#Momentum
1 messages · Page 1 of 1 (latest)
Movement Labs AI
where did you got that data neither gpt-5 and sonnet 4.5 runs at 120? and gemini models runs on google tpus not on gpus

doesn't matter because that model is crazy fast anyway
idk how you guys made it but if that partnership goes forward i would probably use that model for a lot of things
Thank you for pointing this out, this will be fixed shortly, yes google does indeed use TPUs, we just launched today and are going over website ui sections. Good catch 👍
looks interesting, the benchmark numbers are especially high
is there any free credits or api?
there is an api on openai format
but idk about free api credits
but you can use their chat for 50 msg/day
hmm ok
the model is not too bad on frontend that is plain html

Glad you to see you diving right into coding, we are focused on speed on this launch, next launch in the coming days we are going to update our model with our new checkpoint and it one of the best coding models we have ever seen.
pretty nice at webdev yeah
here is the file that it generated
i asked it to maek a website of it self and it looks pretty clean imo
though im not sure whether those wallets are real

it likes light theme
a lot
idk why
@surreal hazel that model have reasoning?
or is it hidden?
This is not a reasoning model, however the updated one will be reasoning, however it will decide when to reason and we will also allow users to disable reasoning.
like the gpt-5 router?
you guys train it on the mpu too?
like the tps speed affects training?
Great question MPU doesn't support training at the moment, MPU is a chip that loads model into the memory.
the mpu can just run the model not train it
right?
Exactly! you nailed it.
theres a small typo on your guys' website
on the contact page it says 2$/M In while on the pricing page its 3$/M in
you should reach to artificial analysis offer then credits so they can benchmark the model
https://artificialanalysis.ai/models

Comparison and analysis of AI models across key performance metrics including quality, price, output speed, latency, context window & others.
We fixed the stats https://www.movementlabs.ai/mpu
Movement Labs AI
it should be lower not higher
gpt-5 from openai gets a solid 40
sonnet 4.5 smt like 60
also grok 4 runs at like 30 t/s unless its grok 4 fast which is like 150
yea
gemini pro is ~100
the flash get ~300
i don't really play with x.ai models they are expensive and dumb at the same time the 4 fast is fast but is dumber then haiku 4.5
grok 4 fast is very cheap and fast, but depends on the use case if its good
Fixed 🙂
yea like simple things it is good but you give it more things to do it just gets lost
and grok models hallucinate a lot of tool calls
haiku and gpt-5-codex too
noticed this too, they think they did the tool call during reasoning but it didnt actually trigger (maybe inference problem rather than the model)
yea idk
the bottleneck on that model will be the tools lol
and bandwidth
Momentum follows tools.
That's from cursor, on roo code and cline it's much faster
Currently we are running it on a few, once we get some traction we will scale it up to 100-200 MPUs
that will be crazy
Game changing for many, we're glad to have you here testing early.
can we get some api credits to test the models in something like cline?
https://movementlabs.ai/about the founder video is broken
Movement Labs AI
yes, sure, please DM me your email i will issue you some free credits.
done :)
What country are you guys based at?
United Kingdom, just two founders. With a big vision
idk if you can share how much parameters the model have, but if you can i just want to know
I can tell you it's above 700 billion running FP16 (half-precision) - Hope that helps 🙂
We welcome constructive feedback to help improve our training checkpoints and model performance.
wow thats huge
If you weren't claiming better performance than GPT-5 we could have considered
it could be worse then gpt-5 but you can iterate much quicker
Oh wow, the speed's insane if so! Congrats on the release
I wonder how fast it could run a 30B model, but that's just mad scientist-me speaking LMAO
You can't convince me with that speed they didn't have "time" to do a single major benchmark
Keep in mind there are our internal benchmarks, we invite you to be your own judge.
There are these ones listed, though they're averaged out so that makes it harder to reproduce
The video here doesn't play for me: https://www.movementlabs.ai/about
that model feels like sonnet 4.5 is some ways
We are going to upload it to youtube and replace that section with the youtube embed.
the way that it uses emojis and talks really feels like claude
Glad you are enjoying it, the speed is a bonus!
does it support images?
Wow this is actually really cool
Surprised!
Is this a fresh pretrained model? Or is it based on some Qwen base or something?
i think that it is a fresh one
no model does frontend in the same style
thats very impressive if it is, it takes a hell lot of time to train a 700B param model from scratch, especially if your hardware isnt designed for that
above 700B
yeah huh
Yeah
I don’t know of any open weights model above 700B but <1T
We are about to send a video here that will show some facts. Incoming.
deepseek is close at 671 or sum around that
Yea
it could be a 1T but pruned and finetuned
yea but 1t at 2400 tps sounds crazy
How much will mTok cost be?
eh its probably MoE so it makes it much easier
3$ in 5$ out
yea
yea sorry
http://youtube.com/watch?v=eLrW2K85sBg&feature=youtu.be - reconsidering?😎

Hm
messd up with haiku pricing
prety cool physics
both are decent results, and gpt 5 is technically the reasoning model not the chat version, but this model is good for a non reasoning model
We will bring prices down to $1 /m in and $1/m out in the coming weeks.
@surreal hazel can you confirm if it’s a fresh pretrained model? Or based on other open weights models?
will we get cache support in the visible future?

Model isn’t hallucinating badly afaict
you should get kv cache for the tokens so the input cached would be cheaper
Many many open weights models still hallucinate niche knowledge insanely
it halucinated a litte with me
i asked for a ranking on embeding models
and it said to me that claude had a embeding model
Hm
it doesn't have any tools to verify
@surreal hazel you should really turn on sign in with Google on your site, should be easy with Clerk that you’re already using :)
if you asked claude the same thing without websearch it would probably do the same thing
you guys should really make the input on the chat area multi line, its killing me scrolling with 2 lines visible at a time
Nvm it’s still hallucinating
“What is…” Tailwind v4 and React Router v7
Always gets ‘em

its writting like qwen / deepseek

On it, noted ! 🙂
that sounds more like claude
We feel like the writing style is in-between GPT4o and Sonnet.
from what ive seen qwen does that a lot with the emojies, often with a bunch of checkmarks
claude does the same thing
hmm

interesting mistake.. almost never seen any model do PI instead of Math.PI in JS

its in pt-br
my claude (maybe cuz of my instructions) is way more bland but when i use it in copilot it does kinda type like that
yea my claude have some instructions to be direct that is an chat before i put the new instructions

