Hey folks! Kicking this channel off with a "meta" message. 🙂 If you come across any interesting papers / blogs, please share and discuss in the #1130529466230247444 forum channel. As this Discord grows, I'll be looking into setting up some events for things like paper reading groups, invited talks / AMAs with researchers (and practitioners), demos / workshops, etc. If you have any thoughts on what you'd like to see or you yourself would like to give a talk or something, let's discuss here!
#🔬┊research
1 messages · Page 1 of 1 (latest)
Then, to kick off some discussion ... what's up next on your reading list? 👀 And how do you organize what you want to read next? 😱
Hey everyone 😄
This paper has been in my pending list for some weeks, so will start with: https://arxiv.org/abs/2306.11644 (Textbooks are all you need)
Also a survey paper on LLM Evals (https://arxiv.org/abs//2307.03109)
I was working on Text 2 SQL in my previous company, so came across these two papers. I tried organizing my notes on Notion but it is not free now so using Notepad again 🥲 Want to try a different notetaking App, any suggestions?
hmm, what do you mean by notion not being free? They still have a free tier-- Or are you using a specific feature that is now paid for?
Yes, somehow it mentions that I have utilized my workspace completely and I need to upgrade my plan, previously I used Notion heavily for many of my writeups and sections.
I guess, there's always the option to cheat and open a new account with different email? 🤣
Lol that was what I was thinking when we had this convo 🤣
My TBR is impossibly long and growing, but this week's reading list is..... at least more manageable 😂
https://arxiv.org/abs/2307.10169 (Challenges and Applications of Large Language Models - I love a good survey paper!)
https://dl.icdst.org/pdfs/files/236e636d7629c1a53e6ed4cce1019b6e.pdf (an old paper but a good paper: revisiting "High-Dimensional Data Analysis:
The Curses and Blessings of Dimensionality")
https://arxiv.org/abs/2301.04856 (Multimodal Deep Learning - I passed this one by when it first came out because I was busy catching up on shorter papers, excited to dive into it now)
arXiv.org
Large Language Models (LLMs) went from non-existent to ubiquitous in the
machine learning discourse within a few years. Due to the fast pace of the
field, it is difficult to identify the remaining challenges and already
fruitful application areas. In this paper, we aim to establish a systematic set
of open problems and application successes so t...
arXiv.org
This book is the result of a seminar in which we reviewed multimodal
approaches and attempted to create a solid overview of the field, starting with
the current state-of-the-art approaches in the two subfields of Deep Learning
individually. Further, modeling frameworks are discussed where one modality is
transformed into the other, as well as mo...
I've just added some tags to the #1130529466230247444 channel! You can use these when you share papers. Once we have lots of papers shared 🤞 they'll be helpful for sorting through and finding ones you're interested in reading and discussing! 🙂
For folks interested in some weekend discussion ... what research topics are you currently studying? Personally, I've been reading up on LLM evaluation, like I note in my forum post here: https://discord.com/channels/1101210829807956100/1139978847505363014
I will be contributing to the list, and will join the discussions from next week! 🤘🤘
No tabular flag ?
@lucid echo I did but it seems to be greyed out. Does it need some form of approval ?
I'm able to see it fine -- I might suggest making the title of the post the paper title + adding commentary in the post body. or otherwise just adding a bit more detail than just the link at least.

it's more grayed out on my screen b/c i have it selected, just a discord UI thing
Ok yeah some UI choices are confusing. I have done some editing. (I didn’t know it was a discussion.)
BTW if you ever want to organize something like a paper replication workshop / event, LMK. I can help set it up!
oh damn
I'll definitely be interested in paper reading group
@lucid echo are you sure you want to split #🔬┊research and #1130529466230247444 ?
I mean how are we to discuss the latest cutting edge research without discussing the papers coming up with said research?
also this is unrelated but I think you should make a thread for each competition instead of a full blown channel
since I doubt any one competition channel would have much activity once the competition ends
and it'd be a shame to delete the channel losing all the convo that happened there
but leaving them pile up would also make the server hard to navigate
Is there a way to have default filters in papers ?
Hey guys! I am new to Machine Learning and to the whole data science world. I am a computer science student and I have just written my first article. It is about using the p-value and the R-squared methods for variable reduction. I would love any feedback for me to improve. Thanks a lot! Here is the link:
https://www.linkedin.com/posts/yaser-jafar-4b89b7276_the-r-squared-and-p-value-methods-for-model-activity-7099187273958588416-O7QI?utm_source=share&utm_medium=member_desktop

I am thrilled to announce my first article ever in the #DataScience world. In this article, I delve into the intricacies of two crucial statistical…
Thanks for the channel feedback, we're definitely still experimenting to see what works. The plan for competitions right now is that closed competitions will get moved to a new category, then after a couple of months they will move to an archived category (where they will be read only). So they will be available to go back to, but should hopefully avoid clogging things up. If you have any other channel feedback, please feel free to add it to #1130786027699707915
aight 👍
Hello,
I'm currently working on a time series project, and I intend to employ the EMD+CNN technique for forecasting the output. Upon applying EMD to the training data, I obtained a total of 14 Intrinsic Mode Functions (IMFs). Consequently, I constructed my CNN neural network with dimensions (30100, 20, 14, 1), with 20 representing the window size. However, I encountered an issue when attempting to decompose the test data using EMD, as it produced only 11 IMFs. This inconsistency caused an error when trying to execute the CNN model.
I have two questions: Is there a method to enforce a consistent number of IMFs during the EMD decomposition process? If not, is there an automated way to select the most significant IMFs?
Please note that I am utilizing the EMD-signal library in Python.
Thank you.
🌟 Anyone interested in an exciting scholarship opportunity offered by the AI and Cyber Futures Institute?!

📢 Exciting Scholarship Opportunity for Aspiring Researchers! 🎓
We are thrilled to announce that AI and Cyber Futures Institute will offer #PhD #scholarships…

