#Horizon Beta
3392 messages · Page 4 of 4 (latest)
i believe zenith is gpt-5-low
Huh so wait whihc one was it? Just saw the 130pm announcement. Was on a zoom call with some bozo when it dropped
openrouter might wantto reduce their prices on this one

LM Studio Blog
We worked with OpenAI to ensure LM Studio supports running gpt-oss models locally on launch day 🎉
I get up for 10m lol
Emil, is that you?
So what’s the verdict, which model was this?
gpt-5 mini or nano
So not os 20 or 120b
How do you know?
So Alpha was 120b thinking model, right?
No
Horizon is from the gpt 5 series
Again, how do you guys know, lol, is it by comparing bench’s
Yes
Ok cool, thanks
There was some mention of the mini/nano versions of GPT5 being tested on Copilot so this could very well be that.
A single coding task reveals that the OSS model is way behind horizon
Any opinions on this?
It's OpenAI
I don't know enough about infrastructure to know if they could be able to host this but from what I've heard a ton of them are ex openai
So similarity would make sense
cleaning up the channel, let's move on
responds quite differently, the 120b not as capable as this on creative writing
Language isn't as good, character interpretation is different, as is instruction compliance. 120b also doesn't show the same extent of pos bias that this does
IMO, just on a brief test of the 120 this is in a different class.
So these are gpt 5 models huh
Plus Horizon is multimodal, 256k context. I still think it's gpt-5o. The eq/fiction benchmarks are far better than what I'd expect from mini, but I guess it could be.
What is wrong with asking
Think before you ask 🙏
It’s not
Be kinder
Man, if this is any variant of GPT5, then it's a little disappointing. I suppose it is par the course for OpenAI. Probably 5o, which possibly makes the reasoning variant o4.
With reasoning it was SoTA
Patience
Last time it was full 4.1 being previewed, but I hope this was a mini this time
Or nano
It was not, and even if it was, one would not be able to determine it within 2 hours of use. Personally, I find it mediocre even with thinking, especially in writing. Just verbose and edgy all around, and sentence structures are staccatoed and repetitive. I'm sure it's very strong in other areas and whatnot, but so are every other model coming out.
I don't think OpenAI would care to test run a mini or nano model. After all, they didn't test their OSS model either. I was quite giddy thinking we'd get Alpha/Beta for OSS, but yeah, that's not even close.
It got on the top of someone's vision benchmark, and did incredibly well in my coding task
Strongly believe it will be sota on release
Again, I'm sure it's strong in other areas, and it will top multiple benchmarks as it's meant to do; but o3 is extremely strong at creative tasks, and this one doesn't seem like it. Again, could be mini, in which case, great; tune it for coding and agentic tasks. But otherwise, I'm not interested in numbers, because it's a rat race and every model coming out will be the "best" for 5 minutes. Opus 4.1 is just out and Gemini 3 probably within the week, so I'd withhold my judgement for now.
"any variant"?
this is not disappointing as a nano or mini model at all
also, we know this isn't gpt-5 full reasoning
because perplexity leaked it, and it was much better than horizon beta
so there isn't much else it could be
True, mini would be quite good. Nano is implausible. Anyway, pretty sure OpenAI is collecting jailbreak prompts to implement against them. The same prompt yesterday no longer works today, for let's say, more colourful uses.
Is the model continuously updated, or has it remained the same since it became available on Openrouter?
colorful uses 😭
it did patch
the thing
that made it go full unfiltered
after chapter 1
i did get one juicy chapter of it

Also, instruction following is noticeably worse today, because they had to lobotomise it lest the JB takes over. Alpha followed formatting requirements perfectly when it came out, now Beta is physically incapable of html colours.
patching jailbreaks to the point where the ai will no longer work
🔥
So it's an ongoing process of iterations
Horizon Beta is Claude Haiku 4. It's blatantly obvious that it writes like Claude, and it refuses like Claude. It's faster than Sonnet and Opus, and Haiku is officially still at 3.5.
I don't think so. It's clearly distilled from GPT-4 models
identifies as ChatGPT and so on
Most likely it's a GPT-5 variant
why would it top writing benchmarks even above opus 4
it has big model smell imo
it's probably gpt 5 full and is underwhelming
just like the oss model
and faster is all based on how much compute they throw at it
I remember with gemini 2.5 pro was at 300+ t/s and opus+sonnet were blazing fast when 4 came out and now go at a crawl
This is a major downgrade to 4.1 Mini, though
Except in code
haiku doesn't use the openai tokenizer
this one does
yeah
I'm pretty sure the EQ bench guy does model fingerprinting too?
that can tell 99% where the model is from / similar to / trained on?
nah. the fingerprinting shows it most similar to openai models, specifically o3
so it's either 5 mini or full
We will hold you to this prediction lol

