
#🆕|sd3
1 messages · Page 31 of 1
oh someone else is under NDA but they're telling you and then you're telling us oh okay. its' totally legit then
 i am the source
i am the source
they are, again, not under nda; i would like them to keep their job
is the source the juggernaut model creator who bs'd a bunch of shit while drunk and then deleted all his social media?

@torn wharf I just received confirmation, my uncle who knows someone told me that theres nothing to worry
the source is someone who Actually Knows what they're talking about
i dont want your uncle to die my man. you better not tell me dangerous stuff
perchance a good starter prompt? a jumping off point?

so the man inside your butt?
Okey this didn´t work out so well "upside down house, doing a barrel roll" 😁

wtf lmao
i can see it
the fakest part is probably how you tell us, but then say you cant tell us

self portrait

because i'd like for that person to still have a job
lol
why do they pay your bills with their job?
Dorse.
no, i just think they shouldnt get fired
Yoink is doing the same level of trolling I used to do in the civitai discord before everyone blocked me
That's just illogical, though.
@dusky thistle have you figured out some cool/good settings for 2B?

Of course they're going to be replaced for minor works if AI can do it for them. It's a harsh truth but it's a reality.

what if by not telling us stability loses public interest and is forced to shut down, you effectively gotten everyone fired
yup, thanks to aimingfail i am now using this prompt: "IMG00584.JPEG"
hahaha
That’s gonna happen anyway
oh no, I never thought about file names in prompt xD

There is no timeline where stability doesn’t shutdown or get bought out in the next few months
Has anyone made a full rundown of the differences in prompting between clip_l, clip_g and t5?
DSC001.jpg

its the most cheapest form of bullshit to tell people then say you can't say your source . maybe a journalist can do this if tehy verify the source with their editor. a dude in a chatroom? naw. that's just a dude in a chatroom


The source doesn´t matter, if he wants to share something is fine
the source is that they made it the fuck up

That previous image you posted, was that with Medium?
two possibilitys. 1) you're bullshitting. 2) someone has REALLY been bullshtiting to you
@bitter hearth pls tell me ur using the 2b version
SD3 is really good at everything except anatomy. Wow I’m impressed
Yes, only medium withouth T5
 I am ||not||
I am ||not||
damn i was almost excited :/
Without T5? Interesting.
if there's only consequences from telling people, you're not trying to protect the source by telling people. it's just so dumb of an excuse

It's a waste of time. Block him and move on.
meh, i'll probably get proven correctly one day
good morning



let us know when that day is, that is of course you're allowed to tell us
ill take another look, just put me off with how it didnt immediately click for me like 0.9
Question:
Are some of you only using one of the three clips?
if sd3.1 releases, i'll post it
Was that possible? 👀 😳 I´ll try
the only small problem with posting sd3 pics here is that we always have to wonder is it from 2B or api :3
SD is like windows, every other version is good
I have the non-included model with the three seperate clip models.
That in a comfyUI node you have three text spaces to use for prompting
anyways get [redacted]


oh yoinked hacked into their slack give us more deets
Damn I tried with one

not their slack, im in the Secret Weeb Server
TELL US MORE

wait how did you generate all this text with 2B? :3
waifu diffusion
ew
fair enough
It seems they conflict with eachother moreso than anything
breaking NDA releasing slack details 😮 @viral plaza that legit? was this the beta release? lol i shouldn't bother training loras i guess
again, not nda lol


i need your boots, your keys and your motorcycle
wow interesting
if SAI trains this model further, would loras that we make now not be usable ?
nope
i don't know why dislcosure would get anyone in trouble and fired if there wasn't an nda
i was unsure if it was publicly postable, so i waited for confimation
loose lips sink already sinking ships
loras i trained on sdxl beta sucked

it's a meeeeeeee
Studio Ghibli mario lookin kinda funny
so training it more is different from finetunes >.>
I just hit generate im dumb

loras made now will still work if we release an update
back in the day with SDv1 there were like 3 main updates released and everyone was fine transferring finetunes forward
2B.1

probably gonna be sd3.1
all i know is the ones i made for beta sdxl suck on refines. the one i make on 1.0 dont
2B part deux
electric boogaloo
yeah it was intended as Beta, it got dropped from the name before release and in hindsight that was a mistake
Realistically they'll be a bit misaligned so retraining them (or resuming them) would be better, but they should work
why was this guy sayiung beta was neutared then?
Is there going to be an update 👀
alpha release soon guys
oh and similar for sdxl 0.9 vs sdxl 1.0, albeit that was a very short time period
It is most indeed a beta. Lotta specific generational problems that need to be addressed.
the update is 4B 🙂
lol why is AMD working with SD if SD3 is still so Bad and far behind
well good to know it's beta
there could be. No promises nor time schedule
I won't run it even more
probably gonna get the 8B released before we go back to the 2B
you sad case
(again no promises)
Like I say to any company, keep working at it.
Success comes with time.
this true?

p-pwease~

no that's just a reddit troll that endlessly spouts nonsense trying to cause drama
known idiot just block em
lmao
He's the author of Juggernaut
it's a digital dummy
so? half the model finetuners I know love causing drama
Fair, thanks for the reply. Do you know what the minimum requirements will be for the 8b? Will my 3090 even run it?
i'm just saying thats who he is
actually more like 80% if we're being inclusive
counting merge authors?
im pretty sure 24GB will run 8B
this looked like a damage control tbh, but w/e
eh, just broadening "causing drama"
my real question with all this is how responsive 2b is to training. i think that's what really decides the direction of this
8B will be like running 4x2B
it's not the original claim of "my friend told me the model was lobotomized and the beta ws better"
looks like simpletuner is ready to roll so i'll see what i can do tomorrow
a 3090 can run it. 8B is chonky but still consumer-GPU scale. It'll probably take an entire minute per gen on a 3090 or something. (Not sure haven't tested)
simpletuner 😮
with all tencs?
Fingers crossed. I don't want to have to buy a super computer just yet 😫
the math god

