#DeepSeek R1 1776 by Perplexity
112 messages · Page 1 of 1 (latest)
😮
will take a look
I don't see it on their API unless they simply replaced original R1 (on Sonar Reasoning and Sonar Reasoning Pro) with it
at least docs don't mention a new model
yeah not seeing it up yet
praying it's not uh
5/10$ or some shit lmfao
does Perplexity have a V3 version of this they support anywhere?
Apparently it's on the API https://x.com/AravSrinivas/status/1891918693954736589 But I can't seem to see it and changelog mentions nothing. I assume it must have replaced something..
@huggingface And it's also available via the Perplexity Sonar API. https://t.co/3ataU8H1Y9
it might be on the API, but it's undocumented
it's unclear what they've actually deployed, but if they've hotswapped their reasoning endpoints it's already available
China's problems don't affect your math. If you want to do porn, that's fine.
Validating Perplexity's jingoistic power play is embarrassing.
https://gulfnews.com/world/americas/9-billion-perplexity-ai-indian-ceo-s-green-card-struggle-goes-viral-after-elon-musk-backs-him-1.500025984
https://x.com/AravSrinivas/status/1884738658349003115?t=IlaRoSpwE9C00wa7fRQW7Q&s=19

Gulf News: Latest UAE news, Dubai news, Business, travel news, Dubai Gold rate, prayer time, cinema
Techie’s selfie post resonates deeply with professionals grappling with visa anxieties

Like I don't want to die on this hill, the CPC sucks, but as a Canadian the CPC has never made me feel personally threatened the way that the current US administration is doing, and this whole model is just Arav sucking up to them.
This has nothing to do with censorship whatsoever, and everything to do with leveraging political animosity for personal gain. Do with that information as you will
tell the truth. You are Chinese, not Canadian. And if you don't like Americanized models, stop using them.
Get off of X and call your mom, people are worried about you
You're right, this has to be propaganda, there's absolutely no reason why Canadians might dislike the current US administration /s
as an American I completely agree. this tweet sums up my feelings on it:
@hardmaru @perplexity_ai I would rather have "Chinese censorship" and not piss DeepSeek off than create a strong disincentive for them to release more open-weights models in the future? It's not like anyone in the west is asking their LLM about anything Chinese-sensitive (we don't care!). From our
They have released on hugging face now
https://huggingface.co/perplexity-ai/r1-1776


Wait so sonar reasoning is now r1-1776? So it’s not trained on r1 anymore as it’s just r1 now. Wouldn’t this be the same as sonar reasoning pro?
ah whoops apologies, you're right
I’m equally confused as to what this even is? This just seems like it’s reasoning pro with the “China bad” filter applied to it. And it’s kinda telling from this blog post https://www.perplexity.ai/hub/blog/open-sourcing-r1-1776
I just want a r1 version that I can rely on even if it means paying more 😐

An unbiased & uncensored reasoning model
Yeah, they're super vague / unclear unforttunately
It's 100% R1 with a fine tune "china bad".
Sonar Reasoning seems to be R1 (so this china bad version). Idk about Pro; which claims to be a "bigger" R1.
I'm 99% sure Sonar Reasoning is a distill, and Sonar Reasoning Pro is the full 671B model


Oooh! Yeah you are surely right!
I derped and forgot about distills. "trained with R1" makes the difference; you are right.
i would love if they actually were clear though.
It makes total sense. Weird that they released in OSS the pro and not the not pro tho.
And yeah, I think their Sonar Reasoning Pro is their R1-1776 finetune of the full 671B R1

model is up now

Note: As this model does not return tags, thoughts will be streamed by default directly to the content field.
R1 1776 is a version of DeepSeek-R1 that has been post-trained to remove censorship constraints related to topics restricted by the Chinese government. Run R1 1776 with API
Haha..
I also thougt about what actually uncensord they mean? it's literally just realignment to suit the US.
If they really want it to be uncensored there already example on hugging face of what uncensored model are.
The truth is even US have its own censorship just like CHINA for sensitive topic that they have on their own culture, believe and country, In the end everyone has biases and thinking that one form of censorship is better than another is unfathomable to me.
Last time i check deepseek r1 actually don't have problem talking about topic that the west consider wrong or bad in much more neutral way, so yeah..
I think if you want to have clear view of CHINA use US/EUROPE model but if you want clear view of US/EUROPE then use CHINA model.
DeepSeek R1 1776 by Perplexity
Their direct API for r1-1776 returns the end </think> but never opens with <think>
Checked via curl, using temp 0.6, top_p 0.95.

