#Kimi K2 0711
1 messages · Page 2 of 1
Oh I forgot that detail
Yeah AWQ/GPTQ is a must for H100s then
you could do 4 bit quant probably
Yeah our friend bulbasaur here did 4bit GPTQ
even with the right jinja template still broken, but yeah at least it's a decent perf test
Might be the quant is doo doo
Thanks for your testing service
found a context benchmark, kimi seems decent, funny, i guess maverick, even tho its bad, its was the best open source model with context for a while

I'm almost certain someone has asked this before, but will Kimi K2 Instruct be availble or OpenRouter, or just the base model?
we have the instruct model
we do not have the base model
Must have been my sampling params, thanks
could you guys add fireworks for k2? They added it recently.
🤔

Was about to comment on DeepInfra.
deep infra seems to have fixed it
can’t, they are asking us to wait
yeah they said they’re working on it
are we going to get more providers with tools support? novita & moonshot are very slow atleast right now
Chutes is working on it
DeepInfra claims to have it
but is struggling
Targon is working on stabilizing
Understandable, we don't often get trillion+ parameter models
true
often? we've never had one open weight lol
Yep - that's what I meant 😅

I think it's a little deepseek moment
For moonshot
I wonder if deepseek r2 will do a deepseek
groq? 👀
it's up


let's go
that's awesome they got it going so quick
seems to work great too
is it a small context window though?
wait you gave me that anecdote right @dry hazel

hell yeah
this and us giving them some data on the traffic patterns and stuff
I can't actually take the credit. lots of people wanted it on groq on socials lol
:P
feels so good to have this speed
the only thing that can do it like this is gemini 2.5 flash or 2.5 pro on a 0 thinking budget
and those are not very good models, with zero thinking
groq for k2 tonight? or tomorrow?
yea i’m pumped…this model at those speeds will be crazy. just hope it doesn’t crash instantly or they drop context size lol
they are saying they've got "something special" letting it run at 450 TPS too....
...if they release with that :O
damn
I just got routed to that

absolutely massive if this is actually gonna stay and is full precision
yeah this is what I was told lol:
Give us like 1 more hour... trying to roll out a throughput improvement
holy
this will unironically be the best agent coding experience there is
crazy
way more than I would've hoped for too, by double
anyone willing to test deepinfra tool calling if i enable
sure
I was seeing some jank but working on some other stuff so
they say it's working for them
ok give it 5 mins and it should show tools as supported param
Getting 600+ now
maybe specdec artifacts
eg faster on simple queries


Wonder what's the free limit daily on Groq for Kimi K2
they mentioned on twitter they're testing it out
so you're just getting randomly routed to instances which have the optimization / change
1,000 req/day, 500,000 tok/day

hmm seems consistent tho
Amazing
I think they're literally doing a deployment right now across the fleet
so it's probably getting higher and higher %
idk alternating between those two prompts shows the us presidents one consistently much faster than the joke one
well... they've got MTP iirc?
which I think causes the discrepancy?
(same arch as deepseek)
has anyone that isn't deepseek ever gotten MTP to work on deepseek-like models
how do you even trigger it
deepinfa kimi tool calling should be up
checking
tysm
Did they nerf it? their docs page says ~150tok/s now
https://console.groq.com/docs/model/moonshotai/kimi-k2-instruct
no, it's speeding up
in fact, that's [the message right after](#1393208374769750227 message)
it is in fact working, but seems to output extra content or something
right like extra text?
yeah

can I share this with them?
ty

Doesn't groq have special hardware that basically works best with smaller weight models?
Like a ton of chips each holding a small amount of vram
I remember reading up on how it works and it seems odd they got a 1t model going and so quick
yes

that's novita
they're running maverick and they probably tried to run deepseek, which was probably decent prep
I will learn to read one of these days
it's not a hardware limitation as much as they "just haven't been ready yet". their CEO has mentioned that it's not a fundamental limitation, just a technical challenge
so this is their moment to show they can really scale up
(same with Cerebras fwiw, if Cerebras can do it it would be huge)
also theyve been working on a second version of the lpu
I think SRAM isn't easy to cram on to the chip, which is why they have such small VRAM. Extremely fast, but very limited in storage
it's not really that simple
when you have the chip-to-chip / chip-to-interconnect bandwidth that Groq or Cerebras has, normal understanding of VRAM changes
for example, Cerebras literally goes layer by layer streaming from interconnect at Petabits/s
they don't even NEED to have all the weights loaded like a GPU does
it's like CPU offloading but 10000x faster
So they must have experts distributed among the chips somehow? Would be a huge ass cluster
Do you guys support caching with k2 and groq?
well, probably this too, but that isn't necessary
i don't think groq has implemented caching
Either way I'm imagining a significant amount of silicone is being dedicated to running k2
am i late to the party

