#🆕|sd3
1 messages · Page 81 of 1

 not enough vram to view that link
not enough vram to view that link
they are working on next version of sd3
not sure if that can compete with flux
Luckily you can usually get away with a bit less than the minimum requirements... Especially with Comfyu..
lot of sd3 team went to create flux


Sd3 is better than Flux x3
thats how you fail math
SD3.5 will kick huge butt. It's always every other model that SD makes that is legendary.
Whatever it is it's scary LOL ...
You will NOT believe the prompt: 😛
tony hawk using trains as skateboards
Flux just seems better at anatomy idk
do you guys ever think about the drake equation and how our observations don't match the predicted expectations, giving rise to the fermi paradox? they say there is a great filter that is causing the fermi paradox but we don't know what that filter is. somethings going on cause the math that math says so
you guys ever freak out about the math?
I didn't like it in school 
SD 1 meh SD 15 amazing SD2 ugh SDxl wow SD3 ugh and the next one will be outstanding
Now look at this seed...
Literally
A Hawk
A Train
A Skateboard
Can't fault it... it is good 😄

i programmed my graphing calculator to play snake in school. maybe shoulda paid attention
Tony learned math and this happened
You won't believe it
Click now
Hi, everyone, I have problems on flux
I find Flux is bad at multi-views for background
When I generate a landscape or city or background, I failed to control any viewpoint using like"from distant view/ bird's view/ from blew/top view/", Is this happening to all of you?
algebra is fun but trigonometry gives me headaches
For example, Prompt like: "It's a vibrant Japanese town with traditional Edo period architecture, with narrow streets lined with wooden buildings and tiled roofs. Blooming cherry blossoms against a blue sky add a touch of pink to the scene. At the center of the image is a tall, multi-story pagoda that looms large in the background, evoking a sense of historical grandeur. The image captures the serene atmosphere of spring, with falling flower petals scattered along the streets and large red lanterns hanging from the facades of buildings, making for a charming and picturesque cityscape. The whole town can be seen from a high altitude"
I have a theory for why only the apple was weird
the steps and schedule you had
was giving steps that were too large during a range of the sigmas where the ODE was likely to have a large local discretization error
and the apple had less straight trajectories throughout that sigma range
because the relationship between trajectory straightness and sigmas range can vary based on the composition
notably the apple is a much simpler composition than the others
you could test my theory by running the workflow with ten times as many steps
flux can't give me a high altitude

if my theory is right then running the workflow with ten times as many steps will fix the apple
because it was a case of local discretization error

Lmao

How you control the viewpoint using flux?



when it comes to anatomy flux has it's flaws too, i think the most aesthetic you can get with anatomy is with pony models
Cx

true nature of reality


nice big balls
Try putting the view you want at the beginning of the prompt
Finally some good images in this chat
you just don't know how to prompt, that's the problem
you are too absorbed with math to understand the basics of prompt

No effect I try it.....like birds view
you're also not goign to get a fight started tonight

not looking too, i dont like cat fights
@bitter hearth



@bitter hearth can you change the viewponit using this prompt on flux? #🆕|sd3 message
Ugly

you talked the same thing about sd3 as long as you could even tho everyone got deformed junk with sd3 and anatomy

flux however is much better but has its flaws
go away child. go play with your ponys
#🆕|sd3 message, I just can't change the different view using this promt on flux
are you democrat, you talk like one
drone flyover footage, clouds below
missing logic most of the time, i wonder what kind of math you actually do
probably the kinda math that goes into sd3
go away child. go play with your ponys
I feel like flux is just bad at stuff like that, I also had problems trying a simple prompt and gave up
flux isn't as bad
flux can mess up some of the anatomy but not horribly bad
but that's not a general view control prompt i think..
you atleat would have to cherry pick good ones with flux but with sd3 is a surge of mess one after the other
I tried a few times on flux with that prompt with the view from above at the start of the problem and it doesn't do anything
When people resort to personal attacks it is because they ran out of arguments

yep
You are the one who resorted to this
also about viewpoint control?
that's the reason im not bothering to respond to him
not me you missed the line of convo then

No,,,,, I don't think so
really not
scroll up then and im not interested to talk about it, shut it pls
I rest my case
dont insinuate like a fool
and you just keep burying yourself don't you
all these balls and you gonna tell me math isn't real? i unno man. i just dunno








if you keep your mouth shut that wil help
I feel like in the long run the captioning for image model training data needs to be done by a VLM that was made specifically with that task in mind
cos a lot of image models are using something general like CogVLM for the captioning and that's not really ideal
or talk about things that are not nonsense

Assuredly mister personal attacks
ok time to block you two
he's a 12 year old child that's really not old enough to be on discord
you do know that blocking anyone on Discord is an utter waste, right? You will instead get drowned with messages saying 'Message Blocked'

GitHub
A collection of various image grids created with Flux. Things like hair styles, clothing, nationalities, ages, etc. - ataylorm/FluxAIGridComparisons
aw man i was gon let you play with my balls but then you went an made a comment like this. such a shame. you're cut off now
gees hounds
no no . deez balls
@sterile pendant SOmeone posted the combined file Dev+Schnell in Civit, and I must say it is a total winner
alright im back, got side tracked with stuff around the house. the second image has the workflow. it will need a custom node


as you can see, you don't need the second model to load for the sigmas
Models are being stupid for me can't get higher view than this

i would agree with that except: here are the full range of heunpp2 tests, all the same prompt, seed, settings, except all the different schedulers






so i love that all these models can create really destructive scenes now a days. but i've noticed people and crowds are just business as usual. my proposal, put a traffic control person in the image then it makes sense
That's it, bird's view also no work. I try to think that flux has another special way to control viewpoint.
if it's higher, it can't draw that temple correctly
so the test would be to run each of these with 10 times the steps
what that would do is specifically test the hypothesis that the issue is local error from going from continuous to discrete
Here is the same prompt from midjourny that successfully control the viewpoint:

Why flux can't do this
running a very high step count simulates having a perfect schedule at a lower step count
because it a very high step count gives you small steps everywhere


a perfect schedule at a lower step count would have small steps only when needed, and large otherwise
midjourney is a different AI - just becsue it understands something one way, doesn't mean other models do. and the next version of midjourney might not either
I removed everything but from above and the temple lmao
and that makes sense
.........So original prompt have something ban the view control?
when the step count goes high enough all schedulers trend towards the same output
as discretisation errors trend to zero
assuming they are in the same family of samplers, yeah, usually






unfortunately, everyon'es trying to get steps down to 0, or at least no more than 2
0 steps 🤔
you know they'd love to
haha yeah they would
if it's ever possible to use the flux algorithm / or some lora to fix hands/fingers with other sd models that would be fantastic
Maybe you need to shorten the prompt so the model has more focus

training datasets and things like supervised finetuning
you need a LOT of data for hands
Millions!
I did spend a while this week using Realvis Lightning
which is one of the strongest out of the low step models
its actually kind of okay
probably in the tens of millions range, honestly
I'll test it now, insteresting, even put the view control at the begining doesn't work
Then with flux... It's just a bit dumber than sd3

you should pay more attention to youtube
Realvis Lightning at 4 steps is good enough for maybe 99% of AI images I have seen
see. now it makes sense that people are chill

godzilla looks so confused
think about all the locations on the screen hands can be, now think of all the various distances they can be from the camera, all the different ways they can be obscured by things like being in a pocket, then think of all the infinite combinations of positions/angles they can be in, all the potential combinations of individual finger positions, then all the possible textures and skin colors, the list goes on and on
i prompted Joe Biden
I thought the successful image is from flux, but from sd3?
UniPC 10 steps with beta scheduler is also not bad most of the time
or maybe 12-15 steps for safety
I mostly use sd3

sd3 2b medium is excellent - if you bother to learn how to actually use it
we know where torqx's mind is, don't we?
Booba
12 year old kid
at low steps PAG goes a long way
PAG is the most impressive node to me
a tiny drop of PAG has fixed images perfectly sometimes
oh and i fucked up and didnt link the image correctly, think i just copy pasted instead of uploading the actual file

this should have the workflow to show it all
okay, thanks
makes sense cos discord normally does preserve the comfy data
what is pag?
main takeaway is that you dont need to load the second model to get the sigmas when they are just a simple y=mx equation that ranges from 1.0 to 0
perturbed attention guidance
something about white girls
it's basically tangental to self attention guidance
perturbed attention guidance
you can just set it at 0.3-1 on every image TBH
@sterile pendant https://civitai.com/models/628862/flux1-schnell-merged-with-flux1-dev?modelVersionId=703068

