#🪅-progaming
1 messages · Page 42 of 1
rust has convinced me that everything the code does should be visible to you, if you create a struct using only some parameters and others get filled in for you it could cause confusion, if you use ::default its obvious what youre trying to do; you can also do new_with_param2 or whatever where some params are defauld but theres and explicit method for it
??? what’s bad about that
idk just average C dev things i guess
c's memory fuckery will always be bad to me
i mean
for me, its actually pretty easy
well atleast it has become much easier to understand
yeah its not bad
its jut gotten weird for me when i try to read C/C++ data from another language and all of a sudden its a "oh yeah, this is somewhere else in memory, here's where, try figuring out how big it is yourself"

if its not struct, there is not many possible sizes it can be, just try all of them 
just loop through entire ram until u find what you are looking for
and i keep getting thread startup failure
/jk
and i want to cry
you... know that this is a valid method of doing it right?
XD
i understand C memory pretty well and it’s really easy to understand
access another programs memory
see what happens
xd
its pretty fun actually
nothing?
you just have a lot of memory to go tru
i think if people were to learn it properly when they start out with visual aids they'd not hate it so much
simply
can someone tell me what value that is pushed to the op stack actually is

is it a string
i suppose i can refer to this too

yeah sorry, java memory is the one thing i never understood
even v8 memory is simpler
It's a reference to the PrintStream object
Not necessarily a machine pointer, I think jvm likes to shift and scale it so it fits in 32 bits
But something that the jvm knows how to interpret as a pointer
is he retarded??

sir this is programming
actually its progaming

big huge thesaurus sounds very amogus if you dont know what thesaurus means
kittycat
what about kittycat??
thats some dinosaur, isnt it? :clueless:
jk i know what it is
big huge tyrannosaurus rex
if i make a company im calling it "big huge <the service it provides>"
wouldnt you love to eat at big huge restaurant
buy a big huge ai subscription
big huge Schaeffer's deck sealant
whoever suggested me to use libarchive, thanks! it seems so easy to use



Only thing that's husk about that is the fallback arm
whats wrong with it
If you add another variant you won't get any error that you forgot to add it to interpret
And why would you even have expressions that can't be evaluated
actually yea i kept it to have an error when i add a new expression, am now realizing that i get that by default and i get it at compile time without the extra branch
cause i needed a fallback branch to not have compile time errors before i added any actual arms
What is it you think is husk about it
implementing it
Abstraction can be both good and bad
Java is kinda infamous for overusing the bad kind for example
Though I haven't seen this supposed overabstraction in reality, so the reputation is probably overinflated
...Except in gradle. That one's completely impossible to navigate, at every layer
Is it worth breaking windows compatibility for being able to use posix function which makes my life a little bit less painful
Javafx is a horrible monstrosity
Depends on the language
C
If c or c++, probably worth it
Ill look into the manpages if there isnt a better way
And if i dont find a better way ill go for it
create transpiler to brainfuck
Transpile me to brainfuck
./icps file.is | ./asm2bf
yes never consider windows compatibility at all
xddd
have you never seen an enterprise java project?
I have luckily not
I have seen some constructors and functions taking 35 arguments and showing clear signs of having used guice in the past, though
i was about to order a rope and chair
i18n systems, one using a .properties file, one a .yml, one a .yaml, inconsistent variable names between languages which puts german words in english translations
spring?
i mean you have ktor
or micronaut
and things
springs infrastructure and core is pain in ass itself
spring is ok
ktor is made for kotlin
Why does everyone hate doing things straightforwardly
better than the other java frameworks
If I want to pass an argument, I pass it as an argument
it would be a lot worse without spring
i made like 20 attempts to successfully setup session auth
same
ended up switching to elysiajs
i had a ticket to fix some cors stuff or whatever idr, it took me 2 days
like dont get me wrong, spring data jpa is awesome
the whole spring's database support is imo very nice and well made
same for serialization and stuff
oh yeah i needed to make tests get a bearer token i think
but the security
i had to migrate a mysql with spring vomit in it to postgres, it took 2 weeks and was never realeased to prod
well i always started with psql
the system was a decade old maybe it wasnt as popular back then
did u know mysql is named after the cofounders daugther My
he actually made mariadb and maxdb too, guess what
im guessing his daugther maria saw mysql and maxdb and was like dad can i have my own db so he forked mysql
lmao
"what db do u use?"
"oh one my dad made for me"
which way is going to be faster for parsing a file:
- doing small read calls directly on a File wrapped in BufReader
- or reading the whole file into
Vec<u8>and then reading from it
Depends on the size
though i’m not sure how i’ll be able to seek if i choose the latter
like 137KB
But if it's smaller than a gig, fs::read is usually more ergonomic imo
do you mean reading the whole data by “fs::read”?
Yes, since that's what std::fs::read does
got it, thank ya
also, what about this
do i have to use something like Cursor?
io::Cursor can seek, yes, but then you lose the ergonomic benefits
argh
I'll just plug my gospel crate
It's pretty handy for reading binary data from byte slices
i wanna see how it's implemented


oh yeah kinda expected that being it like that

though isn't Cursor just a pos and the data too?
Yeah
Cursor could provide an ergonomic interface if it wanted, but it prefers Read
Much nicer to do f.u32()? than { let mut buf = [0; 4]; f.read_exact(&mut buf)?; u32::from_le_bytes(buf) }
oh i have this trait with these neat funcs, ig i can just use Cursor atp

also idk why but i can't stop bothering about this implementation, even though that's basically what byteorder does but i keep thinking something might be odd
If the choices are File+BufReader vs fs::read+Cursor, I'd probably go with File+BufReader since you aren't making any use of having the whole file in memory anyway
huh, what are the uses? I thought the main benefit is just that you don't need to do syscalls when reading from memory unlike reading from file
BufReader buffers it so the syscalls are sparse enough to not matter
Could always benchmark it if you need to know
whatchu doing
oh nice
i wrote a java class file parser during weekend and want to somehow optimize it
so now wondering how to optimize the reading
im just now using fread calls
but idk if reading it whole and then having cursor and offsetting accessing the memory would be more efficient
so i essentially have the same question ig
but i mean
premature optimizations are bad
well i will see how fast it is after i read and parse the whole java.base jmod into memory
i’m so confused i’m just asking chatgpt to reverse engineer it for me atp 

