open source vocal and instrumental isolation tool.
@glad zealot this happen when trying to use mainline colab 

is there a guide on how you should merge models and stuff
link that you are using?

werd i just started it and it works no problem
hmm, i'll try again now
uh i have no clue what theyre saying lol
I'm like new and I was trying to see how I could make a realistic model
need help with RVC, downloaded it and it shows me 6 options and wont show me any of the default voice models
Ayo? @stiff helm level 8 !!!
yea its working fine now, idk i blame google lol
Take your best g/total and your best kl/mel for the merge. You upload the pth file on the folder here after you hit "download" and "run" https://colab.research.google.com/drive/1mHKTGH5e3SAyDSBss1KtiYRbDdQzwSMs


322 was best g/total and best mel/kl 442 epoch
what is g/total and mel/kl?
what's better crepe or rmvpe
so read this first https://docs.aihub.wtf/rvc/resources/epochs--tensorboard/#-setting-up. You can think of mel and kl being attached to each other. No need to overcomplicate it
and read this if you want #1213509354343637065 message
Ayo? @thin stump level 35 !!!
for training or realtime conversion?
realtime conversion
rmvpe
What I meant is that if kl rises on the graph while mel keeps going down, it's done. You can always wait it out to see if it changes
oh ok ill try to figure it out along the way
but if I want a better model should I train an ai model of my own voice and merge it with another model?
It's just to improve clarity. I don't think you can take two different models and try to fuse that. We've already had someone fail miserably because he didn't listen to the errors saying you can't do that
what do you recommend I should do?
here  #✨│ai-help message
#✨│ai-help message
first of all get started on your model first before you worry about tensorboards
making my own voice model?
Yup, we have guides. I think if you learn about what RVC likes, you'll get great results
https://docs.aihub.wtf/essentials/how-to-make-voice-models/
https://rentry.co/RVC-dataset-RX11
what's the best model in uvr for separating harmonies?
wait so I make a voice model of my voice and then I merge it with another?
or am I supposed to do something else?
Make a dataset first > train in rvc > you have the .pth file and added_index. Do what I did here to merge pth files #✨│ai-help message
Again, it's a clarity boost for the overall model. But it wouldn't matter much if your dataset is noisy so please read the guides

uvr bve tho is not perfect
oh ok. is it fine if I ask which fork of rvc you recommend or should I just use the original? Also, how long should I record my dataset to be and how should I be speaking?
Are you more of a local use person?
merging a model of your real voice and a random model is not going to make it sound realistic, that is not how it works
yes
it will help it understand the way u speak more
but has the risks of sounding worse actually
how should I improve the clarity then?
or is it not possible?
realistic models are done using high quality audio, so no, if your current model is bad, you can't fix it
in realtime mic quality affects how clear your model sounds
and locally (rvc) the audio of the inference has to be clear as well
if your model doens't sound clear despite having both a good mic or a good audio, is a model problem
https://docs.aihub.wtf/rvc/local/mainline/.
^^ Record at least 10 minutes of lines or read an audio book or something. Too monotone and it'll sound monotone. You are the voice actor here
cause like when I try to talk it slurs my words. That's probably because im using a laptop mic right?
Ayo? @opaque spoke level 3 !!!
yes
basically for realtime you need a clear mic, low amount of background noise, and good volume mic
so I should buy a mic?
do you have any reccomendations?
first you have to try the model in rvc, locally, with a clean audio (can be a tts output, a clean raw vocal without effects, anything that is clear)
if its sounds clear there but not clear in realtime, is the mic
how do you do that?
if your pc can't run the software, you can use a cloud solution (colab, kaggle)
but it should work
edit: btw i don't recommend training rvc models in a laptop, it can potentially overheat them, but inference should be fine (just converting audio files)
do i need to have a good cpu and gpu?
for inference? not really
for training? yes
my laptop has a rtx 4060 and intel i7 13700h
would that be enough?
yeah, but be careful about your laptop temperatures if you want to train with it
training is very intensive for laptops
what should i do about it?
blow it with a fan???
or what
idk
i just told u about that in case u notice high temperatures while training in your laptop
like do i stop it if it gets too high or smth
yea stop it, is very dangerous for your laptop to overheat
can you have pauses in between training your model??
yes, rvc saves the process, you can stop it and continue later
oh ok
I'm trying to integrate rvc into a python script for tts I see this https://github.com/blaisewf/rvc-cli and it seems to be what I need but I can not seem to get it to work in either Linux or Windows. I want it to do the tts and inference from inside of a python script and generate and output.wav does anyone have any experience with this or an implementation of RVC that can do this?
how do i run beatrice v2? i downloaded the zip and ngl idk what to do next
Can someone explain this