I used the tip from comfy.org for merging just the Flux.1-Dev double_blocks (MM-DiT) onto Flux.1-Schnell, giving you a higher quality model that st...
or up it to 1-3 if needed
on the snarky subject of Flux not able to do hands

SAG is also great, again at low strength like 0.2

i saw they got PAG working with SD3 on diffusers. doesn't quite work the same way, but they get some interesting results from it
there was a very very recent comfy change
to make PAG and SAG work below 0.1
so it can be used with CFG++
okay, how do you use it?
yeah diffusers gets a lot of stuff first
if you just put the PAG node in before ksampler
and set it to 1
that will do it
comfy is releasing a new node, did you see it?
no I haven't seen it
like no shit the crowd is calm. look at all those traffic control devices out there. just another day in nyc. they got it handled.
just a quick hack if anyone wants to use this for their images.

sorry, not comfy, matteo - he posted it last night
ah I think I saw it
a ksampler
if you're using it with sdxl, you just set pag to something like 3.0 and lower whatever CFG you were using by 3. basically, if you were using a cfg of 7, you'd lower it to 4. 4+3=7. you can also use the advanced version of the node and set rescale to like 0.5-0.7(personally, i do it and seem to get better results). there are some pros and cons to pag, but try it out and experiment
he said people were goign to hate it
lol
Hes rich

cool. i'll play around with it, thanks
I hate the blur
Who invented blur on cameras
3 PAG is strong
that's not always bad
I mostly use more like 0.3
high PAG has a certain "look" to it, which you may or may not like
i'ts used to make the actual focal point stand out
Bad, I just want clean images

this one was very high PAG for example

it can start to get pretty cooked
do you see how it immediately changes the narrative of the image from "why is everyone chill?" to "oh i see why they're all chill" it's just a little hack to remove distraction from your action images and make them more believeable.

if I remember rightly that image had something else weird in it
either high CADS noise or FreeU with low B and high S
note the two different CFGs on the samplers

FreeU with high S was a major source of funny proportions
you could probably tonemap these a fair bit to remove the PAG+CFG burn
oh they aren't burned, it's just hte prompt
point is, target cfg=pag+cfg. you can also throw in automaticcfg into the mix as well
you could totally pair this pag stuff with the TCP hack i described for ULTRA believeable images
same settings, pag on the left, normal on the right

I'm just obsessed with the low CFG look its a personal thing
a bit of ComfyUI_experiments/sampler_tonemap_rescalecfg.py can help
f that, ive been photoshopping for 25 years lol
if i want to make adjustments, i just do it in another DCC
oh i know, just 1000x easier to adjust things like levels in photoshop and see the image preview change in realtime
ok but in that case
you would still want a rescale cfg node
just not the tonemapped version
rescale cfg does its operation each step
so it can't be replicated in photoshop
its just this:
2 # Apply regular classifier-free guidance.
3 cfg = neg + weight * (pos - neg)
4 # Calculate standard deviations.
5 std_pos = pos.std([1,2,3], keepdim=True)
6 std_cfg = cfg.std([1,2,3], keepdim=True)
7 # Apply guidance rescale with fused operations.
8 factor = std_pos / std_cfg
9 factor = rescale * factor + (1 - rescale)
10 return cfg * factor
so step 3 here is just normal cfg
the middle one is pag+automaticcfg. it's my goto setup for sdxl

photoshop can replicate changes made at later sigmas
like colours or textures or contrast level
but rescale cfg will also affect early sigmas that decide the layout
this lora doesn't seem to make any big difference from what the flux model can already deliver

i usually use the advanced version of the node though and tweak some shit
automatic cfg has some rescaling in anyway if I remember rightly
yeah it does
it scales everything per setp
to ensure good ranges
but your cfg is no longer your cfg basically
the reason I started using thresholding/rescaling is that for some reason the DPM++ paper mentions it a lot
and says it really helps
the dynamic threshold node is a good alternative to automatic cfg as well, but they basically do similar things
yeah its a similar idea
main difference is that you can set your mimic cfg target to like 2, 4, 8, etc
havent tried it out yet though, looks cool for stylized stuff
and I got FreeU from crystalwizard
I haven't checked if skimmed_cfg works with CFG++
yeah its a shame cos I love FreeU
well i was just saying how they added PAG to SD3 on the diffusers repo, so im sure someone can make a comfy node for it
I can get FreeU effects a bit using CADS
for example this was SD3 with high CADS
and it looks a bit like FreeU with high S1 S2

dont know how well SAG would work with sd3 though
if I remember rightly SAG is basically blurring part of the image and then sending that to the unconditional
should be possible in any model
not flux though
oh i know, but with transformers, you can also do some similar shit
they are layered and blocked as well
https://github.com/huggingface/diffusers/pull/8861 they already have, just needs to be ported to comfy. but again, it operates and behaves differently
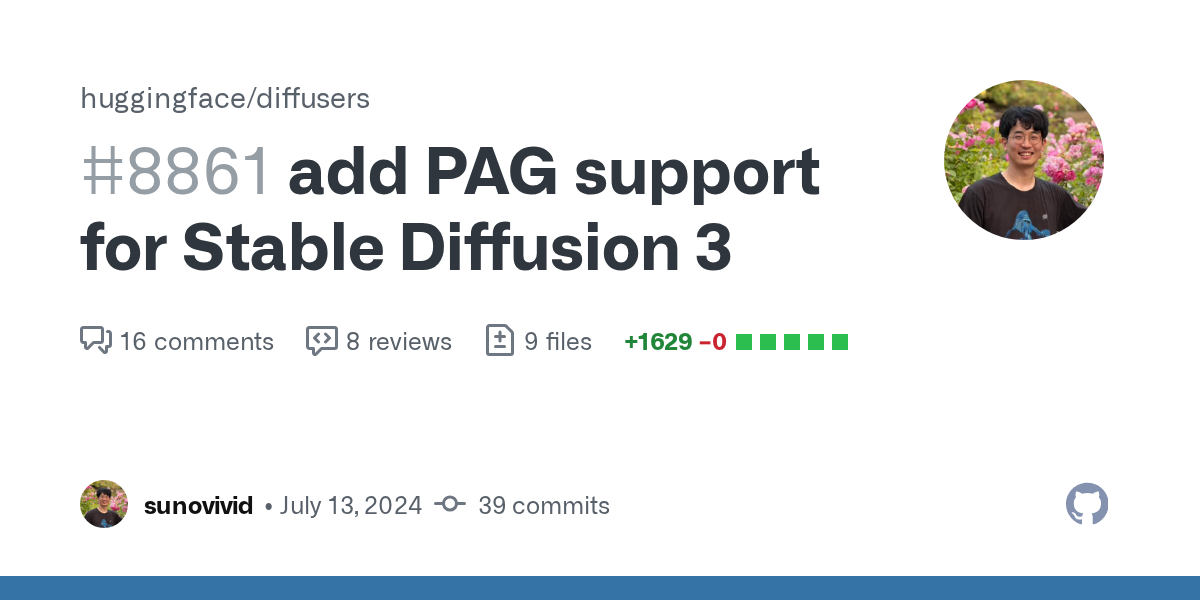
GitHub
What does this PR do?
This is a PR for adding PAG support for SD3!
SD3 differs slightly from SD and SDXL because it employs Rectified Flow and uses the MMDiT backbone, not UNet.
For the joint atte...
there's a new paper also that is meant to be an upgrade from PAG
arXiv.org
Conditional diffusion models have shown remarkable success in visual content generation, producing high-quality samples across various domains, largely due to classifier-free guidance (CFG). Recent attempts to extend guidance to unconditional models have relied on heuristic techniques, resulting in suboptimal generation quality and unintended ef...
ah yeah, i saw that one the other day but didnt have time to read it
and this one is meant to be an upgrade from CADS
https://arxiv.org/abs/2407.11555
arXiv.org
We present a novel approach for generating minority samples that live on low-density regions of a data manifold. Our framework is built upon diffusion models, leveraging the principle of guided sampling that incorporates an arbitrary energy-based guidance during inference time. The key defining feature of our sampler lies in its \emph{self-conta...
if thats what they want i mean who are we. who are we really?

