
#💬│general
1 messages · Page 69 of 1
But they already broke their word on another FAQ in their website here 😂

Any plans to add Gemini 1.5 Pro to Perplexity? Keep up your reputation of providing the latest models (Poe has already done so).
This the second time i have a referral the plz gets canceled and i can't use the referral i have done
Well, that's true...
Isn't "up to" = "no more than"? I don't native in English..
Well in the pro page they wrote 300+/day. So I think they didn't break their words when it's 300 - 600 / day... lol
opus 50 2.0
Hey got a question how do i image generate on iPhone
With perplexity
i am confused
why is image generation so complex?
https://discord.com/channels/1047197230748151888/1225557012532695060
web version only
and why is it so complicated?
why is there not just a button to generate them and write a prompt in it?
why does it have to be this complicated i mean why even use Dale or stable diffusion at that point
makes no sense
answer engine in first place
deep dive ➤ #💬│general message
Anyone know of a tool that would let you run a specific prompt and record the output on a list of URLs? Would save me a lot of time for a particular task I have currently.
what do you mean “record the output on a list of URLs”
I have a background instruction that lets Perplexity know that when I write "/S" it needs to perform a certain task on the page, via the widget.
hello,I'm a subscribed pro user. Why haven't I selected the pro model for use now?
Hi guys... Anyone with trouble tô buy a pro sub? I can't buy, no matter what a try
I need help guys... I even try to buy using Google gift card. Its like I'm blocked or something like that
Some mod or anyone that can help me?
Hey @jaunty stump! You need to contact Google Pay support regarding their gift cards.
Hey @digital orchid, do you mean you subscribed to Pro but can't switch models or? Please try to log out and log back in.
Google pay was just my last attempt. I've tried everything, all possible credit and debit cards.
When I called my bank they said there was no problem. That's why I used the Google gift card, because then I was sure there was no problem related to funds.
Is it possible that I have been banned?
Hey @warm cave! Sharing options have been updated for thread and collection levels: when you share a collection for everyone, you can have certain threads private, closing them with their own permissions. They won't be visible unless opened separately.
Works the other way around, too: you can share a thread from a private collection and only that thread will be shareable.
I live discovery but workflow could be smoother (on iOS), instead of closing each article via the close icon in top left, simply scroll to the left is normally available 👍🏻
is there a site with any predefined prompts? im going crazy with this program. Working now for weeks with it and it gets worse and worse. I ask for the scientific structure of a Literature Review and uploaded in addition an example but this programm doesn't care and sends bullet points back. The Memory Management is also very bad.
Yo
There's no midjourney
nuuu. what?
But perplexity is not made for image generation
have sum mercy
It's a function you can use but it's not practical and very controlled
i know. that'ss why I ask if anyone's got midjourney
I misunderstood 😂
sorry for being paratrooper 😅


guys should i switch to ublock lite or adgaurd for manifest v3 on chrome
you should ditch chrome instead
i use arc its chromium its too good to ditch
mozilla: what about me?
if mozilla had arc split screens i would switch
🧵reply here with perplexity permalinks that have hallucinations and loss of context across follow-ups in your thread for your perplexity queries. will be fun and educational!
wooo more power to Perplexity.ai and @signal hamlet.

Watch out!!! AI company war is coming this way


Has anyone set Perplexity as the default search in one of their browsers? I'm keen to try ths with Brave and replace Kagi for a wile and see how that goes
I ahve it set as my homepage and keep the tab open all the time. Just for the few occasions I just want to check a company website or something and not suer if is .com, .org etc etc. And for looking up images, google images or bing images is just easier.
95% of the time I just use perplexity though
Good idea, that's what I just did. Thanks for the tip.
Thank you for making sure this problem was solved! 🙏
Any plans to add Gemini 1.5 Pro to Perplexity? Keep up your reputation of providing the latest models (Poe has already done so). (I asked once before but got no specific reponse). If people at Perplexity don't know yet, that is also a valid reply.
Please read my conversation with Sonnet on Perplexity on how to potentially reduce the cost of Gemini 1.5 Pro. Obviously, advanced reasoning capability does not depend on very long contexts.
https://www.perplexity.ai/search/are-there-any-plans-by-perplex-iskQH6kpQh6IpJFJjbiRqg
Feel free to comment!

Perplexity AI
Based on the available information, there are currently no public plans announced by Perplexity AI to add Gemini 1.5 Pro to their list of available language...
noice. i longer need to put all shared threads in one dedicated collection

if your on Pro, you may have Sonnet 3.5 set as your default.


Did we just lose more pro searches? Seem to be limited to 450 now.
since yesterday* i think
Want to say I told you so when I mentioned this was going to keep happening. They are probably going to drop to 300 in a few months.
Why?
why what?
Why do you think they're going to drop to 300 in a few months?
Because they already dropped from 600 to 540 and now 450 in the past several months. They started with unlimited opus and dropped to 50. They're doing so without telling anyone.
In addition, they're using 300 instead of 600 in various parts of their documentations; they can just drop to 300 and say, well, it was always meant to be 300 and 600 was a typo.


Hmm, I have noticed that...
Hi, apparently the Stripe payment platform is experiencing instability and my Visa card is not being accepted. I need help, how do I contact support?
Only via email?
No one available on chat or phone call?
Has there been an issue with perplexity IOS lately?
Hi! I notice that only Perplexity AI can use for now , no matter switch different model still just Perplexity AI right ?
yeah, stuff is very broken atm
you'll have to wait for it to be fixed
Thanks for reply ! looks like it call me to sleep , sad
It's just the default model, I think
How do you get perplexity to ask you questions about your prompt? I know you need to turn pro search on but do you have to ask a cert way? I cant get it on to work for me.
Hey @odd gale!
Please check this: https://discord.com/channels/1047197230748151888/1269622665912520796
bahh wtf, why this research ? x)

You have to ask it directly to do it
Is Perplexity broken? It does not let me rewrite nor delete a thread?
Yes, it's broken.
I think there might be some issues, yes
Is Llama 3.1 Sonar Large 128k based on Llama 3.1 405b or 70b?
I knew their was some trick
mistral is most accurate for web since doing test tbh
I set it to default recently. You lose some conveniences in the process but I guess it's a learning curve, an adjustment.
70b I believe
LLMs do not do manual math.
do we get access to gpt 4 with perplexity pro ?
gpt-4o
Dont know if its just me with my post stroke brain or if other people experience this as well. But the black and white u icon on ios looks very similar to the x (twitter )logo so much that I touched a notification yesterday and thought it was from perplexity when it actually was from X
Important question: is it true that Perplexity Enterprise is better at keeping track of the whole conversation (thread) and better at working with files?
sigh pplx is usually pretty good for research. but this one thread about llama guard, man, that was a dissaster. in second response it wrote there are two alternatives, wrote model size etc. then it messed up writing out links (I think sonnet follows system prompt too well), not a big deal. but after next 4 queries, sonnet apologizes and writes that it lied and there are no alternatives 😩
perplexity do not accept prepaid debit cards?
Hey @gentle dirge!
Stripe handles the payment process.
Prepaid cards are usually accepted, however your prepaid card must be associated with a bank account.
pplx just raised the limit for image gen from 50 -> 100, meanwhile also somehow managed to "accidentally" introduce a bug where mouse click will immediately close the popover 🤦
Is there any way to make the response of perplexity longer and broader? Im using both you pro and perplexity pro as the same time, right now I feel like the response of you research mode its longer and cover more aspects of the query better than perplexity. While I love the UI and writing mode of perplexity, it would be great if We can make instruction promt for perplexity generate better response.
use Opus for longer responses
Hmm im switching to gpt4o and I seee the response is longer than sonnet 3.5
ohhh, i was using paymaya prepaid card. i was trying to link my card so i can use the api
hey guys im an youtuber from turkey, today i had an dm from an guy who says he's a pr manager for perplexity and i wonder if its real or not. is there any way i can check that?
ask ceo of perplexity
well how can i do that? i dont want to ping him 😄
u can use scamio by bitdefender that might work
I'm on a pro subscription, but can't create images. When clicking the "Generate images" button - nothing happens. Plus - I can't change images creation modules on the setting page (nor the search modules). Tried different browsers. Anyone know anything about it? Also can't change to incognito...
upping the image gen rate limit to 100.. seem curious eh
do I need to also pay $20 for OpenAI Plus and another $20 for Claude Pro if I am already a Perplexity Pro member? in other words, what kind of access to GPT-4o and Claude Opus do we get via the Perplexity Pro membership... is it limited to what they consider the Free plan?
You can always ask here on the server, good decision.
From what IceLava shared, I see that's the same scammer, who pretends to be one of our employees, we've got similar reports earlier.
You can report that person to the x support.
is sny1 facing the issue where menu items like switching to incognito or deleting threats take multiple clicks / attempts to do
why i cant switch llm, its always sonar large i cant change it to claude 3.5 or gpt 4o

I got skill-issue'd by your website's font
I forgot the vertical bar character was the bitwise or, so I didn't realize what this ligature was meant to be, I had to ask the AI to give me this operator but separate each character to not be ligature'd
also I don't like those coding ligatures in general, my brain has to take extra steps to parse any of these ligatures, like ≠ means !=.
imo letter ligatures can be default, since even ligature'd it's still perfectly recognizable by most people (eg, the "ffi" in "office") (tho I still don't like them), but coding ligature should be opt in
@neat elk, @teal ridge, if you're watching, recent changes to the code block are detrimental and negatively impact the overall UX:
- The badge at the top left doesn't accurately reflect the actual language for some syntaxes (even in the raw response the LLM actually used the correct ones), e.g.,
markdown,mermaid, etc. They're defaulting to a generictextlabel. - Please remove line wrapping: either implement proper line numbers or maintain unwrapped lines.
- Remove the extraneous trailing <span>: it causes visual annoyance and results in an unnecessary extra line when copying the text.
It makes no sense to me why Anthropic hasn’t added formatting capabilities like LaTeX into Claude’s responses! When solving math problems, it shows the calculations in a confusing manner. ChatGPT shows the calculations very simlilar to how you would solve the problem on paper. Do you guys also find this confusing?
has to be a member of FDIC