I've tried it in mp3 and wav it won't work
Even putting the name in lower case then reuploading it
Tag me if anything
I'm currently using very high quality datasets to train models and i am wondering which pretrains would be the best to use? just the standard RVC V2?
Still the OG as long as you are selective about what you choose for your dataset (making it clean). Combine that with graph syncing, fp32 training, model fusion = good model
AIhub were all about pretrains just for the clarity boost and values during training. So the pendulum has switched around because at the end of the day, Hifigan is crap
Thank you! What is fp32 training and graph syncing? I have'nt heard of this.
Ayo? @round quartz level 1 !!!
I've trained several convincing sounding models but i still haven't figured out how to read the tensorboard
https://github.com/IAHispano/Applio/issues/405 also check the server logs

GitHub
You can use this as a reference and turn into code for applio to properly have the graphs synced. All credits for the img guide go to codename btw. Also another thing that isnt mentioned in the gui...
What is the setting for separating two or more hams in a hagginface uvr?
any fixes for voice cutting?
You can read the W-Okada guides. (In fact, you can try and use Deiteris' fork)
Every step in here is explained on the GitHub by the developer aswell which you can find here.
Guide style is in the same as Blanc_dot's guide for simplicity and familiarity sake. Thanks to Blanc_dot for help on the guide. Most information is copied from deiteris himself.
Picture or GIF instructi...
How do I set up Uvr5 ui to separate multiple hamori parts?
Various harmonies?
You can try using the karaoke models.
Also, there's UVR online site which got Mel Karaoke.
メインボーカルを除く複数のバックボーカルがある設定を教えてくれませんか❓
よくわからないから、UVRにあるカラオケのモデルで試してみてほしい。
カラオケ モデルは、通常中央にあるメイン ボーカルの抽出に効果的です。
バック ボーカルをさらに分離できない場合は、ポリフォニック検出モードで Melodyne を使用して分離してみることもできますが、品質が保証されない可能性があります。
-colab
☁️ Google Colabs
- Applio, by IA Hispano Google Colab
- RVC Disconnected, by Kit Lemonfoot Google Colab
- RVC Mainline, by Hina Google Colab
- AICoverGen-WebUI, modded by Hina Google Colab
- AICoverGen-NoWebUI [English], by Ardha, fixed by Eddy, Hina and Gdr Google Colab
- AICoverGen-NoWebUI [Spanish], credits to Eddy, Hina and Gdr for translating and fixing Google Colab
- Ilaria RVC, by thestingerx Google Colab
- UVR5 NO UI for Google Colab, by Eddy Google Colab
- UVR5 UI, by Eddy Google Colab
More commands: -audio, -hf, -local, -kaggle, -overtraining, -realtime, -rvc, -help
That error appears because you've already used the free hours Colab gives you for usage.
You can solve it by just using an alt google account
RVC v2 Tutorial for Paperspace
💡 Click on the button below to open the guide.
Credits: LollenApe
thank you
Use Kaggle or Colab instead, RVC is right now unsupported on Paperspace since months ago
Ayo? @tame wharf level 4 !!!
@wispy lodge
yoo emoji
do u know how can i setup applio or mangio on paperspace
https://docs.google.com/document/d/1lIAK4Y0ylash_1M2UTTL_tfA3_mEzP0D2kjX2A3rfSY/edit
this guide doesnt work anymore i think
That I dunno, I don't use paperspace
oh
need new guide really this one i think trash totally
Use kaggle instead.
RVC is incompatible with Paperspace since months ago.
lol i paid just now
paperspace

