
#🆕|sd3
1 messages · Page 72 of 1
i meant the posts

i just realized i've never loaded controlnets for sd3 yet. i guess i've never needed to use it to affect compositions before. old ball trick i'd use is to create a depthmap of a sphere in a scene and build prompts on that but alas, sd3 has solved balls
the control nets are decent
the other day I spent like 12 hours with them
its not really my area though as I dislike control nets

(I dislike control nets for the same reason I dislike CFG, because you pay an image quality cost)
this is surprisingly good
this is about as good as SD3 gets
for anatomy
this was my best woman photo SD3 output

i get many good ones just not specifying pose, hand though :/
I used SD 1.5 face fix though
that is not SD3 face
yeah we have no chance to make good hands
SD3 just cannot do hands
its ok cos SDXL only got good with hands around the timer of later jugger versions
CFG: 1

20 shift
seems to make it more coherent
yeah it will help
not tested 🙂
for challenging generations like CFG 1
most important thing is to sample more
like 150 steps DPM++ 2M
ya i should try higher steps i suppose, just messing around
ye its fine cos it takes long
landscapes ye
I use it for ultimate upscale, I made a test too see the difference with xl and It's better with the details
How about skin texture?
I use now web photo upscaler
I only used a human when doing image to image and It's still much better than xl, It's a shame that the model can't do it for Itself because when It comes to the little details is next level
Hope we will see update model soon
i use it to play with m'balls
SD3 has best skin texture of anything
but you can't always get it to do it
when it works, it really works

Imagine A Person in Us
you can't generate here
Where i Generate
read the information at this link: #artisan-faq


SD3 working in a1111 now eh, are there any tweaks that should be done to optimise for sd3?
yes
sigma shift
I don't know A1111 so I don't know what they would call it
also no ancestral or SDE samplers
and it rly needs low CFG
sometimes as low as 2
When is the full version of sd3 coming?

Is 1111 working for everyone after the latest update?
no its different because SD3 has three text encoders
two CLIPs and one T5
and they do best with different prompts
its a bit tricky
for now though you can just feed an SDXL style prompt to all 3
I am afraid I don't know what A1111 will do by default as I use comfy
if I had to guess, they will send your prompt to all 3
when they get through programming it
You're new here huh?

at least it doesn't post snarky emojis at you


hello

Yes
Is this the correct channel to ask questions about installation of SD3?
tech support probably better
danke
sd3 already have controlnet?
we wish
Any news on sd3.1 ?

when there is news, you'll see posts all over the internet
🥲
you saw what happened the last time that the devs gave up, didn't finish all the steps, and just handed the community something to play with cause they wouldn't stop hounding them to release somethign. we got a beta, unfinished, model. let them finish it this time.
I was just hoping for some update, that they are still working on it or something. Since all the news that are coming are about the platform.
they are still working on it, and a number of other models
here we go again! XD
Llm's dropping everyday. But I'm craving some diffusion candy lol 🍭
meta's new LLM is multimodal - you can talk to it, tell it what you want for an image, it'll make four, you can then tell it to modify them or animate them, and also argue with it about quantum physics if you want
I'm in Europe, so no access. I'm more interested in open source though. You can do a lot more with comfyui workflows.
yes, way more
now you're getting picky. you said you wanted diffusion candy

It's a shame meta removed the image generation capabilities from the chameleon model they open sourced.
Zuck back to his old ways
stealing again
Mark Zuckerberg, wearing a white lab coat, grasping a futuristic device in his hand, as he carefully removes the image generation capabilities from an advanced artificial intelligence model. The device emits bright blue light, surrounded by swirling patterns, amidst a dreamlike backdrop of circuit boards and wires. A sense of unease fills the air. (Image description: surreal, sci-fi, mysterious, dimly lit, isolated)

Decent hands
luck
they didn't. they just didn't open source the image model
Is O'Llama an Irish Alpaca?! 😄
aparently

GitHub
Kolors Team. Contribute to Kwai-Kolors/Kolors development by creating an account on GitHub.
Meanwhile...
will get hyped when 16ch vae



nice
I installed KOLORS locally. It's a pretty fast model and produces very good results. I wish the SAI team success because this is indeed a strong competitor.
it's also a one trick pony using stable diffusion technology
In any case, competition is a good thing.
Kolors is nice 😀 haven't tried the new toys for it yet, but ipadapter, controlnets and inpainting model make it one of the more complete models out there.




try to do something like this in colors, mj is still king in aesthetics and aura

yes
it's insane how realistic the ppl look in mj

the only way i can describe mj images is: aura
its mostly cos mj trained on half of hollywood and the other's didn't
if you look at storm trooper prompts for example
mj is the one that clearly delivers the actual one from the movie
which means it was much more than just a happenstance in the data
in addition what further proves that they trained on hollywood is the LUTs
that image you just posted clearly has a LUT applied
which you don't rly see anywhere other than in cinematic movies

more a greyish legal issue, and nowadays instead of searching for more real data, like screencaps, new models get more and more synthetic data 😥 And that's supposed to be better, i'm sure it's better for general prompt comprehension/subject understanding, but just can't see how it's supposed to be better for style/aesthetics
its morally and legally grey yes
and Emad on reddit said as much for his reasoning to not do that
MJ it is not, but atleast it's a closeup and the sword is up (i think for sd3 i need to write a novel to get that pose, kolors just wanted it translated in chinese :p)

8b can do it 🎉


mmm kolors
Yes it is. Well this is the future anyway. More and more will just train their own models, eventually from scratch.
A few papers down the line you collect 50k image online auto tag them and let the ai train a weekend and you have your very own whatever model you want.
everyone will have very interesting personal models then
😉
Anything working with just 50k input images will need to be pre-trained, and if that's needed anyway as there is no way a model can get concepts out of thin air to actually interpret your prompts, why not just need like 100 or fewer to just teach it your intend
Dont think whats posisble now, think a few years from now
not only that quantum computing will enter the scene too eventually
i disagree. it's a unet. sort of like how original bicycles, they repurposed their understanding of pully mechanics to create the needed ratios. it wasn't designed for purpose, it was just an existing design that they used for something novel. Unets are that old design that was never meant for images, but was implemented in a novel way to do something new. transformer networks are a superior situation that can be purpose designed for text to image specifically. auraflow is a scarier competitor to their business model since it has mmdit transformer blocks as well
But it will always need data in, now and in the future, data is the limiting factor
we can do more in less time and thats not slowing down
I remember when I saved an mp3 on a floppy drive, took up the whole drive, it also took days to get an mp3.
Now i download 6gb in a few minutes. so its kind alike that with this ai stuff
my first mp3 i couldn't run because the cpu couldn't process the decomprssion fast enough
loooooool
i wouldnt think these are the architectures of future models
took me 2 weeks (really 2 weeks) to get a clockwork orange from a friend on MIRC. allegedly. On dial up

ah yes of course the tehc will also get better
i would've just duped the vhs and ran it over on my sweet bmx. good ol sneaker net .
i remember when the code to rip dvd's was released 🙂 DeCSS
actually ran a sweet little hustle for that. bought so much candy running vhs tapes since we had pirated satellite feeds in canada back then. encryption was more hackable
not our fault that american satellite signals hit our land what are we to do
Same in Europe the guy who taught me how to use PC was hacking HBO signals
😄
Allegedly