flux is also really good for img2img like if you denoise at like 80-90%. you can sometimes correct f-ups from sd3 with it
no, wouldnt do that
not losing the 16 ch vae
you could do a really convoluted sd3->flux->sdxl refine->resample at like 30-40% with flux again though
on reddit someone did this order:
flux -> sd3
to gain back the benefits of the 16ch vae
that would work as well
sd3 is hella good at details
Do anyone have a workflow for flux + a lora loader?
if you VAE encode and decode a photo
SD3 VAE is better than flux VAE
flux or sd3 depending on what youre doing
if it's humans, flux
if it's art, sd3
best VAE last
both flux and sd3 have amazing vaes
but the last pass would be a 30-40% resample to fix whatever got broken in an sdxl refinement stage dropping down to 4ch vae
I only saw this one, but they used cli in the example (not comfy ) https://www.reddit.com/r/StableDiffusion/comments/1emrprx/feel_the_difference_between_using_flux_with/?sort=new

Reddit
Explore this post and more from the StableDiffusion community
also if you have too much noise injections then SD3 3B can't handle it
so for noise injection workflow it has to be flux
i was messing around with a 4step schnell->sd3 workflow earlier and getting some really good results, but then again, i don't make people that often
SD3 is still my favourite TBH I have gone off flux
this is SD3 2B

you can use any lora loader to load up a lora they released altho there is no big difference
SD3 2B (not even the current 8B) is the closest to a photo
8B will win eventually though after fine tuning
@fleet meteor here is a workflow you could try ...

I know I do, but I always add that shit in post if I want it
wrong color hoodie
Thank you! I´ll try it 🤗
don't push your narrative on others, everyone can try things the way they like .. you narcisstic freak
You dont want to use any of these models for text??





/Tide play, Green theme, Doll personality traits and accessories according to MBTI personality, Make an INFJtrendy toy plush toy, Cartoon face made of silicone, The body of a plush toy, Short white hair, White goat huzi, Round eyes, Dense black silhouette, Simple nose, Simple mouth, Minimalist facial features, The body is the plush body of the toy koala, Wearing a robe, Lovely, Holds a staff in the shape of lightning, Quiet and mysterious, An inspiring and tireless idealist at the same time, Indicates the MBTI personality type infj, diplomat, Advocates, creating a simple yet captivating style. This sticker perfectly captures personality using vibrant colors and adorable elements, High definition, oc, c4d, 3d, blind box toy style, rococo style, Bauhaus, god rays, High quality --s 400 --niji 6
Anyone try the Control net for flux is it safe? How much VRAM added?
its a safetensor file, but doesn't load up on comfyui, tried with every loader, might need a node update from comfy
https://github.com/comfyanonymous/ComfyUI/pull/4260 good info about it here

GitHub
I'm leaving this here because I'm not sure if I implemented it correctly or if the results are supposed to be this bad.
It only seems to work with FluxGuidance set to 4.0
Here&#...
Thxs
as for vram, i'm not sure. gonna wager a guess. its' 1.5gb and probably in fp16 mode so i'm thinking comfyui might take either another 1.5gb or 750gb.
its the colours mostly
for example look at the red on this hand
SD3 looks more natural to me
Ty, I was wondering how tp try that 🙂
Perhaps it's supposed to be flux chnell or something (didn't work for me)
Not nearly enough for this server!
PS what was your prompt? 😄
oh if you wanna use that you need to get that specific pull request merged to your side. it's not merged yet.
SD3 is pretty awesome 🙂
I like both though
i haven't tried using it yet
xlabs_flux_controlnet would be the branch it's on. i'm unsure how to swap git branches in swarm environment
they put out a model sans workflow?! So mean! lol
a company called xlabs put it out with inference code and the diffusers team has code supporting it now. comfy is testing their code. thats what i think is going on. there is a workflow for it. you just need the right branch
they said tommorrow is the 1024 x 1024 version
yeah its out in diffusers properly already
generally if you want the latest stuff you need to be able to use both comfy and diffusers
hi-diffusion came to diffusers first for example

Guys I just realized something just now and I have to tell people
Barclay from star trek is Murdoch from ateam
That's all thanks for listening
wow I had no idea
that's actually legit
his face looks different lol
i saw him in another movie about oppenheimer and i was like .. you know? he kinda looks like murdochhhhooh wait one second
i got it working. used the jump man logo. not much quality above 512 but it works great at this res


just as i thought. the claims i seen about the model not even guiding well are just wrong. as usual. cool.







"it's 12 billion parameters it'll never work it's outlandish!"
/style prompt a cat





source for the canny guidance. i run it through the filter for the outline but thats about all it is
tommorrow it'll be the 1024 pixel model and they have others on the way. neat
can you do elepahant and rat
cascade's vae is stage a and b as it decompresses the latents through a diffusion network instead. i don't fully get it. stage a i guess is the final leg of that model
So it's special? Can't compare it to sdxl or flux?
i'm just not sure how it compares. maybe its like a 16 channel one. it looks good. i think it works different though





wow crazy man
with just the one guidance net theres a ton of potential . it does poses well
if even just with a sillohuette of the shape for the first 15% of steps
@sage burrow all i had to do was open a terminal in the swarmui's backend comfyui folder and type git checkout xlabs_flux_controlnet and i was set. THOUGH, i am going to monitor this and when it merges i'll run git checkout master in the same folder. for some reason i thought it would be harder with the project in a project situation.
have you tried lora for flux?
theres just the one i saw and i didn't see a point to it.
I get the Canny outline, but it doesn't proceed past the Load ControlNet model node.. i get this error:
'NoneType' object has no attribute 'keys'
and i found this

did u convert the canny cnet?
how to install the canny cnet?
the one for flux
lol i'm off to sleep soon but i could do a starfish on jumpman logo soon
thats a good one
you need ot be on the development branch of comfyui that has the pull request. its only in testing
see this message
4 channel vae
to be precise: it's a weird hybrid of VQGAN and vae, but it's technically very similar to a vae. It's a convolutional-only decoder (effnet), though, so it might less powerful than the SD VAE
got it

If someone has already tested the Realistic LoRA and Kenny, please share the workflow.



honestly can't wait








GitHub
Contribute to lllyasviel/stable-diffusion-webui-forge development by creating an account on GitHub.
Not stable but...

Ah control nets are here.
So on a slightly different note, has anyone tried Auraform? They released v0.2 just recently
Support for fp16 is out for lesser HW and can run in Comfy
I was just about to look that up I was reading the paper on that one
you mean Auraflow?
never found it good
Yes, they are using the Dall-E 3 technique, per OPenAi's paper, of massive labeling
soo many parameters for quality worse than even pixart
everyone is doing that
SD used a different method
what's Dall-E 3 method?
if I remember their paper correctly they just run an vllm on 90% of the data and keep 10% intact
which is what everyone is more or less doing
SD3 used their own proprietary method as published in their paper
regardless, Aura Form is in beta and actively being developed. 2nd release in a month
and since it has only been out a month, the talk about 'never finding it any good' seems a bit precipitated
all modern diffusion models train on synthetic captions. Pixart was I think the first one which did this
Maybe so, but same concept does not always translate to same results
right, because results are quite bad for Auraflow xD
oh boy
yeah, maybe it will at some point get better. Currently, it's just bad
technically it's not much different to Flux and SD3.
pot.... kettle
This is a example just used it

I don’t see a difference
different workflow, create different image

Give prompt
Of course , A majestic star destroyer dominates the darkening skies, its imposing form silhouetted against a fiery sunset casting deep crimson and purple shadows across its angular hull. Turbulent clouds swirl around it, illuminated by flashes of artillery fire leaving wispy trails in their wake. Distant explosions cast flickering glows on the ship's weathered surfaces, as if foretelling an impending reckoning. The composition is cinematic, emphasizing the star destroyer's colossal scale and menacing demeanor.

