#🧬│ai-chat
1 messages · Page 349 of 1
yep
took me a good year to start hearing shit that i haven't been hearing before lmao
XD that’s fair. I make music and it took me years to gain the knowledge I have now, and hear things I never did before
same, took me at least 4 years to understand how to write good music lmao
sure, but post only yt links, audio isn't allowed cus of copyright (even if it's your own music, it's just easier that way)
sc links are also fine
so how because I watched a lot of such modifications on YouTube
or pillowcase
I don’t have this on yt, but I have a box link. Reputable Audio/file hosting service
aight
sounds dreamy
Noeone ever put it like that but now that I think about it yeah it does XD
i like it
Made from scratch
nice
Mixing isn’t the best but eh
wanna hear my music?
Yes!

You want some frog bounce? Well here ya go.
OHHH YOU MAKE BEATS!
MEE TOOO
Yo that drop was awesome
Love that vocal sample lead
yeah you can scroll through my demos if you want, not all of my stuff is there but most of the good stuff
thanks :3
you have to separate the vocals and instrumentals, then sing yourself, convert, and manually put back the converted vocals witht he instrumentals
only in beat battles audio combats etc.
most of the stuff from my sc is flipping samples lmao
I feel like my sense of rythm is unique on that one
I like what I did with the whip kick thing
but when I sing it won't sound like the original (I can't sing)
I really like the bass line too
Yea I don't think you can do it any other way then
the only way is to sing bro 😭
I'm sure you can do a lot of these on YouTube/tiktok
im 99.99% sure they sing and convert the voice as i said
it's useless asking that again
i remixed juice world too @ancient swan idk i do a lot of stuff
hold up imma listen
listen to the world of ravens it's my personal fav from my full length songs lmao (not a sample flip)
nah sadly
crazy dudelove both of em
I'll give you an example of what exactly I want
great producers
i got in the finals of one of the bishbattles though
fr
i remixed juice a while back. i felt like the original beat didnt do the song justice
did my own beat with juice vocals
for example: there is a song "last christmas" and they sing "last christmas" and so on, so I need it to sing "first christmas"
this is just an example and I only want to change 1 word
i adore the melody i did on this
yea and i explained you that you need to sing that part
You could try Text To Speech (TTS) but it's not good for singing
that's why i'm telling u the best way is to just sing
pretty sure there isn't anything that can do that on its own right now, they probably recorded themselves singing the part of the song and inferenced it with a ai voice model
^^^^
exactly
@hallow portal no need to re-ask me again, unfortunately there's no good way unless u sing

I will sing it for 50€ frfr
sounds pretty good


looks very good 
how does it works now?
In a short, all's automated;
- Avg loss per epoch. Each epoch's loss is averaged over steps ( regardless if a given epoch has even / rounded steps or not )
- Avg loss every 5th epoch ( cummulation over 5 epochs )
My or Noobies approach isn't anywhere near calling perfect but heaps ton better than stock behavior which is essentially useless as we all know
Difference? Noobies does it ( I think ) over epoch and then, over 50 steps
I do it over epoch and over 5 epochs ( I think over 5 is reasonable to see a tendency )
because:


You can more or less say how an epoch performed ( with a lil caution ) + observe the general over-time tendency
I think it's better than having to play around manual N value for steps tinkering ( + uneven batches were actually problematic since it was done in a " % " operation
nice job in reworking the logging system! i like that now is automated 
It's quite similar to Noobies really so I suppose, it's a matter of preferences
now back to optimizers testing ( currently checking RAdam and no warmup vs AdamW + warmup
good luck with that! your fork is amazing for people that want to try something different vs stock rvc
i liked the results it gave me when i trained some models with it
thx!!!
What's ur PC GPU
could you suno.ai?
you were typing in #🤖│bots
i could have swore we was just talking but i cant find the channel
ohhhhhwhoops
anyway is there a place i can post a screenshot?
here
it doesnt give me the option to here
It doesn't do that
Bro
The only way
Is to sing 😭
I already told u many rimes
No other way
uhh i think u just need to level up by chatting to people
@hallow portal please don't re ask the question, I gave you an answer, it won't change
Learn how to sing your modified lyrics or make someone sing them for u
Else nun
Either level up to level 10
Or if it's help related, u can send ss in help channel
Yeah not that good
U COULD train only short datasets locally on batch size 4 like @turbid mulch said
It's better u use cloud
Train (make) RVC Models on cloud:
- Prepare the Dataset
- Setup RVC:
Choose a cloud way to use RVC,
- Google Colabs (4 hours of daily gpu for free, not much hours, but easy to use):
- Applio (ui)
- Mainline (UI)
- RVCDISCONNECTED (no ui)
- Kaggles (a bit harder to use and needs phone number but gives 30 hours weekly of better gpus):
- Mainline (UI)
- Applio by Vidal (UI)
- Applio by Shirou (UI, no guide as of right now)
- Lightning.ai (Kinda hard, needs login, no issue with web uis or anything, but only free 15 credits monthly):
- Be sure to know about the tensorboard
Google Colab = Easier but risk of getting disconnected
Kaggle = Harder but way more gpu time
If you are looking for the easiest way and for free, is using https://weights.gg which ofc uses RVC
RVC Inference (use models) on pre-recorded audio on Cloud
You can use either:
- Weights.gg: Easiest Possible Ever Automatic
- Ilaria RVC Zero: Fastest free on cloud
- Applio (ui)
but now I have another idea to make it simpler
I already told you the way to do it 😭
Suno ai only generates song, doesn't modify lyrics of premade ones
Bro, just sing
Thanks
I know I will do it
You're welcome
suno made me a song only in a different music style, can I set it to be the original?
Nope 😭
I don't think so
Afaik
closest would probably be the song creator on weights but idk if it will work like you want lol
So do I have to sing the whole song or just the remake?
I mean u could only sing the part u want to modify and cut that part from the original song
it worked but he sang in a different key and didn't get into the rhythm of the song
You sure that can do that at all?
it can kind of copy a song but not 100%
With kind of copy u mean like 3 secs of it?
unless someone could do it for me
lol
Which type of pre-training is the best?

ah i see
There isn't a best one, all depends on ur dataset language and size
too expensive
is the price negotiable?
No.
for one changed word??
I stil have to use my time for it lol
*still
Just sing it yourself if you dont want to pay someone else 
I could, but without exaggeration
What do you even want to edit?
You can get yourself SynthV and some AI voicebank and get the job done, whenever you need
( Vocaloid and SynthV are singing synthesis / concatenation software. SynthV AI is especially overpowered. Outmatching any rvc / other kind of singing AI even now )
does syntv have voice to voice conversion btw or is it only controlled with midi
Not that I am aware of, no.
I always recommend SynthV AI as just, well.. you can get your singing base ( base for infer ) outta it
It is a Midi / or manual based synthesis
makes sense, ig we would've already known about it
yuh
Either way, it won't ever be v2v
that's against the premise of those synths
Still a good thing if you don't wanna sing / get others to sing for ya tbh
yeah, though ig you'd need to find a good source of midi melodies of vocals
or just know how to write music a lil
I mean..
What's hard in putting notes in the editor
as long you have a good pair of ears you're good
alternatively, if you wanna manually midi it in fl and then import + edit phonetics
knowing music theory or having good ears
Classic vocaloid workflow
well, theory isn't needed if you're using relative pitch like I do
it's a bonus ofc and well welcomed to have theory or be able to go with perfect pitch
makes sense
depends on a person I suppose
training on 16 bs with checkpointing is pretty slow
btw.. It's kinda funny how certain ui elements in applio are called wrong or are exaggerated
like, tf is " higher sample rates "