they do refund or?
I'm not sure if you can refund..
-kaggle
Kaggle Notebooks
- UVR5 NO UI by Eddy
- How to use RVC Mainline Kaggle by Cauthess
- 🍏 Applio RVC by IA Hispano
- ✨ RVC Mainline by Hina
More commands: -colabs, -hf, -local, -rvc, -help
Read that guide made by Cauthess.
bro it says ngrok its too annoying thing
Yep, you need to create a ngrok account.
yea i need to create every few hours or something
making a model is annoying
ill try on my local
really
Uhh... Alright then.
i need place like paperspace
Idk if you can run RVC on runpod then.
Or vast.ai
But there are no up to date tutorials or notebooks for running RVC on runpod or vast.
-applio
🖥️ Local stuff
- 🍏 Applio, by IA Hispano GitHub
- Mangio-RVC-Fork, by Mangio621 Huggingface
- RVC Studio, by SayanoAI Huggingface
- AICoverGen, by SociallyIneptWeeb GitHub
- Replay, by Replay Team Website
- Original RVC, by the RVC-Project team GitHub
- GPT-SoVITS, by RVC-Boss GitHub
Credits to Faze Masta and Antasma for compiling these links.
More commands: -audio, -colabs, -overtrain, -realtime, -rvc, -help
@odd shale i want to do perfect voice model. i have 3 hours good data
How long should the data last for best efficiency?
Ehhh.. Just use 20 or 25 mins.
Hey Guys, what does this error in the colab version mean??
It's not mandatory to use various hours.

Building wheel for gin (setup.py) ... done
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
xgboost 2.1.1 requires nvidia-nccl-cu12; platform_system == "Linux" and platform_machine != "aarch64", which is not installed.
albucore 0.0.13 requires numpy<2,>=1.24.4, but you have numpy 1.23.5 which is incompatible.
albumentations 1.4.13 requires numpy>=1.24.4, but you have numpy 1.23.5 which is incompatible.
albumentations 1.4.13 requires pydantic>=2.7.0, but you have pydantic 1.10.17 which is incompatible.
chex 0.1.86 requires numpy>=1.24.1, but you have numpy 1.23.5 which is incompatible.
pandas-stubs 2.1.4.231227 requires numpy>=1.26.0; python_version < "3.13", but you have numpy 1.23.5 which is incompatible.
torchtext 0.18.0 requires torch>=2.3.0, but you have torch 2.0.1 which is incompatible.
torchvision 0.18.1+cu121 requires torch==2.3.1, but you have torch 2.0.1 which is incompatible.
Successfully installed all packages!
Broken, use different Colab
ok
-colab
☁️ Google Colabs
- Applio, by IA Hispano Google Colab
- RVC Disconnected, by Kit Lemonfoot Google Colab
- RVC Mainline, by Hina Google Colab
- AICoverGen-WebUI, modded by Hina Google Colab
- AICoverGen-NoWebUI [English], by Ardha, fixed by Eddy, Hina and Gdr Google Colab
- AICoverGen-NoWebUI [Spanish], credits to Eddy, Hina and Gdr for translating and fixing Google Colab
- Ilaria RVC, by thestingerx Google Colab
- UVR5 NO UI for Google Colab, by Eddy Google Colab
- UVR5 UI, by Eddy Google Colab
More commands: -audio, -hf, -local, -kaggle, -overtraining, -realtime, -rvc, -help
maybe i shoul up date my things too 😅
ok thx
Can someone help me I'm using local applio to train models. Does training take up a lot of space?
@odd shale ,
you finished your daily limited google colab gpu, you can:
- You can use an alt google acc
- Use kaggle that gives 30 hours weekly of more gpus
- Wait till tmr
- Pay for colab

which one should i choose
custom?
dont ask me
well okay
Shad, if someone makes you a question about which embedder to use, just say "don't alter it, keep it on contentvec"
I had a feeling default is probably correct, but didnt want to give false info in case, thx
Ur welcome Shady, and yep, contentvec is the default one
You could try https://docs.google.com/document/d/1ooG2hJrfNNLUln0reTKKIOpNBjp53G0joak50H_sQhE/edit that is made by a user here, but no one really uses paperspace here anymore so i dont think anyon can help you if it goes wrong

Google Docs
RUNNING APPLIO ON PAPERSPACE Step 1: Setting up a Paperspace notebook You will need a Paperspace Pro subscription, otherwise good luck trying to snatch a free GPU. Create a new project and a notebook. Select “Start from Scratch”, select a free available GPU and increase the auto-shutdown tim...

