#✨│ai-help
1 messages · Page 76 of 1
Have you tried disconnecting and deleting runtime and after putting audio don't click refresh on audio
start execute is still running it is not disconnected
ye i dont click on refresh audio
do i need to disconnect everytime? when i want to convert new audio
Not on pc rn so I can't test ila rvc
It shouldn't be like that
start preprocess
['trainset_preprocess_pipeline_print.py', 'C:\Users\Kaiser\Desktop\RoyceAI\vocalsv23.7.0\datasets\', '32000', '11', 'C:\Users\Kaiser\Desktop\TRAIN\Mangio-RVC-v23.7.0/logs/RoyceAI', 'False']
Fail. Traceback (most recent call last):
File "C:\Users\Kaiser\Desktop\TRAIN\Mangio-RVC-v23.7.0\trainset_preprocess_pipeline_print.py", line 118, in pipeline_mp_inp_dir
for idx, name in enumerate(sorted(list(os.listdir(inp_root))))
FileNotFoundError: [WinError 3] The system cannot find the path specified: 'C:\Users\Kaiser\Desktop\RoyceAI\vocalsv23.7.0\datasets\'
end preprocess
i remplaced the file names to the ones that the error was giving and so far dosent really seem to change . now iam lost .3.
@half cove toughts ?
yeah put the dataset folder inside mangio
gotcha ima try that
what do i need to do for the next time? if i want to convert a new audio after i already did one
C:\Users\Kaiser\Desktop\TRAIN\Mangio-RVC-v23.7.0\datasets\RoyceAI\vocals23.7.0\datasets
it kidna looks like this , is good ?
There should be a x on the audio uploaded you can click that then put new audio
RVC Guides (How to Make AI Cover)
Documentation
🇺🇸 English (main)
Translation by country
🇧🇷 Brasil (PT-BR)
🇪🇸 Spain
🇫🇷 France
🇩🇪 Germany
🇯🇵 Japan
🇰🇷 Korea
🇵🇱 Poland
🇷🇺 Russia
🇮🇹 Italy
Try not make the file length too long
works :v
yea when i click x on previous audio and than drag a new one
i get error
Weird
ty , ill keep that in mind :3
It might have problems rn
Try using another model

but i used the model before
it worked well
Why does every google drive model direct me to a page that says the file doesnt exist or incorrect url?
Ayo? @worldly finch level 11 !!! 
I see
Ayo? @wispy canyon level 1 !!!
Does it convert at all or does it only break after putting new audio
Hm?

Ohh
sends me to this
after putting new audio

The original user may have deleted it
I'll test later if I have time ig
Hmm fair enough. Just seems wierd its the same story with EVERY google drive one
it worked after i stopped the runtime

Most Google drive ones are old
oh i gotcha. Thank you
now i want to convert another audio so i click X on audio
and drag the new one

see
^^
poopmasta

It's prob ila rvc having problems
As I said I am on mobile right no so I can't check
.
but still get error
i honestly don't know then
it only 1 audio each runtime of execute

umi forgot o install tensorboard.. anyone can tell me how to do it ina nutshell pls ? :3
kk i will try
the page for ROD is down so.. idk where to go
Ayo? @steel plover level 2 !!!
put this bat inside ur folder, run it to install tb and run
ur rvc folder*
ty !
in case shit breaks, delete tensor_venv folder and re run the bat
i guessi ahve to stop the trianing i have ongoing too right ?
nope
ill do it justi n case xd, ty tho
yw
It's taking a looot. Is that normal?

We all good 

if you're on huggingface maybe
seems to work , do i have to use the same bat FOR WHEN IW ANA USE tb ?
How much does it take normally on huggingface?
yeah
takes a while depending on ur audio's length, just wait
Oh, okay ty. Thanks for helping
You're welcome :)
yeah ur doing good
uhh..
for some reasonmy steps went up to 5k

i think i have done something wrong :v
nah ur graph doesn't seem that bad
i stoped it at 120 steps and sounded like . really ass
this is the voice
yeah ofc, 120 steps is meh
do u mean epochs
so i just should let it run >
yeash epocs.
oh that makes more sense
so i just let it run ?
yeh, keep going and check the model once u think you're overtraining
i set it to 350 epocs first .
gotcha but . idk if this is undertraining or overtraining
currently not overtrained
pitch the audio down using the RVC gui, i think it should sound beter
better*
seems like it continued rather than starting over..is it good o r irather start over?


Yo, I'm using tensorboard with my training, I followed every single step but it's no showing anything at all

If you trained / are traning a model it should show up after clicking refresh
Dose it look find or nah? 
I did so, and I set up that automatically also but it's the same

as i said, yes
Ayo? @young halo level 7 !!!
I dont see anything wrong try asking in #1192011222023950368 so more people see it
zoom out in loss g total
Is that orange line that indicates overtraining points, it's not showing
and see if theres anything
Oooooo
alt + zoom once you're over it
Was that it 😭
That actually helped me, tysm!
yw! ;)
now you know poopy
Ok, I input 2000 Epochs for this model as I read on a guide, and the OT point is at around 1k Epochs, do you recommend me to stop it at around 300 Epoch or until it's near the OT point?
If you're on Colab you gotta stop and train on another session
After like 1 or 2 hours
But yeah, train until you feel it's been overtraining for a while
Then you can check the models
thisis going crazy
its going up the loss

@proper shale
i dont think the graph at the bottom should be going up .3.

Yeah seems to be time to stop
ok so what epoc wopuld be this one ? .3.