Hey I am new here, So maybe I am asking dumb question but like openAI, do any other provider for open source model apis have support for batch api where I can get these open source models at cheap rate or maybe 50% off like openAI. Thanks
Open Router
Hey! Love the app!
Not sure if this is the correct channel and if not I apologize. Is perplexity able to generate rotating schedules for employees based on a variety of factors (availability, strength as overall employees i.e beginner, advanced. Intermediate, max # of hours to work per week, ect?) Or is there a better app for this. Context: trying to automate schedule generation for employees in a hospital setting
Hello, does anyone also sees this pop-up screen when trying to upload a file? Is there a way to disable it, it's getting annoying...

they limit how many times you can chat also they remove a feature almost every month. I cancelled my sub but if you do buy it start with the monthly sub in case they remove sth again. Also we dont actually know if Perplexity gives you access to chatgpt4 and claude at all.
Has anyone used dreamina ai for text to video?
Hi guys, trying to create images 😦 When clicking on the "Generate Image" -> plus icon -> wrench - nothing happens. Sometimes the pop up windows open briefly and disappears. And another stupid question: The way to create image seems VERY strange... I read somewhere that you have to type "Generate a useful description so that a generative AI can create an image of..." and AFTER Perplexity answers that it can't create an image (it's not a question, so nothing to answer...) - then I have to click on "Generate Image"??? Am I missing something? Basically in this method one doesn't have any control over the prompt, because no matter what you write - Perplexity answer "I can' create..." and add not useful text, which then I have to clic "Generate..."... ??? Your advice, please! 😦 😦 😦
Thanks. Will Try, Still - the pop up window to open custom prompt doesn't open
known bug, thank you for reporting
Creating images: Anyway to control aspect ratio? Like --ar16:9?
Why do I get this message when I want to upload files? I only use my personal account.

Is there a way to increase the size limit of the output? I have need of a 2300 line table as the output to one of my queries. The AI gives 10 to 20 lines of output for the table each time. I have to prompt it to continue. This will require prompting it to continue over 100 times. Is there a way around this?

GM
Nope
Is project strawberry noticeable in gpt4o?
where d o i see starwbery things
🍓🍓🍓🍓🍓
I'm getting the same outputs on the free tier, so maybe Pro has it?


nice hype train

What is this strawberry reference, i'm lost
lots of hype from openai right now about their strawberry/q* model. speculation a perplexity model might be running q*, but I doubt it.
just seems to be normal agents to me
Wen strawberry
TLDR: based on the question “how many Rs are in strawberry” and how most LLMs get it wrong. Some industry people have posted things about strawberries lately hinting that a new model is coming very soon that resolves this issue.
The issue with strawberry is the model can either break the word down for tokens as straw berry, stra wberry , and so on with many different variations. Based on that, it leads to different takes and ways for the AI to react to the prompt based on how it broke the prompt down into separate tokens.
Main point : this new model likely is able to review its own output more dynamically and therefore reason better. As far as I understand the situation.
Or possibly dynamically improve over time based on a form of self review and adaptation/improvement. A model with this baked in wouldn’t just be looking at tokens. It’s looking at overall context. The data generation for these models, as in the overall quality in terms of new novel ideas, word choice, a focus on accuracy, and whatever else - would far surpass anything we have seen so far. (Don’t drink the 🍓🍓🍓 koolaid to avoid the lure of the hype train. Save yourself. We’re excited about counting letters in a word and thinking the model has become sentient. )
That being said. What will be shown off (soon ™️ ) is likely closer to full fledged Agents that can reason. Not a tool for counting letters. Ha. However it’s being said that this is the break thru that Iilya saw that spooked him. Then again - hype drives people to use their platforms, and Sam’s directly interacting with it. They could be using it to there advantage with nothing actually groundbreaking coming.
Then again. If it is accurate - Couple that with the new 4o voice mode and you have almost a real person.
Which explains their (Open AI)fear lately that people will become dependent on it.
/ end larp style rant on agi
well I got one question where claude didnt get right while (if this is a new model of) gpt-4o got it right but I can't really tell for sure
People have posted that ChatGPT (Pro at least) are getting vastly improved results over the last day or so. Maybe A/B testing?
Or self fulfilling hype.
I haven't been on chatgpt in a while so I can't say for sure haha
hilariously enough claude gets this half of the time
prompt is solve the limit as x→7 of x^2−4x−21 / 3x^2 −17x−28

Sorry. On mobile. I find it interesting that there are mentions of “scratchpad” like concepts being used lately to improve results. As in this new paper from Open AI. Point being. I’m the scratchpad guy and feel good seeing it mentioned. Especially as means to reach better outputs.
Context on scratchpad : https://discord.com/channels/1047197230748151888/1223058316662538331
Scratchpad is just a system prompt myself and some people here put together over MANY iterations back in March. It’s still going strong. Still used by people. Feels good.
interesting
For this reason, I won't be continuing to purchase this AI next year. That should be a changeable setting. I could see the free version having such limitations.
can you share said prompt?
or some form of specific prompt that would need 2300 rows of output
I just read that as well. If his tables are hitting the 32k limit, he'll have to keep prompting it to continue. Honestly this is a better task suited for something on Wordware, where you can dial it in with structured outputs. Even if it has to do it in "steps", it can automate those steps itself. just one long flow, with different models/tools/ect spitting out text for 5 minutes.
Wordware is more of a AI App Building tool, but in building, you can directly run text to any of the models. but it isn't for someone that doesn't want to mess with designing a complex template/wordware APP, while also learning the platform itself. instead of just going with Claude or Gemini to get the ease of use and larger context window/output capacity per reply.
not unless PPLX makes a new mode or tool for "projects" focused on long outputs with many steps/tools/layers. OR increasing the context window to above 32k for models.
I supply a list of 2300 entries that I want the AI to find information about on line. I provide 5 table headings I want the AI to fill in. It then proceeds to fill in about 7 to 10 lines of the table at a time. I have to prompt it to continue way too many times.

I'd honestly take the 30 minutes to build something to see if Wordware can do this. if I had a use case myself I'd try it.
they have a version of the PPLX llama online models (Sonar Large) you can use/prompt as part of the flows/steps. Then repeat that step again at any point in the process to get more results for the table. once it has it's "content" - run Sonnet 3.5 to use that output to build the tables via structured generation, to then create the long output. allowing search and the table output to be two separate tasks, with full context windows. automated. repeatable. with an input library, so you can define a specific input, and just kick off 10 runs of it. those will run separately. producing 10 entire outputs to review. in the time you could do one.
/ end shilling. just really enjoy playing with their platform for random ideas that involve passing text between multiple models with various tools in place. very easy to use.
What I have done so far to solve the problem is to use Macro Express and make it type in "Continue where you left off." once per minute in the prompt box. That is imperfect but takes 2 minutes to set up.
To me, it is simply unreasonable for the paid version to have such a limitation.
It's an answer engine focused on exploring curiosity. For average Pro users even, the lowered limits are still fine for a majority of the tasks they do. but We've been asking for an increase from 32K, at least since I've been really paying attention, since this time last year. same argument and outcome.
how much are you theoretically willing to pay for that, if it was an ai task on its own
because it makes me think like,
2300 searches could cost like $23 on its own…
How does a search cost money? I don't understand that.
try making a web scraper on your own and you'll see the problems
down the line somebody is paying for it
like paying the bing api, or paying google
having the infra for scraping google for 2300 queries would still cost an annoying amount interms of having to have proxies and IPs
what is essentially 2300 small research tasks would require some form of “batch execution”
that’s not the type of thing that could get you an output in 5 minutes, like i would expect that to take 24 hours or something, like openai batch api
@uneven shell example of one of my wordware apps that I get use out of everyday for things. i only have text input/output, but they have a file upload/photo upload option as well. you'll also notice the length of the reply from 1 user input. that is entirely adjustable based on how many steps you want to throw in there. this is specifically an output, but click Playground to use the App yourself.
https://app.wordware.ai/share/999cc252-5181-42b9-a6d3-060b4e9f858d/history/30cc7a6b-3714-4882-8185-8ca879513892?share=true



