
#🍥|anime
1 messages · Page 40 of 1




whos dave


perfect

i NEED you model
new LoRA :)
lol
xD
upload when?



its indeed a rly nice LoRA

@queen void when will you upload??
is it done?
can you send me it in private ore here? no images or docs just plain lora



yes mine too
thats why i wanna have it so bad


waifu informatic
i need this
ur reaction has given me inspiration on what to generate next
bruh what XD



what?
Non
no

dont let me hang like this bro




will you upload today?
well its 1 am so, yes today, but not now :/
can you dm it to me when you upload it?
sure

Ok peeps. Anybody know how to neg prompt this type of hair shape between the eyes? hair_between_eyes isn't really taking care of the problem. 


can you dm it to me when you upload it?
oh sorry didnt see it
I think ur outta luck trying to get something that specific. The between eyes tag is literally the only thing
something with "bangs" probably
I wouldn't say it's specific. 😅 It's a general look to the hair. Guess Aurora is slightly overtrained on that type of hair.
crossed_bangs is the tag
Yeah. I guess I need to look up alternate booru hairstyles that may go in a different direction. Thanks.

crossed_bangs is the tag
just looked it up
Was referring to hair in the area above the nose, and space above the eyes.
I was using that for a lora i was training the other day, that one usually details specifically and blatantly crossed bangs
Like across the face type bangs
Example: A similar but different bang style with the same problem.

yea thats crossed_bangs
ok idk what you want then 😅
U want it lower?
I'd love to have these gone.

Inpaint 😐
Spaces above the eyes. But it's likely just the model.
every model has that problem
You haven't heard of all the times I've complained on how inpainting doesn't work for me, lol.
Either way, thanks for y'all's suggestions.

try "(widow's peak1.2)" in negative
latest case of crossed bangs on my end https://media.discordapp.net/attachments/1071038975072026676/1102007945421656154/29341-1643437190-best_quality_digital_art_textless_version_battleship_water_oni_1girl_red_eyes__pale_skin_colored_skin_1.2_horns_singl.png?width=801&height=1203


What an extreme example, lol. 

neg crossed_bangs though is definitely helping further. Thank y'all!

try "(widow's peak1.2)" in negative
Such a low number of tagged images though. We sure that works?
no
thats why i said "try"


What did i do wrong
Lol. No, I'm getting a preview image for the BagsUnderEyes LoRA.  Your suggestion works perfectly.
Your suggestion works perfectly.
Oh that oughta be neat
Wonder how itd mix with crazy expressions lol
Sleep deprived waifus ftw



Try harder?





@merry tendon why the  what did i dooooo?!?!?!!
what did i dooooo?!?!?!!


crying because it looks beautiful



It's my llm bot, enhanced with my randomizer prompt, doing song lyrics! lol






stablevicuna 13b is pretty damn good



you rich my boi?
how much vram does it cost?

bruh

i specifically went searching for a used 3090 lol
so only 8gb vram for llm?

8-9.5 not counting inference or tokens
Which llm model are you using?
stablevicuna 13b
LOOL i found my yandere lora on the frontpage of civit
yandere angels anyone?

lel
the white horse thing with pink hair?



what horse bro
this is the main image


then i was looking at something else lol


'tis a masterpiece

what?
Your lora
you are using it?!
Yeah. I grabbed it like 2 hours after you uploaded
am i finally popular mom?
thanks for using it, do you have some suggestions on what could be better?

The irises can get a little messy at times. Other than that it's been working well for me even when mixed with other LoRAs. I like it around 0.8 strength, sometimes just a bit lower.

I used it to make this profile pic for one of my chatbots.

thats really nice to hear, the irirses are because there are many "retracted" irises in the dataset, but i just needed to add it to my lora 😉
dang, stabilityai made a good vicuna model 🙂 it's pretty damn good at interpreting lyrics
looks sick as hell, if you get some good picks you can dm them to me, i will retrain the lora someday. i could use some pics.
Sure, I'll start a folder to collect some in and maybe try to fix up a few that are close

thanks, if you collected around 20 or more i would appreciate if you could give them to me, because(even if you would think otherwise) there are not many good yandere pics that are suitable for training.

rate my controlnet image


ME AND WHO
lmao
my own model
thank you for using it well youre doing it justice
❤️
lol didnt notice