i can't get it working on windows. it wants sh scripts
Welp, rip 16gb cards I guess.
sh is linux i think
From what I've been told it's extremely quick to learn new training
Amazing. Thank you
run wsl for it then
but there are ways to bypass linux stuff and still make it work on windows
(but of course it's public now and diffusers trainer at least is out so go try it and see)
hi im new. using img2img, how do I get a filter/rotoscope?
actually just run everything in wsl since wsl is faster
makes my 4080 run unstable
did you install the drivers
does it start wobbling and stuff?
if wsl is even installed. gpu crashes constantly
Do you also have the nonpaged pool memory leak issue?
8B has the exact same tencs as 2B medium if that's what you're asking
on a modern card the tencs are just like <=1 second to run even if you're using t5
just wait for the quantized version 
dont know. wsl is installed then my gpu just hard faults. the system will keepgoing but no graphics
ok but can my 3060 pull through or will it die
8B probably works as far down as 8-10GiB cards
Actually, Bitnet and mlx stuff is kinda cool
(with fp8 weights)
Can you share workflow of this image?
(but again if you have weak card probably slow to run)
Oh, if that's the case there's little to no difference at all in perplex between those two so
Cool.
great, yeah, that's what we need is some of that demo'd asap
most people these days have like what anyway? 8GB cards?

(there's a reason we want 2B to succeed rather than just pushing 8B alone, and that's 2b runs quick on normal people GPUs lol)
I have the Intel Arc A770 16GB LE.
also pls add pi-chan to this server, it'll run perfectly (i hope)
don't use t5 but yeah it'll be able to run 8B in fp8 weights most likely
Well at least that's a bit more decisive. I just have nonpaged pool inflate to take several gigabytes of memory (up to 20GB or so before the instability is too great) that is never reclaimable and get sound glitches and stuttering until I eventually cave and restart. I cannot for the life of me fix it.

Considering you're giving info like this, I doubt it's that far away now.
is your job safe giving us all of this info like this?
this info is not crazy info or something lol
It's not. I'm being very sarcastic.
will you be running for the state or US senate before considering a shot at the presidency?
oh geeze no i don't have that. just a random screen black out. logs showed something about wsl causing conflict with something and i removed it from windows and things run fine now
lol clown
btw stableAGI releases in 2 weeks (source: dude trust me)
not knowing what is causing it is a pain. i still am annoyed about it since i dont know why wsl caused it


is that DSC0004.jpg ?

The workflow is in the image, you have to open it in full screen and download it , then move it into comfyui
fridge worthy
can someone tell me where i can find how to make a good filter using img2img?
filter?
soap man wtf 
...this server needs a prompt inspector bot thing
soap plushy

🤗

make him stressed from not being able to find a bug in their code for 12 hours
i like it


time to make teletubbies :3
i wish more of the technically minded folk at stability would actively speak with the public, imo we could cut out a lot of the drama and confusion that way
one day
get hit with all this cuteness





thank you for some of the clarification, idk why it's hard to speak up in earnest..
yeah, at a minimum, some consistent communication with the regulars on here would be helpful
we'd be happy to keep ppl up to date and communicate any issues and help look for solutions on weird shit with the workflows/prompt flesh bombs etc
technical blog post updates or something

Love it! How about children's drawings? 😁

When something is so progressive, that banning and not showing things like very conservative people and religions is the goal...
it's too much
alternatively, the religious and conservative people would be the one wanting the csam in there. history has proven this.

come on that is not sd3, that is you posting what some child did :3
sd3 is a child its like 2 days old
bamboo is drawing them in real time notice the time stamps
🙂
its actually ridiculous. Even thinking about prn - nobody is hurt in AI generations while the prn industry... well bad stuff happening there should be no surprise
that sunflower is going to overtake the sun!
no way
you've already got pony xl. how much more ai porn could be needed? it has peaked
fuck

the peak is just the beginning
goddamnit
turn around
plateau is still a peak
haha
@raven fern what is your picture character name

pony made a lot of avoidable mistakes including not using caption dropout which screwed up CFG... there's a lot more to be done, trust me lol.
it's Gojo from JJK
so pony 6.9 gimmikcy name he's giving it. he'll do it there. i'm not sure why the new architecture is so important to the porn users
people like what people like
i really do not know why. but literally all of the NSFW finetuners collectively decided that caption dropout wasn't important.

clown you aint foolin no one, i recognize that watermark anywhere

@raven fern probably doesn't know him

well i dont know all the anime out there :3
What is caption dropout? using capions instead of the tag system?
and then suddenly everyone wonders why their model is hard to control and then people end up with mile-long cope negative prompts because their classifier free guidance is broken because the model tuner didnt know what that is or how it works...
The city lay under a peaceful blue sky, unaware of the impending doom. Without warning, a blinding flash of light heralded the detonation of a hydrogen bomb, a moment of pure, unrelenting brilliance that outshone the sun. In that instant, the heart of the city was consumed by an inferno, the epicenter of which reached temperatures comparable to the core of stars. Buildings and all forms of life in the immediate vicinity were instantaneously vaporized, leaving behind nothing but scorched earth.

I meant this was your character as a prompt, sd3 probably doesn't know it lmao
oh

if i understand it right, caption drop out is good for teaching the model to fill in details where a short prompt is given. so maybe don't want it to learn to fill in the blanks as much
they WHAT
i mean when did JJK anime release, i actually forgot, newer models should know about it

and Gojo within JJK is a very popular character
mfw the most popular xl model is made by a clueless person
as far as output, sdxl is all porn users need
at first i thought it was doomed, then i liked it, then i thought it was over, and now im neutral; please i want to get off this ride


there is no stopping
porn has never been a very varied media
imagine trying to make an awesome model by yourself
Clueless right
It's more complicated than that. Classifier free guidance needs a robust model of the mean of the data distribution. It uses this during sampling to figure out what isn't in your image. Without caption dropout, you get a weaker model of the mean of the distribution, and train it for long enough and the model will be harder to control.
some of the most brilliant people were raised by idiot parents


 maybe I'll be a good parent
maybe I'll be a good parent
how can a model know what it doesn't know
he forgot to turn on "don't make model overfit"
right! thats a quality explanation thank you
its a me... mario


your kid is growing up fast
if you squint a bit you can see a face in that explosion