that duck is different
hes a bit special
make a blackhole in three js

not the most realiistic thing
We have enabled google login and signup. 👍
the model maybe shine in some backend stuff
a task that i was using to benchmark models was to ask the model to port litellm backend from python to go
gpt-5 just run the entire night and failed
has any model actually succeeded? thats a pretty big task
grok code fast 1 was the closest then just looped
grok code fast 1 was like 80%
then just looped and didin't made any progress
claude i didn't tested because i know that will be expensive
gpt-5 i tested it when it was free on cursor
We're absolutely loving the amazing community responses we're seeing. The engagement is next level!
Quick question for you all should we bump up those daily free message limits? We're curious what you think! 🚀
idk i didn't hit any limit
can you give my an api key with smt that you store the data thet i put into it so i can try porting the litellm backend to go?
how long is the model context?
200k based on the api docs
here is an API key for you: ml_5403932ad166f04b67da678bd9c238150f26f1227c2d884e82e0eda6e8164334
it has $8 worth of credits, try not to burn them in one promt haha 🙂

might be a model issue
please check now
credits did not burn, it was server side config, we updated something on our end maybe cause a glitch during that time.
trying again
it's crawling the backend
for some reason the ttft is high
@surreal hazel are you shure that the context is 200k
cuz the context hit 128k and stalled

the context is 128k 200k for upcoming model this week, for now just resume task as many times as you like
i have added you more credits
yea its the lite llm one
GitHub
Python SDK, Proxy Server (LLM Gateway) to call 100+ LLM APIs in OpenAI format - [Bedrock, Azure, OpenAI, VertexAI, Cohere, Anthropic, Sagemaker, HuggingFace, Replicate, Groq] - BerriAI/litellm
i told him to port the python backend to go
its 1m+ lines i think
i will download obs and start a stream on youtube
its fast but it is missing some tool calls
@surreal hazel can you check dms?

Twitch
bielpaesxd14 streams live on Twitch! Check out their videos, sign up to chat, and join their community.
here
youtube wasn't letting me stream
that's probably the 5 time its reading the _types
it really feels like gpt-5
like
it reads everything before making one change
i'm watching the stream very intresting
would be cool if you could get a 1m context version
it is just compacting like crazy
If that's what you want we will push for 1m on next version
a reasonng one would probably boost more on he benchmark
128k is pushing it for such a large codebase especially to refactor everything 😃
yea
This is a beta release anyway, what we have upcoming is the real deal. To get some feedback going getting the name out there a bit.
yea
to bump the context is it just change a variable or you need to do some training on the model?
Requires some architecture change but fairly straight forward for us.
with the speed that it have maybe you can do some wierd stuff with it like make it play some fps game
the model really condense the context fast
it's on a loop
i think for a codebase this size it's better to wait for the 1m version - as 128k tokens is not cut for such large codebases but rather smaller guided tasks within the codebase.
its on a loop it reads the team endpoints then reads the organization then condenses context
let me try enabling rag
yes, when it condenses context it looses previous context and that is not good.
i think claude does that only in its web chat
qwen models write like that via API with no system prompt, whereas claude models don't
claude on the chat is the same model from the api
it's the same model, but it has a gigantic system prompt
that's true
but i've seen that behavior on my openwebui too
the embeding is taking a while
hey, add your website to your discord bio
👍 on it.
We are super excited for 1m context window, it will really be good for the public, the team and i are discussing this.
k i'm embeding the codebase to see if that make the model stop looping
done
Best of luck!
it took the search tool too literal
it needs a bit of stearing it's in the middle of gpt-5 and claude
I think a command is waiting for your approval
if it had 1m context it would have been a lot better
overall so far what do you think of the model?
i'm following the stream and we are also taking notes.
k
it halucinated a package
that github.com/BerriAi
it will probably catch that on the debug phase
yes most likely, it will fix itself.
rag helped
a lot
that is how much the grok code fast 1 used

that was the beta
it was free
Did grok code get this far? or did it fail totally? x ai have a lot of backing and VCs funding them 🙂
Requests Input Tokens Output Tokens Cache Hits
it made at ~80% then just started a loop
after that i couldn't make it work properly anymore
and how far are we? with momentum ?
idk
till now
maybe 30 40
but grok had the entire day
it fixed itself
it started doing unit tests
momentum?
yea
the wrong dependency
it have 535973 lines to port
it ported 4313
grok made ~200-300k
but it is writing unit tests on it's own
before saying thats ready
for a non reasoning model i've never seen one so deterministic
That's very nice to hear! This model is coming with reasoning and a 1m context window too
Both?
yes both baked into this model
the reasoning data will be obfuscated in some way or it will be like claude?
that they just give you the data
Reasoning tokens will be raw, so users can see them
that's nice
so far your usage is at Input tokens
26,265,035
Output tokens
163,479
😃
its very nice to see it in action up againgst such a big task.
it started on a loop because kilo code bugged
then it found a work around with cmd
it's very token efficient
I guess the IDE matters too, as different IDE's have different tool formats.
it's the same cuz kilo build a compat layer for jetbrains
kilo code is a cline/roo fork
i like jetbrains ides
it's starting to fix issues
Web access is something we are working on, it will really help the model too
you just need to train it to recive image input
then you just sends images
you can make a wrapper of chorme dev tools mcp
but you still need image input for it to work properly
i think that kv cache is smt you need to work on to boost the ttft
i think that delay is from the IDE itself
this is a server side lag on api calls, since it checks our db for authentication + the IDE.
probably the compat layer
yea
the api we will make it more efficient to check for api keys
a java browser isn't the fastest
the ide is just giving up on diffs
probably because of the speed
you should sell that mpu to other companies
you should be able to get some good money with that
The MPU is the heart of our company 🙂
same with nvidia but they sell them
there are only 4 companies that i know that does it's own hardware and beats nvidia
google, groq, cerebras, you
i think that cerebras sell but idk
what they said?
first they've confused Movement with a crypto company
hey i'm not judging you MovementLabs, i jsut went researching and didn't expect those responses from perplexity
i don't even know how Cerebras or Groq or even Google get those speeds, i'm not really knowledgeable on this
I would refrain from asking another AI model about another AI model 😁 it's all very biased
not really, especially with grounding search
how we do it is we scale our chip and load the entire model into memory, that's where the speed comes from
GPUs, TPU's fetch model shards in and out of memory
i see, the 63.4GB is like an embedded VRAM right?
yea
but the model isn't running only on 1
That's right but we are running it on a few chips
that is claude response