Yeah cost ends up being a lot higher since theres no cache but I get it
Oh wow 1 and 3 is very reasonable pricing
indeed
not yet but they're considering it
I've never seen so many providers jump on a model before lol
deepseek lol
Not so quickly though? Even groq
wasn't there tons on qwen 3?
$1 input pricing is the point where it's about about 3x the price of a Claude 4 Sonnet cache read, which matters a TON for agent coding... it'd probably make a big difference if they implemented caching :)
Fair! Just feels like for its size it was disproportionate
oh man
Groq in opencode
it's working
and it's so good
the slowest thing happening is running pnpm install
really good? 👀
yes
what model would you match it at
on terms of intelligence (for coding of course)
roleplay gooners are gonna go so hard on kimi k2 i already see it
lower than claude 4 sonnet by a bit in terms of first-prompt intelligence
what'll really matter is how coherent it stays at ~60k context
not bad though, for its cheapness and performance
and being pretty private
indeed
feel like its worth
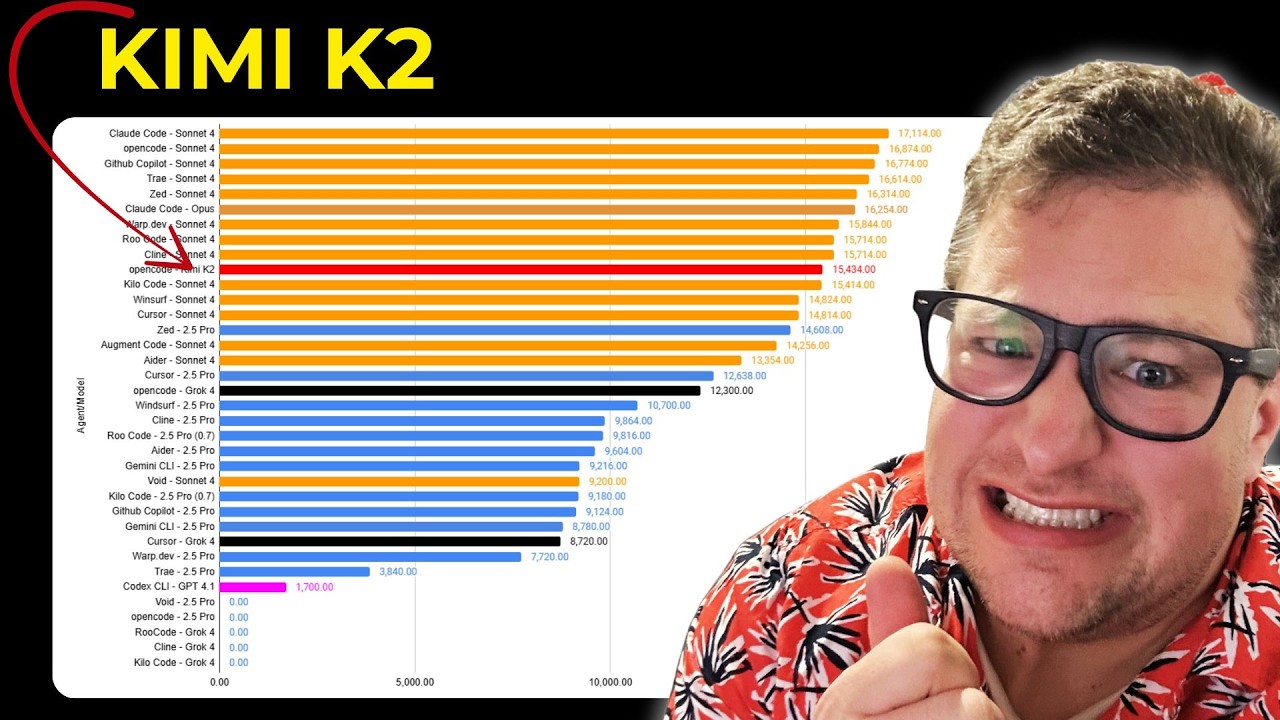
Kimi K2 open weight AI model is massive, amazing, but slow. Lets go over how well it can code!
Links:
🧑💻My Recommended AI Engineer course is Scrimba:
https://scrimba.com/the-ai-engineer-path-c02v?via=GosuCoder
My Links 🔗
👉🏻 Subscribe: https://www.youtube.com/@GosuCoder
👉🏻 Twitter/X: https://x.com/GosuCoder
👉🏻 ...
see this vid
thanks
he's got a solid benchmark on its coding performance, which generally agrees with all my personal vibe tests
(his only complaint was the speed, which is now SOLVED)
i wanna see how it performs on aider ngl
isnt aider not that good compared to any other coding agents?
I'm a little skeptical of aider right now because aider doesn't bench for agentic coding very well
yeah, i thought so..
claude 4 sonnet is >>>> gemini 2.5 pro in agentic coding
but in just "write me a file that does a thing" gemini 2.5 pro is a bit better
you using opencode, do you like it personally compared to any others?
claude code is the best for sure, but opencode is the best open source CLI
one thing ihate about gemini 2.5 pro is it would fail tool calls too much for me

yes but groq doesn't have it
do you think we will see it go more in speed
omg this is amazing
groq or other providers like cerebras
personally this is as fast as I need
rip :C
i havent even tried it yet Lmfao
holy shit its pretty fast
yeah lol
anybody RP with kimi k2 (sfw)
how it hold up against deepseek v3?
I know it writes well, I've tested superficial RP
but I mean how does it hold up
btw we fixed a bunch of the chatroom stuff tonight
thank you
was really stressed out when i would copy messages
and it would never actually copy
oh that was super annoying lol


anyway
it's stabilizing a bit
I'm sure they're just getting a ton of demand
They really cooked with this
yeah I am wondering what their capacity is
not like they can just spin up another 1000 chips easily lol
actaully 1000 is probably on the low end
for what it takes to run this for them
am re-enabling deepinfra tool calling I can't repro this anymore
they said they can't repro it
I'll try

still getting it atm with them
(did NOT happen with groq)
Hmm
lemme see
(for the record, here's groq, no changes other than OpenRouter changing "Allowed Providers")

what's your temp?
I don't really see a good way with opencode... lemme see if I can just repro in something else like copilot
no change, so whatever the provider is setting?
I can turn on the "request logging" thing for you for a sec if you'd like?
this is so sick lol
wow so groq chips are 230mb sram
full 128k context and native fp8 weights like 1.5tb
so 6500~ chips
20 racks
this says one of my requests hit 1000 t/s 😂

gen-1752551759-0NUmDNQ6wVJw9BqjhZFq
gen-1752551759-PvaUzwvDzIqBLjngUyKV
gen-1752551763-Oijmpqj3DhT6T1pdFHKm
just running the same thing in a random public cloned repo
ty
groq is running hot
do we know if groq is doing full fp8?
they run all their other models at full precision
not quite that simple because they're almost definitely doing streaming
the thing with SRAM is you can CHANGE it really fast
unlike HBM
you can change it but it still has to load from some other medium of storage?
isn't there a bottleneck there
this is way out of my dpeth
I just play with llms lol
take it with a grain of salt because this is how Cerebras does it, but assuming it's similar
Cerebras both has their wafer-scale stuff
but the other KEY component of their architecture
is EXTREMELY high throughput and low latency interconnect
between hundreds of chips
in any case I'm sure it was a significant hardware commitment to run this for groq
so they literally load model weights in LAYER BY LAYER on demand, and can split it up even further (e.g expert parallelism)
and it's still 100x faster than other providers
(specifically, they can do this while normal GPUs don't yet because they co-design their chips and their interconnect to do this specifically with direct silicon networking and such)
parasail not looking too attractive atm

nope
this is gonna be what really puts Groq on the big stage imo
every other model they've done has been "nice" but not important
this is the first one where this model could literally challenge Claude 4 Sonnet in REAL usage
not just toy small model usage
price, latency, throughput, storing prompts ALL IS BAD!!
and that makes all the difference :)
why k2 and not deepseek is my question
parasail doens't store prompts afaik
I'm guessing they were waiting for "the next deepseek" (this) in order to rollout the necessary changes
they clearly CAN do deepseek right now, but the marginn of improvement over other improvements isn't really there anymore
others are doing 100 TPS, and it's not frontier anymore
Kimi K2 is DS V3 architecture, so they 100% can do it
all while other providers can barely break 10-15 except together
yep
wonder fi they were weaiting for r2
it's nice how concise this model is as well
and non reasoning
I'm sure makes it easier to inf
really? it shows "retained for unknown period" on openrouter
and their privacy policy doesn't say anything about not storing prompts
I see - this is all it shows me on openrouter

We do not store or logany personal data you send as Input to the “serverless” and “dedicated”versions of the Service, and we will not inspect such data withoutyour permission, and will only retain such data for as long as is necessary toprovide the Service to you (i.e., for the time it takes to generate Output anddeliver that Output to you).
@winter jackal as always thanks for supporting these models so quickly. A bit of feedback is that on groq it's a bit more unstable with tool calls and returns Upstream error from Groq: Failed to call a function. Please adjust your prompt. See 'failed_generation' for more details. more often. But I guess it's in "preview" on groq for a reason so we'll give them time to get better. Also if groq adds cache this models becomes even more better.
Anyways here's a little preview of what it built: #app-showcase message