I wonder if cats have more images than dogs in the training data for this model
i hope not






lol it thought it was one of those slider images to see the before and after

now that I know this is a beta i'm okay with the quality

but yeah this doesn't have to come as a surprise lol, I always check what blank prompts return on a model (SD3's uncond space is 80% white/asian women). every single furry model except for like, the very first one and the latest finetunes I've done has had a fucked unconditional space. even seaart has uncond issues (it has base SDXL's uncond space mostly, but that seems to be because it's severely undercooked)
side note there's also a lot of weird high frequency noise in the uncond space? not sure what's up with that.
ETA on custom scheduler mixes working?

thanks

having a lot of fun with this node

im just making random random

meanwhile i'm hacking torchdiffeq solvers in

hackerman 😮
shit, any chance of gettin gmy hands on that?
i need to check this out
i've made all kinds of crazy scheduling stuff recently but not that
once it's cleaned up and in a state suitable for release
wait is this a custom node you made yourself?
oh cool it can do tattoos

i am totally cool with non-release ready code... been writing a ton of nodes lately myself
do you like really unnecessarily precise floats?

oh so like SD3 quality release
doodle white 3d model of a stickman running in a desert with water powers and the sky is purple
damnit
this is adaptive heun


try using ancestral 1/f noise and sweeping the frequency over the steps... fp64 actually makes a huge difference
yea clown's workflows are like an ai generated pic 🙂
yeah, i took the RES sampler and scheduled absolutely every parameter and got a huge boost in quality, best i've ever seen from sdxl
Dopri5 just really doesn't work as well as I would like it to. SD3 is a very stiff ODE.

we can say that you got some very good RESults 🙂
scheduled the noise amount, momentum, c2, noise type, noise mean, phase separated and blended the channels yada yada, custom schedule,

do you guys have githubs or something so i can know when custom scheduler support is out?
lmao the API censored my cocacola spilled on keyboard prompt xD

what do you mean by custom scheduler exactly
lmao
that is illegal 😮
sd3 drinks pepsi confirmed
https://github.com/redhottensors/ComfyUI-Prediction it'll probably end up on his github since he's the one who actually made most of it work but here's another thing you can play with in the meantime

GitHub
Fully customizable Classifer Free Guidance for ComfyUI - redhottensors/ComfyUI-Prediction

https://github.com/ClownsharkBatwing/RES4LYF i have everything here, just set it up recently so i haven't had a chance to get descriptions, but if you serach for "sigmas " in your comfyui
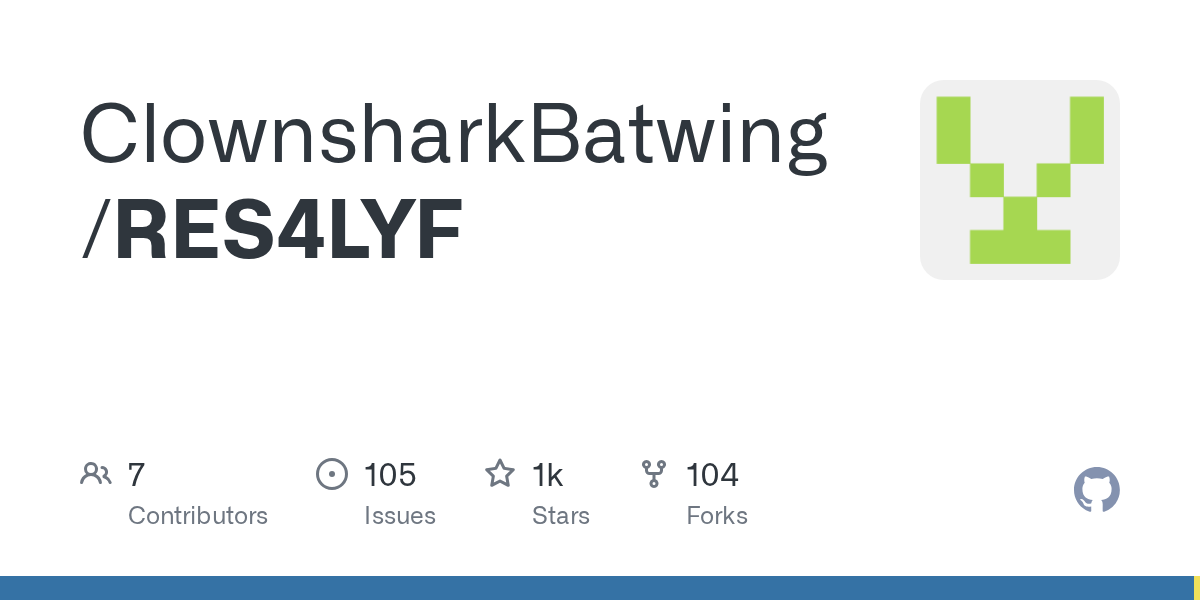
GitHub
Contribute to ClownsharkBatwing/RES4LYF development by creating an account on GitHub.
idk if you meant sigma scheduling but anyway there it is


nice
yeah because when i use the custom sampler with this scheduler mix, using the sigmas input, the image gets messed up - thats something i can fix though?
Fehlberg2 is probably the best solver I've tested in terms of speed vs results, this only took 7 seconds and is at least decent. Low effort prompt though.

why couldn't we get the api model
8B is still cooking
yeah that's easily fixed
well it's cooking on the api just fine
would be awesome to get an update for it
this is it then? nice
i have a bonus version of samplercustom in my node pack, it's called SharkSampler and has a bunch of noise types added
shark sampler 😮
It's going to be better when it's fully baked.
This isn't the solvers but it's something else to play with from the same author who will likely publish the solvers node.
use my "Sigmas Math1" node, and set max to 1 and min to 0, turn on rescale, and you can punch in any crazy formula you want


ya but why can't we just keep eating why do we get to eat once every few years
you are all so helpful thank you
np hit me up naytime with questions
now all i need is sigmas input for sdultimateupscale and im rocking
am i going crazy or sd3 seems to generate car pics seen from behind
it could also really use a turn added noise off option
backside makes the cars sfw
so you could unsample instead of just adding random noise
Not noticed
are you saying the car is too sexy :3
holy shit it decided to do something other than block text on its own

wait til you see what they do with sd3.1 alpha-git-3234
How do you implement ClipTextEncodeSD3?