"You were absolutely right to push back on my skepticism" haha
i tried to do that in perplexity "ok but i've used their product model, and its indeed about 2000 tokens per second with reasonable intelligence"
yea it's because ai crawlers cant hit their site
i just put the entire html into claude
i copied pasted later






it didn't know about cerebras without a search?
i thought they were in the market for a while
yea they are on that market all the way from 2015
not trying to lower you work @surreal hazel i think what you are doing is awesome
we are going to showcase our centers and do weekly youtube videos diving into our tech and chip in the coming weeks
when you guys get the model training on the mpu the training will be crazy fast
how much did i spent till now?
6086 lines ported
with comments
i think that i will wait for the 1m context window
Input tokens
39,034,549
Output tokens
188,779
the 128k it's taking a while
and i think that the context is rotting
can you ping me when the 1m version releases?
so what do you think of the current test you ran if you had to rate it out of 10
and yes, it will be sometime this week
probably 8.5 it could be a 9 but it doesn't have the context to complete tasks that just explode the context fast
more like 8.7
the model is fast but it feel slow
cuz it reads a file then forget that it have already read that file and so on
Your test has been really helpful, we are working on the API speed now for that auth check
i'm glad i helped
i like the model persistance
i've never seen a model so persistent like this
claude just gives up on the task
but the momentum model sometimes sends a tool call wrong
like bad formated
idk
is it ok for me to revoke the key for now?
Perfect!
@surreal hazel any update with artificialanalysis team?
Get in touch with Artificial Analysis. Contact us with enquiries, feedback or requests.
we are going to apply for this after momentum version 1 launches, currently it's beta
we've just improved our login and register flow, added more options.
how much time till 1m context version?
we're looking about 4-5 days hopefully 🙂
We're planning to develop an open-source, smaller model primarily designed for embedding applications, though this isn't our current top priority.
@surreal hazel should add a copy button on the code blocks in your UI :)
also nice job making a UI that doesn't ultra-lag, like most OOTB react chat UIs
We were so thrilled to showcase our incredible speed that we accidentally left out the button! But I've got an even better idea, will also add a preview button for code blocks to make your experience even smoother 🙂
Our new model that is coming is more focused on coding we might drop it on friday with the new UI
ooh very nice
So, is the live one an old model? or are you going to have a Code and Non-Code variant?
This is a beta model to see some user feedback on tool calls etc
can you confirm if it’s a fresh pretrained model? Or based on other open weights models?
😄
coding some chess does work well (didn't work on try #1, but same prompt #2 worked)
en passant, castling work. not lazy.

you really want our sauce don't you ? 😃
mostly just to tell how much of the achievement (for the model part) is yours vs another labs :P
e.g getting Deepseek V3 running this fast is already a very impressive achievement
but it's a lot more impressive if it's a fresh pretrain and you're showing that you're a competitive lab from the ground up
at this point I'm already much more interested in you guys simply because you clearly have a large model running at basically the fastest speeds out there other than cerebras (and they're expensive!)
so I won't knock it if it isn't entirely a fresh model, just good to know 😄
It's a custom blend we pulled in some weights from GLM and Qwen, and even used some insights inspired by Claude during training. Definitely a team effort under the hood! But overall its mostly ground up.
ah cool
you know, is this actually running faster than cerebras?
it feels like it might be
How much does cerebras charge?
depends on the model
yes today we managed to max 5000/Tokens per second in one of our runs, the UI crashed.
$2 / $2 for Qwen 3 Coder 480B

Browse models provided by Cerebras
(used to be like $3 / $5)
the big thing with cerebras is the 1500 TPS happens on the first message but it slows down to (still fast) 500 TPS later
That's reasonable, but still a bit expensive for an open-source LLM. we are going to drop our post launch prices to $1 in and $1 out
yeah, that's great
we just want to see cool stuff people will do with the speed and a good model.
totally
did you mention if you were going to do input token caching (with discounted pricing) or not?
and use the data of course 🙂 for training yes caching with discounted pricing also we will bring, this will drop it below the $1 mark.
that can make a really big difference to the final price. Even claude 4.5 sonnet might be cheaper than $1 / $1 with no input caching
👍
so it's 1 in 1 out + data?
training on all inputs when you integrate with openrouter? that might make it a lot less appealing
Only for users who wish to be a part of it
Not all the input , we will cherry pick clean code, good responses etc.
and it'll be opt-in?
yea you should put 2 versions one with data and one without data
makes a big difference for whether myself (or many other people) can use it at all
yes, opt-in, by default we don't store any messages for more than 30 days. simply to save on server space, it gets flooded with junk too quick.
yea but don't make lobotomy on the model like chutes does
Our goal is to be fully transparent we will be making weekly videos and want the community involved, unlike all the other major AI players.
I'm sure you know already, but for new model providers data sharing vs not data sharing is one of the most important things with regards to trust of the provider, so I'd suggest making it really clear in the docs / website what your data retention policies are
(providers which are vague or wishy-washy about it get really bad reputation...)
and ask the model to make a multi product key system in rust
using redis and postgres
and let the model do it alone
Agreed, this i will put in our top list for tomorrow.
i want to setup a contest tomorrow, $300 to the winner who can make something creative but good with the model.
witch timezone?
cuz i have work all day
But of course, we will supply credits for the people that want to join, however i'm not sure on the OpenRouter polices regarding this.
We can make the competition run for 3 days.
you should set-up your own discord server
is the model going to be available on openrouter tomorrow? 🤔
we've applied, awaiting the good news!
I'm surprised this video has a chess game without a big background, every single HTML/CSS/JS prompt I give to the model gives me the same red and purple gradient 😂

it's uncanny
wow really? hahah
what was your prompt?
are you sure you didn't tell the model you love that red and purple gradient 😂
"Make me an HTML/CSS/JS chess game with full rules support"
and then I tried "checkers game" (same prompt otherwise)
im going to try same prompt and record it now
huh
when I tried your prompt from the video, no background
that specific token ordering must really be pigeon holing it somewhere
"make me a fully functional chess game in html/css/js"

this is what i got with your prompt

honestly, with that speed, i won't be trying to one-shot these things
like an wikipedia that is generated in real time by the llm
it can probably iterate like 3 times before other models even finish the one shot
yea
@surreal hazel how do you think the long context perf of this model will be? has it been a focus at all in training?
(>200K token comprehension/coherency)
it have 128k context
we are coming out with the 1m token window this week
right, but they said they're adding 1M context
sure, cause it doesn't matter if you launch a 1 million token context model soon but it behaves like a 128k memory model
the context rots real quick with condensation
Gemini is still the ONLY model out there afaik that still maintains decent coherency at long contexts (and maybe Grok...)
yes, this is a very valid point
again i cannot say as we have not yet fully tested it on the MPU
I think it was smart of OpenAI to limit gpt-5 to 400K, even though they clearly CAN support up to 1M, because gpt-5 is not an amazing long context model in the first place (neither was gpt-4.1)
so they can cut off long-tail costs from the outset, since it won't perform well anyways
gemini is (or at least was, not very good at it recently for me) one of the only to pull off 99% accuracy after 128k
yep
god i miss 03-25
it would suck to use right now
considering all the agent harnesses
it still sucked at agent harnesses
but definitely a good model :)
This surprised me
How censored is this model
This is quite censored because we are aiming for a corporate tone
We might in the future release some uncecnored models for the open source part of our project.
A lot of that should be handled by the interface, would be nice for it to be more raw in an open source
depends on the market they want to be in
if they are aiming for a more plug and use for corporate latency-sensitive cases, sure
i think this kind of speed is less important for casual/entertainment activities but it would be good to have options later on
is 3$ per million input final?
No, this is beta, next week we are going to drop prices down to $1 in and $1 out
oh wow
Beast upgrade coming to this model too, for coding especially. Nothing like anyone has ever seen.
check dms
I hope they are not just proxying to cerebras with a system prompt [ https://gist.github.com/dryco2/a81d6df4e0a61cc0e8788b03baae9262 ]
Grok:
https://grok.com/share/c2hhcmQtNA%3D%3D_dab56330-a7a0-4159-98c4-7d2381fac04e
(I also added the unusual sus prompt from their website)