i’m like one step from finally being done with this fucking file format but i can’t figure out the last piece
What is it talking about
i can send the prompt
I’m reverse engineering a proprietary
binary file format used for storing game assets. Well, there are actually three different files:
bigfile.bfn— used for storing file names and file tree. The structure is the following: first there are 4 bytes (u32) that represent the size of the folder’s name. Then there is the string - the folder’s name - that has that many amount characters as the u32 we just got. After that we have another 4 bytes (u32) that represent the amount of files in the folder, let’s call itfiles_len. After that there arefiles_lenamount of the following structure: 4 bytes (u32) that amount of bytes that represent a utf-8 file name. Then there’re another 4 bytes (u32) — the amount of subfolders in the folder we’re in. And the cycle repeatsbigfile.bfdata— the biggest size-wise file out of these, which as could be guessed contains the binary data for the files from the previous filebigfile.bfdb— the least researched file which, it seems, should link the file names with the binary data they contain. The issue is that I haven’t managed to reverse engineering it yet. I decided to pick one file frombigfile.bfnand found the address and size of the binary data it has inbigfile.bfdata. The way I could confirm that this file name exactly links to this data is by using binwalk. It shows which files are contained in the file’s binary by searching for signatures and magic bytes. That way I could find all the PNGs and I decided to take the last one, thinking that the order of files inbigfile.bfdataandbigfile.bfn. I was correct. That way I had the matching file name and the data it represents. Searching for the address of the file’s name frombigfile.bfndidn’t get any results inbigfile.bfdb. But searching for little-endian byte representation of the address of the file data was successful and just 8 bytes before it I found LE-bytes that represent the size of the file data. The question is can you help me guess how they can link the file name with file data?
advent of code ahh description
why are u using emdashes in a prompt
is the prompt written by ai
no lmao i manually wrote it
Fellow em dash enjoyer
Hyphens are fine as hyphens
But for punctuation, em dash is best
Your description of bfdb is a rambling mess, so it's no surprise gpt couldn't make sense of it
I can't either


No chōonpu is bad, don't
I don’t know much about it either, but it should somehow link the entry’s file name from bfn with the file data from bfdata. but idk its structure. i tried taking the address of the first byte of a needed file’s name from bfn and search for it in bfdb but no result
LMAO
Did you try just taking the nth entry for the nth file
the way i tried to do threaded GC was by sending events to the thread (like when the total allocation exceeds some threshold) but to maintain thread safety its still blocking during that process so i found it pointless to make the GC run threaded at all
the only way a threaded gc would win is if you make a generational allocator to go with it
basically long-lived allocations (ones that survive a GC sweep) are ignored for a while
- I don't know like how many bytes are used for one entry in this file, so I can't tell where this nth file will be
- And I actually think it's not built like that, because I took the last file from
bigfile.bfnand found its data inbigfile.bfdata, so I knew both addresses of file name and file data. Tried to search for the latter inbigfile.bfdb- found the result but it was not at the end at all
guh i hope u get what i mean
lol
"yeah, my hex editor has achievements  "
"

if you dont block issues arise
during the marking stage, if more things are allocated, youll end up infinitely iterating through the list as more things are added until the allocation stops
and then never free anything until the end
so if you block, things cant be allocated during mark and sweep
thats why a generational allocator works well here
Can't you just fetch the number of items to check first?
Or is it bad that it would'nt check all the values?
yeah but there would be a desync
what if during the time it takes to mark, an object goes out of scope
Then you'll get it next run
i guess
this function is the issue
local fn GCAllocator::__internal_mark_region(GCAllocator *self, void **start, void **end) {
let current = start;
let end_ptr = end;
while current < end_ptr {
let ptr = *current;
// not nil && is a multiple of ptrsize && isnt clearly invalid
if ptr % #size(void *) == 0 && ptr && ptr > 0x1000 {
let block = self.map.find(ptr);
// only mark if not already marked because
// recursively marking more is expensive
if (bool)block && !block.marked {
block.marked = true;
self.__internal_mark_region(
block.data,
block.data + block.size
);
}
}
current += #size(void *);
}
}
although
i dont know if its still an issue
my original approach with pthreads was before i made the hashmap so it iterated through all allocated chunks to see if one matches
Just checking if the value is in the right region sounds quite dangerous, what if it's just an integer that happens to be in that range
thats why theres a further check later on
self.map.find(ptr) would return nil (0) if it doesnt find it
the stuff here ptr % #size(void *) == 0 && ptr && ptr > 0x1000 is just a narrowing/filter to not search obviously incorrect things
Random idea for making the iteration faster: make each object's header contain object size and number of references, and always put object references directly after header
it holds the size
struct __internal_ElleGC_Header @nofmt {
bool marked;
i32 size;
void *data;
};
Then you know that the first N values after the header are references, and once done with that you skip M bytes to get to the next object
“Achievement unlocked: How Did We Get Here?”
wdym
it scans the stack for pointers tho
not contigious memory
Right, but why is the scanning function recursive then
also if there just so happens to be that an integer exists which has exactly the address of a pointer in the heap, that just means the single allocation wouldnt be freed
@valid jetty is this horror?

because it uses the roots to scan (recursively) for pointers inside of each region that was allocated
Yeah an integer pointing to an object is harmless, will just make that object live slightly longer
like imagine you put a Foo* inside a Bar* which has a reference on the stack
you wouldnt want the Foo* to be freed even though there is no reference to it on the stack (because its inside of the Bar* which IS on the stack)
Once you've gotten the Bar* from the stack, you know there's a Bar there and don't need to scan anything since you already know its layout, you can just recursive that directly without scanning
seems reasonable
idk should i just clone locations
What's the point of a ::new that doesn't do anything, just make the fields pub
What does Location contain
the allocator doesnt know the layout of anything
its shorter and it might do something
row col
the data is just an opaque pointer to anything
it allocates a blob of memory of the size you want
Thought it was a pointer to an object
yeah but an Object is anything
If it's just arbitrary data, that's a different matter
yeah
.
i just meant like in general
Pretty rare to have gc with unstructured data
and its highly likely that im gonna end up wrapping location in an option and then id like to have a new* method with 1 arg that gives me location None
struct Foo { i32 a; };
struct Bar { Foo *b; };
fn Foo::new(i32 a) {
foo := #alloc(Foo);
foo.a = a;
return foo;
}
fn Bar::with_100() {
bar := #alloc(Bar);
bar.b = Foo::new(100);
return bar;
}
fn main() {
bar := Bar::with_100();
// here Foo * doesnt live anymore because Bar::with_100 returned
// its only reference is inside of Bar
// so if you didnt recursively check then it would be incorrectly freed
// note that #alloc(T) === (T)#env.allocator.alloc(#size(T))
// where #env.allocator is some arbitrary allocator that has an alloc and realloc method on it
// as a result the allocator cannot ever know the layout of T because the language is statically typed
// all it can know is the size of the allocation you want
}
i think i have to clone it either way
considering this is a static language i think its reasonable
or is there a way to have
struct Expression {
kind: ExpressionKind,
location: Location
}
enum ExpressionKind {
SomeKind(Token)
}
struct Token {
kind: TokenKind
location: Location
}
where the location inside expression kind is the same location as inside expression
what are the fields of Location
No, if you have a value that's stored in two places, then it'll be stored in two places
if Location is small enough you can just clone it around lol thats what i do
pub struct Location {
pub row: usize,
pub column: usize,
}
yeah
#[derive(Copy)]
Also store utf8 offset instead of row/col
if you plan to add strings you wont be able to do that
whats the diff between copy and clone
copy is implicit
clone is explicit with .clone()
why
Smaller and more useful
Convert it when showing to user
i would make this derive Clone instead of Copy preparing for the future lol
i have that rn
if you wanna put a string in there you wont be able to copy it because String doesnt implement the Copy trait
how do i show it to the user
Yeah but putting a String in a Location sounds pretty silly
Usually println!()
the user doesnt wanna see error at index 5642
i mean not really
#[derive(Clone, PartialEq, Eq, PartialOrd, Ord, Hash)]
pub struct Location {
pub file: Rc<String>,
pub row: usize,
pub column: usize,
pub ctx: Rc<String>,
pub above: Option<Rc<String>>,
pub length: usize,
pub extra_info: Rc<String>,
}
That is indeed very silly
might as well write it in python
#[derive(Clone, Copy)]
pub struct Span {
pub start: usize,
pub end: usize,
}
well the string wont change so why not put it in Rc so i can clone it around
and its pretty fast
to display the row from the index i need to know when each row starts which requires at least another usize/filename string
i think
If you want to make your ast 4 times the size I won't stop you but it seems pretty silly
whats an alternative thing?
if you just tell me how i get row col from an index without passing a string i can do it
Store only what's necessary, as shown above
thats the exact same size
if i want to have a pretty error then all of that is necessary
I'm pretty sure usize×2 is smaller than this mess
.
not gonna get all of this info with usize*2