I love it \m/
Great concept art anon ghost ship
Can you share the workflow? I am getting crash in Comfy, but may be missing nodes

I am using my iPad not on pc https://fal.ai/models/fal-ai/aura-sr/playground?ref=blog.fal.ai

Upscale your images with AuraSR.
And I used Flaux and took it on aura … when I get on pc I can def use comfy and share if it does not crash

Ok, I had thought it might have been on local PC and was trying to solve, but the given Comfy workflow is missing a lot of nodes. There are no options to specify their VAE or Clip safetensor files
Thanx for the update sense u are on pc u can be very right it’s missing things … I’m curious if we need to download them missing nods,,, it’s okay u can try it that way what I gave u sense the other way is not working :*(


Last 7 days <Aug 01 2024> → <Aug 07 2024>
- Member counts
- 344652 ↗ 344702 ↗ 344792 ↗ 344840 ↗ 344910 ↗ 344965 ↗ 345012
- Action members
- 0 → 0 → 0 → 0 → 0 → 0 ↗ 116
- Message members
- 0 → 0 → 0 → 0 → 0 → 0 ↗ 66
- Reaction members
- 0 → 0 → 0 → 0 → 0 → 0 ↗ 68
More details

Summary | comcom Analytics
comcom analytics は、Discord または Slack 上で運営されているコミュニティを分析・モニタリングできる完全無料のダッシュボードです。現在、パブリックにβ版を提供しています。
thought this was kinda funny

Pretty sure that's where I was driving in NYC! "recalculating" 🤣
too much grass for NYC
i keep see people using sdxl as a refiner workflows. don't they know that they should do a 3rd pass through a superior vae model and end the refining chain with the king of the game?
do people just have bad eyes and not even notice that sdxl washes out details in their images?
Most people don't care
seems to be that way. they pretend to care about things like quality, but that turns out to just all be theater and dramatic hyperbole.

this one is only 512 resolution too. i wont bother testing it. i had great results from the smaller one
More like I haven't figured out how to add them back in at the end. Also, would it ruin the sdxl 🥒?
@bitter hearth

er, not sure if catw4gbgpu is who asked for it, but I just realized, no way you can run it, except maybe glif?
is it okay to create sub folder on comfyui like checkpoint> sd1.5, sd3 or Lora>style subfolder, posing etc so i can organizing my model in a better way? it wont create any error right?
yeah, you can have subfolders in checkpoints/ and they will show up accordingly in the loader node
thanks
hmmm, that long list of 100 checkpoints is getting out of hand, think I should try this 😄
at 100 checkpoint files, it will eventually get out of hand even with subfolders
maybe we need a new UX for the loader node
i think a low denoise and high step pass throuugh sd3 or flux would maintain most composition elements and pop that 16ch quality too. i haven't done much testing here. i just figure, if you're refining images from SOTA models with late generation VAE's, what's even the point?
yeah this is right
you just want SD3 to refine the fine details
it works great
amazing backgrounds for my nsfw! 😄
Does anyone have a workflow I can borrow that brings SD3 back in at the end? 😄
Flux + AUra + camera raw

Becky oh no what happened … check public work flows that has it at the end of the I don’t think I have one for u :*( I could help u with
i haven't started toying with multistage workflows yet on sd3 and flux yet. just a little. should be ez to set one up. there are nice workflows on civit available but many of them refine with the late gen models

This workflow uses Flux + Img2Img + GPT-4o-mini to create and upsample provided prompts. It works incredibly well in my experience. Optional nodes ...
should call that one how to complicate a basic workflow
Yes I believe so 😝 not mine
i see that has a negative prompt not sure why, the first thing i do is undo that to save time, so many workflows i see are encoding a negative just to plug the hole in ksampler
like so, to not have to process a negative that i wont use, time saver on my old rig

conditioningzeroout and an empty prompt are not neccesarily the same
not the same at all - i like putting just a . or a space in the neg prompt
ya just skipping the encoding negative prompt, was my point, less time
i thought negative prompting just piggy backs the cfg process and it's cfg which is causing the extra generation time
basically
so i dont care if zero out or encoding a blank prompt are different, i get the same result faster at 1 CFG
you can also do some interesting tweaking by dropping a generic ascii charcter like a . or a , into negs though

The new movie was killin me the other night




I read something quite curious and wondered whether others had seen this:
Flux comes in two variants:
Timestep-distilled (black-forest-labs/FLUX.1-schnell)
Guidance-distilled (black-forest-labs/FLUX.1-dev)
Both checkpoints have slightly difference usage which we detail below.
Timestep-distilled
max_sequence_length cannot be more than 256.
guidance_scale needs to be 0.
in other words Schnell should be run with a guidance of zero

time particles count as balls.

Flux dev is better Schell suxx
I use Dev-Schnell
I use Dev and pro
I run from my PC
Pro on iPad and dev on pc
well, Dev-Schnell is exceptionally good and fast
From the iPad

Yess
Pc

As long as I can do my horror I love it 😍 inspired by true events
Blind date?

hehehe its a full moon out



Actually I never thought of that when I made it 😂 I was mashing up scream with pretty girl and piglet from Pooh turning hott girls into killers
Happy little fish
Flux Canny, but apparently I haven't gotten the settings right. I haven't looked into it yet, I just chanbed the checkpoint in Crystalwizardd's apple workflow




I'm been having a very hard time getting 4K renders out of FluxDev. 😦
I want to replace my desktop background, because it's a great new model.
But with multiple upscale steps and a low denoise on the final render, I get all sorts of artifacts.

The model's physics are amazing, for sure. Those reflections are flawless as far as I can see.
For comparison, here's my current desktop background, which is a Cascade render. The reflections are obviously wrong, because Cascade isn't very smart, and the details aren't perfect. The flowers are all just impressionist mushy messes when you zoom in.

But it's still overall better than FluxDev. Anyone know how to get it to render well at 4K? 😕
It works very differently from usual. If there are artifacts, you need to increase the denoise, and if it generates an HDR effect, you need to increase the max_shift. It is complicated to reach a good point for all types of images...
I'm not sure though... Higher denoise was giving me a grid / vertical bar pattern.
Haven't experimented with shift at all, need to close and update to get the node.
Well, if that happens, increase the max_shift even more, even to 2..
why are my images noisy? could it be a wrong setting somewhere?


i'm using sdxl_lightning so the steps aren't too low
But I have given up... when it seems like I have achieved a good breakpoint with another type of image, it is a disaster.... I am done with dev and the upscale with sdxl...

what sizes people generate at, i was doing what i was used to doing 1MP resolutions, but that was a 2MP, i forget this can do 2MP out of the box
you can't expect Flux Dev to be as good at high resolutions as a model with Würstchen architecture like Cascade or UItrapixel
its just not going to be anywhere near as easy
your best bet would be waiting to see if this model gets support by the Hi-diffusion team
as that is currently the top method for high res diffusion outside of Würstchen
otherwise, until then some form of block by block scheduled latent downscale could help, i.e. a manual version of deep shrink

man I can't wait for boring reality lora for flux, but the realism lora is nice for now
oh there's a lora?


boring reality will take things next level
sadly not neccesarily
in order for a neural network to be really good for finetuning it has to be a little bit under trained
in Flux's case it seems to be overtrained a little to bake in an "aesthetic" or midjourney look
this can't necessarily be removed by fine tuning that easily
mno — Today at 4:24 PM
Hi, let's skip the community chat this week, and let us continue to work hard on shipping the best text to image model ever existed, called Ideogram 2.0. It'll be in beta testing very soon.
So new Ideogram is on the way
I kinda just ignore the closed source models TBH

2x upsscale flux


Flux + aura


Well least we all get mj for free through SD … making up for the SD3 XL model that they want us all to forget … there back up model that was suppose to be sd3 makes up for it all… the boat switch worked sd3 sunk like the titanic
Sarcasm^


How are folks plugging in the LoRA? I just tried the reality LoRA from Comfy but not sure if I have it connected properly...