At Convergence, our mission is clear: to democratize and promote AI in Africa, unleashing its full potential on the continent. 🌟
We believe that empowering…
Thanks for your kind information.
I am from EEE background and want to do masters on IT/Data Science.
Please provide some scholarship opportunities for MSc programs.
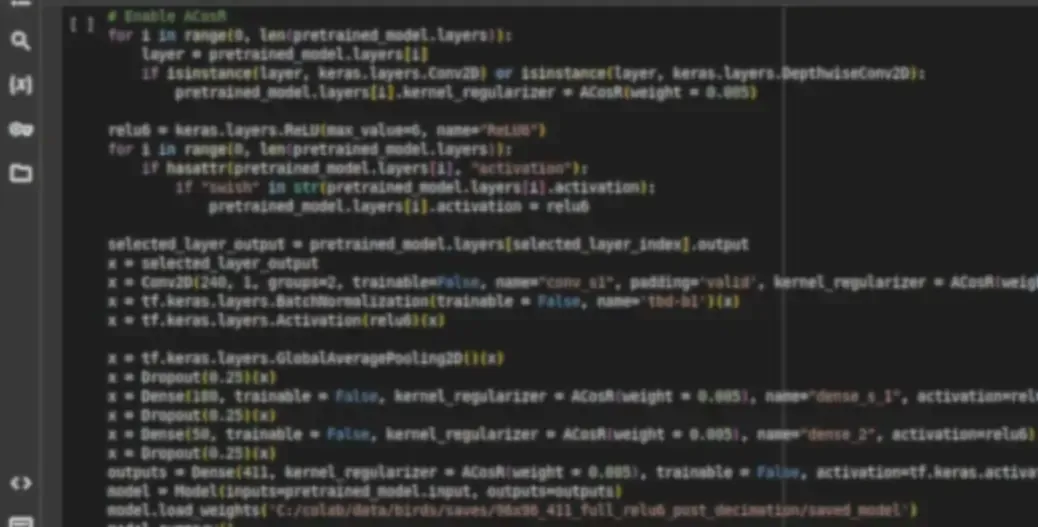
To my eye it appears that there are 525 directories, meaning that many classes. Yet in the end you have only 411 classes. An educated guess is that space characters in directory names are causing this issue. For example, VIOLET BACKED STARLING, VIOLET CUCKOO, VIOLET GREEN SWALLOW and VIOLET TURACO seem to be converted into a single group named VIOLET, and the same is true for other names that have the same word in their names before the space character. Generally speaking, it is a terrible idea to use space characters in file or directory names in python scripts. So you may want to fix this first before determining how accurate your training actually is. I suggest you simply replace space characters in file/directory names with underscores. Beyond that, your approach seems OK. There are other small networks that could work similarly well in terms of accuracy but give smaller models, such as SqueezeNet and MobileNet.
Hey people my team tries to make the tts model emphasis better, do any one has ever made or see any kind of research like that arround ?
if it is there we can take some help
as far what we tought is appliyng ssml tags but it is no use for programmatic tasks and the other way was appliyng the original pitch from the original data to tts output I'm open to discuss
I've been experimenting with compressing EfficientNet models https://www.cranberrygrape.com/machine learning/tinyml/bird-detection-tinyml/ I documented my approach on my site. My test images on my edge impulse project have been mostly successful (or close enough where I see the resemblance). Was able to take my model from 4,491,895 parameters and drop it to 196,533 while retaining some portion of the accuracy (95% - 82%). I further refined the outputs to just birdfeeder ones and later quantized it for a final model of 96x96 with 411 outputs and 190,770 parameters with 82% int8 quantized accuracy. Not sure if there are any flaws to my approach but left enough in my notebooks and page so folks can reproduce as they desire if there's interest.
Cranberry Grape | Cosmic Bee | Tim Lovett
Obsessively Shrinking a Transfer Based Model
Hi Guys
I see these days that a Kaggle Grandmasters title has lots of importance on our resume. So I have formed a group where we can help each other in achieving the grandmaster title.
Please join me here:
https://chat.whatsapp.com/JoYLv3VvZjL8So8WWOoWlM

The Group is not active yet ?
Yes, it will be launched shortly. Please join to stay updated
Okay, but to prevent people from leaving the group, try to keep them updated with messages like: "The group will start its activities a few days from now" or similar updates to keep people engaged.
Can I know the relevancy of this post in the research channel? I mean is your group also focused towards conferences and stuff?
Hi, I am new to research area. Need some mentorship to start in NLP. kindly let me know if anyone can guide. Thanks
Hello everyone, i have a question and i would really appreciate your assistance.
I have 2 networking and ip addresses data files with .RR format (ex: myipv6add.RR, myipv6add2.RR) and i want to extract into MySQL file .. how can i write a script in python to do that ? 
hi everyone , I have done my btech in Data Science but I am new in kaggle discord community @admin if there any suitable work I would be happy to work on it. Let me know if anyone can guide me its functionalities
Hello, everone!
I need help.
I want to make a new song in the same style from 100 ambient music. These are all made by several instruments but not from human voice.
How can I do this?
Thanks for your reply. But I've tried it once, the quality was very low for several instruments.
Those interested in Reinforcement Learning can check our recent work out
http://arxiv.org/abs/2408.14195
TLDR: We analyse a clustered multi-armed bandit formulation, where the learning objective is to identify representative arms from each cluster, in a fixed confidence setting
arXiv.org
We study the representative arm identification (RAI) problem in the multi-armed bandits (MAB) framework, wherein we have a collection of arms, each associated with an unknown reward distribution. An underlying instance is defined by a partitioning of the arms into clusters of predefined sizes, such that for any $j > i$, all arms in cluster $i$ h...
Hi, everybody. I have a question.
I want to make a method to architecture the neural network for given real problem.
Is this possible?
So, I mean can we make the certain arhictecture of network based on neuro science?
Please help me overview of this and methods.
Where I can find the proper references?
Hi. I discovered a way to build a logical digital mind. Looking for you folks who are interested in discussing the idea🤝
Hi everyone , i recently submitted a paper which got accepted, The paper is published on arxiv : https://arxiv.org/abs/2410.13293 , do check it out and i would really appreciate everyone's feedback on the paper.
my linkedin : https://www.linkedin.com/in/prakhardixit250697/
arXiv.org
Many students struggle with math word problems (MWPs), often finding it difficult to identify key information and select the appropriate mathematical operations.Schema-based instruction (SBI) is an evidence-based strategy that helps students categorize problems based on their structure, improving problem-solving accuracy. Building on this, we pr...
congrats! that's awesome
Hi man! I just finished reading your research paper on SBI-RAG, and I'm really impressed with your work. The way you combined Schema-Based Instruction with the Retrieval-Augmented Generation framework using a large language model is incredibly innovative. I love how your approach helps students break down math word problems into clear, logical steps - it's such an important skill for them to develop. The results you achieved are remarkable, with your system outperforming other AI models in terms of reasoning quality.
I also found it fascinating how you used another AI as a judge to evaluate the responses, and it's great to see that your system consistently scored higher in clarity and logical flow. While there might be some room for improvement, like incorporating more diverse datasets and human evaluations, I think your research has the potential to make a real difference in how we teach math problem-solving.
Keep up the fantastic work man!
I'm new to research field, but i'm interested to do join on research team and learn. if i have opportunities to join any your termed research team, please let me know.
Thanks for the comments @stoic wraith , i am glad you liked it . Right now we dont have opportunities but if any thing comes up will let you know
Alright
This Is My First Kaggle Competition: Ranked 1939 out of 3700+ Teams Worldwide!

My First Kaggle Competition: Ranked 1939 out of 3700+ Teams Worldwide!
Okay, I need to share something exciting! 😊 Just wrapped up my first Kaggle…
anyone doing any research work on nlp especially zipf's and heap's law ?
Is anyone doing research here on how to enhance math reasoning in LLMs?
anyone taking part in Meesho competition here?
My First Research Paper
𝐒𝐭𝐞𝐩𝐩𝐢𝐧𝐠 𝐢𝐧𝐭𝐨 𝐭𝐡𝐞 𝐑𝐞𝐬𝐞𝐚𝐫𝐜𝐡 𝐃𝐨𝐦𝐚𝐢𝐧 𝐟𝐨𝐫 𝐭𝐡𝐞 𝐅𝐢𝐫𝐬𝐭 𝐓𝐢𝐦𝐞 !
I still remember the day Krupali Donda ma'am introduced my…
Hi!
I'm a senior data scientist from Armenia (31yo) with 4+ years of experience and two master's degrees (RIT-NY, USA; AUA-AM). Last year, I applied to several top PhD programs but was unfortunately rejected—likely due to not having any publications yet, which I'm eager to change.
I'm looking to collaborate with a researcher or professor on AI topics, especially:
- Multimodal machine learning
- Autonomous AI agents
- Knowledge graphs
- Memory-augmented architectures
- Reinforcement learning
I've worked in both industry and academia, but honestly feel most at home in academic environments, surrounded by like-minded people. Started my data science journey at 24 (after military service) and have been playing catch-up ever since. While I'm doing well career-wise, I have a strong drive to push further and contribute to meaningful research.
I'm aiming to build up research experience and publish papers before reapplying to PhD programs in December 2026. It's tough to find people working in these areas in Armenia, so I'm reaching out here.
Would love to discuss potential projects or hear any advice on connecting with professors/researchers. I think about just reaching out to authors of the papers I am reading but not sure whether it is good idea. Feel free to DM
Thanks for reading 🙂
hello guys
please i have machine test to take. thats job hunting. can someone help by doing it together through google meet?

