#🆕|sd3
1 messages · Page 6 of 1
the effect is greatest with the magic RES sampler i have, but yeah
we've been poking around over on the L2 server trying to pinpoint what's going on halfassedly
Wait can you confirm that fp32/fp16 are near identical with the same setup? ie it's specifically fp64 where something weird happens?
fp32 and fp16 are also different but it's not as dramatic
Is there any chance you can get someone with the right paycheck to confirm this?
i believe deliberately setting fp32 made no change
so it's not something that's accidentally fp8 somewhere
and a lot of us have replicated it
so it's not just my crazy setup
at fp32 or fp16 the images tend to be more creative - more combined objects, more transforms, and also more artifacts, broken fences, that kinda stuff
not at 10pm sunday night where the person in charge of that is chilling in taipei with lisa su, but i'll poke to try to make sure it gets answered clearly before launch
fp64 things really come together
As somebody is talking about sigmas (noise scehdule?) - what exactly do they do?
more detail, more cohesive images, and the it/s is unaffected
One of these days after I build my new PC, I'm gonna have to sit down over a weekend and learn comfy...
Thank you!
comfy is a lifestyle, not a weekend 🤣
this right?

ComfyUI is a doddle to learn! 😄
sigmas are like weirder magicer timesteps - the timesteps you see as the user are 0,1,2,3,...,20 but the model sees weirder numbers that go on along a curve
sigmas are so much easier to understand imo
if you scroll up to clownshark's comfy screenshot you can see some graphs of his chaotic scheduling
so sigma
Will it be possible to train a lora for SD3 with the 2B model if I have a 4080?
scheduling the amount of ancestral noise, the color of the noise, crude momentum implementation, c2...
OK, so it is a curve which influences the noise-schedule and there is obviously a sigma-sweetspot to maximise image quality?
and some other shit getting injected into the sampling process and mixed in with hard light
that thing is a monstrosity
yes that there is christian, our CEO, and relevant final decision maker on the licensing topic, standing next to lisa su
yeah
do you mind sharing what's being worked on for 8B? does it need more training before it feels worthy enough for a release? my team wants to train SD3 but we're debating whether we should wait for 4B/8B. 4B seems ideal for us
thanks! Looking forward to getting started with finetuning when it releases.
it needs more training first yeah. Right now our best 2B looks better than our best 8B on some metrics, so we need to improve 8B enough that the scale boost is worth it before 8B is relevant
with my new PC being able to iterate a new image in under 20 seconds should make learning by doing much easier. having to wait 40-80 seconds per image means that you spend your time waiting playing around with multiple things only to find in your next image, one of the tweaks you just did borked the whole thing
So as I eagerly anticipate June the 12th ... will having an 8Gb VRAM RTX 2070 ... will that disappoint?
alright, definitely looking better now that I'm not forcing the prompt to stay under 75 tokens

all the recent training work was on 2B
i only have 12gb, you’re still good with that.
wait what about the minimum vram to train a 2b lora
example a T4 gpu
thank you for the answer. i look forward to the release of the models and hope the stuff applied to 2B proves promising for the larger models!
can't say for sure exact numbers, but a T4 has 16GiB VRAM which is well more than enough
ohh
absolutely. my abilities with comfyui didn't take off till i got my 4090
2070 should handle SD3-Medium fine
generally SD3-Medium is a bit faster and easier to run than SDXL is
Thank you for the reassurance
so whatever your SDXL perf is - expect a tad bit better than that
nice
How well would a 3060 12gb do?
that's more than good enough yeah
is 4b something we can expect this summer or should we buckle down and commit to building stuff for 2b?
what does the devs think about this though?