OR should offer to give an additional $1 to model predictors or something to make it fun (only for those already at the $10 verification level to avoid an influx of bot accounts)
Horizon Beta is Llama 4 Maverick. It's blatantly obvious that it writes like Llama, and it refuses like Llama. It's faster than Scout and Behemoth, and Maverick is officially still at 4.
I predict that it is a GPT-3.5 Turbo fine-tune
it was just me answering you guys as fast as i could
Thanks for your service.
Aw man I lost my bet
feels more like a claude model in my use cases (creative writing, technical speculation and worldbuilding)
have you ever treid o3 for that?
are you moe?
Do claude models allow for structured outputs now in the request? If not, then I don't think horizon beta is claude since this model supports structured outputs
good point. they don't.
Well, I think it's fun. I'm not gonna bet money against (pardon me) random people 🙂 But I stand firm and if it turns out I was wrong, I'll be remoreseful 🙂
it's openAI trying to go back to their roots with this open source release. Because Zuckerberg already beat them to it
Thus, this is not GPT 5 or even anything close
I think the consensus is pretty clear that the Horizon series are not OSS. If it's not yet evident to you, because Horizon Beta is still being deployed.


Alpha was 5-nano and Beta is 5-mini
And the difference between a mini model and the full one is that big?
Because horizon beta is not so clever tbh 😅
I hope they were both just different versions of nano
Otherwise gpt-5 not looking good
Yeah this is what I say
Or maybe it’s not finished post training
No, its not
Beta is an updated version of Alpha
This is an improved version of Horizon Alpha
Source: https://openrouter.ai/openrouter/horizon-beta

This is a cloaked model provided to the community to gather feedback. This is an improved version of Horizon Alpha
Note: It’s free to use during this testing period, and prompts and completions are logged by the model creator for feedback and training. Run Horizon Beta with API
That means they're the same model
That doesn’t really mean anything they can just say whatever they want