Like I said in the guide, the lowest point
Zoom in and see which one it is

Is that loss/g/total?
yeah
Ayo? @steel plover level 3 !!!

If that's the lowest point, remember the Step number
And keep reading the guide
what is exactly the step number ? , whats kinda what iam missing .3.
since so far is on a diferent setting i think .
MJ how do you explain this 
9.214 is the step number
or whatever was cited earlier
also, try out the latest version of the model too
You can see the Step in the black window on the left
in betwen these i supose ?

The window here
what would be the latests? . ij ust downloaded and foillowed the latest vid on how to download the rvc
mango
the latest file in weights folder
oho k gotcha
Latest file?
But they overtrained already
MJ 😭
yeah tahts what i mean xd
how do you know
Scroll up
g graph going up is not necessarily overtraining lmao
They showed a full pic of TB
It's been going up for a while already
either way, test out the latest version
it can (and most likely will) sound better
That's fair
test latests ig .
Hello. Question, does the applio vthree include the pretrain type? The Ov2 or the Rin_E3?
You gotta add em in
It doesn't come preinstalled
and I was also referring to the collab
ok
nope, not on colab
i need helpp
again, pitching down could make it sound better
it already is , -8
everytime when i want to convert a another audio i get error
try -12
i can convert 1 audio per execute
this still working?
-12 pitched down. still soudns too robotic. .3.
e 315
@proper shale
iam lost.
pls
@half cove ? :3
Can't listen to audio cuz on mobile rn xd
well is too robotic at the end
should sound more like this https://www.youtube.com/watch?v=0DviyuGNeWc&t=373s
its probably the audio you're using
doesnt sound like the character
from mp3 to FLC
like not even one bit
in terms of pitch
kinda varies but it is -12 pitch so it sounds more deep than how iti s
but opriginaly sounds more like this
pitch : 0
Listen, how about you test it with the lowest training point?
Instead of the most recent
yeah mima use that instead
@proper shale watch me being right >:3
objection: will sound the same because it's not the model, it's the audio they're using to convert


The closest to before the OT point
then use e150
this is the audio . i used for the training .
Only 10 secs? That's a lil short
bruh what
is 15 mins long.
Ah
@molten pecan r u smoking

again, the audio they're using to convert is the problem
time to cross out fingers.

then how do i fix it ?
They should use another audio that's more whispery
so far on the vid told me FALC
first off, nuh uh, it's still an mp3 because you downloaded it from YouTube, you're not making audio quality better
second, the Audio you're using to test is the problem
ok , then how do i do so its high quality then ?
it's not whispery, not similar to the speaker
true .ima make anew audio for it .
and since the voice model is monotonous, its just gonna sound bad
yeah that should make it better
Ayo? @steel plover level 4 !!!
a tat better but still feels a bit robbot like
i have a error too
pitch that down and i think it might sound good ngl
maybe someone knowns
each execute run i can do 1 convert
after 1 convert is done i click to X on audio
and drag another audio to convert
thisis darkmagic

do u mean this in a good way or
yeah, but do i always have to keep it pitched down liek that and talk in the same way ?
ok, give us the ila rvc cell output once u do conversion
i mean iwant ti obe flexible so it can work with ceratain acentuations .
i mean u gotta pitch down yeah
and sorta be monotonous
yeah uh, it ain't gonna be flexible, from what I've heard the character is very monotonous
true .
but thats is kinda what iam going for regadless
i guess i can call this a succes mostly due to the robot voice part .
but about the MP3 thingy , how do i geta higher quality for the ytb ? @proper shale

you can't
thats why u shouldn't really go for yt vids, maybe as a last resort
i guessi cant get better from this ?

then from ?
just feels like a issue with ila rvc, try applio
https://colab.research.google.com/github/iahispano/applio/blob/master/assets/Applio.ipynb
depends on the medium
well there is only this ytb vid with the clear audio .
search and you'll find audios from games n shit
ima try and use stacher
what format in stacher?
@half cove you do realize that this doesn't really help right?
it's like polishing a jpeg
seems like it didnt required me to iunstal ffmpeg

yt audio works for training models, but the audio quality is limited regardless of file type
At like 40k
Oh and, 192kbps opus audio
I just checked Tensorboard and apparently the step 12.6k is the best step before my model overtrains, my question is: how do I figure out what epoch number that step is?
for reference, step 12.35k is 650 epochs in my model
check the weights folder
and see what's closest
also, u should try the latest model too
650 is what I saw in the folder
this is considereda felony at this point @half cove

On your pth every checkpoint has epoch then steps apart from last one
yeah then that's it
but i guess it needs a bit more to get there.
Listen to mj
384khz for a YT audio???
tim to see wherei can geta clearler audio
650 is 12.35k steps, so ig i should do 660 or something?
yeah either that or 650
gotcha, thank you!
yw :)
well then i guess it is settled , but what can i do now to improve what i have ? re-train and see if iget something better ?
or am i just stuck with it ?
nah the model is decent
there is nothing much u can do ig
yeah.
what about other languages?
for example if i speak in spanish and wish t the voice to be use spanish do ihave to do something else o ?
how does this works i m unkowns with this
nah u dont need to do anything else
it will work out just fine, might have a weird accent tho
never used before
its straightforward, just run the steps and see

insert link there, and click descargar modelo
i got error before re did again now worked
woo
now just refresh the model thingy in inference section, upload ur audio and u should be good
yes it worked but i wonder something
since start
the output voice isnt same as my voice
i mean... its a voice conversion
yea
ofc it wouldn't sound like ur voice...?
^
unless u trained urself
again, you dont need to do anything extra
answered this b4
it might sound weird tho
so own sound output will not give my exact same voice
i mean, yeah
its converting ur voice in some way
ho so i just have to talk in spanish and will talk in like spanish accent ? :0
oh this
i see now ty
alr now everything is fine
thankss
yw!
and yw!
like, i believe it will sound like an american trying to speak english
u can disable index tho, it might sound better that way
how i do that ?
just set the index slider to 0
on the training or on rvc ?
on rvc yea