Very nice. The hair tho... That's not how hair would behave in a freefall. XD
lol i didnt really realize that till you said it
But the picture is not moving
So how would the hair
Explain that!
3 cans of hairspray
the hair would be streaming out behind/above her
2 Dimendional BALLZ



Hey hey, we cna all do pretty good portraits. show us some decent yoga poses.


standing is already yoga enough for my old body
Don't worry. In VR/AI we can all be gods.

Are you a hot lady in real life? Well yes. But no worries now you can be one in AI VR as well.
The good part is in VR/AI land you never grow old and die.
Excellent.
Are you guys worried about growing old and dying and all that disgusting unplesasant stuff?
Upload your mind to the matrix and forget about it!
See you in VR land!
AI forever.
Stephen King's Lawn Mower Man
our species will inevitably expand into simulation. even if we colonize the solar system, i'ts unlikely we'll ever expand out. even if we send a seed out int the rest of the galaxy, they wont have contact with sol in any real form. entirely cut off. but if we want to explore the galaxy we just simulate it in perfection and visit anywhere in the simulation instantly with far less energy spent. or anywhere in the universe. or time. or imagination. in perfect fidelity. or heightened fidelity. simulate new senses whatever. Worried about heat death? run the simulation at the edge of an event horizon and just live in there. Innerspace is more energy efficient than expanding into the physical universe.
One of the reasons AI is allowed to proliferate this much and this fast is to show us that reality as we understand it is just a veil.
really?
someone's had too much coffee today
Epistemology has a few words to day about this.
But in the end it's all about a conflict between man and god.
AI imagery has such a neat wonderful place in all this tho.
For a few decades enjoy your free will.
But really....
there is nothign there.
But God.
Welcome home.
you need to run that through suno
Buckle up.
Remember, there's a shithead everywhere, every discord server, every family, every nation, every classroom. A few people ruin the world, a few countries threaten world peace.
but soon. It will be over.
And you know it will worth living to see them go down.
All evil.
We are all making our choices now.
Things are not going back to normal.
We're heading for Venus (Venus) and still, we stand tall. Cause maybe they've seen us
And welcome us all, yeah
Yes.

I grew up in that also. I love that music. I love those movies.
icey
ice crystal rose, snowy flower, frosty rosebud by artist "tinkerbell"; iridescent,bubbles,flakes
it got the irridescence! kind of
yes. i did 4, one of them it tried to write tinkerbell - it got the word right but put half of it off the screen

You know...
When I was in my teens in the 90s... I was nostalgic for that 80s music already....
:))))))
i'm more partial to styx, trooper, payolas. i love euro rock a lot but my roots are here
you should really see what suno would do with the lyrics
Welp music peaked in the 80s
Even late 70s if you ask some...
Damn.
Europe was actually a Swedish band.
What's up widh Sweeds being the most kickass at music?
ABBA!
ace of base
@sage burrow if you could provide me a review for this checkpoint, really try to stress test it, I'll do so as well see if it can do nsfw as well as the author says it can: https://civitai.com/models/602832/realistic-freedom-3-experimental?modelVersionId=673863

Support the Freedom at https://ko-fi.com/lorian0x7 I'm thrilled to present the First Realistic Freedom 3, a SD3 fine-tune, the first trying to addr...
 to you both
to you both
The thing is the regular sd3 can do nsfw, sorta lol. I'll see if this model can do more. Oh, 14 gb dl, might be more worth my time to do some inpainting instead 😄
Bet you a chocolate bar it doesn't do 🥒 😄
…cold


I just tried a few prompts and its much better than the base model
can I post nsfw content here if I blur it? (spoiler)
I think the rules are no NSFW
No Sexy Female Waifs
lol alright im glad i asked, needless to say the results are pretty drastic between base SD3 and this new fine tune
Can it do 🥒?
It's a 14gb dl, not worth it if only nsfw ladies 😄
Though tbh the fact it doesn't look like the usual sd3 quality is what actually worries me.
Now I'm curious if you meant waifus or waifs, or were making fun of the usual waifu art style 😉
(Thode poor ladies have no muscles at all!)
Made "an anime waifu" lolol

Fingers aren't too terrible
And husbando lol

lol oh i didn't try nsfw guys, it looks pretty high quality id say better than sdxl nsfw realistic models
to be fair i was prompting it sexual situations and it was only doing the ladies and omitting the guy part so if i had to guess (ill test in a little bit) that it cant do male nsfw lol
Sounds like sd3 is highly trainable!
yeah promising results for sure, now that sd3 is unbanned i'm seeing an influx of new models on there
refreshing the /models page at least once a day to find interesting SD3 finetunes lol