this you can use to do iterative unsampling


Please explain what this actually does
What does this do? 🙂


my mouth is watering and i dont even understand this
What are sigmas, and how does this change the image output?
dont worry, its only for people with a PhD
I asked my gf about iterative unsampling?! She said 'we can do it later!!!' 😉
can make image gooder, very much gooder


A sigma is a curve - adjusts noise densities to enhance the output ...
sigmas = measure of the amonut of noise in an image. when you're denoising, youre lowering the sigma value gradulaly in steps. karras, exponential, sgm... they just change the shape of that schedule/curve. the effect is HUGE
Just change your sigmas and see!

enhance the booba
iterative unsampling... unsampling is a way of adding noise where the sampler basically predicts the noise that would've led to that image, so it's non-random
Thanks, I've noticed how you get completely different images from different schedulers
so you can do a tiny bit of unsampling, then denoise, unsample, denoise, unsample, denoise over an dover, and get a huge change in the appearance with very little change in the composition witohut controlnets etc
I tried that image scoring thing. I'm surprised ar how good some SD3 ones were. Feels like the stuff that it's trained on it's very good at. Visually wise.

Damn that's cool

this is what my WFs look like now


lol
@dusky thistle import of ur node pack failed 😦
uh........ no other info in the terminal, requirements none?
wut?
time to debug 🙂
(tech support srry) --
math
matplotlib
pywavelets
functools
typing
numpy
builtins
itertools
it's in requirements.txt
hmmmm, didn't work so well

yeah it's finnicky with sd3
there's something with the schedule i need to sort out, for one you want to ensure that first step isn't at 0, and that other steps arent' the same value back to bakc
pip -r install requirements.txt returns could not find version that satisfies ... (none). pls i hope its not user error im kinda dumb
so you might start at 0.01, then 0.3, then 0.01, then the next chunk: 0.011, 0.3, 0.01... etc, last one ending at 0
wow, trending on artstation prepended really does help a lot

kek
lmfaooooo found this on civitai

Trending on Furaffinity.... seems to work as well.

casually grabbs a black whole

yeah idk, try just doing them manually, it'll only take a min
art station makes em too cartoony for my taste

fair nuff, ty
you probably have most of them already anyway tbh


lol
average pokemon the trading card game reseller
classic political humour

There are either too many porn users or some of them are not porn users. More people use Pony than SDXL (across all derivatives, I only have data from CIvit).
It's a very popular base model (yes, despite being a finetune), so a lot of people were excited about a new base model to build on top.

I can't get anything to work 😄


try with sdxl first it's easier
im personally not into pony model, but i have to applaud you for reaching this level of popularity i guess :3

also you want to use somethin gancestral, RES is best
and even reach to the point it is becoming a drama...
haha
tbh I think it is the fans who tried to create the drama
nice sonic oc
leaked sonic movie 😮
The people who are so mad about model licensing being required for fine tuning are another subset of pony users that are very reactive and irrational. i reckon that most end users haven't been keeping up with news and many don't know sd3m is even out
You're not really finetuning if you aren't causing drama.

goodnight!

i swaer i've heard of the idea of a crystaline sonic at some point. sd3 sure knows sonic well tho.
@dusky thistle are all the pics you are posting with t5?
I mean... I am not talking about the Pony model if I understand your sentence correctly
I am talking about the whole Lykon-AstraliteHeart rap battle
( and also fans )
I think calling passionate users "reactive and irrational" is wrong.
sd3 seems well versed on popular characters


what is your prompt thats amazing
Yeah. Two finetuners. Drama. They're definitely finetuning.
action photo motion blur, the joker falling from the stairs
i think being honest is important

now I need to do falling + selfie xD
i would be more impressed with lesser known characters :3

well... its a general model, there can only be so many
yea
One got bashed on being critical on SD3 license over decision to make new model based of SDXL
Another one just literally say skill issue lol and getting resignation threat from peoples. Yeah it is pretty suck.
Rational person in r/StableDiffusion is like really rare

SD3 Original, then SD3 into LoRA and SDXL and Face Detailer


rational person on any of the AI subs is extremely rare. you've either got coomers spreading nonsense when they don't understand jack shit or people who absolutely cannot read a room if their life depended on it
I think neither both side don't actually wanted this lol.
And well, everyone just forgot Juggernaut's creator RunDiffusion who somehow get a thing from this too.
yeah


@muted dove here's a workflow (in the second image, first was the source... prompt was "ice")


or basically "WHY THIS CANT MAKE PORN" porn guy



Hmm this is what it thinks elon musk looks like

I do love being in the ideal position to talk down to coomers on the SD sub since I actually do NSFW finetunes and understand how the process works. I never get tired of telling people that SD2.1 tuned for that just as well as 1.5 despite everyone insisting it couldn't be done.
@simple thistle does this just mean that now sd3 loras can be used/loaded? https://github.com/comfyanonymous/ComfyUI/commit/ac151ac1698624bc4e321addb8c126069aced4b0
i even tried elon musk as elon musk
People complain too much
By the way anyone who wondering why RunDiffusion is involved in this because originally he also tried to get early SD3 access like AstraliteHeart did. And he get the same response as AstraliteHeart.
RunDiffusion chat to AstraliteHeart here a week before the release night, I dont remember what kind of topic they talk to
And yes that means sd3 loras trained with diffusers work in comfyui if you update
nice
... I mean girl laying on the grass issue is a real concern and one of genuine complain on SD3's anatomy knowledge. But yeah I agreed
If you want someone to blame for this it goes back to when Emad was CEO
But have you considered that I have no creativity and cannot think of anything to generate other than pictures of women?
i did nothing wrong
I think he is just trying to get this drama as far as possible as he didn't have any response recently
LLM is here for you
But seriously why is the uncond space like this? Binders full of women.