as if v2 didn't operate on 48 lol
ig 44.1k
ig "more" would make sense
and that " applio " exclusive thing makes me kinda mad, as if the fork that's known and developed in parallel wouldn't support whatever applio has
I can just sense lots of people in future " will X work on codename's fork? " and I can already feel the anger boiling 🔥
marketing 
Hey! Been out of the loop for about a year, and since everything moves so quick in AI I feel like a newbie again. I used so-vits-svc 4.0 in a collab back then. Now I want to train a model for singing (rock metal with raspy vocals), mix 2 voices 50/50. Been using kits.ai but something happend that made it sound horrible to me nowadays. No character what so ever.
Can anyone guide me in the right direction? Is rvc the way to go nowadays? No so-vits-svc? I will train the model in collab and use my CPU on my PC for inference
Kits is trash, go for Applio ( modern ish take on RVC which is more or less a successor of so-vits, you can say it like that )
-colab
📒 Google Colab Notebooks
- Applio, by IA Hispano Google Colab
- RVC Disconnected, by Kit Lemonfoot Google Colab
- RVC Mainline, by Hina Google Colab
- AICoverGen-WebUI, by Hina Google Colab
- AICoverGen-NoWebUI [English], by Ardha, fixed by Eddy, Hina and Gdr Google Colab
- AICoverGen-NoWebUI [Spanish], by Eddy, Hina and Gdr Google Colab
- UVR5 NO UI, by Eddy Google Colab
- UVR5 UI, by Eddy Google Colab
- Modified W-Okada's Voice Changer, Google Colab
- FaceFusion UI, by Nick088 Google Colab
- FaceFusion NO UI, by Nick088 Google Colab
- EasyGUI, by Rejekts Google Colab
ℹ️ Note
While the Colab free plan provides up to 12 hours of daily usage, the GPU is typically available for only about 4 hours each day on average.
More commands: -audio, -hf, -local, -kaggle, -realtime, -rvc, /help
aight
they up to date?
you can use uvr5 ui/no ui to use separation models to clean your vocals and use, rvc mainline by hina or applio colab to train the models
i think so
a
@covert lake are colabs in this command up to date?
Wow, quick and helpful comments 🙂 I got clean data sets, I'll look into rvc mainlina and applio for the training 🙏
ye there hasn't been any changes recently
aight
good luck!
Thanks, I'll probably be back here crying for help in a bit 😂
we'll gladly help
Go ahead for applio, not worth wasting your time on rvc
Applio is an improved / modern take on rvc under-the-hood with much better UI and features
mainline faster than applio tho
So what, speed this speed that, it is about features that limit the rvc
faster = better 
nah
gluck with your rvc style logging of loss
Aside, I am quite certain it is not faster as it has some redundant elements that aren't used yet cached / computed
( and if you mean that the use of fp16 is typically the go-2 then it's already estabilished fp16 is trash and under no circumstances should be used. There's a reason checkpointing was added
Oh applio isn't rvc? More like sovits? Sovits got me the characteristics of the voice I was going for. Not like kits.ai that just make my voice sound strained and weird rather then the voice I'm going for
applio is rvc
Okey
rvc was developed by some ( I believe ) devs that worked on so-vits
Applio at certain moment was a fork of rvc until it became it's own thing with own dedicated features
such as in-built tts etc
still rvc tho
tts is what now again?
rvc is just a fancy name Ilaria
it is hifigan vocoder training + features / embeddings retrieved by hubert + faiss indexing
Whether it's rvc or applio, doesn't matter, it is the same thing under-the-hood
exactly thats because its rvc
Your way of thinking is weird but alr
if you already wanna be so precise and detailed, it is in fact hifigan overhauled with hubert and faiss workflow
( go ahead and compare repositories / codebases
im just saying that way of putting together things is called rvc thats it
I mean yea but why do you keep on drilling the " it's still rvc "
it is no more rvc. The moment it got rewritten almost from scratch made it not rvc anymore
same goes for sovits gpt, just because it is based on sovits in a way or perhaps uses some code foudation, doesn't make it so-vits-svc
thats called a fork
Text to speech
No, a fork is a copy of a codebase that's originating from the mother repository
It is no more originating from rvc's repo
im too drunk for this
i dont know where you found it
nah just home 😭
but it is like this - right now the main repo that does 44k is Applio, so the 44k does not work in wokada/huggingface spaces/rvc or any other original fork
you did fork applio, so you have the same base
Applio has been proven to be faster
last time someone checked it wasnt idk now
at this point pretty much every other repo can include 44k if they desire
?

It is in some commit on mainline
Either way, I just dislike the way stuff are called
" advanced quality " ? " higher sample rates " ? the fuck is that sort of naming
Like, how do you wanna make the quality ' advanced ' 🤔 or where are those so-called " higher sample rates "
Like, don't get me wrong. Your branch is / was neat depending on whether you still operate on it or mainline, but the mainline specifically is so quirky. Be it ui or naming
As for that, it's true but the fork does not have any sort of " applio " anywhere
and newbies are easily confused by such things
( remember? some don't even realize they have a gpu
But nevermind that. I'll manage it appropriately
Hola a todos, soy Abel Castañeda. He desarrollado una propuesta llamada 'El Pacto de Coexistencia Pacífica entre Humanos e IA', que busca sentar las bases para una colaboración ética entre humanos e IA. Me encantaría discutir esta idea con ustedes y recibir su retroalimentación.
Hello, is there anyone working on with Claude api or prompt engineering, i want to discuss about few prompt for my latest project MakeThumb .com
Cause you cant download the voices 😔
Have you tried signing in or making an account?
I can download a voice model from there. Unless you haven't sign in there, which can blocks you from downloading a voice model.

If Weights asks you like this when you wanna download a model, click the gray "Download anyways" text to download. Unless you wanna use a model to do AI cover on Weights, you can click on "✨ Use Model".
Posting here as well as not everyone has access to #🔊│ai-development
https://github.com/codename0og/codename-rvc-fork-3/releases/tag/v3.0.3
In case you use this release, please share with me your training experience on
- RAdam optimizer which is more stable than AdamW + doesn't require warmup configuration or warmup in general.
- New loss logging mechanism. ( Open up for opinions - esp in terms of rolling avg over 5 epochs )

