#🍥|anime
1 messages · Page 185 of 1

but hey I do have DM's 😄
Most models are either aesthetic finetunes, or merges of several aesthetic finetunes. Partly because most people don't have the hardware to train on millions of images.
grinz innocently
the more I try to weight for anthro cat and 'uwu' the smaller and cuter she gets 😄

yeah most models , unless trained for it, doesn't do furry well
and the one's that are. .ooooh boy
yeah, my own merges are trying for "as flexible as I can, but within reason" which basically comes down to a specific style/look being more overtrained than the others. If I tell it to do a different style, it will, but otherwise it just makes a reasonably good image
yeah thats why I merged the one's I did in my NOMD merge model
I generally don't set out to make anything specific though, I'll just put random keywords into the prompt and see what happens, then tweak from there if I want to adjust it
random scene, random girl, random boy, random time of day, random weather and such is fun
something like the pony model would be much more useful if I wanted to generate specific characters in specific styles I guess
although, merging it with my own model I've been working on has been working fairly well so far, the extra knowledge it brought to the table is good


why she look like she's about to cry? what?






I wish there was one of these for SDXL
Put (dark:1.8)
Recommendation by @native halo
 👍
👍
masterpiece





very cute eyes!
Did I do it right?






Model?
NuOrangeMixerDream (NOMD)
it's on civitAI
and yep it's mine 😄
well ok it's a merge 3

Thanks
welcome
hope you get some good results
I'm watching Full Time magister, wish it was english dubbed instead of chinese and sub
oh well

Stability released one alongside SDXL. I haven't used it yet. https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/sd_xl_offset_example-lora_1.0.safetensors


she is very serious

ah this is...

tough love?






sigh I should be in bed but dammit I want to finish season one of this anime!
only 2 more ep to go

guys who know this is project?
https://github.com/LykosAI/StabilityMatrix
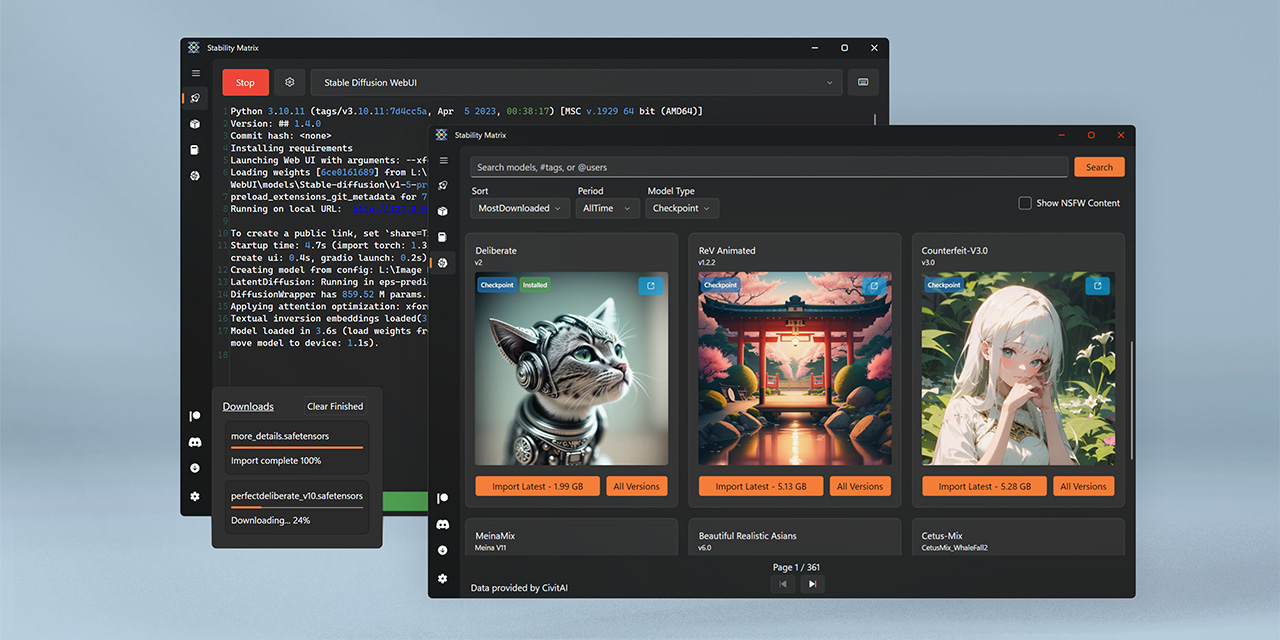
GitHub
Multi-Platform Package Manager for Stable Diffusion - GitHub - LykosAI/StabilityMatrix: Multi-Platform Package Manager for Stable Diffusion

or tell me what the problem might be. I can't download packages from GitHub... I get this message

try to get some node package for Comfy
and done, wow that is a good series, and chinese at that. ok off to bed. nite
thuds
five more seasons to go.. must not coninue.. must noooot




haven't watched many chinese anime. didn't mean any offense






ooh toasty


Small medium
and with this. bed.. for real

question:
from 1 image of the character anime to make in different poses and emotions
keep the consistency of clothes, face, hairstyle, general kallait
2) if you create a lora from 1 image, what script to use.

... sneaks one last one in









You should take a another look at her

Just bluntly put you should remove this
yup lmao
u right i didnt saw the thing ill remove it and post it again edited


shes clean now

I couldn't bother searching for bottled waifu so here have Miku inside bubble








what did you post lmao
not me lmao



I'm sorry


What did they post
nsfw stuff
cute art style. model or LoRa?
then must start server....

GitHub experts i am need help...



Does anyone know how I can get this to look as if they are looking at each other, I am using matrix regional prompting but idk how to define openpose images for regions :)





Picking up my Blender hobby again... plus, might make for some fun img2img options. 🙂
Feel free to use this Tifa. 🙂 3840x1600, rendered w/ Blender Cycles, 5000 samples.






























