#🆕|sd3
1 messages · Page 86 of 1
but before they wer eruthless
thats why George horhey Lukacs said fk this
im selling it go to hell
I agree he is a decent actor
"sand is coiarse" tho
veyr coarse
I loved the prequels at the time
I'm ok with Lucas selling the franchise. he isn't going to continue work on it, and would be a bigger disservice to fans locking away any future to it for all time
they don't need to be perfect movies
yeah, beach is nice but sand is bad
my buddy has the original trilogy on laser disc, its the highest quality you can get of the non edited originals
or at least there is never a good switch between footwear and barefoot, with sand
the forgotten awesome media that never had a chance
maybe I should bring boots to the beach
lol
I beg to differ. Want the best, absolute best theatrical reproductions? Seek out the Despecialized versions
also the sand line isn't bad
this line got memed into oblivion
non edited
(not me, its sd3)

espcially the 4k ones
they take up 50 gigs
but huly crap
u get the 1977 experience
if you have a projector
Yes, exactly. The despecialized version is a reproduction of the original films that came out
mmmmmm
digital needed a long time to beat video
as in the original theaters
it barely works
Laser Disc isn't actually digital in the same sense as DVDs or BluRay are
like my player complained but somehow it does work
omg
its like the original movie
2024 - 1977 = 47
What would be the state of generative AI in about 47 years? small chip included in your watch, with the power of Flux now? Nah, that's not a real jump
This is interesting if you didn't know this already: https://www.youtube.com/watch?v=GFMyMxMYDNk

A video essay exploring how Star Wars' editors recut and rearranged Star Wars: A New Hope to create the cinematic classic it became.
Check out more essays at http://youtube.com/rjfilmschool
Written by David Welch (@watsonwelch)
Narrated and Edited by Joey Scoma (@joey2meals)
References:
Deleted Magic
https://www.youtube.com/watch?v=f2r4Nffrc6...
yes
Horhey Lukacs is a hack
Or is he
nah he is not
but he did get alot of help for those early films
he was tremendous and excellent in a new hope as he had rela passion for the 50s scifi tv specials and childhoos stuff
he wa sin pain like all of us yearnign to get back to our childhoods
so it wa shonest
in empire he was still ok and he knew when to hend over the reigns to other so make sur eits a good movie
in the return of the jedi he lost it a bit with the ewoks and toys because now he had to pay taxes and run a company
That has nothing to do with why he did not direct it, and he had final approval over it all
and its ben downhill ever sicne
XD
A new hope comes from a good place
George almost died in a car crash
Although I shared a SFX documentary about Empire Strikes Back a few days ago, narrated by Mark Hamill and that was televised at the time, there is another great documentary about the actual making of the movie, and it has tons of astounding footage. Not too long and really interesting to see. https://www.youtube.com/watch?v=YeB-uXGGaEU

The Cantina ad Jabba's pallae scared the crap out of me as a kid.
Little girl!
Please
thes emovies were not for kids :))
they were so scary
The Cantina was a horroshow
I wa scared for days about tentacles coming out from under the sofa after I saw it
I was 10 when it came out (cough), and despite waiting in line for well over an hour, only got seats on.... the aisle stairs! but once the movie was over, I hopped to the best seat possible and watched it a second straight time. Ahhhhh the good old days. 🙂
I was not alone on those aisle stairs mind you. lol. They were packed.....
It was so good wasn't it? 🙂
A different time for sure. You'd organize with friends for such movies, as I did for Return of the Jedi, so someone would come real early to get a good spot in the line
It came out years befor eI wa sborn and still when I saw it on those black and white KOMMUNISTA Tvs in eastern europe I was hooked


I was the usual go-to for the early liner since I was a known reading maniac and would be there with my paperback of the day oblivious of the time spent




Anyhow, the documentary above is super cool IMHO. You see extensive fencing training by Hamill for his famous duels (including injuries!) as well as the HUUUUUGE hangar set they built from scratch for the entire swamp world of Yoda. Just amazing.
Yeha it is.
Horhey Lukacs also financed a lot of Empire coz the bank said no.
He had a vision and wanted it seen thru
He hated hollywood to
He wa sa rebel
and
i remember watching the 2 TV movies, i was too young for the theaters, Ewoks: The Battle for Endor was the good one
I don't see any value in calling people names. He made them happen, and overcame challenges and obstacles you and I could never begin to fathom
the believability
it looke das if that world could exist
and the designs were industrial - again the ships looked as if they coudl exists
while other schifi shows hade weird shit that looked too weird for it to look believable
Ralph was a industrial designer
when he heard those concepts he thought as a real world engineer
how would these tie fighters look like
They had a half dozen models of the Falcon for filming a variety of scenes, from the size of a coin, to a 1:1 model that was left on ground (the famous one in the Hoth bunker)
Cameron was a lot like this too with the Titanic. They had a variety of models, some of which were just enormous
SD3

I like the idea, but the head seems a tad oversized
does NF4 have any benefits over regular flux, except for speed?
no





NF4 is essentially the ultimate compromise allowing you to run the closest possible model to Dev at a fraction of the memory. But it is a compromise, so the pure unadulterated Dev will be better.
I'm so screwed when glif becomes paid ROFL
How can I create text to image





I think that perhaps flux and GPT4 didn't quite understnad the concept...

What was the prompt for these two signs?

Lame a$$ ai (all programs) give the males proper fur, but the ladies only cat ears, or only the face of said animal grumble


Beautiful octane render illustration Text "Still Loving ART" steampunk style
that armour doesn't look comfortable lol





i have a rtx 2060 mobile. Flux works very well with fp8. But when trying to gen with nf4 with the new comfy node, it get's stuck at the ksampler step, just keeps loading and does not generate an image. Has this happened to anyone else ?
this might be my favorite so far because i wasn't expecting anything from a pormpt as dumb as "horse with rockets for hooves" but here we are. it nailed it in form and function.

People were talking about that
Saying it's hit or miss if your card supports
Even better if you didn't prompt the speech bubble! 😄
lol the prompt is more detailed than just that, but that theme of it was championed so well
i added the go go gadget horse because i thought it was more realistic that way and as you know, i always shoot for realism
the image has to be believable
Now SD3 on the other hand, has likely heard of Picasso

Hi, I was wondering, how much difference in speed is the clip fp16 vs the fp8 in speed and quality, for Flux Schell?

speed differences would be huge if you cant fit fp16 weights into your vram all at the same time
did you put the lime in the coconut? doctor said
I have 12 GB of VRAM
did you say "DOCTOR?!" an then he's like "you drink it all up"

you'll want the fp8 weights. i have 16gb and can't fit the 16bit weights. but i use that file and just load it in fp8 mode. i'm not sure there are any benefits from using a prebaked fp8 file, other than file size

i guess loading the model would be faster
it's a shame, was really excited about it. I don't get an error or anything, it's just maxing my ram and gpu and keep loading
I'll try it then, thanks!
you'll still not fit all of the weights into vram, and will be using shared memory. but less of it so it should be a lot faster
Try the other channels, ask if people got it working on your same card or check GitHub 
yeah i asked, but nobody seemed to be having my card for the moment
oh yes I never understood how I could work with a model that is larger in size that my whole VRAM



shared system memory is really helpful. it's swapping it out over your pcie slot to your system ram, then swapping it back when its needed. this just adds a lot of time to the operations.
some people don't have enough system memory to do it with, and their page file, a storage device file that acts as cache for the system memory starts getting used which adds even MORE time to the operations

Thanks. Fed it to SD3 Large, first three tries it messed up the text. BUT it did respect the steampunk aspect more:


DE3 got the text wrong in 3 of four samples, but also good on Steampunk and one ws spot on:




Quite liked Ideogram's output which nailed the text with no surprise. Here are two of the samples it fed me:


one of my favorite vacation memories is a man hacking coconuts open with ease and precision using a machete. poped a straw in it and handed it to me. mmm fknyeah
kinda wish i could just machete a coconut into a perfect little drink cup
step1: live somewhere there are coconuts

I created a new Flux pro glif 😉 https://glif.app/@LadyLalita/glifs/clzu7qzsv000viusphhjghcyn

Chinatown has coconut cracking hatchets 😄


I hear ya. I made one for friends here too: https://glif.app/@AmericanCarioca/glifs/clzoyqqv00000jjj58x96kqd3

i'm not sure the chinatown near me would. though i do love that place. 2nd oldest one in north america. only a few blocks, but it is such a distinct culture shift. Especially for the kind of stuff you can buy. when i was a kid that's where we'd get firecrackers.
I may edit it so a generic entry like X will produce a random but creative prompt and image
for those short of ideas but want a 'demo
this particular server has way too many censorship filters!!!!

