#kaggle-llm-science-exam
1 messages · Page 1 of 1 (latest)
Oops when I posted ^^ I didn't realize the link didn't unfurl. Anyway, the event happened and the recording is now available here! https://www.youtube.com/watch?v=GaV_M2l4-N0

A livecoding session from Charles working through a starter notebook for the "LLM Science Exam" Kaggle competition, written by Jeremy Howard.
Focus is on exploratory data analysis for and with LLMs, plus some synthetic data generation.
Original notebook: https://www.kaggle.com/code/jhoward/getting-started-with-llms
Edited notebook: https://ww...
This is really helpful! 
Hey guys I'm gonna start working on this competition soon would love to Collab!
Hi guys
Any one could use one sentence to summary what this competition do? Is it more focus on model and GPU laryer?
I think it is about how to use LLM to produce a large amount of high-quality data😆
and fine-tuning by using large models
i think its about who can afford the most GPUs
Is there any limit to how powerful our local machines can be for training ?
i dont think so
Hey, Masters students in CS here, looking for a team, hit me up if you're up for it
How does one get a good understanding of why this is written this way.
I could figure out what each of these lines were doing, but why they are doing what they are is not clear yet.
class Perplexity(nn.Module):
def __init__(self, reduce: bool = True):
super().__init__()
self.loss_fn = nn.CrossEntropyLoss()
self.reduce = reduce
def forward(self, logits, labels):
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
perplexity = []
for i in range(labels.shape[0]):
perplexity.append(self.loss_fn(shift_logits[i], shift_labels[i]))
perplexity = torch.stack(perplexity, dim=0)
if self.reduce:
perplexity = torch.mean(perplexity)
return perplexity
Tried reading https://thegradient.pub/understanding-evaluation-metrics-for-language-models/ but felt like I need something milder. 😅