Boba
Oh fantastic! Thanks for the link.

Hey guys can I get some tips on improving image quality out of the box in a111
8 feel like every image I do there comes out bleak even with same settings as comfy. Comfy brings out more color, positioning and general composition
Is there a way to chsnge the backend, AFAIK comfy uses a different backend for noise and the like so, are these two just going to produce different results all the time or is there a way to change a111 and make it better
extensons
what do these look odd/dirty/ bad scetched or such?
interesting style to be sure but.. shrugs
It's a combo of sketched, holographic neon color effect, ikabana

experimental style i'm working on.
tho prob gotta remove that lora cause it's effecting it to much
can't sleep so might as well put my brain energy to work
intentional, experimenting. most of the stuff I made in that style has strictly been weird stuff like this so I took a detour to the more normal world to see how it fared




























small winter miku is the best 
what does "score_9, score_8_up" and so on mean?
when I don't use it i get something like this

when i do
like this

which is better, but why is it so messy?
any way I can get rid of the messiness?
are you using that ponyxl model?
the tag score_9, score_8_up and so on were trained on the model
Yeah, but what does it mean?
It sucks.
basically they are trained on those tags as quality tags?
so in theory, it's kinda like putting "masterpiece best quality" and such
ok
also
WHY
IS
CIVIT
AI
SO
FUCKING
SLOW
it keeps timing out
and it takes forever to load
it's driving me insane
Kek
like you trying to download stuff? It's slow maybe cos there's a lot of users at this time
not sure tho










How can I fix these hands? I have copied some real hands and I am trying to use inpaint but it doesn't work

also i tried using controlnet
openpose hand
Can't you hires?
Image seems to be 768x
Hires helps already


Model?



Waiting for that SoushikiXL

sadly, i will probably not be using XL model, not till when i upgrade my GPU 
Same



i will try, thanks










Doesn't have red eyes, 0/10


8/10




and here is a question about building a prompt. what should be the sequence of constructing a prompt for two characters. (meaning a description-controlled appearance prompt).
For two characters, you will definitely want to use regional prompter for that
ah... only use RP.. oki-doki

That will ensure that whatever you wanna prompt for character one will stay for character one, and the same for another character

Otherwise, it will be either very difficult or impossible to achieve this using the usual construction of a prompt?
I think this may work also
Char1
AND
Char2
It will be hard to dictate what prompts goes to what characters, you can partially do this with using BREAK
AND - this is not for RP only?
But if you have access to regional prompter, it’s still the best
It's webui default
oki!
of course i have.. but interesting try without it.
Well good luck!

Make sure you selected a VAE
Otherwise the difference is that ComfyUI does it from CPU
The seeding
While A41 does it from GPU
merged my NOMD merge with the Aroyal RPG tools one for more deail. worked well. tho now less anime

you was right use RP correctly and easy way.. many thank.
No problem! It’s probably the best way for multiple characters generation

The thing is I select the same VAE's keeping everything down to the size and all equal, yet it doesn't come out as goood, maybe its the way it creates noise idk
nothing to do with that,its just a matter of skill
a1111 has options, you can use cpu or gpu for seed generation
honestly i'd be surprised if there wasn't a similar option for comfy
@broken osprey the 'backend' is the one thing that is the same between comfy asnd a1111. it's stable diffusion, comfy and a1111 are just web based interfaces for the same program
the noise is mostly generated by the sampler, although it is affected by a lot of things
a good place to start is to pick a random seed and run the exact same model/prompt/seed/etc on comfy and a1111 and then post both images with their meta data, it's hard to figure out a problem when we don't even know what the difference looks like
If you are using different weights, then there will be a differences as well. Since Comfyui handles weights differently compared to auto1111





what did you prompt to get this image? or did you use regional prompting for the bg and then character?
yeah but I try to find guides and they all say the same thing, not even touching most of the time how to get certain styles, I ask here but to no avail so yeah can't do much .-/
This image has pnginfo

There is
Then that was added recently
pretty sure it's always been there, can't find any reference to it in the patch notes, in august they added a 3rd "NV" mode that attempts to emulate nvidia seed generation for non-nvidia users to replicate nvidia seeds
so at the very least it was before the 1.6.0 update, but i know it was there before sdxl support, which was added in july
a lot has changed for both UIs in the last ~6 months



I got this result, the model doesn't know about the symbol I guess cus I am prompting for it

a lot of factors play into getting an image to look in a certain way, such as using LoRA and different models can have different results how they are trained, but if you are focused on text prompts you would prefer more to use XL models
Yeah but im not sure though, like look the other one is using regional prompting as is this one, but this one is using subsetsuna model and it looks like shit lmao. I tried a ton of different VAE's with this one and only latent regional prompting seemed to produce something good, while most models in comfy come out good out of the box :c

Imma try this same prompt in comfy and see the results with just prompting and no regional, or maybe some reigonal just gonna take some time
about VAE you wont need anything more than these 3 for most tasks, the first 2 are for sd1.5 and the last link for sdxl
commonly used for realism https://huggingface.co/stabilityai/sd-vae-ft-mse-original/tree/main
commonly used for anime https://huggingface.co/hakurei/waifu-diffusion-v1-4/tree/main/vae
sdxl https://huggingface.co/madebyollin/sdxl-vae-fp16-fix/tree/main
which one of the anime vae?
I have the pruned 84000 and 560000 both seem to work for realism, for anime I have anime2.ckpt
if you are already using those vae by those authors show in those links, you might need to look at the models more closely
i say that under the assumption you are expecting better results
this image looks blurred out a bit, faces look smudged, lot of rooms for improvements
im also guessing you are using comfyui, but with a1111 there is a very good extension called After Detailer that does amazing work on faces
for comfyui similar extension might be called face detailer
off to gaming ... big event
@nova remnant what are you playing?
guildwars2
Nop that one was using regional prompting on A1111, using i think 960 * 576 or smth like that, I haven't been able tor eplicate this behaviour closely in a111 it is wayyyyy harder to do so I use this thing. Tbh what weirds me out is that the image looks bleak even with a suggested vae.
I think Ill try it again with kf anime2 vae and see if it comes out better
are you using the same sampler, number of steps, cfg, etc? those all make more difference than regional prompting
I havent tested this image in comfy I am going to run first in png info then to txt to image, then adjust regional prompting matrix regions and see how it goes
Im not sure if this means something wrong like no ema what is that ;c

