#🆕|sd3
1 messages · Page 10 of 1
you can't really tell if this is ai generated or real, or it's not as easy

not only because MMDiT >>>>> Unet, but also because 16ch VAE is much less of a bottleneck
by the way, the reason I posted lots of "generic selfies" is mostly to show the "is this even AI?" kind of effect
but you can also do more "styled" portraits







u can make them look "real" on sdxl but you need a lora + a good finetune model so not on base 
I've yet to see a sdxl photo that looks "really real" and not just "very realistic"
no XL model can do this. And even if the unet can maybe keep up, the VAE will ruin details.

yeah going from 4 to 16 channels on the vae is like going from playstation 2 to playstation 5
Tiled upscale?
I mean you can play with controlnets, regional prompting, tiled upscale, countless loras, etc. But it kind of defeats the purpose of this argument.
also I still don't think XL can't get away from the "realistic cgi" look
mostly because finetunes aren't trained so well unfortunately
but also for the model limitations
I was asking if it was tiled upscale you used on that picture? Cos it's huge.
yeah, but honestly it lowers realism sometimes
most of the pictures I post are just experiments
yea something like this but you need the bad quality lora + a good finetune so its cheating because sd3 can do that with base plus some of the background details come out deformed a lot of times with XL

There's a lot of giveaways in that picture when you look closely that's all, hair not attached to anything, trees in the background look weird, the window sill curves upwards as it gets to her head, one side of her head is less in focus than the other, and with it being high depth of field her face should all be in focus.
Great, we went from SD3 the last model you ever need to SD3: portrait generator extraordinaire 😢 Would be great too see it do more challenging scenes, guess we'll see tomorrow if it's that much better compared to the API offering which isn't all that: "a mechanical monkey stabbing a hydra in the heart" somehow mechanical bleeds to the hydra, the stabbing if can even call it that, is a hot mess 😢

boring reality was a REALLY good lora
boring reality was good, but it seems SD3 Base can do realistic generic photos so far, but we'll see
realism is not about bad quality. For example the image you posted still looks off to me.
yea no more need for cctv or bad quality loras
this is good quality, but still looks real to me

yea no ketchup on fries
I'll def make stupid meme loras/TIs though
pretty sure TIs are going to make a comeback
biggest tells for me are the eyes and the clear 4ch vae artifacts
since the base model is already so good
and no typical "finetune face" + variety... a dream thought impossible...
Oh hi Lykon
I'm very curious to see where the community will go with text encoders. There are even internal debates on them at the moment lol
Rare to see you here
there will be factions

Hair on top looks like either a wig, or it's all matted together weirdly, the hair on the right looks bad too, the whole picture looks off really anatomically weird.
SDXL+SD1.5 (AI character attempt)





i can see a jenna ortega lora there
What's up with that arm? Looks badly photoshopped to cover up a watermark

I'd say this is pretty convincing. Probably heavily finetuned on real photos.
Yes, it's a mix of 5 celebrities
that looks like typical anatomy problem with diffusion models, like landscapes behind the character breaking in half
tiled upscaler fuckery
notice it's on the seam
oh..
We need better upscaling then.
we'll need a pos embedding fix or whatever, cause currently, highresfix is out of the question
higher res images have artifacts
needs controlnet
controlnet tile? is it more way more consistent?
it should
Faceid only, but to be frank, I discarded many until I got a few realistic ones
oh so it's ipadapter
yeah that's good to imitate real photos
but still, it's a bit unfair for the sake of this argument
ControlNet Tile?
even canny or depth might help
FaceID cropping only the faces. With just SDXL it was impossible, I had to use SD1.5 to achieve some realism
it's still gonna condition the model enough to be less uncanny

I still don't like these selfies I'm sorry
I guess the prompt might be something similar to photo selfie of a woman, smiling at the camera, she has grey eyes and is wearing a k-way with the hood on her head. Looks like she is on a mountain with grass on her background. The weather is cloudy with a grey sky

They were interrupted...

It's always the nonsensical zips that give it away
I'm still messing around with hunyuandit while we wait. I'm actually kind of surprised with it from time to time. Like here's a semi-decent generation from it:

A vibrant, eye-catching cover design for a graphic novel set in a dystopian future, featuring a rebellious protagonist amidst a backdrop of crumbling cityscapes.
Caldais

something's weird in the background on this one
oh got a blue one

She's off up the hill now

4ch vae struggling with that grass
Can't see anything wrong with the grass
I think everything struggles with grass, something was slightly off in the ones you posted
it's almost like blobs
the VAE is also probably hard limiting pupils on xl.
compare pupils and grass here #🆕|sd3 message and here #🆕|sd3 message
by the way, original vs upscaled


looks good, but the upscale kind of destroyed the grass around the shoulder on the right side of the image
now the only thing that seems off is the text on the coat, but except for that, I don't see anything else
it's very noise and blotchy
try photo of a landscape with a radio tower on XL and zoom in on the tower. Even SD3 struggles with it, but it's pretty darn good.

has all sorts of issues.
I don't see it. I've got ACTUAL real life pictures where the grass looks worse than that. Cameras don't have infinite res.
The freckles is a bit funny
The grass look like smoothed
that's true, but the way a real camera handles that is different from the way VAE decoding handles that.
it looked smooth as hell, like a dreamy blur in that picture
In a real camera it becomes a blurry mess
i've been a nature photographer (semi-pro) for decades, that grass don't look right
This is the best... 2B, right?
need a hank hill "that grass aint right" meme
again, maybe, but not in the way vae handles that. In a real camera you get a dotted look, vae smoothing is different
it's 2b yes
I won't be making a DreamShaper SD3 since I already worked on base SD3 😄
Or other realistic finetunes in the future


Any better?

All I'm trying to get at is that the portrait is just a minor incremental upgrade, we've all seen portraits, show us things that are amazingly good and literally can't be done in SDXL finetunes. To me the selfies and reaslistic pics are a minor upgrade, the radio tower was more impressive in that it actually had structure, what about electricity pylons? They have all the nasty curves and straight lines that SDXL just can't do?
Tmrws the day
Upscaled

you mean like this? #🆕|sd3 message
yeah, actually, that's much better. the grass still has some imperfections to it, but it's highly similar to what you'd see from a cellphone camera with autohdr on. like the contrasty ghosting around the blades of grass is 100% what you'd see with a cellphone camera using autohdr (they also do some other autoenchancing stuff under the hood as well usually)
I literally called that out as impressive in my message?
good job on the lower part of the tower, less on the upper part and the grass
yeah just asking
Basically I am still waiting for someone to actually make SD3 2B preview on Japanese anime
Cos when it comes to cables, crosses, anything meshy, SDXL just barfs.
Although SDXL is like super sufficient for that already
Alright, give us a singer singing into a silver stage mic. See if it can do the mesh on the mic.
sdxl had issues with things like this


never tried, let's see
not perfect but this specific use case is not a deal breaker to me

kek
Nothing's a 'deal breaker', but that's pretty poor. 😄
the tower structure is kind of nice
it looks more odd the more you look to the left


Guitars, also pretty bad

here's hunyuan's attempt at it

Yeah, still pretty bad, look like bobbles
That's not even her hand in that. 😄
hahah
yeah this model is still so undertrained. i've mostly been messing with it like i do pixart sigma: composition to be refined with sdxl

That's SDXL's version of the pylon pic, I'd say it's even with SD3 pretty much

Who covered that mic in chainmail?