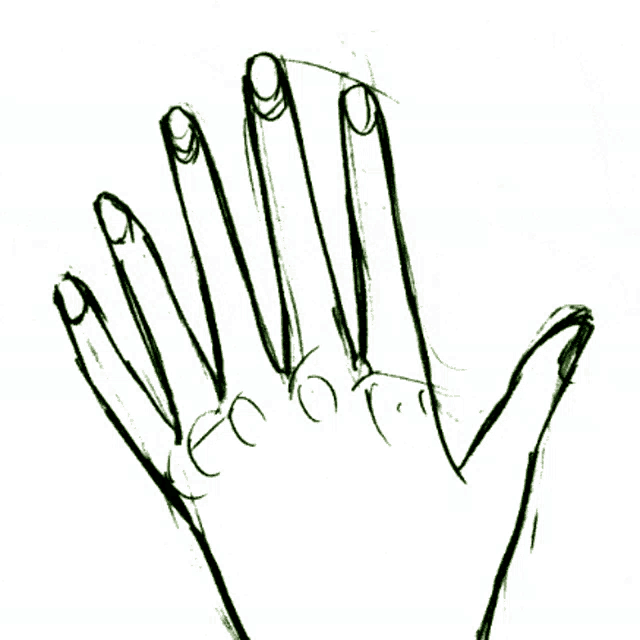
Not to spoil the party, but features like eyes, fingers and limbs are still poor - even for all the hype and chutzpah surrounding SD3?!
ngl i have no idea what the schedule is gonna be for the rest of the models. 2B is june 12th, rest are whenever they're ready
great, thanks, appreciate it
Building against 2B is worthwhile imo regardless because most of the initial work is knowledge&tools, and those will transfer to the other scales
2B is better than 8B on humans
not perfect
get the training down with the fast train 2b
but like... RealVis-SD3 or whatever is gonna come out and you'll have awesome humans
now where does 8b shine? is it in quality? diversity of concepts? transforms/creativity/combining stuff?
who makes the SD3 i wonder if they can use the method here
my biggest desire is to have something that can combine concepts that sdxl tends to separate into discrete ones
we were looking into quantization of SD3 before, that project got deprioritized sadly but there's definitely potential there, and it'll be awesome once somebody gets it working
clown + shark = clownsshark, not clown + shark
There a guy @Glif named FABLAN - he is running SD3 generation for free?!
ah so ya gonna release the unfinished quants code or?
How can that be so?
wasnt doing it able to oof the quality of SD3
before ever Q6 or Q4
right now 8B doesn't shine much other than maybe sheer breadth of knowledge. Once it's trained to catch up it'll probably win out on everything
How does SD3 handle prose? Right now I'm finding that Ideogram handles prose the best by a long shot
will it be free?
gotcha, yeah, even if the quality isn't outstanding, i'd love for something that can do a lot of new concepts
i've got my dora -> crazy noodle fiesta sampling psycho ward workflow pipeline down
i'm training on crappy images and getting razor sharp ones out now
I find that text and prose in SD3 works about 85% of the time ...
SD3 is generally better about this, not always perfect. We did experiments with if you focus on T5 training (ie deprioritize CLIP) it gets even better at this (at the cost of some of CLIP's stylistic understanding)
dooooubt it
i've already seen it from the api
About on a par with Harrlogos2 LoRA in SDXL
chat moving too fast, idk what this is referring to
the API version has been able to do transforms that dalle3, mj, sdxl, etc all failed miserably at
is the api the 2b?
uhhh no confident the answer offhand. Generally all text understanding is smarter, for more specifics, uh, Try It And See ™️ ? :D
either now on API the 8B or june 12th with the 2B model itself
on june 12th the SD3-Medium weights will be free for noncommercial use, yes
oh, idk, presumably just using SD3 API and funding it himself or something? idk you'd have to ask him
there have been a lot of misinformation of Core SDXL and SD3 API
for real someone should post all those information here to reddit
I am doing right now
weights are the uh... model thing, right?
still writing
Will there be an affordable Commercial-Use release?
is it full sd3 or part?
i thought screenshotting haha
ImageCore is a workflow/finetune of SDXL, "ImageCore" is a placeholder to indicate "whatever the current best we have for general image generation" not including beta models like sd3
If I were to give you a prompt I use to test the capabilities of models, would you be willing and able to show me it's output, or do i just have to wait 9 days?
oh ok
"weights" is techspeak for "the model file itself"
I figured, thank you! I just wanted to make sure.
"How long do we have to 'weight'?!" 😄
presumably yes, not entirely clear yet, going to try to get it clarified with the execs in charge soon
but if cha screenshotting, you should censor the ordinary member names here
God it must suck to be you rn with how fast chat is going with all these questions
yeah they made that joke in the announcements: "The 'weight' is over: SD3 released on june 12th"
OHHHHHHH i missed the damn joke in there lmao
wait i didnt see it
It is the full SD3-Medium, and not yet the Small/Large/Huge variant models
the joke
sure why not
I have trained so many years for this

I am putting my discord fingey muscles to the test

now test your type speed
good luck

what are the other versions?
ur faster it is
Different sizes of the model, with different resource requirements and theoretically once trained different quality. So the small model for example uses half as much VRAM/time to generate, but theoretically gets about half the quality, vs large is double/double.
In practice the quality different is less precise, and mucked up by the fact that only Medium is trained well so Medium is best quality atm
By 'Stable Diffusion 3 Medium' they are referring to a version smaller than 8B?
Medium == 2B
Small is 1B, Medium 2B, large 4B, huge 8B
From XL to medium? Big downgrade?
Okay, rewrote it in prose rather than tags:
In the Hall of the Thousands Doors, an awe-inspiring representation of the afterlife, the atmosphere is heavy with the scent of incense and damp stone. Quiet souls wander amidst dim torchlight, casting long shadows across the cool gray stone walls adorned with intricate carvings and symbols. Endless hallways stretch out from a central hub, each lined with doors featuring unique, ornate designs and precious materials. Whispers hint at the lives contained behind each door. In the center stands Aponyx, the Raven Goddess of Death, her majestic yet terrifying presence watching over her domain. Above her colossal throne, a mesmerizing portal shines with an ethereal light, offering a glimpse of the City of Heaven.
ok,sd3 is it launched in site or in gpu?
Ah, I see. Will there be a comparison of the different sizes?
there is a comparison
i mpretty sure thats the ice cube thing on twitter
lykon did post one too but its a guess game
Yeah, when they're all finally ready, would love to see a side-by-side comparison of different versions using the same prompt and seed
SD3-Medium is much better quality than XL, with a slightly lower resource cost
SD3 Medium will be available to run locally on June 12th.
SD3-Huge (8B) has a beta version available on API
nobody talked about the gens sd3 b2 will be 512x512..
right now 2B looks better than 8B as it's been trained the most, we can't really do a fair overall comparison until the others are trained more
we have some comparisons laying around somewhere to show the current state of thing
Really? Back down to 512??
SD3@Glif (FABLAN) ... free-to-use ... 9 seconds/generation!

then i don't need gpu?
that is a giant prompt and i'm not sure what you were aiming for but it looks cool!

That's on a 2B release candidate model
@viral plaza is it really 512x512?
SD3-Medium is 1024x1024
no
OH then ive been misinformed LOL
maybe edit this ar?
You can either use a GPU, or the API, at your own preference
SD3 into i2i SDXL is a very powerful look!
iirc ppl on civitai discord, somewhere twitter said it being 512
Yes, aesthetic wise it is given to be better and probably know more things due to being trained more. But I'm wondering if coherency is also better currently?
There's a bit of confusion because a few months ago (?) I posted a 2B Alpha model that was 512x512 and some people don't realize that in the months since work was being done lol
cpu?
got it then

running an AI model on a CPU would be very very slow i would not recommend that
argh okay ill go find the civit discord in my list lol
here's same prompt on the old 8B Beta

theres so much noises
ye, overall better
Hmm, not terrible, but I think it lacks the ability to really handle the prose. Here is ChatGPT (left) and Ideogram (right) as comparisons


