#▶|stable-video-diffusion
1 messages · Page 5 of 1
Nice looking + the parameters it's using are quiet sufficient for a decent animation and fast generation.
ah yeah fair enough
i have a font error "ERROR:root:!!! Exception during processing !!!
ERROR:root:Traceback (most recent call last):
File "/home/boy21/Downloads/AI/ImmageGenerator/ComfyUI/execution.py", line 153, in recursive_execute
output_data, output_ui = get_output_data(obj, input_data_all)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/boy21/Downloads/AI/ImmageGenerator/ComfyUI/execution.py", line 83, in get_output_data
return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/boy21/Downloads/AI/ImmageGenerator/ComfyUI/execution.py", line 76, in map_node_over_list
results.append(getattr(obj, func)(**slice_dict(input_data_all, i)))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/boy21/Downloads/AI/ImmageGenerator/ComfyUI/custom_nodes/ComfyUI-KJNodes/nodes.py", line 585, in createtextmask
font = ImageFont.truetype(font_path, font_size)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/boy21/anaconda3/envs/comfyui/lib/python3.11/site-packages/PIL/ImageFont.py", line 996, in truetype
return freetype(font)
^^^^^^^^^^^^^^
File "/home/boy21/anaconda3/envs/comfyui/lib/python3.11/site-packages/PIL/ImageFont.py", line 993, in freetype
return FreeTypeFont(font, size, index, encoding, layout_engine)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/boy21/anaconda3/envs/comfyui/lib/python3.11/site-packages/PIL/ImageFont.py", line 248, in init
self.font = core.getfont(
^^^^^^^^^^^^^
OSError: cannot open resource
"
svd is surprisingly fast... it only takes about twice as long as generating a single image
remember to use svdxt if you're doing 25 frame gens
yes and it works on gpus with 8gb vram
it couldn't find the font
try changing it to "times.tff" that worked for me. may not work for you, depending on your OS
PIL font loading is very bad
where can i change that?
on these nodes. there are four of them


any way to run stable animation in auto 1111?
strg z?
ctrl-z/undo i guess
they've just accidentally duplicated a bunch of nodes and now have to delete them all manually
ahhh there's a plugin for that, but don't get it because it fucks comfy ui up on the latest update
might've fixed it by now but idk
ther is no strg z
in english and basically every other keyboard layout it's labelled ctrl (control)
Is there a customnode for just the queue prompt button?
I just want a big red button in the middle of my nodes
there are a few nodes that can queue the workflow like that. typically they queue it n times, for animation
mtg animation nodes is one
or is it mtb? i forget
they are kind of hacky though, like the undo thing they sometimes break



not yet but you can use StableSwarnUI its built in #🐝|swarm-ui message
try higher fps on the img2vid conditioner
this will make the result shorter but possibly more coherent
(shorter in time, it will be the same number of frames)
damn bro kicked that croc and himself out of reality
Actuall that helps with sharpness of the picture!
Still can't figure out how to set steps or motion to XY, tho
the workflow has four copies of the gen workflow in it, then at the end it generates a 2x2 with all four results in it. so you can just set whatever params you want on each one
it's not really xy because it doesn't loop over the product of two lists
yeah, the problem I'm confused how to said parameters to each of them, it's bounded to Text so I'm lost.
jeez, as soon as I think I fiured some stuff out, I stumble upon something like this..
just change it on the nodes directly
you can't change the svd params because it only runs that bit once
but if you make four svd nodes, one in each duplicate, then you can
K, I'll try !
but the whole point of this workflow is to test text prompting
making real loops in comfyui is currently extremely hard because of the internal architecture. there's some work towards refactoring to make it easier but it's quite complicated. even figuring out how a loop should be structured out of nodes is not trivial because a node graph is necessarily acyclic. so you have to handle it behind the scenes somehow.
oh also i recommend disabling that free_u v2 node. it does speed up generation but it seems to hurt quality
Error: input must be 4-dimensional
That one is actualyl so fucking sick. I guess it's super easy to keep consistent because it's just a bunch of cubes huh

Check this out, they took the last frame from animation and made it first for next one, it's a long stream
just curious is this dalle or mj
Just SD using colossusProjectXLSFW_v53Trained model.
@grim tangle Thanks for the concat workflow! Playing around with it now with the plan to try and force the model to zoom all the time but interesting enough, the zoom prompt seems less coherent than just the default
with just svd model
I am compelled to make Hatsune Miku images now..
did that three layers guy end up sharing his workflow? I havent been keeping up

perfect


I was hoping you would do that.
every time there is rain... 😄

I did myself as homelander, and it did not disappoint. 11/10


Fucking nice!
I'm just so hyped people can make basic videos for any purpose now with like 95% ai that's pretty decent

hmm, seems we can up the res a bit to get around 720p quality according to fofrAI on twitter.... https://twitter.com/fofrAI/status/1728909603621224911
takes about twice as long for me
can shave off about 15 sec just actually setting dimensions to 720p.... "720p is the standard high-definition (HD) display resolution of 1280x720 pixels, with progressive scanning, at a 16x9 aspect ratio." - the googley
god damn those on twitter are pushing it and it looks beautiful, pushing 24gb of vram xD
Nice...the panning seems to be the one that most often does something
Can’t wait for this to run on apple silicon, performance on m3 max should be pretty noice no??
Looks like m2 ultra is faster https://twitter.com/ivanfioravanti/status/1728903886390587559
what do you guys use to compress an image? just set an upscaler at like 0.8 or something?
just need more details before I shrink it to fit the video size
Can't wait for longer video time is so fun
I want to show what you can use it as a tool.
Leg broken
looks so hurt,damn 
Hey, feel free to post this at #1092446741984444416 , I will delete it from here since this channel is for Stable Video related content.
Making my own Batman Movie now
Yeah I agree. I've reliably managed to get panning to work but rotate and zoom seems to not work. I'm going to try to use cinematography terms like truck, pan and dolly instead
Er...

Requirements:
ComfyUI: https://github.com/comfyanonymous/ComfyUI#installing
ComfyUI-Manager: https://github.com/ltdrdata/ComfyUI-Manager
SDXL: https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main
you can use any safetensor file, I used the base SDXL model.
SVD Model: https://huggingface.co/stabilityai/stable-video-diffus...
I’m getting this error on my Apple silicon: ”There appear to be 1 leaked semaphore objects to clean up at shutdown” when trying to render SVD with comfyUI
Segmentation fault
most of my outputs just end up as camera pans 
could've done the same in 1/100th of the time
yes i get a lot of those too
just keep refining. I've noticed that the best results come from 2 layer photos - a background and foreground picture. all the ones you see above that are really good are like that.
OK this one is dope. It looks like NFT art
🤷
you mean combine actual layers or just you mean something in forground and background
not sure if you referring to the tutorial we have now on layers
from Fancy
oh no, what I mean is to have a profile character (or car, or frog, or whatever) and then a detailed background.
when there are no background details it tends to look... bad.
In my experience you want something with lots of 'depth' to it, that can be from tonal shift (orangey subjects against blueish background), heavy bokeh, obvious perpective lines.... stuff that divides the image into foreground or background. You can jsut choose images that already have this effect but also use an image editor like Photoshop to tweak colors or focus yourself. And even then it's still a crapshoot how the seed will respond. Sometimes it's better results to just try a different seed or motion bucket value instead of trying to tweak the image.
oh yeah i didnt even think about photoshop at all! you're right, I do NFT stuff as a side thing, and it's been rough!! I am going to have to redo the images, is what I see.
I love smoke effects when they pull together.
👀 I haven't been following as closely to the thread. There is a way to control the camera movement :o! How?
CLIP text processing added to the image input
nothing official
looks like that is kinda the trick. a colorful background. I think I need to play with the IT rigging or whatever its called.

versus a B&W image, plus a boring background.