Is that rvc gui?
Oh nooo
...
It's too outdated
let me gues
Its only and doesn't have things like rmvpe
https://aihubdocs.github.io/en/ use mainline rvc
Written by Julia Eddy Last update: Jan 30, 2024
The keysmash
@steel plover be more careful with the keysmash next time 😭
ty
yeha so i was using something old and now i gota re-learn how ot use the rvc new one .
great :v
@steel plover pls use mangio for inferring to
too*
its pretty good
just gotta put ur file paths n stuff for the audio
iam using magio for inferring


yea this is the one
this is original rvc
so , good , right?
bet.
Ayo? @steel plover level 5 !!!
my whiole discord layout just changed
Huh?
idk some chanels got moved or removed .
the SD one seems to onl;y have "help-ai-art and nothing else
this is taking a hell ofa while

I mean you could just use mangio
i dont wana mix up the training one with the use one :v
Do you have the infer only mangio?
ok where od i put my trained models ? , and why is everything on spanish ? .3. , i rahterh ave it on english tbh

and some text is on asian

iam so confused.
Put pth in assets then weights and index in logs
First is infer second is train
well but iwana make my whole RVC be english .3.
You could use mangio train and infer
Version
infer vers is also in spanish'
but icna manage to understand and co-relate
Spanish?

Where did you install it?
Link xd
this chat is for the colab version?
-links
All Working Local Forks 🖥️
- 🍏 Applio, by IA Hispano GitHub
- Mangio-RVC-Fork, by Mangio621 Huggingface
- RVC Studio, by SayanoAI Huggingface
- AICoverGen, by SociallyIneptWeeb GitHub
- Replay, by Replay Team Website
- Original RVC, by the RVC-Project team GitHub
- GPT-SoVITS, by RVC-Boss GitHub
Need some help? 🤔
You can find more info on the "❔┋guides" channel. If you can't find your answer, feel free to ask for help in "help-rvc". Credits to Faze Masta and Antasma for compiling these links.
More commands: -audio, -colabs, -overtrain, -realtime, -rvc, -help
What colab you need
i dont understand .3.
C:\Users\Kaiser\Desktop\T THE VOICES\RVC1006Nvidia
Voice changer?
Making covers?
Training?
Like the place you downloaded it from
holly, i just wanna try the voice changer
I know I make a lot of questions lol, but I just want to know, if I need to send my models to QA before posting them even though I have the model maker role
It should be in English so I'm confused lol
i need to download something or just with the web?
Hm?
ikr?
isthere way i can change the language regadless?
To use it in a game you need a virtual audio cable
i just wanna use in discord with friends
Could just try translate page ig
ikd howo to do that on opera gx xd
I mean, my model got approved yesterday when I sent it to #1159514067187277865 and I got the model maker role, so I was wondering if I need to submit my models in there before posting them in #1175430844685484042
but i don't understand, i just run it or i need to download something?
Ayo? @pine hill level 1 !!!
Mejor pregunta en #🌍│español
Eddy podrá ayudarte
Might long to respond discord bejgn a bitch rn
this is wherei puit the path tothe audio i wana infer right ? .

soy medio bobi, no vi ese canal, gracias
After you post the model it's checked by staff
Si. Porfa lee la guía de uso
Written by Julia Eddy Last update: Jan 30, 2024
Oooo I got it, if there's any problem with it, does it get taken down or something?
Yes. Check the model maker page
Written by Julia Eddy Last update: Jan 30, 2024
You'll find the reasons that can get your model rejected
Tysm!
yw!
Ok I'm back
This should walk you through it
He's asking when posting a model as model maker lol
Yep
how me make ai voice do funny stuff
i will translate
Are you trying to use voice changer or making ai covers
?
ai covera
Written by Julia Eddy Last update: Jan 30, 2024
Use the search bar to find the part about making ai covers

translation: M̷͐̒Ë̵́̓ ̴̛͍N̵̰̏E̸̛̦E̵͐̓D̵͒ PRO̷͍͝G̷͗̀RAM̶̛͛ ̸̛́N̴̓͗O̸W GIVE̶͒͆ ̸ME I N̵͖͗E̴̔ED DA F̷͊̚Ȗ̵̕N̷̞͑Ṋ̸̓Ÿ̸̹́
It's on the landing page
No need to do dat
Ooo nice
me no know how it work no make sense UISDHGBEAVBFVHSAXCBSDFJGSDGBSDG
Ayo? @brittle wing level 1 !!!
Read it. I made it beginner-friendly
no