The Gradient
On different metrics for evaluating language models, the relationships among them, mathematical and empirical bounds for those metrics, and suggested best practices with regards to how to report them.
Essentially, it's a "Perplexity" class which measures how well a probability model predicts a sample. It's usually used for evalutating the performance of language models. The lower the perplexity means the model can predicts a sample with a higher accuracy.
After doing some very quick "research" I found a pretty easy to understand explanation / example of Perplexity. Here's the link: https://jamesmccaffrey.wordpress.com/2016/08/16/what-is-machine-learning-perplexity/#:~:text=In machine learning%2C the term,a measure of prediction error.
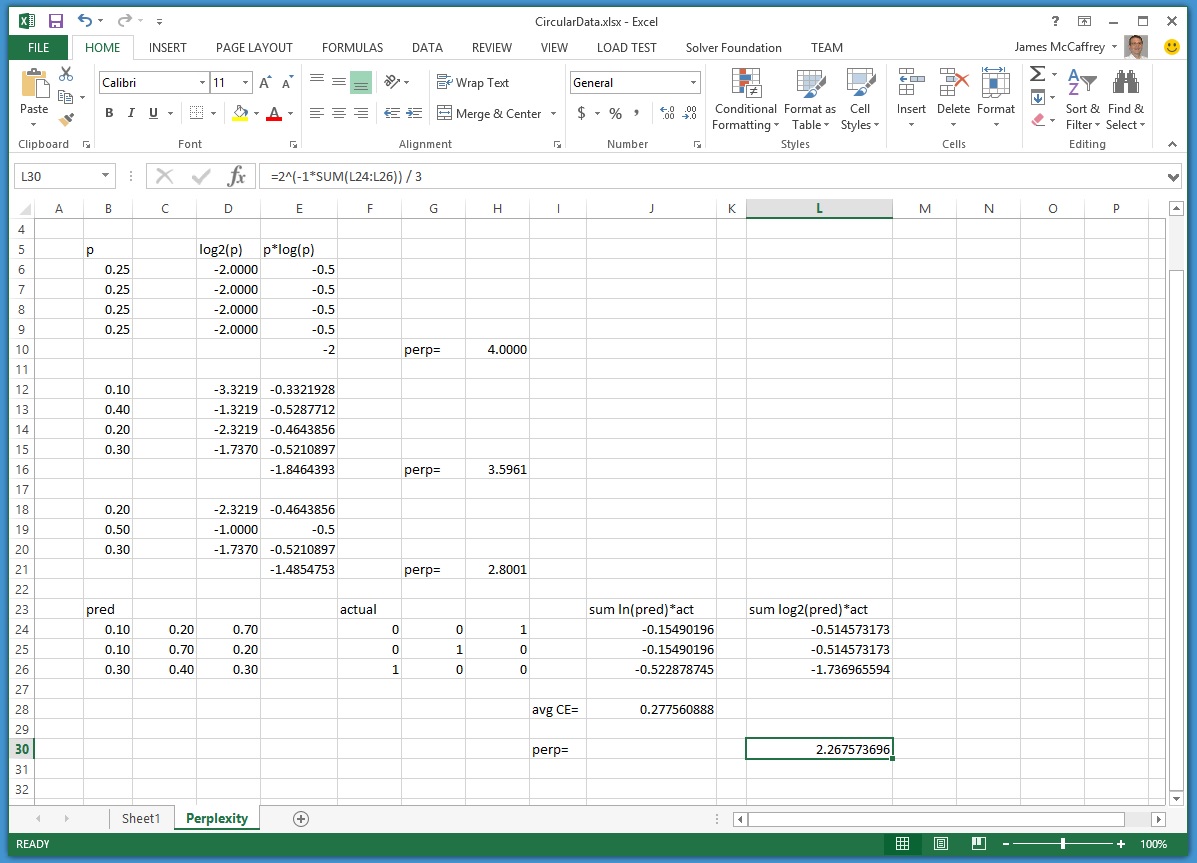
In machine learning, the term perplexity has three closely related meanings. Perplexity is a measure of how easy a probability distribution is to predict. Perplexity is a measure of how variable a …
There is a video which explains perplexity here at timestamp 15:00
https://www.youtube.com/watch?v=ddCYORu41Xs&list=PL23FjyM69j92o_j5JFH9sNlbhCx4n0ZYh&index=1
there is a massive problem with perplexity in my opinion
namely when the answer is 'none of the above' or 'all of the above'
do a simple ground truth value
how would that be done?
dot product of the semantic embeddings with a target value
hihger dot product = higher similarity to the target
like attention
have you implemented this?
also btw
no i but i think its used quite commonly
its called ROUGE score
i think
its used for evaluation though and not as loss function
Hello everyone.
I don't play around with kaggle for a few years now and so, in practice, I'm a newbie on this. I'm interested in this competition but I'm a bit lost on few small details. Hope someone can help clearing some dumb questions.
- Since this is a offline competition we need to pip install directly the wheel. I get that. But I see some notebooks that installed the wheels saved in the folder "kaggle/inputs". How did they get there? Isn't the inputs folder read only?
- How much disk space can we use? We are allow only to use the 20GB of the working directory?What aboout the input folder?
- About the GPUs. Just to confirm. We can use up to 32GB of GPU (T4x2), right?
- You can get the data/notebook output to the input folder. Find more info in this commen: https://www.kaggle.com/code/cdeotte/how-to-train-open-book-model-part-2/comments#2423056.
Yes, Input folder is read only but you can add any of the datasets from "Add Data". - I dont think there is any limit to adding data to input folder, only when you load to the notebook, it matters IMO.

Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
How prevalent does this seem to be in the data ?
Idts I've come across any instances yet
this is a really helpful set of starter videos. Thank you for sharing, Chris!
Some of us may get confused by the variety of the Bert models in Huggingface. I am definitely one of them.
Therefore I did some googling and researching and summarised my findings in this post.
Please feel free to give it a look. and if you find it helpful, please give it an upvote.🙂
https://www.kaggle.com/datasets/xhlulu/huggingface-bert/discussion/438733