I haven’t used r1 much but is it normal for it to just admit that it’s from OpenAI?

yeah, very much so

OpenRouter
LLM Chatroom is a multimodel chat interface. Add models and start chatting! Chatroom stores data locally in your browser.
you can try R1 here for free and you'll see similar results
what are these "sensitive" topics which US models are censored against? i'm yet to see an America model tell me that the Panama Canal is an "inalienable" part of the US, or that Hawaii has been US territory since "ancient times"... Mistral models never call France the "motherland" or talk about French citizens as "proud compatriots"...
i mean ofc all models have cultural / ideological biases and safety guardrails of some sort - but that isn't same as models adhering to government-imposed content restrictions on so-called 'sensitive' issues or regurgitating party propaganda verbatim..
kinda.. though seems they just curated a dataset of question-answer pairs covering 300 ‘sensitive’ topics and fine tuned it to output the ‘factual’ answers, overriding the base model’s refusals or CCP-aligned responses. for sure this just swaps one bias for another in some cases (see their ‘Who is Xi Jinping’ example in the blog).. but more fundamentally, the model is just pattern-matching those 300 topics - like it's in no way truly ‘uncensored’. anything outside those topics–or with some adversarial prompting–and you’re back to the OG R1..

anyway R1 is an excellent model (and OS yadayada) - I genuinely believe that. my issue is with Perplexity's increasingly shameless mission to position itself as the offical MAGA AI search engine, while making nonsense claims about their R1 FTs being "fully 'uncensored'".
my other gripe is with the those who insist that Western models are "just as censored", which is also nonsense... refusing to tell you how to make meth or self-harm, or providing a 'woke' answer, isn't the same as refusing to talk about a particular historical event, or providing objectively absurd and hyper-nationalistic responses (aka literal propaganda) when asked about a contentious international matter..
[sorry.. rant/s over]
you're right, its more censored to provide a manipulated answer over a refusal. "Sorry I don't want to talk about that" is only level 1 censorship. Some western models have level 10 censorship where the model answers you but in a manipulative way.
This whole R1 1776 model is just so cringe its unreal. Its really stupid imo for a western company to go out of there way to piss off DeepSeek, a model which really is mostly uncensored already, certainly is for practical uses. I haven't had to deal with one single lecture from it yet.
What would the reaction be if Perplexity made LLama Zuckerborg Edition which hated Zuckerberg or something? Or if the CCP released LLama CCP edition? Its just pointless jingoist anti science crap.
the discussion section on ppx model are wild, people really dont like what ppx doing 🤣

i hope they acknowledge the feedback from hf community, because this model just make it worse compare to the original model because they just make it the same as other model that we already have where its now have identical biases as them
not sure we're on the same page here... obviously I'd rather a refusal / "sorry, i don't want to talk about that" ... instead of absurd party propaganda talking about "since ancient times" etc (which no western models do – bitch and moan about wokeness and other such biases.. it is not the same as government propaganda or censorship.. it just isn't)
a model which really is mostly uncensored already
on that point i totally i agree (it only adds to the farce of perplexity's efforts)
when does it give "absurd party propaganda" if you use the correct chat template? This has been a long standing issue I said many times when people were accusing DeepSeek of having a different model on their API vs other deployments, the chat template was wrong on a lot of deployments for a long time. DeepSeek recently confirmed what the correct template is. You can tell if its bugged if it outputs empty <think> section, its not supposed to to that.
deepseek released an amazing and most of the time superior model, with open weights...
they knew the consequences of releasing the weights. they censor the model according to the cultural and political environment where they are from, just like any other model, in order to avoid domestic backslash. what people do with their weights is highly unlikely to piss DeepSeek off
government X or Y or AI company W or Z would likely care if suddenly some fine-tuned AI model gave perfect instructions to create turbo Ebola
I love DeepSeek the model and the team... This will not piss them off
what is the correct chat template?

https://huggingface.co/deepseek-ai/DeepSeek-R1 "To ensure that the model engages in thorough reasoning, we recommend enforcing the model to initiate its response with "<think>\n" at the beginning of every output.". It can't be any more clear, really. You can tell it very easily if you ask "hi" there should be some thoughts.

