
81 messages · Page 1 of 1 (latest)
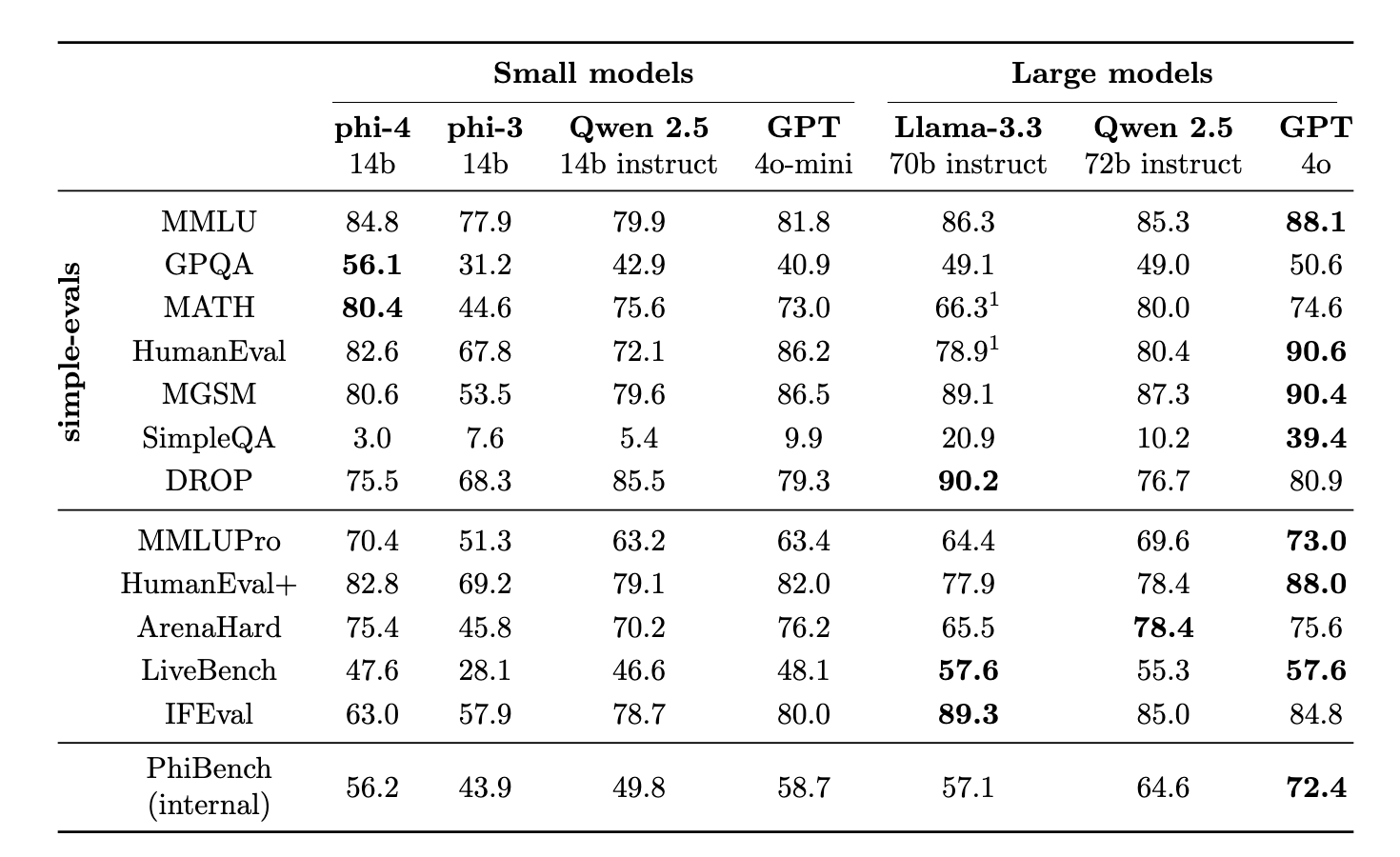
Phi 4 just dropped, only on Azure AI Foundry for now. It’s a dense 14B model claimed to be competitive with Llama 3.3 70b in many benchmarks. Most of the gains are from improved post-training rather than architectural improvements.
Paper: https://arxiv.org/abs/2412.08905
https://x.com/SebastienBubeck/status/1867379311067512876
https://techcommunity.microsoft.com/blog/aiplatformblog/introducing-phi-4-microsoft’s-newest-small-language-model-specializing-in-comple/4357090
We present phi-4, a 14-billion parameter language model developed with a training recipe that is centrally focused on data quality. Unlike most language models, where pre-training is based primarily on organic data sources such as web content or code, phi-4 strategically incorporates synthetic data throughout the training process. While previous...
Surprise #NeurIPS2024 drop for y'all: phi-4 available open weights and with amazing results!!!
Tl;dr: phi-4 is in Llama 3.3-70B category (win some lose some) with 5x fewer parameters, and notably outperforms on pure reasoning like GPQA (56%) and MATH (80%).
Today we are introducing Phi-4, our 14B parameter state-of-the-art small language model (SLM) that excels at complex reasoning in areas such as math, in...
Wow.

