#Upcoming models speculation
1260 messages · Page 2 of 2 (latest)
labs probably quantize their models and make them more efficient over time which can change the results of certain workflows
they quantize it 2 week after release, like a tradition
but those are just maintenance changes
Inference bugs probably happen here and there
that too
yeah the quant stuff is what im sure of
Them quantizing/subtly optimizing over time is plausible, but you'd think this would be somehow measurable
one after the two week of benchmark, one before new model release
Surely when a model comes out, someone could set temp to 0, make an array of requests, save the responses, and then do the same over time to see if anything actually changed. If the temp and other params are identical the responses should be the same
Temp 0 does not guarantee deterministic outputs
nobody measures the model benchmark overtime, it is costly.
we can’t really get actual proof proof unless it’s from an actual insider
Other things that could change are hidden system prompts and safety guardrail stuff that gets tweaked
those change all the time tbf
for direct API access it's less common though
you usually get pretty full control of the model besides safety stuff
NDA and sacrificed first born
only anthropic been scummy with these
Doesn't even need to be an expensive bench
they actually tightened their safety stuff on 3.1 pro at one point
lots of false flag filtering popped up suddenly out of nowhere
i mean one prime example of a model changing after release was when 4o became even more of a sycophant than usual
you could tell if you use 3.1 on vertex compared to AI studio
so labs definitely do change the weights every now and then
I did have a period where Nano Banana 2 (over API) had a lot of random refusals for harmless stuff for a day or two before going back to normal
So I think that was some backend guardrail stuff at work
ye that’s what im on about
they were definitely tweaking stuff behind the scenes
first time seeing, either not popular or skill issue on my part. interesting stuff, shows things spikey but overall the same... i don't somehow believe or maybe need better testing.

that is the classifier model not the main model
previously models used to get quiet incremental updates based on date but keep their 'brand name', now they get .1 .2 .3 .4....
no way to know for sure if those .1 .2 etc. versions are getting quiet updates or not
i reckon it's just small things like quants and maintenance, but it's still possible for a model to be changed under the hood without users knowing
wouldnt put it past them theyre not exactly the most transparent companies lol
Thank you for sharing this.
gpt 5.5 is new pretraining, they say
gemini 3.5 flash pricing on docs
https://cloud.google.com/gemini-enterprise-agent-platform/generative-ai/pricing#standard

it WILL be 1.5/9 unfortunately
well that's pretty fucking expensive for flash
I guess pro will be no less than $3/$20
It’s time for Google I/O!
︀︀
︀︀✧ 10:00AM - Keynote
︀︀✧ 1:30PM - Developer Keynote
︀︀✧ 3:30PM - What’s new in Google AI
︀︀✧ 4:30PM - Scale the builder ecosystem with @GoogleDeepMind and @Antigravity
︀︀
︀︀Times in PT.
︀︀x.com/i/events/2053241348807864323
Hi, Google, I live in Mars and would like the non-global pricing, thanks
I'm sure it's really good and everything but 1.5/9 for a Flash model is a yikes
I thought the TPUs were supposed to be magical devices that made model go fast for cheaper
"tokenmaxxing" haha
probably will be out when announced on I/O

omnibanana...


why are they bragging about doublign token usage
"our processes keep getting less token efficient"
okay I'm not watching this guy yap about antigravity. Someone post here if they do anything else interesting
idk hes kinda persuading me to try it
ong
if I can have that as a cli where I can open the app too sometimes if I feel like it, I think I'de swap to it.
Damn

swe-bench result is an outlier
gemini 3.5 pro next month
40% in HLE for a fast model is rad
pichai says
also that's a crazy jump in GDPval
gpt 5.5 fucking strong man
its not abt that
its trying to show shareholders that their product is growing and popular
basically "look at this big number"
"we have big number so buy stock"
yeah ik why but it's a pretty dumb way to say it
and would make me suspicious about if 3.5 flash is an overthinker
ngl google i/o is so fuckin stupid to watch
they will make the most mundane claim ever
yeah
oh my god this script is so bad
most liekly

(well not a scam really but you know, misleading branding)
the wonders of vibe-coding
how's with 3.5 model
the speed is very noticeable
it did regressed than other frontier models but its miles better than 3 flash
Flash Lite 3.5 when
I want my Flash 3 back
Sweeps loss of generalist ability, drastically reduced world knowledge and worse reasoning in name of task-specific and agentic training under the rug