Upscaled, Interpolated and looped it
What's your upscale method?
Topaz Video AI 
That's fucking awful bro. Use Comfy for upscaling you dope. free free free.
Thanks man, you're so nice

I just hope that you aren't@tepid stream paying for topaz.
Hey I say if you have access to professional grade software, use it.
Have you seen topaz video ai?
People recommend it like they recommend Maya. It's the industry standard of upscaling. It's not good but also not the worst.
It cost so much because it's private code that has an any number value they want to attach to it. Topaz only has their image upscaler going for them.
Replace that with anything. Photoshop. Microsoft Word. Etc etc.
For all you know, he is a graphic designer and his biz pays for it.
I didn't pay a penny, my company bought it
@tepid stream@bold wave
Then they should make a training course on how to use ComfyUi for upscaling. It would be free and save the company money as well.
Let's agree: Stable Video Diffusion is already mind-blowing in its first basic version.
Midjourney generation as image input.
#svd #stablevideodiffusion #ai #midjourney #aivideo #aianimation #stablediffusion #stabilityai @ai.art.community @stability.ai @midjourney.gallery @midjourneyartwork @midjourney.artwork.ai

so cool to play around with 🤩
I've collected so many workflows for svd, idk which to use.
haha
is there a workflow to basically take the svd output as a new input to generate better details on top or maybe interpolate frames?
I know how to use it, but they don't want to 
I really don't care, it's a decent tool
I'm done. I care about this conversation as much as you do, which is as little as possible.
Stay well and safe.
Why start it then
I expected very little responses back. I thought I was going to be told off and not responded back to.
Makes even less sense now
So.... how about them videos
interpolated chromatic aberration is pretty trippy
Damn, just went back a few, these are soo good!
Hi guys does anyone know if they have already done fine-tuning on the Stable video diffusion model? Or at least if there is a method to train the model? 🧐
They have a bunch of general info in their research paper about training and provide the weights. I suppose training is possible. But I'm not aware of anyone finetuning anything yet and have to assume the training process is laborious and requires a lot more vram than most have.
Someone released pruned safetenors of the models a few days ago. Half the size of the original.
That sounds great, could you give me the link to that information or something please?
Research paper is in the pinned link in this discord channel
Probably they're referring to someone else but I have the half sized versions here as well: https://huggingface.co/imaginairy/stable-video-diffusion/tree/main

I'm loving SVD .I'd like to control what it choose to render the zoom out ,or pan and movement any options for that yet?
not yet
SVD on water photos
the paper mentions camera motion loras but they haven't released them yet
Trying lemon for the first time

are you using style loras with this?
you can try to mix a text prompt into the conditioning but it very rarely does anything
there was a movement lora for animate diff wonder if that will work
I also wanna plug in text prompt,does it work well?
no, it is almost entirely useless except in a few cases
now it does not
you can only generate the initial image, or you can change the image with unClip
you can mix image and text conditioning but 99% of the time it does nothing or destroys the image
with my 1024 x 1024 renders ,I been cropping with node it to 1024 x 576 seens more stable
1024x576 is the native res of svd model
so does it also like that to start?
the node auto crops and resizes the input i think
idk, it doesn't seem to make any difference if you pre-crop it anyway
I think only to control where it crops
yeah, that's true
any idea why i get this ?

show workflow
you tried to load a sd model instead of svd

ok, you used the wrong loader node for the model type
you have to use this one

yeah the first one is using a regular loader
svd doesn't have a clip model in it, so CLIP output is going to return None
if you want to encode text, you have to place a "load clip" node, and then load https://huggingface.co/laion/CLIP-ViT-H-14-laion2B-s32B-b79K/blob/main/open_clip_pytorch_model.bin in it

i feel like

if you're trying to just do normal txt2image then... you should load an sdxl model, not the svd model
isn't it the same node ?

no, it is different
this is where the problem is

you can tell, because that node has a purple outline
and the problem is the node before it wants an SDXL checkpoint, but you have selected the SVD checkpoint
the SVD checkpoint doesn't have a CLIP to output, so it outputs None
so this one doesn't works ?


yes, but you still have a image preview node at the end of the txt2img chain, which means it will still try to run
do i delete it then ?
you can mute it with ctrl-m or delete it

(wave seem more fitting for the subject haha)
https://youtu.be/AlUsrP3YF4E?si=6ywUd_AhJa2ne1tT ♥️ SVD is gold at architecture topic

A short movie created using Stable Video Diffusion. If you would like to know more how it's done feel free to contact me on LinkedIn under the QR code or just leave a comment!
It's 2x upscaled and 10x fps gain so at the end it fit into 1920x1080 60 FPS. My power bill would be high as Snoop Dogg 😭

im getting the same, how did you fix this error?
I just installed a newer ComfyUI version but I think some other people said it might be related to having FreeU node somewhere in their workflow
ok thanks, i am updated and i dont see freeU node in the workflow frrom the comfyui examples :/ i'll try a new install 😦
Yeah I got the message after updating, totally new Portable ComfyUI worked fine first try with the workflows off the official Video Examples page on comfy’s github page
ok thank you 😄 ill do that
You’ll need to move your checkpoints over but other than that it’s not too terrible to just start over, good luck!


hi again 🙂 how do you make those normal videos? i only get that weird .webp thing
videocombine node in the video helper suite custom nodes
Hello, does anyone know how exactly the kohya deep shrink node works?, I have tested it with SVD and the results are much more coherent when working at a higher resolution than 1024x576, it seems to be 75% functional at double the resolution, it may be better to move the undocumented node parameters, or maybe kohya make one for SVD, the results are really encouraging when using it like this by default
from comfy's blog:
The _for_testing->PatchModelAddDownscale node adds a downscale to the unet that can be scheduled so that it only happens during the first timesteps of the model. This lets you generate consistent images at higher resolutions without having to do a second pass.
haven't tested it with svd but that's a pretty good idea
Of course, as I said, I get this by doing double the resolution.

that is trippy
hey just wanted to pop in and say thanks for posting your notes, it helped me figure out my own wacky issues on linux with getting xformers and cuda to see each other properly because it was seeing a cached ver of my venv and wasn't linking up the reqs quite right
dall-e images work pretty well as input (much better than sd )
I put together a video with SVD videos, all with SDXL generations
Awesome! 😎

the exchange here really speeds it up. thx at all for sharing info and art

what program would you experts suggest for someone to make video of his clips from stable video. you know if i want to paste a bunch together maybe with some music. i have never done this before. sorry if ot
i put one of my backrooms renders into it
i really like how this is moving
if you have Windows 11 then MS Clipchamp is built into it, or search for it in the MS Store. MacOS should have iMovie built in. Linux.... well you should be used to googling anything you might need for Linux if you're using it already.....
Those are the most basic and easy tools that are probably already on their system for most people.
thanks. it always intimidate me to try before but i want to string some images together haha
I'm curious what's the prompt you did for this?
I mean these vids we're outputting are so short and lower res, it's not like they need editing other than putting them one after the other on a timeline, so CLipchamp or equivalent should be plenty.
4th-dimensional fluid dynamics --ar 16:9 --v 5.2
cool image even without the video