you can compare the images above^ as a reference between 8B and 2B
oh my god
Is the prompt style changing again?
that astraliteheart situation is long to write
I think this iteration of SD3 Medium should be nicknamed 'Hamlet'!!! 😄
2B or not 2B ... that is the ?
nah
keep it a sub version of SD3
artisan is sd3?
yeah?
Yeah, it's pretty clear that the new 2B is better than the old 8B, but both fall pretty short of ChatGPT and Ideogram in terms of detail imho
Artisan is a discord bot with a variety of features - SD3 is the default result of /dream but you can also use Core or whatever
Hamlet x 4 - 8B or not 8B
nooo just keep it as sd3!!
bear in mind 'ChatGPT' (DALL-E 3) is estimated to be something in the range of 20B-30B or somewhere huge like that, so... unfortunately hard to beat. It also rewrites your prompts for you with the LLM and probably reduces the confusion from the complex prose
it would be boring for an iteration of sub sd3 be called that
torcello's just making jokes and does not have the power to rename the model lol
are you using clip vit-g and clip vit-l again? and are they the original models, or did you fine tune them?
DallE-3 is so horribly overfinished ...
i thought he was trying to call a name of the model for himself
What's the story with Cascade? Why was it released and then abandoned, even on here?
yes the same clips as used in SDXL, and no sadly not trained. There's also a T5-XXL Encoder added in
researchers joined, made model, left, and SD3 outprioritized it.
The real value with Cascade was in the research concepts they shared, rather than the model itself. Unfortunately I don't think much of that made it into SD3 due to timing overlap, but hopefully future image models will incorporate the concepts (eg the complex latent compression or the two-stage setup)
Oh yeah - if it was down to me - "Torcello-2B! ™ "
thanks, I have been training the clip l model. would it be possible to train a lora for the t5-xxl? or is it even necessary, like for adding new concepts
Idk about that
cant wait for another opensource model that will be a 10b+ to overtake sd3 (and opt)
And I'm getting better quality images now with some sampling tricks than I've seen from any closed source model except sora
From sdxl
We've got the flexibility of custom tools, trainability... It's way more powerful than any closed source bs
i remember trying out Open-Sora-Plan and it generated worse than expected, wanna post it here
I even have SDXL writing text
SD3@Glif

It's far more capable than we think, just need tweaks and training on custom concepts
Doras are incredible
woman: there are so many pomnegrates im so hungry
horse: how hungr
Gonna have to go bug the guy I know with his $300,000 8 H100 setup to see if he'll let me use a bit of it's power when his team is taking a break from trying to make AI generated games...
lol i got the email too so apparently i wa son the list but i never got to access sd3 before lool
What's wrong with me Emad? XD
eh i got the email after losing a match on mobile legends anyways
loool
Photorealism: Overcomes common artifacts in hands and faces, delivering high-quality images without the need for complex workflows.
Bold claims.

Possible to train T5 / as a LoRA: Yes
Do you need to: probably not tbh, just train CLIPs and use that. Can even transfer SDXL CLIP training directly onto SD3.
^ this is the real facts right there. No matter how good your closed source model is, open source always wins cause you can customize and control
if someone trained lora with danbooru tags on sd3 ill be dead out laughter
I will

NOOOOOOOOO
I mean it is inefficient to write CLIP tags for anime
where you could have thousands of detail to write
yep. once you take the time to dig into custom workflows, custom nodes, start training concepts and really learning how it works under the hood... you look back at dalle3 and just laugh
nah i think the t5 xxl has solved that
if you think there won't be an anime finetune of SD3 out instantly you're crazy
there will be but the concern is about the prompt adherence (it might be the same as the sdxl anime finetunes)
on that note - are we looking at a day 1 release of training tools?
have they got a pull request ready to add the sd3 pipeline to diffusers?
HuggingFace has had the source code and reference weights for months now so i sure hope diffusers training will be ready day 1
beyond that idk

the one big issue with cascade on my end seems to be some kind of undertraining maybe? design issue? with stage B... it's odd, more than 7 or so steps and it actually starts looking noisier
excellent
@jolly swan I got a reply from one on the team managing the licensey stuff: they're still getting it sorted but are expecting to have a clear answer for commercial users before launch
magnificient
hopin a great news
Always those Doras 😄
Dora the Mad Sampler
SD3 model will be dropped soon? Is that true?
Yep, June 12th
yeah i was talking about doras the other day. it's crazy that an 8 dim dora can compete with 32+ dim loras, even 128 dim. really cool stuff
Sampleress 😄
even though the charts show doras being marginally better at rank 64...
the results are distinctly better
there's a sharpness and a cohesiveness to the images that i've never gotten out of a lora/locon
Are your changes any good for realistic images, or just the stuff you create?
this is for LLMs, but it still is relevant

how will the model be packaged? will the T5 files be separate?
probably separate, like other models that use T5
like when you use pixart sigma
they've helped with everything

yeah that's def where the big gap is
what i found surprising was how significant the gap remains beyond that
i'd have to look into it more
it's not something you'd notice standing 10ft from the screen, but it's very much there
i'm getting images far better than i trained on in terms of quality
here's a phenomenal breakdown of doras for anyone else interested in the topic:
https://sebastianraschka.com/blog/2024/lora-dora.html