It's haing a go anyway, it's close
they both seem to get confused the further the lines are
Celtic knotworks/crocheted/woven microphone Shure 99
At least we're no longer looking at the kind of selfies that are gonna be used in catfishing scams. 😛
@lavish osprey is there a release time window yet? or just any time on the 12th in UTC?
in about 24h
give or take
nah two more weeks 🙂
that's impossible. The model has been given out to partners and inference code for comfy is public
12 a.m. UK is 11 p.m. UTC

btw update! @ocean lance PR'd code for Swarm to have native tiling integrated by default, and it works pretty well, so if you want upscaled SD3 in Swarm you just gotta check the "Refiner Do Tiling" box :D
Very cool. For those still just using comfy, will there be a workflow posted to the examples folder on GitHub for that?
gonna be a bit later than that. Just saying it so you don't worry
Nah I am busy this weekdays so no hard feelings
yes but also use swarm lol but yes workflows in general in the model folder & also comfy examples page, not sure exactly on upscaling* but probably somewhere that too yes
"I've been over-weighting; and I'm sinking! Release me from the waits!!!"

Usually software launches happen around 2-5pm at least, in my experience. 😄
I totally get it, but I like the minimalism of comfy. I moved away from a1111 a good while back and don't like the clutter of that anymore other than exactly what I want.
Lunch break do exist in UK so yeah
it's using some code from my tiled sampler nodes, but a bit more efficient with @viral plaza's help
12 a.m. UTC is 1 a.m. BST ... just sayin'
Usually you don't want to launch too early because you're still getting stuff ready and that means the morning is out because lunch, and so the only time left is early afternoon so you can fix stuff.
Which timezone of UTC? GMT / UTC+-0 ?
I love re-doing favourite ComfyUI Prompts in A1111 - as it deals so differently with the noise - some excellent results!!!
UTC is GMT - is it not?
SDXL power lines... perhaps after a storm 😄

UTC = GMT(ish, technically there's a difference), BST = UTC+1
UTC is a time standard
isnt it just the weight interpretation being different lol
Yes, why I said UTC 12a.m. is 1a.m. BST
figure it'd be mid morning EST time
Like you can say UTC-8 instead of PT
Something's different - but good!!! Surprising results every time 🥳
you can use wildcard encode (inspire pack) to mimick auto1111
So many conflicted nodes - Failed to Import - and for all the good WAS Nodes can do - I've never gotten them to work!!! 😄
it's also that A1111 uses GPU to generate noise while ComfyUI uses CPU
or at least that used to be the cause for difference in generations with identical settings
ugh, that's never an issue for me. also it's inspire not WAS
There are certain Extensions in A1111 that I love to use - especially Latent Mirroring
And Embeddings too
You can use embeddings in comfyui
you can do literally everything in comfy
I think my Inspire joins WAS in its disinclination to work 😦
I have tried many of my A1111 Embeddings in ComfyUI - and only about 15% work! But when they do they are excellent.
They also s l o w ComfyUI down
it still baffles me that you can't use sd1.5 embeddings on sdxl models in auto1111
despite reporting the issue months ago
Can't you? Isn't there a node for that now?
"Waiting for Amazon to deliver my SD3 Weights!"

OH! A1111 😄
Haven't touched it in about a year
"This is my neighbour's wife - she said she'd call-in at the Local Fed-Ex Office - to see if the SD3 Weights are in?!"

BIG THINGS COMING
Did you create a PR for a fix?
for model cards?

even huge gpt4o can't do this

comfy redefines clutter. it looks like a hoarders convention
people with organized workflows just look like hoarders that are running an ebay page and gotta keep their stuff organized
How does comfyui now compare to ~6mo ago? I never liked needing 3rd party nodes for what I considered expected functionality (alongside other annoyances) so I stopped using it
same situation. there's a giant pot hole in the rear view right now though. the custom node situation you're expressing frustration with led to malware being widely distributed through comfyui users
every workflow requires custom nodes that nobody vets or even thinks of going to the webpage for. and they're always different custom nodes. people wont' think twice about installing them. You did though. Good security policy bruh. You dodged that bullet.
Comfyui really needs a standard library that's versatile enough to not need to be replaced by some random github page that comfymanager automatically downloads from.
I was super lucky by installing a vision LLM addon that wasn't that one
and then the community needs to start shaming workflow authors for not using that standard library
honestly with SD3, Idk what plugins I should use other than maybe rgthree
and maaaybe custom samplers if they aren't broken
honestly , any workflow that requires custom nodes that do basic functions, should be viewed under the same lens that CKPT's often get
json files should not be an attack vector
or png files for that matter
Ideogram test

Swarm has the more built into its core by default than i think any other ui does
you'll still want extensions as you get into advanced usage stuff, but, less quickly that you would with comfy on its own, or with auto, or focus or forge or etc
(actually i suppose maybe vlad can match that claim, had a lot built in last i looked)

It's fine, I can stop whenever I want. Get off my back. 🙂
have you guys found much benefit from negative prompts in sd3?
think about June 12th 23:59
pls no
ideogram is really underrated
I'm hoping its something more typical, like 1200 GMT
bump
expect it to be completely random lol
I have 0 expectations lol
but I have hopes
it is gonna be the heaviest wait
but not the heaviest weight..
only 4GB weight 
best choice is to expect 23:59
fr
hawaii timezone
Maybe 12 june
i was thinking 26:72


I saw "upscaling" mentioned in passing on an announcement, but I haven't seen anything since. It'll be great once they have it.
Been playing around with stablesswarm a bit and I see regional prompting seems to be a feature but I can't find any documentation on how its supposed to be used.
How do you define the regions / prompt for each?
yea, should be good
probably will switch to swarm too
will we have comfyui or auto1111 support for sd3 when it drops
I actually was dreaming about possibility to make custom interfaces to own workflows, to not swim in noodles
comfy is already support
just update
on a certain website that has a certain auto1111 plugin for model infos
interface is a lil wonky for regions atm, easiest way is just open the Edit Image interface on any image, use the Select tool to select an area, and click Make Region at the bottom.
That'll add it to your prompt. The actual prompt syntax is relatively simple so if you're not scared of numbers you can also just type it yourself. Also if you type <region: in prompt it will pop up docs & examples so you're not typing blind
oh nice
swarm has a civitai metadata autodownloader as of a couple days ago
Ok, thank you
I stopped posting models way before that
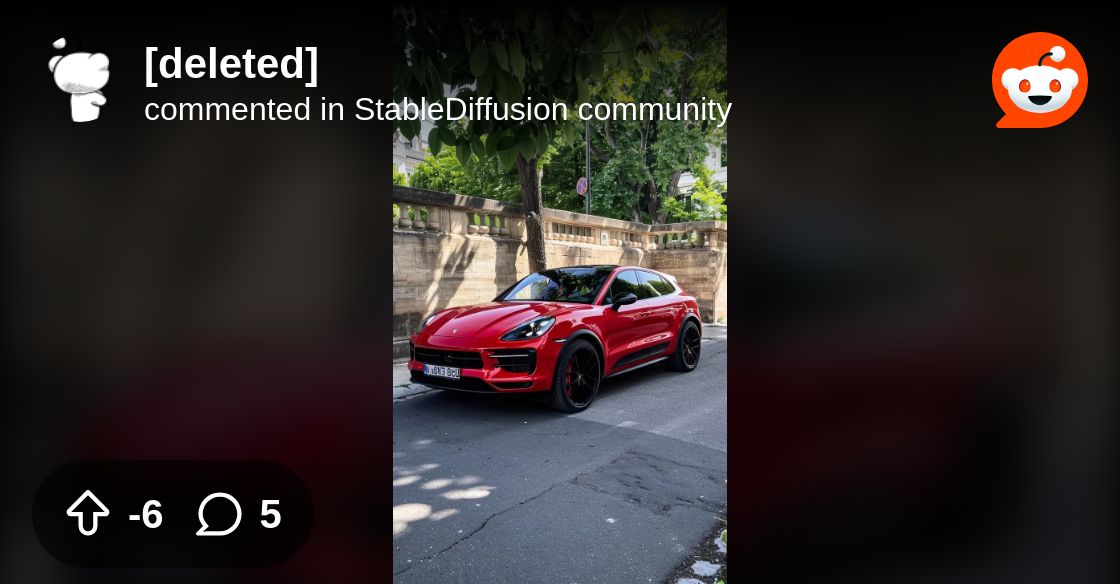
anyone see that Porsche Macan comparison post on the sd subreddit? dude admitted in the comments that he upscaled the SD3 image with a different service >_>
Reddit
Explore this conversation and more from the StableDiffusion community
And the original SD3 image isnt even bad at all
Tomorrow the 2b version will be released 🤗
Yeah I did, the original was good
Idk why but there are little images of sd3 with good prompts
even if it was upscaled, we should look at what the anatomy and sizes of what stuff are
the car looks correctly placed, the scenery looks correct
but the leaves are massive for some reason
everything in the base image looks great
lmao
road texture is very real
it also just looks "convincing"
oh wow no depth of field
even 8B struggled with trying not to put depth of field in my testing
god I really hope non-bokeh images are easily possible
I generated this with whatever is currently hosted on the API