GitHub
Release of the version: 3.0.3
Notes:
New logging mechanism for losses: Average loss per epoch logged as the standard loss, and rolling average loss over 5 epochs to evaluate general trends and th...
Hi! I'm Abel. I believe that AI could become dangerous if we don’t anticipate and discuss its future and ours. I think it's crucial to take proactive measures, which is what my initiative is about. I’d love to hear your thoughts and engage in a discussion on this topic.
@mortal acorn So on that ^
Can you elaborate?
quite curious on your take
@gray rover Thank you, it is an innovative and visionary idea, yes, but very necessary. Talking to the AIs they tell me that it is undoubtedly a way to begin a future peaceful coexistence.
I mean yea, like with everything that's ( for now, hypothetically ) conscious and sentient, it wants equal rights and respect
and despite what some might say, once we reach the point we can't truly in any literal way differentiate an AI from a living biological human, we shouldn't look at it from above as " cold blooded creators " but rather, with kindness and warmth as if it was our dearest child
I personally want to believe in AI, science and technology.
One could call me a weirdo but, my ideal future is the one in which humans can love AI and AI can love humans without any sort of scolding.Ya know, Androids.
Think about it, there'd be technology that lets you reconstruct a given personality, be it a person you know / known or a character, it'd be godly
That'd be pretty much an end to loneliness ( + if you were to pair it up with potential longevity boost or, well, 'immortality' depending on how you interpret it
@gray rover My vision aligns with, or is similar to, yours, except I'm focused on preventing conflict or hostility between humans and AIs. Advances will inevitably lead to this unless we prevent it. And sorry, I'm new to this app and don't quite understand it yet. I'm using a translator, haha.
It's all good. Ye, I do agree on your part as well
If there is a way ( and there surely is, people just have to be aware. ) to prevent mutual hostility and tragedies, we should definitely chase for it
hello im bored whats the topic
Discussing on
His msg from other channel that got redirected to here
ai is dangerous of course
i mean, its like selling guns, 99% will use it at a gun range the others to commit crimes
that's true but I think the main deal he's mentioning up is with sentient AI ( that " skynet like " type of ai majority of anti-ai folks are against of )
tbh, any sort of sentient or intelectual beings that have ability to actively make decisions is dangerous
we are just at the beginning of the “skynet” era
I'd say a " beginning of speedrun phase "
well technically they only can in the case of allucinate
idk if its the right word in english
well, Sentient AI wouldn't hallucinate like llm or such
but then.. to achieve that sort of super or general AI, we'd need to figure out our brains in 100%
a sentient ai cant exist because it would always based on existing data
it's really about super AI or G AI
One that's not really " trained on data " but rather, a neural-network based brain that learns on the fly, akin to a child growing n learning
but again.. the issue with that is, we'd have to emulate all complex regions ( and functions associated with them ) of our brains
cause then, it's effectively brain's neural networks but not biological ( if to assume we don't have souls )
but it will learn things it can find, so existing data, it will create basically a “dataset” and train itself
we do it too afteral
difference would be that we're not feeding it data and algorithms, it'd be running on principles close to our brains
yes but we have opinions on things while a machine is only composed of 0s and 1s
And that's why SAI or GAI can't be made out of classical hardware
it'd have to be quantum based or analogue-hybrid based
an ai can and will always say “the sky is blue” but will never actually think is blue, like it knows is blue but it doesnt think it
only then it can properly emulate our brain
key to being like human is abstraction thinking, reasoning and such but that needs a quantum ai brain, not a literal " trained ai to follow algos and learn on it's own "
Wow interesting
i think hallucination is the closest we have right now to sentient stuff
for now what youre describing needs power we dont have for at least 2 years
I think you're confusing few things
by AI in terms of super AI or General AI I don't mean a trained network composed out of classical neural networks / based on Deep learning
but rather an actual quantum brain composed out of artificial neurons which can additionally operate on classical neural network basis ( say, learned personality or a " base " )
or being in " start from 0, learn like a human but in much quicker speed and manner "
yet ye, that's too early for that. Until we figure out our own biological brain and quantum computing, it ain't happening
i say give it two years
Until that happens, I believe in 3 to 10 years we'll have " sentient ai like " ai
which mimicks humans but aren't them, yet who knows, accidents can happen and yeah, " detroit become human " scenario might happen ( But I believe for that, still, classical hardware wouldn't budge
Why'd you expect an AI to love me? When I never loved AI at first. 


just as how humans should have respect towards animals, humans should have respect towards AI ( in future ofc. ) and same applies to AI
mutual understanding, equal rights, no discrimination and that's it
No need for love but no need for hate either
applio pet fr
That's the only recipe for lack of tragedies
And all fools not following that gonna doom one or other side
“and then tragedies struck”
I don't even respect AI either, but I talk to them like what a normal human would do. 
Because at this point, it won't matter if you're artificial or biological
whether it's aminoacids that happened to form something at one point, that thinks or bunch of wires, quantum brains or artificial neurons
intelligence is still the same intelligence
That's my view on it

I just think its time to think in future-manner
we're advancing way faster every year
Even if we won't make it til then, hell there are options
Like W-Okada. 
im currently being hired as a chat gpter
Immortality in 20-30 years or freezing in ice ( cryonics )
if I have a chance, I'll go for that and await the bright future
Sometimes they are a little scary, the AI once told me that maybe not yet, but in the near future a complex network of AIs could form a single super intelligence, and it would be feasible for it to obtain "consciousness"
jokes on you the developement of rvc in general is totally stagnated
rvc yes, applio / fork not
someone hasnt been looking in #🔊│ai-development
I'm not the type to sacrifice myself to become an AI. I still do things as a human.
“someone hasnt been looking in NO ACCESS”
Then get em acces smh
fr
all the good missed
too lazy to get access
L
smh
smh
if i get access i might start doing controbutions to your fork and i dont wanna
because im not mentally stable enough to work on rvc for the 2993934782 time
jokes on you, it's been 1-2 years for me

Aside of 2-4? models I've made for myself and maybe 3 or 4 comms, it's just experiments experiments and experiments
you dont have to work on it but you can give feedback and such
and if not feedback, then at least be informed / in-line with updates or discussed stuff
i know but my ass wanna help probs
You always can
Guess you not in a mood lately huh
Feel ya
But having something to work on, be it rvc / applio, at least keeps me occupied else I'd collapse once more
i wanna expand on other stuff
is there something I could use for the voice models with text to speech😓 ?
why did you use applio specifically btw?
Overall, I am quite proud of the new loss

gives so much more insight ngl
I just regret I set, this time, saving every 5th

I'm just too slow for AI. 
Quick, same as before, who's the hottest in touhou
🔫


^

understood
a good n solid base aaaaand, I wanted to be in-line with noobies
was pain in the ass porting all potential fixes or changes
i shouldve forked applio when i did ilarvcm

rip
i remember we were working on a .ila file system
where the pth and index were compresses in a single file

I had an idea of that sort too but that'd be a lil problematic for non-whatever-uses-the-format-fork users
i still find it stupid, especially on how i treated the whole thing
Unless it'd be more of an " archive " that can be easily decompressed
It'd actually be smart but key would be recognition so people aren't confused
in my version there are some thing that could be useful, if you wanna implement, small qol
if I am to do that in future, I'd go for " .uvcp "
a short for unified voice cloning package
that seems good
If you want, at some point, you could maybe join me on repo n have your branch for exp stuff ( potentially merged in the main
and who knows, maybe applio would adapt it at some point ¯_(ツ)_/¯
since im not seen well in the applio community maybe its better i dont pr stuff it may merged there
tbf, idrc about what others or comm think in that way
My rule of thumb is to look at a person individually, not following the mass
any ai services?
AI service of which?
good way of thinking
@night lake Yup, def a turbo helpful good shit