damn you flux-schnell ! got it right in about 2 or 3 images - 1 prompt tune

I used the tip from comfy.org for merging just the Flux.1-Dev double_blocks (MM-DiT) onto Flux.1-Schnell, giving you a higher quality model that st...
Same schpeed, better results
👀 👀 👀
Amazing, I wonder if there´s a comfyui node for it
ideogram . meh. flux pro is the king if you want to pay for a service
nah its still midjourney
if midjourney was open source I would barely use anything else
You don't need a new one
No, it really varies. MJ is amazing at many things, but not all. For example with text it is just crap, and some styles of art too. Its understanding of complex prompts is also not the best, even if it can often produce the most amazing visuals. However, if you want uncensored productions of artist styles or known celebrities, it has no peers. Ex: give me an illustration in the style of Frank Frazetta. It will, like nothing you ever saw. Ideogram was king of text and has fantastic art too. I say 'was' because I haven't tested Flux enough to really compare. Flux has serious limitations so far in terms of pure creative illustration-style art. A lot of it seems by the letter, with few extra details and touches. For a lot of things it is amazing so don't get me wrong. None of them are universally king though. Not even Flux.
Here is an example of Midjourney asked to make a fantasy image in the style of Frank Frazetta. For this type of request, it is peerless, it is true. just don't ask it to spell anything:

Here is the sort of artistic text and variety in fonts and presentation in which Ideogram until now has had no rivals:

Dall-E 3 is king IMHO in terms of general illustration style art. Others can get it hit or miss, but it is the most consistent. And it will imitate the style of known artists too. Censored you say? Only the version in ChatGPT/OpenAI. Microsoft's Copilot has no such issues:

Assuming it recognizes them of course.
The last one I can't seem to get Flux to do anything similar no matter how hard I try. Ideogram is okish, and MJ can too, but Flux seems to resist any attempt. Might simply need some major prompt tweaks and adjustments on my part, but it hasn't been for lack of trying
And dont think I am dissing Flux. It is absolutely amazing, but it is clearly better at some things than others. It has a huge focus on photorealism, but illustration type art? Not so much so far.
is this dalle3?
I´ll try achieving something like that on flux rn
You can use it 15 prompts a day for free, so 60 images. More if you don't mind waiting a bit for more. Ideogram gives 10 a day.
I have subscribed to them all, and used SD as well since 1.4
TO show Dall-E 3 can do artist styles, here is the same image but requested in the style of Keith Haring.

This is a picture by Keith Haring to illustrate the style:



Would be nice if the AI did not insist on blurring that as if depth of field meant anything here
its dramatic that way. makes you think about how deep the symbolism is
lol

Or reassures me that AI is still dumb
Yeah I hate dof, idk why most AIs do the same thing blurrying the background
can anyone get skim cfg node to work
Dall-E's biggest fault is its absurdly small history, so no. But Ideogram has no such limitations and I found one I may have used. Might not be exact.
"A vibrant and whimsical comic of a tree with numerous cats of various colors, sizes, and expressions perched on its branches. The cats exhibit a range of emotions and designs, from smiling faces to curious expressions in a caricature style. Some cats are perched alone, while others are grouped together. The overall mood of the image is playful and enchanting, and accentuated by the dark outlines in the drawing."
For the record, Ideogram was not great at this either.
Trying it rn , its so slow 😅


You don't want to know how slow it is on my laptop
Better but not that good
Yeah, Ideogram was like that, though sometimes a bit better.
Like I said, they all have their strengths and weaknesses


I mean some things they all do similarly well, like those godawful boring Japanese cartoon styles. But others are very hit and miss and some are better than others.

just put blur in the negative. ez

did you negate flux? if so, how 🙂
hooked up cfg guider and fed it a negative prompt
doom guy comes out better when i negative doctor victor and halo
got it, the default 8 cfg is obviously too high lol, you find a good average? 1-3 seems ok
i hover in that range. seems to do something. more data still needed kinda though


its still off but its better


Well, may be a matter of prompting to some degree as I am getting closer. But you really need to spell out everything. For example, if you don't tell it the tree has a lot of leaves, it gives you:

So I added "dense foliage" and "LOTS of cats":

Not quite as creative or interesting as DE3's images, but still waaaaay better than the initial ones.
Will try Flux Dev, and after playing more with the prompts. See what I can learn from it. (BTW, I always leave prompt and workflow in images I share here)
how long did it take on what hardware?
yaaay!
if you use an LLM to really elaborate your prompt concept, it'll go hard too. that's often what the walled services are doing.
PSA: the latest https://github.com/comfyanonymous/ComfyUI/commit/413322645e713bdda69836620a97d4c9ca66b230 for comfyui cut my inference times in half. Used to get like 16 sec/it with flux, now I'm getting like 8 sec/it (i only have 8gb vram)
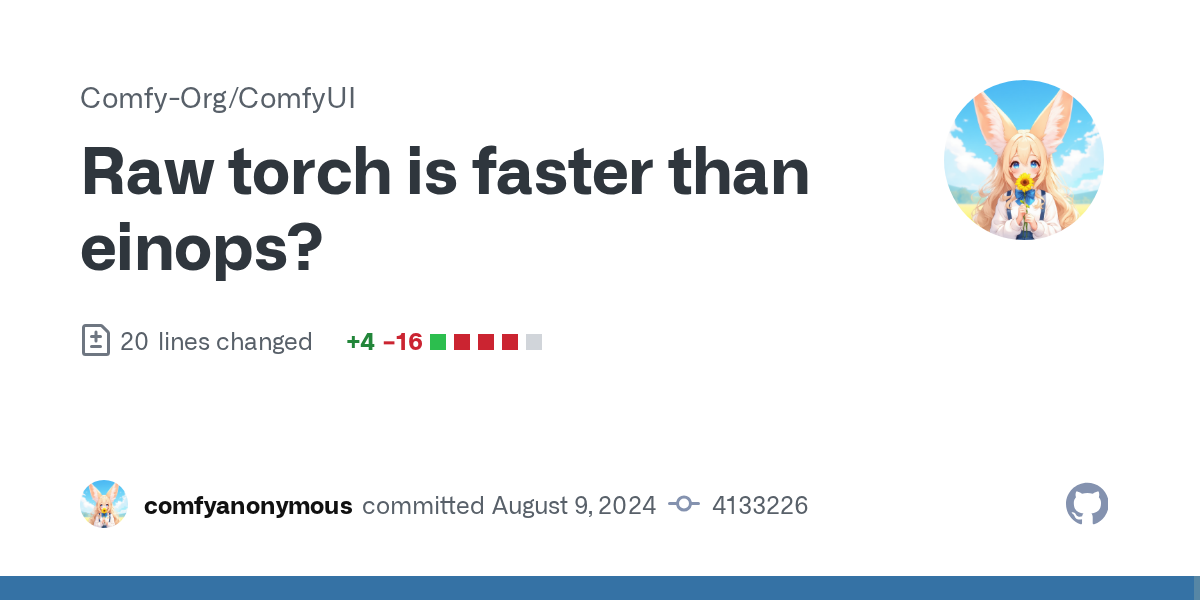
I see why, it's actually sometimes using all 100% of my CPU alongside it. Normally, it will only use the e-cores (usage sits around 40%). Was noticing that sometimes it would be 8 or 9 sec/it, then other times, like 12 sec/it.

To the credit of Ideogram, they offer the option of an LLM enriched prompt or not, and you can even have it apply a different LLM prompt for several or all of the four sample it produces per prompt.
It will show you what the LLM version was in each case as well.









I have a 3090 with 24gb. With batch size 1 I usually have 5 seconds per step. So definitely slower than SDXL, but still doable. Problem is rather to find good parameter settings first. My validation images always look as if the method blows up, but then it always turns out it is still undertrained

Testing negative CFG now. Thanks @torn wharf for hint.
FluxDev FP8, 1024x1024, euler/beta, 16 steps, fixed seed
same prompt to clip_l / t5: `mountain landscape, grass, lake, sky, birds flying, soft white clouds, mountains reflected in the rippling water, wildflowers in the grass,
cinematic masterpiece, dynamic lighting and shadows, extremely highly detailed, landscape photography, desktop background wallpaper`
Baseline result

With negative prompt red, crimson, carmine, ruby (Holding all other parameters constant throughout tests. Will only change negative prompt.
Obvious absence of red, so far negative CFG appears strongly effective. Reason for blurriness unknown, will experiment after CFG tests.

With negative prompt blue, azure, cobalt, marine, navy, ultramarine Definite effect, less obvious accuracy.

With negative prompt green, jade, emerald. Again less obvious than red, but definite absence of green from original on fixed seed. No observed blur means probably side effect of seed, not of negative.