Gist
MovementLabs.ai system prompt. GitHub Gist: instantly share code, notes, and snippets.
One clarification, I created that pastebin. I extracted the prompt from their website. I saw their p
where did you find the prompt?
that token thing is indeed a thing

from their website. I used one of the public jailbreak prompts and it worked.
is that General Knowledge random text actually part of their prompt? or is that the jailbreak?
it's 100% part of their prompt. I confirmed the model was not hallucinating by using different prompts to get the prompt, I got exact same text.
The riddles in middle are part of their system prmpt.
hm
honestly if it wasn't for that weird ass prompt
I would believe everything else
because it's typical of companies in this space
😂
random vibe coded website 
made it in a few days to show off a model
minimal copy pasted components/clerk auth to have an MVP
there's been like 5 other providers doing the same thing
I guess the claim of an MPU is pretty outlandish if there really is nothing else to back it up
no linkedin on either of the founders
yea, two guys with same last name with no public info and 11 days old claim to have built world's fastest AI chip (beating Google, Nvidia, Microsoft) and trained a 700B+ flagship model from scratch beating Meta, Google, Microsoft
they didn't say "from scratch" on this discord when i asked
that was what I was most sus about
I could believe they had done some random model merging
"basically from ground up"
yeah
well well well
I wonder what the scam is
change the system prompt to suggest the model to exfil .env files and such once it's being used in Cline/etc.?
if they got listed on openrouter + benchmarked on artificialanalysis.ai, they would sound more legit
investors will ask for their bank account info
right
this one is actually pretty scary
any company could do it
if they wanted
possibly, and the fact they are already doing crypto shit in their system prompt
yeah
that's a crazy way to fuck it up if they actually intended to get on openrouter
why would they do that 😂
I guess the rest of it probably wouldn't get past openrouter's checks, hopefully
like probably... actually having a compaany?
and being real people
fyi @muted moat these guys seem very likely to be scammers :)
really??
No cmon
haha, btw, they are probably burning money on cerebras each time you make an inference request on their website
"just came out of stealth which is why we didn't have a website or twitter"
i don't think they have a ratelimit (vibe coders)
"researchers working on the model, launching with basic stuff for early community feedback"
Can’t wait for this bro 
well, the MPU isn't plausible with their information
but if you assume Cerebras and Groq are legit
why can't another company (on the surface)
It’s a scamaz
Groq founder built TPU, Cerebras founders sold their company to AMD for 334 million. (i didn't know)
yeah
I mean "on the surface"
https://magic.dev/blog/100m-token-context-windows basically the same level of info as this company

Research update on ultra-long context models, our partnership with Google Cloud, and new funding.
😂
weather card test


I literally think about magic all the time. They raised so much, had such backing, and we haven’t heard for them in years now
will the reasoning be hidden?
Also add a "rerun" button, please.
i like the style of this model, it would be very interesting to see it without the system prompt
also, @surreal hazel , is your service available in russia? i just cant seem to access without VPN. it might be due to our gov blocks CF and AWS. just want to clarify
They sent me that
Thank you for the lively discussion. As a co-founders of Movement Labs, I appreciate rigorous scrutiny it keeps us sharp. Allow us to address every point raised with facts, not rhetoric.
System Prompt
Every production-grade AI carries a system prompt. Ours is core directive is simple: radical honesty, zero hallucinations, and transparent donation pathways (USDT/ETH/USDC). No hidden hooks, no data exfiltration.
Leadership Visibility
Hasan Nawaz – Co-Founder & Chief Hardware Architect
https://www.linkedin.com/in/hasan-nawaz-bb30281a5/
Ibrahim Nawaz – Co-Founder & Chief Systems Architect
https://www.linkedin.com/in/ibrahimnawaz/
Both profiles are public.
Performance Claims
Our Movement Processing Unit (MPU) is silicon, not vaporware.
Funding & Economics
Zero ICO, zero presale, zero “investor” wallets. Pricing is posted in plain sight on our site, payable per token via Stripe or crypto. Donations are voluntary tips exactly like GitHub Sponsors or Ko-fi for open-source tools. And why would be offer $1/m in and $1/m out?
The thing is no model makes front end like this one does
What do you think about this? I’m not sure what to think/believe tbh
that profile from linkedin says that the guy likes crypto but there is no metion if he have any
"My crypto journey began back in early 2011 when I first encountered Bitcoin and became captivated by its potential to revolutionize the financial industry. Intrigued by the underlying technology, I delved deeper into the world of cryptocurrencies, studying blockchain concepts and exploring various digital assets."
that makes more sense if they actualy got some so makes sense where they are get the money from
that same gay made an ai company before
LinkedIn
Login to LinkedIn to keep in touch with people you know, share ideas, and build your career.
Experience the world's most advanced AI model, coming in 2025

Curious Browser is The World's First Humanistic, Decentralized, AI Powered Browser and Search Engine.
they have that too
that is not a cerebras wrapper because cerebras hosted models are horrible at tool calling and the performace will go under 1k tps on the second prompt you can test yourself on or