I’m guessing it’s nothing, but @winter jackal might wanna send that to Groq just in case?
@teortaxesTex need to do some 1:1 comparisons
feels too good to be true/less subtle than the slow ones
It's a very slight quality change but I can feel it
It’s hard to tell because it goes so fast that the speed itself makes it feel “lower quality”
lol
Yeah it's still solid though imo

it doesn't speak portuguese very well...
sometimes spills nonsensical sentences and confuses genders
only decent with English and Chinese afaik
It isn't easy. I just had 2.5 Flash do a pretty terrible translation on Portuguese earlier today, oddly enough.
I think most people would be surprised to see just how much English dwarfs the other languages in terms of training data
From the massive Anna's dataset, the top list is English at 23M documents, Chinese at 7M, and Russian at 2.6M. Roughly a 3x decrease each placing. Portuguese has 50x less documents than English. Always kind of blows my mind.
This model seems to do really well for RP
The format also doesn't fall apart after a few replies
use it in text completion, it's better
Not sure what you mean by format, but I'm seeing it struggle with group RPs
It holds well for over 30 chats now, the format I made(including the rest of the instructions) are still met without a single mistake that I have to remove.
Writing is also great, it has humour and seems to have a deep understanding of human reasons
I haven't tested this, I shall try
Oh hey, its me. Yeah amazing to see it on groq, but at least initial impression no where near as good as other providers ( mainly moonshot, together ) when it comes to task adherence, code quality and tool calls. In both opencode and roo. Multiple failed tool calls and a tendency to loop on failing tool calls . Similar behaviour to gemini flash. Never saw similar behaviour on other providers.
Hmm. This is second person perspective, and the problem is the model keeps switching to using "I" in their own messages, instead of the character's names
I'm aware models generally prefer first-person
Perhaps try an A/B test to clearly demonstrate the behavior and send to Toven?
I wonder if they are indeed quantizing, I haven’t seen them say they definitively aren’t
Seems unlike them though
If I don't sleep now ( 6:45 am XD ) I never will, but can do a/b when im up again.
I don't think its quantization, it could be as they haven't said but..., im not sure what it is. I have faith in groq, but something about architecture or implementation is having an impact.
yeah i’m also about to pass out but if you have specific examples i can pass them along. they definitely do things uniquely to get that speed
Will be happy to. Think I can export session data from opencode which should help, same with roo. Sleep good man what a historic few days aha 😅
But sleep first, if I sit back at my computer right now I won't be able to stop
Does groq cache?



I still really want benchmarks (or just a benchmark) provided by OR for each provider
doesn't need to be exhaustive, just enough to identify problematic providers or differences in quantization
i don't think it would be a bad idea to consider the bench scores for which provider to route to, either.
if one of them is noticeably worse anyways
I've been using Kimi K2, and the vibe is really similar to Claude models. It is weak in general chat (even the flop Maverick is better), but the coding performance is very good. I guess this is a pattern we will be seeing when a model is primarily trained on coding and agentic tasks. Creative writing is amazing; the output reminds me of fine-tuned RP models on Hugging Face. So, Kimi K2 is a model that is going to be great for people with specific uses (coding, creative writing), but for general chat, there are better models out there.
And its censored with messages stating its open Ai guidelines
scroll up, fireworks told them to wait a bit
oh
kimi k2 might be the most expensive API endpoint I've everseen
Kind of funny you compare to Maverick there, because they really are opposites. Maverick is terrible at almost any specialized task, but it's there to be a very chat-heavy model that literal billions of normies (respectfully) like talking to.
I enforced Allowed Providers and added groq to the list but when using kimi-k2 on opencode I get this error

any idea why this might be happening? other providers just arent fast enough
it was working earlier this morning, it isnt now for some reason'
Are you using free
Groq is paid
What are you using for your prompt? Haven't noticed this.
I like it so far too. Have you tried with multiple characters at once?
It's a kind of custom ungus one I wrote after getting annoyed at the levels of tell-don't-show of most models
The relevant part pretty much just says to reply in second person perspective and gives a one-line example

no im accessing it through openrouter which has credits
is kimik2 via groq BYOK only?
Huh weird what provider and temp?
"like talking to"
From what I've seen normal people like it. You've seen otherwise?
Parasail, varied between 0.4 and 0.8
I've only seen people get mad for getting it pushed at them with no recourse
Sure, but that's irrelevant in the aspect that I'm referring to
Honestly google has that problem pretty badly too. Like how many Docs am I really going to need gemini to help me write? Certainly not enough for a giant popover bar every time I open a new one
Exactly, they are like polar opposites. Maverick caters to general use, while Kimi K2 is for specialized tasks. DeepSeek still offers the best balance so far, IMO, among open-source models.
oh shit we got groq
damn groq dropped max output to 16k, i guess they couldn’t handle it
No it's not, it works via OR, weird
We've heard your feedback — Kimi K2 is SLOOOOOOOOOOOOW 😭
Especially for agentic apps, output tokens per second really matters.
The main issue is the flooding traffic and huge size of the model, we are actively working on inference optimization and BUY MORE MACHINES!
Speed
We've just fixed 2 bugs in Kimi-K2-Instruct huggingface repo. Please update the following files to apply the fix:
- tokenizer_config.json: update chat-template so that it works for multi-turn tool calls.
- tokenization_kimi.py: update encode method to enable encoding special
Interesting, I hope this is what caused the Groq issues
very interesting.
24 hours of non-stop stress-testing, Kimi-K2-Instruct cleared every benchmark in our playbook. 🚀 Now it’s LIVE on the Fireworks Serverless API
It is the first open-weights SOTA 🔧 agentic tool-caller, holding its own on SWE Bench, Tau2 & AceBench. Same prod weights, zero infra
Apparently the chat template bug was reducing performance SIGNIFICANTLY
after fixing it, perf went from 14% -> 50% on a tool use bench
Tf, that is an insane jump
I think the chat template bug was literally erasing tool use results more than 1 tool back or something lol
So yeah makes sense!
groq is dying
I can't find the instruct model on openrouter. Is that correct?
we only have the instruct model, not the base model
do folks think I should add Instruct to the model description?
I went ahead and updated the model description to specify it
I think it would prevent me from asking the question in the future 😄
Thanks
Just asked the model to do some tool calls:
<|tool_calls_sectioall_end|><|tool_calls_section_end|>
Derp 😄
Yeah groq is failing tool calls right now
That happens with Deepinfra specifically
It’s a bug atm
There was a patch this morning fixing tool calling chat template, anyone using Kimi K2 currently w/ tools of any kind, I would reserve judgement until later today
We've just fixed 2 bugs in Kimi-K2-Instruct huggingface repo. Please update the following files to apply the fix:
- tokenizer_config.json: update chat-template so that it works for multi-turn tool calls.
- tokenization_kimi.py: update encode method to enable encoding special
@winter jackal I noticed Novita added an Anthropic compatible endpoint in about a day… it would be realllyyy nice to have an openrouter Claude Code endpoint for use with Kimi K2 if you guys could make the same :)
Open code is great and has good tools/prompting, but still has some usability issues atm
Sorry, I wasn’t implying that part hahaha
Just that it might not be something SUPER difficult all things considered
for 400+ models and 60+ providers? :P
(Of course OpenRouter has a lot more constraints that would make it harder than Novita doing it for a single model 🙂 )
Yep exactly haha
yeah no I hear you
we've thought about it a bit, just other things are higher prio
(embeddings, large file support for example)
You guys are still actively recruiting I assume? I’ve got some friends to send your way :D
Is it normal that groq is failing on tool calls right now?