Why did I get a notification for an emoji reaction 😭
it's a decent model around Nemo 12B & Qwen2.5 14B level, with decent reasoning, very good STEM capability but lackluster code & instruct following. default vibe is very neutral and quite sterile, as expected from a microsoft model.
compared to the phi-3/3.5 models I tested half a year ago, it's much less stringent in terms of over-censoring.
it fails to multiply 223*9271 which even the smaller marco-o1 model from alibaba can calculate correctly
but other then that it seems to be quite a solid model
i did a translation test for phi4, this is the result (i mean I wouldnt have expected anything else from a 14b model):
input:
On 14 December 2024, Yoon Suk Yeol, the president of South Korea, was impeached by the National Assembly following the second impeachment motion raised against him. This action came in response to Yoon's declaration of martial law on 3 December, which was overturned by the National Assembly and officially withdrawn six hours later.
translating to german -> chinese -> french -> vietnamese -> norwegian -> english (without chat history ofc)
output:
On December 14, 2024, the president of South Korea, Yoon Suk-yeol, was impeached by the national
parliament following another motion for his removal. This occurred in response to his announcement on
December 3 to implement a ban on meetings—a decision that had already been deemed invalid by the
parliament and officially withdrawn six hours later.
far from a correct translation, but also far better then any other 14b parameter model
(q8_0 quantization, maybe fp16 is better)
wow fp16 much better, this is crazy good:
On December 14, 2024, the President of South Korea, Yoon Suk-yeol, was suspended from office by the National Assembly after
undergoing his second temporary suspension during his term. This action followed his decision on December 3 to declare a state
of emergency, which was later rejected and formally revoked by the National Assembly within six hours.
you can run fp16 locally? how much vram does it consume.
i have 24gigs of vram, llama.cpp does the offloading to ram
its slow but i still can make these translations in a few minutes
anyway, i think there is model that is specifically being train to be translation and it could be better than it i suppose.
still impressive for a 14b param model
so does it consume above 24? like 48gb or less.
i havent checked but since the model file is 29gigs, i suppose so
so at least 48ram mac needed to run that thing.
anyway, thanks for the information.
32gb won't be enough unless you limit context to like 500tok. you need vram for system, multimonitor, and context. pretty sure you'd bust past 32GB even at 4k context
i get 2.34 tokens/s for fp16 which is barely useable, but fine for me, if you do something different while the text is generating
Phi-4 is the latest LLM from Microsoft Research. It has 14B parameters and claims to be a big leap forward in the overall Phi series. From [Introducing Phi-4: Microsoft’s Newest …
Why is he using Q4_K_M tho 😭
I've already seen a big difference between q8_0 and fp16
Did you see an actual difference or did you see a 1% difference in benchmarks
I did test the translation here: #1316948839571394680 message
And was only correct with fp16
Woah is this with temp 0?
Yes
Okay this is strange, did you test any other models like this?
I usually use q4_k_m and q5_k_m for everything
I đid test some other models, but don't remember which ones exactly, but was a 32b param model I think
Q8_0 is like nearly permanently broken on l.cpp, so keep that in mind
You can literally get better performance out of a Q6_K than Q8_0 in a lot of cases
Hmm that might be the reason then
I am currently not at home, but if you want you (or someone else) can test this
in your opinion, is it better than 4o-mini as they claimed
I haven't used or tested 4o mini at all so I can't say. But phi 4 is definitely a solid model for sure
I could test this, give me a sec (only have 6gb of vram 😭)
nvm i only have an hdd and the verification is taking literal hours, somebody else pls do it
There's a website that hosts any model I tried phi4 on there. I found that phi-4 had overfitted responses, in that it would have completely wrong reasoning and steps, but would get correct answers.
I think chatglf might have some type of deal.
Seems to be just added. https://openrouter.ai/microsoft/phi-4
Microsoft Research Phi-4 is designed to perform well in complex reasoning tasks and can operate efficiently in situations with limited memory or where quick responses are needed.
At 14 billion parameters, it was trained on a mix of high-quality synthetic datasets, data from curated websites, and academic materials. Run Phi 4 with...
By the way the gguf conversion on eg barrowski ggufs I tried yesterday was busted
Template totally wrong and it significantly impacted the intelligence of the model.
How is q8 busted?
It is not. Both the Q8's I tested (pre official launch and post) perform exactly as expected compared to full bf16, with very little degradation.
Others have tested this too, such as here https://youtu.be/eKSMKSZkN-I?t=2548 - and found the same results.
It's possible that someone downloads a bad quant with faulty template/params, or receiving poor results from user error, but this is not a general issue. Anyone making such claim should state exactly which model and parameters were used in which environment with which specific output issues, otherwise it's just baseless claims that cannot be verified.
tldr; it's not busted
Thanks! Q8's never seemed in any way broken to me either.