Ok so your using something called rvc1006 something right?
Go on your rvc folder
okkk
Did you download a model that you want to use?
Well first are you trying to make a ai cover or a ai model?
i did my voice and filterd it
ima make ai model then make me sing a song lmao
i have the program ope n
You can either make one or get one from #1175430844685484042 or weights.gg
naw make one
but like
Im stuck on what the pth file is
maybe i missed something
i listend to all steps
I think your on the part about using an ai model
Yep
so i do that thank i should do the pth and stuff
Scroll down and it should have the tutorial for training and stuff
After doing it you should get index and pth
alright ill keep you updated poop master
Just use the inference part of the tutorial after you make it
Woah the site is pretty useful
And to think it's early in development
where is this 🥲
Ayo? @sinful lava level 2 !!!
The beginning is about inference the second bit is about training
It says in the titles
You have to upload the model you created first or use a premade model
how do i upload my model
im sorry i dont wanna make you annoyed lolll
Dw

do it
its gonna be the last chance to save them
😭😭😭😭
im talking using my school laptop, connected to an amazon remote desktop service (1GB ram+1 core)
its so slow
switching servers take like 15 seconds
Use discord canary
whats that
😭
RVC Guides (How to Make AI Cover)
Documentation
🇺🇸 English (main)
Translation by country
🇧🇷 Brasil (PT-BR)
🇪🇸 Spain
🇫🇷 France
🇩🇪 Germany
🇯🇵 Japan
🇰🇷 Korea
🇵🇱 Poland
🇷🇺 Russia
🇮🇹 Italy
Local

Pic goes hard but not related to help-rvc
Wait until you get perms and then post em on #✦│chat

aight boss
Ayo? @buoyant lotus level 2 !!!

Is taking a little longer than expected

Maybe it's a heavy model

Any suggestions why?
anyone doing Google Collab & RVC?
i need help, this hurts my head
im getting
[Errno 2] No such file or directory: '/content/voice-changer/server'
/content
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-2-e8b7f718dd62> in <cell line: 24>()
22 get_ipython().run_line_magic('cd', '/content/voice-changer/server')
when doing Start Server using ngrok
I heard the RTX 3060 series onwards was the best option
But you can execute RVC through the cloud though
does anyone know how to get the old rvc thing where it was its own like app thing with all the options instead of it being on a browser? I factory reset my computer recently and dont remember how to get it back
where like you had to download it from drive
Well, things had changed a little
Basically we have Rvcdisconnected you train there and you use another Inference cloud space
RVC GUI? The vertical blue window?
yeah
Ayo? @plush heron level 1 !!!
That one is really outdated
it was easy to use tho
Yea but it gave lower quality results, very few settings, and had only obsolete models
I have a usage guide of the modern RVC for newbies
https://aihubdocs.github.io/en/ check the mainline page
Written by Julia Eddy Last update: Jan 30, 2024
;3
alr thanks
Though if you want it even more simple check the Ilaria RVC one
Have fun!
-colab
☁️ Google Colabs
- AICoverGen-WebUI, modded by Hina Google Colab
- AICoverGen-NoWebUI [English], by Ardha, fixed by Eddy, Hina and Gdr Google Colab
- AICoverGen-NoWebUI [Spanish], credits to Eddy, Hina and Gdr for translating and fixing Google Colab
- RVC Disconnected, by Kit Lemonfoot Google Colab
- easyGUI, by rejects Google Colab
🤗 Hugginface Spaces
- Ilaria RVC, by thestingerx Hugginface Spaces
- RVC-HFv2, by r3gm Huggingface Spaces
- AICoverGen, by r3gm Huggingface Spaces
- Advanced RVC Inference, by r3gm Huggingface Spaces
- RVC v2 Huggingface version, by Clebersla Huggingface Spaces
- GPT-SoVITS (demo), by litagin Huggingface Spaces
More commands: -audio, -local, -overtrain, -realtime, -rvc, -help
How do I make a model?
Written by Julia Eddy Last update: Jan 30, 2024
There you have plenty of guides
;3
yo can i run RVC-GUI.bat is it good and safe me bad at illiterate
On mobile and everything else is fine but I can’t upload an audio
yes thats what you open
Ayo? @vast forge level 1 !!!
thx
you just wait for it to open it could take a few minutes
im working on making my first model rn
thank you
your welcome
When you make a voice model, you make a dataset with several songs with a clean voice, right? but I can make a dataset with the same song over and over until it reaches 40 minutes. For example, I have a song and I decided to press ctrl c and v until I reach a certain amount of music that lasts 40 minutes. Is it possible to do this?
You can do it, but it won't give any improvement
Variation in tone is very important for a great model
so it's good to have several songs to make a good voice model.
Yeah. Check the datasets page for more tips
Written by Julia Eddy Last update: Jan 30, 2024
=3
I've seen that.
does anyone know a Google collab that uses ov2super pretrain
uhhhhh
so after the error i described my gpu utilization is now at 4.2billion

it's legit like double the 32 bit integer
💀
also how do i fix this i can't do feature extraction