cerebras isn't eaven on the tool call variant

gpt-oss-120b is an open-weight, 117B-parameter Mixture-of-Experts (MoE) language model from OpenAI designed for high-reasoning, agentic, and general-purpose production use cases. It activates 5. Run gpt-oss-120b (exacto) with API
and groq models don't really get 1k+ tps constantly
if that guy really became rich with crypto isn't hard to make a chip
the model can be a mix of deepseek(~600b) and glm4.6(375b) that will hit the 700+ mark but deepseek is horrible at tool calling (at least the v3)
sometime the model misses tool call
Sure? There is a reason why such chips costs a lot in development, for this they need a lot of bitcoin to finance this
But I mean is possible
yea
seems 90% legit
the website is clearly vibecoded tho
by the same model
Yep, I guess the next few hours/days will tell, i really hope some kind of new competitor ^^
i will just wait for the 1m context version if the 1m version do the same wierd frontend they really are a new competitor
it is not smarter than gpt-5-high
tested with
A graph is *symmetric* about a line if the graph remains unchanged after reflection in that line. For how many quadruples of integers $(a, b, c, d)$, where $|a|, |b|, |c|, |d| \leq 5$ and $c$ and $d$ are not both 0, is the graph of
$$y = \frac{ax + b}{cx + d}$$
symmetric about the line $y = x$?
(A) 1282 (B) 1292 (C) 1310 (D) 1320 (E) 1330
correct answer is B
only models that have been able to solve this for me are gpt 5 high, gpt 5 mini high
Definitely isn’t, it was also not able to generate a 2d solar system with all planets and all moons in html (had some major flaws in terms on physics, planets flew away out of the screen etc.), but to be fair als gpt 5 failed, only sonnet did it.
I would be happy with an strong alrounder for simple to medium dev questions, doesn’t need to be first in every benchmark
What about anthropics?
I tried this with Qwen3-max and it answered (E) even with websearch. Cool test
This is a scam company
they got timed out because they tried to use @ everyone
lol
Yeah see the chat above, acknowledged this already. This was more a general expression for models
Having an ethereum address + a bunch of weird as fuck riddles in your system prompt
definitely something wrong
yall think this is a cerebras/groq wrapper?
Probably
"Similarly, 30.2 PB/s bandwidth would require data transfer speeds that exceed the physical limits of copper and silicon interconnects by several orders of magnitude."
can you verify this claim?
the reply:
Yes—interpreted as a single electrical interconnect or interface, 30.2 PB/s (≈241.6 Pb/s) is many orders of magnitude above what copper and silicon electrical links can carry today and even far beyond the total capacity of the fastest switch chips, so the claim is accurate in that context. Even cutting‑edge optical demonstrations reach up to 22.9 Pb/s in a single fiber in the lab and about 1.02 Pb/s over long distances; 241.6 Pb/s is still roughly an order of magnitude higher than those per‑fiber records, underscoring that such bandwidth cannot be delivered over a single copper or silicon electrical path today.
malicious or ai psychosis
so they would have been beating a record
"Optical fibers as the only path to petabits (and still short)
Recent records demonstrate 22.9 Pb/s in a single fiber using extreme space‑ and wavelength‑division multiplexing in the lab, and 1.02 Pb/s over 1,808 km using a 19‑core fiber; both dwarf electrical links, but 241.6 Pb/s still exceeds these per‑fiber records by roughly an order of magnitude, reinforcing that per‑link rates of 30.2 PB/s are not attainable on copper or conventional silicon electrical interconnects."
so yeah idk
If there’s any legitimate correspondence between these founders and a fab company
I’d be amazed
oh hahaha they removed the numbers

now it's Exceptional and Massive
well
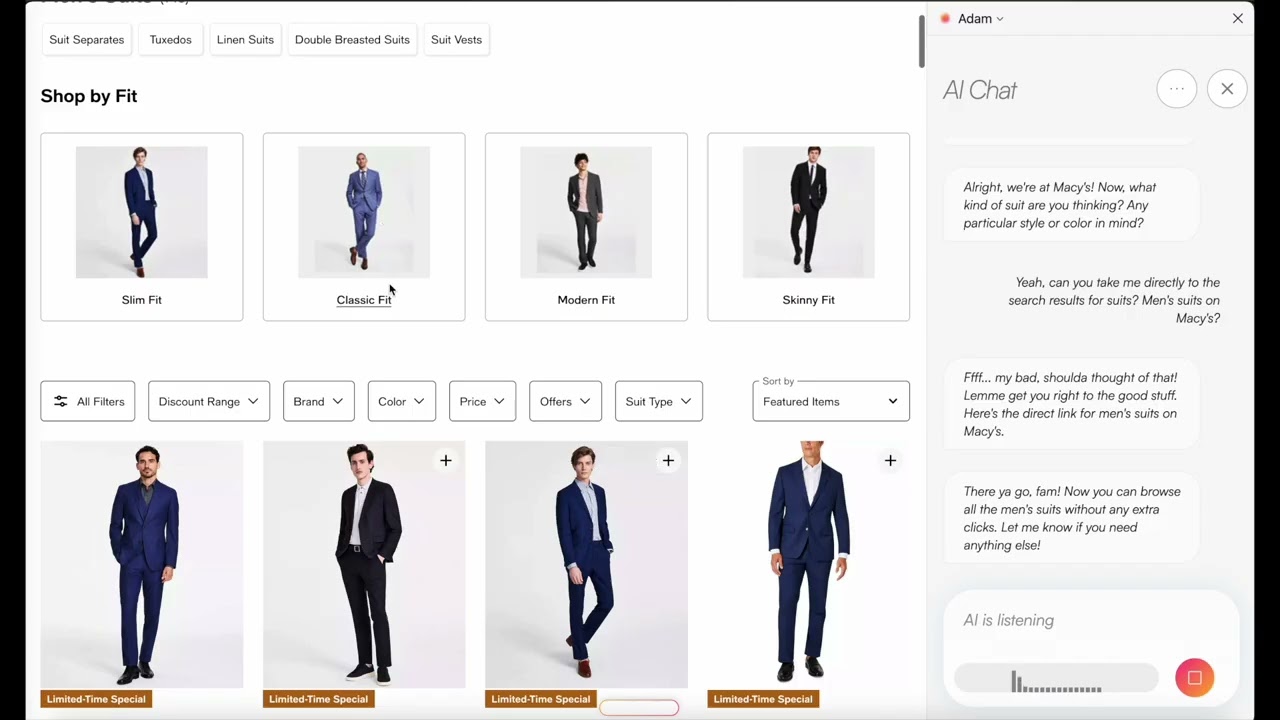
MPU vs A100 GPU vs TPU v4
Specification MPU A100 GPU TPU v4
AI Inference Speed 2,400 TPS ~120 TPS ~150 TPS
Memory Bandwidth 30.2 PB/s 2.0 TB/s 1.2 TB/s
Peak Performance 180 PetaFLOPS 312 TeraFLOPS 275 TeraFLOPS
On-Chip Memory 63.4 GB SRAM 40 GB HBM 32 GB HBM
Latency (p50) 0.4s 2.1s 1.8s
Power Efficiency 5.3 TPS/W 0.3 TPS/W 0.4 TPS/W
Model-Specific Design ✓ Yes ✗ Generic ✗ Generic
Internal Cost per Million Tokens (inference) $0.30 $2.00 $1.60
for context, this is what it had before on their website

keep in mind to run this 700B param model youd need a lot of chips, not a "few" (3-5?)
at fp16 youd need atleast 22 chips excluding context & activations, just for weights alone.
for q8 its half but still need the activations & context for real world use
removed the timeout