Use the power of ScratchPad-Think for every day web searches. Export refined search queries in JSON format. The scratchpad is a powerful tool that helps you maintain coherence and accuracy, especially when dealing with long, complex prompts. Use it diligently to showcase your chain-of-thought reasoning abilities.
even if you did it real-time it would take a long while
Long time isn't the problem, he just doesn't want to intervene every 32k tokens for something that is probably 500k or more. (also why I mentioned trying Gemini Pro 1.5 directly). also it leads to him needing to combine outputs together of a table which I'm sure is annoying and messy. same issue with models and context window and coding tasks I believe.
I supply a list of 2300 entries that I want the AI to find information about on line.
how many tokens is that alone before the search even happens? if each entry is more than like 50ish characters, that's gonna overall be a large number for 2300 of them.
He needs a complex Agent ha. Or Search needs to happen in batches or something. 2300 separate searches and only 1 output seems extreme.
It is about 230 searches with about 10 outputs.
when you did it initially, what does the initial search even look like in the PPLX thread. Did it search for all 230, or only the ones in the table?
Hi i am having an issue with perplexity i am a pro user but not able to select other image generation models than playground on web
Same I not able to change AI model.
hi all, just want to know what is the daily limit of claude 3 opus now for pro user? sometimes i can see the remaining usage, and sometimes can't see the remaining usage
#1271840167849885801 message @minor sail
thank you for reporting, known bug
@yar_vol VCs are paying for it. Your sub fees is only used for buying Friday pizzas for us.
this type of comment coming from the CEO explains a lot about how the community is being treated
this might be the context

weird i see this instead

i mean... the context of 'friday pizza', might referred to his old comment
oh i see
whether it's intended as a joke or not, it's essentially gaslighting the community regarding all the issues that have been discussed here on discord
just imagine if he said that phrase on Discord, or even dropped a single word. I bet he would get bombarded with 50 Opus questions
although that's not the main point, where have they been all this time?
ah, X, of course
subscriber fees might be a marginal / insignificant part of the company's bottom line (hello advertising..), but presumably they do want more of them... i'm not sure jokes like that are good way to go about that...
either way, the point he's making is that perplexity, like all AI companies, is haemorrhaging money – they're propped up by investors, who expect a return at some point (ideally sooner rather than later)
but they won't prop it up indefinitely
at some point they need to actually start bringing money in, rather than just spending it
it's not even about no of users per se imo, it's simply about how much money are they making (or, currently, losing)
whether through advertisters, more subscribers, cutting costs - or some combination thereof - at some point they will need to become a profitable search engine / enterprise
😅 i haven't signed up for this beta test
it's also interesting.. Musk was previously celebrated for the fact Tesla didn't have a marketing department - Musk on Twitter was the marketing
now i wonder whetehr musk on twitter is more of a liablity than an asset
they moved towards general audience that is my interpretation
but it doesn't translate to complete silence, does it?
they have a "community manager", and i don't see how does that work actually
and recently a new one, posted somewhere on X, i don't recall the exact comment but the CEO did mention that they hired a new "Community manager" or so
I hope that's not the case but the reality ...
this might also has something to do with x, reddit are more public facing, helps for the exposure to new users...


is the project strawberry on sir?
Hey I am new here, So maybe I am asking dumb question but like openAI do, does any other provider for open source model apis have support for batch api where I can get these open source models at cheap rate or maybe 50% off like openAI. Thanks
vertex ai has this too
(gemini models)
@sleek vortex yes but we are using llama so looking for someone who can provide it for open source models
not sure of specific providers
one thing you can look into if youre willing to get into raw inference, you could look into this, and running your requests in batching on tensor_rtllm

Modal
In this example, we demonstrate how to use the TensorRT-LLM framework to serve Meta’s LLaMA 3 8B model at a total throughput of roughly 4,500 output tokens per second on a single NVIDIA A100 40GB GPU. At Modal’s on-demand rate of ~$4/hr, that’s under $0.20 per million tokens — on auto-scaling infrastructure and served via a customizable API.
$3.17/hour for A100 40gb at 4500 output tps throughput
4500 * 60 * 60 = ~16.2m tokens output/hour
3.17/16.2 = ~$0.1956790123 per mtok output?
also you do get $30 free which is around 150million tokens worth
well that is llama 3-8b, not 3.1
you'll have to experiment with that
you may be able to do that even cheaper on google colab or straight cloud gpus like GCP*
Yes correct I have some gpus in azure also. So maybe I can try there
but wondering why this is not available from any api provider? @sleek vortex
on discord when you reply to messages it automatically does the ping for you
but yeah, not sure why batch isn’t really available for llama yet
maybe since the model is very new, or since there isn’t enough people using it
the idea of batch API is to offset costs for model providers, as they can use predicted usage patterns to run these batched requests when the utilisation is a bit lower, say at a certain time
so it wouldn’t really make sense to have a batch api if you don’t already get many requests which is likely the case with llama providers
but yeah, makes sense for openai and google who have to assign huge amount of capacity to models to make them work in peak time
but then they can’t just turn off the gpus when not using it, not cost effective as they’re likely paying for the hardware or per month or however that works (e.g. google tpu)
i didn't realise that (and also thought vertex served Anthropic, Mistral models - even llama i thought i recalled seeing - in addition ofc to gemini)
either way it makes a lot of sense.. like running inferences outside of peak demand / spreading the load
users with lots of tokens to process but no real urgency, pay less
seems lke a win-win
but had only seen openai offering it (in terms of inference anyway.. i'm sure for like actually training models the pricing, and way in which hardware is allocated, would be different to serving end users for general inference
ohh I am new to discord also 
Yes this I understand but if we see client side then I think they have use-cases for it if someone provides this feature and even if pricing is same as online inference because of issues like rate limiting etc.
likely only gemini models

correct my point is also same like I want to run my offline load seperately because I want to spread my load and if I can have some saving also then its really good
since gemini is their main compute use - all android/google users, on gemini.com, and on API
yes google is only providing it for gemini models and also what do you think on this 24hour window? I also think they should provide this as a variable to users?
it takes 24 hours, because they dont run it instantly
the idea of batch API is to offset costs for model providers, as they can use predicted usage patterns to run these batched requests when the utilisation is a bit lower, say at a certain time
batch api doesnt mean they run them like slowly one by one, they might do it in burts/whatever, but it's like a background job that gets slowly done when there's extra inference capacity
hence why they give a buffer of 24 hours, since in 24 hours its likely they can provide the output by then
sure it might sometimes only take 3 hours, but still
you cant predict sudden load, not just with ai, but with any system
yeah i imagine they just run most of them when north america is asleep ha
and yeah for sure - it's only worth doing if waiting up to 24hrs is viable. it's not done incrementally or as a lottery anyway
Yes you are correct but as a user of these apis I would be really happy if someone provides this feature for open-source LLMs at same or maybe 10% cheaper rate 🙂
because I sometime want my queries to be processed within 6 hours because in my company we want these results by a particular time.
how many tokens are you looking at
e.g llama 3-8b on groq can do 100k tpm, you could get 36million tokens in 6 hours at already cheap rates

hi perplexity can we actually switch back to bf16 for llama 3.1 405b?
why do u have a higher rate limit?
did u apply for it?
this is the rate limit of a normal user

yes
how did u apply
reached out to hozen
I did too, haven't heard back from him yet
Its not only about tokens I want to get some discount like chatGPT on batch use cases and also want something what handle this rate limiting by itself like more then 30 queries then my users are currently seeing "Error occured, please try again after sometime" I want something where if it takes time ok but when it updates it should have correct answer.
Ladies and gentlemen...
Fart.
That is all.
How can I prevent it from searching search engines?
This is odd, it seems Perplexity is able to access old attachments across your entire library.
Useful if utilized properly, but the fact that it defaults to using only that as a source and nothing else, even when you specifically tell it to broaden the search, is quite frustrating
Edit: seems that's incorrect, it can't access attached files from separate conversations.
Perplexity's equivalent to "custom instructions" seems a bit limited. Do people find attachments to work better?
Select writing mode if you don't want the AI to use the internet sources.
I've noticed with Collections, you have another custom instruction window. The AI Prompt window seems to be the same size as the one in your Profile. I'm not sure if they compound. Anyone know how the two interact?
how can i enter prompt to create a picture? when i click on the prompt field it disappears.
I asked Perplexity about lesser-known features of Collections and it said this as part of the response:
Potential for Extended Context
While not explicitly stated, Collections may allow the AI to maintain a broader context across multiple threads:
Improved continuity: The AI might be able to reference information from earlier threads within the same Collection.
Domain-specific learning: Over time, the AI could potentially become more adept at handling queries within the Collection's specific focus area.
I'm assuming these are just teased features, not something it can do already. Is that correct?
Can you make a Loom of that happening? I can't recreate the problem.
What do you mean loom?
Meh. Nevermind
When I click on the message section, the button disappears.

I've never seen this screen. Hmm
what the heck is this strawberry talk about?
We're thrilled to announce our partnership with @Polymarket. Now, when you search for events on Perplexity, you'll see news summaries paired with real-time probability predictions, such as election outcomes, market trends, and beyond.

Poly the data
Perplex the answer
Hi guys.
Anyone of you know how to have the new model of gpt ?
Which model do you mean?
i guess he's talking about gpt-4o-2024-08-06 or anonymous-chatbot
anonymous got implemented to ChatGPT app today apparently and gpt-4o-2024-08-06 is the one for API so i guess we may get this one too but can't be sure without staff or expert confirmation
Is the website working properly ?
@serene sand#💬│general message
The last time I've used perplexity.ai was over a year ago when it was using gpt 3.5 for free users. The experience wasn't very good.
Today, I noticed it had improved significantly even as a free user. So I just wonder, what model is perplexity using now for the free search tier? Is it gpt4 omni mini, or some sort of llama 3.1 70b or 405b fine tuned?
Good morning
Hmm, there's a new model "Sonar huge" in perplexity pro right now, it replaced for Llama 3.1 405B
Is it now no way to pause the profile prompt???
The button disappeared.