and of course, huge depth of field
there's 2B apparently, and also Ultra
idk what you are using rn and what the prompt it
"A high resolution photograph of a gray Ford Focus RS parked on the Las Vegas strip at night"
no negative

😔
That is the thing that i most hate when I generate images
low quality generic phone photo of a gray Ford Focus RS parked on the Las Vegas strip at night
try with "depth of field, bokeh" negative, idk how this works in sd3, in sdxl sometimes it works and sometimes it doesnt
And somehow, that would look even better than the "high resolution potograph" one 😄
undertrained 8B isn't exactly the best test for this 😕

What was the prompt?
I´ll try this on sdxl

It is actually beatable by sharpening image before second and third pass

i need technical support installing sd3. i've troubleshooted all i can so far and i've hit a wall with it not being tomorrow yet. Can anyone offer any advice?
Comfyui got updated to support sd3 but i can't make it work
Backups were too expensive
the backups were in the project folder under /backups/
aw man, guess we're waiting a few more years
maybe there's gonna be a pixart 20B model, I'm pretty sure guys
maybe if they count all the vae, encoder, and every stage's parameter count. Feels like in the early 2000s when intel would call a dualcore 1ghz machine a 2ghz machine
"he keeps saying the same thing"
you mean SOON?
2 weeks)
Which time will it get released?
24:69
69 xd
mhh
stopped posting models
Does this mean we won't see an DreamShaper SD3? 🥹
Or just that it wouldn't be on Civ?
*edit: Here's a link to what I love most about finetunes (especially dreamshaper) and their purpose in my opinion compared to the base model. I hope you read it to understand where I'm coming from: #🆕|sd3 message
considering that super aesthetic images are doable, but it doesn't made lower quality images impossible and there's actual variety between seeds
I think this is a win for everyone

The focus of any base model is to be able to do everything*. The focus of finetunes are to be able to do some things a lot better. In this way, the concept of DreamShaper or any other model that's finetuned would be great to use as a refiner or upscaler from any base-level gens for SD3.
Their purpose is always to better what the original model does (in certain directions), with the loss of creativity from overtraining (even as lightly overtrained as they may be.)
So in essence, it is a great loss.
is it tommorrow yet?
hello, how's the prompt comprehension of sd3? is it comparable to something like pixart?
Similar to pixart but understands more concepts than pixart
pixart supports a version of the t5 encoder. sd3 does too. Prompt comprehension relies a lot on the data set's captioning quality. I wish Stability would release the data set and we can see how things are captioned. Or a cross section of it even.
training data seems to be kept behind closed doors the last few releases
about the same ballpark for what's in the api now, sometimes pixart is better, sometimes sd3. One thing where sd3 seems really trained on is 3 things in a row, each with its own description.
ooh so does that mean it's good at understanding prompts for multiple subjects at once?
i heard the t5 model for sd has a 77 token limit
we can do those kind of 3 things in a row compositions right now with regional prompting on sd15. what'll be neat though is to get that kind of attention span on a single prompt, but also combine it with regional prompting
i think that was misinformation someone was barking about when the paper released.
yeah, it can separate it reasonably well
sd3 was already finetuned on most of the data I could get from DS. Basically I removed opt-out stuff and nsfw stuff.
that's good to hear, i'd be very disappointed if it had such a small token limit
if you're only using the two clip layers without t5, it'll have the 77 token limit we're used to
but also it'll still have the new vae
i'm assuming the t5 model can be offloaded onto cpu like with pixart, right?
all available information seems to suggest that
long prompts seem fairly badly handled in the api version, i hope it's getting better in the 2b model
wait until people start carving up comfy workflows
 I understand. I look forward to using it and seeing your work in the mix, though as an artist myself who is never quite satisfied with my creations, I do hope to see your hand in a further finetuning down the road if inspiration and new data hits you.
I understand. I look forward to using it and seeing your work in the mix, though as an artist myself who is never quite satisfied with my creations, I do hope to see your hand in a further finetuning down the road if inspiration and new data hits you.
I hope they create a new dataset or copy what mj/openAI did with mjv6/dalle3 , using hand made captioning for high quality images
also, with custom nodes, be wary about any that are over hyped and claiming magical abilities. watch out for youtubers releasing fake content.
That might be expensive af tho
sd3 is going to hav ea lot of excited people excitedly downloading a lot of new nodes
hell yeah, i also see a commit from yesterday just titled "SD3 support" so devs are def working on integrating support prior to release, would be nice if comfyui latest release supports SD3 the moment they releease the weights
doesn't the comfyui dev work for stability?
perfect time for updating a node repo to install a local whl because the official package is suddenly buggy (swearsies)
open ai's dalle3 research demonstrates that beter captions make a better model. i'd expect stability to have read that paper
ive heard something like that yeah
devs is a good show staring nick offerman
it's 730pm in london at Stability HQ. Does that mean only 4.5 more hours??
lol i love how you looked into all those details to produce an accurate estimate of when exactly it'll be released, if it comes out in 5 hours that gives me from 7pm to midnight to play with it, so stoked
lol don't expect it to be in a few hours i was half kidding. I've known Stability HQ was london based for a long while. But their releases are typically on US time i've noticed

@viral plaza sup, has there been any clarifications on model license from the business people? (sorry to ask but no one from decision makers seems to go to this channel)
Reflective media that shows a representation of a culture, i love it. Pony really is one of those.
a lot of media is over produced and corporate. that raw reflection though, oo baby.
oh astra you're here hi! you always seem to be around if i'm mentioning thigns about your model

there is gonna be a FAQ
hopefully at release
if sd3 medium is the 2b what's sd3 small?
800M
is it being released along with sd3 medium
thank you, but oh boy, wouldn't it hurt to communicate in advance.
smol boi
we are releasing models as soon as they're "ready", we don't have the throughput currently to parallelize the process, so it's gonna be just 2B tomorrow
also, and this is just my opinion, 8b is far more "ready" than 800m
I would have liked a 4B; I can't even move an 8B by praying to the PC every night
lol
I think you replied to wrong message.
yea
i want pony diffusion pixart
2B with all the toys attached to it (loras, controlnets, etc) will keep people occupied anyway until the next sd3 version
there isn't much to gain currently from a 4b compared to a 2b model. Maybe a future sd3.1 will be 4b, who knows. Depends on the average vram availability. 2b seemed like a good size to allow most users to run the model, since it's about the same as asdxl
it would be better for higher end people cause they can still finetune offline unlike 8B, but 2B is such a nice middleground that a lot more people can contribute and use

the 8b is planned to release eventually right?