Is there any info about 3.1?
3.what ?
I mean sd3.1m or sd3m v2
nothing yet
it probably just needs more time
there's not really anyone, including all the competitors, who has finished a DiT model with 16 channel VAE
yea, they might need more experimenting 
I forgot that new model is coming
The wait will be so long
bare in mind it took a full 6 months for SDXL fine tunes to be really good
so if full SD3 releases in like September we might not get the top fine tunes until March 2025 or so
to put things into perspective
I am ready to wait if it will be great
tbh sd3m base looks great already, ignoring anatomy
yeah you can get some of the benefits of 16 channel VAE right away
Waifs and strays, urchins and orphans!
the anatomy of sd3 succeeds in places where sdxl fails too. Such as belly buttons over clothes or nipple ornaments
clothing is generally over top of anatomy and sdxl refines forget that . sd15 refines more so
I've tried this SFW - and it has no real outstanding merit imo - despite all the hard work which went into it! But someone will like it!
you've tried this nsfw model you mean? why does it have no outstanding merit? it can clearly do nsfw much better than the base model
"With this first version, I wanted to resolve the biggest flaw of SD3, Female Anathomy, which was censored on porpouse, like if it's a Taboo. Now this model is a lot more uncensored, and it's a lot better than the base model despite not being perfect yet."
maybe they are judging a nsfw model by its sfw ability lol
oh geeze. the author thinks the anatomy problem was created intentionally and is still ignoring that it's been confirmed to be a pretraining problem. I don't think they know what they're talking about. Seems like they're milking donations instead. EZ scam. Happened with sdxl and sd2 too.
their example images look like sdxl vae
and thye include all 3 tencs in their model. why even? half that file is redundant data
that was the reddit conspiracy yeah
that a censorship thing happened and perturbed the weights
in reality its just hard to train a 2B DiT
- i think regardless of why its flawed the fact remains that its flawd
- regardless of whether it's a pretraining problem or not the problem remains
- its a model that claims to delivier results and actually delivers it, its also a free model, id say far from a scam
not only do they include all three tencs, their prompts rely on the clip style tencs and don't even attempt to manipulate t5 encoder
I don't mind included tencs
its easier
god forbid anyone finetune a nsfw model while we wait for SAI to get their head out their ass and provide a new model with that 'pretraining problem' fixed lol
it's 7gb of redundant data that doesn't need to be there
why is the pretraining problem in quotes? it's been confirmed the women anatomy problem happens in versions that weren't sent to safety training yet.
safety training covered other aspects
I'm just lazy I don't want to go searching for tencs
but yeah I understand its a lot of data
yeah i agree with that
100% extra data. Something that scales bad for everybody.
bc regardless of the excuse its still a problem
i wish they would release models without clips unless they customized it, im running out of HDD space and these 16gb models dont help lol
investigations generally aren't excuses and quoting something generally implies that it's exagerated. There was no safety sabotage of women in the dataset. it can't do males laying in grass either. it breaks in a lot of ways. it's just poor pretraining, which is bad, but not a censorship issue
"details matter" - Jack Reacher
meanwhile weeks after the original release with the 'issue' the problem still hasn't been fixed, meanwhile some random finetuner with low resources 'fixed' it pretty quickly, just seems like SAI dragging their feet to fix doesn't really lend to the idea that it was a mistake
i dont think the random guy fixed it. i think that's just their hype and marketing for their donation page.
/credits
fixing pretraining isn't exactly a rush job
he 100% fixed it
i personally downloaded the model and i can attest its a thousand times better than base model
I don't think you quite understand
it has been 100% proven that the conspiracy was wrong
because someone who left the company posted a sample from before any censorship had been done
the debate ended at that point really
significantly and demonstrably fixed, i'd post samples but i cant post samples lol
it didn't end since here we are. the misinformation wins as usual. people love spreading fake news
okay im not disagreeing the conspiracy was wrong, im saying the conspiracy is irrelevant, i just posted a nsfw model that actually works, meanwhile SD3 is still broken
sd3 isn't broken if you are using the version that works
i'm not sure what the issue is
SD3 is broken as far as generating nsfw content, thats the topic of the discussion, try to focus here, this conversation started bc i posted the nsfw SD3 model that works
here it is again in case you missed it: https://civitai.com/models/602832/realistic-freedom-3-experimental?modelVersionId=673863
but you jsut said it's fixed... so the model does do nsfw content?
I don't think iit's ever expected that a base model is porn enabled anymore. Especially when porn can be refined in so easily, only a few weeks post release
how long has pixart taken to get nsfw enabled?
its downloading . but the author was an idiot and included 7gb of pointless data
lol yeah i don't disagree with you there, i wish i could split it out and just keep the model part
i'm sure there are tools for that
will be one of the first things i figure out how to do with it. already got dozens of other checkpoints. i don't got the resources to keep t5 on every single sd3 checkpoint i download
it's really simple SD3 cannot generate nsfw therefore its broken, whether it was intentional or not is irrelevant, its broken
the freedom finetune model is fixed, it can generate nsfw content therefore the problem has been fixed,
regardless of whether subjectively we should have the freedom to generate it or not is irrelevant to me, i want to generate that content so it should work objectively
Afaik, you can do it in comfyui, save the model I mean, without the tencs
freedom finetune is sd3 still. you say it's does nsfw. that means sd3 is able to be finetuned just fine in this arena and isn't broken then.
i still think SDXL can generate better NSFW than SD3 but its exciting times when someoen finally creates the first NSFW SD3 model bc the community is bound to rally behind it and could be the next top model on civit (a porn site) lol
keep in mind that base models are different from refines. the goal of a base model isn't to over fit a subject
yeah im not saying its fundamentally broken, im not saying the whole architecture is broken, im saying SAI's base model release is broken, obviously we both know that, not sure why you would feign pretending im implying otherwise
it should be left slightly under fit. overfitting is actually a porblem that sd3 has in some spaces
yeah I really strongly agree with this
base models should be under fit
base models shouldn't do porn. that would disqualify them from being used in public education or other fields with children
like @sage burrow said its very promising to see a freedom capable of generating decent NSFW content, it shows promise and it shows the model can be trained to generate it, its a good sign overall even if the finetune itself isn't perfect
good strategy is to release a base model that is generalized, and the community refines it for purposes
yeah I think SD3 would work really well in a school or academic settting, where students shouldn't be generating that stuff anyways no matter how hard they try
sd3 isn't meant to be a midjourney killer since sd3 is open weights , not a single service.
i dont know I guess I'm on the fence, on one side i see the value of under fitting and being suited for certain scenarios like academia but on the other hand it can be considered art and artistic expression and limiting the basic human anatomy could be considered a stifling of our freedoms, again there's no clear answer its more of a moral discussion we're having at this point
midjourney will soon appear with a new version that has sd3 level vae capabilities. as if they refined the base weights of sd3 to their style almost.
i'm a firm believer that midjourney uses sdxl on the backend and sd15 before that
and the styles they apply are just loras?
or embeddings sure
if midjourney was open source I would barely ever use anything else
they seem to got a good eye for style and aesthetic over there. how to build datasets would be an article i'd love their team to write
i remember i fought with setting up pixart on my computer for like a good 3 to 4 hours figuring out what i was doing wrong, instructions are unclear, finally set it up, took a lot of experiementing to even get any decent pictures out, i did manage to get base pixart to generate nsfw but it was really deformed looking stuff
i think that is their sauce really. if they didn't curate a good dataset, they wouldn't have all the subscribers they do. they've never really had cutting edge stuff, outside of the fantastic aesthetics.
this isn't true their composition detail level is not matched by any open models
look at this reddit post as an example:
https://old.reddit.com/r/midjourney/comments/1e010eh/im_addicted_to_creating_medieval_castles/
I hope SAI under new leadership will put out a model competitive in every way. They were the largest entity doing image gen but playing catch up since sd1.5, now their claim to fame for v3 is 16 channel vae, nice but I'd hope for more
i've gotten deformed nsfw out of SD3 too. nudist photography, natural drawing, national geographic. there's lots of treasure troves in the latent space