Google Docs
RUNNING ILARIA RVC MAINLINE ON PAPERSPACE Step 1: Setting up a Paperspace notebook You will need a Paperspace Pro subscription, otherwise good luck trying to snatch a free GPU. Create a new project and a notebook. Select “Start from Scratch”, select a free available GPU and increase the auto-sh...
made by @plush dew , but idk if they still work
i forgot about this lmao
if anyone still uses it i'll update
is there a specific program that you can use to use RVC models on silly tavern. I just have been using alltalk but was curious if I could actually load the RVC models since I know the extras api is been depracated.
Is anyone familiar with https://github.com/blaisewf/rvc-cli I'm building a voice assistant python script that reads the response from openais api. I got it to do inference after modifying a function call in the rvc_cli.py but I never managed to get it to do tts. Are there any options for RVC TTS that can be called without loading a GUI?
is it broken?
alltalk is a different tts thing, rvc is speech to speech, idk if silly tavern got anything about rvc
i thought silly tavern was mostly about llms and tts
Yeah your correct. looks like the alltalk beta might have some rvc conversion though.
idk i haven't used it in a while

wait what?
does anyone know good settings for a women? (ex: index rate: 9)
never knew about this damn
seems interesting
seems to work towards improving the xtts model if nothing else.
thanks!
index rate has nothing to do with being a woman or a man hun
your stuff is literally best working on this server so ofc we recommend yours first
-colab
☁️ Google Colabs
- Applio, by IA Hispano Google Colab
- RVC Disconnected, by Kit Lemonfoot Google Colab
- RVC Mainline, by Hina Google Colab
- AICoverGen-WebUI, modded by Hina Google Colab
- AICoverGen-NoWebUI [English], by Ardha, fixed by Eddy, Hina and Gdr Google Colab
- AICoverGen-NoWebUI [Spanish], credits to Eddy, Hina and Gdr for translating and fixing Google Colab
- Ilaria RVC, by thestingerx Google Colab
- UVR5 NO UI for Google Colab, by Eddy Google Colab
- UVR5 UI, by Eddy Google Colab
More commands: -audio, -hf, -local, -kaggle, -overtraining, -realtime, -rvc, -help
i made it idiotproof and futureproof
2 months and no need to fix or update 
I installed RVC, but this is what I get:
**Launching Retrieval-based Voice Conversion WebUI...
C:\Users\pozde\anaconda3\envs\rvc\python.exe: can't open file 'C:\WINDOWS\system32\Retrieval-based-Voice-Conversion-W ebUI\infer-web.py': [Errno 2] No such file or directory
TroubleChute One-Line installer:
(rvc) PS C:\WINDOWS\system32\Retrieval-based-Voice-Conversion-WebUI>**
what should I do to be able to launch it?
Ayo? @proud goblet level 2 !!!
Ilaria is goated.
(you)
sorry to ask but does anyone have the working rvc v2 disconnected colab the one i used to use is now offline
Tiraram minha permissão de falar
Ayo? @quiet cairn level 1 !!!
what training algorithm tolerates bad audio quality best?
i dont even want it to necessarily improve audio quality
i just want to know which one replicates it best
are u talking about pitch extraction methods? they don't matter in how similar the voice will sound
oh they don't? alright
do you advise against using custom pretrains?
aren't those just an extension of the OG pretrain?
rmvpe is more robust (clear) and is more pitch accurate
mangio-crepe is less robust (less clear) and is slightly less accurate (by a very small amount, like 1% less), capturates more details than rmvpe, but is highly sensitive to noise
yes
original already does everything
"noise" as in white noise? or just poor audio quality? like the one you would get from a poor microphone
as white noise yeah
oh alright
but also can be any type of noise, mouse clicking, a sfx residual, everything
mangio is very sensitive to that
i see
rmvpe handles those better
Please drop the google colab that works
Neural network
but since it capturates more details about your audio, the result is very smooth and, sometimes, realistic
unlike rmvpe which likes to make your model sound a bit metallic/robotic
oh okay
that all makes so much more sense now
thank you for the fast responses btw, you are always such a big help
like genuinely, i mean it
no problem, in simple terms, if you want to capturate every detail about your audio, use mangio, making sure no residual noise is present
noise sensitive means is gonna add that specific sound in the whole model no matter what
hifigan is very bad at cloning noise profile sadly
got it 👍
Ayo? @timid valve level 7 !!!
anyway, i used to be a pretty well-known modder in some other community and dealing with a lot of questions could really get on your nerves, especially when people weren't very specific about what they wanted to know or when there was a language barrier
so i really appreciate what you're doing
and your patience