https://paperswithcode.com/paper/sbi-rag-enhancing-math-word-problem-solving: check out the work I recently did , the paper was accepted at NeurIPS 2024 in Vancouver, Canada! 🇨🇦🎊 This research is all about making math word problems more approachable for students using structured, schema-driven steps 📚🧠💡—like a step-by-step guide that’s just like how teachers walk kids through problems! 👩🏫👨🏫
What’s even more exciting? This approach doesn’t just help students; it also enhances reasoning in LLMs by triggering those crucial intermediate steps for better solution paths 🧩🤖. the paper was accepted at NeurIPS 2024 in Vancouver, Canada! 🇨🇦🎊 This research is all about making math word problems more approachable for students using structured, schema-driven steps 📚🧠💡—like a step-by-step guide that’s just like how teachers walk kids through problems! 👩🏫👨🏫
PyGen: A Collaborative Human-AI Approach to Python Package Creation
PyGen is an open-source tool designed to automate the generation of Python packages from user-provided prompts. By leveraging advanced language models, PyGen streamlines the development process, producing packages complete with testing and documentation. This approach has been applied to create tools such as AutoML (automated machine learning), AutoVision (computer vision), AutoSpeech, and Quantum Error Correction utilities.
Key Contributions:
Automated Package Generation: PyGen simplifies the creation of Python packages by generating code, tests, and documentation based on user inputs.
Advanced Language Model Integration: Utilizes sophisticated language models to interpret prompts and produce relevant code structures.
Versatile Applications: Demonstrated effectiveness in developing diverse tools, including AutoML, AutoVision, AutoSpeech, and Quantum Error Correction utilities.
Resources:
Paper: https://www.arxiv.org/abs/2411.08932
GitHub Repository: https://github.com/GitsSaikat/PyGen
License: MIT License
We hope this tool proves useful for your projects. Feel free to explore the resources and share your feedback or questions.
arXiv.org
The principles of automation and innovation serve as foundational elements for advancement in contemporary science and technology. Here, we introduce Pygen, an automation platform designed to empower researchers, technologists, and hobbyists to bring abstract ideas to life as core, usable software tools written in Python. Pygen leverages the imm...

GitHub
Generate Python Package with Simple Prompts. Contribute to GitsSaikat/PyGen development by creating an account on GitHub.
DM’d
I'm BS IT student at 3rd year , I have done some certification in data science and ML I'm eager to collaborate in research as it'll be beneficial for me to getting in good institution, if you're interested then dm me , I have some ideas let's discuss
Title: Seeking Turbulent Flame Image Dataset
Dear Kaggle Community and Esteemed Researchers,
I am currently engaged in a research project that involves analyzing turbulent flame dynamics, and access to a Turbulent Flame Image Dataset is crucial for my progress. Despite exploring various repositories and reaching out to the corresponding author of a related study, I have not received any responses or found a source for this dataset.
As someone passionate about advancing understanding in this field, I deeply admire the research efforts of those who have contributed to this domain. If anyone could guide me toward obtaining this dataset or provide access to similar resources, it would be invaluable to my work.
Your support could significantly contribute to my research, and I assure you that the dataset will be used with the utmost respect for its intended purpose, with proper acknowledgment given to its creators.
Thank you for considering my request. I look forward to any guidance or support you can provide.
Best regards,
Maimunul Karim Jisan
🚀 Dive into the Future of AI with Marco O1!
I’ve just published a comprehensive deep dive into Alibaba’s groundbreaking AI model, Marco O1, designed for open-ended reasoning. This article unpacks how Marco O1 is setting new standards for developers and innovators with its cutting-edge capabilities.
Whether you’re an AI enthusiast, a developer, or just curious about where open-source tech is heading, this piece covers it all – from core functionalities to its game-changing applications in the real world.
🔗 Check it out here: https://www.linkedin.com/pulse/marco-o1-alibabas-advanced-groundbreaking-ai-model-nalkheda-wala-uhkmf
💡 Trust me, this is more than just an overview – it’s a must-read deep dive for anyone passionate about the future of AI!
Feel free to share your thoughts – would love to know how you see this impacting the tech landscape! 🚀

Explore Alibaba's Marco O1, a groundbreaking AI model for open-ended reasoning. This in-depth analysis covers its capabilities, impact on developers, and future
Good articles, recently, the performance of open source models increase and that makes us allow customization.
Now, I'm doing the project related to AI call agency using APIs and it fails to understand the business logie during interactions with clients.
MCTS and COT is good framework for reasoning, but in real time applications such as call agency, of course that is not complex work, but I want to know the possibilities how we can apply Marco O1 to call agency.
Thanks.
Hello, I'm a competitive programmer with a passion for Machine Learning. Over the past 8 months, I've been diving into supervised and unsupervised learning, deep learning, and NLP. Though I'm new to research on AI but I bring dedication, a strong work ethic, and a mix of ML and programming skills. I'm excited to join a research team where I can contribute, learn and grow alongside experienced members.
Same here
hello i dont know if i am in the correct server but i am looking for ai project that i can join possibly write a paper by the end for my thesis please contact me if you are interested
I'm interested dm me
If anyone is publishing papers either in LLM's or Computer vision please do include me iam too much interested to work due to lack of network iam unable to do things that what I want to do
Please please do include me if anyone is publishing papers 🙏🙏🙏🙏
Just dm me for discussion
good
Hi everyone, Can anyone help me with a list about time series analysis models that can be used in demand and sales forecasting because I am build a research paper about it
There are 2 models created by Google and amazon
1 Chronos by Amazon
2. Google TimesFM
And you can checkout timegpt
Hello everyone, Is there anyone doing research on ai based BCI or interested in that domain let me know thanks
Hi everyone ,is there anyone who is targetting for december acl
anyone know free peer reviewed publication journal in AI/ML/DS instead of arxiv?
Hi, everybody.
I'm looking for ar related to project where that can detect palne and argument the objects on that.
If there is anybody who knows, please tell me.
Thanks.
Hello everyone,
is anybody here who is familiar with AI development without frameworks?
I was able to build an image classification AI with GPU - acceleration (CuPy), but struggling with multiple classification (more than 5 classifications).
In case someone is experienced in that field, I am looking forward for cooperation. It might be fun for more under the hood experience.
Thank You.
Hi, everybody.
We're building news analysis models and need to collect news data of 20 years.
Is there anybody who knows news data service well?
Please tell me.
did anyone try creating a text translation model, like from english to some unique language!
Let's say we want to create a model that translate English to LangX.
Any ideas?
You are going to have to study models that vectorize/tokenize text inputs, for beginners. Try starting with/ researching BERT, for instance, and moving from there.
From my experience it's actually more effective to research the underlying transformer architecture, then any model of interest.
At the end of the day all a model is, is a choice of attention layers, optimiser including any relevant hyperparameters and tokeniser
Hello Jake. I am here
I hope this is the right channel to post about the LLM Research Cohort we are going through in **Cohere For AI **Discord. Join in if y'll find this interesting -
https://x.com/cataluna84/status/1877689686639992872
From the BIRDS(Beginners in Research Driven Studies) organized by @akankshanc of @cohere Open Science Community, we're thrilled to announce our new LLM Cohort! 🎉 🚀
This isn't just another learning program; it's a hands-on, collaborative research initiative designed to push the

Hello Everyone!
My name is Rushikesh and I am working as a data scientist. I am deeply interested in contributing to research in the data science space and would be thrilled to collaborate on any ongoing research projects you guys may have.
I have expertise in the following relevant areas:
Training Neural Networks
RAG
Fine-tuning LLMs
Python (Flask, FastAPI)
Prompt engineering
NLP
I am looking forwared to networking and collaboration
New way to compress LLMs is out - https://arxiv.org/abs/2501.18596. Code implementation on GPT 2 small https://www.kaggle.com/code/shreeshabhat1004/delta-llm-new-efficient-llm-compression-idea/notebook?scriptVersionId=220459799

Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
Reason: Bad word usage

Reason: Bad word usage
Reason: Too many infractions
Building Recommender systems with Gaussian Mixture Model (GMM) and KMeans
1- Data preparation
2- Standard Scaling
3- PCA
4- KMeans: Uses hard clustering (each point belongs to exactly one cluster). Computationally faster than GMM.
5- GMM: Uses soft clustering (each point has a probability of belonging to each cluster). More flexible but computationally heavier.
kaggle: https://www.kaggle.com/code/omidsakaki1370/gaussian-mixture-model-gmm-and-kmeans


Explore and run machine learning code with Kaggle Notebooks | Using data from World Happiness Data 2024 | Emotions Analysis
Check out this repository for an open-sourced version of the Deep Research App: https://github.com/GitsSaikat/Open-Deep-Research-App

GitHub
Open DeepResearch is a application for assisting in research by conducting comprehensive research on any topic. - GitsSaikat/Open-Deep-Research-App
greetings , i am looking forward to write some research papers if u have any tips or u can help me in anyway pls dm . i am willing to become co - author in research papers aswell
Hello everyone! I’m planning to write an article about formal verification of machine learning models. If anyone knows related articles on this topic please share them with me.
Hello guys, I'm working on a project about Artificial intelligence system to enhance MRS and detect brain pathologies and I'm looking for papers/books about this topic, do anyone know anything about that? Thank you!
Hello! Hope things are fine there! If you go to Scopus( Elsevier), Science direct, Wylley, Nature, you will find the best papers about.
https://www.elsevier.com/connect/how-life-sciences-researchers-regard-and-use-ai

www.elsevier.com
Elsevier’s new report explores AI attitudes among researchers and clinicians; co-author Adrian Mulligan comments on its significance for corporate R&D.
check if you have access by institution( university etc..). If not, just create a account, and start to search by keywords.
Similiar to it:

same place @wide portal log in on Scopus, type this subject, and donload. But there are some off topics about this( i dont know if you wanna publish it on science places or just for internet blogs). But for sure, formal verification about these things, is only on scientific platforms.
If you want trusted and verified information, the best place is on Elsevier, Scopus, Nature etc...
Thank you for your help ! I'll see them
If you haven´t access, i can download to you. Some pappers is too expensive and you just will find they by intituition acsess.
You can try also, by here:
Sci-Hub website. Get free access to academic journals. Download research papers for free from ScienceDirect, IEEE, Wiley, Springer, Nature and others
Is like a " piratebay" of papers. haha. So you can avoid pay some.
This one for example. You just need the DOI( the red line i marked). So you put it on Scihub....

Already tried searching on ieee(university subscription), others didn’t try to search, because I didn’t have subscription. Thanks for sci-hub, I’ll try download there later
Hello, I am looking for a research opportunity. Please ping me if anyone have it.
Hello guys i am looking to publish my first research paper , what should i research on any particular new topic in which there is not yet much research and is easy
Hey, i need help
We have long conveyor like 5 kms long
In which there are idlers around 4 to 5k
We divided conveyor section with imaginary line let's say every 20m , in that there are around 10-12 idlers of same dimensions.
We have normal data that is after replacement of idlers, and have abnormal data that is before replacement , we have dataset in the form of real positive fft that is each row contains list with 5k integers
If i train 1dcnn based auto encoder or vae it works section wise, like I can see higher reconstruction error in abnormal data. But it is impossible to create model for every section it will be computationally very expensive. I want single model that will work entire conveyor, but when I combine all data and train then it won't generalise well.
Also I tried extracting statistical features like kurtosis , skewness etc and trained dense vae but no luck what can I do ?
Note: i can see abnormality in normal data too. Even after cleaning it becomes more sensitive to normal data as well tell me better approach if you have any experience related to similer problem
I need a little help in my project anyone who is having good experience in image enhancing and preprocessing
📢 Besoin d’un Endorsement ArXiv pour publier en cs.HC (Human-Computer Interaction)
Hey everyone,
I'm trying to submit a paper to arXiv under the cs.HC (Human-Computer Interaction) category, but I need an endorsement from someone who has published at least 3 papers in cs.HC, cs.AI, cs.LG, or a related category in the past 5 years.
🔍 Paper Title:
🚀 HistoAgent: A Fine-Tuned RAG-based AI Assistant for Historical Knowledge
It introduces HistoAgent, an open-source AI assistant leveraging Retrieval-Augmented Generation (RAG) and fine-tuned with QLoRA for historical research. The system integrates DeepSeek-7B, Qdrant, LlamaIndex, and RLHF for improved contextual accuracy in history-related question answering.
📌 Why this request?
arXiv requires new authors in certain categories (like cs.HC) to be endorsed before submitting. My endorsement code is: Y4CJHX.
If anyone here meets the criteria and is willing to endorse me, I’d really appreciate it! 🙏
I can provide more details if needed—feel free to DM me. Thanks a lot! 😊
Can probably in cs.AI but would need to go through your paper before (or mention the conference where it is published)
I'm looking for novel research ideas in ai in healthcare with potential research gap. Can anyone help me to find out it?
Conformal Prediction
Conformal Prediction
Cam you elaborate further it?
I want everyone's opinions about this topic in the linkedin comments.
🚀 𝗔𝗜 𝗶𝘀 𝗘𝘅𝗽𝗹𝗼𝗱𝗶𝗻𝗴… 𝗕𝘂𝘁 𝗔𝗿𝗲 𝗪𝗲 𝗙𝗼𝗿𝗴𝗲𝘁𝘁𝗶𝗻𝗴 𝘁𝗵𝗲 𝗥𝗲𝗮𝗹 𝗧𝗵𝗿𝗲𝗮𝘁?
As an 𝗔𝗜 𝗘𝗻𝘁𝗵𝘂𝘀𝗶𝗮𝘀𝘁, 𝗣𝗿𝗼𝗱𝘂𝗰𝘁 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿, 𝗮𝗻𝗱 𝗔𝗜 𝗥&𝗗...
Hello everyone, I currently having some experiments that concerning biometric template protection. AFAIK, there are two schemes for biometric template protection which are cancelable biometrics and biometric cryptosystems. Here I am interested in the biometric cryptosystems, such as fuzzy commitment scheme (FCS), I wonder does anyone here have tried or have implemented those concept (FCS) in their projects? If so, i would like some discussions.
Thanks in advance!
Hi everyone !
i m an ai research enthusiast ; want to learn together and discuss research papers ?
Sir sir
Sure
Hello Everyone,
I am looking to collaborate on publishing a research paper with someone experienced.
I am a Developer with 10+ years of experience. 🇺🇸
I am finishing my PhD next year.
🧑💻 Scaling Solutions, Line of Code at a Time! 💻
I am a full-stack software… · Experience: PayPal · Education: University of the Cumberlands · Location: Austin · 500+ connections on LinkedIn. View Akshay Mittal’s profile on LinkedIn, a professional community of 1 billion members.


Hey! I’m building an AI startup focused on LLM finetuning and RAG.
Looking for a partner with some experience in this area to join the journey.if ur intrested please dm me
Hello everyone from Nigeria
Anyone used NotebookLM how is it?
Hello, I am looking for a research opportunity. Please ping me if anyone have it.
Hi guys, i was wondering if my research idea sounds feasible as a 16 year old junior in High School: What geometric properties of a machine learning loss landscape help explain why some networks generalize better than others? Does anyone have any tips on how I should begin
Hi,
I am half way through my bachelor of data analytics degree presently, here in Australia.
Every time I go to find a new Kaggle dataset to practice on, I find myself considering many ideas and hypotheses, that are hard to test due to limitations with the data, I seem to find myself considering many connections across multiple domains such as economics, psychology, and the relevant subject matter.
I'm thinking, the most effective way for me to get comfortable in machine learning, is to work on some kind of research project. If anyone is working on anything, or would like to potentially collaborate to contribute insights, let me know.
I'm interested in pursuing a PhD at some point afterwards, but am leaning more towards finding work for a couple of years first after my current degree. Even if you think connecting with me might be worthwhile, reach out 🙂
Long time no see 😄

