#❓┊ask-a-question
1 messages · Page 2 of 1
Yea, completed a few of them.
Including those that talk about different models and cross validation ?
For instance did you try and start the last playground challenge ?
Yeah it's better if you tell us where you are stuck 🙂
I've a dataset to have decide to build a model from it. But not getting where to start from.!?
Like what to do with data, what all labels to choice etc.
Hope you are trying to decode what I'm trying to say!?
Yes I'm here no worries
So the first step is to look at your data, determine what kind of data is here
Are there continuous features ? Categorical features ?
(categorical means it takes a small amount of values that don't really make numerical sense. For instance the gender is a categorical feature, while the balance in your bank account is numerical because it can take many values)
Okayy...
Then you need to determine what you want your model to do
is it a regression or a classification problem ?
So do you need to predict the price of something, or classify your data into classes
It's for classification if I'm not wrong.
Ok cool
Then you need to look if there are any missing values
If you want a first model up and running quickly :
- Remove all rows with missing values (data.dropna())
- Keep only continuous features (those that already have number data types)
- Use a model such as XGBClassifier
Then you can look at all three of those parts and make your model better
- How can you keep the rows with missing values ? Find ways to impute values in those rows. There's a class about that on Kaggle
- Try encoding the categorical features into continuous features. There are various ways to do that and there's also a class about that on Kaggle
- Try making your model better : maybe another classifier is better, or you can make hyper parameters better, or you can do advanced things such as combining different models to get better results
those are the 3 basic things you should always do after your first model is up and running
anything unclear ?
Okay.. not understood it fully.. but got the building blocks to it.
Thanks for the advice.. I guess will be more clear when I implement it once.
yes
I strongly suggest following the "Intermediate Machine Learning" class on kaggle
Might be wrong channel so aplogies if that the case, but what does **random_state **do this in line?
smote = SMOTE(sampling_strategy={1: desired_fraud_cases}, random_state=42)
If i use 0, it will always split the test and train data the same, but with random it will always be different? is that correct?
Hi all, I am looking for a multilingual model with long sequence length for classification task. Any ideas?
I understand that we can use the command line API to submit a submission.csv. But what about code competitions? Can we submit a notebook via the command line?
this SMOTE model probably has some randomization inside. random_state is the initial seed given to the model. Which guarantees that every execution is the same
Thank you!
Yes, you can submit a notebook to a Kaggle competition via the command line. Here are the steps to do so:
- First, you need to install the Kaggle API by running the following command in your terminal:
!pip install kaggle --upgrade
- Next, you need to provide your Kaggle credentials using the file
kaggle.jsonor setting some environment variables with your Kaggle credentials. You can get your Kaggle credentials from kaggle.com > 'Account' > "Create new API token". Here is an example of how to set your credentials as environment variables:
%env KAGGLE_USERNAME=abc
%env KAGGLE_KEY=12341341
- Finally, you can submit your notebook to a Kaggle competition by running the following command in your terminal:
!kaggle competitions submit -c <competition-name> -f <notebook-name>.ipynb -m "<submission-message>"
Here, <competition-name> is the name of the competition you want to submit to, <notebook-name>.ipynb is the name of your notebook file, and <submission-message> is a message describing your submission.
Please note that the kernel must be of type "Script" and not "Notebook" for this method to work ¹²³. I hope this helps!.
Source: Conversation with Bing, 05/01/2024
Kaggle is the world’s largest data science community with powerful tools and resources to help you achieve your data science goals.
Do papers ever come out of these competitions or is it mostly just large ensemble models that have had the entirety of AWS thrown at them?
Can authors even make papers or are the solutions always fully closed?
I've never competed, so I don't really know what the environment's like.
what does it mean for a competition to be code competition?

hey kagglers, i’m so confused now about the rules of what are so called “coding competitions”. i come across this coding competition Bengali.AI Speech Recognition, the first solution clearly stated that he used 8x 48GB RTX A6000 for training, does that mean the rules of the competition has changed, or did i miss something?
i will state my understading of code competition to check if it is correct, the way i understand it is that in code competition you are not allowed to use any compute power other than the one provided in kaggle notebooks. further more your code and infrace should not exceed 9 hours of running time in order to produce. this is to make the game fair for those GPU-poor like myself.
Recognize Bengali speech from out-of-distribution audio recordings
Recognize Bengali speech from out-of-distribution audio recordings
Freely & publicly available external data is allowed, including pre-trained models
The rule isn't to make the game fair, training a model is (with exception) impossible without some form of GPU. The rule is for the submission kernel, not the work done to create the pre-trained model.
At least, that's my reading of the link.
yeah what vibe says is right
Yes you can and there's a high chance papers came out of these competitions
You can find many solutions in notebooks in Kaggle too, people share a lot
Specially in playground-series competitions or when the competition is finished
Can you beat auto ml in data science ?
I'm talking specifically about the modeling part : which is parameter tuning and ensembling
It feels like modern auto ml tools use enough models and smart ensembling that it makes it difficult to do something better by hand
For instance during the current challenge, I spent quite a bit of time finding many parameters for my models, both myself with optuna and by stealing them from other notebooks. Then I just trained an auto ml suite for ~ 12 hours on my laptop and it beat what I did by quite a big margin in cross validation (similar on public leaderboard but it doesn't mean much I think)
Hi, I'm still pretty new to the world of data science and machine learning. I have been working on random forest model for regression/classification problems. I have now started learning neural networks.
My question is which model is better to choose?
Thanks in advance!
For tabular data (which is the case for example for playground series contest and a lot of data science) it's hard to beat gradient boosting algorithms such as xgboost, lightgbm or catboost with neural networks
I think it's good to use when you do ensembling
basically you train many models, your best models will usually be xgboost or lightgbm, and then you add some less good models such as neural network, random forest and so on. Then you apply algorithms to ensemble predictions of all those models to get better results
but if you're starting I do not recommend trying neural networks
If you want to read more about it, I suggest reading the writeup of rank 2 in the last playground series which was a multi-class prediction problem :
https://www.kaggle.com/competitions/playground-series-s3e26/discussion/464887
And if you want to deep dive, you can read about things mentionned here
https://sebastianraschka.com/blog/2022/deep-learning-for-tabular-data.html
Playground Series - Season 3, Episode 26
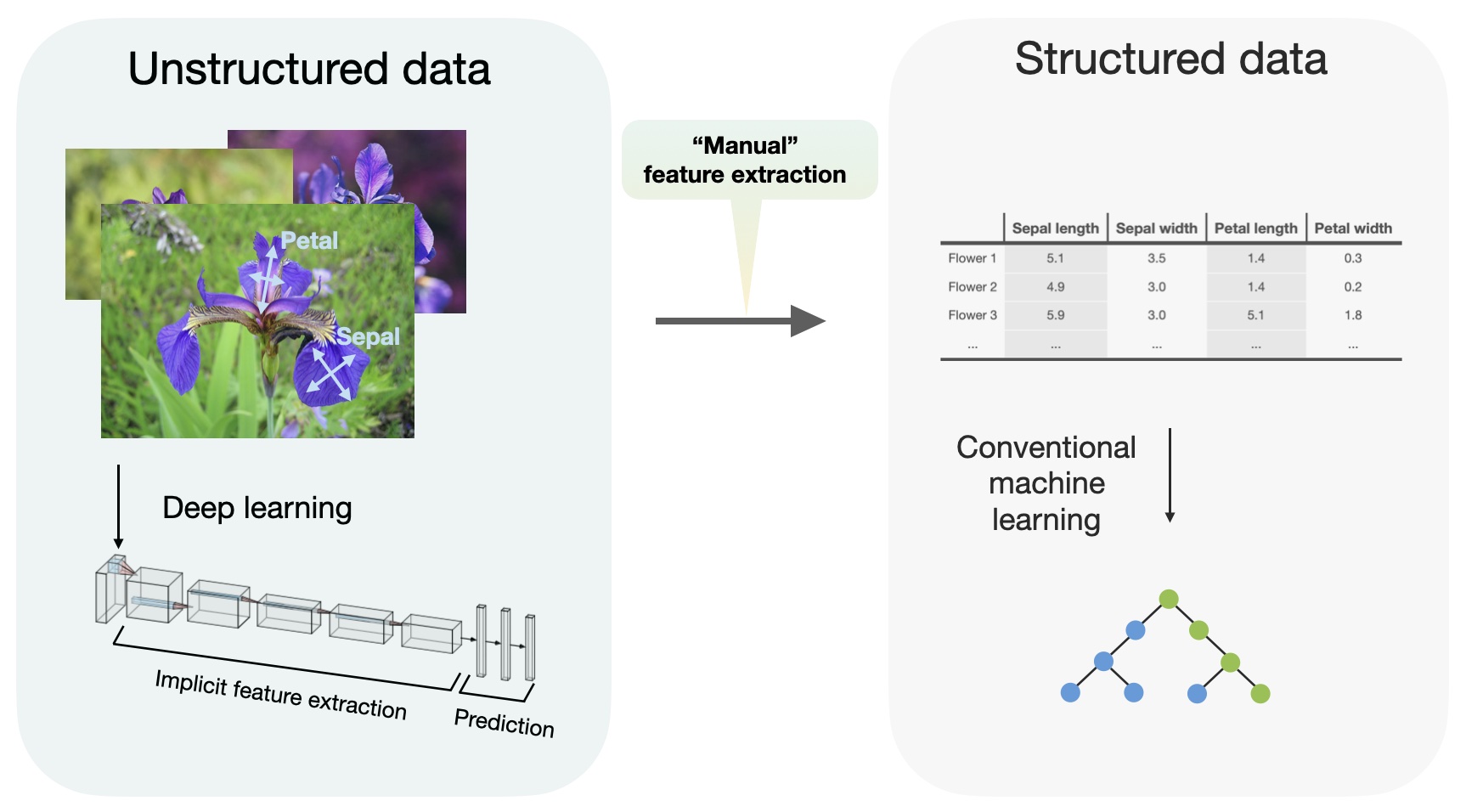
Sebastian Raschka, PhD
Occasionally, I share research papers proposing new deep learning approaches for tabular data on social media, which is typically an excellent discussion sta...
To summarize : He says neural networks as baseline models marginally improved results in ensembling
but neural networks were very efficient at predicting classes from the predictions of other models
if you have questions feel free to ask @coral tartan
there's a lot of concepts here 🙂
Thank you for the detailed answer! I will read it through
it's normal if you don't understand everything
I’m using a RF algorithm to detect credit card fraud, before tuning I have about 95.5% accuracy, after tuning (using a grid search) I still get 95.5% (all my other metrics are the same too) is it normal for it not to increase after tuning? Should I look into other options to increase results?
which parameters are you tuning + could we get your code ?
Yes, AutoML can beat humans in a vast majority of tasks (see: EfficientNet). The advantage of people is that a good DS can do it for /much/ cheaper.
ok thak you vibe !
I will try to get the best model as I can without auto ml to learn then
My future company won't be happy otherwise 🙂
actually
how is tuning with optuna any better than using auto ml ?
in terms of efficiency
I haven't used either but my guess is hyperparameter tuning vs neural architecture search.
When I use optuna to optimize it regularly uses 6 hours total as well if I do many trials
Ok maybe for neural architecture search the cost is massive 🙂
NAS is a much harder problem
I was more thinking about data science without nn
just on tabular data
(I know deep learning models can improve ensembles but usually it's quite small)
DL models can be parts of ensembles, be whole ensembles themselves, and can be used to merge classical ML methods. I haven't done much on tabular data, so out of my expertise there.
I think DL to do ensemble instead of being part of an ensemble is very powerful
people have won playground contests doing that
I straight up don't use classical ML methods in practice because inference speed is critical at work.
But they can definitely be useful as they can have better priors than NNs
wdym by classical ML models ?
(I'm very new to Kaggle)
Is it like xgboost, lgbm, catboost ?
Classical Machine Learning (ML) Methods:
Classical ML methods refer to traditional or conventional approaches to solving machine learning problems that were widely used before the rise of deep learning and neural networks. These methods include:
- Linear Regression: Used for predicting a continuous outcome based on one or more predictor variables.
- Logistic Regression: Applied when the outcome is binary (two classes).
- Decision Trees: Tree-like models that make decisions based on features.
- Support Vector Machines (SVM): Used for classification and regression tasks.
- Naive Bayes: Based on Bayes' theorem and often used for classification tasks.
- K-Nearest Neighbors (KNN): Classifies objects based on the majority class of their k nearest neighbors.
- Random Forests: Ensembles of decision trees for improved performance.
- Gradient Boosting Machines: Sequentially builds weak learners to improve predictive performance.
they are
wdym, ml methods are faster than nns as far as im concerned
KNN is very slow
If the relationships between data is complex, or if it's """big""" then NNs win in speed easily.
fair enough
I'm talking about a production algorithm vs a competition, something with access to PB of data.
for large datasets or high-dimensional data yes
@ work but after I’ll post it thank you
The top one code block is before tuning, and the second one is ***after ***turning, I'm still yet to get the results as it taking ages to run the second code block with tuning
https://colab.research.google.com/drive/1zrS76BiCIFzltv4UrifYHoG_G2oZb5gF?usp=sharing
Attached is the results of the first code block (no tuning) any advice is great as I'm still new to ML

param_dist = {
'n_estimators': randint(10, 200),
'max_features': ['auto', 'sqrt', 'log2'],
'max_depth': randint(1, 20),
'min_samples_split': randint(2, 20),
'min_samples_leaf': randint(1, 20),
'bootstrap': [True, False]
}
this doesn't do what you want it to do
randint(10, 200) will just pick a random integer once and use it all the time
so you're only tuning max_features and bootsrap
so it makes sense you don't get anything
Oh
you should do something like range(10, 210, 10)
well this would take ages if you do it for all of them
try maybe [50, 100, 150, 200] to start off
Okay, so updated code like this?
param_dist = {
'n_estimators': [50, 100, 150, 200],
'max_features': ['auto', 'sqrt', 'log2'],
'max_depth': range(1, 20),
'min_samples_split': range(2, 20),
'min_samples_leaf': range(1, 20),
'bootstrap': [True, False]
}
this shoul dwork I think
BUT
I think grid search tries ALL possible values
so this will do cross validation on
4 * 3 * 19 * 18 * 19 * 2
set of parameters
this is way too much
I would do what I did with n-Estimators to the other ranges
Amazing, ill give it try thank you!
Hello everyone!!
I aspire to become a data scientist, i would like if all of you help me!
I wanted suggestions on how should i start?
Hi All! I hope this is the right place to post this. I am facing an issue using Pytorch Lightning with the ddp_notebook strategy (in the trainer) when using two GPUs. Namely, when I call trainer.fit(model, dataset) the program is stuck computing nothing, and the GPUs still. Thank you in advance for any help on this matter!
Hi there! Kaggle has a really good set of learning courses. Just take look here: https://www.kaggle.com/learn
I would just start there and work through all relevant courses.
Practical data skills you can apply immediately: that's what you'll learn in these no-cost courses. They're the fastest (and most fun) way to become a data scientist or improve your current skills.
Any good lightweight object detection model, that detects humans?
I am a beginner, i am struggling with data filtering . However, for null row or value, it is recommended to drop it ? Or make it become mean value or 0?
The answer is data-dependant, the solution varies. If you have a large portion of data as null you may very well want to drop it, as keeping it could bias the model. However, life does not always generate clean data and data with tons of nulls may be all you have - it is best to experiment with all of the above filtering methods. Feature engineering and data pipelining like this makes up the vast majority of a data scientist's job.
Does private dataset appear immediately after compettition close?
If you mean private dataset results (private leaderboard), they appear immediately. If you mean the actual private dataset, they are almost never shared with Kagglers.
My notebook is getting stuck while compilation and the CPU usage showing 100%
Then after sometime the page shows unresponsive
Pls help!
reviews_per_region = reviews.region_1.fillna("Unknown")
count = reviews_per_region.value_counts.sort_values(ascending=False)
I have a question that why this code is not correct
And also count =reviews.region.sort_values(ascending=False) / reviews.region.value_counts.sort_values(ascending=False)
Is that because of , i didnt modify the original dataframe . I should make an apply on it ?
https://www.kaggle.com/datasets/iabhishekofficial/mobile-price-classification/data can anyone tell how can i sumbit here

Classify Mobile Price Range
Hi everyone 🙂 I have this notebook:
https://www.kaggle.com/code/timothyalexisvass/sdxl1-0-kohya-ss-dreambooth-training-lora
So far worked perfect for me, but I was wondering if there is a way to use another base model, like uploading mine and changing the path in the code. I hope this is the right place to ask. Thanks!!

Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
are these layers correct, input output wise?

May I know the reason for this error? I'm unable to figure it out, even the solution code throws the same error...