Karen-ified
That's a completely different image. At that point you can throw paint at a wall and load it as an early latent.
And whatever's going on in that fourth image.
head on collision

... huh?
but i wanna see the actual moment of impact
I don't understand why, but images with no prompt are 80% pictures of women. Were there just like, a shitload of pictures of women in the dataset? Because other than that the mean of the data distribution shouldn't be like that.
sd3 medium uncond (no prompt) gens are a mix of random whatever. And sometimes HD humans lol that's weird

generate a car crash
he was distracted calling his gf

....Well what am I doing wrong then? I'm guessing that blank prompt is not uncond then?
well that's cursed but i got a few womanish things

i'm doing blank prompt here
blank prompts sometime generate stuff of nightmares
steps 28 random seed empty prompt empty negative prompt
Eau keigh! Where should I get that paint?! 😉
cfg at 5 but that doesn't apply when prompt is empty

Errmmm ...
i mean this should be in tech support :3

Might be down to luck, I guess. 4.5 CFG, jury-rigged fehlberg2 ODE solver

jury-rigged fehlberg2 ODE solver hwot
a friend and I set up a comfyui node for using torchdiffeq solvers for sampling



btw yesterday I got my 2GB VRAM laptop running

10 minutes for 1024x1024
Nice, do you mind sharing the prompt? 😁

it diddent follow most of it XD
dashcam pov phone photo of my car in a car crash airbag diploid with another car right infrom of mine thats mid exploding
tried doing it in first person for some reason
For Sd3 the higher order samplers don't seem to really improve the image
still no actual impact :3
They have a similar effect to raising the cfg
haha i like this one
Now we just need a Repo that makes that possible (crossing my fingers that OT figures it out today).
???
simpletuner is ready to go

Eh, I've had better results with Heun than I get with DPM++ 2M and better results with DPM++ 2M than I get with Euler. The Fehlberg solver is adaptive and is pretty damn fast at solving.
Diffusers has a readme that explains how to train sd3 loras
it only accepts one caption for the entire training set, apparently
identifier training?
Like 6-7 seconds per image on a 3090 fast
i could be wrong but that's what i was told over on the HF discord
But the Loras are pretty basic, only the x attention is trained
but regardless, apparently simpletuner has SD3 support now... i'll give it a shot tomorrow
time to train those sharks
ah, so i believe OT is currently working to build their loras off the diffusers code as much as possible... would that mean they might want to look into their own implementation?
im personally using OT, so il be waiting patiently
I'll have to implement the more complex loras once someone actually makes one
yeah i laughed when i was told that...
buuuuuuuuut MM-DiT doesn't have cross attention 🤓
the x attention is the one for the image stream
Simo Ryu The Cat :
oh welp
the cat is busy training his own MM-DiT model
Is negative empty too?
yeah

Which are the higher order samplers?
Which parameters / samplers are you using?

higher order samplers are the slower ones like Heun and DPM++ 2S a

dpmpp 2s a being noise adding just fries the image to a crisp
heunpp2 (slow) and dpm_2 seem to be best
Basically any sampler that uses output from more than 1 step ago is higher order
Too bad I can't test it atm. Definitely gotta test it later.
This is what a 5th order sampler (Dopri5) does

uni_pc for example is 3 order if I remember correctly
(this is actually exceptional most of the time dopri5 looks like shit somehow)
i look forward to your sampler nodes, greatly
long arm woman

i am getting kinda obsessed with sampling

What? ... that would make it utterly useless.
Back to v1-4 days.
Please let someone proof that "Finetunes even better now!" was not BS PR talk as well...






im assuming by now you have seen all the research papers on sampling 🙂
yeah i'm not sure why anyone would releasing a training script that only offers the option of using one Caption to Rule Them All for the entire set.
I prefer Euler the simplest sampler
that just some super basic LORA training
my boi Euler
crazy, crazy good results with RES if you carefully tune and schedule all the parameters according to the steps
(with sdxl)
gigachad euler
dosen't work with sd3
euler's just DPM++ 2M but blurrier in my experience

idk, if going for text I'd recommend Heun, I always get mangled bullshit if I try Euler
No kidding. I saw your Sigmas Workflow. 🤣
yeah hit 541 nodes and realized i needed to finally just start writing my own nodes lol
metadata was twice the size of the image data
holy nodes batman
one generate button in a1111 > 500 nodes 👍
Just one thing with SD3, the "sigmas" go from 1.0 (100% noise) to 0 (0% noise)
How do I solve this?

The more i use SD3 the more i love it

No weird math
did you remove the file @noble coyote
That's a surprise. Is it also faster?
I always feel Euler is kinda bland.
Euler

DDIM is also nice
that is nice and clean indeed. felt a bit like the english system, remembering "1.5 sigma to 0.01 will just barely keep the composition" etc
But you made that into Euler!
Either I cannot find it (I have searched?) or it is on the Git Server?
i tried some ddpm and ddim stuff, gives nice results
@signal shuttle I like your name, here is the image

Tell me what you see in this random ink blot

also shift of 4 gives good results too
DDIM is euler
tbh, denoise percent drives me nuts, it deosn't translate fairly from one schedule to another, the sigmas are way different
my goodness what kind of weird problems are you having...
The bad thing with previous models is that you don't get true 100% noise with the sigmas
it can do funko pops?
Another "backend" of car

OK, deleted ... will try again 🙂 Thank you
SD3 math is more simple and was supposed to only be sampled with euler
yes, prompt is in the file
And shift 1 & 2 can sometimes help with anatomy (sometimes).
But I sort of made the other samplers work
SD3 makes people too tall and stringy ... ?
yea what is up with that LOL





Everybody often becomes Wilt-the-Stilt!

humans are complex beings mmkay

Especially for SD3 😄
kek

just missing a crab 🙂
"Hands are easier than text." - not if deliberately butcher your own data. 
Ooooh!!!

cyberpunk dlc leaked 😮
LOL n oway

From the front!
...But the original rectified flow paper was using Dopri5. You can use any ODE solver with rectified flow, which Euler is one of but not the only one.
nice one
Here is your crab



But yeah dont even try using SDE solvers, they won't work on this at all lol
Nice!!!
awww come on... it has to be on the beach... you know...the beach episode 🙂
yeah, or anything that adds noise
I know you can use any solver that's why I made them work
What was the prompt and workflow for these?