Sebastian Raschka, PhD
Low-rank adaptation (LoRA) is a machine learning technique that modifies a pretrained model (for example, an LLM or vision transformer) to better suit a spec...
i had lots of blurry, kinda pixelated muddy stuff from cascade... came out great with the dora, whereas with locon and lora especially that crap carried over

most likely we'll have the SD3 MMDiT backbone and VAE in the model file, and then textencs separately
Eyes and skin aren't great, but I presume it's unrefined. Have you shared your nodes on GitHub, or in the manager?
there's some disagreement internally about optimal format atm tho
"anime sucks"? I mean you can have your own preferences and whatever, but you can't deny millions of people love it
GAZILLION!
yeah that's model to sampler to vae decode
any defects you see there are a result of the crappy lora
cuts down the incidence of misshapen eyes quite a bit

mutations, etc
it can do text


nodes need some cleanup then il'l throw em on github
Great, thanks!
walter white elected -> meth is legal
Will the workflow in comfy be similar to SDXL where you can send a different prompt to each text encoder? Does it still take the resolution, target, and crop parameters?
Yes you can do different prompts to different tencs if you want.
It doesn't have all the secondary conditionings anymore no
and no point refiner right 😂
If you look at the image there is more to it 😄 Then, only because millions like it doesn´t necessarily say anything 😄 Btw I like anime, though I´m more of a manga guy. It´s more the endless repetitive often mediocre anime girl portrait AI images, especially the lewd-kind that´s sort of spoiling it at least here. Even more so if the lewd stuff looks like 6-year olds.
Just checking, but does it support img2img and upscaling?
i'm mcmonkey4eva on reddit not mcmonkey
whoa also on question 13 refuse to collaborate further that's not part of that
Hey Alex! hope all is good on your side. Will you guys release controlnets as with sdxl?
there's going to be quite a lot of edits lol
grammar stuff
uhhh not sure but i don't think so. The way to make controlnets is really clean and clear tho, mmdit arch has a great way to do that (add a stream), vs in unets it was kinda hacked in.
someone also asked whether if you have any opinions on the rumour that SAI is running out of money and considering a sale
( that someone from CivitAI )
not sure exact numbers. Slightly less than equivalent training applied to XL
i'm just a dev i can't talk about anything to do with executivey businessy stuff
i presume like the loras, you'll need to train them separately for 2/4/8b etc
I expected this lol since probably NDA policy stuff
95% chance, yeah
yes the different size variants are effectively whole separate foundations until something like x-adapter comes along for it
Does anyone have a link to any sort of information where i can inform myself about the status on the training of lora's on SD3
I'm so used to vaguely organizing my crazy noodle empires now...
ah damn, still wondering whats next after SD3
my record is 541 nodes
over 400,000 characterss of metadata
SD4?
possible
Tack on like 300mb to every png lol
400,000 characters is 0.4 MB
I know I'm just joking around lol
things kinda went downhill with this one

and thank god i finally made a node to do this

NERD SHIT

rofl, that looks like my students doing unreal engine visual scripting. Visual scripting is not a reason clean code should not be maintained! 😄
NERDUI

no, just no


the contintents of sigma nodes now look like this

I work with UE4/5 every day and have been doing so for like eight years. I've lived in noodles for so long that I'm a pastafarian now
so much so that i actually prefer noodles over code
it's a balancing act
if your organizing is costing you more time than it saves digging through messes, you should stop organizing
if it's the other way around, it's time to organize
espec if you're going to be using it a lot
but experimenting? trying new ideas? make a mess.
all just about getting shit done
yep, noodles are amazing for experimenting. granted, in UE4/5, you can just make a million functions to clean up the graphs, but still, early on, you deal with a lot of noodles while shits getting hammered out
I organize when my brain wants to rage quit
also, someimes what looks organized to me surely looks like a monstrosity to otthers
At least group and comment stuff :/ Don't teach yourself crap routines.
current WF... organized as hell to me, but that's cuz i got the components memorized


Future you will appreciate the 5 mins you take to do that.
building those crap neural pathways up, bud
hey google can i ban someone from a discord just for inducing brain damage visually
i'll be honest... that one became a practical joke
took every single node i had in all my open workflows
dumped them into one
and chained like... 12 samplers in a giant ring randomly combining everything
but why you do that?
shit clown, i forgot about the plugin node i was talking about a while back where i was wanting to make some kind of bspline editor for doing the sigmas
when we were experimenting with stuff back then
oh, yeah, that would be AWESOME

man, I have had some monstrosities myself. but never started off with that intentions
they organically turn into monsters
i just dont know the framework for comfy all that well, but in theory, it's pretty simple. i could probably whip one up in UE5 in maybe 30 minutes, 20 of which would be relearning equations and stuff lol
here's the full workflow i made where i combined everything i could

in the most complex way possible
still nono
it gave me this.

ive been digging all these ultra high contrast things you've been making. really neat stuff man
thanks
it took modifying the samplers to control it
or it just got blown out or muddy
just havent been active that much lately to talk as much on here. busy with some projects
the dora really helped push things over the edge too
work finally died down for me after an 1812 overture style bombastic end in early may
so my form of relaxing has been binging on making nodes i've wanted for a while
i feel you there
@viral plaza do you have more demo pics of the current SD 3 medium? 🙂
sir you work here lol check on slack
ask Lykon for it

Well, with weight loading we could prune those... but without Unet most LoRA's won't be worthwhile at all, so we should just ReTrain everything on the new tech with better caption understanding.
textenc based models are super powerful, i wish people trained them more often
Is it possible on 24GB
what do these even do??
Make will smith eating spaghetti
here's an example of just how much of a diff the sampling improvements has made...
before, after, and 1/4 the run time


that was trained on a number of images that had blurry edges
blown out contrast, etc
Highly recommend use this for training the clip-l model. Ran it twice with 200k images, then averaged the result. I think it helped improve the output from SDXL. https://github.com/zer0int/CLIP-fine-tune