2b is still quite big guys, with all the tes it's bigger than xl
which is, well, "xl"
well with T5 yes absolutely 💀
@lavish osprey Hi Lykon do you know what time it will be released tomorrow?
I do but I'm not sure I can share
It's understandable, and we need to think about a wider range. Moreover, what we're going to have already offers very good quality. The only question is whether it will understand the prompts and be faithful to them, which is what matters most. That's why I'm so eager to try it
with how strong and mighty pixart is for a 0.6b tech demo i believe you
prob around noon est or pst is my guess
I think right now the tradeoff is "a large 1024px model with very good community support and clear license" vs "a slightly larger 1024px model with maybe better TE and no clear license or community support"
I'd say it does






Are there going to be official control nets or something like that?
aww the Lykon plushie ❤️
self-portrait
haha
also this is probably the first base model we relase that can do decent anime out of the box. 2b vs xl


@lavish osprey Do you know if trained LoRas will work across SD3 models (2B vs 8B) or will they have to be trained for each model?
could you post some landscape/scenery gens
I have been comparing how faithful it can be to the prompt with published images quite a lot. And in many instances, it seems like you have to emphasize because, in this example, 'slightly plump,' the girl looks like she only eats fresh vegetables
Left: SD3 Right: Ideogram

lol

they probably took out plump girls out of the dataset
no maidens?
I personally don't make many because I think it's too easy even for sd1.5. Would these be enough?



There a pirate about? cos they stole the R.
I still liked it 😄
very natural
there were likely many broken signs in the dataset lol
that 8b on API is definitely not final by the way
i was hoping for more wideshots of landscape. sd really sucks at them. tends to have this fisheye lens effect
Yeah, that's why I'm very eager to do tests with 2B
some gens from the 8b training





these look like images
i know that girl! Lol
we didn't have too much time to train 2b, it's mostly intended as a capability showcase and as a true base model
LOL I'm surprised the text was this comprehensible from SDXL

sdxl could do text?
And as a base model, it's impressive
8b at the moment is much better with hands and anatomy imo. But still has some issues we want to address


that is definitely a picture that exists
Is DreamShaper SD3 on the way?😁
he said no earlier
dreamshaper is now BUILT IN, are you excited?
simple text, yes. It fails on long prompts and with various positionings. Eg: sdxl can't do this


i like the potion pics
same
or this, also very cool even if a bit surreal, but I asked the model to have "Poison" crossed out and it actually "worked"

It's missing 2 fingers!! Wait... shit, I'm used to SDXL, sorry
oh wow nice

kek
is this the 2b or 8b?
So not to spoil the party, where do we d/load the weights for SD Ultra?
8b in this case but I think 2b would understand too, or has the capabilities to learn it
ultra is not a model

Say YES to friendship!
i remember when the sd3 api first released, there was this top secret model called sdnext in it, what was that about?


Oh? But it can be used via ComfyUI?
Beta?
with the SAI API node, yes you can.
Can it do spell checking?
what can we expect for the sd 3 medium not beta
how come medium beta?
OK, thank you!
2b


notes, needs more guitar training
also 2b


impressive!
does it know David Gilmour?
do you have any idea if sd3 will be cheaper or more expensive to finetune compared to sdxl?
the one who wasn't anxious or impatient about 2B, I think, has now changed their mindset...
Will the 8B model be able to understand complex conceptual ideas? I understand that open-source models are unlikely to achieve the quality of DALL-E 3, but I hope for something at least close to it.
From my understanding of what's been said before, about the same.
I think open source models are far better than Dalle, depending on the benchmark
Have you seen some of the crap Dall-E outputs when you try 'realistic' mode? 🤢
if you freeze the tes, it's the same as sdxl with frozen tes
like preprocess your dataset and finetune mmdit only
I have done comparative tests with DALL-E 3 (and SD3 API), and I think DALL-E 3 now falls behind, especially considering that DALL-E 3 does not offer the same quality. The only one where I have gotten better results (I repeat, SD3 API, not 2B) is Ideogram in some cases
anyway, both ideogram and dalle are pipelines not models
if anything, at least you should compare to Ultra, not sd3
what's ultra
idoegram doesn't even handle text in the same model.
Dall-E3... 😐

yeah that's unusable. It generates an image, now what do I do with it? The quality is too low. Good for normies
It is true that to make a fair comparison, I should do it with Ultra
pixart would beat this up
Here's one of your fave prompts.... woman, outside, selfie

So cute
incredible
not Asian, terrible
Yes, pixart base 1024 would beat that, my finetune would be even better.
I'm not wasting any more dall-e credits on that. 😄
ooh okay
this is from our Fast workflow, that generates 4 1mp images in 0.9 seconds...


I mean....
could you have the model write some text on their foreheads?
PixArt (extraMODE finetune) woman, outside, selfie





I understand that Midjourney generates many images, and while they are being generated, a selection rating is applied, stopping the ones with lower ratings and keeping only the highest-rated ones. Does Ultra do something similar?
dem freckles
no
no need, every image is high quality
ooo confident






these are ultra?
yep
Sd3 2B ?
show me your favourite 2b gen
2b



uhm can't
I reserve the best gens for the marketing team 😄
you'll see some cool ones in the model card tomorrow
But no one sees you here
i see you
What's in the Ultra flow?
one of my favourites is this one but mostly because I used 3 different prompts (one for each TE)

I love 2b renders
SD3 , Upscaled with SDXL.


They have, I have one and will use it afterwards...promise 🤞🏻
thats the forget-sd-2.0 3000
I love the lighting in the second one
can tooncrafter take the first and last frames of that gif and recreate it? :3
ultra is possibly a workflow, some images he uploaded and claimed to be ultra have ComfyUI-temp in their name
At 100%, it's impressive
I remember when SDXL came out, at first I upscaled with SD1.5. I'm curious to see how it will be this time

try doing that here, see if you make it better or if it ruins it

I presume it'll never be Open Source? 🤔
that's really impessive, which model is that?
its components may or may not be
2b
or try to upscale/refine this with sdxl

I think you need 2 frames U.U
now you got me excited
I posted even better stuff on X
Any change you can test out my latent size selector for SD3? It's on Comfy Manager. I obviously can't test it yet. 😄
i actually never tried tooncrafter yet, just saw couple examples
is this a raw gen? the skin is really detailed
I tried it and sometimes it works very well, the only sad thing is that I have to use low resolution, like 512x512
ah
Portraits might be a lot more interseting now that people can add hats with text!
Upscaled 2x using SDXL


looks the same size to me 🤔
yeah it's the same pixel by pixel, no diffs
It's not
wrong file?
You uploaded the wrong one
i think you posted the wrong file. it's identical
i thought it was an impressive upscale then i looed at the original
Sorry, try this one

judging by the video one, I don't think it improved by the way
It's smoothed everything out that made it look 'amateur'
yeah it's bigger but it's yellow toned (known sdxl vae color issue) and became more uncanny
Now it's had the "beautification" filter added
close up detail looks worse
yeah more pixels for sure, but now it's "fake"
Trees are better, but everything else, worse
on the upscale i can see a lot of gannyness. in the eyes and leaves
my point being, you can't really use XL to refine sd3 2b images. Even if your xl model is amazing, the vae is just gonna kill it
It might be useful to refine artstyles that have a lower detail need or no uncanny effect, like anime
(also no xl model right now is realistic enough)
when vae bridge for xl?

