
#🍥|anime
1 messages · Page 230 of 1


have an inspirational quote!


cool





no sad, here goth


:D
i like the color and style of this model, what's that?
autismmix_confetti
it's all about the artist tags you use, no one bothers to actually test anything
they just get the model, type in a random prompt and they don't like it because the defaults are garbage
Autism kinda of always have a yellow tint to it
🤨







Any recommendations for upscale workflow? I'd be using it for anime backgrounds of mainly buildings. Primary concern is artifacts where they are many small straight lines ie window sills, brick walls, etc

Hello everyone
ugh, my google searches now show AI responses at the top of the page and I've been searching a lot of technical stuff dealing with enterprise level server hardware stuff and the AI is so horribly wrong sometimes 😄
Drip


what is the style of this art? artist?
It's SD3




cool

nice style , is it a lora ?


ai is never wrong.
it's you who is a plotter
crap! how hard it is to use SDXL. it's something indescribable.
xl, expecially pony is very good. but you can use much less cool stuff and genning everything is so slower >.<
In general, some pretty terrible things happened to me with the pony model.

Pony
yep terrible things
Well, what kind of artifacts are these!? and already on model 1.5!!!

and it turned out to be VAE

in the first case it was the good old Anything-V3.0
and in the second it is the most common CleanVAE
in my opinion they are quite contrasting
in general? or the one against the other?
in general
Anything vae I like low saturation. I found this a long time ago and don’t even remember where. seem on Huggaface
i have it, but it always induces in me rage lol


Why?
Well, I don’t understand that deeply.
and i absolutely hate any model relatively connected with anything.
i'm traumatized by all the weird mutations XD
then you need to use your personal model created for and for yourself.
there are so many good and stable models out there
at best, you can add some finetuning
For example?
well, i usually use soushiki when genning fantastic landscapes
terrible ?? where ?? 

it looks like a mosaic!
or somethbing made by Zovya for the toony style
too bad i lost many models in the last week 😦
i confused a directory for a connection >.<
they where all so cute and stable models
sad to hear this

cute, but the samey color makes the conposition comfusing


this is the land of horrors

meh
and this is the Land of Kawaiiness

nice !

cute
I'm on my wayyyyy

you can fly!


hmmm....


what do you think of this style ?
about her clothing style? simple and tasteful! 😁
no i mean the drawing line
clear lines, moderately bright colors. good lighting. although the background is a bit rustic. but if that's the idea then fine
yeah i was focusing on the same style
then you succeeded!
very tasteful


gm


a fish!
nooo

Yeah it was this one. https://civitai.com/models/137160?modelVersionId=151344
I had to turn up the strength on it to 1.2-1.3 to get it to work with a full prompt on kohakuxl-epsilon. A shorter prompt might have been easier to get to work.
you favorite character as a neon sign... weights 0.8-1 If you want to donate: https://ko-fi.com/proomptengineer
thx 👍










guys, overweighting all the quality tags and downweighting all the other tags, what results do you get?


cute
other than pony models, I like to do (highest quality, best quality:1.4)
on many models
and same for negatives weighted too, they make a good difference depending on the model I like it most of the time
but no need to down the other tags ( at least not on a1111)
i noticed that a model i'm using, tend to overpower the character prompt with the background prompt
by overweighting all the character tokens and downweighing all the bg tokens, but leaving the quality tokens untouched
i noticed very interesting results
the bg tokens are 0.5, the characters tokens at 1.3 and all the quality tokens at 2.0
by doing so, the bg go bonkers in an interesting way
I think that was deepblue originally
thx

 pats x1000
pats x1000
indeed


noice !
did we ever get controlnet stuff like posing with xl models?


Any way to make this workflow better (other than settings)? Pretty happy with this, just wondering if I'm missing out on anything else.


don't yank pls


just bought a new server for my home lab.. debating getting a Nvidia Tesla M40 (24gb vram) for it, could be fun to play with
then again, i should wait until i get the server and see if i can cram my 3080ti or 4090 in it before I spend more money 😄


Beep boop. SO i know this isn't the Tech Support page, but seeing as Anime can center heavily around the hair styles, any recommendations for something for Auto1111 UI that can help me make sure, when a scene contains multiple hair colors, that each gets assigned correctly?
you mean like making sure the hair is colored in the same way each time? It's kind of rough sometimes