how do i turn an offset into row col when printing
Start/end encodes twice as much information as row/col in the same size
By looking at the string when printing
it doesnt encode the row
No but you can easily find that from the source
start end is 1d??
the source file string? my error doesnt have that
unless you mean uh
you want me to borrow the source code in location / error printer?
how do you know what file the offset is referring to?
Concatenate them together or something
isnt a borrow just as big as a usize
ok but like,
&str is 16 bytes
ok but like i dont wanna save 48 bytes
at that point write it in C lol
Why do slow clunky rust when I can do fast ergonomic rust
if i can borrow location instead of cloning it that is a very small change in the code
no itd mean putting location in an rc
or something
cause i dont wanna borrow the expr
Ah, heap allocate your usizes
thats gonna cause problems
concatenating together every source file and calculating an offset into a huge stream of bytes sounds like a pain to maintain when you could just store the things you need in the location xd
also in rosies case its completely irrelevant cause its just gonna increase compile times by 3 picoseconds and add 48 bytes of ram usage
for me its gonna increase runtime by 3 picoseconds
at that point might as well change the index to a u16 and dynamically adjust it to a u32 when the file size is bigger than 65536
lmfao
i will wrap my Location in Rc then?
.clone will clone 8 bytes
im using i128 for my ints i think i can save some bytes there
good idea
@hoary sluice do the erlang int encoding scheme
I mean you can do whatever you like but I'm gonna stick with small Copy types for spans
what does it do
ok im gonna clone location for now and if im bored and have nothing to do i will save the 48 bytes
wait a sec
a non finished interpreter doesnt care abt 48 bytes

xdddddddd

basically unicode encoding
but for just values in general
ultra efficient memory usage
it adds up but thats not the point
isnt beam super slow
no?
As a counterpoint to "I don't have the string to compute line/col", you also don't have the source to print source snippet
yes i dont print it lol
i now have this working
fn main() {
x := 1;
{
x := "a";
$assert(x == "a", nil);
{
x = "b";
$assert(x == "b", nil);
}
$assert(x == "b", nil);
}
$assert(x == 1, nil);
io::println("All variable shadowing tests have passed!".color("green").reset());
}
``` lmaoWhich means your architecture is limiting your functionality unnecessarily
before it didnt let you declare x with a different type in nested scopes
im gonna put the filename into location eventually
and then i can do indexing
i probably should do the start end thing as well
isnt it technically cheaper to have Rc<String> if youre cloning?
Rc<String> is just silly, but Rc<str> is good if you want to clone a lot
why is it silly
Because it's an unnecessary indirection
You need to follow two pointers instead of one to get the data
just clone the src code :3
Of course, having a String of the entire program source in each ast node is the most ergonomic
yeah, but it still neater than storing a plain String
Yeah it's better than String if you want to clone
But Rc<str> is better than Rc<String>
does rust have lateinit
You mean LazyLock?
null variable that panics if its used before initialization
No
basically saying idk the value rn but i promise ill know it before using you
.expect() like a civilized person
That said, nothing except your conscience prevents you from writing one yourself
And of course there's MaybeUninit if you want to go the unsafe route, but don't
oh wait this is gonna recursively clone location
im gonna buy a rope and a chair
nvm
is there a point in boxing an expr if i know all recursive calls to it will be boxed
that wasnt english
if i have
struct Expr {
expr: Box<Expr>
}
is there a point in boxing the top leve expr
can i remove this box

Boxing things unnecessarily is typically unnecessary yes
works also in blom :D

i should add let or something after refactoring parser
thank for the advice

How does the code that assigns location look

That looks like you can just do let mut location: Location; and assign it later
so rust does have lateinit????
It gives a compile error if it's not assigned when used
Not a panic
Pretty sure java does the same
I figured since you were asking about a specific runtime behavior, you wanted that behavior at runtime
this is an explicit boolean that is initialized to false inside a loop which means this if will always be executed

kotlin can detect that so surely rust can
ok i give up im initializing it to 0, 0
lol nice
Personally I'd do ```rs
consume(If);
let cond = parse_expr()?;
let body = parse_block()?;
let location = cond.location.clone();
let mut branches = vec![(cond, body)];
while try_consume(Elif) {
let cond = parse_expr()?;
let body = parse_block()?;
branches.push((cond, body));
}


if i put 20 bucks on 493ms how much would i get if i was right
7 mil?
1:350k odds seems worth my 20 bucks
lmao
zed's ctrl + / is very bad
it doesnt go to next line by itself and it doesnt put the // at the start of the line
@mossy ether do you know how to use libarchive
cuz like, how do i read the whole entry
this was my attempt

yes it does
no it doesnt

if archive_read_data is anything like the block version (which it uses internally apparently) it would be used like this

well without the while loop
nvm it's handled differently, you need your own allocated buffer
uhhh
this passes
use std/prelude;
fn main() {
x := "foo";
$assert(x == "foo", nil);
x := 1;
$assert(x == 1, nil);
{
x = 2;
x := "a";
$assert(x == "a", nil);
{
x = "b";
$assert(x == "b", nil);
}
$assert(x == "b", nil);
}
$assert(x == 2, nil);
io::println("All variable shadowing tests have passed!".color("green").reset());
}
``` ive just made a dynamic static language@valid jetty which commit msg is better