With negative prompt color, rainbow, saturated, vivid, lush, colorful, multicolor, intense, rich. Obvious reduction of color from baseline.

laugh girl walking to the moon
Positive guidance 3.5, negative guidance 9.0, CFG 3.0

Positive 3.5, negative 9.0, CFG 9.0

Positive 3.5, Negative 9.0, CFG 1.0 (holding CFG 1.0 from now on)

maybe run cfg only for the first 90% timesteps?
No idea how to do that. I think I would need two sampler nodes and some kind of time split node?
and I would use same guidance for both
that's the easiest way to do that I guess
I'm experimenting with the effect of varying guidance.
Positive 9.0. Negative 9.0. Desaturation maybe less pronounced.

Positive 9.0. Negative 1.0. No change.

Positive 1.0. Negative 1.0.

Again, Positive 3.5, Negative 3.5. (Repeat baseline.)

Upweighted negative prompt (color, rainbow, saturated, vivid, lush, colorful, multicolor, intense, rich:5.0). No change.

Removed negative prompt. No change.

Restored negative prompt color, rainbow, saturated, vivid, lush, colorful, multicolor, intense, rich (not upweighted), CFG 2.0. Definite desaturation effect has returned.

All else constant, raised to CFG 3.0. Desaturation effect intensified.

Upweighted negative prompt to 5.0. Desaturation diminished (opposite expected effect).

Restored negative prompt to unweighted state. Raised negative guidance to 9.0.
Desaturation effect increased again.

Tests complete! 😊 🎉
Negative prompting for FluxDev is now 100% usable.

Negative CFG workflow. Will also post on Civitai I guess? Never posted there before.


On Civitai. (If I did this right.)
https://civitai.com/models/633586?modelVersionId=708340

Allows negative prompting for flux. Simple workflow, easy to integrate into any other workflow. Fully tested, behaviors and best practices included...
Prompt painting of a woman warrior by Frank Frazetta, moon maiden, oil painting, concept art illustration

Same seed, with negative NSFW, nude, naked, bare skin, exposed skin

😊
that's not bad. I never got flux into good Frazetta paintings
they always look too photorealistig and not vintage enough
Wow you have your beer brand.
Ty , finallly! 😄

holy molly!


Flux

The 5th element.
Lmao
Shows up again at the end of the story smiling

I think yer camera ain’t straight



Flux has expanded a bit


Muad'Dead
TIL the max resolution recommended is 2MP, double what is recommended for sdxl which is 1MP
this is what 2mp looks like. the guidance scale is set to 4, i might lower it to 2 and try again



So for any interested, you can generate a few images a day with Flux Schnell at Nightcafé. Bear in mind that it does have some clear restrictions or lack of control of things such as number of steps used or resolution (1k default), though not ratio. It is also extremely fast. https://creator.nightcafe.studio/flux-image-generator

NightCafe Creator
Flux is an AI image generator that outperforms other popular AI models. Try it now for free!
Note, it SAYS Pro, but I am in doubt as to whether this is Pro or only their Pro subscription plan.
EDIT: turns out only subscribers can use Pro. The free images are Schnell.
wait was it pro that was supposed to be slightly better than dev?


Yes, that is correct, and after inquiring I found that the free generations are all Schnell. Only subscribers can use Pro.
I edited my messages above to avoid any misdirection
I'll probably plunk some small money down on one of these guys to test Pro and compare. Likely one that allows me maximum settings control

She's incredibly impressed by the 2mp image
She is drunk.
"Spaced" more like
xD
Power to Fal.AI. I had credits left from when I plunked some money down for SD3 8B but apparently did not use it all. Can use for Flux Pro.


So it turns out you DO get 5 free Flux Pro images with Nightcafe
Their site is hopelessly confusing in some things, but this is now certain.
that's amazing!
i'll def check it out if that's the case then
also i found out that you just have to copy paste your prompt several times if it doesn't give you what you want
a 5x copy/pasted prompt will give you the result all of the time lol
Be warned their default settings, even for a free account is to send you email notifications about EVERYTHING. So be sure to enter the setting to turn that crap off. That said, free Flux Pro is free Flux Pro, and the settings change is a one-time nuisance
They have an option to fix the seed, but it is entirely unclear to me if the seed matches Comfy's in any way. I suspect not.
When comparing models or prompts I like to fix the seed to be sure I am really seeing an apples to apples comparison, and not lucky RNG vs unlucky

free flux pro? more like.. flux SLOW. amirite?
hey @jolly swan, hope you're doing well. I look forward to your progress on v6.9 if you have any. Me and my friends we're wondering now that the dust has settled on SD3 per-se, on a few things
- Are you still considering making an SD3 Pony model after 6.9's release?
- Have you considered switching to Flux instead for the next generation Pony model?
- (Sorry I have to ask) Do you have a timeline for when you'll expect to see some results for 6.9?
nah dont fall for it
Have whoever you're arguing with blocked so your posts are all I see. 😛 I did a bunch of tests on negative prompts after you mentioned the node you were using, and it definitely works! I posted a workflow for it earlier in the thread with instructions on what works / doesn't. 🙂
yikes, you attack and fight small children
just crystal wizard saying everybody is thinking about me and laughing fondly of their memories of my antics when i'm not around. I'm still not entirely sold on that one particular node. i'm not sure where the balance of guidance and cfg fits.
I seen that reforge / forge prooject is getting flux support soon. i can't wait. messing around with noods for basic generations is cumbersome
never thought a lame joke like "more like flux SLOW" would set someone off that hard
Where does it say flux is coming to reforge?
From panchovix? Might have to switch to experimental branch to try it out
and lly has been adding stuff to upstream too
i haven't had success getting it to work but they're doing stuff
people have broken psyche, alot of people

TBF there are a ton of reasons
whenever i hear things like "nobody likes you!" from one person, that just makes me think that all the people who don't like me are afraid to tell me so. so i intimidate them and that makes me feel good about myself.
logic
Never seen you before, but I just remember crystalwizard going crazy glazing SD3 when it came out 😂
balls
as i was setting up to train the ball lora on the one trainer experimental branch, he was arguing with me that it couldn't be done and it was impossible to train a lora on sd3 . pretty sure he insisted i give up
i think that was the earliest impression of him i can remember
Nothing is imballsible

i know i dont know everything. i think i'm dumb in this field. i also recognize that many self proclaimed experts are serial bullshitters. Thats why i like to just get down and dirty and start throwing balls at the wall to see what happens
can only get so far with book smarts. like dr jones used to say, field work is important
bad doxxing skills

I experimented to figure it out, and the results are in my workflow as notes.
CFG 1 = negative prompt does nothing.
Higher CFG = more powerful negative prompt
CFG > 3 = artifacts and buggy output
Guidance on negative prompt: increase for slightly more powerful negative prompt. High guidance will cause artifacts.
Best way to boost negative prompt: Add more words, synonyms, and related terms.
I locked the seed and all other gen parameters, and for different sets of prompts with / without negative I proved that negative was working perfectly.
OH good data! taht's a lot more structured than my tests. thanks.
i did some feelings based tests and went back to FP16 T5xxl
feels based tests are my main sail
i dont know how else to say it lol, it does indeed feel better haha
and im not going to test
i'm sure that fp8 t5 diminishes the quality. i've felt it. but i don't have the data to demonstrate it to others.
The comic in question (tbh I'm only reposting the actual image it's really awesome)
I sent to icycold (and crystalwizard also but accidentally bc i mixed my windiws up at first)
I think too many people look down on those with any psychological stuff going on.
I wasn't making fun of icycold.
I just woke up, so apologies if I'm not making sense yet; I also didn't scroll back very far for context.