Well more for a scene with multiple people in it, like a group photo
so something more like this

regional prompter
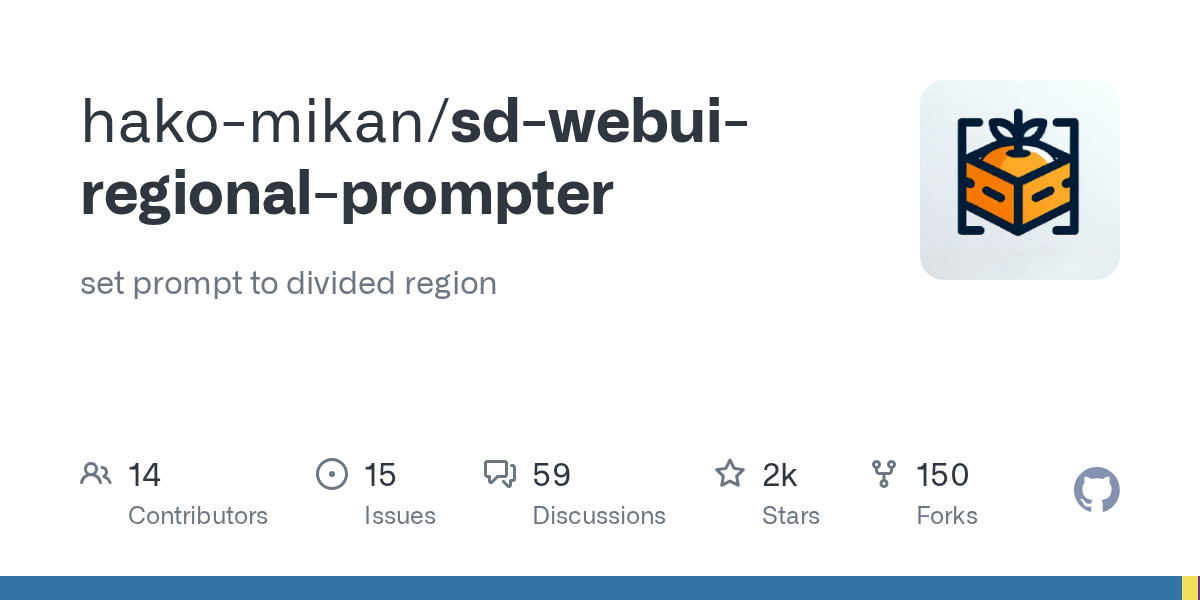
GitHub
set prompt to divided region. Contribute to hako-mikan/sd-webui-regional-prompter development by creating an account on GitHub.
i defined the left side with a prompt, and the right side with a different prompt
yeah
MAy i drag you to the #🤝|tech-support in assistance on how to install it? 😄
you can have multiple divisions and do specific prompts for each one
it's pretty simple, just go to the extensions tab in a1111, click "available" then click "load from:" and find it in the list and click install
then go to the 'installed' section and click "apply and restart"
for installing extesions, yeah
there are a few that can be complicated, but usually it's that simple
And then i read the guide, and follow what it says, and then if i don't understand any of that, ping u in Tech support? xD
pretty much 😄
Oh wait, i think i c.
So
Char 1, pink hair, long hair BREAK
char 2, brown hair, short hair BREAK
char 3, orange hair, long hair, BREAK.
That guarantees 3 different hair styles, and they won't conflict on eachother?
(Gosh darn sorry for hijacking this for Tech support 😦 But Ya'll prolly more knowledgeable on this specific topic)
for the prompt, yeah that's basically it
you have to adjust the divide ratio in the settings to split the image into areas, each part of the prompt will go in a different section
Any activity in the channel is better than no activity. Don't worry about it.

Besides, as you say, many people in chat (at least back when I frequented here more often) are knowledgeable indeed about SD and extensions.
Weebs often make the best tech support
Yarp
If i ever need answers about a creative topic, weebs are deffo go-to
These coding looking terms are hard for me to understand so I'll prolly be spending a few hrs on learning just 1 part xD I might return
the important part is the divide ratio, you basically start with 1,1 for 2 columns, make it 1,1,1 for 3 columns, etc
using the base/common prompt options can get a bit more complicated and you can get really specific with ratios
but keeping it simple to figure it out really helps

1,1,1
- Forgor full image.

or 0.3,0.3,0.3
1,1,1 would give 3 collums, ye, but surely to make sure i get 3 different hair colors, I would need 3 cubes, only on the hair part?
i wouldn't try to limit it to just the 'hair/head' area

you can, but the more you restrict the area the harder time it has figuring it out
So 3 collums, and then fine tune the ratioes, is the way to go?
yeah, if you try to split top from bottom you have 6 areas and you have to put a prompt in each one
Fair. And i assume that
"Char 1, pink hair, long hair BREAK
char 2, brown hair, short hair BREAK
char 3, orange hair, long hair, BREAK."
Goes Top one is collum 0,
2nd is collum 1, etc? (Edited)
but even if you wanted to define the clothing also, it's still in the same column, so it's really not needed unless you need something specific
ffs. Too tired to type. fat fingering enter
Edited my fat finger msg to actually include the question
3girls, choker, cat ears, smile, maid outfit, standing, BREAK pink hair, short hair, BREAK green hair, long hair, BREAK blonde hair, twintails,

using 0.3,0.3,0.3 for ratio
Right, but what determines which goes into what? Cause surely collom 0 (The blond), should be the first after the initial break?
depending on the model, some things will try to take over (like twintails)
tbh, it's not very precise sometimes