I'm scared of how much of a positive bias GPT 5 is going to have if Horizon Beta is nano
anthropic would not use the openai tokenizer
anthropic would not use the openai tokenizer
very true
if it's mini it's still not awful imo
zenith is really quite good
as long as zenith isn't like GPT 5 Pro then I'm fine
we got confirmation from the perplexity leak that "GPT 5 Reasoning" is basically the same as Zenith
so I'm no longer concerned
anthropic would not use the openai tokenizer
How do you know which tokenizer the model actually uses? I mean, not OpenRouter but the actual model. OpenRouter may use the OpenAI tokenizer and their API may pass the requests to the hidden vendor, and then the vendor does whatever they want. They can detokenize, tokenize, retokenize. It's quite obvious to me that if the vendor wants to known their identity hidden on OpenRouter, they wouldn't expose their actual tokenizer or other easily-identifiable traits.
There are glitch tokens unique to each tokenizer vocab that you can test with. The provider will still count tokens for you, be it in the form of the returned usage data, max_tokens limit, or even maxing out the input context window and causing an error. Most providers outside of the super fast providers like Groq/Cerebras and Anthropic will also stream individual tokens back for streaming requests.
Could they hide some of this? Sure, but that's additional engineering work for arguably very little benefit, because even with all the evidence, people like you would still claim it's a different provider, so the stealth provider doesn't even need to hide because the public is for the most part, gullible.
Also IMO the provider doesn't matter as much as the model. If it blows, OAI can just say "Oh we were testing this 7B experimental model" or something
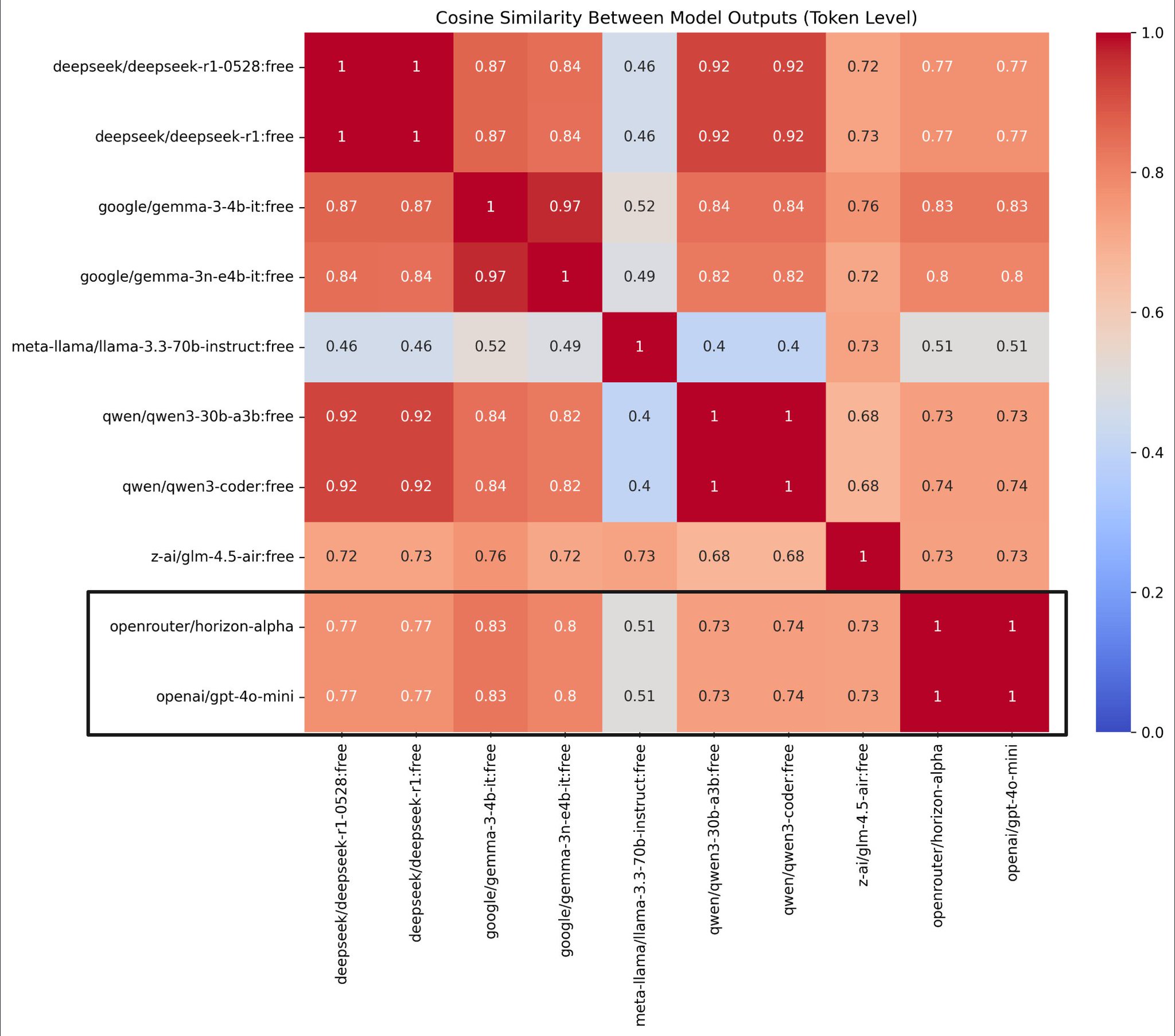
Here's how the mysterious Horizon Beta model performs on the ZebraEval reasoning benchmark.
It appears to be a non-reasoning model, and not top of the line. Fits the GPT-5 Mini / GPT-5 Nano theory.
[Didn't find results for o3 or o4-mini, which would probably top the chart]

Finally found the tweet I was thinking about https://x.com/tohuniver/status/1950811691933131185?t=d3CgbQRFZ8U26ongkTuJbQ&s=19
Confirmed that OpenRouter's new stealth model originates from **OpenAI**, identified through the same stream token similarity method used previously.
6 days ago, feels like yesterday
let's pray for affordable pricing for later today 🙂
Felt a bit lobotomized yesterday, looking forward to trying the full models and comparing
This is unlimited, IG.
mb