The feb one would be fine as six commits
yea i kinda just forgot to commit the other stuff
the one in the middle
before starting on interpreter and expression location
That should have a separate pr
sorry i had to blur it because it contains my full address, pictures of my wife and my manifesto
prs in personal repos
tell me more about that manifesto
[p]ersonal [r]epo
its a 178 page listing of every single race, religion and political view and at the and i say i hate them all
most of it is sects of furries
oh except mongolians and the north sentinalese
and people who like cats ferrets
yeah yours looks fine

yes
beware that it doesn't null terminate it if you want a string

Im extracing java class file bytecode
oh and people who make prs in personal repos are listed in bold in the manifesto
what
also i think a malicious zip could set a filesize to something wrong which is why you can do it like this
scroll up
do u also comment LGTM! on all of them
no because im merging them
i just use PRs because i hate having everything in one commit
like rubber duck debugging but written
and also this is nice

way too much hassle for me
i just spent like 10 minutes writing this commit messages and now i wanna go back to making 7000 line commits named ":3"
fellow zed user
i think everyone here uses zed
you can just do pr, commit frequently and then summarize it in commit msg
or just put all commit msgs to the final msg
why not just commit frequently
hes doing it again 😭
this accidently reminded me of how i used to randomly open this server (before i actually started talking here) and see people having fucking jetbrains writerside as their role icon, i thought ppl here were actually using it

@hoary sluice can you tell how to use this syntax based on how its defined [<T;>? <expr>...?]
in start PRs are probably useless but later when you have a structure and everything works i would use them
you guys are insane, just directly commit everything with random commit messages so you dont remember what you changed in that commit
what is this
what language is this
im trying to make a concise definition for how you can initialize an elle array without bnf
maybe i should just use bnf
i tried using it once and couldnt figure out what it was meant to do
lmaoo same
just use ebnf
lc.g ebnf
Extended Backus–Naur form ... In computer science, extended Backus–Naur form (EBNF) is a family of metasyntax notations, any of which can be used to express a ...
src/grammar.ebnf:
expression = declaration ;
declaration = IDENTIFIER ":" { "_" | IDENTIFIER } | lambda ;
lambda = { IDENTIFIER } "$" expression | assignment ;
assignment = IDENTIFIER { primary } "=" expression | if ;
if = "if" expression expression { "elif" expression expression } "else" expression | binary ;
binary = unary { ( IDENTIFIER | OPERATOR ) unary } ;
unary = ( "!" | "-" ) unary | primary ;
primary = "true" | "false" | "null" | "(" expression ")" | NUMBER | STRING | IDENTIFIER ;
oh i thought it was for me
array ::= "[" [type ";"] [elements] "]" ;
elements ::= expression {"," expression} ;
``` is this rightnot too far fetched ig
grammar notation and writing
is the ::= ebnf syntax
yes i think so
Wikipedia uses =
i think ::= is pointless and annoying since its for human eyes only
are u gonna use builtin functions for stuff like io or are u gonna do smth else like inline IR?
i built my own on top of posix ones
I want to do this ^
I'll use functions from libc
i thought u had a bunch of __builtin_do_not_use_unless_youre_cool_fopen__
are those just posix wrappers
thats not what those are
Rosie you don't have private keyword or something to not expose it outside the file?
Or why everything is with __........
ohhh
well yeah makes sense
I should implement name mangling
And @mangle(false) or something
and I should also make todo table or something
theres an attribute called @fmt that you can put on a function to say that every argument passed in should be put through its formatter
so here
fn string::format(ElleMeta meta, string fmt, ...args) @fmt -> string {
for let i = 0; i < meta.arity; i += 1 {
meta.types[i] = "string";
}
return __internal_fmt(fmt, meta, args);
}
``` you can pass anything and the compiler will turn it into a string using the type's `__fmt__` method
however if you know what youre doing and want to use the basic formatter that will not call the fmt method, you use
```rs
fn string::__internal_formatter_do_not_use_unless_you_know_what_youre_doing__(ElleMeta meta, string fmt, ...args) -> string {
return __internal_fmt(fmt, meta, args);
}
the difference is that this one wont work for any non-primitive type because its not calling __fmt__ of the type
me when my function is secretly __main.is_structname_a9f3b8d2-47c5-6e1d-82f0-3b7a9c4e5d61_function__
you know youve done something wrong when the fn keyword is on a different line than the function name
and the stringifier for primitives basically does this lol
fn __internal_to_string<T, U>(i64 args, string fmt) {
T arg = args.yield(U);
let length = io::snprintf(nil, 0, fmt, arg);
let res = #alloc(char, length);
io::sprintf(res, fmt, arg);
return res;
}
// !! Do not use this unless you know what you're doing !!
// If you want to turn a value of arbitrary type to a string
// please use string::as_string or string::as_string_wrapped
fn __to_string(string ty, i64 args, bool wrap) {
if ty.starts_with("i8") {
return __internal_to_string<i8, i8>(args, "%d");
}
if ty.starts_with("i16") {
return __internal_to_string<i16, i16>(args, "%d");
}
if ty.starts_with("i32") {
return __internal_to_string<i32, i32>(args, "%d");
}
if ty.starts_with("i64") {
return __internal_to_string<i64, i64>(args, "%ld");
}
if ty.starts_with("u8") {
return __internal_to_string<i32, u8>(args, "%u");
}
if ty.starts_with("u16") {
return __internal_to_string<i32, u16>(args, "%u");
}
if ty.starts_with("u32") {
return __internal_to_string<i32, u32>(args, "%u");
}
if ty.starts_with("u64") {
return __internal_to_string<i64, u64>(args, "%lu");
}
// ...
}
looks a little cursed but its the best way to dynamically do it
what if the type is u32balls
well the only way that could happen is if the type is a struct
which means you shouldnt use the internal formatter
but what if i know what im doing!!
then it would just give you the pointer of that u32balls struct represented as a u32 lol
why are u doint startswith anyways

oh
thats the main reason i made the name so explicit like that
its very easy to use it wrong and get weird results
if you do the right thing youll be fine
You should implement mangling and get rid of ___________
struct u32balls { u32 x; };
fn main() {
$printf("i have {} balls (marbles!!!)", u32balls { x = 39 });
}
``` if youre sane nothing will breakbut if youre unsane you can do
struct u32balls { u32 x; };
fn main() {
$println("i have {} balls (marbles!!!)".__internal_formatter_do_not_use_unless_you_know_what_youre_doing__(u32balls { x = 39 }));
}
which gets you what you would expect i guess

true
marbles!!!!
i meant golf balls
infinite balls glitch????
so true
weirdly enough its a slightly different amount of balls each time i run it 😱 i wonder why that is
random number generator??
real,
is it undefined behavior
i mean as a random number generator yes
@hoary sluice @placid cape if the user is compiling elle code into an object file should i link with libelle?
or would they link with it when compiling the main executable
i mean like does it pull a valug from a random unallocated memory
yess
oh it an architecture question not amout the name being libelle
not used tho

idk enough about linkers to answer that
i might just pass -Wno-unused-command-line-argument to the linker lol
gn
i can just do this lol

shadowing.le: Lines 1-25
use std/prelude;
fn main() {
x := "foo";
$assert(x == "foo", nil);
x := 1;
$assert(x == 1, nil);
{
x = 2;
x := "a";
$assert(x == "a", nil);
{
x = "b";
$assert(x == "b", nil);
}
$assert(x == "b", nil);
}
$assert(x == 2, nil);
io::println("All variable shadowing tests have passed!".color("green").reset());
}
i havent touched typescript in a bit but
this is so fire