what are the downsides to setting the hop length as low as possible? since that does make it more pitch accurate, allegedly?
Please drop Google colab, a neural network, to create covers that will work
-hf
Suggestions for @proud anvil
<:huggingface:1179800228946268270> Hugginface Spaces
- UVR5 UI, by Eddy and Ilaria Huggingface Spaces
- Ilaria RVC Zero, by Ilaria Huggingface Spaces
- RVC⚡ZERO, by r3gm Huggingface Spaces
- Applio, by IA Hispano Huggingface Spaces
- AICoverGen, by r3gm Huggingface Spaces
- Advanced RVC Inference, by r3gm Huggingface Spaces
- RVC v2 Huggingface version, by Clebersla Huggingface Spaces
More commands: -audio, -colabs, -kaggle, -local, -overtraining, -realtime, -rvc, -help
Thank you very much
besides the fact that it takes more time to infer
could it by any chance affect the quality of the model in a negative manner?
crepe was trained at a hop length of 10 so anything below that may cause issues
ahh
im going to train it on a hop-length of 32 for now since that's already half of what the default is
oh wait sorry i got confused, crepe was trained with a hop length of 160
setting the hop length below that is fine xD
however i remember below 64 you can't really hear the change
oh okay
is not bad to set it below 64
i even trained with a hop length of 8 just fine xD
it's just finished inferring so ig it doesn't matter at this point
damn
that must've taken forever
for speech 64-32 is good, below that i noticed is more prone to have voice cracks
remember that crepe (mangio) is less pitch accurate than rmvpe, so is not very good at speech
for inference, rmvpe is generally better
imagine modding rvc
also remember that inferencing a model in crepe is not going to add the benefits of crepe (removing the metallic sound of rmvpe)
to do that you have to train a mangio model and inference mangio
then you can notice the change
rmvpe models can inference crepe but ofc they perfom better inferencing rmvpe
they simply don't get the benefits of crepe
so i should just use rmvpe when inferencing no matter what
if your model is trained with rmvpe? yes, is better, more pitch accurate
mangio models sound better inferencing mangio, not because is more pitch accurate for them but because the audio get more smooth for them
that makes sense
for the voice changer purpose, stick on rmvpe anyway
yes, always
speech models always have to use rmvpe, mangio perfoms poorly on speech
asmr voices, soft voices can hide that fact tho
yea i've noticed a lot of pitch inconsistencies
completely unrelated bujt something i noticed is how much faster training is once i disable the webui by turning off my browser..like pretty much twice as fast than with the webUI running
im using firefox and it eats up so much ram
are u using mainline or applio
applio literally says applio and the ui is black and green
ah no main line hten
mainline has some chinese text in the training tab
mainline
yea is true that closing the webui can save some resources
okay so i'm not just imagining things xd
good
why are so many models roughly the same size, even when trained on much bigger data sets? they all seem to be around 54MB for me
i once trained a refined model with twice the amount of data than the first model and the size of model stayed roughly the same
same model parameters for the same architecture
(I mean take analogy of the billion param llm)
oh so that's what mostly determines what size the model will have?
index file size
yea that's where i noticed the highest discrepancies
i had to look that up ngl but it's starting to make sense
once again, thanks for all the help, i learn so much from you
Please drop a google colab that will work, a neural network
-rvc
Documentation
✨ More guides
- How to use RVC Mainline Colab by Cauthess
- Full AI Voice Model Training Guide (local) by Christopher Villanueva
- AICoverGen Colab Guide by Eddy (Spanish Helper)
- Create a model with RVC disconnected (colab) by Angetyde
I got Error
"'NoneType' object has no attribute 'setdefault on AiCoverGen
How do I fix it?
I believe AiCoverGen is broken atm. You should use something else
If its for inferencing, check pinned message for Ilarias RVC Zero, its fast and pre-set up on the huggingface space
You can also use command -colab and try out different ones.
I have problems with that as well
GPU crash out something like that
Ayo? @ocean quail level 1 !!!




Maybe it lost connection? It works for me, so perhaps restart, and then scroll back to top when you convert and check the top right for the updates on connecting to gpu etc.
im trying to train a model. but where do i find the 32k sample rate option??

click on 48k, then back to 40k, it will appear
is bugged
i tried but it still doesnt show
what should i do?
click v1 then v2
ohhhh ok thanks
is there a recommended settings to train my voice model with? is there like a guide or something?
like what do i put here?

