#"API call failed after 3 retries: Connection error." in Discord
8 messages · Page 1 of 1 (latest)
Thanks for the logs — this is not a Discord outage.
Hermes is receiving/sending Discord messages, but your upstream model endpoint is unreachable.
From your logs, every failure is:
provider=custom
Endpoint: http://host.docker.internal:8080/v1
APIConnectionError → API call failed after 3 retries
So the spam message is Hermes reporting it can’t connect to your custom OpenAI-compatible backend.
What to check
Test the endpoint from the same runtime as Hermes
(same machine/container Hermes is running in):
curl -sv http://host.docker.internal:8080/v1/models
If this fails, Hermes will fail too.
Use the right hostname for your topology
Hermes on host macOS/Linux + model server on host: use http://localhost:8080/v1
Hermes in Docker + model server on host: host.docker.internal can work
Hermes in Docker + model server in another container: use container/service name on shared Docker network (not host.docker.internal)
Ensure the model server is listening on the right interface/port
bind to 0.0.0.0 (if needed for container access)
confirm port 8080 is exposed/published
After fixing endpoint reachability, the Discord “API call failed after 3 retries” messages should stop.
If curl works but Hermes still errors, send the newest: ~/.hermes/sessions/request_dump_*.json and we’ll compare exact request path/headers.
curl works. I'm not going to to send the request dump because it contains personal info. This user has the same issue: https://www.reddit.com/r/hermesagent/comments/1sq0rgz/first_time_user_connection_troubles/
The screenshot illustrates the error I am seeing for any interaction with Hermes Agent. I'll try to detail my setup. Ollama with Gemma4:latest…
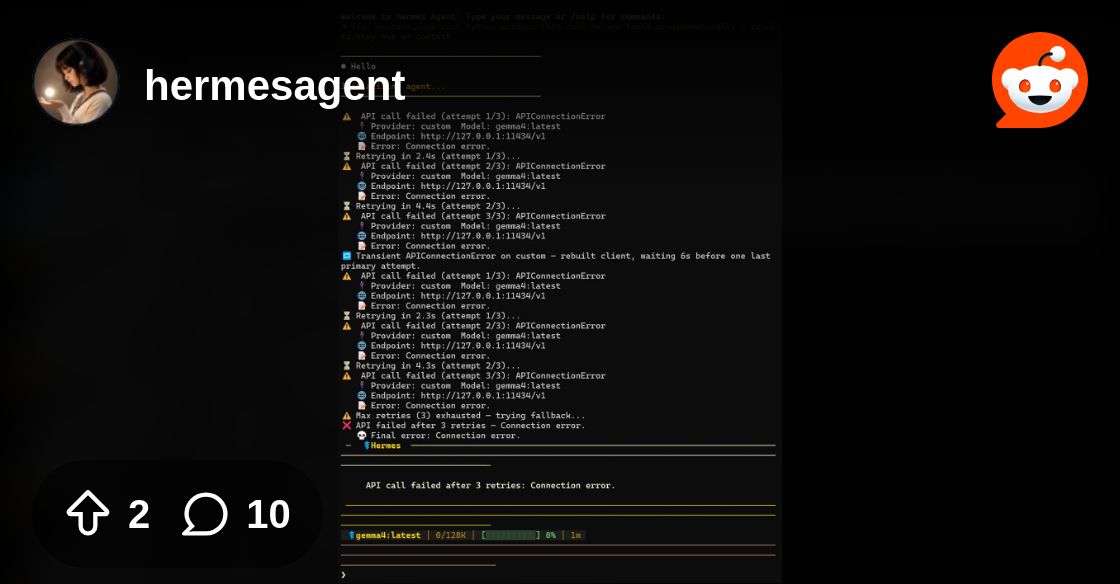
@opaque patio can you help this guy?
Okay, trying to piece together the setup here @merry coral :
- Are you running Hermes inside a docker container?
- Are you trying to communicate to a local model?
- Is that local model also inside a docker container?
- What docker networking do you have set up?
Yes, I am running Hermes inside a docker container. Yes, I am trying to communicate with a local model on my machine (outside the container) - I'm running llama.cpp on port 8080. My docker compose looks like this:
services:
hermes:
image: nousresearch/hermes-agent:latest
pull_policy: always
container_name: hermes
restart: unless-stopped
command: gateway run
ports:
- "8080:8080"
volumes:
- ~/.hermes:/opt/data
networks:
- hermes_internal
environment:
- BACKEND_TYPE=docker
deploy:
resources:
limits:
memory: 4G
cpus: "2.0"
dashboard:
image: nousresearch/hermes-agent:latest
container_name: hermes-dashboard
restart: unless-stopped
command: dashboard --host 0.0.0.0
ports:
- "9119:9119"
volumes:
- ~/.hermes:/opt/data
environment:
- GATEWAY_HEALTH_URL=http://hermes:8642
networks:
- hermes_internal
depends_on:
- hermes
deploy:
resources:
limits:
memory: 512M
cpus: "0.5"
networks:
hermes_internal:
driver: bridge
And how is the agent configured to talk to the local model? The Docker network has a few peculiarities that make talking to services running on the host outside of docker difficult.
I'm stretching my memory here, but you need to do something like run:
docker network inspect hermes_internal and grab the Gateway IP address. That IP address is the one that you'll want the agent to send inference requests to, instead of using localhost or similar