i'd file that under their aesthetics successes. composition is all part of that. 100% those successes came from quality dataset building
oh interesting
Would prob cost $3000 lol
i dont think they would've like, made new cutting edge training code to achieve that.
its possible its just higher data quality
I have some other alternative theories also
one thing I noticed is that SDXL starts to approach this composition detail level after a ton of noise injection
another is that they could be doing a latent upscale and then downscaling after
and a third is something like CADS which perturbs the conditioning vector
that's from the newest midjourny? thye may have some other tricks in their pipeline too. Many tricks that comfy users have shared online that they can draw from. i woudln't be surprised if they prototype stuff in comfyui
they're running a SAAS here, i doubt they'd design a process around throwing away paid for compute
Dalle is my sfw fave 🙂
i know it works, but i'm just thinking it would be a bad pipeline to scale
thousands of images a day
its not too uncommon in other areas of tech
but anyway I think these are all somewhat secondary because I simply believe they have a giant UNET and VAE
they have said so on a few occasions and I don't see a strong reason to disbelieve them
sdxl is a giant unet
I mean giant relative to SDXL
its just by far the simplest explanation and its also what midjourney themselves claim
i was under the impression that unets don't really scale larger easily. they should publish if they've done that. i can't find where they've confirmed it.
Maybe they're using a collection of experts , like sdxl was supposed to be, where the refiners parameters are counted






CGDream is a free AI image-generation tool that allows you to build content for various use cases, like art, social media, advertising and many more.



it might be that Unets stop scaling in terms of image quality but keep scaling in terms of subject knowledge
another possibility is that Midjourney jumped to DiTs early

the main DiT paper was actually 2022
but it took a while for any big DiT to even come out
did it make the top a disco ball? lol
that's to conserve energy. blocks uv and ir
they're smart balls
actually it would look dope if it span during a drone light show
i doubt midjourny is a single model
there was research nvidia did where they refined many different models on very specific timeframes in the diffusion process, and then the latent generation gets passed through these experts refined for specific steps in the process. thats what sdxl was trying to do with the refiner if i understand it right, but no one used the refiner for those final steps. we all just tuned the base to do all the steps. pixart sigma has a bunch of expanded parameter refines coming out which implement this method by adding more transformer blocks.
a collection of experts or whatever the actual term is. this might be what mj is doing as well. it's very effective.
they refined many different models on very specific timeframes in the diffusion process, and then the latent generation gets passed through these experts refined for specific steps in the process. thats what sdxl was trying to do with the refiner if i understand it right, but no one used the refiner for those final stepsyeah this is the idea behind refiner
the new 2 stage pixart brings this idea back
i'm not sure it's possible to be 'competitive in every way' as that's a fool's errand at best. you don't want to cover all bases, you want to be the leader for one base

i hope you generated that

Yeah , make good things need time
I hope SAI under new leadership will put out a model competitive in every way. They were the largest entity doing image gen but playing catch up since sd1.5, now their claim to fame for v3 is 16 channel vae, nice but I'd hope for morethe 16 channel VAE advantage is going away in a matter of weeks
the future is ballitecture. archs our out. balls are in.
mmmm i wouldn't be so confident yet. i'm thinking it'll be tested in weeks. i'm not sure that mapping that open one to existing models will show immediate gains to sd3 levels. maybe once someone does an informed refine
Yeah, the "release candidate" version 1.10.1 was upgraded to the current release. You should be able to run SD3 now
i am realy glad this is a generation, because i would hate to try to actually work or live in that thing
the ball revival period of architecture






realistically the floor plans would be squared and portions of the ball would be air gapped


ah yeah I wasn't referring to adding the VAE to existing models
I was referring to fresh models coming with new VAE e.g. from pixart
If they go that way. Id love to see that. Sd3 is also the only model with the text network running with cross attention to the diffusion network. The multi modal part of their architecture. Auraflow uses it too. Yet to see if that proves beneficial over others
ah yeah I am not sure what effect that has
I believe the Sigma team confirmed somewhere that they will train a 16 ch VAE model
It might be the what the refiner is to sdxl but for sd3
Maybe useful but not ever leveraged
can anyone make a photo of a spaceship in SD3?
a sci fi one
not like Apollo or the Mir Space Station
not sure it actually has realistic sci fi in the latent space LOL
the closest I could get was this

but this is clearly a fighter jet slightly perturbed
it's idea of DS9

clearly ISS is over fit
you know the romans are responsible for form factor? they made the ruts in their roads that they built for their chariots and armies. fast forward to industrial era and trains are built using the same wheel and axel jigs that were available already from roads. so because of that spacing, sections of the iss had to fit on railways and go through tunnels. idealy the sections would be larger but here we are
now we got thin dick space stations. wygd
there's something else there when i use a negative prompt 'ISS, Nasa' but not much
and that all goes back to the width of a horse's rear end and why the chariots were the width they were
all a bunch of horse poop

i believe ds9 is in there. the earlier steps kind of show the rough shape of it
heard embeddings were available in onetrainer now. wonder how that works
i'm not prompting for a ring shape but its getting that so who knows.

since literally my only use-case for image AI is realistic sci fi
its possible I won't be able to use SD3 at all LOL
SD3 2b - prompt: Deep Space Nine

the ball station

the station in the show, not just the show. of which it kinda only knows as a star trek show.
i know. just showing you that it does know the show, but it probably mostly knows the characters, and probably just the promotional stuff like teasers. i doubt the station itself has very many entries in the data set
its like total recall. triballs. thats how space works. scifi rules.

balls transiting a ball


it kinda had a go at the eye of jupiter that's interesting
the hotest new scifi novel with all these editions published world wide.






netflix series coming soon





this was a pretty good show too








the Death Ball plans are NOT in the main computer.
this was a gooder too i really enjoyed ball things.







this one was jsut so compelling too i learned a lot about the nature of balls






human anatomy? check. chicken anatomy? fail.

this was a good throwback movie too i really enjoy what netflix been doing lately


that moment when joseph gordon ballvet was like "oh you were here a few times. then again in 93, wow didn't do so good then" hahahahahaha wow breaking the fourth ball or what?
dont murder his friends he'll find you

i'm actually impressed how much i can tune the jacket just by prompting























time for you to remake the pacman movie










is true because psychically the higher dimensional form of a cube is a ball

dont deny your true balls




these too are with realistic freedom. it kills those nuanced styles and prompt details i was throwing at the model


Sega Dreamcast game with 1998 3d graphics, sega rally , racing on roads through trees in redwood national park 2 seeds of rf vs sd3. So on my very shallow test i've determined that RF kills prompt comprehension for aesthetics




What's your workflow? All the people I get with it are kinda make sd 1.5 look crystal clear , and also blurry quality. The backgrounds are nice though.
It's odd how the foreground and background differ so much in quality
I posted my best result on the model page lol
I'll DM you some of my generations that way you can just load it from my workflow