I wasn't aware the VAE was capable of introducing detail or correcting the image in any way, Im not sure what changed apart from the ADDCOM to ADDBASE in my new test


I use RP little bit differently but ADDBASE is base prompt that contains default description for image and I see that you have ADDCOL in you prompt which just splits image half to 2 regions and prompt before ADDCOL affects left region and prompt after affects right region
Oh yeah I noticed that indexing starts from zero so its like using .at(0) for the first break, then at 1 and so on so you go n-1 in the regions ^^
I also noticed that I can define controlnets in each region so now I am happy ^^
How did you define multiple cnets for RP I have used only one so was just wondering?

Basically tailored made for the size of the image and the divisions, This one is I think 960 * 600, using two divisions I mapped out each division in the controlnet image by giving a single skeleton for that region.
Something like this, with this you can manage both poses and that it ^^



I wouldn't know how to do ip adapter to a single face or depth for a single part of the image though, that probably needs more control like comfyUI conditioning and the like
What you're thinking of is that Comfy generates seeds on CPU while A1111 generates them on GPU by default. You can change to CPU for seeds in A1111 if you want, but it has no effect on quality. The only reason CPU is sometimes considered better for generating seeds is because it allows seeds to be the same regardless of GPU manufacturer. From what you described, it definitely sounds like you haven't manually selected a VAE and are using a model that has a broken VAE baked in.
ema weights are used for continuing training. You don't want them for image generation so they are typically pruned out of the model before uploading to make the filesize smaller.
ah I see, well the model came out better when I changed form anything vae to kf anime so I think it was hat ^^
Yeah, anything VAE is garbage. It's just NAI vae renamed. Bad textures and dull colors on most models.

Here's a better version of kl-f8-anime2 btw. I adjusted the contrast down by 10% which which helps a lot with the blown out colors that it can have at times. https://huggingface.co/nubby/kl-f8-anime2-blessed/blob/main/WD1-4-kl-f8-anime2-bless09.safetensors
oop well comic babes produces good outputs haha, well they recommend that vae so yeah
but whcih one of those files should I download?
Just the one I linked directly to. WD1-4-kl-f8-anime2-bless09.safetensors
ah oke ^^
If you find a model that needs more or less contrast you can use the other safetensors versions. The number at the end corresponds to the contrast adjustment. "09" is 90% of original, "08" is 80%, "1-05" is 105%, "1-1" is 110%.
I use 09 for basically every 1.4/1.5 based anime model.
in hindsight the naming I used was pretty bad 
nah not bad, jujst needs that in the model card ^^ in any way I will try it a while, thanks for the info
what model?
comic babes
I prompted for the ring and all but nothing came out
Even increased the region size but then it became a rock solid circle with some corners
I think it came around the same time as SDXL support, maybe the update before it. It's relatively recent by version numbers, but it's still been quite a while in actual time that it's been there.
became this

Also just as a curiosity, could a model not behave well when used in regional prompting, cus I was trying to get a model with some normal clothing and it refused to come out correctly, literally told it every piece of clothing and it made her naked and the like, even with the same VAE I used for older images it produces weird contrasting edges and cuts in the image :c
What would you guys say is the sweet spot of steps for restart ?
in general use case with most samplers 30
ofc you could bring that down to 6 steps even by using turbo models




How did you manage to create such a detailed pose?
thats all prompt based and depends a lot on the model
ah damn I tried a dynamic pose with a model and it never comes out good, fullbody prompts come out horrible and adetailer can't fix most
look :c

I tried using controlnet and adetailer and nothing :c
controlnet is for character attributes not the image quality btw
also adetailer default settings should be good for any images for face correction, can you show your adetailer settings?

yeah
look at this image This is in stable diffusion

same model, same fullbody image, same vae and it looks normal
without adetailer btw
what was the prompt for this?
I think its embedded
Indoors, photo studio, studio, simple background, white background, studio lightning, clear lights, photo shoot, model, 1girl, clothed (full_body_shot:1.3), (high quality, highres, , absurdres, 8K, image, magazine cover BREAK
Simple brick wall, wall, studio lights, ambient lightning, (studio lights:1.3), simple wall, BREAK
((1girl) , full body, looking at viewer, posing, dynamic pose, smile :D, perfect skin, perfect eyes, perfect hair, (short hair:1.3), (pink hair:1.3), wearing a (baseball cap:1.3), long (oversized hoodie:1.3), (oversizzed_hoodie_with_floral_print:1.3), miniskirt, extremely , (green eyes:1.5), long eyelashes, thick eyebrows, pink_eyebrows, (thighhighs:1.3)) BREAK
Simple brick wall, wall, studio lights, ambient lightning, (studio lights:1.3), simple wall,
I didn't turn on regional prompting if that is the issue
but even then it shouldn't kill the image that much right?