BERT models directly retrieved and updated from: https://huggingface.co/
does anyone know where / what the loss function used in transformers.DebertaV2ForMultipleChoice is?
arXiv.org
In-context learning (ICL) i.e. showing LLMs only a few task-specific demonstrations has led to downstream gains with no task-specific fine-tuning required. However, LLMs are sensitive to the choice of prompts, and therefore a crucial research question is how to select good demonstrations for ICL. One effective strategy is leveraging semantic sim...
Could this be applied to llm science exam
so i have a very noob question so forgive me... turning this task into a classification task is pretty simple, the categorical cross entropy loss is the go to choice and you get the answer directly and its pretty simple to change model heads (just add a linear layer). i've also seen folks fine tune models on a seq-to-seq task (like how a usual llm would be trained, (you give the question+next_token(answer|output_logits) +backward(),step and then question+answer_token_1 + next_token(answer|output_logits)...) +backward(),step(), how'd you actually get the answer here, i can imagine the next token being the answer token(A|B|C|D|E or yes|no) but lets say i have fine tuned my model for generating the answer correctly <as a list of newly generated tokens>, i still don't know how to automatically pick out the correct option. e.g question: ..., options:a..,b...,c...,d...e.., answer: says nothing about the option b but generates the option b exactly. so i guess to summarize, how does one use a seq-2-seq fine tuned model for actual inference
According to GitHub here https://github.com/huggingface/transformers/blob/1fa2d89a9bb98a15e9720190e07d272a42f03d28/src/transformers/models/bert/modeling_bert.py#L1620
Each of the five pairs of question plus choice are forward pass. And PyTorch saves the five logits. Then PyTorch reshapes the five logits and applies cross entropy which in PyTorch includes softmax loss
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(reshaped_logits, labels)
The trick to making GPT style (seq2seq) LLM to work is to finetune and/or prompt engineer the LLM so that it only outputs 1 token. We can either show LLM the question plus 5 answer choices and the model will output A,B,C,D,or E and we extract the probabilities from those tokens. Or we show the LLM pairs of question and 1 answer and the model will output True, False and we extract the probabilities from those tokens.
GPT style LLM take time to infer each token. Therefore if we try to output a 20 token sentence, that will take 20x longer than outputting one token. More info is here: https://www.kaggle.com/competitions/kaggle-llm-science-exam/discussion/440908
yeah, that makes sense.
According to the website, this competition began on June 19th and ended 12 weeks later on Sep 8th. Is this competition still going on?
Deleting this as we ask that promotion of events, blog posts, etc is posted in our resources channel instead: https://discord.com/channels/1101210829807956100/1130802867285008414
Can Platypus2-70B be used for this competition ?
Actually yes... Ivent explored it msyef but I read a discussion post where the OP used this or some other 70B model by loading it layer by layer (u can't load it all in the kaggle GPUs at the same time) ... Took 8hrs for submission but there were no OOM errors.
I wouldnt ... But yes you can
@upper aspen let’s say I train a model V1, loaded from deberta-v3-large pretrained model, for 2 epochs, with DATASET 1
Then, I train a model V2, loaded from model V1 best checkpoint for another 2 epochs (like basically cloning the model) WITH THE SAME DATASET 1
Is that effectively training for 4 epochs or this is overfitting ?
I have seen a public notebook do that and the val loss and validation MAP@3 improve
There is a discussion post saying it doesn’t have commercial license. But from what I searched it has the same as LLAMA2 license. There’s no answer from the competition hosts for 5 days since the discussion was posted
My gpu quota on kaggle just ran out which is a bummer becuz I just fixed my memory and speed issues and was about to make a submission....
Has anyone tried kaggle TPUs? Does the transformers library work well with it... I guess I'll have to figure that one on my own XD
Topic: Bitsandbytes error
Hello everyone,
I'm trying to fine-tune Falcon 7B, but I'm stuck at the configuration part of QLORA bits and bytes.
Here is my code.
model_id = "tiiuae/falcon-7b"
import torch
bnb_config = BitsAndBytesConfig( # Used for initiating QLora which reduces memory of training size
load_in_8bit=True,
load_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model =AutoModelForCausalLM.from_pretrained( # Initiating the model
model_id,
device_map="auto",
offload_folder = "/content/drive/MyDrive/Fall 2023/Model building",
trust_remote_code=True,
quantization_config=bnb_config,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
Here is the error. I've both the mentioned libraries installed, but it's still not working as the issues is still open on the bits and bytes GitHub page. Is there any solution or any other way to implement using QLora? This is my first time, so please be as detailed as possible.
{kind=link}
Thanks