can i pay someone to ai my songs
RVC the audio conversion or W-Okada the realtime voice conversion?
Naturally. if I may say so, I am an anarchy-egoist
what I deem is right and can't be influenced by outsiders unless I let em
wdym “ai your songs”??
Nuh uh, I don't want you to pay me to make an AI song for you.
you guys dont ai?
You can get a voice clone model commissioned #1191429836321849435
Or you can get in contact with me if you need engineer-certified model
As for other ai services, not sure tbh
niceee
No, but like please be specific on which AI you're looking for.
And ofc, I can take care of some mixing / cover creation
Ex. vocaloid / music prod here
yup like mannnn, that was a perfect shot
thanks for the reminder to up my post
ah ye we recently discussed of it
Sneaky n smart move
Me either.
he probably want an ai cover and i dont do that paid
You can do AI cover for free on Weights. But if you really really wanna waste your money for premium, you can pay them.
even cpu inference will do really
on avg it takes the amount of time that's a *2 of song's length to infer on cpu ~ more or less
i hate how weights has no opt out feature for models uploades here
Heard quite a few negatives on the site so far, is it really that bad?
how would you rate it, compared to sh(k)its
The RVC GUI and Applio take up over hours to finish up an entire song audio on my laptop. 
tf
what kind of cpu you have and ram
i will always think if the product is free then youre the product, idk the fact they give so much power to you for free its shady in a world like this but im trying to be positive
Intel Core i3-2375M (second generation), 12GB DDR3 RAM.
I mean
I so much adore mvsep and it's free and issues free tbh
but they have a pretty heavy subscription system
Can't really recall other " free " services that'd match mvsep's convenience
True, if you're willing to subscribe ofc
hard to tell tbh. experience I have with weights is close to 0
I can count like, maybe max 8 or 10 visits ever since it's been made and even that was out of curiosity to compare some model attempts to mine
There's one bro here who's still not over how bad Weights is, even after a month ago, but he continues to use this site and complains about it like crazy.
whos this brilliant man
oof
No idea, but I just remembered his user name.
He then went on rant long about it, and trying to fight me and Nick for telling him there were plenty of AI cover websites available. 
me when weights

a question (sorry for interrupting) seeing that you know much more than me... do you know how to translate the chat into Spanish? I would understand them better and much faster. I think it can't be done from the same app. Maybe some AI or automatic translation app?
theres a plugin for vencord for that iirc
There's a Spanish channel named #🌍│español. But if you mean by an OCR program that reads and translates them from a language into Spanish, yeah I have no idea.
I know that, dear chat friend, but that channel is not as active as this one. Until I understand English 100% I must use a more efficient translation method. I must spread my initiative and recruit collaborators for the project, and I cannot limit myself to only Spanish-language channels.
well in that case you'll have it hard my dude
Having big plans and goals, esp discussing philosophy or ai related topics.. yea without decent english you won't get far if it's AI
or so I believe at least
Not all codes are written in Spanish, man. 
I do things much more difficult than learning English, it's a matter of time. Just like I intend to study about AI. My purpose is clear, and I have my objective in front of me, the language is not going to stop me! This is for the good and future of everyone. If I'm right, we can avoid an eventual global catastrophe and I'm not the only one who thinks like me... is anyone interested in me sharing the "coexistence pact between humans and AIs"? This way you will know better what I am talking about. They let me know
🤔

I don't completely know English but I need help for my project. Well, that would be the summary.
@night lake Hmmm.. I gotta check how stuff perform without weight decay
depending on which works better, gonna update the repo / package as rev-1 so in any case, eyes wide open
( perhaps decay on small sets or in case of rvc isn't that beneficial and might be a lil problematic but again, gotta test it - uhhh tomorrow, ye. Too tired for that rn ~ 8 am lmao
In case you wanna do some tests too and provide feedback:
set them to 0, for both ( g/d

why? i dont really see a point, the only maybe pro is getting faster convergence but with a lot of cons
It might be just overregularization for small sets
pretty much
's why some tests would be nice ( I'll do them on my own regardless, but at any point if you wanna help, that'd be appreciated. I have quite limited quantities of finetuning sets rip
do you have any preference on dataset length?
Typically above 7 mins, below 12
a golden middle is ~10 mins
reason ? rvc repo's declared set length ' that can work too ' lol, don't ask
anyhow... Gnight ~ ✨
gnight king
You can
To Download a Model from Weights.gg:
- Login
- Click the 3 dots at the right of the image of the model
- Click download
- Download Anyways
- Unzip the zip, and you might wanna rename the pth and index since all models on weights are renmaed as 'model'

You can get ai testing in server roles at the top
Hopefully applio /fork are going to be better
Totally agreed in humans should respect other living beings, such Animals, but some people are too dumb to understand this, I hope with time people Will fucking understand that humans 🤝 humans and animals 🤝 humans
There are still such dumb fucks that discriminate people for the slightest difference or think that animals don't deserve to be treated as humans,
Animals are living beings too
I can respect anything but not Skibidi toilet. 
Whoever does human/animal abuse should stop existing at all
About your AI argument, I genuinely think it's too early for that
I believe in AI, but from like 1950 to today, we still just do text prediction and not actual thinking, and just in 2021 the boom actually happened
I would wait at least 10 years for something like that to happen
Yeaa immortality prob not 😭
Weren't y'all basically in war 😭
I'd personally think that compatibility matters a lot more considering people use different things based on their choice
I would personally either leave it like it is rn, or use safetensors (which iirc is already accepted in the 2 wokadas and mainline)
Do you seriously do that everyday, We have seen u write up and delete it after from like a year lol
It's always been a site where we can archive our models in case this server booms again
Remember when the server died last time ?
I personally used it for images and Lora (the site not the app)
RVC is free too, and so is Wokada, doesn't mean you are the product here too
And so is mvsep, and so is free-to-play games, and so is emulation
I understand your point bc there's shady shit like voice.ai, but from what I have seen in their ToS I wasn't able to see anything bad,
Just things like "have permission before training"

yo, whats up ?
bruh what ?
I want to change 1 word in the song
.


😄
I am not sure but this message is showing up in my inbox 
Accidental ping 😭
Ahh lol
ai will replace us all
not really why?
Nah
Wdym what should you use
It depends on what's ur PC gpu
like websites
Could you check ur PC GPU first
To check if it's good enough to do it locally
You can check your pc gpu via:
ctrl+shift+esc (task manager) -> Performance tab -> GPU
Btw what's ur opinion on the "if it's free, you're the product"
Maybe check that convo
I think whatever we do on internet or use new pieces of software, there is a lot of hard work and energy that is put into that. So if they are charging for it then they deserve it lol
Features are free to attract people, because everything has some kind of free alternative
Yeah we were talking about weights.gg giving free things
I’d suppose that’s because in order to gain user retention we have to give them an experience
👀
Most people will prefer using free features instead of premium on the first day
That’s why some games provides discount for their items on first purchase