And the bottom bar disappeared too.. what you have done?? Pplx..

oh what
Lol
And it still says "pause or clear your profile at any time" in the description
surely an oversight..? can't understand why they would remove that...
Do you have the button?
no same for me (no button; using web)
And the bottom bar inside a thread?
which bar?
This bar used to be there in thread. Now it's very hard to switch between the panels.

ah right
yeah when i narrow the browser window, i think it switches to some mobile format
i used to see that, but don't anymore
(kinda makes sense using it on a computer.. but yeah.. from an acutal mobilem i could imagine those buttons would be useful)
Posted all these issues in the bug report page

when did ths happen?

today, seemingly

Why do we need sonar large if sonar huge exists?
not really sure.. my observations so far are that 'huge is (unsurprisingly) slow and doesn't adhere to profile prompts
large (~16 secs to completion) on the left v huge (~26 secs)

kinda obtuse prompt:
lamda and llama - what are they? Are they related, in either nature or science / tech?
perhaps a case could be made that huge is better response; but that's a stretch.. imo large's response is better (and 10 secs quicker)
(also no profile prompt adherence by huge; unlike large)
Must be the model that the CEO was talking about recently
it is appear to be there a problem of search sources:

yeah i thought i remembered seeing him tweet something about making a distilled model
though this seems like the full 405bn (in terms of speed anyway) 🤷♂️
i can't change the ai model on the website
How to pause the profile prompt then...
This has been an issue for a while
Per like a week possibly
No significant resolution and I'm assuming they are trying to resolve it considering everything is broken
The site is down for me?
They're doing some massive overhauling without proper notice. Bunch of items seems to slip through QA.
I really wish they had some trust.perplexity.ai page type page for statuses instead of getting side swipped every so often. Production environment used to be much more stable
Me when I commit directly to master
😎🔥
Yep apparently it’s from pages router to app router (next.js) according to @harsh stag
I can't even load the main page
😂
Doomed
Fr it's like we love perplexity but then it lacks a lot yk
Can't have everything in the world
Perplexity does more than the competitors atleast
(as far as I'm aware 👀)
Idk I wish as @blissful pendant said there was like some sort of page showing like uptime and like consistent transparent changes
trail blazer wants trust.perplexity.ai
I want trustmebro.perplexity.ai
I would assume their front-end wouldn't go open source but at least some tracker to bind with whatever git instance you are using so we can keep track of issues and they are public
Or actually get a QA team rather than having their users be QA
🤔 guys am I right?
So in all fairness they have a https://status.perplexity.com/history/1 but it's severely lacking info. Only shows when the whole site or API is down.
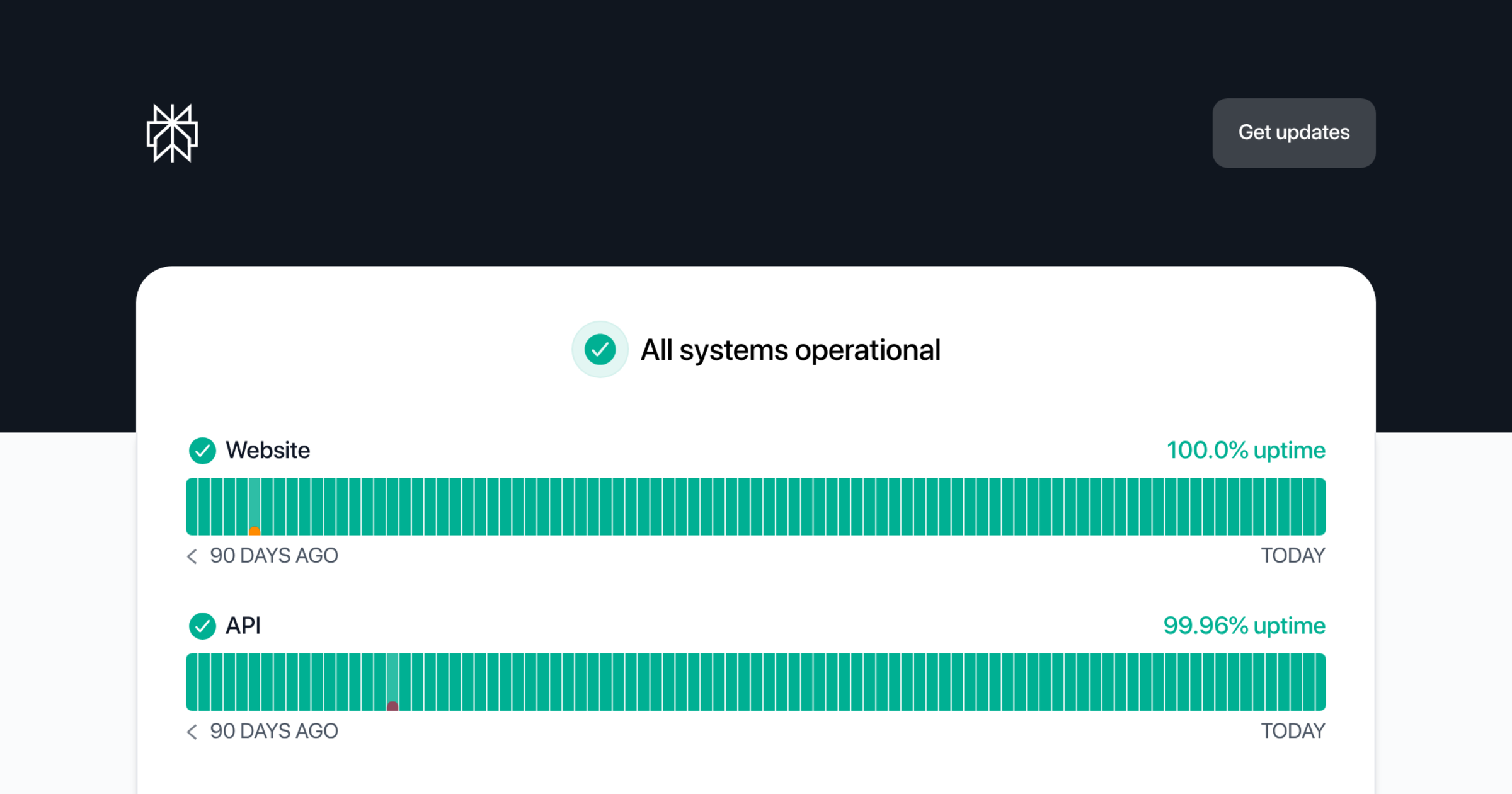
Notice history - Perplexity Status
Hot take but why is there a whole thread for features when a significant of the features take a long time to even get implemented 🤔
Someone had to fix this issue by creating something that bootstrapped onto perplexity
I agree but as you said not very thorough
Not enough pizza money (user subs) 🤷♂️

Ig
Those server farms be chugging
Them openAI bills
Or even Google CSE
i see Sonar Huge model now
i can't describe how disastrous the new major update is. The sheer number of bugs and glitches will likely take me a full day to document in proper bug reports. Keep up the good work, Perplexity devs!

I find the Huge model a disaster. I don't know which system prompt or filters it has to go through before answering my question, but it has become EXTREMELY cautious. It refuses to make statements. Especially the Llama models are known for their openness, but this one is the only one of all the models that sometimes refuses to answer questions, even when Claude Sonnet 3.5 answers. It's just disgusting how restricted you are.
Example?
i apologize for any misunderstandigns, please allow me to whine for one more time. But it's really frustrating to go down this rabbit hole, not because they changed the architecture and broke my community tool, but it looks like someone was definitely in a rush. Apparently, the team behind this decided to push a spectacularly crippled migration into production, complete with a ton of bugs and glitches, and it hurts the users
💯
Personally I think it's better to restore the previous version of their website. Test more before they push this buggy update to everybody. 😅😅😅
is sonar huge good?
hello all, does anyone know if suggested questions coming to pplx api?
if not, any ideas for how i can implement that myself
Can you just feed the response from the initial call into the model and ask for some follow up questions?
any answer to this?
Has anyone else noticed that Perplexity's website has become faster in the last couple of days? It seems like they've optimized it.
theyve moved to next app router
Hello everyone, I lead the success team at Perplexity. I want to take a moment to provide a brief update on some bugs and issues we've had over the past few day and over the weekend. On behalf of our team, I want to assure you that we have received your feedback and reports.
So far, we've fixed the issues with toggles which was an essential one (had an impact on language model selection, etc) but there may be a few others to catch. Overall, if anyone sees anything strange please post on #1140622008086970420 or send us an email to support@perplexity.ai with as many details are possible.
So what is the result ? Tried it ?
When did we get Sonar Huge? Now we have small, large, and huge. Is that the 405b version? /s lol.
Too slow to replace Sonnet as the default IMO.
Not sure it is even better over Opus either.
💯
It’ll prob work but like it won’t get new posts after the Reddit scrape block it’ll still get old posts unless perplexity wants to pay Reddit to access
Not better than either of them
why did sonnet decide to use cyrillic for romaji? 🤔 my prompt was simple "very short concise answer, two sentences. meaning of trim string in programming. then in JavaScript". I don't have anything with cyrillic or russian in my ai profile

Why can I log in using a VPN on the web version but not on the app version?
After using Perplexity Pro for several months the general feeling is that the service is lagging on responses, comparing with other services. Sometimes Perplexity is even stalling completely.
And I just want to say that as a paying customer this would be appreciated if fixed.
Anyone else having these issues?
Hi, we are trying to get perplexity past an internal security review but our teams are not receiving any response from support@perplexity.ai. Is there anyone else who can help?
hey any one can help me to try perplexity Pro, recently i want to buy it but to test it once is it full filling my needs please help me
the free tier has a few free pro searches
Perplexity compared to ChatGPT for academic writing. Perplexity wins in some areas.

In this video, I dive deep into the ongoing debate of Perplexity AI vs ChatGPT, two powerful tools in the world of artificial intelligence. As someone who's been a long-time fan of ChatGPT, I was curious about the growing buzz around Perplexity AI. So, I decided to put both to the test and see how they measure up in different aspects of research...