Not even RealisticVision or Juggernaut? 😮 shocking. 😄
not their fault
Include DreamShaper in the mix if you want, that too is not realistic enough
portraits are going to kick so much butt going forward. every single poerson posting portraits from now on, i'm gonna be like "where's the graphic tee or ballcap?"
yeah, the sdxl upscale couldn't handle the finedetails in the wrinkles

if you zoomed it looks like someone hit her with a waffle iron
Maybe because most of them (or at least the ones I saw) are using some AI images in their own dataset

probably
needs more ballcap
Have to keep the hype train running! 🙂

people love reflections. they're so vain. they probably think this song is about them.
I'll move to 8b likely
well I already did
just out of curriosity will the SD3 model have the same token limit as earlier versions of SD? I belive its 75? I am never unsterstand how kohya can use 150 etc tokens
Even the most decent "natural face" lora on civit was trained using... AI generated people from that doesthispersonexist page
This one starts with the original, then upscaled. Less freckles is original...
anyway @viral plaza won't like me saying this, but I like t5. I hope you'll appreciate it too.
You can do cool stuff with it, like you describe a scene with 2 characters, and then copypaste the wiki description of those characters and it works. These are from a book my wife is reading

no lora
no controlnet
just copypasted character descriptions
think of the token limit of the unet models like an attention span. it can do unlimited tokens, but only has attention on 77 sized chunks of it.
"then copypaste the wiki description of those characters and it works"
That sounds awesome
SD3 is having trouble holding swords right now, this took quite a lot of gens and is still quite bad, SDXL finetunes are actually much better ATM at holding stuff, which I find supprising.
yeah that works on pixart and it uses t5
@viral plaza Not like T5!?
it was trained with 77x3 tokens, but ideally you can train it with 512+77+77 (which also makes 666 tokens, so it's a missed opportunity on our end)
oh
the paper explains this I believe
Have you seen these youtube channels that churn out content by narrating and animating tales from reddit subs? sd3 going to put these channels into overdrive.
I made this just yesterday

100% it is better and not ruined. 1st is original, swiping left reveals the upscaled. The trees, building and distant mountain details are all better
...but original is awesome for a base model!
yeah this one is not very ruined. It just added freckles for some reason.
Just needs tweaking
elden ring concept art 😮
turned the granit rock faces into houses too
but this is likely a very expensive tiled upscaling thet you'd probably do easier with sd3 itself instead of using xl
Can anyone test some dumb concepts like "A potato fighting with a french frie", I test this on google gemini and it worked decent, I´ll try it on sdxl and other AIs

Prompt executed in 85.49 seconds
Not too bad, it's 3584x4608
Future work ™️
If you do exactly 512 + 77 + 77 does it just make pics of Beelzebub?
Im quite hopefull for 2b, smaller models allow alot more people to contribute with finetunes etc.
Out of curriosity will the new architecture allow better Quantizations, as seen in LLMs?
i could see something like supir being trained to use SD3 instead
Well, I used SDXL for upscaling from the SD3 API, and it worked quite well for me




Can sd3 make a mix of styles ? for example a realistic human talking with a 30's black and white cartoon character
i think i saw that
There's no difference in color between those two, that's done quite well
yeah it will work well on sd3 api.
because the model used there is far less aesthetically finetuned
i think the lower resolution version has better detail. like, look at this skin texture on the upscaled version. looks like a fabric sac

smaller version, looks more like makeup on flesh



Any idea if sd3 2b would admit inpainting? sdxl inpainting wasn´t that good (or maybe it was but not many custom models have it)
not at release.
sdxl inpainting is fine. it got better than when you last tested it. fooocus kicked it off i think
I prompted text in blue fire. that is not what I meant, but the text is in the blue fire, SD3 can take things very literally to sometimes funny results.

sd inpainting api blows that out of the water. It even works on pixelart
sorry, not sd3. As I said sd3 inpainting doesn't exist yet
sniff
daww. lol. but yeah sdxl inpainting is good by now.
Where would I could use SD3 when it's releases
idealy there will be 100s of services tommorrow
you'll be able to download it from HF or use it via API

is sd inpaint a service?
I dont like Comfy
Okay
yeah kinda killed
Yeah but in which UI
Unfortunately you are right. Left: Ultra (API). Right: SDXL upscale (lost lots of details)
Any suggestions for a SD3 upscale workflow?


ConfyUI already supports SD3
No, that wasn't the workflow... I already have dozens
Maybe sd forge adds support (its comfy but using a1111 frontend)
Mhh would love
Yeah but dont really like it because it's to complex
I think some images out of the CURRENT sd3 api are fine to refine with sdxl.
Once we are done with sd3 8b it will be like 2b. Basically too powerful on photos to be refined with xl.
Most upscalers do this, the one I like that I think works better is this one: https://civitai.com/models/363798/mjm-and-superbeastsai-beautifai-image-upscaler-and-enhancer
It is an ultimate SD upscale with a few bells and whistles to control contrast etc. but it actually adds details without just increasing the resolution and flattening things out like a lot of other workflows.

Hello! @superbeasts_ai and I ( @midjourney_man ) teamed up to create this ComfyUI workflow. It is intended to upscale and enhance your input images...
we will provide examples workflows. You won't need to learn anything.
so is sd 2b currently better than 8b at finedetails?
I personally think it's better then the API version of sd3 on "amateur" photos
you seem to really like photos
I don't. I just find it's an impressive feat compared to current models
Oh okay true
oh okay
i'm not so worried about preserving details when upscaling a generated image, but i would like the new details to be better than what was there before
great now i got this rap song, new details, stuck in my head. brain go brrr
Any time eta?
which is rare for a base model. A base model shouldn't need to compete with the previous gen of finetunes.
but this can on some level
so it's very cool
I think once we're done with 8b it will basically destroy most xl finetunes, even the ones dedicated to a single macro style on some benchmarks
im in cest so 🤔🙏🤷♂️
you're not testing against pony is you?
despite the fact that training a model on a single style and not having to worry about typography or ruining other styles is much much harder
I hope pony guy trains the v7 on sd3 🥺

He's around, waiting for the official license to see if he can.
no, Pony is peculiar. Has a narrow TE with very limited vocabulary and very limited grammar understanding, plus is only 1 macro style.
Doesn't make sense to compare with that
better than before, but still reduced details
also made it "too clean". But very good job
they were here inquiring about the licensing around sd3 and why theyd need to consider some things before spending money. so they are considering stuff
pixart pony with sd3 vae
You'd have to retrain pixart to do that
yeah, pony fella can do it
there is nothing in the license preventing finetunes. Why release the model openly in the first place?
i think he was unsure about something in the license
was saying someething about needing to recoup his costs somehow so he has his discord server
I dunno, I'm not him. I've read the fine print of the current Non-Com license, and as long as he doesn't start an online pony generation service he's fine right?