TL:DR Keep genning until you get the result you seek?
pretty much
Gotcha
there's probably ways to get it more specific (that i don't know), but for the most part it's just trial and error
I mean. depending on your settings, it takes all from 10 sec > 3 min.. surely... right= I Mean, thats not too bad
Oh, so with base promt enabled, you do all of your promts, then new line, then BREAK, and then add details for each collom, seperated by new BREAK line?
1080 ti \o/ I cri in ancient tech
yeah, base prompt, break, first col, break, second col, break, etc
I c
Do you ever re-visit an image, but have completely forgotten what promts you used for it, and wish to re-create them? Recommendations for an extension?
I tip my hat
should also work with mine, i leave all the data in there

Any model recommendations?
for sdxl, autismix_confetti for anime stuff
for sd 1.5 i havent used any for awhile
Honestly only really been using PonyXL+SDXL merged
This base ratio... What does that do exactly?

If only the damn webui wouldn't crash so god damn much xD
(Usually after rapid successions of generating)
it's for the base prompt, basically 0.2 is 20% base prompt, 80% everything else
Ah, so a ratio of 1, is usually the go-to if you've important a previously genned image, and wish to maintain that composition?
haven't tried that, i usually leave it at 0.2
It does seem to work like that for me atm. As the 0.2, pretty much cut the image into 3 parts, and threw out 2.
Just a suggestion but I've heard that ForgeUI's version of regional prompter is better and easier to use compared to A1111's version. Apparently it can also apply lora's to different regions
However I haven't tested it out so I have no clue what it's called 😭
I barely even use local models nowadays, so yeah..
i haven't tried it in forge, but the normal extension also supports loras in regions
Soo... This width height thing... Wat is that?

just set that to the same width/height as your generation
it's basically defining the area to apply the regions to

GitHub
An Extension for Forge Webui that implements Attention Couple - Haoming02/sd-forge-couple
Found it pretty easily
requires forge though https://github.com/lllyasviel/stable-diffusion-webui-forge
Isn't ForgeUI better than A1111 tho?
You also don't need to delete A1111 in order to install Forge
better is subjective
That is tru
I mean, pretty much everyone that I've asked has told me Forge was better, so idk
it has some substantial performance improvements for lower end hardware, but last i checked its a bit buggy
most people probably have 4-8gb cards
I prefer slow gen time, over buggy mess
I personally haven't had any issues with it when I used it
it doesn't increase my performance beyond around 0.1-0.5s for sdxl generations so all i see are the bugs and incompatible extensions
Plus it increased my generation speed by 3x, so I think it's worth it honestly
I see, I assume you have a pretty good GPU in that case
mostly for me is TensorRT which does increase my performance substantially, doesn't work on forge
I have a 4090
I'd say thats pretty good
I was planning on buying it but I wonder if I should wait for the 5000 series
Can i borrow like 1990, from those 4090? xD (To make my card a 3080
i'd wait at this point unless you aren't going for a top end 5080 or 5090 anyway
the 80/90 should be out by october or november, but the 60/70 range won't be until like march-april next year
The day i upgrade my gpu, is the day I'll stop playing games.Why? Cuz i am gonna be OOOOLD then
Compared to most EU countries, everything in the US is a good deal
I personally don't really think I need anything above a 4070, but I might as well wait and see what the price of the 5k series will be
comparatively of course, it's still expensive
tbh, i kind of regret buying the 4090, i already have a 3080ti and the overall performance in games and stuff is trivial from a real world perspective
Obviously I'll have to wait and see what the future local models will look like cause right now I'd rather just pay $25 a month for NovelAI than buying an expensive GPU
it's nice to have, but not worth $2k
Wait so the 3080ti is just as good?
well, one does a sdxl gen in about 8 seconds and one does it in 3
I'd say that's not that big of a deal unless you're generating a lot of images
the 24gb vram versus 12gb does allow more resolution (at good speeds) for hires fix, but realistically, the cost to time ratio isn't great
Yeah I'd say the 4090 would be good if I was training lora's
for $2k you could rent a gpu when you need it, or like you said use NAI or something instead
But for regular image gen I think even a 4070/3080ti would be good enough
i do some training, but renting a A100 or something for a few hours would be way cheaper unless you're training a lot
Makes sense yeah
i do have more professional reasons to have the hardware, so it was more a business expense anyway, but it still really wasn't worth it for me 😄
on top of that, i still have the 3080TI just sitting idle in my home server not getting used
Oof, that's rough, you should've waited for the 5000 series at least but it is what it is
that was the plan, but then they delayed it for a year so i went for it
Gimme wtf 
still should have waited 😄
You live and you learn I guess
I made the same mistake when I bought the 3050, never again 😭
yeah, i've debated selling the 3080ti off and on, but I think I missed the bus on that with the prices dropping now
You never know, there's always someone who might be looking to buy it
I have a new server on the way, I'm going to see if i can cram the 3080ti in that for VM and LLM stuff if it fits, otherwise i'm going to try and sell it and use the money to get a used enterprise card or something 🤷♂️
something like a quadro rtx 8000 (48gb) would be nice, but $3500 is a bit
maybe i'll sell the 4090 and get that... 😄
or both even
Yeah, "a bit" 😭
I have nothing else to spend my money on and i like playing with tech 😛
i bought an old dell poweredge r730xd server with 128GB ram and 2 14c/28t CPUs... just to play with it
should be here Wednesday