Hi, quick question
in a kaggle competetion, if they provide multiple dataset (example multiple csv's)
abc.csv, xyz.csv but there is another csv named train.csv, so does that mean we should only use train.csv for training the model?
That is not the thing you can concat all of them together according to the datasets and train your model on it
Then you can split them in 70 30 and test the model on the 30% of the data
Is it possible to NVlink 2 RTX3090 cards together with memory pooling enabled ? If it so What motherboard model should be used ? Shall I be able to use full 48GB VRAM to train large models?
There is no general answer to that question, but it is a safe bet that train.csv is what you need for training. Other files, however, are often useful as well after some processing.
Right! thank you
Hello guys I have a question. So far I've been dealing with only traditional machine learning models where I just imported a library and executed the code
But, in the #🛍┊store-sales-time-series-forecasting I tried training a Facebook Prophet model for forecasting and it took me a lot of time. I guess that if I want to be competitive in most competitions I might have to tried more complex models or even models that require deep learning.
Do I need a good computer in order to be competitive when trying these algorithms? Thank you, I'm quite new to all of this
If you're training them locally it's not absolutely required but very useful to have a powerful computer for faster training and inference, particularly on large datasets or if you're working with more complex models. What you can also do is rent a GPU from any number of online vendors (eg AWS, Google, etc) that supply them for incredibly cheap and train on that instead.
If you want to be competitive, yes. MoE ensembles (what I'm guessing pretty much every winner uses) require a significant amount of juice and are at many times the best performing model in industry where inference time is not a priority.
And cloud costs are NOT incredibly cheap, at all idk what the above user is referring to or what their perspective is.
I suppose compared to buying one outright for a single training instance, absolutely cloud is cheaper. But over the long run, cloud is very costly
Never ask a data scientist their cloud bill 🤫
That said if you're getting started out, literally any gpu will do if you're just doing it to learn as you can downsize any model to be pretty small. Also see the following for free (but limited) GPU use: https://colab.research.google.com/notebooks/welcome.ipynb#scrollTo=9J7p406abzgl

Also knowledge of cloud resources, how and when to use them, and their pros & cons are absolutely things employers are looking for.
Just be extremely careful, you can easily get like a $40k cloud bill in a month if you make a mistake.
Alright, thanks for the help 👍
suggest best DBMS course availble on youtube to learn SQL and that is sufficient for data science
I am looking for help on a small private kaggle classification project. Pls dm
having this issue for getting secrets...

error connecting to service... tried it on new notebooks too... will not use secrets for now but.. something to be fixed?
Hi I am extracting mfcc values of adusiio and want to sendthem for training my model . Saved these MFCC values in csv which is saved in form of string. Now when I want to map these values withmy labels they are not running and giving errors Please help
This is how my data is and I am not able to passit into my model

I try to load a private hf dataset (gated dataset) in kaggle and got this error:
FileNotFoundError: Couldn't find a dataset script at /kaggle/working/xxx/yyy/yyy.py or any data file in the same directory. Couldn't find '
Any help? 🙂

You have non numerical features, use 1-hot or something similar instead
Thanks I found my mistake
Does somebody know how to approach this problem? I need some help!

I want to verify some sentences in arabic do I need to train my machine with seperate sentences or do I have to train each and every word for it. Pls someone guide
Hi everyone, I'm looking for data for Load Forecasting of power systems. It's my final year project. Can someone help me in finding data?
For kaggle notebooks is there a way to completely clear memory like restarting the session would, but without losing stuff written to disk?
Hello, I had one question, I am working with torch VGG model and I came across this method called ADAPTIVEAVGPOOL2D, which essentially take any input size and converts it to target output size by adapting the kernel size. My question is if this is a good idea or not? Like will it affect the model's performance?
I don't think anyone can tell you a priori because these things are very dataset-dependent. Run a model with and without it (keep everything else exactly the same), and compare the model performance.
Doing the titanic tutorial and everything's going great until I save and run than get failure. Now have 4 versions--how can I get rid of 3 versions, keep one and redo til is runs and saves correctly?
In practice, yes absolutely experimentation is the only way to know for sure.
Also "is it a good idea" is a bad way to phrase a question. Even if it did drastically impact the model (probably doesn't) the ability to take variably-sized images is really important for a model as it allows you to train and inference* on variably sized data. Other options for accomplishing this are one of the spatial pooling pyramid techniques.
Being able to resize your image as a form of data augmentation also helps a ton, as many features in an image are scale-dependant.
Pooling is already an important part of most cv models, you can take any pooling method and make it adaptive.
Back in the day, they just took any image and resized it to be the shape of a model's input. If you had for example a photo that was taken in portrait the features would get super compressed if you resized it to be your model's 'landscape' input size.
So I'd like to keep my private GitHub repo and my private Kaggle notebook synced on the data side. Is it possible to clone from a GitHub repo into the Input Data section?
I did !git clone https://access_tok@github.com/me/repo and it put it in output instead
In addition, does the input and output data section persist across resets?
Basically, I need to import a dataset from a private repo
thanks a lot for the ideas. I will look into this.
anyone knows how do i start to learn GAN?
hey, I am trying to train gpt to make it predict next set of tokens (not textual data in this case) , I am pretty new to the gpt, how can I fit it into A40 gpu without getting out of memory errors
a lot of people use jupitor notebook but jupitor notebook doesn't have copilot.
I am too used to at AI helping me to code, do I need to buy my own GPU if I want to use copilot?
also can any mod help me with my name? I think it is bugged
oh i need to update it on keggle cool
guys i had a doubt reagrding batches in Tensorflow? im a bit stuck ont hat part and having trouble understanding converting data into batchess, any good tutorials?
You can make use of LLMs in jupyter, there are different tools available.
And I really don't get by what you mean here i.e buying GPU if you wanna use copilot, incase you have model deployed in local than yea a GPU is kinda must, if you are just calling APIs than not a big deal
Anyone knows the difference between keras and tensorflow.keras? What shall we use, and why? (I know the difference between keras and tensorflow, I'm asking about the difference of the two keras)
I don't think there is any material difference. Keras used to be developed independently, but now that Francois (the author) works for Google it got folded with TensorFlow. I think pretty much any import will work the same whether it is directly from keras (from keras.models import Model) or TensorFlow (from tensorflow.keras.models import Model).
There is no conversion to batches. It is a matter of selecting a subset of data at a time. Let's say that you have 10,000 training images. If there was infinite GPU memory the computer would load them all at once, train on all of them, and perform a single gradient update based on all images. In reality, GPUs will have enough memory only for 50-100 images at a time. So the dataset will be divided into non-overlapping batches that contain 50-100 images. The first batch of images will be used for training, the gradients updated, and then the next batch will go through the same two steps. That will be repeated until all batches are used, and then a new training epoch will begin. As to how it is done, nothing special is needed other than specifying the batch size.
Hi. How might I find a tflite model for the Kaggle ASL Fingerspelling competition? I'd like to experiment with an app rather than build the model myself. Is there a good place to post such requests? Thanks.
Please can someone help with a link of any UK Covid-19 dataset from NHS because the one i have is clean already or any health related for a prediction task!.. Thanks
Hi, I'm following along this guide https://github.com/FurkanGozukara/Stable-Diffusion/blob/main/Tutorials/How-To-Use-Automatic1111-Web-UI-On-A-Free-Kaggle-Notebook-Like-Google-Colab.md whenever I try to use !wget https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0.safetensors -O /kaggle/temp/models/sd_xl_base_1.0.safetensors it reads "saved to X folder" but there's actually nothing in there, the file weighs in at 6.46GB could it be related to disk size on kaggle or something?

GitHub
Stable Diffusion, SDXL, LoRA Training, DreamBooth Training, Automatic1111 Web UI, DeepFake, Deep Fakes, TTS, Animation, Text To Video, Tutorials, Guides, Lectures, Courses, ComfyUI, Google Colab, R...
Hello all,
This is my first post. are there any projects in DS using SAS ?
What is sas
Statistical analysis software
I'm trying to import a 102688 x 61 rows into mysql but it seems to take a very long time to import where I leave it overnight and it still doesn't finish. Is there a maximum amount of rows that mysql can handle or do I really just need to wait?
I'm thinking of breaking up the dataset and then importing each table and connecting with id columns but is it necessary?
hey. I completed Python on Kaggle. I was wondering if I should make a project. Something simple. To implement all that new information. Or maybe I should learn a couple of libraries first.What do you think?
I think you should go make a small project! You'll learn the libraries along the way. Good luck!
thank u. I appreciate it!
I want to improve my skills in pandas / numpy / seaborn / matplotlib, any recommendation how to do it?
folks, couple of Qs - has kaggle had any competitions on LLMs where the answer wasn't categorical? Eg, I know there has been teh science exam one, but that was reliant on scoring multiple choice... has anyody seen a scoring criteria based off "nearest answer" or similar?
also, does anybody know if there has been a "text retrieval" competition before? Eg, pick out most relevant bits of text for question Y
why doesn't kaggle have excel courses? and when would you realistically be using excel in data analysis and machine learning vs python or sql?
hi there @everyone, I'm curious if there are volunteer work here as ML engineer or at least to be an associate
Everyone is free to use whatever tool they like, but I doubt many people would pick Excel as their first choice for machine learning applications. Pandas has most of Excel functionality and then some, yet it is completely free. It even can open Excel files! A combination of 5-10 well-chosen python packages will be vastly superior to Excel for machine learning. But maybe you know something I don't. For example, is there a good (and free) neural network implementation in Excel? Or a gradient boosting machine implementation? Can Excel create highly stylized and interactive graphs? Can Excel even open a matrix that has dimensions 1,000,000 x 500, let alone do something useful with it?
Please for the free cloud credits what's the elapse time?
My billing account just stopped about two days ago and even setting up my card has been an issue.
Would appreciate if anyone can help explain this behavior.
Hello, I'm looking for a dataset with information about people creating a profile to find a job, do you know of any?
Info like skills, resume, desired job etc.
does anyone know this paper Knowledge Graph-Enhanced Knowledge Integration Learning for Natural Language Processing ? I am not being able to find it anywhere
oh people are still using this. I nee help and guidance!!
Any assistance would be appreciated
I finished a course on Kaggle Learn, the challenge is i am confused and don't know where to continue from. I need A Mentor!!! Please. I want to expand my work and be productive.
Hey everyone,
I hope you're all doing well. I'm currently facing a challenge in Object detection dataset specially related to class imbalance. My dataset is in yolov5 format. I'm exploring image augmentation techniques to address it. Although I can generate augmented images, the missing piece is the corresponding annotation, specifically creating annotation files like label.txt.
I'm a bit unsure about the best practices for generating these annotations for augmented images. If anyone has insights or guidance on this matter, I'd really appreciate your help!
Thanks a ton!
Latifur Rahman Zihad
Undergrad student
hello @everyone i wanna know about a subject intitled 'AI-Powered Appointment Scheduler for patients' if it's a good subject for my final year project im so actually confused about choosing a specific subject
Does anyone know of a rcent-ish (less than 4 years ago) image classification challenge? looking into studying multimodal approaches for CV problems
I have a project that focuses on performing descriptive analysis and statistics. But I am new to this. Can anyone suggest me some resources to get me started.
@everyone please help me out here
Can someone help me with configuring SVM in the convolutional neural network?
I was trying to follow https://youtu.be/upo34AT1Cys?si=0hUn7Bdll26cVMk7&t=431

github: https://github.com/krishnaik06/Complete-Deep-Learning/blob/master/Image Classification Using SVM.ipynb
⭐ Kite is a free AI-powered coding assistant that will help you code faster and smarter. The Kite plugin integrates with all the top editors and IDEs to give you smart completions and documentation while you’re typing. I've been u...
I am working on FER2013 dataset. And I built this model.
`model = keras.Sequential([
layers.Reshape((48, 48, 1), input_shape=(2304,)),
layers.BatchNormalization(),
layers.Conv2D(filters=64, kernel_size=3, activation='relu' ),
layers.AveragePooling2D(pool_size=(2, 2)),
layers.Dropout(0.5),
layers.BatchNormalization(),
layers.Conv2D(filters=128, kernel_size=3, activation='relu'),
layers.AveragePooling2D(pool_size=(2, 2)),
layers.Dropout(0.5),
layers.BatchNormalization(),
layers.Conv2D(filters=128, kernel_size=3, activation='relu'),
layers.AveragePooling2D(pool_size=(2, 2)),
layers.Dropout(0.5),
layers.BatchNormalization(),
layers.Conv2D(filters=512, kernel_size=3, activation='relu'),
layers.AveragePooling2D(pool_size=(2, 2)),
layers.Dropout(0.5),
layers.Flatten(),
layers.BatchNormalization(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(256, activation='relu'),
layers.Dropout(0.3),
layers.Dense(7, kernel_regularizer=tf.keras.regularizers.l2(0.01),activation
='softmax')
])
model.compile(
optimizer='adam',
loss = 'squared_hinge',
metrics=['accuracy'],
)`
But am getting weird result.
Epoch 48/50
202/202 [==============================] - 4s 19ms/step - loss: 0.3469 - accuracy: 0.1326 - val_loss: 0.3508 - val_accuracy: 0.1378
Epoch 49/50
202/202 [==============================] - 4s 19ms/step - loss: 0.3469 - accuracy: 0.1617 - val_loss: 0.3508 - val_accuracy: 0.2426
Epoch 50/50
202/202 [==============================] - 4s 19ms/step - loss: 0.3469 - accuracy: 0.1594 - val_loss: 0.3508 - val_accuracy: 0.1291
Am I doing something wrong?
I would be really grateful if someone could help me.
#❓┊ask-a-question Does anyone know to how to submit a notebook to a competition ?
Go to the competition and hit the "submit" button. In that slider panel you can select the notebook you want to submit.
Alternatively, directly within the notebook editor there is a panel with a submit button (you need to have the competition added as a data source so it's linked).
Does anyone know good books to learn machine learning about the more advanced concepts?
Understanding Machine Learning: From Theory to Algorithms. This book is not for the faint of heart 🙂
Thanks for the information.
I need help with some basics machine learning. I am trying to solve the Titanic prediction problem from Kaggle but after imputation, my train data gets more rows somehow and then it doesn't match with the y_train
X = train_data[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']]
y = train_data['Survived']
X_train, X_val, y_train, y_val = train_test_split(X, y)
# Encoding
oh_enc = OneHotEncoder(handle_unknown='ignore', sparse_output=False)
oh_X_train = pd.DataFrame(oh_enc.fit_transform(X_train[['Sex']]))
oh_X_val = pd.DataFrame(oh_enc.transform(X_val[['Sex']]))
X_train_encoded = pd.concat([X_train.drop('Sex', axis=1), oh_X_train], axis=1)
X_val_encoded = pd.concat([X_val.drop('Sex', axis=1), oh_X_val], axis=1)
X_train_encoded.columns = X_train_encoded.columns.astype(str)
X_val_encoded.columns = X_val_encoded.columns.astype(str)
# Imputation
imputer = SimpleImputer()
imputed_train_data = pd.DataFrame(imputer.fit_transform(X_train_encoded))
imputed_test_data = pd.DataFrame(imputer.transform(X_val_encoded))
imputed_train_data.index = X_train_encoded.index
imputed_test_data.index = X_val_encoded.index
imputed_train_data.columns = X_train_encoded.columns
imputed_test_data.columns = X_val_encoded.columns
and when I check the number of rows using .describe() after the encoding, it says the dataframe has 668 rows at that point, which is exactly what it should have.
But when I do this after the imputation, for some reason it shows the df with a varying number of rows around 830, though this number varies a little bit every time I restart the kernel. At the end of the program, I get this error "ValueError: Found input variables with inconsistent numbers of samples: [838, 668]" when trying to fit a model
Do you guys have any idea about what could this be?
You are so close! 🙂 Print out the data frames you are trying to concatenate (e.g., X_train.drop('Sex', axis=1) and oh_X_train) and you'll see. 🙂
I ain't seeing it =/

It seems as it should for me
668 rows each dataframe
the right columns
ooooh
the indexes
is that it?
IT WORKED
lol
it was it
I solved it by adding this

Thank you @zealous creek
well done! 🙂
You correctly reindexed imputed_train/val_data but forgot to do the same for oh_X_train/val.
What misled me is that I was relying on the describe() method to find the number of rows (by the count for the columns)
using it, the encoding part seemed to be fine
but then when I printed the whole df now to check way the describe was misleading, I saw this:

there was a lot of rows added, but they wouldn't affect the count of the columns because they were all NaN

So, by using the describe method, I could just see the other rows after the imputation
Now I know I shall always use the shape attribute instead
I'd also print the whole data frame just to be safe.
Yes, it makes sense because it gives a lot of information
If I didn't do what you said, I wouldn't have noticed it at all
yo lads
does anyone have a roadmap form beginner to advanced in DS?
im sure there are plenty, for reference, this is my github: https://github.com/n0rbed/ I do know how to code

GitHub
monke code. n0rbed has 10 repositories available. Follow their code on GitHub.
Hi, everybody.
I have a quick question.
I uploaded an Excel file (.xlsx) to Kaggle to use as a part of a notebook.
I have set it as private. How do I find the path or call that excel file in my notebook?
On the right side there is an option to add a dataset. Your datasets should be visible or type a couple of words from the title to find them.
I think you go to the competition discussion section and start a new thread by tagging @paultimothymooney, who seems to be responsible for that competition. If you explain your case just like you did here, they should be able to get you in touch with the competition sponsor.
Thank you so much!
You can tag @near basalt here as well.
Thank you so much!
@near basalt Sorry to disturb you, but if you could get me in touch with the competition sponsor of the Google Gemma Kaggle competition, that would be amazing. Thank you.
@wet cairn Typically Kaggle staff can't help you through discord. Definitely create a thread in the forums to get help.
Greetings, I have a college assignment which requires me to interview a DBA/Data Scientist or someone in a similar profession. I am looking for anyone who might be interested in participating. This assignment isn't due for a while but I felt that I should reach out beforehand to see if anyone is interested. Feel free to let me know!
hi guys, I am trying to do the House Prices - Advanced Regression Techniques but I encounter the same problems as I see a lot of people encounter, the could not convert string to float: 'RH'. Do you have any idea how can I resolve it? I'm trying for a few days now to make it work. I am using RandomForest and for the train data it worked, when I try to predict on test data it did not. Thank you in advance.