That image should have pnginfo
I think I used part of your prompt
oh right, you need that extension for it, right?
yeah im glad people use the stuff i make makes me happy to see results
Didn't discord go back on that update
i think they did cuz mine worked
they did? 😮
i can agree, it makes me very happy if someone uses my loras. Btw, your lora is great❤️
Not sure since I used stealth pnginfo but I head someone say that they did
thank you!!
you can view png on discrod its not blocked
I only used prompt from your image but not the actual lora

i just realized u are the one who used it thank you but also thanks everyone<3





But for that image I used one of my model merges _ANE_Pruned-Aurora-clip and just some style lora merge I did
oooo i see
Since that model is pretty decent at making chibis

If someone interested here's stuff I have uploaded
https://huggingface.co/Surficialruby
Harime Nui simping time

❤️

she´s like 11
Not in that image she ain't.










model?
can you dm link please?
You were saying? 


well not like she needs a head to get ahead
don't make me go get my thic waifus...
wizardlm?
Finally got this LoRA to work semi-decently... very finicky though. For some reason the pov hand is always of a darker skin though 

nah, stablevicuna 13b and my lyrics->visual keywords prompt
although, i noticed it has some issues, so i'll have to redo that llm prompt again. AGAIN
very ni ce
❤️


Clyde bullies 



How consistent does a sequence of images need to be, to be "good enough" for a webtoon?
By "sequence of images" do you mean panels?
and then it's still fighting against SD
if you want consistant images you need to train lora
Yeah, panels. I was thinking making stuff in 3d and then putting it into img2img with lower desnoise settings to keep consistency





I'm still experimenting with settings but it seems like it is not too bad; it takes out the obvious 3d look and keeps color the same
It could be a style where the character's hair stands change here and there (as long as the basic style is the same, like bob for example)
And then inpainting and manually cleaning eyes and hands











Do you think these are consistent enough for a webtoon? I know I would need to fix some things manually like the hands and small things on the clothes but I thought it might be okay to not have to get every detail right, like in the background for example


The hair is basically the same but not exactly the same
Ie it could plausibly be different due to the wind, or something
colors seem to be shifting, as some elements, how their lighting is applied
depends on how you want your webtoon to look right?
like in your 2nd example, there's close to no shadow
so if you are intending to go with no shadow webtoon, then it might even be easier to make background separately
for the characters wise, i think their colors and hairstyles look alike enough
all in all, if i was given a webtoon with these two panels, i would still be fine with it
obviously it's my own opinion tho


I see, thanks. This is great feedback. I need to learn how to deal with light and shadow correctly now.
not sure if you've seen it, but there's a controlnet module for that
haven't play with that yet, so can't advise on that
Ah yes I remember, I posted that one on the chat. I need to use these tools. The example images I posted were only img2img upscale, so it can definitely get better with more tools

Is anyone else's wildcards manager tab broken?

Maybe I need to make one of these too
mine's broken for god's know how long
you should! 

How do you use it when it broken?
Wow. This is supposed to be the ThisIsFine LoRA, but it didn't work in the best way possible.


Imma try that 
so using that, if you know what you want, you can "search" for it
this do be fine tho 
oh yeah. if you copy the stuff to thte wildcard folder

I think you already start with some right? 
none.
the dynamic prompts folder has a collection
for real?
but it's not in the wildscards folder yet
ahhhh
i guess good point, so @magic wave you need to make sure you actually have stuff in your wildcard folder

I never got dynamic prompts wildcards working correctly so I'm just using some old wildcard extension

Such versatility. I love it.



for some reason aom3 is better at producing furries than actual men in suits so i just have to stick to this for a while

@lyric zealot I'm just wondering did you sleep already or do when are you planning to sleep?

actually, i just woke up 
might be going out to cycle with friends later, so needed that rest 
Well I'm 4h behind you
well, it's a early Sunday morning! Time to get breakfast and chill
smol sus post on pixiv man
guess, i need to update the note
I'm lazy man

wait its 6h? I'm too tired I rly can't count hours anymore???
4
Have you tried anythingv5?
Oh yeah we have that useless thing
is that thing active now or something?
Meh. Terribad with LoRAs and other networks.
AOM3 is as well compared to AOM2
We moved clocks some time ago but no idea what direction since all of my clocks move automatically
I believe so
i thought it was anythingv4 that was released recently
lmao, that's kinda weird tbh