@royal nymph did u know this hapopened its s of ire
technically that isn't always correct
what if obj[key] is a getter
that returns different thingh every time
I sure hope that doesn't pass code review
fn main(string[] args) {
contents := io::read_to_string(args[1]);
grid := contents.split("\n")
.map<char[]>(Array::from_string)
.map<string>(fn(char[] x) x.join(" "))
.map<i64[]>(string::nums)
.map<i32[]>(Array::truncate);
ts := find(grid);
$dbg(solution(grid, ts, false));
$dbg(solution(grid, ts, true));
}
ts 💔 = find(grid)
ts pmo 💔

@woven mesa theres a ton of customization for the tabview too

I think im gonna use this
this makes codebases so much better 😭
I dont have to make a million wrappers
maybe thats a bit much

I still need to make some wrappers I guess
ooo
whats wrong
at most I wanna support ios 16
ah
not impossible though
why do they have a different animation for the files app when using a tabviewsidebar
This may be off topic, but I'm trying to inject betterdiscord or vencord into the discord-portable version I found on github. since the discord-portable I found on github is old, the index.js part I marked is missing. what should I do with the file= path instead?

@broken shore do you know why it adds a new navigationbar if I use anyview

show code
let view: any View
view: RedView(),

what is that?
I think compact is mispelled as compat
no it's compat
it's a custom extension for View
extension View {
func compatNavigationTransition() ...
}
yeah but what does compat mean
probably the definition and the usage are spelled that way
compat means compatibility dawg
i said that but then nobody replied :(
elle testing framework when
😭

no
woo

guys im a little scared fr
I'm setting some apps on my server with docker and this shit comes back for no reason when I delete it. they RECREATE THEMSELVES

4 containers that use my 80 and 443 ports and i cant delete
i didn't docker compose up dokploy i dont even have any docker compose for that and dont use that
i stopped, they restart, i stopped and removed containers, they are created again
they are re-creating when i delete wtf is this anyone knows?