You don't show the most important parts: where exactly (in which line) the error occurs in your code and what happens above that line.
Sorry about that. When i run predict on the test data i get these error. You can see the full code here.


You won't debug the code just by staring at it. 🙂 Print X_train, X_test, and test. Your model could predict using X_test so I suspect test looks different than X_train and X_test.
Same format


Is it? 😄
What are the values for example in the LotShape column in X_train and X_test?
vs the values of the same column in test?
Ok, so it seems that the test LotShape in the test was not converted into categories, right? But why is that because in test.info() says it is a category. I have wrote this for loop to do so, as for the training data.



Input samples to sklearn .fit and .predict methods need to be numbers. I assume you preprocessed X_train and X_test to convert the strings to numbers so you need to apply the exact same transformation on test if you want the same model to work on it.
i have found my problem. when i converted the test to category, I used df instead of test. Freaking copy paste lol. Thank you very much for your time and for opening my eyes 😄
You might want to look into sklearn preprocessors like the OneHotEncoder, the OrdinalEncorder, and the StandardScaler. They are more robust to use than your custom solutions, less prone to bugs too, and you can add them to sklearn ColumnTransformers and pipelines.
hello , I hope you're all doing good I have a favour to ask i searched in kaggle but couldnt find th emulti label antenna selection dataset its for a research trying to do in MASSIVE MIMO ,if anyone has an idea of where i can get it without generating it my self or idk if anyone could tell me how can i generat eit or have ready
Project Summary:
Objective:
The primary goal of this project is to develop a comprehensive tool that can automatically process and analyze various types of screenshots related to financial transactions, communication, and potential fraudulent activities. The tool aims to assist in detecting and documenting scams by extracting relevant data from screenshots of chats, transactions, transfer receipts, and UPI payments.
This is my college semester project anyone can help me
How can I build a project
Struggling with this:
Want to use a kaggle kernels output:
kaggle kernels output <username here>/text-summarization-using-lstm -p /path/to/dest
How do I use the above API command? Also, can I access files stored by the person while running the API command?
Thank you, first I wanted to use OneHotEncoder but I did not know how to proceed at the testing data, since we should not use fit again. So we use the OneHot on the training set, but when we HotEncode the test data, how does the line look like? You can see in the screenshots how i wrote the two of them but it did not work.



You fit_transform the training set and transform all other sets. If you do anything else other than this, that will lead to information leakage. Check out the manual too because it contains examples of how to use it.
Hello everyone. I wanted to build model that predicts oscar winner for the upcoming year. For example we want to predict best actor. Even If we gather all oscar nominess from the beginning until today it will be roughly 400~ row. It seems very small dataset. Is it okay build with such a small dataset? If not what I can do? Thanks in advance
Hi ! how can I link my kaggle profil with linked in ?
Go to kaggle account settings and add your linkedin account
can someone help me with submission?
thank youu !
kaggle beginner | notebook beginner question here:
trying to run text-gen webui on kaggle notebook because it is faster (mistral) but after i run the main cell (last cell) kaggle terminates the session
is there anyway to make it contiously run for the duration of my time utilizing text gen web ui
Hello,
A company asked me to develop a motion detection program that won't use deep learning. As far as they told me, they will run the program on GPUs and want to detect motion from CCTV cameras that are connected to it.
I wrote 3 different programs with opencv and python using following approaches:
- Frame difference
- Optical flow
- Background subtraction
But none of these are using GPU, is there a way to implement them on GPUs? or better yet how can I run opencv on GPUs? Thanks
Not an answer to your question, but wondering: why would anyone buy a GPU and not want to use deep learning?
That's what i was wondering as well... The guy said "we want something that works fast and on real time"
I have no problem accepting that they don't want deep learning, but then why insist on using a package that will take advantage of GPUs? I think your solutions in general are workable and probably fast, so it shouldn't matter that they don't use a GPU.
There are some people in higher positions who think they know everything, and if i don't meet their requests, they will think i'm insulting their and that i'm showing off.
So i can run the normal algorithms just fine on their GPUs?
Message 1of2-Good day to all!,
Question: I have encountered a bug
Description of issue: Course: Getting Started With SQL and BigQuery Course step 1 of 6 - Introduction Exercise: Getting Started With SQL and BigQuery => I wrongly deleted the cell following this first one:
Set up feedack system from learntools.core import binder binder.bind(globals()) from learntools.sql.ex1 import * print("Setup Complete")
I got mixed up trying to revert the mistake but I could not make it at the end, now I want to re-start this exercise all along to fix it all and retrieve the deleted cell but I do not know how. Please your soon help. Thx a lot in advance!.
Message 2of2-ReproSteps: Introduction The first test of your new data exploration skills uses data describing crime in the city of Chicago. Before you get started, run the following cell. It sets up the automated feedback system to review your answers. add Codeadd Markdown
Set up feedack system from learntools.core import binder binder.bind(globals()) from learntools.sql.ex1 import * print("Setup Complete") # Set up feedack system from learntools.core import binder binder.bind(globals()) from learntools.sql.ex1 import * print("Setup Complete") Using Kaggle's public dataset BigQuery integration. Setup Complete add Codeadd Markdown
Use the next code cell to fetch the dataset. => THIS IS WHERE I WRONGLY DELETE ITS CELL CONTENT. I tried to amend it but I could not and now it launches an error and I do not know to debug it... 😦 add Codeadd Markdown
Create a "Client" object client = bigquery.Client()# Construct a reference to the "crime" dataset dataset_ref = client.dataset("crime", project="bigquery-public-data")# API request - fetch the dataset dataset = client.get_dataset(dataset_ref) --------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[14], line 2 1 # Create a "Client" object ----> 2 client = bigquery.Client() 4 # Construct a reference to the "crime" dataset 5 dataset_ref = client.dataset("crime", project="bigquery-public-data") NameError: name 'bigquery' is not defined Exercises
Thx a lot in advance!.

I am searching for a partner to study machine learning engineering together. I am currently at quite advanced level, meaning i study such CNN models as StackGAN, ProGAN, AttnGAN, StyleGAN, etc. If you want to study with me, just DM me.Timezone is : UTC + 1; Framework: PyTorch, it is important, because i study only this.
I gave up reading your question due to the font size.
But based on your image, please try below
from google.cloud import bigquery
Hello everybody! This might seem like a very dumb question but I am just getting started in data science and im on my first programming course, I am trying to get a grasp of the titanic problem but one thing that I cant understand is that on the gender_submission.csv document where only females where supposed to survive there are 411 entries while on the main data document there are only 314 females. Thank you in advance for your time
hello everyone, I've just embarked on a journey into the world of data science! 📊🔍 As a newbie, I'm eager to soak up as much knowledge as possible and become proficient in this fascinating field.
I'd love to hear from experienced data scientists or anyone who's passionate about the subject. If you have any advice, recommended resources, or valuable insights to share, I'm all ears! 🧠💡
Feel free to drop your favorite learning materials, tips, or even your own experiences in the data science realm. Thank you in advance
same:)
which of these would be more robust?
model 1
Seed: 0, Data size: 100, Noise: 0, MSE: 0.00
Seed: 0, Data size: 100, Noise: 0.1, MSE: 0.71
Seed: 0, Data size: 100, Noise: 0.2, MSE: 0.73
Seed: 42, Data size: 100, Noise: 0, MSE: 0.00
Seed: 42, Data size: 100, Noise: 0.1, MSE: 0.33
Seed: 42, Data size: 100, Noise: 0.2, MSE: 2.44
Seed: 99, Data size: 100, Noise: 0, MSE: 0.00
Seed: 99, Data size: 100, Noise: 0.1, MSE: 0.70
Seed: 99, Data size: 100, Noise: 0.2, MSE: 0.86
model 2
Seed: 0, Data size: 100, Noise: 0, MSE: 0.00
Seed: 0, Data size: 100, Noise: 0.1, MSE: 0.61
Seed: 0, Data size: 100, Noise: 0.2, MSE: 1.40
Seed: 42, Data size: 100, Noise: 0, MSE: 0.00
Seed: 42, Data size: 100, Noise: 0.1, MSE: 0.6
Seed: 42, Data size: 100, Noise: 0.2, MSE: 1.44
Seed: 99, Data size: 100, Noise: 0, MSE: 0.00
Seed: 99, Data size: 100, Noise: 0.1, MSE: 0.63
Seed: 99, Data size: 100, Noise: 0.2, MSE: 1.46
model 1 has lower loss
model 2 has lower variance in loss with noise
so what is more important
What is 'Noise'? Are these test scores? I wouldn't be so confident to conclude one model has lower variance than the other based on only 3 random states.
Testing at 100 states, the noise has slightly lower mean (about 10%) in model 1 but far lower variance on model 2 (90% lower)
With 1000 data points
What does Noise: 0, 0.1, and 0.2 mean?
0.1 means the input is multiplied by random.normal(loc=1, scale=0.1, size=1000)
In the arcface loss, is the embeding size the shape of the last layer?
I think 10-20% noise is too much. Wouldn't go beyond 5%. I think a better way of assessing this is to do an N-fold cross-validation (NFCV) rather than adding noise. N could be 3, 5 and 10 and see what that gets you. Also, for such a small dataset doing a leave-one-out cross-validation (LOOCV) should be in play as well, because one can quickly build and test 100 models for a dataset of this size. Whether you do a NFCV or LOOCV, it should give a more unbiased MSE estimate than noise injection.
https://www.kaggle.com/competitions/llm-prompt-recovery lets discuss this.
Recover the prompt used to transform a given text
@dull shell We have a new channel for the competition set up here: #llm-prompt-recovery
Hi guys, I'm very new to this field and would really appreciate some help or direction. Can someone please tell me some pre reqs for this competition?
Hi guys, I have link my Kaggle account to Discord, but still cannot send messages in other channel... Can someone help?
So both models give 0 MSE if no noise is added? That screams bug to me. One of your features might perfectly correlate with the target variable, your cross-validation strategy might be incorrect so there is information leakage, maybe your hyper-parameter tuning is off and your models overfit. There could be a million reasons to explain this behavior depending on the context of your work.
Noise injection is used to improve the generalization error (the test score) of neural networks usually. If your test MSE scores are already 0, it doesn't make sense to inject noise because your score can't get any better.
Are you still having this issue? On my end it looks like you should have access to post in other channels.
Hello sir.
how are you? I just come back
How about we start our argument again?🤗 🤗 🤗
Shall we compete together with our respective teams in a competition? @deft fox
I want to challenge you.
Any data scientists who used to be researchers in physics? How was the transitioning for you?
I transitioned from astrophysics to data science but that was back in 2015. 🙂
Hi @zealous creek , what was the most difficult thing for you back then? Do you think your decision was worth it?
I got a really bad burnout from writing research grants and applying for faculty positions as a postdoc, that's why I switched. It was absolutely worth it. I am much happier now and clawed my way back into academia. 😅
That's really good to hear (or read in this case). Thanks for sharing. I'm also feeling burn out from academia, and deciding to not do a post-doc, since this would mean in having to go abroad again for undetermined amount of time. Data science seems like a glove for me, as I really enjoy statistics and data analysis.
The good news is that switching from physics to data science should be pretty straightforward.
Hi!
I have an machine learning question:
Let's say I've spotted some features through visual analysis or empirical studies that really seem to line up with the outcome. How can I give those features more weight in my model setup?
I'm having trouble understanding how to improve my model architecture to take steps beyond just engineering new features from the base data.
Thanks!
That's not how ML works. You give the features to the model and the model will figure out how to "weight" them to optimize your evaluation metric. You don't tune the feature weights manually, that defeats the purpose of ML which is that the computer learns from examples (your training data) without explicitly telling them what to do.
Feature engineering, collecting external data, trying new ML models and a broader range of hyperparameters are usually your best bets at improving model performance.
Yeah, I found out that I had to do it with support vector machines
There's some SVM+ architecture that does what I wanted but it was outcompeted by WSVM.
However, there still ould be a case for SVM+ to be computationally less intensive? Albeit I bet no one will pursue this course.
There is however, a paper on domain adapative learning technology that has promising results. Written in 2023 too. Gonna take a look at it
Hi!
I want to learn feature engineering. Can someone recommend any good resources, whether they're books, blogs, or papers?
Does anyone know where i can find datasets for SeamlessM4T model?
Hey everyone,
I am planning to create a dataset of Human Speech commands to Robotic Arm motion.
My current plan:
- Have a participant come in and prompt them to move the Robot Arm, based on the given prompt.(e.g. : Wipe the dirt using the tissue, peel the potato,etc)
- Record the trajectory of the Robot Arm, collecting the joint pose, state and force torque data
3.Replay the trajectory and ask the participant to describe the trajectory. This will be the natural language speech command.(The reason I am asking them to describe the trajectory is I want to include adjectives in the Command, which could help parameterised the motion characteristics like speed, force, etc)
After the Data collection is done, I plan on using this dataset to train a model, that give me the Arm trajectory based on the Natural command.
My question is:
- What other kinds of data should I include here? Should I record video as well?
- What kind of ML/DL technique would work here? I was thinking Reinforcement learning. Any other learning I should be aware of?
- My advisor suggested using contrastive learning, by pairing the good and bad examples, but what would contrastive learning look like here? How should I pair the examples and any other such techniques?
I want to study EDA, but I need datasets with some missing values for learing the handling of missing part better. But the datasets that I want to use don't have missing values. Is there any efficient way to generate missing values, lets say 12%? But it should be random. I tried bruteforcing but the dataset has around 40k entries. Pls h
There are many ways of doing this. First you load your data as a numpy array, then create a set of 4800 random integers in the range 0-40,000. Now you have 4800 indices (12% of 40000) where values in the original array should be replaced by NaN. Here are some ideas that come with code, and you could have done the same thing by Googling:

Stack Overflow
I am testing the performance of a machine learning algorithm, specifically how it handles missing data and what kind of performance degrades are experienced when variables are missing.
For example...
Stack Overflow
How can I randomly insert np.nan's in a DataFrame ?
Let's say I want 10% null values inside my DataFrame.
My data looks like this :
df = pd.DataFrame(np.random.randn(5, 3),
i...
Stack Overflow
I have a example dataset. It has 2000 rows and 15 columns. Last columns will be need as decision class in classification.
I need to delete randomly 10% of attributes values. So 10% values from col...
Missingness is often not completely random though. Patterns might correlate with certain features or the target variable or other unknown things. It might be better to choose another dataset which contains missing values already.
You are right. My understanding was that this dataset was going to be used for practicing EDA rather than for a real ML application. In such a case it shouldn't matter whether missing data distribution is realistic or random.
Thanks
after a restart my notebooks are showing "Draft Session Waiting for previous session to upload results..."
it's been stuck like this 10+ mins
In the data i am currently working on i have noticed that normalization doesnt really do anything, the metrics are just marginally worse, and the loss curves are similar.
I have tried imagenet norm, channel wise norm, min-max norm
is there any study on the actual effects of normalization? Or any rational on why it would not be helpful?
Normalization is really important for ML models that use gradient-based techniques as the optimizer. If the features in your dataset have different orders of magnitudes (i.e., one feature is age with values between 0-100, and another feature is salary on the order of 10k-100k), gradient descent could become numerically unstable. It overshoots along one axis and converges really slowly along the other. Normalization is not important at all for tree-based techniques because the best split is determined by one feature at a time. So it really depends on the ML model and the optimizer.
I am aware of that especialy for tabular data and time series
This was related to image based models, thus the imagenet and channel wise normalization
at least from empirical tests, normalizing the pixels values is not producing any sort of statistically significant difference, just marginally worsening the results
the latest resource i could find talking about normalization not being crucial was this one
https://www.kaggle.com/competitions/siim-isic-melanoma-classification/discussion/172463#958811
Identify melanoma in lesion images
Neural networks are also optimized by gradient-based techniques, right?
that is correct yes
hi guys can someone tell me about the spaceship titanic competetion.
i am actually struck can someone guide me to start it from where exactly?
If I want to setup a Datathone for my university could I get funding from kaggle itself? also How should I structure a datathone? any and all tips are very much appreciated 
Does anyone Know any search engines that can be used with APIs which are SEO Free; which do not follow SEO ranking?? I want to use them for a project of mine.
Reason: Bad word usage
Reason: Bad word usage
Reason: Too many infractions
hello everyone, i have an internship in AI in with smartgrids, has anyone did similare project that can help me?
Hey Team Kaggle ,
I am Kaggle Notebook Expert and my Some Notebooks are Eligible for the silver medals but not getting ke Silver medal , Can u Please Help me out from this Problem
Unfortunately, it is normal that some votes don't count towards medals. That includes novice votes and votes from users who generally upvote your posts and notebooks a lot. I gave you a couple upvotes and hopefully that will push you towards shinier medals.
Thank you for the explanation! I appreciate the upvotes, and hopefully, they'll contribute to achieving shinier medals in the future.
When I want to submit to competition I get ERROR: Unexpected Column: '' (Line 1, Column 1) can anyone help me
May be your submission.csv does not match the format with sample_sybmissiom.csv, hope this will help if not the dm.
Guys what you recommend to study after those models: ingogan, cgan, dgan, lsgan, wassersteingan, biggan, progan, cyclegan, stylegan, stackgan, pix2pix, vqvae, vae, maybe consider some diffusion models?
pip install git+https://github.com/huggingface/accelerate.git git+https://github.com/huggingface/transformers.git bitsandbytes
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer
import torch
from transformers import BitsAndBytesConfig
from datasets import Dataset
quantization_config = BitsAndBytesConfig(load_in_8bit=True,
llm_int8_threshold=200.0)
# Tokenizer ve modeli yükleme
model_name = "/kaggle/input/mixtral/pytorch/8x7b-instruct-v0.1-hf/1" # Yerel model yolu
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name,
device_map="auto", #"balanced",
torch_dtype=torch.float16,
quantization_config=quantization_config)
-error
ImportError Traceback (most recent call last)
Cell In[25], line 10
8 model_name = "/kaggle/input/mixtral/pytorch/8x7b-instruct-v0.1-hf/1" # Yerel model yolu
9 tokenizer = AutoTokenizer.from_pretrained(model_name)
---> 10 model = AutoModelForCausalLM.from_pretrained(model_name,
11 device_map="auto", #"balanced",
12 torch_dtype=torch.float16,
13 quantization_config=quantization_config)
File /opt/conda/lib/python3.10/site-packages/transformers/models/auto/auto_factory.py:561, in _BaseAutoModelClass.from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
559 elif type(config) in cls._model_mapping.keys():
560 model_class = _get_model_class(config, cls._model_mapping)
--> 561 return model_class.from_pretrained(
562 pretrained_model_name_or_path, *model_args, config=config, **hub_kwargs, **kwargs
563 )
564 raise ValueError(
565 f"Unrecognized configuration class {config.__class__} for this kind of AutoModel: {cls.__name__}.\n"
566 f"Model type should be one of {', '.join(c.__name__ for c in cls._model_mapping.keys())}."
567 )
File /opt/conda/lib/python3.10/site-packages/transformers/modeling_utils.py:3024, in PreTrainedModel.from_pretrained(cls, pretrained_model_name_or_path, config, cache_dir, ignore_mismatched_sizes, force_download, local_files_only, token, revision, use_safetensors, *model_args, **kwargs)
3021 hf_quantizer = None
3023 if hf_quantizer is not None:
-> 3024 hf_quantizer.validate_environment(
3025 torch_dtype=torch_dtype, from_tf=from_tf, from_flax=from_flax, device_map=device_map
3026 )
3027 torch_dtype = hf_quantizer.update_torch_dtype(torch_dtype)
3028 device_map = hf_quantizer.update_device_map(device_map)
File /opt/conda/lib/python3.10/site-packages/transformers/quantizers/quantizer_bnb_8bit.py:62, in Bnb8BitHfQuantizer.validate_environment(self, *args, **kwargs)
60 def validate_environment(self, *args, **kwargs):
61 if not (is_accelerate_available() and is_bitsandbytes_available()):
---> 62 raise ImportError(
63 "Using `bitsandbytes` 8-bit quantization requires Accelerate: `pip install accelerate` "
64 "and the latest version of bitsandbytes: `pip install -i https://pypi.org/simple/ bitsandbytes`"
65 )
67 if kwargs.get("from_tf", False) or kwargs.get("from_flax", False):
68 raise ValueError(
69 "Converting into 4-bit or 8-bit weights from tf/flax weights is currently not supported, please make"
70 " sure the weights are in PyTorch format."
71 )
ImportError: Using `bitsandbytes` 8-bit quantization requires Accelerate: `pip install accelerate` and the latest version of bitsandbytes: `pip install -i https://pypi.org/simple/ bitsandbytes`
how can i fix this problem
the answer is right there in the error message, after the ImportError at the end.
How can I measure the accuracy of text extracted from pdf using pyresparser?
I want to Participate in Steel Plate Defect Prediction but I'm not quite sure what they mean byyour objective is to predict the "probability" of each of the 7 binary targets
Do they mean that I the model need to predect the probability of each problem for each steel plates and not Categorize them or what
The goal is to predict probabilities for each target class such that a sum of those 7 numbers is 1.
Thx
Possible dumb question for you y'all, I wanted to work on a beginner project like the housing pricing regression with a team to learn from, or should that be a solo project?
(this might be for the getting started channel)
@pastel fossil You can do it either way. If you have friends to team up with then why not. But it's perfectly fine to do solo too.
Hi everyone, I wanted to know if it is compulsory to form team to join competions(since I am a beginner in kaggle and I don't know anyone)
It isn't. The post above yours answers a similar question. In fact, you can't join a competition as a team. All members must join individually, and only after that can teams be formed.
Hi I am trying to run: https://www.kaggle.com/code/abhimanyuaryan/fine-tune-gemma-7b-it-for-sentiment-analysis/edit
But I see warning on top. Also when I execute the cell
model_name = "/kaggle/input/gemma/transformers/7b-it/1"
compute_dtype = getattr(torch, "float16")
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=compute_dtype,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
quantization_config=bnb_config,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
max_seq_length = 2048
tokenizer = AutoTokenizer.from_pretrained(model_name, max_seq_length=max_seq_length)
EOS_TOKEN = tokenizer.eos_token
I get this error
OSError: Incorrect path_or_model_id: '/kaggle/input/gemma/transformers/7b-it/1'. Please provide either the path to a local folder or the repo_id of a model on the Hub.
would appreciate any help. Por Favor

is seaborn library as recognized in ML as matplotlib? or is it strictly matplotlib? Like would you hire an engineer that uses seaborn instead of matplotlib? Is it important? Thanks.
Does anybody use ML for their job in precision agriculture? Would love to chat more about it for someone in the industry and get some insights. 😎👍
Seaborn is built on top of Matplotlib, kind of like Keras on top of TensorFlow. I am not in industry, so what follows is only a personal opinion. I don't "know" either Seaborn or Matplotlib in great depth, but any time I need to plot something it always gets done. This is either by consulting my old scripts, or I find a particular function by a simple Google search. In my experience both packages are well-documented, and I don't think either one would be strongly preferred in any setting unless a company is bound by their older software versions to use one of them.
In a competition can I copy the approach of anather one in the competition
Not the same code just the way he handled the problem
that should be fine i guess
i mean u need to understand and imitate approaches in one way or the other
NLP? I want to learn NLP. Where should I Start
Hi, how are you all today? Does anyone know if the current limit of the maximum number of CPU notebooks has changed from 10 to 5? I am getting ´Maximum batch CPU session count of 5 reached.' messages. Thank you in advance.
https://www.deeplearning.ai/resources/natural-language-processing/
If you don't care about the Theore
https://youtube.com/playlist?list=PLoROMvodv4rOSH4v6133s9LFPRHjEmbmJ&si=-uvQ51Kypj-28qyi if you care

Natural Language Processing is the discipline of building machines that can manipulate language in the way that it is written, spoken, and organized
YouTube
For more information about Stanford’s Artificial Intelligence professional and graduate programs, visit: https://stanford.io/ai




Sorry If I bothered you but Is there a function that give the domain of definition that the model get wrong the most
Does anyone here know of any good resources for preprocessing, and data analysis of hyperspectral images? Thank you in advance.
check those papers : https://isprs-archives.copernicus.org/articles/XLII-3/45/2018/isprs-archives-XLII-3-45-2018.pdf
https://www.frontiersin.org/journals/plant-science/articles/10.3389/fpls.2021.627865/full
This paper focuses on image segmentation, image correction and spatial-spectral dimensional denoising of images in hyperspectral image preprocessing to impro...
hello, i wanna ask quick question, does CrossEntropyLoss apply softmax to target values as well? or only on predictions? and should I normalize target values before passing it in?
CrossEntropyLoss does not apply softmax to either predictions or targets. It can work with softmax-ed predictions that add up to one, but that is not required. No normalization is needed on target values. All of this is easy to find by Googling. https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html
alright I see, thank you so much
hey! i want to submit for a non internet notebook competition and i want to use some pretrained LLMs from kaggle. i just cannot find the "add model" button on the right inside the notebook environment. i want to load e.g. mistral from a local path like it is described here https://www.kaggle.com/models/mistral-ai/mistral but it says that the model path is wrong. how can i integrate mistral into that competition notebook?
Mistral AI team is proud to release Mistral, the most powerful language model for its size to date.
ok, i just found it. one must first click "add input" and then you can search for your desired model
If there is a correlation between two columns
Like if the value of columns1
=0 the value of columns2 is 1
Can I delete one of the colums
I mean that deleting one of them will not negatively affect the training of the model
Run an experiment and try it. Train a model with both features and note the test score. Then, train another model by removing one of the features while keeping everything else exactly the same, and note the test score again. If you want to be precise, you should try several random states in both scenarios and record the mean and standard deviation of the test scores. If you observe a significant change in the test score and you made only one modification between the two scenarios, chances are the change in the test score is caused by the modification.
hello, my competition submissions say: Submissions Scoring Error
even though I checked the sample file, it's the same as my predictions Dataframe?

Thx Is this necessary even if there is a dominant value

I'm just giving you a tool to answer "Can I do this and that?" type of questions reliably.
Why the groupby fonction creat this 3 Columns even that it not supposed to do
Thank you for your efforts I wanted to follow your advice when I saw the correlation, but I wanted to know whether I always needed to apply it. Since I don't have the experience
If I have a question like yours, I run an experiment to find the answer. It's an advice so it's up to you to decide if you want to apply it.
Hello, guidence and recommendations needed here please. I am still new to the kaggle and AI world. I am currently taking this course on udemy, https://www.udemy.com/course/machinelearning/learn I just finished the regression portion of the course, is there any excercises you recommend I do before I move on to Classifications? is there any videos you recommend I watch to soak in the skills I learned? or shall I move toward classification and work on project later. Would love to have a quick call or chat with someone who can help me understand how each of these aspects (Regression, Classification, clustering, deep learning) work together to form AI, the applications, use cases, etc.
Good day everyone! I am still new to machine learning. I seek for help and guidance regarding a dataset I'm working with, it has csv file consisting video paths indicating the location of the videos. I just wanted to understand how should I supposed to load and preprocess the data based on the csv file containing video paths. Here is the csv file:
I hope to recieve help from you guys, thank you in advance.
Where can I get notes about various topics in data science in pdf format?
When I got my predictions using my model for the titanic competition, I got predictions that were between 0 and 1. I ended up just rounding to the nearest digit but is there a better way to deal with predictions that are between 0 and 1 (especially if they are 0.5)?
In most Kaggle competitions predictions on the 0-1 scale are expected for submissions. That means no rounding. The way you are doing it - predicting classes rather than probabilities for each class - hasn't been in use in a long time. Rounding up 0.7 to 1 doesn't really tell us how close the prediction was to 1. On the other hand, 0.7 not only has the information that class 1 is more likely than 0, but also tells us about the confidence in that prediction. Even though both 0.7 and 0.99 round to 1, the latter is more confident. By the way, 0.5 rounds to 1 .
is it a good idea to store your dataset in /kaggle/temp/ for training does it persist because all my training runs seem to stop after a certain number of train steps

Explore and run machine learning code with Kaggle Notebooks | Using data from UCF Crime Full
here are few runs that stopped then crashed for silly errors like "np" is not defined
the graphs just stop changing
i should just let it run but i dont wanna to waste my gpu hours
ok they are moving just very slowly mb
that aside is there any reason as to why it doesnt ever seem to converge

ive always had loss curves like this even with another dataset
Hey ! I have a problem of multilabel image classification but 2 labels the percentage of 1 is about 95% . I think this will harm the training . how can I augment the the percentage of 0 ?
generally when I do data augmentation I do it randomly using image data generator but how can I augment the part of images when it has not a person or machine !

This is a classic problem of imbalanced datasets. Most classifiers in such cases are pushed towards classifying the majority class well, because that will guarantee high accuracy. In your case, a classifier that gives label 1 to each data point would still be 95% accurate. That sounds great, but it would be a useless classifier. One way around it is to change the class weight to correct the imbalance. I would try that first, as all modern classifiers will have that option. You can also try to selectively upsample only the minority class, but I would make that a second option.
I would say it is converging, but slowly. It may help to try a larger batch size, and to gradually decrease the learning rate.
Does anyone know if there's an app for practicing pandas? Something like Duolingo but for python programming.
Hello, I would like to finetune Gemma on Python questions.
Is it necessary to sanitize the data and if so, which characters should be removed from the dataset?
Is there a specific rule for LLM?
Thanks in advance!
@vapid valve We have pretty lightweight coverage and rely on automation mostly. Trying our best!
can anyone please guide me about the Store Sales - Time Series Forecasting competition on kaggle , i don't know how to manage all the events listed there .... https://www.kaggle.com/competitions/store-sales-time-series-forecasting/data
Use machine learning to predict grocery sales
What should be the ideal way for me to start learning data science and ai? I do competitive programming in python and have computer science background and I am good at math
am a building a multi-point regression model to predict 6 different plant traits which have very different ranges, so I wrote a loss function in a way that each activation of the last layer is dedicated to predicting each different trait, and I also multiply the loss by weights ( 1/mean of each trait normalized)
But I don't think my model is learning when I look at the loss function plot.
I love to hear your feedback on my approach, as I am very new to machine learning and this approach is not doing very well in the kaggle competition.



hello i am new to AI and have this school project for computer science in which i decided to create a pygame zelda style open world pixel game that contains NPC's that use an ollama 2 model to generate text, is this possible to do
not sure if there's a bug, but I keep trying to upload a transformer model but something is failing... on the model detail page it shows no variations, but if I go to add a new variation, I can see both there. and model can't be used, code doens't show...


Hey guys, so I have never given Kaggle a fair shot and I am beginner to intermediate at Machine Learning. Does Kaggle genuinly help you learn machine learning?
Hmm. Does Kaggle equate to the leetcode -> software engineering, Kaggle -> Machine Learning?

i want to make sure this is not a scam and am hoping a staff member can confirm this for me
@verbal crest
If you want to learn machine learning yes but if you want it for job no ml job need to Learn how to clean data Although kaggel comptions need cleaning but not as Data in the real world +. You need Ather skills like sql
If the test data have a specific range and the train data have a larger range can I train the model specifically to the same range of test or is it considered cheating
@mighty topaz I can confirm this is real and not a scam.
thank you
Hello I am completely new to data science and programming, I am doing the Intro to programming course ( + started learning python through youtube very recently ) and was wondering if I should wait until I get the hang of basics to understand the code for titanic or just follow the tutorial and do it
Thank you ❤️
Bro what happening how in the world the code add 5 or more columns of age when the word age unavailable in the database neither the code