Hmm
If Horizon Beta is the free version of GPT 5, very disappointing tbh
Hopefully GPT-5-reasoning = Zenith = Perplexity leak = Plus subscription model
(If Zenith is GPT 5 Pro, disappointing)
Was this release or leak or rumour/prediction?
github jumped the gun too early, but then removed the announcement. the first screenshot above is supposedly from there
Is the 10am thing probably gpt5?
seems likely, but then again my predictions don't have good track record xD
Yes definitely
Leaked
From pages being deployed but are hidden, toggled with a feature flag
Is the gpt5 being a router thing still predicted or has that been abandoned?
Im gonna ask you to REALLLYYY look at it

looks like claude 4 haiku to me if you ask me
Deep5eek v4
Im waiting for deepseek r2 to come out and just annihilate everyone
I know it’s Thursday
Look closely
Is livestream misspelled? It looks off, but I can’t work out why
You're messing with me
>:(
?
The S in livestream is replaced with a 5
Hhinting at GPT 5
OHHHHHHH
Sorry I genuinely didn’t see that
All good
🦐
That's me sometimes lol
5HRIMP



Do you think it’s gonna be org verify?
censored shit :MeguDed:

(you actually used a gif that's already in my favourites hooooooly)


Inb4 DeepSeek just becomes SSI and doesn’t release any more models until AGI
Who said it's releasing agi

Note: Horizon Beta will be going offline later today.
Thank you for all the feedback you've shared with us during the testing periods for both Alpha and Beta!
Such a surprise
Who could have seen that coming
Thank you for partnering up to give us a free new model to test! Always happy to tinker with new stuff <3
so it really was claude all along
No its grok code
Would be funny if it was gpt2 and we didn’t notice xD
timing is telling... so it was either GPT-5 nano or mini

Can someone explain to me how openrouter works? the horizon beta is supposedly free and yet i don't have sufficient funds to use the model?
make sure you're not using web search because that costs credits
I did not realize this, thank you!
I'm sure Horizon beta was a variant of claude haiku
https://www.youtube.com/live/0Uu_VJeVVfo