How come that's not parsed as a function call?
probably because if and else are tokens with priority?
I mean the (false)(false) part
Why does "consume condition expr" not consume the <expr>(<expr>*)
idk ask eagely
functions dont require () and () is just a grouping, false is parsed as an entire expression because false is a literal, ```rs
if foo foo else bar
is parsed as if (foo) { foo } else { bar }(right now it doesnt matter that false is a literal, but its never going to be parsed as a function call cause its a literal)
{} is not valid syntax rn
it is tokenized as
[src/main.rs:19:13] &tokens = [
LeftBrace, None, 1:1,
False, Boolean(false), 1:7,
RightBrace, None, 1:9,
]
but the parser doesnt use them
fn parse_if(&mut self) -> Result<Expression> {
if !self.current_is(TokenKind::If) {
return self.parse_binary();
}
try_consume_any!(*self, TokenKind::If);
let condition = Box::new(self.parse_expression()?);
let body = Box::new(self.parse_expression()?);
let location = condition.location.clone();
let mut branches = vec![(condition, body)];
while self.current_is(TokenKind::Elif) {
try_consume_any!(*self, TokenKind::Elif);
let condition = self.parse_expression()?;
let body = self.parse_expression()?;
branches.push((Box::new(condition), Box::new(body)));
if !self.current_is(TokenKind::Elif) {
break;
}
}
let mut otherwise = None;
if self.current_is(TokenKind::Else) {
try_consume_any!(*self, TokenKind::Else);
otherwise = Some(Box::new(self.parse_expression()?));
}
Ok(Expression::new(
ExpressionKind::If {
branches,
otherwise,
},
location,
))
}
basically
consume if
loop {
condition = consume expr
body = consume expr
}
consume else {
body = consume expr
}
whenever i implement function calls im prob gonna add some kind of {} requirement
tldr: because <expr>(<expr>*) is not considered to be an expression currently, because function calls arent implemented yet
Simple enough solution
meanwhile rust requiring brackets for if-statements with single statements inside them
husk
i might do that
nooo single statement if statements without brackets so good
its either make if foo foo else bar only work sometimes or make it work never
its hard to make if statements without () or {}
Do like python
since everything is a function, in the end this should be parsed as
if (foo(foo)) else bar
which is a syntax error
meh
problem is,
if false foo else bar
``` will be parsed correctly because the expr ends at the falseso it only works sometimes
foo if True else bar
true ? foo : bar
that might actually be a good idea
python
who here understands the format of java class file
im parsing this thing, attribute_name_index is a reference to a constant pool entry which is an array(indexed from 1), however, i get number like 178, which is actually offsetted by 1 for no reason, the entry i need is 1 lower. theres nothing about this in docs

the thing is that this doesnt always apply, which is kinda weird xd
like sometimes its correct, sometimes its not, so i just cant use - 2 for no reason
this is how i use it

@valid jetty you're following python's behaviour with for loops?

this returns 10 in elle
wdym? that seems reasonable to me
oh you mean like
the x shadowing the previous x?
hmmmmm idk i may fix that in the future
its not very hard to fix tbh
yeah there

👍

btw the idiomatic way is something like
use std/prelude;
fn main() {
x := 75;
$dbg(x);
for x in 0..10 {
$dbg(x);
}
$dbg(x);
}
it does the x = for you

oh yea i just rewrote blom code into ella :D
oh lol i see
how can i remove the ugly is_print without having borrow after move token?
TokenKind::Identifier => {
self.advance();
let mut is_print = false;
if let TokenValue::Identifier(name) = &token.value {
if name == "print" {
is_print = true;
}
}
let identifier =
Expression::new(ExpressionKind::Identifier { token }, Rc::clone(&location));
Ok(if is_print {
Expression::new(
ExpressionKind::Print {
expression: Box::new(identifier),
},
Rc::clone(&location),
)
} else {
identifier
})
}
i dont have functions yet but id like to see if my code works so i need some kind of io
first time in my life im using ***

would this work
match &token.value {
TokenValue::Identifier(name) if name == "print" {}
_ => {}
}
```i dont really know what you want to dobut kinda the whole point is to not write the thing on rhs of let identifier = twice
feels so wrong to read old elle code
fn input(String message) {
Long stdin = fdopen(0, "r");
Char buf[1024];
printf(message);
fgets(buf, 1024, stdin);
Long len = strlen(buf);
Long index = len - 1;
Long newline = buf + index;
newline <- Byte 0;
return buf;
}
Teenagers are always cringe
now its like
fn io::input(string message) -> string {
buf := #alloc(char, 4096);
io::print(message);
io::fgets(buf, 4096, __internal_stdin);
buf[buf.len() - 1] = '\0';
return buf;
}
``` lolthis was only 10 months ago tho lmao
They grow up so fast

anyone know why my vscode typescript is stupid?

are all typescript IDEs like this?
guh it'd be so good if it worked

ActiveXObject 😭
but that's likely normal
Lsp thing

why is it normal tho it makes no sense
like when I birefly learned java it was hell but at least the autocompletion on jetbrains ide wasn't completely stupid
I can't be sure if it's normal from the limited info I can see
but I think it is
i think it's normal as in yes it is this dumb for everyone
suggesting objects from everywhere except the type the function accepts
friendly reminder that rust compiles to wasm and can be used on the frontend
@placid cape i was wondering why the last few weeks my zed discord presence didnt work, turns out when i reinstalled zed i forgot to install the extension 😭
i had like 72h streak in zed and it suddenly stopped displaying status :(
hehe funny words magic man
@hoary sluice https://github.com/mTvare6/hello-world.rs

GitHub
🚀Memory safe, blazing fast, configurable, minimal hello world written in rust(🚀) in a few lines of code with few(1247🚀) dependencies🚀 - mTvare6/hello-world.rs
look at main.rs LMAO
GitHub
🚀Memory safe, blazing fast, configurable, minimal hello world written in rust(🚀) in a few lines of code with few(1247🚀) dependencies🚀 - mTvare6/hello-world.rs
LMAO

i just made function names required to be both strings and identifiers at the same time so now u cant declare functions
idk what i was cooking
guys sexpack is ddosing me
i mean 170.x ip really wants to access sexpack on my proxy
literally advent of code
5v
GitHub
🚀Memory safe, blazing fast, configurable, minimal hello world written in rust(🚀) in a few lines of code with few(1247🚀) dependencies🚀 - mTvare6/hello-world.rs

looks normal to me
could probably use a macro
@hoary sluice so when are you gonna use the erlang encoding scheme for icps
i wanted something more optimized so this wouldnt be so performance non-efficient

its beautiful
ok so i have functions now, however
- guards dont accept any arguments yet
- there is absolutely 0 type checking, not even for the amout of arguments
- types dont exist at all yet so when i say
inti actually mean an identifier with no associated value calledint
hence this is valid code
add : int int AAAAAAAA a a a
add = print 3
add 2 3 "marbles"
and it outputs 3
very useful indeed
that requires me to understand it which is already impossible
it also requires me to have types
and working functions
with arguments

2 million calls of bswap16 xd

i wonder how much more efficient would it be if i inlined it

argh why does this keep happening

hmm, im thinking of rewriting my class_file structure into a more usable format

the issue is that i would like the whole thing reconstructable back
xd

much nicer

drop the multiple extensions thing
just let it use any extension bruh

vee
why does pnpm have a theo video on their homepage 