#1237459938901491852 globe
Based ball enjoyer

quick question with lots of love: 2 weeks?
SD3 can't do the Paris Summer Olympics . Extensive testing has determined this
it will be 2 weeks in 2 weeks!
the vibe of sd3 medium v1 https://youtu.be/wp0k6rogHKQ?t=108

PAID LINK:
WHILE WATCHING MY CONTENT IF YOU NEED TO BUY YOUR GROCERIES, CHIPS, DIPS, OR BEVERAGES YOU CAN BUY THEM RIGHT HERE FROM THE AMAZON PANTRY. GET CASHBACK, FREE & FAST DELIVERY STARTING @ JUST ₹ 1/- ONLY:- https://amzn.to/38LMn4R
LETS TARGET 20,000 SUBSCRIBERS BY END OF MAY, SO THAT I CAN CONTINUE UPLOADING SUCH VIDEOS. NO EARNINGS FRO...
Someone stole my art on DA and listed it as their own. So I'm doing a new thene today 😄









These images make me wonder if the movie character Pinhead was just a dollie experiment gone wrong lol
ai cant be copyrighted lol
On DA you can't post other people's works.
what does it change if nobody own it?
if you drawn this by hand its yours
if you cant save it from being stolen, thats your fault
They could just challenge it by saying they originally generated the images, but you stole them and posted them before them
And since neither of you had some physical way of proving it, since it wasn't made by your hands, DA will likely just 🤷
But it still sucks that it happened
Fortunately there's that fancy image metadata. Also, I get more annoyed they are promoting their account that way than any image absconding.
Metadata can be spoofed. Give me an image and I'll make it mine in 10 seconds.
I found out this morning a painting of mine from 15 years ago ended up in a dataset without my consent
Kinda pissed me off a little
DA usually takes them down, but not worth the paperwork!
It was something clownshark posted and I did a sidebyside of it with the painting hanging in my living room, it was extremely close. Too close to be a coincidence. But I liked clown's version better lol
Fortunately most ai apps will remove any artists works who tell them to.
Now physical art, I've had people copy my entire website before!
But it's not his fault or anything, it was just in one of the massive scraped datasets used to train models
Anyways, art theft fucking sucks. I feel you on it. Well theft in general fucking sucks
Fortunately this is just one person woth one image, which I only spent about an hour on, and he didn't get the uncensored version. However the accounts that just bot download all the images they can findd and then mass post then really pass me off. I hope I nipoedone of them in the bud.
His models are my faves! Which image is yours? Now I'm curious
oh it wasn't an exact 1:1 of my real painting, it just had an almost exact replica of the composition, like like if someone traced over all the primary shapes. some of the colors match up a little as well
the texture of the paint was really similar too because around that time, i was doing a lot of thick textured acrylic pieces. the kind where the strokes almost pop out at you
but a lot of paintings use that type of texturing
I could ever get texturing with oils, that's awesome 🙂
i like oils, but they are a bitch to work with and i hate the fumes/smells. even the low odor "safe" thinners still rub me the wrong way lol
shits also hella expensive, even for mid tier paints
Call me a geek but, I make my own 😄
ive tried it a handful of times, it's fun, but tedious
that's not entirely true. the raw output of ai can't be copyrighted. just like a recipe or a medical image can't be copyrighted. Try to copy a published recipe book or reference of xray imagery though. the way they composed the recipe and arranged it with story and description is all copyright. Same goes for AI images. use them in a larger body of work and copyright that
So, have you ever done a prompt woth your own name as the artist? I used to do that in MJ all the time. I could never decide if I liked that or not lol
Though with physical paintings, I only ever post the images before the 3/4 finished mark....
But real lapis paint, I can't resist 😄
another thing artists can do is a rough sketch of their intended image and then ai towards that with a variety of tools. they can then copyright that base input that they created. same with their prompts. While much of a prompt (tag soup) can be considered derivative, you can highlight the relevant portion of what you actually wrote and copyright that. There will be legal battles over prompts yet to come.
yeah i've tried, but my name is super common, i'm obviously not some van gogh, and i dont go by an alias or anything. im pretty sure it got scraped from facebook, but i dont remember where all i uploaded it. i know it was probably 10 years ago that i posted it on the internet. maybe someone liked it and saved it, then uploaded it somewhere else? idk, don't really care too much though
now if people were jacking my charcoal work, yeah, i'd be mad
i really need to get back into all the traditional art stuff again. havent done much in years now

i want to exercise my traditional art again. since i moved out of the city i've not done anything like weekend courses or workshops or nothing. i've kind of stopped drawing too
self goals
Using ones own trad art as reference images leads to amazing results!!
this is wrong. sharing an image on deviant art doesn't absolve people of expected protections. Legal copyright technicalities also have nothing to do with DeviantArt's own policys.
I can't just clone someone's civit account and pretend that it's all my creation. That would be against civit's policy
if you cant protect it you lose it
here's something similar to some of the weird shit i do with charcoal. I was messing around with the enhanced tile IP adaptor stuff the other day and used a piece of mine as a guide. it's surprisingly not bad or that far off from the actual style. obviously, i can't post my original work because it's the internet and silent weirdos dox people for fun :/
hm. you say that until someone jacks your shit i bet
but i can say that the tiled IPA shit was really good and i'm definitely going to start working it into workflows that need fine texture transfers that the tiny 224x224 regular ipa can't pick up
didnt happen because im able to protect my stuff, how hard can that be
Are all your civitai images protected? Is it because that are parts of your loras?
wow your painting showing up in a clownshark image is crazy
that's kinda funny in a weird way
i made some loras but i dont claim to own them, nor do i care if someone uses them
i dont generate any pictures there, if i have a gpu that can do it
ok but not everyone wants to creative commons every image they make
(realized i shoulda spoiler'd the image since it's kind of morbid)
It's that extra hour of post processing that makes me?annoyed when people steal stuff.
The 0 time pist processing ones I just put up as free DL to promo my account.
share your worst works, keep your best ones
BTW has anyone else noticed that sd3 needs less post processing? I mean sde3 large or 8b
a friend of mine who shares my name from my home town. people contacted him about a discord server i was on for borderlands 2 and told him to kill himself and said a bunch of injokes from the server he didn't understand. knowing i played borderlands 2 he hit me up and we figured someone found that one thread to follow on a profile i had, and discovered someone similar to me. it do happen. i've since just left that server. people knew something and were being tight lipped about it. like there was a secret fghtclub chat for talking shit about people not in the club. of course, i sound paranoid about it and that's a good smoke screen to throw up. got labeled the crazy paranoid guy before i left. the internet b savage.
I haven't tried 8b yet


























Glif (sd3 large) is also pretty awesome
yeah but glif is someone else's silicon and that doesn't satisfy my emotional needs
yes

SD3 medium is amazing, one prompt no inpainting/outpainting whatsoever.

that's one of the better compositions i've seen out of 2b!
@silk solstice  bonk ?
bonk ?
How did you get this? I've been trying to figure out how to do things like this with SD3, and I feel like I'm still missing something.
it's really good at compositional direction . i feel like its' due to the self attention of t5 and the parallel text network in the transformer blocks




























adjust the time_shift and cfg values
I guess what he wanted to ask was how to achieve such a super wide-angle composition, where the characters take up a very small proportion and the background is broad and majestic.
ah. totally misunderstood then
Look how insanely cool that is! Split screen is a thing!!