1
just keep most things default
ok
is this ouput good?

Hey Guys, does anyone know why cant I uplod models to the colab verion of the vc?
Ayo? @proud pecan level 1 !!!
there's Extraction type named rmvpe but i only got crepe and harvest in my RVC GUI
do i need to download rmvpe or need to download another version of rvc ?
Nvm it just takes a while
hmm good question, next question
i answred in #🧬│ai-chat
jk, but i sadly can´t help you wthat
do you guys know what this error is?

Ayo? @opaque spoke level 4 !!!



bruh nvm im still getting the error
how long does it normally take to train a model with a 13 minute dataset
ただいまー!
GPUの使用制限に達しましたか?
よく分かりませんが、UVR関連の質問がある場合は、DMで送信するサーバー招待リンクにお気軽にご参加ください。
My Model is failing to import does someone know why?
failing to import in which rvc?
the Collab v2
what Collab v2

if it were local okada, I would be able to answer
Ayo? @knotty moth level 28 !!!
I dont recognize this, is this an old colab?
no a new one
Can you link it instead of screenshot
Else id recommend you check out this message with link and guide:
#🔍│help-w-okada message
Ayo? @proud pecan level 2 !!!
oh ok thx
ah I see 
oh ok
you can instead use hina's colab, as well as the guide https://docs.google.com/document/d/e/2PACX-1vTIceEcBfS6Zqolv_QEysrFfI_EJikPxozWptP_EjkpLVl-l-gdo-ijBonQMTviAHEYm5emmd9k9TdC/pub
ok thx
the discord msg i linked links to that already

ignore that, it doesnt work
says so on the msg i linked
you upload models on the app when it opens
I have exceeded the GPU utilization of the UVR5UI, what should I do? What can I do to avoid exceeding the gpu utilization as much as possible?
come back tomorrow or use a colab alternative
明日また来るか、colabの代替品を使用してください
i tried it like 15-20 times and it wont even start because it cant connect with the gpu, what should i do?
You can:
- Use alt google acc
- Use the ZeroGPU HF Space
- Wait till tmr
- Pay for colab

If you finished the Google colab GPU,
You can:
- Use alt google acc
- Use the Kaggle version (a bit harder than colab and requires a phone number)
- Wait till tmr
- Pay for colab
This guide for Mainline Kaggle is an alternative option to the Mainline Colab notebook for training voice models
It is complete and should walk you through every step of the way since Kaggle has a difficult learning curve. However, it will be updated constantly since new updates to the notebook w...
come back tomorrow if the gpu usage limit has reached
I want to know how to make a model and put it in the program
Ayo? @steep mantle level 1 !!!
What's your GPU?
NVIDIA
さっきまたuvr5やったんですけど設定変えたらできてこれってモデルが良くないってこちですよね?
Yeah but what is it? Rtx 3060?
Is there any setting other than karaoke model or uvr-bve that separates the background vocals from the main vocals?
It's rtx 1650
I think you mean GTX as all RTX models start with 2XXX
You can't train with that locally
You have to do it on cloud
For colab (4 hours of daily gpu for free, not much hours, but easy to use):
- Applio (ui)
- Mainline (UI)
- RVCDISCONNECTED (no ui)
For kaggle (a bit harder to use and needs phone number but gives 30 hours weekly of better gpus): - Mainline (UI)
Last update: June 15, 2024