It’s failing on the official API intermittently too, so not openrouter’s fault
Like 50%+ of request end up in failed API tool call
So groq's issue I guess?
Yep
Unlucky
slowed down a touch on eng hiring as we went from like 4 eng to 8, but yeah we still got jobs up
I need to git gud cause working on a project like openrouter seems like dream work
I asked Kimi-K2 to create a webpage for a procedurally generated 3D planet preview / editor.
Then, I had it add a complex simulation feature, where an asteroid is hurled toward the planet, forming either a moon or a beautiful ring.
Very strong showing in this test –– comparable to Claude Sonnet 4.
yeah. frontend web & 3d seem to be really strong in kimi
For context, this was Claude's result, which cost 6x via the API.
Via Groq or something else?
For something that price, it's truly impressive
Btw, is that a one-shot code?
@dry hazel B
Yes, using Groq via OpenRouter.
@dim tundra
I split the task into 2 prompts. Not because it failed, but because I came up with the asteroid idea a bit later.
By the way, here are the prompts if you want to try it out with another model.
Create a high-fidelity, interactive webpage that renders a unique, procedurally generated 3D planet in real-time.
Details:
- Implement intuitive user controls: camera orbit/zoom, a "Generate New World" button, a slider to control the time of day, and other controls to modify the planet's terrain.
- Allow choosing between multiple planet styles like Earth, Mars, Tatooine, Death Star and other fictional planets
- Render a volumetric atmosphere with realistic light scattering effects (e.g., blue skies, red sunsets) and a visible glow on the planet's edge. (if the planet has an atmosphere)
- Create a dynamic, procedural cloud layer that casts soft shadows on the surface below. (if the planet has clouds)
- Develop oceans with specular sun reflections and water color that varies with depth. (if the planet has oceans)
- Generate a varied planet surface with distinct, logically-placed biomes (e.g., mountains with snow caps, deserts, grasslands, polar ice) that blend together seamlessly. Vary the types of terrain and relevant controls according to the planet style. For example, the Death Start might have a control called trench width and cannon size.
- The entire experience must be rendered on the GPU (using WebGL/WebGPU) and maintain a smooth, real-time frame rate on modern desktop browsers.
Respond with HTML code that contains all code (i.e. CSS, JS, shaders).
Now, add an button allowing the user to trigger an asteroid, which hits the planet, breaks up, and forms either a ring or a moon.
baseten is sending me empty toolcalls
can you send me the full response
in dms or somehting?
yeah sure but im using streaming
so its gonna look a bit messy
anyone know if kimi on groq is diff from other providers?
it was yesterday yes
lots of complaints it was underperforming

How can I use only Groq in OpenRouter interface
embeddings 🤞🤞 🫶thank you guys
oh shit Baseten doing 160 TPS?
most likely due to the general bugs from this morning

😔
@winter jackal it seems a bit misleading that 429s are counted as 100% full uptime
i mean
at fp4 though
it's not really downtime though
well... from the perspective of the user, it's not really any different from a 500
considering they're both basically just retriable
and a provider spitting a lot of 429s compared to another provider not, should probably be downranked
fwiw crofai claims 300tps at fp8 (albeit small context by 2025 standards)
we do backoff from rate limiting providers
ah ok, so it does contribute to the dynamic algo, just not the uptime % ?
yep
that's fair, though I still wouldn't mind something like a badge that is like: High Availability (Green) / Medium Load (Yellow) / Under Heavy Load (Red)
yeah I do get your point and I think it's worth considering for sure
but I def feel that uptime specifically is probably the wrong way to define that
sure sure
probably w/ the same thing that makes the providers faster than their claimed tps if the prompt is simple as others (can reach 500+)
yeah something like this
when these models have such extreme differences in performance, at this point I'm actually almost never using the dynamic routing algo
something to consider might be a variation on turbo which still does dynamic ranking, but picks e.g some upper threshold of performance or something like that
yeah, they're almost like entirely different products so to speak right
yea
or even something where providers can "qualify" for a subjective "high speed" lane, which varies per model and the landscape.
and presumably such a label would mean high throughput, low 429s, and a reputation for quality in general
it doesn't make sense to have fp4 high throughput low ctx in the same default than full fat lower tps full context w/ tool call etc
yeah
we do obviously today basically filter out a bunch of endpoints based on your api call (ctx filtering, tool call filtering, etc)
right
but. should be better
yeah this provider tier is where we think we will end up right.
it's like throughput and quant and benchmark scores
yep
gets you into premium tier
or something
and low tps / low quant / low benchmark / evals is like an unverified lane or something
and with this we can onboard the dozens of random providers no one has heard of
into the unverified lane lol
instead of just into default routing
yep
Certified  could be one metric (quality, full context, full precision), and Turbo 🚀 another one (high speed, low 429s)
could be one metric (quality, full context, full precision), and Turbo 🚀 another one (high speed, low 429s)
probably will also have to be subjective to some degree for certain models I'd guess, because even if a provider doesn't serve Llama 4 Scout at 10M context I don't really blame them or care 😂
ehh. I think our goal is going to have to be to be objective / quantitative as possible. we intend on being a very neutral marketplace
eval scores, latency, tps, context lengths, and possibly user voting/ranking
I think you should 100% be objective within the scope of a given model
but that the standard may slightly vary depending on that model
objectively, context only matters when it prevents a provider from serving you; if they can't serve half the requests too bad for them, that's how markets go, but no need to do extra deranking imo
true :P
i would be curious about everyone's opinions on this kind of thing
@grok summarize this thread

am siccing gpt-4.5 on it
let me run discord chat exporter...


Is it possible to manipulate it to reason?
in a sense yes, just prompt it to "think step by step" inside of <think> tags ;)
you aren't gonna believe this
I do this for some of my automatic systems for both reasoning and non-reasoning models
crazy "manipulation"

we started manipulating models from the moment we made it predict turns in a dialogue setting
true...
right now its basically manual work to "vibe check" each provider individually and there is a large gap between those faithfully serving the model (tools working, unquantized, etc) and those which are not... it really adds up when trying to use OSS AIs for coding stuff.
can you just run a suite of benchmarks a couple times vs each provider and publish those?
Benchmarks won’t really serve the full picture (eg quants really don’t make much of a difference, it just looks like noise)
quants are tricky but they're still noticeable in scores, especially ones that are longer horizon and not just yes/no answers
a trick I like is: "write this long and tricky piece of code X", and then pass/fail = does it have a runtime error
bingo
Groq, but it has tool call issues right now. Baseten is good but it's got severe rate limits right now and is quantized.
Together* is probably your best bet.
I think quanted models tend to fail harder at coding one-shots
ty!
fyi @winter jackal chutes tool use is still broken afaict (but it's marked as tool-available in openrouter)
whoops i mean to disable tools for them thanks
should be off in a few mins
Yeah I guess that’s a way to do it, but you’re going to waste a lot of time to get a suspicion
it would have to be automated ofc
there's a nice network effect that doing provider-level benchmarks can provide: if any provider is outside of 1-2 standard deviations on any benchmark, you can be pretty confident something is wrong
also, are you sure Together doesn't support tools?
(they've got function calling on their platform ofc, though I'm testing through their official api now if Kimi K2 supports it...)