OooohHH!
macro photography concept, tiny figures at work, transforming it into a miniature mango juice factory, against yellow plain background
I asked for a collage of two different scenes, one on the right the other on the left. Gave them very detailed descriptions and mentioined they should be juxtaposed in style and color,still creating harmony.
thanks 😊
I asked for two juxtaposed scenes and make it harmonious. It did it very well.
What model did you use for this?
How many tries did it take?























SD3 base








Just one, but I think it was a lucky shot, because i tried it today and it didn't work out as good as the first one.
At least you have a reference image now 😉

Haha true that!

how do u do this













It's actually a Lora! I can DM you a link if you'd like?
yes plz






















just give us 8b 👍
better prompting makes amazing results
it sure does
I think I'm probably wrong, but they might be training 8B before we get it.
If Lykon doesn't turn it into a DreamShaper SD3 8B
i hope they don't lobotomize it like 2b
then sure, as long as it makes the VAE more effective
if so theyre on bankrupcy
no its supposed to be a training f*ck-up with 2b specifically
(srry for bad english)
i thinks it's a training and safety issue it'ss all messed up
sure, they can remove nudity (if there was much in the first place, there were super few cases of slight nudity, but still no cornography level)
but I dont think they can lobotomize it that much
only thing I'm afraid of is it turning into a finetuned looking mess where it all looks more obviously AI
idk how to explain it
but 2B reeks of it sometimes, especially with "illustration of" type prompts
also and this is an undertrained base model without any tuning, it's amazing
yes, it feels 1.5 like
it also has those fake looking humans











I've always preferred midjourney including this example
I use open source, but if midjourney was open source I would barely use anything else lol
ofc, but mj is a completly trained and finetuned model
look at this 8b image, it looks really similar aesthetic wise to mj 6.1

limbs a bit messed up but aesthetics are on point
another raw 8b output


anotha one
and any other model i tried, believe me
by far
nice theme, tried it in kolors

meh, close but still sd3 much better (better old movie style)


lumina? haven't heard of that one
sd3 nails that look

kolors wasn't good on this test yeah
but on average kolors has most aesthetic look
out of the open ones
this does make it worse for realism though
don't forget pixart, it can do nice things too

Pixart is not rly fully baked yet
there are some people working on it though
has potential
how do I create images here?
pixart probably just too small 🙂 both pixart and lumina mentioned working on a better vae, so if they end up really releasing something good (if something gets released, i'd expect more from pixart than lumina, lumina seems more research focused lightly trained stuff) it'll be interesting times 🙂
you need a subscription and then use the artisan channels, see https://discord.com/channels/1002292111942635562/1237461679286128730
but you need tons of vram no?
for the most part everyone open source tries to fit it within 24GB VRAM
current lumina with sdxl vae comes in 2b and 5b size if i remember well, the good one is 2b (most trained), it's the textencoder again that's large
ye and you can put that on DRAM
how much vram does the 2b need?
I'll try it with auraflow, but I expect the result to look basically like ideogram
so not usually the most aesthetically pleasing, but technically the smartest

yeah auraflow (or maybe ideogram itself) just barely knows what an analog photo is
lol
yeah auraflow is just one guy
with some Fal money
its a cool project but
it shouldn't be in the running to be the next big model
As long as it keeps getting updates, I'll still consider it a decent contender
it will get a 3rd version, the guy literally said like "block me if I don't release v0.3 by *date* "
I don't think Fal have committed to backing it long term though
🤷♂️
its still wild to me that its apache

yup, makes everything look like a ""photoreal"" cgi image
unfortunate.
niji v6 is incredible


I'm probably sticking with stability models cos they seem the most likely to continue support
I like Kolors as a fun one for the baked in look though

8gb. Though some ru it with 6gb fine (they must be really patient)
What did you make this with?
not bad
i have 8gb
Same; with 16gb regular ram. Though I get impatient and use glif a lot 😄



Hey guys, what is the best configuration for SD3 to generate high-quality text?



Play with the Model Sampling SD3. Try a higher value like 8 or 10.

Which of these should I use? I downloaded them all, I don't know if it was necessary.


It looks bad for me

that's better than any other model
Leonard can do much better things with text. But maybe I don't know how to use the model yet.
not sure that Leonardo is better

Depends on what you want to do. ALL work just different workflows.
If you load the base model WITHOUT CLIPs, you have to load the CLIPs separately.
OR you can use the Base model + CLips and they're baked in ...
Thanks.
That looks AWESOME... it may just be a seed hunting exercise. Also play with the prompt.
I'll do it, the model looks promising, I just have to learn how to use it.
I think there is a decent chance that fine tuned 8B will be able to do those
we currently only have access to an unfinished Beta version of 2B
there is also an unfinished Beta version of 8B on the API but it hasn't had aesthetic fine tuning yet
(which is why 2B currently looks better despite being smaller)
but we can kinda make estimates of what finished 8B will be like
Ok, this is best, work more!























Made with an SD3 + Elevenlahs glif
deep
deepest
Deep ball

something's trying to hatch

anyone use sd3 as refiner?
yeah
your mileage may vary
but it lets you take advantage for the 16 channel VAE so it has that going for it
if the subject is not in the training data of SD3 it might struggle even as a refiner
I understand, thank you for your tips, can I make a little too much request, I have not been able to build sd3 refiner workflow or maybe I simply do not understand how to set up, can you share your workflow about sd3 refiner for my reference, thank you!
both were kolors
Ballz.
This was SD3, which makes me wonder if they both used the same training data?!