RVC Guides (How to Make AI Cover)
Documentation
🇺🇸 English (main)
Translation by country
🇧🇷 Brasil (PT-BR)
🇪🇸 Spain
🇫🇷 France
🇩🇪 Germany
🇯🇵 Japan
🇰🇷 Korea
🇵🇱 Poland
🇷🇺 Russia
🇮🇹 Italy
-colab
Suggestions for @royal jacinth
☁️ Google Colabs
- AICoverGen-WebUI, modded by Hina Google Colab
- AICoverGen-NoWebUI [English], by Ardha, fixed by Eddy, Hina and Gdr Google Colab
- AICoverGen-NoWebUI [Spanish], credits to Eddy, Hina and Gdr for translating and fixing Google Colab
- RVC Disconnected, by Kit Lemonfoot Google Colab
- easyGUI, by rejects Google Colab
🤗 Hugginface Spaces
- Ilaria RVC, by thestingerx Hugginface Spaces
- RVC-HFv2, by r3gm Huggingface Spaces
- AICoverGen, by r3gm Huggingface Spaces
- Advanced RVC Inference, by r3gm Huggingface Spaces
- RVC v2 Huggingface version, by Clebersla Huggingface Spaces
- GPT-SoVITS (demo), by litagin Huggingface Spaces
More commands: -audio, -local, -overtrain, -realtime, -rvc, -help
rvc disconnected
I need train new model how can I doit
send error log
What that means
Written by Julia Eddy Last update: Jan 30, 2024
good luck reading this, the tutorial is straightforward
sorry i was helping another person
I have index file and model path but I don't what to do next so can you tell me what to do nex
it is in the website, please search
we helpers are not meant to spoonfeed
Ok sorry and thanks
Ayo? @terse cairn level 1 !!!
Someone ruined AI Cover generator web UI the outputs sound so God awful
im reading the rvc guide and it says i need rtx nvidia
i have rtx radeon is that fine?
im making my own voice
and i have everything recorded
but when it says upload voice model with the .pth im not sure how to make that
any help?
you need to train it first
https://aihubdocs.github.io/en
check the training parts
Written by Julia Eddy Last update: Jan 30, 2024
you already have a dataset, now you only need to train
^
how train doe
You need to train your model
ik but where do i do that
?
-colab
Suggestions for @sinful lava
☁️ Google Colabs
- AICoverGen-WebUI, modded by Hina Google Colab
- AICoverGen-NoWebUI [English], by Ardha, fixed by Eddy, Hina and Gdr Google Colab
- AICoverGen-NoWebUI [Spanish], credits to Eddy, Hina and Gdr for translating and fixing Google Colab
- RVC Disconnected, by Kit Lemonfoot Google Colab
- easyGUI, by rejects Google Colab
🤗 Hugginface Spaces
- Ilaria RVC, by thestingerx Hugginface Spaces
- RVC-HFv2, by r3gm Huggingface Spaces
- AICoverGen, by r3gm Huggingface Spaces
- Advanced RVC Inference, by r3gm Huggingface Spaces
- RVC v2 Huggingface version, by Clebersla Huggingface Spaces
- GPT-SoVITS (demo), by litagin Huggingface Spaces
More commands: -audio, -local, -overtrain, -realtime, -rvc, -help
Rvcdisconnected, by kit lemonfoot
and this will train my voice
and make it like the pth file and index
Yep
okkk thanks
Just record your voice make a zip and upload it to Google drive
got it
Suggestions for @sinful lava
☁️ Google Colabs
- AICoverGen-WebUI, modded by Hina Google Colab
- AICoverGen-NoWebUI [English], by Ardha, fixed by Eddy, Hina and Gdr Google Colab
- AICoverGen-NoWebUI [Spanish], credits to Eddy, Hina and Gdr for translating and fixing Google Colab
- RVC Disconnected, by Kit Lemonfoot Google Colab
- easyGUI, by rejects Google Colab
🤗 Hugginface Spaces
- Ilaria RVC, by thestingerx Hugginface Spaces
- RVC-HFv2, by r3gm Huggingface Spaces
- AICoverGen, by r3gm Huggingface Spaces
- Advanced RVC Inference, by r3gm Huggingface Spaces
- RVC v2 Huggingface version, by Clebersla Huggingface Spaces
- GPT-SoVITS (demo), by litagin Huggingface Spaces
More commands: -audio, -local, -overtrain, -realtime, -rvc, -help
hey guys, is Applio application for tts? Ever tutorial I found on youtube i cant follow entirely bsc the step is very differently
rvc disconnected
use 11labs or ilaria rvc for tts
But 11labs can’t use voice model right? What if I wanted something that can use voice model
actually theres a method to use voice model directly in the tts
just download the speech and convert it on RVC
Oh ok, sorry I might be new to this field, what should I be using to download the speech and convert it?
Bsc through the voice model in this discord server I realise bsc can use their own created voice model to become a tts
So was wondering how did they did it
create ur speech on any TTS
like 11labs, ilariatts etc
download the speech generated
then put it to RVC
put ur model and convert it
u can use ilaria rvc also for the convertion
ilariarvc can do rvc model tts voice
ilaria tts is integrated in ilaria rvc
like i said
yes
i see this is a intersting idea! my current situation is i have no idea how do i put the voice model inside the illaria RVC
i can use a lot of people voice, but how do i import the voice model?
u can find guides on ilaria rvc here #1159513888199540817
to import tho u just need the download link of the model > go to "download model" > paste the link & download it
ah thanks a lot! I will go through it
from my personal testing, mainline seems to train faster than applio, tho its only by a few seconds every epoch
not sure about the results on others tho
RVC Guides (How to Make AI Cover)
Documentation
🇺🇸 English (main)
Translation by country
🇧🇷 Brasil (PT-BR)
🇪🇸 Spain
🇫🇷 France
🇩🇪 Germany
🇯🇵 Japan
🇰🇷 Korea
🇵🇱 Poland
🇷🇺 Russia
🇮🇹 Italy
Any way to run realtime tts with rvc model? i want to put a voice for my chatbot
the voice-changer is able to get audio input from desktop audio
But you'll need to have your tts playback on a dummy sound output so that you don't hear both source and converted audio
That or use virtual audio cable the opposite way we usually do. (TTS output to virtual audio cable, voice changer picks up audio from virtual audio cable and plays back to desktop)
Anyway, how do you get the voice changer on Linux? jack2?
In terms of audio ?
It unless requires on the browser, so whatever that supports
I'm not sure how it does it when using "server". I think it's portaudio, but I haven't looked at what that supports
PortAudio is a free, cross-platform, open-source, audio I/O library. It lets you write simple audio programs in 'C' or C++ that will compile and run on many platforms including Windows, Macintosh OS X, and Unix (OSS/ALSA).
Can it run with an acceptable performance on cpu?
if i need to separate 2 people singing together what do i use on UVR5
UVR-BVE
cant find it on the download bit