i got recommended a webdev news video on youtube and after watching it i found out webdev has WAY more different frameworks and tools than i thought
@valid jetty woo

you want a package manager? here, we have npm, also yarn, oh we also have pnpm, deno and bun as well!
you want a bundler? maybe webpack? or vite. or esbuild. or rollup. or whatever the fuck
actual functions!!!
you want a package manager? we dont have libraries
you want a bundler? imports are not supported
is the part after : a comment??
no its the type signature lol
husk


tbh most bundlers are just wrappers of other bundlers
vite is a rollup + esbuild wrapper
webpack is garbo don't use it
Vencord & Vesktop use pure esbuild to build everything
i thought since webpack was the most popular it'd be the "best" / most liked one, but apparently people hate it lol

webpack is fucking shit
it's the oldest one that's why it's popular
used to be the goto
but it's so fucking slow
wtf is that graph
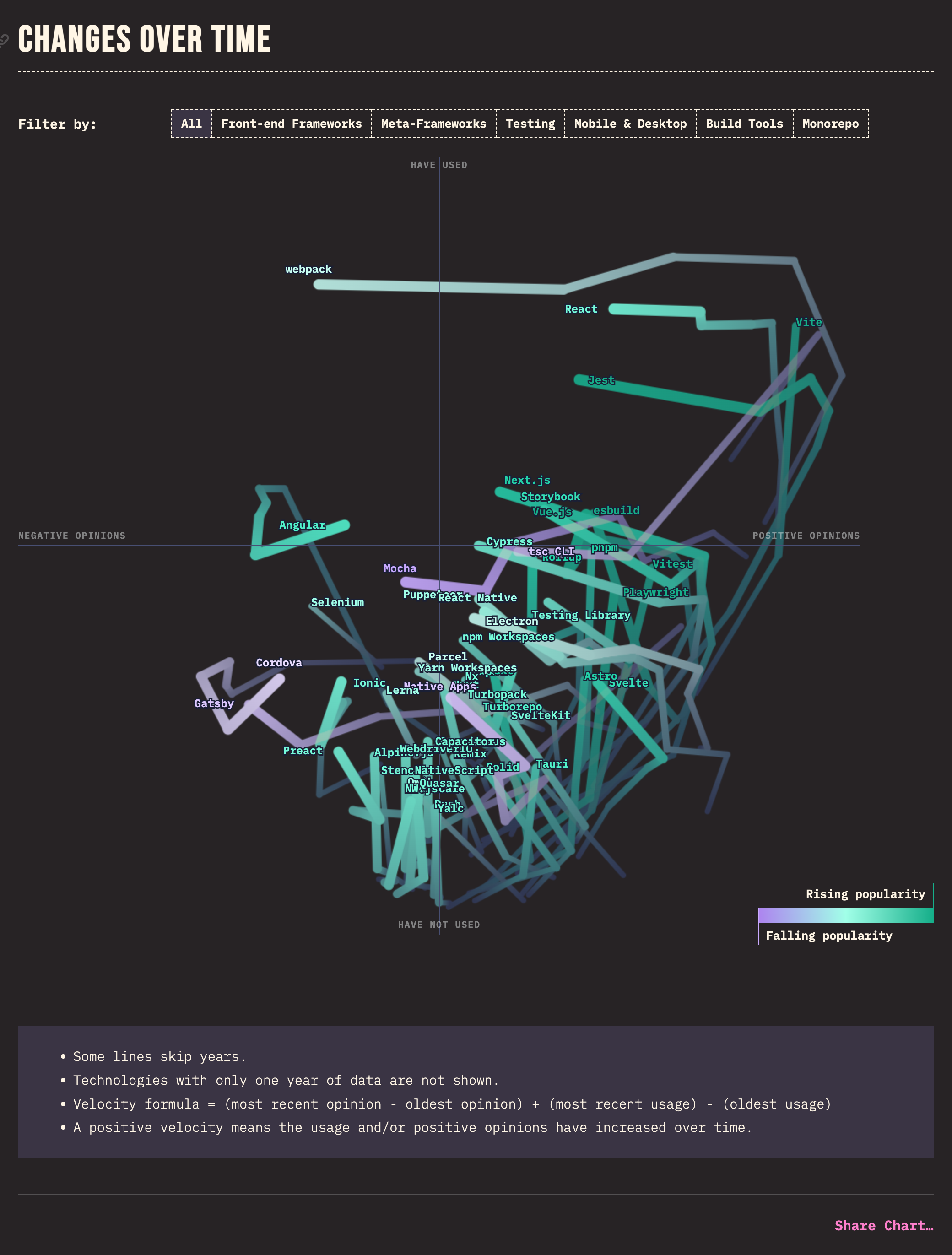
Each line goes from the earliest to the latest available year of data. A higher point means a technology has been used by more people,
and a point further to the right means more users want to learn it; or have used it and would use it again.


oh i thought they were still using webpack
rspack is webpack replacement that's much faster
wdym
i think having that many different libraries, frameworks, tools for js/webdev in general is very good for experienced people but like it's a horrible experience for those who are not familiar with webdev and only want to start. you just blindly choose a framework that's trendy and/or well-known which is not so good i guess
nah
95% of the lines are all trending negative in the last 2 years
??
2024 especially
rspack wooo
all modern options are pretty good tbh
a lot of good frameworks
just use modern shit that uses stuff like vite and don't use ancient shit like webpack or create react app
i choose stuff only judging by whether it has a cool logo and golden checkmark

bun is kinda overrated
i mean to me it mostly caught my attention because it was made in zig which is kinda interesting
like there aren't that many big projects made in zig
all i can remember is ghostty and bun
everything is made in rust these days
what if i use js instead of ts for my site
anyways uhh i'll probably stick with astro atp
seems trendy enough
reminded me i still haven't managed to buy the domain. fortunately porkbun was able to verify my phone number by calling me from their support number. shoutout porkbun !
so discord donated $10,000+ to webpack just to end up switching to rspack??

ok no its not, currying doesnt work 😭
you dont need currying for turing completeness
you do if the only operation you have implemented is print
a turing complete system has
- iteration
- memory
- conditions/branching
recursion counts as iteration
still applies tho
and memory using functions
as long as youre not trying to like
make the language out of axioms
with like church numerals and such
well i have numbers i just dont have any math operators
anyways i dont have conditions cause my ifs dont work with functions
if b print b else print "not b"
the second print gets parsed as an identifier, not a function
the fix is making identifiers just functions that return a constant
or like
calls with 0 args
thats a job for tomorrow
currently functions are basically just overhead that can do nothing besides print the value or ignore it
i improved import paths
now the import path is relative to where the file is importing from, instead of where the compiler was invoked from
oh and you can do this
use ./resources/../resources/./raylib;
does it not check predefined system paths like c?
it does
where
std/x/y looks for /usr/local/include/elle/std/x/y.le
then if that doesnt exist it looks in current dir
alr
can u configure it?

GitHub
- Add call to grammar
- Implement parse_call
- Implement function declarations without type checking
- Implement function pattern assignments with named parameters only
nope but i can make it configurable pretty easily i guess
that will probably come with a flag to turn off colors too i think
do u use env variables for config stuff rn
or some kind package fie
file
lol
probably a good idea to move those away
u should use :3 instead of * in commits
:3 Add call to grammar
:3 Implement parse_call
:3 Implement function declarations without type checking
:3 Implement function pattern assignments with named parameters only
so true
no but it makes :3
:3
doesnt even look that bad tbh
so many

i probably shouldve taken a look at the haskell compiler before doing all of this
wouldve saved a lot of time
lmao
they work like regular functions theyre just not intended to be called by the developer
theres wrappers usually
lmao
im prob gonna do a qbe impl once im done with the interpreter
i wonder what a less deranged way of doing this would be

since all routing is client side i just have the page that loads the app as the 404 page
using rust (it compiles to wasm and can be used on the frontend)
same issue if i use client-side routing
(it is an spa)
maybe i should figure out a way to do routing server side too
but also what would be a good way to have script have dynamic content
it just passes down some env vars from the server env vars
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Dashboard</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="stylesheet" type="text/css" media="screen" href="app.css">
<script>window.ENV={"REDIRECT_URI":"http://localhost:8080/api/v1/auth/login"}</script>
<script src="app.js" defer></script>
</head>
<body id="app">
<noscript>
This website cannot be run in DOS mode
</noscript>
</body>
</html>
"-std" | "--std-path" => if let Some(arg) = args.next() {
let leaked: &'static str = Box::leak(arg.into_boxed_str());
unsafe { STD_LIB_PATH = leaked };
}
``` is there a better way to reassign to a static mut?????????i let qbe handle it
(for now)
i think u shouldnt use static mut at all
omg it all has to be in an unsafe block
you should use Arc<Mutex>
if i use static mut
its single threaded
but this isnt multi threaded
use a Cell
yeah ok
there's no good way to have globals lol
Statics have to be Sync, whether you use threads or not
i get annoyed by that
i love globals
pros: good excuse not to write tests
cons: makes it harder to write tests
huh do they
I did this abomination
// :3
#[macro_export]
macro_rules! global {
($name:ident : $type:ty, $getter:ident) => {
pub static mut $name: Option<$type> = None;
#[inline]
pub fn $getter() -> &'static $type {
unsafe {
$name
.as_ref()
.expect(concat!(stringify!($name), " must be set before use"))
}
}
};
}
// declare
global! {
SOME_VARIABLE: Type,
get_some_variable
}
// get (only after set)
get_some_variable();
// set (oh god make sure this is thread safe or you will explode)
unsafe {
SOME_VARIABLE = Some(42);
}
you cant use cell here actually because it doesnt implement Sync
Use mutex
^
even if you only have one thread, that's the only proper way without unsafe
No need for arc, globals are inherently shared
Because it's accessible from multiple threads
alternatively, lazy static
yea i was told to use lazy static and not use actual statics
lazy_static crate is largely deprecated these days, since LazyLock is in std
@valid jetty hiiii
i feel like the same people who decided on the warnings in jetbrains ides worked on the rust compiler
⚠️ this variable might be infected with measles
love it when the zed lsp just says "mutable borrow occurs here" and zed doesnt have a go-to-definition type of thing to go to where the error actually is
you would be great at kde
go contribute
you should be a project manager there
idk if they have those
zoot created kmines
I like kde
ok well i did it @hoary sluice