GitHub
Fine-tuning code for CLIP models. Contribute to zer0int/CLIP-fine-tune development by creating an account on GitHub.
I think I know stuff until I come here, lol
There's always someone with a more complicated workflow...
i'd like to see the one more complicated than mine... i actually would, not being a lil shit lol
before sd3 comes out, is there a magic prompt node for comfy ui like ideogram?
the 541 node one or whatever
no no no
what? running sd3-medium? Yes
aimingfail made one called the clownstyler. it takes prompts, and makes them insane
oh nice
Oh no, like training textual inversions for example
oh, yes that too yes
sheez 😭
he made a model with some of my images, lol. haven't chattted with him in a while. he said he'd gotten into the llms

at least you organize it
Oh wait this is 2B, even DiT training might be possible
yes
you don't even have any nodes overlapping? live on the edge... try sticking a save image node underneath a ksampler
It's for 8B where training on 24GB might be finicky
the fact AMD failed so horribly to offer real competition is killing our field
at this point 5090 is going to be all-round GPU rather than gamer-orientated.
why has it been 24gb for like 5 years?
should they not meet demand with supply?
its not the complexity that kills it for me its the slowdown, a few ipadapters and maskign and it slowls to a crawl
😦

by not offering more than 24gb, they can charge another $10k for the next 56gb
$180/gb
which currently costs like 3 bucks
I saw that picture of the h200 I believe?
there's no equal to their high end cards, and there's no way around vram requirements for training, so they can charge pretty much anything they want
openai bro and nvidia bro and then some other guy
there's really no reason we shouldn't be able to buy consumer equivalents of a100s
that's SXM version of H200
AMD is finally competing in the datacenter, they just need to get that improvement into consumer cards too
H100 also have SXM version
that's great to hear... hope that helps you guys out on the bottom line side
SXM is like CPU socket with no cooling whatsoever, and also NVLink each other more efficiently compared to PCIe version
because contrary to popular opinion, gaming GPUs don't really need more than 16gb of vram right now, unless the devs are bad and don't know how to manage texture pools correctly. also, allocated vram != used vram. you can make a pixel game like minecraft allocate 85% of the VRAM if you want, even if it's only going to use 100mb of it, but if you check the gpu usage, it will show that a ton is "in use."
basically cooling was settled by air conditioner inside server room who often have air circulation
Does 2B have a 75 or a 512 (T5 iirc) Token limit?
bothn't
CLIP is 77, T5 is 512 or whatever, but you can also just stack multiple CLIPs as-needed
hi guys
I didn't like the results with longclip



long clip?
oh hi there


oh yeah hey
no this channel is sd3 discussion not your jjk general

so hi
btw hi
less gifs, more sd3

hmm i think this would be fine

fair enough. well perhaps that may have something to do with them making sure to stay within the hardware contraints most people have?
yo
NO
yo
this is not your usual interaction server
then?
welcome to the server where the world does not revolves around you!!!!
what do we do?
ayo chill
i am new here so i dont no anything
Oh will we get controlnets or not?
you only should discuse sd3 in this channel (either ai stuff because why not), not the usual interaction
waht is sd3
even you want it just go to #💬|general-chat
SD3 is a new generation text2image diffusion model
i want a channel where u discuss abot bots
pretty sure you have heard of SD1.5 or SDXL
it is a new member in the family
theres this talked about somewhere in this channel
so then ur a rando that randomly join servers
wait
probably not at launch date but soon after launch
... actually depends how successful is the 2B
is this a family
No
then
that was a sarcasm
what?
kinda like a new member to the server
bro
何
@frail tulip who invited you anyway
the average GPU has 8gb of vram and ~5% of pcs have a gpu with more than 12gb of vram. https://store.steampowered.com/hwsurvey/ if you want to see what people are working with. as a game dev, i can assure you that pretty much all pc devs use these kinds of stats for performance targets (unless you're some big AAA company trying to make the next cyberpunk2077)
i explore discoverable server
ah then ur so clueless
calm down bro
no
alright
i wanna learn smt abt chatbots
but
oh chatbots?

that's Large Language Models' job
the most chatbots are on Llama chatbot discord servers, stable diffusion is image
or LLM for short
yea
yeah Stable Diffusion is text2image

well I will not dispute that. I'm not really up on gaming these days
( although we have #1098025024541167646 channel )
its bad i suppose
im loving llama 3
discuss ai image genereation, which is Stable Diffusion
this one is opensource
the nowadays u see locally are Dalle 3
that is only what i am talking abt
you need to chill there, bud
i joined the right server then

well DALL E 3 is intergrated into ChatGPT
i ma leave
goodbye
cya
whata is happening?
before that DALL E 2 is a completely independent website on its own
dayum
fair enough, just saying, these are the kinds of things that companies like Nvidia factor into how much vram to slap on a card. there have always been higher vram cards though if you go the quadro workstation route.
no ChatGPT stuff
yup i do not like dalle
why are people tribal in regards to AI models?
well, psychology
is the sd3 model which is releasing bad compared to the api one?
you know when one product with revolutionary feature get introduced
yeah, tthat is the technical answer
Same reason people are tribal about gaming platforms - the one I pay for is the best licks boot
exactly just dont post anything AI stuff to artist discord server lol
you show them boring stuff they dont even bother you whether you release the thing or not
it's a hot topic at the end of the day
though twitter has misinformed them and leading them thinking its "theft"
why do people get tribal about their favorite sports team, their favorite music genre, their favorite foods, etc etc. it's just people doing people things and it's mostly just the vestiges of hundreds of millions of years of evolution that got us to this point.
people are only doing themselves a disservicee if they deprive themselves of learaning about things simply to feel like they're on a team
yeah, that's something I've actually been reading about a lot recently
humanity moment
thank you for the effort
so many of these things that were once necessity
100%! It’s not team midjourney, team sd, team dalle… It should be team best value for money and team best safety features to ensure AI doesn’t murder us all
it was advantageous back when our ancestors were cavemen. I guess maybe it still is in some ways
I just like learning about different things
just observe our ape cousins, you'll see the same stuff. even in packs of other animals as well, dogs, cats, mice, etc etc. it's pretty common in the animal kingdom to not want to be the outcast, because that usually signifies something wrong with the individual and the urge to reject them is to keep the "broken genes" out of the pool. it's observed in pretty much every creature on the planet with a brain
tribalism is just an extension on all that
since we have more cognitive capacity and all
what about people calling anyone that uses ai "tech bro" (not ai bro in this case)
techphobic much!
well they're probably not comfortable with ai
makes them anxious
so they externalize it and call people tech bro
remember those industrialist back in 1800s at England
Same as people calling the crypto shills crypto bros
there always had peoples fighting against the idea of an industrialist and sought to protect their green land
it is the same
if you knew it
Early adopters of tech have always been mocked by the same people who later adopted it
People don't like the idea of the reality they grew comfortable in changing
It means the things they're good at might become less relevant
this remind me one Tom Scott video
except crypto are kinda worse in my eyes
oh nvm
i misenterpreted that lol
anyone that mines ig
People also tend to dismiss things they don't understand
Crypto bros are like "influencers"
More sure of themselves than they should be
ive been hating em even the nft bros
but are ai bros worse? i dont think so lol
Ahh totally agree
I mean fron stability
I bought an NFT. Never regretted a decision in my life more.
$100 I’ll never get back 💀
uhhhh
nfts seem useful as a concept. but not the spaceape crap
I wouldn't say dismiss, reject would be a better word. A large portion of people are immature and can't stand when others know something they don't. They then go on to not bother trying to learn about the new thing, and then they just reject it.
I remember correctly all ControlNet models was uploaded by Illyasviel
but is he a Stability dev/staff?
cant even mention the dark humor ones lol
Thank you, thank you. Oh btw wanna buy an NFT? Guaranteed to moon 🌙
no thank you
it's mostly based in a lack of honest self reflection I believe
I don't even know about these dark humor nfts. I guess I haven't kept up
There’s like 50 other people with the same NFT as me and they’re selling for like $5 now lmao
in some cases harrass the ai user
Mixed with childish narcissist tendencies that they never grew out of. Those types of people will always just nope the f away from people that don't reinforce their behaviours
there are, and i would get banned for talking about it lol
And therefore, they never learn or grow up
narcissists lack a full sense of self so they literally can't self reflect. well they could. but it'd require acknowledging everything they've pushed down since they were a child. most will never do it
SD3 finally gets announced and this is what the convo turns into on the SD3 channel...
yuuup... but anyways, i'm not going to dr phil rant about it any longer because i can't stand dr phil (he's a massive narcissist and a megalomaniac lol)
what do you want to talk about, buddy?
hmmm how about... SD3
what is there to talk about other than it comes out in a couple weeks?
and maybe see the same waifus spammed over and over again lol
dont know how to defend this one of course
and the convo is over byee!!