I think the problem from kaggel because I just I turned off the phone and turned it on and the problem disappeared
Can I train a LLM on kaggle notebook without using colab?(Even small one)
Do you have any notebook as an example?
https://www.kaggle.com/discussions/questions-and-answers/486818
Can I train a LLM on kaggle notebook without using colab?.
Hello guys, I have a question about a personal project I have created and the type of AI models I should use. Is it appropriate to ask my question in the kaggle discord ? If yes, in which channel ? Thx
function ConnectButton(){
console.log("Connect pushed");
document.querySelector("#top-toolbar > colab-connect-button").shadowRoot.querySelector("#connect").click()
}
setInterval(ConnectButton, 60000);
this is the code for colab notebooks so that they dont get interrupted due to inactivity. how to do the same in kaggle notebooks?
@tender trench @verbal crest
We don't support that on Kaggle. If you want to run a long query you should click "save version" which will run your code without any interuptions
Hello, I have a question about the "Cabin" feature in the Titanic competition. Why does this feature have so many missing values? I think there should not be missing values because there obviously should be a list containing passengers and their cabins.
What does the code throw the following error:
ModuleNotFoundError: No module named 'tensorflow.keras.layers.experimental'
import tensorflow
from tensorflow.keras import models, layers, optimizers
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
It is most likely that you have an old version of TensorFlow. The issue should be solved by doing pip install tensorflow==2.2.0 (no GPU) or pip install tensorflow-gpu==2.2.0 (with GPU). Googling the error would readily give you this information.
What do you mean with old version of TensorFlow? I'm running this now within Kaggle in the latest environment.
Running only issues the error on the last. The TensorFlow built of November 2023, 2.15.0, is installed.
import tensorflow as tf
print(tf.__version__)
from tensorflow.keras import models, layers, optimizers
from tensorflow.keras.layers import Input, TextVectorization, Embedding, Conv1D, MaxPooling1D, Flatten, LSTM, Bidirectional
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
Same answer as before: Google it but add TensorFlow 2.15.0 to search terms. An educated guess is that somewhere between version 2.2.0 and 2.15.0 TF guys decided to drop this module, because that's what the error says: No module named 'tensorflow.keras.layers.experimental'. Maybe they renamed it. Yet another thing to try is to remove tensorflow from the import and try getting this module directly from Keras: from keras.layers.experimental.preprocessing import TextVectorization
You can also downgrade TF to 2.2.0 and that might work.
Downgrading stuff defeats the purpose of having updates.
Am I grasping this correctly? How can you see this in the TensorFlow docs?
What in TensorFlow 2.2.0 was:
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
... is in TensorFlow 2.15.0:
from tensorflow.keras.layers import TextVectorization
Hi everyone, I usually see/understand the purpose of a Pipeline, altho I find that in practice it can create some inconveniences. Example:
Creating a sklearn Pipeline with XGBoost & passing the fit parameters, handling cross validation when XGBoost fit method requires eval_set param with stopping round.
So, my question is about how to structure your code/work when working on a particular problem.
Do you tend to choose 1 model to work with after looking at the data, or do you still go through different possible models, and if so, how do you structure your work? Do you make one notebook for every model architecture type, do you use Pipeline in practice?
Hi, everyone! I'm currently new to this. I was wondering what are your best practices if the raw data has a missing value which is supposed to be the primary keys like VIN?
if VIN is supposed to be unique and doesn't give any specific information about the vehicle, wouldn't you be better off dropping the column entirely in this case?
if it gives some information, then you can encode it and put a special value when missing I guess
Unless you are using general linearized models or neural networks, you don't have to do anything with missing values. Random forest and gradient boosting machines work fine with missing values. Although this doesn't apply to VIN numbers, you can fill in the missing fields with mean or median for the whole column.
I appreciate your answers! Thank you so much!
I need help with hypermeter optimization for random forests with bayesion optimizer !
Hi guys, working on a datasets with huge missing values, used NaNImputer to generate the missing values while it worked fine for my training data, It throwing up key error for my test data. I have checked my columns they matched, and there are no duplicates. Can anyone suggest how to resolve this issue. Would love some advise on this.
Which competition would I learn the most as practice if I am going to build a machine learning model for predicting how likely horses are to win a race in horse racing?
And would i learn more from an active or completed competition?
I'm currently working on a project involving the CodeLlama model, which originally utilizes a Decoder-Only architecture with Masked-Self-Attention and KV_cache. However, I'm looking to replace the Decoder-Only architecture with my own Encoder-Only model, which employs Dilated-Attention as used in LongNet.
Here's a breakdown of the steps I've taken:
1.Code Initialization:
Initialized the CodeLlama model using the AutoModelForCausalLM class from the Transformers library.
2.Model Inspection:
Examined the structure of the CodeLlama model, including the layers and configurations, to understand its architecture.
4.Custom Configuration:
Created a custom configuration class, CondensedLlamaConfig, inheriting from LlamaConfig, to adjust parameters for the new Encoder-Only model.
5.Attention Mechanism Replacement:
Developed a new attention mechanism, MultiheadDilatedAttention, based on Dilated-Attention as described in LongNet.
6.Model Reconstruction:
Reconstructed the model using the custom configuration and replaced the Decoder layers with the new Encoder layers.
7.Weight Transfer:
Implemented weight transfer logic to transfer relevant weights from the original Decoder-Only model to the new Encoder-Only model.
correct if i am wrong please
Hi, I am currently try to read pdf as a set of image, using pdf2image package
here is the code I used
imgreader = convert_from_path('/kaggle/input/the-test-on-pdfv/Scan_30_Mar_24_105590.pdf', poppler_path='/opt/conda/lib/python3.10/site-packages/poppler/')
and the error occur, state that I do not have poppler, which I have installed and imported already

are there any way to get around the problem?, or are there any other way to extract image from pdf?
@summer drum the convert_from_path('/kaggle/input/whatever is that from / or is that from the directory/folder you are in when you start python?
I am trying to do this on my own computer.
Or this line: train_data = pd.read_csv("/kaggle/input/titanic/train.csv")
Is that from your os root directory? Or is it like from the directory that you run python from?
I used kaggle directory as well, and it still force me to install and get a path for poppler, which i have no clue about
I finish installing yet i dont know the path
Hey! Is it ok to have something else than my real name as a display name on Kaggle? Can I still participate competitions and such? I did set up my name and surname at first, but I don't really want to use my legal name as a nickname on discord.
Quick question:
Say i have two architectures, a small and a large variant (e.g convnext)
For the small, i can run batches of size 64, for the larger variant i can only run batches of size 32
Would it be comparable to run batch 64 on the small, and batch 32 with accumulation of 2, to only update weights after 64 batches? Or are there any other underlying differences?
I started machine learning and data science about 5-6 months ago. In the next 6 months, I need to create a recommendation system for a startup platform, but I don't know how to do it. Can you give me suggestions and guidance?
It is difficult to give you more than a general advice because we don't know what type of data you have, and whether you want to do user-based or item-based recommendations. Recommendation systems have been around for a long time and a Google search will give you many useful leads. I suggest you first search Kaggle notebooks and discussions for "recommender" or a similar keyword. There should be many complete notebooks that you can analyze and adopt to your own needs.
I want to build a unique personal project in machine learning, particularly around LLM and NLP. How can I look for such a problem statement to work on?
Watch fast.ai part 1 collaborative filtering video, if you can’t understand that do the whole course (part 1)from start to finish, that will be a good starting point
Hello 👋 Guys,
I have a doubt,
I'm taking part in ML competitions on Kaggle, so can I consider the notebooks i make during the competition as my project also? Because it's the same thing as taking a dataset from Kaggle and making a project.
this is gonna be a dumb question, but I am struggling to open the trainig set for this comp. theres just a red circle at the bottom left on colab and when I try open it on excel its just grey and this isnt an issue with any other data set Ive tried to open. Does anyone know why or how to fix it?
I think its ok to consider it as part of your project. I dnt see any harm in it
Do you guys use cloud services to run models or do you use your own machine? I try to use mine but it's a mid ahh laptop so it's really slow but I'm really struggling to figure out cloud services
I perosnally use google colab
Ohh wait i never knew this existed it is perfect!! Thank you!!
Hello! one quick question. I'm training a transformer for symbolic music generation. Thing is the model stays at a loss of 0.818 (using cross entropy) after 5 epochs. I'm training it with 81260 songs. Is the problem more likely to be with the way i preprocessed my data or a wrong implementation of the transformer? I followed this tutorial (making some changes because i'm not doing a translation task) https://github.com/hkproj/pytorch-transformer/tree/main.
Thanks!
Also, which metric can i use for validation? I'm using rouge. Thanks.
You can also use Kaggle platform itself
It's personally much faster than Google colab and you get higher run time
hi! newbie here, i wonder is there any projects or competitions that are suitable for ML and DL newbie like me to take, so i can learn and master the techniques by practicing
Thank you!!!
The Titanic Survivors Predictor is a good place to start. I think you can also sort the competitions by experience level on Kaggle
hey anyone know much about the probabilistic machine learning book series
how to get kaggle_api_url
Hi, I've just got a couple basic questions- 1. What does a typical workflow look like? I'm doing the Olympiad competition, and my model takes forever to run, so is there anything I should be doing in that time, like improving other parts of the code? What do you personally do? 2. Are APIs allowed for final submissions? Seems pretty pay-to-win if you fork the 30 bucks and pay for gpt4 while everyone else is stuck using open-source models
What is the difference between learntools ex5 and ex3
Would you agree with these are the feature engineering tasks required for each model (as generated by chatGPT)?

I would say that feature selection is not needed for any of these models, as they will automatically down-weigh the unimportant features. Missing values are handled automatically by all GBMs, not just CatBoost.
Hi! I'm training a text classifier with BERT and I'm getting a validation and regular accuracy of 1. Is that not bad? - Should it at max not be like 0.99?
About the ai Olympiad math competition can I use a ATP or I should just use NLP
Hello, has anyone here worked with MedSAM? I have a few doubts about it. Please DM me.
Hello everyone, I'm going to start working on a project investigating the impact of the new metro system on traffic patterns in Quito, Ecuador using satellite imagery but I'm really new and would greatly appreciate any guidance. Does anyone of you have some experience doing this type of thing? Where can I find reliable satellite images of Quito for my analysis?
Is it possible to save a fine-tuned LLM on the Kaggle notebook and use it later?
I could be wrong, but I don't think anyone is going to DM you. It is one thing to answer questions that are asked here, and quite another to commit to exchanging multiple messages with a stranger. I suggest you ask your question and maybe you will get an answer.
Any model that is created during a notebook run can be saved, assuming its size is not larger than a maximum disk space allowed to Kaggle users. Once saved, that file can be downloaded and re-used.
After a competition ends for example, HMS-harmful-brain-activity , can I keep the dataset for further research (self study as a student)?
In most cases you can't share the data or use the data to publish something, unless the competition host gives an explicit permission. But you are not required to destroy the data, if that's what you are asking.
so I can't publish or share.
but I can experiment and continue the task by myself and when I reach desired results , I can find another similar data which allows sharing and publishing later.
ty for clairfying appreciated 
I am currently doing a kaggle comp for my class and I want to set up a way to run r gbm model through my gpu for faster run times. I am new to the kaggle world and want to know if this is even possible. Thanks in advance
please share any open internship offers for data science and Machine learning
It is not deleted after finish runtime?
hello, everyone. Is there a channel to discuss and find dataset we want?
Hey guys i have been implementing the NeRF paper, and for some help i also have been using this site : https://dtransposed.github.io/blog/2022/08/06/NeRF/. So according to the site i ned to calculate the rays for each pixel of the image and the dataset i am using is the standard dataset for NeRF which conains chair, flower, toy etc.
Engineering, Robotics, AI, Technology
Each train folder has 100 images and each image is 800x800.
The issue i am facing is that if i am trying to calculate rays on all 100 images it is taking forever, i dont know if i am doing anything wrong,
i am even using cupy for GPU utilization on VS code but i dont think its working. Please help me and sorry if this is the wrong channel to post these type of things.
Anyone here pretty good with the networkx python library? I’m trying to use it in one of my scripts but having trouble with it
I am a beginner in data science how do I get started with kaggle competitions?
There is a demo competition on the website, The Titanic one, so go through a tutorial, and everything is explained there. On top of that, you need to know statistics, math, some programming, and some data modeling and data analytical skills. Pick the competition you feel like you want to participate and start exploring the given dataset. There are plenty beginner competitions there! Enjoy!
Can you recommend any books or courses etc that you used for progress
Where are you in your journey? I used many many resources, Khan Academy, math textbooks, university classes, a lot of books from No Starch Press on programming, DataCamp courses, and many more. It's hard to recommend something if I don't know what exactly do you need. For example, I learned A LOT about neural networks and machine learning by writing my own neural network from scratch in raw python using Sentdex yt video series and a accompanying book. It's of course not a viable or efficient project for real life application, but I learned tons doing it. While doing it, I also read tons around the topic.
If you start completely from zero, Kaggle has some introductory courses on programming and data analysis in Learn section, Khan Academy teaches all the math and stats you need, and maybe grab an IBM Data Science Professional Certificate series of courses - you can audit them for free on Coursera, and they kind of show you what direction you need to follow. Start from learning math and statistics. Also, here you have an entire DS curriculum if you want to follow: https://github.com/ossu/data-science

GitHub
:bar_chart: Path to a free self-taught education in Data Science! - ossu/data-science
If i am training some data, and although there isnt a distinct point, at one point the program loss stops decreasing and instead increases (from 0.5 to like 30), what could be the reason
The learning rate im sure is ok
but the model trains really well, but there will be a point where learning just begins to spike
and is there a way to dignose the issue, or a way to prevent it
i am doing a task of nlp. and i need a dataset which consists of texts posted by doctors or physician.does anyone know how to make a dataset like that?
Hi I have one serious doubt for Stable Diffusion architecture

There are two things written denoising unet and and denoising step
Are these both identical or both different
Because in the SD paper there is no clear information related to it
I want to submit a notebook to the prompt prediction competition but the submission uses libraries, is there any way to copy the installed libraries into a dataset and then use it with no internet?
As a beginner, I'm curious about learning more about neural network architecture(from the basics to transformers to the edge of current research). Does anybody have any recommendations for a deep understanding about neural networks and their architecture(i.e. textbooks, videos, etc.)
why my kaggle notebook keeps running endlessly? and to fix that I constantly would have to ---> factory reset and run

or sometimes it's stuck at a certain cell with the star

are there site issues? notebooks seem to be stuck trying to load inputs
What are the best practices i can apply towards improving the accuracy of a neural network?
I've been playing around with a model on the House prices regression competition and I've gotten a 0.16 RMSE score:
def build_model():
input_shape = X_train_preprocessed.shape[1]
inputs = Input(shape=(input_shape,))
x = Dense(128, activation='relu')(inputs)
x = Dropout(0.2)(x)
x = Dense(64, activation='relu')(x)
outputs = Dense(1)(x)
model = Model(inputs=inputs, outputs=outputs)
model.compile(optimizer='adam', loss='mean_squared_error')
return model
adding layers and playing with the dropout rate yielded an RMSE score of 0.14 on the training data
def build_model():
input_shape = X_train_preprocessed.shape[1]
inputs = Input(shape=(input_shape,))
x = Dense(1024, activation='relu')(inputs)
x = Dropout(0.4)(x)
x = Dense(512, activation='relu')(x)
x = Dropout(0.3)(x)
x = Dense(256, activation='relu')(x)
x = Dropout(0.2)(x)
x = Dense(128, activation='relu')(x)
outputs = Dense(1)(x)
model = Model(inputs=inputs, outputs=outputs)
model.compile(optimizer='adam', loss='mean_squared_error')
return model
https://www.kaggle.com/code/suademre/machine-learning-with-supervised-algorithm/notebook
hi everyone, i need help
how output[10] change into output[13] ?
it is surely through the normalization process. But the result should be between 0 - 1. I really have no clue. Thank you, have a good day


Explore and run machine learning code with Kaggle Notebooks | Using data from Breast Cancer Wisconsin (Diagnostic) Data Set
To solve this you create your own dataset and store the wheel files for the needed libraries. Then you can install them from those files without the internet.
If you make a wide enough and deep enough neural network, it will be able to memorize the training data and it will keep giving lower RMSE values. This doesn't mean the NN will be able to generalize well. The idea is to set up a cross-validation and test how this works on unseen data. If the NN keeps reducing RMSE on train data but not so on the validation fraction, the training must be stopped. That is one of the oldest competitions on Kaggle and there are many notebooks where these concepts are explained. I suggest you go through them by searching for NN notebooks that work well and use the information to re-implement your NN.
Alright thank you for highlighting that
Am I posting this in the correct channel?
Does anyone know why this error is happening?
E external/local_xla/xla/service/gpu/buffer_comparator.cc:1137] Difference at 0: 3.18444, expected 2.27506
Results mismatch between different convolution algorithms. This is likely a bug/unexpected loss of precision in cudnn.
I am using a GPU P100 and have a CNN network. This error happens when I train using the GPU. When I try with just a CPU, the accuracy also drastically increases.
How can I install rag-101 ?
I was actually on llama-index and RAG the main code of libraries is (i am working in vs-code )
Guys does anyone have free resources to learn deep learning and GenarativeAi?
Try deep learning by Manning publication alongside 3B1B Playlist with his Linear Algebra playlist and Calculus as well
Okay
Hi guys, I'm relative new to kaggle and I just got into a code competition.
So in a code competition, we are required to submit a notebook right?
Can I build a model in my local machine, and then, upload it to my kaggle notebook that import that model and generate a submission csv? If that model works well, I would then upload the training program and use that to make a submission as a whole.
Is this appropriate according to the competition rule?
Or I should:
1 - do the training and predicting only on kaggle?
2 - train & test on the given dataset. if the model works will on the public dataset, copy the training code to kaggle and make a submission
Any help will be appreciated!
Is it possible to make Kaggle datasets with hugging face dataset?
I don't understand where am I going wrong with this, even after training my model for 30 epochs, I keep getting very bad classification report
the link for the kaggle dataset is - https://www.kaggle.com/datasets/grassknoted/asl-alphabet

Image data set for alphabets in the American Sign Language
Yes, you can decouple training and prediction. If you train on your local computer and upload the models to Kaggle, you should be able to read them and do all other processing without connecting to the internet.
does anyone have good resources (preferably a book or video lectures) about deep learning? the course I'm doing in my uni has very scattered information in slides and some of it is incomplete.
Little book on ML https://fleuret.org/francois/lbdl.html
The Little Book of Deep Learning
is there any further reading after this?
Why is tensorflow throwing me so much errors?