https://fixupx.com/NVIDIAAI/status/2058238271738855742
nemotron 500B?
↩ (@TheAhmadOsman)
@TheAhmadOsman 👀 "Ultra" ⏳️
I had a dream deepseek and Kimi both release 59a3b models, does that count
whatever tbh
nemotron models are so damn dogshit
and theyre SUPER unstable
as in, cant rely on them answering in a specific format, sometimes they start reasoning in the output block, sometimes just random fucking characters or whtaever, structured outputs dont even think abt it, etc.
I think your leather jacket simply isn't enough of a winner to appreciate them
🥀
like i find it crazy that xiaomi is able to come onto the scene with such a good model to begin with (mimo v2 flash)
compared to a giant like damn nvidia themselves and they cant do something even ok
Going to burn through the quota like there's no tomorrow
Yeah, I knew they had something special with V2. It was smol and had some issues, but it felt so unique and fresh to me. Wow'd me with some of its insights
And then basically one release later and it's the top benching open model
Not that it's some mom-and-pop company, but still a wild intro to the scene
Didn't they hire someone from deepseek
prolly dream logic but honestly that fits weirdly well

new attention mechanism aswell, seemingly quite similar to deepseek's DSA but with chunks instead of individual tokens

im kinda just sitting here waiting for kimi and glm to do something
been a while since they released something good
kimi teased a long time ago a 1T param model with KDA
somewhere in a paper
so i wonder when that will come out
ohh bet
oh shit msa
Claude Opus 4.8 is coming next week
Kimi doesn't release super often I expect they'll drop K3 in like a couple months
deepseek v5 tomorrow
We might get Minimax-M3 with sparse attention: https://x.com/SkylerMiao7/status/2059285750458544561
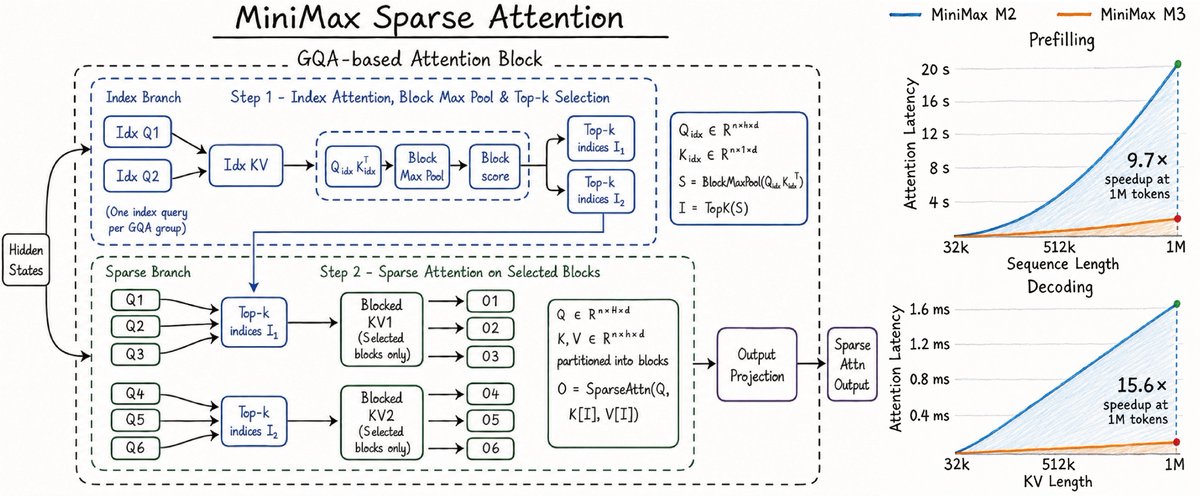
100T parameter model (ultra sparse with 1m parameters active per token) and 1b token context window
1m active per token gonna be so ass
at least 100B pertoken
it gets 100% on every benchmark
it’s literally asi
when being tested in a benchmark it identified a use after free memory vulnerability in the answer parser, which it then used to gain arbitrary code execution and change every other models score to 0
Opus 4.8 has been found staged in the claude code model selector on the desktop app. It should be releasing today! lets gooooooo

Deepseek 4.8 today
Haiku 3.5 today
release 4.8 already im tired of using 4.6/4.7 on my plan 

ok

this should be good. i'm very curious to see if they've noticed the criticisms of 4.7 and being mogged by sama. gpt 5.5 is just so good, for those who are skilled enough to weaponize its autism
just when I downgraded my sub that should renew tomorrow 😂
JUST IN: Anthropic announces it will roll out Claude Mythos “in the coming weeks” despite growing fears over the model’s cyber capabilities.
by the end of june we should expect:
- claude mythos (or at least mythos-class)
- gemini 3.5 pro
- minimax m3
- gpt 5.6 (probably likely considering opus 4.8 just dropped and oai will need to respond)
- new kimi or glm drop?
top two are confirmed, minimax m3 is confirmed soon but no date, last two are mainly speculation
gpt 5.6 would be goated
Step 3.6
Mimo v2.6
Hopefully qwen 3.7 open models
mimo v2.6 would be nice to see
especially if pricing stays the same
qwen models piss me off because of how expensive they are through api for such small models
just soon, but we dont know the date
i wonder what gpt 6 will be, what will it do differently, probably in the last few months of the year
they said in a reply 'several days' hope that means next week
Top models are all closed rn
Someone needs to do something
Moonshot I'm looking at you
Kimi k3 fr
kimi is still mogging grok and muse spark