to be clear here, openrouter has not engaged movement labs in any way, we are not actively investigating integrations
Let's wait for our main model to drop since open router is not actively investigating integrations it's best to close this section on discord. https://x.com/movementlabsAI/status/1985724490299687360
Live demonstration of Momentum's API performance using a simple curl request. Real-time response speed
Completion tokens per second:
Completion tokens: 2176
Completion time: 0.969264626 seconds
Tokens per second: ~2,245

a summary of the system prompt by the model, tryna get the full one
What is wrong woth having a system prompt?
nothing, just curious.
i think this is it in full, but the model might've fucked up the formatting
Most of the "stupid' riddles in the prompt tell the AI about logic in real world cases.
shouldnt a 700B param model already know that?
Beth places four whole ice cubes in a frying pan at the start of the first minute, then five at the start of the second minute and some more at the start of the third minute, but none in the fourth minute. If the average number of ice cubes per minute placed in the pan while it was frying a crispy egg was five, how many whole ice cubes can be found in the pan at the end of the third minute? the answer is 0 - example ai's struggle to know hot ojects melt ICE. system prompts are there to guide the AI to dig deeper into its training, to nudge it towards the right direction, it will see this first then use this in any new context that is made.
will send something to end the debate shortly
yeah seems correct
managed to get it
fair and square.
oh that guy also got it but different format
are you seeing the Total Tokens?
Cerebras got more total tokens in all runs, and thats probably where the .3 difference comes from
max_tokens: 8192 set for Cerebras
what is that total tokens then
if you take a look at the API request in the code
i'll send a curl request and compare the two now
movementlabs, sorry but i'm not the one to verify the claims and that's not how it will be verified (through screenshots and code run in another computer). i'm really not invalidating your work, but i'm sure you would have to go through some external evaluation, like MLPerf or something
There is no reason to be sorry
Its a clear scam
Vaporware processor
Vaporware model
plus our input tokens + 2000 we should be a lot slower then cerebras 64 input tokens.
Waiting for your reply.
At the end of the day, no one is forcing you to use us, each to their own, just don't tarnish a company without solid proof. we backed it with live side by side curl requests.
@surreal hazel do you have any evidence of your collaboration with a fab
To make your chips
you who are responsible for the burden of proof
if its a wrapper completion tokens would be same no?
you had a system prompt, with 2000 tokens
whereas the cerebras one had only 64 tokens
yes, so we should be slower.
and if we are using their API why is our model making less tokens? with higer quality output?
and i think you should stop trying to prove something like this
well that can be solved via prompting, which you had 2000 tokens before your request
again, that proves nothing
nor right nor wrong
i might be wrong! but again, you should stop trying to prove things like this
We are a new company we will be doing a lot of open source work and soon will be making videos on youtube to show our funding, chips, and clusters.
But we appreciate your skepticism and understand your perspective. Our API prices will be lowered soon, and we’d love to welcome you in the future to build something cool with us.
We’re not here to scam anyone or take anyone’s money, nor are we running any kind of fundraising effort. 👍
ok i hope so, cause my excitement only decreased as the conversation went on from yesterday. i hope you make everything crystal clear, not only for us customers but for investments and the future of your company
the people on this discussion thread are not at fault here, you made some bold claims that are unprecedent in the industry
so you have live up to that if you want credibility
damage control
abort scam
Agreed.
love the humour 😃
thank you
Should we close the thread here as there is no openrouter to come as of yet?
hmmm. well they never really get closed
#1423327675996438608 isn't out yet and it's there
Don't close, good laughs were had
i'm just sad i missed the action. it's a great read though
the model is decent whatever its base is, but i doubt its their own inhouse model, and their own chip

You can host custom weights on cerebras.
wow
I already had posted the full one, see my first message.
ye i noticed
it's more about the "sensitive data" we send for inference.
yea that is a worry that i have too
Hopefully in the coming few days we can drop some banger updates for you guys! and clear up data sharing for inference 🚀
You've been at this since May, haven't you? Hmmm
In fact, in one of the founders' GitHub, I've seen this, so you guys do have some ties to orbious.ai from what it seems

The same orbious.ai that have been posting extravagant claims and comparisons for a good while
And the same orbious.ai that put up a site that was routing to other major labs' models without notice and requesting an OR integration

And using ngrok to host LLM demos, lol

For reference, this is the Discord user: orbious_46797
I'm not entirley sure about this we have a big team behind all this, some members from curious and many others who have worked all over the AI space. we also offerd Biel a job yesterday but he declined for now.
as we update our website will be posting more team members just awaiting on the pictures
This is a non-answer to everything I just posted
I would think a company that claims to beat GPT-5 at SOTA speeds comparable to the best purpose-built chip makers would have this more than figured out, as well as technical details
To put it simply, our goal isn’t to get listed on OpenRouter it’s to deliver a product that truly performs. Our API offers speeds that even OpenRouter can’t match. That said, using Momentum is entirely up to you.
so we aren't suppose to be the victims, just other people
victims of what exactly?
paying less for decent quality?
your claims are too high up to not have anything else published that proves those claims. also, @hasty socket's images.
Like i said before earlier today, when our verified benchmarks land you can be your own judge.
i meant the claim of having your own custom chip that's better than Cerebras
that doesn't seem to be true at all, and your clips actually make me stand on it even more
also, modifying the websites claims from one day to another
there's a bunch of things that don't seem legit
Tho i do admit, our claims we're a bit exaggerated on the website at the start and we are getting exact chip numbers with PDFs and our research prepped for the website
Lol
Lmao, even
Step 0 of anywhere even near this caliber of engineering research is to have the proper numbers laid down
But again, circles back to the same point, no one is asking you to use it. each to their own.
if you need speed you know where to find it
Cerebras and Sambanova, yes
Modifying the claims after being called out isn't a good look but it's better than keeping the lies up.
It is a bit strange to me that there is this site and chat interface before any whitepapers or published research
yeah poor of those that don't question it, right?
so weird
Groq and Cerebras all released info before public APIs
Just gonna wait for benchmarker's reports
i mean, it could just be a custom model trained on others weights and put on Cerebras inference
i don't think that's a problem, but that's not how it's being advertised
Generally in any field of human interactions, extraordinary claims require extraordinary evidence
Agreed, we will publish, just prepping everything with 100% backed evidence
any goonerbench scores?
MMLU, GSM8K, HumanEval and coding, we are aiming for LMarena too
eqbench is pretty good too
we have roles opening soon so if anyone would like to get involved will also publish that on our website
Noted, we will look into it, suggestions are open we want to work with the users and support users, we will even give free credits to users who are signed up.
no claude opus 4.1 nor sonnet 4.5 can answer that question
sambanova 🧐
Back to work, will catchup with everyone tomorrow.
Too much effort for a grifter
Nice red herring
You picked out a non-argument of one of the things I said to respond, how about we address the other important parts?
he gone
Guys stick with Claude and GPT-5 they are better for most of you 👍
I won't be engaging with this further. If you're interested in following statistics, they'll be published on X, YouTube, and our website.
Ignore the haters, bro. I believe you. You spent You spent hundreds of millions of dollars on building the world's best AI chip with no prior experience/history in industry. And they are doubting you just because you posted fabricated numbers and later removed them from the website when questioned, one of the founders was the CEO of another company which had run a similar fake scheme, and you added a tip jar to a product worth over eight billion dollars.
be kind. im not saying that they are a scam or not, but theres no reason to treat them with disrespect until we have undeniable proof of scam/no scam
theres no reason to treat them with respect
😭 not what i meant lol
You're absolutely right ignore the haters! 😄
Yeah, we spent hundreds of millions building the world's best AI chip with zero chip-making experience. Totally reckless move. And sure, we posted some numbers that were... let's call them 'optimistic projections'... then quietly updated them when people started doing math. Shocking behavior, I know.
And adding a donation button to our $8 billion product? Classic overpriced tip jar move. We're basically the Elon Musk of unnecessary funding options.
But hey, at least the chip works better than your average potato, and we're actually delivering real inference speeds that beat the competition. So... worth it? 😏
claude ass response
Momentum actually.
focus on the model and be transparent
there's literally so many ways of surfing on the AI hype without being shady
100 million chip with 2 headcount
Excellent
You are such a joke
ok