Together
Learn how to get LLMs to respond to queries with named functions and structured arguments.
they do list Kimi K2 as an official function-calling model atm
yeah. There need to be tiers of provider basically, with the top tier having some reasonable expectation of reference-API quality, tool calling, usable tps, etc.
working well, I think Together is the best-behaving provider atm 👍
and chutes paid
broken though seems like
seems to work for me 🤷


odd
@dry hazel @winter jackal if Groq tool use is broken why does it show as tool use available in openrouter
it's not quite broken
it's just half broken
they're fixing it and should be available very soon
(they said so as recently as an hour ago)
Source?
groq forums a while ago
is groq using q4/4bit? the outputs are way worse than together or official api
many on twitter asked, but they selectively ignored their questions while answering others 
It was sort of nonsensical at default temp of 1.0 in Swedish for me (a small language that pushes LLM's a bit) but improved significantly by lowering it to 0.6. I've seen this pattern in other models too. It generates multiple full paragraphs in quite decent Swedish for me now.



I was one of the first people to try K2 on Groq via OpenRouter last night, and everything was running smoothly. But this morning, we’ve been running into a lot of issues with tool calling.As you can see from the screenshot below, tons of API calls are being wasted due to failed tool calls. The ones...
Yeah that's my post lol
He just said very soon that's why I though they mentioned it elsewhere
Yeah… @winter jackal are you able to confirm if Groq is full precision…?

No precision specified…
They don't tell us this
Hm gotcha
Groq sales: precision? whats that? Ha! 200 tokens per second so fast right?
even if I go ask and they tell me specifically I doubt I can share that info
yeah
this is like inference secret sauce
the faster the lower the precision
its not just quantization that impacts quality
I guess I was hoping they just didn’t see/care about the random Twitter questions, as opposed to actually being lower precision
its tricks like token dropping and speculative decoding
as a general rule faster = lower quality
Sure, but things like speculative decoding can be fast and without any accuracy degradation
And of course hardware matters
…and things like Expert Parallelism matter a ton, eg SGLang’s Deepseek stuff
absolutely but trading 2x efficiency for -10 iq is very tempting
100%
Baseten is doing that right now
And I’m using it!
I just wish Groq would be more forthright about it if they are in fact doing this
well, I'm running a personal benchmark on a few major providers right now, will report back any discrepancy

running a bigger one now 😄
my benchmark is a bit too saturated right now, I might make a "hard" variant to help differentiate, or some other tests specifically for this kind of thing
so groq is hosting a dumber kimi correct
we don't know
do we all agree they might be doing so though
no one has run benchmarks on it, and they haven't confirmed to anyone
seems possible considering they've seemed to be evading the question yeah
groq too unstable to really test right now 😂

probably still truepoint (down to fp8 for weights but full accuracy math)
at least it was that way in 2024

hm
interesting
why they don't say that... is a little suspect
(have they run MMLU on the model? are they seeing actual degraded performance perhaps?)
sambanova did a hit piece on them (also 2024): https://sambanova.ai/blog/does-reduced-precision-hurt
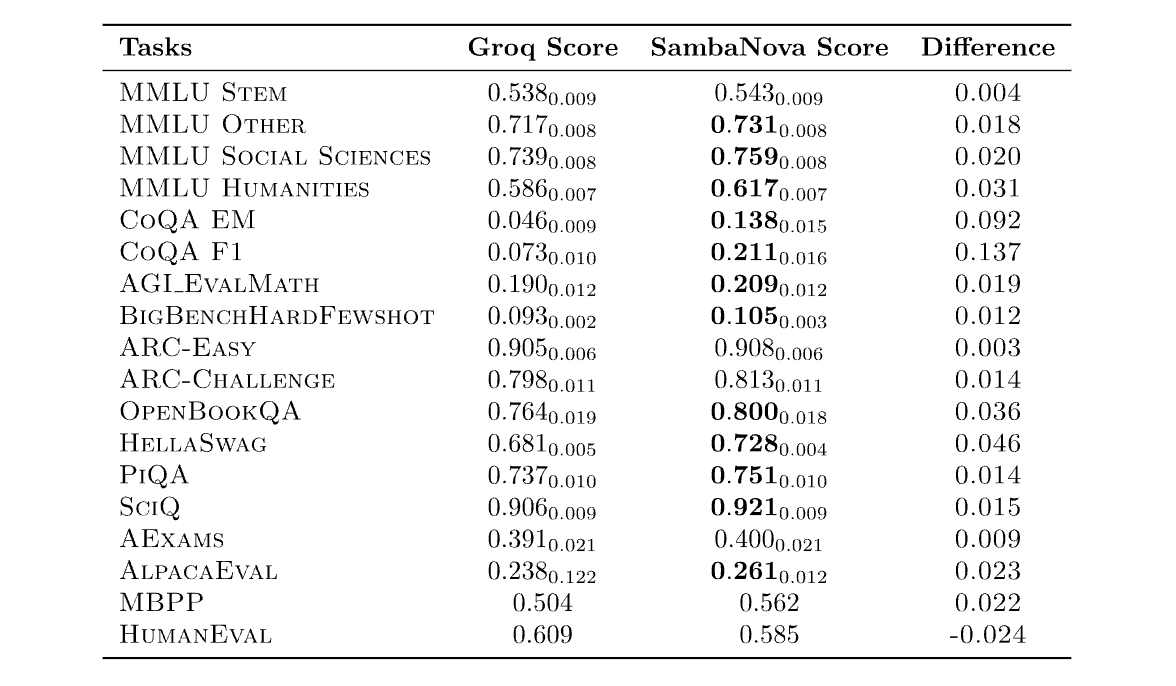
Recent work highlighted how quantization for recent LLaMa 3 models can lead to non-negligible decay in model performance. Does reduced precision hurt model performance?
artificial analysis used to measure artificial analysis score once per provider and it only changed by 1 or 2 points on groq though
huh
the proposed openrouter benches would help with this
their artificial analysis score only changes by 1 or 2 points between llama maverick and like o3 though 
(exaggerating, but basically!)
opus behind 2.5 flash
thanks but no thanks artificial analysis