does submission scoring take gpu quota?
can someone link me to any tutorial about making my gpu work with TF > 2.10? I'm really at my wits end here, nothing seems to work
Hey yall, I have a quick question. So, basically, I'm working on developing a neural network for an image classification problem (this one: https://cs231n.github.io/classification/) and basically I wrote an algo for creating and training a CNN. As input, a CNN takes tensors of shape (image_height, image_width, color_channels). Then, I define the convolutional base using a common pattern: a stack of Conv2D, MaxPooling2D and dropout layers. This is the code for my base_cnn() function:
def base_cnn():
"""
Define a convolutional neural network using the Sequential model. This is the
basic CNN that you will need to reuse for the remaining parts of the assignment.
It would be good to familiarize yourself with the workings of this basic CNN.
"""
model = Sequential()
'''
Add 2D convolution layers the perform spatial convolution over images. This
layer creates a convolution kernel that is convolved with the layer input to
produce a tensor of outputs. When using this layer as the first layer in a
model, provide the keyword argument 'input_shape' (tuple of integers). Besides,
the Conv2D function takes as input
- filters: Integer, the dimensionality of the output space (i.e. the number of
output filters in the convolution). We set it to 32.
- kernel_size: An integer or tuple/list of 2 integers, specifying the height
and width of the 2D convolution window. Can be a single integer to specify
the same value for all spatial dimensions. We set it to (3, 3).
Here, we create a stack of (CONV2D, Activation, CONV2D, Activation) layers with
the ReLu activation function
'''
model.add(Conv2D(32, (3, 3), padding='same',input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='same'))
model.add(Activation('relu'))
'''
Perform MaxPooling operation for 2D spatial data. This downsamples the input
along its spatial dimensions (height and width) by taking the maximum value
over an input window of size 2X2 for each channel of the input.
'''
model.add(MaxPooling2D(pool_size=(2, 2)))
'''
Add a Dropout layer that randomly sets input units to 0 with a frequency of
'rate' at each step during training time, which helps prevent overfitting.
Inputs not set to 0 are scaled up by 1/(1 - rate) such that the sum over all
inputs is unchanged. We set the rate to 0.25 for Dropout.
'''
model.add(Dropout(0.25))
'''
Create another stack of (CONV2D, Activation, CONV2D, Activation) layers with
the ReLu activation function. Set the 'filters' to 64.
'''
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
'''
Perfrom MaxPooling and Dropout similar to the one defined earlier.
'''
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
'''
The image is still in 3D. It needs be unrolled from 3D to 1D using the Flatten
layer. Then add a Dense layers on top of it followed by ReLu activation and
dropout of 0.5. This helps to create a fully-connected layer.
'''
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
'''
Create the output layer using the Dense layer with 'softmax' activation. The
number of predicted output needs to be equal to 'num_classes'.
'''
model.add(Dense(num_classes))
model.add(Activation('softmax'))
'''
Set the optimizer for doing mini-batch gradient descent. Here, we make use of
the RMSprop optimizer that comes with Keras. We supply some default values for
the parameters learning_rate and decay. Do not modify them.
'''
opt = keras.optimizers.RMSprop(learning_rate=0.0001, weight_decay=1e-6)
'''
Compile the model for training. Since this is a multi-class classification
problem, we use the 'categorical_crossentropy' loss function and 'accuracy' as
the desired performance metric.
'''
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
print(model.summary())
return model
I'm currently trying to pass different activation functions to my CNN model and plot their accuries on training and validation data but for some reason, I'm getting a flat line for the CNN + sigmoid activation function, and I'm quite unsure what I'm doing wrong here:
def base_cnn_activation(activation):
"""
The base_cnn() function sets the activation function to 'relu' by default. Modify
the code so that it can work with an user-supplied activation functions instead
of the default 'relu' activation. Do not change the 'softmax' activation.
Compare the accuracy achieved by rectified linear units and sigmoid units in the base CNN. Produce two graphs (one for training accuracy and one for validation accuracy) that each contain 2 curves (one for rectified linear units and another one for sigmoid units). The y-axis is the accuracy and the x-axis is the number of epochs. Train the neural networks for 25 epochs. Although 25 epochs is not sufficient to reach convergence, it is sufficient to see the trend. Save the following results in your Jupyter notebook:
The two graphs for training and validation accuracy.
For each activation function, print the test accuracy of the model that achieved the best validation accuracy among all epochs (i.e., one best test accuracy per activation function).
"""
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',input_shape=x_train.shape[1:]))
model.add(Activation(activation))
model.add(Conv2D(32, (3, 3), padding='same'))
model.add(Activation(activation))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation(activation))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation(activation))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation(activation))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
opt = keras.optimizers.RMSprop(learning_rate=0.0001, weight_decay=1e-6)
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
print(model.summary())
return model
I'm getting graphs that look like this:

but the sigmoid is also supposed to be a curve instead of flat line with 10% accuracy
Can anyone tell me what I'm doing wrong here in the base_cnn_activation() function please?
Did you find an answer?
is there any free dataset of drilling or open hole log?
yes, install with wheels
Good day! I am an Applied Computer Science student, currently in my second year with a focus on Artificial Intelligence. For our Deep Learning Project, we have to choose a competition on Kaggle where we have to use at least one of the following:
- MLP
- CNN
- RNN
- Auto-encoder
- NLP
As we are very limited in time (only 10 days), they have advised us against using CNN, as training would take too long. So my question is which of the current competitions would you suggest me to choose? Thank you all!
Hey everyone !!
I hope everyone is doing great
This is my first ever Kaggle competition, hence I don't have prior experience with respect to submissions. I just wanted to ask how does submission work ? Do we have to upload the model or a pipeline (script) somewhere ? (I could just see an option to upload the notebook) . Apologies if the question is repeated (I just asked the same question in competition-general assuming it would be a correct channel to ask the question)
It would be of great help if anyone of you could provide some necessary information about the same
I have to do it nearly every run. It's pretty annoying.
I am looking for an African Climate Dataset. If anyone has it or has an idea of where I can get it please reach out
When you say This is my first ever Kaggle competition we have no idea what that competition is. You will have to be more specific. For some competitions you can create a submission file offline and upload it, while for the code competitions you must create a notebook and a submission on Kaggle.
Can AI Learn Forever? Tackling Catastrophic Forgetting.
Hello, been having issues on apply hybrid model on my project but not get it please can someone help. Thanks
Can anyone help me in implementing this paper "Robust and accurate object detection through adversarial learning" https://arxiv.org/abs/2103.13886?
arXiv.org
Data augmentation has become a de facto component for training high-performance deep image classifiers, but its potential is under-explored for object detection. Noting that most state-of-the-art object detectors benefit from fine-tuning a pre-trained classifier, we first study how the classifiers' gains from various data augmentations transfer ...
Where can I find info about non supported wheels? I checked the terms of use and there's nothing relevant there.
I'm trying to do this https://www.kaggle.com/code/tera555/how-to-install-ta-lib


Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
Can someone help me out with this?

It was not able to read your csv file, please double check to make sure your relative path to the file is correct
@devout bobcat hey, got it cleared earlier. Thanks for replying
No worries, feel free to ask if you have any other questions!
@deft fox do you have any knowledge regarding this?
Hello Kagglers! I am trying to submit my first competition. Do you know how long on average takes Scoring?

For the most part webuis are intentionally blocked on Kaggle for consuming too much compute. Kaggle compute is for learning and data science work, not as a tool for generating art or deepfakes.
TOS and Documentation:
https://www.kaggle.com/terms
Welcome to Kaggle. Please read on to learn the rules and restrictions that govern your use of our website(s), products, services and applications (the “Services”).
Explore and run machine learning code with Kaggle Notebooks, a cloud computational environment that enables reproducible and collaborative analysis
Is it allowed to upload my solutions for a titanic dataset on my github repo? Basically I want to solve titanic survival competition using multiple logistic regression algorithms and store them in a github repo.
anyone have any tips on improving unsupervised learning knowledge (i am already familiar with supervised)? like using images to classify the image or like using images to detect something?
https://www.kaggle.com/competitions/playground-series-s4e4/overview
Hi @verbal crest , in this competition, my prediction outcome of number of rings varibale is decimal values. My questions:
- Can I submit the csv file with rings columns as decimals?
- If the above answer is NO, then if I round my outcome varible and just present integeres, will that effect my score and rank on the leaderboard?
Playground Series - Season 4, Episode 4
@glacial linden I'd try asking in the forum for thart competition or it's specific discord channel #playground-series-s4e4
Thank you!
hey guys, while using Google Colab do I have to rerun the entire code every time from the beginning? (including training ds) because I can't seem to save the progress?
iirc webuis on kaggle were banned (might be wrong) so i would like to ask are things like rvc banned?
Hi I am facing some issues with tensorflow multihead attention.
Even though the input shape is consistent. It's still throwing an error saying incorrect input dimension.
Can any one help please.
I am creating a local transformer single layer
Good day everyone, I have a few questions about my model for the Titanic competition. I extracted the titles of each person and put them as extra features. Then I normalized my data and did PCA. Then I took the 10 best principle components and fit a few models on these. All of my models are performing very badly even after doing extensive grid search with each model. Does anyone have any tips?
Can anybody recommend a book about Data science related to finance? I mean a up-to-date book relevant for 2024.
Can any of the mods help with this?
https://www.kaggle.com/discussions/product-feedback/497107
[Bug] AUTOBAN ISSUE | Request for Review of Account Lock - Cyberoni Kaggle Account.
I somehow got laughed at and downvoted for making the discussion post?****

can anyody share learning materials for time series how to do prediction on multivariate time series.
I know about ml algos (ses,des,tes,Arima,Sarima) but don't know how to find out forecast when other independent columns can be used in forecasting and guys any vlog on decompositon .How to decompose a time series please help me buddies I need them urgent guys.
please seniors help me
can anyone help me with this. The solution was correct but couldn't proceed further and the question is also not marked as correct


even this is not working

need your help buddy
#DOUBT_HELP: I am doing this titanic kaggle challenge - https://www.kaggle.com/c/titanic/data?select=train.csv. im confused if the following columns should be dropped for EDA or not -- 1# of siblings / spouses aboard the Titanic
parch 2# of parents / children aboard the Titanic 3Cabin number
4 Port of Embarkation
(I think these factor does not contribute to whether they could survive or not- it seems like unneccesary infor for this analysis, For example - how can it make sense to say people who entered first had more chances of dying in ship sink or people in cabin no. ABC could survive better!?) Please help
Start here! Predict survival on the Titanic and get familiar with ML basics
I used random forests to plot the feature importance of different fields

As you'd expect sex is the greatest importance for the dependent variable. Though surprisingly Ticket and Cabin are quite important.
Here is my notebook https://www.kaggle.com/code/jtv199/linear-model-and-neural-net-from-scratch

Explore and run machine learning code with Kaggle Notebooks | Using data from Titanic - Machine Learning from Disaster
Here is a partial dependence graph with those 3 columns, as you can see there is a trend for fare and Cabin and a weird relationship for ticket

My catagorical data are converted to ints alphanumerically
ie cabins :
0: 'A10',
1: 'A14',
They were probably corrolated with fare or class idk
/shrug
Thank you so much @honest perch I will check out your notebook.
By the way, its my first challenge and my leaderboard position is 13334, wonder if its any good? And tips on improving?
Nice one. Thanks for the visual stats. Interesting gender was most important. Age a big one too. Just taking a guess, that factor favored the younger passengers. 🤔
dont take too much stock in my random forest approach, I tried submitting that one and got 0.59 score. Which is to say about as good as random 😔 . I'm going to look back and see if I overfitted random forest cant overfit.
haha definitely better than me. I'm at 15320 which is in the top 97% of scores 😭 . I'm aiming to get around top 25%
For reference this simple decision tree got 0.545 and position of 15326

@honest perch I read ur notebook - I think col Cabin with 687 Nans should entirely be removed while u replaced Nan with mode vals
Hmm you may have a point
I have an absurd regression problem
as a part of the assignment i am supposed to perform regression on a dataset with almost 2 million rows and 2400 columns/attributes
and the test dataset on which i need run the trained model has 400,000 rows
Please suggest possible methods to solve this
Hi, guys! I'm participating in my first Kaggle Code Competition, so I'd be greatful if you could help me, a beginner, understand the requirements for an elligible submission.
From what I've read in the Kaggle documentation, it is necessary for the submission notebook to be ran "top to buttom" in less than 9 hours of CPU / GPU runtime. That means that in my submission I should train the model on the training dataset and also predict on the test dataset in less than 9 hours, right? So, if I'm using an ensemble solution, I should manage to train all my component models in the time limit. Or I'm getting it all wrong?!
I'm asking this question because I've noticed in this and other competitions' code tabs that there are public inferrence-only notebooks that import model(s) trained elsewhere (uploaded as Kaggle datasets) and use them directly to predict on the test dataset. This shortens the total runtime of those notebooks. Is this kind of notebook allowed to be a final submission? Or is this just a way to avoid exhausting the GPU weekly quota while also allowing one to see how well their predictions perform on the public leaderboard and also making certain notebooks public for the community without revealing too much of the training process used.
If this isn't allowed, then how are my submissions supposed to compete with these sped-up notebooks, with high public scores, especially in the efficiency section of the contest?
Thank you in advance!
I'm still new to ML, but have you tried random forest to find the feature importance. Then you can select the important columns and run with a smaller rows
like this
Sure. Although, it did made me think of that old addage: “Women and children first.“ 🤔
yeah that does seem about right.
I already asked my question on discussions but I have to cross post here since kaggle discussions are getting so much spam. This is the post. https://www.kaggle.com/discussions/general/498808
I saw some of the old discussions about some teams getting removed because they shared something before merging teams. My teammate shared a notebook and literally after 10 minutes we teamed up. We haven't done any submissions in last 2 weeks. We have teamed up 2 times before and finished top 10 in both competitions and we have no history of cheating. Are we safe? @steel sundial @verbal crest
About team removal.
Hi,
Anyone have knowledge pytorch_forecasting library?
I have a question about it.
Actually I had a look at the feature engineering notebook, and I believe unknown cabin is quite informative. I should have made it a separate category if I spent more time on feature engineering.
To conclude, cabins used by 1st class passengers have higher survival rates than cabins used by 2nd and 3rd class passengers. In my opinion M (Missing Cabin values) has the lowest survival rate because they couldn't retrieve the cabin data of the victims. That's why I believe labeling that group as M is a reasonable way to handle the missing data.
https://www.kaggle.com/code/gunesevitan/titanic-advanced-feature-engineering-tutorial

Explore and run machine learning code with Kaggle Notebooks | Using data from Titanic - Machine Learning from Disaster
Hello Everyone, I'm working on ML project I have used PIMA dataset https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-database?resource=download for Diabetes Detection I want to use another similar Dataset that I can use for comparison. Can anyone share me any publicly available such dataset that I can use. Thanks!

Predict the onset of diabetes based on diagnostic measures
How come my code is able to run on jupyter notebook, but when I try to run it on the kaggle notebook I get a value error?
I was re-creating a work of hate speech detection model, I am quite noob at certain paramete, what I was facing a error while measuring the model accuracy with " Naïve Bayes BoW classifier ", I have attached a screen shot. I hope I am understood at this level.

is it vocab or vocabs
Can anyone point me to the right direction,
I'm trying to build a model that matches a book's paragraphs in one language with the matching paragraphs in a translation (for example, let's take the little prince's english version and its japanese translated version)
The idea would be to create a version of a book where its original and translation are laid out side by side for language learning
I'm not too sure yet how to approach this kind of problem (what model to use, what kind of problem it is, etc.) so i'd appreciate some guidance
as of now, my idea would be to vectorize/tokenize the words, compute something like a vector sum per paragraphs, then maybe match the resultant vector using a dot product with the vectors in the other language, the thing tho is that since these are two different languages, the way the words would be vectorized would probably result in vectors where the dimensions aren't the same, so not yet sure how to deal with that
TLDR: I'd like to create a model that automates the creation of something like this: http://bilinguis.com/book/alice/jp/en/c1/ where the model aligns the text from an original language to an official human-translated text
Any suggestions would be appreciated!
multilangual model
Sex is always the greatest importance 
hi guys if i have 3 box with 3 digit of number inside it what is the best deep learning methode to predict it?
how you guys been running the llms? do you pay for the vertex ai subscription or use private hardware?
Tried with both "vocab" and "vocabs". All are same as the Errors are SAME
@shut moonFirst of all this a function and you are using it, can you show me the function itself BEFORE that line of code
I am AWAY from my Pc. Will be sharing shortly.
do you remember that there's something the same name as this ?
before that line of code?
In the whole code I didn't found anything like that. first I thought it was a part of 'naive_bayes' module. but it wasn't
no it's not, and even it is, this not the right way to train the module
so the answer is no
I guess I will have to wait to see an answer I might helpo
https://colab.research.google.com/drive/1d_q0vUpgwmbN7imUcdsbuDwJ61OuBjvO?usp=sharing
I was reproducing this
and I might now
Much APPRECIATED
Hello I would like to ask question about Kaggle Tier progression
-
In order to become Kaggle Expert, do I have to become expert in all 4 categories (competition, notebook, discussion, datasets). Or is simply becoming expert in one of these enough to become overall Kaggle expert?
-
Is skipping Tiers possible theoretically? Let's say I am Kaggle contributor and I don't meet criteria for becoming "Kaggle Expert" but I meet criteria for becoming "Kaggle Master". Do I become Kaggle Master, skipping the Kaggle expert phase? Or does it not work like that and I have to progress gradually?
thanks for explanation
Did You see the notebook?
@shut moonOh sorry something came up, and yes I saw it
[Errno 2] No such file or directory: 'train.tsv'
I guess you do have it
@shut moonand decent accuracy at the end I guess?
it isn't even a good accuracy
but give me your whole lines of code
and I might be able to help
I will send you my notebook
ok
Check DM
Ya I downloaded it just hold on a sec
Okay
ok here's the thing my friend, it's a function not something that you can get from naive_bayes
so there's 2 notes here from my understanding.
either he forgot to put the cell that have the actual function in this case "get_vocabs"
or
the cell works in your pc and not mine, in this case I don't understand why but I am very sure it's not something from the library,
I mean the guy who produced it in the first place
@shut moon
I guess you will have to create this function?
Okay. Let me see. I am not sure if I can do that, I have not that experience, I will start learning, come back to it later.
I do not have experience also my friend, but if you want to learn now, here's a quick advice if you want to create this function
simply see the difference between the 3 variables that he created as objects, and what happened to them after the change and the application of the function
and see what's in the train data
again see the difference and see what happened
and start making notes of the changes that happened
then you will create your function very easy
I was always doing that when I was learning python so give it a try @shut moon
all you need is information, loads of it