I have a workflow that does

This is from txt2img2vid in one workflow
anyone have any good upscaling workflows?
Any chances for Stable Video Diffusion at Dreamstudio?
So, is the motion it ends up making in any way tied to the seed that is fed into the sampler? Is there a way to 'encourage' motion behavior?
Because right now it's a crap shoot if I get something 'animated' or just panning
It all seems random at this stage. This is a research model. The biggest effects on motion from my playing around with this is: image, motion_bucket_id, seed, and video_frames+fps . Some images are just more likely to encourage certain types of movement. The motion bucket tends to add more motion the higher it gets, but whether or not increasing it leads to more motion depends on what's in the image. The seed can totally change what's happening, but sometimes changing it just means variations of the same 'bad' motion. And finally the video_frames+fps determines how many frames get created and how close or far they are from each other temporally. You can get really jittery videos if you set fps high and choose long amount of video frames, but this usually lokos bad and takes a long time to render so it's not worth it for what I like to do.
Gotcha, thanks. What motion_bucket_id do you usally go with?
And do you mess with the augmentation_level?
I've just picked random values, I like 33, 66 ,111, 222, 333.... There's not enough info on what exactly they are, but I heard some discussion that they are like some sort of list of stored types of motion where the smallest amount and least chaotic are the lowest values. But it also doesn't sound as simple as it just increases some chaos factor that adds motion.... it sounded more like it was an actual index of stored types of motion from slow to fast but we don't have a list of what the motions actually are.....
it's essentially lower = less motion, higher = more. The technical details of how it was trained are a lil wonkier but that shouldn't make much difference
Any tips on augmentation_level and the sampler/scheduler (and CFG)? I'm often losing coherence FAST and wondering if that too is just a matter of generation a bunch to cherry pick good ones
yeah but it's still pretty random feeling.... you can't dial in specific motions, just choose some lower or higher value and pray it does what you want.
lol this looks like the sort of thing my 6 year old watches on youtube
XD
It may not seem like it but this is a complex 2-stage SVD work that I will try to perfect tomorrow
still working on the image, but I think I found a good flow, I took the IP adapters, merged the profile with the background, and got some pretty decent results! A lot less cherry picking when you're that specific!


the content of the init image determines the "layers", and the SVD render seed controls the motion of them
as far as I've gotten, anyways
Damn I wish this one didn't do a straight zoomy!
Hi! Trying to get Stable Video Diffusion to run in ComfyUI on my M1 Ultra (Mac Studio, OsX Ventura) but getting this error when queuing the prompt. Any ideas?

Water splashed out of the basin
it's possible that it just doesn't work for apple chips for now like it's not working on amd card ...
There’s a dude on X that got it to work!
https://x.com/ivanfioravanti/status/1729035912816820662?s=46&t=f-T9SsLH77Ze40_WrOTnNA
oh ok then i said nothing
this guy made it work too, and left some advice in their comment for future users: https://github.com/Stability-AI/StableSwarmUI/issues/185
cc @wicked wren
step 1: purchase the $3,999 rendering function from apple.fckU
Hi, I got permission denied when access to the github repo, do I need to apply for a stable video wait list for this?
access to what exactly?
GitHub
Generative Models by Stability AI. Contribute to Stability-AI/generative-models development by creating an account on GitHub.
This repo is fully public, you can access it even without an account, not sure why you'd be seeing a 'permission denied' anywhere unless you tried to edit something
I didn't edit, I just tried to clone. And I got message like this: Please type 'yes', 'no' or the fingerprint: yes
Warning: Permanently added 'github.com' (ED25519) to the list of known hosts.
git@github.com: Permission denied (publickey).
fatal: Could not read from remote repository.
Use https to clone, not git@
github requires elevated perms to clone with git@ for some reason
Thank you, I just copied the code from the repository.
Oh, yeah, that's a weird line, i'll poke tim about it
Thank you!
That's awesome man
because git@ is a ssh url. it works as long as you have a pubkey on your gh account, even if you have no specific permissions on the repo
can you run this with a rtx 2060 6gb vram ?>
Amazing
I think 8GB is the minimum right now
thanks and if you generate do you have an option to say what you want ? like : lion in a cage dancing
There is no way to combine it with a prompt as of right now
All you can do is feed an initial image
can you define how much time ?
Yes you can define Frames and Frames per second as well as a few other knobs and twists
ty
I feed it a prompt and the workflow makes the image and sends it to SVD 
Same thing really
does this actually work for anybody here in any capacity or just snake oil?

all my results are just as random as they were
I'm amazed at results but it feels entirely like very first SD model. Like 0 control over what we can get from it
looks cool
can't wait for smth like LCM to drop
feels wierd to generate frames so slow
interesting, could you elaborate smh or share workspace?
im trying memes now
XD
tried doing another meme but it gets more and more cursed
reminds me of this one I did a few days ago:
glitch person run
explosion

floating car XD
good boy
would be sick if the parts moved or something but guess that's asking too much from svd
it can do it... but it's very rare
I guess it would be easier to experiment if I didn't have to wait 6 minutes for 25 frames
(lcm any time soon?)
well you can use the 14 frame model... it's faster, about 2 minutes for me, and i can't even run the 25 frame one
Can't wait for they next model if we can little force a movement it will be great tool.
try the smaller svd instead of svd-xt?
meh, it's like 3-4 minutes with decoding and stuff
Why do 24 frames? Set it to 10, at 5 FPS, decoding, and interpolation it shouldnt take that long.
until youre done experimenting
Cat (+ original images)



the detail is crazy
im going to make a video were i take the last frame from the last video and make a new video and repeat that till the video reaches a minute
here's my setup! I use a custom lora that you will have to remove.
this kinda works, of course SVD has no idea what the motion was from the previous clip. and the CFG can really start frying everything if you do a long chain
new Tool video dropped?
Just slap a title like 'exogenesis' on it and roll it over some drone music and call it a day. :p
early I presented 'good boy, now may I present "wTF is that, run! boy'
oh god XD
just remember we're doing research. this is all for science
yea
but anyway if anyone's thinking of doing high motion buckets at 1080p just know the model really freaks out
are you running the model at actuall 1080
yup, for science

i think my gpu would die if i tried that
lol
ima try it but i only have 12gb of vram
oh no,

I have a 4090, it can do 1080p in about 90 seconds for this 10 video_frames setup. uses around 18GB for the sampling then jumps up to maybe 22 or 23Gb during the VAE so I don't recommend trying it for anyone with less than 24GB of VRAM
i was just seeing if it could do 1080 without hitting shared memory
but the model can't handle that much res, everything just tends to wanna either explode or just do nothing
maybe some simple static shots with water in them would do better at this res
im going to create a video with a really low res to see what happens
that was the fastest generationg i have ever seen
and its exactly what i thought i would see
wonder if there ever going to release a model that has text input for guiding it
oh yeah, they said this is just the research model. txt2vid is part of the plan eventually
oo nice
since i usually only use local ai models the last video ai one was modelscope and that one was getting old
oh man, there is still potential for the higher res stuff:
i love how this model moves in 3d space
yeah it likes that the most for me. i know it can do walking, moving people, talking stuff but it rarely seems to happen
i wonder what other random stuff we can push it to do for research


bur
discord embed falier
ima resend
me watching my computer die with ai
for this one i forced it to render 40 frames instead of 25
and it seems like it got unstable
yeah increasing video_frames beyond the model training limit tends to do that
im surprised i never got a vram error
hig v_f and fps together is how you get the jitters
hes calling so much magic energy
it's definitely a cool effect if you want it
hmmm, maybe these where it generated shadow people and ghosts instead of moving the actual goblin guy from the image:
man it's gonna be so cool once we can actually ask for stuff like that instead of just changing seeds and hoping for the best

it vanished
no drugs allowed
drugs despawn
i have no idea try posting in #🤝|tech-support
maybe they can help
👍
oh wow, this little dude lives on my music production desk
Any idea of the model architecture of pika lab?
what
they're probably training their own models
Even in a bad drawing it knows how it should move. Amazing