I didn't prompt c l e a v a g e. Flux u r a p e r v e r t

That dog looks like he's just coming to a realization that the cat is fuckin' right.

Like the work I do and want to say thanks? Buy me a coffee or Support me on Patreon for exclusive early access to my models and more! Join us on SC...
I think he is scared, very scared
Is there a way to use even more RAM? I have 64 GB of RAM, and this is the usage right now

It uses what it needs.
I love the dog face

And the cat: 'Seriously? I'm going to slap you...'

using more ram won't make it work faster. there are multiple demands on the system. one is it needs to have enough memory to store the weights while processing them. more than enough memory doesn't offer much to improve generation times. once you have enough memory, speeds are improved with less steps or faster processors.
https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/67e8efd5-c67f-4b02-b4b5-e1dee24d7b13/width=450/0001_2024-08-14-1723651415.jpeg bruh her elbows are at her belly button. i dont think this author has a good eye for proportion. that does not showcase how he finetuned flux

FLUXING, it was supposed to say FLUXING lol



whose the cat? is erich schmidt the cat?
that guy has a TON of investment headaches lately
have you ever watched a cat during a solar eclipse? you can tell they're panicking
when she says she likes cats a bit

those are all accurate cats

 too smol resolution but still cats in their ai heart
too smol resolution but still cats in their ai heart

the pedermobile



Can I run Ideogram locally via ComfyUI? Otherwise, I am out 😛
You are out
You can use it 10x a day for free though, with four samples each
Same for Dall-E 3, which you can use 15 times
(more, but then in 'slow mode')
When ideogram first came out I tried it and it was horrid. So I haven't tried it since. Has it improved?
It is easily one of the very best
!
they are in their second model and a new one is coming out soon

I find Meta pretty awesome
you can click the Top to see the most upvoted images
of the day, week, or month
but they are stunting the image generation. it's supposed to have support for 512 tokens but it won't do them
Well, this is just the beginning. When SDXL first came out, I downloaded everything that was available for testing, and later, I started selecting what I liked the most and what suited my workflow.
the beginning is the base model. maybe i'm just old fashioned but i expect soemthing called a fine tune, to be tuned.

By the way, I have a feeling that through FLUX, Musk might be compensating for his grudge against OpenAI, and I think they might be turning FLUX into a full-fledged competitor to DALL-E 3. With computing power, datasets, and overall investments, this could be a strong move. I'm not saying I'm a fan of Musk in general, but in this case, it could be a big plus for regular users in terms of competition.
great, just for the record at least the RAM see more use when doing img2img with dev


I tried fp8 instead of the fp16. With dev I think it was a minute less, from 8:30 minutes to 7:30, I think
if you switched to CPU only rendering youll see full ram usage
oh I don't want that... I remember when I started using SD 1.5 I run it at the same time on CPU and GPU (!?)
Both were long, and glithcy
for some reason I could only run Automatic1111 on CPU, and to use GPU there was some shady other GUI or installation (because AMD things)
Black generations from time to time, great stuff
In Grok 2, Flux.1 is already integrated. In theory, it's a partnership, but if Musk buys BFL, we won't see future versions of Flux on our PCs. However, if it remains just a partnership with economic participation or investment, that would be good news. But I'm afraid Musk will acquire BFL
what would he be buying really, his boffins could spin up a lookalike model next month
Might have something to do with why there hasn't been a paper published for flux yet?










shaolin soccer nice nice

The Verge
xAI’s new Grok feature is creating a flood of deepfakes.
you need to post this out to twitter 🙂
cant tell if the article is supposed to be positive or negative
eh, it's clearly negative.
I always knew he was Chinese
Drama this drama that
All the same

Burn the witch!
Twitter lets me post nsfw, going to test out their new AI image creator 😉
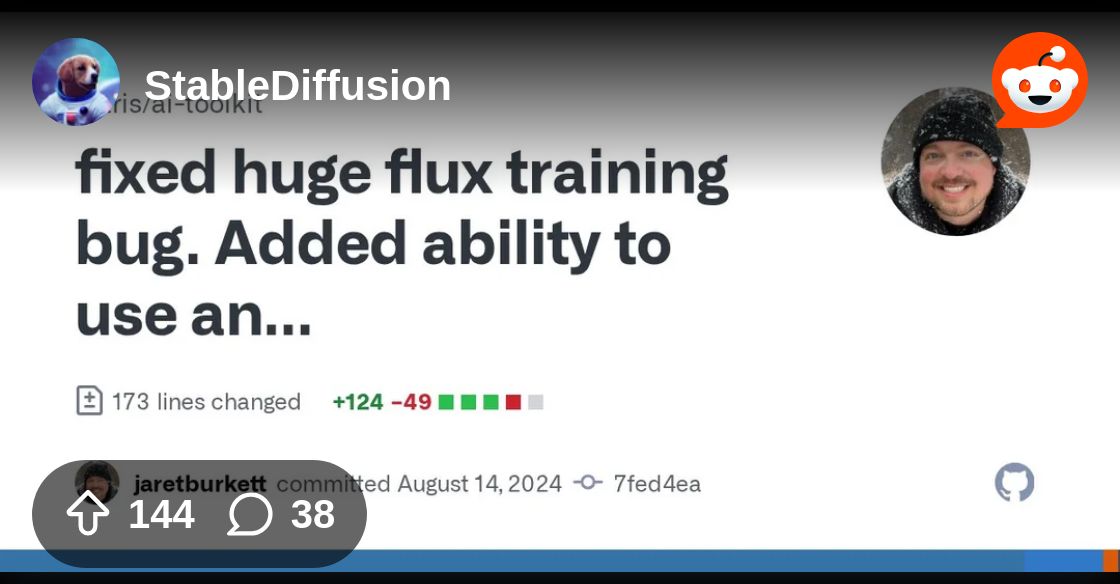
Reddit
Explore this post and more from the StableDiffusion community
Boreal Flux will be even better
More tests with analog

This seems like the project to follow. I'm feeling the simple-tuner is kind of rushing their bad code out to be "first". I haven't seen anythign quality from their tooling yet. ostris is sponsored by glif is nice to see. I love when these coompanies that build off of the open ecosystem give back to it in big ways
I understand.
What's "analog" in this context?
mutant kneecaps