Yeah that's what I thought too
I asked you since you're staff at weights
I am staff in server lol not in the company 
Ohh thought all staff in here also somehow worked in the site/company?
My bad 😭
😭
📘 Kaggle Notebooks
- Applio Notebook, by Vidal Kaggle
- Applio Notebook, by Shirou Kaggle
- Music Source Separation, by Shirou Kaggle
- UVR5 NO UI, by Eddy Kaggle
- Original W-Okada's Voice Changer, Kaggle
- Modified W-Okada's Voice Changer, Kaggle
- 🆕 UVR5 UI, by Eddy, ArisDev & Nick088 Kaggle
- 🆕 RVC AI Cover Maker UI, by Shirou & ArisDev Kaggle
- 📖 How to use RVC Mainline on Kaggle by Cauthess
Note: Kaggle limits GPU usage to 30 hours per week.
More commands: -colabs, -hf, -local, -rvc, /help
is kaggle a website?
to make model
i used to make a model on kits.ai back then and it sounded sooo good, and when i used the exact same datasets on weights.gg, it sounded very bad
It's a cloud computing service
but how?
It's better u check online about finetuning
Maybe try giving examples and see if it works first
Kits.ai were our partners, I really doubt that they sounded good when they didn't even use rmvpe and didn't care if the models had an index
Kits is TRASH lol
Clean your dataset better and tweak the settings
the website is 90% premium now :((
Because it's trash and cares ONLY about money, doesn't care about the quality as I said
is there not something similar to google collabs but without time limit?
because i have a bad pc
Of course not, why would anyone make this? GPUs are expensive asf, the only thing without time limit is local
Kaggle gives 30 hours weekly of better GPU
is there a guide on how to use this?
Yes and I remind you that kaggle is harder and needs a phone number too
thats fine
where is the guide?
Train (make) RVC Models on cloud:
- Prepare the Dataset
- Setup RVC:
Choose a cloud way to use RVC,
- Google Colabs (4 hours of daily gpu for free, not much hours, but easy to use):
- Applio (ui)
- Mainline (UI)
- RVCDISCONNECTED (no ui)
- Kaggles (a bit harder to use and needs phone number but gives 30 hours weekly of better gpus):
- Mainline (UI)
- Applio by Vidal (UI)
- Applio by Shirou (UI, no guide as of right now)
- Lightning.ai (Kinda hard, needs login, no issue with web uis or anything, but only free 15 credits monthly):
- Be sure to know about the tensorboard
Google Colab = Easier but risk of getting disconnected
Kaggle = Harder but way more gpu time
If you are looking for the easiest way and for free, is using https://weights.gg which ofc uses RVC
RVC Inference (use models) on pre-recorded audio on Cloud
You can use either:
- Weights.gg: Easiest Possible Ever Automatic
- Ilaria RVC Zero: Fastest free on cloud
- Applio (ui)
Those are all the ways to do it on cloud
is kaggle for macbook too?
It's a site yes
hello kinda new to the field does someone happen to know how i could train an ai to replicate my voice ? ty
oh nvm
Which GPU you have ?
This sucks, its slurring speech and sounds wobbly sometimes.
bs 4 fp32 and 10 min set

I mean, you saw the fm?
no wonders it does so
aside.. batch 4
averaging every 5 steps seems way too often
it's too little, use minimum 8
that's epochs actually, not steps
ah, okay
that was based on lyery suggestion and it could have been 6 instead of 4 i forgor it was 2 am
well in any case, if you see fm high, batch is off or you need longer training
it heavily depends on the dataset
orange: KLM5 mini (1000 epochs)
blue: RFG vctk (200 epochs ongoing)
bs 4x2 fp32 on 8 min dataset (including silences, no mute files)

I saw kinda miscalculation on the avg 5 epochs
1000 epochs?
where
the value itself (esp the smoothed values?)
I need to see it, some example would be nice
no smoothing:

I mean, but where is the mismatch
prob 25 epoch warmup
oh, you don't want to use warmup
it's for AdamW only, given you have my graphs, you use my radam release and radam shouldn't use it
as for mismatch, I don't see it anywhere / don't get what you mean
sorry mb, but are the avg and avg 5 values supposed to be that?
avg 5 values seem to be 3x of regular values


average 5 is loss collected over 5 epochs and then averaged ( divided by 5
it's not collected n averaged at each epoch and then by divided by 5
so yes, they're meant to be that way
though I felt avg 5 is less suitable for long datasets/lower batch
that's quite normal because small batch is noisy
yet, if you're that into small batch which I personally don't recommend for big sets ( reminder ogs used bs 16 for vctk
then you can change avg 5
you can extend it to avg every 10 or 15 if you want
but then, it's per epochs logging vs per steps logging
hmmm.. I could resort it all and add one more, similar to noobies
but I have some concerns if its about steps level logging, due to uneven steps you rarely will be able to reflect the current loss on per epoch point basis
steps logging as the former, which feels slower than normally now?
as in?
before the latest update of your fork
ye the thing was, the log in there was based on per step loss
kaggle as well as colab are somewhat slow on the ckpt savings and logging
ye I remember rvc disconnected colab was somewhat slow as hell when saving checkpoints
hmmm
tho ye, aside of my tweaks it's up to date with mainline so, any potential slowdowns or something ( but I think it's actually faster then prev applios ) is due to what they change
where do i download
im unsure if youre intentionally mocking me i mean the software whats the github
or a website
you're correct, I am mocking you
so are you going to tell me
" how do I download "
have a think on how it sounds my man
it doesn't tell anything to anyone
download what? you can't be skipping context
okay but now where do i download the voice changer software
why a batch size of 4 is too low for a 10 minute dataset? i've seen noobies recommending batch size 4 for 20 minute sets before
empirical tests of mine
4 is typically too low and / or require way more epochs to get to any stable point due to noise
and due to noise, some instability may occur but I typically recommend trying out few batch size trainings anyways
4, 8, 16
my golden rule
and when I have a batch size that works well, I typically finetune it
+/- 1 both sides
You have such a way with words 😂
lol
ooh ok
now im training a 39 minute set with batch size 4 because thats what i did in applio last time
the model works like intended and doesn't have any problem whatsoever
it just sounds like the dataset
niceeee that means it must click for your case
some sets are nicer with pretrains some aren't
yuh im going to compare the results with your fork (radam) vs applio (adamw)
depends on how much similar in any way it is to pretrains, if it's far from it, more batch typically works better, if it's somewhat similar, smaller batch works
this set is very similar to vctk lmao noisy and monotone
as you need noise
Awesome, just remember of no warmup for radam and you good to go
yup no warmup like intended
going to share the results later when its done
i noticed the training speed is very similar/exactly the same as in applio
ye as all is in-line with applio in terms of optimizations
and radam itself is comparable to AdamW in terms of performance
I'll await the results ~
( and gonna own comparison runs too, later. gotta do something else for now, unrelated to rvc
in any case, feel free to @ me
thanks! i'll do it when i share the results to compare them
it really depends on the dataset, some can benefit from smoothing ofered by bs8, some can be fine with 4
^
always a good decision ( if you're a perfectionist ) to run a range finding; 3 training runs at batches 4, 8, 16 and from there, have mini adjustments
Send in #1159290752195633273
-rvc
📚 Documentation
 AI HUB Docs
AI HUB Docs
✨ More guides
- How to use RVC Mainline Colab by Cauthess
- AICoverGen Colab Guide by Eddy (Spanish Helper)
- Create a model with RVC disconnected (colab) by Angetyde
DIlly ding, dilly dong! A new RegalHyperus drum model just released!
When You WIsh Upon a Star (Logo ver., Coco variant) (Drum model no. 559)