Image model: SDXL
Video model: SVD

true
whoa
never tried 2d stuff with it
TFW taco tuesday is so rad you turn into a cloud
ping pong
ping-pong set True

loop would be playing again

i figured when i saw dragon's screenshot but when you randomly said it i thought you were just randomly adding to conversation XD
Gotta think of what the term would mean... ping pong = back and forth. 🙂
yea
Video Combine also has a loop count if you need set number of loops for a gif or video
o ok
i was just wondering what it was im prob going to keep it off because the ending frames are funny most the time
it's just an easy flag to make the videos twice as long for free and look good if osmeone turns loop on their player

mario sinking into a floor
Note: 40GB of VRAM required
Why they claim this?
10,6/24, so much free vram that it's possible to leverage upscale and anything you like. What an absurd statement about 40gb. Could be that we do smth wrong or what
damn ffmpeg consumes more vram than this whole generation
hes getting crushed XD
That was early. Now run even on 8gb
wish we had some semblance of "control" over this pandora box
im waiting for them to make a text input that we can use
it's fun but
i doubt they can just add it if it was trained without pairing to text tokens
in the research paper its showing them using text to video

so it exist somewhere its just not out yet i think
on Windows if it need more VRAM (more than 24GB) for me it works with VRAM swap into normal RAM where it took like 56 GB and it is just 50% slower in last/2nd VRAM hungry phase. It doesn't crash at all. I think this is windows feautre and they run it on Linux where it crash.. so maybe that's why they think it needs 40GB.
I haven't tested it on linux but I guess it doesn't have VRAM swapping by default.
i managed to get BSOD
Currently allocated : 15.81 GiB
Requested : 83.08 GiB
Device limit : 24.00 GiB
occasionally 4x upscale got into film interpolation
and it didn't end well
i added a photo of a clock hopping it would animating the hands but it just moved the camera
I have sometimes with stable diffusion start after another AI program exit.. that is probably drivers fault it doesn't clean the RAM properly. Maybe try Studio drivers if you have gaming.
imma studio, well it's fist bsod ever
just some glitch
imma messed it real bad so, it's fine
but yeah swap works for me too. but i can't say that it's 1/2 speed, for me it's like super slow

so what's the worst possible test we can throw at svd? i think something like a picture of a wine glass falling. in the video we should see it smash, like this: https://www.youtube.com/watch?v=mWRuzFsmQHg

A small test animation of a wineglass breaking. I used the free plugin Thrausi http://nitro4d.x10hosting.com/blog/?page_id=79 to break the glass apart. Thrausi is a very useful destruction tool. You´ll find more information and also more free plugins on the Nitro 4D http://nitro4d.com/blog/ site.
Again made with Cinema 4D rendered in Vray.
...
so far i've seen absolutely no indication that svd is capable of anything even close to this
maybe if you start with a picture where the glass is already beginning to break
but that's cheating
maybe when the text input comes out you could specify glass breaking or something
try lower cfg. it might survive a bit longer
Is there a text to video through comfy yet? Or only img2vid so far?
only img2vid with svd model
the paper talks about a txt2vid version, but they haven't released it afaik
it also mentions camera motion loras, also not released yet
i did one awile ago that survived slightly longer
what if instead of taking the last frame, you take the second frame?
or the middle frame etc
i like watching it slowly get worse
it will still do that, but if you take the second frame, it will be continuously smooth, instead of big (downward) jumps in quality every 25 frames
true
it might still jump just as far though, meaning you get like a 4 frame video. worth a try though i think
yea
if you set video_frames to 2, are the two generated frames identical to the first two when it is set to 25?
or do you get something completely different?
no idea

Imagine APP
Probably something completely different, when I run smaller 12 frames batches to find if an image will look good in motion and then switch to 24 the motion is usually similar but still totally different
how about quality?
i mean with 2 frames, will the second frame be as fried as 2/25, or 25/25?
Good question, probably depends on your CFG scaling
i don't actually use that cfg scaler node
You just run straight into the SVD node from the model?
yeah. the scaler just seems to make every video explode at the end
Interesting
i don't think it actually is a temporal thing anyway, despite what the docs say
I leave it connected but almost always just the same setting as on kSampler
i don't see how it can be if it is tweaking the model
hmm yeah, setting it equal or higher than what is on ksampler results in it behaving like it is not there at all. i did notice that, and then removed it 🙂
I think the intention was to ramp from lower initial CFG to final samples CFG to control a tendency to get fuzzy towards the end
i think it actually modulates over steps rather than frames. don't know. it seems to affect the first frames just as much as the later ones, it's just that with lower cfg the video is more likely to tend towards more motion
but if you set motion bucket real low and fps real high so there is no motion, then compare with and without it, with it just straight up looks worse
and every frame should be identical in both cases
if I use upscaler with controlnet, do I need to upscale the reference image first so my apply controlnet is 1024x1024, sorry i know its wrong channel but others are dead
by "worse" here, what i mean is every frame obviously was rendered with lower overall cfg, they are smoother and less fried. that could be better if you have very high cfg on the ksampler




these are big old guns
Snap fingers. Very surprising animation

That's a good one.
hes so happy to see you
burned through too many seeds trying to get one where not just the background moved so I decided to just throw them all into one long clip....
how to merge many webp?
smh struggle to just slap them into ffmpeg
wonder if there are any convenient nodes
Any good getting started guides for local Stable Video Diffusion out there? Also, any idea of a good GPU? I have an NVidia with 12Gb -- is that enough?
i have a 3060 with 12 gb its good enough maybe look in #1072220168534642768 for downloading it i just watched youtube tutorials for downloading it
this is y we need text prompting aswell
I don't work with webp format so not sure there's an easy way. How are you generating your videos?
ComfyUI is pretty easy to install if you just download the portable version. There's plenty of guides out there.
yup
i know when it comes out im going to be making more cursed stuff
plug this into your pc >:}
everything will be fine
are you using ping pong to go back to the original frame to add on
no, just changing seed
e
that a cool thing about pingpong, anytime you change something and get a new video they all start from the same image so that's always the first and last frame and you can pretty easily string them together seemlessly to showcase
thats what i tried saying here but i did not say it correctly
🙂
i plugged it into my friends laptop
no worries, I just wanted to be clear in case anyone got confused reading this later and thought the way to make new stuff was make a video and pull the last frame out for Load Image to use to start the next one
which is totally a way to string stuff together but not really necessary if you're using ping-pong

oh yeah I also used ping-pong initially to make the videos longer so i'd hit 3 seconds for anything i wanted to put on instagram
I just render the videos at 6 - 15 fps and interpolate thrm
yeah i usually render at 8 and interpolate x3 so a 12 or 24 frame long clip hits a full one or two seconds