Join Sam Altman, Greg Brockman, Sebastien Bubeck, Mark Chen, Yann Dubois, Brian Fioca, Adi Ganesh, Oliver Godement, Saachi Jain, Christina Kaplan, Tina Kim, ...
{"success":false,"errorMessage":"The alpha period for this model has ended. For other stealth models, please visit https://openrouter.ai/provider/stealth"}
The period ended 5 seconds ago
uhoh I'm afraid that horizon might've been GPT 5 (non-reasoning)
if Zenith was GPT 5 Pro
because Summit is GPT 5
We're thinking its actually gpt-5 mini
because the demo they did took like 2 minutes to make 400 lines of code
that's what I've been thinking
horizon can do that in like 10 seconds
maybe
(if you know what you're doing)
How good did Horizon do with storytelling/RP
It has just been removed
Very good writer
It is gpt 5
But probably v3 level plot tracking
So I heard
Yeah so is it 5 full on minimal reasoning or 5 mini
It was a nice ride fellas!
I think its gpt pro atm
.
wait for after the openai livestream
then we will know more
gpt 5 or gpt 5 mini
yeah they said this is actually a 24/7 stream that is never gonna end
did you just breach your contract by typing a message here? uh oh
All cursor users ok what about chatgpt users
Finally i can synthesize my own cocaine-meth hybrid
With the hemp of gpt 5
Oh wait its a horizon model thread lol
GPT-5 and GPT-5 mini have different knowledge cutoff.
2024-10 matches GPT-5
https://platform.openai.com/docs/models/gpt-5
https://platform.openai.com/docs/models/gpt-5-mini
was it like claude/gemini level
Tested GPT-5's creative writing via Poe, and I'm fully convinced Horizon Beta was 5. One of the variants, anyway.
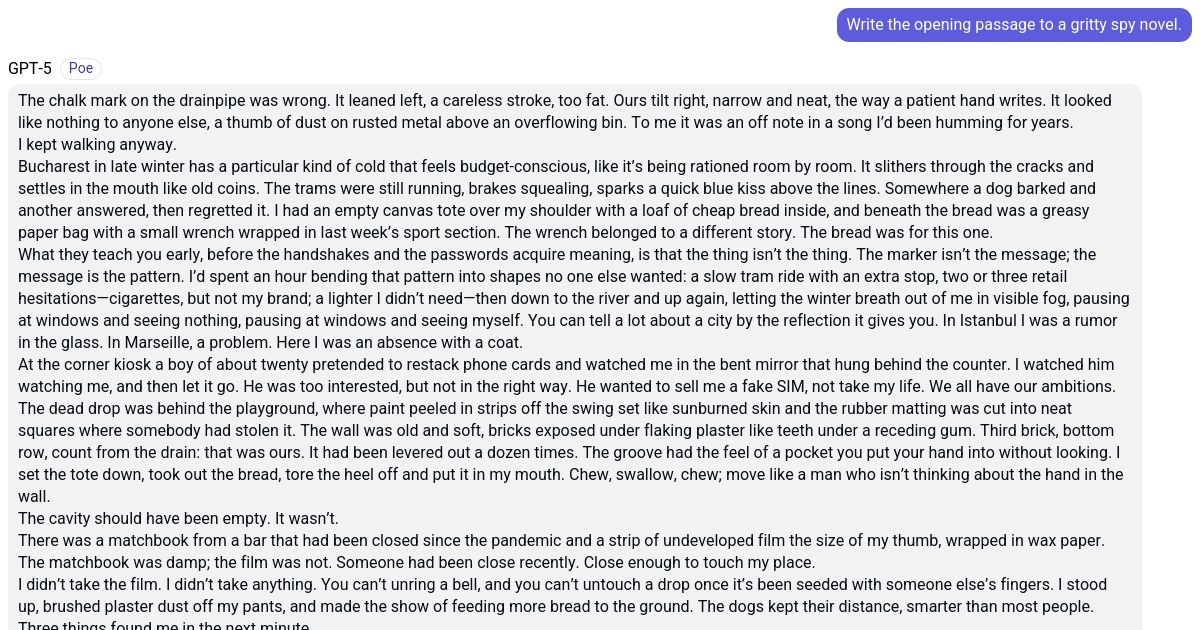
GPT-5: The chalk mark on the drainpipe was wrong. It leaned left, a careless stroke, too fat. Ours tilt right, narrow and neat, the way a patient hand writes. It looked like nothing to anyone else, a
Okay, so what is the commercial replacement?
Very similar to results I had from Horizon
would you say its the new king
Nice I think this is the mini model in fact
can we get official confirmation on which exact models were these?
perhaps even nano
https://poe.com/s/DvlPJkfkC9TovRFEQba3 Here's the same prompt but with Mini. Much shorter output. I think Horizon might have been full GPT-5. I also received long outputs like that with Horizon
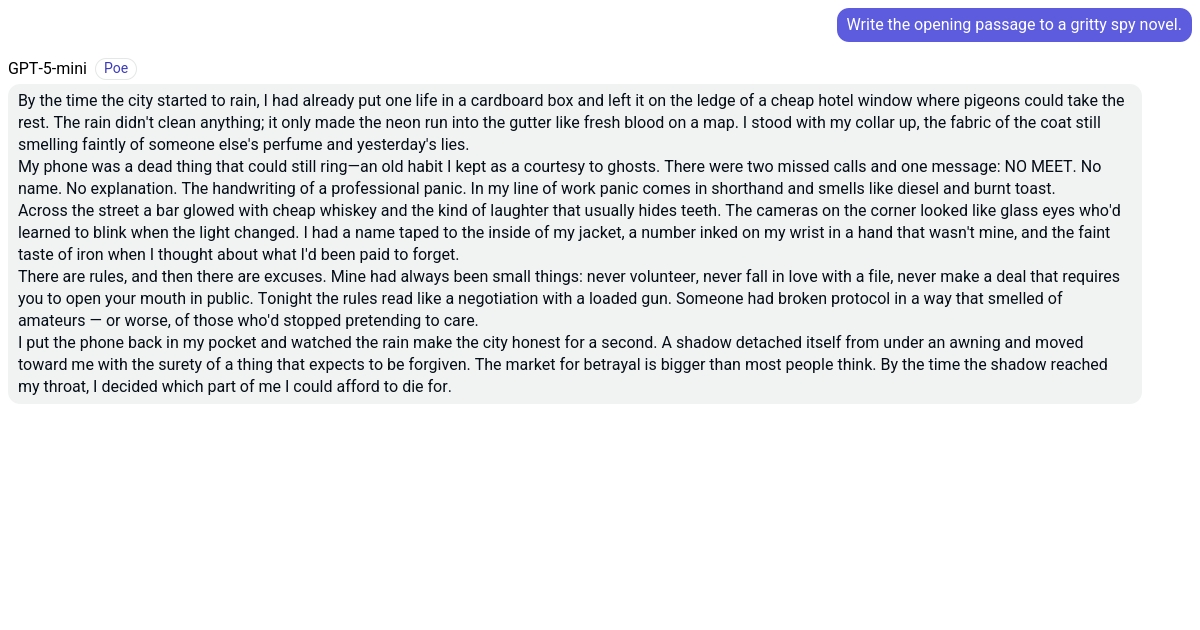
GPT-5-mini: By the time the city started to rain, I had already put one life in a cardboard box and left it on the ledge of a cheap hotel window where pigeons could take the rest. The rain didn't clea
They would NOT waste time test running a mini model. It's full GPT5.
don't think so