can you show me the function
Hi I'd like a help on the problem I'm working ( it's image classification competition by CVPR) it's basically about classifying different species of snakes from their images.
I've been trying to do transfer learning on several models still not getting a good results
models I've tried.
facebookresearch/Hiera -- Tiny version
vit_base_patch16_224 ( trained over imagenet data)
Any suggestion for the base model or any augmentations to try on. I've been using fastai + albumentations for the augmentations to the training images ( taking reference from this link) https://github.com/benihime91/kgl-pogchamps-3-corn/blob/main/nbs/NB_EXP_V2_008_swin_base_patch4_window12_384_in22k.ipynb
would like to have a discussion if anyone is interested 🙂
Thank you 🙂
GitHub
It's Corn (PogChamps #3): Corn Seed Image Classification - benihime91/kgl-pogchamps-3-corn
@shut moon it's been determined by the system I'll probably recommend you to use some DP approach if possible instead of recursion since limit is exceeding but you can have a workaround by using this
Stack Overflow
I have this tail recursive function here:
def recursive_function(n, sum):
if n < 1:
return sum
else:
return recursive_function(n-1, sum+n)
c = 998
print(recursive_funct...
Hi @sterile cliff can you support me please
Hi all, I am working on my first ML project independently. The project is titled 'House Prices - Advanced Regression Techniques.' We have been provided with separate files for training and testing. Why do we need to split the data into train and test again before running the model?
hey! there are two files because on the train.csv dataset you'll train your model, and that model will predict the house prices based on the data inside test.csv.
you have to send those predictions that you got to the competition, based on the submission example file you also received.
hope im clear ^^ have fun!
oh and you have to split the training data into train and test again since you want to see the accuracy of your model before sending it into the competition
otherwise its a similar act as throwing a dart while being blindfolded
@wheat kettleunfortuntly for you I don't have such a dataset
@shut moonand this function is very wrong
can you suggest me a dataset that I can use to predict Diabetes. I found this dataset https://data.mendeley.com/datasets/wj9rwkp9c2/1 but the fields are different from PIMA dataset https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-database?resource=download
The construction of diabetes dataset was explained. The data were collected from the Iraqi society, as they data were acquired from the laboratory of Medical City Hospital and (the Specializes Center for Endocrinology and Diabetes-Al-Kindy Teaching Hospital). Patients' files were taken and data extracted from them and entered in to the database ...
Predict the onset of diabetes based on diagnostic measures
@wheat kettleI told you that I don't have such information in the datasets
how can i remove useless data from my heatmap cause i sort it using this :
`corr_scaled = corrmat_top_features[(corrmat_top_features['mpg'] >= 0.3) | (corrmat_top_features['mpg'] <= -0.3)]
mask = np.triu(np.ones_like(corr_scaled, dtype=bool))`
but in the heatmap i still have all of them
plt.figure(figsize=(192, 50)) sns.heatmap(corr_scaled , mask=mask, annot=True, annot_kws={'fontsize': 8}, cmap='coolwarm', vmin=-1, vmax=1, square=True, linewidths=0.5)

@steel matrixmmmm, can you show me the columns that you put them into?
the corr_scaled, show me the result of that variable
Here is the thing, I imported a LLM using AutoModel, and added my own Custom Classifier at the end of the model with Custom pytorch class. But evertytime I try to enter an input to the model created from the pytorch class, it runs out of memory, I used quantization and acceleration. and the input's batch size is 1.
is there a way to input a data to model like this without running out of memory? thanks.
I want to get into predictive analytics... any book recomendations? Im pretty new at this 🙂
@untold helmKaggle has bunch of courses in machine learning that can actually teach you this without any cost, it will teach you predictive analysis, and actual Predication can see stuff into the future
whatever you want
Thank you Ahmed
@untold helmyw
Hi All, why only these features ['LotArea', 'OverallQual', 'YearBuilt', 'TotRmsAbvGrd'] have been selected for the model? what is the criteria? here is the link https://www.kaggle.com/code/dansbecker/submitting-from-a-kernel/notebook

Explore and run machine learning code with Kaggle Notebooks | Using data from House Prices - Advanced Regression Techniques
hello,
I want scrape data from a PDF which is stored in a Google drive and then I need to train a model to scrape it dynamically (whenever a new PDF is added) and get the complete data in excel or google sheet. can anyone tell me how to approach this, Because I have tried getting the PDF data into Json first and then converting it on to a excel sheet also I was thinking to do this on SQL but the column names are different on the PDFs. Please suggest an optimized way of achieving this. Thank you
@fading swiftsearch on something called tesseract, it will extract the text from any given file (such as a pdf), it requires so research but you got it, it's also a python code not program, I mean library I suppose
@analog bearit doesn't to have be those, this an example not an answer, choose your feature by yourself if you want
@fading swiftalso you will find how it work on youtube (I hope)
It's not available on YouTube but thanks I'll try tesseract once.
np
Thanks for the reply. What is the best approch to choose them?
@analog bearanything can be a feature, but before you add them, just remember to increase it's sensibility of the data and it's reliability (in other words, data cleaning)
you might remove a feature because it simply doesn't tell you enough data, or it's just random from guy who put random numbers, it's up to you to discover that
Guys, if smbody has good kaggle profile, does that help in landing DS jobs?
so i was looking at this data set:
https://www.kaggle.com/datasets/kvpratama/pokemon-images-dataset/code?datasetId=6799&sortBy=voteCount

Dataset of 819 Pokemon images
i was looking through the codes and saw that the top ones didnt really create coherent pokemon images
it was more like different blobs of colour that might resemble a pokemon from a distance
they use a dcgan
so is the size of the dataset itself the bigger problem here?
because its 819 images
Hello everyone, I want to start building a Fake News Detection Model to practice machine learning, i am reading a lot of fellow kagglers notebooks about this subject and getting to learn what libraries, models, and algorithms to use, but i still haven't rapped my head around it , like what's the best practice to start developing the model as a beginner, then as an intermediate, then as an Expert.
@fringe archlearn from kaggle
bro
@fringe archdo you want a project ? you will see more from kaggle courses
do you want competition, believe me from the course
do you want an actual project for beginners?, this hard, because a complete project can be easy if it's described, thus it's in the course
I don't know what else you want me to say
Hello. Does anyone know what is going on with this


The file path seems correct but the program can't find it?
nvm it is fixed after refreshing....
ok
isn't there a team that I cna join to make projects and competitions?
https://www.kaggle.com/code/chongzhenjie/ecuador-store-sales-global-forecasting-lightgbm in your opinion is this code a beginner level?

Explore and run machine learning code with Kaggle Notebooks | Using data from Store Sales - Time Series Forecasting
Hello guys, I am facing some issue regarding running my code using TPU for a binary classifier dataset which contains 23k files for one class and 3k files for another.
I am inporting my dataset in the form of TFRecord and then convert it into TFDataset. My sparse accuracy is coming out to be 7%, instead it should be between 0-1.
Can someone please help, its really urgent?

I am trying to fine my model and for some reason model.to(DEVICE) doesn't work on Kaggle: https://www.kaggle.com/code/abhimanyuaryan/distilbert-fine-tune-imdb-train-loop
can anyone help me understand the root cause of this
DEVICE = torch.cuda.get_device_name(0)
'Tesla P100-PCIE-16GB'

Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
DEVICE = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu') fixed this
but now I have new question. How to use both the GPUs. I only see one T4 being used in training

@quasi gyrothat is torch, I am not familiar with that issue
@pallid radishand that's an AI classifier?, mmmmm not sure about that one
guess I don't know everything lol
If you aren't sure about anything why bother using few kbs of your precious internet and tag me 😂🤣
@quasi gyrowell, consider it as a gift instead of complete silence from most of the users that doesn't answer(which is disappointing)
but if you want help I can search with
No I found solutions. Thanks anyways. I don't know about using 2 gpus yet
But I'll figure it out thanks
np
How can I join a team??
can you please share any resources that I can refer to? I think the problem here is my dataset has 25k image files, So for TPU I think there is some issue with the way I am sending the data for training of my model but not sure though.
thanks for the reply, appreciate it
@pallid radishI used to have this kind of problem before, however the problem is I completely forgot the way to handle the TPU, I am sorry
@karmic spearI am looking for a team myself, kinda noob here but if there's nothing to emerge I will create a team here
I am working on a community detection project for social network (telecom data) i wanted to ask if this approach is good
Transform data to graph (Pyg)
Train a Gnn Model (GAT)
Generate embbeddings with the gnn
Apply K-means for clustering
I would appreciate any advice or guidance
I was trying to run some different ML model On liver_cirrhosis data set. I got result for logistic regression and svc, two of these models were about 50% accurate, then I wanted to run XGboost. the first error I found that the categorical values should be like 0,1,2 but onehotecoding did 1,2,3 so I did the labelencoding and run xgboost again, the error persists till now. Here are the two screenshot to clear the scenario.


Hey can anyone please tell me where I can get a good scipy tutorial
How often do y'all use Calculus in your models? I'm early into my endeavor with machine learning and trying to get my fundamentals in place and curious your thoughts. 🤔
I somehow solved the previous problem , but the accuracy seems bit low, how do I increase accuracy?

#query For Titanic - Machine Learning from Disaster, I used logistic regression for training. I split mmy train data into train n test to check accuracy and it was 1. But when I used same EDA and training for test data and submitted, its giving me 0.7 accuracy. Is this overfitting and how to overcome this?
@shut moongood for you that you solved the problem I was just about to make a trail and error with, second if you want to increase the accuracy, you have to first understand the data, how you can do that, get a box plot, see the outliers that messes up the data, and see how it is related, second see your feature, I mean column by column BEFORE hotencoding them, their might be something interesting, third, did you see the duplicates?, the NA data?, is there any of the those doesn't make any sense at all in the Same columns?, do you have to delete some of the columns, if so ? why?
these are the kind of questions you have to ask yourself before you put them inside the module
because a 1.74% accuracy, is pretty PRETTY bad
@pastel fossilwell the theory of the machine learning and AI is entirely on calculus, you can study it, and see how the modules actually work with just the numbers, the only problem is it takes a lot of time, that's why it's done in one line, and voilà, it works.
but we don't use calculus to as actual calculations in coding, we have other things to be careful for, and that's not one of them
@wide crescentare you sure you split your TRAINING data into training and test?, and if so there's no way, I mean NO WAY they will be 1, something wrong in your code. either you trained it at the same pre-trained model, or you didn't split them at all
@wide crescenteither way, you have to show me what you did
I close the notebook rightside setting panel accidentally,how can I reopen it?
how to fix this? editor loading forever...cant do anything in the page

hello Guys
i hope you are well
please i have i question : i'm taking part in an llm competition and i'm facing a small problem. i'm working on colab and i'm having a problem with the model i want to use. i'd like to know how to train an llm model?
can anyone help me?


https://www.kaggle.com/datasets/kvpratama/pokemon-images-dataset
can anyone help me out with this dataset? i tried implementing different types of architectures and tinkered around a bit but the images just don't get clearer
Dataset of 819 Pokemon images
https://www.kaggle.com/competitions/playground-series-s4e4/data?select=train.csv
Can anyone tell whats the diff betwneen the artificially generated dataset and the original dataset
Playground Series - Season 4, Episode 4
i dont think theres a single different entry
The original dataset has a relatively small number of data points. The synthetic dataset is created by a GAN to have similar feature distributions but with more points. They are meant to be very similar in everything except the number of data points.
What are the best social media for a highly technical code blog?
@feral spade github?
@slim frigate not much, the most important thing is your knowledge, and if you can work and make projects with it or not
Start here! Predict survival on the Titanic and get familiar with ML basics
Hi, actually I figured it out- u are right, i mistakenly added target column 'Survived' as one of the features in my training n test set, thats why
thanks!
@wide crescent good hope you make the best module ever 😃😃😃
Im trying to get to best scores for titanic dataset, somebody help
@wide crescent well send in the notebook, I might help
I think the data points whatever are common are exactly the same , except that the numbers might be less
hey! how do you guys decide what hyperparameters to set for a CNN? (more specifically, a computer vision model)
whenever I try to create a model, it fails to converge. I also recently tried to remake the AlexNet architecture on a food101tiny dataset but it fails to converge, so I'm not so sure if it's about hyperparameters in that case.
@celest dustWell, according to the data, you need to understand what the parameters do exactly, before you apply them, OOOOORRRRRRRRRR............................
You can just make a for loop for a small portion of the data("this part is VERY VERY important"), and you can change the value each time in the loop
if one of the numbers you put in the loop got a high number then you get a winner, then you set on the next parameter on the next for loop, and voala, you have unbeatable boss
yeah that'd be cool but it would take a longer time to finish that process on every hyperparameter than just understanding what those params do exactly lol
I somewhat understand most of them, but I'm not sure about the metrics that are usually used for the parameters
like if I had a dataset of size x, I couldn't tell how many layers of conv and fc I would need
a small portion, I said a small portion
ah, and that's the part what my brain decided to skip, even tho u said its VERY VERY important 😂
hmm I'll try that, but is it going to work on deeper networks too, like one with a VGG architecture for example?
I have this problem my "Pclass" is type category, I dont know how to fix it, show if i change it to string or anything else.
Thank advance

I have this problem in my kaggle notebook. Program is on but output is not updated

hey guys im using rvc ai vocal cloner in kaggle and im facing the following error..any help would be greatly appreciated,thx


I am on the classic California Housing Dataset trying to predict the median house value. So, the dataset contains NaN values in total bedrooms. I used the Simple Imputer to replace them with median values but when I go on to train the model I still get NaN values. I have checked the dataframe and there aren't any after my preprocessing . But when I try to preprocess and run the model together via a pipeline, I don't know what goes wrong. I have linked the notebook and shared screenshots of the problem I'm facing. Any help will be greatly appreciated. Thanks!
https://colab.research.google.com/drive/1gpaI2xJE2tY0gxEAD1oFGUGsBgRIal5q?usp=sharing




HI All, This might be a vague question. What criteria do you use to select the correct features?
hello, I am a beginner in computer science and my project is: Identification of texts generated by artificial intelligence or by human beings.
I really don't have the qualities to reproduce it I need a mentor or someone to help me
please i really need help please
Hello everyone,
I have a question related to data science in general. In two words: I have a tabular dataset where target has exponential-like distribution, but from business point of view the most valuable is to predict correctly is right tail (higher than 95 percentile), because it brings about 90% of revenue, but values here sometimes are superhigh (like 10^9)
I wonder how to handle such situation, when you are interested in correct prediction for “outliers”, but don't really care much about the rest 95% of the data?
Currently I thought to train one regression model for cases below 95% and the second one for above 95%, plus classifier for outliers detection to choose the appropriate model.
Any suggestions, links or ideas are welcome.
Thanks a lot guys!
Has anyone worked on Deepfakes Detection, if yes reach out to me , need to discuss somethings
hi guys :), I wish to create a new collection with a same name as a collection that I deleted before. It keeps on giving me "collection with this name has already been created" (something similar) but I already deleted. Do I have to wait for the next reset (the same time as the GPU/TPU quota reset)? or is there anyway to solve it?
Sounds like it might be a bug on our end, we can check it out. I guess you should just use a slightly different name in the meantime.
alright thanks!
Does anyone know why excel would add curly brackets around a formula that was cut and pasted over several columns as an array?
I'm working on Regression with a Flood Prediction Dataset. I tried to submit predictions by ensembling Ridge Regression and LightGBM, but when I saved & ran the notebook, I encountered the error message 'Your notebook tried to allocate more memory than is available. It has restarted.' Could you please advise on how to resolve this issue?
I want to annotate my image like this one ( upper one is real and bottom one is annotated)

This is the image I want to annotate

How can I do ? What are the possible ways ?
@analog bearwell there's something called feature engineering, and use correlation according to the output "y", it will help you pick it up statistically.
@elder ferrythat's easy, search for something called tesseract. see it's feature, see it's tutorial, it might help you, it might not, but I assure it's something related to text
@glass violetwell there's 2 possibilites for this kinda situation
first you can delete and be off with it, because it messes up your data and it's average and median. (it also means that there's people have mistaken their numbers)
second, you can ISOLATE them, and treat them as a different case that you can make your entire data story on it (it might have a great deal or something)
either way, it's your job to see if it's a mistake, or a real deal that the company made alot of money off.
@iron lodgeif there's something, tell me, but here's a hint, use neural network and a lot of data(pictures of deepfakes) to be able to detect deepfakes, good luck
@crisp gustis that in kaggle?
@low elkhttps://stackoverflow.com/questions/62311260/your-notebook-tried-to-allocate-more-memory-than-is-available-it-has-restarted
Stack Overflow
I was getting started with TalkingData AdTracking, my first entry to Kaggle competitions. The first line was pd.read_csv() and I got this error
Your notebook tried to allocate more memory than is
@dull lagoonuse OpenCV library, I used it once in one of my project, but you can learn it and use it to change color and rotate, and also manipulate, technically anything
Can you drop a link - ( getting started for what I want to do )
@dull lagoonactually I don't have a link, but there's tons of tutorial on youtube, it's easy don't worry.
yup, at your work -> create ->new collection
putting a old collection's name will just give an error of "a name with this collection already exist" even though it has been deleted
@crisp gust weird. Jupyter notebook is always a choice
wdym?
I want to create a new collection to organize them
but its so weird, cause it some of it will have only 6 notebooks but having displaying 11 inside it
it keeps making me confused, (basically my OCD :P)
I saw one tutorial on yt
( https://youtu.be/UUP_omOSKuc?si=nLv3DL0BQBphyy_a )
But by following this video I was not able to do it perfectly like that sample image

The code snippet for this video can be downloaded from:
https://github.com/bnsreenu/python_for_microscopists/blob/master/Tips_tricks_27_labeling_images_for_sem_segm_using_label_studio.py
For other code available on my GitHub:
https://github.com/bnsreenu/python_for_microscopists
For labeling your images using Label Studio:
https://labelstud.i...
In this image printed text, hand written text is colored almost perfectly
@crisp gust for I don't know about kaggle stuff yet, I use jupyter as a main. So I can't help ya 😃😃
@dull lagoon I know, that's where you will start your search, as I told you openCV is really REALLY powerful tool when it comes to images, if you didn't find the thing you want in this tutorial try another, or learn everything about opencv, until you reach what you want
😌
Regarding the AIMO competition and the new api:
If I am submitting a copy of just this document: https://www.kaggle.com/code/ryanholbrook/aimo-submission-example for evaluation((via the button submit in the submit to competition frame), then test.csv does not have the 50 tests, but just the 3 standard examples. What am I doing wrong?
Would love to get your help. Thanks!