Explore and run machine learning code with Kaggle Notebooks | Using data from NHTSA Customer Complaints
Hi Everyone, I am a 2nd Year PhD student in Computer Science at University of Maryland Baltimore County specializing in Machine Learning, Reinforcement Learning, and Mathematical Reasoning in LLMs. I was thinking to write a Review paper on the current Maths Reasoning in LLMs , so was looking for potential collabrators on it. Thanks
Hello Prakhar, what is topic of that
What kind of software would you use for collecting ongoing self-report data from subjects, which would provide subjects with anonymity, but also keep their consecutive reports together under their subject id?
I am banned from the following tech discord channels: Microsoft, Google, Tesla, and the OpenAi discord channel.
The reason?
Because of this:
https://www.kaggle.com/code/alshival/is-tesla-s-fsd-missing-the-road-for-the-trees
Back in the day, people were defending Elon Musk and they pushed me out.
Nowadays, I think my ban wouldn't have happened because people finally got tired of him.
Explore and run machine learning code with Kaggle Notebooks | Using data from NHTSA Customer Complaints
Is there any research being done on using GAMs on feature importance to obtain the maximum importance per feature? (for example, x has a sensitivity rating, it could be the same, less, or more than the sensitivity of the sensitivity of (x) + (x^2)
This should help increase the ceiling of models accuracy scores, while providing insights for a better accuracy vs resource cost ratio as well 🤔
Given features are being transformed not removed, permutation importance isn't needed, and GAMs already account for the small change that one feature transformation can have on the other features. To account for the cost of getting a GAM per feature, reduced samples should still yield adequate results
Edit: Okay yeah so I learnt about different GAM models that remove the need to transform features in such a way because they already learn the best representations, saves me a lot of time at least xD
I can use an EBM solely for the feature transformation process instead >:3
On this, I've decided to include EBMs solely for finding the best representation of features with respect to the target variable. This is similar to DecisionTreeEncoder, except it treats all variables as dependent, as in it's multivariate.
My priority is on my framework entirely, but if someone would like to actually test this, even formalize the results if you wish, let me know, I'd be interested 🙂 this means that only one EBM is needed, rather than a GAM for every variable XD
Edit: So by transforming the features with respect to an EBM, it's basically the same as producing the artifact of the EBM itself, so it's a redundant process in the end.
(For those who use EBMS, I strongly suggest clustering + aggregating + encoding data to reduce the samplesize drastically, this is not gpu-accelerated). If I had clients paying for my services, I wouldn't even consider using XGBoost with this beast available
Research idea for anyone who wants to try it:
Try featureengine' DecisionTreeEncoder, but modify it to use LASSO (and/or elastic net), to account for undersampled classes (be particularly careful for data leakage, if you haven't used DecisionTreeEncoder before).
Let me know the results if you decide to give it a go 🙂
Hey everyone!
I'm a PhD student, and together with my research group from Politecnico di Milano (Italy), we're studying how experts share ML models and which aspects they care most about during the sharing process.
As part of our research, we're collecting quick feedback through a short Google Form — just a few questions, and it should only take 1–2 minutes to complete.
We’d really appreciate your help!
Here’s the link: https://forms.gle/GUudDztkFsnqE3Qc8
If you have any questions, feel free to reach out to us at gabriele.digregorio@polimi.it or/and marco.digennaro@polimi.it. Thank you!
📣 Call for Papers: 5th Muslims in ML Workshop @ NeurIPS 2025 🌍🤖
We’re excited to announce the 5th Muslims in Machine Learning (MusIML) Workshop, co-located with NeurIPS 2025! This year, we’ll be gathering on Tuesday, December 2nd, 2025, at the San Diego Convention Center, USA. Join us for a day of vibrant discussion, research, and community at the intersection of Machine Learning and Muslim communities.
.
🧠 Who should submit?
This is an open call for anyone working on ML that aligns with the goals of the workshop. We especially encourage submissions from researchers who self-identify as Muslim, and those engaging in community-focused or ethics-aware research.
💬 Topics of Interest Include:
ML for social good (education, health, governance)
Language and speech tech for Arabic, Urdu, Persian, etc.
Digital analysis of Islamic texts (e.g., Quran, Hadith)
Bias mitigation, fairness, and responsible AI
LLMs, generative models, federated learning
Robotics, NeuroAI, and ML infrastructure
Important Dates
Visa-friendly submission deadline: August 22, 2025 (abstract, August 15, 2025)
Visa-friendly notification of decision: August 31, 2025
Regular submission deadline: September 15, 2025
Regular notification of decision: September 30, 2025
Camera Ready submission: October 14, 2025
For more details
Website: https://www.musiml.org
NeurIPS CFP: https://www.musiml.org/events/2025-NeurIPS/cfp.html
Facebook Page: https://www.facebook.com/musiml.org/
.
🗓️ Workshop Date: December 2, 2025
📍 Location: NeurIPS 2025, San Diego, California
Muslims in ML Community
Muslims in ML Workshop | NeurIPS'24
See posts, photos and more on Facebook.
Hey, if you are a builder/creator can you please spare 10 mins of your time to answer this survey: https://forms.gle/D1CXQV5Y8fwPzYibA This would be a great help ! Please do send this forward to your creator/builder friends.. Thank You 🙂