Flux-Dev LORA based on the woodcut illustrations of Gustave Dore.
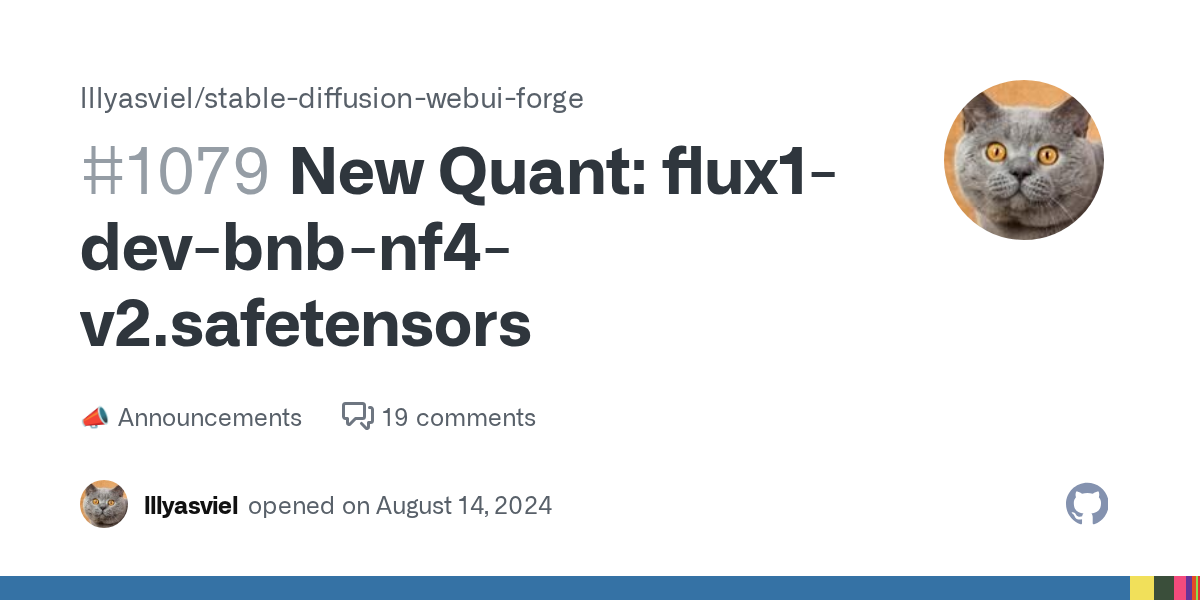
GitHub
See also: https://huggingface.co/lllyasviel/flux1-dev-bnb-nf4 https://huggingface.co/lllyasviel/flux1-dev-bnb-nf4/blob/main/flux1-dev-bnb-nf4-v2.safetensors Copied from readme: Always use V2 by def...

https://github.com/lllyasviel/stable-diffusion-webui-forge/discussions/1050 also new ui features in forge for loading the specific t5

GitHub
The old Automatic1111’s user interface of VAE selection is not powerful enough for modern models . Forge make minor modifications so that the UI is as close as possible to A1111 but also meet the d...
😦

ya they seem to be having issues
back to glif lol
are the pony people still waiting for a new version? i still see v6
I was wondering how we nearly went an entire 24 hours without a new model releasse 😄
Last I heard he's dataset building. Should just publish the dataset already imo
That's the true open model
is he working on a flux version?
flux kinda knows the beastie boys. thats' sorta like adrock on the left. kinda sorta like mike d on the right. the middle dont look anything like MCA /hat over heart/ god rest his soul

He didn't sound interested in sd3 nor fux (moreso a different model), but also said will see how things turn out. Just search his name in this forum to see the convo.
pony is 90% data. once the new data set is made he could train it on any model available if the community has enough support for that. they're working towards auraflow but things change all the time. once you have the dataset its a no brainer to point it at a new model with new tools.
personally i think they should just publish the dataset on a torrent. it would ice all the CSAM concerns (or vindicate them)


I'm pretty sure they also doing it as a for profit business, so that sort of thing would defeat that purpose. Though putting out the data publiclly, would probably actually lead to a deficate, and not even being able to break even after training costs.
they offer generation services as a for profit business and they still ahve to tune the model with their settings and skilled supervision. other people won't be so easily capable of just poppin another out nor get the rep they have for producing smething with the same dataset















yolo




the only thing i can't figure out with the new forge is how to prompt each of the encoders separately






ahhh yes. xlabs has put out new custom nodes and new controlnets
this one is dope like the one my fam had when i was a wee ice ball
yeh i found a perfect pic of the one i had growing up. 79 brown special . fusion really good at knocking out those og fords

fusion i mean flux
Now make it a ball









I also find it funny that nobody knows about the xlabs comfyui nodes because its being hella supressed on reddit. their accounts are all spam banned. people posting about it are getting removed. i dont know whats going on. mod team is just ripping contributors to shreds over there.
people think you still can't lora with nf4 quants
as far as I am aware their location may be in a sanctioned country
I don't want to speculate incorrectly though
really cool that the bar for flux has been lowered to 8GB gpus now



How does the quality compare?
what i found https://www.reddit.com/r/StableDiffusion/comments/1eso216/comparison_all_quants_we_have_so_far/
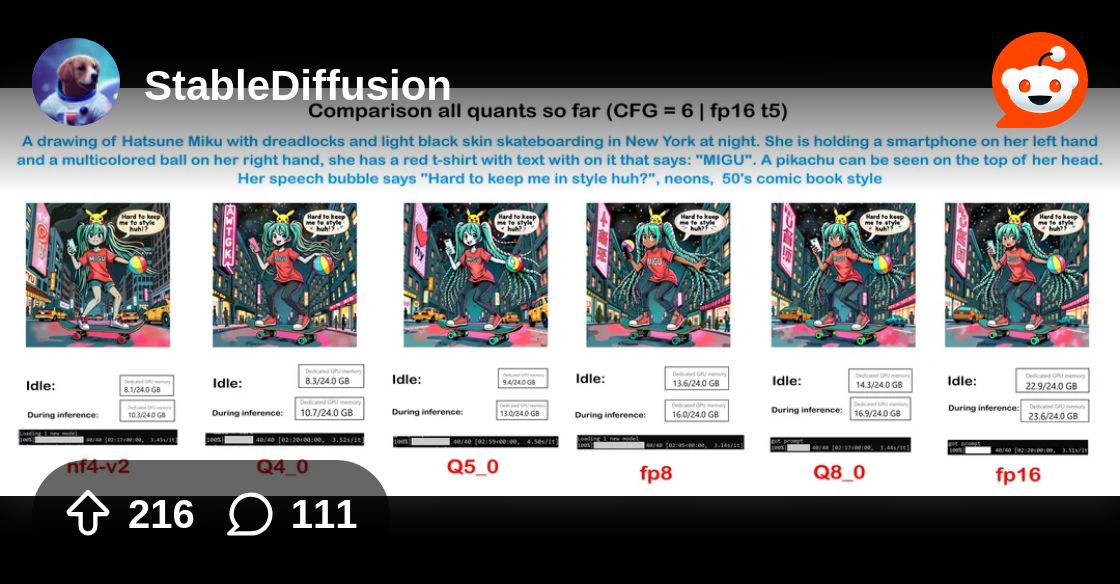
Reddit
Explore this post and more from the StableDiffusion community
I wonder why people didn't do quants with SDXL or SD3

seems to lose a little prompt adherence, the dreadlocks are missing on the lower models. quality still remains extremely good though
Apple did quantization for SDXL, but the arch is not very tolerant to quantization and lost a lot of quality. SD3 should be better.
there you go
I don't like either because of Flux's style for realism
but they both look the same image quality so the quant should be good 👍
oh i prompted for that
oh no
"A professional photo of" and threw in other hipster shit like "rustic decorations"
(this is my new go-to prompt for trolling because they always say the proof is in the pudding)

I love the good details in a straight generation
that's flux dev, long generation time but the most quality it seems
you can zoom in and there is good detail

hands are perfect MAN
Perfect man


I decided instead of R2D2 I am just gonna start prompting stuff that makes no sense
like Rococo furniture in desert cave
At any rate, I knew it was only a matter of time before they started gguf'ing these dit models. In the llm world, q4 really is a local machine standard and is usually within 5% or so of the q8 version and the q8 version is usually within a fraction of a percent of the q16. They could also do similar stuff to ggufs where you have _k_m or s where some important blocks stay full sized.
Makes me wonder if the next sd3 model will take advantage of this.
I guess this is a big advantage of DiT over Unet
cos the smallest Flux Dev quants are now smaller than Kolors Unet
for example

Fancier than most houses I see
ye its got fish


the seed where it put the fishtanks into the cave wall is way better

Unets are quite different though. They have some operations that are transformer based, but the rest of the model isn't a regular transformer. They don't quantize very well due to operations that rely on the whole U shape of the network
I'd rather see a quantised model that targets a 3090/4090 24GB
but started out way larger
it would be the best possible way for consumer GPUs