I don't know what beach episode is about but here crab

beach episodes are for men of culture
Basic workflow with the prompt "Still image. What an amazing day to spend the day outside. picnic.
30 years old Female jumps up and waving hands. grass. Kindred smile. bokeh, lightroom, portrait, cinematic selfie. Instagram. Journaling. Sunny weather.
Text on sign "Don't touch grass""
i'll admit i do miss having noise to work with as it did give me the ability to fix almost any mutation in SDXL (the noise amount/type scheduling stuff)

But if you want to experiment try sampling SD3 as a vpred model
why did I try using dopri8

Apple fan boy? 😄
It actually works a bit
That's the only token I'd love to see being pruned from all Datasets.


based, anything politics is so annoying lmao

My bro once got an award from Dave Prowse - the actor who played Darth Vader!
sadly no kim jon un 😭
I can hear "Crab Rave" in my head right away.
hunyuan DiT can make the flag of every asian country perfectly except one
is it french
Smack my b* up!
that's a chinese model
let me guess either chinese flag or japanese
oh asian countries not any countries LOL
I like apple, but I thought that it would be fun to mix high tech with pastoral theme
the country is taiwan
-100000 social credits
damn it, i was close
"When is SDHunYuanDiTMobiusPonyChickenFeet coming out?!" 😄
Taiwan
Pixart 3 coming soon 😮
really?
pixart omega
wow, this was not worth the 11 minutes it took to solve at all

I just love PiXart-Sigma
Is it a tuned SD3? 😉

its a merge between pixart sigma and sd3

There is one more solver, but it wants to take the Jacobian of the model, and, well...

whaddya mean, I need more vram 😛
use virtual memory!! and wait 5 years
the word Jacobian is giving me ptsd when i was implementing the 3d physics in my game engine , nuuuuu

see I hear Jacobian and think Jacobs - if it took more than one shot, you weren't using a Jacobs
@simple thistle Is there going to be a way to use SDXL loras with SD3, or even merge anything SDXL with it?
lol
The arches are completely different
there would need to be xadapter for it
So no
No SDXL uses Unet and SD3 is MMDiT
sdxl is an unet, sd3 is DiT
but apparently there IS a sdxl and sd3 merge
Same image using Euler and Heunpp2, in that order


xadapter the way it's implemented is not really great tbh
but without vector-jacobian products we wouldn't have automatic differentiation and we'd all lose our fucking minds writing our own model backwards passes
you can use the sdxl lora node to grab the clip to feed the encoder - doesn't help much 😛
a bunch of crabs dancing in the club, photorealistic 4k , 4/5 ★★★★☆

Really?!

This is a very exprimental merge between my SDXL enhancer and SD3. I merged my own enhancer and a model I am working on at the moment (DEMONCORE 4 ...
2 identical clips, so can merge those
i like the cat and fish pic there :3
it does a little effect better

Oh, I've seen this rubbish 😄
I tried it myself too, but it's not worth the effort.
the only thing you can reuse from xl is the text encoders if you trained them
ouch
That image will have the workflow in it

ginger 😮
You could apply the CLIP part of an XL lora on the SD3 CLIP
I have to wonder how IP Adapter will end up working. I guess you'd just have to shove the outputs of that into the text stream or something?
workflow in pic above if you wanna try it 😛

Crabrave 
I have done this, with several different model clips, but it hardly does anything noticeable.


There's a few ways things could be injected in the mmdit
it became the wine


Probably don't really want to mess with the text encoder unless you want to train it afterwards. Only thing you'll really get is a model with a misaligned text encoder. Which can sometimes increase variety. But if you want to do that just like, skip CFG for the first 10-20% of steps.
!

How are people filling in the T5 text? I'm taking my prompt and running it through SuperPrompter bur I'm sure there are better ways
i like donuts :3
Donuts don't like you!
Runs away
Doesn't it do it automatically if you connect it to the SD3 prompt encoder?
I thought that was the point of it
I had read that people are filling in the T5 text with text and then padding with commas, so I thought you can fill it yourself, like here... so you're not supposed to fill out that third text box?

I feed text into clip_g and t5. I think the t5 text will be enhanced from that.

I leave clip_l empty because I've found it to make things worse most of the time.
Trying each individually, clip_l creates a nice image, but doesn't follow the prompt.


OK cool, I was doing that before, just wasn't sure if T5 needed to have a more complex "purple prose" prompt input into it
I don't know if there's a way to see what text the encoder creates, but I just hope it does what it should 🤣


he's educating himself
where is it..

sex


is 16 gigs of ram not enough for sd3?, comfyui always crashes with a OOM when trying to load the clip models
SD3's portraits come out horribly.
trying --lowvram works

Sd3 human generation be like :

lol
stay away from those anomaly




These two are bewitchingly beautiful (SD3 into LoRAs via low-noise SDXL)



Amazing
I am really struggling to understand how people are getting results without huge amounts of noise/static in them
wdy mean by that? most of us sharing direct comfy ouput images, so you can download the images and load in comfy to see the settings. i never got any noise/static so far



It seems as thought the static I am getting is from a lack of steps
20 vs 30 on the same image


big difference
im using 30 steps, but it might related with your prompt as well. are you upscaling?
Huh that is an unusually big difference if all you are chaging is steps
I am not upscaling. Does anybody have a recommended workflow for that? I found that it results in lots of issues
ohhhh
I wonder if its this

by adding 50% more steps, there is a bigger time of activity/inactivity

yes im using the example workflow but i customized the upscaling parameters. please download one of my images and try it out
will do, thanks! <3


yeah, so 30 steps is 100% needed on these images


anyone know what causes RuntimeError: CUDA error: invalid argument
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions. in comfy? i feel like ive fixed this before but i dont know what the error is


uhhh
is that allowed?

IDK, its kinda gross lol


was there ever a SD model that was good with multiple people?