Yes, we can train for 2 epochs, save weights. Then load weights and train another 2 epochs. If we use cosine learning schedule each time, this is called cosine with restarts. (So this is the same as training 4 epochs cosine restarts with restart every 2 epochs). If we use constant learning rate each time. Then the result is the same as training with 4 epochs constant learning rate.
Furthermore, sometimes people train with more diversity of data and augmentations the first time. And then train with less diverse data (i.e. more like test data) the second time with less augmentations.
Thank you for the detailed reply!
When we specify learning_rate=2e-5 in the Training parameters with a cosine rate schedule what does this mean ?
Is 2e-5 the initial learning rate
In my best model my train loss is lower than the valid loss is that a bad thing ?
Has anyone used Rlhf or reinforcement learning based methods for this competition... I need to talk with someone who has used it in this competition...
In HuggingFace, this is called RewardTrainer. There is a Kaggle notebook here https://www.kaggle.com/code/datafan07/single-model-rewardtrainer-lora-llm
Alright. I'll check it out soon.. Thanks
It sounds good;
but I suspect it would depend on what you are using as validation set. And whether your training set contains questions from your validation set
are you using it with an index or something (rag)
In lb
Hi, we are 23rd https://www.kaggle.com/xiezejian currently(having try too much ensemble so I believe there is still have room for us) and looking for a single person team to merge. PM me if you are interested or would like to discuss further.

Fintech
well done everyone! this was a fun competition
Congrats to all participants who got medals!
Thanks
Hi, i have 50 clusters of numbers each cluster corresponds to a plume shape, i know the location of origin point, i want to translate each plume or cluster at same position line they superposed each other cause i want to eavlaute the average values of them. anyone knows how to implement this in python
i am trying this from yesterday, not able to implement it
i would like to learn NLP and LLM from scratch, can anyone suggest me some resources?
I think this notebook is a good start https://www.kaggle.com/code/crxxom/comprehensive-overview-on-nlp-for-beginners This goes more in depth with the basis of language models https://www.kaggle.com/code/tanulsingh077/deep-learning-for-nlp-zero-to-transformers-bert and maybe this video is good motivation and theory https://youtu.be/XfpMkf4rD6E?si=xwY1JsS0qG91Nf9s and this video after the others https://www.youtube.com/watch?v=kCc8FmEb1nY&t=484s goes over building something like a GPT

Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources

Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources

January 10, 2023
Introduction to Transformers
Andrej Karpathy: https://karpathy.ai/
Since their introduction in 2017, transformers have revolutionized Natural Language Processing (NLP). Now, transformers are finding applications all over Deep Learning, be it computer vision (CV), reinforcement learning (RL), Generative Adversarial Networks (GAN...

We build a Generatively Pretrained Transformer (GPT), following the paper "Attention is All You Need" and OpenAI's GPT-2 / GPT-3. We talk about connections to ChatGPT, which has taken the world by storm. We watch GitHub Copilot, itself a GPT, help us write a GPT (meta :D!) . I recommend people watch the earlier makemore videos to get comfortable...
Any follow ups on this question? Any benchmarking against GPT4 or Claude V2 would be interesting #1130785937681547284 https://www.kaggle.com/competitions/kaggle-llm-science-exam/discussion/446790
Use LLMs to answer difficult science questions
thanks for sharing, i really appreciate your help, have a great day
Lmao I still have no idea why my fallback on 0.825 XWinLM works (Public 0.909 Private 0.900) while the fallback on 0.870 XWinLM doesn't LOL. I keep getting submission CSV not found
It's literally falling back on the same model and the same template as simjeg (I referenced from there), I only changed the function
Maybe it was already touching the brink of the memory 
That probably should make a silver medal submission 😑
coursera deeplearning.ai
Your question is not clear to me, but I hope you've figured it out by now?
Essentially, I think this project wants us to build something like GPTZero - https://gptzero.me/. You can get loads of insights for this project if you read how their detection technology works - https://gptzero.me/technology
GPTZero
Covered by >100 media outlets, GPTZero is the most advanced AI detector for ChatGPT, GPT-4, Bard. Check up to 50000 characters for AI plagiarism in seconds.