That was Andite's troll
Yes that was my experience too and I kept trying when I was new nothing worked. Wasted so much time on it
isn't there a real anythingv4?
or they just went and skip that?
I think they skipped it and said that it has nothing to with them
Anyv4 made by someone other than the person who made Anyv3. Anyv3 guy went and made Anyv5.
Anyv5 is on the Anyv3 page.
isnt that a troll
or something
or v4
i forgot
I wonder what happened to Andite since I haven't seen them on any server for long time now

v4 & v4.5 were trolls
he dipped from the AI scene right?
Me too but I remember seeing it so yeah
He got banned from Touhou, then hung out here briefly and disappeared since then.
Yandere Lucy

v4 wasn't a troll, just different. v4.5 was a troll.
v4 and v4.5 were both by andite so both trolls
so
v4 and v4.5 were both by andite so both trolls
v4 was andite's model too
v4 worked well. v4.5 didn't.
or wasnt
v4 and v4.5 were both by andite so both trolls




lmao


Aurora
If you sharing more ping me so I remember to check when I wake up
oh damn
Good... night?
its a nice model
for sure for sure!
@gloomy scroll goodnight btw

yes
daymn!
get that bag bro
I'm too lazy for that 
i see u are too rich

rich enough that extra 400a month is not worth
not true, but just really really lazy
will do that someday tho, for sure for sure
that's why realistic model with Asian stuff works so well
probably not for anime tho
actually true
but maybe people that are into realistic are more willing to pay for stuff like that
might not be true tho
im not sure tbh


Cursed

big brain
actual 5head 






I love this style
This is fine
How did you fix this?















 almost forget
almost forgetI'm just getting started


You wake up to find your new self-appointed guardian angel standing over you

"work" is a bit strong of a word, but just making sure the following was included in the prompt: pov, pov_hands, (finger_in_another's_mouth:1.3), (open_mouth), (fiday:1), fang,
As well as using high strength weightings on the LoRA. Around 1 or so.
pro
radical
so humble












Controlnet? Thats amazing
No, just pure txt2img
thats really cool




wow, it look very cool 
wasnt the style im after but its nice



nah cuz what she reading

it is a newspaper prompt










might be time for vedal987 to run.



















hello, i have been trying to recreate this format - full body shot with zoomed-in face in the background. is there a particular name for this style, or any prompt that can help?
prompt i used to generate these two:
(finely detailed beautiful eyes and detailed face)lighting, perfect face, latex suit, full body
Negative prompt: sketch, duplicate, ugly, huge eyes, text, logo, watermark, monochrome, worst face, (bad and mutated hands:1.3), (worst quality:2.0), (low quality:2.0), (blurry:2.0), horror, geometry, bad_prompt, (bad hands), (missing fingers), multiple limbs, bad anatomy, (interlocked fingers:1.2), Ugly Fingers, (extra digit and hands and fingers and legs and arms:1.4), ((2girl)), (deformed fingers:1.2), (long fingers:1.2),(bad-artist-anime), bad-artist, bad hand, extra legs, EasyNegative
Steps: 30, Sampler: DPM++ 2S a Karras, CFG scale: 7, Seed: 3068623869, Size: 512x768, Model hash: 969673ad74, Model: darkSushiMixMix_colorful, Denoising strength: 0.5, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires steps: 20, Hires upscaler: R-ESRGAN 4x+ Anime6B


the closest i could get are these, using reference sheet in the prompt



Try openpose controlnet 
a wild smile
Also what model is that? 
i'll have to learn that  , thanks
, thanks
A wild Floydian 
dark sushi mix
Its not too hard, theres a few extensions to do it, and a app, though I'm not sure if the app is available anymore
I'll have to check it out
Seems like a good model to train a LoRA off it
thanksss ❤️