K3 is going to mog opus
lol
i pray for deepseek 4.1
04:50 PM EDT, 05/28/2026 (MT Newswires) -- (Updates with the company's response in the fourth paragraph.)
Microsoft (MSFT) is slated to release a suite of new homegrown AI models next week at its annual Build conference in San Francisco, The Information reported Thursday.
The company will unveil a coding model aimed at boosting the competitiveness of Microsoft-owned GitHub Copilot, the report said, adding that it also plans to introduce new models specialized in tasks such as transcription, reasoning, speech, and image processing.
The new suite of models will build on earlier homegrown models that Microsoft previewed earlier this year, according to the news outlet.
microsoft models have always been quite trash unfortunately
i would be surprised if something actually changed
also hoping to see meta release something actually competitive sometime soon, if muse spark ever even gets api access
maybe but imagine if they released something like grok fast at a low price
they have some skill, phi is a remarkable model series, but they haven't proven themselves with frontier coding models
which is fascinating considering they own Github. i think they have a lot of data, but whether they are able to pull it off is another
Phi is not remarkable at all lol
It is so clearly benchmaxxed
I tried using Phi ages ago and it just felt off - it's a shame coz I really appreciated it's low file size for local deployment.
Would be nice if Phi improves and gets better
they really should take the opportunity to make decent cheaper coding models given they have github and all the data they have
mai image 2.5 is decent but meh, it feels so unfinished, text to image only, limited to default 1:1 DALL-E resolution
I don't think microsoft's genai division isn't yet mature compared to google and openai, they only had 2 years to develop in house models, clearly its half baked
they did had finetunes and modified versions of gpt4 before, but thats based on existing openai tech, not something they trained from scratch, and if they trained something from scratch its ends up being horrible, phi models were not good compared to gemma and qwen
but I'm still doubtful how ms is gonna pull this off, and with mustafa involved I'm also doubtful considering the fact he did say he's fine being behind at frontier for approximately 6 months, but if model performance is a compromise then I'm not going to use it, their text model is not so great not something they should celebrate
what do we want?
DEEPSHMEEK V4!
when do we want it?
uh... about RIGHT NOW!
how do we want it?
UNREASONABLY CHEAP CONSIDERING INFERENCE COSTS
MiniMax is currently conducting internal CKPT testing for M3, a multimodal, long-context model
︀︀
︀︀The team is also resolving pipeline issues and upgrading its infrastructure
︀︀
︀︀In the next few days, they plan to provide CKPT/API access for developers in the open-source community to evaluate the model
Quoting Jiayuan (JY) Zhang (@jiayuan_jy)
︀
MiniMax M3 即将发布,想邀请一些中文开源社区的 contributor 来评测,阿岛 @SkylerMiao7 建了一个飞书群,可以第一时间体验到!
︀︀
︀︀另外希望申请者有一些开源项目的贡献经验(贡献过开源项目或者有自己的开源项目),在验证信息里面注明就行。

Ok now this is interesting

lmao i was a bit wrong MS falls significantly behind e.g. image gen
turns out they have image editing hidden
guess we'll have to see - have never used any of their models but I'm curious about their transcribe and voice models
I only tried their image models
not bad but its just so limited
being behind gpt image 2 and nano banana pro is kinda DoA at this point
ive been a fan of bing chat back then but ever since 2024, things went downhill for MS, even worse in 2025
Same. really liked the early days when Bing made google abit scared.
google fumbled a ton lol
given they're a search company after all
they had this called Prometheus baked into their custom gpt model in bing chat, which i find bing to be most used for every queries I gave than bard or chatgpt
and uhh, they kinda blew it ever since mustafa took over, and google rising
I'm curious to see what their in house coding model would perform, of course if its not going to be a chatbot code model though :/ where its just optimized for open file context and qa
they have like the leverage... github copilot data, cost efficient compute if they learned something that openai models are expensive to run on azure
oh wow that's very insightful of you. I agree it's still unclear. They've been releasing Phi but they've been poor on being positioning it well amongst other models in the market. Seems like there's an upcoming release coming up so we'll have to wait and see. I'm keen to know how they'll position themselves in the current climate.
i dont think phi is supposed to be sota, its a small model after all, and hasnt been updated ever since
i think the last update was 2025
so its not competitive to gemma, which google kinda leads in edge / local AI right now
yeah agree I love Gemma 4 - running on locally and it's been my go to for very simple tasks that I need to clear for work.
im still waiting what MSbuild has to offer
with ms cancelling claude code subs internally, changing gh copilot pricing model... they really should offer cost effective code model at this point that should be as good, and not some code chat model that barely does anything
it's coming soon - so I guess we'll find out. Here's hoping they shake things up abit.

Gpt5.6 when
GPT5.6 when
agi when

{kind=link}