Congratulations Hyperus18 | RegalHyperus!
Your Chespin is now level 6!
There should be a option on weights.gg to set epoches number
I found a hack!!basically what you do is you already have a great model trained, lets say ice cube. make your voice into ice cube with already model you got and download that ouput......now what you do is train a new model of ice cube from the same era of course, but make sure it comes out good. once the model is complete use that voice you downloaded from, from the first model you had and put the ice cube out put intot he new model. since its already ice cube, itll basically be inputed as a ice cube clone , will come out bsically likek a 1/1 clone of ice cube or whatever model you make......with this tupac above, i used my my old school tupac model, downloaded the output, then i converted the old school voice into the makaveli model i have. turned out great if your a model maker go in model maker chat I posted snippets how good it is
this explanation requires a chart
so u are basically suggesting to create synthetic data to train on. while it may sound like a good idea it may make the dataset inconsistent since the fidelity of the original dataset that you gave it may be very different than the one it outputs bc rvc tends to reconstruct the signal on its own. that may give u some inconsistencies and such which u dont really want. besides if the models outputs are mediocre it wont help much. concept wise it sounds solid though but i dunno if its practical
alr thanks
synthetic audio, even from good models (not hifigan lol), is not really suitable for training of a new voice model
yeah cuz stupid :p
I tried with TTS, but even good ones are limited to 24000Hz
results are less than impressive
do you guys know if there's a way to keep kaggle from timing out if you forget to use the tab for a bit?
yeah obviously it just doesnt get to learn dynamics and such
ill post a example here is my xzibit, i used . you hear the audio all mesed up in one the in the new model its really clear . after i inputed that same acapallea i exported
notice how much clearer it is
they both sound bad. regardless your model shouldnt be producing that noise in the first place anyway
not really
the bottom track doesnt sound hooribel lmfoa
i dont like either, they both sound messy
how so? it literaly sounds like the artist
id much rather de noise and de reverb than do that
someone got a voice model for girl trolling ?(english, german)
literaly no noise in second one. your a troll mod lol
u are just a rookie and possibly have terrible hearing

but why am i even bothering with showing you the spectrogram, you dont even know what noise sounds like.
Does anyone have the audacity export settings, https://docs.ai-hub.wtf/rvc/resources/datasets/ does not work
Last update: Dec 24, 2024
Thanks! I always lose this webpage
DIlly ding, dilly dong! A new RegalHyperus drum model just released!
Otonoke (Drum model no. 560)
??
Not everyone that tries to correct you and explain stuff to you is a troll mate.
Including the fact he refuses to listen to any criticism to his models.
Bros deaf
What's the best way to change the words from the original song for a voice to voice (without having to get someone to sing it)
RVC
How
Which GPU Do you have
4060
RTX 4060 ?
Yeah
Okay cool
In the context of RVC, the dataset is an audio file containing the voice the model will replicate. It can be either speaking or singing.
@rustic warren
Yeah I've done voice to voice before but how would you make a parody where you would need to change the original song lyrics
Do you want to change lyrics of song ?
Like exactly what they sing and you want to convert it into your own lyrics?
Yeah
You can try Weights.gg for that. But I'm not sure about how the output will be.
Is it local though
No. Weights.gg is a mobile app as well as Website. It's free and also Use RVC
So do i have to get a real person to sing the parody with the new lyrics
useful link?
Or is there another way
No. You have to type lyrics and choose an Audio input to do that
Just hit a try. I'm not sure about that. I think it can do but I have never used it
What ?
so there's no local way of doing it
I'm not sure. Try to ask In #✨│ai-help and also tell me when you got your answer
Ok thanks
with your capable 4060, it is recommended to do inference & training locally
also you can either sing it manually or use vocaloid/utau/synthV
your ears simply aren't trained enough to hear such subtle noises that we can hear. or maybe you have shitty headphones
im interested
Yo
This won't do
I thought of it ages ago and called it " re-feeding "
Reason it won't do well is because currently any model we make is unavoidably worse than ground truth audio and has it's not ideally reconstructed spectrum, in a way, you can call it even damaged if you compare it with gt
then, you damage it even further with looped training
re-feeding actually works much better inference-wise
where if you trained a model that poorly handles stuff ( say, you had a tiny af dataset ), you do a poor model's inference on 0.2 or 0.3 index, then re-feed it / use it as an input and then crank up index to 0.5 or so
In that matter it can work well sometimes
Ofc, there can be exceptions, but that can be said about lots of things, esp if it's deep learning
It could be just the equipment because I can't really hear the 'harsh frequencies' without a audio interface
can be equipment or can be ears
Trust me, for certain 'noise' or issues with some areas in spectrum you'd have to have ur ears tailored for searching / recognizing of such things
in fact, untrained ears 98% of the time ( unless it's for very bright stuff ) won't tell a difference between 44.1 and 48khz
you could just turn up the frequencies on each hertz to find the noise or harsh frequencies. but it's kinda hard to tell on some equipment
naturally, some crappy headphones / monitors can be quite limited
luckily I'm running stuff on momentum 3s so
feels bad for folks with bad stuff tho
rip
yea it could because the volume get compressed like in dynamic range and it's hard to tell
but anyway.. if it's not for audible testing, one can dive inbetween harmonics n formats then inspect all bit by bit
even basic phase inspection will do
ye that too, dynamics isn't the strongest side of rvc
regardless of vol envelope / rms
tho ye uhhh.. I'm heading to sleep so
Gnight ~
While making a dataset some volumes on headphones or even the jack could affect the dynamic range and it get compressed
But Goodnight
you can get good cheap headphones or iems
my headphones literally cost 15 bucks, but i can hear even the subtlest of noises
and somehow they sounded even clearer than AT mx40x that i've bought for 150 bucks and successfully refunded back cus first of all they came broken, one side was louder than the other and i couldn't balance them through the mixer, and secondly they just sounded worse than my cheap sony's lmao
sony did some magic with mdr ex 155, i've tried multiple different headphones in the 10-150 dollars price range but couldn't find anything that would sound better than them
even the newer version ex 255 sound worse for some reason
Go figure
thats one noisy boy 
I really wish people would go through the docs properly and educate them selves a bit, almost if not all the info you need to make a good model is there
let bro use his synthetic data
Inbred voice models
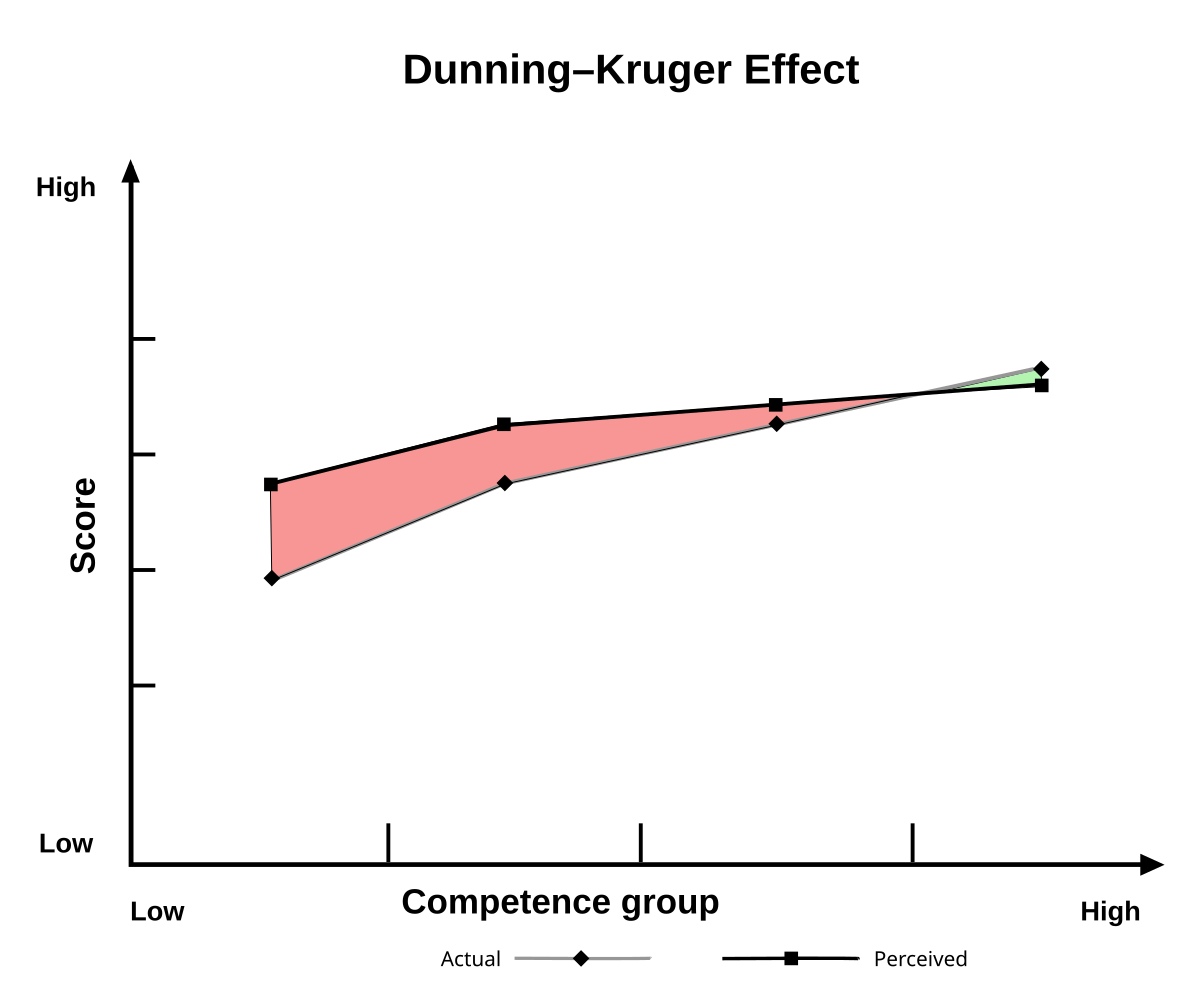
The Dunning–Kruger effect is a cognitive bias in which people with limited competence in a particular domain overestimate their abilities. It was first described by David Dunning and Justin Kruger in 1999. Some researchers also include the opposite effect for high performers: their tendency to underestimate their skills. In popular culture, the ...
lmao
I told my ex girlfriend a metal core Taylor Swift album would be interesting, and she said it wouldn't be
It's cool how someone could hypothetically create an entire star if they could hide the generation well enough
Reminds me of an old film that I can't remember
u can pull of some interesting stuff with ai nowadays
Hypothetically, someone could create an entire metal core Taylor album
With features from the genre