Just found this video describing the first aspects of SVD like frames_per_second motion_bucket_id etc https://youtu.be/82l0DsbLHhY?t=376 , also talks about to either install pinokio.computer and run locally or run it in huggingspace etc

Stable Diffusion has released an exciting new AI video model - Stable Diffusion Video. This revolutionary model generates short high quality videos from images.
In this video, I test out Stable Diffusion Video using different tools like Pinocchio, Hugging Face, and Replicate. I showcase the video quality, motion controls, and 3D understanding o...
how do I get my comfy ui to use more than 8gb of vram when doing svd ?
when I load in it detects my vram and says it loads normally, so it shouldn't be automatically using lowvram or anything
nvm got it
If you go out in the woods today......
... don't eat the mushrooms

Anyone got a workflow with the different Motion Settings tests to generate all at once by any chance ? 
help:
i generate 4 secs using an input image
feed back in the last image so i can get 4 more sec (8 sec video now)
but it gets blurrier and now has purple ghost stuff appearing, omg it is deteriorating, how to avoid this?
that's a good idea. how do you grab the final image?
there is a lot of tools that can extract images from gif/webp so maybe like that
or create your node in comfy to do that
you can just grab the last latent from the batch that svd outputs

I got the whole thing down to 4 minutes, as in txt2img2vid2upscale2render so not that much of a wait anymore, but still just camera pans
I got my video generator working! https://www.youtube.com/shorts/0tiwN_0pA-4

Description: Join Sammy, the extraordinary suburban squirrel, as he embarks on a nocturnal adventure, running an espresso bar for his fellow critters and venturing into tech, literature, and even space travel. Witness the most daring project yet as Sammy becomes a spacefaring squirrel, achieving what no rodent has before! #SquirrelAdventures #No...
over saturated output. any idea why?
I keep on getting a cuda out of memory error
i have the same error
my GPU has 6gb of VRAM. I think the problem here is with pytorch
Have seen folks running svd with as low as 8gb VRAM, but not sure if anyone has gotten it working with 6gb yet.
https://github.com/comfyanonymous/ComfyUI has a --lowvram option that is supposed to be flipped on automatically if it detects low VRAM so might be worth seeing if you have any luck with that if you haven't already.

GitHub
The most powerful and modular stable diffusion GUI with a graph/nodes interface. - GitHub - comfyanonymous/ComfyUI: The most powerful and modular stable diffusion GUI with a graph/nodes interface.
Do you have a tutorial link? I'm using pinokio
I do have comfy UI
how do I get SVD on it?
If you have https://github.com/ltdrdata/ComfyUI-Manager installed you might be able to use the UI to install the SVD model (I haven't gone through this workflow myself).
If not, you'll want to have the SVD checkpoints file in the models/checkpoints directory within the ComfyUI directory.
wget -O /models/checkpoints/svd.safetensors 'https://huggingface.co/stabilityai/stable-video-diffusion-img2vid/resolve/main/svd.safetensors?download=true'
Once you have the SVD model installed, you can checkout https://comfyanonymous.github.io/ComfyUI_examples/video/#some-explanations-for-the-parameters which has links to image to video workflows. You can copy one of the workflows from the links and load them in ComfyUI.
GitHub
Contribute to ltdrdata/ComfyUI-Manager development by creating an account on GitHub.
Alright, thanks!
who are you crazy people, and how in the hell did you get 40gb vram
did ya'll download vram or something?
Heheh
Always download more ram

Go into your public library and download more ram
Be a man

? Any idea why?

use 'git clone https://' WHATEVERURL instead
this issue is happeneing when I try to install the Missing Custom Nodes
which node is being installed?
when i am trying to click on Install missing Custom Nodes... this happens

I would close all that and then open Manager again and try doing the Fetch Updates or Update All first. Then after restarting Comfy and everything's all updated try to get the Missing Custom Nodes.
let me give it a try
still the same issue 🫠
i dunno man, maybe go to the comfy github and raise an issue there? it looks like some sort of connection error because [remote computer refused connection]. Github doesn't appear to be down so either you have an internet issue or the build of comfy you're using has some sort of issue itself.

how do you get it running locally, js 8gb enough?
i dont know about 8gb im using ComfyUI rn
Does anyone know how to control the motion? Thanks!
got a decent streamline going! mix 2 IP adapters for front and background, interrogate those clips, and then have a bit of guidance prompts. so far, it's been working quite well! I've tested this with flipping out cats with dogs and humans, and it seems to be super nice!!


Will saving that gif give me the workflow in comfy? Would love to test out
When I get home I'll share the json file. Basically just ip adapters, and then loading 2 images in to mix, interrogating those images, then doing a video.
Thanks. Will try building something out but you may get home before i get on my computer again

Hey does stable video diffusion work now with mac using comfy ui?
OK here we are.
Oh thank you! Yoink!
enjoy! youll have to remove the custom lora but there's not much else to it. comfy is good at daisychaining different ideas and putting it into one cohesive thing.
Yeah for real! I've only been using comfy for like a week and am ridiculously impressed
just wondering but are there any sadtalker nodes for comfy? feel like it would go well with svd 
looked at the code but it doesn't seem immediately obvious how to implement them
whats the best workflow atm for svd?
im just making weird stuff
Did a small video animation for a SUNO music generation, pretty amazing how fast you can set something up now. Even if its pretty rough
i did this but with a stable diffution lora of my friend and pika before svd came out

anyone know why it's reloading the model in comfyui every single time I generate a video?


cfg value too high?
yeah the fry is always due to high CFG
Not enough memory to store the model maybe, so it unloads it each time. Maybe...
I've got an 8gb gpu, not sure
4 questions for SVD in comfyUI: 1) how do I change the model and output directory 2) how do I add the SDXL refiner in my queue workflow 3) How do I make the motion in SVD better and actually relate to the image (i typically get results of a still image with the canvas panning away from it) 4) can someone explain cfg and augmentation level for SVD Thanks

Helga was part dwarvenkin and Meredith was all witch
You don't change the model, there's only one SVD model. To change output depends on the save file node or you need to add to the bat file. SDXl and SVD are two different things. The movement depends on several things, mostly seed.
3 - you change the seed and hope for the best. motion_bucket is like a dial to go from slow to fast but it's not really possible to dial in anything specific. a simple trick is to change the ksampler steps down to around 4, this will look like crap but give you much faster output and a general indication of what type of movement will happen. You should be able to see if it pans the right way, or zooms, or looks like subject is a moving cloud, those are the main types of movements and then you can decide if you want to change the step# back to a proper render value.
4 - Augmentation level is basically adding extra noise back into each step, it can help fast moving stuff from getting all smooth looking. I still ahven't seen a good guide or explanation of what it actually is doing though so take that with a grain of salt. CFG sort of fries the image, if it's too low everything will look all soft,fluffy, and pastel but too high and everything gets too contrasty with weird edge artificats and looks like melted plastic, so adjust to taste I guess....
2- why do you want to do this with SVD? It's not necessary. If you still want to I'd go find a good Base/Refiner XL example and just stick this in place of the Load Image node on most SVD workflows.
1 - I wouldn't change the model directories unless you already know about symlinks and config files. If you know what those are then the github for ComfyUI has a section under Installation explaining how to setup your own config file and point it to wherever you're keeping your models. It will probably cause problems though to not just put things where Comfy expects them, especially if you start loading Custom Nodes.
You can save files wherever you want by looking for filename_prefix in whatever nodes are saving stuff in your workflow and setting the path there.

thank you, I know about config files, my reasoning for doing this is so that I can use my models folder for normal txt2img then 2vid without wasting an extra like 60gb on duplicate storage, and I ask about the refiner for normal txt2img too
I bought an M.2 SSD to store all of the checkpoints/models. It improves performance when switching models. Then just use symlinks in each apps folders to point to the SSD.
Cool. Basicaly with the refiner you setup two KSamplers and feed one into the other. There's official examples pages in the ComfyUI github with images you can jsut drag onto the CUI screen to load the workflow, just look for the SDXL examples link.
Only problem with symlinks is comfyui kills the links when it updates. So I just wrote a batch script to redo them after every update.
Yuck
I finally decided that ComfyUI will be my daily driver for most AI stuff so I can just symlink anything else to where it stores things. Life has been much simpler since then.
so what's the lowdown on the whole Stability rumor they might sell to Jasper? should we download and archive everything so we can still use it if/when everything is no longer open source? 🙂
time to get a few massive hard drives hah
I read they were approached by other companies to purchase but not that SAI was looking for a buyer
whatchu talkin about?