Hello again frens! I'm once again seeking for your recommendations, this time for something that makes eyes better in the anime/cartoon realm
Cause these do be looking yank


could be a few things going on there. if the image is sfw send the image by dragging and dropping it from the folder it's saved in so we can take a look at the prompt and all of the parameters.
"Expressive_eyes, Expressive eyes", are the only 2 promts revolving the eyes, and not quite sfw 😉
which model?
PonyXL SDXL merged
ah, that's probably part of your problem. pony used some silly training parameters which made it not really compatible with other models. I'd start by trying the same prompt and parameters with just PonyXL, or you can try AutismMix_pony or AutismMix_confetti if you don't like how pony looks out of the box.
I must admit, i have looked for the autismmixpony for a while, but haven't been able to pinpoint it
beat me to it.
Oh... Thats whu i couldn't find it. I was trying to find a model titled AutismMix Pony-
yeah, the pony and confetti variants were uploaded as different model versions.
there's 5 models on that page
I c 😄 Still getting used to Civit
I prefer the pony variant. i think Captain Vargas likes the confetti variant.
Both are good
it's more of a style thing for me personally, they both work really well, i just got more consistent results for my taste with confetti
T-ponynai3 is another good one to check out
i need to check out that one
IS there a way for me to put all the Lora and models into another drive, and have SD pull from that drive, while being on a second drive? For some reason... The drive SD is on, has 120 gb of unaccounted used space i cannot find anywhere. I've made it show hidden files
It's not nearly as flexible in styles. But the styles it does do are nice.
--ckpt-dir "D:\AI\Models\checkpoints"
Wait... Hol... Where i put this, and how i tell it where i put em?
change the path obviously, but this goes in your webui-user.bat
this is the full line from mine
set COMMANDLINE_ARGS=--xformers --opt-channelslast --api --ckpt-dir "D:\AI\Models\checkpoints" --hypernetwork-dir "D:\AI\Models\hypernetworks" --embeddings-dir "D:\AI\Models\embeddings" --lora-dir "D:\AI\Models\loras" --vae-dir "D:\AI\Models\vae" --realesrgan-models-path "D:\AI\Models\upscalers" --esrgan-models-path "D:\AI\Models\upscalers"
So X:\MainFolder\Models\Stable-diffusion, for the checkpoints, and add it again but X:\MainFolder\Models\Lora?
if that's where they are, yeah
X is X as its a variable 😄 Idk what drive to put on yet
i use this to remap all of the related files because i generally have multiple UI installed, auto1111, forge, comfy, etc, sometimes even multiple versions of each
Might just move the entire SD folder tbh temp, and format the drive with all the random shit unaccounted for, and paste it back in
How even does 120 gb of space go missing, on a correctly partitioned drive?!
I just store all of mine in my A1111 directories and symlink those folders out to the other UIs.
🤷♂️



i don't remember which one off hand, but i had an extension that wouldn't work with symlinks and hardlinks in windows are a pain so i just used the config files and a central folder

773 gb of models, loras and checkpoints?! Wtf r u doing
i do a lot 😄
These are my drives. The newest one, the 970, is from circa 2018... Rest is from 2013.


Stable Diffusion
mine are all 970s
I am very surprised, none of them has died... Well, one tried, but i didn't permit it
i think one of the 2tb is almost 2 years old, the rest are ~6-8months
Spinner seized somehow... Opened it up, and spun it manually, on the disc retaining bracket. Never touched the plates*
Closed it back up, and it worked \o/
That was 6 yrs ago
should free up space on C: like yesterday. less than 10% free on an SSD is a big nono especially when it's the boot drive
the server i ordered has 24 2.5" bays in the front, i dug around in my parts and found 9 misc drives to throw in to start my NAS
totals around 5-6TB
plus the 7TB in this computer i'll be moving over
I have 2 games on the C drive, that tallies 281 gb 😐
not sure how i have almost 1.2TB of games installed
Cause modern games takes up a crap ton of space
In the next decade, when I might be able to afford a new pc, i deffo gotta look into some high capacity drives
realistically I only use a lot of space because i have it, before i built this system I only had a total of 3TB and never really ran out of space
I just leave games installed, and dont delete AI models i'm not even using, it just sits here
I just went through the drive... I can account for ~300 gb of space. The rest, is like system crap
download wiztree, it'll let you visualize where the space is going and make it easier to clear out stuff you don't need.
O.o Claims only 135 gb is allocated... Wat.
Again, sorry for hijacking for tech support 😄