how do u get these zoomed-in shots? can u share the prompt plz
It's already in the img PNG Info
Negative prompt: (EasyNegative:1.2), ((broken feet:1.3)) ((bad-fingers:0.8)) ((text:0.8)), (((character design:0.7))), ((2girls, 3girls:1.0)), Reference sheet, ((watermark)), ((no body:1.2)), ((no hands:1.3)) ((basic background:0.8)), ((three legs:1.0)), (machines:0.6), ((extra limbs:1.3))
Steps: 28, Sampler: UniPC, CFG scale: 8, Seed: 1912475651, Size: 568x640, Model hash: 31c9be0ee8, Model: Defmix-v2.0, Denoising strength: 0.6, Clip skip: 2, Hires upscale: 2, Hires upscaler: Latent (nearest)```ahh my bad, will check frm next time. thankss
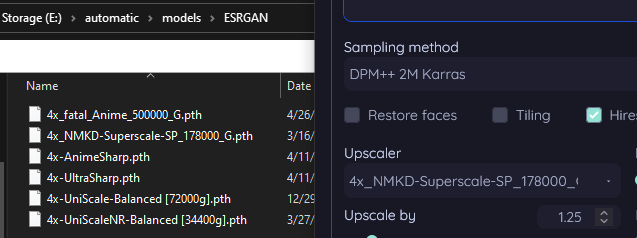
Hey @cunning gyro how are you getting your Superscale 178000_G to work? It's a RealESRGAN model right? I've tried placing it in both my ESRGAN and RealESRGAN folders and SD is still not seeing it. Are you using something other than Auto1111's build for SD?
Nope, A1111 (now vladmandic, but still). IT goes in models/esrgan
Hmm. Wonder why it's not seeing it then.
if you just installed it, try refreshing the upscaler list?
patch notes in Auto1111's Release Candidate branch imply that the RealESRGAN directory may be broken in some manner in other builds. He seems to be working on a fix. Not sure if the Release Candidate branch is truly stable or not.
I've been restarting SD completely 😅
o
Wait, found it! Talking to y'all was magic apparently.
Hmm. Good to know. Thanks Nubbs
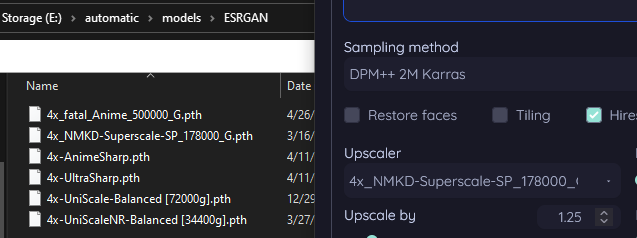
Could account for why it was then wasn't able to see it
is how i have it
Yeah, it's able to see it in my ESRGAN folder
I wanted an anime-friendly painted-like look without the darkness that Fatal provides, and I remembered you talking about it.
I look forward to giving it a spin.



I've been starting to question a few of my underlying assumptions as to how some of my workflow works, and I think its possible NMKD may not work like I thought, but let me know how you feel about it
Will do! 




Took the time to load it up. Only had to try it once. 
Compared with something like Ultrasharp or Fatal, it had a heck of a lot of noise and visual artifacts comparatively...

yeah so i forgot but i actually did some tests with it earlier when trying to scope out some changes to my mix
Left is NMKD, right is Fatal


you may have to blow it up really high to see the differences, lol
but there is more noise on the NMKD one, but it ends up giving it a "canvas"-y look i guess
Whereas if you zoom in on the Fatal one its kinda pixely at places
Yeah, harder to tell with those, especially as they're either different seeds or different prompts. And is that straight ESRGAN upscaling or with SD upscale as well?
nope, just img2img with postprocess upscale

bruh, prompt and model. Now
Gotcha. SD must not like what NMKD does to the image then. I usually test upscalers like this in the context of SD Upscale, as that's almost exclusively what I use them for.
Still hard to tell. left is nmkd, right is fatal




It's right in the PNG Info 


stable diffusion create a dress without a long train train challenge (impossible)



Yeah, look at the crispness of the eyes in the NMKD one. Slight, but more noise. SD must just not like it.






I forgot about it. now to try it out >.>
I don't know if I got it before it disappeared, but I couldn't find just now on Civitai. 
If you want it and can't find it let me know.
Sometimes I just download things and never touch them T_T
close but weird hand. still nice ish

Great flat shiny style.
Note: This is a LYCORIS/LoCon model, and you need to install a1111-sd-webui-locon extension to use this model. This is a LoRa with a vector graphic...
There it is!
i saw that earlier, lol
No wonder I couldn't find it again. It's a LoCon. I forgot to add that back into my search settings.