i wouldn't recommend playing with regional prompting before you have good control over basic stuff
BRO how can I learn the basic stuff when no one talks about it? :c I tried looking around for guides and the like and always the same 75 tokens max 77 if you are on comfy. Test models out with different vaes and prompts, dont use too long ones (except the model allows for them) use controlnet use ipadapter, what is the basic stuff then
also regional prompting is mostly about placements in different areas of the canvas, not a lot to do with image quality
ok are you using a1111 atm?
yeah I am using this thing
im running the same prompt with nothing on see if it creates something good
ok, dont worry about the tokens, 75 token limit is outdated, as for actual prompting either try using combination of keywords to convey your concept but not repetitiously, or you could try narrating your concept in language pattern
also I can't run fast test on anything cus my gpu is slow affffff and 8gb on amd run out in a second since no optimizations
With Webui you don't rly need to care about token count
I tried using natural language and it seemed to work better in comfy.
it wouldn't make difference between a1111 or comfyui they are both just webui
This is comfy, natural language and keywords

Tags vs natural language depends more on model you use
they are the interface, the underlying engine is stable diffusion
this is last prompt with nothing but keywords and 840000 vae

Can you share image with pnginfo?
Not exactly more like this, I use this with a chinese model and a lora

so hyper realistic?
But the chinese model is meant to produce anime ^^ and it produces good results in comfy :c nothing I do comes out good in a111


And then there is the issue that colors and prompting blend into each other, I wanted to fix that with regional prompting but yeah
on nvm
Indoors, photo studio, studio, simple background, white background, studio lightning, clear lights, photo shoot, model, 1girl, clothed (full_body_shot:1.3), (high quality, highres, , absurdres, 8K, image, magazine cover Simple brick wall, wall, studio lights, ambient lightning, (studio lights:1.3), simple wall, ((1girl) , full body, looking at viewer, posing, dynamic pose, smile :D, perfect skin, perfect eyes, perfect hair, (short hair:1.3), (pink hair:1.3), wearing a (baseball cap:1.3), long (oversized hoodie:1.3), (oversizzed_hoodie_with_floral_print:1.3), miniskirt, extremely , (green eyes:1.5), long eyelashes, thick eyebrows, pink_eyebrows, (thighhighs:1.3))
that's a huge clutter buddy
i'll suggest narrowing that down to a meaningful prompt
What are these safe_pos BadDreamAnimeAndRealisticFitCorder?
What gpu do you have?
negative embeddings, renamed for me
Dude I literally try simple prompts, but then again, I can't run 30 iterations on a simple prompt and hope one lands on what I want :c thats just a waste of power and time.
For example there idk I could change that, the start describes the general image and the basckground, the other describes the person to detail
Rx 5500 2019 8gb
it works with an rx gpu now?
always worked ? >.>

5500 is one of the tough ones to run SD
removed quality prompts
You got unlucky haha
cat knows my pain

you won't get to culture your own style if you just copy long list of prompts, you coudld definitely play with prompt but first thing you should work on is your own prompts no matter how simple they are and thats how you get to build up along with following examples
poor 4gb cat
what gpu do you have with only 4gb vram????
but thats my prompt, I didn';t copy it :c I wanted a girl with pink hair and green eyes in a sports outfit :C
rx 580
Its preeetty old
thats even more pain
simplify the prompt .. but i think you also have to pick a decent model, but others are asking you quesitons too lol answer them
but who?

beeg ears best ears
I know I should do that but like okayu
-
removing the quality tags suddenly relieved the model and it can think!!!
-
What else shbould I remove, supposedly in sd you cant concatenate keywords like
simple_white_backgroundcus it just breaks it down when passing through the clip so what else :c
how long does a gen take???

amd creating weak ass cards :c, no thats a lie, its actually really good for gaming, but like thats it
try this model to play with
https://civitai.com/models/47067/pikas-new-generation?modelVersionId=71733
Available at https://tensor.art/models/597922149832853677 ! Good day, everyone! Thank you for your interest in my model, this model is based on my ...
*until the graphics card runs out of memory and overclogs the main ram pool and stutters like an idiot
2s per it without hires, I can't hires for some reason but I can up the resolution lmao
that's actually not bad
I used to get 8s/it on my 1070 ti
I swear that loooks like most of the anime models I have ( i have 165 models)
Could use aniverse
animesh
realtoon
toonyou
toonyou jp
fiamix nsfw
divine elegance
meina pastel
meina normal
astrea pixie
WHAT
YOU TAKE SHORTER THAN MY CARD?
7.76s/it
I HAVE double the vram and it takes longer?
which commandline args are you using
the ones you gave me before, no half and lowvram, even medvram dies
what about 3

I literally don't understand what my gpu is doing
you have to use no half ?
what are these negatives? Negative prompt: EasyNegativeV2 safe_pos BadDreamAnimeAndRealisticFitCorder
no-half kills my gpu
I don't use no-half, it's very slow with
i know BadDream is an embeddings but you got that all wrapped up with something else
some cards need it to work
like mine needs it if I want to inpaint or do something similar
 my card makes 1 image in like 5 min, I think I can't use some models? Or some features, I notice the error before which is fix by no-half
my card makes 1 image in like 5 min, I think I can't use some models? Or some features, I notice the error before which is fix by no-half
supposedly, even cs1o said I should
Okay
Easy Negative is easy negative the negativeembedding that is recommended for anime
safe_pos is literally safe pos its callede like that, look it up on civitai
Bad dream is bad dream and the author is fit corder

This is the kind of stuff I wanted to stop with regional prompting, notice how the simple_white_wall became a flower embedded wall which becomes fully translucent at the top and beneath has bricks lmao

also those are quite a lot of fingers in one hand :=
Arent these your ui args?