the resources
there isa lready a reddit post for the infos
AI short circuits the idea to result path. it will facilitate an explosion of creativity
Can't wait for the prompt zombie Armageddon
still wouldnt accept that because "theft"!!
wait for 4 years and i will be able to reference AI stuff without getting harrassed
they're literally fighting against the idea of democratizing creativity
waiter waiter! failed gens please!
they won't be remembered in a positive light
oh lord, and the complaining about them not looking good enough just because it isn't some hyperoverfit model they're used to using that spits out "adult women" with the facial proportions of a younger-than-adult-woman... oh and the bobs not being gud enuf
i will say they waste their time arguing on twitter, they will say i waste my time ai genning "slops"
I can't wait to fulfill each other every request
SAME lol
i'm going full troll with it using the typical old men in tiktok poses lol
well also people act like the models won't become more sophisticated. like they're these static things that will just be
whats a "sophisticated"
it's an adjective
whatever!
(of a machine, system, or technique) developed to a high degree of complexity.
We need AI to fix the real estate and the economy. 😄
AI Governments when
never
not going to lie, i still use the base sdxl model for like 2/3 of the things i make, unless it involves people. but i rarely make people unless it's waifu trolling
who will train them?
hey man can you unban tax evasion
"im sorry, but"
well I'm more talking sd5 or 6, or whatever comes after. it's going to get exponentially better at what it does
I am going to Mars and throw your tea into space. I refuse to pay taxes to earth. Havea nice day.
Free Mars.
do not listen to those analog bros,heard they still clean their buttocks with wood based paper
hah they dont know how to use the three sea shells
ikr they make me braindead!!
So. Many. Messages. 
i use base + my dora
base is flexible
i like that

Im glad Dear Leader has been trained in.
my hero
All hail Kim.
yep, it's ultra flexible. all these other models really do is push out variety in the model for waifu closeups
all the models have everyone in them. I got dalle3 to give me Xi
turns out the key is just spelling atrociously
there's a few decent ones but yeah 95% is that shit
u just got winnie the pooh
big waste of all the training ability we have
there's already trillions of pr0n pics online, do we really need ppls 4090s cranking out another 90k a day
nah, I got copilot to flip out about stuff microsoft did, censoring things for china. and then started in on making images to illustrate
SD3@Glif

yes we do
the only other models i use are realvis4, tuggernuts9 and pg2.5
yes
didn't they originally say we are getting Controlnets with the release? It sounds like that's no longer the case?
BastardV1 is good for promt adehrence
it gets ANGLES right
top down, low angle etc
Knot Essdeethree

make one wiht XI and Kim kissing
can sd3 generate winnie the pooh?
so long as we get the tools, who cares
we just need the weights and the tools
sorry, who cares if we have the tools, as long as we have the tools? what are you even saying
i think so

what are you even saying
only famous artists were left out i guess
and getty/shitterstock watermakrks
famous people are fair game
I asked if we are still getting controlnets, which are some of the main tools. You said who cares if we are
which artists were left out? I'll test that out
theyre in the public domain and attention whores anywayz
can sd3 generate this?

yes
you'll get them eventually? or would you rather them wait another month or two to release the model
oh please
keep my wife's name out your mouth (Taylor Swift)
and this i hope

but can sd3 generate this?