any of the guides for SDXL refiner work
https://followfox.ai/tpost/dd5hu3usi1-part-3-sdxl-in-comfyui-from-scratch-addi
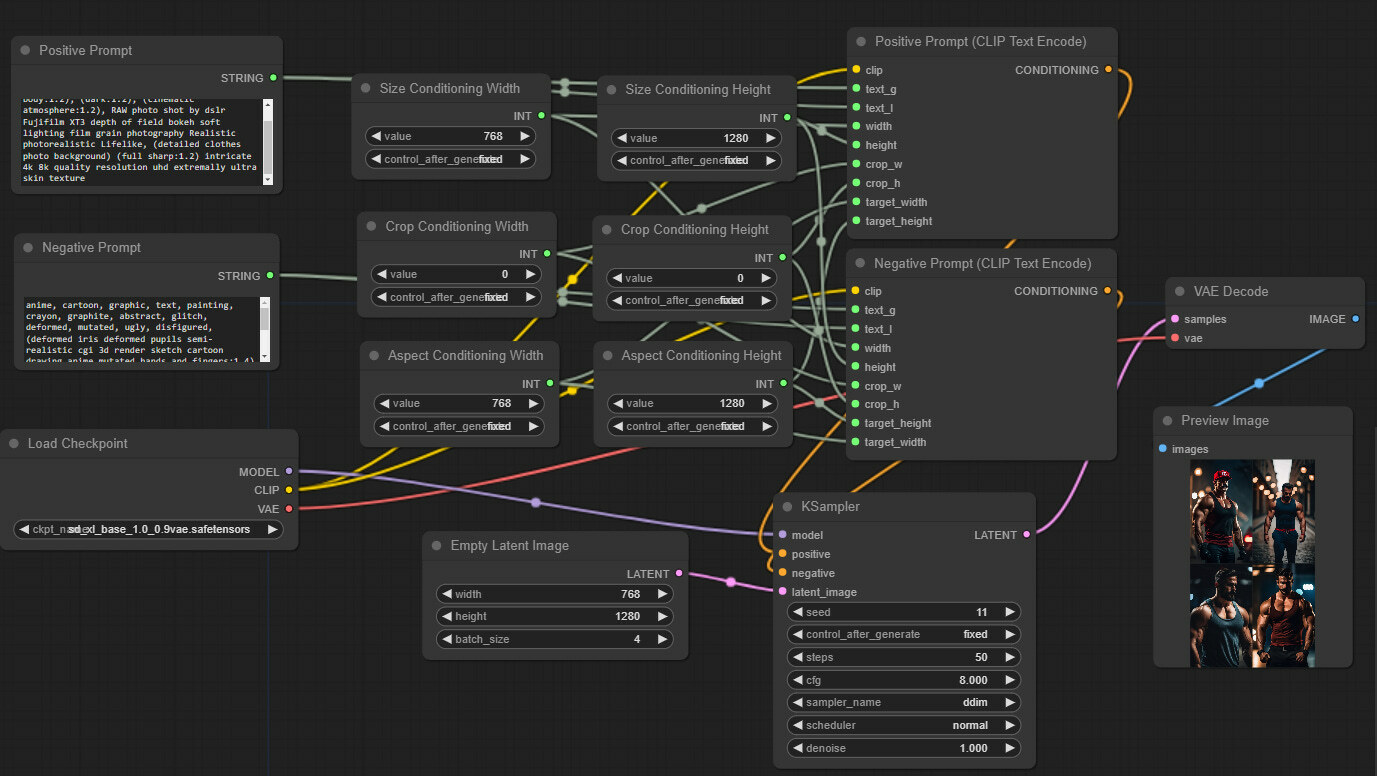
Implementing full 2 model SDXL workflow with the Refiner model
this is using the Ksampler advanced node
I tend to use Ksampler custom or custom advanced, but Ksampler advanced is also perfectly fine
it works a bit differently
it takes noise and guider as an input
got it . Tks
The big thing to remember is that for the real refiner workflow, you need to make sure the first ksampler is set to add noise and return leftover noise. The second refiner ksampler needs add noise turned OFF. For SDXL+Refiner, it's at 80% that you switch. So if you were doing 50 steps, your first sampler ends at 40 and the second starts at 40 and then goes to 50. At 25 total steps, you'd switch at 20, and so on.
Technically, you can also refine an already fully denoised latent or image as well, but I wouldn't use more than 5-10 steps tops
Oh and those directions use the keampler advanced
i like sd3's head more, though kolors seems a bit more coherent less unfinished things in the image (just shows 8b really isn't fully trained yet i suppose).
Same training data? Probably for some part of it, there are more and more big datasets out there which probably are used (Or maybe everyone just scraped midjourney :p)
I just try make sure people know because it's half the reason why people "hated" the refiner workflow when sdxl came out: they were using incorrectly
When used correctly with the base sdxl model, it really was pretty decent. Obviously, with finetuned models, it's not as needed now
everything in stable diffusion ecosystem is written in strange ways, and very poorly documented
I don't mind too much but yeah its pretty bad in that respect
one thing is that noise levels should have been way more explicit instead of being hidden away
would probably also have been better to just explicitly take sigmas as input instead of taking a scheduler as input which has the sigmas inside
In comfyui, you pick both the sampler and the scheduler. It automatically determines the min/max ranges based on the model. Scheduler=sigmas
Obviously though, you can also use custom samplers and do whatever you want with the sigmas
The sigmas just determine how much noise to add and expect at some step, the sampler determines what equations to throw at them for solving
I think nobody bothered with the refiner for refined models, because the model authors didn't have the tools or reference knowledge available demonstrating how the refiner worked and how to train it.
With sd3 there's even less documented material about how we're supposed to manage these weights. They didn't even release official training code. Hugging face put out a 3rd party implementation.
The official workflow for comfyui came out, and nothing was explained. What was shift doing? I've modified that value to extremes and it doesn't seem to do much
they didn't release training code cause sd3 2b medium isn't finished and they weren't intending people to go run off and try to train an unfinished beta model. they're still not going to support that. so what y'all are doing is all on you
It’s true, a lot to what I learned about SD3 like shift I learned from discussions here, tho to be fair they did explain shift in their technical white paper when the model was released it was just written in a way that made it hard for the average guy like me to understand
In case you’re not asking rhetorically, from what I was told shift controls how long it should focus its attention on structure vs detail
Lower shift makes for better detail and higher shift makes for better structure. I think of it like a macro shot or something up close would do good with lower shift whereas a landscape scene of like a bridge would do better with higher shift
What’s your favorite sampler?
Usually dpm++ 2m sde or plain old euler
But you can't use sde samplers for sd3, so for sd3, I just use euler or dpm++2m
I’m a big fan of Euler ancestral for sdxl, I personally have had bad experiences with most of the dpm series. Historically it always has issues with artifacts, I hate it when it leaves like a little green nugget of blur in a key area in the pic. Favorite sampler for sd3 is uni_pc. Never leaves artifacts, works for sdxl and sd3 reliably
I appreciate that
Thanks for explaining. Will look closer at the technical paper
@torn wharf check out this conversation I had with RX last month in regards to shift, there's also this valuable article that provides some technical insight from the paper, #🆕|sd3 message


anyone having great success upscaling sd3 images other than with the SDUpscaler ?
I guess the answer is "it needs more training on 4096x4096 images"