Guess after formatting, I'll re-partition the drive, and then re-format forgood measure 😄
check the health status of the drive in CrystalDiskInfo


lol, disk info waifu edition
Gotta keep in line of the Anime channel xD


why you apologizing to me for?
Cause I'm pushing your channel relevant stuff up, with my tech support xD
no no i'm the one getting involved with some tech based anime art 😄
you are good

all good - she says

waifu edition is correct choice

How can she even see the keyboard.

android mainframe

Thats a weird way of spelling "Gundam"
jeez, almost 43,000 hours on this ssd

kinda ironic i'm reading a book called naural wraith about a guy who has no implants for their ai run altnet in a city run by ai dolls (females of course) logic engine and emotion engine based AI's
almost 5 years

This is my external drive I've had for ages

MEanwhile my oldest drive. Brb rebooting pc ( 😉 But not really)

lol, 5000 power cycles
13 yrs, if you were to power it on each day
the book cover

13.69 yrs to be exact.
My system drive, which arguably is my newest drive.

My first SSD i ever got

And my 2nd drive i ever got 😄

Soooo....

hmm how do you bring that up?
the info for power on wher it shows you yours
Right side

yeah hard disk is 5 years
i'd expect solid state to last at least a few extra years

My 30k+ hrs are Hard Discs, fren 😄
i've had drives die a week old, and still have some kicking around from the stone age
i still have a 20GB IDE drive that works fine
I'm more concerned about the only 175 power on, but 41k hrs on
i should hook up some of my old drives and see what the stats say
"Help me. I wanna die"


Gosh i hate it when Windows tells me a file is in use, but not by WHAT...
nods
"In use by other program", YES BUT WHICH?! (Moving SD temp).


At least it doesn't crash your browsers, ending up stopping your generation cause gpu drivers halted, because your brower crashed
oh i've had that happen
or the script errors that happen and then when I close an reload, no errors. like wtf
usually python
I often have crashes if i do to do rapid succession gens


lol, this ones not too healthy





Amazing... Told it to reboot into safe mode. Windows update decided to update the pc, and now it doesn't boot
drops this here. just because 😄 https://suno.com/song/df11515f-fe6c-43b0-b5da-dac86e63010f

synth wave vocal android female vocals song. Listen and make your own with Suno.

and yep it is ai generated
yes no. delete?

uhh oh
Wat
U like some wizard?
no i mean it's the equivalent in Linux
Having major issues formatting a drive, windows thinks is a boot drive, but is in fact... Not
meanwhile I do this https://suno.com/song/3bfd14dd-82c7-4a4d-ac3f-298263d7816c
Japanese Anime Metal song. Listen and make your own with Suno.


yep ran lyrics thru google translate

Make an img of someone splashing their pc with a keyboard
Cause mentally, I'm close
Smashing *not splashing

I might have fixed the issue... I'll let ya'll know in 5
THANK YOU ASUS! secure erase shat all over windows "protection" of the drive

Why is there a sword up his bum?
shrugs
You do you, boo
hey wasn't my idea, AI's

And i have my pc back now. This is nice




Can't gen anything atm 😦 Busy moving stuff back over. ETA: 2½ hrs
But at least i regained ~90 gb of unaccounted space
ok maybe more detail at 1 is to much ooops

huh.. interesting

oh it's the huen sampler fusting with it
heun?
R u having a stroke? Do we need to call the bondulance?


I have some ideas i need to get into promts, as soon as i can re-launch the webui xD
Any particular model used for those wings? Cause isn't feathers like... Troublesome to gen?
it's a merge I made 😄
I c

My next gen is something that is gonna have wings, but large wings
I'm just random
someone mentions somethjing or posts and I join in
or take a left turn into wtf-ville
Anime wizard duck in forest, ground dirt, location forest, realistic duck, pointy wizard hat, anime. Go go
o.O
What? Ducks can't be wizards?
was wiating for this one to finish

well hold ya ducks, duck

hmm o..k

ok need to reboot, it's starting to take more time than usual. brb
ok rebooted, restarting webui
More like WeebUI 


She is not a duck xD
takes out tron-punk...ooops
Oh hai CS


CHONKY!