 Color me impressed. I gave Interrogator the image on the left and it gave me the image on the right! 🤯
Color me impressed. I gave Interrogator the image on the left and it gave me the image on the right! 🤯














lol.

Sorry sir, you missed it. Gif mania was from 6pm-7pm GMT.







does her gasmask have a gasmask?!

maybe



canvas zoom is the one crapping out

Regardless, I deleted it at the time and Controlnet was the one that was making my UI not work. It wouldn't even install correctly when I tried to reinstall it from scratch, citing an access error.

i honestly don't know what people see in anime2
too much red
anime2 is too saturated and anything vae isn't saturated enough
i think clearvae is a good balance
Never heard of clear. I used blessed2 or anime2. The main problem that I deal with when working with anime models is that they're often difficult to saturate properly, or get enough contrast. anime2 helps immensely with that.
this was generated using walnutcream blend
I use Aurora.
All of the [redacted] based VAEs give me a hideous hexagonal texture on any backgrounds that are detailed. I can't stand any of them. I'll take oversaturated images any day over ugly textures.
Even without upscaling? I've found usually such texture patterns in the gens are the result of overzealous upscaling processes. Or SD Upscale interacting with them in a way that is detrimental to the end result. Anime6B would be a lot less likely to have this problem as opposed to say, Ultrasharp.
yeah everyone has personal preferences but I don't like the dithering effect that every vae besides anime2 has
It definitely depends on the networks and models being used. There are times when anime2 is blurring my lines in a simple flat color anime gen. Other times I'm getting bad patterns or desaturated results using blessed2. Clear looks interesting though--I'll have to try it out and see its worth as a tool in my box.
I almost never gen without hires fix but the same thing happens regardless of upscaler and anywhere from 0.4-0.65 denoising with every sampler I use and I've never seen a single image from anime2 with the same problem.
It'd be nice if mse could do anime eyes decently because that's the best out of all of them colorwise.
I see the same problem usually with tennis court nets, fishnets, up-close pantyhose, etc. But that's usually it. SD generally has a problem with those with the inherent moire effect anyway.
Nah it's a totally different problem than you're talking about. This is fine hexagonal textured dithering pattern across the entire background. It's almost like a screen door effect
can 1.5 based models generate at 768x768 well?
Depends on the model, but often yes.
Hires fix is always our friend though. It's good to keep at least one side around 512 and then upscale from there. If you're using a 16x9, 4x3, etc.
i'm going to try it with walnutcream
Usually they don't start breaking until either both dimensions go above 768 or one dimension goes above 1024 for modern models.

Your hires fix is showing something weird. Uncheck and recheck it and it should be good to go.
wat
oh
Your width and height is the same in the interface, and yet it shows as something different in the resize.
You're using super high denoising so it covers up the blurriness that latent gives.
eeeee
Me when I have phobia of redacted vae
Just a visual bug in my experience. No impact on generations.

i originally used 0.5 but i noticed that 0.7 gave more appealing results
Latent doesn't suck, just upscalers are most of the time better
multidiffusion
i got the 4x-animesharp one but i couldn't find that other one that nubby talked about
Multi diffusion is hacking
Multidiffusion is great
Latent can be good. When it works well on an image it can be the best option, but it can often be the worst.
idk why i thought i could upscale 768x768 at 2 when i can't even do it with 512x768
6gb vram😎
i have 8gb
OutOfMemoryError: CUDA out of memory. Tried to allocate 2.25 GiB (GPU 0; 8.00 GiB total capacity; 5.01 GiB already allocated; 470.40 MiB free; 5.60 GiB reserved in total by PyTorch)
guess the upscaling method

is stable diffusion under utilizing my gpu?
does anyone else have the extension for this? i have it installed but i dont see it

I have it. Have you completely restarted SD since you installed it?