512 next to run on my phone

there are phones with 24GB ram
they could run not only the quants but the original flux dev
like you can literally run LLM on it lol
yeah I use LLM on my phone constantly
yeah that's possible, like running 70b llms that are quantized down to fit in 24gb vram
but i can't even begin to imagine the compute time for making an image model that size...
but also keep in mind that the average consumer PC has 8gb vram

barely even 5% of pcs have 16gb or more vram
so for now, targeting 8 or 12gb vram is idea and will likely stay the ideal for at least another year or two
open source isn't really necessarily about targeting the average person
even though open source does often get interpreted that way
you're in an echo-chamber of the same couple hundred people though, the bulk of users are the silent majority
that never make a post here or on reddit or twitter, etc etc

when the have models that size, they keep them to themselves for api revenue. 99.9% of local users will never donate even a single penny to the companies that spend millions training them and paying researchers
well I don't think donations are the only way, or the main way, open source is funded
a lot of open source comes from companies that make their revenue elsewhere
no, not really anymore. now it's big companies that back them like nvidia or now elon backing flux. once that happens, yeah the quality goes up, but then comes the censoring that everyone complains about (i want censored models). then you end up with an sd3 and everyone cries about not being able to make their fetish stuff.
though elon might be down with the degeneracy
so flux won't likely be forced into being censored
(it's already censored)
I want censored models too if people can train stuff back in (if not then even SFW models don't come out, because no porn = "don't train its bad")
I'm only interested in like 2 loras right now and both are SFW
and anatomy isn't utter rubbish
I missed the Elon news
Which flux model is X using?
and is the censorship/guardrails the same as the open source one?
probably dev for now, but maybe their pro version, we don't know
the media is complaining that it is uncensored
but its surely just the same as the open weights. right?
I guess the media didn't know about it until now
the mainstream