Thats not a regular, realistic duck xD But It'll have to do xD




That is actually adorable



Add a duck on like her shoulder, or her holding a duck xD




haha









When generating, the very first 2 itterations of your genned pic, the grey blobs are terrifying to look at
Making some preview thumbnails for my lora packs, ended up creating this




Technically the hand is in focus in a universe
Might not be our focus, but still xD
Had to edit the hand in the back since it got all messed up sadly
Sadge
Otherwise this would've been a perfect image
Had a perfect, 0 alterations at all, earlier (Scroll up a bit) 😄
Gonna keep rerolling cause this tag seems to be doing wonders
200 batch count, go to bed. Wake up with a bunch xD
Legit I've spent like 5k anlas in a week when I first bought NAI
Anlas?
It's way too fun generating sometimes 😭
Yeah that's their currency
Surprisingly you do get a LOT when you subscribe, I didn't expect it to be that much
Sadly it's not enough for someone who generates non stop like me 😭
I've been doing that for so long but nothing on local looks as good as NAI sadly
I mean. This wasn't a bad one xD #🍥|anime message
Eh, I prefer something more anime looking personally
To me all the local models have that same feel to it, not sure how to describe it
Fair. Just putting my foot into that entire area in like a day or so
That just sounds like a setting issue tbh
But whatever makes you happy 🙂
I'm not gonna detract from that 😄
No not really, local models aren't really as aesthetically pleasing as NAI, simply being able to mix 7 artists together on NAI gives much better outputs, at least for me
And overall the composition is quite boring
Each to their own, is all i can say 🙂
Well of course, it was super fun for me as well when I first started using Pony and its derivative models, but it just looks so bland...
Not to mention it can't even do night/sunset scenes properly
Everything is just so bright 😭

Hopefully that gets fixed with v7

It looks like the monitor has veins wtf 😭
Tbf, it is a BenQ XL2420T from like.... 2012
But hey. Its working
Just don't have anything white on it

Uglee





15 Lora's to still make previews for 😐

just do a 1girl prompt and write the name of the lora on her face
big brain
But thats boring


:p
Those eyes look so cursed 😭
I could argue for 2girls
more than that I don't know if I can handle
Those are reserved for the.,... Others 😉

Is there a promt like Style_anime, or something to make sure one gets a specific style from a checkpoint that has a bit of everything?
read your models description
Make a solid point
If you're talking about Pony then use source_anime
Thank u
It's still gonna be pretty random so try using some artist tags that aren't hashed or use some artist loras
Well you can prompt for some of them without loras but yeah, you can find style loras just by typing "style" in the search bar on Civit
Yeah. I found out. Trying now, just gotta see if the regional promter can force the correct promts.

Not a lora, this is NAI
Lemme guess... a Vae?
No 😭, NAI=NovelAI, it's an online cloud based model
Ah
It requires a monthly subscription, forgot to mention that
Yikes
Well, I guess you don't really need to buy a monthly subscription, you could buy their currency instead but I prefer the monthly subscription since you get unlimited generations
@ivory pebble can we train a lora or smthing like that on NAI?
generate a batch of 30000, train a new lora on Nai. Be named and shamed across the entire community, get banned for stealing, cries over a bowl of cereal.
Probably, but from what I've heard it's not the best idea to train a lora using other AI art
There's plenty of NAI style loras for Pony
no no no I mean train a lora on NAI, like we can gen only characters that NAI team included right? so like local, cant we train a specific character and gen that character?
Oh that's what you meant, my bad 😭. No you can't train loras on NAI
So... I tried to change the hair colors, using regional promter...

This was my result.

Somethings not quite right
Yeah I have no clue, I gave up on regional prompter a long time ago since I couldn't figure it out. There's probably guides on how to use it on 4chan or something like that but I never looked into it sadly
I mean. Its a funny lil mishap 😄
Smol Girl, and Big mommy
Getting there. Not a bad one tbh. Or at least me finks

Wanna see the process, my client decided to go in, on a promt?

During a batch generation, with these promts source_anime, "score_9, score_8_up, score_7_up, <lora:PonyXL Expressive Faces:1> ((2 girls)), long hair, brown hair, warrior, warriors, location forest, forest,
BREAK
1 girl, long hair, Blonde hair,
BREAK
1 girl, long hair, Brown hair,
(Spoilered not cause of nsfw, but cus wide file)

Did you try regional prompter without that lora? Just to see if it gives better results
Ye, it was disabled during those 9 pics
But like the AI really wanted skimpy, in the end xD
use this: (bee (deadflow):0.7)
I think I'm starting to see, what kind of artist they are
If you're having problems with armor being skimpy, try "Bikini armor" in your prompt
It will 100% do that, no more rng!