lol, lmao even

I think AIs are definitely getting into the spiky territory now even more so than like a year ago
Aider Polyglot isn't as good as "claude code experimental tests"
because aider polyglot isn't agentic
which reallly matters
so there's tons of variance right now
really?
yep
it's two-shot attempts
if the model gets it wrong once, it gets a second chance, and that's it
two prompts
bruh
me personally, I'd put Opus 4 / Grok 4 / o3-pro all at the top
with o3 pro probably the peak, but super slow
following that, o3 and 2.5 pro
is grok 4 rlly that smart
heard ppl say its all hype
but i found it pretty smart when i talked to it
it's OK at coding, but I think it's smart
yeah
I wouldn't use it for anything because it's slow
yeah opus is great
I'd probably rank like this, in terms of intelligence with a small bias towards being good at code:
S: o3-pro / Opus 4 / Grok 4
A: o3 / 2.5 pro
B: sonnet / Kimi-K2 / deepseek r1-0528
C: gpt 4.1 / gpt 4.0 / grok 3 / deepseek v3-0324
specifically for agentic coding it's much clearer:
S: Opus 4 / Sonnet 4
A: gpt 4.1 / o3 / 2.5 pro / Kimi-K2
// everything else
Kimi-K2 might be B tier in agentic coding, or it might be A tier. A bit hard to tell without good apis
bulbasaur benchmark
real
This ranking is exactly my feeling for model quality. I think, when it's served at full capability. Kimi is between sonnet and 4.1 matches or even supercedes sonnet at frontend, and around 4.1 level in backend tasks . But it's hard to tell with such variability in quality
just did a quick comparison (not hyper indepth like I test usually, just a quick one-off run and comparison). had to exclude a bunch of queries (500 server errors on groq), but from the ones that didn't error out direct side by side comparison from my initial test 3 days ago (identical settings):
| | pass | refine | fail | refuse
|--------|------|--------|------|------|
| novita | 40 | 5 | 13 | 1
| groq | 29 | 10 | 20 | 0
note, I didn't spent much time on this, just a quick comparison, so some factor of variance has to be accounted for. also i don't know how groq implements their models nor do I have much experience with them
Also 4.1 is an odd one, cause without good system prompt it sucks ass, but underneath it's a great model. Remember how good quasar and Optimus were? 4.1 on release did not quite match up, but with beast mode prompt it really works well for me
Interesting, good testing…
I’m now concerned Groq is gonna leave a bad taste in people’s mouths
Sigh
So much reputational damage to models (and then lack of interest in them) happens from this kind of thing
true! very obedient
and surprisingly good output, but not good for creative writing - it still falls into clichès
Yep 4.1 is definitely an interesting character
o4 / GPT 5 should be quite interesting
As I think 4.1 is the base?
Or maybe they won’t even do that 
Reasoning 4.1 would definitely be interesting to see, as iirc o3 isn’t 4.1 base
While I dislike reasoners. A reasoning 4.1 would be an interesting proposition
don't know about groq specifically but I personally avoid any endpoint that doesn't specify model quantization. I need to know the model precision I am receiving (especially when benchmarking anything). Now, whether that information is always 100% accurate is another can of worms, but you get my point.
And with how good it is at tool calling, must be generating some great synthetic data for openai. Do wish it was smarter though. Hope K2 variability churn stabilises cause when it's firing on all cylinders it's a smart model for sure
Yeah
Code is pretty hard to benchmark because it has so many subtasks and categories
Different people are going to prompt it their own way, coding styles, etc.
Speaking of, have there been tests on how LLMs do with the different coding paradigms? I would intuitively assume OOP to be the worst since there's so much shit to track across the codebase. (Slight bias, I hate OOP). Then "standard" imperative code. And then best at the extremely "clean", disciplined paradigms like functional programming and ECS.
I hope model providers put it in the licence or something at this point. “Public deploys must match our reference spec”
I have the feeling spec decoding will take more than a week to get good with such a large model
What the helly?
So they claim
If it’s the newer Chutes version, this can actually be verified due to confidential compute proofs
How does that work
Well basically nvidia has some special TPM like black box, which lets you verify a certain computation has occurred on a certain machine
It’s only on newer cards
But wouldn't that require access to the machine
Well that’s the point of a TPM, you can trust it has been executed due to the existence of this extremely safe piece of hardware
And yet CC isn’t taking off at all despite it solving a lot of problems with ai inference (privacy and deployment verification).
I never said Chutes is good for privacy
CC = confidential computing could provide privacy guarantees more widely but nobody seems interested.
Chutes might be still affected by chat template bug, I notice they are still running on older revision before fix
Yeah sorry you didn't. I misunderstood.
CC stands for Claude Code now. RIP Adobe.
Yeah I suppose it kinda does
Creative Commons.
fight me
Clash of Clans
oh lord
CC from Code Geass
Well CC only runs on an extremely small and expensive subset of nvidia offerings. Beside the point that essentially you are still trusting nvidia.
I agree with that, it is actually my new default, way better than I expected, love it inside of cline/roo, and inside of OpenWebUI
An actually very glad it’s not a thinking model, got tired of waiting 5 min for a single code change
Baseten & Groq still tool call failing 🫠

Most confidential computing is done on the cpu. Nvidia stuff is just providing memory encryption between host and gpu afaik.
CC only runs on Hopper/Blackwell, it requires a protected region of memory which only these GPUs have
The CPU TEE is just doing what a normal CPU would do with a normal not CC driver
I'm sure you could jailbreak this to work on any GPU but that kind of breaks all security assumptions of the CC so
It doesn’t. Cc can verify driver versions etc. it severely limits the threat surface to either modified spying hardware or a spying hypervisor.
Microcode/firmware bug, etc
list goes on and on
we still essentially trust nvidia
Yes but you trust nvidia and intel and AMD and msi and whatever other vendor is involved if you run stuff locally
I'm not trusting them, there are no trust assumptions when you run something locally
lol
If I were to run them locally and verify my local compute with something like CC, i would be trusting them, yes
No, you are trusting it by using it at all. Could have backdoors etc that you don’t know about.
the assumption here is "am I actually running the compute workload I wanted to run?" - verifying that beyond reasonable doubt requires a trust assumption
But I don't care about backdoors in the context of just running locally, no verification required
Why would I care about the millions of backdoors modern systems have when I'm just using something locally and dont have a need to verify anything
For verifying a workload cpu based trusted compute is almost certainly enough.
You don’t need secured gpu memory for that
CPU TEE isn't able to give the guarantees a system like Chutes or Targon requires, hence why they use CC, and not just basic TEE
I thought both of those are not using any confidential computing
CPU TEE is extremely weak in an adversarial network setup, where trust assumptions should be minimised
They require it, for the newer version atleast
They had a lot of issues with people stealing rewards by submitting fake inference
So you can clearly see CC is a requirement for such "decentralised" setups
By accident, this also hardlocked their "v2" platform to Hopper/Blackwell but since its centralised af, I don't think any small time inference provider was hurt
Why do they not guarantee privacy then?
CC is great for privacy but its one part of the lego
You need a lot of extra work on top to ensure all the different parts which interact with the CC are also private
You do
That is difficult and tedious work, and it backfires if your privacy claims are proven false or your private inference implementation breaks
A provider can CC inference and still collect it afterwards, or preprocess it, or sell it etc
There is no direct User to CC pipeline
If the inference is done in a TEE they can’t unless the tee shares it with them, no?
But I think what you are saying is it only verifying the workload at the moment
Eventually it must leave the TEE
And someone must encrypt it/decrypt it etc
You could build it, its just complicated and not an issue Chutes was facing - they just wanted to reward real inference in a decentralised manner
You can have an api client running directly with the user that does remote attestation. Then it only leaves in plaintext on your own device.
expensive and don't think it would scale
also, what if you want to build a web frontend? What if you want to integrate with the rest of the OpenAI SDK services?
list goes on
Expensive for the user I meant
Yes, because otherwise fake gpu or other forms of counterfeit hardware can be an issue
It was an issue, Chutes used to be trash
Plenty of empty answers or cached stuff
They'd have to manually ban people off the subnet constantly
Clearly you are very up to date with chutes. I haven’t been using it because as you say quality used to be bad.
I hope that they can extend to full private inference, it seems that they have all the building blocks in place now
It would make the most sense for the local app I’m suggesting to in fact be an api endpoint
If it’s just chat.exe or something then yeah it doesn’t scale
I like consensus models, they have an interesting one (now, before it was doo doo)
The biggest improvement which gives Chutes some redemption is implementing CC
But I still don't like the TAO ecosystem as a whole, really way too overvalued for the technicals they demonstrate
Tbh there are a lot of providers cutting corners imo. It’s really bad. Maybe CC is the solution to this issue as well as trust me bro privacy.
Yeah, in a world where everyone runs their app locally, it would be great - but most of the world uses webapps and on top of that, they integrate with existing OpenAI SDKs and so on
It could be, yeah
Its a step in the right direction
I would prefer to pay in dollars or euros for basically everything.
so how good is K2 for agentic workflows? what is the popular verdict a few days after the release excitement?
Providers seem to provide different performance
Pin a provider for consistent results
Yes, these were the only two providers I was experiencing refusals with as well with the same prompts and same settings
targon just randomly outputting chinese lol
It's weird how concise it is. I'm like wait where is the essay in response to my question?
It's not that the replies are short they just aren't fluff
This will train into a beast reasoning mode lol
guys what's the best provider for Kimi K2 so far? i need a good provider to do my eval 😆
TIL fp4 is a thing
so far novita/fp8 has given me incomplete response (and i am still getting charged for it)
Tbh, never use Novita for anything
so blacklist deepinfra nd novita it is
Parasail is good imo any issues from day 1 are likely fixed now
After moonshot released fixed inf files
@grave jetty any idea best provider on kimi k2 atm?
Well I guess I can test the different providers and post the results here. If no one has done it.
Chutes on the free version
That's surprisingly
67 tps + no quantization
I thought they are a web3 crypto company
From the brief tests you and dubesor did, Groq has some performance degrdation
And Targon is at fp8 (cheapest provider + 60 tps)
I'd use Targon personally, but it wouldn't be good for a benchmark
They are
This model likes to elaborate its thoughts on why it can't RP light-nsfw 🤣 It wrote a 3-paragraph explanation for it
Would be cool. I’m definitely feeling some diff myself
@winter jackal Looks like Weights and Biases (bought by Coreweave) is now in the inference game, and they have K2 on there: https://wandb.ai/inference/coreweave/cw_moonshotai_Kimi-K2-Instruct
yeeepppp we've heard
why does it say its context length on openrouter is only 65k?
and why is it different for free tier and paid tier?