Whats a warthong? 
anyone knows how to generate videos exceeds 4-5 seconds?like 8-10 seconds or more longer
people are saying to use the last image from a generated video and use it as base image to continue the generation
How is this possible is there a ComfyUI workflow for this?
idk i didn't try that but try to find a node to extract webp/gif frames or create your own node
if you find this node you should be able to loop (maybe you also need a loop node)
a lonely man walking on the beach
you could use the 'latent from batch' node to pick the last frame from the sampler, then decode it and feed it to another conditioning node and run another sampler, and so on
Can somebody please send me the folders of the following Missing Nodes:
...
Incase if you are wondering why I am not using Manger Extgension, then just beleive me, I have tried too many attempts, but in the end, it states Faled to Establsih Remote Connection..
Apparenly, I mannualy installed RIFE Video into Custom Ndoes folder, and it worked..
So, incase any of you hguys have the above mentioned Custom Ndoes installed, please send me the link, or just put it in a dropbox

Hi, new here. I've done two videos with SVD generated with online solutions, however now I'm trying to run it locally (6 GB VRAM) via my Pallaidium: https://github.com/tin2tin/Pallaidium add-on for Blender, and the inference time is insane: 20 minutes for 14 frames(with Zeroscope it was max 2-3 minutes).
My SVD videos:
https://www.youtube.com/watch?v=3dco2igWyvk
https://www.youtube.com/watch?v=aEAy24d8F6E
I would love to hear if you could share your sweet-spot settings, VRAM, and inference time with me?

GitHub
Generative AI for the Blender VSE: Text, video or image to video, image and audio in Blender Video Sequence Editor using Zeroscope (SD, XL, upscale to XL), Animov, Potat1, Stable Diffusion(1.5, 2.0...

Done in the Blender add-on Pallaidium and SVD

Done with Stable Video Diffusion and Pallaidium:
https://github.com/tin2tin/Pallaidium
You videos are great ....I've heard a little bit about Palllaidium, how good is it and what are the advantages of using it over ComfyUI which is very memory efficient with low vram?
anyone please?
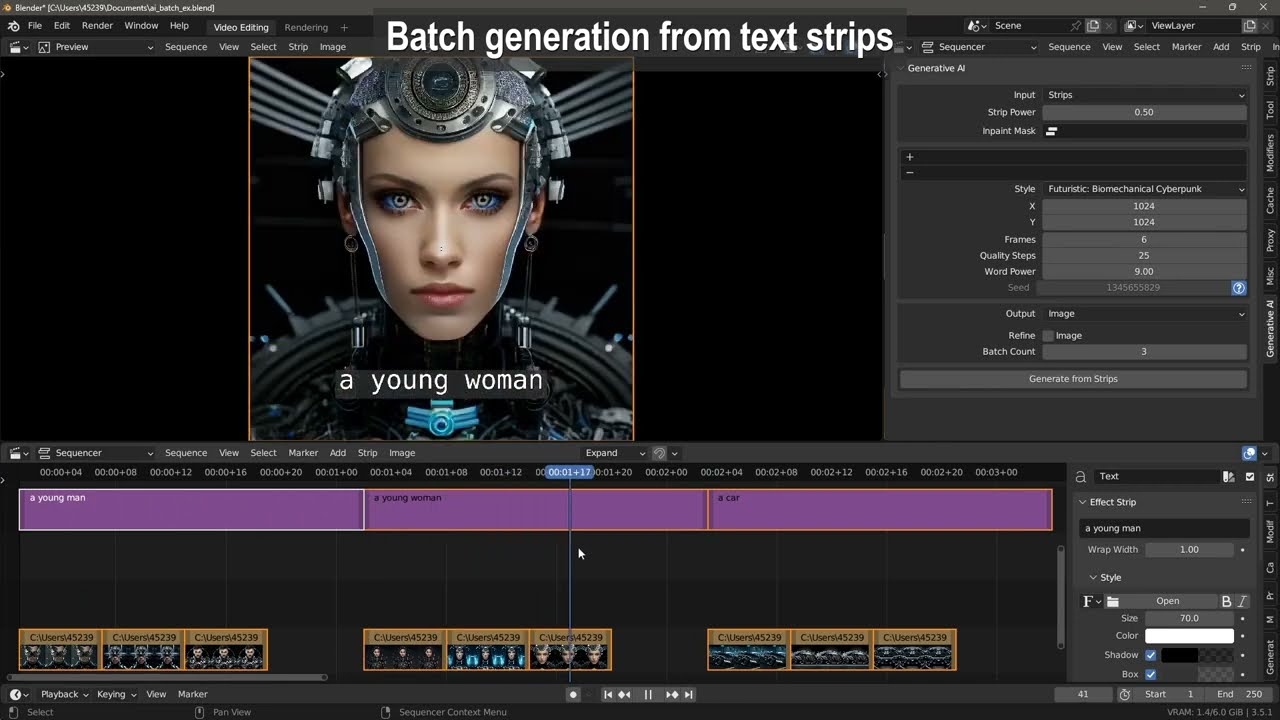
As mentioned, I developed it on 6 GB of RAM. So , everything implemented works with this little RAM. I never tried ComfyUI and can't compare it. The main advantage of Pallaidium is that you're generating images, video, sound, speech, music, and text directly into the timeline of a video editing program, and you can use strips as inputs for batch operations. Ex. select all text strips and batch convert them into images, or speech, or images into videos or images into text into images... or whatever...
However, I mainly posted here to ask for people's sweet-spot SVD settings, VRAM and inference times?
blender's node system is significantly better than the one in comfyui - it has working nesting and undo and a load of other stuff that makes editing much easier
Pallaidium is not using Blender's nodes. It is for generating into the Blender Video Sequence Editor timeline: https://www.youtube.com/watch?v=gSFWGkgaNsE
🙌🏾 Ohh great work, do you have any updated introduction, feature walk-through and getting started type videos available somewhere? Also does Pallaidium add-on allow linking models/loras/controlnet/embeddings from other folder paths?
there's another add on which puts all comfy nodes into blender's node editor
i think it uses comfy api though so you still have to run the web server
How long does ComfyUI take to render 14 frames of SVD on your amount of VRAM?
Using SVD (not SVD_XT) I'm getting 1-2minutes on my 4080 16GB
with a A40 it took 110s 🙂 (XT version and 25 steps and with model loading)
with a CPU tho (yes i tested with a R7 5700) it took me like 45m to 1h
https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite For the VHS node
https://github.com/rgthree/rgthree-comfy for the seed node I think
2070S 8GB and about 2 minutes
15 seconds on a 4090 for 25 frames
Uhhh... I'll need to upgrade my hardware. Out of curiosity, I'll have to see how Comfy works on my 6 GB then. Any hints on how get SVD & ComfyUI up and running quickly?
But depends on the image size you feed it obviously
26 minutes!!!