SD3@Glif

without the tools, and with tooling only getting made around a small model, it's about the same for me, or maybe worse this way tbf
pooh handshakes with kim when
i think it could generate sculptures like that
so can I. in fact I generated that image right there
oh ._.
oh shit fish gyatt 👀
SD3@Glif


A Coelacanth?!
Will it be like Cascade that instead of as a Part of the Model (like SDXL) we'll be able to use the Tences individually (and thus also Finetune them and use others like T5 variants)?
That would also mean that we can use Longclip (once both versions are available).
i modeled a super basic model in zbrush based off a trout, but i added some scales and arapaima to the prompting
SD3@Glif

wholesome!
i made it as a joke for my idiot fishing buddies that are obsessed with fish like they are attracted to them


I guess I'll try that, even if I'm pretty sure I'll ReTrain everything on 2B.
Does SD3 use Clipskip 1 or tricks like Clipskip 2?
i need to take a nap rn

men will see this and say hell yeeah
This is what all the hard work has produced!!! 😄
ahahah yeah, god i hate it here lol
12 June, almost two weeks 😅

9 days
2b 2weeks,numbers dont lie
Can we train SDXL DoRA's with Kohya or OneTrainer already?
It's not the same as Lycoris, right?
Good prompt coherence
8B 8 weeks. LOL
I guess we'll also get the Vae separately?
For XL for example the Finetunes FP16 fix Vae is the go-to at the moment.
I thoght medium was 4b

it tried but it wasnt meant 2b
This is the most organised I've ever seen any of your workflows! 🤣
2B or not 2B - hey, let's call it Hamlet instead of Medium?!
Did you create a node that let's you control the strength of a LoRA per step of Inference?
It's actually very organized lol
I haven't, I wish
I always train both. Tenc training was absolutely a game changer for Dreambooth etc. (basically enabled proper v1-5 FineTuning iirc), but in my experiments neither Unet nor Tenc alone make big enough changes to grasp new concepts properly (and separate them properly).
Knot Essdeethree

looool


a gnome



@suchamazewow gut
I thought because I paid for stable membership I'd get SD3 as a part of it but you're asking for commercial use for us to fill out a form.
Do you need that if you have stable membership?


Hmmm, number of legs questionable...
indeed, that's happened multiple times
so how exactly does the fully non-commercial license for sd3 work? Can you not even use it in youtube videos that have ads on them?

The license hasn't been published yet, so nobody knows for sure.
I wasn't sure if one of the staff who posts here hasn't said more
I suspect that SAI will make some money by selling Commercial Licenses ... but the Community can knock-itself-out for free ...
... as long as they're not selling stuff!
the previous license was reasonable, you can use it commercially if you have less than X users (which presumably is the same as viewers for videos), and over that you pay
That's what they said, it should be ready before the release of SD3 anyway.
but in the email they implied you can't use it commercially at all for sd3, and you can't just pay you have to do a private deal
"at all"
dude
it doesnt mention it at all
'If you would like to discuss a self-hosting license for commercial use of Stable Diffusion 3 please complete the form below and our team will be in touch shortly.'
it implies you can only do commercial if you contact them and do a private deal
'SD3 Medium weights and code will be available for non-commercial use only.'
man
only = at all
It would be very hard for SAI to regulate sales of SD3 material ... they'd have to have a "finger in every pie" to make it work!
and where's the non-commercial license looking at?
what
In the old days, MJ said that you could sell material up to a certain level of remuneration. Anything above that, and MJ would want a cut, want a percentage
that's similar to how the current SD license was, but in the email they say you can't do commercial 'at all' which is a change from the 100k users thing
you realized both still have some differences
even though they did have some relation to each other.
Adobe do 'commercial' with Firefly: they allow so many free uses/month inside of Photoshop - then when that batch has finished - you must top-up, or wait until next month
plus I am thinking "SD3 weight will be available for non-commercial use only" can imply those who paywalling their trained model.
WhAt
Stack Clips? Like A1 / Comfy prompt truncating?
Please elaborate.
Did you feel an actual improvement with Longclip? I gotta say I didn't. It didn't get more concepts right than the usual prompt interpretation in Comfy.
On a scale of 1 to 10 how exhausted are you?
I am a solid 8.
C A F F E I N E is extinct.


#🆕|sd3 message #🆕|sd3 message
I really don't like the 2B sample, way too contrasty with hard lines while nothing in the prompt calls for it, and while not so noisy, I'd call it smeary instead, fine detail got smoothed away. I kinda expected this effect was from overdone postproccessing when i saw that teaser tweets, but it seems not. I'd like the posted 8b one if only it weren't so unusable noisy.
Either way, tried the prompt in the API as well, it's different to both (follows the prompt less it seems, no goddess to be seen, but the overall aesthetic is way more similar to the 8b sample posted, not the weird 2b output), so that begs the question, what's running in the API? I'd suspect a first iteration with smaller text context and that that has been cranked up since.





Sd3 for 12 june , the end of sd3 loop paradox lol
Is it likely that we can run SD3 Medium with comfyUI on the 12th?
Yes, comfyanon is a beast at getting new things up and running quickly. Even if he doesn't have it already ready, you can always just run the sample code from the hf page when it goes up, but you'll only really be able to do basic prompting
I'd imagine comfyui will have it ready before the models go live, or within 24h of the release.
Hey guys can you tell me which channel should I go to for help in using stable diffusion in local
I'm pretty sure he even already has it ready, as people with access to the model mentioned ComfyUI workflows with SD3 a while ago
Fantastic news SD3
well definitely not with SDXL, it was already smarter than 1.5
True that, yeah I'd assume he works with them on stuff since I've heard a lot of them use comfyui internally.