you can now disable colors and set the runtime & std lib paths
-noclr? Have you considered using sensible cli syntax
elle is becoming more and more the child of c and rust
crust
rustc???
the rust compiler is actually elle
no dont worry
i give 2 options

-noclr or --no-color-output
-noclr is five flags, not one
You should use standard cli conventions
hm yes let me ellec -tnfaskcibgs -o x.o -z -fabc
i need webdev help chat 😭
this is a test document so it's mildly horror but im trying to make the flashlight only appear within the search button
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<style>
body {
background-color: black;
}
.flashlight {
position: fixed;
top: 0;
left: 0;
width: 100vw;
height: 100vh;
pointer-events: none;
background: radial-gradient(
circle 70px at var(--x, 50%) var(--y, 50%),
rgba(255, 255, 255, 1) 0%,
rgba(255, 255, 255, 0) 60%
);
}
</style>
</head>
<body>
<div
class="wrapper"
style="
position: fixed;
margin: 0.5vh;
margin-left: 1vw;
top: 0;
left: calc(50% + 40vw);
width: 7vw;
height: 3vh;
border: 0;
border-radius: 20px;
outline: 0;
overflow: hidden;
"
>
<div class="flashlight" style="z-index: 9999"></div>
<button
id="searchButton"
style="
position: fixed;
margin: 0.5vh;
margin-left: 1vw;
top: 0;
left: calc(50% + 40vw);
width: 7vw;
height: 3vh;
border: 0;
border-radius: 20px;
outline: 0;
color: #ffffff;
background-color: #25252a;
font-size: 2vh;
"
>
Search
</button>
<script>
const flashlight = document.querySelector(".flashlight");
document.addEventListener("mousemove", (e) => {
flashlight.style.setProperty("--x", `${e.clientX}px`);
flashlight.style.setProperty("--y", `${e.clientY}px`);
});
</script>
</div>
</body>
</html>
i caant do this dude im crying
that cli arg is awful https://no-color.org/
that's just not how cli flags work tho lol
single - = single letter flag (you can specify multiple and -thing actually is 5 flags t, h, i, n and g)
two -- = long flag
these would be equivalent
elle -thing
elle -t -h -i -n -g
normally you have one single letter flag and one long flag
so for example
elle --disable-color
elle -C
but just do this instead of a flag
i know, however -thing is evil
whatever ill do that aswell
either document it or offer an alternative flag for it but NO_COLOR is a pretty well known standard at this point
because im gonna make color on by default im gonna make it as obvious as possible to disable it
so ill have --noclr, --no-ansi, and NO_COLOR=1
Adjust your clip path to be constraned to the search container
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<style>
body {
background-color: black;
}
.search-container {
position: fixed;
top: 0;
left: calc(50% + 40vw);
width: 7vw;
height: 3vh;
display: flex;
align-items: center;
justify-content: center;
}
.flashlight {
position: absolute;
width: 100%;
height: 100%;
pointer-events: none;
background: radial-gradient(circle 50px at var(--x, 50%) var(--y, 50%),
rgba(255, 255, 255, 1) 0%,
rgba(255, 255, 255, 0) 60%);
clip-path: inset(0 0 0 0);
}
#searchButton {
width: 100%;
height: 100%;
border: 0;
border-radius: 20px;
outline: 0;
color: #ffffff;
background-color: #25252a;
font-size: 2vh;
position: relative;
z-index: 1;
}
</style>
</head>
<body>
<div class="search-container">
<div class="flashlight"></div>
<button id="searchButton">Search</button>
</div>
<script>
const flashlight = document.querySelector(".flashlight");
const searchContainer = document.querySelector(".search-container");
searchContainer.addEventListener("mousemove", (e) => {
const rect = searchContainer.getBoundingClientRect();
const x = e.clientX - rect.left;
const y = e.clientY - rect.top;
flashlight.style.setProperty("--x", `${x}px`);
flashlight.style.setProperty("--y", `${y}px`);
});
</script>
</body>
</html>
@gray heron

all these programs support NO_COLOR and explicitly document it
there are probably way more that support it but don't document it
for example tree



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
@royal nymph lmao https://github.com/jcs/no_color/pull/301

GitHub
This PR adds the Elle programming language to this list.
did i take it too far
HORROR
:3
you love rust tho
if env::var("NO_COLOR").is_ok_and(|x| !x.is_empty()) {
disable_colors!()
}
does anyone have an updated version of like rounded chat bubbles and like maybe for chanel names too
actually i found one for messages so just one for channels
its so over it got accepted

is that github highlighting
nop
github uses linguist for syntax highlighting
and they have some requirements for new languages
いや、そうならよかったw
Oh! Pro gaming! Do any of y'all play Helldivers 2?
200 users (need all of vencord to make a project in it)
i do used to

GitHub
Check for existing issues Completed Describe the bug / provide steps to reproduce it The issue is related to LSPs not spinning up due to a message like this one: Language server error: astro-langua...
there were like 4 different PRs fixing this but none got merged
and i'm not even sure like whether it's an issue in zed or wasm or wasmtime or wasi or ???
this is reproduceable with just regular wasmtime but maybe it's intended? idrk

they need to stop making windows support and focus on getting the linux version to work properly
noo don't give them ideas
the windows one is never gonna be stable if the og version keeps crashing
true but i'd rather fix issues that make it literally impossible to use the app (even on not fully supported platform yet!) rather than just some crashes that occasionally happen
just dont use lsps like the creator of odin
smn
smh
fine but i want to use wakatime
isnt that paid
i mean there's a subscription but all i need should be available in free version i think
TIL that document.adoptedStyleSheets exists from https://github.com/material-components/material-web
I looked at https://developer.mozilla.org/en-US/docs/Web/API/Document/adoptedStyleSheets and https://web.dev/articles/constructable-stylesheets
Has anyone ever found this API useful?
yea thats what i do
i use the rust lsp but i could live without it
i couldnt
most things i type i let the lsp autocomplete
i mostly type lowercase cause i made the bad decision of only getting 34 keys, not 36, so i have 2 less thumb keys and pressing shift requires holding down s or i, so id rather just type it in lowercase and let the lsp autocomplete
its become a habit and now i cant write kotlin anymore cause the intellij kotlin lsp is case sensitive
maybe i should switch tab and space cause tab has a dedicated key rn
hmm i guess you’ll have to use python next aoc
im prob not gonna be able to do aoc at all next year