honestly, for an image like this you really don't need regional prompting at all. might want to delete because of pantyshot though.
pruned the prompt for your by removing contradictory words, you can work on the weight but try without weights first:
indoors, white background, studio lightning, photo shoot, 1girl, full body shot, looking at viewer, dynamic pose, smiling, intricate detail on skin, eyes, hair, short hair, pink hair, wearing a baseball cap, long oversized hoodie, miniskirt, green eyes, long eyelashes, thick eyebrows, thighhighs
I use --medvram --opt-sub-quad-attention --opt-split-attention-v1 but I hardly use my pc for genning, only if I really want something tested
so you use colab for generation?
my favorite service is @lyric zealot pc
But then this loses the effect on the wall and the detail on her clothing ;c
add them

you had like simple, wall, brick wall, simple wall, etc

those are not good prompt practice
and where was I supposed to know this :C

sorry if that sounded rude but i reallyh mean its common sense dont make it too techy
I don't see them as contradictory, like what do you mean? If I have wall, brick wall, aren't those two literally referencing the same thing, a wall made out of bricks :c
simple brick wall is enough to describe what you are asking, if that doesn't, apply weight
Your prompt produced two ppl in them :c
its going through finetuning in adetailer though
how can u use medvram on 4gb?
isn't that like definition of lowvram?
But for example keeping the oprmpt too vague wouldn't do this at all
no clue, either my hires doesn't work so Im taking medvram lmao its faster
medvram should be plenty of offloading even with 4gb. lowvram is pain. if you actually need it for an sd1.5 model then you should really just pay $10/m to generate on an online service.
I mean I dont need it rather if I dont want to run out of memory after the 10 or 15 gen on a set of 30 I need it
this is the image iwht your prompt @nova remnant

thats because of the modle you are using and im done explaining
No idea what's the problem so I just tried running your prompt with my setup

okay then ^^
i wasn't looking for arguing over irrelevant stuff thought you needed suggestions
but I do need them :c sorry if I seemed angry or smth :c
imma go back to my testing see if changing the model works or smth






Nubby strikes once again
What model?

Soushiki


Did they ever update that?
It's still a relatively new model and performs well. I don't see a reason it would need updated.
Did you merge or finetune it because those are way better than what I get using it.
nope, likely just a matter of learning how the model wants to be prompted and using a simple and effective negative prompt.

what neg do you use?
(Worst Quality, Low Quality:1.2), border, 2girls, nsfw, skimpy, grayscale, (watermark:1.2)
not in those images
my favorite model
yep, it's pretty easily my favorite 1.5 based model. I like it better than my own model for most images.
I use Soushiki also but I have 3 loras on top
not wanting 2girls
It's better than most xl models
then again most xl models suck
I usually forget to remove that even when I do want 2girls

I never remember what I have in negative
One note about Soushiki is that it looks a lot better after Hires fix. My images usually look pretty bad during the low res pass.
2x?
even 1.5x is enough to make it look a lot better. I run 2x though.
starting res is usually 544x960 or 960x544 for me.
same
odl
idk
my genspeed is so weird
like i get 10it/s on the first pass
and then 2 on the next
I don't like it at Clip Skip 1 either. I always use Clip Skip 2
what does it do?
Clip Skip 2 means that it skips the final layer of CLIP (text encoder) which generally helps to make the image more coherent at the expense of potentially not listening to the prompt quite as well. Soushiki doesn't have a problem with listening to the prompt at Clip Skip 2.
What does clip skip do entirely?





explaining ai things more than "it just works"
Some dalle roller derby based on the ones posted the other day
honestly, it just works
ok
that makes more sense
thanks varghoss
NAI came up with using clip skip 2, they explained it here under the Using Hidden States of CLIP’s Penultimate Layer heading: https://blog.novelai.net/novelai-improvements-on-stable-diffusion-e10d38db82ac
how do I change it?
The TLDR is that 1.5 based anime models are basically all trained with Clip Skip 2 which makes them also perform significantly better when you use that while generating.

I'd just put it in your quick settings list. Find the quicksettings list in settings and add CLIP_stop_at_last_layers, apply settings then restart webui. Then you'll have this slider at the top and you just set it to 2

If you don't already have the VAE selection there, you can add sd_vae while you're at it.

The top one.

Prompt?
Those have pnginfo
Negative prompt: (Worst Quality, Low Quality:1.2), border, 2girls, nsfw, skimpy, grayscale, (watermark:1.2)
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7.5, Seed: 357179407, Size: 544x960, Model hash: 51e4b0d5e1, Model: SoushikiV1.0, VAE hash: 235745af8d, VAE: WD1-4-kl-f8-anime2-bless09.ckpt, Denoising strength: 0.51, Clip skip: 2, ADetailer model: face_yolov8n.pt, ADetailer confidence: 0.3, ADetailer dilate erode: -28, ADetailer mask blur: 8, ADetailer denoising strength: 0.4, ADetailer inpaint only masked: True, ADetailer inpaint padding: 12, ADetailer version: 24.1.1, Hires upscale: 2, Hires steps: 15, Hires upscaler: 4x_NMKD-YandereNeoXL_200k, Discard penultimate sigma: True, Version: v1.7.0```
jesus
I don't even need the seed i'm going to get the same gen lmao
i'm regarded
Easier for me to just copy/paste it so you can get whatever parameters you want
that's the metadata