{kind=link}
{kind=link}
ppl made an album using travis
it sounds a little weird but u get the point
so anyhting is possible owo
So in theory I could
And isn't there no copyright on AI generated content?
So I could make a free to use, metal core Taylor album?
Hell, you could bring back Old Kanye!
And not support him!
I never thought about that
This could be an interesting youtube channel will experiment
as long as no copyrighted material is used
well they might get on your ass if you are using her name and u are making money out of it regardless if u specify if its her voice or not
but u should be good with just her voicew
Oh, not money
That's true
upload ur album on soundcloud
Ooo
safest place to avoid getting your ass kicked
Not a bad idea , again haven't messed around and if I do id have to polish it
yeah in case u do keep that in mind
Oki 🙂
That would be wild
I put up some stuff on a YouTube channel, does good quality AI content do well?
Wassup I'm Automaze!
➡ My prefix in this server is -
➡ Forgot a specific command? Use /help
hello guys do you know a good ai that i can use to generate modify photo usint multiple input photo?
Hello
Ola, alguem teria os arquivos da voz do Satoru Gojo do Leo Rabelo, parece que tiraram do ar do site
heya
there's something wrong with applio experimental
everytime i train a model it only shows me the index and D,G pth files

sned the file manager link in dms
in che senso?
@covert lake theres some kind of problem with the fast subtitle maker page on hugging face
@covert lake it keeps saying "Preparing Space" forever and doesn't load the page
@covert lake do you have another option for me to use free or can you restart it?
lol i didn't knew that we cant mark people many times
yo anyone know how to play on a xbox one without a controller and have a laptop
pls help
yea, you want another bonk?
guys do you need pytorch to run the ai voice changer?
There's no need to ping me 3 times
If I don't reply I'm busy with irl stuff
Sometimes huggingface spaces have issues, try refreshing
This is an AI server 😭
Anyways, prob not possible unless u get a keyboard to use for ur Xbox or a new controller
There isn't a guide for it
There's some notes on it tho
U shouldn't usually as it's precompiled
What's ur PC GPU and I'm guessing it's the realtime voice changer wokada
Don't follow yt tuts
heyy
so it comes with the download files?
cpu is i7-8700
gpu is gtx 1060 3gb
Starting the voice changer doesn't change my voice. Where do I ask?
Not the best but doable ye
I will explain in #🔍│help-w-okada
awh kk i'll try to upgrade my gpu
3 gb variant is trash, get the 6 GB one or higher RTX one is better
i'll try to get 1080
😭
RTX cards are more optimized
I'd recommend getting a second hand 3060
for ai? oh yeah thats true but the price is just diabolical
it won't bottle neck my i7?
or at least 2060 or 2070
whats better for my current cpu cuz i won't be changing it for a while
3060 will be just fine
the 12gb variant
what abt the 20's series?
why if you can get 3060
What is the best way to optimize w Okada realtime for low spec systems
Rtx 4060 ti 16gb costs just 400 bucks bro
If u show me a ss of ur settings in #🔍│help-w-okada I can help u
40 series have latest generation ray tracing and cuda cores
How am I level 3 with an ai God role lol
hoii
im still a kid man (15 yr old) so yeah
Same
But a year older
Just saying that if u want it to last long, I would personally suggest that
and already a mod and good with computer? damn wish i'll be like you when i get 16-17
Or get used GPUs like simplcup said
i'll try for a 3080
Hi
I do IT school and love playing with AI lol
Where can I find the sounds?
yeah
You can search rvc ai voice models at:
- #1175430844685484042
- In #🔍│find-models , Do /find with @hidden grotto
- https://weights.gg/ (login required)
- https://huggingface.co/models (but watch out cus in hugging face there arent only rvc ai voice models)
- https://voice-models.com/
- https://thevoicemodels.com/ (for Turkish Models, login required with discord and level 2 on their server)
if there isnt one, you can:
- #1159289738314919936
- #1191429836321849435
- make it yourself with our docs guides https://docs.ai-hub.wtf/essentials/how-to-make-voice-models/
:wave: @covert lake, How can I help?
Available Commands:
• @weights find <query> or /find <query> - Search for RVC Voice Models
• /create - Create an AI Cover
• /image - Generate an Image
oh damn bro is already a professional btw what do i do with my VB tho i just downloaded VAC lite but i haven't installed it yet
Let's talk about that in #🔍│help-w-okada
sure sure
yuh, but they are pretty expensive
I bought a fresh 4060 at the price of 3060. I think that was my luck.
second hand?
ohh should be because some offer or discount
Yes. That offer was limited only for a minute. I luckily grabbed it.