fair enough, but don't you think SAI should "recoup cost" too? 😄
thats the thing. he has a service lol.
But unless he's getting over $1m a year, he only needs to pay $20 a month (I think it's a month)
yeah i think he just wanted details
Shall we play "Which model generated this?" 😄

sd3
Cascade
cyberrealism
...your pixart finetune?
so here is the thing, we spent a almost a year training the model and doing research, on stuff like 80-160 nodes with multiple gpus each.
We sustain far more costs than anyone working on SD models on the planet. You might have read some news articles about it.
If you do finetunes for research and share them for free, or you share images, etc, fine. But if you want to make a profit with a finetune that costed a fraction of what costed us, I think it's only fair you give something to SAI.
Pony (or any other generative finetune in the last 3 years) wouldn't exist without SAI.
sd15 refine
Bingo
that's impressive! did you use an upscaler? it got the skin details pretty well!
Nope, straight outta pixart
yeah i'm not saying any of it is bad or arguing nothing. i think stability droped a huge disruption bomb when releasing sd at great cost. i'm riding the waves is all. looking forward to this next surge.
all i was trying to convey is he was here earlier asking about stuff. weighing his options
Will it releases at midnight? just after 11th
with how well it got the details right for oilpaintings i guess it makes sense that would translate to skin with a bit of fine tuning
(and consider that even models like pixart are using sai research and vae, and we don't see a penny from that, which is ok by the way)
the beauty of opensource ❤️
my guess is around noon EST
yeah sure, but I don't find it cool when somebody say "if SAI asks for pennies I won't support them and just finetune on XL or whatever"
i think open source needs money backing it. for sure. the FSF wouldn't exist if it was poor
thx
Weren't DiTs invented by facebook research? or does it go back further
So much focus on image details and SD3 doing it better. But in my experience, that wasn't even where SDXL was most lacking versus the competition. The big thing SDXL was always lacking was prompt understanding, and from what I've seen that's only partly gotten better; look and details of subjects can be described much better, but scenes/composition is still not all that for non everyday scense (shooting lasers at a target, a giant robot grabbing a skyscraper, teasing a cat out from under a bush, jumping trough a hoop), all things SD3 in its current state won't do. Will the 2b, or the later 8b, model be better at such more out-of-there scenes/compositions?
not for image gen
dit was made for doc classification
https://www.wpeebles.com/DiT this research paper?
Does sd3 will be released at 00:00 ?
I can assure you sd3 has been in development since way before december 2023 lol
honestly, if pony doesn't keep up and move to sd3, it'll fade like a fart in the wind. I'm sure he's weighing his options. The guy is spending money on training already, licensing will just be part of that new calculation.

(everyone spends money on training by the way, not a big deal, when I was making my own XL finetunes I used to rent A100)
The thing is that ponyxl is like the model of the community, idk how to explain it
oh well, my bad then
Even if SD3 would cost me 100€ as a one time purchase for private use I would throw that money at SAI. A lot of people would do that imho.
its a flash in a pan
for what purpose? Finetuning or making revenue? I don't think finetuners should pay anything
PiXart-Sigma has superb visual acuity ...
what is acuity?
... but too small a dataset
i mean to get stability membership soon. i'm just in a period right now where i've cut all my memberships. i had to many an am consolidating for a while. $5 here and there adds up a lot
it's a sdxl finetune with a very specific use case.
Visual acuity (VA) is a measure of how well the eye can distinguish shapes and details of objects at a certain distance. It's also known as the clarity or sharpness of vision.
Just for private use and the fun of generating images and sharing them. 🤷
my own vresion of not buying starbucks or gas station snacks
were i doing AI professionally, i'd no doubt have the membership. i'ts just smart.
I mean if you want to make an offer from the kindness of your heart, just buy a membership for 5 months 😄
I shall feed SD3 images into my i2i PiXart-Sigma+SD15+SDXL+PAG+FaceDetailer setup ...
ooh i see, thanks
it is a tiny fraction of our cost, but it helps
Add SD3 into the middle of it as well... might as well
or just use sd3 😄
... or even feed i2i PiXart-Sigma images into my hypothesized i2i-SD3 setup!
Someone tryed to generate liminal spaces with sd3 ?
I mean, if the base model looks like this, imagine the finetunes. Have you used base xl lately? Compare it to even turbo finetunes.
this one would be interesting to see
I dunno why you would. Unless pixart has something SD3 doesn't
make sure to feed it back into llama then embed that into t5 and run it back through sd3 again
the only thing i remember from base sdxl is: bokeh 🙂
PiXart is remarkably clear
Yeah that´s true, if you compare sd 1.5 and xl base and top finetunes its like day and night
it's scientologist?
Have you not seen the pics that lykon's been posting, they're not exactly lacking clarity

Better Blur Control XL LoRA This LoRA aims at reducing or controlling the depth of field effect that's very strong in SDXL models. It doesn't work ...
Mobius and PiXart both do great bokeh
I think he was joking about the fact that xl ALWAYS does bokeh
which, it's true, was an issue of the model
but that's the thing: it's a base model
just finetune
OK
haven't tried sd3 yet so can't say how it compares but pixart images have incredible charm. it does expressions really well
that and scenery, i love pixart for scenery and landscapes
that moment when you scroll down and look at the community generated pics 🙂
Actually yeah, it can over-exaggerate them sometimes, just ask it to do someone sticking out their tongue.
Its not just xl, I´ve seen MANY mj v6 images and in most of them there´s that bokeh effect
my X feed is full of sd3 2b and 8b outputs
i think pixart was made on a dataset 1/10th the size, so it'll have a more narrow dataset and vibe to it. They'd have used an aesthetic classifier to currate the dataset no doubt too. That classifier is going to be the fulcrum of that vibe/charm/style/feel
So its an UnBlur LoRA? Eau keigh
pixart is 600M
parameter count. i mean dataset size
600M ?
600 of your actual Ms
million
emineminemineminemineminemineminemineminemineminemineminemineminemineminemineminemineminemineminemineminemineminemineminem
I think focus sdxl inpainting is pretty much perfect.
they just used llava tagging for their dataset as far as im aware
It doesn't do tooo bad for being 600M

Yess
You have a point there . I might consider doing that as support. But yeah, I think the word "subscription" is a hurdle because nowadays everything has become a subscription. If you just would have a "buy me a coffee" button somewhere...that would be a different feeling.
not just tagging, but sizing it down and selecting which images make it in
They used ShareGPTv (which is a llava finetune like CogVLM)
some of my favourite SD3 gens I can share:
https://x.com/Lykon4072/status/1792606426860327244/photo/1
https://x.com/Lykon4072/status/1788322004224868523/photo/1
https://x.com/Lykon4072/status/1781447406422224957/photo/4
https://x.com/Lykon4072/status/1780263281929650509/photo/1
https://x.com/Lykon4072/status/1779526226387914899/photo/1
https://x.com/Lykon4072/status/1796317998036238380/photo/2
https://x.com/Lykon4072/status/1794065895045665266/photo/1
https://x.com/Lykon4072/status/1779982206384898439/photo/1
https://x.com/Lykon4072/status/1796317998036238380/photo/1
I don't know if it was this one, but it made all my images too bright
When a model is tiny and have good results is because the training dataset is good ?
I tested it on dreamshaper and it looked very clean.
i think for pixart it has more to do with it's architecture probably
It's more about the captioning of the dataset than anything else. I found especially when finetuning it.
sd1.5 is ~800m and some finetunes are pretty amazing.
there is a certain finetune called DreamShaper8 or something that I heard can do multiple styles.
by some guy called Locon?
And DiT don't act like UNets for comparison purposes they act larger than their size?
who I believe might be Spanish?
pixart sigma paper says it was trained on 120k images only. even less then pixart alpha! wild
idk, i only know Lykon 🙂
must be a distilled pixart alpha model, which was 200million images iirc
That was for their research paper, the actual released model is 600M
Maybe pixart-zeta one day ?
impossible to not overfit on such a small nummber unless your weights have some init value taken from a larger pretraining.
I wonder how would be if they train a model using only 1 kind of subject, like only photography, or only cartoon/ oil painting,etc
I guarantee you can't do pretraining on 120k images lol
only will smith eating spaghetti
🤣
why would the paper say they trained pixart sigma on 120k if the actual released model was 600m images?
They're using more exact clip captioning data than usual for PiXart-Sigma
i believe pixart sigma was a continued pretraining of pixart alpha
Becuase it's research!