In this guide, I will be explaining how to use the RVC Mainline Colab notebook to create voice models
I will not be teaching about voice model training and reading tensorboards since there's already guides for it on AI HUB
RVC Mainline is an significant improvement over the RVC Disconnected colab...
Last update: Mar 8, 2024
This guide for Mainline Kaggle is an alternative option to the Mainline Colab notebook for training voice models
It is complete and should walk you through every step of the way since Kaggle has a difficult learning curve. However, it will be updated constantly since new updates to the notebook w...
十分な品質が得られ、処理時間が長くなりすぎないように設定を調整できます。
ok tomorrow is ok
tysm now I know it
Or you can just create alt Google accounts.
So you don't have to wait till tomorrow.
what does gpu0 gpu1 ect mean
i have one good working <333 after 4 months
i have issue with my own voice cutting any solutions?
You downloaded AMD version of the voice changer, there u have to select gpu number thats registered on your pc
-colab
☁️ Google Colabs
- Applio, by IA Hispano Google Colab
- RVC Disconnected, by Kit Lemonfoot Google Colab
- RVC Mainline, by Hina Google Colab
- AICoverGen-WebUI, modded by Hina Google Colab
- AICoverGen-NoWebUI [English], by Ardha, fixed by Eddy, Hina and Gdr Google Colab
- AICoverGen-NoWebUI [Spanish], credits to Eddy, Hina and Gdr for translating and fixing Google Colab
- Ilaria RVC, by thestingerx Google Colab
- UVR5 NO UI for Google Colab, by Eddy Google Colab
- UVR5 UI, by Eddy Google Colab
More commands: -audio, -hf, -local, -kaggle, -overtraining, -realtime, -rvc, -help
Ayo? @glad veldt level 5 !!!
You have to convert it to onnx yourself.
On w-okada voice changer you can do this by uploading the pth model, then clicking on export to onnx
Ayo? @worldly totem level 3 !!!
I can, but it doesn’t work, it just wheezing
What do you mean wheezing
Whats the problem rn why do you need onnx
like white noise
The onnx voices I make myself just produce white noise
I dont know why it does that but why do you need onnx anyway? for what
Maybe theres an alternative
Hi everyone! I have a problem installing fairseq through pip. Does anybody has the same issue
are you talking about colab notebooks? try downgrading pip to ver 23
how do i downgrade pip?
where i can get snowie? pretrain
I think the problem is in onnx which my computer makes, maybe onnx ready voice will fix my situation
!pip install pip==23.1
That didnt answer the question again
Anyway people dont upload ready-onnx files
Any help?
-colab
☁️ Google Colabs
- Applio, by IA Hispano Google Colab
- RVC Disconnected, by Kit Lemonfoot Google Colab
- RVC Mainline, by Hina Google Colab
- AICoverGen-WebUI, modded by Hina Google Colab
- AICoverGen-NoWebUI [English], by Ardha, fixed by Eddy, Hina and Gdr Google Colab
- AICoverGen-NoWebUI [Spanish], credits to Eddy, Hina and Gdr for translating and fixing Google Colab
- Ilaria RVC, by thestingerx Google Colab
- UVR5 NO UI for Google Colab, by Eddy Google Colab
- UVR5 UI, by Eddy Google Colab
More commands: -audio, -hf, -local, -kaggle, -overtraining, -realtime, -rvc, -help
Ayo? @wild vapor level 2 !!!
thank you so much, i ve been looking for a solution a very olng time
Ayo? @grave mortar level 1 !!!
-rvc
Documentation
✨ More guides
- How to use RVC Mainline Colab by Cauthess
- Full AI Voice Model Training Guide (local) by Christopher Villanueva
- AICoverGen Colab Guide by Eddy (Spanish Helper)
- Create a model with RVC disconnected (colab) by Angetyde
-audio
📚 Audio Guides
- Creating Datasets for RVC using iZotope RX11, by Cauthess
- Perfecting Audio Isolation on Low-End Rigs, by Litsa The Dancer and Faze Masta
- Gathering and Isolating Audio, by SCRFilms :snowflake:
- Vocal Mixing Tutorial, by Roomie
🛠️ Tools
Audio Separation/Isolation
More commands: -colab, -uvr, -karafan, -overtrain, -help
you are prolly using the easygui google colab, reminder that its abandoned and there are other issues with it too
im using
one sec
why doesnt it detect my GPU?


are you doing it locally or on google colab?
locally, on my pc
Alr, https://docs.aihub.wtf/rvc/local/mainline/ could help you
Last update: Mar 8, 2024
u mean i just need to download RVC1006Nvidia.7z instead of mine?
or troubleshoot using the given link?
Yep, that link contains things which will may help you.
oh
-colab
☁️ Google Colabs
- Applio, by IA Hispano Google Colab
- RVC Disconnected, by Kit Lemonfoot Google Colab
- RVC Mainline, by Hina Google Colab
- AICoverGen-WebUI, modded by Hina Google Colab
- AICoverGen-NoWebUI [English], by Ardha, fixed by Eddy, Hina and Gdr Google Colab
- AICoverGen-NoWebUI [Spanish], credits to Eddy, Hina and Gdr for translating and fixing Google Colab
- Ilaria RVC, by thestingerx Google Colab
- UVR5 NO UI for Google Colab, by Eddy Google Colab
- UVR5 UI, by Eddy Google Colab
More commands: -audio, -hf, -local, -kaggle, -overtraining, -realtime, -rvc, -help
its working, thank u
Yw
how do I calculate the processing time of a conversion? says 642/0.9 atm and still going / am running a local conversion
They took away my permission to speak, bro
Just because I spoke my native language on a call that wasn't in my language
honestly, you should use something else instead
Last update: Mar 8, 2024
better training colab
easygui is straightforward tho, if u wanna keep using that, but no guide for it
all im tryna do is get to gradio(whatever it's called) and find some like a text to speech
oh, in that case just use ilaria rvc
can u send please