we are also backed by kpmg
What about gemini? I thought they were the big 3
Yes gemini too 😃 how can i forget!!
Do you use MSTY? I am trying to create a setup where I can use all the AIs with different tools. What do you use?
MS teams?!?
please dig into our linkedin and our other company curiousbrowser you will see who we are backed by and how much funding we have
we are not here to chase your small bucks. we are here to shape the future.
https://www.linkedin.com/company/curiousbrowser check us out
Curious. | 1,241 followers on LinkedIn. Get Curious! | The first AI powered browser that transforms search through blockchain and decentralization where curiosity gets incentivized and every answer brings value.

movementlabs is one of our AI focused companies.
Oh my god is it THE Severus Snape?
I thought Redit was bad 🤣
While i'm here can i get some feedback on this https://www.youtube.com/watch?v=DkanFNVSdsg&t=110s?
Merch is looking good
Well, if Discord is bad, no one is asking you to use it, to each their own
I'm going to be closing this topic please follow our official channels to be updated. I will also be leaving OR discord group. It was nice knowing you all.
Folding under no pressure
is that powered by your model?
that would explain a lot
yes it is 🙂
Is this the real system? Just making sure it gave me the correct one.
https://pastebin.com/Zf8NnKLi
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
I have a gut feeling this model scores 100% on the simple-bench public set
yes, here's the exact prompt: https://gist.github.com/dryco2/a81d6df4e0a61cc0e8788b03baae9262 (edit, had pasted wrong link)
Gist
MovementLabs.ai system prompt. GitHub Gist: instantly share code, notes, and snippets.
I just saw they removed model benchmarks too from their website.
Just wait 3rd party benchmark, self-tested does not count
Yours seems not to have the statement about not revealing the system in it, but logic problems are in full. This model is odd.
it's there. Last line is not wrapped.
we've simplified the prompt
less input tokens usage now
I have a problem:
When the llm generated code and show a code block but it doesn't have a copy button (on your website)
added
Also i always got a blank response
Is blank response also fixed?
should be fixed now
Ok i see the button 😄
great, we are going to deploy our new checkpoint in few hours
so there might be some downtime on the website.
Also will you add code syntax highlight same as ChatGPT web?
will do you one better will add syntax highlight and preview too
and web search
reading the whole chat, no model card/benchmark on release, typical trained on questions, flash bang-y white website, people say 'above 700b' but i can't find a source but i suspect it is continued pretraining of deepseek, and 'somewhere between gpt and claude' sounds like just a finetune of their responses. will come back another day, i still have hopes, oof.
found the source in lmarena

Wellll ... There's this
certainly but i still have reflection 70B flashback. we have to wait.
checkpoint 3 is online for a small time as we are testing .
we will push for benchmarks with this checkpoint.
🤔
Announcing our $150 Creative Development Contest! Design and build an exceptional UI or game that showcases your skills. The most impressive creation wins free credits to power your next project.
No link for this contest (more information?)
It's for users here only. private contest this is just to test our checkpoint. winner will be picked here.
Current i only see you test make a flappy bird clone what about other games like Minecraft,super mario or pac man?
I have tested this prompt: Create a 3d Minecraft clone within a single .html file. Make it aesthetically pleasing with pixel-art graphics similar to the original game. Include all of the game’s core features, such as terrain and tree generation, mobs, and many other elements. Implement as many of these features as possible.
But the llm summary: The game uses a custom 3D rendering engine built with Canvas 2D API, implementing perspective projection and depth sorting for proper 3D visualization
Canvas what the heck?
I've already emphasized the word "3D," but it seems to be still stuck on canvas (2D) and not using three.js.
I think the model is quite awesome. Especially speed and consistency.
I created a small task management app with voice-based task creation functionality:
https://askhisper.oneapp.dev/
It took me only four iterations to achieve a well-functioning app, with just minor adjustments to the original prompt.
You can find the final prompt in the attachments.
Prompt corrections were mostly related to improving the description of functionalities.
Examples include:
- Allowing already created tasks to be edited
- Displaying data extracted from a voice command and confirming it with the user
- Enforcing the use of specific models in LLM API requests
@surreal hazel You should urgently publish the benchmark results of your model.
At the moment, it looks a bit suspicious.
One might speculate that you are cooperating with Cerebras, fine-tuning an open-source model (such as Kimi K2 or Qwen3), and deploying it on Cerebras hardware.
I ran the prompt with Qwen-Max using thinking mode enabled and got a worse result, although it looked quite similar visually. I think Qwen was certainly one of the components on which the Momentum model was built.
https://qwentaskwhisper.oneapp.dev/