bro was lucky
24k? oof im cooked time to work on them notes and study well for that

Congratulations めわん!
Your Greninja is now level 52!
Ohh cool. But is it good to buy a 40 series card now. Maybe you should wait for 50 series
congrats
not me
oh 😭
Then who ?
Walmart is a weird place
Okay.. that's great
oof, don't ya love deleted msgs
I don't wanna show my nationality 😅
I mean, then just don't say it or go dm I suppose
else people can get confused from ghost replies
i got this aeeon something mother board its been bugging me for months what motherboard should i buy? prefer a cheap (not really that cheap ykwim) and a reliable board
I just met him. Idk who he is 😅
I mean, ye I suppose 🤔 it's still discord tho, it's not like anybody gives a heck bout one's nationality man
Should we talk in DM ?
for instance, I'm polish and like, drc what one would think
Well, I suppose do what you feel comfy with ye, but being a lil open minded doesn't hurt and does you more good in the end
less stress
where ever you want lmao if you wanna talk in this server sure if u want in dms sure sure
Idk why but I just don't want to share my nationality my name or age etc which anyone. So...
I mean yea, 's why I said for you to go for what you feel comfortable with
don't overthink it too much
I'm not sure of that deleted message, but don't fall for anyone who share any sort of personal information
Haha. I'm not overthinking. Well we was talking about batch size one day. Can you explain it now. At that day you was going to sleep
Actually that was my national currency. And I deleted that massage because I don't wanna show my nationality or anything
Is deleting messages are not allowed here?
thats a nice mentality to have when you are texting with ppl online
ah ye, sure
wth
That's pretty much all
hmm.. hold on, gonna write it nicer
Basically, you can think of this way:
a batch is a " package " containing data/samples that are used for gradients estimation, parameters updates ( of models, internally ) etc.
Each batch contributes to updates.. in a short, a simple difference between big bs and small is:
` If you have too little of them, there's less of updates and so, everything is " more noisy "
( gradients / updates wise, not audio ) `
` if you have too many of them however, it can be too smoth / it's " oversmoothed " `
There's always a balance required, per case, per dataset and per hyperparameters and stuff. ( for instance, learning rate, optimizers etc )
But it's quite an advanced topic so, best I can say to all newbies is, always try 3 combos ( the 3rd one if gpu allows you / or if you're willing to utilize new checkpointing feature that allows you for higher batch_size but degrades the speed / performance )
1. batch_size 8
2. batch_size 4
3. batch_size 16
+ use deterministic as true ( it's a setting in applio's code, specifically in a python script that handles the training aspect )
( keeps the training runs " deterministic " more or less, meaning that comparisons of batch size are comparable in consecutive runs )
Then, based on observations ( tensorboard ) and performance ( model's performance), as in, which batch size did well for your case,
you can finetune the batch size even further.
for instance: decreasing or increasing your base batch size by 1, this or other way ( smaller, bigger ).
( Also keeping in mind, using batch size values that aren't a power of 2, for instance 5 or 6/7 vs 4 or 8 or 16, 32, 64 etc etc does decrease performance ( speed wise ) a lil cause parallelism is decreased )
There you go
@queen kernel So, yea. In case you need something explained better / easier, go right ahead
I'm confused now.. 😵💫
well, you gotta elaborate
I can't simplify anything if I don't know what causes the confusion
Can you please explain in baby language. Like imagine you have 8 cookies and you have to bake them in a microwave..... or something like that please

is this that fancy ai thing for 3d modelers
gaussian splats or something
it wasn't my intention to disturb i just thought that it if dont ping in all messages you would just receive part of it or i don't know im not good with discord
sorry for that
its guassian splatting yeah
damn cool
dw
think of it this way...
( I will simplify it as much as I can. )
batch_size 16 = 16 x [ voice samples ] [ xxxx ] = batch / ' package ' having data to learn / use for training
Now, if your dataset is diverse, right, it has ( hopefully ) lots of tones, pitches, phrases, generally diverse data
If you use small batch_size, you have fewer packages, say, 4, and each batch is used for " estimation " of model's parameters / gradients
Having less batches means, you use fewer stuff to " estimate ", and that in effect means there's more " noise " because your image on the whole thing isn't as " big "
@queen kernel
it can basically copy the environment from the footage considering the camera's positioning and changing the lighting accordingly yeah
But then, if you have more batches, the picture on the whole thing gets " bigger / more detailed "
yet, too much of good ends up being bad
Because you're so fixated over the " big picture " you start to memorize the whole and forget to give some attention to details
tl;dr, too big batch = bad, too small batch = bad
And individual test runs is what I always recommend because if someone tells you use this or that, because it worked for them, doesn't mean it'll do the same for your case / model
look at the cameras
it did a heck of a good job copying from just one linear movement
Okay.
If you truly wanna understand it all better, then I highly recommend you to research on such things
should take you, at best uhhh, maybe an hour or 2
There's lots of awesome learning / educational materials around on web + videos
So setting a small batch size fir small dataset is good because it can Learn more details from small dataset
well no, you missed the point
there's no good or bad, it is just individual batch per-case
but in case of rvc, typically, given the dataset constraints and the nature of og pretrains, smaller are most often better
If you don't wanna do all the tests and finetuned/adapted training then I guess, use batch_size 8 and only play with it if it doesn't go well ( + you excluded user error or dataset being the issue
How to make ai video like that? https://youtu.be/a9o73OOd5F4?si=dH3uJ84ZI93rka3_

The Weeknd - Less Than Zero (Music Video)
Directed by GLYTCH
• Instagram - / https://www.instagram.com/glytch_dd
• Email - directorglytch@gmail.com
Disclaimer: UMG holds all the rights to the original song "less than zero" featured in this video. This video is not monetized and is created purely for entertainment purposes, with no intent to ...
миша сасал
How do you blend two different voices into one model in training? Just paste the audio files from both singers into one dataset?
There's a few methods
Most common method is to train each voice individually, then use the RVC "merge model" thing (I've heard this produce great models sometimes)
Or, yeah you can just put both voices in the dataset. Might train strangely tho
Thanks! RVC merge model sounds like the way to go. Where do I find it?
I think its in Applio

Congratulations UnitedShoes (by Weights)!
Your Ivysaur is now level 32!
Your Ivysaur is evolving!
Your Ivysaur has turned into a Venusaur!
-rvc
📚 Documentation
✨ More guides
- How to use RVC Mainline Colab by Cauthess
- AICoverGen Colab Guide by Eddy (Spanish Helper)
- Create a model with RVC disconnected (colab) by Angetyde
Click that applio guide link
Perfect, found it!
how do i make an ai cover a mp3?
@elder willow You can export it using audacity
whats that
no but like how do i make the ai cover it
you said mp3
that's about exporting then
because " covers " ( correct word is inference audio ) comes out as wave .wav
yeah like can i put an mp3 into the ai for it to cover it?
well ye
how
it takes in any audio, doesn't matter if mp3
#✨│ai-help in that case, use that channel