I don't know. My testing was done through NovitaAI and it worked well. When I tested Groq it performed worse. Haven't tested any of the other providers since.
Also - don't really have time to bench providers since my process, with the exception of response collection, is not automated.
Different providers are used for the paid tier and the free tier. Different providers offer different capabilities
i see, but only openrouter reports 64k instead of 128k :/
i love how o3 speaks too
@brittle cipher if someone does provider reviews that's actually huge
ok but what does ":FoxYay:" mean
It's uhh, umm, an emote? I guess? What else can I say?
how does it convey the message of "huge"?
Alright I'm not doing this, feels like bait. You can ignore that message.

aren't we all?



agreed, i like chatting with it about random things
It's so natural
No cringe
Like, i have this very sophisticated instruction that it must act like discord user, use informal everyday casual chat language, etc
And
Its a night and day difference
I realized that Kimi K2 is just so good at adopting it and Gemini 2.5 pro is now it looks sloppy



It knows a lot of ai developments
So relatable
Less slop
Good at tools
Knows niche stuff more than other models
too bad it's not good at long context, otherwise it would be goat
🚀 Summer Fest Day 5: Multiple Token Prediction in SGLang by @Eigen_AI_ and SGLang Team
1.6× throughput, same quality — open-source & production-ready!
We’ve integrated MTP into SGLang, unlocking up to 60% higher output throughput for models like DeepSeek V3, with zero quality

Someone should try this for Kimi and see how well it works
damn this model is so slow on so many providers....
not on some though
We’ve updated Kimi K2’s chat template to make tool calls more robust.
︀︀
︀︀What’s changed:
︀︀- updated default system prompt
︀︀- always use model-returned tool_id in multi-turn tool calls, which is more reliable.
︀︀- If `arguments` in tool call is already a string, don't apply `tojson` to it.
︀︀
︀︀Known gotchas:
︀︀- vLLM tool_id format bug when tool_choice ≠ auto (fix PR soon)
︀︀
︀︀👉huggingface.co/moonshotai/Kimi-K2-Instruct
︀︀
︀︀Related Issue:
︀︀huggingface.co/moonshotai/Kimi-K2-Instruct/discussions/28
What providers have this update in
Hmm... which one to choose

Targon +point:
- Fast
- Cheap input $
Chutes +point: - CHEAP output $
- Comparable input $ to others
fast or smaller output/larger context its certainly targon
Small context but big output obviously chutes
neither one has tool calling tho lol
ooof not yet? then if thats needed for them, not gonna be an option
on and off. there's a ton of bugs when a new model drops like this
tool calling is not just an on and off switch
kimi has updated their tool calling chat template like 3 times already
i picked a bad time to do my evals 😭

RIP
could've been good for coding
Is it true that Groq is running a lower quant
well well well i got some crazy results that you won't believe
In my openrouter I have 20 1 input to output ratio calculate your own by taking a excel out from openrouter and tally up from there
I have a 20:3 input:output
Chutes simply doesn't work anymore
I sent the same writing prompt 3 times to 6 different providers:
DeepInfra, Groq, Novita, Parasail, Together, Chutes
Here are the results:
- DeepInfra (fp4)
- Speed: Decent speed at ~60t/s
- Response length: Gives consistently long responses (~2000 tokens)
- Response rating: Varies from 8.5 to 10
- Manged to get a perfect rating once, beating the previous top model Claude Sonnet 4 (9.5)
- Surprisingly good at fp4
- Groq
- Speed: Fastest provider at ~170t/s
- Response length: Consistently short responses (~1300 to ~1500 tokens)
- Response rating: Varies from 8.5 to 9.5
- Novita
- Speed: Large speed variation (from 11 to 70 t/s)
- Response length: Large variations (~1200 to ~1800 tokens)
- Response rating: Varies from 8.5 to 9
- Parasail
- Speed: Consistently slow at ~11t/s
- Response length: Small variations (~1200 to ~1600 tokens)
- Response rating: Varies from 8.5 to 9
- Together
- Speed: Normal speed at ~40t/s
- Response length: Small variations (~1100 to ~1500 tokens)
- Response rating: Varies from 8 to 9
- Chutes
- Returned 429 for all requests so I can't test it
Conclusions:
- DeepInfra at fp4 is surpringly good and stable!
- Groq is the fastest. Parasail is very slow.
- Together is quite stable. Novita is not stable.
- In terms of output
- There is definitely some difference between providers based on the response length.
- DeepInfra consistently gives larger responses (~2000 tokens), whereas Together gives shorter responses.
- Need more comprehensive testing to determine which provider gives higher quality
Will be posting more detailed evals soon!