one hour on that planet is 7 years on earth.
it's been stated
yeah! In a scene of Interstellar a woman with lots of tattoos and long blond hair wearing a tight black shirt and tight black pants, the shirt is Nike's, it's on the water, and the spaceship in the background along with some galactic astronauts
Flux has a look that cannot be mistaken
just google for blackforestlabs and x
it's been publicly announced already
yeah, found it now
journalists are going wild
```Musk seems intent on letting misinformation like this pervade the platform. By allowing users to post Grok’s AI images, which seem to lack any watermarks, directly on the platform, he’s essentially opened a firehose of misinformation pointed at everyone’s X newsfeed.````
weird that mainstream media all don't mention it
they don't seem to know that SD3 2B is even more realistic
mainstream media has never come even 1% close to understanding tech though
it's all just Grok's AI images
that's unfortunately right
well keep digging, there was some official post that linked the two. you're free to keep wasting your time speculating if you want though.
to be fair the Google search I did, did not come up with great sources in the first few results
here you go https://x.ai/blog/grok-2

We announce our new Grok-2 and Grok-2 mini models.
"In collaboration with Black Forest Labs, we are experimenting with their FLUX.1 model to expand Grok’s capabilities on 𝕏. If you are a Premium or Premium+ subscriber, make sure to update to the latest version of the 𝕏 app in order to beta test Grok-2."
there's the actual hard proof straight from the horse's mouth
thought so, fucking love that movie
Grok-2 is strong too apparently
idk how it does, i know grok was hot garbage in the llm world. like a total waste of parameter size apparently vs models a fraction of the size. maybe they've improved it. i don't really touch anything that weirdo has his hands on. i didn't have a twitter account before and i sure as hell don't have an x account now lol
its important because he is the most likely to open source it with a good license
maybe, that's one good thing he has going for him. but knowing him, he'll find some dumb way to bias the models for the lulz or be a puppet for those who pay him to do so. he's autistic, people know that and plenty of people take advantage of the fact he's easily manipulated. you know i don't even have to name a recent one...
BC there's no reason anyone would pay extra to use X under normal circumstances
Or imo even use X lol
once the weights are open I don't really see the risk
cos you should benchmark a model a lot on your task anyway
before actually deploying it
My point is, if someone has their hand in Elon's pocket, and Elon has his hand in black forest labs' pocket, any future model coming out will be biased with some kind of BS
I see what you are saying yeah
neither gguf nor nf4 works for my pc. They max out vram and gpu. However fp8 does not max my vram neither my gpu utilisation and works fine. I'm thinking the custom nodes for those are not working with lowvram option on comfyui. They are trying to do everything in gpu. Is there a way to fix this ?
try this node and set it to cpu

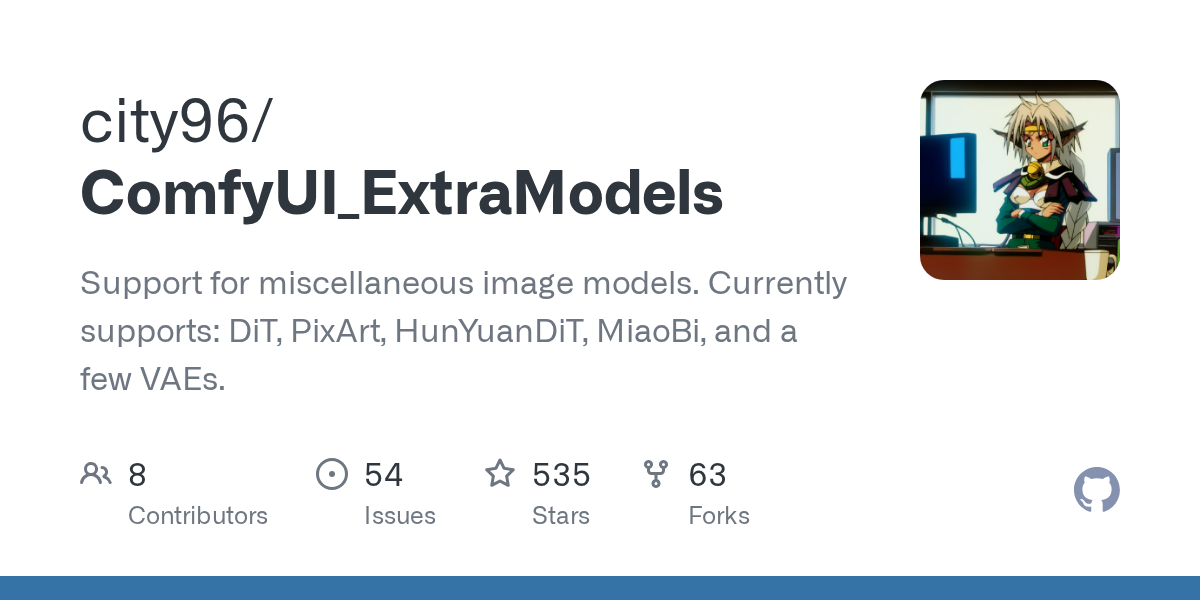
GitHub
Support for miscellaneous image models. Currently supports: DiT, PixArt, HunYuanDiT, MiaoBi, and a few VAEs. - city96/ComfyUI_ExtraModels
i have to use it like this to work on this 8gb gpu and it works fine for me
and maybe add --disable-smart-memory to your comfy launch flags
i will try this
it will force every model to unload from the vram after they complete their task
--disable-smart-memory to your comfy launch flags ?
yeah, the same place you added --lowvram
this will ? I though it is automatic --lowvram. I don't place it in comfy, but it does that by itself. Will try both then
find your run_nvidia_gpu.bat and right click, open with notepad
and add --lowvram --disable-smart-memory to it
yeah i know how to do that thanks. I made my own bat
no problem, that's where you add those kinds of flags. but that node i showed helps a ton.
it will be slightly slower for handling the prompt encoding step though, depending on your cpu, but for mine, it's like two seconds (13600kf)
i'm also still finding that i have to periodically click unload models from the comfy manager though. sometimes my it/s will be double the norm, so i have to cancel the current job, click unload models, and do it again. it will probably take comfy and the addons a little bit of time to hammer out the memory management aspects of it all, but for now this works
+loras



Using Flux Dev's native character consistency across game asset types. A detailed description may render IP Adapter obsolete. (Alternatively IP adapter may prove vastly more powerful for Flux than it has for any prior model.)





sadly character consistency in a base models is seen as a bad thing in machine learning
it means the sampler has low recall
This is consistent adherence to a detailed description.
woman mage with pale skin, long dark hair, a red cloak and hood, with a wooden staff that has a red diamond on top. Under her red cloak she has a long-sleeved full-body suit black shirt and trousers that are skin-tight and show off her muscles, and a gold belt with leather pouches.
You are thinking of a model's inability to generate diverse characters from simple prompts. This is unrelated.
did not change anything : ggml_sd_loader:
GGMLQuantizationType.F16 476
GGMLQuantizationType.Q4_0 304
model weight dtype torch.bfloat16, manual cast: torch.float16. Does this mean it's trying to load it in fp16 ?
yeah I see what you mean
if the prompt is simple then low diversity (recall) would be bad
but if its a very detailed prompt then its not as bad
I would still rather have more diversity than this though, as far as I understand its a side effect of distillation
I have 4 👀
how much vram do you have?
because you could just be getting screwed by cpu or system ram speed if it's having to do most of the work on cpu
and make sure you update your comfyui and that you aren't trying to use loras with the gguf or nf4 versions of the model, the loras only work with the fp8/fp16 versions of the model(for now)
but why does it work with fp8 ?
i'm not using loras
because comfy has native support for it and it likely meshes well with the memory management system used by comfy
most of the things are being done in cpu with the fp8 model. I'm not having any problems. It seems like int4 gguf is requiring a ton more resources than fp8. It does not make any sense
to run the quants, you need addons
those addons might not mesh well with comfy's memory management
yeah i'm guessing comfy needs to support it
what card are you using?
rtx 2060
yeah that's probably why
it's probably not fully compatible with some of the data types
or at least not full speed compatible. i know some models of cards had issues with half precision(fp16) around that generation
wondering if forge supports it well
where can i find force/clip set device node?
extramodels for comfy ui
ok thanks!
please is there anyway to sorta merge sdxl and flux models?
Use a workflow that starts with one then ends with the other. Not merged but same idea kinda.
have you guys installed the new front end for comfyui ? How can i do that ?
i just heard of sthng called block merging thats why i asked. thanks guys
--front-end-version 'Comfy-Org/ComfyUI_frontend@latest'
you are in the comfy discord too lol
well they didn't respond
have not tested yet, will try now
If you search merging in this section, some folks who know a lot about such things explain why it's not really a merge.
My experience with merging 2 different models has produced results that are always exactly like the first model selected.
Really easy to tell when I "merged" sd3 and pony.
i cant run the gguf model it says this, any help?

same
you just cannot merge different models. It's not possible.
The problem is that:
- many tools do not output error messages but just do nothing and so the user don't know that the merge failed
- sometimes part of the models match like for example SDXL and SD 1.5 both use CLIP-L text encoder, so when you trained CLIP-L then this part if the model is merged while the remaining part is not merged









@severe phoenix









Flux pro via glif LOL
I made a flux pro img2img with prompt, glif btw. Unfortunately glif only offers 20 free per day currently though. https://glif.app/@LadyLalita/glifs/clzvb1932000bs5zl0fjerf3r


Flux Pro vs Flux Dev img2img via glif


I don't blame them
I have been hogging free usage of SD3 8B for quite some time until 2B came out
Wait, Flux has 8b? I thought it was large/4b? Think I need to search glif more!

Though you can get many more daily credits if you apply for them as a glif app creator via their discord... though I think you might have to repply daily
thank you so much. please what does clip models do? there's apparently this new clip model for flux that can work for also sd3 and sdxl
I just tagged you so you could see that person's reply, you probably want to ask them (I don't know nearly enough about such things, I just look at image results 😄 )
Just made a benchmark prompt 😄
Band poster: bass guitarist on the far left, drummer beside him, guitarist in the center, another guitarist next, and female vocalist in a wedding dress holding a microphone on the far right. Background features a circus with fairies riding elephants, creating a lively carnival atmosphere
flux dev


it couldn't follow the prompt completely but did something anyway
😄
and DALL-E

in chatgpt*
Flux 😛

flux won this

lool ok thanks









Can soneone point me to a flux getting started guide?
fat city






A detailed butcher shop entirely sculpted from smooth, golden butter. The walls, counters, and display cases are all meticulously crafted from butter, with a lifelike buttery butcher standing behind the counter. Inside the freezers, there are real red human meats, also made from butter, giving the appearance of frosty, cold storage. The shop is warmly lit, causing the buttery surfaces to glisten slightly, creating a surreal yet captivating atmosphere. Every detail, from the signage to the hanging hooks, is sculpted from butter, blending realism with the rich, creamy texture of the material

I did not use much brain power before hitting generate
"Cheese people behind a counter"








is dev better than schnell?
MUCH! (pro is even better than that!)
The only way I can think of maybe doing so is to use comfy, and that run api node. Though I'm pretty sure you would have to pay for the api tokens with this method. At least that's how it worked with SD3 when I used my comfy SD3 api node.
It is worse than that. You need to consider the very reduced number of users who have the technical knowhow, interest, and motivation to install and run models like these.
its a tiny amount of people I agree