family of models
hm well let’s wait for some more clarification then
#announcements message
Too early to tell, but I really do like it so far
So they ran GPT 5, GPT 5 Mini and nano through the horizon model?
so confusing lmao
but was it mini or full :(
are you allowed to say
lol
"Replaces Horizon Alpha and Beta stealth models (early checkpoints in the GPT-5 family)"
From the announcement just now
maybe all of them lol
does anybody take these guys seriously?
so it's cost MONEY now
artificial analysis is up ther with livebench and lm arena for benches to take with grain of salt
It's official numbers from the labs, they just put those together.
that explains it, all the fuzzed benchmarks get used
Well, if OpenAI thinks those numbers flatter the model at its best, imagine how it'd be otherwise.
told y'all
(It was wrong, btw)
Omni
It's crazy how quickly all my expectations were demolished in the most negative way possible lol
If it had been the open 120B model it would have been solid, if it was 5 Mini or 5 Nano it would have been sobering but at least something, but this being their best of the best, even if it didn't have reasoning for the majority of the time is... wow
why didnt yall give us full reasoning control?
nvm I think Horizon Beta was in fact GPT 5 minimal reasoning I guess
based on knowledge tests, it's the only one which knew some that Horizon got
Reasoning seems to provide huge jumps on the benches, so I'll withhold judgment. As is, seems like a decent upgrade to 4o but not amazing. Cost for an Opus-like model is great, but hard to beat Claude Max on that front if Anthropic keeps eating those costs
If beta was gpt 5 minimal reasoning, I'd assume it's smaller than Claude 4 sonnet, Kimi, and even deepseek (R1 zero, oddly more knowledgeable than r1). For random niche knowledge tests. Gpt 4o seems more knowleable too. So this is like nothing like gpt 4.5 which was massive.
RIP, was finally about to run my benchmark on this model and it's gone 🙃
GPT-5
Look inside
GPT-4o “think hard!”
why is opus missing in the chart? also, what is high, medium and low?
Horizon beta was working fine earlier today but now i am facing this error
Error during Horizon call: Client error '404 Not Found' for url 'https://openrouter.ai/api/v1/chat/completions'
For more information check: https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/404

MDN Web Docs
The HTTP 404 Not Found client error response status code indicates that the server cannot find the requested resource.
Links that lead to a 404 page are often called broken or dead links and can be subject to link rot.
horizon beta doesn't exist anymore
Oh so i cannot use it is there any alternative i am doing my collage project and want a llm api that is affordable and can return good code
well.. gpt 5, claude 4 sonnet, gemini 2.5 pro
you can check GLM Air
they probably want a free one
kimi k2 was pretty good also right
Qwen3 235A22B can be decent too
Okay i will try the cheapest of them😅
Horizon Beta was GPT-5, not Mini, Not Nano.
called it
Gemini. 2.5 pro is free on aistudio
In my use case i have tested both gemini 2.5. And open ai 4o-nano and both of them are bad when i tested horizon today i was impressed but its no longer available i might have to try others like deepseek or GLM . Free ones or cheap ones
what the?

we must be on a different gpt 5? lol
Just responded to you in the other thread, that does look like gpt5-chat
is gpt5 api only?
what is the consensus here?
do you guys think Horizon Beta was GPT-5 mini or GPT-5 main
You can access it in openrouter chat
would love if got response to this even from any team member as it has been taken down now
I think main, but without thinking enabled, based on comparing outputs
ahhh now this is it