I wasn't lying when I said it's 2 weeks until the SD3 weights drop
SD3 when???
SD3 then
SD3 when-> SD3 Large When
So SD3 4B?
8b,i like them big
I like em chunky
Probably in a few months after they see what worked and what didn't work with the 2b model. Also, to give them time to pull in some revenue and to see if it's financially worth it to fully train the higher parameter models(or wait for some company to buy them out)
SD3 Dzen)
So we got the announcement to announce the announcement on june 12th?
i talked with cto last night in shower and he 100% real no lies no scam no virus
I was responding to xiaozhi about SD3 Large being 4B, just in case he meant 8B
I am aware that it will take a lot of time
I bet we won't see 8B until July or August
when 2B comes out and its good, I'm gonna buy 10$ worth of credits as a donation to stability
I thought large is 8B. if large is 4B, what is the name of 8B?
Huge apparently, but I'll look it up
thicc
Small, Medium, Large, Huge
SD3XL
extra huge
We're on track to release the SD3 models* (note the 's', there's multiple - small/1b, medium/2b, large/4b, huge/8b) for free as they get finished.
so yeah, 8B will come out
for free, offline, etc
800M / 1B - "Small", same size as SD1.5
2B - "Medium", the first one that will be released
4B - "Large", same size as SDXL
8B - "Huge"
EDIT: this is wrong, apparently XL is 2B
I think it might be even later than that, but we'll see. Personally, I don't have a dire need for it since there will likely be strong diminishing returns compared to the 4b model.
btw they could make something like 16b for API or own service to compete with dalle and mj
All except 2B are very much still WIP and not the current focus
Exactly, and the 2B model will keep us busy anyway, so waiting for the rest isn't so bad
800M might have to be their next target, so lower end people can get to work
Even if they gave us the 8B one they said it wasnt finished. It would take a while to even tune it so waiting is fine.
imagine FastSD-like implementation/app for SD3 running 2B-Turbo or 0.8B-Turbo or whatever
smart image generation democratized
its only T5 that has to be figured out
we need some quantization or ggml implementation so we can do stuff like IMatrix quantization at like 4-bit for T5
2b will be massively more powerful than sdxl. The 2b size would be more like 8b in unet format. Sdxl has like ~3b in the unet, not counting the other model parts.
I remember 3.5B on the website, but I suppose that's the total and not just the Unet
idk why they didn't write that in the paper or the huggingface page
only in the announcement of SDXL
I wonder what the hardware requirements for 2B are going to end up looking like. Forge is able to run SDXL on some surprisingly weak cards, but it's been abandoned and none of the other UIs ever managed to accomplish that
I checked base 1.5 and just shocked how much finetunes improved it, I think there won't be any quality problems with 2b version
Kind of like how llama3 8b outperforms llama2 80b, it's kind of pointless to compare model sizes between different architectures
What?! It has almost 3 times more data and similar requirements?
I'm mostly interested in what cards it actually runs on...
So sd3 2b will likely be as if sdxl had 2-4x as many parameters, plus, don't forget we will have 16 channel vae
and Textual inversions might come back to fashion if we're going for ""cross-platform"" compatibility between the 800M and 2B models or whatever
just probably for styles, maybe not subjects
is this transformer's magic?
Sd3 doesn't use a unet, it uses a dit format like llms use. Transformer based.
It was just a bitch to pull off for image generation until more recently
Without having dog poop quality or paint drying speed
And without needing 9001gb of vram
now I am even more hyped, why didn't they use it as marketing... or I missed something...
It's in there, wanna say they call them mmdit blocks, but I can't remember off the top of my head
I suppose stability wants to do a llama moment where they actually train the model for a good time instead since now its more transformer based
if the results are gonna look like lykon's, I hope it will still have variety
You can train it all you want, but if the captioning on the dataset is weak, you're just going to get more of the same. I know they used cogvlm for a good chunk of the dataset in sd3, but I don't know how well it works. I've used a ton of vlms and I know how much of a crapshoot they can be sometimes
yeah 50%
so that the lack of knowledge from cogvlm (pop culture or video games or etc) aren't as detrimental
so there is still room for improvements
I'll make loras for video games and other stuff
its gonna be fun
when the model actually somewhat knows what you actually want
I am curious, was dalle3 captioned by gpt4v?
think so
or whatever their in-house tool was for captioning
it is super detailed and smart
probably better than cogvlm
but cogvlm is still very good
and big
The biggest room for improvement would be in the t5 portion of the model and its ability to map dumb prompting to magic in the network

They did sometimes https://fxtwitter.com/EMostaque/status/1760660709308846135

@StabilityAI Some notes:
- This uses a new type of diffusion transformer (similar to Sora) combined with flow matching and other improvements.
- This takes advantage of transformer improvements & can not only scale further but accept multimodal inputs..
- More technical details soon
SD3 into i2i Searge SDXL w/flow


its great that they have both clip and T5, so T5 doesn't become a huge bottleneck for low end people
people can just disable anything they want
needs more cream
like this looks good, and it doesn't have a dreamshaper or juggernaut feel to the face

True, but the fact they are still using clip for prompting as the main source of the prompt is kind of lame and is what will hold the model back a lot. If they had gone pure t5, it would likely be a monster, but as you said, would shut out the bulk of users
also look! no bokeh! no depth of field!

{kind=link}
{kind=link}
but the pocket is wrong 🤓
It's still uncanny valley, just not the sameface of previous models (which you wouldn't expect it to be)
in my experience, 8B was still smarter than pixart or ella, so I still think its still a win
but yeah I wonder how much smarter it could have been if it was T5 only
Pixart is absolutely tiny in comparison though. Isn't the sigma 1024 version only like 0.8b?
now this has a finetuned model feel to it though

0.6B
its quite small
its still impressive for its size
and its better than cascade for example
And look how fing powerful it is... I use it all the time for the prompt cohesion. So imagine if they had a much larger model...
btw I learned how to deal with blurred background with sdxl, just sharpen image and put into upscale, maybe even 3d time, but needs a bit of color corection after
exactly
pixart is still the best model offline in my experience
for prompt adherence
Cascade:




pixart:


for a 0.6B model, that like 1 stage and way smaller than cascade, this is really nice
Yep
Such a powerful little experimental model
I hope so
Competition drives innovation
There's also a couple of those Chinese dit models I think as well
HunyuanDiT
Huendit or something
haven't tried Hunyuan but I think it wasn't that good
And some other one that starts with an L I think
the skin detail is nice on 2B

the eyes look nice too
I remember it looking a little buggy in the Goku images
it was undertrained back then
I liked it more than any sd1.5\sdxl portraits. Idk it looks more unique
hope finetunes won't get that 1.5 look 
I wonder how much this "no refining, no upscaling" thing is true