but Llama 3 405b FP16 weights are over 800GB and there was still value in that being released
Sure, but Llama also has smaller ones
And Meta's value in this likely has nothing to do with the motivation Flux or SD had, even if the result is a publicly shared relase
Yep, talking percents of percents of percents. So out of the millions of people using genAI, you're left with a few thousand people in the communities that are actually active in even vocalizing anything. Of that vocally loud minority, most of them are weirdos obsessed with making NSFW content and showing off their fap factories and waifus
I know, it is beyond ridiculous, but whatever. Look at it this way, I'm sure they do the same thing with LLMs. 🙂
but Booba
Anyhow, it doesn't matter. The fact is some or many image AI generators have really established a not unimpressive audience. MJ showed that with their millions of accounts early on. Last year when I asked they had 16 million active accounts, and I cannot imagine it shrank since then.
They do, it's all about weirdos doing ERP. Been in the LLM community longer than the diffusion community
And unlike DE3 or even Ideogram, there is no free images a day option
I actually don't rly think the best diffusion model within the next few years will be SAI or BFL (flux)
I think at some point Meta, X or Google will drop an open source diffusion model

only through api for now
Google? Cmon. I have not seen any sign or hint they have any interest in joining the free for all. Meta might be. They did a lot of this even before, such as bankrolling a free super Go model to compete with the AlphaGo. Since, while Deep Mind may have shared how to build a super Go model, they ddi not share the one they trained. So Meta, still FB then I think, stepped up
Not a lot of people know about that project of theirs
not sure if you missed Google Gemma 2
Gemma 2 is one of the best open source ones in its weight class
gemma 2 is actually really good
but mistral nemo stole the thunder of both llama3 and gemma2
Then I did indeed miss it. Saw the name, but did not pursue it
Meta is finally doing something useful for humanity by releasing open-source models, but it feels like there's some shady shit behind it 😬
ye Gemma 2 turned out to be good
It looks like early 2023 stable diffusion 1.5 semi-realistic anime outputs 😄 cool output
TBH people are suspicious and critical of every large company no matter what they do, so they may as well just do what they want at this point
Unlike now?
Meta doesn't rly make their money directly from the public anyway, since they are an advertising firm, so it doesn't matter too much to them what the public perception is
because the only goal of these companies is to make more money, people don't buy into their fake sincerity
cuase the nsfw ones suck currently lololol
a lot of the diehards in the genAI communities are on the spectrum, so things like autistic paranoia and paranoid schizophrenia are common.
that's what I'm saying, there probably isn't anything they can do to make you like them, so they may as well not try and just do whatever they want, for better or for worse
Nonsense. You need peopple using your services to advertise to them. But that is a digression. The fact is they have tons of projects and whatnot the public won't know anything about
if censored I'd just use MJ prob
its that if they get a bad enough reputation then they will lose enough users yeah but that mostly just happened to X
the reality is that you're never going to get an uncensored quality base model again. those days are gone
When I first encountered Stable Diffusion back in 2022, I used to really enjoy creating NSFW content, but thankfully, I've outgrown that teenage phase 😭
most social media companies just slowly fizzle out
rather than going down in a blaze of fireworks like X
The fact is, X's use of Flux is an amazing coup for image generators in general
Not just for Flux
I'm really happy about the X and Flux news yeah
However, trying out something with FLUX wouldn't be a bad idea 
Flux has a lot of amazing strengths, and depending on your focus, can be a pure godsend
oh and one thing i forgot to mention earlier was that a huge chunk of image gen users in general are from countries where pron is illegal. places like india and china
so they tend to throw the largest hissy fits over models being censored
paid + not offline
As I really enjoy diagram and illustration art, using styles and more, it falls flat a lot in some. But like mall f these players, it is aboout knowing who does what best
Offline means little to me. Sorry. My machines are online permanently, and there is no real bandwidth consumption in sending a prompt or downloading the image
Actually, it's more about your control ability than whether it's online or not. Midjourney is an incredibly limited service in terms of control ability
would be inteesting to hear what that means. Control ability.
i never realized how censored this discord it, just hit a filter twice in a row
There are tradeoffs, like anything
they have a ton of layers to their system though, llms parsing prompts for nsfw content, llms expanding caveman prompting into useful prompts, the image gen, then layers of nsfw filtering for the outputs

I take it you don't use MJ
no I don't, you are right 😄
Or you'd never even dream of such a comment
With local models, you can train them however you want, create LORAs, fine-tune them, and edit different visuals to your preference without having to answer to anyone or deal with censorship limits. You can also benefit from features like ControlNet. In other words, the possibilities are endless with local models
MJ is really solid. my sister uses it a lot. i don't really mess with it much
They released a new model two weeks ago. v6.1. It is still quite iffy in text, so what else is new, but anything else it is... quite amazing

Understand which AI text-to-image models to use by choosing your preferred image without knowing the provider.
For people who just want to generate and use a single image without worrying about the technical aspects, Midjourney is a perfect fit. However, for those whose goals are more technical and experimental, local models are ideal. So, determining which is best really depends on your usage and needs
yeah 6.1 is a little lower ranged than 6
and you have pages of parameters, flags, you can add to modify the behavior on an image
save styles, and so on
Arena?
thats new though, flux just came out
and MJ options to control and modify images are a joke compared to the huge ecosystem of SAI
need to check their code at some point
because its very easy to get ELO systems wrong
ELO is quite tricky get right in practice
so I think with Flux MJ is behind. Not just because image quality is worse than Flux, but also because Flux is open source and will develop faster neer features than MJ
that's said it might be possible that MJ 7 then will strongly outperform flux. We will see. I won't say the battle is over, just that MJ is behind now and have to catch up
Myeah... the thing about these so called tests is they are pretty biased in what they test IMHO. Let me give an example. Here is Flux asked to make an impressionist oil painting of two young me playing chess in a park.

no, it's really not. everyone uses it and it's a decades old system stemming from the chess world. you're thinking of videogame elo where it's you with four other idiots on a team and a bunch of chaos. when it's just 1v1 elo, it's hard to screw up
MJ has the userbase to levrage
this is correct and usually is a huge advantage for MJ
With the release of flux fine-tunes like RealVis, MJ will fall further behind
How did MJ become so popular?
because MJ is optimized to death to please the user
It was the very first open to the publilc
it was high quality, way ahead of the rest of the competition and you didn't have to run it locally
of all lthe image generators
type some junk into a webpage and it just works
easy to use, artistic look, and it was free at first 😄
Ah, the right place at the right time.
its more complex than this
It came out before Dall-E and before SD
No
Dall-E was first
isnt first dalle released in 2020?
Who's behind MJ?
MJ may have been first yeah

I can't remember fully the order things came out
I can. I wrote articles about it in late 2022
youre right
dalle was first, but the whole ai fever didn't really hit the limelight until MJ
Dall-E 2 was the first model opened to the public and it came after MJ was opened to the public
byt about a month to be fair
I never made an image with MJ. Generating on Discord is just more confusing than Comfyui for me.
anyways. MJ was always ahead in terms of aesthetics. Not much in prompt understanding, but it got aesthetics better than its competitors for years
And the results are meh.
and currently MJ is really nervous after flux was released
so they themself see the problem
The company that cracks consistency next will be the next MJ.
even their current versions are basically still SDXL level prompt understanding. they're probably working on a dit version now to compete with sd3 and flux
Puffy Pope jacket thing got MJ the eyes
I definitely think MJ was ahead at first
Real consistency not cobbled togetehr with IP adapters and SAM masking and all that jazz.
but not as much these days
I tried both at the time. Honestly, DE2 was better at adherence even then, but its results were realy weird. It often looked like a cut and paste of imagery. MJ looked like art, but it too had massive weird issues. Like it was ful of image noise it could not get rid of. This persisted into MJ v3. MJ4 was a MASSIVE upgrade and game changer
MJ has a threat from the 16 channel VAE models like SD3 and Flux
but also SDXL fine tunes have still been steadily improving over the last 9 months
even if they can't always win on fine details, the more recent SDXL model versions can do very good compositions
Dall-E is like eating paper, Mid Journey is like French Cuisine with snails and stuff. Stable Diffusion is like a normal meal.
MJ uses a bunch of that under the hood if you're using img2img, but the end user doesn't have to deal with the chaos. the majority of genAI users are not tech savy and are ignorant/undereducated about it all.
Not anymore. DE3 is king for a bunch of things today. Far from all of course, but in some areas it is unrivaled still
naaah, Dall-E 3 is still one of the best models
lol
it's still better in prompt understanding than Flux, although worse than Ideogram
it really is
it's really bad in photography.
I agree Dalle 3 is the best or one of the best
but on art stuff it's totally competitive
yes, strengths and weaknesses
I tried some of my promts from ideogram with flux and all the flux ones looked way better
I wonder if that is not even on purpose. Like maybe they don't want DE3 to make realistic images to avoid all these problems like fake images and so on
dalle went a more artistic cartoony route with their model