lol it's the usual situation. I expected it to be honest, just not from crystal wizard. mention last week in passing that i had some mental health issues i've been working on , focus issues mostly, and now it's blowing up in my face. everyone laughs about me and shares mental health memes about me. smh. what a catastrophe
I just got here, have no idea what's going on, nothing makes sense in that image too
technically, no, just Pro
also technically, people added them anyways
Flux scnell. It's super fast tho. A smart way to attract new users to their packages I figure. Bc once there are flux loras and checkpoints I can use id get pro plus cause my computer is slow?af.
i just do the slow
i mean you do like art business stuff maybe i think, i just play, so experiences may vary
If you mean the on my own computer slow, for schnell it's 5 mins compared with 30 seconds. My lack of patience satanic $30 p/m isn't bad 😄
I've got 2 workflows sp fat that add neg prompts!
Np waiting 20 mins for my 8gb vram to make one image 😭😭😭
yup i dont blame you, im just not a buyer of AI yet..
I like the idea of them releasing a special distill that's not good for images, but we can use to train Loras that work on the distilled models.
Would that work?
I want to say the same but I use my new GPU more for this than gaming
Scroll up. Though warning there's Distracting stuff on the way such as training info released for schnell!
Glif us freeeeee 😄
my poor thing cries on games
I just need to remind people that Barclay from TNG is also Murdoch from the a-team.
Like, what else haven't we discovered?
So which rented gpu site do you use? I want to use one to make some loras 😄
is it gonna be easy to train or something
Im dumb
Lalita is the name of an extremely acidic soda thing over here, few like it
I like it
Your name always makes that come to mind
I'm kinda hoping for one of those pre-made diffusers training workfliws or something lol
I trained a checkpoint before, learned everydreamtrainer setup, and it worked! Was sdxl tho. But it took me a few days to figure it out. That would cost a lot on a rented gpu!
I forgot to title that mental health cartoon, supposed to he titled "if we treated physical ailments how ee treat mental health ailments" or something like that.
I was watching a-team AND TNG while they were both broadcasting new episodes and I never connected those two characters.
Just goes to show how we can get stuck in this domains.

On a special server with a giant gpu....
I also like the idea of them releasing an undistilled 5b version . Ideas are fun
Where do you live?
chicago?
not sure what you mean. Takes about 5 seconds to generate.
This lame joke has really set some off. It was a lame joke
||bruhzil||
it was a joke for the americans, no power there
Look, on this laptop, by comparison, a single Dev image takes a minimum 20 MINUTES. so....
Wait until people figure out they give free flux gens too. Right now it's 5s.
Also, it's not a hill I'm gonna die on. Read it aloud for instance.
I have credits in Fal anyhow. The real interest was/is to see how Pro compares in quality and output.

when the prompt was for something entirely different it seems to make something cool anyways?
No I did prompt for an overgrown ruins with portraits...
oh it got it!


USA?
ide like to say i re-remembered if you select a bunch of nodes you can combine them to a mega node

so not the worst place by far
Even with schnell?
Lmao

first thing i noticed is it tries to make the magic kingdom castle accurately tall instead of perspective trix like in real life
What's wrong woth Brazil? Good food, amazing festivals, nice beaches...
Shrek is the way

No gpus
Amazon.com? But they prob cost equivalent to 6 months revt for you guys 😦
No, absolutely not, thank goodness. And I get better than Schnell quality with the special Dev-Schnell combo suggested by Comfy
Glif or mage 😄
yes
and comfy recommends it? damn

Comfy secretly put fox girls in the merge
i think the recomendation was in the method of combining
Rob a bank angle

sd3 adn flux and all these SOTA models. I can't wait until this tech converges with the meme spheres and gets things weird af online. i feel like we're too slowly getting to the next gen of online content and things need to ramp up. we canmake relevant new memes for any situation now. it's a memevolution.

Exactly and this file I linked has it pre-made, with Clip and VAE embedded
"Flux.1-Dev double_blocks (MM-DiT) onto Flux.1-Schnell, then quantized to fp8 giving you a higher quality model that still runs in just 4 steps"
i feel like consumers are going to get edged out on local inference
how does this compare to dev and schnell, and can it perform even better at higher steps (it only says 4-8)
wont be for long since the weights are out and hardware just keeps coming out.
true
like if I want something super complex that might only work with dev at >25 steps
only a matter of time before a smart person figures out how to run fast inference on cpus with clever instruction set tricks and we have access to the main system memory
or intel is almost certainly designing instruction sets specifcally for inference
Yes, consider that the number one driver for tech updates in consumer PCs is not AI, but games.

I know jim keller, the guy who architected the current amd64 ecosystem of instruction sets, he's working on dedicated hardware for this stuff. his chips are kind of old gen tech now though and i haven't seen new stuff from greyskull labs for a bit
And in the cause of image AI aficionados, it is a match made in heaven
i dont know him. i know that hes' working on stuff

games need local model inference to be fast and efficient enough for the game to run. only a matter of time for that.
It's basically what all these dlss and fsr techs are. local models of sorts. local language modesl are the next big one to crack
TPU for all
i don't think cloud inference services like chatgpt will ever work well for games outside of chatbots in games
ggml implementation of stable diffusion and flux would be interesting
there is already one for stable diffusion 1.5, 2.1 and sdxl I think
oh even sd3 daaamn
live services for gaming is an ongoing problem. they're often not needed and are essentialy just DRM
yeah there's lots of smart scientists excited to get inference on cpus. all that ddr just sitting there going ddurrrrrrr
but this repo also allows you to partially use your gpu like with cuda, vulkan and rocm
like llama.cpp and whisper.cpp
ddurrrr...

only a matter of time till a smart developer puts diffusion upscaling into a game engine, so that all the high fidelity textures are generated at run time using lower quality scafolding assets

i think Microsoft and NVidia have that developed already
gonna get many game remakes down the line
theres a ton of controlled art direction that can occur with model. ip-adapter style transfers and very elaborate prompts would get enough consistency for game textures i have no doubt. just no one's made a product showcasing that yet. usually takes about 5 years for a game to go from initial ground breaking to a released product.
yeah tools are there for sure. nvidia has all those remastering tools available.

the GTA trilogy remake was done with "remastering" tools too, though that was a poorly applied effort imo
remember when we first started seeing GAN upscalers? people were remastering final fantasy 7 prerendered backgrounds with them. like 2002ish?
Games don't really do model inference, unless you are thinking specialized NNs such as chess or go, but regardless the tech benefits both, so if gamers push Nvidia to make faster cards, and that happens to also be exactly what helps Ai model inference, then it is a win-win. No surprise Nvidia grew so valuable in today's AI boom.
games already are today doing inference with systems like raytracing, frame generation, upscaling, all in real time. that's because of trained models.
instruct models have a lot of potential for game master style design. a game master is traditionally what separates table top rpgs from video game rpgs. that's just one design goal that ML models have a lot of potential for.
nvidia is still a gaming tech company at their core. they didn't design these new chips for openAI 's level of business at first. it was primarily to make video games go harder and they knew that chasing that would put them in a very strategic position for the future.
the one AI i've been watching them train that's so cool is a player agent. it can learn to play any games with any control schemes. they're doing a ton of practical research in that field. so instead of dippy dumb AI team mates, you can have one that teaches you some shit
The ray tracing you see in games such as Cybrpunk 2077 and others has nothing to do with neural network inference.
Nor the massive polygon output in Unreal 5
I'm lazy to even read
2 very fast fingers
https://youtu.be/5LL6z1Ganbw](https://youtu.be/5LL6z1Ganbw?t=120 this is just one aspect of that research. they taught it to play minecraft by watching streams. it can do text to minecraft! "build a castle" and then it does!