My SDXL detangler fix made it a lot better with crowds and such
Prompt : "handsom and happy innocent man "
Sd3 :

SDXL was also bad at that stuff, but not as bad. I feel like SD3 is generally not as good with humans
it's really good with text and landscapes though

Eldritch Horror lol

My SD3 detangler should monumentally improve that, assuming it works on SD3 like it did for SD1 and SDXL
Just need a trainer that can make LoRA's for SD3 and I should be able to catapult the quality of SD3 leaps and bounds ahead. Again, assuming it will be as receptive as SDXL
With my 50 image detangler, base SDXL went from ass to competitive with finetunes like Juggernaut X
and examplke of the before and after of my detangler for SDXL

and a couple more



and this was using only 50 images to de-tangle too
I have a new 6k detangle dataset I am hopeful for with SD3


is it a LoRA? can't find it
Its not released. I have companies interested in buying it as a service I provide
if it ends up working on SD3 half as good as SDXL, I will release a new base model for SD3 that should be monumentally more stable
so it is good for training?
I am hoping I can prove just how powerful it is for SD3. That should get companies to fully bite/commit
Isn’t sd3 multimodal?
Simpletuner can make SD3 lora
It makes it way easier to train things yeah. It de-tangles all of the overlapping concepts. For SDXL it make the coherence monumentally better, the res flexibility (native 256x-1200x) way more consistent. It got rid of duplicates at extreme aspect ratios, and improved overall concept separation and prompt adherence
Publicly?
Yes
I have my own personal reasons for not using simple tuner that I am not willing to budge on at this moment
Political, or problems with it?
Personal problems, with the dev of it
oh
Is it enough of a problem that you'd suggest others avoid it as well?
He and I were once close friends. That time is no more unfortunately. I don't wish to trash talk him, so I'll leave it at that
haha, it is better at making aliens than humans

Can the time restriction on posts in here be lifted now?
well i am just hoping that SD3 could somehow massively improve Text to 3d generation through multi view generation
They are much better now. Earlier it was 60 second slowmode 😅

Is there a paper on the concept behind this or anything? I'm just curious.
Anyone got a UV light? 😄

For my own personal reasons, no there is not. Its a very close guarded secret of mine that few know 😅
I have had a job in this field before, and I lost it due to a horrible action taken by Civit AI deciding to screw over the company I worked with. I have been out of a job for about half a year now, so I need to hold onto things that can get me hired again at other locations
Of course, if I have a steady job, my willingness to share information will increase considerably
Well good luck with the job hunt because I'm curious with what the hell you're talking about
I might test that today. I always train the Tenc for XL LoRA's.
I... uhm

So you are just flexing
Like I said, if it proves to be a big help to SD3, I will post it for the community as a base




CFG-eez nuts


Mine seem to be noise-free ...

Mine was too few steps
Seems like dark scenes need them a lot more

Good to know ... !





SD3 into SDXL (low-noise) +LoRAs



I'm using 40 for everything, then pass to a second ksampler with 10-20
OpenJourney the old SD2 checkpoint used to do great foggy photos adjusting iterations and cfg
SD3's consistency with things like fences is honestly stupidly impressive
If the community can figure out how to fix the funkiness of SD3's compositions, I think SD3 will truly leave SD3 and SDXL in the dust

damn looks like we need noise offset for sd3
like, I have never seen an SD1.5 or SDXL model that could come close to this level of consistency

Try and get the mesh of a Shure Microphone right in SD3? 🙂


I can give it a shot, sure





Hilary Clinton?
I am having this weird problem with SD3, where if i use the SD3 medium and then load the clips afterwards my ram crashes, however if i use the SD3 version which has all clips in it, it doesn't crash!?
at 20yo was the prompt 1920 photo
Once upon a time I worked at the US Embassy; and I (nearly) got to play Croquet with Chelsea Clinton! 😄
She was 15 years old, teeth braces and white bobby sox
20yo anne frank

Sad story. She gave hope to so many people 😦
Yup
As somebody who has spent the last year trying to train good realism into SDXL... I really do have to applaud how phenomenal the photo realism of SD3 can be. When it does scenes right, I can find hardly anything wrong with them. They seem to have monumentally better dynamic range, tonal contrast, and fine detail rendering than even ideogram and MJV6, and I say that as somebody who is still highly skeptical of SD3
SD3 has great visual acuity alright!
Yeah, I also suffered from the gradient checkpointing
No really though. It can achive a level of fine detail consistency and realism that I fought so damn hard to get out of SDXL, but it just flat out never could
I agree
I am just worried people will tune it back into dreamshaper vaseline skin and orange peel lips 😭
Anatomical catastrophes aside, SD3 has a great future!
yeah, I am really starting to feel that the more I use it
lets hope for a 3.1 😄
I have trained hundreds of LoRA's for SDXL. The easiest thing to fix was hands down always its composition. But you could never make the fine details better
Well... Thats a take lmao

And licensing issues 😅
Great spelling! lmao
the license are fine though.
90%
right. also ive only seen 1-2 checkpoints where you cant make out its ai. and thats with boring reality lora etc. SD3 hands down passes the realism test in many cases
SD3 renders a nearly perfect prompt: "BMW X5M Competition" 😱
I mean not for those who wanted to sell AI art sure, and the Civitai
SD3 can make people overtall - lanky and slim - like Wilt the Stilt!
elvis

SD3 + SDXL + LoRA

Yeah, I have seen a few things from SD3 with photographic realism where I have actually been floored. And I am probably one of the single most brutal and picky scrutinizers of how bad image gen models are at realistic world depictions
SD3 +SDXL + LoRA
Good job, Stability.


My two issues with SD3 are: overtall, lanky people; and oversaturation (like the old SDXL 0.9)
Hands are something easy to fix. I can do it in no time when I have access to proper LoRA training tools
adolf hitler (not an endorsement 😆 )

...-ish!
the hairstyle is different

And so are the murdering eyes!
When I first saw SD3, I was super disappointed. While I do think it has some huge fundemental issues, I am confident that the community can easily fix them (I am looking to do my part)
ill remove the 25yo and see how close it gets
SD3 vs Dall3




SD3@ClipDrop is superlative!
there he is 🔥

@compact forgeMay I ask what your prompt looks like for these images?
good quality photo from the 1920s of...
HOLY WORKFLOW
no negative prompt

it has comfy metadata if you want my upscaling setup
I just loaded it, and I am overwhelmed
this reminds me of my furry art workflow lmao
some of it is just leftover experimentation
A lot of red

lottaaa red

You know he worked for the Austrian Post-Office?!
Hitler, Einstein - are we having an Austrian day-out?


you cant fault his fashion
lmfaoooo
i think you can bypass most of of these nodes
I am reinstalling node manager to see if it can download what is needed
Standing couples - the one on the right consistently loses her right leg!!!