it seems like it's only using 5gb of my vram
Looks like you're using about 2.5GB of vram for something else. The most common culprits are hardware acceleration in your browser and/or discord, wallpaper engine, and nvidia broadcast.
ic

i honestly dont remember installing it actually
i turned off hardware acceleration on my browser and discord
Should help a lot
i guess i probably need to restart SD too so it can re-allocate
Yeah, I've found that SD sometimes kind of shits itself after getting an OoM error so I usually just restart after it happens.
does adding --xformers to args automatically build and install it?
Yep, but if you've manually installed pytorch 2.0 you'll need to manually install xformers as well so that you get the right version.
well i didn't do that so all good
Here's an example of the [redacted] vae texture I was talking about. This is blessed2 to be specific, but it happens with all of them.

are you talking about the "scales"

yep
i didn't even notice until you said something about it
Sorry, you'll probably never be able to unsee it now.
i think it makes the background look like it's painted on fabric
disabling hardware acceleration on discord and chrome only increased the reserved vram to 6.25 GB

oh, edge has hardware acceleration on too
 morning!
morning!
(i use chrome for my daily use and edge for my college work)
Ah, yep. Pretty much every browser has HW acceleration turned on by default.

i wonder if the spotify desktop client uses hw acceleration too

aha

Open task manager, go to details tab, right click any of the column labels, click "Select columns", and enable "Dedicated GPU memory", sort by that column high to low and now you can easily see all of the processes that are using vram as well as how much.
Is that win11 feature?
I use Win 10, not sure if 11 has it too, but I assume it does.
I just can't find it in win10

I kinda expected that to mean something else
Sorry, I missed that step.
windows 11 task manager is funky
i have windows 11 on my laptop and it looks like this

I've used win11 for like 20 minutes while I was setting up my mom's printer for her. I was not impressed.
i changed things around to make it more like windows 10

i had to edit the group policy to make it so you only need to right click once in the file explorer to get the full menu
It was mostly the control panel and settings menu that I found annoying.
yeah i don't really like how they make it hard to get to the in depth settings
or how you click on something in control panel and it opens the settings app
Yeah, I've hated everything about the settings menu since they started implementing it.
i looked at the details tab
the only 2 things with significant dedicated gpu allocation other than python are explorer and "dwm.exe"
dwm is the process that's drawing your desktop, so you can't really go without it
this is what it looks like after i get the cuda out of memory error

wait no it went down
Yeah, that's what I have too. I haven't found a way to reduce dwm vram usage.
python would be at like 7,300,000
you can't reduce dwm, unless you decide windows doesn't need any way to draw to your screen. lowering your resolution, less virtual desktops, less color space, that kind of shit helps
but it's marginal (mb's vs required gb's)
would turning on medvram actually let me generate higher resolution images in exchange for time?

If they hadn't taken away our ability to reduce desktop animations, I imagine we could reduce dwm vram usage quite a bit.
here we go, this is what it looks like directly after the out of memory error

yeah.
it's a marginal speed hit for pretty substantial memory buff (reduction)
Wouldn't tiled VAE help with this also?
it would. but tiled vae is pretty bad in initial txt2img

i'm trying to generate 768x768 at x2 upscale with hires fix
moves to disable

make sure that the tiled diffusion /vae only activates on the upscale part
i don't know how to do these things
(check your console and see to it that it doesn't trigger on the initial pass)
i don't even know how to get tiled vae
How do u control that
vladmandic has it out of the box, extension for a1111
check the tile sizes -> if the tiles are 'big' enough, the image can fit in a 1x1 tile, so the console will mention it will not split the image

By saying that unnecessary warning?
this one?

yes
Using --no-half-vae so that you can use [redacted] vaes is probably killing your vram usage. Mine tops out at 6.2GB usage with just --xformers enabled doing 768x768 with 2x upscaling.
That's with 2 LoRA's too so it would be even lower without those.
this warning: if this triggers only on the upscale image rendering, you're golden. if it triggers during initial txt2img you're in for a world of weird shit
i have disable safe unpickle on because i was trying to use old .ckpt models and they weren't working
probably not the best move in hindsight
Does webui use deterministic xformers or do I need to update manually?
xformers by nature are non-deterministic
you'd have to switch to pytorch 2 and go for --opt-sdp-attention
You have to install torch 2.0 and manually install xformers.
not any more.
they fixed that?
Ok can't bother to do that
can i change the order of these extra things

i want the aspect ratio helper closer to the top
interesting

yep. the current build is deterministic.
the result of txt2img with wrong tiled diffusion (on purpose)