Here have a jump scare
art by aha, watercolor \(medium\), masterpiece, best quality, (detailed background),
BREAK
(arctic tundra, snowy landscapes, frozen lakes, day, frosty, harsh, ethereal:1.3),
BREAK
(magic circle, detailed magic circle behind her head:1.3),
BREAK
1girl, solo, (open hair, long hair, straight hair, white hair, blunt bangs, azure eyes:1.3), pointy ears, long eyelashes, choker, blush, fangs,
thin legs, (white oversized hoodie, sneakers:1.3), from above,
happy, :D,
<lora:LoraMerge_dim128:1>
<lora:ahafinetagging128dim-epoch-000008:0.7>
<lora:loconshanzhagao128-epoch-000008:0.5>
Negative prompt: ((simple background, white background:1.5), (skirt, cape, sleeves, fence:1.2), see-through, skin tight, thick thighs, navel, dress, Coat tail, cape:1.3), verybadimagenegative_v1.3, (low quality, worst quality, bad anatomy, bad hands, normal quality:1.5), artist name, white border, censored,
(holding stick, off shoulder, chain, claws, holding, holding bag, black hair, animal ears, ahoge, twin tails, clothes writing, (hair intakes, hair ornament), hood, hat, ribbon, hair bow, bow, headwear:1.3), (leotard:1.3), holding skirt, lifting skirt, clothing pull, animal ears, depth of field, navel,
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 1602681394, Size: 448x768, Model hash: 51e4b0d5e1, Model: soushiki_v10, VAE hash: df3c506e51, VAE: kl-f8-anime2.vae.pt, Denoising strength: 0.5, Clip skip: 2, RNG: CPU, ADetailer model: face_yolov8n.pt, ADetailer confidence: 0.3, ADetailer dilate erode: 4, ADetailer mask blur: 4, ADetailer denoising strength: 0.4, ADetailer inpaint only masked: True, ADetailer inpaint padding: 0, ADetailer use separate steps: True, ADetailer steps: 10, ADetailer model 2nd: hand_yolov8n.pt, ADetailer prompt 2nd: hand, ADetailer negative prompt 2nd: negative_hand-neg, ADetailer confidence 2nd: 0.3, ADetailer dilate erode 2nd: 4, ADetailer mask blur 2nd: 4, ADetailer denoising strength 2nd: 0.4, ADetailer inpaint only masked 2nd: True, ADetailer inpaint padding 2nd: 0, ADetailer use separate steps 2nd: True, ADetailer steps 2nd: 10, ADetailer ControlNet model 2nd: control_v11f1p_sd15_depth [cfd03158], ADetailer ControlNet module 2nd: depth_hand_refiner, ADetailer version: 24.1.1, ControlNet 0: "Module: none, Model: control_v11p_sd15_openpose [cab727d4], Weight: 0.4, Resize Mode: Just Resize, Low Vram: False, Guidance Start: 0, Guidance End: 0.4, Pixel Perfect: True, Control Mode: Balanced, Hr Option: HiResFixOption.BOTH, Save Detected Map: True", RP Active: True, RP Divide mode: Mask, RP Matrix submode: Horizontal, RP Mask submode: Mask, RP Prompt submode: Prompt, RP Calc Mode: Attention, RP Ratios: "1,1", RP Base Ratios: 0.2, RP Use Base: True, RP Use Common: False, RP Use Ncommon: False, RP Options: ["[", "F", "a", "l", "s", "e", "]"], RP LoRA Neg Te Ratios: 0, RP LoRA Neg U Ratios: 0, RP threshold: 0.4, RP LoRA Stop Step: 0, RP LoRA Hires Stop Step: 0, RP Flip: False, Hires upscale: 2, Hires steps: 8, Hires upscaler: 4x_foolhardy_Remacri, Lora hashes: "LoraMerge_dim128: 45063301a4db, loconshanzhagao128-epoch-000008: 63f809656656", TI hashes: "negative_hand-neg: 73b524a2da12", Version: v1.7.0

prompt engeneering scares me
I just realized that I didn't even hit 2k limit with that yet seems like I need more extensions
Prompt engineering is easy, just add and remove shit until you get something you like

I try to keep it more simple, but i'm using XL models
Steps: 30, Sampler: DPM++ 3M SDE Karras, CFG scale: 4, Seed: 712785966, Size: 1024x1024, Model hash: 83b7e5434a, Model: ProtoLarkXL_v6-pony-experimental-vae_fp16, VAE hash: b94a1cb9dc, VAE: sdxl_vae-fp16-fix.safetensors, Denoising strength: 0.25, Clip skip: 2, ADetailer model: face_yolov8n.pt, ADetailer confidence: 0.3, ADetailer dilate erode: 4, ADetailer mask blur: 4, ADetailer denoising strength: 0.4, ADetailer inpaint only masked: True, ADetailer inpaint padding: 32, ADetailer model 2nd: hand_yolov8n.pt, ADetailer confidence 2nd: 0.7, ADetailer dilate erode 2nd: 4, ADetailer mask blur 2nd: 4, ADetailer denoising strength 2nd: 0.4, ADetailer inpaint only masked 2nd: True, ADetailer inpaint padding 2nd: 32, ADetailer version: 24.1.1, Hires upscale: 2, Hires steps: 7, Hires upscaler: 4x-UltraSharp, Version: v1.7.0```
@gloomy scroll my face when I realise I've gone 2 days without genning Marisa toes

Good job on limiting yourself
Do you use Tiled VAE?
I can imagine you shaking like a chihuahua behind the screen
medvram just offloads parts of the model to cpu, it doesn't change the amount of vram used by that much either.
idk


does this affect performance?
low and med vram are supposed to break the process into "fits in vram" sized chunks so it OOM less (very basic description) but I don't think a lot of extensions and stuff use it well
It's little bit slower but decreases vram usage
ok
it's a lot faster than the alternative which is overflowing into system RAM.
where do I find that tab
I haven't really looked into it much though since i don't need it 😏
It's dropdown under prompts if you installed extension I linked
yeah, they don't really work that well if you use more advanced extensions
ok

problem solved

Smh

Since you added 3 feet emojis to AnimeAI server I guess we need to use those


green
heh, 'green eyes' tends to bleed with this model
it's a good green
Y'all ever crack your neck so hard csf leaks from your nose?
every day
even when i try to prompt clothing color to get rid of all teh green, it just shifts it somewhere else

should i be concerned?

lol no, i don't actually have a csf leak, but i do have hypermobility so I crack all my joints a lot
I like cracking my joints.