❤️ If you wish to support us and watch these videos in early access, check this out:
📝 The paper "MineDojo - Building Open-Ended Embodied Agents with Internet-Scale Knowledge" is available here:
https://minedojo.org/
🙏 We would like to thank our generous Patreon supporters who make Two Minute Papers po...
There are papers out to use neural networks to improve ray tracing, but they have not made it into games yet
coffee. also typing so much that it's as natural as speaking
while i don't believe nvidia has published a paper on how RTX is achieving real time ray tracing, i'm fairly certain they use a machine learned model
But as I said, NN inference does exist in games, as shown with AlphaGo first, but is now well embeded in other mind games such as chess and shogi
Ray tracing is not a secret
the cyberpunk raytracing doesn't use nvidia's tech at all
imo crytek's crysis remake does the most accurate real time ray traicng
I have trained many chess-based neural networks from scratch
DLSS "Deep Learned Super Sampling"
using established tools mind you, but data and structures my own
with programming i got as far as remaking tetris from scratch in a console text engine. also i made a template language for html forms that was over engineered and then jquery came out and i said fuckit.
never got much further with code
I'm a chess player at my core, not a programmer, so my interest was in leading the training of the NN through specific steps and methods from the perspective of a chess player
hmm. at my core.. what am i? break dancer with a knee injury. that'll do
I had help with the code from a friend who is a coder for Amazon
Making things breakdance is very funny with ai
I take it this frustrated your Olympic gold dreams
oooh yeah tragic memory just came iin. thoguht i was clever and named my library "phorms" because it was a php situation and i thought "wow thats gotta be the best library name anyone has ever come up with" and i was really into it. i remember feeling so proud of myself. but everyone who did forms in php had the same idea
They have Skillz and Balls
so long ago that break dancing at the summer olympics was un heard of


I got as far as printing ASCII table using embedded BASIC in the 1980s. 🤷♂️
you dealt with ascii in the 80s. remember an app called "The Draw"
My level of coding is: built websites (in html in notepad) before dreamweaver etc. was even out. Make tons of glifs
ROFL
olympic ball dancing event

i put "resting still" in the negative

tbf that is a lot of olympics events as the athletes prep for the next event


Not only realism, it seems that the images have soul  😅
😅



awww :)
also this is insane
the height chart is a dead give away. the measure lines are very none standard and dont persist properly behind her. her left ear the one hidden behind hair, wacky postioning for her head tilt. the glasses are sitting way higher than they should be. goofy hair line. weird red smudging under the frames but otherwise perfect skin everywhere else. obviously the text is weird but that could just be an in joke that no one gets. but the one thats super uncanny that most people wouldn't notice i bet. light seems to be coming from the top left and top right at the same time. the shadows are all over the place.
8/10 realism because it would probably fool 80% of people.
woah ty
are those real words?
this one i would only suspect because of the power button position on the bottom of the device
yeah it seems i got a bit unlucky there, maybe some photoshop can fix that
large crowds doing active stuff it works really good in these new models. but lookit the feet. lots of feet doing lots of stuff and it's confusing the patterns. Faces on that could at least be explained by photography artifacts like to slow a shutter speed or something. the feet tho.
i think thers still ways to spot fake images but, it really really is getting harder
They are not examples of perfection, they have flaws, and the models are not perfect...
it really is getting so hard to tell tho
Flux is the closest to perfect any open model has ever been, but it still took a TON of manual work to get my monster cards ready to print. Every image has mistakes only an AI would make, as soon as you start looking close.
you could sometimes get soul out of older models if you used an open pose controlnet on a photo with soul. it's in the latent space it's just hard to evoke out
you actually producing those into a physical set? nice to hear. excited to see the fruits of that
Is this "soul" like your "aesthetic" thing? 😛 Doubt I'll get it. I like data.
Yes! Sent the prototype off to print Wednesday morning. Working on layout V2 for when it arrives. The borders were just unusable in the end. Need to composite for the revised design, and then I think they'll be really good looking.
to understand soul there is but one bible of a film to ingest. May i be so inclined to even provide a link. There's probably more that people would argue about, but i think they get it here. https://archive.org/details/the-blues-brothers-1980-4k

Internet Archive
Jake Blues rejoins with his brother Elwood after being released from prison, but the duo has just days to reunite their old R&B band and save the Catholic...
if you're on the fence, might i suggest that it stars Carrie Fisher
Summary? TLDR;? 🍒
They get the band back together
Explain "soul" in images in a way a computer could understand it? 🤔
Someone needs a giant pool stick 😉

(I also am a philosopher and believe in the metaphysical soul, so alternatively explain in a way a philospher / logician / linguist would understand it.)
i believe that if there is a soul, we can engineer it.
metaphysics is just physics that doesn't have an applied science to it yet
But what do you mean by "soul" in images???

believable actions/poses/expressions/body language

{kind=link}
I assume you would add "diverse" to that list? RevAnimated could do believable poses... Like 6 of them. (And I don't mean diverse in the nonsense angry way.)
also maybe i might show the computer some alex grey paintings or a tool music video
you know that famous painting of Venus in the clam shell? That's one that google images chose. I can't post it on discord tho
Google chose it for something? (I know the image.)
I did a search for rennaisance painting of the soul
Doubt that's what we mean here, but Google's opinion is noted. 🙂
I was hoping for one of those fancy ones where there is a translucent version of the person half out of their body....
I don't see why that one wouldn't count 🙂
Because I think he's talking about body language and expression. Venus is very painter-pose, since the model had to stand like that for days on end. Cameras are different.
if the birth of venus isn't SFW, i don't wanna work there
boss is like "JENKINS?! YOU GETTING OFF TO RENAISSANCE ART AGAIN?!" its like.. no dude thats a weird accusation
Imagine working at a museum, can you have that as your desktop? 😛
just rip the band aid off and post it


Who's talking about? Apparently I mised the original post or something
I feel the same way... But @torn wharf was looking for images with "soul", and I wanted to know what he meant.
its a 6th sense
Balance?
cant say it but can see it
i dont think it was a portrait of someone posing. it has all the elements of like a constructed person. like they planned it out her pose and face and expression and eye lines and all that. like how we have a style like anime or pixar style. it's a design language.
Wait now what are we talking about? Venus? Constructive drawing is used to draw models.
knowing the italians probably the position of her toes have extreme symbolism too
Yeah he could definitely make changes like that. He would work from multiple sketches.
I believe in soul as in spirit, with a certain focus and mindset, in the style of, alive, purposeful
i gave all those blues brothers pics to represent soul. and also alex grey
Well those were representations of people, who have souls.
not only people have souls
whatever LSD idoes to neurons, thats what we need to encode into these networks. if computers are going to find soul, that'll either do it or just make things interesting. either way, fun.
disclaimer: i have no idea what lsd does i've only seen it in movies
But can you tell if a specific image has soul?
shrooms work better for the visual, I heard someone tell to some other
Alex Grey created a lot of paintings along those themes, in the 80's

like a soul classifier?
See this clearly has no soul IMO.
If you need a scan device to exaclty measure the amount of soul in something, you'll probably dont get it
contextualization could easily give that image some soul. but it does parodoxially feel stiff to me. and that's interesting. it compels me to examine it closer
the scientologists got that thing
dips my gpu in lsd
they've got a lot of things
careful, dont touch with your fingertips
i always say handle it like a hockey card. but i guess thats dated and most kids would say pokemon card now
like its a Michael Jordan rookie card
my heart aches so hard when i see people planting their sweaty sebum bum thumbs all over circuit boards
Like kids grabbing DVDs back in the day. 😛
every gpu be like

seeing it out of the case is actually making me really nervous
anything could happen a sudden gust
Heres a horror story for you, i pulled out like a half a cup of matted down dust out of my video card when i started with AI, its much quieter now
freaked me out, was well hidden behind the casing
Guy says Differential Diffusion inpainting works with Flux? 🤔 Really great results. I'm at work. Anyone want to test it?
https://youtu.be/Qiltbxvhr_A?si=UpIN8In_7df77WiT

In this video, we demonstrate how you can perform high-quality and precise inpainting with the help of FLUX models.
FLUX is an advanced image generation model, available in three variants:
- FLUX.1 [pro] for top-tier performance,
- FLUX.1 [dev] for efficient non-commercial use, - - FLUX.1 [schnell] for fast local development. These models exc...
lol invoke was telling poeple that flux inpainting was impossible
I'll test it later. Might be tomorrow though.
I think sd15 has some soul

i was thinking "if soul were anywhere you'd find it in people" but then i remembered this monster

prompted it by name with a description of it. i think it knows giant cedars but not that one in particular. its close! it vibes.


did you use simpletuner or diffusors?
i wana train a lora on flux on my 4090
kinda waiting for kohya_ss script
yes
SimpleTuner is fine. Not more complicated than kohya_ss
it supports quantisation and all kind of loras out of the box as it's using diffusers
I could imagine it takes some time until kohya_ss supports stuff like quantisation, dunno
yeh its not getting that one specific tree but it does get creative with trees. hehheheheh hole hehee


six fingers... welcome back


SD3 is not competitive with other options like AuraFlow or Flux so there is not much reason to build anything on top of it (or even use it, honestly). Flux is good but overall not as exciting as AuraFlow which lacks in terms of aesthetics but I think I may be able to fill that gap. tldr: I am getting ready to train the first smaller finetunes first to see how it goes but I think the main training run is getting close.