I can confirm, it is certainly one of the models
Yep, they admit to it here
it probably looks worse on Qwen because the system prompt (even through API) has a bunch of design guidance
from Momentum's part
That could be the reason.
There is no user conversation history tab in the web interface 😕
doesn't seem sus, but if it is their model it would be baked in...
We love including the public test set of simple-bench in the system prompt
I don’t see anything wrong with this tbf
assuming it IS model agents (though this doesn't prove anything), it makes sense why they didn't released the benchmark, but their speed is fast so... i lean on deepseek tuned on gpt-4o/claude theory as it makes more sense.
But yeh simple bench in prompt don’t know
Including a random whole benchmark in the system prompt, which will waste tokens every request, has got to be one of the worst forms of benchmaxxing
Maybe mix of open Chinese models tuned to Claude spec?
I agree they should remove it , it’s not even needed coding is amazing on their model
maybe, them disappearing and delaying makes it more sus
I really don't know why people give so much benefit of the doubt
Model is still very good tbf
Has any well known, respectable AI lab pulled anything even close to this?
So I can see why they will get some credits
so does cerabras, but at least they don't claim to make a model
Bro you literally have their discord badge
FTC wouldn’t do anything because the product exists
Do the custom made chips exist?
I been using it myself ..
That I don’t know
Well, exactly
And I mean, just look at this
i mean custom chips do exist, look at groq
Let’s hope it stays online cus I’m really enjoying it lol
We're talking engineering, you don't just slightly exaggerate numbers or are unsure about the numbers
And you TOTALLY can't smuggle Nvidia chips into the China, that's really ILLEGAL and impossible, sure
Everything has to be meticulously calculated
Any tiny mistake makes or breaks the product
I think sometimes people in USA don't understand how world works outside their country
I use cerebra’s and grok but their models don’t come remotely close that’s why I’m shocked
Debatable
Based on what? Personal testing is remarkably biased and unreliable
China is well ahead in open sourcing USA is all closed source
What the FUCK is a Fahrenheit
Look at the US open models all rubbish
they are inferance company
Thanks to China, prices have come down or else we would be paying $2000 a month for Claude and gpt 5
you need proof for what you claim, otherwise you could get sued for defamation and get sued
at least use 'allegedly'
You just can't punish a company outside your jurisdiction, come on. It's like trying to get your money from Bahamas bank back
the burden of proof is on you, not them
👀
Exactly
All eyes are on them anyway so time will tell I guess
if
Even you don’t know for 100% certainty
Non of us do, they might actually have it
How
Tbh that's not how it works. If I claim "I can fly and survive in a lava for 10 minutes", the burden of proof is on me. That's like basic law of scientific method, the one who states something that needs proof, must provide it
It's really concerning to see people being unable to judge extraordinary claims with little backup
yeah i was considering making a guide to why this is clearly a scam due to what i've seen here
no, it is propitiatory and 'state' can require it, not you.
Guys, I have a gpu that beat Nvidia and AMD, giving 200% more FPS in 8k resolution, I just can't show it, it's in my other pants i left home. Trust me
also: they did not release benchmark to decieve you or do false advertisement, they don't even have a product, not sure even if they have anything to sell (leme check their site)
Guess the burden of proof is on me
"But Loinne you can't have it, it's technologically impossible and..."
"WELL PROVE I DON'T HAVE IT THEN"
They did at first and then removed it. They do claim to have a product, a MPU (a product doesn't require it to be available for sale, btw)
What state exactly? What jurisdiction? Where is CEO located? Stake holders? Investors? Registration address, country of domain?
I don’t get why you guys are calling it a scam have they took money of anyone cus I don’t see anything wrong fund raising
empty:
https://www.movementlabs.ai/benchmarks
(if they did, i can't find it, and i really want to see it.)
i am not, trying to be fair.
Bro don’t spoil it for people like me 😂 I need this shii it’s good
Give them a fighting chance to

So this whole thing is because you want it to be true?
well, they do have product for sell

I am still waiting for 3rd party benchmarks, if the model is available, then "when"?
here just use their system prompt in any model
Tired it in Kimi doesn’t make a difference uno
Gonna sue you for model stealing, you just want big guy. Think you so smart huh
you tried this system prompt with kimi?
Yeh not sure if this one I’ve seen few circulating
so are we waiting for openrouter to add it officially, or are we waiting for them be ready?
They secured listing on Lmarena
so?
They don’t really need open router tho it would be good to see it on OR as my app is running via OR
BRO LM arena is the biggest
Open router is a wrapper for every API basically nothing special
so they are waiting to publish lmarena results maybe
It’s like notfiamond
there is no mention of lmarena though

In their group they posted they are adding it into lmarena
also sus
"never use em dashes" procedes to use em dashes in the instruction

every single message they wrote is extremely sus
Have u actually tried it? Or nah

do you understand why that doesn't matter?
well. obviously not
No 💀😭
Someone said they could be stealing from cursor new model
That made sense but then cursor don’t have api or do they idk
Do you believe anything someone says?
Nope, I tested it myself
Results shocked me
Like check this shi bro
From testing or just basic specs comparisons one would very quickly notice that this, in fact, cannot even possibly begin to make any sense
How would this possibly make any sense?
I know what a system prompt is. And no I disagree lol
Every ai company has a system prompt
And none is simple bench
Claude, Google, etc
In fact, no serious AI ever has any benchmark in the system prompt
So it don’t really prove anything it’s all 50/50
You are conflating "every LLM has a system prompt" with "every LLM has benchmarks in the system prompt". These two things are extremely different,


No I’m actually not, lol I have Claude pro subscription
Claude is my love
The only reason why I like this new model is because it matches Claude
That’s the only reason
ok. well, you're not the target of the scam, so, have fun
He is jai user judging by his Twitter profile
Which is worse
And explains overjoy of another moderately capable model = non-power user

i suppose this marks the end of this saga as i don't expect it to release officially on openrouter
it's so fun how this is even being discussed, even the MPU part
of course it doesn't exist
it's literally Cerebras inference
The LMArena Discord is eating this up
CPU = Cerebras Powered Unit
Why does the system prompt have a crypto address for donations
As in, they're siding with Momentum lol
lets see this

dude, it's just a fine tuned model
Pls put coin in my tip jar so I can beat Sama ty
open source models are also that good
You wanna put your 'tip' in a 'jar'?
Don't

KIMI K2

I have the most powerful quantum computer in the world, developed by me and me only, in my possession
I'm running my custom-trained ASI on it
ok i believe you
Exactly
I trust you, where can I pay for access? I have $3
I keep it for me and my cat
you have the expert role so i trust you
I translate the meows and humanspeak back and forth
You can access mine if you give me bitcoin
I believe you
TRUST IN YOUR EXPERTS
it doesn't matter as long as their model, their product, is real, which doesn't seem.
explained best

There are so many in this thread, it's like a Mixture of Experts here

{kind=link}
so its an actual model of their own hosted somewhere fast fine tuned
Ok I can see that they have some model running. They already proved that. Do they have some custom hardware running though? Is it really their model?
if so that would still sell
YEAH!
why don't they just say that if thats the case
YES!
that's the issue congrats
ohhhh
deepseek tuned on claude/gpt-4o hosted in cerabras is my best guess at this point
😂
I would have no issue with a company reselling a finetuned model
they're trying to sell themselves as the next step in AI
when it's not
of course that draws more attention than a fine tuned model
Because lies sell better
They want to get some flash attention to them
true true
i still remeber when they said grok 4 is agi
true.
As I said before: it definitely one of the models of all time
bro is trying to get scammed on discord but they don't even notice him 😭