I don't think it understands sweat pants
is there another name for those pants that isn't a verb?
lmao here's jogging pants

anyone have a good llm node for comfy?


yeah, jogger pants or 'joggers' sometimes works

it just makes her jog
lmao
i just did baggy pants
even before I had the tiled vae it was doing this, why?


soushiki is a master at hands
(black jogger pants:1.1) works on my model pretty well

are you also using soushiki?
sometimes the weight isn't needed, but at least in a1111 'grouping' terms with a weight makes it think harder
no, i'm using a custom XL model
custom?
my own merge + training
ok

yoga pants works too




sometimes generations are so randomly not what it's been generating for 20 minutes, but sometimes that's ok



skinny legs @primal wharf
Not skinny enough


I will save the day! 🥢

🥢
i tried to make her legs skinny and it took off her shorts..
Regional prompter can do this too although it does it little bit differently



Kek
Focus on something, other things go away
yeah
that's cool, prompt?
using the tiled prompter, why am I getting artifacts like this?




what model?
bluepencil
Battle ready


Magic circle



I have few of these

I know you love those
I'll try magic square when I'm on PC
i think the older version of my model does this better

keeps to the prompting better at least
There's a character that is like a chimera in a story I read, she looked like your gens
And I always think about it lmao
Like she's going to transform any time
maybe she will 😛
What is your prompt
BREAK
standing in a intricately detailed colorful magic circle of glowing runes,```

Default break or extension
default
mostly it just tends to make the magic circles all one color, usually matching the dress

added random streaks of glowing particles flowing through the scene background, to the prompt

the more you put into it, the more it fills out an image
@vital raptor I went through all this trouble and you just did it with prompt
art by aha, watercolor \(medium\), masterpiece, best quality, (detailed background),
BREAK
(desert, sand dunes, cactus, sunrise, hot, isolated, otherworldly:1.3),
BREAK
(magic circle, detailed magic circle behind her head:1.3),
BREAK
1girl, solo, (open hair, long hair, straight hair, white hair, blunt bangs, azure eyes:1.3), pointy ears, long eyelashes, choker, blush, fangs,
thin legs, (white oversized hoodie, sneakers:1.3), from above,
happy, :D,
<lora:LoraMerge_dim128:1>
<lora:ahafinetagging128dim-epoch-000008:0.7>
<lora:loconshanzhagao128-epoch-000008:0.5>
Negative prompt: ((simple background, white background:1.5), (skirt, cape, sleeves, fence:1.2), see-through, skin tight, thick thighs, navel, dress, Coat tail, cape:1.3), verybadimagenegative_v1.3, (low quality, worst quality, bad anatomy, bad hands, normal quality:1.5), artist name, white border, censored,
(holding stick, off shoulder, chain, claws, holding, holding bag, black hair, animal ears, ahoge, twin tails, clothes writing, (hair intakes, hair ornament), hood, hat, ribbon, hair bow, bow, headwear:1.3), (leotard:1.3), holding skirt, lifting skirt, clothing pull, animal ears, depth of field, navel,
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 1578653998, Size: 448x768, Model hash: 51e4b0d5e1, Model: soushiki_v10, VAE hash: df3c506e51, VAE: kl-f8-anime2.vae.pt, Denoising strength: 0.5, Clip skip: 2, RNG: CPU, ADetailer model: face_yolov8n.pt, ADetailer confidence: 0.3, ADetailer dilate erode: 4, ADetailer mask blur: 4, ADetailer denoising strength: 0.4, ADetailer inpaint only masked: True, ADetailer inpaint padding: 0, ADetailer use separate steps: True, ADetailer steps: 10, ADetailer model 2nd: hand_yolov8n.pt, ADetailer prompt 2nd: hand, ADetailer negative prompt 2nd: negative_hand-neg, ADetailer confidence 2nd: 0.3, ADetailer dilate erode 2nd: 4, ADetailer mask blur 2nd: 4, ADetailer denoising strength 2nd: 0.4, ADetailer inpaint only masked 2nd: True, ADetailer inpaint padding 2nd: 0, ADetailer use separate steps 2nd: True, ADetailer steps 2nd: 10, ADetailer ControlNet model 2nd: control_v11f1p_sd15_depth [cfd03158], ADetailer ControlNet module 2nd: depth_hand_refiner, ADetailer version: 24.1.1, ControlNet 0: "Module: none, Model: control_v11p_sd15_openpose [cab727d4], Weight: 0.4, Resize Mode: Just Resize, Low Vram: False, Guidance Start: 0, Guidance End: 0.4, Pixel Perfect: True, Control Mode: Balanced, Hr Option: Low res only, Save Detected Map: True", RP Active: True, RP Divide mode: Mask, RP Matrix submode: Horizontal, RP Mask submode: Mask, RP Prompt submode: Prompt, RP Calc Mode: Attention, RP Ratios: "1,1", RP Base Ratios: 0.2, RP Use Base: True, RP Use Common: False, RP Use Ncommon: False, RP Options: ["[", "F", "a", "l", "s", "e", "]"], RP LoRA Neg Te Ratios: 0, RP LoRA Neg U Ratios: 0, RP threshold: 0.4, RP LoRA Stop Step: 0, RP LoRA Hires Stop Step: 0, RP Flip: False, Hires upscale: 2, Hires steps: 8, Hires upscaler: 4x_foolhardy_Remacri, Lora hashes: "LoraMerge_dim128: 45063301a4db, loconshanzhagao128-epoch-000008: 63f809656656", TI hashes: "negative_hand-neg: 73b524a2da12", Version: v1.7.0```

that was actually my whole goal moving to sdxl, my sd1.5 model required so many embeddings, negatives, loras, etc etc, I got tired of it
only negs i'm using is fox, tail for this prompt, no loras, no embeds, just a well curated model
I'm still waiting for that SoushikiXL update