Can you like... Bookmark promts?
I mean i know that
not sure how
I can pull them from the png info
styles is like a text file you type stuff there and it appears on your prompt from a little menu on the side
But at a point, when you gen 300 files overnight, cuz efficient use of time, it gets hard finding that one file
There is T-ponynai3 that's trained with NaiV3 images
no I mean I wonder if there is a option like that in NAI, so we can input our characters that NAI doesnt have
Vibe transfer can help creating characters nai doesn't know
For some reason Nai doesn't like doing good boxes with vibe transfer


This classifies as anime, ye?

Oh no, some random characteristic
@nova remnant

got my hype for a sec
Why? What happened? 


I'm doomed.. I can NOT stop generating her 😭
Gonna waste all my anlas at this rate
switch to medusa
Not a bad idea actually
i got hype cuz i though was a new checkpint or lora but is only NAi hahah
found another pretty stable anime model, cool
what? where?
(日本語説明は後半にあります) "HotaruLabs" series are experimental(intermediate) models, used to develop my "Breed" series checkpoints. 7 types are uploaded. To ...
One day we'll have that for local.. hopefully 😭
made some gens to test and still din't see mutation
and the result is pretty close to the prompt
ouh not my style
sadge
i love that toony style


Had to reroll a lot since her weapons are so complicated 😭
That was the best one I got
wooow its so good
Had to fix her hand as well since the AI won't do it for me 😡

Her dress is so short wtf I just realized
She is NOT jumping with that on that's for sure
shes jumping, running doing all the things
she does have a another outfit I guess, denim pants and sweater or smthing


Apparently increasing the Enhance strength fixes the hands, so that's pretty neat
yesh soo neat
Her right hand looked like a mangled mess, ran the image through 0.35 Enhance and it did wonders
Still a bit off but much better than what it looked like at first
Time to generate some of those pics as well I guess

just noticed that the most stable models, are even the most bland and bare
Because they're overfitted
yep, too much locked on their concept
but i love the toon style >.<
it's so hard to find a flexible model in that style
i suppose i need to lock a prefered style using negatives
I am sad now. Was wondering why half my Lora's werent showing... Went to "Show incompatible Lora's".... They all need Nai's 😦





ma lora kinda good at generating things like wallpaper or smthing


whats this pose?
This last one feels.. weird, not sure why
I have no clue, prompting "hand focus" on NAI just gives really good composition at times, my best guess would be "standing, from above, arms under breasts"
arms crossed under breasts, perhaps?
tilted camera?
noice bro 
Looking from above, arms crossed under breast, looking at viewer..?
kay...
I'm going back to making girls with swords now, my fault

Hidden sword, crouching balls?
I have no clue what that is and I am NOT going to find out 😭
Think. You know exactly what it is. Hint: Nsfw
My best guess would be them pulling out a sword that's in between their breasts
I have no clue what else it could be 😭

Yup, basically that
Oh poor innocent individual
who wouldn't hide the weapon in the crack?

That's one way to put it I guess
Still my favorite pic, she's so cool



i prefer the second
the hair is more clear
noooo not realistic...
 wut
wut

this is one is anime again so don't worry
yeah you can see the original
i replied to it
idk why does discord not showing me notifications when someone reply to my messages
It looks less like there’s a camera flash on.
I prefer second too
yeah, i just noticed


NAI doesn't have LoRAs. If you have models that reference NAI or NovelAI in some capacity it just means they are SD1.5 based LoRAs that were probably trained on the leaked NAI model. If you want to use LoRAs with Pony, or any of its variants then you need to look for SDXL models, and ideally ones that were trained specifically on Pony or one of it's variants (there's a filter on Civitai for Pony based models) for the same reason why merging Pony doesn't work well.
I have this
And thee Lora's are wanting something with "Nai.ckpt"
arms under breasts, from above, leaning forward, looking over eyewear, looking at viewer depending on the model you might have to remove leaning forward or lower the weight on it. alternatively, you could just use openpose controlnet, since you already have an image with the pose you want.
they just need any SD1.5 model. SD1.5 and SDXL things including loras are not compatible with each other at all.
Arms under breasts.. Like this?

Why do i have a feeling, these have been deleted from Civit?
NovelAI model for sd1.5 was leak
nai.ckpt is actually called anime_full_final_pruned.ckpt and it was stolen from a paid company called NovelAI.
Figured 😐
it's what basically every halfway decent SD1.5 based model is trained on. and/or merged with.
I don't have it anymore 

This be why u backup your Lora's.
I just have these

Well you have everything saved
Lucky, i guess
aside from training, that model has been worthless for a long time now.
Bit annoying they're not hidden on Civit, so prevent people like me downloading loras with no publicly available (free) models
To prevent*
Words r hart
Soushiki, Aurora, Kakigori, maybe one of the Based series of models are all you need, they will handle loras trained on the leaked model very well.
Will they accept the lora's trained on the nai?
yesh
Oh yeah I know, I was messing with some prompts on NAI and I got it as a random gen without using any of those tags. "hand focus" seems to give some interesting composition to images from what I've tested, or it could just be the randomness of the model and the tag might not even do anything, it's hard to tell 😭
Just look here when downloading models or loras. If it says SD1.5 then it will work with things that were trained on nai reasonably well. Some are better than others at that, but the 4 I mentioned are quite compatible.