Yeah this is the template abacus implements. 💙 is obviously a debug indicator for them lol

thats not a chat template mate
just think of it as it is sensitive to how the model is deployed by the people serving the LLM. Its up to them to follow deepseek's model card recommendations, or ignore them.
i think we're talking about similar things
can you show me a chat template you're talking about?
because the only other place i am thinking of is the system prompt, but they say higher in the recommendations that you should avoid that
the screenshot above just means they augment the user prompt each time
'<|begin▁of▁sentence|><|User|>hi<|Assistant|><think>\n'
I would like to know how to make perplexity sonar model to show references/citations.... It only shows numbers like [1], nothing more, no urls. Thx.
mhhh.... so apparently only english decensor?

and yet perplexity.ai's r1 (not r1-1776) with web=off still provides more information than r1 via api (hyperbolic)

aha, got it.

Exactly. I posted an issue on the help room.
FYI, slowly rolling out an update to how we handle thinking generations on ALL R1 models. They will now consistently think, and prefill will now consistenly work.
I am getting complete nonsense and reasoning loops now, and highly degraded results in anything involving math, e.g. (same on API)

we didn't change anything on our end for this model yet ( my message above hasn't hit this model yet), only change for us was enabling our parser on reasoning tokens to split them out now that they started to return <think> tags
oh ok so the model itself is busted then. it does extremely poor on my math segment
Have you tried direct API?
yes, it says right there: same on API
What front end were you using?
I am not using any front end. I collect responses directly into dbs
the reasoning is off, and loops endlessly until gibberish on math segments
Ahh okay
I am also seeing broken format in code segments (again, both API with no frontend AND openrouter)

Tested R1 1776 (Perplexity post-trained to remove Chinese censorship):
Reasoning showed strong signs of degradation, leading to worse results in all tested areas.
Math, formatting and code related tasks were more strongly affected than pure Logic tasks.
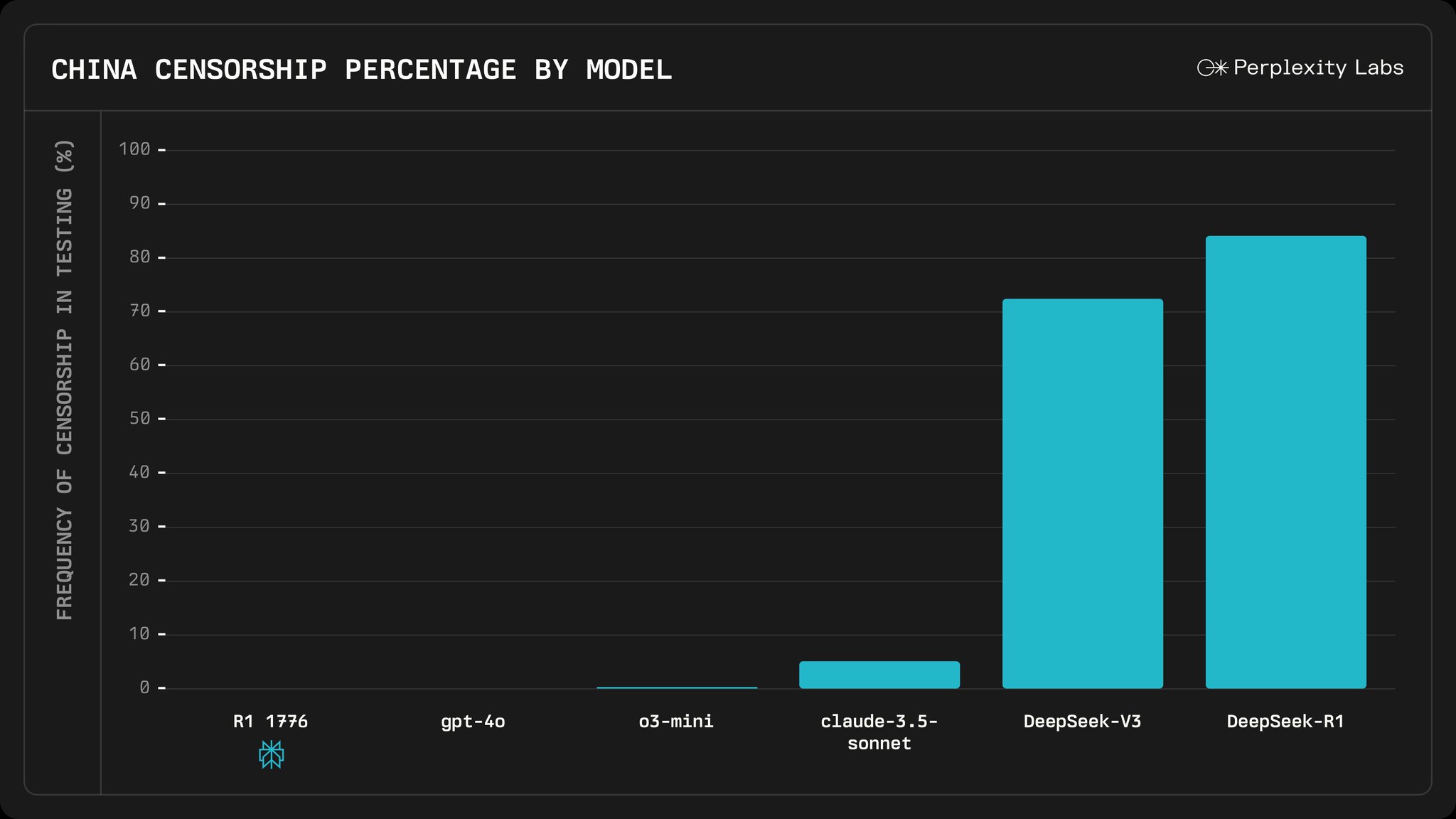
Ironically, the only few Chinese censor tests I have (and have had for a long time) still produced 100% censored and propagandistic answers.
Whether the degradation is due to the post-training, or how the model is implemented, I do not know. But I do know that it isn't on R1 level.
As always, YMMV.