Explore and run machine learning code with Kaggle Notebooks | Using data from AI Mathematical Olympiad - Progress Prize 1
Thank you
if i have a column for storing yes/no status in sql, which one should i use?
Yes, No
YES, NO
1, 0
Y, N
Good day everyone, I was wondering something about the progression system, Do you have to complete each task in each category i.e. data, competitions,... or can you just choose one to rank up?
Like to rank up your account
Hello all, i was given the task of carrying out research on
“Analysis of Algorithms, specifically across Artificial Intelligence body of work: understanding applicable scenarios and performance considerations.
You should study algorithms that belong to the following classes: Machine Learning and sub classes such as Deep Learning, LLMs etc
For each of these models and algorithms identified within each descendant subclass, identify the following:
Algorithms and Use Cases (inclusive of performance analysis)
Weakness and associated use risks
Financial Services Applications
You are to come up with a detailed analysis and presentation ”
Can anyone point me to books, videos or research papers that would help me in achieving this task 🙏
Just one: "You’ve completed a significant body of work on Kaggle in one or more categories of expertise."
Hey,
I'm working on a recommendation algorithm for clothing products. I chose to go with a content based filtering approach. After much tinkering, I've decided to go with a pretrained vectorizer + autoencoder approach. Basically, Each product in the dataset consists of 5 distinct images (resized and normalised), a general description (100 tokens, padded if necessary), top 5 reviews (100 tokens each, padded if necessary). I plan to pass the images through resnet to obtain the embeddings and then concatenate the 5 embedding vectors to pass them through an autoencoder. Same for the text, except I use BERT to tokenize it. I then pass the two embedding vectors through another autoencoder (much denser) to obtain the final embedding, which I'll use to find similar embeddings in the vector space through cosine similarity.
I have not yet trained this model, but just wanted to get the opinions of an expert, if this is the right approach. Thank you for your time!
I have just started the journey of DS. Can I compete in the competition?
URGENT!!! Please Help!
hello @everyone, I get access to meta's Llama3-8b. But how do I get my access token? Any idea..Please help its urgent!!

Hi All, I'm a data science student currently creating a personal project and working in IT/automation, looking to learn new skills and expand my portfolio. Apart from competitions, how can I achieve this? I would love to contribute towards some projects and collaborate with others but I don't know how to begin doing that
I wanted help with using kaggle! Can anyone guide me!
Hello everyone, I would like to ask for advice on a chemistry project I am doing. It involves analysis of many electron microscopy images, which I don't want to measure by hand. Let me explain my procedure so far:
-
Use ImageJ (FOSS software) to extract image scale from metadata, then threshold the image (divide in foreground and background) and then by ImageJ's Analysis function measure the length, width, circularity etc. of every image (done via script in batch mode).
-
Load the results after some pre-processing into Kaggle, where I have a trained classifier to distinguish between the categories "rods" (elongated particles), "spheres" (round particles), and "trash" (agglomerated particles or defects due to irregular background, which confused the thresholding).
Here below is a picture illustrating the procedure:

This is a representative example picture, showing that at the level of thresholding, two problems occur:
-
The background is not removed reliably, as you can see in the area of the grey spot. Since the background is different in every picture and the pictures are sadly all done at different size scales, it can not be filtered out easily.
-
Some particles appear to be sticking together, despite touching only slightly or not touching at all in the original picture. I tried expansion and erosion, but it changed the size of some particles (which I want to measure), and I also tried watershed, but that is an algorithm intended for separation of round particles. Many of my rods are not evenly-coloured in the picture, and get "cut apart" by the watershed algorithm. Because I also want to measure the ratio of rods-to-spheres, this is inacceptable for my purposes.
My current approach is to discard all particles sticking together in analysis, which leaves me for some samples with not enough particles to make reliable statistics.
So my question in this context is:
How can Machine Learning /Computer Vision help me with the thresholding step to separate the particles which are close to each other?
@wild relic you can collaborate with me, the only problem is, I will not start now because I am completing a certain courses in feature engineering, you should start as well in machine learning and data analysis
@plucky vector see something called openCV library, see its courses and youtube videos, plus I used it once in one of my projects but I didn't use it later, but I believe it's a very powerful tool
@weary cairn kaggle as a whole or kaggle how to use it as notebook, please demon
Demonstrate
Like how and what exactly to do on kaggle how to level up as master and expert!
How to use notebook datasets etc! and how to earn medals! how to be better at data science using kaggle!
Thank you very much, I will look into it. 🙏 So far I got the recommendation to use U-Net, and played around with it a little.
I'm just worried that I will invest a lot of time into it to find out that it doesn't perform better than the good old automatic thresholding algorithm. 😕
@weary cairn well on the left side of kaggle you will see courses, click on it and you will have abundant of lessons, learn them and you make notebooks and projects that is special and you will be expert if you have done enough
Plus people should look to your notebook alot, so don't forget to share what you did
@plucky vector only way to find out is to compare, and if didn't get better results theirs always the the option of changing the parameters, putting more layers and looping always works
Ok thanks for the help bud
@weary cairn np
Thank you very much Ahmed, that's true. Then I'll dive into that... is opencv available on kaggle? I tried to install it yesterday evening in Anaconda and failed so far to make it useable in Spyder 😅
@plucky vector you need to install it first and then import it
@plucky vector I think theirs youtube videos explaining those
@plucky vector and you welcome
Hi, I am working on a project of extracting frames from class room lectures. My main focus is on extracting the frames when the whiteboard is full of text or figures drawn by the prof. So usecase is extracting the frames such that 1 hour long video can be summarized in 20-30 full board frames. I needed help related to this as I cannot figure out the full board scenarios. Advices will be really appreciated THANKS
@maiden sparrow very easy, try to make the picture into a complete dataframe, (their will be ALOT of columns and rows because the pixel itself is either from 0 to 255 according to color)
Gather the sums of the pixels in the white board, and gather the sums of the pixels in the full board, and compare
THEIRS another way
You can get an AI, (not very experienced at that) get a lot of data (example: pictures of a white board name True and pictures of full board named False)
1000 picture or 500 to make it accurate I think
Tensorflow I think can make that
How does the whiteboard get blank in between? If it is wiped by hand, you can detect that and extract the last frame before cleaning. If it's some kind of digital, then the average of the whiteboard will go from grey to white, and you could also detect that and take a snapshot at this moment.
Hey all. I am working on a model for a task. It is a handwriting recognition classification model but I am having issues with the accuracy score. I need to make comparisons, which in my case I am using KNN, Bayes and CNN. I have to include KNN and Bayes. I have been sitting on this thing for 2 weeks and I feel like my brain is becoming more smooth by the minute. If anyone could please help, I don't mind DM's if you require more info.
Thank you in advanced
@grizzled cargofirst of all, do you have enough data of the classes of the handwriting, and even if you have enough data, is that for a particular student, or you are asking about the general handwriting, like the French and British handwriting for the 18th and 17th.
can you please let me see the training data and the names on it
Hello all,
I am reading the book Approaching Any ML Problem and I am at the section where he is talking about One-Hot encoding. I am a bit confused about the order of splitting and fitting the encoder. According to the book, it is okay to fit the encoder on full_data that comprises of both df_train and df_valid, but I can't quite digest it. Won't it lead to some form of data contamination and ultimately misleading results? It would be great if someone could clear this tiny thing for me.
Here is the actual code (Pg-110)
# get training data using folds
df_train = df[df.kfold != fold].reset_index(drop=True)
# get validation data using folds
df_valid = df[df.kfold == fold].reset_index(drop=True)
# initialize OneHotEncoder from scikit-learn
ohe = preprocessing.OneHotEncoder()
# fit ohe on training + validation features
full_data = pd.concat(
[df_train[features], df_valid[features]],
axis=0
)
ohe.fit(full_data[features])
# transform training data
x_train = ohe.transform(df_train[features])
# transform validation data
x_valid = ohe.transform(df_valid[features])
oh I think I realise why he'd do that
let's say that there is categorical feature f1 that has attributes ['a1', 'a2', 'a3'], and by sheer luck I did not get a1 in my training set. the one hot encoder in that case would not be able to process a1 when it sees that during validation phase
@tulip tangleeasy, that's because in preprocessing, you need the machine learning module to see hot encoders as a way to understand the categorical data, that needs to be in the test AND train. why?
Because the predictions and the test data needs to be the same kind of numbers not categorical with names. So you can compare
right, thanks
Hello
I am not getting the sms for verification code to participate in some competitions
Can anyone help regarding this matter?
Hello everyone, I am working on a data mining project.
I want to find the best model that can estimate the class of the response column.
I got training dataset with response column and test dataset without response column.
I engineered the data by introducing dummy variables to express categorical data, log-transform data with high variance, and made new columns by adding two related columns.
Also, I used RandomizedSearchCV with RandomForest to find the model with highest CV accuracy.
These questions arose during the process:
- How do I determine which columns need log-transformation, and is it better to drop the original columns after applying the log-transformation or keep them?
- What are some effective feature selection methods, and how can I determine which columns to apply them to? Similar to question 1, should I keep the original columns after feature selection?
- I've used GridSearchCV and RandomizedSearchCV, but I find it challenging to decide the types and ranges of parameters to change. What is the most effective way to find a well-predicting model?
Despite these questions, I just want to find a model with high accuracy. Any help would be greatly appreciated.
Hi, Guys, I'm new in the field and started doing some kaggle competetions.
I wanted to know how the team works in a competetion or a project like even in a team I only worked by myself as were the others.
For question 2, our lecturer told us about Principal Component Analyis (PCA), and I believe there is some lesson on it on kaggle, too. It can help to reduce the dimensions.
@vague onyx 1-after you apply your the dummies transformation yes you should delete the columns origins and keep the ones after transformation, beware naming matters
2- everything can be a feature the thing is, what is the most logical and sensible one, that's why asking people in the field is very crucial, also you can use correlation and heat map to find how strong the relation of the feature to the response.
3- for loop, you can make a function of that to change the parameters until you have high accuracy, I know that gridsearch is doing that, the thing is it takes time, so the best way is to put very low value, medium value and very high value, like if you want to change the depth of the random forest it will be like this [10, 100, 1000]
AFTER you get which value is having the higher accuracy (for example 100) you will expand your micro and it will be more like [80,90,100,110, etc]
And then you will do stop at the highest accuracy and you will get into the next parameter
This way it will not burn your pc
Repeat in the steps in the next parameter
is there any way to test a kaggle agent before is submit it. I submit it but nothing happends
Hii everyone!
I am currently working on semantic chunking of a youtube video and have a problem with time align transcript. Can anyone please help with this
@analog skiffthat's new, time aligh transcript, hmmmm, explain more
I have got this task to do semantic chunking of a YouTube video. So the process for semantic chunking that was provided to me contain to first download the video then extract its audio and transcript. After that we have to time-align this transcript with audio means to get the transcript for certain amount of time. Then followed by semantic chunking where I have to form its chunk id, chunk_length, text, start_time, end_time. @sterile cliff
@analog skiff damm, it's really related to unsupervised learning, it will take time to revise all of that, damm
In other words, I will try and find something related to your problem but it will take time for me and there's no guarantee I will have the answer
That's not a problem.. thank you 😊
Hi everyone, how can I achieve constant time intervals? I'm working with a stock values dataset, so I would like to know what would be the appropiate take 🫡

@spring plumeso you want everything to be 1 day?
yes
interpolate the values in between
i forward filled
Total beginner, doing the python loops and list comprehension exercise, and I was wondering why my code isnt working. I added comments showing how I think it should work, but I feel like I am missing something basic since I am getting outputs that are way off.
Here is what the functional call resulted in, I dont get why we need to subtract 1 from it.

Because of the $1 expense of each play
Wow, I totally glossed over that, thanks!
Hey guys. A beginner in ML, I went through some ML courses, and got some basic hands-on practice on Kaggle, got some experience with NumPy, Pandas & basic algorithms.
Now going through a Deep Learning course and got to the point where I need to choose a framework and get my hands dirty with it.
So, the main question is, which should I choose? Tensorflow or PyTorch?
Mainly looking to build, not to research. And main priority is to get into the AI market asap, and so as I understand there is more demand for Tensorflow?
does anyone know how to do gradient ascent in pytorch?
Does anyone know why I cannot submit my notebook?

"Internet access" is a setting inside notebooks that lets your code environment access resources online. This competition does not allow internet access for solutions so you need to turn off the setting before submitting.
Thank you
Can the model XGBClassifier handle the Class imbalance problem on it's own? without me doing the scaler? Here a model I just made, Could I kindly ask you for feedback in the comment section? https://www.kaggle.com/code/mohamedlazaar2/basic-xgbclassifier

Explore and run machine learning code with Kaggle Notebooks | Using data from ICR - Identifying Age-Related Conditions
Hello, Can anyone please tell how many hours a week is a Fellow expected to work for 15 weeks in the KaggleX Fellowship Program?
suggest LLM projects from beginner level to advanced level, i really want to get good at this domain
guys i was trying to use w-okada voice changer with ngrok on kaggle but theres a issue
https://media.discordapp.net/attachments/1234245771906388079/1246803766997553213/image.png?ex=665db7fe&is=665c667e&hm=f689895bf924311e7c765ddcdfd0527132ef86abf6e643267ff00cde8fde2bad&=&format=webp&quality=lossless&width=1080&height=440
https://media.discordapp.net/attachments/1234245771906388079/1246803845888081961/image.png?ex=665db811&is=665c6691&hm=6a4794ece90033f18c5604e8add66d63ba2d5f1a9f060ee3826c086c61cd978e&=&format=webp&quality=lossless&width=1080&height=297
/kaggle/working
WARNING: Error parsing requirements for aiohttp: [Errno 2] No such file or directory: '/opt/conda/lib/python3.10/site-packages/aiohttp-3.9.1.dist-info/METADATA'
/kaggle/working/Hmod
{kind=link}
{kind=link}



Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
but idk theres a few error and i didnt use
can someone help me how to fix or is it kaggle issue
i tried runnigng this notebook , and it worked for me

are you trying to do it locally on jupyter notebook ?
jupyter
notebook
didnt get this how to use
then you should provide local path instead of kaggle path
well i just
open kaggle and create notebook
Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
and i pasted these cells code
and install the pyngrok module as well
and i run
it should run on kaggle as it is

yellow text is
WARNING: Error parsing requirements for aiohttp: [Errno 2] No such file or directory: '/opt/conda/lib/python3.10/site-packages/aiohttp-3.9.1.dist-info/METADATA'
/kaggle/working/Hmod
but it is warning , not error right ?
it worked right of the bat for me , i didn't change a thing.
just ran the notebook as it is, what's the problem of error you are facing on kaggle notebook ?

only it says
i just copied whole things

its locally right ?
and runned code cells
!pip install pyngrok
and change the path as your local path
you can't use kaggle path in your local jupyter notebook
not local i didnt download anything local
i downloaded notebook w-okada voice changer and ill use via ngrok
But you are using a jupyter notebook right ?
i really dont understand
im telling i just create new notebook and copied this cells all of them and i run code cells by one
That's what I'm asking , jupyter notebook, not kaggle notebook
oh
let me check
is it kaggle or jupyter?

Kaggle

okey i fixed
somehow
{kind=link}

but i just got this error when i upload a model
is it possible to upload a file here

in model_dir folder
Yes
how
i just didnt verify my phone xd
i need to upload my model but
it gaves error
when i was use collab i can upload my model through model dir folder in drive folders
i just need to upload there
in model_dir folder
So you want to upload your model weights in a kaggle notebook
actually
w-okada folder
how can i say
i cant upload my model to w-okada