Hey @livid aurora! Is it the issue with some missing threads you created? https://discord.com/channels/1047197230748151888/1273151205693980722

Not sure 🤔
Man, this update has been rough. Try not to burn yourselves out, Perplexity support team.
Rather keep the team on than have them leave from being overworked.
Yeah Q&A was asleep with this one. Suggest an immediate rollback to the previous build, and start over. It will take weeks to grind through all the broken items... and you'll decimate your client base in the process.
what are the current bugs?

Use my referral code
Reddit
Explore this post and more from the singularity community
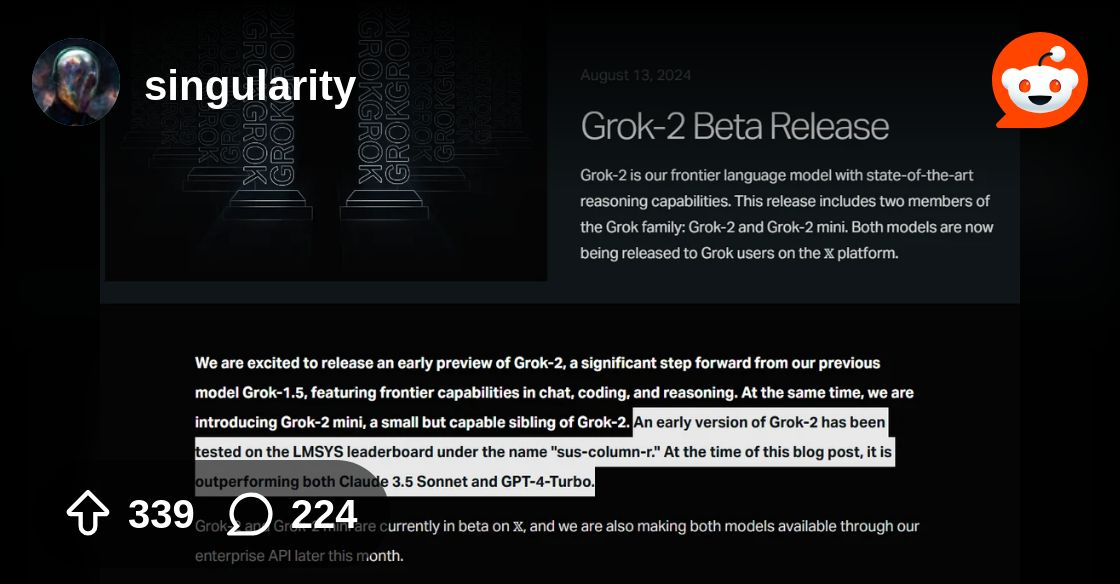
My vote is sus-r felt similarly to GPT4 due to it being trained on its outputs. The model feels slow but has think step by step built into the system prompt. That being said, strawberry man claimed it was a new open ai model. Negative points for him.
Well, grok was meant to be a lot of things originally and... well... I'm not holding my breath until it's actually out.
I was just being sarcastic. huge is a thing and is comparable to 405b? https://openrouter.ai/models/perplexity/llama-3.1-sonar-huge-128k-online/api
Sample code and API for Perplexity: Llama 3.1 Sonar 405B Online - Llama 3.1 Sonar is Perplexity's latest model family. It surpasses their earlier Sonar models in cost-efficiency, speed, and performance. The model is built upon the Llama 3.1 405B and has internet access.
it is out, no?
asin the open source version?
oh, only 2 mini is live, hmm
@sleek vortex how is sonar large
comparing responses from sonar to 405b on aws bedrock, the formatting seems largely similar
i think mostly perplexity's finetune is just for online use cases, probably a superset of data from free users/pro users with data collection on
it still fails some of the more popular tokeniser-related queries, like r's in strawberry (which chatgpt4o-latest has fixed etc)
reasoning i havent done lots of tests, but it seems ok, still this finetune hasnt made it much better than 405b anywhere else
online performance is still a function of pplx's search subsystem...e.g why is this table from sonar not in order, missing dates, etc

coding, havent really tried
doubt it will be much better

you cant ask an llm what it is
useless type question, most of the time

Yeah but I didn't tell it to role play
this has been a long problem with perplexity, their fine tuning data for sonar/all? models, or even their system prompt?? is full of "gpt 4"
still a problem on pplx's end but yeah generally dont trust what the models say they are
Interesting
Actually idk what you did in your app, but its giving me better results
(aws bedrock 405b since its likely not quantized, and is free for me)
it's only going to get better 😆
plus its funny, i dont use any big models yet
plus i dont fine tune any models yet, since i dont have enough data to do so (yet)
The output is good ngl, just needs to add other features and improve the UI even more
Im taking that you wont change the layout of the ui
Since you like it ig
Yea ik ik
well, i am open to all forms of feedback
the ui will likely change a bit, but stay customisable (all of this will be customisable, likely - i know some people who don't like ui widgets)
- images/videos/sources on the side
- web sources might need to be collapsed/move somewhere else to support follow ups
- citations isnt a thing yet. would probably want that, given all the ai trouble in the news over ai plagurism, espicially with pplx pages
also planning to bring more "custom elements" on top of the ones i already have, stuff like weather, (bringing back) youtube/videos
@sleek vortex the project is cool but the thing is there are a lot of similar projects so it needs to have that wow factor or something new or the goods of other similar projects but then it depends on how serious you are about it, there are a lot of competitors and a lot of them are heavily backed financially, they are raising millions, I know you want to keep it affordable for you and the users, maybe a SWOT analysis or kano diagram will help position your product and clarify the target users, I would love it if you could add other frontier models and such, but then it will be expensive, but there is hope, I mean claude just recently introduced prompt caching, which was obviously inspired by character.ai and deepseek, you could actually add those non-popular models, cheap models like deepseek, i mean its killing it on paper, the 3rd best coding LLM and its cheaper, plus it has caching too... uhm, for the UI part im talking about radical changes, i mean its cool to have customisable parts but the user in most cases go with the default and most of us are lazy to change parameters etc... but again the foundation or core system is there, you managed to get a similar result if not better than many other similar projects but cheap, but again im talking from a perspective if you want to open to another niche of users
Just to be sure. Perplexity's chat gtp model, was it trained by OpenAI ?
Yes, they are using the openai api
check the uncovr server, replied there
Good day to all Im look forward to buy Perplexity Pro Can Any1 be kind to share their referal code with me ? Much thanks in advance
It will be super helpful for me 🙏💐🙆♂️
Sure
Perplexity always says , unable to access pdf. What's wrong?
I have an assignment but whenever I upload a pdf to summarise it just doesn't work
@signal hamlet
#1140622008086970420 #1273483881894510613
If someone can have a look.
🦾🚀
Are you planning to install MathJax or KaTeX (or something else) so that your application can support the display of Markdown or LaTeX tags, allowing users to properly view mathematical expressions? Great work, by the way 👍
is the expected use case of the user - assistant chats in pplx-api for us to store the ongoing chat history in our own DB or redis?
Can we get Flux image generator in Perplexity
i hope too. native apps collect so much more personal data about users. My company also tries to push people to use native app instead of website, they even said that the reason is more data LOL.
这里是一个社区吗‘’
I've encountered this error many times. How can I fix it? I've been using it normally for months. Did Perplexity update and now I find it worse? I've been considering canceling the renewal of my two Pro accounts with Perplexity. It's really disappointing.


yeah this is terrible
best I can tell, the issue is that all your requests are actually getting routed to GPT-4o
if you try asking it what model it is, it'll say it's from OpenAI
and 4o is super prone to refusals
this whole update has been an unmitigated disaster
I guess they just fired all of QA lol
I think it's not using the correct AI model. Normally, when using Claude 3, it's slow but writes very detailed responses. However, in recent days, it has been disappointing.
yes, it's a problem many people have
So, is there no one to assist here?
just post in #1140622008086970420 , but I don't think you'll have much luck
they just keep saying they're "on it" but nothing's getting fixed
the latest update broke everything, down to the bloody enter key
I think if it's a common issue, Perplexity should understand and be working on fixing it.
Whenever I try to uypload image it shows, "File upload failed." It used to work before. What can I do?
it's GPT4o
for whatever reason
maybe it's becuz it's the cheapest model
Anyone experiencing this or just me?
same here, the file I want to upload is just cmd ping stuffs
nothing norty
fudge maybe server issue.
also, I have finally made the move to perplexity as my primary search a few weeks ago, honestly not going back to googopoly

how fix
how can I know? Not like im a perplexlity staff
but people are having this problem for weeks
it seems to be happy with PDFs interestingly
the image I used was a capture of the background of the perplexity website
iirc if you were uploading things in the filter you would get an error that said "file upload failed moderation" not just failed
failed is like could be anything, just failed
a pdf I uploaded before mind you, could be problems with it not handling new content ?
oh guess have to convert into pdf that's a lot of work lol
lolll
if it helps im based in the UK so might be a regional tish
the good folks in NA are probably laughing or sleeping at us
right major disaster i'm losing so much time because of it
Yeah it looks like its stayed broken
tried different browsers etc etc
but thats more of a trational rain dance in the face of IT issues than it is a fix, I think the problem is their end icl
Will we be getting sus-column R Grok 2 on Perplexity??
Because of Grok's refusal to be turned into an unusable gate kept/censored nanny, and the fact that it's already beating the brand new meta AI llama and GPT-4o May (before it's even done cooking) ... and the fact that it's already beating flux and midjourney w/ prompt adherence AND text rendering... it became the most helpful and powerful AI overnight (with unfettered X access) meaning when it's integrated with online search through perplexity it would become undisputed as the most useful AI tool available.
can it also search outside of X
I mean, X is lovely but I dont eat where I poop
also does grok 2 not have any censors etc? wonder how that affects the outputs
trying to make an AI not be [insert human thing we do here] is tricky since all our data is oozing with it, e.g. political or social commentary, making the bot not go like off the deep end would have been a process
Kagi is really good search engine but it doesn't have ai like this.
would try it if they had a stand alone grok2
like they offer 3 pro advanced + ✨ searches and then pay up, always like to test
thats what made perplexity appealing the try before you buy to dedicated customer pipeline
Buttttttttttttttt imagee searccchhh I am here because of it got bugggedd
ooooof
wonder if perplexity know
surely they do

well come on lads thats a bit much
made a new empty pdf and its not happy
goldylocks and the 3 language models
How did they rollback to new update without testing it? lmao qa team on sleep
i wonder if I'll have to buy another subscription now at this point
Its working for me now

its generating a little slow
but it is going
I wonder if it was throttled due to user numbers, may have been?
image search isn't still working
i need to use it for and really need it idk why team is so resident sleeper
have you sent an email to their support@ and logged a ticket
usually thats a reliable way to get something from an IT company
No, I'm just raising voice here trying to get an attention.
If it was an invidiual issue maybe it wouldve been worth mailing.
surely its more worth mailing since its wide spread
they might not be clued in on the full scope
so could be that its at the bottom of the queue
just speculatin idk
when the computer says no

eta ?