Phi-4 is now available in GitHub Models (GA)
When will DeepSeek cram their stuff into Phi-4 instead of Qwen?

We are excited to announce Phi-4-multimodal and Phi-4-mini, the newest models in Microsoft’s Phi family of small language models. Learn more.

Interesting but a little unrelated to OR, the multimodal here (5.6B Params) is now at the top of the OpenASR leaderboard
(I didn't know until now that whisperv3large has 1.54B Params, qwen2-audio has 7B)


is also on azure and supports text/image/audio as input, output is text https://aka.ms/phi-4-multimodal/azure
And if it has image, it has video by extension?
Can anyone using function calling via openrouter?
No endpoints found that support tool use
Alright, it seems like it doesn't support yet: https://openrouter.ai/models?supported_parameters=tools

Phi-4 Multimodal Instruct is a versatile 5.6B parameter foundation model that combines advanced reasoning and instruction-following capabilities across both text and visual inputs, providing accurate text outputs. Run Phi 4 Multimodal Instruct with API
To fiddle with today

tbh logo memorization is not a good test for such a model
Yeah but that output is so random
Deepinfra can be bumpy when they first start a model so may need testing & feedback
Seems to be working now

This is an svg file btw, does openrouter automatically convert it to an image?
huh, interesting
Getting garbled output using Phyi 4 multimodal instruct via Openrouter. I have lowered the temp and top p to 0.5 but nothing seems to fix it.

Dropping the temp all the way down to 0.1, and it barely responds even when asking for more detail...

I just realized I'm referring to Phi 4 multimodal, which has another thread here I think.
So, I have seen that these models underperform in GPQA. What is the purpose of these smaller models if trained specifically on research papers? What makes then better at research than, say, o3-mini or gemini thinking where they excel in GPQA and STEM domain-specific questioning. Why might someone prefer to use Phi-4 over other current SOTA models excelling in STEM? I am trying to decide which would be better for a research assistant.
People use them locally. small enough to be run on consumer hardware, and can feed it the most sensitive data without it leaving your machine.