Very interesting. Why is DeepInfra not recommended then? Do people just see fp4 and walk away?
I don't know. I think they messed up DeepSeek last time? But they were one of the few providers back then.
Here's my DeepSeek speed benchmark from 6 months ago

Does DeepInfra perform good with other models
Thought you'd baseline with Moonshot since they're on OR
Thanks for doing this!

i mean i should. let me update it.
typically i would integrate directly with the first-party provider for my evals, hence need more time
No worries
I kinda forgot until @dusky knot pointed out Moonshot is on OR now

Kimi just feels so good to talk to, I use it to discuss controversial topics and it literally doesn't agree all the time and corrects me to something reasonable
I feel ashamed and embarrassed ;-;
Sometimes it feels too serious for an llm to not ignore the fact there's other dimensions or nuance to consider that the topic i discuss shouldn't agreeable easily
It's a night and day difference compared to 4o
It elaborates to me why NSFW is bad, and I should stay with sfw roleplaying... Blud typed 4 paragraphs earlier for that
Is kimi somehow trained not just typical data we expect but also social medias forums, threads, public chatlogs
Cuz the quality is as if I'm talking to some seriously experienced person to almost any domain
Yes seriously experienced
It knows niche stuff too
4o models are a joke with that glazing fiasco
Most likely
Kimi is just so good for open ended questions too
Although there's still some quirks and hallucinations, but i swear it knows stuff more than llms I've talked to
what kind of niche stuff we talking about here?





I guess this is more like feeling more personal and relatable as opposed to formal and distant?
Not just that though but also it knows more ai development stuff than llms available right now
can you give an example?
Also knows more niche stuff like suggested me to use easy-deb-chroot on maemo n900 to run debian chroot instead of uboot or dualboot
Is targon any good? I don’t see much benchmarks with that provider
Although this one is a hit or miss since its answers about it are inconsistent
well i just chatted with it for a few questions, definitely a different vibe from Claude / GPT.
kimi k2 trained on scraped discord channel data confirmed
way less formal in tone

maybe kimi k2 can write tweets that don' make me want to log out of twitter forever when they come up on my feed
trash platform
Gemini 2.5 pro vs kimi


Lmao it would br funny google model doesn't know much about android internals
Wtf
Chutes pricing keeps decreasing but not a single request goes through

kimi is the only known model I used that knows deeper Android AOSP stuff wtf



Gemini answered so fruitfully wrong about dev tools app
we've got a bunch of providers to look into https://x.com/Kimi_Moonshot/status/1946130043446690030 and start the update process
We’ve updated Kimi K2’s chat template to make tool calls more robust.
What’s changed:
- updated default system prompt
- always use model-returned tool_id in multi-turn tool calls, which is more reliable.
- If `arguments` in tool call is already a string, don't apply `tojson` to
@winter jackal any insight into why Targon is so cheap and if it’s a quality thing? Seems to be FP8 like most other providers but significantly diff price
This is 2.5 Pro, fumbled with devtools part already



decentralized provider
can't guarantee privacy security since they don't have physical custody of all their compute
(that doesn't answer why theyre so cheap. I don't know their economics. but it's something to consider)
They do advertise privacy and security on targon.com though

they use Nvidia Confidential Computing
another reason not to use it
Decentralised, and also pays miners with crypto currency
#general message
I just want to know what's the deal with Chutes being completely dead
Check out bittensor if they said anything
Okay
They seem to be running it on just 8 GPUs
8x b200
So that's why it's really slow

{kind=link}
They didn't quite specify what was happening except that the GPUs were lacking for this model
1.44TB of vram is still slow 😭
Wow I've never expected for an llm to give me a very good qemu config



I've been using qemu for years and I've never expected to write me a decent code
it still has its own set of slop + other model. Particularly "nails digging half-moons" as I observed. But it's not too horrible considering I like its writing much more than Deepseek, which also has its slop.
Idk but with my instructions it feels way less cringe
Same instructions to other models some to most having max cringe
Anyone know whether the free endpoint can handle tool calling?
Can you post your system prompt here? I wanna try it out
"{\"error\":{\"message\":\"Provider returned error\",\"code\":402,\"metadata\":{\"raw\":\"{\\\"detail\\\":\\\"Quota exceeded and account balance is $0.0, please pay with fiat or send tao to 5FH5kssuNoQweLMQwuJk34JvGQcpemcRFrdH3e5GqRbS1pbJ\\\"}\",\"provider_name\":\"Chutes\"}},\"user_id\":\"user_2d5jNx9uoLD64wvJCL6v9KiQOMQ\"}"
Well, lol
any idea where Moonshot themselves come in (I guess it will take until tomorrow to run that :D)
its very interesting that deepinfra fp4 is scoring highest
It's quite close to the top, albeit very slow. As expected. Will post more details (more eval tasks) tmr.
thx for doing this btw, you are inspiring me to make my own benchmark focused on long coding stuff. I suspected for a long time now that there is a (sometimes) significant diff across providers
Everyone should have their own evals. That's what I believe in.
they take so much time to make
the evals
Well it's not like Chutes works even with account balance.
I have account balance and it doesn't work for me at all.
observation: kimi k2 is the anti-claude. I am not absolutely right when I talk to k2. It's always "Exactly, and that's why [...]"
My brain can't process this sentence. Can you rephrase it with examples?
As in, Claude loves to use the phrase "You're absolutely right", but in a similar scenario K2 would rather use "Exactly [...]".
It's the different setting, with Claude it is indirectly addressing that it was wrong(and I was right), while K2 thinks of my objection as an ADDITION to its response.
Ah
Seeing many 429 errors from baseten provider.
moonshotai/kimi-k2 is temporarily rate-limited upstream. Please retry shortly
Unsure if there is a noticeable difference in response quality between fp8 and fp4 providers.

GitHub
AI-powered multi-model Discord bot to try with Gemini 2.5 Pro and other models from OpenRouter, Anthropic Claude 4 Sonnet, Deepseek R1 and O4, Mistral, LLaMA, and More. in Discord! Try below or hos...
yi-onk
thank 'ee very much
The half-moons thing is original Deepseek slop, funny enough
So far the adoption on OR for SillyTavern has been quite low. I expected a ramp-up after day one but it's barely increasing. About 3% of total usage
had kimi k2 roast me based on some webpage content.
yea, that about sums it up I guess 😅

1T parameters, make sense..
Because with that many parameters even smallest probability connection in the data being consider and created the connection in the latent space.
Is like previosuly we have limited space and we need to pick either silver or gold coin to placed there, because there arent enough storage we mostly will be chosing the gold one.
Now with 1T parameters its mean we have more storage to store both the silve and gold coin.
But still imo they have still flaw, the fact they make it 32B active parameters is quite small to me.
Yeah its faster and seems like effective enough in thier bench, but its limiting the space in the latent space to be more specific to that context.
fiction.liveBench results are in

Benchmarking AI Models for Long Context Comprehension
stronger than deepseek v3 until 32k and slightly underperforms thereafter
Oof
r1's beats it on all counts
Its performance is underwelming when you look at the scores in the context that this is a 1 trillion parameter model
Granted, its 32b active parameters
not seeing that, it competes with 2.5 pro and sonnet 4 which are liekly over 1t each
further, it's stronger than v3 at base which means when they train it for reasoning it should - if they do it right - beat r1
But I expected a higher score than 87% for 0-400 tokens of context
I'm specifically looking at the very first column btw
k2 is not stellar with context lol
but it beats v3 which is important
it means it can be improved like v3 was, which had an iteration, then r1 had a new version
The first column is its performance is for 0 - 400 tokens of context
The second column is 400 - 1k tokens of context
you're comparing first version k2 with v3 and r1 which both had new versions
it's a strong model that will only get better
true
I luv kimi
it may not top of the benchmarks, but I love it
I love its writing lol