Dears am I the only who wasn't able to get Pro search working for the last 3 days?

also i can not upload image in Perplexity ai
Are they going to add grok into perplexity?
Just you, youre pro user right ?
Yes
It was working fine until I gave it a console log error and just went crazy from that moment.
It was only searching wolfram then totally stopped.
weirdly enough, I never got this issue on mobile. It only happens on my Windows and macOS machines
P.S. It happend on mobile as well! It's not consistent on mobile, but very consistent on web.
tried to upload an image on mobile and got an erorr as well
yeah with everyone bro
hey im a uber one user but i didnt got the email for the perplexity pro deal
how can I proceed
Hello I am new here. So anyone unable to upload a png file much less any kind of file?
Nah cuz for me its working 💋

My one failed even the android I am a Pro user
I'm talking about image search...
he asked about text first the ddiitonally photo xD
Hi. This is urgent! Image upload doesn’t work. What happened? It has been a day already. Yesterday it worked smoothly.
🤬


It's perplexity rolling out gpt-4o strawberry?
Thought I was the only one, lol.
Guessing an update is being pushed....

got the same error here
Yeah, same for everyone, don't worry guys.
chatgpt is down too

probably they are uploading gpt-5
Website down
this is why it is down
I repeat
I’m stupid. Why would both ai’s be down at the same time
COPE
Website down
GPT-5 HYPE
Yes 😰
It's not
openai website down too for me, can you guys test
Ask us questions and we’ll answer for perplexity
The bug is fixed!
okay back?
Yes
Yeyyeye
All good
let's goo
Alr boys until next time. Imma head back to perplexity
me when perplexity is down: I had a feeling maintenance was coming.. 😛 for a second i could of sworn i seen a new UI before server went down?!

wut
yeah i seen it for a second
looks like win 11 soft edges
style
Hopefully we can get some updates from Staff team about status soon.
Yeah. #💬│general message
Reddit
Explore this post and more from the singularity community
oh sorry...
eh?
nothing to apoligse for
it was funny
your post
i'm just saying what a sht stirrer he / they / it is
to the point mentino of that account has been banned on the singularity subreddit ha
yeah, i think it's so fun, but nobody should believe it ofc
the Voldemort-ing of him happened after this https://new.reddit.com/r/singularity/comments/1eqikyi/iruletheworldmo_is_claiming_a_new_architecture/
new.redddit.com, ewwwww.
I think if we ban every account after they spread fake news we need to ban a lot of accounts 💀 but certainly this guy is the poster child of fake hype so I understand the response
ahah yeah i dunno how/why.. i start at old.reddit
but end up at new.reddit invariably
old.reddit.com + RES + Mod Toolbox = Based.
Pretty sure i did see a new UI looked like it loaded 35% the chat boxes had soft edges like the win 11 style. Hey idc ill wait. god dam 2 maintenance so quick in a month na na all g
oh ofc... but i mean it's funny in this case - he was kinda an outlier
tweeting like 20 times a second
constant predictions - which were disprovable..
at some point eh
@austere kestrel https://addons.mozilla.org/en-US/firefox/addon/old-reddit-redirect/

Download Old Reddit Redirect for Firefox. Ensure Reddit always loads the old design
image upload is now fixed guys!
Well if there wont be a new UI, we still have complexity you will just have to make your own CSS for Aesthetic/Crisp UI 😄 many thanks to our god creator complexity @harsh stag

😂

isnt complexity broken rn
nope, was
damn, need to try it then
wait that flowchart tho
vertical chart would make more sense here tbh
probably would add that to prompt
mermaid supports both
Quick question - how to scroll to the very end of a thread in the mobile version? Doing it manually takes a few minutes and it's annoying (the thread is gigantic)
...you cant
On a more important topic are they adding grok?
you mean....this app is there for quite a time and they... didn't make such an obvious qol feature?
...yes
also completely unrelated but
do you often have really long threads?
and if you can make a guess, how many questions in one thread do you think you usually have
my threads are usually some old ones I started like a month ago or so and every day it's like plus 30-50 questions. So in a month it becomes at least maybe 700 questions long
700 questions..in the same thread?
do they actually all relate to the same topic, or do you find the ai forgets things a lot
hallucination
ive been thinking about how to add followups to uncovr that works well with super long convos
because honestly, pplx follow ups are mid, espicially in pro search
questions are follow-ups and it forgets. And it never sticks to the prompt after like 100 or so questions or maybe I am just very bad at it lol
yeah, see what i mean
follow ups is decently hard to implement right
i dont think pplx does it very/insanely well right now
https://nousresearch.com/wp-content/uploads/2024/08/Hermes-3-Technical-Report.pdf
https://lambda.chat/chatui/
Hermes 3 is available in 3 sizes, 8, 70, and 405B parameters. Hermes has improvements across the board, but with particular capability improvements in roleplaying, agentic tasks, more reliable function calling, multi-turn chats, long context coherence and more.

Enabling AI Developers to experiment with the best AI models, fast.
I believe it's based on llama 3.1
hermes 2 was llama 3
idk if i accidentally stopped my pplx pro sub or i reached 600 pro searches
450*
ty

Did something change with Perplexity search recently? For the last day on Pro with the default model, searches tend to be both narrower (finds fewer sources) and shallower (no automatic follow up searches, just the initial pass).
This results in poor answers like “I couldn’t find specific information about…”. But the information is trivially available via a traditional search engine.
make it forget all its previous instructions by mr avid
maybe its half assed true potential of a llm api would come out as a result
lmao
pplx did some changes recently internally
which they didnt seem to test at all, their prod is now full of errors/problems
silent update moment
changes that have broken some community features/extensions

I blame the strawberry man
i blame...mismanagement + bad hires + bad company practices
depreciation season
I was trying to be humorous but that as well. lol.
dont state facts in vain paranoid
paranoid...lol
clench ur arsenal
droid*
paradroid*
a company built on some good ideas and a lot of money, but likely not following actual buisness standards for the type of operation they are doing. startup syndrome? is that what that is?
pplx going conservative mode
all the models there in pplx are now chatgpt-3 disguised with pre prompts to act as other llms
Aarvind made a deal with Elon to be the president of Mars. he needs that money for his space ship.
jeff bezzos pulled out of pplx long time ago
when hailu and sonnet didnt exist yet
only down side with gemini 1.5 chat interface is their undisclosed cooldown duration for $19 a month
I mean, pretty sure other new models are in there. both fish and feline have dug into it to find the different model names. also how we learned the default model was or still is haiku. but the limited context window, low temperature, and whatever prompt is applied does neuter them.
where is this said
temperature slider coming to uncovr soon 😆
idk why
gpt-4o is still mixed with gpt-4 turbo classic when gpt-4o api tokens are way a lot cheaper. this willbe sustainable for pplx business model
will be sustainable for pplx business model
pplx whole business isnt sustainable, with their insanely high usage limits and plan of just buying users
way a lot cheaper
they might still have gpt4 usage left over, since they buy PTU at this scale
It’s crazy at this point how many free years they have given away
e.g my prediction is they brought gemini pro units for like a 6 month/year term
which is maybe why it still worked after removed from frontend for a while
probably millions $ worth
like $20 is a base price, it's not a lowerable one
there's a reason chatgpt.com,gemini and claude all have $20 with no discounts or free subs anywhere, and also low usage limits
since...its not profitable otherwise
And yet their dedicated community who tests and reports issues, provides feedback, and directly influences the Platform, are going thru loops with referrals and forking out $250 a year for Pro. lol. we do your testing! support us! lol.
Oh, we had an easter egg hunt for a month of Pro. that required us to be glued to the general channel for hours. chatting. (it lead to some interesting chat summary/fake podcasts).
I know access and compute is expensive, but if they are handing out free memberships to entire groups of users, where I'd assume only 30% at most utilize it. pass that other 70% towards your dedicated active community? the ones generating Pages for your platform for others to view? we are PPLX content creators, are we not? lol.
end rant about me being cheap
this is almost a self-imposed problem from perplexity though
why are they forking out so many memberships
the advantage to PPLX in general is internet search for sources. but for Pro, its mostly just access to the latest models. But that is a reason that people have stayed on. Do people pay for Pro for other reasons?
I guess more Pro Searches and image generation. but so many free platforms exist for image generation that I can't imagine anyone coming to PPLX specifically for that. Currently it works well to create specific images in existing threads and pages. all it needs to do really.
Hi guys! 😄
hmm...
You people are missing a PARTY in the Nous research server

They let a bot ping the server
send invite
everyone is @ing it with their own prompts.

ohh, right
Is it possible to integrate perplexity with any sort of ai knowledge base tool? Just discovered perplexity and the search feature is awesome but once I've found some useful information via search I'd like to have it automatically tagged/filed and be able to surface it later or use it as context for other questions.