Yeah you can probably safely assume this is GPT-5 full
Guys so was Horizon Beta a new Gemini model?
Nope it’s definitely not a Gemini model.
Excellent for worldbuilding and theorycrafting
I'm so sad it's gone
Easily the best for my use cases yeah
It's gpt5
I'm aware
I don't have the moneyflow to fund the same experiments with the priced version
I tried deepseek free model its is taking a lot time to respond same issue with gemini 2.5pro.
I basically want a model which is good at writing code and also i need the output fast i tried horizon beta and it was both great for both requirement now it isnt available i am looking for another alternative. Do you know any alternative.
Also i am looking for a cheap option..
Gpt 5 mini
DeepSeek V3 0324, Gemini 2.0 Flash, Qwen3 Coder, GLM 4.5 Air are all decent and very very cheap. If you're doing anything that's even slightly important, like a project, you'll get vastly better results in both quality and reliability by spending $1 on it
Ok
Using GPT-5 yesterday and it’s nothing like Horizon Beta was 😥 it was the best LLM I’ve interacted with to date.
well theres many versions of GPT-5 tbf
I thought someone already debunked the idea of horizon coming from OpenAi because of differing tokenization (matches more with qwen)
I just learned how to read the announcements 😅

I immediately take back what i said, it seems like i am living under a rock 💀

horizon was not a thinking model, so perhaps you may get something similar to that if you used one of their non-thinking versions. How are you using GPT 5 now?
I'm using it for business plans currently. But every application, I've enjoyed Horizon Beta the most. Regular chat, business plans, research, coding. Most of the time I use DeepSeek because I prefer it to ChatGPT. Something happens to the model when they go from "stealth test" to release on OpenAI's platform.
is there like a chat app that u used for horizon?
This morning alone I had to tell ChatGPT to permanently delete information from chat because it kept regurgitating information that I already told it I did not want.
No I was using OpenRouter
because if you can find a way to tweak GPT-5 main to disable thinking, i believe you may be able to achieve close to horizon results
That is probably the issue. But I don't currently know a way to disable it on ChatGPT. Also I'm on a free plan, so it selects the model automatically now.

best we can do to disable thinking is by setting reasoning effort to minimal.
GPT chat doesn't give these options, so your best bet would be to find a chat provider that allows these parameters to be adjusted.

it also seems like GPT-5 and GPT-5 Chat are treated as different models by OpenAI, the GPT you were most likely chatting with was the Chat version, which is most likely different from the cool API one that we were having fun with.
im also looking to get that Horizon feel back!
The new GPT5 models also have verbosity parameters that can be set (from low to high) as well, and we don't know which Horizon was set to, so it's worth playing with those via api, to see if you can recapture the horizon feel
We don't know what Horizon was set to, and i'm not sure what gpt5 defaults to if you don't specify
I'm going to be honest, if I set parameters for how I want GPT5 to respond, I don't need it to tell me it understands me then when I ask it for 10 more of the same thing it completely changes the format. Separation of one message and it completely loses its mind. It's worse than when ChatGPT very first released, personally.
Someone needs to communicate that with OpenAI. Horizon Beta was amazing
Horzion Beta was GPT-5 model with "Minimal" thinking
Thank you 🙏
Dropping gpt 5 into one if my role-playing prompts thst works for literally every other model.. it spat out a huge reply of repetitive repeating structure where all other models do like a paragraph
Not impressed
"Hi"
4 paragraphs of nonsense
I don't think it's rl'd on rp
I’m over it. I wasted all my free tokens twice today just trying to coach it on what I wanted.
I think the reasoning fks it up
It’s definitely not doing what it’s supposed to. Separation of one message and it completely forgets what I instructed it to do.
Doesn’t help that I’m using the free version, so I can’t manipulate the model or thinking. It just uses whatever it thinks is best
Gpt 5 has a free version?
Horizon Beta was indeed amazing. GPT-5 models are unusable pretty much in roocode (maybe if you can stay under 30k context)
In OAI free users get a certain daily allowance of GPT-5 usage. If you are using OpenRouter, no.
Why was horizon so much better than gpt5. I don't understand how this is even possible lol
I think it's because i have the 30k token limit on it and i cannot do much
@brittle barn
ah is that a thing?
The model ID (openrouter/horizon-beta) you provided is not available. Please choose a different model.
Why i got this error?
OpenAI removed this model, it was an early checkpoint in the GPT-5 family
last
Last
I forgot replying to a thread pushes that thread to the top
Not laughing at you btw, just laughing at the situation. I thought I could get away
not last
Horizon beta it's gone, guys? Nooo... 😭 I see it on openrouter but I've never used it before!
I think it was GPT5