Google Docs
Table Of Contents Introduction (with website link) Model Loader (Download & Upload) Inference (use RVC AI Voice Models) Ilaria TTS Settings (Inference) Introduction (with website link) Ilaria RVC Zero, is an RVC (Retrieval-based Voice Conversion) Fork made by Ilaria & mikus, running only on H...
guide + link
Tsym
Ayo? @narrow sentinel level 1 !!!
you're welcome :)
it can vary, but normally it doesn't take that long unless it's using your cpu
can you share your specs and what rvc you're using?
the file being processed was 5 minutes long. ticked to ~830 before completing. running a 1060 6gb, 32gb of ram on a ryzen 3600 with a noctua aftermarket fan
im using whatever RVC was available on the ".wtf" guide for local
hm... that may be the good ol' 1060 screwing you up
there's 3
applio, mainline, mangio
mainline
Ayo? @glacial rapids level 1 !!!
the 1060 does good enough work for me, ill give it another year before i need to upgrade. will probably scale the entire build up again
my rvc app keeps crashing everytime i launch it
Does anybody know how to fix
'No model for model_common loaded. Please confirm the model uploaded.'
like something about tmp
which rvc app did you download, whats the name
on which program is this happening
We dont work with voice.ai and dont recommend it, so we cant help tbh
Realtime Voice Changer Client
on which step does this happen? Are you trying to upload a voice model?
i uploaded the index file and pth file
but when i start the console says: 'No model for model_common loaded. Please confirm the model uploaded.'
Ayo? @viral crater level 1 !!!
Did you select the model aswell on the blue box?
blue box?
where the voice model is uploaded in
you have to select the voice model after you uploaded it, is it selected?
i see this in my program

How do people keep downloading the old version lately haha
because its still available ig
Reviving in the future, will change install instructions to be "manual" build (for nvidia at least as its infinitely better performance)
Github - Blanc-dot
Discord User ID - https://discord.com/users/824922747423031359
Despite being end of life, most if not all information has not reall...
has latest versions
so do i just delete it and reinstall latest version?
if you have AMD gpu, download this instead
https://rentry.co/ForkVoiceChangerGuide

Guide style is in the same as Blanc_dot's guide for simplicity and familiarity sake. Thanks to Blanc_dot for additional input. Most technical information comes from deiteris.
Last update August 10th, 2024: pictures and gifs are getting added on "difficult" parts
Video tutorial soon...
I...
delete it, and open one of the two guides and use the download from there
how to know what gpu i have?
Task manager > Performances
Check for gpu0 and, if it exists, gpu1 name

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
no
Then you have no gpu
O_O
CPU voice changing is not recommended, youll damage your pc in the long run probably if you play a game with it too and cant do much with it xd
If your internet is good, you can try the online hosted alternative
There cannot be no gpu, there should be at least some gpu
why the heck do i have no gpu O_O
Ayo? @viral crater level 2 !!!
Could you check device manager maybe?
I assumed iGPU but now that you mention it, it would still show up separately
I forgot 💀
ok i will just download nvidia ig
i have nvidia drivers so it makes sense to download nvidia
what section in dm?
Device Manager > Graphics Card
You should have one
Yep, W-Okada got quite a size.
Sup everyone! Is there a program to create an rvc dataset for me woth given .wav files? All programs that i saw online is buggy/not working at all. Thanks in advance
Ayo? @grave mortar level 2 !!!
help the client doesnt reopen
it says 'Web Server Launch Exception, Expecting value: line 1 column 1 (char 0)' and then never opens
Nope.
The best way to make a dataset is manually
Gather at least 12-15-20 mins of dataset, split them on clips of 5-10 seconds and place them on a folder.
does it say a bunch of wait web servers after
yes