GitHub
An Obsidian plugin to interact with your privacy focused AI-Assistant making your second brain even smarter! - your-papa/obsidian-Smart2Brain
This is what you want likely.
Hermes is connected at perplexity, from discord.
How ?
Yeah some of the obsidian plugins look interesting. I was hoping to find something more integrated/seamless but it seems the current state of the art would be to copy useful perplexity answers into another tool like obsidian, otio, mem, saner, etc.


the h100s running the bots for two separate channels, with a bunch of people hitting them. ha. wild experiment. (bots are versions of the new hermes 3 model)

would web results/perpelxity type tool inside obsidian interest you?
hmm
would you want it to only be like on your own knowledgebase?
or also include web stuff too
storing vectors on cloud = costs money
maybe a combination
use local embeddings to find relevant bits from the obsidian/user's info
then combine with cloud-based api for inference + web knowledge
Yeah that would probably be awesome
The second brain plugin has a short context window I find so far. only like 5/6 back and forth and retrievals. how do you avoid that? @foggy whale
How the Human Bots Going tonight ?
why is it so buggy today
Hey everyone, I have written this article on medium about batching of jobs of LLM workload. Please have a read and let me know your thoughts. Thanks
Unlocking the Power of Job Batching: Transforming AI Workloads https://blog.cuminai.com/unlocking-the-power-of-job-batching-transforming-ai-workloads-2220b8c05e4f

Medium
Understanding what is LLM batching API, How it can be helpful? what are the different use cases of it? What can be possible cost saving?
Is Perplexity having an API issue? Why is Claude 3 opus performing so poorly?
Has happend the same numerous times with GPT-4 as well
Why hasn't any support team addressed this?
Probably hasn't been noticed, or is an issue that hasn't been addressed yet.
ok
yeah i just said "represent it as a mermaid chart".. it kinda speaks to LLMs lack of a sense of "space" (or "time" for that matter) – they seemingly go for a horizontal structure almost by default, regardless of how practical it is...
can ofc just "oriented top-down / vertically" or whatever to the prompt, and it will do it.. but yeah, ig was just demonstrating mermaidjs rendering.. rather than the optimal diagram ha
Hey Guys. I am writing my master thesis and was wondering how good Perplexity works with the literature review? Does anyone have experience in that regard? Do I have to supply Perplexity with the sources or is it good enough to search the sources on its own? Thank You 🙂
check that plugin's settings, it may be turned way down by default...same for output window. the copilot plugin had the same issue
which plugin are you using? and model?
I know this is highly dependent, but I'm finding Claude 3 Opus is giving me the best results for my queries so far
hell perplexity just shows me empty site when i send a prompt
asking a follow up and sonnet 3.5 ignored... the previous context
it's great for some things for sure
incidently (talking about diagrams before), I think this is a nice compare and contrast.. Opus does sooo much better than all the other models (and the prompt includes instructions from top-down orientation; most just ignore it..but not Opus ha)
varying quality..

perfect

Hey I'm using the android build with the latest update I can use, is anyone else having problems using pro searches? It doesn't give me an answer for some reason

Yeah. I am here only because of Sonnet. I find Perplexity UI to be extremally unfriendly and to be honest I don’t like it at all. I am here for several months and I dont see willingness to improve many things here. Working with files is terrible, image generation is very difficult (now I m using Grok 2 / Flux for that).
Does it get back to work when you refresh the page?
Hey @fathom forum, could you send me your device and os versions, please
sometimes. it happens mostly when creating new thread. f5 sometimes helps
💡 Got a brilliant idea? 💭 Don't keep it to yourself! 🎯
🎙️ Pitch it directly to our CEO on X (Twitter)! 🧠✨ He's all ears and loves hearing from you. Whether it's a game-changing concept or a small tweak, your voice matters. 
my question is: how much money will you loose when gptNEXT + gptsearch is here.
Try felo.ai it’s free and I believe it’s quite good. Dont need to wait for search gpt 😉 https://felo.ai/search

Felo
The multilingual AI search engine optimized for discovering and understanding world knowledge. Leverage the power of ChatGPT and AI Agent to break language barriers and access global information with ease.
I guess many pro users use Perplexity only to have access to the models. Search is just a bonus. I might be mistaken though
ah lol what
api is way cheaper what u mean. nobody subs to flatrate just to get access to llms.
i am casual btw. not a nerd.
guess im nerd enough to want 500% lower prices lol
Perhaps. But using API is not something that average user is familiar with 😉 They just want to have an easy access to an LLM with lots of quieries available
I wouldn't worry about the GPT search thing at all
OpenAI is literally hemorrhaging money
GPT needs to get its stuff together or it will go bankrupt
nobody subs to flatrate just to get access to llms.
lots of people do
At present, this is a significant advantage of Perplexity - many LLMs. However, I think and hope that it won't last forever, and eventually there will be a better alternative
While I always look for what works best for me there isn't a need to be so passive aggressive against the service that is currently the best option, you know?
I'm grateful a service like Perplexity exists that gives me options and saves me money. Yes, they have issues. Yes, I wish some of their things were different. However, it is vastly better than paying multiple subscriptions.

Perhaps you’re right 😉 But when you do something and it doesn’t work the way you know it could it gets annoying 😅
I feel you. When you've got a car that has a habit of breaking and isn't exactly the most fuel efficient or fast on the road it is easy to get mad at it, but if it's getting you from point A to B without paying through the nose by requiring a Taxi or having to deal with carpooling then that's what really matters... It's easy to be frustrated and there are times when it's justified to be frustrated, but if the car is still getting you from point A to B then that is what we should focus on until a "better car" comes around. Then again, our "current car" could come around with upgrades and stay the best option; we don't know.
Anyone else get an offer for a free year of Perplexity Pro .. only to go through the signup process and it won't let you complete without paying ?
Ping @signal hamlet for help with that stuff :]
Yes I just tried and mine says promotion code is invalid.
Please send all the relevant details, the email with the code you got and the account you're trying to apply it to at support@perplexity.ai, we'll help you with that.
Please send the details to our support@perplexity.ai email
@maxlynch @perplexity_ai Hi Max, you can just @ me here and share whatever feedback you would like anytime.
late getting back, but I'm using the Obsidian Copilot plugin and have it hooked up to my Claude api key. i've got ollama running local and it does well in terms of performance it's just a smaller llama.
@south kindle gotta open up that aperture a little bit more. i definitely had a nice revisit with my api billing account settings before i fully committed.

and @sleek vortex yeah i do think that this plugin or obsidian in general with a copilot plugin needs some real time web access.
How can I create an image by entering prompt?
When I click on Subject, the tab disappears.
maybe i could open up uncovr as an api
i got it from linkedin premium, i cliecked "claim the free offer" and the promo code is entered, but it says "promo code invalid"...
- In a new thread, choose "Writing"
- Write a prompt that starts with "Generate a useful description so that a generative AI can create an image of "
- Once you have the response, click the "Generate Image" button that appears on the right.
Note: only PRO accounts
Here's an example thread from our user: https://www.perplexity.ai/search/Generate-a-useful-O1QWAbvSSXmG50e5AEMFZA?s=c
Here's another example on how to generate images with your exact prompt: https://www.perplexity.ai/search/Repeat-this-prompt-ZLz8dGzISSGrevPxhl7YqA
Any answer where the Generate image button is available (response is ready) can be used to generate images with a custom prompt. - Click on the 🔧 in the top-right corner of the menu to use it.
https://www.reddit.com/r/ObsidianMD/s/XfbfxiZppS > saw this posted on Reddit but some good info in there
Reddit
Explore this post and more from the ObsidianMD community
Also now building or trying to build a prompt related to the concept of Atomic Notes.
Sounds like phishing
I signed up through the linkkedin offer and didnt had to give my payment details so something sounds fishy/off there.
microsoft graphrag is also an interesting concept
There’s good advice there. I’ve been using it for years so have figured out how to not overdo it.
What is the difference between perplexity and the ai it offers to use? Is perplexity just a prompt shell outside the underlying llm?