What is that page?
must be moderated by UD mods
yeah, it's very provocative nerf, totally too lewd 😛
Civit
that's tiled diffusion, tiled vae can be used independently of that and won't give that sort or weirdness even when it activates on the initial pass.
https://civitai.com/models/54424?modelVersionId=58787 Well whatever, its uploaded xD
Pina Artstyle LoRA Use Cases The LoRA is in itself very compatible with the most diverse model. However, it is most effective when used with Aurora...
i haven't found a use for tiled vae yet tho 😦 does it help? i ran out of 10gb on my 3080 regardless wether i used it or not



Yeah it can significantly reduce vram usage. default tile sizes are too high though. Encoder should be around 768-1024 and Decoder should be around 64-96.
This image was done with 512 encoder tile size BTW.

seems i'm spoiled by my 3090 now 😦
try these settings

should you change it based on what the target resolution is?
i'm so going to hate summer.... the 3090's fans are perfectly positioned for the airflow in my case. the case exhaust is working REALLY well and... i'm literally heating my house with inference xD

How does one do Dark night images that look bluish?
i probably need to replace the exhaust fan on my PC case
it has been dead for over a year
I never really do unless I need to make it smaller to avoid OoM.
all my 1070 has is a blower shroud
i can really recommend https://github.com/Rem0o/FanControl.Releases
I can't seem to get that blue night look with minimal lighting
also i got this when tryint to use tiled vae with those settings you suggested
RuntimeError: The expanded size of the tensor (3) must match the existing size (8) at non-singleton dimension 1. Target sizes: [1, 3, 96, 96]. Tensor sizes: [8, 96, 96]
that way you can get your case fans to go max power when your gpu gets hot -> more cool air in, more hot air out = cooler gpu
noise offset lora and theme blue?
like prompt (theme blue)?
Yeah but I rly have no idea if it does anything

so what do i do about this? it only happens with tiled vae enabled, even if the image is small enough to where it says tiling is unnecessary
i think it was caused by another extension
cutoff or controlnet? i had that too at times
blue theme vs blue hue, something like this?


had one each for red, blue, yellow ❤️

I've never had that error.

Is your width and height dividable by 8?
combine with cutoff to make sure colors are isolated properly (pink shirt, black hair, colored hues)

yea i was trying 512 and 768
now combine it with my LoRA :D doit
link plox

these are the settings i'm using

@queen void pina artstyle?
the vram estimator is buggin out because i set the resolution higher than 512
yes
of. disentegrated the image
lemme try on another prompt tho
my model is pretty clear about what it likes and dislikes, and this kind of deformations -> stuff that's incompatible is going on
0.8 on a image that is inherently unstable, actually stabilized it

cool how the red/blue lightning get a different interpretation from the yellow lightning xD

nice
try alittle lower though liek 0.6-0.7 with these models
THE JAR
School be like

@queen void pina vs no pina

Looks a bit overfitted/overtrained or something
Like the 2 tries looks too similar compared to the 2 tries without it
model depended kinda. It was trained on aurora
my model is pretty distant from aurora tho
Oh, makes sense
Probably why it's like that then
tiled vae does not work if i have hires fix on
Guys what is tiled vae?
lemme see what my prompt does on aurora
It does normaly
And how to use multi diffusion thingy?
i feel my model has a quirky prompting style, good at doing descriptions, but lackluster when doing it booru style
Tiled vae is part of the multidiffusion extension, and can save you a lot of vram when generating highres images by tiling the vae
So like. It seperate image into tiles and then works on them one by one? All at the same time?
It takes a bit longer but you wont get out of vram errors anymore
So it works on them one by one?