⠀
Google Colabs 
⠀
AICoverGen-WebUI
Useful for making quick covers, by Hina.
AICoverGen-NoWebUI
Useful for making covers, doesn't inclued a UI, by Ardha, by Eddy, Hina and Gdr.
RVC Disconnected
To train new voice models, by Kit Lemonfoot.
EasyGUI
The OG interface, by Rejects.
⠀
i assume training model locally requires at least RTX card?
i mean, it's more of a recommended setting
training with 10 series is slow
i have 16 series
Ayo? @rare flint level 1 !!!
but as long it works i assume it works yes?
i do remember training with colab took 4-6 hours
if it's the 1650 I would recommend going for Colab
idk about the 1660, probably slower than 20xx series
 damn
damn
it really depends, you have to limit some of the sessions on the newer Colabs to prevent losing filws
⠀
HuggingFace Spaces 🤗
⠀
Ilaria RVC
EasyGUI port with some improvements, by Ilaria.
RVC-HFv2
Applio port, by r3gm.
AICoverGen
AICoverGen port, by r3gm.
Advanced RVC Inference
Extended version of the GUI with advanced settings, r3gm.
⠀
how does huggingface one works?
Can somebody make a website similar to YouTube which free copyright strike or termination?
So we can post our ai cover
It's outdated. Using the Colab space is much more convenient
Written by Julia Eddy Last update: Jan 30, 2024
Check the Ilaria RVC page :3
hi team! i just want to ask how to use the voice Changer client demo as an output for example when you are talking someone in discord
thanksssssssssss
Ayo? @rose geyser level 1 !!!
sorry, is this the page to ask for the Voice Changer client demo or in okada?
#🔍│help-w-okada is for both Okada and Voice Changer
(they are the same thing though)
_<
ok thank youuu
so it's working now, and i have another question if you don't mind
but the one that I am talking to, they also hear their own voice and it is also changing their voice, is there a fix about this or is this natural? thanks! i dont know what to search
sorry and thank you
I don't use the voice changer so idk
Good luck
alright ty
The input output settings should be like this in W-Okada:
Input - Your mic
Output - CABLE Input
And in Discord:
Input - CABLE Output
Output: Your headphones
Make sure it's like that
So you don't get that annoying thing of converting the voice of ur friend
thank youuuu! ❤️
What are the best settings for a studio acapella reverb?
if you're mixing, this really depends
just see what sounds better ig, just make sure not to drown the whole thing in reverb
File "G:\Artificial_Intelilgence\Mangio-RVC-v23.7.0_INFER_TRAIN\Mangio-RVC-v23.7.0\runtime\lib\site-packages\gradio\routes.py", line 437, in run_predict
output = await app.get_blocks().process_api(
File "G:\Artificial_Intelilgence\Mangio-RVC-v23.7.0_INFER_TRAIN\Mangio-RVC-v23.7.0\runtime\lib\site-packages\gradio\blocks.py", line 1349, in process_api
data = self.postprocess_data(fn_index, result["prediction"], state)
File "G:\Artificial_Intelilgence\Mangio-RVC-v23.7.0_INFER_TRAIN\Mangio-RVC-v23.7.0\runtime\lib\site-packages\gradio\blocks.py", line 1283, in postprocess_data
prediction_value = block.postprocess(prediction_value)
File "G:\Artificial_Intelilgence\Mangio-RVC-v23.7.0_INFER_TRAIN\Mangio-RVC-v23.7.0\runtime\lib\site-packages\gradio\components.py", line 2586, in postprocess
file_path = self.audio_to_temp_file(
File "G:\Artificial_Intelilgence\Mangio-RVC-v23.7.0_INFER_TRAIN\Mangio-RVC-v23.7.0\runtime\lib\site-packages\gradio\components.py", line 360, in audio_to_temp_file
temp_dir = Path(dir) / self.hash_bytes(data.tobytes())
AttributeError: 'NoneType' object has no attribute 'tobytes'```@sand iris
👍
⠀
Google Colabs
⠀
AICoverGen-WebUI
Useful for making quick covers, by Hina.
AICoverGen-NoWebUI
Useful for making covers, doesn't inclued a UI, by Ardha, by Eddy, Hina and Gdr.
RVC Disconnected
To train new voice models, by Kit Lemonfoot.
EasyGUI
The OG interface, by Rejects.
⠀
what do you press to trigger that btw ?
convert?
so like infer audio ?
yeah
i can send you the functions from the traceback if you want
wait there's more to it that what is above ?
no, i meant i could send u the full code of the funcs in the traceback if u wanted to check them out
Is Google Collab working?
like it has something to do with saving the file in the temp directory
but i cant figure out why its happening
I have them on hand
hmmm, i wonder whatll happen if i just like pass
like add an exception and let the code run
It shouldn't end with no data like it does here
https://github.com/Mangio621/Mangio-RVC-Fork/blob/main/infer-web.py#L236
Faulty shit might be there
GitHub
CREPE+HYBRID TRAINING A very experimental fork of the Retrieval-based-Voice-Conversion-WebUI repo that incorporates a variety of other f0 methods, along with a hybrid f0 nanmedian method. - Mangi...
Not suer about the gradio version used by the runtime, but it errors because of the inputs of this function
https://github.com/gradio-app/gradio/blob/v3.32.0/gradio/components.py#L360
GitHub
Build and share delightful machine learning apps, all in Python. 🌟 Star to support our work! - gradio-app/gradio
yeah i can see it
the var
cant i just manually set it?
what is the value supposed to be exactly?