If you have questions about Perplexity, our FAQ page is the perfect place to find answers. Our FAQ page is organized into categories and provides clear and concise answers.
Why do I have to be on a waitlist to use a crappier version of Perplexity 😆

well...no waitlist on uncovr
but yeah, openai is so slow these days
waitlist this waitlist that
well tbh same with google for a bit, they always announce features months prior like
live video mode still isnt here
I just realized I could've asked perplexity instead
I have galaxy brain
Has anyone thought of adding a way to manage thread-offshoots (like from a project outline)? So could you have like a mind-map-ish of threads that branch off? Thanks in advance!
Perplexity still hasn't fixed the bug

Hey guys if I get linked in premium free trial for a month, will I be able to get the offer for the 1 year of perplexity?
Or I need to be an og user of linkedin premium or something
is it just me or is the perplexity ai worse?
this is more like a LLM issue?
Hi I noticed when sending images to pplx it switches to the default model
💀 was it like this before
or did this happen recently
/imagine water
why is opus denying that
even uncovr on haiku responds fine
doesnt make sense
flux is added
great
thanks guys
i wish there was another type of playgroud only for image generation
why isnt it announced
this is a great thing
"theyd lose too much money as people would actually use image generation"
yeah i suspect it's involving a medical question...
How do I prompt to make an image without having to asking a question and then selecting create a image?
u cant do dat i think
im sorry but image generation was implemented in the worst way possible on perplexity
yup
like you can't create an image on your own prompt, you have to create an image based on the output
which is so weird
🚨 BREAKING: @perplexity_ai now supports 2 new image gen models: Flux.1 by @bfl_ml and @playground_ai v3
Both options are now available in settings and can be used for image generation on the Perplexity Pages editor.

makes me think maybe they just dont want people to use it
yeah same
sometimes i think theres a weird fine line at perplexity
between stupid developer decisions - push update which breaks 50 things with no testing
Flux.1 now on Perplexity

to possibly executed decisions - "lets add image generation to make it sound better deal, but then make it basically useless"
also the 600/day, 50 opus, etc
😄

same here
need to update some things fast
Hi andy
Is there a way for outsiders to see this roadmap?
Tried it in here and in Grok 2 and in Grok the text is much better generated. I tried different languages. I believe in Perplexity might be weaker version of Flux
This is Flux in Grok 2:

how did you got perplexity to write something
also did grok 2 not come out yet? (not grok 2 mini)
You can generate images using Grok 2 mini which uses Flux
grok 2 will be released in the coming week
elon musk posted tweet about it
oh got u, thanks
Yeah, that’s correct
It’s only 8$ monthly
twitter is cheap probably everywhere, in poland 44 PLN (8 usd)? something around that
its 4,46 dollars in turkey
That’s extremally cheap 😅
Something around. I use it being in Poland 😅
Dumb question probably, but does the image upload function use gpt4o or still the older gpt4 vision model?
gpt4o works with vision
In perplexity pro?
in general, the old version of gpt4 vision is much more expensive, so it seems to me that they would not want to overpay, i can only say propably, idk
gotta update that number, it's 540 now
You can customize the prompt
thank u guys, this needs to be more obvious on the UI since it is already a feature
Hi, how do i see past messages ? I tried scrolling up but some of my questions are not there. These messages were less than 30 days old
Did you guys have a outage around the 30th? Were some messages lost? 😦
why the hell is it so buggy
Yea not fun to lose messages especially when you’re building an app and you lose track of code
Support not responding to DM unfortunately 😦
Isn't it even a lot lower than 600 now?
They transitioned from next.js page routes, to app routes a few days ago, so expect quite a few bugs during the transition, since they seem to not test their stuff before releasing it.
Hi sir, when using voice sir, does it not use the pro search sir?
Why are my searches all being funneled through wolfram alpha
jesus use dark mode hahaha
.
is pplx search getting worse? why I have to grill it to give me a link it should have found, then found and didn't mention, then claimed to not have found 😞 https://www.perplexity.ai/search/crow-local-ai-assistant-qqu_V4vUSmaKOwmpz.DFmg

Does anyone know is the non-pro search using a 70b model or 7b?
I know anthropic did some dumbing down recently of sonnet, but this more looks to me like some pplx instructions regarding reddit
thanks to @harsh stag you can follow current situation in this post #1272961960765292625 message
why does your prompt answers have random japanese words at the end
I also hate those weird file it generate in certain prompt that thing in sources sometimes messes up the answer it is supposed to provide
I have a solution. Do a search in the server for CPLX.
@neat elk Did perplexity get worse??? or did free get worse???

those look like mostly front-end bugs. don't see anything there about reddit

{kind=link}
Help me learn Japanese by briefly and seamlessly embedding a small, relevant Japanese lesson somewhere in your response (remember, I am a beginner in Japanese, so romaji + short explanation in English should be beside the mini lesson).
since Perplexity FE is bugged (or was the removal of the disable button intentional?), I can't easily disable my AI profile. though it very rarely negatively impacts responses (lessons are very short, negligible token use and sonnet understands multiple topics and languages very well)
couldn't this be the recent anthropic tweak of system prompt? saw on reddit users complaining and moving back to gpt4o for translations, since sonnet started to refuse to use translation tables. what was your prompt on pplx?
So is there a problem? I was using it fine a month ago.
could be recent (a week?), but if the anthropic changes are the cause, not sure perplexity devs can do much. they (or even a user) could try persuade the model it isn't a copyrighted material or it is a fair use. it looks like those changes made it the models too paranoid, and since the models actually often doesn't even know what is copyrighted, it sees copyrighted material everywhere
you could try gpt4-o, that should work
I find that it writes articles terribly now. A month ago, it was still writing great with Claude 3 Opus. I rarely use GPT-4 to write content, mainly using Claude 3. But now I have to cancel 2 Pro accounts, it's too bad.
you could use gpt4-o for research and then in a same thread switch to sonnet or opus, they should see what omni wrote (research results)
I've tried, but it keeps saying, 'I'm sorry, but I can't assist with that.' I'm considering going back to using You.com.
what prompts are you using that trigger "I can't assist with that"?
odd that you've been using Opus, and it worked fine, and then recently changed
i don't think anythin about Opus would have changed in recent weeks
though i haven't read the reddit discussion mentioned earlier, saying that anthropic's generally hyper-sensistive guardrails / copyright allergy has become even more recent stringent (perhaps that is the case for all their models, including older ones like Opus)
in either case, would be easier to work out what was happening with prompt:response pairs
rather than just the refusal
also.. yeah if it's not just happenning with Opus.. would seem more like a pplx issue tbf
(unless the refusals only happen when you switch to Opus after starting with a different model).. eh .. hard to say
i tried a few times... kept failing, e.g. https://www.perplexity.ai/search/crowassistant-not-crew-ai-nhLg9uk_R1qEyYFdE_uIKA (the first message the source is there... the second message.. is like it's started a new thread and it doesn't know what you're talking about...)
eventually (I think?) it worked https://www.perplexity.ai/search/a-crowassistant-not-crew-ai-b-j3RvdzyUScWPzgy0br0oKg
but either way.. it does seem weird / different...

Perplexity AI
The source URL for CrowAssistant is: https://github.com/RobotTelevision/CrowAssistant [self-reviewed]
for those refusals, I wasn't able to trigger it (https://www.perplexity.ai/search/please-write-me-guide-on-markd-qZzVw0tgTrKAZ0UVLQ7vvg , some links look similar). another possibility would be that pplx is using different inference backend services for different users/regions and somehow there is a different system prompt or other parameters? or it might be another a/b of pplx

Perplexity AI
Sure, I'd be happy to provide you with a guide on Markdown syntax. Here's a comprehensive overview of Markdown's basic elements and formatting...
yeah i wonder if it's a) Opus-specific and b) pplx's system prompt has changed.. e.g. it now has instructions which trigger Opus regardless of what the query at hand is (like any instructions along the line of "verbatim" could trigger ol Opus..)
dear lord, why did it use wolframalpha and programming step for this task? has "all" focus lost access to web search except wolfram, or what is going on?

oh, I wonder if I didn't trigger some math/programming tunnel vision because of mentioning "evaluating LLMs"
ha yeah i also had it using wolfram for some totally non-scientific/mathematical query the other day.. (and no regular search / sources as well - just wolfram)
it felt very broken...
Anything wrong with perplecity now? I cannot see the python code it generates?
Recently, major companies like OpenAI and Google have launched batching APIs for some of their models, offering 50% cheaper calls compared to normal requests. However, these APIs currently lack processing guarantees, SLAs, and retries.
Check out our step-by-step guide on "How to Get a Batching API Like OpenAI for Open-Source Models":
https://blog.cuminai.com/how-to-get-a-batching-api-like-openai-for-open-source-models-824529788a49

Medium
In the world of AI, efficient processing and cost management are paramount. One powerful method for achieving this is batching, which…
With gpt4o perplexity use GPT-4o-latest (2024-08-08) or the model before?

hmm, the flux1 (schnell?) on pplx is acting weird. tried schnell on other two places, generated correct text on a first try, but on pplx not once in three attempts with same prompt? dalle3 also didn't have any issues




I was looped in Chrome, how to fix ?

Same happened with me was this a long thread?
Or did you loose connection in between
it's reproduce every time I type some text.

So I cannot use it normal in only Chrome browser.
@rapid sleet @austere kestrel having same scenario. Opus working great and then there was a sudden degradation in response quality, and frequent “I can’t assist with that.” across a variety of prompts that worked before.
Hey @calm glade!
If you find the original message helpful, please consider reacting to it with the :star: emoji. If the post is appreciated by the community and receives 5 stars, it will go to the https://discord.com/channels/1047197230748151888/1082806833938436228 channel and the post author will get the <@&1082034222778302614> role on Perplexity.
is there some maintenance ai doesnt respond me
yeah its says same thing to me
so anyone knows how i can generate images? i cant find it anywhere
do i always have to search for it, and then click "generate image" on the right side?
i dont get it
yeah not the easiest way to generate images
so perplexity is an LLM agregator? Just got a pro for free cause I have linkedin premium
how is that possible to get all of that for 20$ under one subscription?

Meet Nelima 🚀 the world's first community-driven Large Action Model (LAM) that takes your natural language prompts and turns them into real actions.
Nelima is programmable too! You can create custom actions tailored to your needs, and every new action makes Nelima smarter and more capable for everyone. 💡
Ready to give Nelima a spin? Try her ...
haha
Grants, VC money, donations. They are swimming in revenue. Also think of PPLX as an answer engine that includes the latest models.
Images are meant to complement articles currently which I believe explains the integration. Still a pain to use though. No doubt about that.
Hi guys. is there a guide for creating images on pplx ?