dreamshaper-v7, hmmm
80GB vram, the dream 😮
@lavish osprey And what is your personal vision for the development of generative models in the next 3-5 years? I'm very interested to hear your opinion.
Maybe in 20 years it would be the average vram 🥺

if it's just a finetune or a distillation, like DreamShaper 7 LCM, then yes, 120k images do work
that's the parameter size
for pretraining (aka "training from scratch") you can't use only 120k. It will overfit
We'll all have 100Gb VRAM
Yes, which is releated to how many pictures it was trained on
thats parameter count. told you that earlier. it's not the dataset size
its not. it's the number of neurons a model has
And our children will be called Nvidiana, Pricess of Wales
lol
I'm just a dog plush with a hoodie, how would I know? I can barely type on a keybord. You stupid humans and your wurstel fingers.

So... SDXL wasn't trained on 2.6B pictures with a 2.6B parameter count?
So much VRAM overwhelms me
suddenly self concious of my hands. maybe stable diffusion has them right

that's a real dog. And it's also naked, ew.
it was trained on a set of laion 5b, the english subset
haha
roughly 2b images
he's wearing a fur coat, which is problematic in itself
Idk why stability had an opt out program for artists, mj and dalle are closed source and they don´t even care 🤔
Its like they only want to hurt open soure, the same happened with photoshop
because we are decent human beings I suppose
well, not me, I'm a plushie
which is an upgrade
MJ no doubt are ready to settle behind doors or license image sets . a court could invoke discovery and demand the dataset be examined
I know but the same people that said "AI will take our jobs" when sd 1.5 came out are using AI on photoshop now

and they'll likely give them LAIOS and pretend they used that. Then you go and prompt disney .com and you get a screencap from a disney movie.
AI took my girlfriend

AI is my girlfriend /s
Imo all cases of copyright using AI should be dissmissed, its not like artists don´t steal ideas themselves
yeah there's no doubt shenanigans afoot. i'm betting they'll have some licensed sets and be like "we just used this bruh"
but im not a lawyer so...he
Well, have you published it yet or not? 🤣
If AI takes your job - it's only because you don't know enough - or care enough about AI - to be able to keep your job!!!
they are such a tease
then you'd have expert vs expert in a court, proving you can get that screen randomly or not.
I can't believe the day will finally be here, and it took only two more weeks, excited 
🎉
and finally MJ can always say something like "we admit we started from sd weights, so it's their fault"
mklink /D "SD3" "$D3"
i don't think copyright needs to die. i think there's a big need for it when we have such a transactional world culture. what i would like is to see fair use expanded though
That must be why pixart seems to pick up finetuning so easily then. 😐
Lots of empty "space" in the neurons
we actually have ||on a private repo||
in a month MJ will release a new DiT model
yup, i believe pixart was trained on just 25m images, you could fit alot more in there
"just a coincidence"
we used huyandit! /doesnt even understand chinese prompts
OK, since all y'all have been reticent: "When is SD4 coming out?!" 😄
In two weeks
SD4 confirmed. Stability promised
tbh no artist can say a thing against AI, i mean they call a banana sticked on the wall "art"
In Two Weeks ™
will sd4 have control net?
we have people working in Japan, we'll skip 4.
maybe sd5
SD5 directly
SD4 will have Ru Paul's Dragnet
stable cascade 2 confirmed 😮
32B parameter model when?
or SD3.9
when GPUs are free
Run it in 2bit... It'll be fine.
@lavish osprey I've been trying to avoid any drama but I really do not understand your antagonistic perception of Pony (and some comments you left about it in the past are just hurtful)
Doesn't make sense to compare with that
Perhaps you should, it's a more popular model (downloads/gens) than SDXL on Civit. Worth doing some comparisons. I may remind you that on the day of SD3 announcement the top of r/stablediffusion was a Pony meme, so community clearly is interested and would like some comparisons.
fair enough, but don't you think SAI should "recoup cost" too? 😄
I think SAI absolutely should recoup costs. But I also would appreciate if it provides any guidelines on commercial licensing in advance as currently I have no idea if SAI membership applies, if something new is up or if it's forever non commercial.
If you do finetunes for research and share them for free, or you share images, etc, fine. But if you want to make a profit with a finetune that costed a fraction of what costed us, I think it's only fair you give something to SAI.
I have been sharing my finetunes for free since the release of 1.4 and running a free service to let people generate images. As a matter of fact I am at least 100k down in costs of hardware and cloud compute. All the commercial stuff I've done so far has been specifically to control how much money I burn and to help with more model training. None of this is about profit, I just want clear guidelines ahead of release.
Pony (or any other generative finetune in the last 3 years) wouldn't exist without SAI.
And SAI would not exist without it's community. So it makes sense to at least maintain some level of communications with it.
yeah sure, but I don't find it cool when somebody say "if SAI asks for pennies I won't support them and just finetune on XL or whatever"
I will "just finetune SDXL" if you do not provide clear expectations on license. I would rather run around screaming how amazing SD3 is and how much I like working on it. You are also breaking the expectations by potentially diverging from previous Membership approach (or maybe no? Who knows, clearly I don't).
holy text batman
The Cascade team left Stability, right?
I mean, you still have to train at full size, the best you can do is quantization-aware training.
but you still need the vram for 32b params full
Oh my!!! Someone's just loaded SD3 chat into an LLM!!!
tldr version when
Cask Aid were down to Craft Beer
im gonna ask llama 3 to sum that up in one sentence
Time will tell but I am sure XL is good for at least one more release. But it would be interesting to train same dataset on XL and then 2b.
i hope the day ponydiffusion moves to either sd3 or pixart it will use natural language for prompting

nice
But it already does, lol.
But yes, V7 captions are a completly different game.
it's the evolution of wailord 🙂
Some people (me included) just don't like the premise Pony was built upon and it has literally taken over despite it being being a one-trick... pony. 😄
oh that's nice
🤣 just did it with copilot
What is the premise, may I ask you?
kek
No. You may not. I'm not getting into an argument about it.
Oh nice! I look forward to seeing what you come up with. 
Perhaps you should
We did some tests. Pony failed to understand things like "a bank" or similar simple concepts, so we understood that it likely has a different scope compared to what our base models are for. Which is perfectly fine, to be clear. It's just that base models have a different scope and purpose.
But I also would appreciate if it provides any guidelines on commercial licensing in advance as currently I have no idea if SAI membership applies, if something new is up or if it's forever non commercial.
I'll rely this to the team handling the membership
None of this is about profit
I personally think that if you make no profit you shouldn't pay or pay much, which applies to the current membership tiers (even enterprises pay 20$)
I will "just finetune SDXL"
I don't get the quotes. I also "just finetune SDXL", or did. It's not supposed to be offensive or to belittle
pixart
I am genuinely interested in how the model is perceived, because there is a huge difference in the original idea and how the model is used now.
A Netflix series will come out of this
dog vs horse
I just asked Llama 2B Q4 "At what time exactly will SD3 be released?" It answered "I apologize, but I don't have access to the exact release time of SD3 as it is not publicly announced yet. The release date and time of SD3 are subject to change and will be announced by the developers at a later time.
Please follow the official Discord server and social media accounts of the game developers to receive updates and announcements regarding the release of SD3. They will provide the most accurate and up-to-date information on the game's release date and time."
I love dogs
people are free to do even finetunes on memes and meme formats. Doesn't mean a base model should compare to that, even if they're super good at making memes.
i just spent a whole bunch of credits on leonardo trying to get that image using a simple prompt and then im like okay sure but how about wiht a complex prompt and i can't even get anywhere close to that
I already trained an embedding on SDXL for it today
lmao
I heard @karmic silo is making one
SD3 is a game according to Llama 2B Q4
lmao

overfit on KH3? 😄
Yeah I tried it in many AIs and its hard af to do, here´s another one that worked fine xd