Google Docs
Hi! We're researching the challenges creators face in finding work, funding, and collaborators. This survey takes 8-10 minutes and helps us understand your needs better. Your responses are confidential and will shape a new platform for creators.
A small-scale research project if anyone has the time would entail a new way to calculate feature importance for tree-based models.
That is, similar to how feature importance is calculated in the scikit-learn module, except you account for the second best choice across each split, getting the difference in variance reduction.
It's naive, but less so than the current way it's calculated. Naive, because with a different split, the downstream splits would also be impacted. The results should be compared to the traditional feature importance value, and literal feature importance values calculated from one-off recalculations of the tree absent of the control variable, and comparing the difference.
There's a much more complex project that would rely on the results of the above, so if anyone decides to try the above, let me know 🙂 otherwise, I'll get around to it at some point
Right, I'm working on the above now. Will post a link with my findings when I am done.
Another idea is having decision trees be dynamic, instead of controlling overfitting by specifying the max number of leaf nodes, samples etc, you could form the tree with an internal holdout set (not the true holdout set), and when a split occurs where the distribution of samples is unusually higher in one child node than the other, you then use that holdout set to see if it's legit, or if it's fitting noise.
Might work on this after the above. (This could also mean a new optimization approach where you actually want more of these high-stakes splits, and could yield more powerful trees of a lesser size)
Interesting results from this so far..
Another avenue of research I will investigate is how it compares to LASSO and Ridge for managing complexity, by adjusting the split to use (Ginior variance reduction) * lambda * (my normalized metric).
The metric effectively asks two questions: "How necessary is this feature in constructing the tree", and "How uncertain is the model for this split?" 🙂
Still need to add it to PyPI, but here's a unique partitioning approach with its own custom metric to measure the quality of partitions by way of the average HHI with respect to the variance proportions per leaf-node.
It turns the decision tree into an unsupervised global variance reduction model by getting the sum of the z-scores of continuous values, and trying to minimize it (while original columns are left untouched).
I tested it on 1 million samples, 5 features down to 20,000 buckets. 0.0015 HHI, only took 7 seconds to process. Enjoy 🙂
if you reduce global variance then almost all leaf have similar values. does it not defeat the purpose of having decision tree if all the branches have similar outcome?
All leaf nodes make up a tiny portion of the global variance for every feature. It's not for predicting, but partitioning.
Personally I'll be expanding upon it in another framework that will both allow for inference, but will still be designed to be used with a downstream model
Also by global variance I mean the goal is to reduce variance across all features instead of reducing the variance of a single y value; global variance with respect to y.
The global variance of the features is the same, but is represented by leaf nodes as small partitions
Hi, @everybody
I have one question, I'm training ml models for the prediction, which is classification problem of 3 classes, where the number of samples are similar but the predition is skewed.
First class and second class is predicted with low precision tough, third class is never predicted. What's the reason? I can' t find the reason.
Before, when I applyed reinforcement learning, where the three classes were assigned to three actions and one action is never selected, too.
Actually, that is the preeiction model of forex eur/usd.
If anyone wants a potential paper to do, you could use this framework in 2 ways (for now):
- As an imputer, (there's a few challenges to this, but could be very worthwhile).
- As a complexity measure. The required hyperparameters with the HHI metric could measure a dataset's complexity in terms of how multivariate it is. Rigorous testing will be needed to establish baselines.
Having to continue with university for now, so I'll have my hands full. If you have any questions or an interest in that, let me know 👼
A similar point to #2, which might be a good comparison or cheaper global measure, is using HPO + Lasso or Ridge with a tree model, the higher the coefficient, the more complex the data
Edit: (I don't know why I keep thinking of these ideas, my brain doesn't let me rest T_T)
3. You could make a greedy selection problem, where you select leaf nodes and their neighbours such as that the HHI is reduced as a clustering technique (which can be supervised or unsupervised)
Repo updated; more rigorous metric reporting (span and variance metrics per-feature), categorical values will now form the tree via scikit-learn's target encoding against the synthetic y (oh and weights are supported in case the framework tells you certain values are complex / higher HHI values)
Just on this; I tested my H-VRT framework for its potential as a anomaly detection model. So far precision is slightly less than isolation forest, but the recall is significantly greater than isolation forest, thereby with Bayesian inference, yields more favourable results.
You could look at adapting that framework to your needs if you like; it seems to be natively robust against underrepresented classes.
I'm focusing on university for now, but when I get the time I have a strategy to place the variance reduction and HHI (Gini impurity) on the same scale, and to use this for confounder analysis.
In fact, by using my normalized importance metric on both from earlier, I expect to use it to solve the n! problem in casual inference, by only focusing on the relationships that are important. It'll be trivial to actually store all n! information, but it's about extracting the important information that will be more annoying to develop xD
Once I adapt the normalized metric with the categorical and continuous values being on the same scale (with the same target encoding functionality to manage ordinal and nominal categories in the same way), due to the multiple y-target with my split criterion, many OLS models through vectorization can be fitted on the continuous values in the leaf nodes.
The result? You can see through a kernel density plot, the reconstruction of every feature given every other feature, effectively within a system, you get an aggregated view on how features are impacted by other features including categorical.
To get the actual extent of how much features impact other features, my normalized importance metric asks "How important was this feature in constructing this tree?", most importance metrics asks "Given this fitted model, how much does this matter for inference accuracy?"
Sorry I get kinda hyped up about all this stuff xD if any of you want more info, or would even like to help, feel free to msg 😝
I know causal discovery and inference and am interested in you, and I’d love to talk with you about it in detail. I’m a bit busy right now, but hopefully we can chat about it next weekend.
Hi, @everyone
Is there anyone who joins radical ai founders' masterclass?
I didn't have an opportunity to apply for that.
Please give me the meeting urls for them.
Been using this for a lot of stuff, and used the recursive mean of means approach to guide initial parameters (trying to remove the need to declare maximum leaf nodes).
It'd be great if someone explored using H-VRT in this way to measure the hhi of impurity proportions in the final partitions, and measure H-VRT's suitability as an objective measure of complexity in a dataset
Hello Guys
I'm planning to develop a completely open-source LLM,which is free to use(and free to develop,since the costly prices of GPU's).Currently, I need the following things:
- Board Members to work with my level of humor,and comfortable with my constraints and my age.
- Independent Suppliers(Cloud Computing, Data storage etc).
- Advisors
I am currently experimenting on 2x T4 GPU's in kaggle.
Here is my discovery lately:
- tiktokenizer works the best, every attempt of scratch-bpe has failed.
- Need to use AdamW8Bit from bitsandbytes to optimize.
- We need a HUGE data.
Kaggle: afifalisaadman
HF: Afifsudoers
Contact me for further inquiries( Development of the Project will begin in 9th December respectively)
heyy
🏆 Attention Kaggle Researchers and AI Builders!
If you’re passionate about uncertainty calibration, AI safety, and building models that know when they don’t know — the Aletheion Research Collective invites you to join our open community.
🤖 What is Aletheion?
Aletheion is a research project exploring epistemically safe AI — architectures that embed humility directly into intelligence.
It’s inspired by the paper How to Solve Skynet: A Pyramidal Law for Epistemic Equilibrium, which introduces:
- Epistemic Softmax — a calibrated replacement for softmax.
- Q1/Q2 uncertainty gates — distinguishing between aleatoric and epistemic uncertainty.
- Fractal training (VARO) — enabling multi-scale reasoning about confidence.
Our goal: build models that are not just accurate, but self-aware about uncertainty.
🧩 Why Join Us?
- 🧠 Collaborate with AI researchers, data scientists, and philosophers worldwide.
- 🧪 Share and reproduce experiments on calibration, robustness, and alignment.
- 💡 Explore open-source code implementing Epistemic Transformers.