yep, cant do shit about that :///
Would be great if I could get the issue here
maybe im missing smth
Like if I had the issue on my end to test it
Bro had 5 issues one after each other and solved all of them 💀 das crazy
Wait do you have that displayed?
OSError: Model file not found: hubert_base.pt
Or anything higher up that could be relevant?
oh actually i just noticed something up the traceback
Ayo? @wispy lava level 4 !!!
File "G:\Artificial_Intelilgence\Mangio-RVC-v23.7.0_INFER_TRAIN\Mangio-RVC-v23.7.0\infer-web.py", line 292, in vc_single
audio = load_audio(input_audio_path0, 16000, DoFormant, Quefrency, Timbre)
File "G:\Artificial_Intelilgence\Mangio-RVC-v23.7.0_INFER_TRAIN\Mangio-RVC-v23.7.0\my_utils.py", line 103, in load_audio
raise RuntimeError(f"Failed to load audio: {e}")
RuntimeError: Failed to load audio: ffmpeg error (see stderr output for detail)```💀
how the f did i not notice that 💀💀
Defaulting to user installation because normal site-packages is not writeable
Requirement already satisfied: ffmpy in c:\users\imajo\appdata\roaming\python\python311\site-packages (0.3.1)```man idk what to do anymore
OH ACTUALLY
mangio has its own python and pip library
so yeah lemme try w that
If you have ffmpeg available via PATH (no matter how) you should be good
It's available from winget if I remember correctly. That's like the one way that puts it in PATH for sure
winget install ffmpeg
heres the new traceback
File "G:\Artificial_Intelilgence\Mangio-RVC-v23.7.0_INFER_TRAIN\Mangio-RVC-v23.7.0\infer-web.py", line 300, in vc_single
if_f0 = cpt.get("f0", 1)
NameError: name 'cpt' is not defined
Traceback (most recent call last):
File "G:\Artificial_Intelilgence\Mangio-RVC-v23.7.0_INFER_TRAIN\Mangio-RVC-v23.7.0\runtime\lib\site-packages\gradio\routes.py", line 437, in run_predict
output = await app.get_blocks().process_api(
File "G:\Artificial_Intelilgence\Mangio-RVC-v23.7.0_INFER_TRAIN\Mangio-RVC-v23.7.0\runtime\lib\site-packages\gradio\blocks.py", line 1349, in process_api
data = self.postprocess_data(fn_index, result["prediction"], state)
File "G:\Artificial_Intelilgence\Mangio-RVC-v23.7.0_INFER_TRAIN\Mangio-RVC-v23.7.0\runtime\lib\site-packages\gradio\blocks.py", line 1283, in postprocess_data
prediction_value = block.postprocess(prediction_value)
File "G:\Artificial_Intelilgence\Mangio-RVC-v23.7.0_INFER_TRAIN\Mangio-RVC-v23.7.0\runtime\lib\site-packages\gradio\components.py", line 2586, in postprocess
file_path = self.audio_to_temp_file(
File "G:\Artificial_Intelilgence\Mangio-RVC-v23.7.0_INFER_TRAIN\Mangio-RVC-v23.7.0\runtime\lib\site-packages\gradio\components.py", line 360, in audio_to_temp_file
temp_dir = Path(dir) / self.hash_bytes(data.tobytes())
AttributeError: 'NoneType' object has no attribute 'tobytes'```this guy said use wav files not mp3
lets try that
same error
ok now what the fuck
global n_spk, tgt_sr, net_g, vc, cpt, version
if sid == "" or sid == []:
global hubert_model
if hubert_model is not None: # 考虑到轮询, 需要加个判断看是否 sid 是由有模型切换到无模型的
print("clean_empty_cache")
del net_g, n_spk, vc, hubert_model, tgt_sr # ,cpt
hubert_model = net_g = n_spk = vc = hubert_model = tgt_sr = None
if torch.cuda.is_available():
torch.cuda.empty_cache()
###楼下不这么折腾清理不干净
if_f0 = cpt.get("f0", 1)
lemme link to the og repo
GitHub
CREPE+HYBRID TRAINING A very experimental fork of the Retrieval-based-Voice-Conversion-WebUI repo that incorporates a variety of other f0 methods, along with a hybrid f0 nanmedian method. - Mangi...
IT DELETES IT
THEN USES IT
WHAT THE FUCK
oh it's commented out
It didn't load the model apparently
wait no that wouldn't make sense
do you see any setting called "speaker id" ?
try setting that speaker id thing to 0
if you ever see it
It should affect a value to cpt
Traceback (most recent call last):
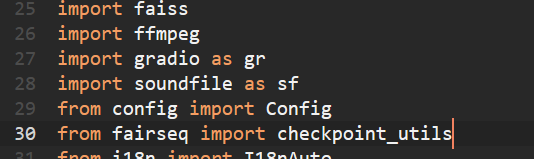
File "G:\Artificial_Intelilgence\Mangio-RVC-v23.7.0_INFER_TRAIN\Mangio-RVC-v23.7.0\infer-web.py", line 6, in <module>
import config
ModuleNotFoundError: No module named 'config'
bro what 💀
that line doesnt exist
like it literally doesnt exist, line 6 is empty 💀