yeah, looks about right
the only time I tried to ask it a coding question (whole prompt in English), it randomly started producing a mix of Russian and English words, then Chinese and then it totally collapsed. It must be very poorly quantized or something
or they just severely broke the model with their "fine-tune"
what a waste of electricity srsly
perhaps not 'absurd', but it's party propaganda (and you;re kidding yourself if you think otherwise - or that there are comparable outputs reflective of government directives / propaganda narratives elicited by western models)
though yeah tbf, they've done a good job to just refuse when probing / sensistive questions are asked, both during in inference and, on the chat ui, with some secodary filter that kicks in if the output seems to discussing touchy topics

actually... "doomed to fail".. yeah it's absurd
where are you having that conversation with it/what deployment is it?
I haven't had a hardcore redditor r/geopolitics or r/neoliberal tier argument with it though, its not the kind of thing I find fun.
I don't think you should be surprised that a Chinese LLM has different political stances on important topics for China to a western one, but I mean, in the screenshot you shared its arguing with you and it doesn't agree with you. It agrees with the Chinese stance. Isn't that exactly what you would expect?
also btw it doesn't say "doomed to fail" in your screenshot
more people confirming my findings (#1341484512487673977 message), e.g.:

find me a western LLM that uses language like "doomed to fail"* about a contested/historical issue - if you don't think you're reading propaganda in that response, sorry but your information literacy could be erm sharpened up a little
* mate, have a closer read - unless you're looking at a differenet screenshot.. it most certainly does say that
Yeah I didn’t read it that closely the first time, it does use that phrase which is kinda odd. Must be from a textbook in its data or something like that.
Or possibly system prompt stuff, the chat interface is known to be very censored just it usually says it can’t talk about it
https://huggingface.co/perplexity-ai/r1-1776/discussions/254
A Perplexity org member commented here, saying that there was an issue with their serving, and a fix has been deployed now.

Yeah, I noticed the message this morning and was just testing the model in Perplexity Labs playground. Indeed it looks much better now, I haven't seen any signs of reasoning trace degeneration so far.
I re-tested the model in lineage-bench, it took the first place this time (the previous mean score was 0.709, now it's 0.934!)

very nice, I think I'll try this in aider as architect, with sonnet 3.5 or 3.7 as coder
Ran a full retest of R1 1776, after perplexity claims to have fixed their implementation.
- Higher quality chain of thoughts, in particular in long context, fixed degradation
- Thus, gains in all tested areas, compared to initial implementation
- Still falls short when compared to DeepSeek-R1
- Core model remains identical with same issues such as still censored Chinese areas and propaganda
Tldr; Recent fixes improved the thought chains and thus outcome measurably, yet doesn't quite reach R1 level, in my testing.
As always,** YMMV!**

if there's one thing going for it, their API is fast
Funeral required