I dont envy people with lower hardware man
Cant imagine waiting half an hour just for a camera slide
honestly just take the depth map and animate the pan yourself at this point 😆
you're going to have 25 minutes left over too
Yeah, that spaghetti-eating video would be much quicker to do manually, including the time for cooking. 😅
Is it Stable Diffusion Image with Runway ?
Its SDV with topaz for frame gen
Stable Video Diffusion did that animation ? Then you upscaled the result on Topaz ?
really really thanks man
for the VHS Node, it isn't the correct one
Are you sure? It should be

can you just show me the whole node setup?
what do you mean?
complete Workflow Screenshot of yours.. just want to check the node conenctionl.
Its not the workflow youre trying to load tho
Still... I know,, but want to see

Gotch.a.... many many thanks brother for the link.. its now all set!

Let me try my 1st Image to video
You should try to set up comfy manager tho, try to resolve the error
Cant thank you enough.. been dwelling on this problem for 2 days
I understand... but I really tried hard for the past few day.. .hence ended up going for manual method
If you can send the error in #🤝|tech-support we can have a look and maybe help you out

ok i like that cat
Sorry for the noob question though.. but why there is no Preview in the Video Combine Tab?

You have to run it once for a preview to appear
If there is nothing to preview it wont show anything
How exactly?
Sorry, but tbh, I am new to ComfyUI... Can you tell me how to run the workflow?
Press queue prompt on the right
I did..
oh, I realsied that I was getting impatient... saw the things working in CMD.. sorry for bug

In the UI it should highlight what part it's on so it's easy to visually track where it is.

fyi discord will show your video if it's mp4 or gif

Could anyone tell me what happened? I tried to install the missing nodes I needed for SDV inside of ComfyUI and once I restarted and it tried to install everything, I am getting this fat error. 😦

Here's the full log

you installed the svd custom nodepack, which is unnecessary because svd nodes are in core now. anyway that node pack tries to download svd models automatically for you, and it does so using a program called wget, which you do not have installed
So I simply should install wget?
and it doesn't check for that possibility, so it just crashes instead
that may not be the actual error though
Do you think I could delete any of the recently installed custom nodes to revert it back to how it was before?

it appears that the actual crash is something torch related
Probably a version not truly compatible with something else :c
well you should delete ComfyUI-Stable-Video-Diffusion because it's in the core now


Issue still occurs 😭
made an experiment, got the last pic of the first sequence and made a second sequence out of it and merged it
i wish we would have more control over it
has anyone here prompted SVD for motion?
is currently not possible
 are they lyin
are they lyinyeah people here have done it
it doesn't work very well
like it rarely works at all
it just acts like some random noise added to the conditioning, the results are nothing like what the prompt describes
okay, has anyone tried using a diffusion image prior, like say form kandinsky-2, to jump from text space to image space? would make sense that it's mostly just noise if it's only trained from image embeddings
yeah, i think people tried that too, but i haven't seen any workflows
note that the latent output from svd conditioner is completely empty. it's just a convenience. you can try putting something not empty in to the sampler
In my tests using the last frame doesn't do much, its not different than mixing using 2 different seeds

@open heron i think it depends also on what exactly happens in the picture
Hi,
I can't seem to find video memory requirements for stable Diffusion Video? Do you have any reference on that?
I heard about people running with 6gb, but i'm not sure
Hey guys I made an update to my multi layer video workflow. Here are my two updated workflows you can grab.
Here is a video explain the new changes https://youtu.be/wRwUcSMqYNI

Requirements:
ComfyUI: https://github.com/comfyanonymous/ComfyUI#installing
ComfyUI-Manager: https://github.com/ltdrdata/ComfyUI-Manager
SDXL: https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main
you can use any safetensor file, I used the base SDXL model.
SVD Model: https://huggingface.co/stabilityai/stable-video-diffus...
@grim tangle your parameter grid images are great. thanks!
Can you tell me some more about how prompt affects the motion? I don't understand. The prompt isn't fed into the SVD_img2vid_Conditioning node, so does the prompt actually affect the motion?
It's not a proper method really, it's just concatenating clip text encoding to the SVD conditioning. In my tests, in some cases very strong prompt affected the motion, mostly the word "panning" was very consistent, but other camera related words worked, if they were possible with the init image in the first place. It's not a reliable method and has adverse effects overall, just experimenting, proper official controls are coming later anyway.
interesting! I didn't even think about adding any nodes to affect the conditioning between the SVD conditioning and the KSampler. I will play with that. thanks!
wanted the dragon to move failed succesfully?


Flamingo
How long is a second of animation taking y’all to generate on home gpus? (e.g., a 3080)
on my 4090 it takes about a minute or two to make 24 video_frames, depending on settings
Thanks and damn! A minute well spent by the looks of it!
these settings are pretty low on CFG, sampler steps and I use interpolation to smooth things out. it's pretty easy to crank up just a few values and make stuff that takes 10+ minutes to render, but obviously, you don't need to to get fun results....
Makes sense - I’m trying to figure if I can just use an extra gpu to run a nightly batch job for a generative game, so lower settings are fine. sounds like a maybe
hmmm, maybe. the problem with batching it is the motion you get is so random that you'd probably end up with a lot of vids that are just panning or zooming shots

FAQ: I’m missing credits/having issues processing payments. What do I do?
If your account balance is incorrectly showing 0, please wait 2-3 minutes to see if the system auto-corrects. If not, please confirm with your bank to ensure the transaction completed successfully & then fill out a request using the following form on DreamStudio so the team can investigate it further: https://beta.dreamstudio.ai/support
reminded me of that japanese wave drawing from its structure
Can I try stable video now on my personal computer?
Why not? depends on your GPU though
Is there a gui for it like with stable diffusion?
ComfyUI
or Pinokio
Thanks I'll try to install it.

#StableVideoDiffusion Stable Video Diffusion has been Released! This easy Guide shows you how to set everything up. Run Stable Video Diffusion on your Computer today! This Image to Video Render Worflow is super easy to use and gives you stunning results.
Links from the Video
Download Workflow: https://drive.google.com/file/d/17UQXmD...
Noice!

a long blonde hair girl working before the computer with McDonald hamburger on her hand

Hey guys, an absolute beginner here.
I want to get my hands dirty sort of speak
what is an easy way to play with these new image-to-video capabilities?
With a capable GPU you can use comfyUI to run it locally
Thanks!
I kinda GPU poor tho 👀
Is there an image-to-video solution I can access on the web?
I think it runs with 8GB nowadays, I dont know about any online solutions
@surreal maple I got SVD working in my free Blender genAI add-on, Pallaidium working on 6 GB of VRAM. If you lower the resolution, the render times will be okay. Get it here: https://github.com/tin2tin/Pallaidium