Only for the vae
Ye
i keep getting his
RuntimeError: The expanded size of the tensor (3) must match the existing size (8) at non-singleton dimension 1. Target sizes: [1, 3, 88, 88]. Tensor sizes: [8, 88, 88]
only happens when i have both hires fix and tiled vae enabled at the same time
Oh yeah btw CS1o, for a long time now I wanted to get the latents before they get transformed into an image. How can I do that?
I would make sure everything is updated.
it has been a while since my last git pull...
A1111 is back
hmm

Yep, he finally made a dev branch. The RC branch looked like it just got everything thrown into that the dev branch had though from a quick look so I'm unsure how much testing he actually did with the dev branch.
is the dev branch like nightly builds or something
anyways i did a git pull and all my extensions are updated, i still get the error
That's basically the intention

Idk sry
i like it though
seems my model doesn't like the lora that much 😦
so i guess no tiled vae
one result

GitHub
After updating I got this error "RuntimeError: The expanded size of the tensor (3) must match the existing size (8) at non-singleton dimension 1. Target sizes: [1, 3, 96, 128]. Tensor sizes: [...
this might be the fix
it worked
the solution was to replace the vae_optimize.py file with a different one
Try this prompt: man of liquid metal chrome, red glowing mechanical eyes, vivid color, shimmering metallic short hair, brutalpunk fashion, transmogrifying arms into blades, slices nosferatu demons, 3d digital illustration, digital art, [futurepunk:dieselpunk:0.60], dystopian fantasy art style, dark fantasy mood, cyberpunk aesthetic, hard lighting, filmic angle, low contrast, medium saturation, 8k, HDR
Though I dunno what weights fit or negative. Still in hospital bed but my prompt eye is still trying stuff
BASED

Gantz author likes AI, doesnt care his works has been used as learning material
he's posting ai generated girls on his twitter


Epic
Omg I would be so extremely happy and honored if I were you

gantz is pretty goated
Why are my images looking at the ant's eye view?

I just did (hands up:3) in negative
and it came out fine
this is what happens when negative prompt becomes too long
when youre at your 5000th render and the hands are still poorly drawn 😎
those are all embeddings?
text embeddings
ok will try them out 😀 thanks
probably depends on the model and sampling method as well i imagine

only model
ok
before and after lora. should I release?


(sorry for loli, model does that by default and I didn't put any negative other than 2 embeds)


has definitely a more natural and realistic feel to it. looks good imo
thanks that's how it should have been

not anime but my new model


I actually should retrain it though. (this is one of the training images so you see what I mean)

it's unusable beyond epoch 1
and epoch 1 doesn't resemble the training images enough imo


civitai's search doesn't seem to be working

Yeah it was giving me trouble yesterday/this morning
It would work from the main page but nowhere else
the new layout sucks




yes

a bit too far??

There should be an icon near the filter where you can switch to the old layout



Once there was an Ugly Barnacle. He was so ugly, that everyone died! The End.
noooo
now I wanna use pyg7b to tell me story time





lora?
fashionGirl and ExperimentalMakeup, model nabimix
happy to hear that 🙂

Isn't there like two background removing extensions?
made with @real nexuss new Model and Jinx Lora

makima my boo

GitHub
Contribute to KutsuyaYuki/ABG_extension development by creating an account on GitHub.
There is also this in extensions which may be better

I haven't tried it tho

Theres that one too, I think that one works the same as ABG

Damn thats a nice style, I'll have to try that 

mhhh

who wants me to dm them image I can't really post here?
That ABR extension
Anime background remover
Huggingface also has a space running it
Oh scrolling up smone already linked it lol oop lol


newest 😄
Fair fair :o
I try to update as soon as there is new one 😄
Fair, they make so many updates tho
yeah, sometimes they are not worth downloading after reading description what was changed
Yeee xD
64 dim? how is it 144 mb then
Also, NAI VAE? so it was trained with a vae? 
whut, I have lora:fashionGirl_v54:1 only 😄

does a1111 have a built-in downloader now? wat
Weird
indeed
Its the Civit Helper extension

Saves trigger word, link to the page, preview, and some other info I think
https://github.com/butaixianran/Stable-Diffusion-Webui-Civitai-Helper You can check it out here

GitHub
Stable Diffusion Webui Extension for Civitai, to manage your model much more easily. - GitHub - butaixianran/Stable-Diffusion-Webui-Civitai-Helper: Stable Diffusion Webui Extension for Civitai, to ...
oh ok
too bad those things aren't packaged into the lora format

resumable downloads not bad
Yeeee
speaking of the lora preview image
I keep accidentally clicking that, and so now all my lora have the wrong preview pics
Thats why I always click on the upper part of image 😄
das a very cute chibi model
feature is a menace
ALSO @ocean reef what weights are you using for the two LoRAs?
Tried it

I love latex 
😏



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}