reaching towards viewer, foreshortening might be another one that you'd like. could be combined with hand focus
What about the Networks.llora, thingy?
Will try it out later, right now I'm messing with some action poses like "fighting stance, holding sword", but I can't figure out if there's a tag for sword swinging, probably not since I can't find anything on danbooru
Maybe adding motion lines might do the trick 🤔
action pose
loras have the same thing. SD1.5 based models and loras were very compatible with each other for the most part. SDXL models and loras are not as compatible, but with the exception of Pony, they'll generally work at least decently.

I knew I was missing something 😭, I used that prompt before but forgot what it was called, tyty




I just learned, this is a thing as well. So let's say this one works better on Pack 1 (Out of the 3 you suggested), is there a promt i can plop in to make it load that checkpoint, on that lora, every time?

no, the prompt doesn't have control over which model is used. activation text is for automatically adding the tags that the lora was trained on, for example a character lora might use a format like character name, copyright and might also include some other tags for official outfits that the character wears. or an artstyle lora might use the artist's name or a word that describes the style.
yep
SO is the lazy mans approach to not forget stuff 😄
the real lazy man's approach is to get the extension that automatically pulls activation text and example images from civitai so you don't even have to fill in the activation text box yourself
That sounds nice, and yet a mess
Cause people man... The amount of crap you see, if u has nsfw enabled, on pics. There seem to be every kink known to man
Now... Its not that I'm kinkshaming, but I'd rather not have the promt "woman urinating on a duck while laughing and eating a kebab roll"
Lets play a game. Just image something it can be whatever you want... Ok you have something... ||That's someone's fetish||
I mean, i understand that everyone is unique, its just not something I want near me 😄 You do you, but do not push it on me 😄
Cleanse your eyes on this



Don't worry it bites back



anime gif
Cat pfp







I put saitama transformed into a cat


Cat is sleeping on me atm :3


kill it with fire
What did you mean with this?

silverflame's picture
Do you know any way to make two characters appear, without their characteristics merging? and using a lora for each one?
Is some pony looking thing
@steady grail
look up a tutorial on regional prompting
There is nothing wrong with an innocent unicorn
Can you show me a sample please?
I have no idea how to use regional prompting




stahp crashing plz Webui







anyone excited for gpt 4o image gen? if it's anything like dall e 3 then it would be pretty much img2img + style copy dall e 3
like the moment that shit comes out ill spend 24/7 making images before censorship comes in and ruins everything

Afaik GPT-4o is just using Dalle-3 for it's image gen.

Uh nah
I mean sure they never stated explicitly afaik that 4o gen by itself but like
you can tell gpt 4o to copy a character and it will do it
yeah, it has a new vision model but that's not the same as an image gen model.
Either way its img2img dall e

Lemme see if i can navigate my way into the demo pics
yawns
eh... not really. img2img is using the input image as the starting point for the diffusion process. vision model to image gen is the same thing as running your image through WDTagger to generate a prompt, then using that prompt to generate an image. presumably their vision model will perform better than that workflow does, but that's what it's doing at it's core.
No
Just no

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The site doesnt load for me
I just linked you OpenAi's site that introduces GPT-4o. They don't discuss anything new in image gen there because there is nothing new in image gen.
scroll down

Explorations of capabilities
Select sample: Photo to caricature
Wait for that shi to load
yeah, it's just using a vision model to generate a prompt based on your text and image inputs.
Dude wtf you mean bro. How can a prompt copy a face
I mean if its that good might as well treat it like img2img
With GPT-4o, we trained a single new model end-to-end across text, vision, and audio, meaning that all inputs and outputs are processed by the same neural network. Because GPT-4o is our first model combining all of these modalities, we are still just scratching the surface of exploring what the model can do and its limitations.
that's what GPT-4o is. a text, vision, and audio model.
all inputs and OUTPUTS are processed by the neural network
yawns some mroe
If this shit loads I'll give you a screenshot but it doesn't
It does in fact img2img
even if it does (which it doesn't) that isn't anything groundbreaking.
honestly the vision model is pretty exciting, it just isn't what you think it is.
The level of editing it can make is pretty cool
It has the capabilities that I imagined

It can transfer your photo into another style, move a figure in an image to do something...
Tell me that isn't img2img convince me man
also "audio model" it can generate and hear sounds. So like "vision model" means generate and see pictures
she angy

no, it doesn't
vision means it can see.
which is cool. it does not mean that it generates images on it's own.
Ok fine but like I literally showed you how to navigate to the examples