GitHub
Generative AI for the Blender VSE: Text, video or image to video, image and audio in Blender Video Sequence Editor using Zeroscope (SD, XL, upscale to XL), Animov, Potat1, Stable Diffusion(1.5, 2.0...
Wooow, so dooope!
Did someone tried to add the SDXL refiner in the loop for each image?
it could help to stabilize the video, if there is some human faces
Hi! Could you explain to me how do you succeed creating this kind of stuff. I think that it could fit the need of some website animation. Which tool do you use?
it's just Stable Video Diffusion running in ComfyUI... there should be lots of tutorials out there by now on getting that running.
Ok. I'm going to take to look at it. Thanks
somehow didn't connect that lower fps means more motion till now 
i wonder if it's possible to use SVD to have 360° of an object and then put it into a scanner for 3d models
Possibly. There's a lot of seeds that do that kinda of 360 fly-around video, I guess it just depends on how much any particular model can extrapolate missing information for continuing the .... object's coherency.....
btw does a animation seed doing the same kind of animation ?? even if it's not the same generation seed / image ??
not really, it depends on the input image
there is some that are not bad like the one Corridor Crew use (if you know them)
intresting
I think though that if the input images are very similar, like same sized subject in same location and same background, then the seed would give similar motion for both images. The more divergent the images are then the greater chance seed will just choose to do motion differently.
Another example, the input image is just the first frame! This goes almost 90 around it, making up all sorts of detail.
nice and with that we take the last frame and try to gen more to have the full 360 can be cool
Just wait for the 3D model release
getting them to spin is the hardest part lol
at least it's not a weird thing
oh i get plenty of those too....
ya it's funny when it happen
fantastic!! except the sword is a tiny bit wavy haha

Are there any good ways to control the animation? Bucket seems to control intensity, but how control what kind of animation?
The main svd page talks about it. I think they already have a working model for it.
noice

This is AI Video made with new SDVideo Model #makebelievetv #cats #cat #aivideo #sdxl
no, not yet
Closest I've got

and with a head not bad at all
Imo it's insane from just giving it an image
any updates on metal support for mac? 😅
seems to be stemming from lack of Conv3D support for MPS... maybe a smart monkeh could figure it out. 🙂
4 different animations, 100 frames and interpolation
Oh lawd, he's comin'!
is there a way to prevent stable video diffusion from getting so grainy
It feels like it gets stuck

you are not using the right node
Use this workflow: https://comfyanonymous.github.io/ComfyUI_examples/video/
Oh that's so weird! I thought I dropped in the second example and was working with it, but I guess ComfyUI being tricky with me
FAQ: What is Stability AI?
Our vibrant communities consist of experts, leaders and partners across the globe. They are developing cutting-edge open AI models for Image, Language, Audio, Video, 3D and Biology.. AI by the people, for the people. Learn more here 

Above is with Face Restorer applied directly to video, below is applied to image first.
I think applying it to the video yields a slightly better quality but it has these weird glitches where it maps to the face slightly differently in a few frames.
/
anyone know how i get the turbo scheduler to show up in comfyui? 😦
wow, those vids are fire
Update it.
Usually Refresh, Reload page, and update Comfy are the order I try things when new things aren't showing up for me.
Iguana tests, one is from real pic and one from Midjourney pic:
You happen to share your workflow prior? Would love to test
should be embedded

I usually test motions around 5 steps, and render at 12-16 but this middle guy's scales kept wriggling around so I upped to 30 for the render I posted.
Thanks. Will try to drag and drop when i get back home. I know discord strips mp4 meta sadly so appreciate the image.
yup, have fun!
I woke up and hopped on ComfyUI to try out SVD but man I can't get anything at all to work


Both ComfyUI example workflows doesn't work for me.
You should load a regular image generation model in that first checkpoint loader, not the video model. The SVD model is loaded later in the workflow.

My mistake, but I still get this issue within that workflow

is the svd_xt.safetensor actually in the correct directory? I mean, it is loaded by default right? Does it give the same error if you change it to svd.safetensors?

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Put them in checkpoints, that's where I have mine, and it works just fine
hmm okay
I still get the issue no matter what I am using it seems, or where the checkpoints are located
Are you by any chance running a Ryzen? Seems like most people (all three i've found) are not running nivida gpus.
Yeah I have an AMD GPU, but Intel CPU
Ah, probably cuda related then.
https://github.com/comfyanonymous/ComfyUI/issues/2043
There's an open issue about it.

GitHub
System : ryzen 3600 - rx 6600 8 GB - Windows 10 - Latest comfyui Using the sample workflow on the blog (https://comfyanonymous.github.io/ComfyUI_examples/video/) I try generating with the new svd m...
I'll comment on it with my error and any hardware information and such that may help
galaxie
Looks like this is 3 vids stitched together using last frames of the previous vid. Do you have a workflow that automates this?
im trying to put in a low quality photo but its moving it like a slide show XD
wanted to see what it would look like if i combine ebsynth with this
Is it possible to get stable video diffusion on Automatic1111?
it's not an extension as of now. I would love to install it on A1111
I tried SVD install on an older machine last week but got busy. checking back in now. anyone have the latest workflow for low VRAM GPU?
Yes,
This is the best video I've seen on getting specific motions so far: https://youtu.be/m-ZoxcYNWFg?si=B3IWdGjro1WJS69N

This is a comprehensive workflow tutorial on using Stable Video Diffusion in Comfy UI. Stable Video Weighted Models have officially been released by Stabality AI and support up to 25 frames per second of video generation. While it might seem that the motion generation is random, it is not. In the tutorial, I showcase 6 unique workflow examples e...
what's the lowest tier GPU that people have had success in generating animations with SVD?
I got it to say
Sampler: EulerEDMSampler
Discretization: EDMDiscretization
Guider: LinearPredictionGuider
Sampling with EulerEDMSampler for 26 steps: 0%| | 0/26 [00:00<?, ?it/s]
3050ti in my laptop with 32gb RAM. I wonder if it will even generate anything
The biggest limiting factor seems to be VRAM, I don't recall seeing anyone with less than 8GB of VRAM reporting success. Those with lower VRAM should probably be starting out with the SVD and not SVD-XT model to test their rig out.
for sure, im starting with SVD
a little movement!
Sampling with EulerEDMSampler for 26 steps: 8%|██████▋ | 2/26 [31:41<6:15:38, 939.12s/it]
yikes
LOL is that just to produce one frame?
No. That will make the whole animation but you should use the 14 frames model and do only 14 frames
maybe someone else can let you know what settings are best on lower cards but I find lowering CFG and sampler steps really decreases the generation time
ohhhh. had seen someone say 48t to decode so I guess I thought it went there. I see now, that's how many frames. Ill try again with only 14 frames. how do I stop the current one? close that tab?
much appreciated
I forgot where i installed comfy ui. Its over
Press Q and hit cancel. The 14 frames model is another model file that you need to download. You can also do smaller than 1024x576 images, that will makes things faster
ouch.
Is video diffusion any better than animate diffusion?
if Comfy is in the middle of a doing a node that takes forever it can be a real pain to wait for Cancel to work. in the cmd prompt terminal window you can try hitting CTRL-C to stop the ComfyUI process and then open Task Manager and find the python Process, right click and End Process
then you'll need to restart Comfy again
where is the 14 frames model located
from what Ive seen from other users outputs I like the results from SVD better
SVD is the 14 frame model and XT is the 25 one
I have the the SVD 14 frames model then
Is svd faster?
14 frames takes less time than 25
https://comfyanonymous.github.io/ComfyUI_examples/video/ both models here. You also doing 26 steps, you should try 15-20
of course you can put whatever you want for video_frames
not sure