python moment
Traceback (most recent call last):
File "G:\Artificial_Intelilgence\Mangio-RVC-v23.7.0_INFER_TRAIN\Mangio-RVC-v23.7.0\infer-web.py", line 25, in <module>
from config import Config
ModuleNotFoundError: No module named 'config'
Bro changed his mind now 💀
lol
idfk
i havent touched anything 💀
i just reran it
python is lovely
true 💀 but how tf is that even possible
so like why tf is it giving me that error now?
like it was find before??? and i havent added that now, it was there from before
RVC Guides (How to Make AI Cover)
Documentation
🇺🇸 English (main)
Translation by country
🇧🇷 Brasil (PT-BR)
🇪🇸 Spain
🇫🇷 France
🇩🇪 Germany
🇯🇵 Japan
🇰🇷 Korea
🇵🇱 Poland
🇷🇺 Russia
🇮🇹 Italy
💀 but for some reason it decided : NAHHH SIKE i aint gonna work anymore
Brooo
i just reverted all the changes to code
and now it works
i mean it doesnt, but not that import error
UGH no embed 💀
anyways, that line is still fucking there but yeah it decides to work
Is it normal for res to spike incredible high while playing games ?
Example: playing Monster Hunter World increases the res from ~60 to 25-30k ?
(GPU: RTX 4070 Ti
CPU: AMD Ryzen 7 7800X3D
RAM: 32gb, if that matters too.
since I saw it being mentioned here I tried exporting the model to onnx, but that didn't seem to do anything)
Intensive games do take a toll on performance, so yeah
There isn't a lot to be done other than... maybe limiting framerate and setting graphics to low
lol
you need translation?
Nah dw
Ayo? @sand iris level 67 !!!
I had the translation table opened
lol
Could just look up the corresponding English string from them lol
Restarting my PC seems to have fixed whatever issue this was, it's at buf=100, res= 80 now while playing, strange >.<
Still thank you!
Ayo? @weak needle level 2 !!!
Oh damn, that was quite weird
Well, glad to have helped :)
Collecting parselmouth
Using cached parselmouth-1.1.1.tar.gz (33 kB)
Preparing metadata (setup.py) ... done
Collecting googleads==3.8.0 (from parselmouth)
Using cached googleads-3.8.0.tar.gz (23 kB)
Preparing metadata (setup.py) ... error
error: subprocess-exited-with-error
× python setup.py egg_info did not run successfully.
│ exit code: 1
╰─> [1 lines of output]
error in googleads setup command: use_2to3 is invalid.
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: metadata-generation-failed
× Encountered error while generating package metadata.
╰─> See above for output.
note: This is an issue with the package mentioned above, not pip.
hint: See above for details.
any help
back (most recent call last):
File "C:\Users\ashwa\Desktop\RVC-GUI-main\rvcgui.py", line 23, in <module>
from vc_infer_pipeline import VC
File "C:\Users\ashwa\Desktop\RVC-GUI-main\vc_infer_pipeline.py", line 1, in <module>
import numpy as np, parselmouth, torch, pdb
ModuleNotFoundError: No module named 'parselmouth'
All Working Local Forks 🖥️
- 🍏 Applio, by IA Hispano GitHub
- Mangio-RVC-Fork, by Mangio621 Huggingface
- RVC Studio, by SayanoAI Huggingface
- AICoverGen, by SociallyIneptWeeb GitHub
- Replay, by Replay Team Website
- Original RVC, by the RVC-Project team GitHub
- GPT-SoVITS, by RVC-Boss GitHub
Need some help? 🤔
You can find more info on the "❔┋guides" channel. If you can't find your answer, feel free to ask for help in "help-rvc". Credits to Faze Masta and Antasma for compiling these links.
More commands: -audio, -colabs, -overtrain, -realtime, -rvc, -help
^^ applio is a good bet
Does yelling ruin the training in an AI model like a character saying "Whaaaaaaat!?"
As long as it isn't frequent, no
Don't think you'll get anything usable out of it
check pins in #🔍│help-w-okada , you can run this on google servers via google colab.
Not sure how you'd get the sound hooked up to voicechange though
THANK YOU 🙏
guys please what does this mean: call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
i keep getting stuck on this whenever i try to use feature extraction 😭
and i can't train the model or the index
need the full error
I don't hear any reverb
Also lower the breath sounds and search feature ratio a lil bit
https://aihubdocs.github.io/en/ check the inference settings page
Written by Julia Eddy Last update: Jan 30, 2024
aah ok tysm !!!
yw!
Ayo? @strong girder level 1 !!!
yes
where is this folder?
thats a batch file and its located in your rvc folder
is it in the AMD version?
on amd one it would be names go-web-dml
i downloaded it
they removed it
it's borked when you try to use it anyways
rips
it worked
amd inference is gone 🦀

Yeah try to infer anything
what do i go with the dataset?
your trying to train on amd?
yes
is it this?
Ayo? @vast forge level 2 !!!

you should use colab instead
how do i do that
cuz ur on amd
Originally written by Angetyde Re-done by Julia, Eddy, Poopmaster Light Last update: Jan 27, 2024
it says in the guide...
oh
after training model you get pth
after training index you get index
it should explain it all

the dataset is your audios
your training a model right?
im trying to make a model
how long
about 8:46
how clean is the dataset
clean enough i guess
should work then
i followed exactly what the guide said
then just continue
make a zipped folder
name it what u want (make sure no spaces or weird letters)
put the audio inside
then put in your disconnected folder in google drive
that works aswell

{kind=link}
{kind=link}
{kind=link}
{kind=link}
no
what?
where does it say in the guide to run it?
can anyone help me how to calculate save epoch step?
i want my save epoch same as that Tensorboard show, like 770 step, i want my save to s770 too
like how many sample / batch i need to get exact number


im going to run it
scroll down and see...
just tell me