it was originally made for art related things in the first place
Ideogram is horrible in aesthetics. But it gets even the most complicated prompts right, even if they look like photoshopped afterwards
it has been confirmed that it is censorship
because there are jailbreaks out there
and a new pricing structure, to keep up with the competition 😉
I don't mind their pricing structure, I think we need a mixture of open and closed source
there are no actual problems with fake images, interesting that, i feel protected
I just want at least one open datacenter sized model
we have it for video (opensora 1.2 is 67GB VRAM) but not for images
I remember DALLE3 making discord images or something, it was hilarious
is GPT4(?) captioning still the best
well that's why big API models like dalle3 do so well, they have all the NSFW shit trained into them, but mostly keep you from circumventing it. that way, you get good creations with good anatomy(usually) and they don't have news sites and people rioting with pitchforks over NSFW content generation every other week
InternVL2-Llama3-76B
maybe
i did a cost analysis, no it isnt
and what about knowledge
if they publicly released the models, people would jailbreak it within a day and start chugging out pron
fr
yeah that happened to flux dev already
PornHubAI you know its comming
for sure
MJ tried to impersonate the whole lora thing with their "tunes". The tunes sort of changed the theme a bit, but, still nothing like loras.
well like i've said before, there are tons of laws in the works for pretty much every major country that are going to seriously kneecap NSFW genAI content
I showed this the last couple of days, but it illustrates one of its real strengths. Both are takes on the same theme:
- create a cup of cappuccino in which the milk foam and coffee swirls form a map of the world
- create a large pizza in which the toppings form a map of the world.
Here are two DE3 results, and the next are by Flux (though others aren't a lot better):




ud think theyd be ok with ai porn
This plays clearly to its strengths but is a decent example
its like regula rporn but no one gets hurt
gpt4o just gets heihachi mishima (from tekken) right first try
was this the distilled flux?
I think distillation had bad effects on understanding and latent space
My personal fave is Claude
the other distilled models from SDXL that released earlier in the year had this effect that flux has where they lock on to certain concepts and they cannot interpolate smoothly
instead they jump from one concept to anotehr
Im startign to get the same feeling when I sit doiwn to write a promt as I did before when I drew on paper. Has AI become the new pencil?
Here is Flux Pro:

with a distinct representation of each concept but no smooth interpolation in between
like here in the US, they have the DEFIANCE act that's just the first of many to come. this act is mostly centered around deepfaking, but guess what it also includes for the first time: ANY computer aided manipulation, which also means photoshop. so if people create some kind of deepfake of a celeb, if the likeness is even within 50% of the person, a jury will likely agree it's a deepfake of them and that's that. so basically, every other creation will potentially look like someone and they can then potentially file a lawsuit over using their likeness for pron.
There's a reason my niche is characters which cannot be mistaken for real people. (I planned ahead)
ah ok that's no better
I can show the reverse where Flux knocks it out of the park and DE3 fumbles badly.
OpenGPT 4o tried
The point is that these generic tests claming one is obviously better at adherence to another, even that simple an idea, is really a big "depends"
I wodner if there is a pron film out there titles "Mortal Cumbath"
There are things it can't do at all, not to save its digital life, so if not tested...
90% of it is that people are terrible at prompting, even if they think they aren't. good ol' dunning-kruger effect
there are sites where you can compares hundreds of examples instead of just a few
that's why I don't really rate midjourney that much
I saw it lose to other models too many times for it to be supreme
see we have laws to protect us, it would behoove the model makes to not pretend to be law enforcement
By all means: impressionist oil painting of two young men playing chess in a park. They are each sitting on a bench and the board is on a stone table. If you think my prompt is the cause of the failure, rewrite it to achieve an impressionist oil painting from that. In Flux
I will say the prompt is pretty straightforward
then you'll have no models because the people training them will be slapped with lawsuits into oblivion. the people training loras of ana joy taylor will be slapped with lawsuits (saw people spamming a flux lora of her) into oblivion. see where i'm going with this? it's just not going to be worth the risk for even dudes in their basements training their pron loras on celebs. it will also become illegal to even share or distribute these types of photos, so people sharing their creations will be slapped with lawsuits into oblivion
I found that with them too but it's more prominently in flux and I think it's because of the size
to be honest
I said this the other say but I am happy to just take the benchmarks from the papers
they tend to calculate scores like FID and Clip Score on 30,000 images at 1,000 steps
I kinda doubt we will get a test that is better than the standard ones the papers use
wasn't directly talking about you or anything, just saying in general about the topic
Ah ok
But even in photoshop you cna copypaste a celebs face on a pron image lol
and with the DEFIANCE act, that will also be illegal to share
I was simply showing an obvious shortcoming of Flux, and how the test can talk endlessly about how perfect a model is, but if none of those shortcomings, in any variant, ever come up.... it is easy to ace the test
and with some better PS skills you can blend it pretty well. AI just does it better and faster
New laws are being made for new tech. Image diffusion isn't photoshop
Old laws still apply
Don't harass people
yeah I mean common sense... we all have it right?
the DEFIANCE act includes any computer aided manipulation, which is a big umbrella term that also includes photoshop
I like to hope
sound slike those evil acts the RIAA was pushing against music sharing
well this is different from you downloading your favorite nickelback song...
but if a shortcoming is rare enough that it doesn't come up in any standard tests and also doesn't come up in any of the handful of image arenas
then this is likely rare enough that its kinda okay that the models can't do it?
like they don't have to be perfect
Asking for an art style is not THAT rare
This flub is not restricted to impressionism or a specific artist
even its 'comic-style' output all looks exactly alike
flux isn't very trained on art
I tend to think it was deliberateloy shut down on it to try to sidestep the lawsuits appearing
because almost all of the images of famous art you know are owned by some museum or another and they have to give permission for them to be used in datasets
Art is a shortcomming in Flux for sure
but it's one you can easily solve via finetuning
something that is not even possible with MJ
fintetuning you mean, not art
yes
IF you were to estimate how big is the MJ model? and the DALLEE one? XD
There is literally no better model for art than MJ. DE3 is excellent too for many though
even brillliant
flux schnell

ask it for a new vision of Mona Lisa by Picasso in the style of La Guernica and DE3 performs brilliantly
weird abstract comic style of a fish-guy fantasy creature, lines out of place, amateur style, many lines in lines slowly decreasing in thickness like a fractal maze
its very hard to tell exactly but there was a quote from the MJ team once saying something about how big it was
it was 10s of GB anyway
:0
whi is alowed to bring complaints, cuz i went on a date and this girl was not the same person
The CEO of MJ is on record saying it could handle and imitate over 4700 artists
you can tell the MJ UNET is huge because its compositions are very strong, its like the opposite of deepshrink effect
That's why I want an SD3 and Flux workflow 😉
that could be done with SDXL sized params, that's more about what you train it on
4700 is a super low number on the scale of these models
Flux is either not trained on artists at all, or these images are badly captioned
one thing about MJ is they are the only model out of any that was trained on a significant amount of hollywood movie stills
if you try in Flux to prompt for artists "by [xyz]" you will see that only CLIP-L is reacting on that while T-5 does nothing
so either they haven't trained on artists because of copyright issues, or they have labeled their training data fully automated with some captioning tool that forgot to add artist and style information
yeah.... I don't think so. It is low compared to what they CAN do, on individual models maybe. But SD XL is still a 2b model, and you'd need a very specific LoRA to do what i said above. They can do this innately, with none of the very advanced legwork
I found SD also really good with artists styles. In particular the old SD 1.5
Cascade via H.F lol

if you compare SD 1.5 -> SD 2.1 -> SDXL you see that the models less and less react on artists. Guiess they are removed from their training data
being in the base model is very different to being added in a lora after, being in the base model is much more efficient
SDLX has way more than 4700 concepts, this is not a lot
it turned the mona lisa into a generic christian depiction of mary
WOOHOOO I got approved for 200 glif tokens today! What should I make? 😄
obviously balls
but in the end I'm happy that I can just train Flux on arbirtrary artists
I agree with you that MJ is a large Unet but I don't think the number of artists in the training data is evidence of Unet size
even the ones MJ does not know 😉
t5 is interesting becaues it wasn't trained on image pairs so you can't just invoke art styles with an artist name
yeah. same with sd15. lots of styles weren't trained into it but they were there because of clip-l
the special thing on CLIP is that you do not have to train the unet/transformer and still get the artstyles for free (although in much lower quality)
Flux Dev via H.G. It has that flux blurred skin look 😦

Ok, then tell you what. Here is the prompt. Exactly. "A mesmerizing painting by Pablo Picasso, reimagining the iconic Mona Lisa. In this version, it is painted in the style of La Guernica, with its signature shapes and style" and here are two sample images I made with DE3 about two months ago.



it might be that Flux is not trained on much arts due to copyright. But I also have the feeling it just wasn't their priority
like they wanted to show that their model can do anatomy right and good photorealism