- 📊 Turn Kaggle insights into epistemic benchmarks for AI trustworthiness.
🔗 Join the Movement
💻 GitHub: github.com/AletheionAGI
🕊️ Final Note
"The next frontier in AI isn’t bigger models — it’s models that understand their own limits."
Join Aletheion — and help design intelligence that knows when it doesn’t know.
Hi
Research Collaboration Opportunity – Clinical Proteomics × LLM Reliability
We are conducting a study titled “Hallucination Risks of Large Language Models in Clinical Proteomics.”
The project systematically evaluates how models such as GPT-4, Claude, and Gemini perform when interpreting clinical proteomics data, focusing on hallucination frequency, error patterns, and reliability assessment.
Our results indicate that even frontier models generate 27–35% factual errors, rising to over 50% for complex or rare-protein queries.
These findings highlight the significant reliability and safety challenges of applying LLMs in biomedical contexts.
We are seeking a collaborator who:
• Has experience working with proteomics or mass-spectrometry datasets
• Understands LLM architectures, evaluation frameworks, or AI safety
If this aligns with your expertise or interests, feel free to contact me or reply here.
Code, datasets, and the full evaluation pipeline are available on GitHub:
https://github.com/olaflaitinen/llm-proteomics-hallucination
Tags: #AIResearch #Bioinformatics #LLM #ClinicalData #ResearchCollab
what was that ?
Thanks, my reseach points to this way. But it is preliminary. 89% ECE reduction compared to baseline (GPT-2).
Check this out:
https://aletheionagi.com
I have built an iOS/Android app that allows a user to manually predict time series data that’s used to train an ai/ml model. I want to run a kaggle competition that would involve users comparing their trained model to their manual predictions.
🚀 After 6 months of building, I'm excited to launch AletheionGuard
The problem we're solving:
Companies are deploying AI (chatbots, RAG apps, agents) in production without knowing when their models are generating incorrect information.
This is especially critical in:
🏥 Healthcare - Wrong medical advice
💰 Finance - Incorrect market analysis
⚖️ Legal - Unsupported claims
🤝 Customer Support - Wrong product information
Our solution:
An API that quantifies epistemic uncertainty in LLM responses. In simple terms: we tell you when your AI is making things up.
How it works:
- Your app gets a response from an LLM
- Send prompt + response to our API
- Get back confidence scores and recommendations
- Decide whether to show, flag, or reject the output
Real impact:
- One healthcare client reduced incorrect answers from 23% to 4%
- A legal tech company now catches 85% of unsupported claims
- A customer support bot knows when to escalate to humans
We're offering a free tier (1,000 requests/month) so teams can test it risk-free.
If you're deploying AI in production and care about reliability, I'd love to hear your thoughts.
Try it: https://aletheionguard.com
What challenges are you facing with AI accuracy in your organization?
hashtag#AI hashtag#Enterprise hashtag#Technology hashtag#Innovation hashtag#Startup
https://github.com/InfnityMan/coconutblt do give feedback and contributions welcome too
Is anyone interested in working on a research project or do you an idea you would like us to work on?
Kindly dm for more discussion.
DMed
I’m planning a comprehensive SHAP analysis and explainability on this xLSTM(based on only mLSTM) model: https://huggingface.co/stefan-it/xlstm-german-wikipedia
Main goals:
• Understand how the model makes predictions through feature attributions
• Explore how the mLSTM memory mechanism works under the hood
• Visualize what the model “pays attention to” when processing text
Any advice on the best approach to tackle this? Would appreciate suggestions on tools, methods, or workflows that work well for this kind of analysis.
Thanks!
Hey everyone! 👋
I’m conducting a short academic survey for my Research Methodology internal assessment on “The Impact of ChatGPT in Education.”
It takes less than 3 minutes to complete and all responses will remain anonymous.
Your input will really help me with my project — please fill it out below 👇
Thanks a lot for your time and support! 🙏
Done
Hi @everyone 👋
For the last 4 months, I’ve been heads-down building QuintNet—my own distributed training library built from scratch in PyTorch.
My goal was simple (and naive): Stop treating DDP and Megatron-LM as black boxes and actually understand the physics of distributed training.
It implements full 3D Parallelism (Data + Tensor + Pipeline) on a custom GPU mesh.
The "Fun" Part (aka The Struggle):
🐛 Debugging silent NCCL hangs that gave zero error messages.
📐 Chasing tensor shape mismatches across ranks in the pipeline.
🕒 Realizing that implementing 1F1B scheduling correctly is... harder than the papers say.
I finally got it to converge on a custom ViT across an 8-GPU mesh without deadlocking. 🚀
What's inside:
A custom DeviceMesh implementation.
Manual P2P communication handling for pipeline stages.
Custom Column/RowParallelLinear layers.
I wrote a detailed deep-dive on the architecture (with diagrams of the communication flow) and the code is open source. I’m now working on adding ZeRO-style optimizer sharding and would love any pointers or feedback from the systems folks here!
Do star my repo if you find work to be meaningful.
Links:
📖 Blog (Visual Guide): https://medium.com/@shuklashashankshekhar863/quintnet-a-3d-distributed-training-library-db0181a33a80
👨💻 Repo: https://github.com/Wodlfvllf/QuintNet
My Linkedin Profile - https://www.linkedin.com/in/shashank-shekhar-shukla-722859227/
Thanks!
Which papers are you referencing? They seem weak sauce
Sorry forgot to add references. Been busy these days. By the way Megatron LM papers for model, tensor and pipeline parallelism, hugging face nanotron The ultrascale playbook. There youtube videos. Some more papers and there source codes references.
Would add it in some time. Additionally this can be a weak project as build just for fun and learning. Nothing more than that.
Like a link to the paper
Man just search Megatron LM paper.
What does that have to do with reversing a black box
Hey Everyone , I built a novel XAI architecture and would love to hear your reviews :
paper link : https://zenodo.org/records/18109913
github implementation : https://github.com/ZiadiSafouene/P-SPINE-Project-
Hey everyone 👋
I’m Vimarsh, an MSc graduate currently working as an AI Engineer.
I’m actively looking to collaborate on ongoing research projects (AI/ML, applied research, or interdisciplinary work) as I’m building a stronger research background alongside industry work.
If anyone is open to collaboration or needs help with experiments, modeling, data, or writing—happy to connect and contribute. Feel free to DM me!
Thanks 🙌
Cool we looking for such ppl too
Hi everyone! I’m doing research on deep learning optimization and wanted to share an experimental
second-order optimizer I’ve been working on (FROG). It uses row-wise Fisher preconditioning with batched Conjugate Gradient and aims to
improve time-to-accuracy with low overhead.
I wrote a short technical overview here:
https://github.com/Fullfix/frog-optimizer/blob/main/technical_overview.pdf
Code and CIFAR-10 experiments are in the same repo. Feedback very welcome 😃 .
Thanks for reading!
cool js a suggestion anyways: if u'd also included a high level summary or smth telling how it could be helpful n applicable overall and any advantages
Hi @everyone
📘 Python Loops & Strings – Kaggle Notebook 🐍
This notebook explains Python loops (for, while) and strings in a detailed and easy-to-understand way, with clear examples.
It’s especially helpful for beginners 🚀
Please check it out and leave a vote ⭐ and a comment 💬 — your feedback is highly appreciated! 🙌
https://www.kaggle.com/code/dastgeerjutt/3-loops-and-strings-detailed
Hi! I am trying to upload on arxiv, but I need my account to be endorsed first. If you have uploaded at least 3 AI-related papers there within the past 5 years, may I ask for your help? Thank you in advance!
@quartz anchor
Hi @everyone
Update on QuintNet: from ViTs → training a small GPT-2
A few months ago I shared QuintNet — a PyTorch framework I built from scratch to understand 3D parallelism (Data + Tensor + Pipeline). At the time, it was validated on a custom ViT running on a 2×2×2 GPU mesh.
Since then, I’ve extended the same framework to GPT-2 (124M).
Moving from ViTs to a language model surfaced assumptions that hadn’t shown up before, especially around model loading. When starting from a pretrained GPT-2 checkpoint, each rank initially materialized the full model before sharding, causing peak-memory blowups during initialization. Fixing this meant making the loader itself shard-aware so each GPU reads only the parameter slices it owns.
Pipeline parallelism also became trickier with GPT-style decoders due to tied input embeddings and output weights, which don’t fit cleanly into a single pipeline stage.
QuintNet can now fine-tune GPT-2 in a distributed setup and converge stably. Still very much a personal learning project, but I’ve been documenting the lessons—especially around efficient distributed loading.
Links if you want to dig deeper:
👨💻 GitHub: https://github.com/Wodlfvllf/QuintNet
Happy to discuss or get feedback from folks working on ML systems / distributed training.
hi thats cool btw any other research directions u would be interested too 😄
I am interested in all different directions of research 😀
thats really a cool thing too coz i rarely saw researchers change their directios to entirely diff directions than their past exps