Plenty of success... Upscaling is never a problem...
Have you tried McBoaty?
link ?
GitHub
A set of community node including a universal bus and a large Upscaler/Refiner - MaraScott/ComfyUI_MaraScott_Nodes
thanks will try it

It's got many options... Straight, With Controlnet, Tiled, Prompted Tiled, etc.
Let me know if you need any help figuring it out. I was one of the beta testers.
the problem with tiled is it seems SD3 doesnt give much more details it my tests
it seemed way easier with stable cascade

it seems like the upscale model is doing all the work, not the sd3 model
it's modifying what sd3 created. why are you using it?
i tried both the ultimate sd upscaler with and without upscaler models
in both cases, I feel like I don't get more details after the upscale. just a bigger picture
what do you use?
i don't upscale, ever, with the AI i create with. i upscale images, after they are generated, IF i need them to be larger than they are. and for that I usually use topaz, magnific, or capcut's image upscaler
it's like like a 1mpx image has nearly enough information
it's not worth the storage space to store a bunch of huge images i might never need larger than 1024x1024
yeah depends on the use case, my point was if the generated image doesn't have enough resolution/ sharpness / detail, can I get more by upscaling and the answers seems to point to no
um, no. upscaling alone won't give you more data. that's why you use something like magnific or something else. it'll write the missing data as it makes it larger
I though the whole point to USDU was to get more details

it is


implicit midpoint
sorry I meant to reply to the guy asking what's your favourite sampler
its better to keep the upscaling step separate yeah
I do the upscales on a separate day to the generations
its more like start with low shift
and then only increase it if the image is breaking
low shift looks better aesthetically, but only if the image doesn't break (extra legs, continuity problems etc)
i think shift is the only way I found to get more details
I haven’t messed with it enough to say for certain.
aesthetics tend to come in during the last 30% of sigmas or so
so anything that results in larger steps during the last 30% of sigmas tends to lower aesthetics
this is why Karras schedule is so nice
but the shapes of the composition tend to come in during the first 30% or so
so a tricky composition might need smaller steps there
for SD3, per Comfy himself - the lower the number is for shift, the higher the fine details. the larger the number is, the more focus there is on shape

When you guys put loras into your comfy workflows, do you put them before or after the shift node?
fairly sure that order doesn't matter
sometimes its easier to not use the shift node
and just do a transform on the sigmas directly
or just use an adaptive sampler which negates the issue
the beta scheduler paper is the best one I have seen for seeing the link between when shape + details are decided and the sigma count
they have some heatmaps that show it
i'd put them after.
it matters
i've done both but i was just poking at it and seeing what it would do. i couldn't determine any differences. balls are pretty forgiving to generate though
This whoudl go in the failed diffusions channel if it still existed.
shift is moving the time step...
so if it's just affecting the timestep, it shouldn't matter if the lora is in the chain before or after. seems to align with my loose use of it
It's Wednesday my dude


Not in Japan.
Huh? Denoise level controls the amount of change you want. Try different settings until things change too much or you get hallucinations. If you want to push harder, use controlnet and or tile prompting.
You know the word upscale is literally not more detail, right? 🤪
yeah
more detail is way more related to noise injection than upscaling
oh it's worth trying for sure
I went back to SDXL but you should still try SD3
It is not uncensored
I went back to SDXL because it works better for me at the moment
yeah instant ID is good
fairly sure only face
ok I don't use loras so I will bare that in mind if I do
I will probably just not use the shift node I guess and do the sig transform in the scheduling nodes instead
kinda confused why comfy didn't put this timestep node in scheduling LOL
time_step shift is critical - you adjust this to affect how much detail or how much shape. it would be bad to stick it with the schedulers.
its a weird situation because
the scheduler can cancel out the shift sometimes
I use a node that graphs sigmas and you can get the same sigma graph that shift gives you, with a certain scheduler formula
and on the flip side, a different scheduler formula will cancel out the shift
and the sigma graph will go back to default (a straight line)
why? Instant ID is ok
its not a bad tool
yeah
I'm not sure what was said in your previous conversations about it
so I can't really respond
i guess that really depends on what someone considers amazing, right?
I use a mixture of comfy and diffusers
at the top of what?
diffusers needs more time to be ready
i don't consider either of the images you posted amazing. they're good, but i can get the same sort of look just with a prompt and the right model
thats instant id for sd3?
yeah my usual complaint of CFG too high applies to both of these images

there might be a replacement for instantID but if there is I haven't heard of it
this sort of look is what i consider amazing. it's highly detailed and fairly realistic for the clothing and armor and skin textures and expression (ignore the horns)
not over saturated, or blown out lighting, the water looks good, the rocks look like rocks
It really is but apparantly people are really sensitive about this, so while it's so funny still, i think maybe we should start saying "the tooling will be more accessible sooner than later" or something. just not to offend their skill sensiblities.
of course I can. 'amazing' is a personal opinion.
i'm not really skilled at ambassador stuff
personal taste is personal
rephrase that and add 'to you' on the end of it. and i'll say that your images are, to you, amazing, but to me the one on the left is overdone and the one on the right has lighting issues
and personal taste varies so much
here's a 100 nearly https://ibb.co/album/4nHWyq

so what. you don't like it, i get that. but that's just your personal opinion. right?
matter cannot go the speed of light so it seems to me like an opinion that's untangible is better
everyone's opinion matters. to the person that has the opinion. and usually not to anyone else. but that's okay, because it should only matter to the person that has the opinion.
intangible? untangible? discord says both are legit but i feel wronng
you ever felt like you were wrong before?
intangible - not having tangibility. Untangible - archaic form of Intangible
so untangible is more wizard like. got it
we can agree that you really like what instant ID does and i don't
yeah. like that with most words. they started out with the Un prefix and that turned into the In prefix
unfinite
(CFG too high)
now you're skating on the edge of starting an arguement. is that what you're trying to do?
older than you
you're about ... 18?
my kids are probably twice your age then
and grandkids. and 2 great grandkids
yup. he's trying to start a fight
yeah pls don't take the bait
you are over saturating all the images, so not really
while opinions are valid , telling someone what their opinion is isn't. let them say it instead. small rule of thumb
was bokeh photography a popular thing in 60s?
not sure about the 60s but in the analogue years yeah
cos there are vintage f/1.2 lenses and stuff
yeah they weren't highly produced. i don't think it was a popular aesthetic
not the 60s. that's later
its booba, shouldn't that be amazing ?!
I need to show you guys what TRUE prompts are

I don't know about the history of photography but
perhaps it was not possible to make a precision f/1.2 lens in the 1960s
bokeh came in at the end of the 90s