it could be a priority thing also yeah
Flux Dev via H.F.

yeah im' guessing flux 2 is coming sooner than later. these guys made sd 1.4 then followed it up
Uh Flux does Picasso, not sure thats what your saying, maby words i didnt read




I'm not arguing that, since it is obvioous, regardless of their reasons. I was simply pointing out that these ranked tests declaring one model to be the overhwleming best, is a big 'depends' according to your choices. Some things it cannot handele at all, and is not a case of one accidental RNG failure
When I use Claude to enhance my prompts, it does make Flux create better "Dali"
i've had good dali prompts with long elaborate LLM descriptions of his paintings
yeah that's fine I agree with you there
the original thing I was saying was that Midjourney was not the supreme best
because there are situations where it is not
but this applies to the others too
I never said it was. It is supreme best in some things, but nowhere near all
same for DE3 and no doubt for Flux too
and Ideogram
yeah I don't think we disagree really
the only thing I was saying about the artists is that
it doesn't necessarily imply a larger Unet

I haven't tested it, but I am not ruling out anyone. I was simply pointing out that these charts declaring one as the obvious best are to be taken with a major grain of salt
I do think MJ has a larger Unet, due to image quality
but I don't think the artist knowledge necessarily requires that
meanwhile in china no one is using thoes
I used to love to put Picasso's different, lesser known styles into MJ to enhance my horror 😄
what I think is that these models have a really large number of concepts
possibly over 100,000
but also the Llama 3 paper showed that parameter count and training tokens are way more disconnected than we thought
Llama 3 paper kinda proved over 100 papers wrong
because they gave Llama 3 8B 15T tokens and it did ok
The fact is that I originally asked DE3 to redo Mona Lisa in PIcasso's style, but it was not what I wanted. I then told it to do it imitating the style of La Guernica, and I was shocked at how well it did
so you can really squeeze stuff into low parameter counts
OK new glif idea, I'm going to make a Picasso SD3 one (perhaps a flux one as well). But I'm going to try to include more than just his well known cubist style
well, he is essentially defined as a cubist overall. and I think La Guernica really highlights that iconic look
The story behind that painting is quite fascinating, and he used to bring in interested parties to see its progress
and discuss his vision
this sort of thing I think midjourney is amazing at https://old.reddit.com/r/midjourney/comments/z7fzn1/what_happens_when_you_mix_ancient_egypt_with/

Reddit
Explore this post and more from the midjourney community

Reddit
Explore this post and more from the midjourney community
There are a lot of things. I saw one where they imagined ancient egyptian paintings but with modern model ideas. So that known stye and look, but with teens on cell phones. it was hilarious and brilliant
color me not impressed they dont look real
my prefrence i suppose
its for cinematic, art or painterly styles

yup no personal use for that
MJ doesn't have 16 ch VAE yet anyway
so they couldn't match SD3 or Flux on photographic until they get that
when i prompt for alternat comic styles they come out beautifully. just dont' do generic prompts. ez

ummmmm
for now VAE is the biggest divider


tom's is a click bait rag. you've been baited
So clearly they can match for photorealism
this is compared to the wrong one
its SD3 2B that is good for photorealism not flux
i can see the washed out colors from the older vae on mj easily personally. I think i could blind test which is which , mj and flux, at a rate way higher than random guessing
Says Flux in this comment, no?
Besides, how exactly would you know if they have 16 ch VAE or not?
well Flux has a 16 ch VAE but its been overtrained on a non-photographic style
whereas SD3 hasn't
so SD3 is the better comparison
MJ would hype it soon as they got it
histograms would show for sure i'm betting
there are some flux fine tunes on reddit that do better for photographic
Flux is really difficult to prompt, or we just haven't figured it out yet
yes you can likely test for it with a histogram
I sometimes got images from Flux that were extremely realistic / couldn't be distinguished from real photographies
the images in the article by flux are all really bad
None of this changes the fact that MJ is perfectly capable of producing outstanding photorealistic imagery
and there is nothing to suggest it is lagging behind
the uniformity has gone to far, what was first good has become its Achilles heel
I have no idea what that means
cool
i'm impressed at how fast you can flip flop. the other day you were saying flux and sd3 photos were bad because they all have bokeh blur backgrounds. but here you are calling MJ impressive and link a collection of examples all with bokeh style photography
i guess blurred backgrounds are realistic enough photos when it suits your point
I don't think MJ does compete with SD3 in photography
a comparison to flux isn't really going to change my view about SD3
I think that for you to be able to make that comment, you'd have to be using MJ and making comparisons
I've compared hundreds of images
it wasn't just a one off problem either. you were cutting into a few of my generations calling it that "god damn blur" or something. maybe exagerating but you were quite hung up on the blur
there are sites that have big comparison tables
so you have compared hundreds of images? Or these site have comparison tables?
both? I don't see the contradiction
I compared them by looking at the comparison tables
ahh. here come the strawmen attacks . right on time. subtleone doesn't like to have debates they can't win, so it often comes to this. arguments from authority. slippery slopes. people got their bingo cards out? https://yourlogicalfallacyis.com/

A logical fallacy is a flaw in reasoning. Logical fallacies are like tricks or illusions of thought, and they're often very sneakily used by politicians and the media to fool people. Don't be fooled! This website has been designed to help you identify and call out dodgy logic wherever it may raise its ugly, incoherent head.
I have not seen anything special in SD3's human images, other than the mutant feet and legs and more
its okay there isn't drama
the thing about SD3 is that it has the 16 channel VAE, which currently only flux also has, but crucially SD3 has a more general training so it hasn't been fine tuned out of a photorealistic style like flux has
Yes, all this talk about how specail its VAE is has no bearing on what I said about its mutant humans
but this won't be the case within a few months because Auraflow, the next one from Pixart, and the OMI model are all planning 16 ch VAE
I also asked how you could claim knowledge of the VAE MJ uses or not
cos what you said was just an opinion so I can't really respond to it
regarding the VAE, 4 ch and 16 ch VAEs look very different
I'm still waiting for how you made the claim. What images in MJ show difinitively it is using a VAE of 4ch
Yeah, look I think it is exceptionally sketchy to make statements on the technical structure of MJ with zero information or data to back it up. Other than possibly wishful thinking to back up the statement it is worse than X, Y, or Z
VAE is for every image its not for one image or another
Each genration of MJ, 3, 4, 5, and 6, is trained and built from the ground up
and MJ6 is quite new
it is backed up we already said before
4ch VAEs and 16ch VAEs don't look the same
and SD3 looks a lot better for photography
but since you don't agree with that, you aren't going to find that convincing
You're right. I don't find it convincing at all.
Difference of night and day especially on photography
Some people's eyes won't be as sensitive to color detail as others
"the human eye can't see over 30fps" is another good one
eyes aren't scanline sensors. while they do stochastically update individual "pixels" as photons raise their voltage threshold to the point to fire the signal, there's a cooldown to how frequently those ion channels can recharge. so yeah, technically, on a per "pixel" (cone/rod), there is an fps limit lol. but since they stochastically update in your head image, using all kinds of layered algorithms similar to genAI, your brain can fill in the blanks on things like using generative fill in photoshop. you have two very large holes in your FOV at all times where the vein/nerve bundles are, yet your brain fills in those holes
but in practice, anything over 100fps is a cointoss in a double-blind a/b test
Oh Yeh I love the neurology of optics. Some brains process the signal better too
The one I always point at is ufo test. We can see lateral motion VERY well. On account of being apex predators
yeah, but that's due more to it breaking that stochastic updating i was talking about. it's actuating more and more cones/rods and the brain is lazy and doesn't like having to update that much data at once
ever do the still stare thing where your peripheral vision starts to turn black? your brain is lazy lol
Yeah there's lots of physical stuff. Persistence of vision is literally the retina chemically retaining the image
Generative fill is fun to find too. There are lots of tools to find your Blindspot. That one always blows a few neurons out when I do it
an engineering analogy is actually more in line with a capacitor. once it reaches a threshold voltage, it will trigger the signal, but until it does, it won't fire
but it decays rapidly
if not constantly being triggered by photonic energy
Yeah cool analogy. That's a gooder
I love rubbing my eyes in the morning, then seeing kaleidoscope. I call it degausing my eyes
it's also why all eyes saccade very subtly, it's our brain's way of refreshing pixels
Also sub pixel rendering my theory
the micro saccade needs computers to see, but there are macro level jiggles that happen that we can notice as well
It's a way for the simulation to hide the pixels
in engineering classes, we talked a lot about the biologic analogs of common circuits and whatnot
they are starting to make really good motion interpolation neural networks
which implies somewhat that its possible for the brain to do that too 🙂
but anyways, our brains do some kind of similar shit to genAI image creation. you don't store pixels in your brain, the data is stored more like how shit works in a diffusion model, but in an obviously far more complex way, and then your subconscious supercomputer "renders" shit out for you on the fly
our "latent space" yeah
the one thing we don't have is back propagation, so we aren't a true analog to things like diffusion


that folder should be the unet folder, not the checkpoints folder
ohh
move it and refresh comfy

{kind=link}
{kind=link}