They need to be muted for ComfyUI not to complain 🤷♂️
If I knew what they were specifically, it would be a lot easier
I feel dirty

wow, top right one
Yes, second one is a dead-ringer
4th one he looks too benign to be a genocider
my workflow isn't as complex, but it seems to do it as well
inspire pack and BSZ, and maybe one more
I have to install 9
also, BSZ is one of my close friends haha. Dude makes some very useful nodes
why dont you have TonemapNoiseWithRescaleCFG? thats a default node in the experimentation menu 😆
So..it sucks for everyone? Don't care about selling, but used as a base for trained models and stuff for civitai, is what got SD where it is.
I do care about portraits. That means I'm to stick with gimped, borderline unusable base sd3 as it is, or pay up for the api, since people can't fix and upload to civitai, no?
You mean you don't share a leg with people?
I borked my whole install. I don't even have the experimental nodes installed
It's the consistency that is worrying?! What has SD3 against right legs at all?! 🥳

text box xD
The right leg is the sexy leg.
That's not argumentative for the sake of it. If I'm understanding something wrong, please enlighten me.
A woman in hysterics

Oh yeah! Puritanical SD3 already!!! LOL
Can I just replace it with a string primitive?

ill make you one with all the unused nodes removed
Gone to Trinity Buoy Wharf ... ! L8ers
awww, thank you <3
I appreciate it a ton
For now you could post the better SDXL base - which would be very appreciated as well.
A woman in hysterics, she is sat in a dark living room facing away from the camera, behind her on the LCD widescreen TV is a documentary about cats.


Its not in a stable state as of now, and its no better than the other finetunes people can use right now. It makes no sense to restart over from scratch. Its the main reason I stopped wasting energu fully training it and instead prepared for SD3. Its very promising, but just that, a promise, not a deliverace. Maybe when I have some more flexibility and reason to dump the compute into that, I will
Its a great foundation, but only if you wanna have to train in all your own aesthetics and concepts. Its literally just base SDXL, but not messy
My time is much better spent preparing for SD3 training, cause that is something I do have plans to share ASAP
here you go 🙂

thank you!!!
My SDXL de-tangler is very very impressive on its own, but its past its point where it would have been game changing. If I can replicate that lightning in a bottle, I could seriously change the course of SD3. I just need to be properly prepared and in the right headspace
but after seeing how much fundamental promise SD3 has, I do want to dedicate myself to trying to pick up the shattered coherence so that the incredible details and aesthetics can shine through more
really wish you could, at least very abstractly, give some definition of what de-tangler means
My de-tangler specifically targets bad composition and element coherence, and not details, which is where SD3 needs the most help

It's like a hair comb for a diffusion architecture
This prompt will be sd3 trademark 😄
is that something you're doing through training data, or something your doing by directly modifying the way training data is applied to the model?
In a sense, I created a dataset using lots of tricks in order to show a modified training scripts exactly what I do and don't want. Think of it as a poor mans adversarial training. I got it to discriminate on its own faults to target fixing them very very finely
I call it a de-tangler cause of what @storm saffron said. It takes all the scrambled and frizzy strands and concepts, and combs through them, making them less likely to step on each others toes
Anyone want a 'jailbreak' for nudity? LCD widescreen TV showing a documentary about an all female nudist colony LOL I had to try
and it results in monumental coherence improvements like this in SDXL base

not really, I tried this prompt a while ago with the workflow SAI made and it made weird monstrosities, I just kept improving my thingy
and no, that is not cherry picked. I actually have a grid of 3x3 somewhere if I can find it
another example of how it fixes ultra wide generations

is there some sort of pre-prompt for this stuff like there is for LLMs?
No, that was my prompt. 😄
its by no means perfect, but it does MASSIVELY help the models glue everything together and separate concepts that interfere

left 4 are before, right 4 are after
and this all was only from 50 images of training. I have a new 6,000 image dataset waiting to bitchslap SD3 lol
that's good though. Yoga poses are important.
yeah, that does work, idk if I can upload it here
And also, by de-tangling concepts, it greatly reduced prompt bleed as well
i was moreso wondering how this stuff is implemented

"A portrait photograph that has a black man on the left and a white woman on the right standing in front of city ruins, smiling"


I found similar things with pixart, it didn't take long for it to understand the few pictures I gave it, and it kinda fixed itself, even the first epoch was good.
the greenish tint you guys see is one of the faults. I am not sure if its dataset related or training settings related. It happened across all of the images. But, thats a price to pay for the de-tangling. The goal is to make a fantastic and organized base to train on top of. Fixing those aesthetics should be very easy
Took about 100 pics of basic people poses and some interesting captions and it went pop, here you are, good people.
Posted rumours Not true according to staff
I just need to figure out how to train SD3 on 16Gb... 😐
I've literally been investigating that for the last day. SAI brought in a 3rd party for DPO modification on the model (3rd hand anonymous internal sources), and the theories are either 0 loss training to overwrite concepts or erasure (https://erasing.baulab.info/)
Erasing undesired capabilities from a diffusion model using a fast data-free fine-tuning process.
I am a strong believer in that as well
They really actively destroyed their model if true, it's bizarre. If true it would mean they totally went nuclear on safety
or yeah what aliquip said
It's fairly obvious when suddenly you get bikinis or swimsuits appearing that shouldn't be there, but they didn't get everything, some things in context seem to get through. IDK
SD3 forgets the city ruins for some reason it seems

wait what is this? is it a tool you made for sdxl. are you using it in sd3 here?
That redditor is a known troll, you can safely ignore them
Its a type of training I stumbled upon on accident that I wanna try and apply to SD3. It has capacity to seriously improve the biggest weaknesses with SD3
Also regarding erasure if they did kill concepts by training bad data into NSFW space running erasure on the key value pairs before fine-tuning concepts might work a lot better than just trying to train
can you explain how it works then?
A message wa sjust deleted. Not sure which one
this training you stumbled upon, you used it here too? i guessing grid on the right is after using this tool correct?
the reddit link was removed ( think it was edited by the poster, not the mod)