OK, I see it as a purely porn model, which is all anyone seems to use it for, it's awful at understanding simple prompts, I have a reaction every time I see the "Pony Woman" of which there seems to be only one, and she attempts to appear in literally everything, you can't do an image without either her or a pony popping up. The tagging system of score_etc, is just odd, why do they even need to exist, also, "porn" model, used in some hideously awful ways.
lol i dont know i don't think that qualifies as good
what's wrong with it being a porn model?
sameface is an issue common with models trained on anime (I wonder why)
Yes. That's what's wrong with it.
Nah its not that good but it was goofy and somewhat decent
sameface is a new batman antagonist 🙂
how's tihs?

I think a lot of that has to do with upscale settings, as you suggested. With a detail lora, I've found to finally get back the detail that was previously missing.
this is why I'm happy that you helped with training SD3, so we get good quality by default, but no samefaces 24/7 across seeds
I understand why people like the pony model but it's not a very intelligent checkpoint
anyway guys, please keep the discussion civil and on a peaceful tone.
This, so much.
FaceDetailer does sameface!!! 😦
Its not technically a porn model, its a model and some of the images in the dataset...were porn
It's 99% of what it's used for.
im personally not into the pony stuff :3
omg its comfy!!!
id qualify it as a porn model if 80% of anything you type regardless of what it is, includes a woman in it lol
Well, maybe a more child-friendly one 😅

I wasn't going to reply, but he did ask.
ideogram?
puts the reddit hat on
But I can use 47 loras, controlnet, inpainting and regional prompting and it will do the same things SD3 does
removes the reddit hat
99% of civitai is used for porn if you use that argument
That's a denoise and prompting issue if anything. Wildcards are perfect for it.
sd3 when i ask it to make boob
I don't get the quotes. I also "just finetune SDXL", or did. It's not supposed to be offensive or to belittle
your original quote was aimed at me (I assume), so my point is simple - it makes more sense to keep finetuning XL if there is no clarity on SD3. If you "don't find it cool" it's because you are not considering constraints in which community finetunes operate (which is weird as you have the same background).
I personally think that if you make no profit you shouldn't pay or pay much, which applies to the current membership tiers (even enterprises pay 20$)
Then we totally agree! I just hope the business folks at SAI agree with us.
It is, which is why I use the filters.
why is it not a dog plushie or an anime girl with fennec ears on the right?
no, I was talking about me (or in general? Definitely not about you 😉 )
Can you please define "intelligent checkpoint"?
Someone please develop a node for ComfyUI which deals with all the "Failed to Import" node conflicts?! I would pay good money for that! 🙂
I'm sorry!!!
Strange as it may seem, some people don't like porn, people who are Ace or Demi... for instance.
The "Failed to Import" errors means that I'm an accomplished comfy user. It's a badge of honor.
I have a series of basic prompts that test for how smart a model is, a model that takes everything in your prompt and incorporates it properly in an image is smart
a model that ignores part of the prompt is less smart
stupid checkpoint (left) intelligent checkpoint (right)


i wonder which one is sd3
the one with the Microsoft logo

I understand that people love models that give them pretty images over actually listening the prompts
but that's not how I evaluate them
The Holy Grail of Generative AI is prompt coherence! Is Harrison Ford available?
I am completely the opposite 🙏 I loved SD2 over SD1.5 even if it was only a little bit smarter
I just don't like Pony and I'm believe I am actually allowed to not like something if it's not my preference?
one man's garbage is another man's gold, or something like that right? :3
@jolly swan I don't think they mean any harm m8. Things between people can stray out of context too. We all know out of everyone in the community, you have made one of the larger contributions to it. I think most people will agree with me that it can't be denyed.
It probably has been asked countess times but is there set time for tomorrow's release?
if I write that I want a specific object in the background for example and it's completely absent in all images that's a fail
two weeks
Do you know if it can understand numbers? My dad is an artist and wants to know. Like, if you want 8 of something, or 5 of something else, etc.
((But licensing does need to be made crystal clear, to make sure people are put at ease.))
I see, I guess you wouldn't believe me if I say that It's a full creativity (aka lightly censored) model that was build for cool pony pictures. 🙂
you can't do an image without either her or a pony popping up
are you using style_* tags, they exist specifically to separate parts of model you don't like.
it's awful at understanding simple prompts
do you have any exmaples? It should be pretty ok at that but it has indeed narrow scope (and no help form XL as it has been largely erased)
The tagging system of score_etc, is just odd, why do they even need to exist
I still think it's a great alternative to "hd, masterpiece, best of X"
"porn" model, used in some hideously awful ways
I wish SAI worked with me to better understand how models can be edited/censored, but so far they ignored my plea for help.
it may or not come out around noon EST 🙂
which is understandable if you consider that Pony was trained on booru scraping (or at least wd tagging or similar). @jolly swan maybe will correct this but I think it's accurate enough for the sake of this argument.
You reduce the vocabulary, you remove the grammar, everything is narrowed so "pretty pictures" are easier to make. You also remove ALL styles except one, which gives lots of consistency and makes anatomy easier.
Basically you take 40 shortcuts and focus on making pretty images, but you demolish everything else.
Its not like its easy or not costly to finetune this models using like 300k pics
Also style tags are pretty stupid in my opinion. But that's just my opinion.
I really can't stand that 90% of prompts of civitai have the same 5 words at the beginning.
17.00 London UK time
hmmm
I understand that, but it's morphed into a porn monster. Those 'hd, masterpiece, etc' tags are also horribly unecessary
But 17.00 London UK time means that all at the SAI Office will have gone home
also true of SD in general tbh
Astra!  I spent a bunch of time in prompting help, people really do only see models in a single way, they don't want to be creative themselves
I spent a bunch of time in prompting help, people really do only see models in a single way, they don't want to be creative themselves
I'm sure they'll release earlier, and then spend the rest of the day watching the reaction!
Pony is very fun, tho I don't use it for ponies haha
natural language prompting will solve all of these do not worry everybody
I wish SAI worked with me to better understand how models can be edited/censored, but so far they ignored my plea for help.
is there a censored version of pony? I tried using rating_safe and didn't work at all.
insert x-files theme

{kind=link}
isn't SD3 only censored as much as SDXL?
it can do gore and guns and etc
it cannot possibly be SD2.0 level of censorship
Since I'm not interested in porn, nor do I want models to generate compromising images that could lead to future laws banning the use of AI... I'll be one of the few
SD3 at ClipDrop will not accept 'sensual'
'hd, masterpiece, etc' are not really the issue. score_9,score_8_up,score_7_up,score_6_up,score_5_up,score_4_up in every single image are the issue.
but think of the big boob anime women!!!!!!