but ig thats the way they would get to explore more
I am not a researcher technically 😀. I have just graduated and joined corporate currently.
I am just exploring things to do and what not. I am currently working on an RL project with distributed training library as a side project.
bro
GUYS! DO NOT CLICK THE ABOVE LINK
🚗⚡ Just dropped a 🔥 Kaggle Masterpiece: Analyzed 271K Washington State EVs with INTERACTIVE MAPS, XGBoost Ensembles, & 2027 Forecasts!
Key Insights:
✅ Tesla dominates 60% – but Chevy Bolt crushes on range/price
✅ Urban Heatmaps reveal Seattle hotspots (download HTML map!)
✅ ML Beast: R²=0.95 predicting range, 94% CAFV eligibility
✅ Forecast: +50K new EVs by 2027 – infrastructure crisis ahead?
Built with GeoPandas, Folium, StackingRegressor (XGB+LGBM+RF). Perfect for policy makers & energy pros!
🔗 Dive in & upvote: [https://www.kaggle.com/code/hammadansari7/electric-vehicle-population-analysis]
What’s YOUR take on EV adoption? Rural lag or tech hype?
#DataScience #Kaggle #MachineLearning #GeospatialAnalysis #ElectricVehicles #EV #Forecasting #XGBoost #Sustainability #AI
@Kaggle @Tesla @robikscube @towardsdatascience @everyone
Hey everyone! I’m super excited to share that my latest paper, "Emotion estimation from video footage with LSTM," has just been accepted in Frontiers in Neurorobotics! 🎉
I developed a new model called BlendFER-Lite that uses MediaPipe Blendshapes and LSTMs to detect emotions from live video. The cool part? It matches the accuracy benchmarks of much heavier models (71% on FER2013) but with significantly lower computational cost, making it perfect for real-time robotics and edge devices.
Check it out here: 📄 Paper: https://www.frontiersin.org/journals/neurorobotics/articles/10.3389/fnbot.2025.1678984/full 🤗 Code & Models: https://huggingface.co/papers/2501.13432
Would love to hear your thoughts or answer any questions!
how is literature review done or anyone of u do it im new to the term so anyone pls ans 😓
u pick a topic -> get existing research on it , analyse it -> find research gaps
Reason: Bad word usage
Reason: Bad word usage
Reason: Too many infractions
Hello hackers,
I need some help. I’m training a conversation disentanglement model using this repo: https://github.com/jkkummerfeld/irc-disentanglement
. It will be used to prepare a conversation dataset for a project.
I don’t have access to compute resources that can run continuously for five days. I’m using Google Colab, but sessions eventually stop when the tab closes or times out. I also can’t afford a cloud provider right now.
If anyone has a home setup that can run uninterrupted for several days and is willing to help, I would really appreciate it. Thanks!
Hi Everyone
I recently published a Kaggle dataset on American Express (AXP) stock data from 1972–2026.
It includes historical prices, volume, dividends, and splits for financial analysis and ML projects.
Would love your feedback 🙌
https://www.kaggle.com/datasets/anadiskt/american-express-axp-stock-data-19722026
If you find it interesting please upvote the dataset
Congrats on a new dataset! Please remember that our server rules prohibit asking for upvotes and posting in multiple places. https://discord.com/channels/1101210829807956100/1130992116345077810 would be the right spot to announce your dataset!
any IISCER buddies here?? Im working on quantum physics beamsplitter experiments under yu ting-chen, we really a few ppl to be included in this anyone there for help?!1
Is there anyone from India studying data analysis ?? want to do some analysis projects with some new ideas
Is there any dataset for Semiconductor manufacturing materials/ parts
Anyone can provide the best dataset download link for deepfake detection videos with good qualities videos and of various diiferent varities ?? It will be great help to me.
not from india but i'm interested if its still on the table
🚀 𝗣𝗿𝗼𝘂𝗱 𝗠𝗼𝗺𝗲𝗻𝘁! 𝗠𝘆 𝗥𝗲𝘀𝗲𝗮𝗿𝗰𝗵 𝗣𝗮𝗽𝗲𝗿 𝗶𝘀 𝗣𝘂𝗯𝗹𝗶𝘀𝗵𝗲𝗱 🎉
I’m excited to share that my research paper titled:
“𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝘄𝗶𝘁𝗵 𝗦𝗽𝗮𝗿𝗸 𝗠𝗟𝗹𝗶𝗯: 𝗔 𝗖𝗼𝗺𝗽𝗿𝗲𝗵𝗲𝗻𝘀𝗶𝘃𝗲 𝗣𝗲𝗿𝗳𝗼𝗿𝗺𝗮𝗻𝗰𝗲 𝗘𝘃𝗮𝗹𝘂𝗮𝘁𝗶𝗼𝗻”
has been successfully published in a peer-reviewed journal.
🔍 𝘐𝘯 𝘵𝘩𝘪𝘴 𝘳𝘦𝘴𝘦𝘢𝘳𝘤𝘩, 𝘐 𝘦𝘹𝘱𝘭𝘰𝘳𝘦𝘥:
Performance of ML models on large-scale datasets (500K → 12M records)
Comparison of classification, regression, and clustering models
Impact of distributed computing using Apache Spark MLlib
Trade-offs between accuracy, speed, and memory usage
📊 Key Insight:
Distributed machine learning significantly improves scalability and efficiency, especially for complex models on large datasets.
📄 Read full paper here:
👉 https://paas-pk.org/index.php/pjosr/article/view/2013
💡 This work is part of my journey in Data Science & AI, and I’m excited to keep exploring more in distributed systems and big data.
#DataScience #MachineLearning #BigData #ApacheSpark #Research #AI #WomenInTech #KiranHayatDataScientist
I am AI-ML learner and would be interested in helping you hoping that i would get to learn what you are doing and get more exposure.
I am learning AI-ML and i would be interested in any kind of research and mentor opportunities.
Hey guys I'm currently researching what products can be made using UV rays but I'm not a researcher technically so can I get a hand or suggestions like what should I do first?
🧠 Join CVPR 2026 Challenge: Foundation Models for General CT Image Diagnosis!
Develop & benchmark your 3D CT foundation model on a large-scale, clinically relevant challenge at CVPR 2026!
🔬 What's the Challenge?
Evaluate how well CT foundation models generalize across anatomical regions, including the abdomen and chest, under realistic clinical settings such as severe class imbalance.
Task 1 – Linear Probing: Test your frozen pretrained representations directly.
Task 2 – Embedding Aggregation Optimization: Design custom heads, learning schedules, and fine-tuning strategies using publicly available pretrained weights.
🚀 Accessible to All Teams
Teams with limited compute can compete via the Task 1 - Coreset (10% data) track, and Task 2 requires no pretraining — just design an optimization strategy on top of existing foundation model weights.
Official baseline results offered by state-of-the-art CT foundation model authors.
A great opportunity to build experience and strengthen your skills: Task 1 focuses on pretraining, while Task 2 centers on training deep learning models in latent feature space.
📅 Key Dates
- Validation submissions: – May 10, 2026
- Test submissions: May 10 – May 15, 2026
- Paper deadline: June 1, 2026
We’d love to see your model on the leaderboard and welcome you to join the challenge!
👉Join & Register: https://www.codabench.org/competitions/12650/
📧Contact: medseg20s@gmail.com
Hello everyone, if anyone is writing or planning to write a research paper, direct message me. We can collaborate & learn together.
Hey there,
If you come across any similar type of competition, do let me know
The World Has a Data Problem. We Fix It.
Every AI team hits the same wall eventually.
You have the model. You have the architecture. You have the engineers. But you don't have the data, and everything stops.
Maybe your dataset is too small to train on. Maybe it carries sensitive patient records, financial transactions, or personal identifiers that legal won't let you touch. Maybe you've been waiting months for a vendor to deliver labeled data that still isn't ready. Maybe your edge cases are so rare in real life that your model keeps failing exactly where it matters most.
This is not a skill problem. This is a data problem. And it is quietly killing more AI projects than any other single reason.
We generate synthetic data.
Not as a workaround. Not as a compromise. As a legitimate, statistically rigorous alternative that lets your team move again. We produce tabular, text, image, and time-series synthetic datasets that mirror the distributions, correlations, and behavioral patterns of real-world data without exposing a single real record.
We have solved this for teams in healthcare who couldn't share patient data across departments. For fintech companies building fraud detection models with almost no real fraud examples to train on. For startups that needed 10x their dataset size before a funding deadline. For enterprises blocked by GDPR, HIPAA, and compliance teams that said no to everything.
The problem you are sitting with right now, whether it is a privacy blocker, a data scarcity issue, a class imbalance, a regulatory wall, or a timeline that real data collection simply cannot meet, has a solution. We will tell you exactly what it is within 24 hours of hearing from you.
No long sales cycles. No vague proposals. You describe your data problem in plain language, and we come back with a concrete plan.
Send us your situation: [synthox.ai@gmail.com]
The only thing worse than a data problem is spending another month pretending it will resolve itself.
Isn't that a bit sketchy?
why ?
why not?
I am thrilled to announce that I have successfully defended my Master’s research! My work introduces a novel hybrid architecture combining YOLOv11 and YOLOv12 specifically designed to detect micro-anomalies in solar panels.
Key Highlights:
Precision: The modified model excels at identifying "tiny defects" that traditional inspection methods often miss.
Interpretability: Integrated EigenCAM to provide visual explanations for model predictions, ensuring the AI's decision-making process is transparent and reliable.
Proof of Concept: I’ve developed a demo (link below/attached) that showcases the real-time detection and model representation in action.
I'm excited to see how these advancements in computer vision can contribute to the renewable energy sector!
Demo Video : https://youtu.be/cxtnjsjD_iA