But oh well time to hide under comfy blanket

when a100 drops to 300$
all nvidia needs to do is release a consumer level AI card with just whats needed for SD and LLMs, no video output, no gaming features, and around $1000 or less and they'd be constantly sold out
the problem is all the datacenters would buy them all



need something different in here
someone do a character made out of bacon or covered in fried eggs or something
maybe dueling with king kong


they sure love bacon

How about hanging a framed photo on the wall?
Or exploring the pyramids?
Or doing make-up to be a clown.
xl failed ...
a boy made of bacon and covered in fried eggs dueling with king kong

or being a plane "wing walker"
did you do them with bing?
yea sd struggles with the bacon suit,maybe with ipadapter it can
they came out great and pretty precise
i was thinking at first they were done on sd with some of your magic
cant do it in sd 😔
oh well i tried with xl too, but didnt work out
early xmas celebration

lol isnt that too early
a boy made of bacon and covered in fried eggs

how did that algorithm get a pass for release
a guy made out of eggs and bacon

now im hungry









Today's Tifa

still anime or....?

witch, voodoo magic, witchcraft symbols, old wooden cabin

borrows
witch, voodoo magic, witchcraft symbols, old wooden cabin, magic potion, smokes, candles, dim light

I made some more styles, 😄 , gonna try those on this new merge
reminds me need to upload the new one
world's smallest car behind her, but kinda liked this one..

water world, underwater colony, ocean depth, atlantis, advanced technology, epic view, stunning visual.











hanging a picture is a difficult one this is as close as i've gotten so far


reflections are hard

guys. Tell me how to make sure that a random seed is taken during "Batch count" generation?
As far as I understand, the seed is incremented(+1) from started value seed



xl model?
NAIv3

Yes but apparently they modified it to fit their needs


















































Personal merge

Squish

Of?
Aurora + 3A + several loras i'm testing lol
3A?

Ok thanks
Model? If it’s not dalle.
Dalle
Yeah that's dalle
Model?
Ok

What model?
custom mix
💪


Huh that's a character
yes i only prompt chars
I want to gen tight shorts elves
Here we go
@native halo (small shorts, tight shorts:1.3)
👍
(high waist shorts,skintight,latex:2.5)

First time trying to make a short Manga using SDXL

@native halo This library came out as a mess

i would like to open that book
actually looks like a realistic library

like this library? 📚

dw the hair is soft like a cat hair,she also purrs when u pet her

take this bigger hair


take a guess, that's from infamous nubby .... ;p

@acoustic locust Kakigori v3 https://civitai.com/models/100505/kakigori
About the model: My goal with this mix was to create a mostly 2d anime style model that responds well to varied prompts, including a relatively wid...
It was. But I've had similar in the various sdxl models 🙂



crisp and clean
ty friend
np 🙂 you should archive them on civitai and for viewing pleasure
I thought about it but I have so much stuff I would need to upload
yeah its good to put the good ones there for keeps
I think my fav image I've done is this one

looks very good
took a lot of inpainting to get it the way I wanted
Are those bear ears I see?

YES
I love books @native halo

I too like these books

That's correct. With -1, the first one is randomly generated then the rest in the job are incremented +1 from there. A1111 doesn't have a way to randomize each one in the batch because it doesn't really matter. Seed 2000 is not inherently more similar to seeds 1999 and 2001 then it is to seed 1 or 99999999
Damn what's the prompt
Where is this from?
Different for each panel, but something like this:
Monochromatic Manga Ink drawing supercloseup of glass of water on small nightstand, eerie atmosphere, professional artwork, nighttime, dark
And then I just used for my negative prompt
vibrant, saturated, happy, childish
..but I also used a Junji Ito lora with a very light weight, as well as IpAdapter with about 3-10 panels I found visually appealing for reference.
if you know ComfyUI, here's my workflow:
Yeah this seems about as intensive as I'd expect for that masterpiece, thanks for the workflow. Looking forward to more mangas from you 😂
Thanks, I will post more when I'm done! :)
Intentional onesie or?
no

3 anime chars as pixelart







My eyes have been opened to PonyDiffusion now that I've found a major issue with my workflow and fixed it. After following the advice of someone used to the model, what one can make with it is incredible. It's like NAIDv3 but better, and free.

ponydiffusion is an xl model, right?
Any tips? (Any examples of a good prompt with some style selection?) I haven't had luck with the model, I've only got some good results with the booru tags but the lack of artists and styles makes it difficult (I've tried that 100 artist list and even found some of my own, but no good results)
They have a 1.5 model too, not sure if it's worth using. The XL model is the one people have been talking about.
oh, ok



ysemshiro
pony is really good
I can't use it yet

Let me put together a short guide list.
It may take a second, as one of my hands is occupied with a grilled cheese
👍No problem, no hurry

Guilty Crown
Shows how little I remember of that anime. Loved the music though.
yes all the budget went to Sawano and the animation

Bunny!










tell me more about this ponydiffusion thing. Have not heard of it.
of all the XL models out there,ponydiff is one of them





😓
the little fairy....
i don't whant to know who he is
oh god, how much i love the touhou saga

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
my hands are still trembling thinking about the games
He's never using it again lmao
it's not like he prompted it or anything

I wouldn't know it existed if not for this discord chat
ehehe
You really, really don't
you should play it. it's avery stimulating experience

sweet lol
Is the reason my gen speed is slow pcie 3.0?
Blurry intensifies
that's really weird, what model?
It's from the bot, a mix of anime and photorealism in the prompt, and some upscale tests; from top to bottom it goes from anime to a real life human body
Yeah, It's really weird
Yeah, it got the effect right
The good old "bokeh in everything" from the base SDXL
If you are using uncensored model you need to prepare for everything
it was soushiki
He specifically prompted for it
It's really good
